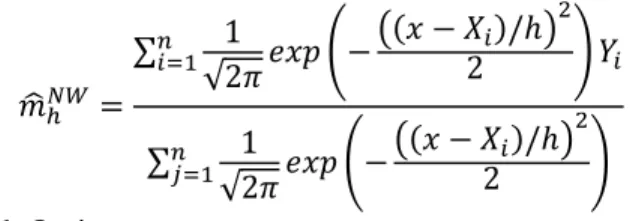47
PERBANDINGAN MODEL REGRESI KERNEL DENGAN MODEL REGRESI
POLYNOMIAL DALAM DATA FINANSIAL
Nur ’Eni1
1 Jurusan Matematika Program Studi Statistika, Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Tadulako
Jalan Sukarno-Hatta Km. 9 Palu 94118, Indonesia
Abstract
Regression analysis is used to see the influence between independent variable with dependent variable, but see the relationship pattern first. This can be done by two approaching, parametric approach and nonparametric approach. Kernel regression is one of nonparametric approach model and kuadratic polynomial regression is one of parametric approach model. The aim of this research is to abtain the best regression model by comparing kernel regression model with kuadratic polynomial regression by using financial data with RSME criteria. Mastercard Incorporated (MA) stock data will be use in this research in 2nd January 2008 until 31st December 2008 period. The result shows that for MA stock data, the best regression model is kernel regression with RSME = 16,00147 and bandwith (h) = 25,64.
Keywords: Regression Analysis, Nonparametric, Parametric, Kernel Regression, Kuadratic Polynomial Regression, RMSE, Bandwidht.
Abstrak
Analisis regresi digunakan untuk melihat pengaruh variabel independen terhadap variabel dependen dengan terlebih dahulu melihat pola hubungan variabel tersebut.Hal ini dapat dilakukan dengan melalui dua pendekatan yaitu pendekatan parametrik dan nonparametrik.Regresi kernel merupakan salah satu model dengan pendekatan nonparametrik dan regresi polynomial kuadratik merupakan salah satu model dengan pendekatan parametrik.Tujuan dari penelitian ini adalah untuk mendapatkan model regresi terbaik dengan membandingkan model regresi kernel dan model regresi polynomial kuadratik dalam data financial dengan menggunakan kriteria RSME.Data yang digunakan adalah data saham Mastercard Incorporated (MA) periode 02 Januari 2008 sampai dengan 31 Desember 2008. Hasil penelitian menunjukkan bahwa unutk data saham MA, model regresi terbaik adalah model regresi kernel dengan nilai RSME = 16,00147 dan Bandwidht (h) = 25,64.
Kata kunci: Analisis Regresi, Nonparametrik, Parametrik, Regresi Kernel, Regresi Polynomial Kuadratik, RMSE, Bandwidht.
1. Pendahuluan
Analis regresi merupakan analisis statistik yang digunakan untuk melihat pengaruh variabel independen terhadap variabel dependen terlebih dahulu melihat pola hubungan variabel tersebut (soemartini., 2007). Dalam beberapa kasus-kasus financial, banyak ditemukan permasalahan hubungan fungsional antara dua variabel Y dan X dimana bentuk-bentuk hubungan secara parametrik tidak dapat digunakan.Sehingga dapat digunakan teknik-teknik estimasi secara nonparametrik untuk menyelesaikan permasalahn nonlinearitas tersebut. Pada umumnya estimasi dengan nonparametrik tidak memerlukan asumsi hubungan fungsional antara variabel sehingga model-model nonlinear secara umum lebih sulit dianalis daripada linear, karena jarang ada metode yang dapat dengan mudah dipakai dan secara empiris untuk diimplementasikan, oleh karena itu fenomena dari nonlinearitas ini menjadi suatu masalah tersendiri bagi ekonometri keuangan.
Untuk data financial model yang digunakan pada regresi nonlinear adalah model regresi poliynomial (Sudjana., 2002), dalam hal ini digunakan model yang berbentuk kuadratik. Oleh karena itu, diadakan suatu penelitian untuk membandingakan kinerja dari model regresi kernel dengan model regresi polynomial kuadratik, sehingga pengguna dapat memilih model regresi mana yang lebih baik digunakan.
2. Rumusan Masalah
Adapun rumusan masalah yang akan dibahas dalam penelitian ini adalah bagaimana mendapatkan model regresi terbaik dengan membandingkan model regresi kernel dan model regresi polynomial kuadratik dalam data finansial berdasarkn nilai RSME.
3. Tujuan Penelitian
Berdasarkan latar belakang dan rumusan masalah di atas, maka tujuan yang ingin dicapai dalam penelitian ini adalah untuk mendapatkan model regresi terbaik dengan membandingkan model regresi kernel dan model regresi polynomial kuadratik dalam data finansial berdasarkan nilai RSME.
4. Tinjauan pustaka 4.1 Nonlineraitas Dalam Data Finansial
Metode-metode ekonometri kebanyakan didesain untuk mendeteksi struktur linear dalam data finansial (Yuwono, p., 2004).Sebagai contoh, uji-uji timeseries yang banyak digunakan untuk memprediksi return-return dari asset, penekanan ujinya lebih pada kombinasi autokorelasi-autokorelasi return, dimana prediksi secara linear adalah sebagai fokusnya. Dan
kebanyakan model-model dengan vairabel-variabel ekonomi yang lain seperti konsumsi, dividen, dan tingkat suku bunga, model-modelnya adalah linear.
