BAB I
PENYAJIAN DATA
1.1 PENDAHULUANData mentah atau data yang diperoleh dari proses pengumpulan data pada umumya masih berupa data yang tidak teratur. Agar data tersebut lebih bermakna, maka proses pertama adalah mengelompokkan atau mengatur data mentah tersebut ke dalam bentuk-bentuk tertentu agar lebih berarti dan mudah untuk penggunaan selanjutnya. Selain ditampilkan dalam bentuk distribusi angka-angka, data juga bisa ditampilkan dalam bentuk grafik. Tampilan berupa grafik pada prinsipnya bertujuan agar data secara sekilas mudah dipahami, selain disajikan dalam format yang lebih menarik. Pemilihan grafik dalam penyajian data tergantung dari jenis data yang mau disajikan. Dalam hal ini dibedakan berdasarkan atas data kualitatif dan data kuantitatif.
KOMPETENSI KHUSUS, Diharapkan pada akhir perkuliahan nanti mahasiswa/i
dapat menyajikan data-data dalam bentuk grafik, dan dapat menginterpretasikan tampilan grafik-grafik yang ada.
1.2 PENYAJIAN
PENYAJIAN DATA
Bentuk-bentuk tampilan atau penyajian data pada dasarnya ada dua jenis :
1. Tabel
Data biasa ditampilkan dalam bentuk tabulasi, yang berarti terdapat BARIS dan KOLOM dalam jumlah tertentu. Tabel sendiri bisa dibagi penggunaannya berdasar jenis data yang ada. Jika data adalah kualitatif, maka penggunaan TABEL KONTINGENSI lebih dianjurkan karena tidak adanya decimal dalam data kualitatif. Sedang untuk data kuantitatif, agak sulit untuk menampilkannya dalam sebuah table kontigensi. untuk itu data kuantitatif biasa disajikan dengan sebuah STEAM AND LEAF DISPLAY, atau menyusunnya dalam sebuah distribusi frekuensi.
Contoh :
Penggambaran data kualitatif.
Remaja Muda Dewasa
Suka 2 5 12
Cukup suka 7 21 30
Tidak suka 5 11 21
Selain dengan table kontingensi, data juga bias dikelompokkan berdasar besaran-besaran tertentu, yang disebut kelas-kelas, desertai sebuah kolom yang berisi frekuensi tertentu. Tabel semacam ini biasa disebut dengan Distribusi Frekuensi.
Contoh Penggambaran data kuantitatif. Berat Badan (kg) Frekuensi 25 - 40 10 41 - 56 27 Di atas 56 7 2. Grafik (Diagram)
Selain disusun dalam bentuk table kontingensi atau distribus frekuensi yang hanya menonjolkan angka-angka, data juga bisa disajikan lebih menarik dengan tampilan berupa grafik, seperti grafik batang, grafik lingkaran, grafik garis dan sebagainya. Pada distribusi frekuensi, selain data ditampilkan dalam bentuk frekuensi perkelas, data juga bias divisualkan dalam bentuk histogram atau polygon.
Contoh Poligon :
Selain dengan table atau grafik, data khususnya data kuantitatif bisa pula dusajikan dala bentuk STEAM AND LEAF atau ORDERED ARRAY. Ordered array adalah menyusun data-data secara berurutan (order), bisa dari data terkecil ke data terbesar atau sebaliknya. Sedangkan steam and leaf merupakan tahap lanjutan dari ordered array. Setelah data tersusun, kumpulan data tersebut bisa disajikan dalam bentuk data pokok lalu disertai dengan angka decimal yang ada. Jadi penyusunan steam and leaf akan efektif pada penyajian data yang mempunyai angka decimal, seperti tinggi badan 173,3 cm, berat badan 56,7 kg dan seterusnya.
Grafik Batang (Bar), Lingkaran ( Pie), dan Pareto.
Penyajian data dalam bentuk grafik sebaiknya dilihat pula pada tipe datanya.jika data bersifat KATEGORIKAL, seperti data nominal dan ordinal, maka grafik yang sesuai adalah Bar Chart ( Grafik Batang), Pie Chart (Lingkaran) dan Pareto.
1. Grafik Batang (Bar Chart)
Grafik batang sebenarnya mirip dengan histogram, hanya grafik batang tidak perlu berdasar atas kelas-kelas pada sebuah distribusi frekuensi. Disebut bar (batang) karena setiap kategori yang ada akan ditampilkan dalam bentuk batang. Dengan demikian jika ada lima kategori, nanti akan ada lima batang, sedangkan panjang atau lebar setiap batang akan ditentukan oleh frekuensi yang ada pada setiap kategori. Jika kategori A mempunyai data sebanyak 40, sedang kategori B mempunyai data sebanyak 80, maka secara visual, panjang Bar B akan dua kali (80/40) panjang Bar A.
Contoh 1. Berikut adalah data penjualan mobil di Indonesia mulai Januari-Juni 2002.
Kategori Sedan
Merk Jumlah (unit)
Toyota 5661 Mitsibishi 1799 Suzuki 1463 Isuzu 1237 Daihatsu 1093 Honda 717
Kategori Non Sedan
Merk Jumlah (unit)
Toyota 37991 Mitsibishi 37654 Suzuki 29239 Isuzu 14140 Daihatsu 10142 Honda 3449
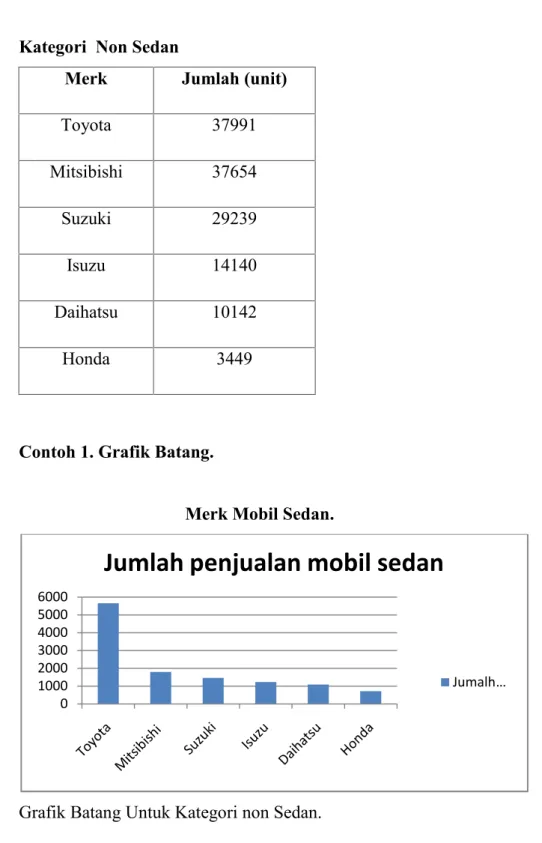
Contoh 1. Grafik Batang.
Merk Mobil Sedan.
Grafik Batang Untuk Kategori non Sedan. 0 1000 2000 3000 4000 5000 6000
Jumlah penjualan mobil sedan
Jika pada pembacaan batang di atas mengalami kesulitan, pada grafik biasa ditambahkan Grid atau garis pembantu untuk memperjelas posisi batang, atau dalam kasus ini memperjelas jumlah unit mobil yang terjual untuk merk tertentu seperti yang tertera pada grafik.
Dengan bantuan grid seperti ini member garis tiap 5000 unit, jumlah penjualan mobil bisa dilihat dengan mudah. Misalnya merk Isuzu bisa dilihat diperkirakan mendekati 15.000 unit. merk Honda cukup jauh dari 5.000 dan seterusnya.
Variasi lain adalah apabila diinginkan penonjolan satu atau beberapa data yang dianggap penting, sehingga harus tampak berbeda dengan data lainnya. Sebagai contoh ditonjolkan data penjualan mobil non sedan merk Suzuki dengan tampilan bar yang berbeda disertai dengan adanya nilai pada label. Seperti pada grafik batang di bawah ini.
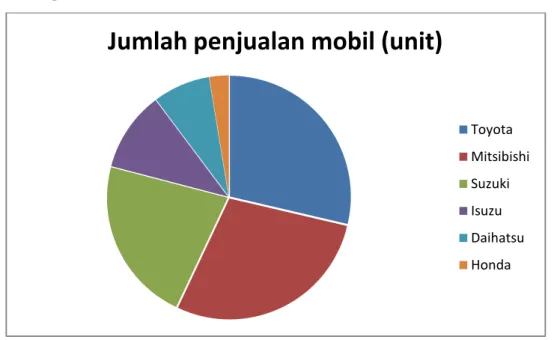
2. Grafik Lingkaran ( Pie Chart) 0
10000 20000 30000 40000
jumlah penjualan mobil non sedan
Jenis grafik yang biasanya menampilkan data kualitatif adalah grafik lingkaran (pie). Jika pada grafik Bar, setiap bar (batang) mewakili frekuensi tertentu dari data, maka pada grafik pie, frekuensi data dinyatakan dalam besar irisan yang ada pada grafik. Pir Chart sebenarnya mirip dengan histogram, hanya pada diagram batang tidak perlu berdasar pada kelas-kelas pada sebuah distribusi frekuensi. Dengan demikian jika ada lima katergori, nanti aka nada lima batang karena setiap kategori yang ada akan ditampilkan dalam bentuk batang. Sedangkan panjang (lebat) setiap batang akan ditentukan oleh frekuensi yang ada pada setiap kategori. Jika kategori A mempunyai data 40, sedang kategori mempunyai data 80 maka secara visual, pangjang batang B akan dua kali panjang batang A.
Kategori Sedan
jumlah penjualan mobil)
Toyota Mitsibishi Suzuki Isuzu Daihatsu Honda
Karegori Non Sedan
3. Grafik Pareto
Grafik Pareto sering digunakan dalam penggunaan statistic untuk pengendalian mutu (quality control), yang menggambarkan komponen mana yang lebih menonjolkan kuantitasnya dibanding yang lain, sehingga perlu perhatian khusus.
