1
ANALISA DATA MINING UNTUK MEMPREDIKSI PENERIMA
BEASISWA BIDIKMISI BAGI SISWA SMK MENGGUNAKAN
METODE NAIVE BAYES
DIAN FRASISKA
Program Studi Teknik Informatika, Universitas Pelita Bangsa Korespondensi email: pelitateknologi@gmail.com
ABSTRACT
Data mining is a process that uses statistics, mathematics, artificial intelligence, and machine learning to extract and identify useful information and related knowledge from various large databases. In this study using data mining techniques with the Naive Bayes method to predict students who are considered capable of providing accurate results in classifying scholarship recipients into two classes, namely feasible classes and improper classes. The problem that often arises, namely the inaccurate distribution of scholarships to students, for example students who are not actually eligible for a scholarship but get a scholarship, on the other hand students who are entitled to get good scholarships are outstanding scholarships or underprivileged scholarships but do not get scholarships. Based on the background of the problem, this study aims to help the Syafa'atul Ummah Bulakamba Vocational School in bidikmisi scholarship selection, Naïve Bayes Algorithm for prediction in the bidikmisi scholarship recipient process for Syafa'atul Umak Bulakamba Vocational School students, Measuring accuracy, precision and recall on the algorithm Naïve Bayes to predict bidikmisi scholarship recipients for Syafa'atul Ummah Bulakamba
vocational students. The research method used is the Naïve Bayes algorithm. While this study will use a confusion matrix to test and measure performance. Based on the test results, the Naïve Bayes algorithm produces an accuracy value of 93.48%. Based on the results obtained, it can be concluded that the method used has good accuracy performance and can increase the accuracy value.
Keywords :
Data mining, Naive Bayes Algorithm, RapidMiner
1. Pendahuluan
Pendidikan adalah usaha sadar dan terencana untuk mewujudkan suasana belajar dan proses pembelajaran agar peserta didik dapat menambah potensi yang dimiliki oleh dirinya. Fungsi pendidikan sangat penting sebagai salah satu faktor pendorong pembangunan sebagai sumber daya manusia dengan tujuan meningkatkan kemampuan pada masyarakatnya dalam mengembangkan ilmu pengetahuan.
Disetiap lembaga pendidikan khususnya sekolah banyak sekali beasiswa yang ditujukan kepada siswa, baik yang berprestasi maupun yang kurang mampu. Beasiswa ditujukan untuk membantu meringankan beban biaya siswa yang mendapatkannya.
2 Untuk memperoleh beasiswa tersebut
harus sesuai dengan kriteria-kriteria yang telah ditetapkan, seperti jumlah penghasilan orang tua, jumlah tanggungan orang tua, jumlah saudara kandung, nilai rata-rata, dan persentase kehadiran siswa.
Selama ini proses penentuan penerima beasiswa hanya dilihat dari nilai rapot, dan tidak menggunakan penilaian lain untuk menentukan berhak atau tidaknya siswa tersebut memperoleh beasiswa, namun pengolahan data beasiswa di SMK Syafa’atul Ummah Bulakamba pada umumnya masih menggunakan cara yang masih manual, yaitu belum adanya komputerisasi dalam penerimaan beasiswa sehingga banyak masalah yang terjadi. Permasalahan yang sering muncul, yaitu kurang tepatnya penyaluran beasiswa terhadap siswa, misalnya siswa yang sebenarnya tidak layak mendapatkan beasiswa tetapi mendapatkan beasiswa, sebaliknya siswa yang berhak mendapatkan beasiswa baik itu beasiswa berprestasi maupun beasiswa kurang mampu tetapi tidak mendapatkan beasiswa. Tujuan dari adanya beasiswa yaitu memotivasi siswa untuk selalu meningkatkan prestasi akademik maupun non akademik, membantu siswa yang kurang mampu tetapi berprestasi, dan menumbuhkan rasa percaya diri siswa untuk berkompetitif dalam mengembangkan potensinya.
Data mining adalah serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual.
Dalam penelitian ini menggunakan teknik data mining dengan metode Naive Bayes untuk memprediksi siswa
yang dianggap mampu memberikan hasil yang akurat dalam pengklasifikasian penerima beasiswa ke dalam dua kelas yaitu kelas layak dan kelas tidak layak.
