Journal homepage: jurnal.pelitabangsa.ac.id
1 Pemetaan Warga Miskin Calon Penerima Bantuan Rumah Tidak Layak
Huni (RTLH) Dengan Metode Algoritma K-Means
Citra Setia W1, Aswan S. Sunge2, Listian Indriyani A3
Program Studi Teknik Lingkungan, Universitas Pelita Bangsa Korespondensi email: pelitateknologi@gmail.com
Abstrak Informasi Artikel
An uninhabitable house is a dwelling or residence that is unfit for habitation because it does not meet the requirements for occupancy, both technically and non-technically. Social Assistance for Uninhabitable Houses (RTLH) is the provision of stimulant assistance in the form of money for the purchase of building materials for the restoration of Uninhabitable Houses from local governments to individuals, families, groups and communities that are not continuous and selective which aims to protect against possible occurrence of social risk. In Indonesia, there are many houses that fall into the category of Unfit Houses.
The government in dealing with this issue provides assistance programs to areas where there are still many uninhabitable houses such as in Selokerto Village. The implementation and implementation of the assistance program is still not optimal because there are still
Diterima:
Direvisi:
Dipublikasikan:
problems with data that often changes or does not match the conditions of existing residents and there is no method for grouping or mapping potential beneficiaries with the concept of data mining clusterimg k- means will help overcome problems that are not yet optimal. This study aims to assist the process of grouping and determining the prospective beneficiaries. Grouping using the k- means algorithm clustering divides into three clusters, namely cluster 0 with a total of 77 families, cluster 1 with a total of 74 members and cluster 2 with a total of 269 families. This study is also to find out the value of the Davies Bouldin Index (DBI) test with a test result of 0.401.
Keywords
Data Mining, RTLH, K-means
I. Pendahuluan
Bagi pemerintahan Indonesia masalah kemiskinan adalah satu masalah yang belum bisa diatasi.
Kemiskinan merupakan masalah sosial ekonomi yang senantiasa hadir
ditengah-tengah masyarakat. Tingkat kemiskinan yang terjadi dalam suatu negara menjadi salah satu ukuran untuk mengukur baik buruknya perekonomian suatu negara. Indonesia sebagai negara berkembang dan memiliki jumlah
2 penduduk yang besar tidak dapat
terhindar dari masalah kemiskinan.
Kemiskinan di Indonesia disebabkan oleh berbagi factor, diantaranya tingkat inflasi yang berfluktuasi, pertumbuhna ekonomi yang lambat, tingkat pengangguran yang tinggi dan kebijakan pemerintah yang mempengaruhi kebutuhan pokok.
Kebutuhan pokok manusia terbagi menjadi tiga yaitu sandang, pangan dan papan. Sandang memiliki arti pakaian, pangan memiliki arti makanan, dan papan memiliki arti tempat tinggal. Rumah (tempat tinggal) adalah salah satu aspek dari kesejahteraan masyarakat yang harus dipenuhi karena rumah merupakan kebutuhan hidup yang utama selain sandang dan pangan dimana tempat manusia berlindung, mempertahankan dan meningkatkan kualitas hidupnya.
Setiap keluarga selalu berupaya untuk memiliki rumah yang layak huni, meskipun secara objektif belum seluruh keluarga dapat mewujudkan keinginannya yang disebabkan oleh beberapa faktor, terutama faktor ekonomi keluarga karena kemisikinan.
Pemerintah melalui Kementrian Perumahan Rakyat telah melakukan berbagai kebijakan melalui program- program penyediaan perumahan dan perbaikan prasarana dan sarana permukiman. Dalam penyediaan rumah layak huni kemampuan pemerintah masih terbatas dalam sistem kepemilikan rumah. Sebagai langkah lain dalam memenuhi kebutuhan rumah yang layak bagi MBR, pemerintah mengeluarkan kebijakan dengan pengembangan dan pendayagunaan potensi keswadayaan masyarakat melalui rehabilitas rumah tidak layak huni yang diatur dalam Peraturan Mentri Pekerjaan Umum dan
Perumahan Rakyat (Permen PERUP) No. 13-PRT-M2016 tentang Bantuan Stimulasi Perumahan Swadaya (BSPS) bagi MBR, sebagi upaya mempercepat pemenuhan kebutuhan rumah yang layak di Indonesia.