4.2 Perhitungan Analisis Besarnya Pengaruh Pajak Daerah Terhadap PAD Kota Palu
Dalam realita, tidak semua model dapat diduga dengan pendekatan regresi parametrik karena tidak adanya informasi yang lengkap tentang bentuk kurva regresi.Dalam pendekatan seperti itu, dapat digunakan pendekatan regresi non parametrik (Hardle, W., 1990). Untuk sebuah sampel berukurann data pengamatan, {𝑋𝑖𝑌𝑖}𝑖=1𝑛 , hubungan antara varibael-variabel
tersebut dapat dinyatakan dengan model regresi sebagai berikut:
𝑌𝑖 = 𝑚(𝑋𝑖) + 𝜀𝑖
𝜀𝑖~ 𝑁(0, 𝜎2) 𝑖 = 1,2, … , 𝑛 (2.1)
Estimator-estimator nonparametrik yang banyak digunakan adalah estimator-estimator smoothing, salah satu contoh dari smoothing (penghalusan) adalah regresi Kernel.
4.3 Ide Dasar Penghalusan (smoothing)
Tujuan dari smoothing adalah untuk membuang variabilitas data yang tidak memiliki pengaruh sehingga ciri-ciri dari data akan tampak lebih jelas sehingga kurva yang dihasilkan akan mulus. Smoothing telah menjadi sinonim dengan metode-metode nonparametrik yang digunakan untuk mengestimasi fungsi-fungsi.
4.4 Fungsi Kernel
Fungsi kernel, dinotasikan dengan 𝐾(𝑥),merupakan suatu fungsi yang pemanfaatanya diberlakukan pada setiap titik data. Berikut adalah sifat dari suatu fungsi kernel yaitu:
a. ∫−∞∞ 𝐾(𝑥)𝑑𝑥 = 1 b. ∫−∞∞ 𝑥𝐾(𝑥)𝑑𝑥 = 0 c. ∫ 𝑥2𝐾(𝑥)𝑑𝑥 = 𝜇2(𝐾) ≠ 0 ∞ −∞ d. ∫ [𝐾(𝑥)]2𝑑𝑥 = ∫ 𝐾2(𝑥)𝑑𝑥 = ‖𝐾‖ 2 2 ∞ −∞ ∞ −∞
Dalam metode kernel penaksir densitas untuk suatu nilai x dinotasikan dengan 𝑓̂ℎ(𝑥), yang
dinyatakan dalam rumus berikut:
𝑓̂ℎ(𝑥) = 1 𝑛ℎ∑ 𝐾 ( 𝑥 − 𝑋𝑖 ℎ ) 𝑛 𝑖=1 (2.2)
Berikut adalah bentuk umum dari kernel K(x) dalam penggunaannya terhadap bandwidth :
𝐾ℎ(𝑥) = 1 ℎ𝐾 (
𝑥
ℎ) (2.3)
Teorema Penaksir densitas kernel :
Jika fungsi kernel merupakan fungsi densitas ∫−∞∞ 𝐾(𝑢)𝑑𝑢 = 1, maka estimator fungsi dengan menggunakan fungsi kernel juga merupakan suatu fungsi densitas probabilitas.
4.5 Penaksir Densitas Kernel
Dalam penaksir densitas kernel terdapat dua macam parameter (Hardle, W ., 1990) yaitu: a. Bandwidth h, dan
Untuk memilih h dari fungsi densitas kernel K maka perlu dilakukan pemeriksaan terhadap asymtot tak bias dari 𝑓̂ℎ(𝑥)sebagai berikut :
𝐸[𝑓̂ℎ(𝑥)] = ∫ 1 ℎ𝐾 ( 𝑥 − 𝑢 ℎ ) ∞ −∞ 𝑓(𝑢)𝑑𝑢
Berdasarkan sifat dari fungsi kernel :
𝐵𝑖𝑎𝑠⌊𝑓̂ℎ(𝑥)⌋ = ℎ2
2 𝑓 "(𝑥)𝜇
2(𝐾) + 𝑜(ℎ2), ℎ → (2.4)
Sedangkan untuk variansinya adalah :
𝑉𝑎𝑟[𝑓̂ℎ(𝑥)]=𝑛−1ℎ−1‖𝐾‖22𝑓(𝑥) + 𝑜((𝑛ℎ)−1), 𝑛ℎ → ∞ (2.5)
Setelah bias dan variansi diperoleh selanjutnya kita akan menganalisis MSE yang merupakan kombinasi dari variansi dan bias kuadrat dari 𝑓̂ℎ(𝑥) sebagai berikut :
𝑀𝑆𝐸⌊𝑓̂ℎ(𝑥)⌋ = 1 𝑛ℎ𝑓(𝑥)‖𝐾‖2 2+ℎ4 4 (𝑓 "(𝑥)𝜇 2(𝐾))2+ 𝑜((𝑛ℎ)−1) + 𝑜(ℎ4) (2.6)
Dalam prakteknya penggunaan rumus MSE sangat sulit untuk digunakan karena terdapat fungsi densitas yang tidak diketahui yaitu f(x). Untuk alasan ini maka didefinisikan MISE (Mean Integrated Squared Error) sebagai berikut :
𝑀𝐼𝑆𝐸[𝑓̂ℎ(𝑥)] = 1 𝑛ℎ‖𝐾‖2 2+ℎ4 4 (𝜇2(𝐾)) 2 ‖𝑓"‖22+ 𝑜((𝑛ℎ)−1) + 𝑜(ℎ4) (2.7) 4.6 Regresi Kernel