Grafik ini merupakan gabungan antara tampilan grafik batang dengan grafik garis dengan cirri khas data-data untuk pembuatan grafi pareto selalu diurutkan dahulu dari yang terbesar sampai yang terkecil .
Kategori Sedan
Merk Jumlah (unit)
Toyota 5661 Mitsibishi 1799 Suzuki 1463 Isuzu 1237 Daihatsu 1093 Honda 717
Jumlah penjualan mobil (unit)
Toyota Mitsibishi Suzuki Isuzu Daihatsu Honda
Kemudian data diurutkan dari terkecil hingga terbesar.
Kategori Sedan
Merk Jumlah (unit)
Honda 717 Daihatsu 1093 Isuzu 1237 Suzuki 1463 Mitsibishi 1799 Toyota 5661
Dan jika ditampilkan dengan grafik Pareto akan tampak sebagai berikut :
Pada grafik Pareto, sumbu X menampilkan data kualitatif, yang pada kasus ini adalah merk-merk mobil yang terjual, sedangkan sumbu Y menampilkan jumlah unit mobil tertentu yang terjual. Pada sumbu Y ini juga, pada sebelah kanan, terlihat persentase mobil tertentu yang terjual yang karena berbentuk komulatif . Jika tampilan setiap nilai individu dinyatakan dalam bentuk bar, maka tampilan secara komulatif dinyatakan dalam bentuk garis (line).
Dari grafik di atas terlihat secara menyolok bahwa mobil merk Toyota terjual paling banyak, kemudian diikuti merk mobil lain yang gradasi penurunan gambarnya (tinggi bar) cukup landai dan tidak terlihat menyolok seperti mobil Toyota tersebut.
Dari grafik ini, sesuai tujuan Pareto, perhatian harus diberikan pada satu atau beberapa data dengan jumlah besar, yang adalah mobil merk Toyota.
KATEGORI NON-SEDAN
Merk Jumlah (Unit)
Toyota 37991 Mitsubishi 37654 Suzuki 29239 Izusu 14140 Daihatsu 10142 Honda 3449 Lain-lain 12737
Jika diurutkan secara descending (dari terbesar ke terkecil), maka table menjadi :
Merk Jumlah (Unit)
Toyota 37991 Mitsubishi 37654 Suzuki 29239 Izusu 14140 Lain-lain 12737 Daihatsu 10142 Honda 3449
Dan jika ditampilkan dalam grafik Pareto menjadi :
Dari grafik di atas terlihat mobil merk Toyota kembali menjadi merk yang harus diperhatikan karena mempunyai persentase terbesar. Namun berbeda dengan tampilan Pareto pada modil non-sedan, pada mobil sedan, selain merk Toyota, merk Mitsubishi dan Suzuki mempunyai persentase yang hampir sama dengan Toyota. Dengan demikian, selain Toyota, kedua merk tersebut juga patut mendapat perhatian.
GRAFIK LINE (GARIS)
Dari namanya, grafik jenis line pada prinsipnya bertujuan menyajikan data dengan menghubungkan sekumpulan data dalam sebuah garis. Sumbu horizontal menampilkan keterangan data yang akan disajikan, seperti bulan, periode, kelompok produk dan sebagainya. Sedang sumbu vertical menyajikan data kuantitatif dari keterangan yang ada di sumbu horizontal.
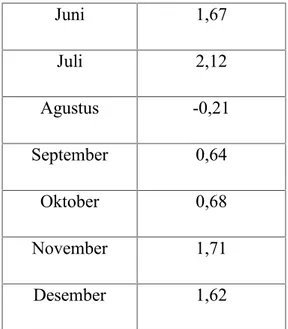
Sebagai contoh, berikut data inflasi tahun 2001 :
Bulan Inflasi (%) Januari 0,33 Februari 0,87 Maret 0,89 April 0,46 Mei 1,13
Juni 1,67 Juli 2,12 Agustus -0,21 September 0,64 Oktober 0,68 November 1,71 Desember 1,62
Gambarkan grafik garis dari data di atas.
Dari grafik di atas sekilas terlihat terjadi penurunan tingkat inflasi yang tajam dari bulan Juli ke Agustus. Sebaliknya dari Agustus ke September juga terjadi lonjakan inflasi yang cukup tinggi, yang meningkat terus sampai November.
Hal inilah yang menjadi keunggulan tampilan data dengan grafik dibandingkan jika data ditampilkan lewat serangkaian angka, dimana perbedaan data tidak bisa dilihat secara tepat. Selain itu tampilan lewat grafik garis seperti di atas langsung bisa dilihat bahwa tingkat inflasi cenderung meningkat dari waktu ke waktu.
TABEL KONTINGENSI
Table kontingensi bisa digunakan jika data yang ada berbentuk kualitatif, seperti jenis kelamin, tingkat pendidikan dan sebagainya. Data tersebut meliputi data dengan skala pengukuran nominal atau ordinal. Pada banyak buku, data tersebut bisa juga dinamakan data kategori, yakni data yang didapat dan kemudian dimasukkan dalam sebuah kategori tertentu. Ciri khas dari data ini adalah data berbentuk bilangan integer (bulat), sehingga data tidak mengandung unsure decimal.
Untuk lebih jelasnya, berikut disertakan kasus sederhana, untuk menunjukkan barbagai variasi tampilan data dengan table kontingensi.
Kasus :
Data komposisi kepemilikan STASIUN RADIO di berbagai kota di Jawa :
Radio Jakarta Surabaya Bandung Bogor
AM 4 14 5 2
FM 34 11 21 3
Pada table kontingensi di atas, baik data jenis radio maupun data kota adalah data kualitatif, karena keduanya adalah data nominal. Dengan demikian, pasti kedua variable tersebut tidak mengandung decimal, karena tidak mungkin jumlah stasiun radio AM ada 2,5 buah, atau jumlah stasiun radio gelombang FM di Jakarta berjumlah 15,4 buah.
Variasi Tampilan Tabel Kontingensi
Walaupun secara dasar tampilan table kontingensi adalah seperti dua contoh di atas, yang mensyaratkan adanya baris dan kolom, namun dalam praktek table di atas bisa ditampilkan dalam berbagai variasi, sesuai dengan tujuan yang diinginkan.
Table Kontingensi dengan Total Jumlah
Variasi pertama adalah menampilkan sel TOTAL atau JUMLAH, baik dari sisi baris atau sisi kolom. Dinamakan TOTAL, berarti dilakukan proses penjumlahan pada setiap isi baris atau isis kolom yang relevan.
Sebagai contoh, table kontingensi data radio di berbagai kota di Jawa bisa ditampilkan sebagai berikut :
Jenis Gelombang
Radio
KOTA DI JAWA TOTAL
Jakarta Surabaya Bandung Bogor
AM 4 14 5 2 25
FM 34 11 21 3 69
TOTAL 38 25 26 5 94
Dari table di atas bisa dilihat tambahan informasi yang berguna, yakni :
Jika dilihat dari TOTAL KOLOM, maka jumlah radio FM secara total berjumlah lebih besar disbanding total rdio AM. Perbandingan tersebut bahkan dua kali lebih (69 dibanding 25 atau sekitar 2,76).
Jika dilihat dari TOTAL BARIS, maka kota Jakarta mempunyai jumlah total radio (gelombang AM dan gelombang FM) terbanyak, sebesar 38. Sedang kota Surabaya dan Bandung hamper berimbang (25 dibanding 26).
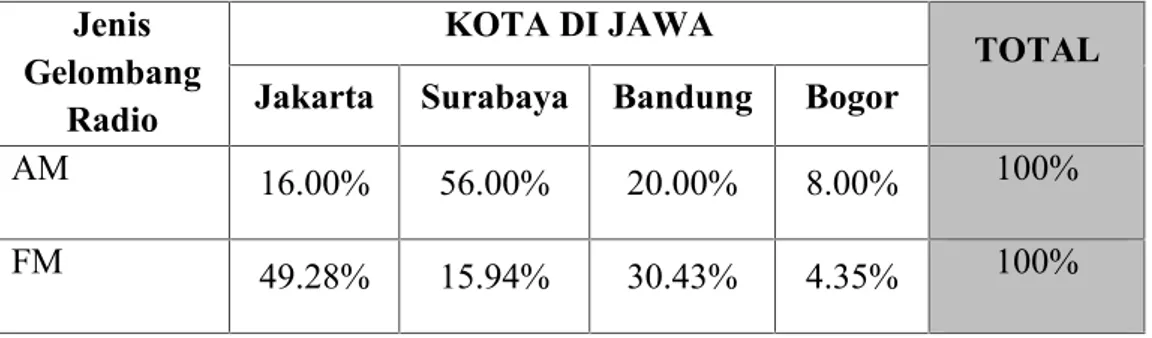
Table Kontingensi dengan Persentase pada Total Kolom
Pada variasi ini, total kolom dibuat 100%, kemudian isis baris diubah dalam bentuk persentase, sehingga total persen pada suatu baris adalah 100%.
Untuk jelasnya, berikut hasil pengubahan dalam persentase kolom dari data radio di atas :
Jenis Gelombang
Radio
KOTA DI JAWA TOTAL
Jakarta Surabaya Bandung Bogor
AM 16.00% 56.00% 20.00% 8.00% 100%
FM 49.28% 15.94% 30.43% 4.35% 100%
Keterangan :
Sel untuk radio AM di Jakarta jika diubah ke persentase menjadi : 4/25 x 100% = 16%
Sel untuk radio FM di Surabay jika diubah ke persentase menjadi : 14/25 x 100% = 56%
Demikian untuk persentase kota Bandung dan Bogor, dengan ketentuan setiap isi sel yang bersangkutan dibagi dengan total radio AM di keempat kota
Sel untuk radio FM di Jakarta jika diubah ke persentase menjadi : 34/69 x 100% = 49,28% (dibulatkan dua angka di belakang koma) Sel untuk radio FM di Bogor jika diubah ke persentase menjadi : 3/69 x 100% = 4,35%
Ketentuan yang sama dengan perhitungan radio AM, yakni setiap isi sel yang bersangkutan dibagi dengan total radio FM di keempat kota tersebut, yakni sejumlah 69 buah.
