TUGAS KE 1
MATA KULIAH STATISTIKA
AGUS SUSANTO : 1609200060039
Manajemen Prasarana Perkotaan Magister Teknik Sipil Program Pascasarjana
Universitas Syiah Tahun 2016
Jelaskan istilah-istilah di bawah ini dan berikan contohnya. 1. Parameter
Parameter adalah bilangan nyata yang menyatakan sebuah karakteristik dari sebuah populasi. Contoh : mean populasi, varians populasi dan simpangan baku.
2. Statistika Inferensi
Statistika inferensial adalah proses pengambilan kesimpulan-kesimpulan berdasarkan data sampel yang lebih sedikit menjadi kesimpulan yang lebih umum untuk sebuah populasi. Penelitian inferensial diperlukan jika peneliti memiliki keterbatasan dana sehingga untuk lebih efisien penelitian dilakukan dengan mengambil jumlah sampel yang lebih sedikit dari populasi yang ada. Pada penelitian inferensial, dilakukan prediksi. Statistik inferensial membutuhkan pemenuhan asumsi-asumsi. Asumsi paling awal yang harus dipenuhi adalah sampel diambil secara acak dari populasi. Hal tersebut diperlukan karena pada statistika inferensial perlu keterwakilan sampel atas populasi. Asumsi-asumsi lain yang perlu dipenuhi mengikuti alat analisis yang digunakan. Jika yang digunakan adalah analisis regresi, maka asumsi-asumsi data harus memenuhi asumsi analisis regresi.
Metode analisis statistik yang digunakan dalam statistik inferensial adalah T-test, Anova, Anacova, Analisis regresi, Analisis jalur, Structural equation modelling (SEM) dan metode analisis lain tergantung tujuan penelitian. Dalam statistik inferensial harus ada pengujian hipotesis yang bertujuan untuk melihat apakah ukuran statistik yang digunakan dapat ditarik menjadi kesimpulan yang lebih luas dalam populasinya. Ukuran-ukuran statistik tersebut dibandingkan dengan pola distribusi populasi sebagai normanya. Oleh sebab itu, mengetahui pola distribusi data sampel menjadi penting dalam statistik inferensial.
Contoh :
Pada pemilu presiden 2014. Berbagai lembaga survei melakukan quick count untuk mengetahui secara cepat kandidat presiden mana yang akan mendapatkan suara rakyat lebih banyak. Lembaga survei tersebut mengambil sebagian sampel TPS (Tempat Pemungutan Suara) dari total TPS populasi. Hasil sampel TPS tersebut digunakan untuk generalisasi terhadap keseluruhan TPS. Katakanlah diambil 2.000 sampel TPS dari 400.000 populasi TPS yang ada. Hasil dari 2.000 TPS adalah statistik deskriptif. Sedangkan jika kita mengambil kesimpulan terhadap 400.000 TPS adalah statistik inferensial.Kekuatan statistik inferensial tergantung pada teknik pengambilan sampel dan proses randomisasi. Jika proses randomisasi dilakukan dengan benar, maka sampel yang lebih sedikit dapat memprediksi nilai populasi dengan baik. Dengan demikian dapat menghemat anggaran pengambilan / pengumpulan data.
3. Populasi
Populasi merupakan keseluruhan (universum) dari objek penelitian yang dapat berupa manusia, hewan, tumbuh-tumbuhan, gejala, nilai, peristiwa, sikap hidup, dan sebagainya yang menjadi pusat perhatian dan menjadi sumber data penelitian.
Jenis-jenis Populasi , Populasi dapat dibagi berdasarkan keadaan (kompleksitasnya) dan berdasarkan ukurannya.
Populasi berdasarkan keadaannya
Populasi Homogen: populasi dikatakan homogen apabila unsur-unsur dari populasi yang diteliti memiliki sifat-sifat yang relatif seragam satu sama lainnya. Karakteristik seperti ini banyak ditemukan di bidang eksakta, misalnya air, larutan, dsb. Apabila kita ingin mengetahui manis tidaknya secangkir kopi, cukup dengan mencoba setetes cairan kopi tersebut. Setetes cairan kopi sudah bisa mewakili kadar gula dari secangkir kopi tersebut.
Populasi Heterogen: populasi dikatakan heterogen apabila unsur-unsur dari populasi yang diteliti memiliki sifat-sifat yang relatif berbeda satu sama lainnya. Karakteristik seperti ini banyak ditemukan dalam penelitian sosial dan perilaku, yang objeknya manusia atau gejala-gejala dalam kehidupan manusia yang bersifat unik dan kompleks. Misalnya, apabila kita ingin mengetahui rata-rata IQ mahasiswa Unpad angkatan 2009 (berarti rata-rata dari semua Fakultas).
