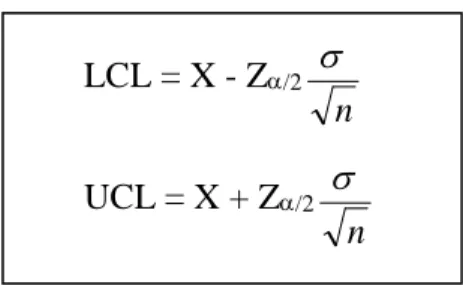2.1. PENDAHULUAN
Bab ini akan menjelaskan dasar dan teknik statistik yang digunakan didalam Pengendalian Kualitas (PK). Statitistik memegang peranan yang sangat penting didalam PK, sehingga pemahaman terhadap statistik akan memberikan dasar yang baik didalam memahami prosedur, teknik dan analisis yang ada didalam PK.
2.2.ARTI STATISTIK
Statistik adalah bagian dari matematik terapan yang mempelajari metoda ilmiah untuk mengumpulkan, mengorganisir, meringkas, menggambarkan dan menganalisis data untuk mengambil suatu kesimpulan dan keputusan.
2.3. POPULASI DAN SAMPEL
Didalam kita mengumpulkan data, seperti misalnya jumlah suatu komponen yang cacat dari suatu hasil produksi, adalah tidak mungkin jika semua data yang ada kita kumpulkan, terutama jika jumlah data tersebut besar. Sebagai gantinya biasanya kita hanya mengambil sebagian kecil saja dari data tersebut untuk diperiksa. Data dalam jumlah keseluruhan disebut populasi sedangkan sebagian kecil yang diambil untuk dianalisis disebut sampel. Tujuan pengembilan sampel pada umumnya adalah untuk membuat perkiraan terhadap keadaan populasi.
Populasi dapat bersifat terbatas dan tak terbatas. Sebagai contoh, populasi yang terdiri dari semua produk yang diproduksi suatu pabrik perhari adalah bersifat terbatas, sedangkan populasi yang terdiri dari semua produk yang diproduksi secara terus menerus dapat dianggap merupakanpopulasi yang tidak terbatas.
2.4. TEORI KEMUNGKINAN 2.4.1.Kombinasi Unsur
Ada sejumlah cara dimana n unsur dapat dikombinasikan kedalam kelompok- kelompok yang berbeda yang terdiri dari n unsur. Sebagai contoh, misal terdapat 5 orang
pemain bulutangkis A, B, C, D dan E. Dari 5 orang ini akan dibentuk sebuah pasangan ganda bulutangkis, maka banyaknya alternatif cara yang mungkin dilakukan adalah :
AB AC AD AE BC BD BE CD CE DE
Jadi terdapat 10 cara yang mungkin dilakukan. Persoalan seperti ini disebut dengan persoalan kombinasi. Perhatikan dalam hal ini AB adalah sama dengan BA. Jadi dalam persoalan kombinasi masalah urutan unsur tidak diperhatikan.
Kombinasi dari n unsur yang diambil sebanyak r unsur pada setiap saat dinotasikan dengan : C(n,r) atau nCr dan jumlahnya adalah sama dengan :
C(n,r) =
)!
(
!
! r n r
n
untuk : r n ... (2.1) Dimana : n! = 1x2x3x ... x n
1! = 1 dan 0! = 1 Contoh 2.1 :
Dari 5 produk yang ada 2 produk akan diambil untuk dilakukan pemeriksaan. Ada berapa alternatif kemungkinan terambilnya 2 dari 5 produk tersebut ?
Jawab :
2.4.2 Permutasi Unsur
Himpunan r item yang diambil dari himpunan n item dengan memperhatikan urutan disebut dengan permutasi. Jadi dalam hal ini urutan AB tidak sama dengan BA.
Permutasi dinotasikan dengan P(n,r) dan banyaknya adalah sama dengan : P(n,r) =
)!
(
! r n
n
... (2.2) 2.4.3. Ruang Sampel
Himpunan dari semua “outcome” yang mungkin dari suatu eksperimen statistik disebut dengan ruang sampel dan dinyatakan dengan simbol S. Masing-masing
“outcome” dari ruang sampel disebut dengan unsur atau anggota atau titik sampel.
Contoh 2.2.
Misal empat buah produk diambil secara random dari suatu hasil proses produksi dengan dua kemungkinan, yakni terambil produk baik(B) atau cacat(C). Tentukan ruang sampelnya.
