Journal homepage: jurnal.pelitabangsa.ac.id
1 ANALISA KELASTERISASI UNTUK MENENTUKAN KUALITAS POWDER COATING PANEL LISTRIK DENGAN MENGGUNAKAN
ALGORITMA K-MEANS
( STUDI KASUS PADA PT. CIPTA TEKNO MANDIRI )
Gohan Nababan1, Edy Widodo2
Program Studi Teknik Lingkungan, Universitas Pelita Bangsa Korespondensi email: gohannababan96@gmail.com
Abstrak Informasi Artikel
Powder coating is a negative charge dry painting technique that will coat the box panel object. In the form of a powder it is used in a layer of small particles then dissolved in a dry form and heated to polymerize and preserve the coating. The clustering method approach can be applied in analyzing the level of potential quality of spray products produced by utilizing a dataset of recording the process of spray products during the period April 2019 – December 2019 which consists of 219 data records. The applied K-Means algorithm model has results that show a new insight, namely the grouping of spray product quality levels based on 2 clusters, cluster 1 (C0) is the OK Product Potential category which consists of 106 data from 219 tested datasets and cluster 2 (C1 ) is a Potential NG Product consisting of 113 data from 219 tested datases. Testing using the RapidMiner Studio application can also produce similar insights, namely each cluster has group members which are divided into 2 clusters, with each cluster having a centroid value. The optimal results are 80.59 & 78.03 for C0 and 77.41 & 64.15 for C1, with the Davies-Bouldin Index evaluation value of 0.756.
Diterima: 1 Agustus 2021 Direvisi: 2 Agustus 2021 Dipublikasikan:
Keywords
Data Mining, K-Means, Powder Coating
2 1.Pendahuluan
Powder coating ialah sistem
pengecetan yang berkembang pesat dalam dunia industri dewasa saat ini merupakan sistem yang pada awal ditemukan tahun 1967 di Autralia. Sistem pengecetan powder coating
tidak mempergunakan bahan
cair/pengencer yang biasa dilakukan pada cat konvensional. Sebelumnya pada proses powder coating objek disterilkan dari kotoran atau debu yang menempel. Setelah itu untuk mencapai daya rekat yang maksimal maka box panel di keringkan proses akhir dalam mesin oven sekitar 10 – 15 menit dengan suhu 180 – 220 C0[1]. Dalam bidang industri yang semakin hari semakin berkembang pesat baik
perusahaan swasta dan negeri,
perusahaan yang bergerak manufaktur maupun perusahaan jasa yang akan
berlomba untuk menciptakan
pelayanan yang terbaik kepada
pelanggan. Sehingga dengan hal tersebut maka yang perlu diperhatikan ialah kualitas dari produk yang dihasilkan perusahaan..
Ketebalan panel listrik memiliki standar ketebalan yang bervariasi sehingga menyebabkan hasil yang tidak standard dan menunjukan ketidak pastian dalam hasil yang didapat.
Aspek yang menunjang agar
konsumen puas dengan kualitas panel listrik tersebut dapat berfungsi sesuai
kebutuhan konsumen dan salah
satunya kualitas ketebalan. Dimana dalam ketebalan ini terdapat data yang
bervariasi yang menunjukan
ketidakpastian dalam hasil yang didapat. Maka dari itu para operator panel khususnya bagian painting berusaha semaksimal mungkin untuk menghasilkan kualitas produk panel
listrik yang baik. Banyak percobaan secara manual untuk memperbaikinya baik dari pengaturan keluaran dan tekanan arus listrik, serta cara untuk menggerakkan tangan yang secara manual ditujukan kesebuah panel listrik tersebut. Proses dasar yang menunjang agar konsumen puas dengan kualitas hasil proses painting
tersebut dapat berfungsi sesuai
kebutuhan konsumen dan salah
satunya kualitas ketebalan.
