BAHAN AJAR
BIOSTATISTIKA DAN EPIDEMIOLOGI
(MMS-4411)
Disusun oleh: Dr. Danardono, MPH.
PROGRAM STUDI STATISTIKA JURUSAN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS GADJAH MADA
Daftar Isi
1 Pendahuluan 2
1.1 Tujuan Pembelajaran . . . 2
1.2 Biostatistika dan Epidemiologi . . . 2
1.3 Profesi Biostatistisi dan Epidemiolog . . . 3
1.4 Metode dan Proses Pembelajaran . . . 3
1.5 Latihan dan Tugas . . . 4
2 Desain Penelitian 5 2.1 Tujuan Pembelajaran . . . 5
2.2 Penelitian dalam Bidang Ilmu Hayati, Kedokteran, dan Epidemiologi 5 2.3 Penelitian observasional . . . 7
2.4 Penelitian Cross-sectional dan Longitudinal . . . . 7
2.5 Penelitian Follow-up . . . . 8
2.6 Penelitian Case-control . . . . 8
2.7 Penelitian Klinis . . . 8
2.8 Model Statistik dan Kausalitas . . . 9
2.9 Latihan dan Tugas . . . 10
3 Statistik dan Ukuran dalam Epidemiologi 15 3.1 Tujuan Pembelajaran . . . 15
3.2 Prevalensi dan insidensi . . . 15
3.2.1 Model untuk Prevalensi . . . 17
3.2.2 Model untuk Insidensi . . . 20
3.3 Faktor Resiko . . . 23
3.4 Inferensi untuk RD, RR dan OR . . . 25
3.5 Latihan . . . 29
4 Perancuan dan Interaksi 31 4.1 Tujuan Pembelajaran . . . 31
4.2 Konsep dan Identifikasi Perancuan . . . 31
Daftar Isi iii
4.3 Metode Standarisasi dan Mantel-Haenszel . . . 34
4.3.1 Standarisasi Langsung . . . 34
4.3.2 Standarisasi Tidak Langsung . . . 35
4.3.3 Mantel-Haenszel . . . 36
4.4 Interaksi . . . 37
4.5 Latihan . . . 39
5 Model Linear Tergeneralisasi 41 5.1 Tujuan Pembelajaran . . . 41
5.2 Generalisasi Model Linear . . . 41
5.3 Regresi Logistik . . . 43
5.3.1 Model dan Estimasi Parameter . . . 43
5.3.2 Interpretasi Parameter Model . . . 44
5.4 Regresi Poisson . . . 48
5.4.1 Model dan Estimasi Parameter . . . 48
5.4.2 Interpretasi Parameter Model . . . 49
5.5 Latihan . . . 55
6 Uji Diagnostik 58 6.1 Tujuan Pembelajaran . . . 58
6.2 Sensitivitas, Spesifisitas dan Nilai Prediksi . . . 58
6.3 Kurva ROC . . . 61
6.4 Latihan . . . 63
7 Analisis Data Longitudinal 65 7.1 Tujuan Pembelajaran . . . 65
7.2 Deskripsi Data longitudinal . . . 65
7.3 Model Regresi Data longitudinal . . . 70
7.3.1 Naive Model . . . . 72
7.3.2 Model Linear Umum untuk Data Longitudinal . . . 73
7.4 Latihan . . . 75
8 Analisis Data Survival 77 8.1 Tujuan Pembelajaran . . . 77
8.2 Fungsi Survival dan Hazard . . . 77
8.3 Kaplan-Meier dan Life Table . . . . 81
8.4 Membandingkan Distribusi Survival . . . 84
8.5 Model Regresi Data Survival . . . 86
Daftar Isi 1
9 Konsultasi Statistika 91
9.1 Tujuan Pembelajaran . . . 91 9.2 Konsultan Statistik . . . 91 9.3 Penggunaan Perangkat Lunak Statistika dan Teknologi Informasi . 92 9.4 Ringkasan Metode dan Topik Lanjut . . . 94 9.5 Latihan . . . 94
1
Pendahuluan
1.1
Tujuan Pembelajaran
Setelah selesai melakukan pembelajaran pada bagian ini, mahasiswa diharapkan dapat:
1. Menjelaskan pengertian biostatistika dan epidemiologi dan penekanan matakuliah ini
2. Memberi contoh profesi yang berkaitan dengan biostatistika dan epidemio-logi
3. Mengidentifikasi bagian-bagian pada RPKPS yang berkaitan dengan Tu-juan umum pembelajaran, metode dan proses pembelajaran, penilaian dan sumber referensi
1.2
Biostatistika dan Epidemiologi
Biostatistika adalah statistika yang diterapkan pada ilmu hayati, kedokteran dan epidemiologi. Armitage and Colton (1998) mendefinisikan Biostatistika lebih sempit lagi, yaitu metode statistika dalam kedokteran dan ilmu kesehatan, atau dikenal juga sebagai medical statistics. Sedangkan ilmu statistika dalam bidang biologi, lingkungan dan pertanian sering disebut sebagai biometrika (biometrics).
Definisi Epidemiologi menurut (Last, 1995) adalah
The study of distribution and determinants of health-related states or events in specified population, and the application of this study to control of health problems.
1.3. Profesi Biostatistisi dan Epidemiolog 3
MMS-4411 mempunyai penekanan agar lulusan bisa bertindak seperti layaknya konsultan dalam bidang Biostatistika. Untuk itu, materi yang diberikan tidak hanya berupa metode saja namun juga aspek komunikasi, konsultasi dan pengetahuan terkait seperti epidemiologi dan terminologi dalam bidang kese-hatan. Matakuliah ini diharapkan akan membuka wawasan lanjut mahasiswa karena banyak pengembangan teori statistika yang berawal dari permasalahan dalam bidang Biostatistika dan Epidemiologi. Selain itu melalui matakuliah ini mahasiswa diharapkan untuk mulai berpikir dan bertindak bukan hanya sebagai statistisi saja, tapi juga sebagai orang yang mempelajari bidang lain dan dengan sudut pandang yang berbeda dari seorang statistisi.
Matakuliah ini dapat diambil setelah mahasiswa mengetahui dan memahami dasar serta teknik metode statistik secara umum dan mampu melakukan analisis statistik dengan beberapa metode tertentu. Matakuliah MMS-4411 diharapkan dapat mendukung kompetensi lulusan program studi statistika, khususnya untuk lulusan yang mempunyai minat dan konsentrasi pada bidang Biostatistika.
1.3
Profesi Biostatistisi dan Epidemiolog
Profesi biostatistisi dan epidemiolog banyak diperlukan di bidang-bidang seperti tersebut di bawah ini,
• Lembaga penelitian
• Akademik atau lembaga pendidikan
• Lembaga pemerintah bidang kesehatan atau rumah sakit
• Industri obat dan farmasi
• Konsultan
Di Indonesia profesi seperti tersebut belum sepopuler profesi seperti dokter, apoteker atau dosen, namun di negara maju dan di negara ASEAN seperti Singa-pura profesi ini sudah cukup dikenal. Lembaga penelitian asing yang melakukan penelitian di bidang penyakit tropis biasanya juga membutuhkan tenaga biostatis-tisi dan epidemiolog lokal. Perencanaan aspek kesehatan, termasuk di dalamnya asuransi kesehatan dan kematian, yang baik dan terukur akan sangat memerlukan ahli di bidang biostatistik dan epidemiologi.
1.4
Metode dan Proses Pembelajaran
Metode dan proses pembelajaran untuk matakuliah ini dapat dilihat pada RPKPS (Rencana Program Kegiatan Pembelajaran Semester) MMS-4411.
1.5. Latihan dan Tugas 4
1.5
Latihan dan Tugas
1.1. Sebutkan matakuliah apa saja di program studi Statistika UGM yang terkait matakuliah MMS-4411.
1.2. Carilah kuliah (course) sejenis MMS-4411 di internet atau sumber lain yang mudah diakses (misalnya handbook suatu program studi) baik yang berba-hasa Indonesia maupun Inggris. Tuliskan alamat situs internet kuliah terse-but terseterse-but atau dapatkan hardcopy/softcopy dari handbook suatu program studi, kemudian tuliskan materi atau kompetensi yang diajarkan serta meto-de pembelajarannya.
1.3. Sebutkan metode apa saja yang pernah saudara pelajari sebelum mengam-bil matakuliah ini. Berilah satu contoh analisis data terkait penelitian di bidang epidemiologi, kesehatan atau ilmu hayati untuk masing-masing me-tode yang telah saudara pelajari tersebut.
1.4. Lewat jejaring sosial yang mungkin saudara punyai, carilah lulusan atau alumnus program studi Statistika (dari perguruan tinggi manapun di Indone-sia) yang mempunyai profesi terkait konsultan biostatistika, epidemiologi atau pekerjaan lain yang memerlukan kompetensi seorang biostatistisi atau epidemiolog.
2
Desain Penelitian
2.1
Tujuan Pembelajaran
Setelah selesai melakukan pembelajaran pada bagian ini, mahasiswa diharapkan dapat:
1. Menjelaskan tujuan penelitian dalam bidang epidemiologi 2. Menjelaskan tipe-tipe penelitian
3. Mengidentifikasi desain penelitian yang digunakan dalam suatu penelitian 4. Mengusulkan desain penelitian yang tepat untuk suatu permasalahan 5. Menjelaskan peran statistika dalam penelitian di bidang ilmu hayati,
kedok-teran dan epidemiologi
6. Menjelaskan proses pembangkitan data dikaitkan dengan desain dan model statistik
7. Menyebutkan matakuliah lain yang terkait dengan topik desain penelitian
2.2
Penelitian dalam Bidang Ilmu Hayati,
Kedok-teran, dan Epidemiologi
Menurut Kleinbaum, Kupper and Morgenstern (1982), ada 4 kata kunci tujuan penelitian di bidang epidemiologi, yaitu: describe, explain, predict dan control. Selengkapnya dapat dijelaskan sebagai berikut:
2.2. Penelitian dalam Bidang Ilmu Hayati, Kedokteran, dan Epidemiologi 6
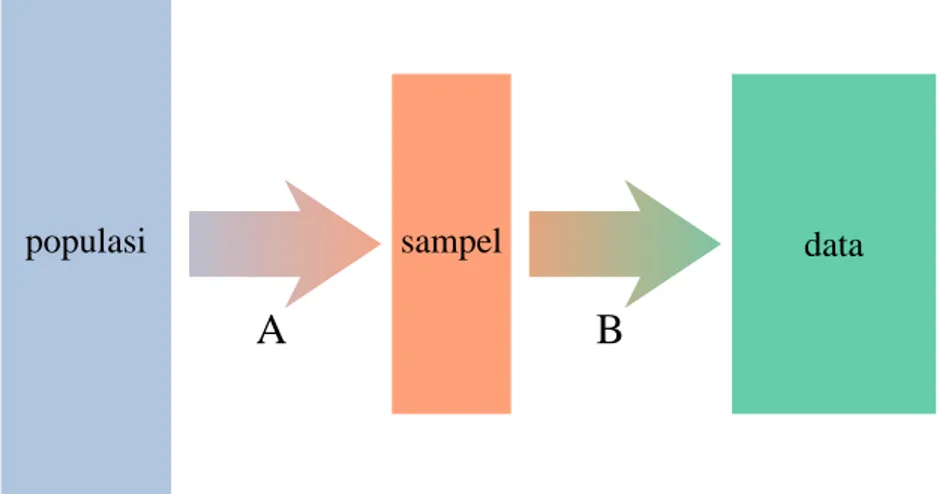
populasi
A
B
sampel data
Gambar 2.1: Skema penelitian secara umum dimulai dari pendefinisian popu-lasi dan unit popupopu-lasi, tahap A: pengambilan unit sampel dari popupopu-lasi; tahap B: pengambilan informasi dari sampel.