Analisis :
Dari table di atas, dari persentase terlihat stasiun radio gelombang AM terbanyak berada di Surabaya (56%), sedang jumlah terkecil ada di kota Bogor (8%). Sedang stasiun radio gelombang FM terbanyak berada di Jakarta (49,28%), sedang jumlah terkecil juga ada di Bogor (hanya 4,35%). Dari kedua angka terbesar, terlihat juga bahwa sekitar setengah (50%) dari stasiun radio AM ataupun FM praktis ada di satu kota tertentu saja (AM di Surabaya sedangkan FM di jakarta).
Table Kontingensi denganPersentase pada Total Baris
Sama dengan variasi persentase kolom, total baris dibuat 100%, kemudian isi kolom yang diubah dalam bentuk persentase, sehingga total persen pada suatu kolom adalah 100%.
Hasil pengubahan dalam persentase baris dari data radio di atas :
Jenis Gelombang
Radio
KOTA DI JAWA
Jakarta Surabaya Bandung Bogor
AM 10.53% 56.00% 19.23% 40.00%
FM 89.47% 44.00% 80.77% 60.00%
TOTAL 100.00% 100.00% 100.00% 100.00%
Keterangan :
4/38 x 100% = 10.53%
Otomatis sisanya (yakni radio gelombang FM di Jakarta) adalah 100% -10.53% = 89.47%
Sel untuk radio AM di Surabaya jika diubah ke persentase BARIS menjadi : 14/25 x 100% = 56%, sedanf FM adalah 100% - 56% atau 44%.
NB : perhatikan bahwa kebetulan saja baik dengan persentase KOLOM atau
BARIS kota Surabaya mendapatkan hasil 56%.
Demikian untuk persentase kota Bandung dan Bogor, dengan ketentuan setiapisi sel yang bersangkutan dibagi dengan totak radio di keempat kota teresbut.
Analisis :
Dari table di atas, dari persentase terlihat jumlah stasiun radio gelombang Am hanya lebih banyak di kota Surabaya, sedang di ketiga kota lain, jumlah stasiun radio FM lebih banyak dibanding radio AM. Bahkan di kota Jakarta dan Bandung perbandingan tersebut sangat nyata, yakni sekitar 8 berbanding 1.
Table Kontingensi denganPersentase pada Total Baris dan Total Kolom
Pada variasi ini, persentase pada satu sel, yakni TOTAL kolom dan total BARIS (lihat pada table kedua,sejumlah 94 stasiun radio) dibuat 100%, kemudian isi sel diubah dalam bentuk persentase.
Hasil pengubahan dalam persentase baris dan kolom dari data stasiun radio di atas :
Jenis Gelombang
Radio
KOTA DI JAWA
TOTAL Jakarta Surabaya Bandung Bogor
AM 4.26% 14.89% 5.32% 2.13% 26.60%
FM 36.17% 11.70% 22.34% 3.19% 73.40%
TOTAL 40.43% 26.60% 27.66% 5.32% 100.00%
Sel untuk radio AM di Jakarta jika diubah ke persentase BARIS dan KOLOM menjadi :
4/94 x 100% = 4.26%
Sel untuk radio FM di Surabaya jika diubah ke persentase BARIS dan KOLOM menjadi :
14/94 x 100% = 11.70%
Demikian untuk persentase sel lainnya, dengan ketentuan setiap isi sel yang bersangkutan dibagi dengan total stasiun radio, baik gelombang AM atau FM di keempat kota tersebut, yakni 94 buah.
Analisis :
Dari table di atas terlihat bahwa jumlah seluruh stasiun radio paling banyak ada di Jakarta (40.43%), sedang terkecil ada di kota Bogor (hanya 5.32%). Sedang jika dilihat dari jenis gelombang radio, terbesar tetap Jakarta, dengan jumlah stasiun radio FM sejumlah 36.17% dari total stasiun radio di keempat kota tersebut.
Ummary Tabel
Summary table berfungsi untuk meringkas berbagai informasi yang bertipe kualitatif. Berbeda dengan table kontingensi yang mempunyai banyak baris dan kolom, summary table hanya mempunyai satu kolom yang berfungsi untuk meringkas seluruh informasi yang terkandung dalam setiap baris yang ada.
Sebagai contoh, jika table kontingensi yang menggambarkan komposisi radio di kota-kota di Jawa disajikan dalam sebuah summary table, maka ventuk table adalah :
Jenis Gelombang Radio Jumlah
AM 25
TOTAL 94
Perhatikan table di atas yang tidak menampilkan perincian radio AM dan FM per kota, karena yang diinginkan adalah ringkasan jenis gelombang radio. Pada summary table, bisa juga diberi tambahan sebuah kolom yang berisi persentase masing-masing data pada sebuah baris :
Jenis Gelombang Radio Jumlah Persentase (%)
AM 25 26.6
FM 69 73.4
TOTAL 94 100
Walaupun kolom summary table di atas lebih dari satu kolom, namun kolom kedua ini merupakan penjelasan tambahan saja dari kolom ringkasan.
Jika akan ditampilkan ringkasan jumlah stasiun radio per kota, maka tampilan menjadi :
Kota Jumlah Stasiun Radio
Jakarta 38
Surabaya 25
Bandung 26
Bogor 5
TOTAL 94
Perhatikan walaupun angka-angka pada kolom ringkasan berubah, namun secara total jumlah stasiun radio tetap, yakni 94 buah. Dari table ringkasan tersebut terlihat bahwa kota Jakarta memiliki stasiun pemancar radio terbanyak, tanpa memperhatikan jenis stasiun radio.
1.2.1 LATIHAN
1. Berikut adalah komposisi Pembangkit Listrik berdasarkan sumber energy pada Negara-negara Eropa :
Sumber Energi Pangsa Pasar
Fosil (minyak dll) 50%
Nuklir 35%
Energi yang dapat diperbaharui 12%
Lain-lain 3%
TOTAL 100%
Dari tabel di atas buatlah GRAFIK Pie, Bar serta Pareto.
2. Berikut adalah target persentase sumber enrgi yang dapat diperbaharui dari seluruh sumber energy yang ada pada berbagai negara Eropa :
Dari table di atas buatlah grafik Bar untuk data tahun 1997 dan tahun 2010. Bandingkanlah grafik keduanya.
Negara Target tahun 1997 (%) Target tahun 2010 (%)
Austria 70,0 78,1
Portugal 38,5 39,0
Denmark 8,7 29,0
Italia 16,0 25,0
Belanda 3,5 9,0
Belgia 1,1 6,0
BAB II
DISTRIBUSI FREKUENSI
2.1 PENDAHULUAN.
Seperti yang telah disinggung pada modul pertama yaitu penyajian data, Distribusi frekuensi pada prinsipnya adalah menyususn dan mengatur data kuantitatif yang masih mentah ke dalam beberapa kelas data yang sama, sehingga setiap kelas bisa menggambarkan karakteristik data yang ada. Seperti missal jika ada kelas data upah bulanan “ 200.000 – 300.000” yang berisi frekuensi “100”, maka bisa diartikan bahwa ada 100 orang yang menerima upah bulanan antara Rp. 200.000 sampai Rp. 300.000.
Walaupun pada pembuatan suatu distribusi frekuensi ada aturan-aturan tertentu, namun sebuah distribusi frekuensi pada dasarnya tidak ada aturan yang mengikat, sehingga sebuah data mentah bisa saja ditampilkan dalam bentuk lebih dari satu distribusi frekuensi. Pembuatan sebuah distribusi frekuensi lebih tepat jikatetap mengikuti pedoman-pedoman yang ada, namun juga tidak meninggalkan unsure subyektivitas .Dalam modul ini akan dijelaskan langkah –langkah pembuatan table frekuensi dan beserta sketsa grafiknya.
Kompetensi Khusus, Diharapkan setelah mengikuti perkulian ini mahasiswa/I
mampu menyajikan data dalam jumlah besar ke dalam table distribusi frekuensi.
2.2 PENYAJIAN.
Distribusi frekuensi
Data hasil pengukuran biasanya dapat disajikan dalam bentuk diagram seperti pada modul sebelumnya, juga bisa pula disusun dalam sebuah table yang disebut table frekuensi atau distribusi frekuensi yang yang terdiri dari distribusi frekuensi tunggal dan distribusi frekuensi berkelompok.
Berikut ini akan diberikan sejumlah data hasil pengukuran tinggi badan ( sampai sentimeter terdekat) dari 40 orang mahasiswa/I semester I Pendidikan Matematika.
148 150 160 168 150 149 160 160 151 154 156 159 164 163 169 168 170 170 177 150 153 160 165 170 175 158 168 166 167 174 173 155 158 162 166 164 159 163 156 163
Dari data tersebut di atas dapat diperoleh ukuran paling rendah ( minimum) adalan 148 cm dan ukuran tertinggi (maksimum) adalah 177 cm. sehingga selisih antara data tertinggi dan data terendah disebut sebagai jangkauan ( Range).Untuk data di atas range = 177 cm – 148 cm = 29 cm. Jika data tersebut disusun dalam table frekuensi data tunggal maka tentu akan sangat panjang. Untuk itu data tersebut
harus disusun dalam sebuah table yang disebut table frekuensi data berkelompok atau distribusi frekuensi data berkelompok.
Berikut adalah langkah – langkah pembuatan table frekuensi data berkelompok : 1. Menentukan jumlah kelas
Jumlah kelas pada prinsipnya bisa ditentukan secara subyektif, walaupun secara umum jumlah kelas yang bagus berkisar antara 5 sampai 20 kelas. Jika jumlah kelas terlalu kecil, misal ada 500 data dengan jumlah kelas hanya 5, maka banyak informasi yang penting akan hilang.namun jumlah kelas terlalu banyak juga dengan data yang relativesedikit, misalnya untuk 50 data ada 20 kelas, maka tiap kelas relative hanya mendapat 3 data.
H.A Sturges (1926) mengajukan sebuah rumus untuk menentukan jumlah kelas dari sekelompok data :
Ket :
k = jumlah kelas n = jumlah data
misalkan untuk data nilai ujian matematika dari 78 mahasiswa, maka jumlah kkelas yang dianjurkan adalah :
K = 1 + 3,322 log (78) = 7,28 atau dibulatkan menjadi 7.