Namun terdapat konsumen yang ingin
tau tentang informasi ketebalan
powder coating, rata-rata ketebalan
sebuah box panel listrik yang
konsumen pesan ialah lebih dari 50 mm karena di ini memiliki data yang menjelaskan lebih dari 50 mm bisa dikatakan tebal dan layak diproduksi dan jika dibawah 50 mm maka box panel dikatakan tipis bila hal itu terjadi maka proses spray powder coating akan diulang. Hal ini terkadang diabaikan oleh perusahaan, yang menganggap resiko tersebut tidak terlalu berpengaruh. Tapi hal ini bagi
peneliti dijadikan sebuah
penelitian,guna untuk mencari nilai
clustering yang nantinya akan
dijadikan acuan yang pasti mengenai akivitas penelitian ketebalan powder coating.
Penelitian ini dilakukan dengan
menggunakan algoritma yang ada pada data mining yaitu algoritma K-Means. K-Means merupakan metode atau
teknik yang diterapkan dalam
pengelompokan data. Data mining merupakan bentuk penggalian data yang digunakan untuk menggali pengetahuan dari jumlah data yang besar. Berdasarkan uraian masalah
diatas maka penelitian ini
k-3
means untuk menentukan klasterisasi data. Sehingga dalam penelitian ini mengambil judul” Analisa Klasterisasi Untuk Menentukan Kualitas Powder
Coating Panel Listrik Dengan
Menggunakan Algoritma K-Means ( Studi Kasus Pada PT. Cipta Tekno Mandiri )”
I.Metodologi
Pada penelitian ini, tahapan yang akan
digunakan dalam melakukan
clustering terhadap data powder coating, dalam penentuan atribut untuk mempermudah penelitian sehingga penelitian dapat berjalan dengan baik dan sistematis, serta memenuhi tujuan yang diinginkan, penelitian deskriptif
ditujukan untuk mendeskripsikan
suatu keadaan atau
fenomena-fenomena apa adanya. Kategori
penelitian deskriptif merupakan
kategori yang digunakan untuk
menggambarkan atau menganalisis suatu hasil penelitian tetapi tidak digunakan untuk membuat kesimpulan yang lebih luas. Pendekatan kuantitatif banyak dituntut menggunakan angka,
mulai dari pengumpulan data,
penafsiran terhadap data tersebut, serta
penampilan hasilnya, dengan
menggambarkan sesuatu berdasarkan data yang dikumpulkan dalam bentuk angka mengenai fakta-fakta yang ada. 2.1 Tahap Penelitian
Tahap penelitian dapat didefinisikan sebagai penguraian dari suatu proses
penelitian yang untuh untuk
mengidentifikasi dan mengevaluasi permasalahan yang terjadi. Pada gambar di bawah ini merupakan tahap Penelitian.
Gambar 2. 1 Tahap Penelitian Gambar 2. 2 Tahap Penelitian
Dalam proses clustering data harus melalui tahapan - tahapan pengujian
data dengan algoritma k-means,
pengolahan data dan yang akan dijadikan proses pengujian adalah data hasil proses powder coating panel listrik dan sebagai data yang akn diujikan dan menghasilkan nilai sebagai hasil clustering.
2.2 Pengumpulan Data
Sumber data primer di dapatkan
dengan menggunakan teknik
pengumpulan data.
1. Sumber Data Sekunder
Dalam penulisan penelitian ini, penulis tidak hanya menggunakan metode
pengumpulan data dengan cara:
Wawancara, Studi Literatur dan Internet saja. Tetapi mengunakan
metode pengumpulan data yang
diperoleh langsung dari sumber objek penelitian. Dalam hal ini, penulis mendapatkan data dari laporan hasil dari proses pengecatan atau laporan pengecheckan. Berikut ini adalah data proses powder coating atau laporan pengecheckan dan gamabar box panel listrik.
2.3 Pengolahan Data
Pengolahan data pada penelitian ini menggunakan teknik clustering data, data mining untuk klasterisasi kualitas powder coating atau hasil produk tidak ok dengan menggunakan algoritma
k-4
means Data dapat diproses dan dijadikan dataset dalam penelitian ini, data tersebut akan dibagi menjadi data training, testing dan memisahkan data sesuai kebutuhan dalam penelitian ini agar dapat model yang diperoleh, memiliki kemampuan generalisasi
yang baik dalam melakukan
klasterisasi data, data training atau data testing adalah bagian dari data powder coating yang dilatih untuk membuat klusterisasi data atau menjalankan fungsi dari sebuah algoritma sesuai dengan tujuannya dalam penelitian ini sehingga dapat melihat keakuratan atau performa dari suatu data.