Populasi berdasarkan ukurannya
Populasi terhingga: populasi dikatakan terhingga bilamana anggota populasi dapat diperkirakan atau diketahui secara pasti jumlahnya, dengan kata lain, jelas batas-batasnya secara kuantitatif, misalnya:
a) Banyaknya Mahasiswa Agroteknologi Kelas A, Angkatan 2009, Faperta, Unpad b) Tinggi penduduk yang ada di kota tertentu
c) Panjang ikan di sebuah danau
Populasi tak hingga: populasi dikatakan tak hingga bilamana anggota populasinya tidak dapat diperkirakan atau tidak dapat diketahui jumlahnya, dengan kata lain, batas-batasnya tidak dapat ditentukan secara kuantitatif, misalnya:
a) Air di lautan
b) Banyaknya pasir yang ada di Pantai Pangandaran. c) Banyaknya anak yang menderita kekurangan gizi d) Kedalaman suatu danau yang diukur dari berbagai titik Contoh :
Populasi Mahasiswa Universitas Syiah Kula Populasi Mahasiswa Fakultas Pertanian
Jika yang ingin diteliti adalah sikap konsumen terhadap satu produk tertentu, maka populasinya adalah seluruh konsumen produk tersebut
Jika yang diteliti adalah laporan keuangan perusahaan “X”, maka populasinya adalah keseluruhan laporan keuangan perusahaan “X” tersebut
Jika yang diteliti adalah motivasi pegawai di departemen “A” maka populasinya adalah seluruh pegawai di departemen “A”
4. Statistika Deskriptif
Pada statistik deskriptif penelitian hanya menggambarkan keadaan data apa adanya melalui parameter-parameter seperti mean, median, modus, distribusi frekuensi dan ukuran statistik lainnya. Pada statistika deskriptif, yang perlu disajikan adalah:
a. Ukuran pemusatan data (measures of central tendency). Ukuran pemusatan data yang sering digunakan adalah distribusi frekuensi. Ukuran statistik ini cocok untuk data nominal dan data ordinal (data kategorik). Sementara nilai mean adalah ukuran pemusatan data yang cocok untuk data continuous. Ukuran deskriptif lain untuk pemusatan data adalah median (nilai tengah) dan modus (nilai yang paling sering muncul).
b. Ukuran penyebaran data (measures of spread). Ukuran penyebaran data yang sering digunakan adalah standar deviasi. Ukuran penyebaran data ini cocok digunakan untuk data numerik atau continuous. Sementara untuk data kategorik, nilai range merupakan ukuran yang cocok.
Contoh statistika deskriptif yang sering muncul adalah, tabel, diagram, grafik, dan besaran-besaran lain di majalah dan koran-koran
5. Sampel
Sampel adalah bagian dari populasi yang diharapkan mampu mewakili populasi dalam penelitian
Contoh :
Contoh Ukuran/Jumlah Sampel (n) untuk Memperkirakan Proporsi/Persentase Populasi Akan diteliti “Berapa Besar Persentase Sumber Biaya Pendidikan SD Negeri yang Berasal dari PAD di Kabupaten Bandung”. Misalnkan seluruh SD Negeri yang ada di Kabupaten Bandung berjumlah 2000 sekolah. Bound of error atau kesalahan sampling tertinggi yang dikehendaki tidak lebih dari 5 persen. Tingkat kepercayaan yang digunakan 95%.
6. Sensus
Sensus adalah cara pengumpulan data apabila seluruh elemen populasi diselidiki satu per satu. Data yang diperoleh tersebut merupakan hasil pengolahan sensus disebut sebagai data yang sebenarnya (true value), atau sering juga disebut parameter.
Contoh :
hasil sensus penduduk tahun 2015 memberikan data sebenarnya mengenai penduduk Kecamatan Jaya Baru (jumlahnya menurut jenis kelamin, menurut umur, menurut pendidikan, menurut lapangan kerja dan agama)
Jelaskan hubungan antara statistika deskriptif dan statistika inferensi. Gunakan contoh kasus yang konkrit untuk menjelaskannya.
Statistik dibedakan menjadi dua macam tipe aplikasi yakni statistik deskriptif dan statistik inferensial.
1. Statistik deskriptif
Statistik deskriptif merupakan tipe analisis yang meliputi pengumpulan data, penyajian data, dan peringkasan data. Tipe analisis ini hanya sebatas mengolah data dan menyajikannya saja sehingga tidak dapat digunakan untuk mengambil suatu kesimpulan dari apa yang telah diteliti.
2. Statistik inferensial/ induktif
Statistik inferensial merupakan tipe analisis yang digunakan utnuk mengkaji, menaksir dan menarik kesimpulan dari apa yang telah diteliti sehingga dapat digunakan sebagai pedoman dalam pengambilan keputusan.
Dalam statistik induktif/ inferensial terdapat beberapa langkah yakni:
Menentukan hipotesis nihil (Ho) dan menentukan hipotesis alternatif (Ha atau H1). Menentukan statistik tabel
Menghitung kriteria pengujian atau statistik hitung
Menarik kesimpulan dan mengambil keputusan sesuai dengan hasil perbandingan antara statistik hitung dengan statistik tabel yang ada atau dengan melihat tingkat signifikansinya yakni apakah Ho ditolak atau diterima.
Pembagian metode statistik induktif: 1. Berdasarkan tipe data
Data bersifat kualitatif (nominal dan ordinal), analisis dapat dikelompokkan pada bagian statistik non parametrik. Seperti Uji Wilcoxon, Kruskal-Wallis, Friedman dan sebagainya. Data bersifat kuantitatif (interval dan rasio), analisis dapat dikelompokkan pada bagian
statistik parametrik. Seperti Uji T, Uji F (Anova) dan sebagainya. 2. Berdasarkan jumlah variabel
Analisis univariat, digunakan untuk menganalisis satu variable. Misalnya Uji T.
Analisis bivariat, digunakan untuk menganalisis dua variabel. Misalnya analisis korelasi sederhana dan analisis regresi sederhana.
Analisis ganda/ faktorial, digunakan bila hanya satu variabel dependen tetapi lebih dari satu variabel independen yang dianalisis. Misalnya analisis korelasi ganda dan analisis regresi ganda.
Analisis multivariate, digunakan untuk menganalisis dua atau lebih variabel dependen dan dua atau lebih variable independen. Misalnya cluster analysis, factor analysis, discriminant analysis dan sebagainya.
