i
MESIN PENCARI KOLEKSI PERPUSTAKAAN
MENGGUNAKAN
BINARY INDEPENDENCE MODEL
DAN
VECTOR SPACE
MODEL
STUDI KASUS :
PERPUSTAKAAN UNIVERSITAS SANATA DHARMA
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Teknik Komputer (S.Kom.)
Program Studi Teknik Informatika
Oleh: Roy Syahputra NIM : 085314107
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
SEARCH ENGINE FOR LIBRARY COLLECTION WITH
BINARY INDEPENDENCE MODEL AND VECTOR SPACE
MODEL CASE STUDY :
LIBRARY OF SANATA DHARMA UNIVERSITY
THESIS
Presented as Partial Fullfilment of the Requirements To Obtain the Computer Bachelor Degree
In Informatics Engineering
By: Roy Syahputra NIM : 085314107
DEPARTMENT OF INFORMATICS ENGINEERING FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY YOGYAKARTA
iii
iv
v
vi
HALAMAN PERSEMBAHAN
vii
ABSTRAKSI
Vector Space Model dan Binary Independence Modeladalah 2 metode yang dipakai untuk memodelkan hasil Pemerolehan Informasi. Pada metode Vector Space Model, setiap potongan kata (token) dalam dokumen dilambangkan sebagai vektor dan dihitung jarak kedekatannya dengan kata pencarian menggunakan Cosine Similarity. MetodeBinary Independence Model menghitung peluang munculnya kata pencarian pada dokumen dengan menggunakan prinsip peluang Naïve Bayes.
Pada tugas akhir ini dibuat mesin pencari untuk membandingkan kedua metode tersebut. Perbandingan dilakukan dalam hal unjuk kerja dan lama waktu pencarian. Unjuk kerja diukur dari nilai precision dan recall untuk masing-masing metode. Lama waktu pencarian diukur dengan menghitung waktu setiap metode mulai dilakukan sampai metode selesai dilakukan. Koleksi yang digunakan berupa 72 buah ebook dan 34 buah Tugas Akhir dengan 2 bahasa, yaitu bahasa Inggris dan bahasa Indonesia.
Hasil percobaan menunjukan bahwa rata-rata lama waktu pencarian untuk metode Vector Space Model lebih cepat dibandingkan dengan lama waktu pencarian metodeBinary Independence Model. Akan tetapi hasil perhitunganaverage precision
viii
ABSTRACT
Vector Space Model and Binary Independence Model are two methods that been used to modelize retrieval result in Information Retrieval. In Vector Space Model, every word in a document represented as vector, and the similarities compare to search keyword’s vector measured using Cosine Similarity. Binary Independence Model count the search keyword probabilistic shown up in a document using Naïve Bayes’s principal.
In this thesis, a search engine were built to compare thus two methods. Comparison will be made in terms of performance and searching time. The performance will be measured by the value of precision and recall for each method. The searching time will be measured as the method starts to search until it has done the searching process. The collection that used in this thesis were 72 ebooks and 34 thesises within 2 languages, Bahasa Indonesia and English.
ix
x
KATA PENGANTAR
Puji dan syukur saya panjatkan kepada Tuhan Yang Maha Esa karena segala berkat dan rahmat yang telah diberikan sehingga saya dapat menyelesaikan tugas akhir dengan judul “Mesin Pencari Koleksi Perpustakaan Menggunakan Binary Independence Modeldan Vector Space ModelStudi Kasus: Perpustakaan Universitas Sanata Dharma”.
Pada kesempatan ini saya ingin mengucapkan terima kasih kepada pihak-pihak yang telah mendukung saya selama pengerjaan tugas akhir ini. Ucapan terima kasih ini saya tujukan kepada:
1. Ibu Paulina Heruningsih Prima Rosa, S.Si., M.Sc. selaku dekan Fakultas Sains dan Teknologi Universitas Sanata Dharma.
2. Ibu Ridowati Gunawan, S.kom., M.T. selaku ketua jurusan Teknik Informatika Universitas Sanata Dharma.
3. Ibu Sri Hartati Wijono, S.Si., M.Kom. selaku Dosen Pendamping Akademik dan Dosen Pembimbing TA, atas kesabaran dan perhatian dalam mendampingi saya selama melewati proses penyelesaian studi.
4. Bapak JB. Budi Darmawan, S.T., M.Sc. dan Bapak Puspaningtyas Sanjaya Adi, S.T., M.T. selaku Penguji TA, atas saran dan kritik yang diberikan untuk menunjang Tugas Akhir ini.
xi
6. Cameroon dan teman-teman dekatnya, atas seluruh bantuan dan dukungan yang diberikan selama pengerjaan Tugas Akhir ini.
7. Responden Kuisioner, atas kerjasama dalam menilai Tugas Akhir ini.
8. Teman-teman Teknik Informatika angkatan 2008, atas dukungan dan persahabatan.
9. Seluruh pihak yang membantu kelancaran dalam penulisan Tugas Akhir ini, secara langsung dan tidak langsung, yang tidak dapat saya sebutkan satu persatu.
Saya menyadari masih banyak terdapat kekurangan dalam penelitian ini. Saran dan kritik akan selalu saya nantikan untuk perbaikan-perbaikan di masa yang akan datang.
Akhir kata, saya berharap tulisan ini dapat bermanfaat bagi kemajuan dan perkembangan ilmu pengetahuan serta para pembaca sekalian.
Yogyakarta, 27 Agustus 2012
xii
DAFTAR ISI
HALAMAN JUDUL INDONESIA... i
HALAMAN JUDUL INGGRIS ...ii
HALAMAN PERSETUJUAN...iii
HALAMAN PENGESAHAN... iv
PERNYATAAN KEASLIAN KARYA ... v
HALAMAN PERSEMBAHAN ... vi
ABSTRAKSI ...vii
ABSTRACT...viii
LEMBAR PERNYATAAN PERSETUJUAN ... ix
PUBLIKASI KARYA ILMIAH ...Error! Bookmark not defined. KATA PENGANTAR ...ix
DAFTAR ISI...xii
DAFTAR GAMBAR ...xvii
DAFTARLIST CODE... xx
DAFTAR TABEL...xxii
DAFTAR LAMPIRAN ... xxv
xiii
1.1. Latar Belakang ... 1
1.2. Rumusan Masalah ... 3
1.3. Tujuan Penelitian ... 4
1.4. Batasan Permasalahan... 4
1.5. Luaran ... 5
1.6. Metodologi Penelitian ... 5
1.7. Sistematika Penulisan ... 6
BAB II LANDASAN TEORI ... 7
2.1. Perpustakaan ... 7
2.1.1. Perpustakaan Universitas Sanata Dharma ... 7
2.2. Information Retrieval... 8
2.3. Document Processing... 9
2.3.1. Tokenizing... 9
2.3.2. Stop-word Removal... 9
2.3.3. Stemming... 10
2.4. Document Indexing... 17
2.4.1. Inverted Index... 17
xiv
2.5.1. Hash Table... 18
2.6. Bayesian Model... 18
2.6.1. Binary Independence Model... 18
2.6.2. BM25 ... 22
2.7. Vector Space Model... 24
2.8. Perhitungan Contoh Kasus... 26
2.9. Recall and Precission... 42
2.10. Metodologi FAST ... 43
BAB III ANALISIS DAN PERANCANGAN ... 46
3.1. Analisa Sistem ... 46
3.1.1. Fase Definisi Ruang Lingkup (Scope Definition Phase) ... 46
3.1.2. Fase Analisis Masalah (Problem Analysis Phase)... 47
3.1.2.1. Analisa Sistem Saat Ini... 47
3.1.2.2. Analisa Kebutuhan Sistem Baru... 47
3.1.3. Fase Analisis Kebutuhan (Requirement Analysis Phase) ... 48
3.1.3.1. Diagram Use Case ... 48
3.1.3.2. Narasi Use Case... 48
xv
3.2.1. Langkah Penelitian ... 50
3.2.2. Disain Fisikal ... 51
3.2.2.1. Entity Relational Diagram ... 51
3.2.2.2. Physical Design Database... 53
3.2.2.3. Antarmuka ... 55
3.2.3. Flowchart... 56
3.2.4. Analisa Hasil... 61
3.2.5. Diagram Kelas ... 61
BAB IV IMPLEMENTASI ... 63
4.4. Documet Processing... 63
4.4.1. Tokenizing... 63
4.4.2. Stop-word Removal... 65
4.4.3. Stemming... 66
4.5. Document Indexing... 82
4.6. Document Searching... 91
4.7. Modeling... 91
4.7.1. Vector Space Model... 92
xvi
4.8. ImplementasiUse Case... 119
4.8.1. Halaman Pencarian ... 119
BAB V HASIL DAN PEMBAHASAN... 121
5.1. Hasil Penelitian ... 121
5.1.1. Hasil Pengukuran (kuesioner)... 121
5.1.2. Hasil Pengukuran (waktu pencarian) ... 134