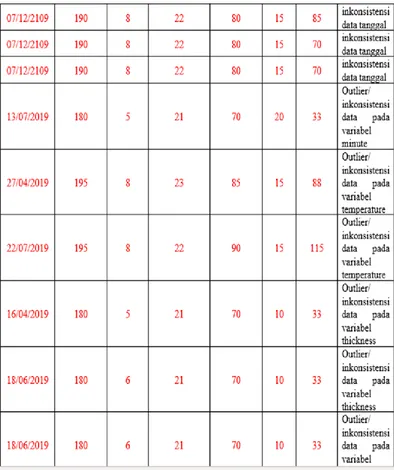
2.4 Data Cleaning
Pada tahap data cleaning
merupakan proses pembersihan dari
data yang akan dipakai untuk
penghapusan data dengan membuang missing value, duplikasi data, dan memeriksa inkonsistensi dari sebuah data dan memperbaiki kesalahan pada
data. Proses pembersihan data
dilakukan secara manual dengan bantuan software spreadsheet atau microsoft excel
Tabel 2.4.1 Data Cleaning
2.5 Data Selection
Data Selection merupakan proses pemilihan data dari sekumpulan data operasional yang ada sebelum masuk
ke tahap mining data maupun
informasi.
Tabel 2.5 Atribut Awal Dataset
NO Nama Atribut Type
1 Tgl_produksi Date 2 temperature Numerik 3 Hight_air Numerik 4 Tekanan_spray Numerik 5 electrostatis Numerik 6 minute Numerik 7 thickness Numerik
5
Atribut yang dipakai hanya atribut electrostatis dan thickness yang keduanya memiliki tipe data numerik.
2.6 Data Transformation
Tahap data transformation
merupakan proses mengubah format data awal menjadi sebuah format data standar untuk proses pembacaan data
dengan algoritma pada program
maupun aplikasi yang digunakan, kemudian proses pengujian data
denagan menggunakan program
maupun tool yang digunakan.
Berikut adalah hasil pengolahan data awal setelah melawati tahapan diatas untuk dijadikan dataset pada tahap selanjutnya.
Tabel 2.6 Data Transformation (Dataset)
2.7 Pemodelan
Pada tahap ini dilakukan
pemodelan data, metode yang dipakai pada penelitian ini adalah algoritma
k-means yang merupakan sebuah
klasterisasi sederhana yang
mengaplikasikan dengan asumsi ke tidak tergantungan (independen) yang tinggi, dan tools yang dipakai adalah
RapidMiner Studio. K-means
merupakan metode clustering
sederhana berdasarkan data dimana
dilakukan melalui training set
sejumlah data secara efisien dan mengasumsikan bahwa nilai dari sebuah input atribut pada kelas yang diberikan tidak tergantung dengan nilai atribut yang lain.
2.8 Pengujian Data
Pengujian data dilakukan untuk
mengetahui hasil perhitungan yang
dianalisa dan untuk mengetahui
apakah fungsi bekerja dengan baik atau tidak. Setelah data dihitung secara
manual, kemudian data diuji
menggunaka tools Rapid Miner untuk memastikan apakah hasil perhitungan berjalan baik dalam menentukan klusterisasi dari sebuah data.
1. Menentukan jumlah klaster yang
akan dipakai, dalam penelitian ini dipakai 2 jenis klaster, yakni klaster Potensi Produk OK (C0) untuk produk yang memiliki potensi hasil produk dengan kualitas OK dan Potensi Produk NG (C1) untuk untuk produk yang memiliki potensi hasil produk dengan kualitas NG.
2.Inisialisasi K pusat klaster ini bisa dilakukan dengan berbagai cara, namun yang paling sering dilakukan adalah dengan cara random. Pusat-pusat klaster diberi nilai awal dengan angka-angka random.