Untuk keperluan analisis data pada bidang riset, metode statistik induktif yang ada dapat dibagi sesuai dengan kegunaannya, antara lain:
1. Analisis statistik komparatif (perbandingan dan perbedaan), misalnya : independen sample t test, paired sample t test, one way anova.
2. Analisis statistik korelasional (uji asosiasi), misalnya crosstab untuk korelasi dua variabel data berskala nominal (kategori), korelasi dua variabel data berskala interval/ rasio (korelasi Pearson), korelasi parsial data berskala interval/ rasio.
3. Analisis prediktif, misalnya analisis regresi sederhana dan regresi ganda.
4. Analisis multivariat, misalnya cluster analysis, factor analysis, discriminant analysis dan sebagainya.
Terkadang dalam suatu penelitian hanya digunakan salah satu dari kedua tipe aplikasi tersebut. Tetapi dapat juga digunakan keduanya, yakni penelitian yang menggunakan data deskriptif terlebih dahulu kemudian dilanjutkan dengan menggunakan tipe aplikasi inferensial/ induktif yang dapat digunakan untuk mengambil keputusan dari penelitian tersebut.
contohnya, peneliti ingin mengetahui kecepatan internet dalam suatu laboratorium yang ingin membuktikan semakin banyak pengguna internet akan memperlambat kecepatan internet. Maka penelitian dilakukan dengan memperoleh data kecepatan internet bila digunakan oleh 1 orang, 2 orang, 3 orang dan seterusnya. Data-data tersebut disajikan dalam bentuk data deskriptif. Berangkat dari data deskriptif maka untuk mengetahui besarnya pengaruh pengguna internet terhadap kecepatan internet, maka data-data tersebut perlu dianalisis menggunakan tipe inferensial yang dapat menghasilkan kesimpulan sehingga dapat digunakan untuk mengambil keputusan atas kasus tersebut nantinya.
Deskripsi atau penggambaran sekumpulan data secara visual dapat dilakukan dengan dengan dua cara yakni deskripsi dalam bentuk tulisan dan deskripsi dalam bentuk gambar.
1. Deskripsi dalam bentuk tulisan,
Bisa kita dapatkan dari output SPSS yang secara otomatis muncul. Dalam program SPSS, statistik deskriptif dapat dilakukan dengan menu deskriptive statistics yang terdiri dari: - Frequencies,
Digunakan untuk menampilkan dan menggambarkan data yang terdiri atas satu variabel saja. Jika terdapat lebih dari satu variabel maka variabel-variabel tersebut akan ditampilkan secara terpisah.
- Descriptives
Digunakan untuk menyajikan data statistik deskriptif pada sebuah variabel seperti rata-rata (mean), deviasi standar, variasi dan sebagainya.
- Explore
Memiliki fungsi yang sama dengan menu “Descriptives”. Perbedaannya adalah dalam menu Explore ini akan diolah semakin kompleks dan dilengkapi dengan cara menguji apakah data yang outlier serta uji kenormalan sebuah data, yang dapat dukur dengan uji tertentu atau ditampilkan dalam bentuk box-plot, steam, and leaf dan normal probability plot.
- Crosstab
Digunakan untuk menyajikan data dalam bentuk tabulasi, yang meliputi baris dan kolom. Ciri crosstab adalah adanya dua variable atau lebih yang mempunyai hubungan secara deskriptif serta data penyajiannya berupa data kualitatif, khususnya data yang berskala nominal.
- Ratio
Digunakan untuk menyediakan ringkasan statistik yang berupa perbandingan-perbandingan. Rasio ini sering juga disebut sebagai rasio statistik, yakni hasil pembagian dua variabel yaitu semua data yang bertipe rasio yang mempunyai nilai positif.
2. Descriptive dalam bentuk gambar/ grafik
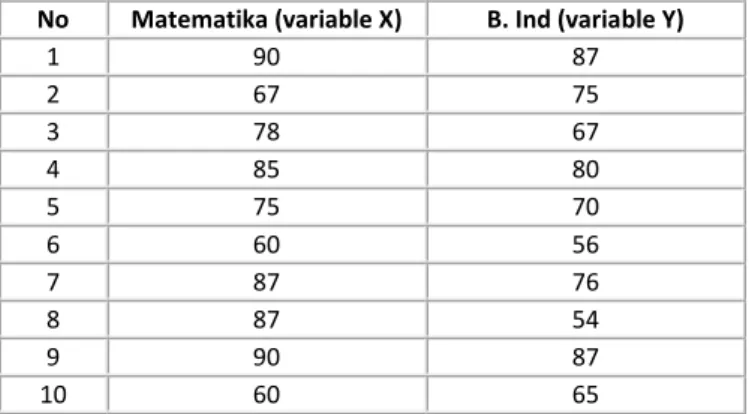
Data yang disajikan dengan grafik digunakan untuk melengkapi deskripsi yang beripa teks, supaya data tersebut tampak lebih impresif dan komunikatif dengan para penggunanya. Berikut ini disajikan salah satu contoh analisa yang menggunakan tipe statistik deskriptif Tabel di bawah ini adalah data-data perolehan nilai dari 10 siswa untuk mata pelajaran Matematika dan Bahasa Indonesia. Yang nantinya akan dianalisis menggunakan tipe analisa deskriptif.
