PERBANDINGAN HASIL DETEKSI KEMIRIPAN TOPIK SKRIPSI DENGAN MENGGUNAKAN METODE N-GRAM DAN EKSPANSI
KUERI
Disusun oleh :
Dwi iswanto L200100014
Pembimbing :
Husni Thamrin
PROGRAM STUDI INFORMATIKA
FAKULTAS KOMUNIKASI DAN INFORMATIKA
UNIVERSITAS MUHAMMADIYAH SURAKARTA
PERBANDINGAN HASIL DETEKSI KEMIRIPAN TOPIK SKRIPSI DENGAN MENGGUNAKAN METODE N-GRAM DAN EKSPANSI
KUERI
Dwi iswanto, Husni Thamrin
Informatika, Fakultas Komunikasi dan Informatika Universitas Muhammadiyah Surakarta
E-mail : dwiiswanto1@gmail.com
ABSTRAKSI
Perbandingan deteksi kemiripan topik skripsi antara metode N-gram dan ekspansi kueri pada penelitian ini diartikan sebagai aplikasi pendeteksi skripsi berbasis web dengan menerapkan metode pencarian seperti metode N-gram dan ekspansi kueri lalu melakukan perbandingan di antara ke dua metode tersebut.
Meskipun Topik skripsi mahasiswa S1 tidak harus orsinil, namun naskah skripsi dari tiap mahasiswa harus berbeda dan tidak mengandung duplikasi atau unsur plagiasi . Oleh karena itu diperlukan pengecekan/pemeriksaan terhadap dokumen skripsi apakah mengandung kesamaan isi. Bagi petugas pekerjaan memeriksa kesamaan / kemiripan topik skripsi merupakan pekerjaan berat dan memakan waktu., oleh karena itu dilakukan upaya penyusunan program yang dapat melakukan sebuah proses deteksi kemiripan antar topik-topik skripsi tersebut.
Tujuan dari penelitian ini, membangun sistem deteksi kemiripan topik skripsi dengan menerapkan metode pencarian yang mampu mendeteksi kemiripan dokumen skripsi, seperti N-gram dan ekspansi kueri.
Beberapasoftware yang digunakan, yaitu sistem operasi Windows 8, XAMPP versi 1.8.2 yang mendukung web server Aphace, database MySQL dan Bahasa pemrograman PHP, Sublime text 3 sebagai code editor, browser Google Chrome 34.0 yang telah mendukung HTML 5.
Hasil ahir dari penelitian telah terbukti bahwa metode N-gram dan ekspansi kueri mampu memberikan hasil deteksi kemiripan dan memberikan hasil berbeda di masing-masing metode yang di terapkan. Pemberian bobot di masing-masing metode akan sangat berpengaruh pada hasil pencarian. Penentuan batas skor minimal menentukan ukuran kemiripan dari setiap metode, ekspansi kueri memiliki hasil lebih baik di banding N-gram dalam deteksi kemiripan.
PENDAHULUAN
Skripsi adalah karangan ilmiah yang wajib ditulis oleh mahasiswa sebagai bagian dari persyaratan akhir pendidikan
akademisnya (KBBI, 2001). Pada
kenyataan saat ini jumlah topik skripsi yang dibuat semakin banyak. Topik skripsi satu dengan yang lainnya, bisa jadi akan serupa baik dari segi topik dan maksud yang akan di sampaikan.
Meskipun Topik skripsi mahasiswa S1 tidak harus orsinil, namun naskah skripsi dari tiap mahasiswa harus berbeda dan tidak mengandung duplikasi atau unsur plagiasi . Oleh karena itu diperlukan
pengecekan / pemeriksaan terhadap
dokumen skripsi apakah mengandung kesamaan isi. Bagi petugas pekerjaan memeriksa kesamaan / kemiripan topik skripsi merupakan pekerjaan berat dan
memakan waktu. Oleh karena itu
Dilakukan upaya penyusunan program yang dapat melakukan sebuah proses deteksi kemiripan antar topik-topik skripsi tersebut.