5.2. Analisa Hasil Penelitian ... 137
5.2.1. Unjuk KerjaVector Space Model(VSM)... 137
5.2.2. Unjuk Kerja BM25 ... 139
5.2.3. Perbandingan Unjuk Kerja VSM dan BM25 ... 142
5.2.4. Perbandingan Lama Waktu Pencarian VSM dan BM25 ... 144
BAB VI KESIMPULAN DAN SARAN ... 146
6.1. Kesimpulan ... 146
6.2. Saran ... 146
DAFTAR PUSTAKA ... 148
xvii
DAFTAR GAMBAR
Gambar 2.1. Prosestokenizing... 9
Gambar 2.2.FlowchartalgoritmastemmingBahasa Indonesia Nazief & Adriani .... 13
Gambar 2.3.FlowchartPorter Stemmer ... 16
Gambar 2.4.Inverted Index... 17
Gambar 2.5.Vector Space Model... 24
Gambar 3.1. DiagramUse Case... 48
Gambar 3.2. Diagram blok (indexing) ... 50
Gambar 3.3. Diagram blok (searching) ... 50
Gambar 3.4.ER DiagramPerpustakaan Sanata Dharma... 51
Gambar 3.5.ER Diagrampenelitian... 52
Gambar 3.6. ERDiagram... 53
Gambar 3.7. Rancangan Antarmuka ... 55
Gambar 3.8.Flowchart Tokenizing... 56
Gambar 3.9.Flowchart Stop-word Removal... 56
Gambar 3.10.Flowchart Stemming... 57
xviii
Gambar 3.12.Flowchart Porter Stemmer(Porter, 1980) ... 59
Gambar 3.13.Flowchart Document Indexing... 60
Gambar 3.14.Flowchart Document Searching... 60
Gambar 3.15. Diagram kelas... 62
Gambar 4.1. Halaman Pencarian... 120
Gambar 4.2. Halaman Tunggu ... 120
Gambar 5.1. Hasil pencarian VSM skenario 1... 125
Gambar 5.2. Grafik Unjuk Kerja VSM pada pencarian seluruh isi dokumen ... 138
Gambar 5.3. Grafik Unjuk Kerja VSM pada pencarian judul dokumen... 139
Gambar 5.4. Grafik Unjuk Kerja BM25 pada pencarian seluruh isi dokumen ... 140
Gambar 5.5. Grafik Unjuk Kerja BM25 pada pencarian judul dokumen ... 141
Gambar 5.4. Grafik Perbandingan Unjuk Kerja VSM dan BM25 pada pencarian seluruh isi dokumen ... 142
Gambar 5.5. Grafik Perbandingan Unjuk Kerja VSM dan BM25 pada pencarian judul dokumen... 143
Gambar L.2.1. Screenshoot Skenario 1 VSM ... 173
Gambar L.2.2. Screenshoot Skenario 1 BM25 ... 173
Gambar L.2.3. Screenshoot Skenario 2 VSM ... 174
xix
Gambar L.2.5. Screenshoot Skenario 3 VSM ... 175
Gambar L.2.6. Screenshoot Skenario 3 BM25 ... 175
Gambar L.2.7. Screenshoot Skenario 4 VSM ... 176
Gambar L.2.8. Screenshoot Skenario 4 BM25 ... 176
Gambar L.2.9. Screenshoot Skenario 5 VSM ... 176
Gambar L.2.10. Screenshoot Skenario 5 BM25 ... 176
Gambar L.2.11. Screenshoot Skenario 6 VSM ... 177
Gambar L.2.12. Screenshoot Skenario 6 BM25 ... 177
Gambar L.2.13. Screenshoot Skenario 7 VSM ... 177
Gambar L.2.14. Screenshoot Skenario 7 BM25 ... 178
Gambar L.2.15. Screenshoot Skenario 8 VSM ... 178
Gambar L.2.16. Screenshoot Skenario 8 BM25 ... 179
Gambar L.2.17. Screenshoot Skenario 9 VSM ... 179
xx
DAFTAR
LIST CODE
List 4.1.Tokenizing... 64
List 4.2.Stop-word Removal ... 66
List 4.2.Stemming... 67
Listing 4.3. Mencari kata dasar (root word) ... 74
Listing 4.4. Penghapusan awalan kata (prefix) ... 81
List 4.3. Table ... 82
List 4.5.memasukan obyek ke dalamtable... 82
List 4.6. Word ... 83
List 4.7. WriteTableToText... 85
List 4.8. TableConfiguration.txt... 86
List 4.9. Pembacaan kamus-kamus ... 86
List 4.10. Pembacaan informasi koleksi daridatabase... 88
List 4.11.Document Processinguntuk setiap koleksi ... 89
List 4.12. Pengisiantabledari hasilstemmingkoleksi ... 89
List 4.13. Penyimpanantableke dokumen teks... 89
List 4.14. writeTableToTxt ... 91
xxi
List 4.16. Idf ... 92
List 4.17.SmoothingIdf... 93
List 4.18. Idf kata pencarian... 93
List 4.19. Pencarian dokumen relevan ... 94
List 4.20. Penambahan opsi status kata pada pencarian ... 96
List 4.21. Document ... 99
List 4.22. Tf_idf ... 100
List 4.23. Similarity ... 101
List 4.24. Selection sort... 101
List 4.25. Pencarian dokumen relevan ... 104
List 4.25. lookUpWordAtDocument... 108
List 4.26. getRelevanDocumentFromDocAccList ... 111
List 4.27. getAvdl... 113
List 4.28. hitungBobotDokumen... 116
List 4.29. hitungBobotPeluangKata ... 117
List.4.30. Waktu Pencarian BM25 ... 118
xxii
DAFTAR TABEL
xxiii
xxiv
xxv
DAFTAR LAMPIRAN
Lampiran 1 Contoh Kesioner... 150
Lampiran 2ScreenshootHasil Pencarian... 172
Lampiran 3 Tabel Perhitungan Interpolasi PrecisiondanRecall... 180
1
BAB I
PENGANTAR
1.1. Latar Belakang
Perpustakaan Universitas Sanata Dharma Yogyakarta merupakan perpustakaan yang berada di Universitas Sanata Dharma (USD) Yogyakarta. Perpustakaan terdiri dari 2 (dua) unit perpustakaan yaitu Perpustakaan Kampus Mrican dan Perpustakaan Kampus Paingan yang dikelola secara sentralisasi. Perpustakaan kampus Mrican merupakan perpustakaan Pusat, yang terdiri dari 4 (empat) lantai, sedangkan Perpustakaan Kampus Paingan merupakan perpustakaan cabang, yang terdiri dari 2 (dua) lantai dan berkonsentrasi pada pelayanan pengguna bagi civitas akademika USD yang berada di Kampus Paingan. Perpustakaan Mrican dan Paingan dihubungkan dengan jaringan komputer untuk dapat melayani penggunanya secaraonline.
Untuk membantu pemustaka melakukan pencarian koleksi, Perpustakaan Universitas Sanata Dharma menyediakan sebuah sistem pencarian koleksi. Sistem pencarian koleksi ini dapat diakses oleh pemustaka untuk menemukan sendiri koleksi yang diinginkan. Sistem akan mencari setiap koleksi berdasarkan jenis kata kunci berupa judul, pengarang, subjek, penerbit, tahun terbit, dan lainnya yang dimasukkan oleh pemustaka. Dengan demikian, pemustaka harus memasukan kata kunci yang rinci mengenai informasi koleksi yang diinginkan. Pemustaka akan mengalami kesulitan dalam pencarian jika hanya mengetahui beberapa potongan informasi mengenai koleksi yang diinginkan. Hal ini mengakibatkan hasil pencarian yang ditampilkan oleh sistem akan sangat terbatas dan memiliki perbedaan dengan keinginan pemustaka.
Dari contoh yang telah disebutkan, pemustaka harus mengetahui jenis dari potongan informasi yang dimilikinya. Potongan informasi yang tidak diketahui jenisnya akan mengakibatkan hasil pencarian yang tidak diharapkan. Proses pencarian yang dilakukan oleh pemustaka akan terbantu dengan adanya sistem yang memiliki kemampuan untuk menelusuri informasi isi buku dan menemukannya dari potongan informasi yang dimiliki. Salah satu cara yang dapat digunakan dalam membangun sistem tersebut adalah menggunakan metode Pemerolehan Informasi (Information Retrieval). Di dalam Pemerolehan Informasi, terdapat metode-metode untuk mengurutkan hasil pencarian. Binary Independence Model dan Vector Space Model merupakan contoh pendekatan yang dapat digunakan untuk membangun tampilan hasil urut pencarian.
1.2. Rumusan Masalah
Berikut ini merupakan masalah-masalah yang dirumuskan di dalam penelitian:
1. Bagaimana membangun mesin pencari koleksi Perpustakaan Unversitas Sanata Dharma?
3. Bagaimana kecepatan pencarian dari metode Binary Independence Model
danVector Space Modeldalam menangani koleksi Perpustakaan Universitas Sanata Dharma?
1.3. Tujuan Penelitian
Berikut ini merupakan tujuan yang ingin dicapai melalui penelitian:
1. Membangun mesin pencari koleksi Perpustakaan Unversitas Sanata Dharma. 2. Mengukur unjuk kerja dari metode Binary Independence Model dan Vector
Space Model dalam membangun mesin pencari untuk Perpustakaan Universitas Sanata Dharma.