1. Mendeskripsikan status kesehatan populasi dengan cara melakukan enu-merasi kejadian sakit, menghitung frekuensi relatif dan mendapatkan ke-cenderungan atau trend penyakit;
2. Menjelaskan penyebab penyakit dengan cara menentukan faktor yang men-jadi sebab dari suatu penyakit tertentu dan cara transmisinya;
3. Melakukan prediksi kejadian sakit dan distribusi status kesehatan dalam populasi;
4. Melakukan pengendalian penyebaran penyakit dalam populasi dengan pencegahan kejadian sakit, penyembuhan kasus sakit, menambah lama hidup bersama dengan suatu penyakit, atau meningkatkan status kesehatan-nya
Penelitian dalam bidang kedokteran dan epidemiologi secara garis besar sama dengan penelitian lain, seperti misalnya bidang pertanian, biologi dan ilmu rekayasa (teknik). Namun karena penelitian ini banyak melibatkan manusia seba-gai subyek, maka banyak teknik atau metode yang dapat diterapkan pada bidang lain yang tidak dapat diterapkan dalam bidang ini karena permasalahan etika. Mi-salnya, tidak mungkin akan diberikan suatu jenis perlakuan yang membahayakan atau merugikan subyek penelitian.
Gambar 2.1 merepresentasikan skema penelitian secara umum. Suatu peneli-tian dimulai dengan mendefinisikan populasi untuk mana kesimpulan atau hasil
2.3. Penelitian observasional 7
dari penelitian akan dikenakan. Pada tahap ini unit populasi dan variabel peneli-tian harus ditentukan. Unit populasi adalah bagian terkecil dari populasi yang akan digunakan dalam pengambilan sampel. Sedangkan variabel adalah karakter-istik atau informasi yang ingin diperoleh dari unit tersebut.
Bagian A pada Gambar 2.1 adalah bagian pengambilan sampel atau penyam-pelan. Tujuan utama penyampelan adalah untuk mendapatkan wakil yang repre-sentatif dari populasi, tanpa harus melihat atau meneliti keseluruhan anggota pop-ulasi. Pengambilan sampel dapat dilakukan secara non-random ataupun random. Pengambilan sampel non-random biasanya lebih mudah dibandingkan dengan pengambilan sampel random. Namun, pengambilan random menjamin obyek-tivitas dan sampel yang representatif, dan banyak analisis statistik yang disusun berdasarkan asumsi sampel random. Dikenal beberapa macam metode pengam-bilan sampel random yang pada hakekatnya bertujuan untuk mengatasi hetero-genitas populasi, seperti misalnya: sampel random sederhana, stratifikasi, kluster, sistematik, dan lainnya.
Setelah sampel diperoleh dilanjutkan dengan tahap pengambilan informasi dari unit sampel berdasarkan variabel penelitian yang telah ditentukan (bagian B pada Gambar 2.1). Cara pengambilan informasi dapat dilakukan dengan penguku-ran, pencacahan, wawancara, dan sebagainya. Jenis penelitian dapat dibedakan dari apakah ada perlakuan, manipulasi, intervensi atau tindakan yang dinenakan pada unit penelitian sebelum dilakukan tahap B atau tidak. Selain itu, elemen utama yang selalu menyertai penelitian adalah waktu. Penelitian juga dapat dibedakan berdasarkan saat pelaksanaan tahap A maupun B. Lebih jelasnya jenis-jenis penelitian tersebut akan diterangkan pada bagian-bagian selanjutnya setelah bagian ini.
2.3
Penelitian observasional
Dalam penelitian jenis ini tidak dilakukan manipulasi atau perlakuan pada faktor-faktor yang diteliti. Data diperoleh apa adanya dari populasi. Dalam penelitian ini, tidak dilakukan manipulasi, perlakuan ataupun intervensi pada tahap B (Gambar 2.1).
2.4
Penelitian Cross-sectional dan Longitudinal
Dalam penelitian ini, sampel atau data hanya dikumpulkan pada satu titik wak-tu tertenwak-tu saja. Jenis penelitian ini dikontraskan dengan penelitian longiwak-tudinal, yaitu penelitian yang dilakukan dalam periode tertentu. Dalam prakteknya peneli-tian longitudinal dicirikan dengan dikumpulkannya beberapa pengukuran atau
ob-2.5. Penelitian Follow-up 8
servasi untuk satu unit sampel, sedangkan penelitian cross-sectional dicirikan de-ngan satu pengukuran atau observasi untuk satu unit.
2.5
Penelitian Follow-up
Sering juga disebut penelitian prospektif. Dalam penelitian ini subyek diikuti se-lama jangka waktu tertentu atau sampai suatu kejadian (event), nilai pengukuran atau end-point tertentu diperoleh. Penelitian Follow-up dapat berupa observasion-al maupun eksperimentobservasion-al.
2.6
Penelitian Case-control
Penelitian case-control merupakan salah satu contoh penelitian retrospektif. Penelitian retrospektif yaitu jenis penelitian yang berawal dari suatu event atau
end-point. Unit sampel yang memiliki event atau end-point tersebut kemudian
diteliti. Penelitian case-control dimulai dari unit yang mendapatkan kasus (pe-nyakit misalnya), kemudian dipilih sekelompok pembanding atau kontrol (yaitu unit yang tidak mendapatkan atau mempunyai kasus). Faktor atau variabel penje-las yang lain juga dikumpulkan untuk masing-masing kasus dan kontrol.
2.7
Penelitian Klinis
Penelitian klinis (clinical trial) menurut (Chow, 2000, hal 110) adalah ” ... an experiment performed by a health care organization or profes-sional to evaluate the effect of an intervention or treatment against a control in a clinical environment. It is a prospective study to identify outcome measures that are influenced by the intervention. A clini-cal trial is designed to maintain health, prevent diseases, or treat dis-eased subjects. The safety, efficacy, pharmacological, pharmacokinet-ic, quality-of-life, health economics, or biochemical effects are mea-sured in a clinical trial.”
Dalam penelitian ini dilakukan manipulasi, pemberian perlakuan (treatment) atau intervensi pada tahap B (Gambar 2.1)
Tahapan penelitian klinis (Le, 2003):
• Fase I: Memfokuskan pada keamanan obat baru, fase ini adalah uji coba pertama obat pada manusia setelah sukses dengan uji coba pada binatang
2.8. Model Statistik dan Kausalitas 9
• Fase II: Uji coba skala kecil untuk menilai efektivitas obat dan lebih fokus kepada keamanannya
• Fase III: Uji coba klinis lebih lanjut untuk menilai efektivitasnya sebelum didaftarkan pada pihak yang berwenang
• Fase IV: Penelitian setelah obat dipasarkan untuk memberikan informasi yang lebih detail tentang efektivitas obat dan keamanannya
2.8
Model Statistik dan Kausalitas
Dalam terminologi dan notasi statistika, variabel sering dituliskan dengan huruf X untuk variabel penjelas, variabel independen, faktor; danY untuk variabel de-penden atau variabel respon. Dalam Epidemiologi dikenal juga istilah variabel paparan (exposure) dan perancu (confounder) yang termasuk dalam kelompokX, dan outcome yang termasuk dalam kelompokY.
Umumnya setiap penelitian bertujuan untuk mencari tahu apakahX menye-babkan Y, atau seberapa besar pengaruhX terhadapY. Model statistik, seperti misalnya model regresi sederhana
E(Y |X) =β0+β1X (2.1)
merupakan representasi untuk mencapai tujuan itu.
Statistisi memikirkan model seperti (2.1) sebagai suatu ”pembangkit data” (data generating-process). Realisasi dari model itu adalah data yang diperoleh (sering dituliskan sebagai huruf kecil x dany). Apabila model dan estimasi pa-rameternya dinyatakan cukup tepat untuk menjelaskan data, dapat dilakukan infe-rensi atau pengambilan kesimpulan dari model tersebut. Termasuk dalam inferen-si itu adalah penggunaan model untuk predikinferen-si dan kausalitas.
Perlu diperhatikan bahwa sangat mungkin terdapat lebih dari satu model yang cukup tepat untuk menjelaskan suatu set data. Untuk itu harus diingat pendap-at yang mengpendap-atakan bahwa ada banyak model yang baik tapi pilihlah spendap-atu yang berguna. Dikaitkan dengan penelitian di bidang Epidemiologi dan kedokteran, model yang berguna di sini adalah model yang terdiri dari variabel yang ni-lainya dapat atau mudah dimodifikasi dalam praktek dan model yang sesederhana mungkin.
Desain penelitian, atau cara memperoleh data penelitian, sangat mempen-garuhi asumsi model statistik yang pada akhirnya mempenmempen-garuhi penjelasan dan interpretasi dari hubungan X dengan Y. Ambil contoh model sederhana seperti (2.1). Misalkan untuk mendapatkan x(realisasi dari variabelX) digunakan cara
2.9. Latihan dan Tugas 10
observasi tanpa perlakuan pada unit sampel (penelitian observasional) maka mo-del ini kurang kuat untuk menjelaskan kausalitas X terhadapY. Namun bilax diperoleh dengan kaidah desain eksperimental maka model dapat digunakan un-tuk menjelaskan hubungan kausal
Dalam penelitian epidemiologi dikenal prinsip-prinsip untuk mendapatkan bukti adanya kausalitas yang dikenal sebagai Hill’s Criteria for Causality (Armitage and Colton, 1998; Kleinbaum et al., 1982) sebagai berikut:
1. Hubungan (association) yang kuat antaraX(variabel independen,faktor re-siko atau paparan) denganY (variabel dependen, respon atau outcome). 2. Hubungan yang diperoleh harus spesifik dalam arti suatu faktor atau
pa-paran hanya berhubungan dengan satu jenis penyakit saja.