Setelah mempelajari hal tersebut, peneliti akan merancang dan membangun aplikasi untuk mendeteksi kemiripan topik
skripsi dengan metode N-gram dan
ekspansi kueri. Hal ini diharapkan kesulitan dalam mengetahui kesamaan topik skripsi akan dapat di atasi
TINJAUAN PUSTAKA
Dalam penelitian ini ada beberapa pengertian - pengertian yang perlu dikaji. Beberapa kajian tersebut adalah sebagai berikut:
Sugianto (2013) menyatakan dalam penelitianya bahwa Proses dimulai dengan
memecah kata per kata dan
mengelompokkannya sesuai dengan
language model. Kemudian, dilakukan proses scoring untuk menentukan kata mana yang sesuai untuk menjadi pilihan prediksi kata. Hasil pengujian metode N-gram sebagai metode dasar dalam proses prediksi sangatlah membantu pemilahan kata, sehingga proses prediksi menjadi
lebih efektif, mampu menghasilkan
prediksi efektif di atas 20% dari total prediksi yang terjadi. Selain dari pada metode N-gram sendiri, pengaturan bobot untuk masing-masing score kata juga sangat mempengaruhi proses prediksi kata.
Nanang (2014) dalam penelitianya berpendapat ekspansi kueri merupakan upaya penambahan kata atau kosa kata dengan makna yang sama dari kata kunci yang di gunakan. Hal ini penting di
lakukan dengan tujuan untuk
meningkatkan jumlah dan relevansi hasil temu kembali dokumen ilmiah.
kinerja dari Automatic Query Expansion
(AQE) dengan metode conditional
probability dalam sistem temu kembali informasi probabilistic model. Pemilihan dan pembobotan istilah kueri ekspansi menggunakan nilaiconditional probability.
Pengujian dilakukan dengan
memperhatikantermdan jumlahtermyang ditambahkan sebagai kueri, kemudian membandingkan hasil nilai rata-rata precision yang dihasilkan pada setiap tingkat recall dengan hasil metode lain yang telah diteliti sebelumnya. Selain itu, dilakukan perbandingan hasil pada setiap pengujian berdasarkan nilaithreshold yang digunakan. Jumlah term ekspansi yang diujikan di antaranya addterm 2, addterm 4, addterm 5, addterm 6, addterm 8, dan addterm 10. Jumlah dokumen yang digunakan dalam pengujian sistem ini sebanyak 700 dokumen dengan 30 kueri beserta gugus jawabannya.
METODE
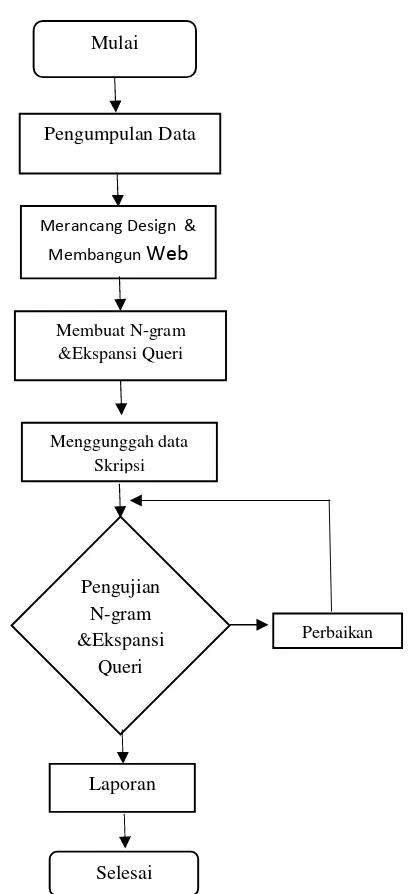
Penulis menggunakan metode Observasi dan Eksperimen dalam penelitian ini. Adapun tahapan penelitian dapat dilihat pada Gambar 1
Gambar 1Diagram alir penelitian Mulai
Merancang Design &
MembangunWeb
Membuat N-gram &Ekspansi Queri
Menggunggah data Skripsi
Pengujian N-gram &Ekspansi
Queri
Perbaikan
Laporan
a. Mulai
Penelitian perbandingan hasil deteksi kemiripan dokumen skripsi antara metode N-gram dan ekspansi kueri dalam pengerjaanya di lakukan beberapa tahap. tahap pertama, yaitu
pengumpulan dokumen skripsi
informatika UMS, dari sumber skripsi terdahulu yang nantinya akan di gunakan dalam basis data program. b. Pengumpulan Data
Tahap kedua yaitu di lanjutkan dengan langkah untuk Mendesign dan membangun web pencarian deteksi kemiripan skripsi. Pertama Tampilan di design dengan menggunakan Photoshop lalu di ubah Ke HTML dan CSS untuk mendapatkan hasil tampilan yang lebih rapi dan lebih baik penulis mengcoding
tampilan web dengan bantuan
frameworkCSS boostrap.