Jawab :
Eksperimen ini dapat digambarkan dengan diagram pohon seperti ditunjukkan dibawah ini.
B BBBB B
C BBBC
B
B BBCB C
C BBCC B
B BCBB B
C BCBC C
B BCCB C
C BCCC B CBBB B
C CBBC B
B CBCB C
C CBCC C
B CCBB B
C CCBC C
B CCCB C
C CCCC Jadi : S = BBBB, BBBC, BBCB, ..., CCCC
2.4.4. Kejadian
Kejadian adalah hinpunan bagian dari Ruang Sampel Contoh 2.3.
Misal diberikan ruang sampel S = t/t>=0 dimana t menyatakan umur suatu komponen elektronik yang dinyatakan dalam tahun, maka : A = t/ 0< t < 5 adalah menyatakan kejadian dimana umur komponen elektronik tersebut kurang dari 5 tahun.
Dalam hal ini jelas bahwa : A S 2.4.5. Komplemen Suatu Kejadian
Komplemen dari kejadian A dalam ruang sampel S adalah sub-himpunan dari semua unsur S yang tidak ada didalam A. Komplemen A dinyatakan dengan A’
S A A’
Kejadian A Komplemen dari A Contoh 2.4.
Misal diketahui ruang sampel S sebagai berikut :
S = buku, meja, kursi, gelas, tas, penggaris dan A = buku, meja, kursi, gelas, maka :
A’ = tas, penggaris
2.4.6. Irisan dari Dua Kejadan.
Irisan dari dua kejadian A dan B yang dinotasikan dengan A B adalah himpunan kejadian yang ada di A dan B
S
A B
A B
2.4.7. Dua Kejadian yang Mutual Exclusive
Dua kejadian A dan B disebut “mutual exclusive” jika A B = A B
2.4.8. Gabungan dari Dua Kejadian
Union atau gabungan dari dua kejadian A dan B yang dinyatakan dengan simbol A B adalah kejadian yang terdiri dari semua unsur yang ada didalam A atau B atau keduanya.
Contoh 2.5.
Misal A = a, b, c dan B = b, c, d, e, f, maka A B = a, b, c, d, e, f
a b c d e f
2.4.9. Menghitung Jumlah Titik Sampel
Jumlah titik sampel yang sebelumnya dihitung dengan menggambar diagram pohon, dapat juga dihitung dengan menggunakan aturan perhitungan sebagai berikut :
Jika kejadian 1 dapat terjadi sebanyak n1 cara dan kejadian 2 dapat terjadi sebanyak n2 cara, maka kedua kejadian tersebut dapat terjadi bersama sebanyak (n1)(n2) cara
Contoh 2.6.
Produk A dapat diproses dengan menggunakan mesin M1 atau mesin M2, sedangkan produk B dapat diproses dengan menggunakan mesin M3, M4 atau M5, maka kedua produk tersebut dapat dihasilkan dengan menggunakan cara sebanyak 2x3 = 6 cara sebagai berikut :
Produk A Produk B
M1 M3
M4 M5
M2 M3
M4 M5
Aturan perkalian diatas dapat diperluas dengan melibatkan lebih dari dua kejadian sebagai berikut ::
Jika kejadian 1 dapat terjadi sebanyak n1 cara, kejadian 2 dengan n2 cara dan seterusnya kejadian ke k dengan nk cara, maka kesemua kejadian tersebut dapat terjadi bersama sebanyak (n1)(n2) ... (nk) cara
Contoh 2.7..
Sebuah menu makan siang terdiri dari sayur asem, ikan goreng, buah dan minuman. Jika ada 4 macam sayur asem, 3 macam ikan goreng, 5 macam buah dan 4 macam minuman, maka banyaknya alternatif menu yang dapat dipilih adalah sebanyak :
(4)(3)(5)(4) = 240 cara.
Kombinasi dan permutasi seperti yang telah dijelaskan dalam butir 2.4.1. dan butir 2.4.2. didepan dapat digabungkan dengan aturan diatas untuk menghitung jumlah titik sampel ini.
Contoh 2.8.
Sebuah sampel yang terdiri 2 TV, 3 kulkas dan 3 mesin cuci akan diambil dari 5 macam TV, 7 macam kulkas dan 7 macam mesin cuci yang tersedia. Ada berapa alternatif cara yang mungkin untuk pengambilan sampel tersebut ?