3. Paparan atau faktor (X) harus mendahului respon (Y), atau sebab harus mendahului akibat.
4. Harus ada penjelasan secara biologis mengapa suatu paparan atau faktor resiko menyebabkan suatu penyakit.
5. Harus dapat ditunjukkan adanya dose-response effect atau biologic gradient yaitu semakin besar tingkat paparan semakin besar kemungkinan terjadinya penyakit
6. Terkait kriteria 5, jika paparan dihilangkan, penyakit juga seharusnya tidak muncul
7. Adanya konsistensi hasil atau kesimpulan yang diperoleh dari beberapa stu-di.
2.9
Latihan dan Tugas
Untuk soal pilihan ganda, pilihlah satu jawaban yang tepat (a, b, c atau d); untuk soal esai tuliskan jawabannya dengan singkat dan jelas!
2.1. Keuntungan desain penelitian case-control terhadap desain penelitian co-hort salah satunya adalah:
a. dengan desain case-control dapat dihitung OR
b. case-control dapat mengatasi masalah etik penelitian terhadap
manusia yang mungkin terjadi pada desain cohort
c. ukuran sampel untuk case-control relatif lebih kecil dibandingkan
cohort
d. dapat digunakan untuk menunjukkan hubungan sebab-akibat (cause-effect)
2.9. Latihan dan Tugas 11
2.2. Keuntungan desain penelitian longitudinal terhadap cross-sectional salah satunya adalah:
a. lebih mudah dilaksanakan
b. ada variabel kontrol yang dapat digunakan sebagai perbandingan c. ukuran sampel relatif lebih kecil
d. dapat digunakan untuk menunjukkan hubungan sebab-akibat (cause-effect)
2.3. Suatu penelitian yang bertujuan untuk membandingkan dua perlakuan A dan B dilakukan dengan cara sebagai berikut: subyek secara random diberi perlakuan A atau B; setelah periode waktu tertentu subyek berganti men-dapat perlakuan yang lain, untuk subyek yang pada awalnya menmen-dapat per-lakuan A kemudian mendapat B, dan sebaliknya. Desain yang digunakan disebut:
a. cross-over trial b. cross-sectional c. cohort d. randomized block
2.4. Desain penelitian yang sesuai dan layak (dapat dilaksanakan) untuk menge-tahui faktor resiko suatu penyakit dengan insidensi yang sangat rendah (seperti misalnya kanker) adalah:
a. cross-sectional b. cohort
c. case-control d. clinical-trial
2.5. Dalam penelitian tentang program atau kebijakan yang berkaitan dengan kesehatan masyarakat, randomisasi pada unit penelitian biasanya sulit untuk dilakukan, meskipun demikian pengaruh faktor (pemberian program atau penerapan kebijakan) tetap dapat diteliti efeknya. Desain penelitian yang tepat untuk permasalahan ini adalah:
a. cross-sectional b. cohort
c. observational d. quasi-experimental
2.6. Misalkan dari teori dan penelitian sebelumnya dapat diasumsikan bahwa perlakuan A, B dan C akan menghasilkan respon individual seperti pada gambar di bawah ini.
A B C waktuT re sp o n Y
2.9. Latihan dan Tugas 12
Untuk meneliti fenomena tersebut di atas desain yang paling tepat adalah: a. longitudinal b. cross-sectional c. multiple cross-sectional d. survival 2.7. Pada tahun 1985 dilakukan penelitian di Inggris untuk mengetahui apakah
wanita yang minum pil kontrasepsi akan mengalami menopause (tidak mengalami siklus menstruasi lagi) lebih awal atau lebih akhir dibandingkan wanita yang tidak minum pil kontrasepsi. Untuk itu diambil satu kelompok wanita yang lahir pada tahun 1930, dengan alasan pada tahun 1985 mereka sudah cukup tua untuk mendapatkan menopause. Berdasarkan catatan di sebuah klinik umum diperoleh 132 wanita. Sebanyak 101 wanita tidak diambil sebagai subyek karena alasan tidak dapat dihubungi, menolak sebagai subyek, belum menopause dan alasan kesehatan. Diperoleh data sebagai berikut:
Umur saat menopause (tahun)
n Mean SD
minum pil 12 47,2 2,1
tdk. minum 19 47,5 2,1
(a) Apa desain studi ini? Jelaskan!
(b) Apakah ada kesalahan fatal dalam studi ini? Jelaskan!
2.8. Sebuah penelitian dilakukan untuk mengetahui keefektivan helm dalam mencegah kerusakan di kepala akibat kecelakaan kendaraan bermotor. Diperoleh data 793 kecelakaan dalam periode 3 bulan sebagai berikut:
Menggunakan helm
kerusakan di kepala Ya Tidak Total
Ya 17 218 235
Tidak 130 428 558
Total 147 646 793
Apa desain studi ini? Jelaskan!
2.9. Jelaskan perbedaan utama antara penelitian prospektif dengan retrospektif dan keuntungan kerugian masing-masing!
2.10. Jelaskan perbedaan utama antara penelitian observasional dengan dengan eksperimental dan keuntungan kerugian masing-masing!
2.11. Sebuah lembaga riset kesehatan akan melakukan penelitian tentang program atau aktivitas yang dapat menghentikan kebiasaan merokok.
(a) Ajukan satu pertanyaan ilmiah (research question) yang relevan menu-rut saudara.
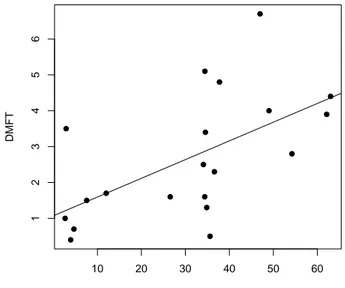
2.9. Latihan dan Tugas 13 10 20 30 40 50 60 1 2 3 4 5 6
konsumsi gula (kg/orang/tahun)
DMFT
Gambar 2.2: Plot antara banyaknya gigi yang rusak dengan konsumsi gula
(b) Apa variabel independen atau paparan (exposure) utama penelitian ter-sebut?
(c) Desain penelitian apa yang sesuai dengan tujuan penelitian di atas? Jelaskan!
(d) Bagaimana seharusnya saudara memilih subyek dan mengukur (mengambil informasi) dari mereka sehingga tidak terjadi bias? 2.12. Gambar 2.2 menunjukkan hasil penelitian epidemiologi hubungan antara
banyaknya gigi yang rusak dengan konsumsi gula pada 20 negara. Gigi yang rusak dinyatakan dengan skor DMFT (decayed, missing and filled
teeth) yang diperoleh dari mean dari survei di masing-masing negara
de-ngan responden anak usia 12 tahun. konsumsi gula diperoleh dari laporan tahunan pemerintah dibagi estimasi total populasi berdasarkan sensus.
(a) Apakah dapat ditunjukkan dari gambar bahwa konsumsi gula meng-akibatkan tingginya DMFT? Jelaskan!
(b) Apa kelemahan studi seperti di atas dan berikan alternatif desain yang lebih tepat
2.13. Dalam suatu studi tentang faktor resiko untuk angina (terkait penyakit jan-tung) subyek diminta menjawab pertanyaan,’Apakah anda merokok’.
Jawa-2.9. Latihan dan Tugas 14
ban diklasifikasikan untuk setiap responden sebagai prokok dan bukan pe-rokok. Kemudian subyek diklasifikasikan apakah pernah mengalami angi-na atau tidak. Setelah data diaangi-nalisis, tidak diperoleh hubungan antara merokok dengan pernah tidaknya mengalami angina.
(a) Dari banyak studi yang telah dilakukan sebelumnya dapat ditunjukkan adanya bukti bahwa resiko mendapatkan angina meningkat seiring dengan naiknya konsumsi rokok seseorang. Jelaskan apa saja yang mungkin menyebabkan studi di atas gagal menunjukkan hubungan an-tara angina dengan merokok?
(b) Apa alternatif desain studi yang lebih tepat? Jelaskan!
2.14. Untuk meneliti suatu permasalahan epidemiologi sering dilakukan lebih dari satu studi yang mana variabel utamanya sama namun populasi dan set-ting studinya mungkin berbeda. Apakah ada keuntungan yang diperoleh dari banyak studi tersebut untuk menjawab satu permasalahan yang sama dalam epidemiologi? Jelaskan!
3
Statistik dan Ukuran dalam
Epidemiologi
3.1
Tujuan Pembelajaran
Setelah selesai melakukan pembelajaran pada bagian ini, mahasiswa diharapkan dapat:
1. Menggunakan ukuran statistik yang tepat untuk suatu permasalahan dalam epidemiologi
2. Menginterpretasikan hasil hitungan ukuran statistik
3. Menjelaskan model yang mendasari prevalensi dan insidensi
4. Menggunakan likelihood ratio test sebagai alternatif inferensi untuk model prevalensi dan insidensi
5. Menggunakan ukuran faktor yang tepat untuk suatu permasalahan dengan datanya
6. Menginterpretasikan hasil hitungan ukuran faktor
3.2
Prevalensi dan insidensi
Definisi sehat menurut WHO adalah: health is a state of complete physical,
mental, and social well-being and not merely the absence of disease or infir-mity. Definisi ini cukup sulit direalisasikan terutama pada definisi dan ukuran
3.2. Prevalensi dan insidensi 16
well-being. Definisi yang lebih praktis yang banyak digunakan oleh epidemiolog
adalah ”ada” atau ”tidak ada” penyakit1.
Statistik atau ukuran paling dasar yang sering digunakan untuk melihat be-sarnya permasalahan dalam epidemiologi adalah banyaknya kejadian atau fre-kuensi kejadian (sakit, meninggal, dsb.). Namun ukuran ini sangat bergantung pada besar populasi dan lama periode pengamatan. Ukuran yang tidak bergan-tung pada besar populasi dan lama periode pengamatan yang banyak digunakan adalah prevalensi (prevalence) dan insidensi (incidence)
Prevalensi adalah banyaknya subyek yang mengalami kejadian tertentu atau
menderita penyakit tertentu pada suatu waktu tertentu. Prevalensi dirumuskan sebagai:
P = d
N, (3.1)
denganP adalah prevalensi;dadalah banyaknya subyek yang mengalami kejadi-an tertentu atau menderita penyakit tertentu pada suatu waktu tertentu;N adalah banyaknya subyek pada suatu waktu tersebut.
Insidensi adalah banyaknya subyek yang mengalami kejadian baru atau
men-dapatkan penyakit baru dalam suatu interval waktu tertentu. Jenis ukuran insi-densi yang sering dipakai adalah insiinsi-densi kumulatif IK dan tingkat insidensi (incidence rate)I.
