BABUI
ANALISA BANGKITAN PERJALANAN
1. Pendahuluan
Secara umum analisa bangkitan peijalanan adalah suatu proses analisa yang dapat menjelaskan hubungan antara aktifitas suatu daerah dengan peijalanan pada daerah tersebut.
Bangkitan peijalanan (trip generation) memusatkan perhatian pada jumlah keseluruhan dari peijalanan. Bangkitan peijalanan dapat didefinisikan sebagai berikut:
“Jumlah perjalanari yang meninggalkan (produced) suatu daerah dengan tidak memperhatikan tujuannya dan jumlah peijalanan yang tertarik (attracted) ke suatu daerah dengan mengabaikan asal mula perjalanan tersebut.” (Wells, 1975, hal.84).
2. Klasifikasi Berdasarkan Maksud Perjalanan
Peijalanan biasanya berawal dari suatu titik asal (origin) menuju ke suatu titik tujuan (destination) dengan maksud tertentu. Oleh karena itu peijalanan dapat diklasifikasikan menurut maksud dari peijalanan yang dilakukan. Klasifikasi ini didasarkan pada dua bagian besar dari peijalanan berdasarkan asal dan tujuan dari peijalanan yang dimaksud.
Klasifikasi tersebut adalah:
a. Peijalanan Berbasis Rumah (home-based).
b. Peijalanan Berbasis bukan Rumah (non home-based).
Di dalam analisa sistem transportasi, peijalanan berbasis rumah diklasifikasikan lagi secara lebih mendetail. Hal ini disebabkan besamya persentase jumlah peijalanan berbasis rumah terhadap total jumlah peijalanan secara keseluruhan. Pembagian dari peijalanan yang berbasiskan rumah (home based) ini dapat dilihat pada bagian berikut ini, yaitu ;
a. Peijalanan antara rumah dengan tempat bekeija (home-based work, selanjutnya disebut sebagai HEW).
b. Peijalanan antara rumah dengan sekolah (home-based education/school trips, HBE).
c. Perjalanan antara rumah dengan tempat belanja (home-based shopping, HBS).
d. Peijalanan antara rumah dengan tempat rekreasi serta peijalanan yang bersifat sosial (home-based social or recreation, HBSr).
Pembagian ini dapat dikembangkan lagi sesuai dengan kebutuhan atau sesuai dengan karakteristik-karakteristik dari daerah studi yang sedang dianalisa.
Namun pada dasamya pembagian yang telah dilakukan merupakan pembagian yang paling sering digunakan dan paling sesuai dengan karakteristik kebanyakan daerah studi. Untuk lebih jelasnya dapat dilihat pada gambar 7 berikut ini.
G am bar 7 Klasifikasi peijalanan berdasarkan maksud dari peijalanan
3. Pengertian Produksi Perjalanan dan Tarikan Perjalanan
Jumlah bangkitan peijalanan pada suatu daerah dapat dibagi menjadi dua, yaitu jumlah peijalanan yang diproduksi oleh daerah tersebut (trip production) serta jumlah peijalanan yang tertarik ke daerah tersebut (trip attraction). Perbedaaan antara trip production dan trip attraction dengan asal perjalanan (origin) dan tujuan peijalanan (destination) akan dijelaskan pada contoh berikut ini.
Gambar 8 Dustrasi produksi peijalanan dan tarikan peijalanan serta asal peqalanan dan tujuan peijalanan
Contoh 1 :
Misalkan terdapat tiga lokasi (lihat gambar 8), yaitu rumah yang terdapat pada zona perumahan (residential zone, zone a) serta kantor yang terdapat pada zona bukan perumahan (non-residential, zone b) dan pasar swalayan yang juga terdapat pada zona bukan perumahan (non-residential, zone c).
- Peijalanan nomor 1 merupakan peijalanan dari zona a menuju zona b, dalam hal ini rumah merupakan asal peijalanan (origin, Oi) dan kantor merupakan tujuan (destination, Dj).
- Peijalanan nomor 2 merupakan peijalanan dari zona b menuju zona a, dalam hal ini kantor merupakan asal peijalanan dan rumah merupakan tujuan.
- Peijalanan nomor 3 merupakan perjalanan dari zona b menuju zona c, dalam hal ini kantor merupakan asal peijalanan dan pasar swalayan merupakan tujuan peijalanan.
- Perjalanan nomor 4 merupakan peijalanan dari zona c menuju zona a, dalam hal ini pasar swalayan merupakan asal peijalanan dan rumah merupakan tujuan perjalanan.
- Pada zona a terdapat dua tujuan peijalanan (dua buah Dj) serta satu asal peijalanan (satu buah Oj) tetapi pada zona a terdapat tiga produksi peijalanan (perjalanan nomor 1,2 dan 4).
- Pada zona b terdapat dua asal peijalanan (dua buah Oj) serta satu tujuan peijalanan (satu buah Dj) serta dua tarikan peijalanan (peijalanan nomor 1 dan 2) dan satu produksi peijalanan (peijalanan nomor 3).
- Pada zona c, terdapat satu asal peijalanan (satu buah Oi) dan satu tujuan peijalanan (satu buah Dj) serta satu produksi peijalanan (peijalanan nomor 4)
dan satu tarikan peijalanan (peijalanan nomor 3).
Berdasarkan ilustrasi di atas dapat disimpulkan pada peijalanan berbasis rumah (home-based), rumah selalu dianggap sebagai produksi peijalanan (trip production) dan tujuannya selalu dianggap sebagai tarikan peijalanan (trip attraction). Sedangkan pada peijalanan berbasis bukan rumah, asal peijalanan merupakan produksi peijalanan dan tujuan peijalanan merupakan tarikan perjalanan.
4. M etode-metode dalam Anaiisa Bangkitan Perjalanan
Dalam anaiisa bangkitan peijalanan, terdapat beberapa metode yang dapat digunakan untuk menganalisa perjalanan pada suatu daerah studi. Beberapa dari metode-metode tersebut yang akan dibahas adalah sebagai berikut;
a. Metode Expansion Factors.
b. Anaiisa Cross-Classification.
c. Anaiisa Regresi.
Semua metode ini memiliki cara-cara yang berbeda di dalam menganalisa bangkitan peijalanan pada daerah studi, namun demikian tujuannya sama yaitu untuk mengetahui karakteristik serta jumlah peijalanan. Selain metode-metode
tersebut, terdapat pula berbagai metode lainnya, namun demikian ketiga metode ini yang paling sering digunakan dalam analisa sistem perencanaan transportasi.
5. Metode Expansion Factors
Metode Expansion Factors berdasarkan rumus perbandingan. Metode ini biasanya digunakan untuk memprediksi keadaan di masa yang akan datang. Untuk lebih jelasnya dapat dilihat pada contoh berikut ini.
Contoh 2 :
Diketahui suatu daerah perumahan yang luasnya 200 ha, memproduksi peijalanan sebanyak 100.000 peijalanan.
Bila direncanakan daerah perumahan tersebut akan diperluas menjadi 600 ha, tentukanlah jumlah peijalanan yang dihasilkan oleh daerah tersebut.
Jumlah peijalanan berdasarkan metode expansion factor adalah sebagai berikut:
Expansion factor = 100.000 ; 200 = 500
Jadi jun-ilah perjalanan (untuk 500 ha) = (500)(600) = 300.000 perjalanan.
Metode ini dikenal juga dengan nama model Growth factor sebab untuk memprediksi keadaan di masa depan digunakan Growth factor.
Rumus dari model Growth factor ini adalah :
T,-F,t, (
3.
