Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran Ͷ
TINJAUAN MATA KULIAH
BAB I PENDAHULUAN
I. 1 Beberapa Definisi
Dalam berbagai media sering dijumpai hasil jejak pendapat dari masyarakat tentang isu tertentu, jejak pendapat itu dilakukan untuk mengetahui gambaran pendapat dari masyarakat di daerah dimana jejak pendapat ini dilakukan. Hal serupa juga dijumpai dalam publikasi-publikasi penelitian ilmiah baik yang ditulis dalam rangka penyelesaian studi mahasiswa maupun yang tertera dalam jurnal-jurnal penelititan. Pada dasarnya semuanya menghendaki gambaran menyeluruh yang didasarkan pada sebagian objek yang diteliti yang disebut sampel. Gambaran ini dihasilkan oleh proses generalisasi atau disebut juga dengan proses induksi .Oleh karena itu, agar diperoleh gambaran yang bisa mengungkapkan keadaan menyeluruh yang sebenarnya, diperlukan dua hal, yaitu proses induksi yang dilakukan dengan cara yang tepat, dan sampel yang tergolong “baik”. Dengan proses induksi yang tepat diartikan sebagai proses yang menggunakan teknik-teknik analisis yang cocok untuk permasalahan yang dikaji serta mengikuti kaidah-kaidah yang mendasarinya. Sampel dikatakan baik apabila dapat menggambarkan semua sifat atau karakteristik dari keseluruhan objek yang diteliti. Untuk dapat memperoleh sampel seperti ini, diperlukan teknik yang disebut teknik sampling.
Terdapat beberapa definisi yang diperlukan untuk membahas teknik ini.
I.1. 1 Populasi dan Sampel
Populasi merupakan keseluruhan (totality) objek, baik itu dari hasil menghitung maupun mengukur, yang dibatasi oleh kriteria tertentu. Objek populasi tersebut terbagi menjadi dua bagian, yaitu objek yang bisa diraba/kongkret (tangiable) dan objek yang tidak bisa diraba/abstrak (untangiable). Banyaknya objek yang ada dalam populasi disebut ukuran populasi (population size) yang biasanya dilambangkan dengan N. Ukuran populasi ini besarnya ada yang bisa dihitung (countable) dan juga tidak terhitung (uncountable). Apabila ukuran populasi
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͷ berapapun besarnya, tapi masih bisa dihitung, maka populasi tersebut dinamakan populasi terhingga (finite population). Jika ukuran populasi sudah sedemikian besarnya sehingga sudah tidak bisa lagi dihitung, maka populasi itu dinamakan populasi takhingga (infinite population). Apabila suatu penelitian dilakukan terhadap semua anggota populasi, maka prosesnya dinamakan Sensus
Dalam suatu penelitian, seringkali peneliti tidak bisa memeriksa seluruh anggota populasi (sensus). Oleh karena itu, hanya diambil sebagian saja dari anggota populasi sehingga diperolehlah sampel yang besarnya dilambangkan dengan n. Adapun proses pengambilan sebagian anggota populasi tersebut dinamakan sampling.
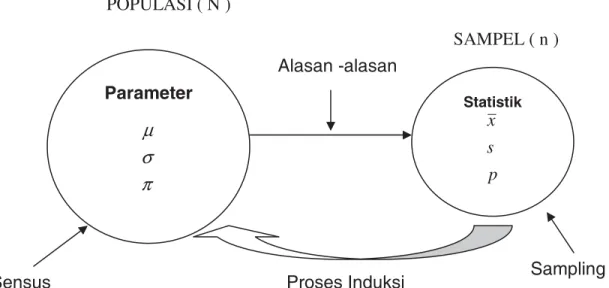
Gambaran mengenai proses sampling bisa dilihat dari ilustrasi berikut ini :
Gambar I. 1 Proses Sampling
Terdapat beberapa alasan sehingga peneliti cenderung lebih memilih proses sampling daripada sensus, yaitu :
a. Mengurangi biaya, apabila kita melakukan penelitian terhadap sebagian dari anggota populasi, maka akan berakibat pada penghematan biaya.
b. Masalah tenaga, jelas bahwa semakin banyak objek yang kita teliti, maka akan berakibat pada semakin banyaknya tenaga yang kita butuhkan baik itu tenaga pengumpul data / pencacah, pencatat / entri data maupun pengolah data. Apabila ada keterbatasan untuk ketiga hal tersebut, maka sampling merupakan alternative terbaik untuk dilakukan.
c. Efisiensi waktu, apabila diinginkan kesimpulan yang segera, maka sampling akan lebih tepat untuk digunakan. Hal ini dikarenakan dengan memperkecil
Parameter
π
σ
μ
Statistik p s x POPULASI ( N ) SAMPEL ( n ) Alasan -alasanProses Induksi Sampling Sensus
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran banyaknya objek yang akan diteliti maka data akan lebih cepat diperoleh dan dianalisis.
d. Tingkat ketelitian lebih besar, dalam suatu proses penelitian dari mulai pengumpulan data, pancatatan, dan penganalisisan data harus dilakukan dengan benar dan tepat. Apabila kita telah memakai tenaga-tenaga yang berkualitas baik dan diberi latihan intensif, serta pengawasan terhadap pekerjaan lapangan diperketat tetapi memberikan volume pekerjaan yang besar dan cenderung monoton, maka akan menimbulkan kebosanan baik itu dari pencacah maupun peneliti. Oleh karena itu, akan diperoleh data yang kurang dapat dipercaya kebenarannya.
e. Penelitian bersifat destruktif (penelitian yang sifatnya merusak), sensus tidak mungkin dilakukan untuk objek yang sifatnya merusak. Misalnya dalam menguji golongan darah seseorang, maka tidak mungkin semua darah dikeluarkan untuk diperiksa. Jadi dalam hal ini, sensus tidak mungkin lagi untuk dilakukan.
f. Faktor ekonomis, yang dimaksud dengan ‘faktor ekonomis’ adalah kesepadanan antara biaya, tenaga dan waktu yang dikeluarkan dengan informasi yang akan diperoleh. Apabila nilai dari infomasi tersebut tidak sepadan dengan biaya, tenaga dan waktu, maka sensus menjadi tidak baik lagi untuk dilakukan.
I. 1. 2 Unit Observasi
Suatu objek dimana perlakuan dilakukan disebut unit observasi. Ini merupakan unit dasar dari observasi yang terkadang disebut elemen. Dalam penelitian tentang perilaku masyarakat, maka individu masyarakat adalah unit observasi.
I. 1. 3 Populasi Target
Populasi Target merupakan keseluruhan kumpulan pengamatan/observasi secara lengkap yang akan dipelajari. Menentukan populasi target merupakan langkah awal yang penting pada saat seseorang akan melakukan penelitian. Dalam beberapa keadaan sulit untuk menentukan populasi target. Sebagai contohnya, dalam pemungutan suara dalam bidang politik, apakah target populasinya harus semua orang
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran dewasa yang layak memilih? Semua pemilih yang terdaftar? Semua orang yang dipilih pada pemilihan terakhir? Pillihan dari target populasi akan memberikan efek statistik yang sangat besar terhadap hasilnya. Jadi, dalam setiap penelitian seorang peneliti pada langkah pertama strateginya harus menentukan secara jelas populasi targetnya yaitu yang nantinya akan menjadi cakupan kesimpulan penelitian. Oleh karena itu, apabila dalam sebuah hasil penelitian dikeluarkan kesimpulan, maka menurut etika penelitian, kesimpulan itu hanya berlaku untuk populasi target yang telah ditentukan.
I. 1. 4 Populasi yang disampel
Populasi yang disampel adalah populasi dimana sampel akan diambil. Pada suatu saat tertentu setelah peneliti menentukan secara tegas populasi targetnya, peneliti tidak bisa memperoleh keterangan mengenai populasi targetnya, sehingga populasi yang ditelitinya berbeda (lebih kecil) dari populasi sasarannya.
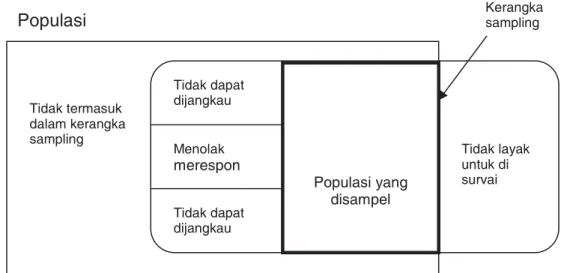
Jadi dalam suatu penelitian survey, idealnya populasi yang disampel adalah juga populasi target, namun keadaan ideal ini jarang terjadi. Contoh, dalam survey masyarakat, populasi yang disampel biasanya lebih kecil dari populasi target, seperti tampak dalam gambar berikut :
Populasi yang disampel Tidak termasuk dalam kerangka sampling Tidak dapat dijangkau Menolak merespon Tidak dapat dijangkau Tidak layak untuk di survai
Populasi Kerangka sampling
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͺ Populasi target dan populasi yang disampel dalam survey atau jajak pendapat terhadap suatu kebijakan dari para pemilih melalui suatu telephone, maka yang menjadi populasi target adalah semua pemilih yang terdaftar. Namun tidak semua pemilih mempunyai telephone, dengan demikian pemilih yang mempunyai telephone dan yang mau menelephone serta berhak merupakan populasi yang disampel.