No Matematika (variable X) B. Ind (variable Y)
1 90 87 2 67 75 3 78 67 4 85 80 5 75 70 6 60 56 7 87 76 8 87 54 9 90 87 10 60 65
Carilah sebuah artikel dari sebuah publikasi baru-baru ini (koran, majalah, dsb.) yang membahas suatu hasil dari kajian statistika. Kemudian, jelaskan hal-hal berikut:
1. Populasi dan sampelnya, apakah data sampel memadai (baik)?
2. Apakah hasil yang diungkapkan sampel menggambarkan parameter populasinya?
Jika kita akan meneliti karyawan sebuah perusahaan yang banyaknya 1.000 orang, maka seluruh karyawan yang seribu orang itu disebut sebagai populasi penelitian kita. Tiap-tiap karyawan dari seluruh karyawan yang seribu orang itu disebut sebagai subjek penelitian, sekaligus kita sebut sebagai anggota populasi penelitian kita. Jadi, dengan demikian, dapat disimpulkan pula bahwa populasi penelitian itu adalah keseluruhan subjek penelitian.
Ada kalanya, karena berbagai keterbatasan, kita tidak mungkin meneliti (“menanyai” atau mengumpulkan data — bisa dengan wawancara, observasi, angket, tes dsb. — dari) seluruh anggota populasi. Jadi, kita tidak bisa melakukan studi populasi. Kita mau tidak mau harus mengambil sebagian daripada seluruh anggota populasi tersebut. Sebagian subjek penelitian yang kita teliti (“tanyai”) langsung itu kita sebut sebagai sampel. Cara-cara bagaimana mengambil sampel dari populasi penelitian disebut dengan sampling.
Pertanyaan yang sering muncul berkaitan dengan pengambilan sampel (sampling) itu adalah mengenai seberapa besar (banyak) jumlah sampel (“sample size”) yang patut diambil agar hasil penelitian yang dilakukan bisa diyakini benar. Apa makna bisa diyakini benar itu?
Pertama, karena tidak semua anggota populasi diteliti, diyakini benar itu artinya seberapa tinggi hasil penelitian dari sampel itu taraf “kebisadipercayaannya” akan mencerminkan seluruh anggota populasi. Maksudnya, data yang dihasilkan dari sampel itu benar-benar akan relatif sama dengan data yang diperoleh jika penelitian dilakukan terhadap seluruh anggota populasi. “Nyicipi” rasa sayur setengah sendok dari sepanci itu yakinkah akan sama persis dengan jika “makan” seluruh sayur itu? Tentu tidak. Sebab ada kalanya tidak “galoh” (merata rasanya di seluruh bagian).
Terjadinya hasil penelitian yang tidak bisa diyakini bahwa betul-betul benar itu akan diperbesar apabila sampel yang diambil “terlampau kecil” berbanding jumlah keseluruhan anggota populasi. Kedua, walau bagaimanapun, hasil penelitian itu tidak selalu bisa diharapkan betul-betul benar (yakin 100% benar). Karena berbagai faktor, hasil penelitian itu dapat mengandung kesalahan (error, galat/”ghalat”). Salah satu kesalahan itu terjadi karena ada yang “secara kebetulan benar.” Murid yang sebenarnya “tidak tahu” bisa saja menjawab soal ujian “cekpoin” benar, karena kebetulan memilih pilihan jawaban yang merupakan jawaban yang benar.
Kesalahan (error/galat) yang terjadi karena kebetulan itu lazim dilambangkan (direpresentasikan) dengan “taraf signifikansi.” Jelasnya, taraf seberapa besar kemungkinan terjadinya kebenaran karena kebetulan saja benar. Dalam bahasa lain seberapa besar taraf “toleransi” akan terjadinya kesalahan karena faktor kebetulan benar.
Untuk ilmu kealaman taraf signifikansi itu disepakati para ahli (dalam berbagai literatur umumnya menyatakan sama) yang “terbaik” sebesar 0,01. Maksudnya hanya ada 0,01 atau 1% saja kesalahan karena kebetulan itu terjadi. Jadi, dengan kata lain, yakin sebesar 99% bahwa hasil penelitian itu benar. Itu artinya, karena tetap berhati-hati, tidak ada yang “patut” diyakini 100% benar.
Untuk ilmu-ilmu sosial disepakati yang “terbaik” itu sebesar 0,05 . Maksudnya hanya ada 0,05 atau 5% saja kesalahan karena kebetulan itu terjadi. Jadi, yakin 95% bahwa hasil penelitian itu benar. Ini karena tingkat kepastian (keajegan) “orang-orang” (sosial) itu relatif tidak seajeg seperti gejala kealaman. Dalam pengambilan sampel, kedua aspek tersebut di atas menjadi salah satu perhatian utama. Jika hasil penelitian diharapkan mencapai taraf signifikansi tinggi (taraf kesalahan karena faktor kebetulan kecil), maka jumlah sampel dituntut lebih banyak
dibandingkan harapan taraf signifikansi lebih rendah (banyak kesalahan yang disebabkan ada yang “karena kebetulan benar” lebih besar).
Salah satu cara menentukan besaran sampel yang memenuhi hitungan itu adalah yang dirumuskan oleh Slovin (Steph Ellen, eHow Blog, 2010; dengan rujukan Principles and Methods of Research; Ariola et al. (eds.); 2006) sebagai berikut.
n = N/(1 + Ne^2)
n = Number of samples (jumlah sampel)
N = Total population (jumlah seluruh anggota populasi)
e = Error tolerance (toleransi terjadinya galat; taraf signifikansi; untuk sosial dan pendidikan
lazimnya 0,05) –> (^2 = pangkat dua)
Untuk menggunakan rumus tersebut, pertama-tama tetapkan terlebih dahulu taraf keyakinan atau
confidence level (…%) akan kebenaran hasil penelitian (yakin berapa persen?), atau taraf
signifikansi toleransi kesalahan (0,..) terjadi.