1)
di m an a;
J". = Jumlah perjalanan masa depan f. = Jumlah perjalanan saat ini
= Growth Factor
Fi merupakan faktor perbandingan antara keadaan saat ini dengan prediksi keadaaii di masa depan. Sebagai contoh, bila faktor-faktor yang mempengaruhi karakteristik peijalanan adalah jumlah kendaraan, konsumsi bahan bakar (liter/orang), jumlah pekeija, yang terdapat pada suatu zona, maka Fj akan berbentuk:
F,=
(3.2)di m an a:
C f = Jumlah kendaraan masa depan C". = Jumlah kendaraan saat ini
P f = Jumlah konsumsi bahan bakar masa depan P'. = Jumlah konsumsi bahan bakar saat ini
= Jumlah pekeija masa depan
= Jumlah pekeija saat ini
Contoh 3 :
Diketahui perjalanan saat ini pada suatu zona beijumlah = 50.000 peijalanan/hari.
Faktor-faktor yang mempengaruhi karakteristik dari peijalanan di zona tersebut adalah jumlah kendaraan, konsumsi bahan bakar (liter/orang) dan jumlah pekeija.
Data-data karakteristik saat ini (tahun 1996) serta prediksi data-data tersebut empat tahun kemudian (tahun 2000) telah diketahui. Tentukanlah prediksi jumlah peijalanan di tahun 2000 pada zona tersebut.
Tabel 2 Karakteristik peqalanan dari contoh nomor 3 Faktor Karakteristik Tahun 1996 Tahun 2000
Jumlah kendaraan (C) 25.000 37.500
Konsumsi Bahan Bakar (P) 185.000 268.250
Jumlah Pekeija (W) 89.000 142.400
Growth factor = (37.500 : 25.000), (268.250 :185.000), (142.400 : 89.000) - 1 .5 ,1 .4 5 ,1 .6
Growth factor keseluruhan adalah = (1.5)(1.45)(1.6) = 3.48 Prediksi jumlah peijalanan pada tahun 2000 = (3.48)(50.000)
= 174.000 perjalanan/hari.
Pada dasamya metode ini hanya digunakan untuk memprediksi peijalanan secara kasar, banyak faktor yang mempengaruhi peijalanan namun tidak dimasukkan ke dalam perhitungan berdasarkan analisa Expansion Factors ini.
Hasil yang didapat kurang teijamin keabsahannya, oleh karena itu metode ini jarang dipergunakan dalam analisa sistem transportasi secara menyeluruh.
6. Analisa Cross-classification
Metode ini dikenal juga dengan nama category analysis. Pada metode ini langkah pertama yang harus dilaksanakan adalah menentukan faktor-faktor yang akan dijadikan dasar dalam menghitung jumlah peijalanan, baik yang dihasilkan berdasarkan keluarga (disagregat) yang biasa juga disebut sebagai dwelling unit (d.u) yang merupakan satuan tempat tinggal, maupun berdasarkan zona (agregat).
Faktor-faktor yang mempengaruhi sistem transportasi merupakan faktor-faktor karakteristik dari sebuah rumah tangga atau sebuah zona.
Faktor-faktor tersebut antara lain adalah sebagai berikut:
1. Pendidikan 2. Penghasilan
3. Jumlah kendaraan bermotor
4. Jumlah pekeija 5. Jumlah pelajar 6. Jeniskelamin
7. Ukuran rumah tangga (jumlah anggota keluarga)
8. Serta karakteristik lainnya yang dianggap mempengaruhi peijalanan, tergantung dari keadaan geografis suatu daerah dan lain sebagainya.
6.1. Kelebihan dan Kekurangan dalam Proses Analisa dengan Menggunakan Metode Cross-classification
Analisa Cross-classification (atau analisa klasifikasi silang) ini memiliki beberapa kelebihan serta kekurangan, yang perlu diketahui sebelum mengambil keputusan untuk menggunakannya. Kelebihan serta kekurangannya antara lain akan diuraikan pada bagian berikut ini (Willumsen, 1990, h a l l 13).
6.1.1. Beberapa kelebihan dari metode analisa Cross-classification
1. Pengelompokan atau pembagian kelas-kelas klasifikasi dari analisa Cross-classification tidak tergantung pada pembagian zona-zona dalam daerah studi.
2. Asurnsi-asumsi dasar tidak diperlukan untuk membentuk hubungan dari setiap variabel.
3. Hubungan yang terdapat di antara kelas-kelas dalam Cross-classification tidak harus sama.
6.1.2. Beberapa kekurangan dari metode analisa Cross-classification
1. Tidak dapat dilakukan perhitungan atau prediksi terhadap keadaan yang berada di luar jangkauan dari klasifikasi, kecuali terhadap kelas-kelas dalam klasifikasi yang terbuka (sebagai contoh, rumah tangga dengan kepemilikan kendaraan bermotor beijumlah 5 buah atau lebih).
2. Tidak dapat dilakukan pengujian statistik (misalnya goodness-of-fit) terhadap model hasil analisa.
3. Terlalu banyak jumlah sampel yang dibutuhkan, sebab kalau jumlah sampel terlalu kecil maka setiap nilai dari bagian pada klasifikasi akan mempunyai tingkat keyakinan/kepercayaan yang berbeda disebabkan oleh perbedaan jumlah sampel untuk setiap kelas-kelas dalam klasifikasi.
4. Tidak adanya patokan serta cara yang efektif di dalam memilih jenis variabel-variabel untuk diklasifikasikan dan juga di dalam memilih pengklasiflkasian yang terbaik berdasarkan variabel-variabel yang tersedia.
5. Bila perlu dilakukan penambahan jenis variabel pada klasifikasi, rata-rata diperlukan peningkatan terhadap sampel dalam jumlah yang cukup besar.
6.2. Proses Analisa Cross-classification
Setelah semua faktor-faktor yang diperlukan telah ditentukan, dalam hal ini termasuk jenis variabel-variabel berdasarkan karakteristik, maka langkah berikutnya adalah mencari data dari faktor-faktor tersebut, yang bisa dilakukan dengan berbagai cara (lihat pada Bab II). Bila keseluruhan data telah didapat,
dilakukan proses klasifikasi untuk mencari rata-rata perjalanan (trip rate) yang teijadi.
Klasifikasi ini biasanya didasarkan pada hubungan antara salah satu karakteristik dengan karakteristik lainnya yang dianggap memegang peranan terhadap peijalanan pada suatu daerah studi. Sebagai contoh adalah jumlah anggota dalam sebuah keluarga dengan jumlah kendaraan bermotor yang terdapat pada setiap keluarga tersebut (tingkat kepemilikan kendaraan bermotor). Angka rata-rata peijalanan ini kelak akan digunakan untuk memperkirakan jumlah peijalanan di masa datang. Contoh berikut ini akan menunjukkan proses klasifikasi serta perhitungan peijalanan berdasarkan metode Cross-classification.
Contoh 4 :
Pada suatu daerah dilakukan 0-D (origin-destination) survei. Hasil dari survei tersebut dapat dilihat pada tabel 3. Buatlah analisa berdasarkan Cross
classification untuk mencari rata-rata peijalanan (trip rate) berdasarkan jumlah orang p€;r d.u dengan kepemilikan kendaraan bermotor.
Penyelesaian kasus di atas dilakukan dengan cara membuat tabel cross
classification. Di mana pada tabel terdapat jumlah orang/d.u serta jumlah kendaraan bermotor yang ditetapkan sebagai faktor-faktor karakteristik yang mempengaruhi rata-rata peijalanan di daerah studi. Untuk membantu penyelesaian kasus ini, dilakukan tabulasi dari keseluruhan data teriebih dahulu.