Regresi kernel adalah teknik dalam statistik non parametrik yang digunakan untuk menaksir nilai Ekspektasi Bersyarat suatu variabel random. Nilai Ekspektasi lazim dinotasikan dengan E(Y|X). secara matematis, untuk nilai x sebarang, estimator smoothing untuk m(x) dapat dinyatakan sebagai beriku
t𝑚̂ (𝑥) =1
𝑛∑ 𝜔ℎ𝑖(𝑥)𝑌𝑖 𝑛
𝑖=1 (2.8)
Dimana 𝜔ℎ𝑖(𝑥) dapat didefinisikan sebagai fungsi terbobot: 𝜔ℎ𝑖= 𝐾ℎ(𝑥 − 𝑋𝑖) 𝑓̂ℎ(𝑥) (2.9) Dimana : 𝑓̂ℎ(𝑥) = 1 𝑛∑ 𝐾ℎ 𝑛 𝑗=1 (𝑥 − 𝑋𝑖) (2.10)
Dengan subtitusi (2.9) ke dalam (2.8), diperoleh penaksir kernel Nadaraya-watson 𝑚̂ℎ(𝑥)dari
m(x) sebagai berikut (Eubank, R.L., 1988):
𝑚̂ℎ𝑁𝑊=
∑𝑛𝑖=1𝐾 (𝑥 − 𝑋ℎ 𝑖) 𝑌𝑖 ∑𝑛𝑗=1𝐾 (𝑥 − 𝑋ℎ 𝑖)
(2.11)
Pilihan fungsi kernel yang akan digunakan dalam penelitian ini adalah kernel Gaussian, yaitu :
𝐾𝐺(𝑥) = 1
√2𝜋𝑒𝑥𝑝 (− 𝑥2
2) (2.12)
Karena fungsi kernel yang digunakan adalah kernel Gaussian maka pada fungsi kernel
𝐾 (𝑥−𝑋𝑖
ℎ ) , ( 𝑥−𝑋𝑖
𝐾𝐺( 𝑥 − 𝑋𝑖 ℎ ) = 1 √2𝜋𝑒𝑥𝑝 (− (𝑥 − 𝑋ℎ 𝑖) 2 ) (2.13)
Bentuk-bentuk fungsi kernel dapat dilihat pada tabel berikut:
Tabel 4.1 Beberapa bentuk fungsi kernel
4.7 Pemilihan Bandwidth Optimum
Pemilihan bandwidth merupakan langkah yang sangat penting dalam mengestimasi kurva regresi kernel Karenaakan memberikan bentuk pada estimasi fungsi regresinya. Pemberian nilai Bandwidht yang terlalu kecil akan menghasilkan kurva estimasi yang kasar, sebaliknya bandwidth yang terlalu besar akan menghasilkan kurva estimasi yang sangat mulus. Terdapat beberapa cara pendekatan yang dilakukan dalam pemilihan bandwidth optimum, salah satu diantaranya adalah dengan menggunakan metode plug-in.
4.7.1 Metode Plug-in
Sebenarnya pemilihan bandwidth optimum lebih ditekankan pada penyeimbangan antara bias dan variasi, karena itu dengan meminimumkan MSE maka permasalahan antara bias dan variasi dapat diminimumkan juga. Pendekatan dengan menggunakan plug-in method lebih didasarkan pada perluasan dari Mean Integrated Square Error (MISE) untuk penghalus kernel yang dapat dilihat pada persamaan (2.7)
MISE diperoleh bukan secara fixed dari variansi dan biasnya, karena variansi dan bias dari fungsi merupakan pendekatan maka hanya diperoleh asimtotiknya, yaitu Assymthotic MISE (A-MISE). Untuk itu penggunaan 𝑜((𝑛ℎ)−1) dan 𝑜(ℎ4) dapat diabaikan sehingga :
𝐴 − 𝑀𝐼𝑆𝐸 = 1 𝑛ℎ‖𝐾‖2 2+ℎ 4 4 (𝜇2(𝐾)) 2 ‖𝑓"‖22 (2.14)
Untuk memilih bandwidth yang optimum gunakan persamaan (2.14) yaitu dengan cara meminimumkan nilai dari A-MISE sebagai berikut :
𝐴 − 𝑀𝐼𝑆𝐸[𝑓̂ℎ] ≈ (𝑛ℎ)−1𝐶1+ 1 4ℎ
4𝐶 2
Sehingga ukuran bandwidth optimumnya adalah :
ℎ𝑜𝑝𝑡= ( ‖𝐾‖22 (‖𝑓"‖ 2 2(𝜇 2(𝐾)) 2 𝑛)) 1 5 ⁄ (2.15)
Untuk memperoleh nilai dari ‖𝑓"‖22, asumsikan bahwa f(x) adalah fungsi yang berdistribusi normal dengan parameter 𝜇 dan 𝜎2, sehingga :
‖𝑓"‖ 2 2 = 𝜎−5 ∫ (𝑓"(𝑥))2 ∞ −∞ 𝑑𝑥 = 0,212𝜎−5
Untuk nilai ‖𝐾‖22 dan 𝜇2(𝐾) dapat dilihat dari table 2.1 sebagai fungsi kernel Gaussian.