I. 1. 5 Unit sampling
Unit sampling merupakan segala sesuatu yang oleh peneliti dijadikan kesatuan (unit) yang nantinya akan menjadi objek pemilihan. Jadi unit sampling itu adalah unit yang diambil sebagai sampel. Unit sampling ini bentuknya bisa individu yang berdiri sendiri yang disebut satuan elementer (Elementary Unit), dan bisa juga kumpulan individu yang disebut Cluster. Misalnya, apabila universitas dibagi ke dalam beberapa fakultas dan dalam penelitian fakultas ini yang akan dipilih, maka fakultas tersebut mejadi unit sampling. Tetapi apabila universitas dibagi menjadi beberapa jurusan dan jurusan ini yang akan dijadikan objek penelitian, maka sekarang yang menjadi unit samplingnya adalah jurusan.
I. 1. 6 Kerangka sampling
Kerangka sampling (sampling frame) adalah daftar unit sampling yang ada dalam sebuah populasi. Dalam survey tentang pendapat masyarakat akan suatu kebijakan, maka bila unit samplingnya adalah rumah tangga, daftar yang berisikan rumah tangga, nomor rumah serta alamatnya dan karakteristik lain yang berkaitan, disebut kerangka sampling.
Dalam teori sampling, apabila kita harus menyusun sampel, kemudian terhadap data yang dikumpulkan dari sampel ini kita ingin melakukan analisis secara statistis, maka sampel yang kita susun tadi harus merupakan sampel random. Sampel random hanya bisa disusun apabila ada kerangka sampling. Oleh karena itu untuk bisa memperoleh sampel random, kerangka sampling mutlak harus ada.
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͻ
I. 1. 7 Bias
Parameter-parameter populasi hanya bisa diketahui nilainya jika penelitiannya sensus. Dalam penelititan yang bukan sensus, untuk mengetahui nilai parameter tertentu, dilakukan penaksiran melalui sampel.
Definisi :
Apabila dari sebuah populasi kita akan menaksir sebuah parameter θ dengan penaksir
θ
ˆ , makaθ
ˆ disebut estimator untuk θ. Contoh :- Kita ingin menaksir parameter μ dengan X , maka X adalah estimator untuk
μ
- Kita ingin menaksir parameter σ2 dengan s2, maka s2 adalah estimator untuk
σ2
- Kita ingin menaksir parameter π dengan p, maka πadalah estimator untuk p. Apabila harga ekspektasi untuk sesuatu penaksir tidak sama dengan parameter yang ditaksir maka penaksir itu dikatakan bias.
Definisi :
Apabila
θ
ˆ merupakan penaksir untuk θ yang memenuhi persyaratan bahwa rata-rata untuk semuaθ
ˆ nilainya sama denganθ
, maka dikatakanθ
ˆ adalah penaksir tak bias untukθ
.Definisi:
Apabila parameter yang akan ditaksir adalah θ dan penaksirnya adalah θˆ maka bias didefinisikan sebagai | ) ˆ ( |θ Eθ B= −
Bias adalah selisih mutlak antara parameter yang ditaksir dengan ekspektasi penaksirnya.
a. Bias dalam pemilihan unit sampel
Sampel yang baik adalah sampel yang bebas dari bias (bias dalam pemilihan unit sampel) terjadi bila beberapa bagian dari populasi target tidak ada dalam populasi yang disampel. Bila suatu survey dirancangkan untuk mempelajari pendapatan rumah
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͳͲ tangga yang tinggal menetap (tidak termasuk komuter), maka taksiran rata-rata pendapatan rumah tangga akan mungkin terlalu besar, sehingga memberikan taksiran yang bias.
b. Bias dalam pengukuran
Sampel yang baik adalah juga sampel yang mempunyai sifat bahwa responden merespon pertanyaan dengan akurat. Bias dalam pengkuran terjadi bila instrument yang digunakan untuk mengukur cenderung akan memberikan hasil yang berbeda dari yang sesungguhnya. Jadi instrument tersebut gagal untuk dapat mengukur apa yang sebenarnya harus diukur.Mengukur apa yang seharusnya merupakan hal yang memang sulit dalam penelitian sosial karena penelitian biasanya berkaitan dengan pengukuran karakteristik manusia, yang kadang-kadang tidak bersedia untuk mengatakan hal yang sebenarnya. Dla survey penelitian yang dilakukan terhadap petani dalam rangka pemberian bantuan makanan maka mereka akan cenderung merendahkan hasil pertaniannya dengan harapan memperoleh bantuan pangan.
I. 1. 8 Error sampling dan nonsampling
Dalam poling pendapat sering dijumpai pernyataan bahwa sampel yang diambil menggunakan margin error sebesar 5%. Margin error menggambarkan besarnya sampling error yang ingin diambil oleh peneliti, yaitu error yang dihasilkan akibat penelitian menggunakan sampel (bukan populasi), Idealnya error harus sekecil mungkin, namun bila memperkecil error berakibat bertambah besar sampel. Jika peneliti mengambil sampel lain yang berbeda, maka jelas akan didapat nilai taksiran yang juga berlainan. Error sampling biasanya dinyatakan dengan terminology probabilitas.
Jadi error sampling merupakan selisih antara nilai parameter dengan nilai statistik penaksirnya.
Definisi:
Apabila θ merupakan sebuah parameter dan θˆ merupakan penaksir bagi θ maka error sampling didefinisikan sebagai:
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͳͳ |
ˆ |θ θ δ = −
Error sampling bisa pula berarti semua bentuk error yang ditimbulkan karena proses sampling. Apabila kekeliruan yang terjadi bukan karena proses sampling maka kekeliruan itu disebut non-sampling error. Sebagai contoh adalah kekeliruan pengumpulan data sebagai akibat kekeliruan questioner, pemilihan unit sampel dan ketidakakuratan merespon. Jadi non-sampling error adalah error yang tidak dapat ditandai dari variabilitas satu sampel dengan sampel lainnya.
I. 1. 9 Presisi dan Akurasi
Presisi menunjukkan kekonsistenan atau keseragaman dari nilai penaksir. Makin seragam nilai dari suatu penaksir, maka makin baik presisinya. Dengan kata lain bahwa datanya semakin homogen. Dalam ukuran statistik, presisi dinyatakan dengan standard error Jadi penaksir yang baik adalah penaksir yang memiliki standard error paling kecil .
Sedangkan Akurasi menunjukkan jarak terhadap target. Dalam statistik, yang menggambarkan akurasi adalah bias yaitu selisih antara penaksir dengan yang ditaksir.
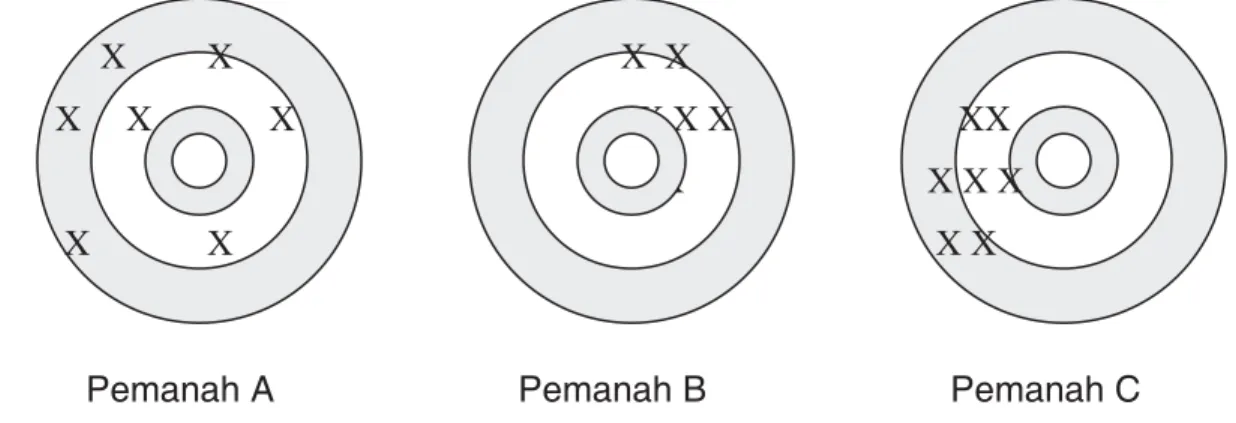
Gambaran mengenai presisi dan akurasi bisa dilihat dengan menggunakan pemisalan berikut : X X X X X X X X X X XX X X X X X X X X
Gambar I. 3 Ilustrasi presisi dan akurasi dari suatu taksiran
Gambar di atas dimisalkan sebagai target panahan. Tiga orang pemanah menembakkan anak panahnya masing-masing pada tiap target tersebut. Dari hasilnya terlihat bahwa ternyata pemanah A memiliki tingkat presisi dan akurasi yang rendah,
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͳʹ dalam arti bahwa hasil dari tembakannya tidak tepat sasaran dengan variasi yang tidak konsisten. Sedangkan untuk pemanah B menghasilkan suatu tembakan yang konsisten sehingga bisa dikatakan bahwa dia memiliki presisi yang tinggi, tetapi masih tidak tepat sasaran atau akurasinya rendah. Untuk pemanah C memberikan kondisi yang terbaik, yaitu memiliki presisi dan akurasi yang tinggi, artinya selain tepat sasaran, juga hasil tembakannya konsisten. Dalam masalah sampling, kondisi seperti pemanah C-lah yang diinginkan.