2. Metodologi
Dalam penelitian ini akan dilakukan analisa menggunakan metode klasifikasi dengan algoritma Naive Bayes. Data dihitung dengan menggunakan algoritma ini sesuai dengan metodenya kemudian dicari hasil akurasinya. Dalam tahapan ini akan dilakukan beberapa langkah pengujian data yaitu seperti berikut :
Gambar 3.2 Langkah pengujian metode
Pengolahan data menggunakan metode algoritma Naive Bayes
1. Hasil pengolahan data menggunakan algoritma Naive Bayes.
2. Menganalisa hasil algoritma Naive Bayes dengan RapidMiner.
Data siswa akan di olah menggunakan algoritma Naive Bayes, kemudian akan dilihat tingkat akurasinya dan keterkaitan antara setiap. Algoritma Naive Bayes akan mengevaluasi setiap atribut target. Naive Bayes tidak menghitung relasi antar atribut-atribut
Menganalisa hasil algoritma naive bayes dengan rapidminer
Hasil pengolahan data menggunakan algoritma naive
bayes
Pengolahan data menggunakan metode algoritma naive bayes
3 contributor prediksi, tidak seperti
metode decisition tree. Bentuk tugas yang dilakukan algoritma Naive Bayes adalah hanya klasifikasi.
3. Metode Pengumpulan Data
Metode yang digunakan pada pengumpulan data dalam penelitian ini adalah menggunakan metode pengumpulan data secara primer. Data primer yang digunakan di dapat secara langsung pada objek penelitian yang digunakan.
Data beasiswa diketahui memiliki atribut sebanyak 7 dengan satu diantaranya adalah merupakan kelas prediksi. Berikut ini merupakan atribut serta kelas yang terdapat pada data set:
Tabel 3.2 Atribut Data Penelitian Atribut Keterangan
Nama Atribut yang di fungsikan sebagai ID Jenis Kelamin Atribut ini Menginformasikan jenis kelamin
JPO Atribut ini
menginformasikan jumlah penghasilan orang tua siswa pemohon
JTO Atribut ini
menginformasikan jumlah tanggungan orang tua siswa pemohon
Nilai Atribut ini
menginformasikan nilai rata-rata rapor siswa Atribut Keterangan
Beasiswa Atribut ini menginformasikan keterangan siswa layak atau tidak layak untuk mendapatkan beasiswa
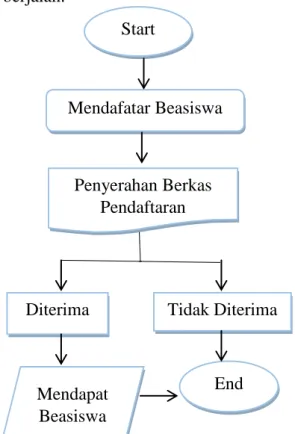
A. Analisa Algoritma Naïve Bayes Berikut adalah flowchart analisa algoritma Naïve Bayes yang sedang berjalan.
Gambar 3.2 Analisa Algoritma Naïve Bayes
Keterangan :
1. Sekolah melakukan pemilihan calon peneima beasiswa bidikmisi.
2. Siswa melakukan pendaftaran beasiswa.
3. Siswa yang memenuhi syarat langsung menyerahkan berkas pendaftaran.
4. Sekolah melakukan verifikasi calon penerima beasiswa yang layak atau memenuhi syarat, bagi yang tidak memenuhi syarat tidak diproses. 5. Sekolah mengumumkan calon
penerima beasiswa yang berhak mendapatkan beasiswa, Start Mendafatar Beasiswa Penyerahan Berkas Pendaftaran Diterima Mendapat Beasiswa Tidak Diterima End
4
4. Pengujian dan Validasi Algoritma Pada tahap ini peneliti menentukan teknik data mining yang digunakan untuk mengelolah data yang telah disiapkan sebelumnya. Teknik yang dilakukan yaitu dengan klasifikasi menggunakan algoritma Naïve Bayes. Berikut merupakan langkah-langkah yang dilakukan pada tahap ini yaitu : 1. Perhitungan Naive Bayes secara
manual, data yang digunakan dalam perhitungan naïve bayes secara manual diambil 1 sampel data, data yang diambil oleh peneliti yaitu data siswa dari sekolah SMK Syafa’atul Ummah Bulakamba yang jumlah muridnya 525 siswa
2. Penerapan metode Naïve Bayes menggunakan RapidMiner, implementasi dengan menggunakan RapidMiner bertujuan untuk memudahkan dalam proses pengelolahan data yang berjumlah besar serta untuk mengetahui tingkat akurasi terhadap data dan metode yang digunakan.