Jadi dari 78 data tersebut akan dibuat table frekuensi dengan kelas berjumlah 7.
NB. Rumus sturges adalah sebuah alternative, dan tidak diharuskan digunakan dalam setiap kelas.
2. Menentukan interval kelas
Setelah jumlah kelas ditetapkan, langlah selanjutnya adalah mengisi interval
Dimana :
I = interval kelas
Range = nilai tertinggi – nilai terendah K = jumlah kelas
3. Menyusun Distribusi frekuensi
Dengan jumlah kelas dan panjang interval kelas yang telah diperoleh, maka disusunlah table frekuensi. ( seperti pada contoh).
Ada beberapa istilah dalam table distribusi frekuensi yang harus diketahui yaitu : 1. Interval kelas ( class interval)
Interval kelas atau sering juga disebut selang kelas, adalah penanda sebuah kelas. 2. Lebar kelas ( class width)
Lebar kelas adalah selisih antara nilai-nilai pada interval kelas. Setiap interval kelas interval seharusnya lebar kelas yang sama.
3. Titik tengah kelas ( class midpoint)
Titik tengah kelas adalah nilai tengah setiap interval kelas. Misalkan interval 10 – 16, maka titik tengahnya adalah : (10 + 16)/2 = 14.
Demikian seterusnya setiap kelas seharusnya mempunyai titik tengah kelas yang berbeda beda.
4. Batas kelas ( Limid Class)
Batas kelas adalah nilai-nilai yang membatasisebuah interval, yang dibagi menjadi batas kelas atas dan batas kelas bawah. Seperti pada contoh di atas yang menjadi batas kelas atas adalah 16 dan batas kelas bawah adalah 10. Untuk penggunaannya batas bawah kelas dikurangi dengan 0,5 dan batas atas kelas interval ditambah 0,5.
5. Class Boundaries
Pada banyak distribusi frekuensi, untuk menghindari sebuah data bisa masuk pada dua kelas yang berbeda, maka batas kelas diperluas, baik ke bawah atau ke atas. Seperti pada contoh kelas di atas maka : batas kelasnya dapat diperluas (10,5 – 16,5).
Berikut adalah contoh pembuatan table frekuensi atau table distribusi frekuensi dari data tinggi badan 40 mahasiswa di atas:
1. Seperti telah dihitung Range dari data tersebut adalah 29 cm. Dan panjang interval kelas adalah 5 ( i=5).
2. Banyaknya kelas (k) atau panjang kelas dapat dihitung sbb. K = (range/i) + 1
= (29/5) + 1
= 6,8 atau dibulatkan menjadi 7.
3. Jadi table distribusi frekuensi dari data tinggi badan 40 mahasiswa tersebut adalah:
Tinggi badan (cm) Turus (Tally) Frekuensi
145 – 149 150 – 154 155 – 159 160 – 164 165 – 169 170 – 174 175 - 179 II VI VII X VIII V II 2 6 7 10 8 5 2 = 40
Dari table yang ada maka dapat diketahui bahwa jumlah mahasiswa yang tingginya kurang dari 60 adalah 15 orang.
GAMBAR DISTRIBUSI FREKUENSI
Setelah table frekuensi distribusi di susun, maka langkah selanjutnya adalah bagaimana menampilkan distribusi frekuensi dalam bentuk grafik, sehingga selain lebih komunikatif dan menarik untuk dilihat, juga pengguna secara tepat bisa
mengetahui hal-hal penting pada sebuah distribusi frekuensi ( seperti contoh siapa yang tertinggi dan siapa yang terendah).
Alat popular yang digunakan untuk menampilkan distribusi frekuensi dalam bentuk grafik adalah histogram, polygon dan kurva ogive yang akan diuraikan sebagai berikut:
Kasus.
Dari distribusi frekuensi yang menggambarkan distribusi tinggi badan mahasiswa
Dari data di atas, dapat digambarkan dalam beberapa grafik sbb:
HISTOGRAM
Histogram pada dasarnya adalah pelengkap pada penyusunan suatu distribusi frekuensi, yang menampilkan frekuensi-frekuensipada distribusi frekuensi dalam bentuk grafik bar (batang).Tinggi setiap batang pada histogram adalah proposional berdasar setiap kelas yang ada.Histogram pada dasarnya adalah grafik bentuk batang yang diletakkan secara vertical, dengan sumbu X adalah titik tengah kelas sedangkan sumbu y adalah frekuensi.
Berikut adalah histogram dari data tinggi badan mahasiswa pada table di atas.
Tinggi badan (cm) Frekuensi
145 – 149 150 – 154 155 – 159 160 – 164 165 – 169 170 – 174 175 - 179 2 6 7 10 8 5 2 = 40
POLIGON FREKUENSI
Poligon frekuensi adalah bentuk lain dari histogram, yang berupa garis yang menghubungkan titik tengah – titik tengah dari setiap batang (Bar).Jika distribusi frekuensi dari data tinggi badan di atas ditampilkan dalam polygon maka hasilnya sbb.
Perhatikan sebuah polygon yang selalu mulai dari titik nol dan diakhiri juga dengan sebuah titik nol pada sumbu X. Poligon frekuensi berguna untuk membandingkan dua atau lebih distribusi frekuensi, yang jika ditampilkan dalam bentuk histogram
DISTIBUSI KOMULATIF DAN KURVA OGIVE
Selain ditampilkan dalam bentuk Distribusi Frekuensi dan visual dalam bentuk Histogram serta Poligon Frekuensi, data bias ditampilkan dalam bentuk Distribusi Komulatif, yakni penjumlahan atau pengurangan setiap frekuensi pada tiap kelas secara komulatif.
Distribusi komulatif bias ditampilkan dalam dua bentuk, yakni Distribusi KURANG DARI atau Distribusi LEBIH DARI.
Sebagai contoh, untuk distribusi nilai ujian Matematika, jika dibuat dalam bentuk Distribusi Komulatif KURANG DARI akan menjadi :
Nilai Ujian Matematika Frekuensi
Kurang dari 5 0 Kurang dari 20 17 Kurang dari 35 30 Kurang dari 50 38 Kurang dari 65 50 Kurang dari 80 63 Kurang dari 95 77 Kurang dari 110 78 Keterangan :
Angka 0 secara otomatis terjadi karena tidak ada nilai ujian yang kurang dari 5 atau kurang dari batas bawah dari kelas pertama. Distribusi komulatif ‘KURANG DARI’ selalu dimulai dengan angka 0.
Angka 17 adalah nilai awal dari distribusi frekuensi, yang ada pada kelas pertama, yakni jumlah mahasiswa (frekuensi) yang mendapat nilai ujian antara 5 sampai 20 (atau dengan batas kelas, antara 4,99 sampai 19,99).
Angka 35 adalah penjumlahan dari angka 17 dan 13. Karena pernyataan ‘Kurang dari 35’ berarti penjumalahan frekuensi semua mahasiswa yang mendapat nilai kurang dari 35, sehingga nilai di bawah 20 pun tetap termasuk pada range tersebut. Demikian seterusnya, setiap kenaikan kelas berarti terjadi penjumlahan satu persatu dari isi tiap kelas, sehingga secara logika, pada akhir kelas akan terdapat frekuensi seluruh data, yakni 78 data.
Kemudian jika distribusi nilai ujian Matematika akan dibuat dalam bentuk Distribusi Komulatif LEBIH DARI akan menjadi :
Nilai Ujian Matematika Frekuensi
Lebih dari 5 0 Lebih dari 20 17 Lebih dari 35 30 Lebih dari 50 38 Lebih dari 65 50 Lebih dari 80 63 Lebih dari 95 77 Lebih dari 110 78 Keterangan :
Angka 78 atau jumlah total data secara otomatis terjadi karena tidak ada nilai ujian yang kurang dari 5, atau semua lebih dari nilai minimum, yakni 5. Distribusi Komulatif ‘LEBIH DARI’ selalu dimulai dengan angka jumlah data total, dalam kasus ini adalah 78.
Jumlah ‘lebih dari 20’ berarti semua data dikurangi jumlah yang mendapat nilai di bawah 20. Karena yang mendapat nilai 20 ke bawah adalah 17 orang, maka yang mendapat lebih dari 20 adalah 78 – 17 = 61 orang.
Demikian seterusnya, setiap kenaikan kelas berarti terjadi pengurangan satu persatu dari setiap isi kelas, sehingga secara logika, pada akhir kelas akan terdapat nilai 0, karena tidak aka nada mereka yang bernilai lebih dari 105.
Jika kedua distribusi tersebut digabung pada sebuah Poligon Frekuensi, maka Poligon khusus tersebut bias dinamakan KURVA OGIVE :
SOAL LATIHAN
1. Buatlah dalam table distribusi frekuensi data nilai mata kuliah statistiksa dari 100 mahasiswa matematika berikut :
45 40 65 67 67 60 80 86 80 85 64 49 40 40 56 50 58 80 80 68 90 95 100 100 70 76 80 95 90 70 65 65 80 85 80 40 45 40 50 55 50 58 80 82 80 65 60 70 75 75 70 60 55 58 58 80 85 80 85 80 90 90 60 60 70 55 50 70 75 80 60 67 65 67 80 80 80 90 95 100 75 55 45 90 95 76 76 55 60 68
86 56 55 58 68 70 70 75 75 60 67 65 80 86 85 78 75 56 46 40
2. Berikut adalah komposisi pangsa pasar sepeda motor periode Januari – November 2002 :
Merk Pangsa Pasar
Honda 64,00% Suzuki 20,70% Yamaha 13,10% Kawasaki 1,66% Lain-lain 0,54% TOTAL 100%
Dari atdbel di atas :
a. Jenis grafik apa yang seharusnya digunakan untuk mendeskripsikan data di atas? Mengapa?
b. Buatlah grafik-grafik sesuai jawaban a.