II. Tinjauan Pustaka
2.1 Rumah Tidak Layak Huni (RTLH)
Rumah tidak layak huni adalah suatu hunian atau tempat tinggal yang tidak layak huni karena tidak memenuhi persyartan untuk hunian baik secara teknis maupun non teknis.
Pada umunya rumah tidak layak huni erat kaitanya dengan pemukiman kumuh karena pada dasarnya di daerah kumuh tergambar kemiskinan masyarakat. Menurut Departemen Sosial, Rumah Tidak Layak Huni adalah rumah yang tidak memenuhi syarat kesehatan, keamanan dan sosial, dengan kondisi sebagai berikut : 1.Tidak permanen atau rusak.
2.Dinding dan atap dibuat dari bahan yang mudah rusak/lapuk, seperti : papan, ilalang, anyaman bambu, genteng dan sebagainya.
3.Dinding dan atap sudah rusak sehingga membahayakan, mengganggu keselamatan penghuninya.
4.Diutamakan rumah tidak memiliki fasilitas kamar mandi, cuci dan kakus.
2.2 Clustering
Menurut Santosa (2007)
“Clustering merupakan salah satu metode data mining yang bersifat tanpa arahan (unsupervised), maksudnya metode ini diterapkan tanpa adanya latihan (taining) dan tanpa ada guru (teacher) serta tidak memerlukan target output. Dalam data mining ada dua jenis metode clustering yang digunakan dalam pengelompokan data, yaitu
3 hierarchical clustering dan non-
hierarchical clustering”.
2.3 K-Means
Menurut Kusuma dewi dan Purnomo, (2010) “k-means adalah sutau teknik pengelompokan data yang mana keberadaan tiap-tiap titik data dalam suat cluster ditentukan oleh derajat keanggotaan”.
Menurut Santosa, (2007) langkah-langkah melakukan clustering dengan metode k-means adalah sebagai berikut [16] :
1.Pilih jumlah cluster k
2.Inisialisasi k kepusat cluster ini bisa dilakukan dengan berbagai cara.
Namun yang paling sering dilakukan adalah dengan cara random. Pusat- pusat cluster diberi nilai awal dengan angka-angka random.
3.Alokasikan semua data/objek cluster terdekat. Kedekatan dua objek ditentukan berdasarkan jarak kedua objek tersebut. Demikian juga kedekatan suatu data cluster tertentu ditentukan jarak antara data dengan pusat cluster. Dalam tahap ini perlu dihitung jarak tiap data ke tiap data pusat cluster. Jarak paling antara satu data dengan satu cluster tertentu akan menentukan suatu data masuk dalam cluster mana. Untuk menghitung jarak semua data ke setiap titik pusat cluster dapat menggunakan teori jarak Euclidean yang dirumuskan sebagai berikut:
dimana:
D(i,j) = Jarak data ke i ke pusat pusat cluster j
Xki = Data ke i ke atribut data ke k Xkj = Titik pusat ke j pada atribut ke k
4.Hitung kembali pusat cluster dengan keanggotaan cluster yang sekarang.
Pusat cluster adalah rata-rata dari semua data/objek dalam cluster tertentu. Jika dikehendaki bisa juga menggunakan median dari cluster tersebut. Jadi rata-rata (mean) bukan satu-satunya yang ukuran yang bisa dipakai.
5.Tugaskan lagi setiap objek memakai pusat cluster yang baru. Jika pusat cluster tidak berubah lagi maka proses clustering selesai. Atau kembali ke langkah nomor tiga sampai pusat cluster tidak berubah lagi. Hasil dari operasi clustering yang terbentuk selanjutnya akan dievaluasi menggunakan Davies bouldin index.
III. Metodologi Penelitian
Data yang digunakan dalam penelitian ini merupakan data primer dan kualitatif, data yang digunakan merupakan data rumah tangga kesejahteraan sosial yang didapatkan dari Kelurahan Desa Selokerto.