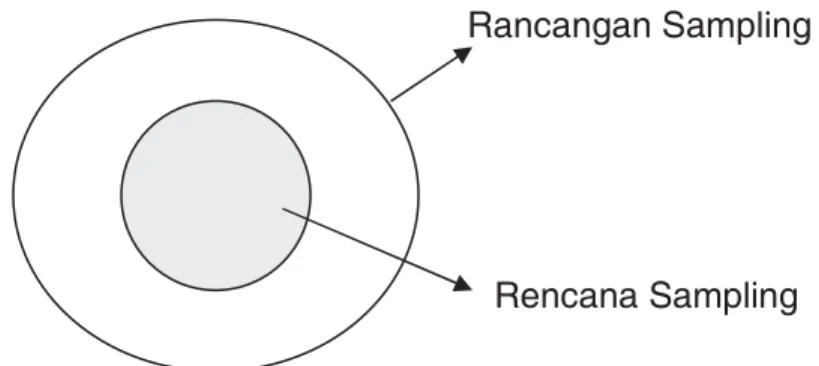
I. 1. 10 Rencana Sampling (Sampling Plan) dan Rancangan Sampling (Sampling Design)
Ketika kita melakkukan proses sampling, maka secara tegas kita membedakan apa yang dimaksud dengan Rencana Sampling dan Rancangan Sampling.
Rencana Sampling merupakan sebuah gambaran garis besar yg menyangkut : 1. Penentuan populasi sasaran
2. Penentuan bentuk dan ukuran satuan sampling 3. Penentuan ukuran sampel ( n )
4. Penentuan cara memilih satuan sampling
Apabila pada rencana sampling di atas kita menambahkan metode penaksiran/metode analisis, maka rencana sampling meningkat menjadi Rancangan Sampling.
Gambar I. 4 Rencana Sampling dan Rancangan Sampling
I. 1. 11 Finite Population Correction (FPC)
Apabila kita berhadapan dengan penelitian yang memiliki ukuran populasi terhingga, maka FPC harus dicantumkan pada rumus Standard Error. Jika
Rancangan Sampling
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͳ͵ populasinya tak hingga, maka FPC dianggap sama dengan 1 dan tidak usah dicantumkan dalam rumus Standard Error.
Bentuk dari FPC itu adalah 1 − − N n N
, tetapi bentuk ini tidak bisa memberikan keterangan mengenai beberapa hal yang penting. Oleh karena itu dalam pembicaraan
ita mengenai sampling, bentuk FPC yang akan kita gunakan adalah :
¸ ¹ · ¨ © § − = − N n N n N 1
Dengan menggunakan rumus ¸
¹ · ¨ © § − = N n
FPC 1 , maka diperoleh dua buah keterangan
yaiotu : a.
N n
, disebut sampling fraction, menyatakan berapa persen sampel yang kita buat
(dari populasi). Misalnya jika ada keterangan N
n
= 0.15, maka berarti bahwa ukuran sampel adalah 15 % dari populasinya.
b. N
n
menyatakan besarnya peluang setiap satuan sampling untuk termasuk ke dalam sampel berukuran n.
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͳ
TINJAUAN MATA KULIAH
I. 3 Distribusi Sampling
Sebagaimana yang telah diuraikan sebelumnya bahwa dengan berbagai alasan, peneliti cenderung melakukan sampling daripada sensus. Dalam
kenyataannya, akan terdapat lebih dari sebuah sampel berukuran n yang mungkin
yang bisa diambil dari populasi berukuran N. Adanya beberapa kemungkinan
sampel yang bisa diambil menunjukkan adanya bermacam-macam kombinasi data populasi yang bisa terambil Akan tetapi dalam prakteknya hanya akan diambil sebuah sampel untuk digunakan dalam penelitiannya, dengan kata lain bahwa hanya akan diambil satu buah kombinasi data. Sampel yang diambil biasanya
dipilih secara acak, disebut dengan sampel acak. Selanjutnya dari sampel tersebut
dilakukan proses analisis sesuai dengan tujuan penelitiannya. Sebagai contohnya adalah pada sampel yang bersangkutan akan diperoleh taksiran parameter populasi
θ
ˆ dari θ (θ merupakan lambang parameter populasi[
μ
,π
,σ
2]
, sedangkanθ
ˆmerupakan lambang penaksir parameter populasi
[
x,p,s2]
). Kumpulan nilai-nilaiθ
ˆ pada sampel-sampel yang mungkin disebut sebagai distribusi sampling dariθ
ˆ.Banyaknya kemungkinan sampel yang bisa diambil tergantung pada proses pengambilan unit-unit populasinya. Berdasarkan proses memilihnya, sampling terbagi ke dalam dua tipe, yaitu sampling dengan pengembalian dan sampling tanpa pengembalian. Sampling dengan pengembalian merupakan suatu proses pengambilan sampling dimana sampel yang telah terpilih dikembalikan lagi ke dalam populasi sebelum pemilihan selanjutnya dilakukan, sehingga ada kemungkinan suatu satuan sampling tertentu akan terpilih lebih dari sekali. Oleh
karena itu, jika sampling dilakukan dengan pengembalian, maka akan terdapat Nn
buah sampel yang berlainan. Adapun sampling tanpa pengembalian merupakan suatu proses pengambilan sampel dimana satuan sampling yang telah terpillih tidak dikembalikan lagi ke dalam populasi, sehingga setiap satuan sampling hanya memiliki kesempatan terpilih satu kali. Oleh karena itu, jika sampling dilakukan
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͳ tanpa pengembalian, maka akan terdapat
(
)
! ! ! n N n N n N − = ¸¸ ¹ · ¨¨ © §buah sampel yang berlainan.
I. 3. 1 Distribusi sampling Rata-rata
Dikatakan distribusi sampling rata-rata karena tujuan dari penelitian ini adalah untuk menaksir rata-rata dari populasi. Oleh karena ada beberapa kemungkinan sampel yang akan terbentuk, maka untuk tiap-tiap sampel yang bersangkutan juga akan terdapat beberapa rata-rata sampelnya. Anggap rata-rata ini sebagai data baru, maka akan terbentuk suatu kumpulan data yang terdiri dari rata-rata dari sampel-sampel. Dari kumpulan rata-rata tersebut dicari rata-rata dan simpangan bakunya, maka akan diperoleh rata-rata dari rata-rata, disimbolkan
dengan
μ
x dan simpangan baku dari rata-rata, disimbolkan denganσ
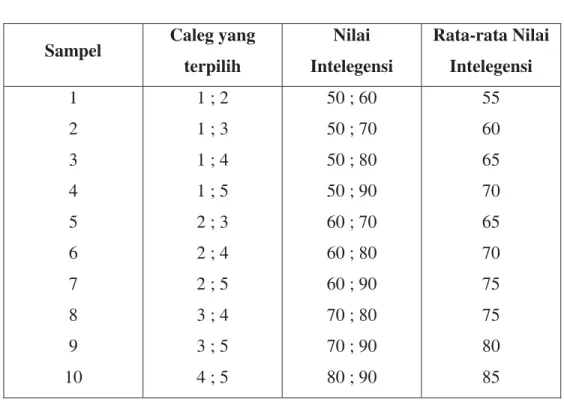
x.Sebagai contoh, pada tabel berikut terdapat data mengenai nilai intelegensi calon legislatif yang menggunakan ijasah palsu. Terdapat 5 calon legislatif yang mengunakan ijasah palsu dengan nilai intelegensi masing-masing 50, 60, 70, 80, dan 90. Dari populasi 5 calon legislatif tersebut, diambil 2 sampel secara berulang-ulang sampai semua kemungkinan sampel terambil.
No. Caleg Nilai Intelegensi
1 2 3 4 5 50 60 70 80 90 Dari data di atas diperoleh rata-rata populasi berikut :
70 5 350 1 = = =
¦
= N X N i iμ
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͳͺ dan simpangan bakunya adalah :
(
)
(
) (
) (
) (
) (
)
14214 , 14 5 1000 5 70 90 70 80 70 70 70 60 70 50 2 2 2 2 2 1 2 = = − + − + − + − + − = − =¦
= N X N i iμ
σ
a. Apabila sampling dilakukan dengan pengembalian, maka diperoleh 52 = 25
buah kemungkinan sampel, yaitu :
Sampel Caleg yang terpilih Nilai Intelegensi Rata-rata Nilai Intelegensi 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 1 ; 1 1 ; 2 1 ; 3 1 ; 4 1 ; 5 2 ; 1 2 ; 2 2 ; 3 2 ; 4 2 ; 5 3 ; 1 3 ; 2 3 ; 3 3 ; 4 3 ; 5 4 ; 1 4 ; 2 4 ; 3 4 ; 4 4 ; 5 50 ; 50 50 ; 60 50 ; 70 50 ; 80 50 ; 90 60 ; 50 60 ; 60 60 ; 70 60 ; 80 60 ; 90 70 ; 50 70 ; 60 70 ; 70 70 ; 80 70 ; 90 80 ; 50 80 ; 60 80 ; 70 80 ; 80 80 ; 90 50 55 60 65 70 55 60 65 70 75 60 65 70 75 80 65 70 75 80 85
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͳͻ 21 22 23 24 25 5 ; 1 5 ; 2 5 ; 3 5 ; 4 5 ; 5 90 ; 50 90 ; 60 90 ; 70 90 ; 80 90 ; 90 70 75 80 85 90
Tabel di atas merupakan distribusi sampel untuk nilai intelegensi. Terlihat dari tabel di atas bahwa terdapat data baru sebanyak 25 rata. Distribusi dari rata-rata tersebut juga bisa disajikan ke dalam bentuk berikut :
Rata-rata
Nilai Intelegensi Frekuensi P(X)
50 55 60 65 70 75 80 85 90 1 2 3 4 5 4 3 2 1 0,04 0,08 0,12 0,16 0,2 0,16 0,12 0,08 0,04 Selanjutnya dapat ditampilkan dalam bentuk grafik berikut :
Intelegensi 90.0 85.0 80.0 75.0 70.0 65.0 60.0 55.0 50.0 Intelegensi F requenc y 6 5 4 3 2 1 0 Std. Dev = 10.21 Mean = 70.0 N = 25.00
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ʹͲ Dalam kenyataannya, suatu penelitian tidak pernah mengambil sampel secara berulang-ulang seperti contoh di atas, namun contoh di atas memberi landasan dalam melakukan estimasi nilai yang diperoleh dari sampel. Dari kumpulan rata di atas, diperoleh jumlah rata = 1750. Maka rata untuk ke – 25 rata-rata ini adalah :
70 25 1750 25 25 1 = = =
¦
i= i X Xμ
Sedangkan simpangan baku ke – 25 rata-rata tersebut juga dapat dihitung sebagai berikut :
(
)
(
) (
) (
)
(
)
10 25 2500 25 70 90 ... 70 60 70 55 70 50 25 2 2 2 2 25 25 2 = = − + − + − + − = − = i¦
= X i X Xμ
σ
Ternyata terlihat bahwa rata-rata populasi = 70 dengan rata-rata dari ke-25 rata tersebut sama, tetapi memiliki simpangan baku yang berbeda. Dari populasi diperoleh simpangan bakunya = 14,14214 sedangkan dari ke-25 rata-rata diperoleh simpangan baku = 10. Selanjutnya dapat dihitung :
10 2 14214 , 14 = = = n X
σ
σ
Ternyata berlaku : n X Xσ
σ
μ
μ
= =Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ʹͳ Persamaan di atas juga dapat berlaku untuk kasus pengambilan sampel tanpa pengembalian jika N cukup besar dibandingkan dengan n, dalam hal ini jika
% 5 ≤ N n .
