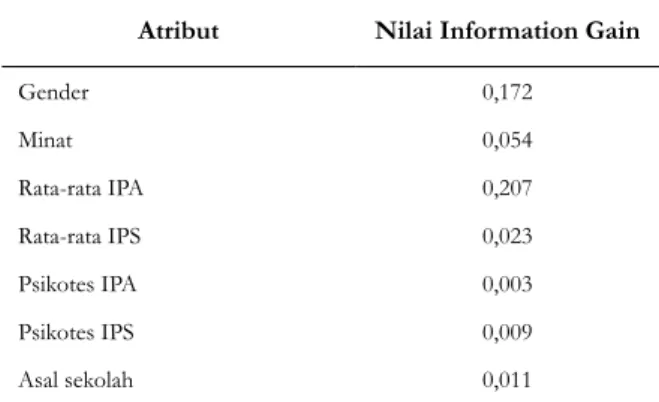
Sedangkan karakteristik yang digunakan terdiri dari jenis kelamin, minat, nilai rata-rata IPA, nilai rata-rata IPS, nilai psikotes ilmiah, nilai psikotes IPS, asal sekolah dan jurusan. Variabel yang paling berpengaruh dalam menentukan jurusan adalah nilai rata-rata IPA, sehingga sekolah harus memperhitungkannya saat menentukan jurusan bagi siswa. Berdasarkan hasil pohon keputusan pada Gambar 1 terlihat bahwa atribut yang paling besar pengaruhnya dalam menentukan klasifikasi jurusan mahasiswa adalah nilai rata-rata IPA.
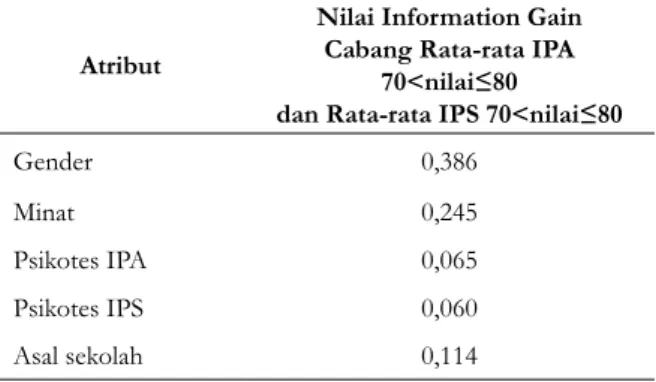
Berdasarkan hasil pohon keputusan pada Gambar 1 terlihat bahwa rata-rata IPA memiliki pengaruh paling tinggi dalam penentuan jurusan di SMA. Penentuan node internal pada cabang rata-rata IPA70 < nilai≤80 diperoleh nilai information gain seperti pada Tabel 3. Dari hasil perhitungan pada Tabel 3 dapat disimpulkan bahwa rata-rata atribut IPS adalah node internal dengan IPA rata-rata sebesar 70 < nilai≤80 karena memiliki nilai keuntungan paling tinggi dibandingkan atribut lainnya.