3. Berikut adalah komposisi Pembangkit Listrik berdasarkan sumber energy pada Negara-negara Eropa :
Sumber Energi Pangsa Pasar
Fosil (minyak, dll) 50%
Nuklir 35%
Energy yang dapat diperbaharui
12%
Lain-lain 3%
4. Berikut adalah targetpersentase sumber energy yang dapat diperbaharui dari seluruh sumber enrgi yang ada pada berbagai Negara di Eropa :
Negara Target tahun 1997 (%) Target tahun 2010 (%)
Austria 70,0 78,1 Portugal 38,5 39,0 Denmark 8,7 29,0 Italia 16,0 25,0 Jerman 4,5 12,5 Belanda 3,5 9,0 Belgia 1,1 6,0
Dari table di atas buatlah grafik Bar untuk data tahun 1997 dan tahun 2010. Bandingkanlah grafik keduanya.
BAB III
UKURAN TENDENSI PUSAT
3.1 PENDAHULUANUntuk mendapat gambaran yang jelas tentang sebuah data mengenai suatu hal, baik mengenai sampel ataupun populasi, selain daripada data itu disajikan dalam bentuk table dan diagram, masih diperlukan ukuran- ukuran yang merupakan wakil kumpulan data tersebut. Dalam modul ini akan diuraikan tentang ukuran gejala pusat dan ukuran letak. Beberapa macam ukuran dari golongan pertama adalah : rata-rata atau rata-rata hitung, rata-rata ukur, rata-rata harmonic dan modus. Golongan kedua adalah Median, kuartil, desil dan persentil.
Ukuran yang dihitung dari kumpulan data dalam sampel dinamakan statistic. Apabila ukuran itu dihitung dari kumpulan data dalam populasi atau dipakai untuk menyatakan populasi , maka namanya parameter.Jadi ukuran yang sama dapat berbentuk statistic atau parametertergantung pada apakah ukuran yang dimaksud untuk sampel atau populasi.
KOMPETENSI KHUSUS, diharapkan setelah mengikuti perkuliahan ini
mahasiswa/I mampu menganalisa data-data sampel atau populasi dengan mengkaji ukuran-ukurannya, dan dapat menginterpretasikan data-data yang dengan melihat ukuran tendency pusatnya.
3.2 PENYAJIAN MEAN
Rata-rata Hitung Sederhana
Disebut rata-rata sederhana karena dalam proses perhitungan frekuensi data serta bobotnya.
Rumus :
=
∑dimana :
Contoh 1:
Data jumlah tamu Hotel AMAN selama seminggu :
HARI JUMLAH TAMU
Senin 120
Selasa 80
Rabu 46
Jum’at 89
Sabtu 202
Minggu 279
Maka rata-rata tamu yang menginap di Hotel AMAN tersebut adalah :
=
=
= 125.Terlihat rata-rata tamu perhari adalah 125 0rang. Perhatikan bahwa yang dimaksud bukan
setiap hari ada persis 125 orang yang menginap di Hotel AMAN, namun jika dirata-ratakan, dari orang yang menginap mulai hari senin sampai sabtu, jumlah tamu adalah 125 orang perhari.
Contoh 2:
Data jumlah tamu yang menginap di Hotel SRIKANDI. Namun berbeda dengan Hotel AMAN, Hotel SRIKANDI hanya menyewakan kamar pada hari Kamis sampai Senin depan saja, sedang hari Selasa dan Rabu digunakan pihak Hotel untuk membersihkan kamar.
HARI JUMLAH TAMU
Kamis 61
Jum’at 79
Sabtu 88
Minggu 92
Senin 48
X =
∑=
= 73,6
Terlihat rata-rata jumlah tamu perhari adalah 73,6 orang dibulatkan menjadi 74 orang. Perhatikan jumlah data adalah 5, berbeda dengan jumlah data sebesar 7 pada contoh 1.
Sekarang jika dianggap di daerah tersebut hanya ada dua hotel, maka berapakah rata-rata(mean) tamu yang menginap di daerah tersebut untuk hari senin dan selasa?
X =
∑=
= 84
Perhatikan jumlah data sekarang hanya ada dua, karena memang cuma ada dua hotel. Dengan demikian, rata-rata tamu yang menginap di daerah tersebut pada hari senin adalah 84 orang.
Untuk hari Selasa, Mean adalah rata-rata dari semua tamu yang menginap di kedua hotel tersebut pada hari Selasa, yakni :
X =
∑=
= 40
Walaupun jumlah data sama, yakni dua, namun data hari Selasa untuk Hotel SRIKANDI adalah nol, karena hotel tidak menerima tamu. Dengan demikian, rata-rata tamu yang menginap di daerah tersebut pada hari Selasa adalah 40 orang.
Rata-rata Hitung dengan Frekuensi
Variasi lain adalah jika setiap data yang dihitung mempunyai frekuensi kemunculan tertentu, sehingga rumus Rata-rata sederhana mengalami modifikasi menjadi :
Perhitungan ini digunakan untuk menghitung rata-rata dari suatu distribusi Frekuensi.
Contoh :
Data distribusi Frekuensi gaji yang diterima karyawan P.T. CLEOPATRA :
Gaji (Rupiah/bulan) Frekuensi (orang)
575.000 6
600.000 11
625.000 17
650.000 8
Keterangan :
Karyawan dengan gaji Rp. 575.000,-/bulan sejumlah 6 orang, sedang mereka yang bergaji Rp. 600.000,-/bulan sejumlah 11 orang. Demikian seterusnya untuk data yang lain. Berbeda dengan kasus sebelumnya, disini ada sejumlah data yang mempunyai
nilai yang sama, seperti data 575.000 ada 6 data, 600.000 ada 11 data, dan
seterusnya.
Namun tetap diperhatikan bahwa semua data haruslah data kuantitatif dan sejenis. Sebagai contoh, jika isi table adalah 6 buah durian masing-masing seberat 5,1 kg, 9 buah nenas masimg-masing seberat 2,5 kg dan 4 buah melon masing-masing seberat 1,75 kg. untuk data dengan campuran buah seperti ini, tidak bias dilakukan rata-rata frekuensi, karena walaupun semua data kuantitatif, namun jenis data (jenis buah) tidak sama. Dengan kata lain tidak mungkin dihitung rata-rata berat buah, karena akan timbul pertanyaan’rata-rata untuk buah yang mana? Hal ini berbeda dengan gaji pada table di atas, yang jelas sejenis, karena semua bersatuan ‘Rupiah/bulan’.
Perhitungan rata-rata gaji karyawan P.T. CLEOPATRA :
GAJI (Rupiah/bulan) Frekuensi (orang) GAJI * Frekuensi
575.000 6 3.450.000
625.000 17 10.625.000
650.000 8 5.200.000
TOTAL 42 25.875.000
Atau dengan penggunaan rumus :
X =
( ∗ (. ∗ ) . )=
. .= 616.071,4
Dengan demikian, rata-rata gaji 42 orang karyawan P.T. CLEOPATRA adalah Rp. 616.071,4/bulan.
Rata-rata Hitung dengan Bobot
Data juga bisa diberi bobot (weight) yang membedakan data satu dengan data lainnya sehingga rumus rata-rata sederhana mengalami modifikasi menjadi :
=
∑∑ Dimana :Walaupun rumus ini sama dengan rumus rata-rata frekuensi, dengan perbedaan pada penggantian symbol f dengan w, namun secara konsep keduanya berbeda. Weighted mean (rata-rata berbobot) berangkat dari pengertian bahwa data tidak mempunyai bobot yang sama, tergantung dari besar kepentingan yang diberikan pada data tersebut.
Contoh :
Perhitungan Indeks Prestasi (IP) seorang mahasiswa, yang mengambil sejumlah mata kuliah tertentu, dan dihitung dengan sks. Pada umumnya tidak semua mata kuliah mempunyai bobot sks yang sama, seperti mata kuliah Matematika mempunyai bobot 3 sks, sementara mata kuliah Sosiologi mungkin hanya 2 sks. Apa yang membedakan
hanya 2 sks? Tentu saja ini tergantung pengambilan keputusan yang memandang mata kuliah Matematika lebih penting dari mata kuliah Sosiologi.
Contoh lain :
Proses penilaian seorang karyawan, dengan memberi pembobotan pada komponen penilaian yang meliputi kedisiplinan (bobot 50%), kerjasama (bobot 30%) dan kinerja (bobot 20%). Perhatikan jumlah bobot pada kasus seperti ini selalu 100% (50%+30%+20%).
Kasus I :
Berikut adalah distribusi mata kuliah yang diambil dan nilai akhir dari mahasiswa bernama Chandra :
Mata Kuliah Bobot sks Nilai (huruf) Nilai (angka)
Matematika 3 A 4
Sosiologi 2 C 2
Ekonomi Mikro 4 D 1
Akuntansi 3 B 3
Keterangan :
Konversi Nilai dari huruf ke angka adalah : A=4
B=3 C=2 D=1 E=0
Jadi untuk mata kuliah matematika yang mempunyai bobot 3 sks, Chandra mendapat nilai A atau setara dengan angka 4. Demikian seterusnya untuk arti data lainnya. Tentu saja disini harus dilakukan konversi (pengubahan) dari nilai huruf ke nilai
angka, sebab jika tidak demikian,proses perhitungan rata-rata tidak bias dikerjakan,
karena adanya data non-angka. Rata-rata nilai Chandra (IP) adalah :
Bobot sks Nilai (angka) Bobot*Nilai 3 4 12 2 2 4 4 1 4 3 3 9 TOTAL 12 29
Atau dengan rumus :
X =
( ∗ ) ( ∗ ) ( ∗ ) ( ∗ )( )=
= 2.41
Dengan demikian IP atau rata-rata nilai Chandra dengan mempertimbangkan bobot masing-masing mata kuliah, adalah 2.41.
Jika IP Chandra dihitung tanpa mempertimbangkan bobot SKS, maka nilai rata-rata adalah persis seperti rumus Rata-rata sederhana :
X = =
=
2.5
Disini n atau jumlah data adalah 4.
