PENGKLASTERAN DOKUMEN DENGAN EXPECTATION MAXIMATION
MENGGUNAKAN MULTIRESOLUTION KD-TREE
Diana Purwitasari, Yudhi Purwananto, Anggit SN
Jurusan Teknik Informatika, Fakultas Teknologi Informasi, Institut Teknologi Sepuluh Nopember (ITS) Kampus ITS, Jl. Raya ITS, Sukolilo, Surabaya 60111, Indonesia
Tel. +62 31 5939214, Fax. +62 31 5939363 Email: [email protected], [email protected]
ABSTRAK
Pada sistem temu kembali informasi, pengklasteran dokumen dengan algoritma Expectation Maximation (EM) membutuhkan waktu dalam estimasi parameter nilai tengah µ, variasi Σ dan densitas data p. Untuk mempersingkat iterasi, digunakan struktur data multiresolution kd-tree (MRKD-Tree) berupa binary tree dengan banyak informasi tersimpan di setiap node. Pada pengklasteran, data harus berupa numerik sehingga untuk data dokumen yang berbentuk teks perlu dilakukan prapemrosesan. Pada tahap tersebut setiap dokumen direpresentasikan sebagai vektor sehingga kumpulan dokumen akan membentuk matriks data numerik yang selanjutnya menjadi data input dalam pengklasteran.
Kumpulan dokumen disimpan ke database Oracle 9i kemudian masuk tahap prapemrosesan dengan bantuan Oracle Text 9.2 untuk menghilangkan stopword dan melakukan stemming. Matriks dokumen terbentuk dari data-data numerik dalam data-database yang akan dinyatakan sebagai struktur data-data MRKD-Tree. Setiap node pada tree menyimpan informasi numpoints, splitdim, splitval, centroid, cov, dan hyperrect. Pada node root nilai numpoints berisi jumlah semua dokumen yang ada, kemudian dilakukan pemisahan secara hyperrectangular berdasarkan dimensi dengan rentang nilai terbesar. Pemisahan terus dilakukan sampai nilai numpoints pada suatu node mencapai batas tertentu. Estimasi parameter dengan algoritma EM dihitung menggunakan informasi dari setiap node pada MRKD-Tree.
Uji kebenaran pengklasteran algoritma EM-MRKD-Tree pada dokumen UseNet Collection menghasilkan error ±3.13% lebih baik daripada algoritma EM untuk data dengan kelas berdekatan dan ±2.27% untuk kelas berjauhan. Secara rata-rata waktu pengklasteran dokumen dengan algoritma EM-MRKD-tree lebih baik daripada algoritma EM dengan terpaut ±10.5 menit. Untuk algoritma EM-MRKD-tree, semakin bertambah jumlah dokumen maka pertambahan waktu yang dibutuhkan dalam pengklasteran cenderung tidak sebanyak dalam algoritma EM. Begitu juga dengan pengujian perubahan nilai threshold 1%, 2% dan 3% dari jumlah dokumen keseluruhan tidak menunjukkan perubahan waktu pengklasteran yang signifikan.
Kata Kunci: sistem temu kembali informasi, pengklasteran dokumen, expectation maximation, multiresolution kd-tree, oracle text.
1. PENDAHULUAN
Proses penggabungan beberapa objek yang memiliki persamaan ciri menjadi suatu kelompok dinamakan pengklasteran[1]. Persamaan ciri objek-objek pada suatu klaster lebih dekat daripada persamaan ciri dengan objek di klaster yang lain. Dengan kata lain jarak objek intra-klaster lebih dekat daripada jarak objek inter-klaster.
Pada Sistem Temu Kembali Informasi (information
retrieval), analisa klaster digunakan untuk melakukan pengelompokan sekumpulan dokumen berdasarkan kemiripan isi menjadi beberapa klaster. Pada kumpulan dokumen (mixture model) terdapat informasi (hidden variable) nilai tengah µ, variasi Σ dan densitas data p untuk setiap klaster. Untuk mengelompokkan dokumen tersebut akan dilakukan estimasi nilai parameter (µ, Σ, p) dengan pendekatan algoritma Expectation Maximation (EM). Secara iterasi akan dilakukan estimasi nilai parameter dan menghasilkan nilai densitas p secara
probabilistik sehingga diketahui kemungkinan suatu dokumen untuk dimasukkan ke dalam suatu klaster tertentu [2].