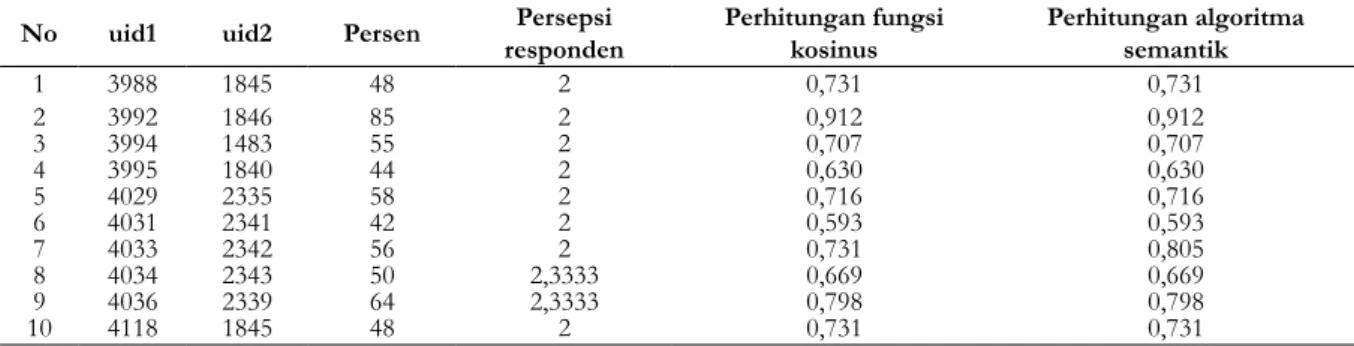
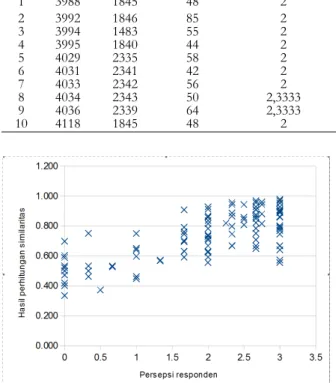
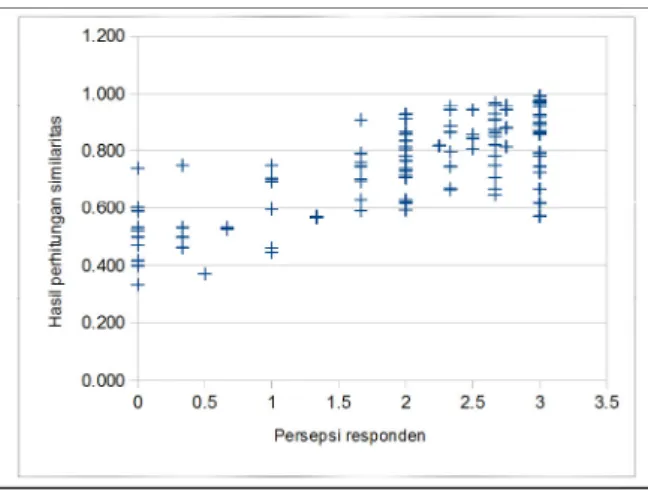
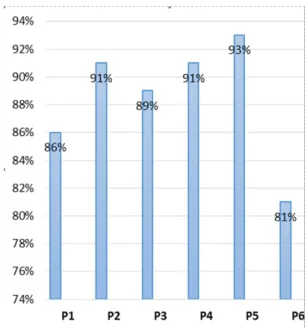
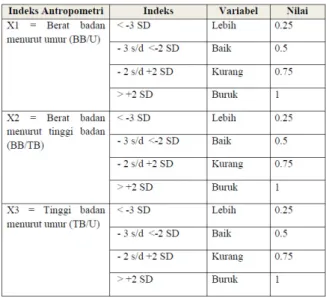
Penentuan internal node kedua pada rata-rata IPA 70 Hal ini dibuktikan dengan nilai rata-rata variabel IPA yang menempati simpul akar pada diagram pohon keputusan. Keefektifan algoritma semantik dengan asosiasi kata dalam mengukur kemiripan teks hasil evaluasi penutur bahasa Indonesia 9 dinilai kurang memadai. Sebanyak 114 pasangan kalimat mengandung skor dengan selisih maksimal 1 poin dan sudah menjadi filter dari 143 pasangan kalimat yang diperiksa. Sebagai perbandingan, penelitian ini juga menguji fungsi cosinus dan perhitungan kesamaan berdasarkan persentase jumlah kata yang sama untuk semua kata dalam pasangan kalimat. Peta korelasi antara skor kesamaan yang dihitung dengan fungsi kosinus dan skor kesamaan makna kalimat. Meskipun algoritma kesamaan semantik berdasarkan jaringan kata menghasilkan tingkat korelasi tertinggi, perbedaan nilai korelasi dari penggunaan fungsi kosinus tidak signifikan, hanya 0,01 poin (setara dengan satu persen). Fungsi cosinus dan algoritma semantic similarity berbasis jaringan kata sama-sama menghasilkan nilai korelasi yang berbeda cukup signifikan dengan nilai korelasi yang dihasilkan perhitungan kemiripan berdasarkan persentase keberadaan kata yang sama. Artinya, sejauh pengamatan yang dilakukan dalam penelitian ini, penggunaan algoritma kesamaan semantik berbasis jaringan kata meningkatkan skor kesamaan dibandingkan dengan perhitungan kesamaan sederhana yang menggunakan persentase jumlah kesamaan kata dalam dua teks. . dibandingkan. Namun, pengamatan dalam penelitian ini juga menunjukkan bahwa tidak ada perbedaan yang signifikan dalam menggunakan algoritma kesamaan semantik berbasis jaringan kata dibandingkan dengan menggunakan fungsi cosinus. DISKUSI Ochoa, “Analisis Penggunaan Teknik Search Engine Optimization (SEO) Terpilih dan Performanya dalam Algoritma Ranking Pencarian Google,” California State University, Northbridge, 2012. Thamrin, “Pengembangan Sistem Automated Scoring untuk Short Answer dan Open-Answer Soal Evaluasi Pembelajaran Daring dalam Bahasa Indonesia,” 2013. Sabardila, “Menggunakan Kamus sebagai Basis Pengetahuan untuk Pengelompokan Teks Pendek Berbahasa Indonesia,” dalam International Conference on Data and Software Engineering, 2014. Lesk, "Automatic Sense Disambiguation Using Machine Readable Dictionaries: How to Tell a Pine Cone from an Ice Cream Cone," in Proceedings of SIGDOC Conference, 1986. Chodorow, "Combining local context and WordNet similarity for word sense identification," in WordNet, An Electronic Lexical Database, The MIT Press, 1998. Palmer, “Verb semantics