b. Apabila sampling dilakukan tanpa pengembalian, maka diperoleh 10 ! 2 ! ) 2 5 ( ! 5 2 5 = − = ¸¸ ¹ · ¨¨ © §
buah kemungkinan sampel, yaitu :
Sampel Caleg yang
terpilih Nilai Intelegensi Rata-rata Nilai Intelegensi 1 2 3 4 5 6 7 8 9 10 1 ; 2 1 ; 3 1 ; 4 1 ; 5 2 ; 3 2 ; 4 2 ; 5 3 ; 4 3 ; 5 4 ; 5 50 ; 60 50 ; 70 50 ; 80 50 ; 90 60 ; 70 60 ; 80 60 ; 90 70 ; 80 70 ; 90 80 ; 90 55 60 65 70 65 70 75 75 80 85
Tabel di atas merupakan distribusi sampel untuk nilai intelegensi jika data yang diambil tanpa pengembalian. Terlihat dari tabel di atas bahwa terdapat data baru sebanyak 10 rata-rata. Distribusi dari rata-rata tersebut juga bisa disajikan ke dalam bentuk berikut :
Rata-rata
Nilai Intelegensi Frekuensi P(X)
55 60 65 70 75 1 1 2 2 2 0,1 0,1 0,2 0,2 0,2
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ʹʹ 80 85 1 1 0,1 0,1
Selanjutnya akan ditampilkan ke dalam bentuk grafik sebagai berikut :
Intelegensi 85.0 80.0 75.0 70.0 65.0 60.0 55.0 Intelegensi F requenc y 2.5 2.0 1.5 1.0 .5 0.0 Std. Dev = 9.13 Mean = 70.0 N = 10.00
Dari kumpulan rata-rata di atas, diperoleh jumlah rata-rata = 490. Maka rata-rata untuk ke – 25 rata-rata ini adalah :
70 10 700 10 10 1 = = =
¦
i= i X Xμ
Sedangkan simpangan baku ke – 25 rata-rata tersebut juga dapat dihitung sebagai berikut :
(
)
(
) (
) (
)
(
)
66 , 8 10 750 10 70 85 ... 70 65 70 60 70 55 10 2 2 2 2 10 25 2 = = − + + − + − + − = − = i¦
= X i X Xμ
σ
Ternyata rata-rata populasi = 70 sama dengan rata-rata dari ke-10 rata-rata tersebut, tetapi memiliki simpangan baku yang berbeda. Dari populasi diperoleh
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ʹ͵ simpangan bakunya = 14,14214 sedangkan dari ke-7 rata-rata diperoleh simpangan baku = 8,66. Selanjutnya dapat dihitung :
66 , 8 1 5 2 5 2 14214 , 14 1 = − − = − − = N n N n X
σ
σ
Ternyata berlaku : 1 − − = = N n N n X Xσ
σ
μ
μ
Selanjutnya simpangan baku dari rata-rata tersebut, baik itu yang diambil dengan
pengembalian ataupun tanpa pengtembalian, dinamakan simpangan baku
rata-rata atau galat baku rata-rata. Ukuran ini menunjukkan variasi rata-rata sampel
sekitar rata-rata populasi ȝ.
I. 3. 2 Distribusi samplng Proporsi
Sebagaimana pada distribusi sampling rata-rata, pemberian nama disrtribusi sampling proporsi atau disingkat distribusi proporsi ini dikarenakan tujuan dari penelitiannya adalah untuk menaksir proporsi suatu peristiwa dari populasi.
Perhatikan Gambar I. 1, dimisalkan bahwa ukuran dari populasi adalah N dan
ukuran sampel yang diambil adalah n. Apabila dari populasi tersebut terdapat Y
buah peristiwa khusus yang akan diteliti, maka proporsi terjadinya peristiwa tersebut adalah :
N Y =
π
Selanjutnya berdasarkan sampel yang diambil, ternyata peristiwa khusus yang
diperoleh ada sebanyak x buah, maka diperoleh statistik proporsi peristiwa tesebut
adalah :
n x p=
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ʹͶ Oleh karena ada beberapa kemungkinan sampel yang akan terbentuk, maka untuk tiap-tiap sampel yang bersangkutan juga akan terdapat beberapa proporsi sampelnya. Apabila proporsi ini diperlakukan sebagai data baru, maka akan terbentuk suatu kumpulan data yang terdiri dari proporsi dari sampel-sampel. Sebagaimana pada distribusi rata, dari kumpulan proporsi tersebut dicari rata-rata dan simpangan bakunya, maka akan diperoleh rata-rata-rata-rata dari proporsi,
disimbolkan dengan μp dan simpangan baku dari proporsi, disimbolkan dengan
p
σ . Ternyata, jika proses pengambilan sampel dilakukan tanpa pengembalian atau
jika kondisi populasi memiliki ukuran yang tidak terlalu besar dibandingkan dengan data sampelnya, yaitu (n/N) > 5 %, maka :
(
)
1 1 − − − = = N n N n p p π π σ π μselanjutnya jika proses pengambilan sampel dilakukan dengan pengembalian atau
kuran populasinya besar dibandingkan dengan ukuran sampel, yaitu (n/N) ≥ 5 %,
maka :
(
)
n p p π π σ π μ − = = 1I. 3. 3 Distribusi samplng Simpangan Baku
Seperti halnya pada pembahahasan sebelumnya, maka dari populasi yang
berukuran N yang kemudian diambil sampel beruikuran n, akan menghasilkan
beberapa kemungkinan sampel. Selanjutnya dari semua sampel yang mungkin
tersebut dicari simpangan bakunya, yaitu s, maka akan terdapat kumpulan dari
simpangan baku. Dari kumpulan tersebut, dihitung rata-ratanya, ȝs dan simpangan
bakunya, σs.
Jika populasi berdistriobusi normal, atau mendekati normal, maka distribusi
simpangan baku untuk n besar, biasanya n ≥ 100, sangat mendekati distribusio
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ʹͷ n s s 2 σ σ σ μ = =
dengan σ merupakan simpangan baku populasi.
Setelah mengetahui sifat dari distribusi sampel, bukan berarti harus melakukan pengambilan sampel secara berulang-ulang sebagaimana yang telah dijelaskan sebelumnya. Distribusi sampel yang telah dibicarakan tersebut
merupakan dasar penting bagi sebuah dalil yang disebut dalil limit pusat. Dalil
limit pusat tersebut menyatakan bahwa jika ada satu populasi dengan rata-rata ȝ,
atau proporsi p, dengan simpangan baku (standar deviasi) σ yang besarnya
terhingga, maka distribusi sampel berdasarkan pengambilan sampel n secara acak
dan berulang-ulang memiliki beberapa sifat :
1. Rata-rata distribusi sampel untuk statistik
θ
ˆ akan sama dengan parameterpopulasi, θ .
2. Simpangan baku untuk parameter θ sampel akan sama dengan σ/√n . Ukuran
ini juga dikenal sebagai standard error (SE). SE memegang peranan penting
pada estimasi parameter dan uji statistik.
3. Jika distribusi nilai pada populasi normal, maka disribusi sampel juga normal. Tetapi yang lebih penting adalah jika distribusi nilai pada populasi tidak normal, dengan jumlah sampel yang “cukup” besar, maka distribusi sampel akan mendekati normal, tanpa tergantung dari distribusi nilai parameter populasi.
Maka dengan asumsi besar sampel yang ”cukup”, distribusi sampel x dapat digambarkan sebagai berikut :
θ
θ - Z σθ θ + Z σθ
α / 2
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ʹ Pada gambar di atas menunjukkan menunjukkan sekian standar error dari rata-rata
distribusi sampel. Nilai α merupakan taraf signifikansi yang menunjukkan derajat
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͵Ͳ
TINJAUAN MATA KULIAH
BAB II
SAMPLING ACAK SEDERHANA
II. 1 Pendahuluan
Sampling acak sederhana merupakan bentuk yang paling dasar dari jenis sampling peluang yang memberikan dasar teori untuk proses sampling peluang lainnya yang lebih komplek. Sampling Acak Sederhana ini merupakan suatu proses memilih satuan sampling dari populasi sedemikian rupa sehingga setiap satuan sampling dalam populasi mempunyai peluang yang sama besar untuk terpilih ke dalam sampel dan peluang itu diketahui sebelum pemilihan dilakukan.Terdapat dua
cara dalam pengambilan sampling acak sederhana ini, yaitu dengan pengembalian
(with replacement), yang mana dalam proses ini adanya kemungkinan bahwa suatu
unit akan terpilih lebih dari satu kali dan tanpa pengembalian (without replacement)
yang mana semua unit yang terpilih tidak akan ada yang sama.