IK dirumuskan sebagai:
IK = d
N0
, (3.2)
denganIKadalah insidensi kumulatif;dadalah banyaknya subyek yang mengala-mi kejadian tertentu atau menderita penyakit tertentu dalam suatu interval waktu tertentu; N0 adalah banyaknya subyek yang belum mengalami kejadian tertentu
atau menderita penyakit tertentu pada awal interval waktu tersebut.
Jenis insidensi yang lain berdasarkan pada pengertian tingkat (rate), yaitu ba-nyaknya perubahan kuantitatif yang terjadi yang terkait dengan waktu.
Insidensi (Incidence rate) dirumuskan sebagai: I = d
N T, (3.3)
denganI adalah insidensi;dadalah banyaknya subyek yang mengalami kejadian tertentu atau menderita penyakit tertentu dalam suatu interval waktu tertentu;N T
1Meskipun demikian penelitian dalam bidang Biostatistika dan Epidemiologi saat ini mengarah pada pengukuran hal-hal yang lebih soft daripada hanya sakit dan tidak sakit seperti well-being dan
3.2. Prevalensi dan insidensi 17
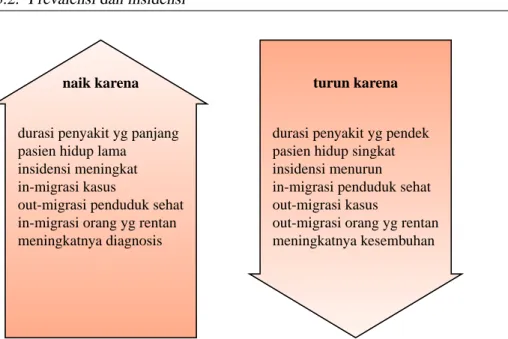
naik karena turun karena
durasi penyakit yg panjang pasien hidup lama
insidensi meningkat in-migrasi kasus
out-migrasi penduduk sehat in-migrasi orang yg rentan meningkatnya diagnosis
durasi penyakit yg pendek pasien hidup singkat insidensi menurun in-migrasi penduduk sehat out-migrasi kasus
out-migrasi orang yg rentan meningkatnya kesembuhan
Gambar 3.1: Faktor-faktor yang mempengaruhi estimasi prevalensi (Beaglehole et al., 2000).
adalah total waktu subyek yang belum mengalami kejadian tertentu atau menderi-ta penyakit tertentu dalam interval waktu tersebut (sering juga disebut sebagai
person-time atau risk-time)
Istilah lain yang sering digunakan untuk insidensi adalah person-time
inci-dence rate, instantaneous inciinci-dence rate, force of morbidity, inciinci-dence-density, hazard).
Prevalensi sangat dipengaruhi oleh banyak faktor yang tidak berhubungan langsung dengan penyebab penyakit, misalnya in-migrasi dan out-migrasi dan perbaikan cara diagnosis (lihat Gambar 3.1). Oleh karena itu prevalensi tidak di-anjurkan untuk menunjukkan kausalitas. Tapi prevalensi sangat membantu untuk menunjukkan besarnya masalah kesehatan.
Prevalensi dan insidensi saling berkaitan, secara umum hubungannya dapat ditunjukkan seperti persamaan (3.4), asalkan prevalensi kecil dan tidak berubah menurut waktu.
prevalensi≈insidensi×durasi (3.4)
3.2.1
Model untuk Prevalensi
Dasar analisis untuk prevalensi adalah Model Bernoulli (Lihat Gambar 3.2) yang mempunyai asumsi sebagai berikut :
3.2. Prevalensi dan insidensi 18
S
G π
1−π
Gambar 3.2: Model Bernoulli.
• tiap usaha (trial) menghasilkan satu dari dua hasil yang mungkin, dina-makan sukses (S) dan gagal (G);
• peluang sukses,P(S) =πdan peluang gagalP(G) = 1−π
• usaha-usaha tersebut independen Fungsi probabilitas Bernoulli adalah
P(X =x;π) =πx(1−π)1−x, (3.5) denganπadalah probabilitas sukses danx= 0,1(gagal, sukses). Dalam konteks Epidemiologi, definisi sukses misalnya terkena penyakit tertentu atau meninggal. Untuk melakukan inferensi berdasarkan model ini dapat digunakan fungsi
likeli-hood berdasarkan data yang diperoleh. Contoh 3.1
Darin= 10orang diketahui outcome sukses (S) dan gagal (G) SSGSGGGSGG (misalnya sukses adalah terkena penyakit tertentu dan gagal adalah tidak terkena penyakit tertentu). Seberapa mungkin data ini berasal dari model binomial dengan (i)π =0,1; (ii)π =0,5?
Jawab: (i) π =0,1: L(π |data) = ππ(1−π)π(1−π)(1−π)(1−π)π(1−π)(1−π) = 0,14×0,96 = 5,31×10−5 (ii) π =0,5 L(π |data) = ππ(1−π)π(1−π)(1−π)(1−π)π(1−π)(1−π) = 0,54×0,56 = 9,77×10−4
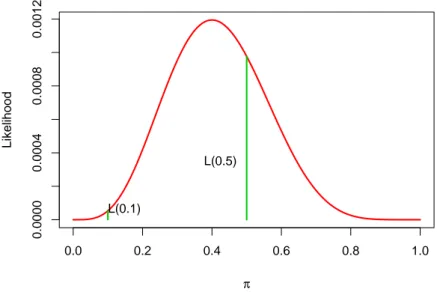
3.2. Prevalensi dan insidensi 19 0.0 0.2 0.4 0.6 0.8 1.0 0.0000 0.0004 0.0008 0.0012 π Likelihood L(0.1) L(0.5)
Gambar 3.3: Fungsi likelihood untuk data biner SSGSGGGSGG denganπ =0,1 danπ=0,5.
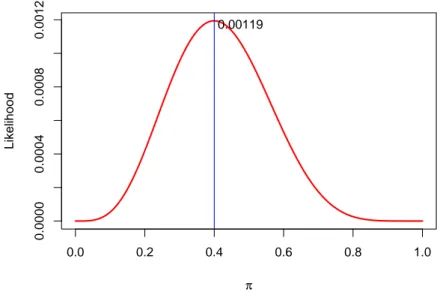
Terlihat bahwa likelihood untuk π = 0,5 lebih besar daripadaπ = 0,1 sehingga dapat disimpulkan bahwa data lebih mungkin berasal dari model Bernoulli dengan π = 0,5 daripadaπ=0,1 (Lihat Gambar 3.3).
Nilai maksimum likelihood untuk data ini diperoleh pada π = 0,4 (Gambar 3.4). Nilai inilah yang sebenarnya paling didukung oleh data. Cara seperti ini dikenal dalam Statistika sebagai cara untuk mencari estimator dengan Metode Maximum
Like-lihood.
Inferensi untuk prevalensi dapat dilakukan berdasarkan tiga prinsip yaitu in-terval konfidensi (confidence inin-terval), menurut teori frequentist; supported range untuk parameter berdasarkan likelihood ratio menurut teori likelihood; dan
cred-ible interval menurut teori Bayesian (Clayton and Hills, 1993). Metode yang
paling sering digunakan dan diterima di komunitas peneliti di bidang epidemio-logi adalah interval konfidensi menggunakan pendekatan Teorema Limit Sentral. Dalam perkembangannya kedua metode yang lain mulai berkembang dan menda-patkan perhatian.
3.2. Prevalensi dan insidensi 20 0.0 0.2 0.4 0.6 0.8 1.0 0.0000 0.0004 0.0008 0.0012 π Likelihood 0.00119
Gambar 3.4: Maksimum Likelihood untuk data biner SSGSGGGSGG adalah pada π =0,4.
3.2.2
Model untuk Insidensi
Model untuk insidensi kumulatif pada prinsipnya sama seperti prevalensi, yaitu berdasarkan pada model Bernoulli. Di sini akan dibahas model untuk insidensi, khususnya incidence rate (3.3).
Pada bagian sebelumnya, prevalensi dapat dipandang sebagai eksperimen Bernoulli, dengan sukses adalah kejadian yang menjadi perhatian, seperti sakit dan lainnya. Model ini dapat dikembangkan untuk insidensi. Dalam insiden-si, khususnya incidence rate (3.3), seorang individu diamati dalam suatu periode waktu tertentu. yang dapat dibagi dalam beberapa interval. Misalnya, seseorang yang diamati selama 3 tahun dapat dibagi menjadi 3 satu tahun interval waktu pengamatan.
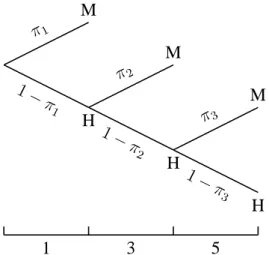
Pada Gambar 3.5 seseorang diamati sampai M (meninggal) yang juga meru-pakan titik akhir (end-point) pengamatan, selama 3 tahun. Apabila dalam 3 tahun tersebut probabilitas meninggal sama, misalnyaπ, maka model yang dapat digu-nakan adalah Bernoulli seperti yang telah dibahas di muka. Namun apabila dalam setiap interval waktu probabilitas meninggal berbeda, misalnyaπ1, π2,π3 seperti
terlihat pada Gambar, maka probabilitas M untuk tiap akhir interval akan berbeda dan merupakan probabilitas bersyarat.
3.2. Prevalensi dan insidensi 21 1 3 5 π1 M H 1− π1 π2 M H 1− π2 π3 M H 1− π3
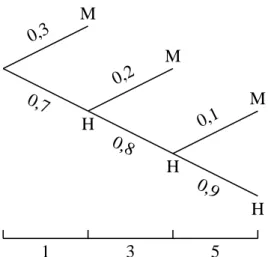
Gambar 3.5: Insidensi sebagai satu urutan beberapa model probabilitas biner, de-ngan sukses M (mati) dan gagal H (hidup).
meninggal pada akhir tahun pertama adalah 0,3. Probabilitas meninggal pada akhir tahun kedua merupakan probabilitas bersyarat, karena untuk meninggal pa-da akhir tahun kedua individu ini harus hidup papa-da akhir tahun pertama, sehing-ga probabilitasnya adalah 0,7 × 0,2 = 0,14. Demikian pula untuk probabilitas meninggal pada akhir tahun ketiga, 0,7×0,8×0,1= 0,056.