and lexical selection,” in Proceedings of the 32nd Annual Meeting of the Association for Computational Linguistics, 1994. Keselj, "Text matching with Google Tri-Grams," in 25th Canadian Conference on Advances in Artificial Intelligence, 2012, pp. Wantoro, "An Attempt to Create an Automatic Scoring Tool of Short Text Answer in Bahasa Indonesia," in Proceeding of International Conference on Electrical Engineering, Computer Science and Informatics (EECSI. PENDAHULUAN Hasil yang dicapai oleh peneliti adalah sebuah aplikasi game edukasi dengan fitur augmented reality sebagai sarana pembelajaran senjata tradisional Indonesia yang terdiri dari beberapa scene game petualangan [4]. Selain aplikasi, hasil lainnya berupa marker yang digunakan sebagai alat untuk mendesain objek 3D dalam penggunaan fitur augmented reality [5], dimana marker tersebut diupload ke sistem cloud sehingga dapat diunduh ketika aplikasi sedang berjalan. Ini adalah halaman beranda saat Anda masuk ke aplikasi, dan halaman splash screen akan menutup secara otomatis dan masuk ke halaman utama aplikasi. Halaman level permainan berupa peta Indonesia tempat asal senjata tradisional, dengan begitu siswa akan mudah memahami asal usul senjata tradisional tersebut. Halaman game petualangan berisi inti dari aplikasi yaitu berupa game petualangan mencari senjata custom dari sebuah pulau yang telah dipilih pada level game. Situs augmented reality digunakan untuk melihat model 3D senjata tradisional yang telah ditemukan oleh siswa. Pengujian aplikasi diperlukan untuk mengetahui apakah aplikasi yang telah dibuat bekerja dengan baik sesuai dengan fungsi yang diharapkan, sebelum dilakukan pengujian dan evaluasi oleh responden. Pada pengujian ini peneliti menggunakan metode black-box untuk mengetahui apakah aplikasi berjalan sesuai dengan fungsi yang diharapkan [6]. Pengujian black box adalah metode pengujian perangkat lunak yang menguji fungsionalitas aplikasi tanpa melihat struktur atau cara kerja internalnya. DAFTAR PUSTAKA Klasifikasi Status Gizi Balita Jenis Kelamin Laki-Laki Menggunakan Jaringan Syaraf Tiruan 17 Status Gizi Balita yang semoga bermanfaat untuk penatalaksanaan. Penelitian [2] dengan judul Aplikasi Jaringan Syaraf Tiruan untuk Menentukan Status Gizi Balita dan Rekomendasi Menu yang Dibutuhkan mengungkapkan bahwa penelitiannya menggunakan algoritma jaringan syaraf tiruan perceptron untuk menentukan status gizi balita. Dalam klasifikasi status gizi balita pada penelitian ini digunakan indeks antropometri menurut Keputusan Menteri Kesehatan Republik Indonesia (No. 1995/MENKES/SK/.XII/2010), yaitu data pengukuran digunakan dalam klasifikasi. berat badan per tinggi badan, berat badan per umur, dan tinggi badan per umur. Pada penelitian ini ditemukan bahwa semakin tinggi