Sampling Acak Sederhana dengan pengembalian yang berukuran n dari populasi yang berukuran N unit dapat digambarkan sebagai n buah sampel independen yang berukuran 1. Satu unit dipilih secara acak dari populasi menjadi unit sampel yang pertama, dengan peluang 1/N. Prosedur ini diulang sampai diperoleh sampel yang berukuran n unit, yang mana bisa terjadi duplikasi unit sampling.
Pada populasi yang terbatas (finite population), suatu sampling yang memiliki
penggandaan unit tersebut tidak akan memberikan tambahan informasi. Oleh karena itu, biasanya sampling tanpa pengembalian lebih disukai karena unit yang terpilih tidak akan terjadi duplikasi. Sebuah sampel acak sederhana tanpa pengembalian yang berukuran n dipilih sedemikian rupa sehingga setiap kemungkinan bagian dari n unit dalam populasi memiliki peluang yang sama untuk terpilih menjadi anggota sampel.
Terdapat ¸¸ ¹ · ¨¨ © § n N
kemungkinan sampel yang akan terbentuk. Oleh karena itu, peluang terpilihnya beberapa individu dalam suatu sampel S dari n unit adalah :
( )
1 n!(
NN! n)
! n N S P = − ¸¸ ¹ · ¨¨ © § =Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͵ͳ
Sebagai konsekuensi dari definisi ini, apabila dilakukan pemilihan dengan Sampling
Acak Sederhana ke dalam sampel yang berukuran n, maka peluang sesuatu unit akan
terpilih ke dalam sampel itu adalah N
n .
Proses sampling dengan Sampling Acak Sederhana digunakan apabila memenuhi beberapa kondisi sebagai berikut :
1. Variabel yang akan diteliti keadaannya relatif homogen dan tersebar
merata di seluruh populasi.
2. Apabila bisa disusun secara lengkap kerangka sampling yang
menyangkut setiap satuan pengamatan yang ada dalam populasi.
II. 2 Keuntungan dan Kerugian Sampling Acak Sederhana
Keuntungan dari digunakannya Simple Random Sampling adalah memiliki bentuk-bentuk rumus yang sederhana, tidak memerlukan pembobotan, dan semua rmus statistika bisa digunakan.
Kerugiannya :
1. Ada kemungkinan bahwa sekalipun menggunakan randomisasi, satuan
sampling yang terpilih tidak tersebar merata atau randomisasi tidak menjamin 100% bahwa pemilihan keadaannya menyebar merata.
2. Apabila ukuran populasi besar dan ukuran sampel besar maka pemilihan
secara simple random sampling secara manual menyulitkan.
II. 3 Proses Memilih Melalui Sampling Acak Sederhana
Dalam pemilihan unit sampling melalui sampling Acak Sederhana, diperlukan adanya kerangka sampling yang tersusun secara lengkap. Setiap satuan sampling dalam kerangka sampling tersebut diberi nomor urut dan banyaknya angka dalam nomor-nomor tersebut sama untuk setiap satuan sampling.
Langkah:
1. Tentukan secara tegas Populasi sasaran misal : Masyarakat di daerah A
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͵ʹ
No Nama Alamat
001 Awal Jl. Merkuri Raya 23
002 Arya Jl. Jakarta 24 . . . 262 Ending Jl. Cikaso 23
3. Tentukan ukuran sampel n
misal n=20
4. Lakukan proses pengambilan sampel
Apabila suatu target populasi telah ditentukan secara tegas dan dari populasi ini akan disusun sebuah sampel melalui (SRS), maka selanjutnya harus dilakukan proses pemilihan dari anggota sampelnya. Adapun proses memilih dalam Samping Acak Sederhana banyak sekali caranya. Dalam buku ini hanya akan dibahas tiga cara yang sering dilakukan, yaitu :
1. Simple Randomization (SR) / Pengacakan Secara Sederhana 2. Randomization Based on Remainder
3. Randomization Based on Permutation
II. 3. 1 Simple Randomization (SR) / Pengacakan Secara Sederhana
Langkah-langkah yang harus dilakukan dalam pengambilan sampel melalui Simple
Randomization :
1. Tentukan populasi penelitian secara tegas study population (populassi sasaran
dan populasi penelitian), yang sebaiknya sama dengna populasi sasaran 2. Tentukan secara tegas ukuran populasi
3. Tentukan bentuk satuan sampling dan susun kerangka sampling yang lengkap 4. Tentukan ukuran sampel berdasarkan perhitungan tertentu. Ukuran sampel
tersebut bisa ditentukan atas dasar statistis (statistical aspects) maupun nonstatistis (nonstatistical aspects)
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͵͵ 5. Sediakan tabel angka random
6. Proses memilih :
a. Secara sembarang jatuhkan suatu benda ke atas tabel bilangan random dan perhatikan angka berapa yang tertuju oleh benda tersebut
b. Satuan sampling selanjutnya diperoleh dengan cara membaca tabel angka random ke bawah menurut kolom yang sesuai. Kalau masih belum cukup, baca ke atas.
Catatan:
1. Simple Randomization adalah randomisasi yang palling sederhana, tetapi banyak menghamburkan bilangan random.
2. Dala praktik, survai yang populasi sasarannya besar, Simpel Randomization
tidak dilakukan secara manual tetapi menggunakan komputer.
3. Semua angka random yang lebih besar dari N dilewat, angka randoom yang sudah dipilih tidak dipilih lagi
4. Bilangan-bilangan random yang sudah dipakai , baik terpilih maupun tidak, tidak boleh dipilih lagi dalam suatu proses pemilihan. Oleh karena itu sangat disarankan agar pada saat menggunakan tabel angka random peneliti benar-benar memperhatikan angka random mana yang sudah dipakai, dan sampai mana peneliti terakhir menggunakan angka random.
5. Proses pemilihan seperti ini disebut Simple Random Sampling dan secara
matematis proses ini menjamin bahwa setiap satuan pengamatan dalam populasi mempunyai kesempatan yang sama (peluang yang sama) untuk terpilih yaitu peluang terpilih: n/N. Untuk tidak menghamburkan bilangan
random kita bisa menggunakan Simple Random Sampling melalui pendekatan
lain.
II. 3. 2 Randomization Based on Remainder (Pengacakan berdasarkan pada sisa hasil pembagian)
Untuk menghemat bilangan random kita melakukan randomisasi atas dasar sisa hasil pmbagian
Langkah kerja :
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͵Ͷ 2. Susun kerangka sampling
3. Tentukan ukuran sampel
4. Sediakan tabel angka random, dari tabel ini kita mulai pada baris ke-1 kolom ke-1. Sebagai catatan bahwa langkah tersebut dilakukan apabila yakin betul bahwa tidak ada orang lain yang akan menggunakan kerangkan sampling yang sama dengan tabel angka random yang sama pula.
5. Sebelum proses pemilihan dimulai, harus ditentukan secara tegas bilangan random mana saja yang tidak boleh dipakai. Untuk keperluan ini kita susun interval-interval
Catatan :
1. apabila diperoleh sisi pembagian bernilai nol, maka artinya adalah satuan sampling yang terpilih adalah nomor yang terbesar.
2. Perhatikan bahwa yang dimaksud dengan sisa pembagian adalah sisa pembagian dari bilangan random yang terpilih dengan penyebut N
3. Satuan sampling yang sudah terpilih (sisa pembagian yang sudah terpilih) tidak boleh dipakai lagi
II. 3. 3 Randomization Based on Permutations
Dalam penelitian eksperimental seringkali peneliti harus membagi sekelompok satuan sampling ke dalam beberapa kelompok secara acak sesuai dengan perlakuan (treatment) yang akan dipakai. Pengacakan yang paling baik dalam hal ini adalah pengacakan dengan menggunakan bilangan yang dipermutasikan (diubah-ubah) secara acak, misalnya; 234, 243, 342, 324, 432, dan 423. Susun bilangan yang telah dipermutasikan tersebut ke dalam sebuah tabel. Pilih secara acak baris ke berapa yang akan dipakai dari tabel tersebut yang kemudian tabel ini harus dibacakan dari kiri ke kanan untuk menentukan bilangan acak yang terpilih sebagai nomor untuk satuan sampling.
II. 4 Bentuk-bentuk Estimasi
Sebagaimana yang telah diuraikan sebelumnya bahwa dalam proses inferensial, terdapat dua kegiatan statistik, yaitu penaksiran parameter dan pengujian
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͵ͷ hipotesis. Adapun pembahasan yang akan diuraikan selanjutnya adalah mengenai penaksiran parameter.