Misalnya kita ambil taraf keyakinan 95%, yaitu yakin bahwa 95% hasil penelitian benar, atau taraf signifikansi 0,05 (hanya akan ada 5% saja kesalahan karena “kebetulan benar” terjadi).
Jika yang akan kita teliti itu sebanyak 1.000 orang karyawan, seperti dicontohkan di muka, dan taraf signifikansinya 0,05, maka besarnya sampel menurut rumus Slovin ini akan menjadi:
n = N/(1 + Ne^2) = 1000/(1 + 1000 x 0,05 x 0,05) = 286 orang.
menggunakan rumus tersebut jika taraf keyakinan (kepercayaan) hanya 90% (taraf signifikansi 0,10)
Berapa banyak sampel harus diambil? Jawabnya:
n = N/(1 + Ne^2) = 1000/(1 + 1000 x 0,10 x 0,10) = . . . orang.
Jumlah sampel yang terambil lebih kecil daripada taraf signifikansi 0,05 (taraf keyakinan 95%), atau lebih besar?
Jawabnya: 1000/(1+10) =1000:11 = 90,9 = 91.
Nah coba pula, agar tidak keliru t.s. 0,10 (taraf kepercayaan 90%) dengan t.s. 0,01 (taraf kepercayaan 99%), hitung juga dengan populasi 1000 orang. Jadinya:
n = N/(1 + Ne^2) = 1000/(1 + 1000 x 0,01 x 0,01) = . . . orang. Ada berapa orang sampel yang harus diambil?
TUGAS KE 2
MATA KULIAH STATISTIKA
AGUS SUSANTO : 1609200060039
Manajemen Prasarana Perkotaan Magister Teknik Sipil Program Pascasarjana
Universitas Syiah Tahun 2016
Soal :
a. Tentukan mana yang sebagai peubah bebas dan peubah tak bebas. b. Buatlah diagram pencar.
c. Tentukan koefisien korelasi dan maknanya. d. Tentukan koefisien determinasi dan maknanya.
e. Apakah ada hubungan linear antara kedua peubah tersebut? Gunakan f. Apakah ada hubungan linear positif antara kedua peubah tersebut? Gunakan
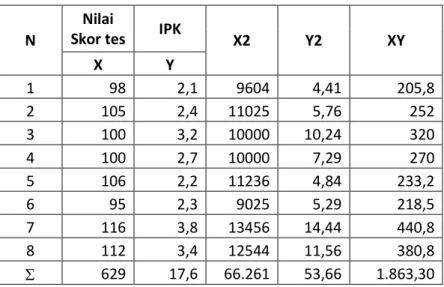
1. Seorang pendidik ingin mengetahui hubungan antara nilai skor tes dan nilai IPK dari mahasiswa, berikut data sampel :
Jawab:
Untuk menghitung koefisien korelasi maka disusun tabel bantu sebagai berikut: Tabel Bantu Analisis Korelasi Product Moment
N
Nilai
Skor tes IPK X2 Y2 XY
X Y 1 98 2,1 9604 4,41 205,8 2 105 2,4 11025 5,76 252 3 100 3,2 10000 10,24 320 4 100 2,7 10000 7,29 270 5 106 2,2 11236 4,84 233,2 6 95 2,3 9025 5,29 218,5 7 116 3,8 13456 14,44 440,8 8 112 3,4 12544 11,56 380,8 629 17,6 66.261 53,66 1.863,30
Berdasarkan tabel bantu tersebut diperoleh nilai-nilai: X = 629 Y = 17,6 X2 = 66.261 Y2 = 53,66 XY = 1.863,30 n = 8
Nilai Skor Tes 98 105 100 100 106 95 116 122 IPK 2,1 2,4 3,2 2,7 2,2 2,3 3,8 3,4
Untuk menghitung koefisien korelasi, maka nilai-nilai tersebut dimasukkan dalam rumus koefisien korelasi sebagai berikut.
r = 2 2 ) 6 , 17 ( ) (53,66 . 8 ) 629 ( ) (66.621 . 8 ) (629)(17,6 -(1.863,30) 8 =
76
,
309
28
,
429
641
.
395
968
.
532
4
,
070
.
11
4
,
906
.
14
=52
,
119
327
.
137
836
.
3
=x10,93
58
,
370
836
.
3
=44
,
050
.
4
836
.
3
= 0,947058Jadi diperoleh nilai koefisien korelasi ( r ) sebesar 0,947058 karena nilainya positif dan mendekati 1 berarti hubungan antara nilai skor tes dan nilai IPK dari mahasiswa kuat dan searah (positif), artinya peningkatan nilai skor tes akan diikuti dengan nilai IPK.
Uji Hipotesis Hubungan (Uji Signifikan)
Pengujian hipotesis hubungan digunakan uji statistik yang disebut Uji t (t-student). Parameter yang diuji yaitu korelasi dinotasikan dengan (lihat bab Estimasi Parameter). Uji hipotesis hubungan pada dasarnya adalah menguji signifikansi koefisien korelasi, apakah besar kecilnya hubungan yang diperoleh itu kebetulan saja atau memang ada hubungan yang sesungguhnya.
Rumus Uji t untuk uji hubungan adalah:
t = 2 2 r -1 2 n r
Selain menggunakan Uji t, pengujian hipotesis hubungan dapat menggunakan kriteria nilai korelasi tabel (rtabel) yaitu dengan cara membandingkan nilai koefisien korelasi (rhitung) dengan nilai rtabel.