Dalam hal ini dapat digunakan berbagai program komputer yang tersedia atau dapat dilakukan dengan manual bila jumlah data tidak terlalu banyak
Setelah data disusun kembali seperti yang dapat dilihat pada tabel 4, maka dibuat tabel Cross-classification berdasarkan jumlah orang/d.u dan jimilah kendaraan/d.u (tabel 4). Kemudian dapat dihitung rata-rata peijalanan/d.u seperti yang dapat dilihat pada tabel 5.
Tabel 3 Karakteristik peijalanan contoh nomor 4
N o Jundah Jumlah Jumlah
Perialanan orang/d.u kendaraan/d.u
1 2 1 0
2 10 5 2
3 15 5 3
4 7 3 1
5 4 2 0
6 8 5 1
7 11 3 2
8 9 4 1
9 11 4 2
10 8 3 1
11 5 3 0
12 8 4 1
13 11 5 3
14 12 4 2
15 5 1 1
16 4 2 0
17 6 2 1
18 9 5 1
19 10 3 2
20 9 2 2
la b e l 4 Tabulasi data hasil survei
Jumlah orang/d.u Jumlah perjalanan Jumlah Kendaraan/d.u
1 2 0
1 5 1
2 4 0
2 4 0
2 6 1
2 9 2
3 5 0
3 7 1
3 8 1
3 11 2
3 10 2
4 9 L 1
4 8 1
4 11 2
4 12 2
5 8 1
5 9 1
5 10 2
5 15 3
5 11 3
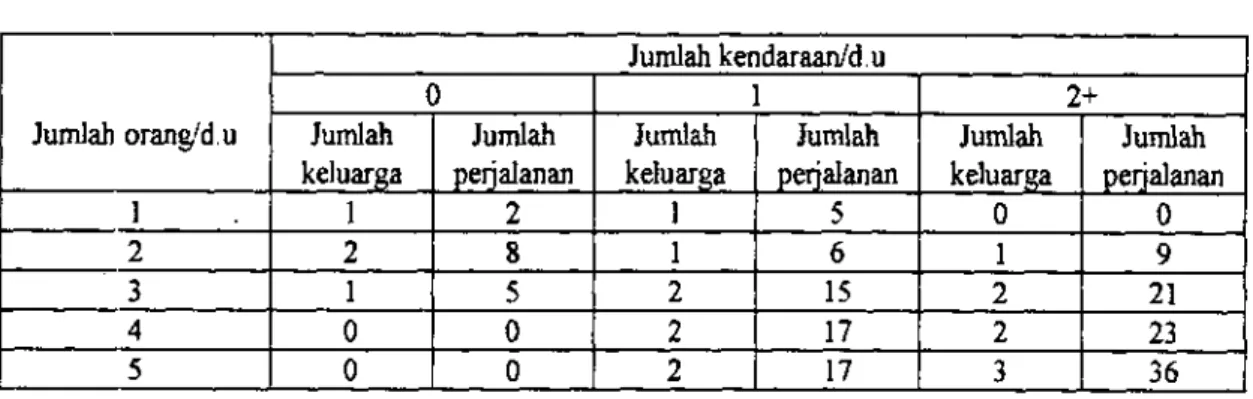
la b e l 5 Tabulasi berdasarkan cross-classification
Jumlah orang/d.u
Jumlah kendaraan/d.u
0 2+
Jumlah keluarga
Jumlah perjalanan
Jumlah keluarga
Jumlah perjalanan
Jumlah keluarga
Jumlah perjalanan
1 1 2 1 5 0 0
2 2 8 1 6 1 9
3 1 5 2 15 2 21
4 0 0 2 17 2 23
5 0 0 2 17 3 36
Rumus untuk menghitung rata-rata peijalanan adalah:
Jumlah perjalanan Rata-rata perjalanan per dwelling unit = --- —
Jumlah keluarga
Tabel 6 Rata-rata peijalanan berdasarkan cross-classification
Jumlah orang/d.u
Jumlah kendaraan/d.u
0 1 2+
Rata-rata perjalanan/d.u Rata-rata perjalanan/d.u Rata-rata perjalanan/d.u
1 2 5 0
2 4 6 9
3 5 7,5 10.5
4 0 8.5 11.5
5 0 8.5 12
Hasil dari analisa ini dapat digunakan untuk memprediksi jumlah peijalanan di masa depan dengan cara yang cukup sederhana. Yaitu dengan mengalikan angka rata-rata perjalanan dengan jumlah keluarga yang terdapat pada daerah studi di masa depan. Sebab angka yang di dapat adalah merupakan rata-rata peijalanan yang dilakukan oleh setiap satu dwelling unit (rumah tangga) pada daerah tersebut.
Analisa Cross-classification yang telah dilakukan berdasarkan dwelling unit, atau dengan kata lain berdasarkan metode disagregasi. Analisa
Cross-classification dapat pula dilakukan berdasarkan metode agregasi yang berdasarkan zona dan bukan berdasarkan individu/nimah tangga).
6.3. Produksi Perjalanan dan Tarikan Perjalanan pada Metode Cross-clasiflcation
Hutchinson (1974, hal. 48) memberikan penimusan untuk mengestimasi trip production (produksi peijalanan) pada daerah studi berdasarkan zona dengan menggunakan data disagregasi. Untuk trip production, rumus tersebut adalah:
P ' = I , h ( c ) t p (c) (3.3)
di m a n a ;
q
p , =-■ Jumlah trip production pada zona i yang dihasilkan oleh orang bertipe q
h i (c) = Jumlah rumah tangga pada zona i yang berkategori c
t p (c) = Rata-rata produksi peijalanan (trip production rate) dari rumah tangga yang berkategori c
Untuk estimasi dari trip attraction (tarikan peijalanan) berdasarkan zona, contoh yang dit)erikan merupakan rumus untuk perhitungan work trips (peijalanan dengan tujuan bekeija/pergi ke kantor) yang tertarik ke suatu zona.
Untuk jenis peijalanan yang lain, perubahan yang teijadi pada rumus tersebut hanya pada parameter serta variabelnya, yang mana parameter serta variabel ini ditentukan oleh jenis peijalanan apa yang hendak untuk dianalisa.
Rumus untuk jenis peijalanan dengan tujuan bekeija atau work trips ini adalah :
a j = H b j ( c ) t a (c) (3.4) di m a n a ;
a , b j ( 0 )
t o ( c )
Jumlah trip production pada zona i yang dihasilkan oleh orang bertipe q
Jumlah rumah tangga pada zona i yang berkategori c
Rata-rata produksi peijalanan (trip production rate) dari rumah tangga yang berkategori c
Contoh 5 :
Berdasarkan hasil perhitungan contoh 4, hitunglah trip production yang dihasilkan pada daerah studi yang dibagi atas 3 zona. Data-data dari setiap zona tersebut (dalam hal ini jumlah penduduk/zona) dapat dilihat pada tabel 7.
Table 7 Jumlah dari dwelling unit pada setiap zona berdasarkan jumlah orang/d.u dan jumlah kendaraan/d.u
Jumlah orang/d.u Jumlah kendaraan/d.u Jumlah rumah tangga dalam setiap zona
1 2 3
1
0 200 0 0
1 0 0 150
2+ 0 0 0
2
0 250 0 0
1 300 225 0
2+ 100 0 0
3
0 200 0 0
1 0 400 0
2+ 0 0 200
4
0 0 0 0
1 50 200 0
2+ 50 0 100
5
0 0 0 0
1 0 100 0
2+ 0 0 325
Untuk menyelesaikan kasus ini, hasil perhitungan rata-rata peijalanan pada tabel 6 dimasukkan ke dalam rumus (3.3), maka akan diperoleh trip production dari setiap zona berdasarkan klasifikasi jumlah orang/d.u dan jumlah kendaraan/d.u.