II. 4. 1 Estomator untuk rata-rata populasi (
μ
x) dan standar errornya (σ( )
X )Dalil :
Apabila sebuah populasi berukuran N kita embentuk sebuah sampel berukuran n
melalui Sampling Acak Sederhana dan dari sampel tersebut diukur variat X yang
mempunyai tingkat pengukuran interval/rasio dengan hasil pengukuran x1, x2, …, xn,
maka :
1. Estomatior tak bias untuk rata-rata populasi
μ
x adalah :¦
= xi
n
X 1
2. Estimator untuk standar error σ
( )
X adalah( )
;(
(
1)
)
ˆ 2 2 2 2 − − = ¸ ¹ · ¨ © § − =¦
¦
n n x x n s n s N n N X i iσ
Apabila dari sebuah sampel berukuran n yang dipilih melalui Sampling Acak
Sederhana, kita bisa menghitung
σ
ˆ( )
X , maka Bound of Error untuk rata-rataμ
didefinisikan sebagai :
( )
X t BE nσ
δ
α ; 1 ˆ 2 1 ¸ ¹ · ¨ © §− − = =secara teori, Bound of Error tersebut menyatakan kekeliruan terbesar yang mungkin
terjadi dengan derajat kepercayaan ( 1 - α ) 100%. Secara fisik, Bound of Error adalah
setengah lebar taksiran.
II. 4. 3 Estomator untuk proporsi (persentase) dan standar errornya
Secara statistis kalo kita berbicara persentase, sebenarnya kita berbicara proporsi (belum dikalikan 100%). Oleh karena itu dalam statistika, analisis mengenai persentasse dilakukan atas dasar proporsi.
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͵ Dalil :
Apabila dari sebuah populasi berukuran nN, kita membentuk sampel berukuran n
melalui sampling Acak sederhana, kemudian dari sampel tersebut kita men variabel X
yang sifatnya (tingkat pengukurannya) nominal dichotomus dengan harga pengukuran
:
xi = 1 jika satuan sampling bersifat A
xi = 0 jika satuan sampling bukan bersifat A
maka eestimator takbias untuk proporsi A dalam populasi didefinisikan sebagai : 1) estomator takbias untuk proporsi
B jika x A jika x x n p i i i 0 1 ; 1 = = =
¦
2) estimator bias untuk standar error dari p adalah :
( )
(
1 1)
ˆ − − ¸ ¹ · ¨ © § − = n p p N n N pσ
Sebagai catatan bahwa dalam praktik survay yang menyangkut penaksiran parameter,ada sebuah perjanjian tak tertulis yang sifatnya optional, yaitu apabila sampling fraction < 0,05 maka finite population fraction (fpc) dianggap 1. Ini artinya
dalam rumus standar Error tidak dimasukkan Fpc. Dalam hal inni diambil suatu
ketentuan berapa pun sampling fraction, Fpc akan tetap digunakan, sebab sekalipuun n/N < o,o5apabila hasil pengukuran variabel X adalah bilangan-bilangan kecil, Fpc besar pengaruhnya.
II. 5 Menentukan Ukuran Sampel
Setelah peneliti menentukan tujuan dari penelitiannya, maka selanjutnya perlu diambil keputusan apakah akan dilakukan sensus atau sampling. Apabila proses yang akan dilaksanakannya adalah sampling, maka diperlukan adanya suatu ketegasan berapa ukuran sampel minimal yang sebaiknya diambil. Ukuran sampel ini akan memberi
isyarat mengenai managability of the research (kelayakan penenlitian). Ada dua dasar
pemikiran dalam menentukan ukuran sampel, yaitu ditentukan atas dasar oemikiran statistis, dan atau ditentukan atas dasar pemikikran nonstatistis.
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͵
II. 5. 1 Menentukan Ukuran Sampel Atas Dasar Pemikiran Non Statistis
Apabila dipandang dari sudut nonstatisti, ukran sampel ditentukan oleh beberapa faktor, yaitu :
a. Ditentukan oleh waktu (time constraint / kendala waktu)
b. Ditentukan oleh biaya
c. Ditentukan oleh ketersediaan satuan sampling, akan lebih terasa di bidang
kedokteran
II. 5. 2 Menentukan Ukuran Sampel Atas Dasar Pemikiran Statistis
Ditinjau dari aspek statistis, ukuran sampel ditentukan oleh banyak faktor, yaitu :
a. Ukuran sampel ditentukan oleh bentuk parameter yang menjadi tolok ukur
analisis, dalam arti apakah kesimpulan yang akan kita ambil dasarnya rata-rata
( μ ), apakah persentase ( π ), atau yang lainnya. Masalah bentuk parameter
uini erat kaitannya dengan tingkat pengukuran variabel yang kita hadapi, apakah tingkat penggukurannya nominal, ordinal, interval, atau rasio.
b. Ukuran sampel ditentukan oleh tipe sampling yang digunakan, apakah
sampling peluang (Sampling Acak Sederhana, Sampling Sistematis, Sampling Acak Stratifikasi, dan Sampling Klaster) atau sampling Nonpeluang.
c. Ukuran sampel ditentukan pula oleh tujuan penelitian, apakah bertujuan
untuk menaksir parameter atau menguji hipotesis.
d. Ukuran sampel ditentukan oleh sifat penelitian, apakah sifatnya
nonkomparatif atau komparatif.
e. Ukuran sampel ditentukan oleh variabilitas variabel (keseragaman variabel)
yang diteliti, makin tidak seragam variabel yang diteliti, makin besar ukuran sampel minimal yang harus diambil.
f. Apabila tujuan penelitian semata-mata hanya membuat taksiran parameter,
maka ukuran sampel ditentukan oleh bound of error penaksiran dan derajat
kepercayaan yang dikehendaki ( α ). Sedanghkan apabila tujuan penelitian
menenguji hipotesis, maka ukuran sampel ditentukan oleh berapa selisih
terkecil yang harus dinyatakan secara signifikan, tergantung pula pada level of significant ( α ) dan kuasa uji (1-
β
)Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͵ͺ
II. 5. 2. 1 Menentukan Ukuran Sample Apabila Tujuan Penelitiannya Menaksir Rata - rata
Langkah kerja yang harus dilakukannya adalah sebagai berikut :
a. Tentukan dengan tegas bahwa tujuan penelitiannya adalah menaksir rata-rata
populasi ( μ )
b. Tentukan dengan tegas berapa derajat kepercayaan yang akan dipakai (pada umumnya statistik klasik menggunakan derajat kepercayaan 95 % atau 90 %)
c. Tentukan bound of error penaksiran
d. Gunakan persamaan : 2 2 / 0 ¸¸¸¸ ¹¹¹¹ ···· ¨¨¨¨ ©©©© §§§§ ====
δ
α S z n n n n n 0 0 1++++ ==== Keterangan :S : Simpangan baku untuk variabel yang diteliti dalam populasi
δ : Bound of error yang bisa ditolelir / dikehendaki
( )
1−α2Z : Konstanta bilangan yang diperoleh dari tabel normal baku
Rumus di atas mengandung parameter S yang dalam praktik jarang sekali diketahui, sebab S hanya diketahui apabila dilakukan sensus. Dalam kenyataannya, S bisa diperoleh melalui cara-cara sebagai berikut :
a. Diperoleh dari hasil penelitian orang lain mengenai variabel yang sama atau serupa yang sudah diterima secara akademik
b. Pendapat para pakar mengenai variabel yang sedang diteliti c. Lakukan penelitian penjajagan (pilot survey)
d. Dengan menggunakan Deming’s Empirical Rule. Menurut Deming, ada
hubungan antara besarnya simpangan baku dengan besarnya rentang (selisih data terbesar dengan data terkecilnya).
Aturan Deming :
- Jika variabel X adalah variabel dengan tingkat pengukuran interval
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͵ͻ miring ke kiri maupun miring ke kanan, maka hubungan antara simpangan baku dengan rentang adalah :
S ≈ 0,25 R
Kurva di atas menunjukkan kurva positif yang menggambarkan bahwa nilai-nilai yang kecil cenderung banyak, kemudian nilai yang besar cenderung sedikit.
Sebagai contohnya adalah aktifitas di pasar. Pada pukul 05.00 – 10.00 yang belanja cenderung banyak, sedangkan semakin siang semakin sedikit, bahkan yang belanja mulai sepi.
Kurva menunjukkan kurva negatif, yang menggambarkan bahwa nilai-nilai yang kecil cenderunng lebih sedikit daripada nilai-nilai yang besar.
Sebagai contohnya adalah pengunjung pada café-café tenda. Pada pagi hari nyaris tidak ada pengunjung. Tetapi di sore hari, pengunjung mulai berdatangan. Bahkan pada malam hari terjadi penumpukkan pengunjung hingga terjadi antrian. Kemudian menjelang pukul 24.00 ke atas pengunjung menjadi sepi lagi
- Apabila X mengikuti distribusi yang bentuk kurvanya normal,
maka hubungan antara simpangan baku dengan rentang adalah:
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͶͲ
- Jika X mengikuti distribusi yang kurvanya uniform, maka
hubungan antara simpangan baku dengan rentangnya adalah:
S ≈ 0,29 R
Nilai S yang diperoleh dari hasil penelitian orang lain bukanlah merupakan simpangan baku populasi, melainkan simpangna baku yang diperoleh dari sampel yaitu s. Tetapi karena penelitian tersebut sudah diterima orang, maka s dianggap menjadi S. Ada kemungkinan bahwa hasil penelitian mengenai vaiabel serupa memberikan s yang berbeda. Dalam keadaan yang seperti ini diambil n yang terbesar.