Jawab :
2.4.10. Kemungkinan Dari Suatu Kejadian.
Jika ruang sampel dari suatu eksperimen mengandung N unsur dengan masing-masing unsur mempunyai kesempatan yang sama untuk terjadi yakni sama dengan : 1/N, maka kemungkinan terjadinya suatu kejadian A yang mengandung n unsur dari ruang sampel tersebut adalah = n/N
Contoh 2.9.
Hasil produksi produksi produk A perhari adalah 2000 dengan 40 diantaranya diperkirakan merupakan produk A yang cacat. Jika seorang pemeriksa mengambil sebuah produk dari hasil produksi tersebut, berapa kemungkinan produk tersebut merupakan produk cacat ?
Jawab :
2.4.11. Aturan Penjumlahan Dalam Kemungkinan.
Jika A dan B adalah suatu kejadian, maka :
P(A B) = P(A) + P(B) – P(A B) ... (2.3.)
Jika A dan B adalah dua kejadian yang bersifat “mutually exclusive” maka : P(A B) = P(A) + P(B) ... (2.4.) 2.4.12. Kemungkinan Komplemen
Jika A dan A’ adalah dua kejadian yang saling melengkapi (complementary), maka : P(A) + P(A’) = 1, atau :
P(A’) = 1 – P(A) ... (2.5.) 2.4.13. Kemungkinan Bersyarat (Aturan Perkalian).
Kemungkinan B terjadi jika A sudah terjadi dinotasikan dengan P(B/A) dan dinamakan kemungkinan bersyarat. Jika terjadinya atau tidak terjadinya B tidak
dipengaruhi oleh kejadian A maka : P(B/A) = P(B). Jika kejadian B dipengaruhi oleh kejadian A maka A dan B merupakan dua kejadian yang saling tidak bebas (dependent event). Sebaliknya jika kejadian B tidak dipengaruhi oleh kejadian A, maka A dan B merupakan dua kejadian yang saling bebas (independent event).
Jika A B menyatakan kejadian dimana A dan B keduanya terjadi, maka : - Jika A dan B saling bebas : P(A B) = P(A). P(B)
- Jika A dan B tidak saling bebas : P(A B) = P(A). P(B/A)
Kemungkinan terjadinya B jika A sudah terjadi dinotasikan dengan : P(B/A) dan didefinisikan sebagai :
P(B/A) = P(A B) / P(A) untuk P(A) 0, atau :
P(A B = P(A). P(B/A) ... (2.6.) Contoh 2.10.
Dalam suatu produksi pelat metal yang akan digunakan didalam suatu proses perakitan, berdasarkan data masa lalu diketahui bahwa 5% dari pelat tersebut tidak dapat memenuhi spesifikasi panjang dan 3% tidak dapat memenuhi spesifiksi lebar. Jika diassumsikan pemrosesan panjang dan lebar adalah saling bebas, hitunglah :
a. Kemungkinan proses akan menghasilkan pelat yang memenuhi spesifikasi baik panjang maupun lebar.
b. Berapa % kira-kira pelat yang tidak memenuhi paling sedikit satu persyaratan ? c. Berapa % kira-kira pelat yang tidak memenuhi persyaratan baik panjang maupun
lebarnya ?
d. Misal sekarang pemrosesan panjang dan lebar adalah tidak saling bebas, yakni jika pemrosesan panjang tidak memenuhi spesikasi maka kemungkinan pemrosesan lebar tidak memenuhi spesifikasi menjadi = 0,6. Pada keadaan ini hitunglah berapa % pelat yang tidak dapat memenuhi spesifikasi baik panjang maupun lebar.
Jawab :
2.5. HASIL PENGUKURAN DATA EKSPERIMENTAL 2.5.1. Distribusi Frekwensi.
Eksperimen dapat terjadi dengan berbagai bentuk. Sebuah eksperimen mungkin dapat berupa :
- Pengukuran massa suatu produk.
- Pengukuran diameter - Pengukuran kecepatan
- Pengukuran umur suatu komponen - Pengukuran temperatur, dan lain-lain.