Perhatikan selisih perhitungan antara tanpa mempertimbangkan bobot dengan mempertimbangkan bobot. Hal ini disebabkan pada bobot SKS yang tinggi, yakni mata kuliah Ekonomi Micro, Chandra mendapat nilai jelek (D), yang hanya bernilai angka sama dengan 1, sehingga akan menurunkan total IP Chandra. Hal ini tentu tidak terjadi jika bobot SKS dihilangkan, yang otomatis membuat semua mata kuliah sama pengaruhnya terhadap IP.
Kasus 2 :
Berikut adalah hasil penilaian seorang Supervisor terhadap karyawan bernama Deddy :
Disiplin 50% 70
Kerjasama 30% 60
Kinerja 20% 90
TOTAL 100%
Keterangan :
Nilai yang diberikan adalah pada skala 0 (sangat jelek) sampai 100 (sangat baik). Data di atas menunjukkan Supervisor menilai Deddy dengan angka 70 untum kedisiplinannya selama bekerja, nilai 60 untuk kerjasama dengan teman sekerja dan 90 untuk kinerja secara pribadi. Perhatikan jumlah bobot yang menunjukkan setengah dari penilaian adalah berdasarkan kedisiplinan seseorang (50%) dan jumlah bobot pada kasus seperti ini adalah selalu 100%.
NB : Bobot 50% bias juga ditampilkan dalam bentuk angka 0,5.
Rata-rata nilai dari Deddy, adalah :
Bobot (%) Nilai (angka) Bobot* Nilai
50% 70 35
30% 60 18
20% 90 18
TOTAL 71
Atau dengan rumus :
X =
( %∗ ) ( %∗ ) ( %∗ )( % % %)=
= 71
Dengan demikian, Nilai rata-rata Deddy adalah 71, yang tetap diukur dari skala 0 sampai 100. Dengan kata lain, tidak mungkin hasil rata-rata ada di bawah angka 0 atau di atas angka 100, jika pengukur awal adalah skor 0 sampai 100. Jika saja skor nilai diukur pada skala 1 sampai 10, maka nilai rata-rata tetap tidak mungkin ada di bawah 1 atau lebih dari 10.
MEAN DISTRIBUSI FREKUENSI
Mean Data Berkelompok (Grouped)
Untuk data berkelompok, atau data yang disajikan dalam suatu distribusi frekuensi, perhitungan hamper sama dengan perhitungan Rata-rata untuk frekuensi. Perbedaan hanya pada penetapan titik tengah kelas sebagai dasar pengambilan frekuensi.
Rumus :
=
∑∑ dimana :Contoh :
Data distribusi frekuensi berat badan remaja sebuah daerah :
Berat Badan (kg) Jumlah (frek/f) 35 – 39.9 6 40 – 44.9 15 45 – 49.9 40 50 – 54.9 38 55 – 59.9 24 Di atas 60 11 Keterangan :
Remaja dengan berat badan antara 35 kg sampai 39.9 kg sebanyak 6 orang. Kemudian remaja dengan berat badan antara 40 kg sampai 44.9 kg sebanyak 15 orang. Demikian seterusnya untuk data yang lain. Perhatikan bahwa batas atas dibuat dengan decimal 9 dengan asumsi bahwa pengukuran berat badan tidak melebihi dua decimal, seperti berat badab seorang remaja akan diukur sampai 37.5 dan tidak 37.55
kg. Dengan demikian, jika seorang remaja mempunyai berat badan lebih dari 39.9 kg, ia langsung dikategorikan mempunyai berat badan 40 kg.
Dengan demikian, contoh perhitungan titik tengah untuk kelas 30 – 39.9 adalah : (35+39.9)/2 = 37.45
Perhitungan rata-rata berat badan :
Berat Badan (kg) Titik Tenga( ) Jumlah ( )
.
35 – 39.9 37.45 6 224.70 40 – 44.9 42.45 15 636.75 45 – 49.9 47.45 40 1898.00 50 – 54.9 52.45 38 1993.10 55 – 59.9 57.45 24 1378.80 60 – 64.9 62.45 11 686.95 TOTAL 134 6818.30 Rata-rata :
=
.= 50.88
Catatan ; Penggunaan titik tengah sebagai alat hitung hitung rata-rata grouped data tentu bias mengakibatkan bias dalam perhitungan. Missal untuk interval berat badan 35-39,9 kilogram,diasumsi remaja pada kelas tersebut sebagian besar mempunyai berat badan 37,45 kilogram.ternyata sebagian besar jusru mempunyai berat badan 36 kilogram. Hal ini tentu mengakibatkan bias perhitungan rata-rata, jika hasil 50,88 kilogram dibandingkan dengan rata-rata hitung berat badan yang tidak dikelompokkan (lihat penjelasan rata-rata frekuensi).
Namun demikian, selisih perhitungan tersebut tidaklah berarti jika jumlah data banyak, seperti di atas 300 data, atau interval kelas relative kecil (missal 35-36.9 kg dan seterusnya).
Coding adalah penggunaan kode-kode (seperti 1, 2 dan seterusnya) sebagai pengganti titik tengah kelas, jika interval kelas adalah sama.
Rumus :
= A +
∑ ..
dimana :
A = kelas dengan kode 0 f.u = total frekuensi N = jumlah data C = interval kelas
Sebagai contoh, digunakan data distribusi frekuensi berat badan remaja seperti kasus sebelumnya.
Proses Pengkodean (coding) :
Cari kelas yang mempunyai frekuensi terbanyak, lalu beri kode 0. Pada kasus ini, karena frekuensi terbesar adalah 40 yang ada di kelas 45-49.5, maka kode 0 ada pada kelas tersebut.
Kemudian untuk kelas di atasnya diberi kode -1, -2 dan seterusnya, dan untuk kelas di bawahnya diberi kode +1, +2 dan seterusnya, sampai jumlah kode mencukupi. Hasil :
Berat Badan (kg) Titik Tengah ( ) KODE Jumlah (frek/f)
35 – 39.9 37.45 -2 6
40 – 44.9 42.45 -1 15
45 – 49.9 47.45 0 40
55 – 59.9 57.45 +2 24
60 – 64.9 62.45 +3 11
Proses perhitungan Mean :
Berat Badan (kg) Titik Tengah ( ) KODE Jumlah (frek/f) f.u 35 – 39.9 37.45 -2 6 -12 40 – 44.9 42.45 -1 15 -15 45 – 49.9 47.45 0 40 0 50 – 54.9 52.45 +1 38 38 55 – 59.9 57.45 +2 24 48 60 – 64.9 62.45 +3 11 33 TOTAL TOTAL 134 +92
Di sini A adalah kelas dimana terdapat kode 0, yakni 45-49.9. karena kelas tersebut mempunyai titik tengah 47.45, maka A adalah 47.45.
Dan c adalah interval kelas yang harus sama untuk setiap kelas yang ada, yakni 5 (bias didapat dari 39.9-35 atau 44.9-40 atau selisih kelas yang manapun dalam distribusi frekuensi tersebut).
Perhitungan Mean :
= 47.45 +
. 5 = 50.88
Perhatikan hasil perhitungan yang tepat sama dengan perhitungan Mean sebelumnya.
Karena sifatnya yang praktis, maka perhitungan Mean untuk distribusi frekuensi jika memungkinkan sebaiknya menggunakan cara penyandian (kode), karena baik dengan cara biasa maupun dengan cara koding, keduanya akan menghasilkan besaran Mean yang sama.
RATA-RATA GEOMETRIK
Konsep Rata-rata Geometrik
Rata-rata geometric biasanya digunakan untuk menghitung rata-rata laju kenaikan atau penurunan dari sekelompok data pada periode tertentu, yang mempunyai perubahan angka secara mencolok.
Contoh :
Tingkat penjualan televise P.T. SUKSES selama empat tahun terakhir adalah 1.000 unit, 5.000 unit, 9.000 unit dan 15.000 unit.
Jika ditanya berapakah rata-rata pertumbuhan penjualan TV, dan dihitung menggunakan rata-rata hitung (Mean), maka didapat :
= =
=
7500
Atau 7500 TV per tahun.
Jika rata-rata adalah 7500 TV per tahun, maka seharusnya dari 1000 TV, periode kedua akan terjual 1000+7500 = 8500 TV, periode ketiga akan terjual 8500+7500 = 16000 TV, dan periode keempat akan terjual 16000+7500 = 23500 TV. Kenyataan pergerakan penjualan sangat berbeda dengan angka-angka sebenarnya, seperti terlihat pada table berikut ini :
Tahun Data Asli Data Dengan Rata-rata
1 1000 1000
3 9000 16000
4 15000 23500
Unruk menghindari perbedaan tersebut, bias digunakan rata-rata geometric, yang mengubah perhitungan rata-rata dengan konsep deret hitung menjadi berdasar deret ukur.
Rata-rata Geometrik
Rumus :
= . …
dimana :
G adalah Rata-rata Geometrik N adalah jumlah data
Dari penjualan TV seperti contoh sebelumnya, jika digunakan rata-rata geometric akan didapat :
= √1000 5000 9000 15000 = 5097.13
Atau jika dibulatkan ke bawah rata-rata laju kenaikan penjualan TV adalah 5097 unit TV per tahun.
Dengan demikian, perbandingan kenaikan antara penggunaan rata-rata hitung dengan geometric :
TAHUN Data Asli Rata-rata Geometrik (factor 5097) Rata-rata Hitung (factor 7500) 1 1000 1000 1000 2 5000 1000+5097=6097 8500 3 9000 6097+5097=11194 16000 4 15000 11194+5097=16291 23500
Terlihat selisih antara rata-rata geometric dengan data asli lebih sedikit daripada selisih antara rata-rata hitung dengan data asli. Seperti pada akhir periode 4, data asli menyatakan penjualan TV adalah 15.000 unit. Dengan rata-rata Geometrik, diprediksi penjualan adalah 16.291 unit. Sedang dengan prediksi menggunakan rata-rata Hitung, hasil yang didapat jauh dari data asli, yakni 23.500 unit. Dengan demikian, jika akan dilakukan prediksi ke depan, maka untuk kasus seperti ini seharusnya digunakan rata-rata Geometrik agar hasil tidak terlalu bias.