Dalam praktik, ukuran sampel bisa pula dilakukan berdasarkan nilai-nilai yang diambil dari ukuran sampel sebesar n. Selanjutnya
digunakan Freund’s Iterative Method, sebagai berikut :
1. Tentukan n0 dengan persamaan berikut :
2 2 / ¸ ¹ · ¨ © § =
δ
α S Z no2. Substitusikan no ke dalam persamaan :
( 1) 2 2 / 1 ¸¸ ¹ · ¨¨ © § = −
δ
α S t n no3. Substitusikan n1 ke dalam persamaan : ( 1) 2 2 / 2 1 ¸¸ ¹ · ¨¨ © § = −
δ
α S t n n4. Substitusikan hasil dari langkah ketiga pada persamaan langkah ketiga itu sendiri. Langkah dihentikan apabila hasil yang diperoleh sama atau hampir sama dengan langkah yang telah dilakukan sebelumnya. Diperolehlah nilai minimum dari ukuran sampel berdasarkan nilai akhir dari iterasi.
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran Ͷͳ Contoh Soal :
Seorang peneliti ingin mengetahui sejauh mana tingkat sadar hukum masyarakat di daerah A. Untuk itu ia perlu mengambil sampel masyarakat. Apabila ia menginginkan derajat keyakinan 95% bahwa kalaupun ada perbedaan rata rata tingkat kesadaran hukum antara hasil sampel dengan rata rata keseluruhan, perbedaan tersebut jangan lebih dari 5. Maka, bila Jumlah penduduk dewasa masyarakat daerah A =500.000, ukuran sampel yang diperlukan adalah: 2 2 / 0 ¸¸¸¸ ¹¹¹¹ ···· ¨¨¨¨ ©©©© §§§§ ====
δ
α S z n 227 586 . 226 5 ) 84 . 3 ( 96 . 1 2 0 ¸¸¸¸ ==== ≈≈≈≈ ¹¹¹¹ ···· ¨¨¨¨ ©©©© §§§§ ==== n 227 89 . 226 000 . 500 227 1 227 1 0 0 ==== ≈≈≈≈ ++++ ==== ++++ ==== n n n n catatan: Skor minimal :40 Skor maksimal : 200 R =160Diketahui bahwa distribusi skor simetri. Maka S=(0.24)160= 38.4
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran Ͷʹ
II.5.2.2 Menentukan Ukuran Sample Apabila Tujuan Penelitiannya Menaksir Persentase (Proporsi)
Secara statistis, persentase itu dinyatakan dalam proporsi. Oleh karena itu, menaksir persentase sama dengan menaksir proporsi. Untuk menentukan ukuran sampel dengan tujuan penaksiran persentase, dapat dihitung dengan persamaan berikut :
a. Jika sebelumnya ada keterangan sekunder mengenai dugaan harga
proporsi , maka rumusnya :
2 0 0 2 / 0 ) 1 ( ¸¸¸¸ ¸¸¸¸ ¹¹¹¹ ···· ¨¨¨¨ ¨¨¨¨ ©©©© §§§§ −−−− ====
δ
π
π
α z n N n n n 1 1 0 0 −−−− ++++ ====b. Jika belum ada keterangan sekunder mengenai dugaan π0, maka
disarankan dipakai π0 = 0,5 sehingga rumusnya menjadi :
2 2 / 0 2 ¸¹ · ¨ © § =
δ
α z n N n n n 1 1 0 0 −−−− ++++ ====Rumus ini adalah rumus ukuran sampel minimal yang terbesar , sebab
perkalian π0 (1 - π0) akan merupakan perkalian terbesar nilainya jika dan
hanya jika π0 = 0,5
Contoh:
Seseorang ingin mendapat keterangan berapa persen di suatu daerah yang tergolong pengangguran, bila derajat keyakinan dipilih 99% dengan bound of error 5%. Diketahui bahwa banyaknya masyarakat di daerah tersebut adalah 12.000 664 05 . 0 2 575 . 2 2 2 2 2 / 0 ¸ ≈ ¹ · ¨ © § × = ¸ ¹ · ¨ © § =
δ
α z nBahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran Ͷ͵ 630 13 . 629 000 . 12 1 664 1 664 1 1 0 0 = ≈ − + = − + = n n n n
II.5.2.2 Menentukan Ukuran Sample Apabila Tujuan Penelitiannya Adalah Melakukan Pengujian Hipotesis
A. Menentukan ukuran sampel bila penelitian bertujuan untuk menguji hipotesis mengenai perbedaan rata rata dengan sampel independen
Gunakan rumus berikut
(
)
2 2 2 1 1 2 ∂ + = Z− Z− S n α βuntuk α dan β yang ditentukan
S adalah simpangan baku dari variabel yang diteliti, dimana diasumsikan bahwa simpangan baku ini sama untuk kedua populasi.
δ menyatakan perbedaan rata rata yang menurut teori /tujuan penelitian
dianggap bermakna Contoh:
Andaikan dalam suatu penelitian ingin diuji suatu hipotesis yang mengatakan bahwa kinerja perusahaan BUMN lebih tinggi dibandingkan dengan non BUMN. Untuk itu penelitian dilakukan. Yang menjadi unit sampling dalam penelitian ini adalah perusahaan bak BUMN maupun non BUMN. Masalahnya berapa perusahaan yang
harus dijadikan sampel bila pengujian ingin mengambil resiko α dan β sebesar
masing masing 0.05. Bila menurut teori perbedaan skor rata rata kinerja antara perusahan BUMN dan Non BUMN sebesar 10
dianggap bermakna dan menurut pengalaman skor terendah dari kinerja adalah 30 serta tertingi 150, maka kran sampel yang diperlukan adalah:
(
)
2 2 2 1 1 2 ∂ + = Z− Z− S n α β =(
2)
2 2 10 2 645 . 1 645 . 1 + SBahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͶͶ
dengan aturan Deming, maka S =0.24×R=0.24×(150−30)=28.8S
Sehingga
(
) (
)
179.55 180 10 8 . 28 2 645 . 1 645 . 1 2 2 2 ≈ = +Jadi dperlukan paling sedikit masing 180 perusahaan BUMN dan non BUMN.
B. Menentukan ukuran sampel ila penelitian bertujuan untuk menguji hipotesis mengenai perbedaan rata rata dengan sampel berpasangan
Gunakan rumus berikut
(
)
2 2 2 1 1 ∂ + = Z − Z − Sd n α β dS adalah simpangan baku dari perbedaaan skor populasi pertama dengan
populasi ke dua.
δ menyatakan perbedaan rata rata yang menurut teori /tujuan penelitian
dianggap bermakna
C. Menentukan ukuran sampel bila penelitian bertujuan untuk menguji hipotesis tentang kebermaknaan korelasi
Untuk menentukan ukuran sampel yang dperlukan digunakan pendekatan berikut: Ukuran sampel ditentukan secara iterasi dengan cara berikut. Tentukan ukuran sampel melalui rumusan :
Pada iterasi pertama, up ditentukan melalui persamaan berikut
¸¸ ¹ · ¨¨ © § − + =
ρ
ρ
1 1 log 2 1 p udi mana ρ menyatakan perkiraan korelasi yang terjadi antara variabel X dan Y.
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran Ͷͷ ) 1 ( 2 1 1 log 2 1 − + ¸¸ ¹ · ¨¨ © § − + = n up
ρ
ρ
ρ
demikian seterusnya sampai diperoleh nilai n yang stabil (konvergen).
Untuk berbagai nilai α dan β serta nilai ρ, Machin and Campbel telah membuat tabel
ukuran sampel sehingga memudahkan untuk digunakan. (lihat lampiran 1.)
D. Menentukan ukuran sampel bila penelitian bertujuan untuk menguji hipotesis
tentang kebermaknaan R2dalam analisis regresi
Bila tujuannya untuk menguji kebermaknaan R2 dalam analisis regresi,maka
ukuran sampel ditentukan melalui rumus:
1 2 + + = k f L n dimana 2 2 2 1 R R f − =
k = banyaknya variabel bebas
L diperoleh dari tabel (lampiran 2) untuk α dan β yang ditentukan
2
R adalah koefisien determinasi terkecil yang besarnya diperkirakan baik
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran Ͷͻ
TINJAUAN MATA KULIAH
BAB III
SAMPLING SISTEMATIS
III. 1 Pendahuluan
Sebuah sampel yang diperoleh dari penyeleksian satu unsur secara acak dari k unsur yang pertama dalam sebuah kerangka sampling dan setiap unsur ke-k kemudian
disebut satu dalam k sampel sistematik. Jadi, suatu proses memilih dikatakan
sampling sistematik apabila dalam pemilihan itu dilakukan pemilihan sistematik
setelah terpilih bilangan acak, dengan syarat bahwa peluang terpilihnya 1 N.
Sampling sistematik digunakan apabila :
1. Bisa disusun kerangka sampling yang lengkap
2. Keadaan variabel yang sedang diteliti relatif homogen dan tersebar merata di seluruh populasi
Sampling Sistematik memberikan sebuat alternatif yang berguna dari Sampling Acak Sederhana untuk alasan sebagai berikut :
1. Sampling Sistematik lebih mudah untuk dilakukan dan oleh sebab itu lebih sedikit subjek yang melakukan kesalahan wawancara daripada Sampling Acak Sederhana.
2. Sampling Sistematik sering memberikan informasi yang lebih banyak mengenai biaya per unit/satuan daripada yang diberikan Sampling Acak Sederhana.
Pada umunya Sampling Sistematik merupakan penyeleksian secara acak pada suatu unsur dari k unsur yang pertama dan kemudian penyeleksian pada setiap unsur k sesudahnya. Prosedur ini lebih mudah dibentuk dan biasanya akan meminimalisir kesalahan yang mungkin dilakukan oleh pewawancara daripada dalam proses Sampling Acak Sederhana. Sebagai contohnya, akan menjadi lebih sulit apabila menggunakan Sampling Acak Sederhana untuk menyeksi n = 50 orang pembeli pada sebuah sudut jalan kota. Pewawancara tidak menentukan pembeli-pembeli mana yang termasuk dalam sampelnya, karena ia tidak memiliki sampling framenya serta tidak
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͷͲ mengetahui ukuran populasi ,N . Sebagai solusinya, ia dapat mengambil sampel secara sistematik (katakanlah 1 dari 20 pembeli) hingga persyaratan sampelnya bisa didapatkan. Ini akan menjadi sebuah prosedur yang mudah bahkan untuk pewawancara yang tidak berpengalaman sekalipun dapat melakukannya.