c. Membuat N-gram & Ekspansi Queri
Tahap ketiga yaitu membuat web sistem dengan metode N-gram dan menggabungkan dengan Ekspansi kueri , sebagai metode yang akan di gunakan dalam kueri mendeteksi kemiripan dokumen di database. Pemeriksaan dokumen skripsi dilakukan dengan
metode pencarian yang mampu
mendeteksi kemiripan topik, seperti N-gram dan ekspansi kueri. Menurut Sugiono (2013), metode N-gram adalah
salah satu metode yang digunakan untuk mencari kemiripan topik. Proses
kerja N-gram adalah memotong
beberapa potongan N karakter dari sebuah string. Sedangkan ekspansi
kueri merupakan cara untuk
mencocokan kata satu dengan kata atau kosakata lainnya yang memiliki arti atau makna serupa. Diharapkan dari
adanya pertimbangan persamaan
makna, maka relevansi hasil pencarian akan lebih tinggi (Elian, 2010).
d. Opload dokumen skripsi dan
Pengujian
Tahap keempat mulai
menyiapkan data dokumen skripsi berupa Judul, abstrak dan diskripsi yang akan digunakan untuk simulasi pencarian kemiripan dokumen, setelah itu data dokumen skripsi ini akan di unggah pada admin web. Dokumen skripsi akan diuji dengan memasukan kata kunci pada form pencarian judul
dan diskripsi. kedua metode
pendeteksian di ujikan, lalu hasil
pencarian pendeteksian yang
1. Diagram Alir (Flowchart) N-gram
Dengan dibuatnya sistem pendeteksi
skripsi dengan metode N-gram ini
diharapkan akan mampu mendapatkan
deteksi hasil temu yang lebih baik dan
relevan pada pencarianya:
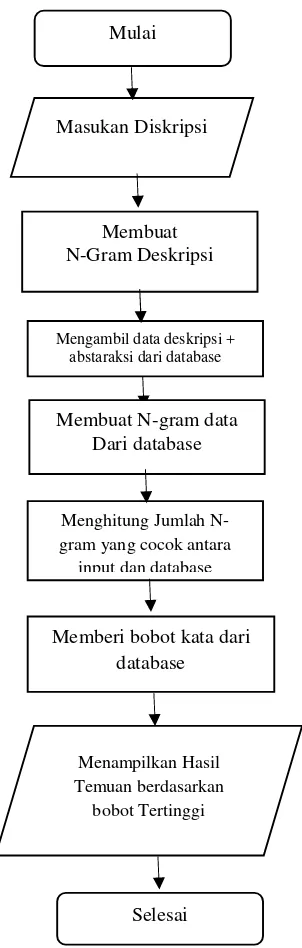
Gambar 2FlowchartN-gram
KeteranganFlowchartN-gram:
a. Memasukan Diskrpsi
Memasukan kata kunci berupa diskripsi pada kolom pencarian dengan tujuan untuk mencari dan menemukan skripsi yang sama sesuai diskripsi yang di input.
b. Membuat N-gram Deskripsi
Setelah kata kunci diskripsi dimasukkan, diskripsi di partisi
menjadi per kata yang telah
dipisahkan menggunakan spasi. Hasil
per kata tersebut kemudian
dikombinasikan menjadi rankaian kata yang terdiri dari 3 kata. Skema rangkaian kata dapat di umpamakan sebagai berikut :
Kata 1–kata 2–kata 3 Kata 2–kata 3–kata 4 Kata 3–kata 4–kata 5 Dan seterusnya.
c. Mengambil data deskripsi + abstraksi dari database
Setelah melakukan proses N-gram, hasil N-gram tersebut kemudian di kueri ke dalam database untuk menemukan data yang cocok.