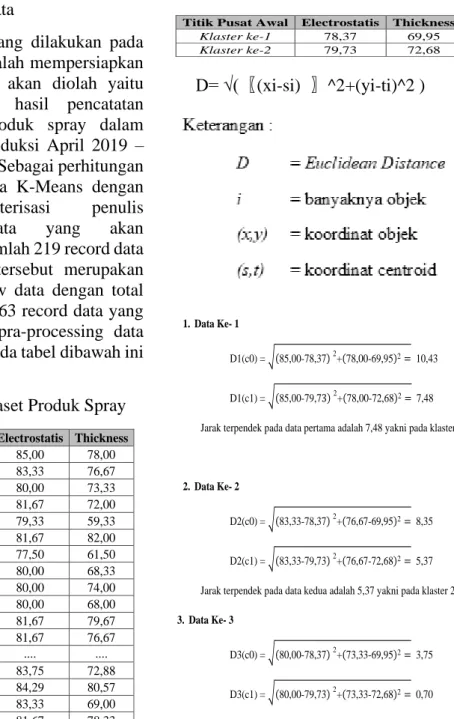
Tabel 2.8 Titik Pusat Awal Klaster
3.Alokasi semua data/objek ke klaster
terdekat, kedekatan dua objek
ditentukan berdasarkan jarak kedua objek tersebut.
D=√((Xi-Si)^2+(yi-ti)^2 ) Data Electrostatis Thickness
Data Spray 1 85,00 78,00 Data Spray 2 83,33 76,67 Data Spray 3 80,00 73,33 Data Spray 4 81,67 72,00 Data Spray 5 79,33 59,33 Data Spray 6 81,67 82,00 Data Spray 7 77,50 61,50 Data Spray 8 80,00 68,33 Data Spray 9 80,00 74,00 Data Spray 10 80,00 68,00
Titik Pusat Awal Electrostatis Thickness
Klaster ke-1 78,37 69,95
Klaster ke-2 79,73 72,68
No Nama Atribut Type
1 Electrostatis Numerik 2 thickness Numerik
6
Keterangan :
D = Euclidean Distance i = banyaknya objek (x,y) = koordinat objek
(s,t) = koordinat centroid atribut (𝑙) 4.Mengelompokkan objek berdasarkan jarak ke centroid terdekat dengan ketentuan jarak hasil perhitungan akan dilakukan perbandingan diantara 2 klaster data terdekat dengan pusat
klaster dengan mengambil nilai
terkecil, jarak ini menunjukkan bahwa data tersebut berada dalam 1 kelompok dengan pusat klaster terdekat.
5.Hitung kembali pusat klaster dengan keanggotaan klaster yang sekarang. Pusat klaster adalah rata-rata dari
semua data/objek dalam klaster
tertentu. Jika dikehendaki bisa juga menggunakan median dari klaster tersebut. Jadi rata-rata (mean) bukan satu- satunya ukuran yang bisa dipakai. 𝑅 𝑙 −1 ᴺ𝑙 (𝑋 1𝑙 + 𝑋 2𝑙 + ⋯+ 𝑋 𝑛𝑙 )
Dimana :
𝑅 𝑙 = Rata-rata baru
𝑁 𝑙 = Jumlah training Pattern pada klaster (k).
Xnk = Pola ke (n) yang menjadi bagian dari klaster (k)
6.Tugaskan lagi tiap objek memakai pusat klaster yang baru. Jika pusat klaster tidak berubah lagi maka
proses klastering selesai. Atau
kembali ke langkah nomor 3 sampai pusat klister mencapai hasil optimal dan tidak terjadi perubahan pada
jumlah anggota di masing-masing klaster.
2.9 Evaluasi Pengujian
Evaluasi dapat dilakukan dengan cara mengamati dan menganalisa hasil dari algoritma yang digunakan untuk memastikan bahwa hasil pengujian
benar-benar sesuai dengan
pembahasan. Melakukan pengecekan terhadap setiap nilai atribut dan model yang sudah dibangun.