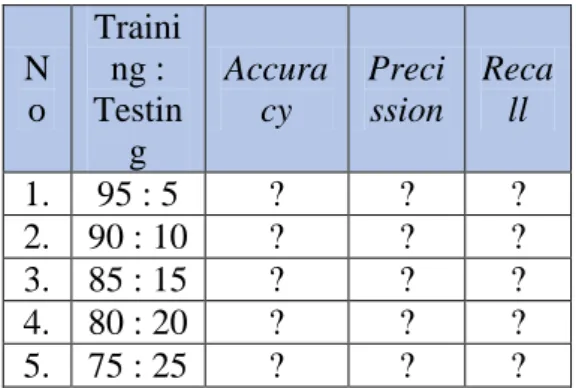
5. Evaluasi Model
Tahapan evaluasi model yang akan digunakan pada penelitian ini adalah dengan menggunakan confusion matrix di mana performa dari suatu model kasifikasi dapat diukur dengan menggunakan model evaluasi ini. Evaluasi pada penelitian ini akan diketahui penilaian dari hasil pengujian algoritma Naive Bayes dan algoritma Naive Bayes. Tahap evaluasi pada penelitian ini akan dihitung nilai accuracy, precision, dan recall sebagai ukuran performansi dari algoritma. Karena pada pengujian dan validasi menggunakan Split validation, maka pengujian akan dilakukan sebanyak 5 kali, dimana percobaan pengujian yang
paling tinggi akan diambil sebagai nilai perbandingan pada setiap algoritma. Berikut ini merupakan tabel evaluasi model dalam membandingkan performansi pada nilai accuracy, precision, dan recall.
Tabel 3.15 Evaluasi model
N o Traini ng : Testin g Accura cy Preci ssion Reca ll 1. 95 : 5 ? ? ? 2. 90 : 10 ? ? ? 3. 85 : 15 ? ? ? 4. 80 : 20 ? ? ? 5. 75 : 25 ? ? ?
Berdasarkan pada Tabel 3.15 diatas, maka dapat diketahui bahwa evaluasi pada penelitian ini adalah dengan mengukur nilai accuracy, precision, dan recall yang dihasilkan oleh confusion matrix. Penentuan nilai yang digunakan pada tabel evaluasi di atas adalah dengan mencari nilai tertinggi, yang ada pada setiap percobaan pengujian. Setiap algoritma akan dilakukan pengujian dan diukur nilai accuracy, precision, dan recall. Pengujian ini juga akan diketahui kinerja dalam meningkatkan performansi terhadap algoritma Naïve Bayes dalam memprediksi beasiswa.
6. Hasil Penelitian
Hasil penelitian akan menjelaskan pengujian yang telah dilakukan terhadap algoritma yang digunakan dalam memprediksi penerima beasiswa bidikmisi bagi siswa SMK Syafa’ayul Ummah Bulakamba. Pengujian yang dilakukan menggunakan algoritma
5 Naïve Bayes dan pengujian dengan
RapidMiner.
a. Pengujian Perhitungan Menggunakan Naïve Bayes Untuk memudahkan dalam pemahaman perhitungan Naïve Bayes secara manual akan dibuat studi kasus sebagai berikut dengan rulenya berupa data testing, terdapat siswa bernama A. Maelin Filaskar dengan data sbb :
1. Tahap 1 Mencari Nilai P(Ci) P(Ci)
Layak dan Tidak Layak P(Layak) P(Tidak Layak)
176/233 57/233
0,7553 0,2447
2. Tahap 2 Mencari Nilai P(X│Ci) a. Jenis Kelamin
Jenis Kelamin
Layak Tidak Layak
Laki-laki
97/176 35/57 0,5511 0,6140 b. Penghasilan Orang Tua
Penghasilan Orang Tua Layak TidakLayak Rendah 94/176 18/57
0,5340 0,3158
c. Pekerjaan Orang Tua Pekerjaan Orang Tua
Layak TidakLayak Petani 85/176 23/57
0,4830 0,4036 d. Tanggungan Orang Tua
Tanggungan Orang Tua Layak Tidak Layak
2 73/176 23/57
0,4148 0,4036 e. Nilai Rata – rata Rapor
Nilai Rata – rata Rapor Layak TidakLayak ≥ 80 171/176 13/57
0,9716 0,2280 3. Tahap 3 mengkalikan semua hasil
atribut “”Layak” dan “Tidak Layak” kemudian dikalikan dengan probabilitas masing-masing kelas P(X│C)*P(Ci). Layak TidakLayak P(Ci) 0,7553 0,2447 P(X│Ci) 0,5511 0,6140 0,5340 0,3158 0,4830 0,4036 0,4148 0,4036 0,9716 0,2280 Hasil 0,0432677725 > 0,0017621855 Status Penerima Layak
b. Pengujian Dengan Rapid Miner Pengujian yang dilakukan pada penelitian ini menggunakan tools aplikasi Rapid Miner. Metode ini dilakukan untuk menghasilkan pengujian dengan lebih efisien. Pengujian dengan menggunakan tools RapidMiner mampu menghasilkan prediksi dengan lebih cepat dibanding dengan metode penghitungan manual. Selain itu pengujian dengan tools ini,
6 juga akan menggunakan sumber data
set yang berjumlah 233, yang telah melalui tahap preprocessing. Pengujian ini juga akan menggunakan metode evaluasi dan validasi menggunakan split validation.