Kemudian subtitusi nilai ‖𝑓"‖ 2 2
= 0,212𝜎−5, ‖𝐾‖ 2
2 = 1
2√𝜋 dan 𝜇2(𝐾) = 1 kedalam persamaan
(2.15), sehingga diperoleh : ℎ𝑜𝑝𝑡= ( ‖𝐾‖22 (‖𝑓"‖ 2 2(𝜇 2(𝐾)) 2 𝑛)) 1 5 ⁄ ℎ𝑜𝑝𝑡 = 1,06 𝑛1⁄5 𝜎 (2.16)
4.8 Pemilihan Model Regresi Kernel dengan h yang Optimum
Sesuai tujuan dari pendekatan regresi nonparametrik, yakni ingin didapatkan kurva mulus yang mempunyai h optimum menggunakan data amatan sebanyak n, maka diperlukan ukuran kinerja atas penduga yang dapat diterima secara universal, dan ukuran kinerja atas penduga tersebut adalah:
4.8.1 Rata-rata jumlah kuadrat residu (Mean Squared Error-MSE)
Ukuran kinerja atas penduga yang sederhana adalah kuadrat dari sisaan yang di rata-rata dengan rumus sebagai berikut :
𝑀𝑆𝐸 =1 𝑛∑(𝑚ℎ 𝑁𝑊(𝑥) − 𝑌 𝑖) 𝑛 𝑖=1 2 (2.17) Untuk i=1,2,…,n
kriteria ini diharapkan memiliki nilai yang minimum, sehingga model regresi kernel dapat dikatakan memiliki h yang optimal.
4.9 Regresi Polynomial Kuadratik
Model regresi polynomial merupakan hubungan antara dua peubah yang terdiri dari variabeldependent (Y) dan variabelindependent (X) sehingga akan diperoleh suatu kurva yang
membentuk garis melengkung. Berikut adalah model matematis dari persamaan regresi polynomial kuadratik
𝑌𝑖 = 𝛽̂0+ 𝛽̂1𝑋𝑖+ 𝛽̂2𝑋𝑖2+ 𝑒𝑖 (2.18)
Dimana variabel Y dan X menunjukkan peubah statistik :𝛽̂0, 𝛽̂1 dan 𝛽̂2 merupakan
penaksir untuk 𝛽0, 𝛽1 dan 𝛽2 yang disebut dengan koefisien regresi sedangkan 𝑒 menyatakan
komponen kesalahn dari bentuk regresi (Tiro, M.A., 2001).
4.10 Estimasi Parameter
Untuk mendapatkan estimasi yang baik bagi parameter koefisien regresi 𝛽0, 𝛽1dan 𝛽2
digunakan metode kuadrat terkecil.Estimasi parameter koefisien regresi 𝛽0, 𝛽1 dan 𝛽2 adalah 𝑏0, 𝑏1 dan 𝑏2 (Tiro, M.A., 2001).Model sampel untuk regresi polynomial kuadratik dapat ditulis
sebagai berikut :
𝑌̂ = 𝑏0+ 𝑏1𝑋𝑖+ 𝑏2𝑋𝑖2 (2.19)
Sedangkan titik taksiran dari e yang didefenisikan sebagai selish antar observasi 𝑌𝑖 dengan nilai
fungsi regresi estimasi 𝑌̂, dapat dilambangkan dengan :
𝑒𝑖 = 𝑌𝑖− 𝑌̂ 𝑒 = 𝑌𝑖 − (𝑏0+ 𝑏1𝑋𝑖+ 𝑏2𝑋𝑖2) 𝑆𝑆𝐸 = ∑ 𝑒𝑖2= ∑(𝑌𝑖− 𝑏0− 𝑏1𝑋𝑖− 𝑏2𝑋𝑖2)2 𝑛 𝑖=1 𝑛 𝑖=1 (2.20)
Untuk nilai 𝑏0, 𝑏1 dan 𝑏2 dapat ditentukan dengan menggunakan metode kuadrat terkecil yaitu
dengan cara meminimumkan Sum Square of Error (SSE), yaitu:
𝑆𝑆𝐸 = ∑ 𝑒𝑖2 = ∑(𝑌𝑖− 𝑏0− 𝑏1𝑋𝑖− 𝑏2𝑋𝑖2) 2 𝑛 𝑖=1 𝑛 𝑖=1 𝜕𝑆𝑆𝐸 𝜕𝑏0 = −2 ∑(𝑌𝑖− 𝑏0− 𝑏1𝑋𝑖− 𝑏2𝑋𝑖2) 𝑛 𝑖=1 = 0 𝒏𝒃𝟎+ 𝒃𝟏∑ 𝑿𝒊+ 𝒃𝟐∑ 𝑿𝒊𝟐 = ∑ 𝒀𝒊 (𝟐. 𝟐𝟏) 𝒏 𝒊=𝟏 𝒏 𝒊=𝟏 𝒏 𝒊=𝟏 𝜕𝑆𝑆𝐸 𝜕𝑏1 = −2 ∑(𝑌𝑖− 𝑏0− 𝑏1𝑋𝑖− 𝑏2𝑋𝑖2) 𝑛 𝑖=1 𝑋𝑖 = 0 𝑏0∑ 𝑋𝑖+ 𝑏1∑ 𝑋𝑖2+ 𝑏2∑ 𝑋𝑖3 = ∑ 𝑋𝑖𝑌𝑖(2.22) 𝑛 𝑖=1 𝑛 𝑖=1 𝑛 𝑖=1 𝑛 𝑖=1 𝜕𝑆𝑆𝐸 𝜕𝑏2 = −2 ∑(𝑌𝑖− 𝑏0− 𝑏1𝑋𝑖− 𝑏2𝑋𝑖2) 𝑛 𝑖=1 𝑋𝑖2= 0 𝑏0∑ 𝑋𝑖2+ 𝑏1∑ 𝑋𝑖3+ 𝑏2∑ 𝑋𝑖4= ∑ 𝑋𝑖2𝑌𝑖(2.23) 𝑛 𝑖=1 𝑛 𝑖=1 𝑛 𝑖=1 𝑛 𝑖=1
Untuk mencari nilai dari koefisien 𝑏0, 𝑏1dan 𝑏2, persamaan (2.21).(2.22) dan (2.23) dapat
[ 𝑛 ∑ 𝑋𝑖 𝑛 𝑖=1 ∑ 𝑋𝑖2 𝑛 𝑖=1 ∑ 𝑋𝑖 𝑛 𝑖=1 ∑ 𝑋𝑖2 𝑛 𝑖=1 ∑ 𝑋𝑖3 𝑛 𝑖=1 ∑ 𝑋𝑖2 𝑛 𝑖=1 ∑ 𝑋𝑖3 𝑛 𝑖=1 ∑ 𝑋𝑖4 𝑛 𝑖=1 ] [ 𝑏0 𝑏1 𝑏2 ] = [ ∑ 𝑌𝑖 ∑ 𝑋𝑖𝑌𝑖 ∑ 𝑋𝑖2𝑌𝑖] [ 𝑏0 𝑏1 𝑏2 ] = [ 𝑛 ∑ 𝑋𝑖 𝑛 𝑖=1 ∑ 𝑋𝑖2 𝑛 𝑖=1 ∑ 𝑋𝑖 𝑛 𝑖=1 ∑ 𝑋𝑖2 𝑛 𝑖=1 ∑ 𝑋𝑖3 𝑛 𝑖=1 ∑ 𝑋𝑖2 𝑛 𝑖=1 ∑ 𝑋𝑖3 𝑛 𝑖=1 ∑ 𝑋𝑖4 𝑛 𝑖=1 ] −1 [ ∑ 𝑌𝑖 ∑ 𝑋𝑖𝑌𝑖 ∑ 𝑋𝑖2𝑌𝑖] 4.11 Estimasi Variansi
Varian σ2 yang berasal dari suku-suku error didalam model regresi 𝑌𝑖 = 𝛽̂0+ 𝛽̂1𝑋𝑖+ 𝛽̂2𝑋𝑖2+ 𝑒𝑖harus diestimasi untuk berbagai keperluan, misalnya untuk inferensi tentang
parameter koefisien regresi yang membutuhkan estimasi bagi σ2. Berikut adalah besaran nilai
dari SSE : 𝑆𝑆𝐸 = 𝑆𝑆𝑇𝑂 − 𝑆𝑆𝑅 Dimana: 𝑆𝑆𝑇𝑂 = ∑ 𝑌𝑖2− (∑𝑛𝑖=1𝑌𝑖)2 𝑛 (2.24) 𝑛 𝑢=1 𝑆𝑆𝑅 = [𝑏0 𝑏1 𝑏2] [ ∑ 𝑌𝑖 𝑛 𝑖=1 ∑ 𝑋𝑖𝑌𝑖 𝑛 𝑖=1 ∑ 𝑋𝑖2𝑌𝑖 𝑛 𝑖=1 ] −(∑ 𝑌𝑖 𝑛 𝑖=1 )2 𝑛 (2.25)
Dengan derajat kebebasan (dk)=n-k-1, sehingga :
𝑀𝑆𝐸 = 𝑆𝑆𝐸
4.12 Pendekatan Analisis Variansi (ANAVA) Dalam Regresi Nonlinear Polynomial Kuadratik
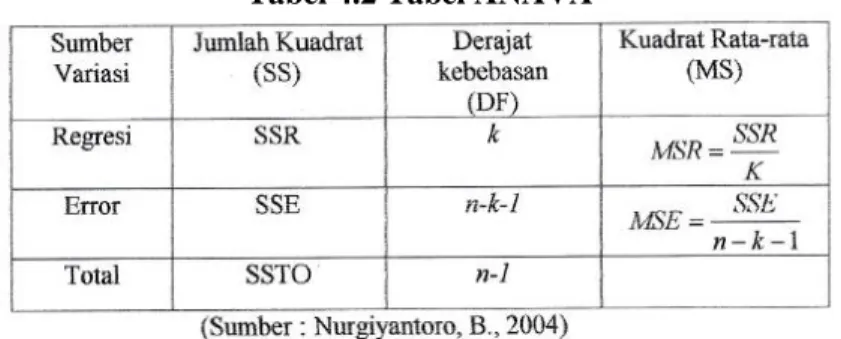
Pendekatan ANAVA ini didasarkan pada penguraian jumlah kuadrat (Sum Square) dan derajat bebas yang berhubungan dengan varibel dependen Y. Penguraian jumlah kuadrat total dan derajat bebas biasanya dirangkaikan dalam bentuk table ANAVA sebagai berikut :
Tabel 4.2 Tabel ANAVA
4.13 Uji Asumsi Parametrik 4.13.1 Uji Normalitas
Pengujian normalitas adalah pengujian tentang kenormalan distribusi data. Pengujian dapat dilakukan dengan menggunakan uji kolmogorov Smirnov,dimana pengambilan keputusan dapat dilakukan dengan melihat nilai dari probabilitasnya.
4.13.2 Uji Linearitas
Uji linearitas dapat dilakukan dengan menggunakan pengujian plot sisa (plot-plot sisa standar sebagai fungsi dari nilai-nilai yang diprediksi).Jika kesimpulan akhir yang diperoleh adalah data berbentuk linear maka data tidak dapat digunakan, tetapi jika data berbentuk nonlinear maka kita dapat melanjutkan pengujian ke tahap berikutnya yaitu uji koefisien regresi polynomial kuadratik.