3. Mengukur kecepatan pencarian dari metodeBinary Independence Modeldan
Vector Space Model dalam menangani koleksi Perpustakaan Universitas Sanata Dharma.
1.4. Batasan Permasalahan
Berikut ini merupakan batasan masalah dari penelitian:
1. Penelitian ini mengacu pada studi kasus di Perpustakaan Universitas Sanata Dharma, dengan mengambil sampel berupa koleksi digital tugas akhir dan e-book.
2. Teknik stemming yang digunakan di dalam penelitian ini adalah teknik
3. Teknik stemming Bahasa Indonesia menggunakan algoritma Nazief & Adriani dan teknik stemming Bahasa Inggris menggunakan Porter Stemmer Algorithm.
4. Bahasa pemrograman yang digunakan dalam penelitian ini menggunakan bahasa JAVA.
5. Model yang akan digunakan adalahBinary Independence Model danVector Space Model.
1.5. Luaran
Luaran dari penelitian ini adalah terciptanya sebuah mesin pencari koleksi perpustakaan yang menggunakan metode Binary Independence Model dan Vector Space Modeluntuk digunakan pada Perpustakaan Universitas Sanata Dharma.
1.6. Metodologi Penelitian
Metode yang digunakan untuk melakukan penelitian ini adalah metode FAST (Framework for the Application of Sistem Thinking). Metode FAST memiliki langkah-langkah sebagai berikut:
1. Analisa Ruang Lingkup
Melakukan analisa terhadap ruang lingkup sistem yang sedang berjalan dan pengembangan sistem baru.
2. Analisa Masalah
3. Perancangan sistem
Melakukan perancangan sistem pada penelitian ini dengan diagram use case, diagram proses, dan flowchart.
4. Implementasi sistem
Melakukan pembangunan sistem sesuai tahap perancangan. 5. Pengujian
Melakukan pengujian hasil sistem dengan metoderecalldanprecision. 6. Pelaporan
Melakukan pelaporan hasil pengujian dan analisa.
1.7. Sistematika Penulisan
BAB I : berisi mengenai pendahuluan dan latar belakang masalah yang ingin diselesaikan.
BAB II : berisi tentang landasan teori yang digunakan dalam penyusunan dokumen dan pembangunan sistem.
BAB III : berisi tentang analisis dan perancangan yang akan digunakan dalam pembangunan sistem
7
BAB II
LANDASAN TEORI
Pada bagian ini, penulis akan membahas mengenai dasar-dasar teori yang digunakan dalam penulisan penelitian. Dasar-dasar teori tersebut dapat dipaparkan sebagai berikut :
2.1. Perpustakaan
Menurut Undang-undang Republik Indonesia Nomor 47 Tahun 2007, Perpustakaan adalah institusi pengelola karya tulis, karya cetak, dan/atau karya rekam secara professional dengan sistem yang baku guna memenuhi kebutuhan pendidikan, penelitian, pelestarian informasi, dan rekreasi para pemustaka. Berdasarkan jenisnya, Perpustakaan dapat dibedakan menjadi 5, yaitu Perpustakaan Nasional, Umum, Sekolah/Madrasah, Perguruan Tinggi, dan Khusus (Indonesia, 2007).Perpustakaan Universitas Sanata Dharma merupakan salah satu yang tergolong Perpustakaan Perguruan Tinggi.
2.1.1. Perpustakaan Universitas Sanata Dharma
(USD) dikelola secara sentralisasi.Perpustakaan kampus Mrican merupakan perpustakaan Pusat, sedangkan Perpustakaan Kampus Paingan merupakan perpustakaan cabang.Perpustakaan Kampus Paingan berkonsentrai pada pelayanan pengguna bagi civitas akademika USD yang berada di Kampus Paingan.Sebuah jaringan komputer digunakan untuk menghubungkan Perpustakaan Mrican dan Paingan agar dapat melayani penggunanya secara online.
Perpustakaan USD tercatat memiliki jumlah koleksi sebanyak 355.567 judul. Jumlah untuk koleksi buku sebanyak 90.210 judul, tugas akhir sebanyak 17.428 judul, NBM sebanyak 1.900 judul, majalah sebanyak 7.186 judul, artikel majalah sebanyak 238.163 judul, dane-booksebanyak 920 judul. Untuk koleksi suara (audio), gambar (image), dan gambar bergerak (video) masih berada pada tahap pengembangan.
2.2. Information Retrieval
Pemerolehan informasi adalah sebuah sistem yang menangani penyimpanan, pemerolehan, dan pengolahan informasi. Informasi dalam konteks ini dapat berupa teks, citra, suara dan obyek multimedia lainnya (Kowalski, 1997). Metode Pemrolehan Informasi terdiri dari beberapa langkah, yaitu document processing
Input: Friends, Romans, Countrymen, lend me your ears;
Output:
2.3. Document Processing
Document processing adalah tahap persiapan dokumen sebelum dilakukan
indexing (penyimpanan urut).Tahap persiapan dokumen meliputi tokenizing,
stopword removal, danstemming.
2.3.1. Tokenizing
Tokenizing adalah proses membagi deretan kalimat menjadi kalimat dan kalimat menjadi token-token. Token tidak hanya terdiri dari kata-kata, tetapi juga angka-angka, tanda kutip, tanda kurung, dan tanda baca lainnya (Schmid, 2008).
Gambar 2.1. Prosestokenizing
Proses tokenizing pada Gambar 2.1.mendapatkan masukan berbentuk kalimat dan memprosesnya menjadi potongan-potongan kata yang menyusun kalimat tersebut. Potongan kata seperti “Friends”, “Romans”, “Countrymen” yang tebentuk akan dapat digunakan untuk proses selanjutnya.
2.3.2. Stop-word Removal
Stop-word adalah kata yang muncul di dalam dokumen tetapi tidak berpengaruh pada proses pencarian. Stop-word juga dapat ditentukan dari kata yang memiliki jumlah kemunculan paling banyak dari sebuah dokumen. Contoh dari stop-word adalah am, is, are be, to, that, this, it, its, etc (Manning,Raghavan,
Input: Friends, Romans, Countrymen, lend me your ears;
Output:
2.3. Document Processing
Document processing adalah tahap persiapan dokumen sebelum dilakukan
indexing (penyimpanan urut).Tahap persiapan dokumen meliputi tokenizing,
stopword removal, danstemming.
2.3.1. Tokenizing
Tokenizing adalah proses membagi deretan kalimat menjadi kalimat dan kalimat menjadi token-token. Token tidak hanya terdiri dari kata-kata, tetapi juga angka-angka, tanda kutip, tanda kurung, dan tanda baca lainnya (Schmid, 2008).
Gambar 2.1. Prosestokenizing
Proses tokenizing pada Gambar 2.1.mendapatkan masukan berbentuk kalimat dan memprosesnya menjadi potongan-potongan kata yang menyusun kalimat tersebut. Potongan kata seperti “Friends”, “Romans”, “Countrymen” yang tebentuk akan dapat digunakan untuk proses selanjutnya.
2.3.2. Stop-word Removal
Stop-word adalah kata yang muncul di dalam dokumen tetapi tidak berpengaruh pada proses pencarian. Stop-word juga dapat ditentukan dari kata yang memiliki jumlah kemunculan paling banyak dari sebuah dokumen. Contoh dari stop-word adalah am, is, are be, to, that, this, it, its, etc (Manning,Raghavan,
Input: Friends, Romans, Countrymen, lend me your ears;
Output:
2.3. Document Processing
Document processing adalah tahap persiapan dokumen sebelum dilakukan
indexing (penyimpanan urut).Tahap persiapan dokumen meliputi tokenizing,
stopword removal, danstemming.
2.3.1. Tokenizing
Tokenizing adalah proses membagi deretan kalimat menjadi kalimat dan kalimat menjadi token-token. Token tidak hanya terdiri dari kata-kata, tetapi juga angka-angka, tanda kutip, tanda kurung, dan tanda baca lainnya (Schmid, 2008).
Gambar 2.1. Prosestokenizing
Proses tokenizing pada Gambar 2.1.mendapatkan masukan berbentuk kalimat dan memprosesnya menjadi potongan-potongan kata yang menyusun kalimat tersebut. Potongan kata seperti “Friends”, “Romans”, “Countrymen” yang tebentuk akan dapat digunakan untuk proses selanjutnya.
2.3.2. Stop-word Removal
Schutze,2008). Contoh dari stop-word Bahasa Indonesia adalah itu, ini, yang, dan, pun. Stop-word Removal merupakan proses untuk menghilangkan stop-word yang berada di dalam sebuah dokumen.
Sebagai contoh untuk kalimat “Perpustakaan digital adalah perpustakaan yang mempunyai koleksi buku sebagian besar dalam bentuk format digital dan yang bisa diakses dengan komputer” akan dikenai proses stop-word removal. Stop-word
yang terdapat pada kalimat tersebut adalah “adalah”, “yang”, “dan”, dan “dengan”. Setelah dikenai proses stop-word removal, kalimat menjadi “Perpustakaan digital perpustakaan mempunyai koleksi buku sebagian besar dalam bentuk format digital bisa diakses komputer”.