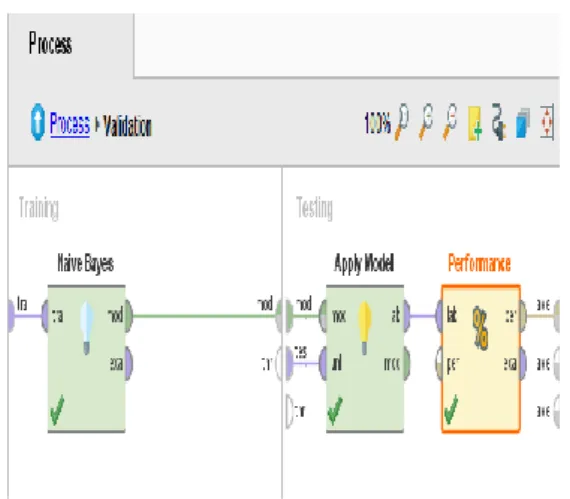
1. Proses Validasi
Proses validasi yaitu melakukan analisis berbagai model dan memilih model dengan prediksi terbaik, paga gambar 4.1 merupakan proses validasi, dimana operator read excel dimasukkan data training dan data testing kemudian dihubungkan dengan operator split validation.
Gambar 4.1 Proses Split Validation 2. Proses training dan testing
Proses training dan testing yaitu melakukan proses pelatihan data pada model Naïve Bayes, sedangkan proses testing yaitu melakukan pengujian data yang akan menghasilkan grafik dan pola.
Pada gambar 4.2 dijelaskan bahwa proses training dilakukan dengan memasukkan model Naïve Bayes pada blok training dan dihubungkan dengan blok testing pada operator apply model dan performance.
Gambar. 4.2 Training dan Testing 3. Hasil Performance Vector
Proses klasifikasi menggunakan RapidMiner dengan Naïve Bayes yang digunakan untuk mengetahui calon penerima beasiswa yang layak dan tidak layak. Disini peneliti akan mencoba 5 pengujian dengan perbandingan 90 : 10 pada tools RapidMiner untuk mencari nilai akurasi tertinggi.
A. Pengujian Keempat yaitu 80 : 20 1) Accuracy
Dengan mengetahui jumlah data yang diklasifikasikan secara benar maka dapat diketahui akurasi hasil prediksi yaitu 93,48%.
2) Precission
Precission adalah jumlah data yang true positive (jumlah data positif
7 yang dikenali secara benar sebagai
positif) dibagi dengan jumlah data yang dikenali sebagai positif. Dari hasil pengujian nilai precission yaitu 83,33%.
3) Recall
Recall adalah jumlah data true positive dibagi dengan jumlah data yang sebenarnya positif (true positive + true negative). Untuk nilai recall yaitu 90,91%.