Pada algoritma EM membutuhkan waktu akibat iterasi yang harus dilakukan saat estimasi parameter. Untuk mempersingkat iterasi, digunakan struktur data multiresolution kd-tree (MRKD-Tree) berupa
binary tree dengan banyak informasi tersimpan di
setiap node. Pada multiresolution kd-tree setiap node tidak mewakili satu data melainkan banyak data [3].
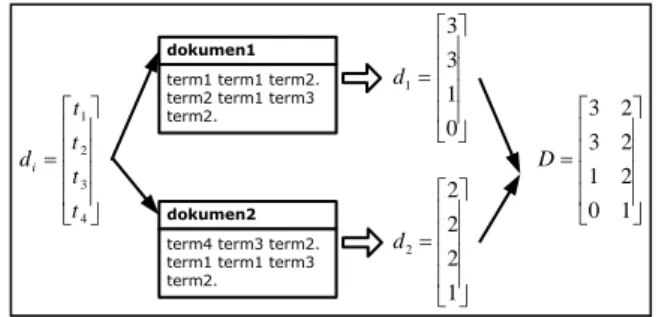
Gambar 1. Matriks Set Dokumen
term1 term1 term2. term2 term1 term3 term2.
term4 term3 term2. term1 term1 term3 term2. dokumen1 dokumen2 0 1 3 3 1 d 1 2 2 2 2 d 4 3 2 1 t t t t di 1 0 2 1 2 3 2 3 D
Pada dokumen, jumlah kata atau term tertentu yang ada didalamnya akan menjadi ciri dokumen tersebut. Sebuah dokumen akan direpresentasikan sebagai vektor dengan elemen-elemen didalamnya adalah jumlah setiap term yang berbeda (Lihat Gambar 1). Terdapat set dokumen D berisi sejumlah N dokumen dan setiap dokumen dinotasikan sebagai di dengan
nilai i=1…N. Terdapat set term T sejumlah M term berbeda yang akan menjadi ciri setiap dokumen di.
Representasi vektor dokumen di=[tj=1, …, tj=M]T
dengan tj adalah jumlah term ke- j dalam dokumen di. Pada Gambar 1, terdapat set dokumen D={d1, d2}
dengan set term T={ t1, t2, t3, t4}. Vektor d1=[3, 3, 1,
0]T yang berarti jumlah term 1, 2, 3 dan ke-4 dalam dokumen ke-1 adalah 3, 3, 1 dan 0. Sedangkan matriks D adalah matriks dokumen dengan jumlah baris menyatakan jumlah ciri dan jumlah kolom menyatakan jumlah dokumen yang ada.
2. MIXTURE MODEL
Misal dilakukan pencatatan tinggi badan mahasiswa Teknik Informatika ITS angkatan 2006. Apabila dinyatakan dalam grafik, maka variabel nilai tinggi badan hanya akan memiliki satu nilai tengah data. Namun grafik pada Gambar 2 menunjukkan adanya dua nilai yang cenderung menjadi titik tengah data. Data tinggi mahasiswa merupakan mixture model yang berarti sesungguhnya terdapat 2 kelompok data dengan masing-masing memiliki nilai tengah dan variasi data masing. Apabila data-data tersebut diklaster tersendiri maka terdapat kelompok mahasiswa putra dengan nilai tengah µ1 = ±177 dan
variasi data σ1 serta kelompok mahasiswa putri
dengan nilai tengah µ2 = ±160 dan variasi data σ2
(Catatan: digunakan simbol σ karena data berdimensi satu). Nilai lain yang dapat ditemukan adalah nilai densitas data p. Setiap data tinggi mahasiswa memiliki nilai p1 dan p2. Apabila pada
suatu data nilai p1>p2 maka data tersebut masuk
klaster 1 dan sebaliknya.