d. Membuat N-gram data dari database Data hasil kueri pada langkah C kemudian di partisi seperti pada
langkah b untuk mengasilkan
rangkaian kata berupa N-gram. Menghitung Jumlah
N-gram yang cocok antara input dan database
Memberi bobot kata dari database
Mengambil data deskripsi + abstaraksi dari database
e. Menghitung jumlah N-gram yang cocok antara input dan database
Hasil N-gram input kemudian di cocokkan dengan N-gram keluaran dari
database. Jika N-gram tersebut
ditemukan sama, maka diberikan bobot nilai pada skripsi. Pada pemberian nilai pembobotan di hitung berdasarkan N-gram Hasil masukkan dan N-N-gram keluaran kata yang sama, yang di mana pada judul jika di ditemukan N-gram kata yang sama akan di beri nilai 3 (tiga) , pada diskripsi bernilai 1 (satu) dan pada abstraksi bernilai 1 (satu). f. Memberi bobot kata dari database
Bobot tersebut dihitung dan kemudian disimpan pada temporary Tabel. Proses ini akan dilakukan
berulang-ulang sejumlah dengan
banyaknya hasil N-gram yang
dicocokkan
g. Menampilkan hasil
Langkah terakhir adalah
melakukan join Tabel antara temporary Tabel bobot dengan Tabel skripsi sesuai dengan id_skripsi yang berhasil di index sesuai pada temporary Tabel bobot. Hasil join Tabel inilah yang kemudian ditampilkan ke browser. Skripsi yang di tampilkan berdasarkan nilai bobot paling tinggi akan di tampilkan paling atas secara berurutan pada hasil pencarian.
2. Diagram Alir (Flowchart) Ekspansi
Kueri
Sistem pendeteksi kemiripan
dokumen skripsi dirancang dan
dibangun dengan tujuan membantu mahasiswa UMS teknik informatika untuk memudahkan mencari refrensi topik skripsi dan mengcek apakah skripsi yang ingin di buat memiliki
kesamaan dengan skripsi yang
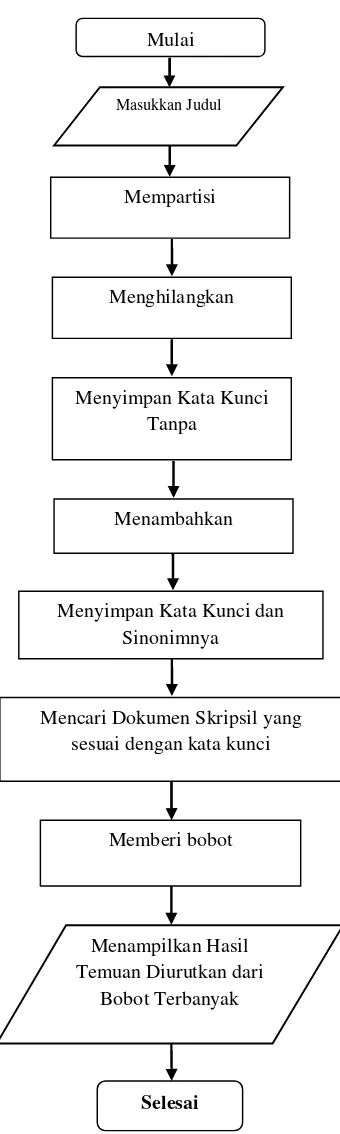
Gambar 3FlowchartEkspansi Kueri
Keterangan :
a) Memasukkan kata kunci.
Kata kunci diperlukan untuk
menemukan data skripsi yang
diperlukan dari sistem deteksi
kemiripan untuk mencari makna lain yang serupa untuk dijadikan sebagai alternatif kata kunci.
b) Mempartisi kata kunci.
Split diartikan dengan mengurai kalimat dari kata kunci menjadi beberapa kata yang berdiri sendiri. c) Membuangstop word.
Hasil uraian kata tersebut kemudian dicocokkan dengan basis data stop word. Database stop word
ini menyimpan data kata-kata umum yang sering muncul pada sebuah kalimat yang dianggap tidak memiliki makna, seperti yang, di, me, dan lainnya.
d) Menyimpan kata kunci tanpa stop word.
Jika kata kunci ditemukan ada yang sama dengan stop word, maka kata tersebut diabaikan. Namun apabila kata tersebut tidak sama dengan stop word, maka kata tersebut akan disimpan kedalam variabel baru. e) Menambahkan sinonim dari kata
kunci.
Variabel baru yang terbentuk selanjutnya akan digunakan untuk mencari sinonim/persamaan kata dan Mulai
Menyimpan Kata Kunci dan Sinonimnya
Mencari Dokumen Skripsil yang sesuai dengan kata kunci
menambahkan sinonim ke dalam daftar kata kunci baru.
f) Menyimpan kata kunci dan sinonim ke dalam variable.