Dengan adanya variabel random didalam proses maka eksperimen tersebut akan memberikan hasil pengkuran yang bervariasi juga. Distribusi Frekwensi (DF) adalah suatu metoda sistimatis yang digunakan untuk mengurutkan dan mengatur data yang bervariasi tersebut kedalam bentuk kelompok. DF biasanya disajikan dalam bentuk tabel yang mengandung dua unsur, yakni kelas dimana data dikelompokkan dan frekwensi yang menghitung banyaknya data didalam kelas tersebut. Contoh DF dapat dilihat pada Tabel 2.1. dibawah ini
Tabel 2.1. Distribusi Frekwensi Panjang 100 Komponen X (dalam mm)
Kelas Frekwensi
60 – 62 5
63 – 65 18
66 – 68 42
69 – 71 27
72 – 74 8
Jumlah : 100
Beberapa istilah didalam DF yang perlu dimengerti adalah : - Lebar kelas
- Batas kelas (class limits) - Tepi kelas (class boundaries) - Titik tengah (class mark) - Frekwensi kelas
Contoh 2.11.
Pada DF panjang 100 komponen X diatas, tentukanlah untuk kelas ke 3 : a. Lebar kelas
b. Batas kelas bawah (lower class limits) dan batas kelas atas (upper class limits).
c. Tepi kelas bawah (lower class boundaries) dan tepi kelas atas (upper class boundaries).
d. Titik tengah.
e. Frekwensi kelas.
Jawab :
Langkah-langkah untuk menyusun DF adalah sebagai berikut :
1. Hitung “range”, yakni selisih antara nilai maksimum dan minimum.
2. Hitung banyaknya kelas yang diperlukan dengan menggunakan rumus “Sturges”
sebagai berikut :
K = 1 + 3,322 log(n) ... (2.7.) Dimana : K = Banyaknya kelas
n = Banyaknya data 3. Hitung lebar kelas dengan rumus
c = Range/K ... (2.8.)
4. Berdasarkan nilai lebar kelas, tentukan kelas ke 1, kelas ke 2, kelas ke 3 dan seterusnya sampai nilai maksimum dari data dapat dimasukkan pada kelas terakhir.
5. Hitung frekwensi kelas dengan cara “tally” atau “schore sheets”.
Setelah DF selesai disusun, biasanya DF tersebut digambarkan dalam bentuk grafik seperti misalnya : histogram, frekwensi poligon atau distribusi frekwensi kumulatif (ogive).
Contoh 2.12.
Hasil pengukuran berat komponen A (diukur dalam gram) yang diambil dari sebuah sampel berukuran 30 adalah sebagai berikut :
79 66 72 70 68 66 68 76 73 71 74 70 71 69 67 74 70 68 69 64 75 70 68 69 64 69 62 63 63 61 a. Susunlah DF nya
b. Gambar histogram, frekwensi poligon dan ogive.
Jawab :
Jika frekwensi masing-masing kelas dibagi dengan total frekwensi maka DF tersebut berubah menjadi Distrbusi Frekwensi Relatif (DFR) seperti ditunjukkan oleh Tabel 2.2. berikut ini
Tabel 2.2. Distribusi Frekwnsi Relatif Berat 100 Kompnen A Kelas Ferkwensi Frekwensi Relatif
60 – 62 5 0,05
63 – 65 18 0,18
66 – 68 42 0,42
69 – 71 27 0,27
72 – 74 8 0,08
Jumlah : 100 1
. Histogram, frekwensi poligon dan ogive dari DFR juga dapat digambar seperti pada DF.
2.5.2. Ukuran Sentral dan Dispersi
Gambaran data hasil eksperimen dapat dilihat melalui parameter-parameter ukur dari data tersebut. Parameter ukur ini dibagi dalam dua kelompok, yakni parameter yang menggambarkan ukuran kecenderungan nilai sentral (measures of central tendency) dan parameter yang menggambar dispersi (variasi) data.
2.5.2.1.Parameter Nilai Sentral.
Parameter nilai sentral antara lain meliputi : - Rata-rata hitung
- Modus - Median - Quatile - Desil - Persentil
Jika data hasil eksperimen diperlakukan secara individu maka rumus dari parameter nilai – nilai sentral diatas adalah sebagai berikut :
a. Rata-rata hitung :
X = n X
n
i
i1 ... (2.9.)
b. Modus :
Modus = Nilai data yang paling sering muncul
= Nilai data yang frekwensinya paling tinggi ... (2.10.) c. Median.
Median = Nilai data yang berada di tengah-tengah
setelah data diurutkan dari kecil ke besar ... (2.11) Dalam hal ini ada dua kemungkinan, yakni :
- Untuk n yang ganjil : Median = X(n+1)/2
- Untuk n yang genap : Median = (Xn/2 + Xn/2 + 1)/2 d. Quartile.