2.3.3. Stemming
Stemming merupakan suatu proses yang terdapat di dalam sistem Pemerolehan Informasi yang mentransformasikan kata-kata di dalam suatu dokumen menjadi kata dasarnya dengan menggunakan aturan-aturan tertentu (Agusta, 2009). Sebagai contoh kata “bersama”, “disamakan”, “menyamai”, dan “kebersamaan” akan diubah menjadi kata dasarnya, yaitu “sama”.
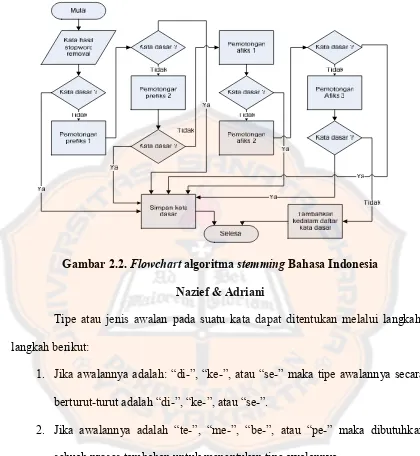
Berikut adalah langkah-langkah Algoritma Nazief & Adriani, yang merupakanstemmingBahasa Indonesia (Nazief, Adriani, 1996) :
2. Inflection Suffixes(“-lah”, “-kah”, “-ku”, “-mu”, atau “-nya”) akan dibuang. Jika berupaparticles(“-lah”, “-kah”, “-tah” atau “-pun”) maka langkah ini diulangi lagi untuk menghapusPossesive Pronouns(ku”, mu”, atau “-nya”), jika diketemukan.
3. HapusDerivation Suffixes (“-i”, “-an” atau “-kan”). Jika kata ditemukan di dalam kamus kata dasar, maka algoritma berhenti. Jika tidak maka algoritma dilanjutkan ke poin (3a)
a. Jika an” telah dihapus dan huruf terakhir dari kata tersebut adalah “-k”, maka “-k” juga ikut dihapus. Jika kata tersebut ditemukan dalam kamus maka algoritma berhenti. Jika tidak ditemukan maka lakukan langkah (3b).
b. Akhiran yang dihapus (“-i”, “-an” atau “-kan”) dikembalikan, dilanjutkan ke langkah (4).
4. HapusDerivation Prefix. Jika pada langkah (3) ada sufiks yang dihapus maka pergi ke langkah (4a), jika tidak pergi ke langkah (4b).
Tabel 2.1.Kombinasi awalan akhiran yang tidak diijinkan.
Awalan Akhiran yang tidak diizinkan
be- -i
di- -an
ke- -i, -kan
me- -an
se- -i, -kan
b. Untuk variabel i = 1 sampai 3, tentukan tipe awalan kemudian hapus awalan. Jika root word belum juga ditemukan, lakukan langkah (5), jika sudah ditemukan maka algoritma berhenti. Catatan: jika awalan kedua sama dengan awalan pertama algoritma berhenti.
5. MelakukanRecoding.
6. Jika semua langkah telah selesai tetapi tidak juga berhasil maka kata awal diasumsikan sebagairoot word. Proses selesai.
Gambar 2.2.FlowchartalgoritmastemmingBahasa Indonesia
Nazief & Adriani
Tipe atau jenis awalan pada suatu kata dapat ditentukan melalui langkah-langkah berikut:
1. Jika awalannya adalah: “di-”, “ke-”, atau “se-” maka tipe awalannya secara berturut-turut adalah “di-”, “ke-”, atau “se-”.
2. Jika awalannya adalah “te-”, “me-”, “be-”, atau “pe-” maka dibutuhkan sebuah proses tambahan untuk menentukan tipe awalannya.
4. Jika tipe awalan adalah “none” maka berhenti. Jika tipe awalan adalah bukan “none” maka awalan dapat dilihat pada Tabel 2.2. Hapus awalan jika ditemukan.
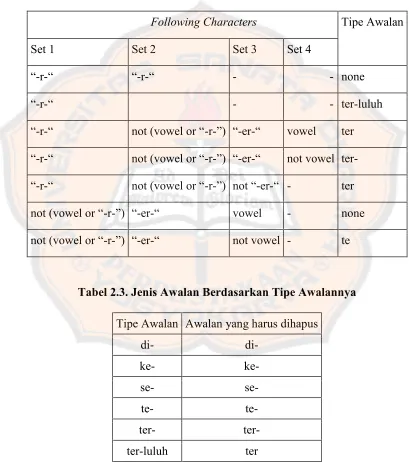
Tabel 2.2.Cara menentukan tipe awalan untuk awalan “te-”.
Following Characters Tipe Awalan
Set 1 Set 2 Set 3 Set 4
“-r-“ “-r-“ - - none
“-r-“ - - ter-luluh
“-r-“ not (vowel or “-r-”) “-er-“ vowel ter
“-r-“ not (vowel or “-r-”) “-er-“ not vowel
ter-“-r-“ not (vowel or “-r-”) not “-er-“ - ter
not (vowel or “-r-”) “-er-“ vowel - none
not (vowel or “-r-”) “-er-“ not vowel - te
Tabel 2.3. Jenis Awalan Berdasarkan Tipe Awalannya
Tipe Awalan Awalan yang harus dihapus
di-
di-ke-
ke-se-
se-te-
te-ter-
Untuk mengatasi keterbatasan pada algoritma di atas, maka ditambahkan aturan-aturan dibawah ini:
1. Aturan untuk reduplikasi.
a. Jika kedua kata yang dihubungkan oleh kata penghubung adalah kata yang sama makaroot wordadalah bentuk tunggalnya, contoh : “buku-buku” , memilikiroot wordadalah “buku”.
b. Kata lain, misalnya “bolak-balik”, “berbalas-balasan, dan ”seolah-olah”. Untuk mendapatkanroot word, kedua kata diartikan secara terpisah. Jika keduanya memilikiroot word yang sama maka diubah menjadi bentuk tunggal, contoh: kata “berbalas-balasan”, “berbalas” dan “balasan” memilikiroot wordyang sama yaitu “balas”, makaroot word “berbalas-balasan” adalah “balas”. Sebaliknya, pada kata “bolak-balik”, “bolak” dan “balik” memilikiroot wordyang berbeda, sehinggaroot word adalah “bolak-balik”.
2. Tambahan bentuk awalan dan akhiran serta aturannya.
a. Untuk tipe awalan “mem-“, kata yang diawali dengan awalan “memp-” memiliki tipe awalan “mem-”.
b. Tipe awalan “meng-“, kata yang diawali dengan awalan “mengk-” memiliki tipe awalan “meng-”.
merupakan algortima stemming yang memiliki langkah-langkah untuk menghilangkan baik prefix (imbuhan) maupun suffix (akhiran) (Giridhar, Prema, Redy, 2011). Langkah-langkah algoritma Porter Stemmer dapat dilihat pada Gambar 2.3.
Gambar 2.3.FlowchartPorter Stemmer
2.4. Document Indexing
Document Indexing adalah proses penyimpanan dokumen secara urut melalui algoritma tertentu. Penyimpanan dokumen dimaksudkan untuk dapat dikenai proses pencarian dan pemerolehan kembali informasi. Salah satu metode yang digunakan dalamDocument IndexingadalahInverted Index.
2.4.1. Inverted Index
Inverted Index adalah sebuah metode untuk menyimpan dokumen secara urut.Terdapat 3 (bagian) dasar dalam membangun Inverted Index, yaitudocument file,
inversions list, dan dictionary. Document file merupakan kumpulan dokumen yang telah diberi nomor urut dalam penyimpanan. Inversion list merupakan daftar lokasi sebuah kata di dokumen yang terdaftar pada document file. Dictionary merupakan daftar kata-kata yang telah mengalami prosestokenizing(Kowalski, 2011).
Gambar 2.4.Inverted Index
2.5. Document Searching
merupakan dokumen yang memenuhi kriteria pencarian. Salah satu metode
Document Searchingyang dapat digunakan adalahHash Table.
2.5.1. Hash Table
Hash Tablemerupakan bentuk struktur data yang terdiri dari kumpulan larik yang berisi data dan dapat diakses kembali menggunakan penomoran indeks khusus (Loudon, 1999).Hash Tableberfungsi untuk memetakan kemungkinan-kemungkinan posisi penyimpanan data dan cara mengaksesnya (Oracle,2010).
2.6. Bayesian Model
Bayesian Model adalah sebuah kerangka matematis (menggunakan asumsi dan penilaian) untuk mengukur ketidakpastian tentang jumlah yang belum diketahui dengan mengaitkannya terhadap jumlah yang telah diketahui (Draper,2007).Bayesian Model banyak diterapkan di dalam menyelesaikan berbagai model permasalahan, salah satunya adalah permasalahan modeling di dalam Pemerolehan Informasi. Metode Binary Independence Model merupakan salah satu modeling di dalam Pemerolehan Informasi yang menerapkanBayesian Model.