3. PRAPEMROSESAN DOKUMEN
Pada pengklasteran, data harus berupa numerik sehingga untuk data dokumen yang berbentuk teks perlu dilakukan prapemrosesan. Pada tahap tersebutsetiap dokumen direpresentasikan sebagai vektor sehingga kumpulan dokumen akan membentuk matriks data numerik yang selanjutnya menjadi data input dalam pengklasteran. Langkah-langkah yang dilakukan pada prapemrosesan dokumen untuk sistem temu kembali informasi antara lain menganalisa leksikal teks, menghilangkan stopword, melakukan stemming, menentukan grup kata, dan membuat struktur kategorisasi kata [4]. Namun prapemrosesan dokumen untuk pengklasteran dengan algoritma EM-MRKD-tree tidak semua langkah tersebut dilakukan. Tahap prapemrosesan dilakukan untuk membentuk set term T atau disebut juga dengan pengindeksan kata dari set dokumen D. Digunakan fitur-fitur Oracle Text 9.2 yang dikhususkan sebagai modul Oracle 9i untuk aplikasi sistem temu kembali informasi [5]. Kumpulan dokumen disimpan ke database Oracle 9i kemudian masuk tahap prapemrosesan dengan bantuan Oracle Text 9.2 untuk menghilangkan stopword dan melakukan stemming. Matriks dokumen terbentuk dari data-data numerik dalam database yang akan dinyatakan sebagai struktur data MRKD-Tree.
4. PENGKLASTERAN DOKUMEN
Untuk mempersingkat iterasi algoritma EM, digunakan struktur data multiresolution kd-tree (MRKD-Tree) berupa binary tree dengan banyak informasi tersimpan di setiap node. Setiap node padatree akan menyimpan informasi berikut: Gambar 2. Ilustrasi Mixture Model
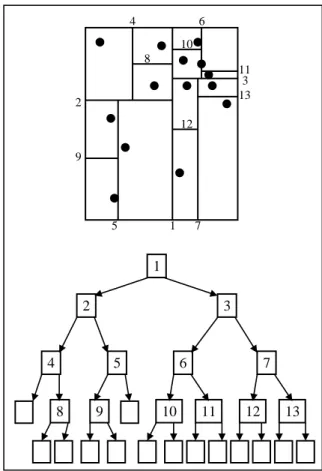
Gambar 3. Ilustrasi Pembuatan KD-Tree
1 2 3 4 5 6 7 8 9 10 11 12 13 1 2 3 4 5 6 7 8 9 10 11 12 13
ND.NUMPOINTS
Jumlah data yang berada dalam daerah
hyperrectangle untuk node ND.
ND.SPLITDIM
Indeks dimensi yang akan digunakan untuk membagi data pada node parent. Pada ruang sampel dengan multidimensi, nilai splitdim ditentukan dari dimensi dengan rentang nilai terbesar.
ND. SPLITVAL
Nilai tengah dari suatu rentang nilai data pada dimensi yang dinyatakan dalam nilai splitdim. Jika pada dimensi tertentu rentang nilai 2-20 maka nilai
splitval = 11.
ND. CENTROID
Nilai rata- rata dari kumpulan data pada dimensi
splitdim yang ada dalam daerah hyperrectangle
untuk node ND. ND.COV
Nilai covariance dari kumpulan data pada dimensi
splitdim yang ada dalam daerah hyperrectangle
untuk node ND. ND.HYPERRECT
Daerah hyperrectangle untuk node ND berupa dua buah array yang menyatakan nilai terendah dan tertinggi dari tiap – tiap dimensi. Misalkan terdapat 4 data dengan dua dimensi, (2,2), (1,3), (4,7), (1,10), maka daerah hyperrectangle memiliki nilai terendah (1, 2) dengan 1 untuk dimensi-1 dan 2 untuk dimensi-2. Sedangkan nilai tertinggi (4, 10) menunjukkan 4 untuk dimensi-1 dan 10 untuk dimensi-2.