Hasil perhitungan tersebut dapat dilihat pada tabel 8.
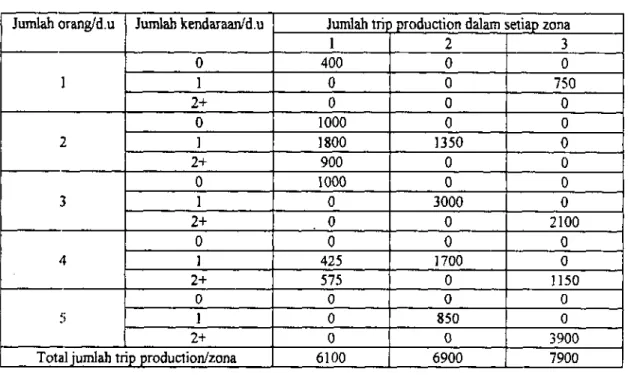
Table 8 Hasil perhitungan contoh 5
Jumlah orang/d.u Jumlah kendaraan/d.u Jumlah trip production dalam setiap zona
2+
400 0 0
750
2+
1000
1800 900
1350
2+
1000
3000
2100
2+
425 575
1700
1150
2+
850
3900
Total jumlah trip production/zona 6100 6900 7900
Total jumlah trip production untuk semua kategori karakteristik dari setiap zona 1. zona 1 = 6100 peijalanan/zona.
2. zona 2 = 6900 peijalanan/zona.
3. zona 3 = 7900 peijalanan/zona.
6.4. Multiple Classification Analysis (MCA), Pengembangan dari Model Dasar Cross-classification
Multiple Classification Analysis atau biasa disebut sebagai MCA, merupakan metode altematif yang bertujuan untuk mendapatkan hasil analisa Cross-classification di mana variabel-variabel serta pembagian kelasnya diuji dengan metode statistik. Seperti yang telah diketahui, metode cross-classification ini memiliki kelemahan, antara lain yaitu tidak dapat dilakukan pengujian statistik terhadap hasilnya. Oleh karena itu dikembangkan suatu metode yang mampu menutupi kekurangan tersebut, yaitu antara lain dengan menggunakan
Multiple Classification Analysis. Metode ini tidak dibahas secara mendetail, namun demikian akan diberikan sedikit gambaran mengenainya. Gambaran ini bertujuan agar diketahui bahwa pada dasamya metode-metode yang biasanya digunakan dapat dikembangkan, sesuai dengan kebutuhan serta tujuan dari pemakaian metode tersebut.
Misalkan sebuah model transportasi memiliki sebuah variabel tak bebas serta dua buah variabel bebas. Variabel tak bebasnya adalah rata-rata peijalanan sedangkan variabel bebasnya adalah jumlah anggota dalam suatu keluarga/rumah tangga serta jumlah kendaraan bermotor yang dimilikinya. Rata-rata keseluruhan dari angka rata-rata perjalanan (variabel tak bebas) dapat dihitung. Selain itu rata- rata pada setiap kelas yang terdapat dalam tabel Cross-classification, juga dapat dihitung. Nilai pada setiap kelas tersebut dapat diekspresikan sebagai deviasi terhadap rata-rata keseluruhan. Berikut ini sebuah contoh yang diambil dari Willumsen, 1990, hal. 115.
Contoh 6 :
la b e l 9 Data-data pada contoh 6
Jumlah anggota keluarga memiliki 0 mobU
memiliki 1 mobil
memiliki V r mobil
Total Rata-rata dari rata-rata perjalanan
1 28 21 0 49 0.47
2 atau 3 150 201 93 444 1.28
4 61 90 75 226 1.86
5+ 37 142 90 269 1.90
Total 276 454 258 988
Rata-rata dari rata-rata
peijalanan 0.73 1.53 2.44 1.54
Pada tabel 9, dapat dilihat data-data yang telah dikumpulkan dan dikelompokkan berdasarkan tiga kategori kepemilikan kendaraan bermotor (mobil) serta empat kategori berdasarkan jumlah anggota keluarga. Pada tabel juga terdapat jumlah keluarga yang disurvei untuk setiap kategorinya dan rata-rata peijalanan yang dihitung berdasarkan baris dan kolom serta rata-rata peijalanan secara keseluruhan.
Perhitungan deviasi dari setiap kelas dalam kategori adalah sebagai berikut, untuk keluarga yang tidak memiliki mobil (memiliki 0 m obil):
deviasi = 0.73 - 1.54 = -0.81, dan seterusnya. Dengan cara demikian akan didapatkan deviasi:
memiliki memiliki memiliki 0 mobil 1 mobil 2+ mobil
deviasi -0.81 -0.01 0.90
Perhitungan deviasi terhadap jumlah anggota keluarga yaitu sebagai berikut, untuk keluarga dengan jumlah anggota keluarga = 1 ;
deviasi = 0.47 - 1.54 = -1.07, dan seterusnya. Sehingga untuk keseluruhan didapat:
Jumlah anggota Jumlah anggota Jumlah anggota Jumlah anggota keluarga = 1 keluarga = 2 atau 3 keluarga = 4 keluarga = 5
deviasi -1.07 -0.26 0.32 0.36
Berdasarkan perhitungan di atas, dapat dicari rata-rata peijalanan dari setiap kategorinya. Sebagai contoh, rata-rata peijalanan untuk keluarga dengan jumlah anggota keluarga = 1 serta memiliki sebuah mobil adalah = 1.54 + (-1.07) + (-0.01), yaitu = 0.46 peijalanan. Secara keseluruhan hasilnya dapat dilihat pada tabel 10 berikut ini.
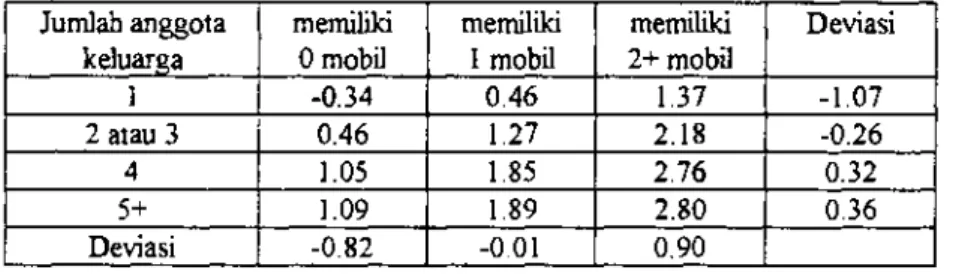
Tabel 10 Rata-rata peijalanan berdasarkan metode MCA
Jumlah anggota keluarga
memiliki 0 mobil
memiliki 1 mobil
memiliki 2+ mobil
Deviasi
1 -0.34 0.46 1.37 -1.07
2 atau 3 0.46 1.27 2.18 -0.26
4 1.05 1.85 2.76 0.32
5+ 1.09 1.89 2.80 0.36
Deviasi -0.82 -0.01 0,90
Untuk angka rata-rata peijalanan yang bertanda negatif pada tabel (misalnya -0.34), dianggap tidak mempunyai arti atau sama dengan nol.