Jika rhitung > rtabel maka hubungan antar variabel signifikan
Jika rhitung rtabel maka hubungan antar variabel tidak signifikan Rumusan hipotesis:
Ho : = 0 Tidak ada hubungan yang signifikan antara pendapatan dengan konsumsi Ha : 0 Ada hubungan yang signifikan antara pendapatan dengan konsumsi
Taraf = 0,05 selanjutnya dapat dicari nilai ttabel pada = 0,05 (uji 2 pihak /2 = 0,025) derajat bebas
Kriteria pengujian:
Ho ditolak jika thitung > ttabel atau probabilitas < 0,05
Ho diterima jika thitung ttabel atau probabilitas 0,05
Uji statistik (Uji t)
Menghitung nilai t dengan rumus: t =
2 2 r -1 2 n r t = 2 2
(0,947058)
-1
2
8
(0,947058)
=896919
,
0
1
2,45
x
896919
,
0
=103081
,
0
197451
,
2
=321062
,
0
197451
,
2
= 6,844319Jadi diperoleh nilai thitung sebesar 6,844319.
Kesimpulan
Karena thitung (6,844319) > ttabel (2,44691) maka Ho ditolak, artinya hubungan kedua variabel
signifikan, atau nilai skor tes memiliki hubungan yang signifikan dengan IPK. Dengan demikian hipotesis yang menyatakan “ada hubungan yang signifikan antara nilai skor tes dengan IPK” diterima.
Pengujian koefisien korelasi dapat juga dilakukan dengan cara membandingkan nilai koefisien korelasi dengan nilai korelasi tabel atau rtabel, sehingga perlu dicari nilai rtabel pada
taraf = 0,05 dan n = 6 yaitu diperoleh rtabel = 0,707 (lihat tabel r). Karena nilai rhitung
(0,947058) > rtabel (0,707) maka Ho ditolak, artinya nilai skor tes memiliki hubungan signifikan
2. Seorang peneliti ingin mengetahui apakah ada hubungan antara umur dengan lamanya seseorang melakukan olah raga perminggu.
Berikut data sampelnya.
Jawab:
Untuk menghitung koefisien korelasi maka disusun tabel bantu sebagai berikut: Tabel Bantu Analisis Korelasi Product Moment
N Umur Lamanya Olah Raga (Jam) X2 Y2 XY X Y 1 18 10 324 100 180 2 28 5 784 25 140 3 32 2 1024 4 64 4 38 3 1444 9 114 5 52 1,5 2704 2,25 78 6 59 1 3481 1 59 227 22,5 9761 141,25 635
Berdasarkan tabel bantu tersebut diperoleh nilai-nilai: X = 227 Y = 22,5 X2 = 9.761 Y2 = 141,25 XY = 635 n = 6
Untuk menghitung koefisien korelasi, maka nilai-nilai tersebut dimasukkan dalam rumus koefisien korelasi sebagai berikut.
r = 2 2 ) 5 , 22 ( ) (141,25 . 6 ) 227 ( ) (9.761 . 6 ) (227)(22,5 -(635) 6 =
25
,
506
5
,
847
529
.
51
566
.
58
5
,
107
.
5
810
.
3
Umur 18 28 32 38 52 59=
25
,
341
7037
5
,
297
.
1
=x18,47
89
,
83
5
,
297
.
1
=45
,
1549
5
,
297
.
1
= -0,837394Jadi diperoleh nilai koefisien korelasi (r) sebesar -0,837394 karena nilainya negatif berarti hubungan antara umur dengan lamanya seseorang melakukan olah raga perminggu tidak searah (negatif), artinya lamanya seseorang melakukan olah raga perminggu menunjukan korelasi negatif.
Kriteria pengujian:
Ho ditolak jika thitung > ttabel atau probabilitas < 0,05
Ho diterima jika thitung ttabel atau probabilitas 0,05
Uji statistik (Uji t)
Menghitung nilai t dengan rumus: t =
2 2 r -1 2 n r t = 2 2
)
(-0,837394
-1
2
6
)
(-0,837394
=701228
,
0
1
2
x
701228
,
0
=298771
,
0
402456
,
1
=5466
,
0
402456
,
1
= 2,565781Jadi diperoleh nilai thitung sebesar 2,565781
Karena thitung (2,565781) > ttabel (2,44691) maka Ho ditolak, artinya hubungan kedua variabel
signifikan, atau umur memiliki hubungan yang signifikan dengan lamanya olah raga. Dengan demikian hipotesis yang menyatakan “ada hubungan yang signifikan antara nilai skor tes dengan IPK” diterima.
Pengujian koefisien korelasi dapat juga dilakukan dengan cara membandingkan nilai koefisien korelasi dengan nilai korelasi tabel atau rtabel, sehingga perlu dicari nilai rtabel pada
taraf = 0,05 dan n = 6 yaitu diperoleh rtabel = 0,7067 (lihat tabel r). Karena nilai rhitung
(-0,837394) < rtabel (0,7067) maka Ho diterima, artinya nilai umur tidak memiliki hubungan
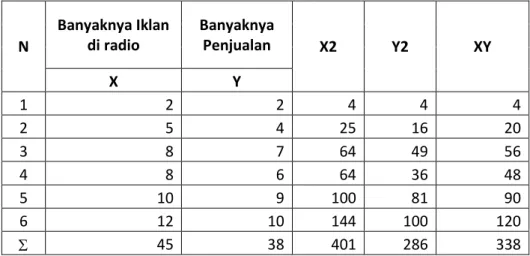
3. Seorang manajer perusahaan ingin mengetahui hubungan antara banyaknya iklan di radio perminggu dan banyaknya penjualan (dalam jutaan rupiah) untuk suatu barang.