Pada node root nilai numpoints berisi N menyatakan jumlah semua dokumen yang ada. Untuk setiap dimensi-j dicari rentang nilai terendah dan tertinggi. Indeks dimensi dengan rentang nilai terbesar akan menjadi nilai splitdim. Kemudian dilakukan pemisahan secara hyperrectangular berdasarkan
dimensi dengan rentang nilai terbesar. Pemisahan terus dilakukan sampai nilai numpoints pada suatu node mencapai batas tertentu (Lihat Gambar 3). Jika ambang batas threshold diberi nilai 0, maka pemisahan data pada node parent akan berhenti jika node child hanya memiliki satu data.
Estimasi parameter dengan algoritma EM dihitung menggunakan informasi dari setiap node pada MRKD-Tree yang diaktifkan melalui pemanggilan fungsi MAKESTAT pada node root. Diasumsikan set dokumen D akan dikelompokkan menjadi sejumlah C klaster sehingga pemanggilan fungsi MAKESTAT(ND, θs) menghasilkan variabel SWk, SWXk, dan SWXXk dengan nilai k=1...C. Diasumsikan θs = {ps, µs, Σs} dengan s menunjukkan
iterasi yang ke-s.
NUMPOINTS ND w SWk k . ... (Rumus 1) CENTROID ND NUMPOINTS ND w SWXk k . . (Rumus 2) COV ND NUMPOINTS ND w SWXXk k . . ... (Rumus 3)
Nilai
w
k dihasilkan dari perhitungan
C y s y s y s k s k s k k kl P kl x P kl P kl x P x kl P w 1 ) | ( ) , | ( ) , ( ) , | ( ) , | ( (Rumus 4)Nilai klk menunjukkan klaster ke-k dan
x
diambildari ND.CENTROID.
5. UJI COBA
Uji coba dilakukan pada komputer dengan prosesor AMD Athlon™ XP 2400 1.99 GHz, memori 1 GB, Microsoft Windows XP Service Pack 2, bahasa pemrograman Java, basis data Oracle 9i beserta Oracle Text 9.2. Data pengujian diambil dari UseNet Collection (20NG) dikumpulkan Ken Lang dengan
url : http://www.ai.mit.edu/~jrennie/20Newsgroups/. Jumlah dokumen mencapai 20.000 terkelompok
N = 250 N = 500 N = 750 N = 1000 N = 250 N = 500 N = 750 N = 1000 comp.graphics 78.00% 80.00% 53.33% 37.00% 70.00% 82.00% 54.67% 37.50% comp.os.ms-windows.misc 18.00% 4.00% 2.67% 2.00% 20.00% 4.00% 3.33% 2.00% comp.sys.ibm.pc.hardware 6.00% 35.00% 23.33% 19.00% 4.00% 32.00% 20.67% 10.50% comp.sys.mac.hardware 74.00% 2.00% 1.33% 1.50% 48.00% 2.00% 2.00% 1.50% comp.windows.x 64.00% 98.00% 65.33% 47.00% 56.00% 98.00% 53.33% 47.50% 48.00% 43.80% 29.20% 21.30% 39.60% 43.60% 26.80% 19.80%
Error dengan Algoritma EM
Nama Klaster Error dengan Algoritma EM-MRKD-tree
35.58% 32.45%
Rata-rata kesalahan
Tabel 1. Nilai Error Hasil Uji Kebenaran Pengklasteran Data pada Kelas Berdekatan
Tabel 2. Nilai Error Hasil Uji Kebenaran Pengklasteran Data pada Kelas Berjauhan
N = 250 N = 500 N = 750 N = 1000 N = 250 N = 500 N = 750 N = 1000 comp.sys.ibm.pc.hardware 68.00% 76.00% 39.33% 30.50% 62.00% 77.00% 43.33% 31.00% soc.religion.christian 14.00% 3.00% 2.67% 3.00% 12.00% 4.00% 3.33% 3.00% sci.med 8.00% 20.00% 19.33% 9.00% 6.00% 19.00% 16.00% 4.50% rec.motorcycles 40.00% 3.00% 1.33% 2.50% 26.00% 3.00% 2.00% 2.50% rec.sport.hockey 52.00% 91.00% 58.00% 42.00% 40.00% 89.00% 50.67% 43.00% 36.40% 38.60% 24.13% 17.40% 29.20% 38.40% 23.07% 16.80%