Jika tidak ditemukan
sinonim dari kata kunci, maka kata kunci tersebut akan disimpan kedalam variabel. Namun apabila ditemukan ada sinonim dari kata kunci, maka kata kunci dan sinonimnya akan disimpan kedalam variabel, sehingga didalam variabel ini akan ditemukan kata kunci beserta sinonimnya.
g) Mencari Dokumen Skripsi.
Langkah selanjutnya yaitu
melakukan kueri ke dalam basis data skripsi menggunakan beberapa kata kunci yang didalamnya mengandung kata kunci sebenarnya dan juga sinonim dari kata kunci.
h) Memberi bobot pada hasil kueri. Pada langkah ini akan dilakukan penghitungan kata yang sama pada judul skripsi dan abstraksi skripsi dengan kata kunci yang dimasukkan
yang kemudian akan dilakukan
perhitungan dengan asumsi sebagai berikut :
Apabila di dalam judul skripsi terdapat 1 kata yang sama dengan kata kunci, maka akan diberikan bobot 2 pada setiap kata yang sama, namun jika ditemukan kata kunci pada abstraksi skripsi, maka akan diberikan bobot 1
pada setiap kata yang sama. Hasil penghitungan judul, diskripsi dan abstraksi kemudian dijumlahkan. maka akan ditemukan nilai bobot pada skripsi tersebut. Demikin juga dilakukan pada data skripsi lainnya yang berhasil dikueri dengan kata kunci yang sama.
i) Menampilkan hasil kueri urut
berdasarkan bobot terbanyak.
Hasil pemberian bobot tersebut kemudian join dengan Tabel skripsi yang selanjutnya ditampilkan urut berdasarkan bobot terbanyak kepada pengguna
HASIL PENGUJIAN
a. Pengujian jumlah hasil temu
Selain mengujikan
Tabel 1.1 Pengujian jumlah hasil temu N-gram
No N-gram Jumlah Hasil
Temu
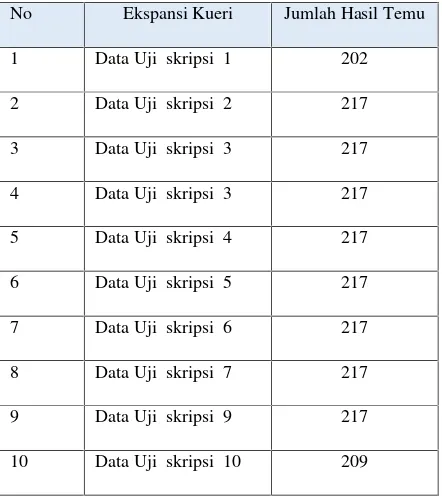
Tabel 1.2Pengujian jumlah hasil temu ekspansi kueri
No Ekspansi Kueri Jumlah Hasil Temu
1 Data Uji skripsi 1 202
Gambar 4 Grafik Pengujian Jumlah hasil temu N-gram dan ekspansi kueri
Dari data tabel 1.1 dan tabel 1.2 yang di hasilkan antara metode N-gram dan ekspansi kueri terlihat masing-masing metode memiliki hasil yang berbeda.
Metode N-gram rata-rata mampu
menampilkan data hasil temu rata-rata sebanyak 100 dan ekspansi kueri dapat menampilkan data hasil temu rata-rata sebanyak 200 dari total data pada basis data sebanyak 227 skripsi.