Berikut data sampelnya.
Jawab:
Untuk menghitung koefisien korelasi maka disusun tabel bantu sebagai berikut: Tabel Bantu Analisis Korelasi Product Moment
N Banyaknya Iklan di radio Banyaknya Penjualan X2 Y2 XY X Y 1 2 2 4 4 4 2 5 4 25 16 20 3 8 7 64 49 56 4 8 6 64 36 48 5 10 9 100 81 90 6 12 10 144 100 120 45 38 401 286 338
Berdasarkan tabel bantu tersebut diperoleh nilai-nilai: X = 45 Y = 38 X2 = 401 Y2 = 286 XY = 338 n = 6
Untuk menghitung koefisien korelasi, maka nilai-nilai tersebut dimasukkan dalam rumus koefisien korelasi sebagai berikut.
r = 2 2 ) 38 ( ) (286 . 6 ) 45 ( ) (401 . 6 (45)(38) -(338) 6 =
1444
1716
2025
2406
1710
2028
=272
381
318
Banyaknya iklan di radio 18 28 32 38 52 59 Banyaknya penjualan 10 5 2 3 1,5 1
=
x16,49
52
,
19
318
=88
,
321
318
= 0,987946Jadi diperoleh nilai koefisien korelasi ( r ) sebesar 0,987946 karena nilainya positif dan mendekati 1 berarti hubungan antara banyaknya iklan di radio perminggu dan banyaknya penjualan kuat dan searah (positif), artinya peningkatan nilai skor penjualan akan diikuti dengan nilai iklan. Kriteria pengujian:
Ho ditolak jika thitung > ttabel atau probabilitas < 0,05
Ho diterima jika thitung ttabel atau probabilitas 0,05
Uji statistik (Uji t)
Menghitung nilai t dengan rumus: t =
2 2 r -1 2 n r t = 2 2
(0,987946)
-1
2
6
(0,987946)
=976037
,
0
1
2
x
976037
,
0
=023963
,
0
952074
,
1
=154799
,
0
952074
,
1
= 12,610379Jadi diperoleh nilai thitung sebesar 12,610379.
Kesimpulan
Karena thitung (12,610379) > ttabel (2,44691) maka Ho ditolak, artinya hubungan kedua variabel
signifikan, atau banyaknya iklan di radio perminggu dan banyaknya penjualan. Dengan demikian hipotesis yang menyatakan “ada hubungan yang signifikan antara banyaknya iklan di radio perminggu dan banyaknya penjualan” diterima.
Pengujian koefisien korelasi dapat juga dilakukan dengan cara membandingkan nilai koefisien korelasi dengan nilai korelasi tabel atau rtabel, sehingga perlu dicari nilai rtabel pada
taraf = 0,05 dan n = 6 yaitu diperoleh rtabel = 0,7067 (lihat tabel r). Karena nilai rhitung
(0,987946) > rtabel (0,7067) maka Ho ditolak, artinya banyaknya iklan di radio perminggu
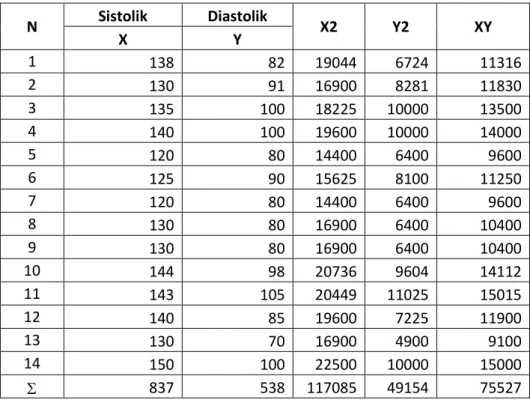
4. Empat belas mahasiswa telah dipilih secara acak tekanan darahnya. Berikut data tekanan darah sistolik dan diastolik (dalam mmHg)
Jawab:
Untuk menghitung koefisien korelasi maka disusun tabel bantu sebagai berikut: Tabel Bantu Analisis Korelasi Product Moment
N Sistolik Diastolik X2 Y2 XY X Y 1 138 82 19044 6724 11316 2 130 91 16900 8281 11830 3 135 100 18225 10000 13500 4 140 100 19600 10000 14000 5 120 80 14400 6400 9600 6 125 90 15625 8100 11250 7 120 80 14400 6400 9600 8 130 80 16900 6400 10400 9 130 80 16900 6400 10400 10 144 98 20736 9604 14112 11 143 105 20449 11025 15015 12 140 85 19600 7225 11900 13 130 70 16900 4900 9100 14 150 100 22500 10000 15000 837 538 117085 49154 75527
Berdasarkan tabel bantu tersebut diperoleh nilai-nilai: X = 837 Y = 538 X2 = 117085 Y2 = 49154 XY = 75527 n = 14
Untuk menghitung koefisien korelasi, maka nilai-nilai tersebut dimasukkan dalam rumus koefisien korelasi sebagai berikut.
r = 2 2 ) 538 ( ) (49154 . 14 ) 837 ( ) (117085 . 14 (837)(538) -(75527) 14 Sistolik 138 130 135 140 120 125 120 130 130 144 143 140 130 150 Diastolik 82 91 100 100 80 90 80 80 80 98 105 85 70 100
=
289444
688156
700569
1639190
450306
1057378
=398712
938621
607072
=x631,44
82
,
968
607072
=7
,
611751
607072
= 0,992359Jadi diperoleh nilai koefisien korelasi ( r ) sebesar 0,987946 karena nilainya positif dan mendekati 1 berarti hubungan antara tekanan darah sistolik dan diastolik (dalam mmHg) kuat dan searah (positif).