Error dengan Algoritma EM
Nama Klaster Error dengan Algoritma EM-MRKD-tree
29.13% 26.87%
dalam 20 newsgroups berbeda. Data untuk daftar kata stopwords digunakan RainBow (libbow) toolkit
url : http://www-2.cs.cmu.edu/~mccallum/bow/. Jumlah dokumen yang digunakan diambil secara bertahap mulai dari 250, 500, 750, sampai 1000 dokumen dengan jumlah iterasi maksimal 100. Pengujian dilakukan pada data-data yang terletak dalam klaster berdekatan diambil dari comp.graphics,comp.os.ms-windows.misc,
comp.sys.ibm.pc.hardware, comp.sys.mac.hardware, dan comp.windows.x dengan perbandingan jumlah dokumen sama. Sedangkan pengujian untuk data-data yang klasternya berjauhan diambil dari comp.sys.ibm.pc.hardware, soc.religion.christian, sci.med, rec.motorcycles, dan rec.sport.hockey juga dengan perbandingan jumlah dokumen sama. Dilakukan uji kebenaran dengan membandingkan tingkat kesalahan hasil pengklasteran algoritma EM-MRKD-tree dan algoritma EM. Hasil rata-rata kesalahan pada kelas yang berdekatan ditunjukkan pada Tabel 1 dan Tabel 2 untuk kelas yang berjauhan.
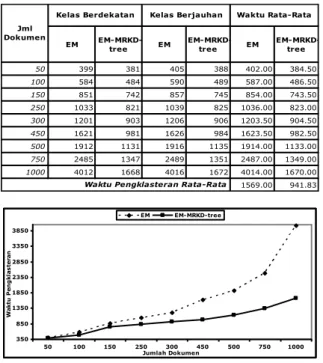
Pengujian waktu pengklasteran untuk data-data dengan kelas yang berdekatan dan kelas yang berjauhan ditunjukkan pada Tabel 3. Secara rata-rata waktu pengklasteran dokumen dengan algoritma EM-MRKD-tree lebih baik daripada algoritma EM dengan terpaut ±10.5 menit. Grafik analisa lama waktu pengklasteran dibanding dengan jumlah dokumen diperlihatkan pada Gambar 4. Untuk algoritma EM-MRKD-tree, semakin bertambah jumlah dokumen maka pertambahan waktu yang dibutuhkan dalam pengklasteran cenderung tidak sebanyak dalam algoritma EM.
Uji coba selanjutnya dengan merubah nilai batas atau threshold yang kondisi pembentukan node leaf pada struktur data MRKD-tree. Diharapkan nilai ambang yang semakin besar akan membentuk tree dengan jumlah node lebih sedikit sehingga waktu pemanggilan fungsi MAKESTAT pada node root lebih cepat mencapai node leaf. Pengujian dilakukan pada threshold senilai 1%, 2% dan 3% dari jumlah dokumen keseluruhan. Gambar 5 menunjukkan waktu pengklasteran yang dibutuhkan oleh setiap perubahan threshold pada data-data dengan kelas yang berdekatan. Sedangkan Gambar 6 untuk grafik yang sama namun dengan data-data dari kelas yang berjauhan. Namun ternyata waktu pengklasteran tidak menunjukkan perubahan yang signifikan seiring dengan perubahan threshold.
6. SIMPULAN
Dilakukan uji kebenaran dengan melihat dokumen hasil pengklasteran yang berhasil masuk ke dalam kelas yang benar. Tingkat kesalahan pengklasteran dengan algoritma EM rata-rata 35.58% untuk kelas-kelas yang berdekatan dan 29.13% untuk kelas-kelas-kelas-kelas yang berjauhan. Modifikasi pada algoritma EM menjadi EM-MRKD-tree memberikan penurunan tingkat kesalahan menjadi rata-rata 32.45% untuk kelas berdekatan dan 26.87% untuk kelas-kelas yang berjauhan.