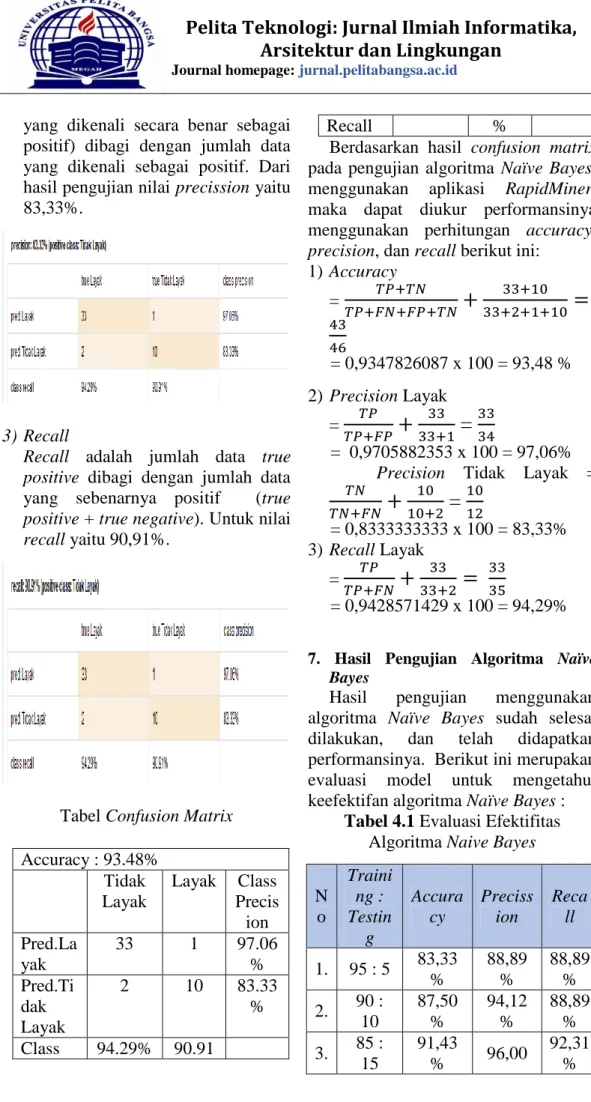
Tabel Confusion Matrix Accuracy : 93.48% Tidak Layak Layak Class Precis ion Pred.La yak 33 1 97.06 % Pred.Ti dak Layak 2 10 83.33 % Class 94.29% 90.91 Recall %
Berdasarkan hasil confusion matrix pada pengujian algoritma Naïve Bayes, menggunakan aplikasi RapidMiner, maka dapat diukur performansinya menggunakan perhitungan accuracy, precision, dan recall berikut ini:
1) Accuracy = = 0,9347826087 x 100 = 93,48 % 2) Precision Layak =
=
= 0,9705882353 x 100 = 97,06% Precision Tidak Layak =
=
= 0,8333333333 x 100 = 83,33% 3) Recall Layak == 0,9428571429 x 100 = 94,29%
7. Hasil Pengujian Algoritma Naïve Bayes
Hasil pengujian menggunakan algoritma Naïve Bayes sudah selesai dilakukan, dan telah didapatkan performansinya. Berikut ini merupakan evaluasi model untuk mengetahui keefektifan algoritma Naïve Bayes :
Tabel 4.1 Evaluasi Efektifitas Algoritma Naive Bayes
N o Traini ng : Testin g Accura cy Preciss ion Reca ll 1. 95 : 5 83,33 % 88,89 % 88,89 % 2. 90 : 10 87,50 % 94,12 % 88,89 % 3. 85 : 15 91,43 % 96,00 92,31 %
8 4. 80 : 20 93,48 % 97,06 % 94,29 % 5. 75 : 25 93,10 % 95,45 % 95,45 % Berdasarkan hasil evaluasi efektifitas algoritma Naïve Bayes, dapat diketahui nilai-nilai evaluasi yaitu nilai accuracy, precision, dan recall yang dihasilkan oleh masing-masing algoritma. Efektifitas Naïve Bayes dalam meningkatkan kinerja performansi algoritma Naïve Bayes lebih tepat digunakan dengan data set.
8. Analisis Hasil Pengujian
Berdasarkan hasil dari pengukuran performansi yang dilakukan oleh algoritma Naive Bayes, maka analisis yang dapat diambil, yaitu sebagai berikut:
1. Performansi yang dihasilkan oleh algoritma Naive Bayes menghasilkan nilai accuracy sebesar 93,48%. Hasil tersebut menunjukan hasil prediksi layakdan tidak layakbekerja dengan baik dan sesuai. Nilai ini terbilang sangat baik dalam memprediksi layakdan tidak layak.
2. Nilai precision yang dihasilkan oleh algoritma Naive Bayes diketahui mempunyai hasil 97,06%.
3. Pengukuran nilai recall yang dihasilkan dari model yang diusulkan memiliki nilai yang sangat kecil yaitu hanya 88,24% dan mengalami penurunan signifikan dari pengujian sebelumnya menggunakan algoritma Naive Bayes. Nilai recall tersebut menunjukan dari seluruh data aktual layak hanya 94,29% yang dapat diprediksi dengan benar, masih 90,91% tidak layak.