Kriteria pengujian:
Ho ditolak jika thitung > ttabel atau probabilitas < 0,05
Ho diterima jika thitung ttabel atau probabilitas 0,05
Uji statistik (Uji t)
Menghitung nilai t dengan rumus: t =
2 2 r -1 2 n r t = 2 2
(0,992359)
-1
2
14
(0,992359)
=984776
,
0
1
3,46
x
984776
,
0
=015224
,
0
407325
,
3
=123884
,
0
407325
,
3
= 27,504157Jadi diperoleh nilai thitung sebesar 27,504157
Kesimpulan
Karena thitung (27,504157) > ttabel (2,14479) maka Ho ditolak, artinya hubungan kedua variabel
signifikan, atau tekanan darah sistolik dan diastolik (dalam mmHg). Dengan demikian hipotesis yang menyatakan “ada hubungan yang signifikan antara darah sistolik dan diastolik” diterima.
Pengujian koefisien korelasi dapat juga dilakukan dengan cara membandingkan nilai koefisien korelasi dengan nilai korelasi tabel atau rtabel, sehingga perlu dicari nilai rtabel pada taraf = 0,05 dan n = 14 yaitu diperoleh rtabel = 0,4973 (lihat tabel r). Karena nilai rhitung (0,992359) >
rtabel (0,4973) maka Ho ditolak, artinya tekanan darah sistolik memiliki hubungan signifikan
TUGAS KE 3
MATA KULIAH STATISTIKA
AGUS SUSANTO : 1609200060039
Manajemen Prasarana Perkotaan Magister Teknik Sipil Program Pascasarjana
Universitas Syiah Tahun 2016
Soal Statistika
1. From a random sample of 70 high school seniors in a particular school
district , the mean and standard deviation of the verbal scores in the
scholastic Aptitute Test (SAT) are found to be 433 and 47, respectively.
Based on this sample, construct a 98 % confidence interval for the mean
verbal score in the SAT for the population of all seniors in this school
district. . (Dari sampel acak dari 70 senior sekolah tinggi di distrik
sekolah tertentu, mean dan standar deviasi dari skor lisan dalam
Aptitute Uji skolastik (SAT) yang ditemukan 433 dan 47,
masing-masing. Berdasarkan sampel ini, membangun confidence interval 98%
untuk skor lisan rata di SAT untuk populasi semua senior di distrik
sekolah ini.)
2. Dalam penilaian mata kuliah statistik diambil 16 nilai mahasiswa dengan rata-rata sampel 8,33 dan standar deviasi 2. Berapa estimasi mean populasi untuk tingkat kepercayaan 95% Jawab : Rumus : Diketahui : n = 16 x-bar = 8,33; σ = 2; z0.025 = 0,49 ) 16 2 )( 49 , 0 ( 33 , 8 ) 16 2 )( 49 , 0 ( 33 , 8
245 , 0 33 , 8 245 , 0 33 , 8
= 8,085
8,575Interpretasi: estimasi mean populasi untuk tingkat kepercayaan 95% yaitu antara 8,085 hingga 8,575
3. 144 karyawan perusahaan yang dipilih secara acak ditanya mengenai besarnya pengeluaran perhari untuk biaya hidup. Ternyata rata-rata pengeluaran sebesar Rp 20.000 dengan simpangan baku yang diketahui sebesar Rp 6.000.
Hitunglah:
a. Pendugaan interval rata-rata pengeluaran dengan tingkat keyakinan 99% b. Pendugaan interval rata-rata pengeluaran dengan tingkat keyakinan 90% c. Interpretasikan hasil yang didapat.
Jawab : Pendugaan interval rata-rata pengeluaran dengan tingkat keyakinan 99% X - Z σ/2 (σ/√n) < μ < X + Z σ/2 (σ/√n) n = 144 Rata-rata (X) = 20.000 Standar deviasi (σ) = 6.000 Interval keyakinan = 99% (0,99) 1 - = 0,99 = 0,01 z0.005 = 0,498
n
Z
X
n
Z
X
/2.
/2.
20.000 – (0,498)(6.000/√144) < μ < 20.000 + (0,498)(6.000/√144) 20.000 – 249 < μ < 20.000 +249
19.751 < μ < 20.249
Jadi interval kepercayaan 99% untuk memperkirakan berapa sesungguhnya rata-rata pengeluaran mengenai besarnya pengeluaran perhari untuk biaya hidup adalah berkisar antara 19.751 rupiah dan 20.249 rupiah.
Pendugaan interval rata-rata pengeluaran dengan tingkat keyakinan 90% X - Z σ/2 (σ/√n) < μ < X + Z σ/2 (σ/√n) n = 144 Rata-rata (X) = 20.000 Standar deviasi (σ) = 6.000 Interval keyakinan = 90% (0,90) 1 - = 0,90 = 0,10 z0.05 = 0,480 20.000 – (0,480)(6.000/√144) < μ < 20.000 + (0,480)(6.000/√144) 20.000 – 240 < μ < 20.000 +240 19.760 < μ < 20.240
Jadi interval kepercayaan 90% untuk memperkirakan berapa sesungguhnya rata-rata pengeluaran mengenai besarnya pengeluaran perhari untuk biaya hidup adalah berkisar antara 19.760 rupiah dan 20.240 rupiah.
TUGAS KE 4
MATA KULIAH STATISTIKA
AGUS SUSANTO : 1609200060039
Manajemen Prasarana Perkotaan Magister Teknik Sipil Program Pascasarjana
Universitas Syiah Tahun 2016