3.1 Dataset Collection
Tahap awal penelitian ini adalah dimulai dengan dataset yang alan digunakan, dalam penelitian ini dataset yang digunakan adalah data warga miskin calon penerima bantuan RTLH dari data DTKS RUTA di Kelurahan Selokerto. Pengumpulan data berdasarkan data yang dibutuhkan dalam penelitian ini. Pengumpulan data dilakukan melalui data warga miskin yang memenuhi kriteria rumah tidak layak huni di Kelurahan Selokerto selanjutnya akan diolah menggunakan algortitma k-means. Berikut data yang telah diperoleh yang tidak dapat langsung diolah, untuk dapat diolah
4 menggunakan metode clustering k-
means diperlukan praproses data agar mendapatkan atribut dan tipe data yang cocok.
Tabel Dataset
3.2 Data Preprocessing
Pada tahap ini data dikumpukan dan diidentifikasikan dari data yang sudah ada dan selanjutnya dilakukan preprocessing yaitu:
1. Data Selection atau pemilihan data merupakan tahap pemilihan atribut mana saja yang akan digunakan dalam proses perhitungan dengan algoritma k-means, karena tidak semua data yang terdapat di dalam data mentah akan digunakan sebagai atribut. Dibawah ini adalah table atribut yang akan digunakan dan tidak digunakan.
2. Pembersihan data (cleaning) yang mana pada tahap ini dilakukan penghapusan atau pemebersihan terhadap data missing value yaitu data yang tidak konsisten atau kosong dan juga dilakukannya
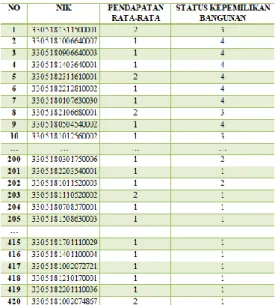
pemilihan variable terhadap data yang ingin digunakan dalam proses data mining. Dalam proses pengelompokan warga miskin calon penerima bantuan RTLH dengan clustering menggunakan 420 data dan mengguanakan dua atribut.
3. Dilakukan peringkasan data atau perubahan data agar mudah untuk dikelola. Dikarenakan nilai sebagaian atribut data non numeric maka diperlukan perubahan data tersebut menjadi numeric.
Perubahan data non numeric adalah sebagai berikut :
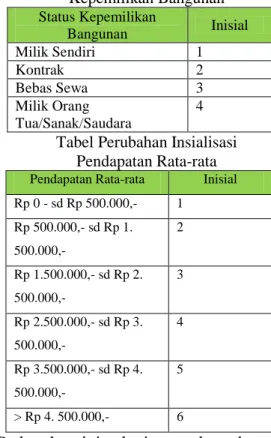
Tabel Perubahan Inisialisasi Status Kepemilikan Bangunan Status Kepemilikan
Bangunan Inisial
Milik Sendiri 1
Kontrak 2
Bebas Sewa 3
Milik Orang Tua/Sanak/Saudara
4
Tabel Perubahan Insialisasi Pendapatan Rata-rata
Pendapatan Rata-rata Inisial Rp 0 - sd Rp 500.000,- 1
Rp 500.000,- sd Rp 1.
500.000,-
2
Rp 1.500.000,- sd Rp 2.
500.000,-
3
Rp 2.500.000,- sd Rp 3.
500.000,-
4
Rp 3.500.000,- sd Rp 4.
500.000,-
5
> Rp 4. 500.000,- 6
4. Pada tahap ini selanjutnya data akan diproses menggunakan tools RapidMiner dan untuk pengujiannya menggunakan performance vector yang ada di dalam RapidMiner, maka data akan dilihat dari nilai akurasi, cluster, dan rulenya. data yang akan digunakan pada metode
5 k-means juga terdapat data jumlah
target cluster yang akan ditentukan terlebih dahulu. Pada penelitian ini jumlah cluster yang digunakan sebanyak tiga cluster. Karena pada penelitian ini bertujuan untuk pengelompokan warga miskin calon penerima bantuan RTLH. Tahapan selanjutnya adalah proses pengolahan data menggunakan algoritma k-means untuk melihat rule dan hasil clustering.