Selanjutnya, untuk interval yang semakin sempit, probabilitas kondisional (untuk M) menjadi semakin kecil pula, dan konvergen ke hazard rate (force of
mortality)
λ = lim
h→0
P(t≤T < t+h|T ≥t)
h (3.6)
Likelihood untuk λ dapat diturunkan dari likelihood binomial dengan men-ganggap bahwa probabilitas sukses adalahλhdenganhkecil,
L(λ) = λDexp(−λY) (3.7)
denganDadalah banyaknya kejadian,Y adalah total waktu observasi. Log-likelihood untukλ
ℓ(λ) = Dlog(λ)−λY (3.8)
Persamaan (3.7) dan (3.8) adalah fungsi likelihood dan log-likelihood untuk distribusi Poisson. Dapat dengan mudah ditunjukkan bahwa penduga untuk λ adalah
ˆ
λ= D
3.2. Prevalensi dan insidensi 22 1 3 5 0,3 M H 0,7 0,2 M H 0,8 0,1 M H 0,9
Gambar 3.6: Contoh satu urutan beberapa model probabilitas biner dan penghi-tungan probabilitas bersyarat).
Contoh 3.2
Misalkan ada 7 observasi dengan total waktu observasi 500 orang-tahun (person-years). Log-likelihood untukλ
ℓ(λ) = 7 log(λ)−500λ
Nilai maksimum untuk fungsi Log-likelihood ini diperoleh pada λ = 0,014 (Gambar 3.7) 0.005 0.010 0.015 0.020 0.025 0.030 −39.5 −38.5 −37.5 λ log likelihood
3.3. Faktor Resiko 23
Contoh 3.3
Sebuah studi tentang akibat buruk merokok bagi kesehatan dilakukan di Inggris pada tahun 1951. Diperoleh data berupa kematian akibat penyakit jantung koroner dikate-gorikan menurut umur dan status merokok (Tabel 3.1).
Tabel 3.1: Kematian akibat jantung koroner menurut umur dan status merokok Kel. perokok bukan perokok
Umur kematian person-years kematian person-years
35 – 44 32 52407 2 18790 45 – 54 104 43248 12 10673 55 – 64 206 28612 28 5710 65 – 74 186 12663 28 2585 75 – 84 102 5317 31 1462
Insidensi untuk kematian akibat penyakit jantung koroner dapat dihitung menggu-nakan rumus (3.9). Insidensi keseluruhan tanpa melihat status merokok dan usia adalah
ˆ
λ = 32 + 104 + 206 +. . .+ 31 52407 + 43248 + 28612 +. . .+ 1462 = 731
181467 = 0,004
karena bilangan insidensi biasanya kecil, nilai estimasinya dikalikan bilangan yang agak besar misalnya 1000. Jadi insidensi kematian di atas adalah 4 kematian per 1000 orang.
Dengan cara yang sama insidensi untuk tiap tingkat faktor resiko dapat dihitung. Mi-salnya insidensi dalam kelompok perokok adalah
ˆ λ1 = 32 + 104 + 206 + 186 + 102 52407 + 43248 + 28612 + 12663 + 5317 = 630 142247 = 4,43 per 1000 orang,
dan untuk kelompok bukan perokok λˆ0 =101/39220= 2,58 per 1000 orang. Kematian
dalam kelompok perokok terlihat lebih tinggi.
3.3
Faktor Resiko
Bagian di muka membahas statistik dan ukuran tanpa memandang adanya fak-tor atau variabel yang mempengaruhi statistik atau ukuran tersebut. Dengan kata lain dalam notasi statistika di muka, sementara hanya dilihat variabelY saja tan-pa melihat adanya X (variabel independen, penjelas, paparan). Dalam bagian ini akan dibahas statistik dan ukuran yang melibatkan pengaruh faktor. Ukuran
3.3. Faktor Resiko 24
ini, seperti yang akan dijelaskan lebih lanjut, sangat bergantung pada pada desain penelitian yang digunakan.
Beberapa ukuran yang dapat digunakan untuk melihat faktor resiko di-antaranya:
• Selisih resiko (risk difference)
• Rasio resiko (risk ratio)
• Odds ratio
Misalkan π1 adalah probabilitas atau resiko untuk subyek yang terpapar dan π2
untuk subyek yang tidak terpapar. Sebagai contoh, π1adalah probabilitas subyek
terkena kanker paru jika diketahui subyek merokok, dan π1 adalah probabilitas
subyek terkena kanker paru jika diketahui subyek tidak merokok. Selisih resiko, rasio resiko dan odds ratio akan dijelaskan berdasarkanπ1 danπ2 di atas.
Selisih resiko didefinisikan sebagai
RD =π1−π2. (3.10)
yaitu selisih antara dua probabilitas π1 dan π2. Karena π1 = RD +π2, selisih
resiko mengukur perubahan pada skala aditif. Jika RD > 0, paparan berkaitan dengan kenaikan probabilitas terkena penyakit. Sebaliknya jikaRD <0, paparan berkaitan dengan penurunan probabilitas terkena penyakit; dan jika RD = 0, paparan tidak berkaitan dengan penyakit tersebut.
Rasio resiko didefinisikan sebagai rasio antara dua probabilitas, yaitu
RR=π1/π2. (3.11)
Karena π1 = RRπ2, rasio resiko mengukur perubahan pada skala multiplikatif.
Jika RR > 1, paparan berkaitan dengan kenaikan probabilitas terkena penyakit. JikaRR <1, paparan berkaitan dengan penurunan probabilitas terkena penyakit; dan jikaRR= 1, paparan tidak berkaitan dengan penyakit tersebut.
Odds merupakan representasi alternatif untuk probabilitas. Untuk probabilitas π 6= 1, oddsωdidefinisikan sebagai
ω= π
1−π. (3.12)
Pernyataan odds dalam penggunaan sehari-hari biasanya digunakan untuk mengekspresikan kebolehjadian, misalnya dalam suatu pertandingan olahra-ga: ”peluang saya menang melawan dia 60:40”, artinya peluang saya menang adalah 0,6.
Meskipun probabilitas dan odds merepresentasikan informasi yang sama, ni-lai rentang ω tidak sama dengan π, yaitu 0 ≤ π ≤ 1 sedangkan ω > 0. Bila
3.4. Inferensi untuk RD, RR dan OR 25
Tabel 3.2: Data dan Model Probabilitas untuk Desain Cohort (a) Data pada tabel2×2
D E 1 2 1 n11 n12 N1 2 n21 n22 N2 (b) Model probabilitas D E 1 2 1 π1 1−π1 1 2 π2 1−π2 1
didefinisikanω1 = π1/(1−π1) danω2 = π2/(1−π2), Odds ratio adalah rasio
antara dua oddsω1 danω2
OR = ω1
ω2
= π1(1−π2)
π2(1−π1)
. (3.13)
Odds ratio mirip dengan rasio resikoRRdalam hal perubahannya yang diukur secara multiplikatif. Interpretasi nilaiORjuga ekivalen denganRR.
3.4
Inferensi untuk RD, RR dan OR
Untuk desain cohort, semua ukuran faktor resiko RD, RR dan OR dapat diesti-masi dari data dan dapat diinterpretasikan. Data dan model probabilitasnya dapat digambarkan seperti pada Table 3.2.
Pada tabel tersebut E adalah variabel paparan (exposure) atau faktor resiko yang diteliti dan D adalah outcome. NilaiE = 1menunjukkan adanya paparan (exposed) dan E = 2 menunjukkan tidak adanya paparan (non-exposed). Mi-salkan variabel paparan yang akan diteliti adalah status merokok, E = 1adalah merokok dan E = 2 tidak merokok. NilaiD = 1menunjukkan adanya disease atau outcome yang menjadi perhatian, dan D = 2 menunjukkan tidak adanya
disease. Misalnya D = 1 adalah terdiagnosis kanker paru, dan D = 2 tidak terdiagnosis kanker paru.
Untuk desain cohortπ1adalah probabilitas mendapatkan disease untuk
kelom-pok yang diketahui sebelumnya sudah mendapatkan paparan, atau dengan notasi probabilitas π1 = P(E = 1 | D = 1). Sedangkanπ2 adalah probabilitas
men-dapatkan disease untuk kelompok yang diketahui sebelumnya tidak menmen-dapatkan paparan, atau π2 = P(E = 1 | D = 2). Total baris untuk model probabilitas
adalah satu karena kelompok paparan diambil dari dua populasi yang berbeda, yaitu kelompok exposedE = 1, dan kelompok non-exposedE = 2.
Estimasi titik untukπ1danπ2adalah
ˆ
π1 =n11/N1 (3.14)
ˆ
3.4. Inferensi untuk RD, RR dan OR 26
Estimasi titik untukRD,RRdanOR dapat diperoleh dengan menggantiπ1 dan π2 pada persamaan (3.10), (3.11) dan (3.13) denganπˆ1danπˆ2.
Selisih resikoRD pada dasarnya adalah selisih dua sampel independen yang berdistribusi Binomial. Proporsi sampelπˆi mempunyai harga harapanπi dan va-riansiπi(1−πi)/Ni, dengani= 1,2. Sehingga estimasi titik untukRDadalah
d
RD= ˆπ1−πˆ2 (3.16)
yang mempunyai galat standar (standard error) σRDd= π1(1−π1) N1 + π2(1−π2) N2 1/2 (3.17) Interval konfidensi(1−α)100%untukRDdapat dihitung dengan menggunakan pendekatan Normal sebagai berikut:
d
RD±Zα/2σˆ
d
RD, (3.18)
denganσˆRDdadalahσRDdnamun denganπi digantiπˆi.
Estimasi titik untukRRdapat diturunkan dari (3.11), (3.14) dan (3.15) yaitu d
RR= ˆπ1 ˆ
π2
Distribusi untuk dRR sangat menceng (skewed), sehingga pendekatan Nor-mal lebih baik jika menggunakan transformasi log daridRR. Galat standar untuk
logRRdadalah σlogdRR= 1−π1 π1N1 + 1−π2 π2N2 1/2 (3.19) Diperoleh interval konfidensi(1−α)100%untuklogRR
logRRd±Zα/2σ
logRRd (3.20)
Karena interval ini pada skala transformasi log, untuk interpretasinya harus dikembalikan pada skala asal dariRRdengan mengambil eksponensial, baik un-tuk batas interval bawah maupun atas.
Seperti halnya RR, estimasi titik untuk OR dapat diturunkan dari (3.13), (3.14) dan (3.15) yaitu d OR = πˆ1(1−ˆπ2) ˆ π2(1−ˆπ1) = n11n22 n12n21 , (3.21)
3.4. Inferensi untuk RD, RR dan OR 27
Untuk menghindari masalah bila ada nij = 0 dapat digunakan allternatif untuk (3.21),
d
OR= (n11+0,5)(n22+0,5) (n12+0,5)(n21+0,5)
(3.22) Distribusi untukORdini juga sangat menceng sepertidRR, sehingga diperlukan transformasilog untuk membentuk interval konfidensiOR.
Estimasi galat standar untuklogORdadalah
ˆ σlogORd= 1 n11 + 1 n12 + 1 n21 + 1 n22 1/2 , (3.23)
Sehingga interval konfidensi(1−α)100%untuklogOR adalahc
logORd±Zα/2σˆ
logORd (3.24)
Interpretasinya harus dikembalikan pada skala asal dari OR dengan mengambil eksponensial baik untuk batas bawah maupun batas atas dari interval konfidensi OR.