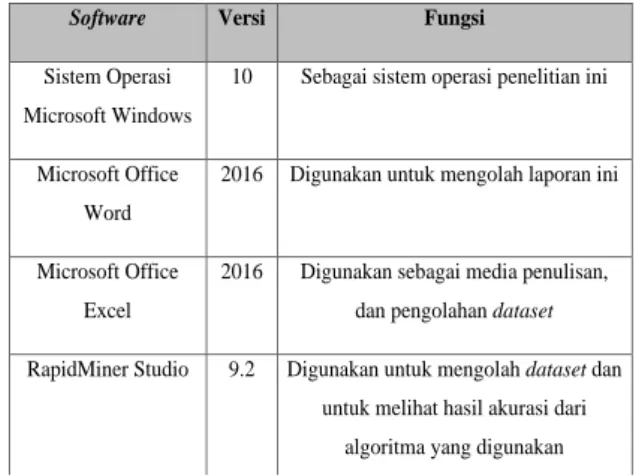
2.9.1 Kebutuhan Perangkat Tabel 3. 6 Perangkat Lunak
(Software)
2.9.2 Kebutuhan Perangkat Keras (Hardware)
Selain perangkat lunak (software) dibutuhkan pula perankat keras
(Hardware) sebagai pendukung
penelitian data mining , yaitu laptop. Adapun spesifikasi laptop dijelaskan pada tabel 2.9.2 dibawah ini:
Tabel 2.9.2 Perangkat Keras (Hardware)
Software Versi Fungsi Sistem Operasi
Microsoft Windows
10 Sebagai sistem operasi penelitian ini
Microsoft Office Word
2016 Digunakan untuk mengolah laporan ini
Microsoft Office Excel
2016 Digunakan sebagai media penulisan, dan pengolahan dataset RapidMiner Studio 9.2 Digunakan untuk mengolah dataset dan
untuk melihat hasil akurasi dari algoritma yang digunakan
7
III Hasil dan Pembahasan
3.1 Penerapan Algoritma K-Means 3.1.1 Analisis Data
Tahapan awal yang dilakukan pada penelitian ini adalah mempersiapkan data, data yang akan diolah yaitu kumpulan data hasil pencatatan proses pada produk spray dalam kurun waktu produksi April 2019 – Desember 2019. Sebagai perhitungan tentang algoritma K-Means dengan
metode klasterisasi penulis
mengambil data yang akan
dimodelkan sejumlah 219 record data , dimana data tersebut merupakan agregasi dari raw data dengan total baris sebanyak 863 record data yang telah melewati pra-processing data seperti terlihat pada tabel dibawah ini :
Tabel 3.1.1 Dataset Produk Spray
3.2 Tahapan dan Contoh Perhitungan Algoritma K-Means
Sebagai perhitungan algoritma K-Means penulis mengambil data yang
akan diolah sebagai sampel
perhitungan yaitu sebanyak 219 record
dataset yang nantinya akan
dikelompokkan kedalam dua cluster. Tabel 3.2.1Titik Pusat Awal Klaster
D= √(〖(xi-si) 〗^2+(yi-ti)^2 )
Spesifikasi Hardware Keterangan
Processor Intel ® Celeron ® CPU @1.50 GHz
RAM 4,00 GB
System Operation Windows 10 Enterprise 64-bit (10.0, Build 16299)
No Data Electrostatis Thickness
1 Data Spray 1 85,00 78,00 2 Data Spray 2 83,33 76,67 3 Data Spray 3 80,00 73,33 4 Data Spray 4 81,67 72,00 5 Data Spray 5 79,33 59,33 6 Data Spray 6 81,67 82,00 7 Data Spray 7 77,50 61,50 8 Data Spray 8 80,00 68,33 9 Data Spray 9 80,00 74,00 10 Data Spray 10 80,00 68,00 11 Data Spray 11 81,67 79,67 12 Data Spray 12 81,67 76,67 ... ... .... .... 215 Data Spray 215 83,75 72,88 216 Data Spray 216 84,29 80,57 217 Data Spray 217 83,33 69,00 218 Data Spray 218 81,67 78,33 219 Data Spray 219 83,33 77,83
Titik Pusat Awal Electrostatis Thickness
Klaster ke-1 78,37 69,95 Klaster ke-2 79,73 72,68
1. Data Ke- 1
D1(c0) = 85,00-78,37 2+ 78,00-69,95 2= 10,43
D1(c1) = 85,00-79,73 2+ 78,00-72,68 2= 7,48
Jarak terpendek pada data pertama adalah 7,48 yakni pada klaster 2 (C1).