nilai variabel maka status gizi balita semakin buruk, semakin rendah nilai variabel maka gizi balita semakin baik.Tabel 1 menunjukkan variabel dan nilai dari setiap parameter antropometri. Output yang akan dihasilkan aplikasi ini berupa penilaian status gizi anak balita yaitu gizi kurang, gizi kurang, gizi baik dan gizi lebih. Konfigurasi jaringan saraf tiruan dibuat untuk mendapatkan hasil penentuan status gizi yang baik, sehingga sistem memenuhi kebutuhan dan dapat digunakan. Lapisan input terdiri dari 3 unit neuron yang merupakan variabel indeks antropometri yang digunakan untuk mengklasifikasikan status gizi balita. Pengguna juga dapat menghitung status gizi berdasarkan data tambahan berupa umur, berat badan dan tinggi badan balita untuk mendapatkan output berupa gizi baik, gizi kurang dan gizi buruk. Selain itu, pengguna dapat melihat laporan data hasil pelatihan, untuk dapat mengetahui perkembangan balita berdasarkan status gizi secara berkala. Jaringan saraf tiruan untuk klasifikasi status gizi balita dengan metode propagasi balik dibangun dengan tujuan untuk membantu tenaga medis dalam memberikan penilaian status gizi balita. Pada menu status gizi terdapat submenu pelatihan JST yang digunakan untuk mengklasifikasikan status gizi balita. Selain itu juga terdapat sub menu hasil asesmen yang berfungsi untuk mencari hasil asesmen status gizi balita dan disajikan dalam bentuk grafik seperti pada Gambar 9. Berdasarkan hasil penilaian status gizi balita di Posyandu letari asih bulan April diperoleh data seperti pada Tabel 4. Perbandingan penilaian status gizi balita di Posyandu letari asih bulan April dengan penilaian status gizi balita di Posyandu letari asih bulan April status gizi anak balita berjenis kelamin laki-laki melalui pelatihan jaringan saraf tiruan dengan metode backpropagation disajikan dalam bentuk grafik seperti pada Gambar 10. Sistem berbasis desktop telah selesai dibuat dengan membuat jaringan syaraf tiruan untuk mengklasifikasikan gizi status anak kecil. Berdasarkan hasil uji sistem Posyandu Balita Lestari Asih Kartasura, petugas Posyandu kini dapat dengan mudah memberikan penilaian status gizi balita. 2] Fitri, Fitri dan Onny Setyawati, "Penggunaan Jaringan Syaraf Tiruan untuk Menentukan Status Gizi Balita dan Anjuran Diet yang Diperlukan". Aplikasi Prediksi Masa Studi dan Predikat Kelulusan Mahasiswa Ilmu Komputer Universitas Muhammadiyah Surakarta Menggunakan Metode Naive Bayes. Aplikasi prediksi masa studi dan predikat kelulusan mahasiswa ilmu komputer Universitas Muhammadiyah Surakarta menggunakan metode Naive Bayes 31 kelulusannya. Hasil dari penelitian ini adalah sebuah aplikasi data mining untuk memprediksi lama studi dan predikat kelulusan mahasiswa Ilmu Komputer dengan menggunakan metode Naïve Bayes. Algoritma