10
Di dalam perbandingannya dengan model-model standar dari Cross-classification, deviasi tidak hanya dihitung terhadap keluarga, misalnya pada kategori jumlah anggota keluarga = 1 dan memiliki 1 mobil, deviasi dari jumlah mobil juga dihitung terhadap besamya keluarga dan sebaliknya. Jadi bila interaksi dari deviasi ini ditampilkan dapat digunakan untuk mengetahui akibat- akibat dari interaksi secara keseluruhan tersebut. Analisa statistik goodness o f fit yang biasanya dilakukan terhadap metode MCA ini adalah :
1. Koefisien Korelasi (r).
2. Koefisien Determinasi (r^).
3. Uji keberartian koefisien korelasi (F).
Hal yang perlu dicatat di dalam metode MCA ini adalah nilai-nilai yang terdapat pada setiap kelas-kelas di dalam klasifikasi, tidak lagi berdasarkan pada jumlah data yang didapat pada kelas-kelas dalam klasifikasi yang bersangkutan.
Melainkan berdasarkan nilai dari rata-rata secara keseluruhan. Oleh karena itu, beberapa permasalahan yang muncul akibat jumlah data yang terlalu sedikit pada beberapa kelas dalam klasifikasi dapat dikompensasikan.
7. Analisa Regresi
Analisa regresi merupakan salah satu metode dalam menganalisa bangkitan peijalanan. Regresi itu sendiri adalah suatu teknik yang dapat mendeskripsikan antara variabel yang tidak bebas (dependent) dengan variabel yang bebas (independent).
Bentuk umum dari regresi adalah sebagai berikut.
V = / ( X ^ X > - ) (3.5)
Selain itu, regresi dapat berbentuk regresi linier, regresi non linier, dengan satu atau banyak variabel.
Berdasarkan sejumlah penelitian dapat dibentuk suatu persamaan regresi linier yang dapat menyatakan hubungan antara variabel X dan variabel Y.
Rumus umum dari hubungan antara kedua variabel ini adalah:
^est.i Cl b2-^2~^ ••• (3-6)
7.1. Asumsi-asumsi pada Analisa Regresi
Sebelum membahas lebih lanjut, perlu untuk diketahui terlebih dahulu beberapa asumsi yang digunakan dalam analisa regresi linier ini.
Asumsi-asumsi tersebut adalah:
1. Varians dari nilai variabel Y pada garis regresi harus konstan terhadap semua ukuran dari variabel independent (X).
2. Deviasi dari nilai Y pada garis regresi harus bebas satu sama laiimya dan terdislxibusi secara normal.
3. Nilai dari variabel X diukur dengan mengabaikan tingkat kesalahan.
4. Hubimgan antara variabel dependent dengan variabel independent harus linier.
7.2. Persyaratan terhadap Variabel Bebas (X)
Dalam menentukan variabel independent (X) dalam persamaan regresi hams memenuhi syarat-syarat berikut ini:
1. Hams berhubungan secara linier dengan variabel dependent (Y).
2. Hams memiliki korelasi yang kuat dengan variabel dependent.
3. Tidak boleh memiliki korelasi yang kuat antara sesama variabel independent.
4. Hams mudah untuk diproyeksikan secara relatif.
7.3. Teori Dasar dari Analisa Regresi
Untuk menentukan nilai dari parameter-parameter pada rumus (3.6), yaitu nilai a dan b, salah satu cara adalah dengan menggunakan metode least square, yaitu dengan meminimalkan nilai kesalahan atau biasa dikenal dengan istilah error (s).
Hal ini dilakukan dengan melakukan penurunan terhadap nilai dari F = Zs^, yang dilakukan dengan c a ra :
S p 5 P
= 0 dan = 0 (3.7)
S a ^ 0 ,
Bila hasil perhitungan dari kedua penurunan ini dieliminasi, misalkan untuk i = 1 akan didapat persamaan sebagai berikut.
( Z r ) ( z r ) - ( E x X S ^ )
n Z x ^ - ( Z z r
n Z x ' - t Z X t
7.4. Uji Statistik pada Analisa Regresi
Di dalam melakukan uji statistik pada analisa regresi, terdapat beberapa jenis pengujian yang dapat dilakukan. Dalam hal ini yang akan dilakukan adalah empat jenis pengujian terhadap persamaan regresi, yaitu sebagai berikut.
1. Koefisien Korelasi (r) dan Koefisien Determinasi (r^).
2. Uji keberartian koefisien korelasi (F).
3. Standard Error of Estimate (Se).
4. Tes Hipotesa(/test).
7.4.1. Koefisien Korelasi (r) dan Koefisien Determinasi (r^) a. Koefisien Korelasi (r)
Koefisien ini bemilai antara -1 sampai +1, yang dipakai untuk menyatakan tingkat korelasi antara variabel dependent Y dengan variabel independent X.
Sebagai contoh, misalkan r bemilai = +1 maka artinya teijadi korelasi yang kuat dan searah antara kedua variabel, artinya kenaikan maupun penurunan nilai X bersama-sama dengan kenaikan maupun penurunan nilai Y. Sebaliknya bila r bemilai = -1 maka berarti teijadi korelasi yang kuat dan berlawan arah, kenaikan pada nilai-nilai X bersama-sama dengan penumnan nilai Y dan sebaliknya.
Tetapi bila nilai r = 0, berarti tidak ada korelasi sama sekali, jadi nilai r yang
mendekati 0 menandakan makin lemah korelasi yang teijadi. Untuk lebih jelasnya lagi dapat dilihat pada contoh berikut ini.
Contoh 7 :
Misalkan hasil suatu hasil siuvei terhadap tiga buah kondisi tertentu, adalah seperti yang terdapat pada label 11. Berdasarkan pasangan X dan Y pada setiap kondisi ini, akan dapat dilihat apa yang dimaksud dengan nilai r = 1, r = -1 dan r
= 0 terhadap korelasi antara X dan Y (lihat gambar 9).
la b e l 11 Contoh kasus nomor 7
Nomor Konc isi A Konc isi B Konclisi C
X Y X Y X Y
1 10 10 10 1 10 9
2 9 9 9 2 9 4
3 S 8 8 3 8 3
4 7 7 7 4 7 1
5 6 6 6 5 6 10
6 5 5 5 6 5 2
7 4 4 4 7 4 7
8 3 3 3 8 3 8
9 2 2 2 9 2 6
]0 1 1 ] 10 1 5
Koefisien korelasi
r = +1 ( kuat dan searah)
r = '1
(kuat dan berlawanan arah)
r = 0 (tidak ada korelasi)
r = + l r=-l
Gam bar 9 Gambaran meneenai koefisien korelasi
Terdapat beberapa perumusan yang dapat dipergunakan untuk menghitung nilai dari r. Namun demikian nilai r biasanya dihitung berdasarkan perumusan yang dikenal dengan nama Product Moment Co-efficient of Correlation (Dajan, 1986, hal. 376). Perumusan ini memiliki kelebihan yaitu dalam kesederhanaan bentuk perumusan serta bentuk perhitungan yang hams dilakukan. Selain itu perumusan ini memiliki tingkat ketelitian yang cukup baik dan dapat dipercaya hasilnya.