Contoh 3.4
Diperoleh data tentang hubungan antara penyakit jantung koroner dengan tekanan peker-jaan seperti pada Tabel 3.3.
Tabel 3.3: Data studi tentang hubungan penyakit jantung koroner dengan tekanan pekerjaan
Tertekan krn. Penyakit jantung koroner
Pekerjaan Ya Tidak Total
Ya 97 307 404
Tidak 200 1409 1609
Estimasi titik resiko terkena penyakit jantung koroner untuk masing-masing kelompok orang yang tertekan karena pekerjaan dan yang tidak tertekan adalah
ˆ
π1 = 97/404 = 0,240 dan πˆ2 = 200/1609 = 0,124
Estimasi titik untukRRdan standard error darilogRRddapat dihitung menggunakanπˆ1
danπˆ2, yaitu: d RR = ˆπ1/πˆ2 = 0,240/0,124 = 1,932 σlogRRd = 1−π1 π1N1 + 1−π2 π2N2 1/2 = 1−0,240 0,240(404) + 1−0,124 0,124(1609) 1/2 = 0,1105
3.4. Inferensi untuk RD, RR dan OR 28
Batas bawah interval konfidensi 95% adalah expnlog(dRR)−1,96×σlogRRdo = 1,555; dan batas atas intervalexpnlog(RRd) + 1,96×σlogdRRo= 2,399. Diperoleh estimasiRRdan interval konfidensinya adalah : 1,932 (1,555 — 2,399 ).
Estimasi titik untukORdanσlogORd:
d OR = πˆ1/(1−πˆ1) ˆ π2/(1−πˆ2) = 0,316/0,142 = 2,225 ˆ σlogORd = 1 n11 + 1 n12 + 1 n21 + 1 n22 1/2 = 1 97 + 1 307+ 1 200+ 1 1409 1/2 = 0,1388
Batas bawah interval konfidensi 95% adalah expnlog(ORd)−1,96×σlogORdo = 1,696; dan batas atas intervalexpnlog(dOR) + 1,96×σlogORdo= 2,922. Diperoleh estimasiORdan interval konfidensinya adalah : 2,225 (1,696 — 2,922 ).
Estimasi titik untukRDadalah
d RD = ˆπ1−πˆ2 = 0,240−0,124 = 0,116 σRDd = π1(1−π1) N1 +π2(1−π2) N2 1/2 = 0,0228
Batas bawah interval konfidensi 95%(ˆπ1−πˆ2)−1,96×σ
d
RD= 0,071; dan batas atas intervalnya(ˆπ1−πˆ2) + 1,96×σ
d
RD = 0,161. Diperoleh estimasiRDdan interval konfidensinya adalah : 0,116 (0,071 — 0,161 ).
Pada desain case-control, Data dan model probabilitasnya dapat digambarkan seperti pada Tabel 3.4. Dalam tabel iniM1danM2adalah banyaknya sampel yang
diperoleh dari kelompok sampel yang mendapatkan disease (D = 1) dan dari kelompok yang tidak mendapatkan disease (D = 2). Dari masing-masing kelom-pok diambil informasi secara retrospektif apakah sampel telah terpapar (E = 1
atau tidakE = 2. Model probabilitasnya juga berbeda dengan desain Cohort kare-na probabilitas kondisiokare-nalnya adalah terhadap diseaseDbukan terhadap paparan E, yaitu probabilitasφ1 =P(E = 1|D= 1)danφ2 =P(E = 1|D= 2).
Berdasarkan model ini, tidak mungkin diperoleh estimasi untukπi, i = 1,2 seperti pada desain Cohort. Sehingga estimasi untuk RD dan RR tidak dapat diperoleh. Bagaimana dengan OR? Apabila estimasiOR dihitung untuk odds paparan dalam kelompok diseased dibagi odds paparan dalam kelompok
non-3.5. Latihan 29
Tabel 3.4: Data dan Model Probabilitas untuk Desain Case-Control. (a) Data pada tabel2×2
D E 1 2 1 n11 n12 2 n21 n22 M1 M2 (b) Model probabilitas D E 1 2 1 φ1 φ2 2 1−φ1 1−φ2 1 1
diseased maka dapat diperoleh
g OR = φˆ1(1−φˆ2) ˆ φ2(1−φˆ1) = n11n22 n12n21 , (3.25)
denganφˆ1 =n11/M1danφˆ2 =n12/M2. TernyataORg =ORd, yang implikasinya
adalahORdapat diestimasi untuk desain Case-Control.
Pada desain cross-sectional statistik yang dapat diinterpretasikan dengan valid hanyalah prevalensi, oleh karena itu desain cross-sectional sering disebut studi prevalensi. Meskipun RD, RR danOR dapat dihitung dari data yang diperoleh dari studi cross-sectional, kesimpulan atau interpretasi yang diperoleh kemung-kinan akan tidak valid.
3.5
Latihan
3.1. Hitunglah odds S (Sukses) terhadap G (Gagal), dengan sukses misalnya adalah terkena suatu penyakit dan gagal adalah tidak terkena suatu penya-kit), bila probabilitas S diketahui adalah:
(a) 0,75 (b) 0,50 (c) 0,25
3.2. Hitunglah probabilitas sukses S bila diketahui odds S terhadap gagal G adalah:
(a) 0,3 (b) 3,0
3.3. Diketahui dari 8 orang pasien kanker rahim, 2 pasien meninggal dunia. Bila kita tertarik pada parameter π, yaitu probabilitas pasien meninggal, nilai manakah yang lebih didukung oleh data,π = 0,2 atauπ = 0,6? Jelaskan! Carilah estimator untuk parameterπ!
3.5. Latihan 30
Paparan banyaknya siswa banyaknya siswa yang diperiksa yang posisif tb
tinggi 129 63
rendah 325 36
Hitung risk difference, risk ratio dan odds ratio untuk paparan tinggi beserta interval interval konfidensinya. Interpretasikan hasilnya.
3.5. Merujuk soal no 2.8 (halaman 12), hitung risk difference, risk ratio dan odds
ratio untuk paparan tinggi beserta interval interval konfidensinya.
Interpre-tasikan hasilnya.
3.6. Suatu studi dilakukan untuk menguji hipotesis yang menyatakan bahwa ada hubungan antara konsumsi teh dan sindroma pra-menstruasi. Satu grup yang terdiri dari 120 pelajar dan 80 pekerja pabrik menjadi subyek peneli-tian dan mengisi kuesioner tentang sindroma pra-menstruasi. Prevalensi sindroma pra-menstruasi di antara pelajar adalah 40% dan di antara pekerja pabrik adalah 75%. Berapa subyek dalam studi ini yang mengalami sindro-ma pra-menstruasi?
4
Perancuan dan Interaksi
4.1
Tujuan Pembelajaran
Setelah selesai melakukan pembelajaran pada bagian ini, mahasiswa diharapkan dapat:
1. Menjelaskan pengertian perancuan (confounder) dan interaksi dan menye-butkan contohnya dalam penelitian epidemiologi
2. Mengidentifikasi adanya perancuan dalam suatu permasalahan atau data penelitian epidemiologi
3. Mengidentifikasi adanya interaksi dalam suatu permasalahan atau data penelitian epidemiologi
4.2
Konsep dan Identifikasi Perancuan
Variable perancu adalah variabel yang memenuhi dua kondisi:
• merupakan faktor resiko
• mempunyai hubungan dengan variabel paparan tapi bukan merupakan kon-sekuensi dari variabel paparan
Secara konseptual perancuan dapat digambarkan seperti pada Gambar 4.1 dan 4.2. Pada gambar pertama variabel F mempengaruhi baik variabel D maupun E, sedangkan pada gambar kedua F tidak mempengaruhi D dan E sekaligus.
Contoh 4.1
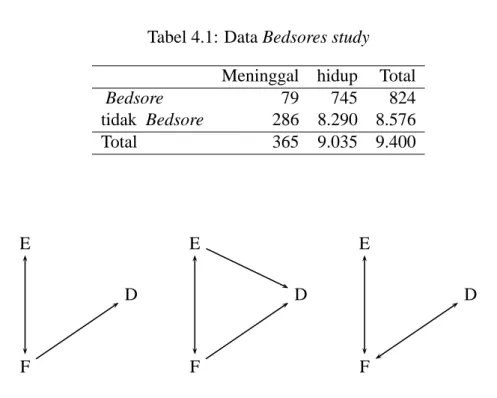
Manula yang mengalami kecelakaan, seperti terjatuh, seringkali menjadi tidak dapat ban-gun dan bergerak dalam waktu lama. Hal ini dapat mengakibatkan bedsores, yaitu luka
4.2. Konsep dan Identifikasi Perancuan 32
Tabel 4.1: Data Bedsores study Meninggal hidup Total
Bedsore 79 745 824 tidak Bedsore 286 8.290 8.576 Total 365 9.035 9.400 F E D F E D F E D
Gambar 4.1: Variabel F adalah perancu antara D (variabel respon) dengan E (vari-abel paparan). Tanda→pengaruh satu arah;↔pengaruh dua arah
F E D F E D F E D F E D
Gambar 4.2: Variabel F bukan perancu antara D dengan E (variabel respon) de-ngan E (variabel paparan). Tanda→pengaruh satu arah;↔pengaruh dua arah
4.2. Konsep dan Identifikasi Perancuan 33
Tabel 4.2: Data Bedsores study distratifikasi menurut tingkat keparahan Tingkat keparahan tinggi akibat penyakit lain:
Meninggal hidup Total
Bedsore 55 51 106
tidak Bedsore 5 5 10
Total 60 56 116
Tingkat keparahan rendah akibat penyakit lain: Meninggal hidup Total
Bedsore 24 694 718
tidak Bedsore 281 8.285 8.566
Total 305 8.979 9.284
pada kulit yang dapat berlanjut ke otot dan tulang dan dapat berakibat fatal. Diperoleh data seperti pada Tabel 4.1. Rasio resiko dari data ini adalah
RR= 79/824
286/8576 =2,9
Nilai RR tersebut cukup tinggi menunjukkan bahwa bedsore mungkin dapat meng-akibatkan kematian. Untuk melihat apakah ada variabel perancu pada data ini diperoleh data seperti pada Tabel 4.2. Data distratifikasi menurut tingkat keparahan penyakit lain.
Dari stratifikasi ini diperoleh RR untuk masing-masing tingkat adalah
RR= 55/106
5/10 =1,04
untuk tingkat keparahan tinggi dan
RR= 24/718
281/8566 =1,02
untuk tingkat keparahan rendah. Dari hasil stratifikasi ini terlihat bahwa bedsore tidak terlalu berpengaruh terhadap kematian karena nilai RR cukup dekat dengan satu. Artinya bahwa tingkat keparahan merupakan variabel perancu dalam hubungan antara bedsore dengan kematian.