Secara umum, Rata-rata Geometrik selalu menghasilkan angka yang lebih kecil dari rata-rata Hitung untuk data yang sama :
G <
Rata-rata Geometrik (cara lain)
Selain dengan rumus di atas, Rata-rata Geometrik bias dicari lewat perbandingan (rasio) di antara data awal dan akhir :
Rumus :
=
.
…
=
Di mana :
G adalah rata-rata Geometrik n adalah jumlah data
Dari penjualan TV seperti contoh sebelumnya, jika digunakan rata-rata Geometrik dengan rumus kedua di atas akan didapat :
=
..= 1,97.
Berarti rata-rata laju kenaikan penjualan TV secara rasio adalah 1,97 dari tahun ke tahun.
Dengan demikian, perbandingan kenaikan antara penggunaan rata-rata hitung dengan geometric : Rata-rata Geometrik (rasio 1,97) 1.000 x 1,97 = 1.970 1.970 x 1,97 = 3.880 3.880 x 1,97 = 7.643 7.643 x 1,97 = 15.057
MEDIAN
DEFINISI Median. Median segugus data yang telah diurutkan dari yang terkecil sampai
terbesar atau terbesar sampai terkecil adalah pengamatan yang tepat ditengah-tengah bila banyaknya pengamatan itu ganjil, atau rata-rata kedua pengamatan yang ditengah bila banyaknya pengamatan genap.
Contoh soal 3. Dari lima kali kuiz statistic seorang mahasiswa mendapat nilai 82,93,86,92 dan
79.tentukan median populasi nilai ini.
Jawab. Setelah data diurutkan dari terkecil sampai terbesar, kita peroleh
79 82 86 92 93 Oleh karena itu, didapat = 86.
Contoh soal . Kadar nikotin yang berasal dari sebuah sampel random enam batang rokok
cap tertentu adalah 2.3,2.7,2.5,2.9,3.1,dan 1.9 milligram.Tentukan mediannya.
Jawab. Bila kadar nikotin itu kita urutkan dari yang terkecil sampai terbesar maka kita
peroleh :
1.9 2.3 2.5 2.7 2.9 3.1
= . . = 2.6
Formula Median untuk Data berkelopok adalah :
Keterangan :
I = Lebar kelas
L = Tepi bawah kelas median
Fk = Jumlah frekuensi sebelum kelas median
Fmed = Jumlah frekuensi dimana kelas median ada
MODUS
DEFINISI Modus.
Modus segugus pengamatan adalah nilai yang terjadi paling sering atau yang mempunyai paling tinggi.Contoh soal 5. Nilai ujian semester dari beberapa mahasiswa matematika tercatat
sebagai berikut: 90,100,50,90,90,70,80,60,65 dan 75. Tentukan modusnya.
Jawab. Modusnya adalah nilai yang terjadi dengan frekuensi paling paling tinggi,
adalah : 90.
Formula Modus untuk data berkelompok Y
.
Keterangan :
MODUS = L +
L : Batas bawah kelas modus ada
d1 : Selisih frekuensi kelas modus dengan kelas sebelumnya. d2 : Selisih frekuensi kelas modus dengan kelas sesudahnya i : Lebar kelas
1.3.1 LATIHAN
1. Sebuah bioskop mencatat adanya penurunan jumlah penonton selama periode 1998-2001 :
TAHUN PENONTON(orang)
1998 5300
1999 5200
2000 4500
2001 4000
Dari data di atas :
a. Hitung rata-rata Geometrik dari penurunan penonton tersebut. Apa arti hasil rata-rata Geometrik tersebut?
b. Jika penurunan tersebut tetap berlangsung dengan tingkat yang sama, maka berapakah perkiraan penonton untuk tahun 2002?
2. IQ rata-rata sepuluh mahasiswa yang mengambil mata kuliah matematika adalah : 114. Bila Sembilan mahasiswa diantaranya memiliki IQ 101,125,118,128,106,115,99,118 dan 109, berapa IQ mahasiswa yang satu lagi?
3. Produktivitas 25 karyawan dari sebuah perusahaan konveksi adalah sebagai berikut : (potong pakaian per minggu)
25 31 37 42 19 20 24 23 30 26
21 22 34 30 32 29 33 31 34 40 21 28 32 33 40
Pertanyaan :
a. Buatlah distribusi frekuensi dari 25 data di atas, dengan interval kelas 5. b. Hitung rata-rata dari distribusi frekuensi di atas.
c. Hitung rata-rata TANPA MENNGUNAKAN distribusi frekuensi. d. Bandingkan dan analisis hasil b dan c.
4. Tentukan mean. Median dan modus dari data tinggi badan 50 mahasiswa berikut. Berat (X) kg Nilai tengah interval Frekuensi 50 - 52 53 – 55 56 – 58 59 – 61 62 - 64 51 54 57 60 63 5 17 14 10 4 50
5. Sebuah bank yang secara agresif berusaha menarik dana dari para nasabah, menawarkan suku bunga tabungan dalam lima bulan terakhir sebagai berikut : 5%, 9%, 15%, 20% dan 29%. Berapakah suku bungan tabungan rata-rata yang ditawarkan bank tersebut?
BAB IV
Terlepas dari ukuran gejala pusat dan ukuran letak, masih ada lagi ukuran lain ialah ukuran simpangan atau ukuran dispersi. Ukuran ini kadang-kadang dinamakan pula ukuran variasi, yang manggambarkan bagaimana berpencarnya data kuantitatif. Beberapa ukuran disperse yang dikenal dan akan diuraikan disini ialah : rentang, rentang antar kuartil, simpangan kuartil atau deviasi kuartil, rata-rata simpangan atau rata-rata deviasi, simpangan baku atau deviasi standar, varians dan koefisien variasi.
KOMPETENSI KHUSUS, Diharapkan pada akhir perkuliahan nanti, mahasiswa/I
dapat mengetahui dan memahami arti dan manfaat dari mengetahui dispersi sebuah data. Dan juga mengetahui teknik perhitungan disperse data.
1.2 PENYAJIAN
1. RENTANG, RENTANG ANTAR KUARTIL DAN SIMPANGAN KUARTIL
Ukuran variasi yang paling mudah ditentukan ialah rentang. Rumusnya : rentang = data terbesar – data terkecil
(R1)
Karena mudahnya dihitung, rentang ini banyak sekali digunakan dalam cabang lain dari statistika, iakah statistika industry.
Rentang antar kuartil juga mudah ditentukan, dan ini merupakan selisih antara dan . Jadi didapatlah hubungan :
RAK = −
(R2)
dengan RAK = rentang antar kuartil = kuartik ketiga
= kuartil pertama
Contoh : Daftar berikut menyatakan upah tiap jam untuk 65 pegawai di suatu
pabrik.
DAFTAR R1
50,00 - 59,99 8 60,00 - 69,99 10 70,00 - 79,99 16 80,00 - 89,99 14 90,00 - 99,99 10 100,00 - 109,99 5 1100,00 - 119,99 2 JUMLAH 65
Dengan menggunakan rumus di bawah , maka nilai-nilai dan dapat dihitung.
= +
dengan I = 1, 2, 3
Hasilnya : = . 68,25; = . 90,75.
RAK dihitung dengan menggunakan rumus R2, maka diperoleh : RAK = Rp. 22,50. Ditafsirkan bahwa 50% dari data, nilainya paling rendah 68,25 dan paling tinggi 90,75 dengan perbedaan paling tinggi 22,50.
Simpangan kuartil atau deviasi kuartil atau disebut pula rentang semi antar kuartil, harganya setengah dari rentang antar kuartil. Jadi jika simpangan kuartil disingkat dengan SK, maka :
= 1 2( − ) (R3)
= 1 2( .90,75 − .68,25) = .11,25
Selanjutnya, karena 1 2( − ) = Rp. 79,50, maka 50% dari pegawai mendapat upah terletak dalam interval . 79,50 ± . 11,25 atau antara Rp. 68,25 dan Rp.90,75.
2. RATA-RATA SIMPANGAN
Misalkan data hasil pengamatan berbentuk , … , dengan rata-rata ̅. Selanjutnya kita tentukan jarak antara tiap data dengan rata-rata ̅. Jarak ini, dalam symbol ditulis | − ̅|. Dengan | |. Berarti sama dengan a jika a positif, sama dengan –a jika a negative dan nol jika a = 0. Jadi harga mutlak, selalu memberikan tanda positif, karena inilah | − ̅| disebut jarak antara dengan ̅. Jika sekarang jarak-jarak :
| − ̅| , | − ̅|, . . . , | − ̅| dijumlahkan, lalu dibagi oleh n, maka diperoleh satuan yang disebut rata-rata simpangan atau rata-rata deviasi. Rumusnya adalah :
=∑| − ̅| (R4)
Dengan RS berarti = rata-rata simpangan.
Contoh : − | − | 8 -1 1 7 -2 2 10 1 1 11 2 2
Dari data di atas, jika dihitung, rata-ratanya = 9. Jumlah harga-harga mutlaknya,yaitu jumlah bilangan-bilangan dalam kolom akhir, adalah 6. Maka
= = 1 ½ .
3. SIMPANGAN BAKU
Barangkali ukuran simpangan yang paling banyak digunakan adalah simpangan baku atau deviasi standar.
Pangkat dua dari simpangan baku dinamakan varians. Untuk sampel, simpangan baku akan diberi symbol s, sedangkan untuk populasi diberi symbol . Variansnya tentulah s2 untuk varians sampel dan untuk varians populasi. Jelasnya, s dan s2
merupakan statistic sedangkan dan parameter.
Jika kita mempunyai sampel berukuran n dengan data-data , … , dan rata-rata ̅ , maka statistic s2dihitung dengan :
=∑( − )− 1 (R5)
Untuk mencari simpangan baku s, dari s2diambil harga akarnya yang positif.