Salah satu bentuk perumusan untuk menghitimg koefisien korelasi adalah sebagai berikut;
/ - = — (3.10)
S x S r
di m a n a :
5,^ - 1 (X. - ^ (Y .-Y ) = N SYX - (lY )d X ) 5^. =■- [ I (X. - = [N IX ^ - (IX)^]'^- 5 , = [ I ( Y i - Y ) '] ’''= [ N I X '- ( I X ) 'j '^
N = Jumlah sample
Hubungan korelasi antara variabel dependent dengan independent hams kuat. Namun demikian di antara variabel-variabel independent (Xi) sendiri tidak boleh terdapat korelasi yang kuat, sebab akan sulit untuk menguji pengaruh salah satu dari variabel independent terhadap variabel dependent (Y). Korelasi yang kuat antara sesama variabel independent akan menyebabkan ketergantungan antara variabel-variabel tersebut, sehingga bila salah satu variabel independent diubah akan mempengamhi variabel independent lainnya.
Untuk menghitung nilai korelasi (r) antara sesama variabel independent bisa berdasarkan rumus yang sama untuk menghitung korelasi antara variabel X dan Y. Dengan melakukan sedikit modifikasi berdasarkan kebutuhan, namun pada dasamya tetap menggunakan asumsi dan dasar teori yang sama. Misalkan variabel independent tersebut adalah Xp dan Xq, maka rumus untuk menghitung nilai korelasi antara Xp dan adalah seperti berikut ini.
SxpXq r
=
SxpSxq
di m an a:
SxpXq
Sxp
Sxq
- 1 (Xpi - Xp) (X^ - X ,) = N SXpX, - (SXpXSX,)
== p (Xpi - X p f ] = [N ZXp' - (Z X ,)']
» [2 ( X j - X , ) V “ = [N - ( X X ,^ ] N = Jumlah sample
2 i 1/2
(3.11)
Interpretasi dari nilai r terhadap deskripsi secara verbal (nilai kekuatan dari koefisien korelasi) dapat dilihat pada tabel 12.
Tabel 12 Nilai r beserta deskripsinya
NL ai dari r Deskripsi
0.00 - ± 0 .2 tidak ada korelasi atau korelasinya dapat diabaikan
± 0 .2 - ± 0 .4 terdapat korelasi namun kecil artinya/pengaruhnya
± 0 .4 - ± 0 .7 berkorelasi cukup kuat atau cukup jelas hubungannya
± 0 .7 ± 1.0 berkorelasi kuat sampai sangat kuat (sangat kuat bila r = ± 1) Sumber ; Aggarwal, 1986, hal.155.
Untuk menguji koefisien korelasi dalam regresi linier, hams dilakukan terhadap semua variabel dependent dan independent. Hal ini diperlukan untuk mengetahui seberapa besar pengaruh dari setiap variabel independent terhadap variabel dependent, baik secara bersama-sama maupun pengaruhnya masing-masing.
Untuk lebih jelasnya akan diuraikan pada contoh berikut ini.
Contoh 8:
Diketahui data hasil survei sepeiti yang terdapat pada tabel 13. Hubungan antara variabel Y dengan Xj dan X2 adalah linier.
Tabel 13 Data contoh nomor 8
Y 64 71 53 67 55 58 77 57 56 51 76 68
X, , 57 59 49 62 51 50 55 48 52 42 61 57
X2 8 10 6 n 8 7 10 9 10 6 12 9
Untuk menyelesaikan contoh nomor 8, langkah awal yang harus dilakukan adalah mencari bentuk dari persamaan regresi berdasarkan data-data yang tersedia, setelah itu baru bisa ^lakukan pengujian statistik terhadap persamaan regresi yang bersangkutan.
Bentuk umum dari persamaan regresi berdasarkan data-data pada tabel 13 dapat diekspresikan dalam model matematika seperti yang dapat dilihat pada persamaan berikut:
Y = a + biXi +bjX2
Untuk persamaan regresi di atas akan didapat tiga buah persamaan yang harus diselesaikan. Berdasarkan rumus (3.7) akan didapat ketiga persamaan tersebut sebagai berikut;
1. S Y = a N + b i I X , + b 2 l X 2
2. lY X ] = a 2X1 + b, SXi^ + bj IX ,X2 3. IY X2 - a 1X2 + b] IX ]X2 + b2 1 X2^
Untuk mempermudah perhitungan, dibuat sebuah tabel yang memuat dasar-dasar perhitungan dari perumusan yang ada.
64 71 53 67 55 58 77 57 56 51 76 68 1=753
Xi
57 59 49 62 51 50 55 48 52 42 61 57 1=643
10
11
10
10
12
S=106
4096 5041 2809 4489 3025 3364 5929 3249 3136 2601 5776 4624 Z=4S139
3249 3481 2401 3844 2601 2500 3025 2304 2704 1764 3721 3249 1=34843
64 100
36 121 64 49 100
81 100
36 144
81 Z=976
YXi
3648 4189 2597 4154 2805 2900 4235 2736 2912 2142 4636 3876 Z=40830
512 710 318 737 440 406 770 513 560 306 912 612 1=6796
590 294 682 408 350 550 432 520 252 732 513 S=5779
Berdasarkan perhitimgan di atas, maka akan dihasilkan persamaan-persamaan 1. 12a + 643bi +106b2 =753
2. 643 a + 34843 bi + 5779 bj = 40830 3. 106a + 5779bi + 976b2 =6796
Setelah dieliminasikan akan didapat nilai-nilai sebagai berikut:
a = 3.6512, bi = 0.8546, bj = 1.5063 Jadi persamaan regresi linier-nya adalah :
Y = 3 .6 5 1 2 + 0.8546 Xj + 1.5063 X2
Selanjutnya vintuk menghinmg nilai dari r adalah sebagai berikut.
Nilai r yang dicari adalah sebagai berikut.
1. Ti2 = korelasi antara Y dengan X i , dengan mengabaikan variabel X2. 2. ri3 = korelasi antara Y dengan X2 , dengan mengabaikan variabel Xi.
3. r23 = korelasi antara Xi dengan X2, dengan mengabaikan variabel Y.
Berdasarkan rumus (3.13) didapat:
Sy = [12(48139)-(753)-] = V (10659)
Sx, = [12(34843) - (643)^ ] = V(4667)
Sx. = [12(976) - (106)^ ] = V(476)
S)X, = 12 (40830)-(753)(643) = 5781
S)x, = 12(6796)-(753)(106) = 1734 5avv,= 12(5779)-(643)(106) = 1190
Ja d i:
r, 2 = 5781 / V(10659x4667) = 0.8196 = 0.82 r, 3 = 1734 / V(10659x476) = 0.7698 = 0.77 f23 = 1190 / V(4667x476) = 0.7984 = 0.80 Kesimpulan:
1. Korelasi antara Y dan Xi adalah kuat.
2. Korelasi antara Y dan X2 adalah kuat.
3. Korelasi antara Xj dan X2 adalah kuat.
Berdasarkan kesimpulan tersebut, maka persamaan regresi untuk contoh 7 m enjadi:
1. Y = a + b X i 2. Y = a + bX2
3. Untuk Y = a + biX] + b2X2 , tidak dapat digunakan sebab korelasi antara kedua variabel independent (X] dan X2) temyata kuat.
Langkah selanjutnya adalah mencari koefisien-koefisien dari persamaan regresi yang bam. Caranya sama dengan yang telah dikeijakan untuk mencari koefisien- koefisien dari persamaan regresi yang pertama. Hasil yang didapat dari perhitungan tersebut adalah:
1. Untuk Y = a + b Xi, menjadi Y = - 3.624 + 1.239 Xi, dengan r = 0.82 2. Untuk Y = a + b X,, menjadi Y = 30.571 + 3.643 X,, dengan r = 0.77
Demikianlah contoh perhitungan dari persamaan regresi linier serta perhitungan koefisien korelasi-nya.
b. Koefisien Determinasi (r^)
Koefisien determinasi ? adalah suatu koefisien (bemilai antara 0 - 1 ) yang menyatakan tingkat hubungan antara hasil penelitian dengan garis regresi untuk semua nilai variabel independent X. Makin besar nilai dari r^ berarti makin tepat suatu garis regresi linier digunakan sebagi pendekatan. Dengan kata lain nilai dari koefisien determinasi merupakan gambaran persentase kontribusi dari variasi variabel independent terhadap variasi variabel dependent. Sebagai hasil analisa
dari suatu penelitian, persamaan garis regresi selalu disertai dengan nilai sebagai ukuran kecocokan (goodness of fit).