2. Data Ke- 2
D2(c0) = 83,33-78,37 2+ 76,67-69,95 2= 8,35
D2(c1) = 83,33-79,73 2+ 76,67-72,68 2= 5,37 Jarak terpendek pada data kedua adalah 5,37 yakni pada klaster 2 (C1). 3. Data Ke- 3
D3(c0) = 80,00-78,37 2+ 73,33-69,95 2= 3,75
D3(c1) = 80,00-79,73 2+ 73,33-72,68 2= 0,70 Jarak terpendek pada data kedua adalah 5,37 yakni pada klaster 2 (C1).
8
3.3 Hasil Pengujian
3.3.1 Evaluasi Pengujian pada Aplikasi RapidMiner Studio
Pengujian model yang didapat dengan menggunakan aplikasi RapidMiner Studio adalah dengan tahapan langkah - langkah sebagai
1.Melakukan import data yang
diperlukan untuk proses pada tools
Rapid Miner. Pada aplikasi
RapidMiner Studio pilih dan klik Import Data, kemudian pilih data yang
akan dipakai serta kemudian
menentukan attribut dan label yang akan digunakan.
2.Pada menu Names & Roles cari fungsi Set Role yang nantinya akan dipakai untuk mengatur role atrribut, kemudian drag ke layar tampilan proses.
3.Selanjutnya pada menu
Normalization pilih Normalize dan drag ke layar tampilan proses, melalui fungsi ini dapat mengatur normalisasi data yang akan dilakukan dari dataset yang dipakai pada proses ini.
4.Kemudian pada menu Modelling, dalam submenu Segmentation, pilih fungsi k-Means, untuk menerapkan algoritma K-Means terhadap proses klasterisasi yang akan dilakukan.
Gambar 3.3. 1 Parameter pada Function Clustering
5.Langkah berikutnya adalah
menambahkan fungsi Performance untuk menampilkan nilai David-Bouldin Index (DBI) yang didapat dari
proses klasterisasi data hasil
pencatatan proses produk spray yang digunakan.
6.Koneksikan semua perintah tersebut
sehingga pada layar tampilan proses terlihat alur sebagai berikut :
7.Lakukan Running Process. 3.4 Analisa Hasil Pengujian
metode klasterisasi, pemanfaatan
algoritma K-Means yang digunakan menghasilkan suatu pengelompokkan klaster terhadap masing-masing data. Dataset hasil pencatatan proses produk spray yang digunakan adalah sebanyak 219 record data yang akan diuji pada proses pembentukan kelompok klaster dengan algoritma K-Means. Hasil cluster model pada pengujian aplikasi RapidMiner Studio menunjukkan dari 219 data tersebut, terdapat 113 data masuk kelompok klaster pertama (C0) dan 109 data masuk pada kelompok klaster kedua (C1), yang dapat dilihat pada gambar berikut.
9
Tabel 3.4 Optimal Cluster pada aplikasi RapidMiner Studio
VI.KESIMPULAN DAN SARAN
4.1. Kesimpulan
Berdasarkan hasil yang penelitian yang dilakukan oleh penulis, kesimpulan yang didapat yaitu sebagai berikut :
1.Pendekatan metode klasterisasi
dapat diterapkan dalam menganalisis tingkat potensi kualitas produk spray yang dihasilkan dengan memanfaatkan dataset pencatatan proses hasil produk spray selama periode April 2019 – Desember 2019 yang terdiri dari 219 record data.