Contoh 4.2
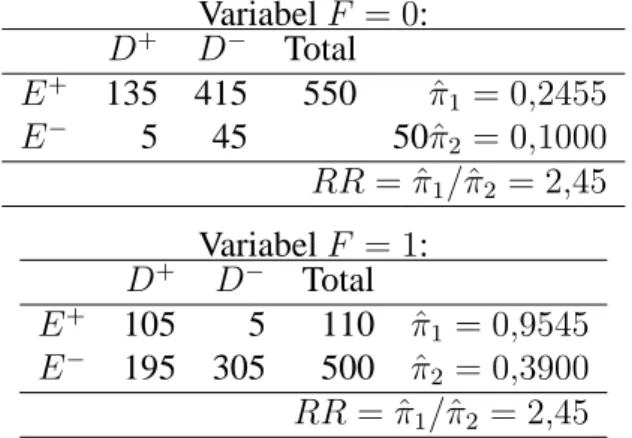
Contoh ini berkebalikan dengan contoh sebelumnya. Ketika tidak ada confounder, ter-lihat tidak ada pengaruh faktor resiko (Tabel 4.3). Namun ketika di-stratifikasi menurut confounder, terlihat ada pengaruh faktor resiko terhadap disease.
4.3. Metode Standarisasi dan Mantel-Haenszel 34
Tabel 4.3: Data faktor resiko dengan disease D+ D− Total E+ 240 420 660 πˆ 1 = 0,3636 E− 200 350 550 πˆ 2 = 0,3636 RR= ˆπ1/πˆ2 = 1
Tabel 4.4: Data faktor resiko dengan disease distratifikasi menurut variabel lain (confounder) VariabelF = 0: D+ D− Total E+ 135 415 550 πˆ 1 = 0,2455 E− 5 45 50πˆ2 = 0,1000 RR= ˆπ1/πˆ2 = 2,45 VariabelF = 1: D+ D− Total E+ 105 5 110 πˆ 1 = 0,9545 E− 195 305 500 πˆ 2 = 0,3900 RR= ˆπ1/πˆ2 = 2,45
4.3
Metode Standarisasi dan Mantel-Haenszel
Metode standarisasi digunakan untuk mengatasi confounding dengan cara mem-bandingkan atau melakukan standarisasi dengan suatu populasi pembanding (standar). Metode ini biasa digunakan dalam Demografi. Variabel atau faktor yang biasanya digunakan dalam standarisasi adalah usia dan jenis kelamin. Dike-nal dua jenis standarisasi yaitu (1) standarisasi langsung (direct standardization); dan (2) standarisasi tidak langsung (indirect standardization)
4.3.1
Standarisasi Langsung
Standarisasi langsung dibentuk dari hasil estimasi banyaknya kejadian (event) yang diperoleh dari model (distribusi) populasi studi (study population), dike-nakan pada populasi standar (standard/reference population). Variabel yang biasa digunakan untuk standarisasi adalah kelompok umur. Data yang diperlukan untuk penghitungan standarisasi dapat disusun seperti pada Tabel 4.5, denganniadalah banyaknya kejadian (misalnya kematian) dalam interval (kelompok umur)iuntuk populasi studi;Niadalah ukuran (banyaknya) populasi studi dalam intervalidan
Mi :ukuran populasi pembanding.
4.3. Metode Standarisasi dan Mantel-Haenszel 35
Tabel 4.5: Data untuk Standarisasi Kel. Populasi Populasi umur studi pembanding
1 n1 N1 M1 2 n2 N2 M2 .. . ... ... i ni Ni Mi .. . ... ... k nk Nk Mk r=C Pk i=1 ni NiMi Pk i=1Mi , (4.1)
dengan C suatu konstanta yang digunakan agar bilangan yang diperoleh tidak terlalu kecil. Biasanya C = 1000, sehingga satuan untuk r adalah banyaknya kejadian per 1000 orang.
Deviasi standar untukradalah
SE(r) = PkC i=1Mi k X i=1 s ni Mi Ni 2 (4.2)
yang dapat digunakan untuk menghitung interval konfidensi 95%, yaitu:r±1,96×
SE(r).
4.3.2
Standarisasi Tidak Langsung
Metode ini menggunakan dua tahapan proses. Pertama model dari populasi pem-banding yang biasanya berupa ASDR (Age Specific Deaths Rate) dikenakan pada studi populasi. Untuk penghitungan ini diperlukan informasi banyaknya kejadi-an (kematikejadi-an) di populasi pembkejadi-anding (dinotasikkejadi-an sebagai mi) karena ASDR = mi/Mi. Harga harapan banyaknya kematian dalam populasi studi berdasarkan model populasi pembanding adalahE =Pki=1Ni(mi/Mi). Diperoleh
standard-ized event ratio (ser) atau standardstandard-ized mortality ratio (smr) jika event yang
men-jadi perhatian adalah mortalitas sebagai berikut, smr=
Pk
i=1ni
4.3. Metode Standarisasi dan Mantel-Haenszel 36
Tabel 4.6: Data Tabel2×2untuk strata ke-i Status Sakit/Event Total
D+ D− E+ a i bi ai+bi E− c i di ci+di Total ai+ci bi +di ni
dengan standard error
SE(smr) =
q
(Pki=1ni)
E (4.4)
Pada tahapan kedua dapat dihitung standarisasi tidak langsung sebagai berikut rindirect=C×smr× Pk i=1mi Pk i=1M i , (4.5)
dengan standard error
SE(rindirect) =C× q (Pki=1ni) E × Pk i=1mi Pk i=1M i (4.6)
4.3.3
Mantel-Haenszel
Untuk data yang distratifikasi menurut variabel perancu, dapat dihitung odds ratio gabungan dari masing-masing strata. Estimator ini disebut Mantel-Haenszel odds
ratio yang ˆ ΨMH = Pk i=1aidi/ni Pk i=1bici/ni ! (4.7) dengan standar error untuklog( ˆΨMH)adalah
SE(log( ˆΨMH)) = s P PiRi 2(PRi)2 + P PiSi+PQiRi 2PRiPSi + P QiSi 2(PSi)2 (4.8)
untuk setiap stratumi,
Pi = (ai+di)/ni, Qi = (bi +ci)/ni,
4.4. Interaksi 37
(a) tidak ada interaksi
p el u an g d is ea se A=E− A=E+ B=E − B=E + (b) interaksi unilateral p el u an g d is ea se A=E− A=E+ B =E− B=E + (c) interaksi sinergis p el u an g d is ea se A=E− A=E+ B=E− B= E+ (d) interaksi antagonis p el u an g d is ea se A=E− A=E+ B= E− B= E+
Gambar 4.3: Jenis Interaksi untuk Dua Faktor ResikoAdanB
Interval konfidensi 95% untuklog( ˆΨMH)adalah
log( ˆΨMH)±1,96SE(log( ˆΨMH)), (4.9)
Interval konfidensi 95% untukΨˆMH sendiri dapat dihitung dengan mengambil
ni-lai eksponensial dari masing-masing batas interval tersebut.
4.4
Interaksi
Dua faktor dikatakan berinteraksi bila efek satu faktor terhadap suatu kejadian penyakit berbeda tingkatnya untuk beberapa strata atau nilai yang berbeda dari faktor yang lain. Istilah lain untuk interaksi yang lebih dikenal dalam epidemio-logi adalah modifikasi efek (effect modification). Bila tidak ada interaksi, seti-ap faktor resiko akan mempunyai efek yang tetseti-ap (homogen) pada tingkat yang berbeda-beda dari faktor yang lain.
Interaksi dan jenisnya dapat digambarkan seperti pada Gambar 4.3. Misalkan ada dua faktorA danB yang menjadi perhatian dan masing-masing mempunyai dua tingkat faktor yaitu terpapar (exposed E+) dan tidak terpapar (non-exposed E−
).
Bila tidak ada interaksi antara faktor A dan B, peluang terjadinya disease (efek dari faktor) dari non-exposed ke exposed akan sama tingkat kenaikannya (Gambar 4.3 (a)). Untuk faktor B tidak terpapar (B = E−
), pengaruh faktor A akan naik dari ketikaA =E− keA = E+yang mana tingkat kenaikannya sama
4.4. Interaksi 38
(kemiringannya) untuk faktorB terpapar (B = E+). Untuk interaksi unilateral
(Gambar 4.3 (b)), efek dari faktorAada jika faktorBterpapar (B =E+). Namun
bilaB tidak terpapar faktorAtidak berpengaruh. Interaksi sinergis terjadi bila pengaruh faktor A searah atau sama-sama naik dari A = E−
ke A = E+, tapi
kenaikan akan makin besar bila ada B terpapar (B = E+). Interaksi antago-nis berlawanan dengan interaksi sinergis. Jeantago-nis interaksi variabel ini terjadi bila
pengaruh faktorAmenjadi berkebalikan ketikaB berubah. JikaB tidak terpapar (B = E−), pengaruh A akan menurun dari ketika tidak terpapar (A = E−) ke
terpapar (A = E+). Sebaliknya jika B terpapar (B = E+), pengaruh A akan
naik.
Untuk mengidentifikasi adanya interaksi, perlu dilakukan analisis baik secara deskriptif berupa diagram interaksi maupun dengan uji statistik. Pengetahuan ten-tang substansi variabel atau faktor yang diteliti sudah tentu diperlukan untuk iden-tifikasi awal variabel atau faktor apa saja yang mungkin berinteraksi.
Untuk menguji interaksi dapat digunakan statistik berdasarkan risk rasio (RR), risk difference (RD) maupun odds ratio (OR). Misalkan ada dua faktor AdanB seperti digunakan di atas. Untuk menyederhanakan notasi, terpapar oleh faktor A atau A = E+ dituliskan sebagai A
1, tidak terpapar oleh faktor A atau A = E−
dituliskan sebagaiA0, demikian pula untuk faktorB. Kemudian
dide-finisikan kombinasi dari faktorA danB sebagai berikutA1B1, A1B0,A0B1 dan A0B0. Notasi A1B1 adalah terpapar baik oleh faktor A maupun B, kombinasi
yang lain dapat diartikan dengan cara yang sama.
Didefinisikan pula probabilitas kondisional mendapatkan penyakit (D+)
de-ngan diberikan kombinasi faktorAdanB sebagai berikut:
π11=P(D+|A1B1) π10=P(D+ |A1B0) π01=P(D+|A0B1) π00=P(D+ |A0B0)
Empat macam resiko terkena penyakit dinyatakan sebagai probabilitas bersyarat terhadap kombinasi antara faktorAdanB ini dapat dilihat seperti pada Tabel 4.7 (a).