Contoh 9 :
Berdasarkan contoh kasus nomor 8, nilai dari koefisien determinasi dari persamaan regresi adalah sebagai berikut.
1. Untuk Y = - 3.624 + 1.239 Xi, dengan r = 0.82 maka P = 0.6724 yang artinya kontribusi dari variasi X] terhadap variasi Y adalah sebesar 67 %.
2. Untuk Y = 30.571 + 3.643 X2, dengan r = 0.77 maka = 0.5929 yang artinya kontribusi dari variasi X2 terhadap variasi Y adalah sebesar 59 %.
7.4.2. UJi K eberartian Koefisien Korelasi (F)
Pengujian akan keberartian suatu koefisien korelasi dapat dilakukan dengan berbagai cara berdasarkan analisa statistik. Di sini digunakan analisa statistik distribusi F dengan pertimbangan analisa tersebut sering digunakan dan memiliki deviasi yang minimum. Selain itu analisa distribusi F dapat dilakukan dengan bantuan program komputer yang telah banyak tersedia sehingga memudahkan perhitungan. Rumus dari distribusi F ini adalah ;
2
IL
di m a n a :
r^ = Koefisien determinasi k = Jumlah variabel independent n = Jumlah sample
Harga dari F yang diperoleh berdasarkan perhitimgan dengan menggunakan rumus (3.15) dibandingkan dengan harga yang terdapat pada tabel distribusi F dengan dk pembilang = k, serta dk penyebut = (n-k-1). Bila harga F hasil perhitungan temyata lebih besar dari harga yang terdapat pada tabel distribusi F, maka koefisien korelasi yang diuji dinyatakan cukup berarti dan dapat dipakai imtuk mengambil kesimpulan.
Contoh 10;
Berdasarkan contoh nomor 8 dan 9, pengujian terhadap koefisien korelasi-nya adalah sebagai berikut.
1. Untuk Y = - 3.624 + 1.239 Xj, dengan r = 0.82 dan r^ = 0.6724 maka nilai F adalah;
n = 1 2 k = l n-k-1 = 10
F = (0,6724/1) / [(l-0,6724)/10] - 20.525
Harga F yang terdapat pada tabel distribusi F dengan dk pembilang == 1 serta dk penyebut = 10 dan a = 0.01 adalah sebesar 10.04. Karena 20.525 > 10.04, maka koefisien korelasi untuk persamaan regresi dapat digunakan untuk mengambil kesimpulan (seperti yang telah dilakukan pada contoh 7 & 8).
2. Untuk Y = 30.571 + 3.643 X2, dengan r = 0.77 dan r^ = 0.5929 maka nilai F adalali:
n = 1 2 k = 1 n-k-1 = 10
F = (0.5929/1) / [(l-0.5929)/10] = 14.56
Temyata harga F ini lebih besar dari harga F pada tabel yaitu 10.04. Oleh karena itu sama dengan di atas, yaitu koefisien korelasi untuk persamaan regresi ini dapat digunakan untuk mengambil kesimpulan.
Pengertian dari nilai a = 0.01 dan a = 0.05 yang terdapat pada tabel distribusi F dapat dijelaskan pada tabel 14 berikut ini.
la b e l 14 Definisi dari tingkat kepercayaan ( a )
a Persentase tingkat kepercayaan
Definisi
0.01 99% Bila suatu percobaan diulang sebanyak 100 kali, maka hanya terdapat 1 kali kejadian dimana nilai rata-ratanya jatuh pada
daerah di luar batas n ± 1.96 Standard Error.
0.05 95% Bila suatu percobaan diulang sebanyak 100 kali, maka hanya terdapat 5 kali kejadian dimana nilai rata-ratanya jatuh pada
daerah di luar batas n ± 2.58 Standard Error.
Catatan untuk tabel 14 ; Angka 1.96 serta 2.58 didapat berdasarkan tabel
distribusi t pada jumlah data tak terbingga (sangat besar) Sumber: Aggarwal, 1986, hal. 174.
7.4.3. Standard E rro r of Estimate [Se]
Se adalah merupakan suatu besaran angka yang dipakai untuk menyatakan tingkat penyebaran dari Yobs terhadap garis regresi. Se ini dipakai juga untuk menyatakan tingkat ketelitian atau kualitas dari suatu persamaan regresi. Makin kecil nilai Se maka makin baik variabel yang diuji. Sampai saat ini belum ada deskripsi yang baku dari nilai Se tersebut. Namun demikian sebaran dari variabel dapat ditinjau dari grafik yang dibuat berdasarkan variabel tersebut.
Rumus umum dari Se ini adalah;
S e = \ D F
di m a n a :
^ res ~ S Yobs.i - bi.SxiYobs.i - - bp.Sxp vobs.i DF = degree of freedom = n - k -1 n= jum lah data
k = jumlah variabel bebas dalam persamaan regresi (X)
(3 .B )
Contoh 1 1;
Berdasarkan data-data pada contoh nomor 8, berikut akan dihitung standard errors of estimate dari variabel-variabelnya.
Rumus (3.13) dapat diturunkan lagi m enjadi:
S e y .x =
1
n { n - 2 ) n i: / - riLK y-{lx)(i:y) n L c ^ -(L x y
sehingga berdasarkan data pada tabel 11 serta tabel contoh nomor 7, akan didapat;
1. Untuk Y = - 3.624+ 1.239 Xi
S'^r.x ~
1
12(12-2) 12(48139)-(753)- 12(40830)-(753X643) 12(34843)-(643)'
makaSe,,^, = 5,399144
2. Untuk ¥ = 30.571 + 3.643 X2
Ser^v =^ [ 1 2 (1 2 -2 ) J[12(48139)-(753)- 12(6796)-(7 5 3 )(l0 6 )f 12(976)-(106)^
maka S cy ^ x 6,015456
7.4.4. Tes Hipotesa (t test)
Tes Hipotesa atau / test merupakan suatu tes hipotesa terhadap koefisien regresi P dari masing-masing variabel independent dalam suatu persamaan regresi linier yang digunakan untuk mengetahui apakah suatu variabel independent memiliki
kontribusi terhadap suatu persamaan linier. Langkah-langkah di dalam melakulcan tes hipotesa ini adalah sebagai berikut.
1. Tentukan Hipotesa
H o ; { 3 = 0
H i ; p ^ 0
2. Menetapkan aturan, yaitu sebagai berikut, nilai t yang didapat dibandingkan dengan nilai t yang berasal dari tabel t dengan derajat kebebasannya (lihat lampiran 1). Bila nilai t > t„ atau taJi atau t < - ta atau - X^Ji maka tolak Ho (dengan kata lain terima Hi).
3. Langkah-langkah perhitungan;
- Tentukan standar deviasi dari X dan Y.
- Tentukan Standard errors of estimate
- Hitung nilai dari t berdasarkan rumus berikut i n i : Y - X
t = - ^ (3 16)
Contoh 12:
Berdasarkan contoh nomor 8, akan dilakukan tes hipotesa terhadap persamaan regresi yang didapat.