4. Hasil performansi dengan algoritma Naïve Bayes dengan prediksi menggunakan RapidMiner
mendapatkan nilai yang paling tinggi yaitu pada pengujian keempat dengan nilai accuracy sebesar 93,48%, nilai precision 97,06%, dan nilai recall 88,24%.
Kesimpulan
Berdasarkan hasil penelitian yang telah dilakukan untuk mengetahui prediksi penerima beasiswa bidikmisi pada sekolah SMK Syafa’atul Ummah Bulakamba, maka dapat diambil kesimpulan sebagai berikut :
1. Metode Naïve Bayes digunakan untuk menganalisa penerima beasiswa bidikmisi terhadap siswa SMK Syafa’atul Ummah, memiliki tingkat akurasi yang cukup baik dalam menyelesaikan klasifikasi rekomendasi beasiswa berprestasi dan kurang mampu. Metode Naïve Bayes merupakan metode yang cukup sesuai untuk menyelesaikan studi kasus dalam pemilihan siswa yang mendapatkan rekomendasi beasiswa berprestasi dan kurang mampu.
2. Proses data mining dengan metode Naïve Bayes dapat menganalisa dan mengetahui prediksi penerima beasiswa bidikmisi bagi siswa SMK Syafa’atul Ummah Bulakamba dengan cepat dan akurat, dari pengujian yang dilakukan menggunakan RapidMiner didapat tingkat akurasi sebesar 93,48%, Precission 97,06%, dan Recall 94,29%. Hasil tersebut menunjukan hasil prediksi siswa. Nilai ini terbilang sangat tinggi yang berarti model usulan sangat baik dalam memprediksi penerima beasiswa bidikmisi bagi siswa SMK Syafa’atul Ummah Bulakamba.
9 Saran
Berdasarkan hasil penelitian yang telah dilakukan untuk mengetahui prediksi penerima beasiswa bidikmisi pada sekolah SMK Syafa’atul Ummah Bulakamba, Adapun beberapa saran yang dapat diajukan antara lain:
1. Menentukan jumlah data training dapat mempengaruhi hasil pengujian karena pola data training akan dijadikan sebagai rule untuk menentukan kelas pada data testing, sehingga besar atau kecilnya penentuan tingkat akurasi dipengaruhi juga oleh penentuan data training. Maka untuk penelitian selanjutnya diharapkan untuk menambahkan data training dan data testing lebih banyak lagi.
2. Tahapan preprocessing yang dilakukan bisa dengan teknik lain, agar data set mempunyai kualitas yang baik, seperti penyeleksian atribut, diskretisasi atribut numerik, dan lain sebagainya.
DAFTAR PUSTAKA
Aditya, Yohan. 2017.”Pengembangan Sistem Rekomendasi Calon Penerima Beasiswa Dengan Metode Naïve Bayes”. Jurnal Jurusan sistem Informasi, Universitas Nusantara PGRI Kediri.
Indrasari, Fadila Nur. 2018”Klasifikasi Penerima Beasiswa Menggunakan Algoritma Naïve Bayes Classifier”. Artikel Sistem Informasi, Universitas Nusantara PGRI Kediri.
Shella, Pradega. 2015. “Sistem Pendukung Keputusan Dengan Menggunakan Decission Tree Dalam Pemberian Beasiswa Di Sekolah Menengah Pertama”. Jurusan Teknik elektro, Universitas Negeri Semarang.
Virgana, dkk. 2014. “Kajian Algoritma Naive Bayes Dalam Pemilihan Penerima Beasiswa Tingkat SMA”. Seminar Nasional Teknologi Informasi dan Multimedia. STMIK AMIKOM Yogyakarta. ISSN : 2302-3805.
Rahman, Antony Anwari dan Agus Suryanto., 2017. “Implementasi Sistem Informasi Seleksi Penerima Beasiswa Dengan Metode Naive Bayes Classifier”. Jurnal Penelitian Pendidikan Indonesia (JPPI). ISSN 2477-2240 (Media Cetak). 2477-3921 (Media Online). Vol. 2, No. 3.
Rahman, Aziz Abdul dan Yogiek Indra Kurniawan. “Aplikasi Klasifikasi Penerima Kartu Indonesia Sehat Menggunakan Algoritma Naïve Bayes Classifier”. Fakultas Komunikasi dan Informatika. Universitas Muhammadiyah Surakarta.
Mulyadi, 2016. “Penerapan Algoritma Naive Bayes Untuk Klasifikasi Penerima Beasiswa Prestasi”. Jurnal Sistem Informasi STMIK Antar