Quartile = Nilai data yang berada di “perempatan”
setelah data diurutkan dari kecil ke besar ... (2.12) Ada tiga macam nilai quartile yakni :
- Q1 = Nilai data pada urutan ke “seperempat” dari seluruh data.
- Q2 = Nila data pada urutan ke “dua-perempat” dari seluruh data = median
- Q3 = Nilai data pada urutan ke “tiga-perempat” dari seluruh data
Prinsip menghitung quartile adalah sama dengan prinsip menghitung median.
e. Desil
Desil = Nilai data pada urutan ke “sepersepuluhan” ... (2.13.)
Jadi ada 10 macam desil, yakni : D1, D2 ... D10
f. Persentil.
Persentil = Nilai data pada urutan ke “seper-seratusan” ... (2.14) Jadi ada 100 macam nilai persentil, yakni P1, P2, ... P100
Jika data hasil eksperimen dikelompokkan dalam bentuk DF, maka rumus untuk menghitung nilai-nilai sentral diatas adalah sebagai berikut :
a. Rata-rata hitung.
a.1. Metoda Panjang :
X =
k
i i k
i i i
f X f
1
1 ... (2.15.)
Dimana : Xi = Nilai tengah dari kelas ke i dengan i=1, 2, 3, ... k k = Banyaknya kelas
fi = Frekwensi kelas ke i.
a.2. Metoda Singkat :
X = A + cU = A + c
k
i i k
i i i
f U f
1
1 ... (2.16)
Dimana : A = Nilai sembarang, biasanya diambil sama dengan nilai Xi yang mempunyai frekwensi paling tinggi.
Ui = (Xi – A)/c c = Lebar kelas b. Modus :
Modus = TKBmodus + c
2 1
1
... (2.17)
Dimana : TKBmodus = Tepi Kelas Bawah dari kelas modus
1 = Selisih antara frekwensi kelas modus dengan frekwensi kelas sebelumnya.
2 = Selisih antara frekwensi kelas modus dengan frekwensi kelas sesudah kelas modus
c. Median :
Median = TKBmedian +
f c f n
m
2 1
/
... (2.18.)Dimana : TKBmedian = Tepi Kelas Bawah dari kelas median
f 1 = Frekwensi kumulatif sampai dengan kelas sebelum kelas median.fm = Frekwensi kelas median.
c = Lebar kelas.
n = Banyaknya data (ukuran sampel) d. Quartile, Desil dan Prsentil :
Rumus quartil, desil dan persentil pada dasarnya adalah sama dengan rumus median, yakni :
- Quartil : Q1 terjadi pada 4
n , Q2 terjadi pada 2
n dan Q3 terjadi pada 4 3n Perhatikan bahwa Q2 adalah sama dengan median
- Desil : Terjadi pada 0,1n; 0,2n; 0,3n; ... dst.
- Persentil : Terjadi pada 0,01n; 0,02n; 0,03n ... 0,50n; 0,51n; ... dst.
Contoh 2.13.
Perhatikan kembali data hasil pengukuran berat komponen A pada Contoh 2.12.
Misal data eksperimen ini diolah secara individu, hitunglah : a. Nilai rata-rata
b. Median c. Modus d. Q1, D3, P65
Jawab :
Contoh 2.14.
Sama dengan Contoh 2.13., tapi sekarang misalkan datanya diolah secara berkelompok.
Jawab :
2.5.2.2. Dispersi.
Dispersi adalah parameter ukur yang menjelaskan variabilitas dari data. Dispersi yang paling sederhana adalah “range” yakni selisih antara nilai maximum dan nilai minimum. Parameter ukur dispersi yang paling sering digunakan adalah suatu besaran yang disebut dengan “simpangan baku” .
Rumus dari simpangan baku adalah sebagai berikut : - Untuk data individu :
s =
n X X
n
i
i
1
2
... (2.19.)
atau :
s =
2
1 1
2
n X n
X
n
i i n
i i
... (2.20.)
- Untuk data kelompok :
s =
2
1 1
2
n X f n
fX
n
i i i n
i i i
... (2.21.)
atau :
s = c
2
1 1
2
n U f n
U f
n
i i i n
i i i
... (2.22.)