Selain itu, lebih mudah untuk dilakukan dan lebih sedikit terjadinya kesalahan dalam wawancara terhadap subjeknya. Sampling Sistematik sering memberikan informasi yang lebih banyak per unit biaya daripada Sampling Acak Sederhana. Sampling sistematik seringkali menyebar lebih seragam pada seluruh sendi populasi sehingga dapat menghasilkan informasi yang lebih banyak mengenai populasinya daripada data-data yang diperoleh dengan Sampling Acak Sederhana. Pertimbangkan contoh berikut : Kita akan memilih salah satu dari 5 sampel secara sistematik dari vouicher perjalanan sekumpulan data sebanyak N = 1000. (yaitu, n = 200 voucher) untuk menghitung proporsi dari voucher yang dicatat secara tidak benar. Satu voucher menggambarkan proses acak dari 5 voucher yang pertama (sebagai contohnya 3 ) dan setiap voucher sesudahnya menjadsi anggota sampel.
voucher Voucher yang menjadi sampel
1 2 3 3 4 5 6 7 8 8 9 10 …… 996 997 998 998 999 1000
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͷͳ Dimisalkan bahwa kebanyakan dari 500 voucher pertama telah diisi dengan benar, tapi berkaitan dengan perubahan yang dialami oleh juru tulis, 500 voucher kedua akan memiliki kesalahan yang banyak. Apabila proses sampling yang digunakan adalah dengan Sampling Acak Sederhana, maka secara kebetulan bisa terpilih kebanyakan (mungkin semua) dari 200 voucher adalah berasal dari salah satunya, baik itu pada bagian kelompok pertama maupun yang kedua dan sebab itu taksiran untuk p menjadi kurang sesuai Sebaliknya, Sampling Sistematik akan memilih jumlah yang sama dari voucher pada kedua kelompok tersebut dan akan memberikan taksiran yang akurat .
III. 2 Bagaimana Menggambarkan Sampling Sistematik
Walaupun Sampel Acak Sederhana maupun Sampel Sistematik keduanya memberikan alternativ yang berguna satu sama lainnya, metode dari pemilihan data sampelnya berbeda. Suatu Sampel Acak Sederhana dari populasi dipilih dengan menggunakan tabel bilangan acak. Akan tetapi metode-metode yang bervariasi dapat digunakan dalam Sampling Sistematik. Peneliti dapat memilih 1 dari 3, 1 dari 5, atau secara umum, 1 dari k sampel sisitematis.
Untuk mendapatkan suatu sampel sistematis berukuran n dari sebuah populasi yang berukuran N, harus ditentukan k sistematis yang kurang atau sama dengan n/N. k tidak bisa dipilih secara tepat apabila ukuran populasi tidak diketahui. Meskikpun dapat ditentukan ukuran sampel secara pendekatan, namun harus memperkirakan nilai k yang dibutuhkan untuk mencapai ukuran sampel (n). Jika nilai k yang dipilih terlalu besar, ukuran sampel (n) yang diharuskan tidak akan diperoleh dengan menggunakan 1-dalam-k sampel sistematis dari populasinya. Hal ini tidak akan menjadi masalah jika peneliti dapat menguanginya dan membuat 1-dalam-k sistematik sampling lainnya hingga ukuran sampel yang telah ditentukan terpenuhi. Namun demikian, dalam beberapa situasi tidak mungkin untuk memulai sampling sistematis yang kedua.
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͷʹ
III. 3 Keuntungan Sampling Sistematik
Dibandingkan dengan sampling acak sederhana, sampling sisitematik mempunyai kelebihan, yaitu :
1. standard Error yang didasarkan pada sampling sisitematik paling sedikit sama presisinya dengan sampling acak sederhana
2. Mudah dilakukan
3. Pada keadaan tertentu, sampling sistematik bisa dilakukan sekalipun tidak ada kerangka sampling.
III. 4 Kerugian Sampling Sistematik
Sampling sistematik bisa sangat merugikan apabila dalam kerangka sampling terdapat periodisitas, teruitama periodisitas yang berhimpit / overlap dengan interval pemilihan.
Sebagai contohnya adalah suatu penelitian yang akan dilakukan mengenai
tingkat kepuasan tamu hotel terhadap prosedur pelayanan di hotel tersebut.
Sampling frame yang digunakanya adalah daftar tamu yang hadir pada saat itu.
Berdasarkan tujuan kedatangannya, tamu hotel dibagi menjadi convention, bisnis,
weekend, liburan, government dan pelatihan. Celakanya , ternyata berdasarkan
sampling sistematik ternyata dalam kerangka sampling ada periodisitas yang overlap
dengan interval pemilihan, misalnya terus menrus terpilih tamu bisnis. Sehingga pada
akhirnya kurang bisa mencerminkan bagaiman tibgkat kepuasan keseluruhan tamu yang ada.
III. 5 Menaksir Rata-rata Populasi dan Total
Sebagaimana yang telah berulangkali ditekankan bahwa maksud dari kebanyakan suatu survey adalah menaksir satu atau lebih parameter dari populasi..
Taksiran untuk rata-rata populasi , μ, dari sampel sistematik menggunakan rata-rata
Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͷ͵
Jika N tidak diketahui maka fpc, ( N – n ) / N pada persamaan (3.2) dan (3.3)
dibuang. Ternyata bahwa taksiran varians dari xsy yang ada pada persamaan (3.2)
identik dengan taksiran varians untuk x yang dperoleh dengan menggunakan
Sampling acak Sederhana. Hal ini tidak menyiratkan bahwa varians populasi yang
bersangkutan sama. Varians dari x diperoleh dari persamaan :
( )
x NN n n V 2 1 ˆ ¸¸σ
¹ · ¨¨ © § − − =Demikian juga varians dari xsy dapat dituliskan :
( )
σ
{
1(
1)
ρ
}
2 − + = n n x V sydimana ρ adalah koefisien korelasi antara observasi dalam sampel sisitematik yang
sama. Ketika N besar, kedua varians tersebut sama jika observasi dalam sebuah
sampel yang ditetapkan tidak berkorelasi (ρ ≈ 0).
Sebuah taksiran yang tak bias dari V
( )
xsy tidak dapat diperoleh denganmenggunakan data hanya dari satu sampel sistematik. Hal ini tidak berarti bahwa
suatu taksiran dari V
( )
xsy tidak pernah bisa diperoleh. Untuk populasi tertentu,ampling sistematik ekivalen dengan sampling acak sederhana, dan kita dapat
Penaksir Rata-rata Populasi,
μ
:n x x n i i sy
¦
= = = 1μ
( 3.1 )Varians taksiran untuk xsy :
( )
sn N n N x Vˆ sy ¸ 2 ¹ · ¨ © § − = ( 3 . 2 )Bound of Error taksiran tersebut :
( )
sn N n N Z x V Z sy 2 2 2 ˆ ¸ ¹ · ¨ © § − = = α αδ
( 3 . 3 )Bahan Ajar Sampling - Yudhie Andriyana
Jurusan Statistika, FMIPA – Universitas Padjadjaran ͷͶ
mengambil V
( )
xsy yang hampir sama dengan taksiran varians dari x berdasarkanpada samping acak sederhana.
Untuk populasi yang mana hubungan ini terjadi? Untuk menjawab pertanyaan tersebut kita harus mempertimbangkan tiga tipe populasi sebagai berikut :
1. Populasi Acak (Random Population) 2. Populasi Terurut (Ordered Populastion) 3. Populasi Berkala (Periodic Population)
III. 5. 1 Populasi acak
Definisi : Suatu populasi dikatakan acak apabila elemen-elemen dari populasi tersebut berada dalam urutan yang acak.
Elemen-elemen dari sampel sistematik yang diambil dari populasi yang acak
diaharapkan akan heterogen dengan ρ mendekati nol. Dengan demikian, ketika N
besar, varians dari xsy kira-kira sama dengan varians dari x yang berdasarkan pada
sampling acak sederhana, sampling sistematis dalam kasus ini ekivalen dengan sangling acak sederhana. Sebagai contohnya, seorang peneliti ingin menentukan rata-rata jumlah dari yang ditulis oleh dokter tertentu selama tahun sebelumnya.. Jika frame (kerangka) mengandung daftar dokter-dokter, cukup beralasan untuk mengasumsikan bahwa nama-nama pada daftrar tersebut tidak berhubungan dengan banyaknya resep yang ditulis untuk obat tertentu. Oleh karena itu, kita pertimbangkan bahwa populasinya acak. Suatu sampel sistematik akan ekivelan dengan sampel acak sederhana untuk kasus tersebut.
III. 5. 2 Populasi Terurut
Suatu populasi dikatakan terurut apabila elemen-elemen dalam populasi terurut dalam dalam jarak sesuai dengan pola tertentu
Dalam sebuah survey untuk menaksir efektivitas dari instruksi dalam suatu kursus yang besar, pelajar diminta untuk mengevaluasi instrukutur mereka berdasarkan skala numerik.. sebuah sampel kemudian diambil dari daftar evaluasi yang disusun dalam urutan numerik yang menaik. Populasi dari pengukuran dimana data sampel diambil dianggap sebuah populasi yag terurut.