4.14 Uji Koefisien Regresi Polynomial Kuadratik
Untuk menentukan apakah regresi polynomial kuadratik signifikan, kita memerlukan uji hipotesis, jika hipotesis 𝐻0 diterima maka bentuk regresi diubah dalam bentuk regresi
polynomial pangkat tiga sampai pada tingkat model derajat yang lebih tinggi (Sudjana, 2003).
5. Hasil dan Pembahasan 5.1 Pengolahan Data
Dalam pengolahan data memaparkan tentang proses model regresi kernel dan proses dari model regresi polynomial kuadratik yang akan diolah dengan menggunakan program R versi 2.6.0 dan program SPSS versi 15 untuk mencari nilai RSME dari masing-masing model untuk
dibandingkan. Fungsi kernel yang dipakai adalah kernel Gaussian dimana batas dari kernel ini berada pada selang (−∞, ∞).Untuk metode regresi nonparametrik kernel dengan estimasi Nadaraya-Watson, diperoleh bandwidth optimum yang dapat memberikan bentuk kurva pada estimasi fungsi regresinya.
5.2 Data Nilai Saham Mastercard Incorporated
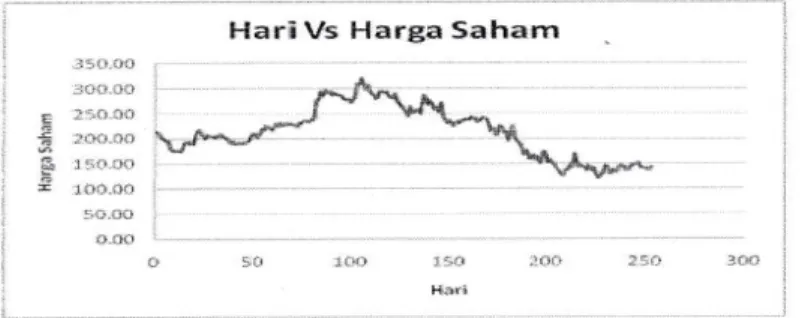
Data yang digunakan adalah data closing price saham harian (diambil pada periode perdagangan terakhir setiap harinya). Data nilai saham Mastercard Incorporated tersebut dapat dinyatakan dalam plot grafik berikut :
Gambar 5.1 Grafik antara Hari Vs Harga Saham 5.3 Regresi Kernel
Dalam mempermudah proses perhitungan maka digunakan program R versi 2.6.0 untuk menghitung nilai kernel dari Nadaraya-Watson Estimate.
5.3.1 Perumusan Model Regresi Kernel
Perumusan model regresi kernel dapat dinyatakan dalam nilai ekspektasi bersyarat Y terhadap X. Nilai ekspektasi ini dinyatakan dalam notasi sebagai berikut :
𝐸(𝑌|𝑋) =∫ 𝑦𝑓(𝑥, 𝑦)𝑑𝑦 ∞
−∞
𝑓(𝑥) 𝑎𝑡𝑎𝑢 𝑦̂ = 𝑚(𝑥)
Untuk mengestimasi m(x) digunakan teknik regresi kernel dimana estimator smoothing untuk m(x) adalah sebagai berikut :
𝑚̂ℎ𝑁𝑊=∑ 𝐾 ( 𝑥 − 𝑋𝑖 ℎ ) 𝑌𝑖 𝑛 𝑖=1 ∑ 𝐾 (𝑥 − 𝑋𝑗 ℎ ) 𝑛 𝑗=1
Estimator smoothing diatas lebih dikenal dengan nama penaksir kernel Nadaraya-Watson (NW-estimate). Selain itu digunakan pula fungsi kernel Gaussian, yaitu :
𝐾𝐺( 𝑥 − 𝑋𝑖 ℎ ) = 1 √2𝜋𝑒𝑥𝑝 (− (𝑥 − 𝑋ℎ 𝑖) 2 2 )
Dengan mensubtitusikan fungsi kernel Gaussian dalam fungsi penaksir kernel Nadaraya-Watson, maka diperoleh bentuk baru dari fungsi penaksir sebagai berikut :
𝑚̂ℎ𝑁𝑊 = ∑ 1 √2𝜋𝑒𝑥𝑝 (− ((𝑥 − 𝑋𝑖)/ℎ) 2 2 ) 𝑌𝑖 𝑛 𝑖=1 ∑ 1 √2𝜋 𝑛 𝑗=1 𝑒𝑥𝑝 (− ((𝑥 − 𝑋𝑖)/ℎ) 2 2 )
5.3.2 Pemilihan Bandwidth Optimum
Sebelum melakukan proses perhitungan terlebih dahulu dilakukan pemilihan bandwidth optimum dengan menggunakan rumus sebagai berikut :
ℎ𝑜𝑝𝑡 = 1,06 𝑛1/5𝜎 =1,06 𝑛1/5√ 1 𝑛 − 1(∑(𝑋𝑖− 𝑋̅) 2 𝑛 𝑖=1 ) = 25,64
5.3.3 Perumusan model Regresi Kernel Smoothing NW Estimate dan MSE Dalam Program R.versi 2.6.0
Dari perhitungan dengan menggunakan program R.versi 2.6.0 diperoleh nilai RSME = 16,00147 untuk ukuran bandwidth = 25.64. sedangkan dalam bentuk grafik hasilnya sebagai berikut :
Gambar 5.2 Grafik Regresi Kernel Dengan Estimasi Nadaraya-Watson
Pada gambar diatas dapat dilihat bahwa pergerakan nilai yang dihasilkan oleh penaksir kernel Nadaraya-Watson akan mengikuti bentuk dari tiap titik observasi yang ada, sehingga akan menghasilkan kurva regresi nonparametrik kernel yang optimum.