2.6.1. Binary Independence Model
Binary Independence Model (BIM) menggunakan teorema Bayes dalam melakukan pengurutan hasil pencarian. BIM mencari tingkat relevansi antara isi setiap dokumen denganquerypencarian (Datta, 2010).
1. Setiap dokumen bersifat independen dan tidak saling tergantung.
2. Kata (token) di dalam sebuah dokumen bersifat independen dan tidak saling tergantung.
3. Kata (token) yang tidak muncul di dalam query pencarian tidak mempengaruhi proses pemerolehan kembali.
Proses menghitung relevansi dokumen dapat dinyatakan sebagai P(D|R), yang berarti peluang dokumen D dianggap sebagai dokumen yang relevan, dan P(D|NR), yang berarti peluang dokumen D dianggap sebagai dokumen yang tidak relevan. Relevansi dokumen didapat dengan menggunakan likelihood ratio (Croft, Metzler, Strohman, 2010) yang dapat dinyatakan sebagai berikut:
( | )
( | )…….(2.6.1)
Jika setiap dokumen dianggap sebagai vektor yang berisi kumpulan angka 1 untuk cocoknya kata yang dicari dengan kata di dalam dokumen, dan 0 untuk tidak cocoknya kata yang di cari dengan kata di dalam dokumen, dapat ditentukan bahwa dokumen yang relevan adalah dokumen yang memiliki vektor yang mengandung nilai 1. Misal adalah peluang dari kata muncul di dokumen yang relevan dan peluang kata tersebut tidak muncul di dokumen relevan adalah 1- , serta untuk peluang munculnya kata , persamaan 2.6.1 dapat dinyatakan sebagai berikut:
Pada persamaan 2.6.2 , ∏: menunjukan nilai kata yang memiliki nilai 1 di dalam vektor dokumen. Dengan melakukan penyederhanaan matematika, persamaan 2.6.2 dapat diubah menjadi:
:
Dan dapat ditulis ulang menjadi: (1 − )
Hasil di sebelah kanan untuk persamaan 2.6.4 memiliki nilai yang sama untuk semua dokumen, sehingga hasil persamaan ini dapat diabaikan untuk menentukan urutan nilai kedekatan dokumen. Dengan menggunakan fungsi logaritma pada hasil persamaan 2.6.4 , akan dapat dinyatakan sebagai berikut:
log (1 − )
(1 − ) … … . (2.6.5) :
Dengan menghitung nilai balik relevansi, dapat dibuat sebuah tabel kesimpulan (Croft,etc, 2010), yaitu:
Tabel. 2.6.1Contingency Table
Relevant Non-relevant Total
Sehingga tingkat relevansi dokumen dapat diurutkan menggunakan hasil pengurutan dari persamaan (2.6.7) untuk setiap dokumen. BIM akan mengurutkan dokumen berdasarkan tingkat relevansi masing-masing dokumen dengan query
pencarian. Semakin besar tingkat relevansi dokumen dengan query pencarian, posisi dokumen akan berada semakin atas di dalam tampilan hasil pencarian.
2.6.2. BM25
BM25 merupakan metode lanjutan dari BIM dalam mengurutkan nilai relevansi dokumen. BM25 menambahkan nilai frekuensi kata ke dalam perhitungan dari hasil BIM (Croft, etc, 2010). Dengan demikian persamaan (2.6.7) dapat ditulis ulang menjadi:
kemunculan dan ketidakmunculan kata yang akan diperhatikan di dalam perhitungan. Semakin besar nilai , nilai bobot kata akan meningkat secra linear dengan . Nilai 1.2 untuk dapat digunakan untuk melakukan perhitungan karena akan memiliki hasil yang mendekati fungsi logaritma (Croft, etc, 2010). Dengan demikian setelah kemunculan ketiga atau keempat kata pada dokumen, akan memberikan pengaruh yang kecil terhadap perhitungan.
Nilai memiliki fungsi yang sama dengan pada query. Jarak nilai adalah antara 0 sampai 1,000, yang berarti bahwa unjuk kerja tidak sesensitif . Hal ini disebakan karena frekuensi kata query jauh lebih kecil dibandingkan dengan frekuensi kata pada dokumen.
Nilai merupakan nilai normalisasi untuk frekuensi kata terhadap panjang dokumen, yang dapat dinyatakan dengan:
= (1 − ) + . … … … . . (2.7.2)
=
= ℎ
=
Nilai parameter berpengaruh terhadap normalisasi panjang. Jika = 0, normalisasi panjang akang diabaikan, dan = 1, normalisasi akan memiliki nilai pengaruh secara penuh. Nilai = 0.75 merupakan nilai yang paling efektif (Croft,
2.7. Vector Space Model
Vector Space Model adalah bentuk pemodelan yang menganalogikan dokumen sebagai vektor yang memiliki besaran. Gambar 2.5.menunjukan perlakuan yang diterapkanVector Space Modelterhadap dokumen danquerypencarian.
Gambar 2.5.Vector Space Model
Sebagai vektor yang memiliki besaran, jarak antar dokumen dapat dihitung menggunakan persamaancosine similarity(Manning,et al, 2008).
( , ) = →( ).→( )
→( ) →( ) ………(2.7.1)
Sim (D1, D2) = jarak kedekatan Dokumen 1 dan Dokumen 2
D1= Dokumen 1
D2= Dokumen 2
→ ( ) = reperentasi vektor Dokumen 1 → ( ) = reperentasi vektor dokumen 2
komponen dari vektor, maka Euclidian Distance untuk vektor → ( ) dapat ditulis ditulis sebagai berikut :
∑ …………(2.7.3)
Dengan melihat pada persamaan (2.7.2) dan (2.7.3), persamaan (2.7.1) dapat ditulis ulang menjadi :
( , ) = ∑ ( ∗ )
∑ ( )∗ ( )
…….(2.7.4)
Nilai Sim(D1,D2) menunjukan jarak kedekatan antara dokumen D1dan D2. Besaran nilai Sim(D1,D2) memiliki rentang dari 0.0 - 1.0. Semakin besar nilai yang
diperoleh, tingkat kemiripan dokumen yang dibandingkan akan semakin tinggi. Sebaliknya, semakin kecil nilai yang diperoleh, tingkat kemiripan dokumen yang dibandingkan akan semakin rendah.
Dalam membentuk model hasil pencarian, Vector Space Model
membandingkan nilai kesamaan antara query pencarian terhadap setiap dokumen yang tersedia. Dengan melihat persamaan (2.7.1), perhitungan jarak kesamaan antara
( , ) = →( ).→( )
→( ) →( )………..… (2.7.5)
Sim (Q, Di) = jarak kedekatanquerypencarian dan Dokumeni
Di= Dokumeni
Q =querypencarian
→ ( ) = reperentasi vektor Dokumen
→ ( ) = reperentasi vektor pencarian
Dengan melihat pada persamaan (2.7.4), persamaan (2.7.5) dapat ditulis ulang menjadi :
, = ∑ ( ∗ )
∑ ( )∗
…….(2.7.6)
Vector Space Model akan mengurutkan dokumen berdasarkan nilai jarak kesamaan masing-masing dokumen dengan query pencarian. Semakin dekat jarak dokumen dengan query pencarian, posisi dokumen akan berada semakin atas di dalam tampilan hasil pencarian.
2.8. Perhitungan Contoh Kasus
Pada bagian ini akan dijelaskan langkah pengerjaan penelitian menggunakan sebuah contoh kasus. Sebagai contoh, terdapat 6 buah dokumen yaitu:
Contoh dokumen
Dok5 = waktu pemrosesan data. Dok6 = data yang informatif.
Dokumen Processing
Dokumen-dokumen tersebut akan dikenai prosesDocument Processing. Tokenizing
Pada proses ini setiap kata pada semua dokumen akan dipilah menjadi token. Dok1 = Waktu dalam pemrosesan informasi.
Dok2 = komputerisasi berbasis waktu. Dok3 = waktu untuk pemrosesan. Dok4 = basis pemrosesan.
Dok5 = waktu pemrosesan data. Dok6 = data yang informatif. Stop-word removal
Proses ini menghilangkan semua stop-word yang terdapat pada masing-masing dokumen.
Dok1 = Waktu pemrosesan informasi. Dok2 = komputerisasi berbasis waktu. Dok3 = waktu pemrosesan.
Stemming
Proses ini akan mengubah setiap kata pada semua dokumen menjadi kata dasar.
Dok1 = Waktu proses informasi. Dok2 = komputer basis waktu. Dok3 = waktu proses.
Dok4 = basis proses. Dok5 = waktu proses data. Dok6 = data informasi.