0 Chart Jumlah hasil temu
0 0 0 0 0 0 0
skripsi 1 skripsi 2 skripsi 3 skripsi 4 skripsi 5 skripsi 6 skripsi 7 skripsi 8 skripsi 9 skripsi 10
skripsi 1 skripsi 2 skripsi 3 skripsi 4 skripsi 5 skripsi 6 skripsi 7 skripsi 8 skripsi 9 skripsi 10 Ekspansi Kueri
Mirip Tidak Mirip b. Pengujian kemiripan skripsi
Berdasarkan hasil data Uji metode N-gram diperoleh sebanyak 33 data hasil. Berikut adalah data Tabel perbandingan tersebut dapat dilihat pada
tabel 2.1dantabel 2.2
Tabel 2.1 Data hasil uji kemiripan N-gram
No Data Mirip Tidak
mirip
Tabel 2.2 Data hasil uji kemiripan ekspansi kueri
No Data Mirip Tidak mirip
1 Data Uji skripsi 1 0 5
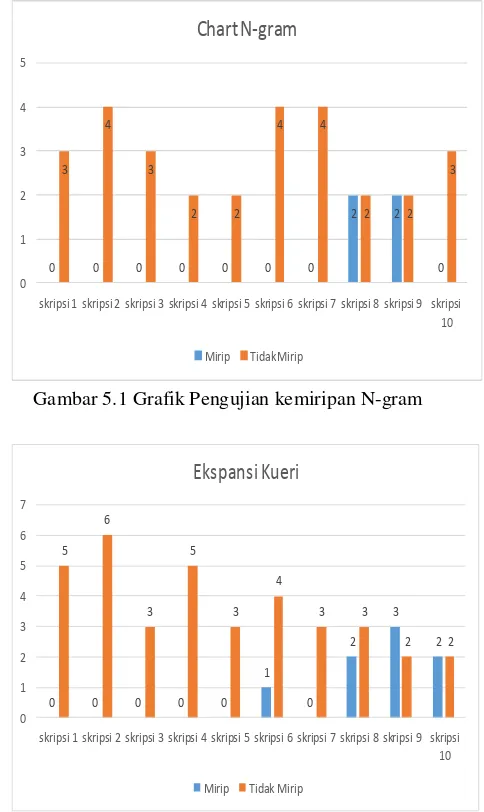
Gambar 5.1 Grafik Pengujian kemiripan N-gram
Gambar 5.2 grafik Pengujian kemiripan Ekspansi
kueri
Dari hasil pengujian di atas terlihat perbedaan hasil yang di hasilkan N-gram dan ekspansi kueri dalam pengujian kemiripan. Terlihat pada hasil pengujian data di atas, N-gram menangkap 4 data yang diduga mirip dari 33 data koleksi
sedangkan ekspansi kueri menangkap
sebanyak 8 data yang diduga mirip dari 44 data koleksi.
c. Menentukan Batas skor minimal
yang dinyatakan tidak mirip dari hasil pengujian yang telah dilakukan
Tabel 3.1 Data batas skor minimal tidak mirip N-gram
No Data Uji Bobot tertinggi data
tidak mirip
Tabel 3.2 Data batas skor minimal tidak mirip Ekspansi kueri
No Data Uji Bobot tertinggi data tidak
mirip
Dari hasil pengujian dan diperoleh data seperti pada Tabel 3.1 bisa di simpulkan bahwa hasil pencarian dokumen dari N-gram akan dinyatakan mirip, jika
nilai bobot skor hasil pencarian
didapatkan lebih dari 9 (Sembilan) dan kurang dari angka score tersebut akan dinyatakan tidak mirip.
Untuk Ekspansi kueri terlihat pada
Tabel 3.2 bisa disimpulkan juga bahwa hasil pencarian akan dinyatakan mirip jika dokumen memiliki bobot skor lebih dari 61 (enam satu) dan kurang dari itu akan dinyatakan tidak mirip.
KESIMPULAN
Kesimpulan dari penelitian yang telah dilaksanakan penulis sebagai berikut:
1. Dari penelitian yang dilakukan telah terbukti bahwa metode N-gram dan ekspansi kueri mampu mendeteksi kemiripan skripsi.
2. Metode N-gram dan ekspansi kueri memberikan hasil berbeda di masing-masing metode yang di terapkan. 3. Pemberian bobot pada masing-masing
metode akan sangat berpengaruh pada hasil pencarian.
4. Penentuan batas skor minimal
menentukan ukuran kemiripan dari masing-masing metode.
DAFTAR PUSTAKA
Departemen Pendidikan dan kubudayaan/Pusat Bahasa. 2001. Kamus Besar
Bahasa indonesia(Edisi ke-3). Jakarta: Balai Pustaka.
Peranginangin, 2006, Aplikasi Web dengan PHP dan MySQL. Edisi ke-1.
Yogyakarta.
Elian, RR 2010, ‘Aplikasi Sistem Temu Kembali Informasi Menggunakan Model
Ruang Vektor Berbasis Web’, Tugas Akhir, UNIKOM, Bandung.
Sugianto 2013, ‘Pembuatan aplikasi predictive text menggunakan metode
N-gram-based’, Tugas Akhir, Universitas Kristen Petra, Surabaya.
Nugroho, Bunafit., 2005, Pengembangan Pemrogram WAP dan PHP, Gaya Media,
Yogyakarta.
Rusidi 2008, ‘Ekspansi Kueri Dalam Sistem Temu Kembali Informas bebahasa
Indonesia Menggunakan Peluang Bersyarat’, Tugas Akhir, IPB, Bogor.