Tabel Data Transformasi
IV. Hasil dan Pembahasan
4.1 Pengujian Algoritma K-means Pada tahap ini dilakukan proses segmentasi pengelompokan data kependudukan. Berikut merupakan penerapan algoritma k-means dengan asumsi parameter input adalah jumlah dataset sebanyak n dan jumlah insialisasi centroid k adalah dua. Data yang digunakan dalam penelitian ini berjumlah 420 data. Untuk dapat melakukan pengelompokan data ke dalam beberapa cluster maka diperlukan beberapa langkah yaitu :
1. Menentukan berapa jumlah cluster yang diinginkan. Dalam penelitian ini akan menggunakan tiga cluster.
2. Menentukan centroid secara random Tabel centroid awal iterasi ke 1
3. Hitung jarak data dengan centroid Eucliden Distance
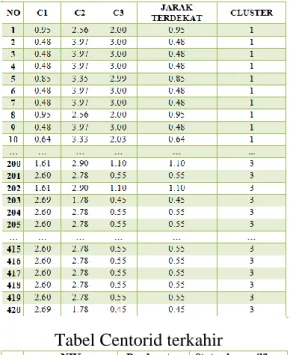
Hasil operasi perhitungan berlanjut sampai data ke 420. Berikut hasil perhitungan iterasi ke-1
Tabel hasil iterasi ke 1
6 Hasil dari perhitungan dari 420 data
menunjukan hasil cluster pada iterasi 2 dan iterasi 3 yang menunjukan tidak ada terjadinya perubahan cluster, maka hasil yang di dapatkan sudah stabil (konvergen), sehingga perhitungan iterasi pada penelitian ini dengan centroid baru berhenti pada perhitungan iterasi ke-3, sehingga centroid yang terkahir tidak mengalami perubahan Hasil pengelompokan data kependudukan dengan proses algoritma k-means, menghasilkan tiga cluster yaitu cluster 0 jumlah 77 anggota, cluster 1 jumlah 74 anggota dan cluster 2 jumlah 269 anggota. Berikut tabel iterasi terkhir
Tabel iterasi ke-3 (terakhir)
Tabel Centorid terkahir
4.2 Pengujian RapidMiner
Berikut adalah proses pengolahan dengan menggunakan algoritma K-means untuk mendapatkan hasil clustering dan rule pada aplikasi RapidMiner.
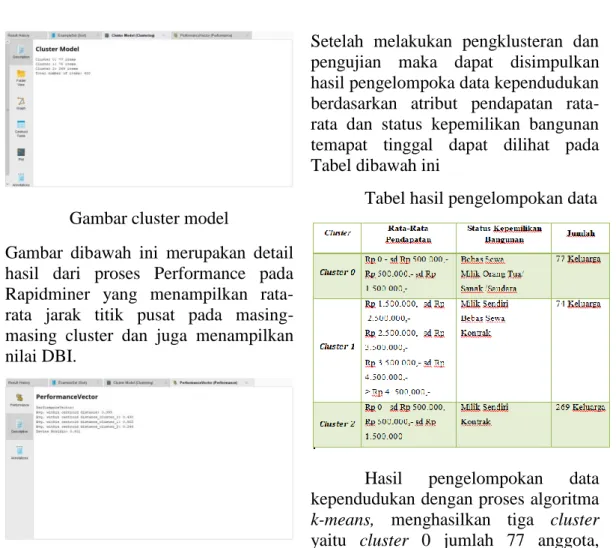
Gambar 4. 1 Design Process RapidMiner Pada tahapan ini dilakukan 4 proses yaitu :
a. Retrieve data test
Pada tahapan ini adalah proses dilakukanya operasi penginputan daaset berupa file berekstensi .xls data rumah tangga.
b. Clustering
Pada tahapan ini dilakukan proses pengoprasian clustering sebagai algoritma yang dilakukan dalam penelitian ini.
c. Performance
Pada proses tahapa ini dilakukan operasi pencarian davies bouldin index. Dimana parameter main criterion disetting Davies Bouldin dan maximize bertujuan memaksimalkan nilai hasil dari DBI.
d. Short
Tahapan ini dilakukan operasi pengurutan anggota cluster 0 sampai dengan cluster 2. Dengan parameter atribut name adalah cluster.
Gambar doibawah ini akan menampilkan hasil pembagian data dengan tiap cluster. Pada cluster 0 memiliki 77 anggota, cluster 1 memiliki 74 anggota, dan cluster 2 memiliki 269 anggota dari jumlah 420 dataset yang telah diuji.
7 Gambar cluster model
Gambar dibawah ini merupakan detail hasil dari proses Performance pada Rapidminer yang menampilkan rata- rata jarak titik pusat pada masing- masing cluster dan juga menampilkan nilai DBI.