Dokument Indexing
Setelah mengalami proses Document Processing, pembentukan indexing
seluruh dokumen akan dilakukan sebagai berikut:
Pembentukaninverted index
Pendataan token:
Waktu = dok1 Basis = dok4
Proses = dok1 Proses = dok4
Informasi =dok1 Waktu = dok5
komputer = dok2 Proses = dok5
Waktu = dok2 Data = dok6
Waktu = dok3 Informasi = dok6
Proses = dok3
Pengurutan token:
Basis = dok2 Proses = dok3
Basis = dok4 Proses = dok4
Data = dok5 Proses = dok5
Data = dok6 Waktu = dok1
Informasi =dok1 Waktu = dok2
Informasi = dok6 Waktu = dok3
komputer = dok2 Waktu = dok5
Proses = dok1
Pengelompokan token :
Term Dok frek Term frek Posting list
Basis 2 2 2 ; 4
Data 2 2 5 ; 6
Informasi 3 3 1; 2; 6
Computer 1 1 2
Proses 4 4 1; 3; 4; 5
Waktu 4 4 1; 2; 3; 5
Modeling
Pada tahap ini sistem akan mengolah data untuk menampilkan hasil akhir pencarian. Sebagai contoh, akan diberikan sebuah querypencarian sebagai berikut :
Query: “menghitung waktu pemrosesan berbasis komputer.”
Querysetelahdocument processing= hitung waktu proses basis komputer.
Vector Space Model
Frekuensi kata i di dalam dokumen j (tfij) :
Term Dok1 Dok2 Dok3 Dok4 Dok5 Dok6
Basis 0 1 0 1 0 0
Data 0 0 0 0 1 1
Informasi 1 1 0 0 0 1
Komputer 0 1 0 0 0 0
Proses 1 0 1 1 1 0
Waktu 1 1 1 0 1 0
Inverse dokumen frekuensi dari kata i (Idfi) :
Term Log10(N/dfi)
Basis Log10(6/2)= 0.477
Data Log10(6/2)= 0.477
Komputer Log10(6/1)= 0.778
Proses Log10(6/4)= 0.176
Waktu Log10(6/4)= 0.176
Pembobotan kata (Wij) :tf*idf
Term Dok1 Dok2 Dok3 Dok4 Dok5 Dok6
Basis 0.477 * 0 =0 0.477 * 1
Informasi 0.301 * 1
Berikut merupakan perhitungan untukquerypencarian: tfiq:
Term Query
Basis 1
Data 0
Informasi 0
Komputer 1
Proses 1
Waktu 1
Hitung 1
Wiq:
Term
Basis 0.477 * 1 =0.47
Data 0
Informasi 0
Komputer 0.778 *1 =0.778
Proses 0.176 *1 =0.176
Waktu 0.176 *1 =0.176
Hitung 0
Query : “menghitung waktu pemrosesan berbasis komputer” N = 6
Idfi = Log10(N/ni)
term tfi ni N/ni Idfi Wi
34
Dengan demikian keofisien Cosine yang akan digunakan untuk menghitung
Vector Space Similarity dapat dituliskan sebagai berikut :
Dok1 (0 T1 + 0 T2 + 0.301 T3 + 0 T4 + 0.176 T5 + 0.176 T6) Dok2 (0.477 T1 + 0 T2 + 0.301 T3 + 0.778 T4 + 0 T5 + 0.176 T6) Dok3 (0 T1 + 0 T2 + 0 T3 + 0 T4 + 0.176 T5 + 0.176 T6)
Dok4 (0.477 T1 + 0 T2 + 0 T3 + 0 T4 + 0.176 T5 + 0 T6) Dok5 (0 T1 + 0.477 T2 + 0 T3 + 0 T4 + 0.176 T5 + 0.176 T6) Dok6 (0 T1 + 0.477 T2 + 0.301 T3 + 0 T4 + 0 T5 + 0 T6)
Query (0.477 T1 + 0 T2 + 0 T3 + 0.778 T4 + 0.176 T5 + 0.176 T6)
Dengan melihat persamaan (2.7.2) jarak antara masing-masing dokumen denganquerypencarian dapat dituliskan sebagai berikut:
| 1|| | =
(0 + 0 + 0.301 + 0 + 0.176 + 0.176 )(0.477 + 0 + 0 + 0.778 + 0.176 + 0.176 )=
0.363
| 2|| | =
(0.477 + 0 + 0.301 + 0.778 + 0 + 0.176 )(0.477 + 0 + 0 + 0.778 + 0.176 + 0.176 )
= 0.908
| 3|| |
= (0 + 0 + 0 + 0 + 0.176 + 0.176 )(0.477 + 0 + 0 + 0.778 + 0.176 + 0.176 )
| 4|| |
Sehingga untuk menghitung persamaan(2.7.6) dapat dilakukan dengan cara :
( 4, )
= (0.477 ∗ 0.477) + (0 ∗ 0 ) + (0 ∗ 0 ) + (0 ∗ 0.778) + (0.176 ∗ 0.176) + (0 ∗ 0.176 ) (0.477 + 0 + 0 + 0 + 0.176 + 0.176 )(0.477 + 0 + 0 + 0.778 + 0.176 + 0.176 )
= 0.547
( 5, )
= (0 ∗ 0.447) + (0.447 ∗ 0 ) + (0 ∗ 0 ) + (0 ∗ 0.778) + (0.176 ∗ 0.176) + (0.176 ∗ 0.176 ) (0 + 0.447 + 0 + 0 + 0.176 + 0.176 )(0.447 + 0 + 0 + 0.778 + 0.176 + 0.176 )
= 0.124
( 6, )
= (0 ∗ 0.447) + (0.447 ∗ 0 ) + (0.301 ∗ 0 ) + (0 ∗ 0.778) + (0 ∗ 0.176) + (0 ∗ 0.176 ) (0 + 0.447 + 0.301 + 0 + 0 + 0 )(0.447 + 0 + 0 + 0.778 + 0.176 + 0.176 )
= 0.0
Dengan demikian, dapat diperoleh urutan hasil pencarian sebagai berikut: Dok2 (0.951)
Dok4 (0.547) Dok3 (0.268) Dok1 (0.171) Dok5 (0.124)
Bianary Independence Model
Peluang kemunculan untuk masing-masing kata pencarian: Hitung = 0/6 = 0
Waktu = 4/6 = 0.6667 Proses = 4/6 = 0.6667 Basis = 2/6 = 0.3333 Komputer = 1/6 = 0.16667
Peluang kemunculan kata pencarian pada setiap dokumen: Dok1 = Waktu proses informasi. = 0.6667 + 0.6667 = 1.3334
Dok2 = komputer basis waktu. = 0.16667 + 0.3333 + 0.6667 = 1.6667 Dok3 = waktu proses. = 0.6667 + 0.6667 = 1.3334
Dok4 = basis proses. = 0.3333 + 0.6667 = 1
Dok5 = waktu proses data. = 0.6667 + 0.6667 = 1.3334
Dokumen 4 dianggap tidak relevan karena menghasilkan peluang terkecil. Dengan demikian tabel contingency menjadi:
hitung waktu proses basis komputer
N 6 6 6 6 6
n 0 4 4 2 1
R 4 4 4 4 4
Untuk setiap kata, akan dihitung bobot (w) sebagai berikut:
Wkomputer= log
. ( ) . ( ) . ( ) ( ) .
= 0.3309
Sehingga dapat dihitung bobot setiap dokumen sebagai berikut:
Dok_id Bobot
Dok1 1.4313 + 0.3679 = 1.7992
Dok2 0.3309 + (-0.33679) + 1.4313 = 1.42541
Dok3 1.4313 + 0.3679 = 1.7992
Dok4 -0.3679 + 0.3679 = 0.0
Dok5 1.4313 + 0.3679 = 1.7992
Sehingga hasil setelah sorting adalah:
Dok1 (1.7992) Dok2 (1.42541)
Dok4 (0.0)
Dok6 (0.0) tidak temasuk hasil pencarian karena tidak memiliki kemiripan denganquerypencarian.
BM25
Peluang kemunculan untuk masing-masing kata pencarian: Hitung = 0/6 = 0
Waktu = 4/6 = 0.6667 Proses = 4/6 = 0.6667 Basis = 2/6 = 0.3333 Komputer = 1/6 = 0.16667
Peluang kemunculan kata pencarian pada setiap dokumen: Dok1 = Waktu proses informasi. = 0.6667 + 0.6667 = 1.3334
Dok2 = komputer basis waktu. = 0.16667 + 0.3333 + 0.6667 = 1.6667 Dok3 = waktu proses. = 0.6667 + 0.6667 = 1.3334
Dok4 = basis proses. = 0.3333 + 0.6667 = 1
Dok5 = waktu proses data. = 0.6667 + 0.6667 = 1.3334
hitung waktu proses basis komputer
N 6 6 6 6 6
n 0 4 4 2 1
R 4 4 4 4 4
r 0 4 3 1 1
Untuk setiap kata, akan dihitung bobot (w) sebagai berikut:
= log
Wkomputer= log
. ( ) . ( ) . ( ) ( ) .
= 0.3309
Untuk nilai k1 yang digunakan adalah 1.2, dan k2adalah 100, serta b adalah
Dok_id K
Kemudian akan dihitung bobot untuk setiap dokumen sebagai berikut:
0.3679 .( . )
. .
( )
= 0.4332
Sehingga hasil setelah sorting adalah:
Dok2 (1.2888) Dok3 (0.5565) Dok5 (0.4332) Dok1 (0.4332)
Dok4 (0.0)
Dok6 (0.0) tidak temasuk hasil pencarian karena tidak memiliki kemiripan denganquerypencarian.