Naive Bayes digunakan untuk menghitung probabilitas nilai data kelas pada data testing untuk setiap variabel dependen (Y) berdasarkan data training. Pada tahap ini dilakukan perhitungan, persamaan (2) dan (3), untuk mencari nilai probabilitas masing-masing kelas yaitu “Tepat” dan “Terlambat” pada variabel Y1. Penerapan Prediktor Masa Studi dan Predikat Kelulusan Informatika Bagi Mahasiswa Universitas Muhammadiyah Surakarta Menggunakan Metode Naive Bayes 33 Tabel 6. Pada tahap ini dilakukan perhitungan, persamaan (4)-(8), untuk mencari nilai probabilitas bersyarat dari masing-masing kelas pada variabel X versus variabel Y1. Algoritma naive bayes digunakan untuk mencari nilai kepercayaan atau probabilitas dari setiap variabel kelas Y1 berdasarkan variabel X yang diusulkan, persamaan (9) dan (10). Nilai kepercayaan masing-masing kelas kemudian dibandingkan untuk memiliki peluang lebih tinggi dalam memprediksi kelas nilai yang terdapat pada variabel Y1. a) Nilai kepercayaan pada variabel Y1 untuk kelas = 'Persis'. Berdasarkan nilai kepercayaan masing-masing kelas pada variabel Y1 dapat diketahui nilai kepercayaan untuk kelas tersebut. Pada tahap ini dilakukan perhitungan, perbandingan untuk mencari nilai probabilitas dari masing-masing kelas yaitu “Cum Laude”, “Sangat Memuaskan” dan. Pada tahap ini dilakukan perhitungan, perbandingan untuk mencari nilai probabilitas bersyarat dari masing-masing kelas pada variabel X ke variabel Y2. Nilai kepercayaan masing-masing kelas pada variabel Y2, persamaan tersebut kemudian dibandingkan untuk mencari probabilitas yang lebih tinggi dalam memprediksi nilai kelas yang muncul pada variabel Y2. a) Nilai kepercayaan pada variabel Y2 untuk kelas. Berdasarkan nilai kepercayaan masing-masing kelas pada variabel Y2, dapat diketahui nilai kepercayaan untuk kelas tersebut. Algoritma naive bayes dapat digunakan untuk memprediksi nilai suatu variabel kelas pada data testing berdasarkan perbandingan nilai probabilitas masing-masing variabel kelas pada data training dengan variabel X yang disarankan pada data testing. Hal ini dilakukan untuk memberikan cara baru bagi mahasiswa dalam belajar dan mengenal teknologi khususnya di TPQ Al-Fadhillah. Adanya website dan e-learning di TPQ Al-Fadhillah diharapkan dapat membantu dan memudahkan pengurus untuk mengelola TPQ Al-Fadhillah, baik dari data guru, siswa, RPP dan mata pelajaran serta e-learning yang dapat membantu proses belajar mengajar. Perancangan website dan e-learning di TPQ Al-Fadhillah 41 digunakan untuk menampilkan informasi, pergerakan dalam gambar,.
HASIL
KESIMPULAN
METODE

Klasifikasi Status Gizi Balita Jenis Kelamin Laki-laki Menggunakan Jaringan Syaraf Tiruan
Aplikasi Pemrediksi Masa Studi dan Predikat Kelulusan Mahasiswa Informatika Universitas