Dimana :
s = Simpangan baku Xi = Nilai data i
X = Nilai rata-rata kelas fi = Frekwensi dari data ke i n = Banyaknya data
c = Lebar kelas Ui = (Xi – A)/c
A = Nilai sembarang; biasanya diambil sama dengan nilai Xi yang frekweinsinya paling tinggi.
Untuk ukuran sampel yang kecil, yakni n < 30 , simpangan baku dihitung dengan rumus sebagai berikut :
s = 1
)
( 2
nx xi
... (2.23.)
Simpangan baku yang ditulis dengan rumus (2.23.) diatas adalah merupakan estimator yang tidak bias terhadap nilai simpangan baku populasi (). Besaran n – 1 biasa disebut dengan derajat kebebasan yang menjelaskan bahwa pada waktu x sudah dihitung maka derajat kebebasan dari data berkurang satu (satu data harganya sudah tidak bebas lagi). Perhatikan bahwa untuk harga n yang besar, nilai s yang dihitung dengan rumus (2.19) atau (2.23.) relatif tidak akan berbeda.
Contoh 2.15.
Perhatikan kembali data berat komponen A pada Contoh 2.12. Hitunglah : a. Simpangan baku dengan pengolahan data secara individu.
b. Simpangan baku dengan pengolahan data secara berkelompok.
Jawab :
2.5.3. Derajat Kemiringan dan Keruncingan dari Distribusi.
Derajat kemiringan distribusi data; disebut “skewness”; diukur melalui koefisien kemiringan yang salah satu rumusnya adalah sebagai berikut :
KKm = s Modus X
= s
Median
X )
(
3
... (2.24.)
Jika nilai KK positip maka distribusi akan miring kekanan, sebaliknya jika KK negatip distribusi akan miring ke kiri dan jika KK mendekati nol maka distribusi akan mendekati simetris (distribusi normal).
(a) Miring ke kanan (b) Miring ke kiri Gambar 2.1. Kemiringan Distribusi
Derajat keruncingan distribusi yang disebut dengan “kurtosis” diukur dengan koefisien keruncingan yang salah satu rumusnya adalah sebagai berikut :
KKr =
10
90 P
P Q
... (2.25.)
Dimana : Q = “semi interquartile range” = (Q3 – Q1)/2
Untuk distribusi normal harga koefisien yang dihitung dengan rumus (2.25.) akan mempunyai nilai 0,263. Gambar 2.2. menjelaskan tiga bentuk dari keruncingan distribusi yang salah satunya adalah distribusi normal.
(a) Leptokurtic (runcing) (b) Platykurtic (landai) (c) Mesokurtic (normal) Gambar 2.2. Keruncingan Distribusi.
2.6. DISTRIBUSI KEMUNGKINAN 2.6.1. Distribusi Kemungkinan Diskrit
Misal sebuah kotak berisi 7 produk baik dan 3 produk cacat. Dua produk diambil secara berurutan tanpa dikembalikan. Misal X adalah variabel random yang menyatakan banyaknya produk cacat yang terambil, maka harga X dan nilai kemungkinannya adalah sebagi berikut :
x : 0 1 2 P(X=x) :
Kemungkinan X=1 dinotasikan dengan p(1) = P(X=1) dimana p adalah fungsi kemungkinan dan P adalah kemungkinan. Himpunan pasangan (x, p(x)) dimana x adalah
diskrit disebut fungsi kemungkinan atau distribusi kemungkinan dari variabel random diskrit X. Distribusi kemungkinan diskrit mempunyai sifat sebagai berikut :
a. p(xi) 0 untuk semua i ; i = 1, 2, 3, ...
b. p(xi) = 1
F(x) = P(X x) = ∑ p(x) disebut dengan distribusi kemungkinan kumulatif dari variabel random X
Contoh 2.16.
Kemungkinan terjual mobil merk “Corolla” pada sebuah “dealler” mobil adalah 0,4. Dari 4 buah mobil yang akan terjual berikutnya susunlah :
a. Distribusi kemungkinan jumlah terjualnya mobil “Corolla”
b. Distribusi kemungkinan kumulatifnya.
c. Gambarkan grafik dari pertanyaan a. dan b. diatas.
d. Jika X=jumlah mobil yang terjual, hitunglah berapa nilai P(X 2) Jawab :
2.6.1.1. Distribusi Binomial.
Distribusi Binomial adalah distribusi kemungkinan diskrit yang dibentuk dari suatu eksperimen yang hanya mempunyai dua kemungkinan “outcome”, yakni “sukses”
atau “gagal”. Kemungkinan sukses biasanya dinyatakan dengan p, sedangkan kemungkinan gagal dengan q yang nilainya sama dengan 1-p. Beberapa contoh eksperimen yang “outcome”-nya hanya terdiri dari dua kemungkinan misalnya adalah : - Mengambil sampel produk : baik atau cacat.