2.9. Recall and Precission
Precission adalah jumlah dari dokumen yang relevan dibagi dengan jumlah keseluruhan dokumen hasil perolehan kembali.
= | ∩ |/| |
= ( | )
Recall adalah jumlah dari keseluruhan dokumen hasil perolehan kembali dibagi dengan jumlah dokumen yang relevan.
= | ∩ |/| |
Kasus yang terbaik adalah jika nilai precission danrecall keduanya bernilai 1 (satu). Hal ini memiliki arti bahwa sistem memperoleh kembali semua dokumen yang relevan tanpa menampilkan dokumen yang tidak relevan di dalam tampilan hasil pencarian (Lee,et al, 1997).
2.10. Metodologi FAST
Metodologi FAST (Framework for the Application of Sistem Thinking)
merupakan kerangka yang fleksibel untuk menyediakan tipe-tipe berbeda proyek dan strategi (Whitten, 2004). Adapun tahapan-tahapan yang terdapat dalam FAST adalah sebagai berikut :
1. Scope Definition Phase
Pada tahap ini dilakukan pengumpulan informasi yang akan diteliti tingkat
feasibility dan ruang lingkup proyek yaitu dengan menggunakan kerangka PIECES (Performance, Information, Economics, Control, Efficiency, Service) .Hal ini dilakukan untuk menemukan inti dari masalah-masalah yang ada (problems), kesempatan untuk meningkatkan kinerja organisasi (opportunity), dan kebutuhan-kebutuhan baru yang dibebankan oleh pihak manajemen atau pemerintah (directives).
2. Problem Analysis Phase
tahap ini akan diteliti masalah-masalah yang muncul pada sistem yang ada sebelumnya.
3. Requirement Analysis Phase
Tujuan dari tahapan ini adalah mengidentifikasi data, proses dan antarmuka yang diinginkan pengguna dari sistem yang baru. Alat bantu untuk memahami kebutuhan yang ada adalah dengan pemodelanuse case.
4. Logical Design Phase
Merupakan terjemahan dari kebutuhan pengguna bisnis ke dalam suatumodel sistem. Dengan kata lain pada fase ini akan menjawab pertanyaan-pertanyaan seputar penggunaan teknologi (data, process, interface) yang menjamin usability, reliability, completeness, performance, danqualityyang akan dibangun di dalam sistem.
5. Decision Analysis Phase
Pada tahap ini akan akan dipertimbangkan beberapa kandidat dari perangkat lunak dan keras yang nantinya akan dipilih dan dipakai dalam implementasi sistem sebagai solusi atas problems dan requirements yang sudah didefinisikan pada tahapan-tahapan sebelumnya.
6. Physical Designand Integration Phase
solusi teknis, physical design merepresentasikan solusi teknis yang lebih spesifik.
7. Constructionand Testing Phase
Mulai mengkonstruksi dan menguji komponen-komponen sistem untuk desain. Ada dua tujuan fase ini yaitu :
a. Membangun dan menguji sebuah sistem yang memenuhi persyaratan bisnis dan spesifikasi desain fisik.
b. Mengimplementasikaninterface antara sistem yang baru dengan sistem yang telah ada.
8. Installationand Delivery Phase
Kegiatan yang dilakukan pada fase ini adalah instalasi sistem, training user, manual sistem, mengkonversi file dandatabase yang ada ke dalamdatabase
46
BAB III
ANALISIS DAN PERANCANGAN
3.1. Analisa Sistem
Berikut akan ditunjukan analisa masalah yang ada di dalam penelitian ini:
3.1.1. Fase Definisi Ruang Lingkup (Scope Definition Phase)
Perpustakaan Universitas Sanata Dharma menyediakan data seluruh koleksi tugas akhir dan e-book di dalam bentuk softcopy. Hal ini dimaksudkan agar para pengguna dapat dipermudah dalam proses pencarian koleksi. Pengguna dapat mencari menggunakan sistem pencari yang telah disediakan. Namun, sistem yang telah disediakan masih memiliki beberapa kekurangan dan keterbatasan akses. Hal ini diakibatkan karena sistem yang disediakan mengharuskan pemustaka untuk mengetahui jenis dari kata pencarian yang akan dimasukan. Hal ini dapat membebani pemustaka di dalam proses pencarian informasi koleksi. Oleh karena itu perlu dibangun sebuah sistem pencari yang dapat membantu pengguna memperoleh informasi dengan mudah dan tidak memperhatikan jenis kata pencarian. Sistem pencari yang akan dibangun harus dapat mencari kata pencarian di dalam isi koleksi, sehingga pemustaka tidak perlu untuk mengingat jenis kata pencariannya.
masing-masing. Metode yang memiliki unjuk kerja paling baik akan digunakan dalam pengembangan sistem selanjutnya. Sistem ini menggunakan kata pencarian yang dimasukan oleh pengguna untuk menampilkan hasil pencarian.
3.1.2. Fase Analisis Masalah (Problem Analysis Phase)
3.1.2.1. Analisa Sistem Saat Ini
Untuk memperoleh informasi data koleksi buku, tugas akhir, majalah, dan e-book di Perpustakaan Sanata Dharma dapat dilakukan dengan cara memilih kategori jenis query pencarian yang akan dicari. Terdapat beberapa kategori pencarian, yaitu pengarang, judul, dan penerbit. Pencarian akan dilakukan secara query database. Sistem saat ini dibangun menggunakan PHP dan database MySql.
3.1.2.2. Analisa Kebutuhan Sistem Baru
Sistem yang dibangun di dalam penelitian ini digunakan untuk melakukan perbandingan unjuk kerja proses pemodelan hasil pencarian. Pencarian dilakukan secara menyeluruh di dalam koleksi. Kata pencarian akan dicari pada isi setiap koleksi. Melihat hasil perhitungan pada contoh kasus antara Binary Independence Model dan BM25, diperoleh bahwa BM25 menghasilkan pemodelan yang lebih unik untuk setiap dokumen karena menghitung frekuensi kata di dalam dokumen. Oleh karena itu, pada penelitian ini pemodelan menggunakan Bayesian Model yang akan digunakan adalah BM25. Proses pemodelan yang dibandingkan adalah BM25 dan
Sistem akan dibangun menggunakan bahasa pemrograman JAVA. Sistem akan menggunakan metode indexing Hash Table dengan bentuk struktur inverted index. Proses stemming akan dilakukan untuk 2 bahasa, yaitu Bahasa Indonesia dengan algoritma Nazief & Adriani, serta Bahasa Inggris dengan algoritma Porter Stemmer.
Proses pengujian hasil akan dilakukan dengan metode precission danrecall. Melalui pengujian hasil, akan dibangun sebuah mesin pencari menggunakan metode yang terbaik.
3.1.3. Fase Analisis Kebutuhan (Requirement Analysis Phase)
3.1.3.1. DiagramUse Case
Gambar 3.1. DiagramUse Case
3.1.3.2. NarasiUse Case
Nama use case : cari dokumen
Aktor : pengguna
Skenario
Aksi actor Reaksi sistem
1. Pengguna memasukan
kata kunciquerypencarian
2. Mencari dokumen-dokumen yang sesuai dengan query
cari dokumen
pencarian pengguna
3. Menampilkan hasil
pencarian
Skenario alternative
1. Pengguna memasukan
kata kunciquerypencarian
2. Mencari dokumen-dokumen yang sesuai dengan query
pencarian pengguna
3. Menampilkan pesan
pencarian tidak ditemukan
3.2. Perancangan Sistem
3.2.1. Langkah Penelitian
Proses yang terjadi pada sistem dijelaskan melalui penggambaran diagram blok berikut:
Gambar 3.2. Diagram blok (indexing)
Gambar 3.3. Diagram blok (searching)
3.2.2. Disain Fisikal
3.2.2.1. Entity Relational Diagram
Berikut merupakan bentuk dari basis data yang digunakan oleh Perpustakaan Universitas Sanata Dharma.
Dengan menghilangkan atribut-atribut yang tidak digunakan,ER Diagramdapat ditulis ulang menjadi :
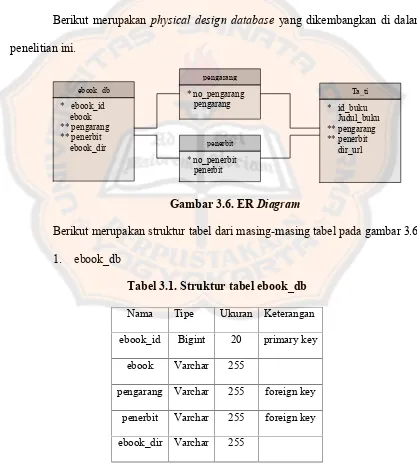
Penambahan atribut ebook_dir pada entitas ebook_db dan dir_url pada entitas ta_ti bertujuan agar informasi alamat penyimpanan digital buku dapat diperoleh. Bentuk penyimpanan digital tersebut akan digunakan untuk melakukan proses indeksing kata.
3.2.2.2. Physical Design Database
Berikut merupakan physical design database yang dikembangkan di dalam penelitian ini.