5.4 Regresi Polynomial Kuadratik
Untuk mempermudah proses perhitungan data dalam model regresi polynomial kuadratik maka digunakan program SPSS 15, dimana output yang dihasilkan akan digunakan sebagai pembanding dalam menentukan metode yang paling baik untuk digunakan.
5.4.1 Pembentukan Model Regresi Polynomial Kuadratik
Model persamaan regresi polynomial kuadratik dapat dinyatakan dalam bentuk persamaan sebagai berikut :
𝑌̅ = 𝑏0+ 𝑏1𝑋𝑖+ 𝑏2𝑋𝑖2
Berdasarkan output program SPSS versi 15 pada table dibawah ini diperoleh nilai untuk masing-masing variabel bebas.
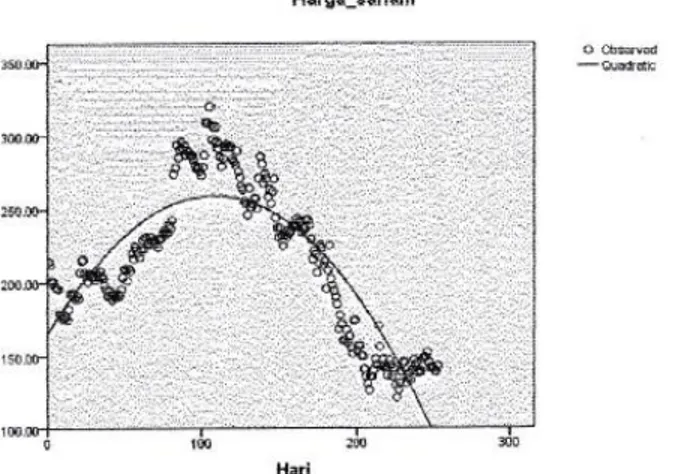
Gambar 5.3 Grafik Regresi Polynomial Kuadratik
Dari gambar diatas dapat pula dilihat bahwa model grafik dari regresi polynomial kuadratik berbentuk parabola dengan persamaan regresi sebagai berikut :
𝑌̅ = 164,818 + 1,743𝑋 − 0,008𝑋2
Namun regresi diatas belum bias ditarik sebagai kesimpulan karena belum dilakukan uji asumsi parametrik dan uji koefisien regresi polynomial kuadratik. Untuk itu tahap selanjutnya adalah dengan melakukan uji asumsi parametrik.
5.4.2 Uji Asumsi Parametrik
Pengujian asumsi parametrik yang dilakukan yaitu dengan uji normalitas dan uji linearitas.
5.4.2.1 Uji Normalitas
Normalitas diuji dengan menggunakan uji kolmogorov smirnov.
Tabel 5.1 Uji kolmogorov smirnov untuk satu sampel
Dari table output diperoleh nilai probabilitas untuk variabel harga saham adalah 0.063. nilai probabilitas ini dapat dilihat dari nilai Asymp.signifikannya. karena nilai probabilitasnya (P) > 0,05 maka data yang digunakan adalah data yang berdistribusi normal.
5.4.2.2 Uji Linearitas
Uji linearitas menunjukkan bahwa untuk persamaan regresi linear, hubungan antara variabel independen dan dependen haruslah linear. Asumsi ini akan menentukan jenis persamaan estimasi yang digunakan.
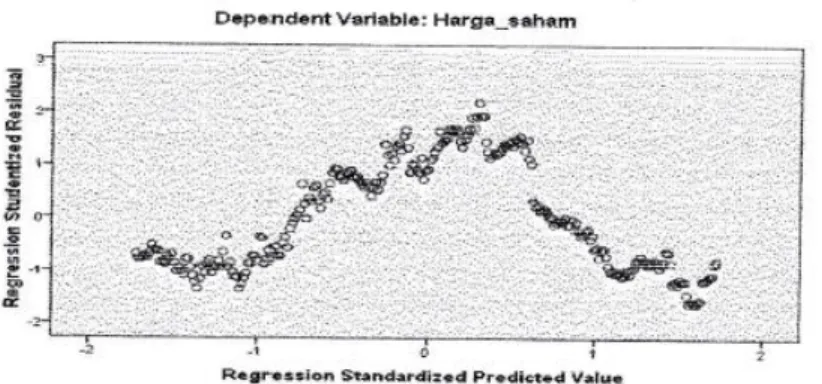
Gambar 5.4 Scatterplot antara standardized residual dengan standardized predicted
Berdasarkan scatterplot diatas dapat dijelaskan bahwa asumsi linear tidak terpenuhi. Hal ini dapat dilihat dari grafik scatterplot diatas yang membentuk suatu pola tertentu sehingga terdapat hubungan yang nonlinear antar variabel.