Gambar Performance Vector Hasil evaluasi dari average within centroid distance mendekati angka 0 mengartikan bahwa masing- masing anggota yang ada di dalam cluster berada dalam jarak yang berdekatan. Semakin kecil nilai davies bouldin index maka semakin baik cluster yang diperoleh dari pengelompokan menggunakan metode clustering. DBI bertujuan memaksimalkan jarak antar cluster dan meminimalkan jarak antar anggota cluster.Hasil perhitungan menggunakan algoritma k-means menunjukan nilai rata-rata jarak antar centroid adalah 0.399 dan nilai DBI 0.401 angka tersebut memiliki hasil yang cukup baik karena mendekati angka 0.
Setelah melakukan pengklusteran dan pengujian maka dapat disimpulkan hasil pengelompoka data kependudukan berdasarkan atribut pendapatan rata- rata dan status kepemilikan bangunan temapat tinggal dapat dilihat pada Tabel dibawah ini
Tabel hasil pengelompokan data
Hasil pengelompokan data kependudukan dengan proses algoritma k-means, menghasilkan tiga cluster yaitu cluster 0 jumlah 77 anggota, cluster 1 jumlah 74 anggota dan cluster 2 jumlah 269 anggota. Cluster 0 didominasi dengan keluarga yang mempunyai pendapatan rata-rata kurang dari Rp 1.500.000,- perbulan dan status kepemilikan bangunan bebas
sewa atau milik orang
tua/sanak/saudara. Cluster 1 didominasi dengan keluarga yang mempunyai pendapatan rata-rata lebih dari Rp 1.500.000,- sd < 4.500.000,- perbulan dan status kepemilikan bangunan milik sendiri, bebas sewa dan kontrak. Dan cluster 2 didominasi dengan keluarga yang berpendapatan kurang dari Rp 1.500.000,- dengan status kepemilikan bangunan kebanyakan milik sendiri dan ada beberapa dengan status kontrak.
Peraturan Pemerintah tentang kriteria calon penerima bantuan Rumah Tidak Layak Huni yaitu status
8 kepemilikan rumah / bangunan sah atau
atas nama milik sendiri dan dilihat dari pendapatan rata-rata perbulan berdasarkan skala Upah Minimum Regional (UMR) daerah Kabupaten Kebumen, Jawa Tengah. Maka didaptkan pengelompokan warga miskin calon penerima bantuan RTLH sebagai berikut :
Tabel pengelompokan calon penerima bantuan
V. Kesimpulan
Dari penelitian yang telah dilakukan oleh peneliti, dapat diambil kesimpulan sebagai berikut:
1. Dengan menerapkan data mining metode clustering k-means dengan data 420 di dapatkan hasil dengan tiga cluster yaitu cluster 0 (kurang cocok menrima bantuan) berjumlah 77 keluarga, cluster 1 (tidak cocok menerima bantuan) berjumlah 74 keluarga, dan cluster 2 (cocok/layak menerima bantuan) berjumlah 269 keluarga.
2. Pengujian menggunakan validasi DBI ( Davies Bouldin Index) diperoleh nilai untuk tiap-tiap cluster. pengujian cluster 0 menghasilkan nilai DBI 0.430, cluster 1 menghasilkan nilai DBI 0.922, cluster 2 menghasilkan nilai DBI 0.401. Karena nilai DBI dari cluster 3 lebih kecil maka cluster tersebut bisa disebut optimal. Dan penelitian pengelompokan warga miskin calon penerima bantuan RTLH ini dengan menerapkan data
mining dengan metode clustering k- means dapat digunakan sebagai salah satu alat penujang dalam mentukan warga miskin calon penerima bantuan dengan cepar dan tepat sasaran.
REFERENSI
[1] Windra, P. B. Marwanto, And Y.
Rafani, “Analisis Pengaruh Inflasi, Pertumbuhan Ekonomi, Dan Tingkat Pengangguran Terhadap Kemiskinan Di Indonesia,” J. Ilm. Progresif Manaj. Bisnis (Jipmb), Vol. 14, No. November, Pp. 19–27, 2016.
[2] Frank Van Steenbergen And A.
Tuinhof, “Implementasi Bantuan Perbaikan Rumah Tidak Layak Huni Bagi Masyarakat Berpenghasilan Rendah Di Kota Padang,” Angew. Chemie Int. Ed.