EM EM-MRKD-tree EM EM-MRKD-tree EM EM-MRKD-tree 50 399 381 405 388 402.00 384.50 100 584 484 590 489 587.00 486.50 150 851 742 857 745 854.00 743.50 250 1033 821 1039 825 1036.00 823.00 300 1201 903 1206 906 1203.50 904.50 450 1621 981 1626 984 1623.50 982.50 500 1912 1131 1916 1135 1914.00 1133.00 750 2485 1347 2489 1351 2487.00 1349.00 1000 4012 1668 4016 1672 4014.00 1670.00 1569.00 941.83 Waktu Rata-Rata
Waktu Pengklasteran Rata-Rata
Jml Dokumen
Kelas Berdekatan Kelas Berjauhan
Tabel 3. Perbandingan Waktu Pengklasteran
Gambar 4. Perbandingan Waktu Pengklasteran
350 850 1350 1850 2350 2850 3350 3850 50 100 150 250 300 450 500 750 1000 Jumlah Dokumen W a k tu P e n g k la s te ra n EM EM-MRKD-tree
Gambar 5. Grafik Perubahan Threshold terhadap Waktu Pengklasteran pada Kelas
Berdekatan
Pengaruh Perubahan Threshold Terhadap Waktu (Data Sama)
0 500 1000 1500 2000 Jumlah Dokumen W a k tu (d e ti k ) 1% 381 484 742 821 903 981 1131 1347 1668 2% 366 468 725 803 884 961 1110 1325 1645 3% 347 447 702 778 857 932 1079 1292 1610 50 100 150 250 300 450 500 750 1000
Gambar 6. Grafik Perubahan Threshold terhadap Waktu Pengklasteran pada Kelas
Berjauhan
Pengaruh Perubahan Threshold Terhadap Waktu (Data Beda)
0 500 1000 1500 2000 Jumlah Dokumen W a k tu (d e ti k ) 1% 388 489 745 825 906 984 1135 1351 1672 2% 373 473 728 807 887 964 1114 1329 1649 3% 364 463 717 795 874 950 1099 1313 1632 50 100 150 250 300 450 500 750 1000
Jumlah data juga berpengaruh terhadap keakuratan pengklasteran sehingga nilai error akan terus menurun. Seperti pada uji coba menggunakan 1000 dokumen nilai error menurun ±25-30% dibanding nilai error saat uji coba menggunakan 250 dokumen. Uji performa dilakukan dengan melihat waktu pengklasteran. Terdapat skenario tambahan untuk melihat waktu pengklasteran dengan menambahkan perubahan nilai threshold saat membentuk struktur data MRKD-tree. Untuk kelas-kelas yang berdekatan, algoritma EM membutuhkan waktu pengklasteran rata-rata 1566 detik sedangkan algoritma EM-MRKD-tree lebih cepat dengan 940 detik. Begitu juga dengan pengklasteran pada data-data dengan kelas yang berjauhan, algoritma EM membutuhkan waktu pengklasteran 1572 detik sedangkan algoritma EM-MRKD-tree hanya 944 detik. Hal tersebut terjadi dikarenakan data sumber dokumen berpengaruh pada pengklasteran dokumen. Untuk uji coba perubahan nilai threshold, pengaruh perubahan waktu pengklasteran dengan algoritma EM-MRKD-tree sedikit sehingga tidak terlalu signifikan baik untuk data-data dengan kelas yang berdekatan maupun berjauhan.
7. DAFTAR PUSTAKA
1. Nayak, Pranyansmita, Cluster Analysis and Clustering Algorithms, 2003
2. D’Alimonte, Davide, Statistical Pattern Analysis Mixture Models, Aston University, UK, 2004
3. Moore, A, Very Fast EM-based Mixture Model Clustering using Multiresolution kd-trees, Carnegie Mellon University, Pittsburgh, PA, 2000
4. Baeza-Yates, R., Ribeiro-Neto, B., Modern Information Retrieval, Addison Wesley, 1999 5. Oracle Corporation, Oracle Text Reference