Dari rumus R5, varians s2dihitung sebagai berikut : 1. Hitung rata-rata ̅
2. Tentukan − selisih, − ,…, −
3. Tentukan kuadrat selisih tersebut, yakni ( − )2, ( − )2, . . . , ( − )2
4. Kuadrat-kuadrat tersebut dijumlahkan 5. Jumlah tersebut dibagi oleh (n - 1)
Contoh : Diberikan sampel dengan data : 8, 7, 10, 11, 4. Untuk menentukan
simpangan baku s, kita buat table berikut.
− ( − )2
(1) (2) (3)
8 0 0
7 -1 1
11 3 9
4 -4 16
Rata-rata ̅ = 8. Dapat dilihat dari kolom 2 bahwa ∑( − ) = 0. Karena itulah disini diambil kuadratnya yang dituliskan dalam kolom 3. Didapat ∑( − ) = 30. Dengan menggunakan rumus R5, didapat :
s2= 30/4 = 7,5. Sehingga = 7,5 = 2,74.
Bentuk lain untuk rumus varians sampel ialah : = ∑ ( − 1)− (∑ )
(R6)
Dalam rumus di atas Nampak bahwa tidak perlu dihitung dulu rata-rata ̅, tetapi cukup menggunakan nilai data aslinya berupa jumlah nilai data dan jumlah kuadratnya. Jika digunakan untuk data di atas, maka dari table berikut ini, dihasilkan : 8 64 7 49 10 100 11 121 4 16 40 = ∑ 350 = ∑
∑ = 40 dan ∑ = 350. Dengan n = 5, dari rumus R6 didapat varians :
=
( )= 7,5
dan simpangan baku = 7,5 = 2,74. Sangat dianjurkan bahwa menghitung simpangan baku lebih baik menggunakan rumus R6 karena kekeliruannya lebih kecil.Jika data dari sampel tekah disusun dalam daftar distribusi frekuensi, maka untuk menentukan varians s2 dipakai rumus :
= ∑ − (( − 1)− ) (R7)
Atau yang lebih baik digunakan : = ∑ ( − 1)− (∑ )
(R8)
Rumus R7 menggunakan rata-rata ̅ sedangkan rumus R8 hanya menggunakan nilai tengah atau tanda kelas interval.
Contoh : Untuk menghitung varians s2dari data di bawah ini tentang nilai ujian
80 mahasiswa, digunakan rumus R7.
Nilai ujian 31 – 40 1 41 – 50 2 51 – 60 5 61 – 70 15 71 – 80 25 81 – 90 20 91 – 100 12 Jumlah 80
Jawab : lebih baik dibuat table berikut.
NILAI
UJIAN − ( − )
(1) (2) (3) (4) (5) (6) 31 – 40 1 35,5 -41,1 1689,21 1.689,21 41 – 50 2 45,5 -31,1 967,21 1.834,42 51 – 60 5 55,5 -21,1 445,21 2.226,05 61 – 70 15 65,5 -11,1 123,21 1.848,15 71 – 80 25 75,5 -1,1 1,21 30,25 81 – 90 20 85,5 8,9 79,21 1.584,20 91 – 100 12 95,5 18,9 357,21 4.286,52 Jumlah 80 - - - 13.498,80
Telah dihitung, dengan harga ̅ = 76,6.
Kolom 3 merupakan tanda kelas, kolm 4 adalah tiap tanda kelas dalam kolom 3 dikurangi 76,6 dan kolom 5 merupakan kuadrat bilangan-bilangan dalam kolom 4 sedangkan kolom akhir sama dengan hasil kali kolom 2 dengan kolom 5. Didapat harga-harga :
n = ∑ = 80 dan ∑ . . ( − )2 = 13.498,80. Sehingga dengan rumus R7
didapat varians :
=
. , = 170,9Simpangan baku = √170,9 = 13,07.
Untuk menggunakan rumus R8, menggunakan data yang sama, maka table yang perlu dibuat adalah seperti di bawah ini :
NILAI
UJIAN . .
(1) (2) (3) (4) (5) (6)
31 – 40 1 35,5 1260,25 35,5 1260,25 41 – 50 2 45,5 2070,25 91,0 4.140,50
51 – 60 5 55,5 3080,25 277,5 15.401,25 61 – 70 15 65,5 4290,25 982,5 64.353,75 71 – 80 25 75,5 5700,25 1887,5 142.506,25 81 – 90 20 85,5 7310,25 1710,0 146.205,00 91 – 100 12 95,5 9120,25 1146,0 109.443,00 Jumlah 80 - - 6130,0 483.310,00
Kolom 4 adalah kuadrat tanda-tanda kelas dalam kolom 3, kolom 5 merupakan hasil kali kolom 2 dan kolom 3 dan kolom akhir adalah produk antara kolom 2 dan kolom 4. Dari table didapat :
n = ∑ = 80, ∑ . = . ∑ . = . .
Sehingga dari rumus R8 diperoleh varians :
=80 483.310 − (6.130)80 79 = 172,1.
Hasilnya berbeda dengan hasil dari rumus R7, karena ̅ yang digunakan di rumus R7 telah dibulatkan hingga satu decimal, yang dengan sendirinya akan menyebabkan adanya perbedaan.
Cara singkat atau cara sandi, seperti ketika menghitung rata-rata ̅, dapat digunakan juga untuk menghitung varians sehingga perhitungan akan lebih sederhana. Rumusnya adalah :
= ∑ ( − 1)− (∑ )
(R9) P = panjang kelas interval
= nilai sandi dan = ∑
Contoh : Untuk data dalam table yang lalu, jika dipakai rumus R9 ini, maka
NILAI UJIAN . . 31 – 40 1 35,5 -4 16 -4 16 41 – 50 2 45,5 -3 9 -6 18 51 – 60 5 55,5 -2 4 -10 20 61 – 70 15 65,5 -1 1 -15 15 71 – 80 25 75,5 0 0 0 0 81 – 90 20 85,5 1 1 20 20 91 – 100 12 95,5 2 4 24 48 Jumlah 80 - - - 9 137
Dari tabel ini didapat P = 10, = ∑ = 80, ∑ . = dan ∑ . = , sehingga didapat varians :
= (10) 80 137 − (9)80 79 = 172,1.
Hasilnya sama dengan bila digunakan rumus R8. Ini memang demikian! Membandingkan rumus R8 dan R9, sebenarnya yang terakhir didapat dari yang pertama dengan menggunakan transformasi
=
berdasarkan dua sifat yaitu:1. Jika tiap nilai data ditambah atau dikurangi dengan bilangan yang sama, maka simpangan baku s tidak berubah.
2. Jika tiap nilai data dikalikan dengan bilangan yang sama d, maka simpangan bakunya menjadi d kali simpangan baku yang asal.
Contoh : Diberikan sampel dengan data : 9, 3, 8, 8, 9, 8, 9, 18. Setelah dihitung
maka s = 4,14.
a. Tambah tiap data dengan 6 atau berapa saja, maka untuk data baru s = 4,14.
b. Kurangi tiap data dengan 5 atau berapa saja, maka untuk data baru s = 4,14
c. Kalikan tiap data dengan 6, maka untuk data baru s = 24,84. d. Bagi tiap data dengan ½ , maka untuk data baru s = 8,28. Simpangan baku gabungan dihitung dengan rumus :
=∑(∑ −) (R10) Atau lengkapnya :
= ( − 1) + ( − 1) + + ( − 1)+ + + −
Dengan s2berarti varians gabungan untuk sampel yang berukuran n.
Contoh : Hasil pengamatan pertama terhadap 14 obyek memberikan s = 275
sedangkan pengamatan yang kedua kalinya terhadap 23 obyek menghasilkan s = 3,08. Maka, dengan rumus R10 untuk k = 2, didapat varians gabungan :
=
( )( , ) ( )( , )= 8,7718
. Sehingga simpangan baku gabungan s = 2,96.4. BILANGAN BAKU DAN KOEFISIEN VARIASI
Misalkan kita mempunyai sebuah sampel berukuran n dengan data , … , sedangkan rata-ratanya = ̅ dan simpangan baku s. dari sini kita dapat membentuk data baru , … , dengan rumus :
=
̅ untuk I = 1, 2, …, n (R11)Jadi diperoleh penyimpangan atau deviasi data dari rata-rata dinyatakan dalam satuan simpangan baku. Bilangan yang didapat dinamakan bilangan z. variable
, … , ternyata mempunyai rata-rata = 0 dan simpangan baku = 1.
Dalam penggunaannya, bilangan z ini sering diubah menjadi keadaan atau model baru, atau tepatnya distribusi baru, yang mempunyai rata-rata ̅ dan simpangan baku
yang ditentukan. Bilangan yang diperoleh dengan cara ini dinamakan bilangan baku atau bilangan standar dengan rata-rata ̅ dan simpangan baku dengan rumus :
= ̅ + − ̅
(R12)
Perhatikan bahwa untuk ̅ = 0 dan = 1, rumus R12 menjadi rumus R11, sehingga bilangan z sering pula diesbut bilangan standar. Bilangan baku sering dipakai untuk membandingkan keadaan distribusi fenomena.
Contoh : Seorang mahasiswa mendapat nilai 86 pada ujian akhir matematika dimana
rata-rata dan simpangan baku kelompok, masing-masing 78 dan 10. Pada ujian akhir statistika dimana rata-rata kelompok 84 dan simpangan baku 18, ia mandapat nilai 92. Dalam mata ujian mana ia mencapai kedudukan yang lebih baik?
Jawab : Dengan rumus R11 didapat bilangan baku :
Untuk matematika = = 0,8. Untuk statistika = = 0,44.
Mahasiswa itu mendapat 0,8 simpangan baku di atas rata-rata nilai matematika dan hanya 0,44 simpangan baku di atas rata-rata nilai statistika. Kedudukannya lebih timggi dalam hal matematika.
Kalau saja nilai-nilai di atas ke dalam bilangan angka baku dengan rata-rata 100 dan simpangan baku 20, maka :
Untuk matematika = 100 + 20( ) = 116. Untuk statistika = 100 + 20( ) = 108,9. Dalam system ini ia lebih unggul dala matematika.
Ukuran variasi atau disperse yang diuraikkan dalam bagian-bagian yang lalu merupakan disperse absolute. Variasi 5 cm untuk ukuran jarak 100 m dan variasi 5