6(11), 951–952., Vol. 7, Pp. 1–
16, 2009.
[3] R. Indayu, “Pembangunan Rehabilitasi Rumah Tidak Layak Huni Termasuk Jamban/ Sanitasi Keluraga Oleh Pemerintah Daerah Kabupaten Karimun Di Kecamatan Tebing Tahun 2012,”
Pp. 1–12, 2012.
[4] Y. Muhtadi, “Implementasi Kebijakan Program Penyediaan Rumah Layak Huni Bagi Masyarakat Berbenghasilan Rendah Di Kota Tangerang,”
Vol. 20, No. 2, Pp. 188–197, 2020.
[5] Y. Kusnadi And M. S. Putri,
“Clustering Menggunakan Metode K-Means Untuk
9 Menentukan Prioritas Penerima
Bantuan Bedah Rumah (Studi Kasus: Desa Ciomas Bogor),” J.
Teknol. Inform. Dan …, Vol. 7, No. 1, Pp. 17–24, 2021
[6] N. V. Waworuntu And M. F.
Amin, “Penerapan Metode K- Means Pemetaan Calon,”
Kumpilan J. Ilmu Komput., Vol.
05, No. 02, Pp. 190–200, 2018 [7] K. B. Aditya, P. Diyah, And Y.
Setiawan, “Sistem Informasi Geografis Pemetaan Faktor- Faktor Yang Mempengaruhi Angka Kematian Ibu ( Aki ) Dan Angka Kematian Bayi ( Akb ) Dengan Metode K-Means Clustering ( Studi Kasus : Provinsi Bengkulu ),” No. April, Pp. 59–66, 2017.
[8] T. Noviana And Y. Novianto,
“Penerapan Data Mining Menentukan Kelompok Prioritas Penerima Bantuan Beras Rastra Dengan Clustering K-Means,”
Pp. 159–174.
[9] R. Rokilah, “Implikasi Kewarganegaraan Ganda Bagi Warga Negara Indonesia,”
Ajudikasi J. Ilmu Huk., Vol. 1, No. 2, Pp. 53–62, 2018, Doi:
10.30656/Ajudikasi.V1i2.497.
[10] M. Abdin, “Kedudukan Dan Peran Warga Negara Dalam Masyarakat Multikultural,” J.
Pattimura Civ., Vol. 1, No. 1, Pp. 1–9, 2020.
[11] S. Yunita And D. A. Dewi,
“Urgensi Pemenuhan Hak Dan Kewajiban Warga Negara Dalam Pelaksanaannya Berdasarkan Undang-Undang,” J. Penelit.
Pendidik. Pancasila Dan Kewarganegaraan, Vol. 1, No.
12, Pp. 1–8, 2021
[12] F. Rahmawati And N. Merlina,
“Metode Data Mining Terhadap Data Penjualan Sparepart Mesin Fotocopy Menggunakan Algoritma Apriori,” Piksel Penelit. Ilmu Komput. Sist.
Embed. Log., Vol. 6, No. 1, Pp.
9–20, 2018
[13] D. Nofriansyah, K. Erwansyah, And M. Ramadhan, “Penerapan Data Mining Dengan Algoritma Naive Bayes Clasifier Untuk Mengetahui Minat Beli Pelanggan Terhadap Kartu Internet Xl ( Studi Kasus Di Cv.
Sumber Utama
Telekomunikasi),” J. Saintikom, Vol. 15, No. 2, Pp. 81–92, 2016.
[14] A. M. Vinka, N. Michele, F. T.
Industri, And F. Seni, “Tematik - Jurnal Teknologi Informasi Dan Komunikasi Vol. 8, No. 1 Juni 2021,” Vol. 8, No. 1, Pp. 1–13, 2021.
[15] J. O. Ong, “Implementasi Algotritma K-Means Clustering Untuk Menentukan Strategi Marketing President University,”
J. Ilm. Tek. Ind., Vol. Vol.12, No, No. Juni, Pp. 10–20, 2013.
[16] E. Purwaningsih, “Analisis Kecelakaan Berlalu Lintas Di Kota Jakarta Dengan Menggunakan Metode K- Means,” Jitk (Jurnal Ilmu Pengetah. Dan Teknol.
Komputer), Vol. 5, No. 1, Pp.
139–144, 2019.