1. Untuk Y = -3.624+ 1.239 X,
standar errors of estimate (Y,Xi) = 2.98 t = (62.8-53.6)/2.98 = 3.09
degree o f freedom = 12+12-2 = 22 untuk a = 0.05, nilai t pada tabel = 2.07.
Karena 2.07 < 3.09 maka tolak Ho, kesimpulannya koefisien mempunyai arti dalam persamaan regresi.
2. Unl.uk Y = 30.571 + 3.643 Xj
standar errors o f estimate (Y,X2) = 2.54 t = (6 2 .8 -8.8)/2.54 = 21.25
degree o f freedom = 12+12-2 = 22 untiik a = 0.05, nilai t pada tabel = 2.07.
Karena 2.07 <21.25 maka tolak Ho, kesimpulannya koefisien mempunyai arti dalam persamaan regresi.
7.5. Kontribusi Hasil Uji Statistik terhadap Variabel Bebas (X)
Berdasarkan hasil uji statistik, dapat diketahui keberartian dari variabel-variabel yang terdapat dalam persamaan regresi. Walaupun demikian, hasil pengujian tersebut tidak dapat diterapkan secara langsung. Artinya, terdapat keadaan di mana suatu variabel bebas gagal dalam uji statistik, namun temyata masih digimakan juga di dalam persamaan regresi. Pada tabel 15, terdapat beberapa kriteria yang biasanya digimakan dalam pemakaian secara praktis terhadap suatu variabel dengan hasil pengujian statistiknya. Selain itu ditampilakan interaksi yang mungkin teijadi pada berbagai uji statistik yang dilakukan terhadap variabel tersebut.
Tabel 15 Berbagai kasus pemilihan variabel berdasarkan uji statistik
Uji statistik Variabel
Sign-test t-test Policy Variable Other Variable
(tes tanda) (tes hipotesa) (variabel utama) (variabel penunjang)
Tanda Benar Berarti Diterima Diterima
Tidak Berarti Diterima Mungkin ditolak
Tanda Salah Berarti Masalah besar Ditolak
Tidak Berarti Bermasalah Ditolak
Sumber : Willumsen, 1990, hal.211.
Penjelasan dari tabel 15 adalah sebagai berikut:
1. Sign-test atau tes tanda adalah merupakan hasil dari tes koefisien korelasi (r) yang dilakukan terhadap variabel bebas (X). Hasil tes koefisien korelasi
kemudian dibandingkan dengan logika pada keadaan saat ini. Seperti yang telah diketahui, bila tanda dari r adalah positif maka variabel bebas searah dengan variabel tak bebasnya, yang berarti kenaikan nilai dari variabel bebas akan mengakibatkan kenaikan nilai pada variabel tak bebasnya. Bila tandanya adalah negatif, maka hal yang beriaku adalah sebaliknya, atau bisa dikatakan variabel bebas berlawanan arah dengan variabel tak bebas.
2. Pengertian dari tanda benar dan tanda salah pada kolom (1) adalah sebagai berikut. Tanda benar bila hasil dari tes koefisien korelasi sesuai dengan hasil analisa dengan menggunakan logika, sedangkan tanda salah berarti sebaliknya. Misalnya, variabel bebas (X) mewakili tingkat pendapatan sedangkan variabel tak bebas (Y) mewakili jumlah peijalanan yang dilakukan. Secara logika bila nilai X membesar maka seharusnya jumlah perjalanan atau nilai dari Y ikut membesar pula. Bila hasil tes koefisien korelasi dari X dan Y bemilai positif, maka dapat dikatakan bahwa hasil dari sign-test adalah tanda benar. Bila hasil tes koefisien korelasinya bemilai negatif,. maka pada kolom sign-test menghasilkan tanda salah.
3. Kotom (2) atau kolom tes hipotesa dilakukan sebagaimana yang telah dibahas sebelumnya.
4. Kolom (3) dan kolom (4), mewakili variabel beserta prioritasnya. Variabel utama merupakan variabel-variabel yang memegang peranan penting dan mewakili karakteristik-karakteristik utama dari daerah studi, atau yang mewakili karakteristik-karakteristik utama dari rumah tangga. Sedangkan
variabel penunjang adalah variabel yang juga cukup penting, namun tidak memberikan kontribusi/pengaruh yang terlalu besar terhadap persamaan regresi atau terhadap model yang dianalisa.
5. Tanda yang salah dengan hasil tes hipotesa yang benar (berarti) dapat teijadi, mungkin dikarenakan jumlah sampel yang terlalu kecil.
7.6. Rejjresi Non Linier
Asumsi- asumsi yang terdapat pada bagian awal pembahasan analisa regresi ini menyatakan bahwa hubungan antara variabel-variabel hams bersifat linier.
Namun demikian, kadang-kadang dijumpai hubungan antara variabel independent (X) dengan variabel dependent (Y) temyata tidak linier. Hal tersebut akan menyebabkan keseluruhan tahap penyelesaian yang telah diuraikan sebelumnya tidak dapat digunakan, mengingat keseluruhan rumus yang digunakan adalah untuk persamaan regresi yang linier. Contoh dari variabel- variabel yang bersifat kualitatif tersebut adalah, jumlah anggota keluarga, umur, jumlah kendaraan bermotor/d.u dan lain-lain.
Untuk mengatasi hal ini dapat ditempuh dengan dua cara, yaitu sebagai berikut;
1. Menggunakan dummy variables.
2. Mentransformasikan variabel X dan Y sehingga dapat memenuhi persyaratan hubungan linier.
7.6.1. Regresi Linier dengan Dummy Variables
Pada kenyataan yang ada, terdapat variabel-variabel yang bersifat kualitatif, sebagai contoh adalah tingkat pendapatan, tingkat kepemilikan kendaraan beraiotor dan lain-lain. Untuk dapat memasukkan variabel ini ke dalam persamaan regresi linier, maka dibuatkan variabel yang diberi nama variabel boneka (dummy variables) yang keberadaanya diwakili oleh angka 1 dan 0.
Untuk lebih jelasnya perhatikan uraian berikut ini.
Seandainya terdapat tiga kategori untuk kepemilikan kendaraan bermotor, yaitu : 1. Kategori 1 (Vq) untuk yang tidak memiliki kendaraan bermotor
2. Kategori 2 (V]) untuk yang memiliki satu buah kendaraan bermotor 3. Kategori 3 (V2) untuk yang memiliki dua atau lebih kendaraan bermotor.
Maka variabel boneka untuk persamaan regresi berbentuk sebagai berikut, 1. Untuk; kategori 1, Vq = 1 ; Vj = 0 ; V2 = 0
2. Untuk kategori 2, Vq = 0 ; Vj = 1 ; V2 = 0 3. Untuk kategori 3, Vo = 0 ; V, = 0 ; V2 = 1
7.6.2. Transformasi Regresi Non Linier
Cara yang kedua adalah dengan mentransformasikan variabel Y, variabel X atau kedua-duanya secara bersamaan. Untuk lebih jelasnya dapat dilihat pada gambar 10 mengenai beberapa contoh proses transformasi. Walaupun cara ini dapat dilakukan, namun pada kenyataanya untuk mencari transformasi yang tepat cukup sulit serta memakan waktu dan tenaga yang cukup banyak. Pemilihan
metode apa yang hendak digunakan sangat tergantung pada kebutuhan serta keadaan yang ada.
Sumber : Hutchinson, 1974, hal. 42.
Gambar 10 Contoh-contoh me-linier-kan hubungan dengan cara transformasi variabel