Gambar 3.6. ERDiagram
Berikut merupakan struktur tabel dari masing-masing tabel pada gambar 3.6. 1. ebook_db
Tabel 3.1. Struktur tabel ebook_db
Nama Tipe Ukuran Keterangan
ebook_id Bigint 20 primary key
ebook Varchar 255
pengarang Varchar 255 foreign key
penerbit Varchar 255 foreign key
2. ta_ti
Tabel 3.2. Struktur tabel ta_ti
Nama Tipe Ukuran Keterangan
ebook_id Bigint 20 primary key
pengarang Varchar 255 foreign key
penerbit Varchar 255 foreign key
dir_url Varchar 500
3. pengarang
Tabel 3.3. Struktur tabel pengarang
Nama Tipe Ukuran Keterangan
no_pengarang Bigint 20 primary key
pengarang Varchar 255
4. penerbit
Tabel 3.4. Struktur tabel penerbit
Nama Tipe Ukuran Keterangan
no_penerbit Bigint 20 primary key
3.2.2.3. Antarmuka
Berikut merupakan rancangan antarmuka yang akan dikembangkan di dalam penelitian ini.
Gambar 3.7. Rancangan Antarmuka
Antarmuka seperti pada gambar 3.7. merupakan antarmuka utama dalam program ini. Pada antarmuka ini pengguna dapat memasukan kata pencarian padatext field yang disediakan dan menekan tombol Search untuk memproses pencarian. Pengguna dapat memilih pemodelan yang akan digunakan di dalam pencarian. Opsi
3.2.3. Flowchart
Berikut akan ditunjukan flowchart dari setiap proses yang akan dibangun di dalam penelitian.
1. Tokenizing
Gambar 3.8.Flowchart Tokenizing
2. Stop-word Removal
mulai
selesai
<proses> Cek kata di dalam kamus input>
Vector<String> potongan kata di dalam dokumen .pdf
Masih ada kata pada Vector<String>?
3. Stemming
- Bahasa Indonesia
- Bahasa Inggris
4. Document Indexing
Gambar 3.13.Flowchart Document Indexing
5. Document Searching
3.2.4. Analisa Hasil
Pada proses ini akan digunakan perhitungan precission dan recall untuk menghitung ketepatan sistem dalam menampilkan hasil pencarian yang relevan. Proses pengumpulan data akan dilakukan secara acak pada beberapa kali pencarian.
Untuk melakukan analisa waktu pencarian, akan dihitung waktu yang dibutuhkan untuk menemukan koleksi pada setiap metode. Waktu pencarian yang dihitung merupakan waktu pencarian dari skenario-skenario pencarian yang telah direncanakan
3.2.5. Diagram Kelas
63
BAB IV
IMPLEMENTASI
Pada bagian ini, penulis akan memaparkan mengenai proses implementasi sistem ke dalam bahasa pemrograman. Sistem dibagi berdasarkan 5 bagian, yaitu
Document Processing, Document Indexing, Document Searching, dan Modeling. Berikut adalah proses-proses yang telah dibangun:
4.4. Documet Processing
Pada tahap ini sistem akan mempersiapkan dokumen untuk dapat digunakan di dalam proses berikutnya. Proses-proses yang dilakukan pada tahap
DocumentProcessingadalah Tokenizing,Stop-word Removal, danStemming. Berikut adalah tahap implementasi untuk masing-masing proses :
4.4.1. Tokenizing
akanmengembalikan nilai bertipe Vector<String> yang telah berisi kumpulan potongan untuk masing-masing kata yang ada di dalam variabel parameter.
public Vector<String> tokenizing(String teks) {
Vector<String> teks_token_vector = new
Vector<String>();
String replaceAll = teks.replaceAll("[^a-zA-Z0-9]", "
");
teks = teks.replaceAll(" ", " ");
teks = teks.replaceAll(" ", " ");
String[] teks_token = teks.split(" ");
4.4.2. Stop-word Removal
Pada proses Stop-word Removal, sistem akan menerima masukan bertipe
Vector<String>. Masukan merupakan hasil yang didapat dari proses Tokenizing.
Untuk setiap kata yang ada di dalam vektor masukan, akan dilakukan pengecekan terhadap kamus stop-word. Kamus stop-word merupakan kumpulan kata-kata yang termasukstop-word dan berupa sebuah file dengan ekstensi.txt. Kamusstop-word
dibaca setiap kali sistem hidup untuk pertama kali.
Pada proses pengecekan, jka kata yang ada pada vektor masukan merupakan kata yang ada pada kamus stop-word, maka kata tersebut akan dihapus dan tidak digunakan untuk proses selanjutnya. Kata-kata yang tidak termasuk di dalam kamus
stop-word akan ditampung di dalam sebuah variabel bertipe Vector<String> . Proses ini akan mengembalikan sebuah nilai bertipe Vector<String> yang berisi kata-kata yang tidak termasuk di dalam kamusstop-word.
public Vector<String> StopWordRemoval(Vector<String>
teks_token) {
Vector<String> teks_token_new = new Vector<String>();
for (int i = 0; i < teks_token.size(); i++) {
if (isInDictionary(teks_token.get(i),
stopWordDict) || teks_token.get(i).equalsIgnoreCase("") ||
teks_token.get(i).length() <= 2 ||
teks_token.get(i).contains(" ")) {
stopWordEngDict) || teks_token.get(i).equalsIgnoreCase("") ||
teks_token.get(i).length() <= 2 ||
teks_token.get(i).contains(" ")) {
Proses Stemming merupakan proses untuk mencari kata dasar (rootword) dari hasil langkah Stop-word Removal. Pencarian kata dasar untuk kata berbahasa Indonesia menggunakan metode Nazief & Adriani dan untuk kata berbahasa Inggris menggunakan metode Porter Stemmer. Proses akan menerima masukan sebuah variable bertipeVector<String> yang berisi kumpulan kata-kata dari proses Stop-word Removal. Kata-kata tersebut dicocokan ke sebuah daftar kata berbahasa Inggris yang didapat dari library Ubuntu 11.04. Library kata tersebut telah dipakai dalam pengembangan sistem operasi Ubuntu sebagai alat bantu untuk pengkoreksian kata-kata berbahasa Inggris. Kata-kata-kata yang termasuk sebagai kata-kata yang terdaftar di dalam
terdaftar di dalam library tersebut akan diasumsikan sebagai kata berbahasa Indonesia, dan dikenai metode untuk mencari kata dasar dari Bahasa Indonesia. Berikut merupakan bentuk implementasinya.
Vector<String> stemming_word = new Vector<String>();
for (int i = 0; i < teks_token.size(); i++) {
String tempTeks = teks_token.get(i).toLowerCase();
String temp = tempTeks;
if (isInDictionary(tempTeks,
fullEnglishDictionary)) {
PorterStemmer st = new PorterStemmer();
char[] toCharArray = tempTeks.toCharArray();
st.add(toCharArray, toCharArray.length);
pengujian yang dikembangkan. Berikut akan ditampilkan implementasi dari pengembangan algoritma Nazief & Adriani tersebut.
public String findRootWord(String string) {
string = string.toLowerCase();
String sebelum = string;
string = clearPrefix(string);
string.endsWith("kah") || string.endsWith("tah") ||
string.endsWith("pun")) {
string = string.substring(0, string.length()
-3);
string.endsWith("mu") || string.endsWith("nya")) {
string = hapusAkhiran(string, 3);
} else {
string = hapusAkhiran(string, 2);
}
string.endsWith("mu") || string.endsWith("nya")) {
if (string.endsWith("nya")) {
string = hapusAkhiran(string, 3);
} else {
string = hapusAkhiran(string, 2);
}
String tempAkhiran = "";
boolean adaHapus = false;
if (string.endsWith("i") || string.endsWith("an") ||
string.endsWith("kan")) {
//tambahan
string = clearPrefix(string);
string = hapusAkhiran(string, 1);
adaHapus = true;
} else if (string.endsWith("an")) {
tempAkhiran = "an";
string = hapusAkhiran(string, 2);
adaHapus = true;
} else if (string.endsWith("kan")) {
tempAkhiran = "kan";
string = hapusAkhiran(string, 3);
adaHapus = true; }
if (isInDictionary(string)) {
return string;
} else {
return string;
} else {
string = sebelum; }
//akhir tamabahan
string = hapusAkhiran(string, 1);
tempAkhiran.equals("i"))
Di dalam methodfindRootWord(String), terdapat pemanggilan method
clearPrefix(String). Method tersebut mengimplementasikan algoritma
penghapusan awalan dari suatu kata. Berikut merupakan bentuk implementasinya.
public String clearPrefix(String string) {
//langkah 4b
String tempAwalan = "";
for (int i = 0; i < 3; i++) {
if (string.startsWith("di") ||
string.startsWith("ke") || string.startsWith("se")) {
if (!tempAwalan.equals(string.substring(0,
2))) {
tempAwalan = string.substring(0, 2);
string = hapusAwalan(string, 2);
}
} else if (string.startsWith("te") ||
string.startsWith("be") || string.startsWith("me") ||
string.startsWith("pe")) {
//mulai pengecekan ambiguitas
if (!tempAwalan.equals(string.substring(0,
2))) {
tempAwalan = string.substring(0, 2);