MenggunakanRR(Tabel 4.7 (b)), faktorAdanBdikatakan tidak ada
inter-aksi bila
RRAB =RRARRB, (4.10)
denganRRAB adalah risk ratio antara resiko mendapatkan penyakit jika terpapar olehAdan terpaparB, dengan resiko mendapat penyakit jika tidak terpapar oleh A maupunB; atauRRAB =π11/π00. Dengan interpretasi yang sama
didefinisi-kan pula RRA = π10/π00 danRRB = π01/π00. Pernyataan (??) dinamakan
in-teraksi pada skala multiplikatif (interaction on multiplicative scale). Berdasarkan skala multiplikatif, tidak ada interaksi berarti rasio resiko paparan bersamaAdan B sama dengan hasil kali rasio resiko masing-masing faktor.
4.5. Latihan 39
Tabel 4.7: Interaksi menurut RR, OR dan RD (a) Resiko, diketahui faktorAdanB
faktor B faktorA B =E− B =E+ A =E− π 00 π01 A =E+ π 10 π11 (b) MenggunakanRR faktor B faktorA B =E− B =E+ A=E− 1 RR B A=E+ RR A RRAB tdk ada interaksi:RRAB=RRARRB (c) MenggunakanOR faktor B faktorA B =E− B =E+ A=E− 1 OR B A=E+ OR A ORAB tdk ada interaksi:ORAB=ORAORB (c) MenggunakanRD faktor B faktorA B =E− B =E+ A=E− 0 RD B A=E+ RD A RDAB tdk ada interaksi:RDAB=RDA+RDB
Pengujian interaksi secara multiplikatif dapat pula dilakukan menggunakan OR(Tabel 4.7 (c)) sebagai berikut
ORAB =ORAORB, (4.11)
denganORAB,ORAdanORB didefinisikan dan diinterpretasikan serupa seperti
RR di atas. MisalnyaORA = [π10/(1−π10)]/[π00/(1−π00)]adalah odds ra-tio antara odds mendapatkan penyakit jika terpapar oleh Adan tidak terpaparB, dengan odds mendapatkan penyakit jika tidak terpapar olehAmaupunB.
Interaksi dapat pula terjadi pada skala aditif (interaction on additive scale) dengan menggunakan RD (Tabel 4.7 (d)). Dengan cara ini, faktor A dan B dikatakan tidak ada interaksi bila
RDAB = RDA+RDB (4.12)
(π11−π00) = (π10−π00) + (π01−π00)
yaitu selisih resiko antara paparan bersama A dan B sama dengan total selisih resiko antara masing-masing faktor.
Apabila faktor yang menjadi perhatian lebih dari dua maka diperlukan model-model regresi yang akan dibahas pada Bab-Bab selanjutnya.
4.5
Latihan
1. Diberikan tabel2×2seperti di bawah yang diperoleh dari studi prospektif dengan variabel paparanE dan variabel penyakitD.
4.5. Latihan 40
D+ D−
E+ 205 76 E− 65 116
(a) Stratifikasilah tabel di atas menjadi dua buah tabel2×2sedemikian sehingga variabel ketiga yang men-stratifikasi tabel di atas merupakan variabel confounder (berikan nama variabelnyaF dan kategorinyaF0
danF1)
(b) Hitunglah OR Mantel-Haenszel dari data tabel yang saudara buat di atas
2. Dalam suatu studi tentang faktor resiko suatu penyakit, variabel status merokok dan konsumsi lemak menjadi perhatian. Misalkan diperoleh da-ta resiko relatif (RR) untuk kombinasi sda-tatus merokok dan tingkat konsumsi lemak adalah sebagai berikut:
konsumi status merokok
lemak tidak pernah mantan ringan berat
rendah 1 1.5 2.0 3.0
medium 1.2 1.8 2.4 3.6
tinggi 1.5 2.3 3.0 4.5
sangat tinggi 2.0 3.5 4.0 6.0
Dalam penelitian ini yang dianggap sebagai tingkat paparan yang terendah adalah tidak pernah merokok dan mengkonsumsi makanan rendah lemak, dan yang tertinggi adalah perokok berat dan menkonsumsi lemak sangat tinggi. Terlihat bahwa resiko semakin naik seiring dengan kenaikan tingkat paparan. Apakah data ini menunjukkan adanya perancuan (confounding)? Apakah data ini menunjukkan adanya interaksi antara konsumsi lemak de-ngan merokok kaitannya dalam mengakibatkan penyakit?
5
Model Linear Tergeneralisasi
5.1
Tujuan Pembelajaran
Setelah selesai melakukan pembelajaran pada bagian ini, mahasiswa diharapkan dapat:
1. Menjelaskan konsep Model Linear Tergeneralisasi (Generalized Linear
Mo-del) dan kaitannya dengan model statistika lain seperti Regresi Linear,
ANAVA, Regresi Logistik dan Regresi Poisson. 2. Melakukan inferensi Regresi Logistik.
3. Melakukan inferensi Regresi Poisson.
4. Mengidentifikasi model yang tepat untuk permasalahan dalam epidemiologi dan penelitian kesehatan.
5. Memberi contoh model GLM yang lain selain Regresi Linear, ANAVA, Re-gresi Logistik dan ReRe-gresi Poisson.
5.2
Generalisasi Model Linear
Model Linear yang sudah dikenal seperi Regresi Linear dan ANAVA juga bebe-rapa metode regresi lain yang cukup populer seperti regresi logistik sebenarnya merupakan satu keluarga model regresi yang lebih luas yang dinamakan Model Linear Terumumkan (GLM :Generalized Linear Model).
Ada tiga komponen utama yang membentuk GLM yaitu
• Variabel random Y1, Y2, . . . , Yn denganE(Yi) = µi dengan fungsi densitas dari keluarga eksponensial (exponential family)
5.2. Generalisasi Model Linear 42
• Prediktor linear
ηi =xiβ =β0+β1xi1+. . .+βpxip
• Fungsi penghubung (link function), yang menghubungkan E(Yi) = µi de-nganxiβ
g(µi) = xiβ
• Fungsi variansiVi
Fungsi densitas f(y;θ) disebut sebagai Keluarga eksponensial (exponential
family) bila:
f(y;θ) = s(y)t(θ)ea(y)b(θ)
= exp(a(y)b(θ) +c(θ) +d(y))
dengans(y) = exp(d(y))dant(θ) = exp(c(θ)).
• jikaa(y) =y,f(y;θ)disebut bentuk standar (canonical, standard form)
• b(θ)sering disebut parameter natural Beberapa contoh keluarga eksponensial
Distribusi parameter natural c d
Poisson logθ −θ −logy!
Normal σµ2 − µ2 2σ2 − 1 2 log(2πσ2) − y2 2σ2 Binomial log( π 1−π) nlog(1−π) log n y Beberapa contoh GLM:
Model Jenis responY distribusi fungsi penghubung Model linear Normal kontinu Normal identitas:g(µ) = µ Regresi Logistik proporsi binomial logit:g(µ) = log1−µµ
Regresi Poisson cacah Poisson log : g(µ) = logµ Model Gamma kontinu, positif Gamma log:g(µ) = logµ Beberapa contoh fungsi penghubung:
• identitas : g(µ) = µ
• logit: g(µ) = log1−µµ
• probit: g(µ) = Φ−1(µ),Φdistribusi kumulatif Normal standar
• power: g(µ) =
(
µλ jikaλ6= 0 log(µ) jikaλ= 0 • log: g(µ) = logµ
5.3. Regresi Logistik 43
5.3
Regresi Logistik
Pada Bagian 3.3 dipelajari analisis untuk tabel 2 × 2. Dalam tabel 2× 2 ini baik respon Y maupun variabel penjelas atau faktor X hanya terdiri atas dua je-nis kategori. Penelitian dalam bidang kesehatan maupun epidemiologi biasanya mempunyai lebih dari satu variabel penjelas atau faktorX. Untuk data penelitian semacam ini dapat digunakan regresi logistik.
5.3.1
Model dan Estimasi Parameter
MisalkanYi adalah variabel random Bernoulli untuk individui, distribusi proba-bilitasYI adalah
P(Yi =yi) =πy
i
i (1−πi)1−yi, yi = 0,1 (5.1) Setiap individuimempunyai karakteristik berupa variabelxiyang mempengaruhi
πi dalam bentuk
πi =
1
1 + exp(−(β0+β1xi))
(5.2) Fungsi seperti πi dalam persamaan (5.2) dinamakan fungsi logistik. Untuk vari-abel independen atau faktor yang lebih dari satu, fungsi untukπi dapat diperluas menjadi πi = 1 1 +e−Z , atau πi = eZ 1 +eZ (5.3)
dengan Z = β0 +β1x1 +β1x1 +· · ·+βp adalah fungsi linear dari p variabel penjelas.
Model (5.3) dapat dituliskan sebagai kombinasi linear dari variabel indepen-den seperti halnya pada model linear sebagai berikut
log πi 1−πi
=β0+β1x1i+β2x2i+· · ·+βpxpi (5.4)
atau
logit(πi) =β0+β1x1i+β2x2i+· · ·+βpxpi (5.5) dengan x1i, x2i, . . . , xpi adalah variabel independen, faktor atau kovariat; dan
5.3. Regresi Logistik 44
Estimasi untuk β = (β0, β1, . . . , βp) dapat diperoleh dengan MLE untuk fungsi likelihood berikut ini
L(β) = n Y i=1 P(Yi =yi) = [exp(β0+β1x1i+β2x2i+· · ·+βpi)] yi 1 + exp(β0+β1x1i+β2x2i+· · ·+βpi) (5.6) Program statistika seperti R, SPSS, Epi-Info, STATA menyediakan fasilitas untuk estimasiβˆ dan kesalahan standarnya SE( ˆβ).
5.3.2
Interpretasi Parameter Model
Untuk model regresi logistik sederhana
logit(πi) = β0+β1xi (5.7) dengan xi = ( 0 itdk terpapar 1 iterpapar dapat dituliskan log πi 1−πi = β0+β1xi πi 1−πi = exp [β0+β1xi] atau oddsxi = exp [β0+β1xi],
yang diinterpretasikan sebagai odds seseorang yang mempunyai karakteristik xi. Untuk orang yang terpapar (exposed), nilaixi = 1 dan odds-nya ditulis sebagai
oddsxi=1. Demikian juga untuk orang yang tidak terpapar, odds-nya ditulis
seba-gai oddsxi=0.
Sehingga odds ratio antara orang yang terpapar (xi = 1) dengan yang tidak terpapar (xi = 0) adalah OR = oddsxi=1 oddsxi=0 = e β0+β1×1 eβ0+β1×0 = eβ0+β1 eβ0 = eβ1 . (5.8)