- Mesin berproduksi : baik atau cacat - Mahasiswa ujian : lulus atau gagal
- Mengambil kartu bridge : kartu merah atau hitam - Mata uang dilempar : “head” atau “tail”
- Dadu dilempar : bilangan ganjil atau genap.
- Dan lain-lain
Distribusi Binomial mempunyai fungsi kemungkinan sebagai berikut :
P(X) = C(n,x)(p)x(q)n-x =
)!
(
!
! x n x
n
(p)x(q)n-x ...(2.26.)
Dengan nilai rata-rata dan varian distribusi adalah :
= np n = Banyaknya percobaan atau ukuran sampel
2 = npq x = Jumlah kejadian yang “sukses”
Ciri dari distribusi binomial adalah sebagai berikut : a. Eksperimennya terdiri dari n ulangan percobaan
b. Masing-masing percobaan hanya mempunyai dua kemungkinan kejadian yang biasa dinyatakan dengan simbol “sukses” atau “gagal”.
c. Kemungkinan “sukses”; yang dinyatakan dengan p; tetap konstan dari satu percobaan ke percobaan yang lain.
d. Antara percobaan yang satu dengan yang lain bersifat saling bebas.
Contoh 2.17.
Berdasarkan data masa lalu, 5% komponen yang dibuat oleh mesin “X” adalah dalam keadaan cacat. Jika 7 komponen diambil secara random dari hasil produksi mesin
“X” tersebut, hitunglah kemungkinannya :
a. Tiga komponen adalah dalam keadaan cacat.
b. Paling sedikit dua komponen adalah cacat.
Jawab :
2.6.1.2. Distribusi Hipergeometrik
Perhatikan eksperimen sebagai berikut. Empat buah produk secara berurutan diambil dari sebuah “lot” berukuran 52 yang terdiri dari produk yang baik (B) dan produk yang cacat (C). Setelah setiap produk diambil dan dan diperiksa keadaannya produk tersebut dikembalikan lagi. Berapa kemungkinannya dua produk diantara empat produk yang diambil tersebut adalah produk yang cacat.Assumsikan jumlah produk cacat dalam lot adalah sebanyak 25%
Eksperimen ini adalah eksperimen binomial, karena hanya ada dua kemungkinan kejadian yakni “produk yang baik” dan “produk yang cacat”. Disamping itu, antara satu eksperimen dengan eksperimen yang lain bersifat bebas dan besarnya kemungkinan selalu tetap. Gambar diagram pohon dan perhitungan kemungkinan dari eksperimen ini adalah sebagai berikut :
Perhatikan kembali eksperimen diatas. Sekarang misalkan setiap produk setelah diambil tidak dikembalikan lagi. Berapa kemungkinannya akan terambil 2 produk yang cacat ?.
Karena produk tidak dikembalikan, maka pengambilan berikutnya akan dipengaruhi oleh pengambilan sebelumnya. Jadi masing-masing eksperimen bersifat tidak bebas dan tidak tetap sehingga distribusi ini bukan distribusi binomial. Distribusi yang demukian disebut distribusi hipergeometrik.
Perhatikan kejadian : CCBB. Kemungkinan terjadinya kejadian ini adalah : P(CCBB) = (13/52)(12/51)(39/50)(38/49)
=
Dengan cara yang sama dapat dihitung :
P(CBCB) = P(CBBC) = P(BCBC) = P(BBCC) = P(BCCB) = Jadi : P(C=2) =
Cara lain untuk menghitung kemungkinan diatas adalah sebagai berikut :
- Produk cacat ada 13. Dua produk akan diambil dari kelompok produk ini. Jumlah alternatif yang mungkin adalah = C132
- Jumlah produk baik 52-13 = 39. Dua produk akan terambil dari kelompok produk baik ini., maka jumlah alternatif yang mungkin adalah = C392
- Seluruh kartu ada 52. Empat kartu yang akan terambil dari seluruh kartu ini mempnyai alternatif sebanyak = C524
Jadi dari eksperimen pengambilan empat produk tanpa pengembalian : - Banyaknya alternatif kejadian akan terambil dua kartu “spade” = C132 C392 - Seluruh kemungkinan alternatif kejadian = C524
Jadi kemungkinan terambil dua produk cacat diantara empat produk yang terambil adalah = 52
4 39 2 13 2
C C C
Eksperimen hipergeometrik mempunyai ciri sebagai berikut :
- Sebuah sampel random berukuran n diambil tanpa pengembalian dari suatu lot yang mempunyai N item.