5.4.3 Uji Koefisien Regresi Polynomial Kuadratik
Pengujian ini dilakukan dengan menggunakan uji-F melalui daftar Anava. Hipotesisnya adalah :
𝐻0: 𝛽1= 𝛽2= 0 artinya model regresi polynomial kuadratik tidak signifikan 𝐻1: 𝛽1= 𝛽2≠ 0 artinya model regresi polynomial kuadratik signifikan
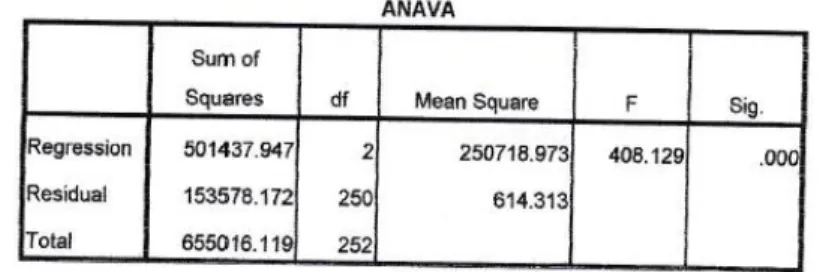
Berdasarkan hasil pengolahan data dengan menggunakan program SPSS 15 diperoleh daftar anava sebagai berikut :
Tabel 5.2 Tabel Anava untuk uji model regresi polynomial kuadratik
Kriteria penguji :
𝐻0ditolak apabila 𝐹ℎ𝑖𝑡𝑢𝑛𝑔≥ 𝐹𝑡𝑎𝑏𝑒𝑙(1 − 𝑎; 𝑘; 𝑛 − 𝑘 − 1) 𝐻0diterima apabila 𝐹ℎ𝑖𝑡𝑢𝑛𝑔< 𝐹𝑡𝑎𝑏𝑒𝑙(1 − 𝑎; 𝑘; 𝑛 − 𝑘 − 1)
Diperoleh nilai 𝐹𝑡𝑎𝑏𝑒𝑙adalah :
𝐹𝑡𝑎𝑏𝑒𝑙(1 − 𝑎; 𝑘; 𝑛 − 𝑘 − 1) = 𝐹𝑡𝑎𝑏𝑒𝑙(1 − 0,05; 2; 250) = 3,035
Berdasarkan output program SPSS 15 yaitu dalam table anava kolom mean square pada baris residual diperoleh nilai MSE = 614,313 sehingga nilai RSME (Root of Mean Squared of Error) adalah :
RSME = √𝑀𝑆𝐸
= √614,313
=√24,785
Nilai RSME juga dapat diperoleh secara langsung dari output program SPSS yaitu dalam bentuk tabelberikut :
5.5 Perbandingan Model Regresi Kernel dengan Model Regresi Polynomial Kuadratik
Dari kedua model regresi yang telah dilakukan yaitu model regresi kernel dengan estimasi Nadaraya-Watson dan model regresi polynomial kuadratik, akan dilakukan perbandingan untuk menentukan model regresi mana yang lebih baik. Ukuran pembanding yang digunakan yaitu berdasarkan nilai RSME dari masing-masing model.
Tabel 5.4 Perbandingan Model berdasarkan pada nilai RMSE
Dari tabel dapat dilihat bahwa model regresi nonparametrik kernel Nadaraya-Watson dengan nilai bandwidth = 25,64 memberikan estimasi yang lebih baik daripada model regresi polynomial kuadratik karena menghasilkan nilai RSME yang lebih kecil dibandingkan dengan regresi polynomial kuadratik sehingga model regresi terbaiknya adalah model regresi kernel dengan estimasi Nadaraya-Watson.
Kesimpulan
Berdasarkan dari hasil dan pembahasan pada bab sebelumnya, diambil kesimpulan sebagai berikut :
1. Dengan menggunakan model regresi polynomial kuadratik diperoleh nilai RMSE (Root of Means Squared Errror) sebesar 24,785
2. Dengan menggunakan model regresi kernel Nadaraya-Watson dengan tipe kernel Gaussian diperoleh nilai RSME sebesar 16,00147 dan ukuran bandwidth yang digunakan adalah 25,64.
3. Dengan membandingkan antara kedua model regresi diperoleh bahwa model regresi kernel Nadaraya-Watson dengan nilai bandwidth = 25,64 merupakan model regresi terbaik karena selain memberikan tingkat kesalahan/error yang lebih kecil, model regresi kernel juga memberikan estimasi yang lebih baik dibandingkan dengan model regresi polynomial kuadratik.
Daftar Pustaka
[1] Dwahjudi., 2009, Power dari Uji Kernomalan Data, (http://www.petra.ac.id) diakses pada tanggal 12 maret 2009
[2] Eubank, R.L., 1988, Spline Smoothing and Nonparametrik Regression, Marcel Dekker, New York.
[3] Halim, S., dan Bisono, I., 2006, Fungsi-fungsi Kernel Pada Metode Regresi Nonparametrik dan Aplikasinya Pada Priest River Experimental Forest’s Data, (http://www.petra.ac.id) diakses pada tanggal 30 Desember 2008.
[4] Hardle, W., 1990, Smoothing Techniques With Implementation In S, Springer-Verlag, New York.
[5] Nurgiyantoro, B., 2004, Statistik Terapan Untuk Penelitian Ilmu-ilmu Sosial, Gadjah Mada University Press, Yogyakarta.
[6] Pujiati, S.A., 2007, Analisis Regresi Linear Berganda,(saduran), Jurusan Statistik ITS, Surabaya.
[7] Santosa, P.B., dan Ashari., 2005, Analisis Statistik Dengan Microsoft Exel Dan SPSS, Andi Yogyakarta, Yogyakarta.
[8] Soemartini., 2007, Pengujian Beberapa Asumsi Pada Data Profitalitas Ekuitas dan Beberapa Faktor Yang Mempengaruhinya, (saduran), Jurusan Statistika Universitas Padjadjaran, Jatinangor.
[9] Sudjana., 2002, Metode Statistika, Tarsito, Bandung.
[10] Sudjana., 2003, teknik Analisis Regresi dan Korelasi, Tarsito, Bandung.
[11] Tiro, M.A., 2002, Analisis Korelasi dan Regresi, Makassar State University Press, Makassar.
[12] Yahoo Finance., 2008 Data Saham Mastercard Incorporated, (http://www.yahoofinance.com) diakses pada bulan Maret 2009.