2.Model algoritma K-Means yang
diterapkan memiliki hasil yang
menunjukkan sebuah wawasan baru, yaitu pengelompokkan tingkat kualitas produk spray berdasarkan 2 klaster, klaster 1 (C0) merupakan kategori
Potensi Produk OK yang terdiri dari 106 data dari 219 dataset yang diuji dan klaster 2 (C1) adalah merupakan Potensi Produk NG yang terdiri dari 113 data dari 219 datase yang diuji. 3.Pengujian menggunakan aplikasi
RapidMiner Studio juga dapat
menghasilkan wawasan yang serupa yaitu masing-masing klaster memiliki
anggota kelompok yang terbagi
menjadi 2 klaster, dengan masing-masing klaster memiliki nilai centroid optimal yakni 80,59 & 78,03 untuk C0 serta 77,41 & 64,15 untuk C1, dengan nilai evaluasi Davies-Bouldin Index sebesar 0,756.
4.2 Saran
Beberapa saran dalam penelitian ini untuk pengembangan lebih lanjut antara lain yaitu :
1.Memperbanyak jumlah record
maupun rentang pengambilan data yang akan digunakan dalam penelitian selanjutnya agar dapat ditemukan banyak lagi kelompok klaster yang dapat dilihat dan dapat memetakan tingkat kualitas hasil produk spray lebih representatif.
2.Pemanfaatan data dalam sistem yang
terintregasi menjadi lebih luas dan dapat digunakan sebagai media dalam mencari pengetahuan dan wawasan baru bagi para stakeholder baik dari lingkungan internal maupun pihak eksternal yang membutuhkan.
DAFTAR PUSTAKA
[1] M. Miqdad, “Penentuan Kualitas
Kayu Kelapa Menggunakan Algoritma Naive Bayes
10
Berdasarkan Tekstur pada Citra,” pp. 1–6, 2015.
[2] S. Rahayu and A. S. RMS,
“Penerapan Metode Naive Bayes Dalam Pemilihan Kualitas Jenis Rumput Taman CV. Rumput Kita Landscape,” Digit. Zo. J. Teknol.
Inf. dan Komun., vol. 9, no. 2, pp.
162–171, 2018, doi:
10.31849/digitalzone.v9i2.1942.
[3] Retno Tri vulandari, Data
Mining. Yogyakarta: Gava
Media, 2017.
[4] Suyanto, Data Mining.
Yogyakarta: Informatika, 2017.
[5] M. A. K-means, S. M. Hutabarat,
and A. Sindar, “Data Mining Penjualan Suku Cadang Sepeda Motor,” vol. 2, no. 2, pp. 126– 132, 2019.
[6] H. Hasanah, W. Larasati, F. I.
Komputer, U. Duta, B. Surakarta,
and K. Clusterring, “PEMANFAATAN DATA MINING UNTUK MENGELOMPOKKAN,” pp. 292–300, 2019. [7] J. P. Informatika, J. T. Jabat, P.
Retail, M. Clustering, and I.
Pendahuluan, “PENERAPAN
DATA MINING PADA
PENJUALAN PRODUK RETAIL,” vol. 8, pp. 26–32, 2019. [8] T.Informatika, “PENGELOMPOKKAN LOYALITAS PELANGGAN DENGAN MENGGUNAKAN KOMBINASI RFM DAN
ALGORITMA K-MEANS,” vol. 5, no. 1, pp. 7–13, 2020.
[9] G. Gunadi and D. I. Sensuse,
“Penerapan Metode Data Mining
Market Basket Analysis
Terhadap Data Penjualan Produk
Buku Dengan Menggunakan
Algoritma Apriori Dan Frequent Pattern Growth ( Fp-Growth ) :,”
Telematika, vol. 4, no. 1, pp. 118–
132, 2012.
[10] M. Miftakhul and S. Prihandoko, “Penerapan Algoritma K-Means dan Cure Dalam Menganalisa Pola Perubahan Belanja Dari Retail ke E-Commerce,” vol. 7, no. 2, pp. 44–49, 2017.
[11] O. Villacampa, “(Weka - Thesis)
Feature Selection and
Classification Methods for
Decision Making: A
Comparative Analysis,”
ProQuest Diss. Theses, no. 63, p.
188, 2015.
12] S. Haryati, A. Sudarsono, and E.
(2015) Suryana, “Implementasi Data Mining untuk Memprediksi
Masa Studi Mahasiswa
Menggunakan Algoritma C4.5,”
J. Media Infotama, vol. 11, no. 2,