- Dalam N item tersebut terdapat D item yang dikategorikan sebagai item “sukses”
(misal item yang cacat) dan N-D item yang “gagal”
Variabel random hipergeometrik “X” adalah jumlah item “sukses” yang terambil dalam sampel yang berukuran n tersebut, sedangkan distribusi kemungkinan hipergeometrik X adalah pasangan antara nila X tersebut dengan kemungkinannya. Jadi rumus eksperimen hipergeometrik dapat ditulis sebagai berikut :
P(X=x) = N
n D N
x n D x
C C C
... (2.27.) dengan x = 1, 2, 3, 4, ... D
Rataan dan varian dari distribusi hipergeometrik adalah :
Rataan : µ = E(X) = N
nD ... (2.28.)
Varian : σ2 = Var(X) =
1 1
N n N N D N
nD ... (2.29.)
Contoh 2.18.
Sebuah lot pemesanan komponen elektronik mempunyai ukuran 40 unit. Lot pemesanan tersebut akan ditolak apabila dari 5 komponen yang diambil secara random terdapat minimal 1 komponen yang rusak. Jika kita assumsikan dalam lot tersebut terdapat 3 komponen yang rusak, berapa kemungkinan lot tersebut akan diterima ?
Jawab :
Contoh 2.19.
Perhatikan kembali Contoh 2.18. diatas. Tentukanlah distribusi kemungkinan jumlah komponen rusak yang terdapat dalam sampel yang berukuran 5 tersebut.
Jawab :
2.6.1.3. Distribusi Poisson.
Sejumlah kejadian dapat terjadi pada selang waktu tertentu. Sejumlah kejadian yang terjadi pada selang waktu tertentu ini akan mengikuti suatu distribusi yang disebut dengan distribusi poisson. Selang waktu tersebut dapat dalam menit, jam, hari, minggu, bulan dan bahkan tahun. Contoh kejadian yang mengikuti distribusi poisson misalnya adalah :
- Jumlah “call” telepon disuatu kantor pada antara jam 8.00 s/d jam 9.00
- Jumlah kedatangan konsumen di suatu bank pada antara jam 8.00 s/d jam 10.00 - Jumlah cacat yang terjadi persatuan luas dari suatu produk
Distribusi Poisson mempunyai bentuk sebagai berikut :
P(X=x) =
! x ex
... (2.30.)
Dimana : X = Variabel random poisson
= Jumlah rata-rata kejadian per-perioda
Distribusi poisson diatas mempunyai arti sebagai berikut : Jika suatu “kejadian”
mempunyai nilai rata-rata kejadian sebanyak kali per-perioda, maka kemungkinan kejadian tersebut terjadi sebanyak x kali per-perioda adalah seperti ditunjukkan oleh persamaan (2.28.) tersebut.
Nilai rata-rata dan varian dari distribusi poisson adalah sama, yakni :
= dan 2 = ... (2.31)
Contoh 2.20.
Jumlah rata-rata cacat yang terjadi pada 20 m2 kertas yang dihasilkan dari suatu proses adalah = 3. Berapa kemungkinan akan ada maksimum 2 cacat pada kertas seluas 40 m2 yang dihasikan dari proses tersebut ?
Jawab :
λ = 3 20
40x = 6
P(X ≤2) = P(X=0) + P(X=1) + P(X=2) =
! 0
) 6 ( 0
6
e +
! 1
) 6 ( 1
6
e +
! 2
) 6 ( 2
6
e = 0,062
Hasil ini dapat dilihat pada Tabel Poisson di Lampiran ...
2.6.2. Distribusi Kemungkinan Kontinu
Perhatikan variabel random kontinu yang menyatakan panjang suatu komponen. . Antara dua nilai, seperti misalnya 163,5 dan 164,5 mm, terdapat nilai yang tidak berhingga banyaknya, salah satunya misalnya adalah 164 mm. Kemungkinan kita mendapatkan komponen yang mempunyai panjang = 164 cm sebenarnya adalah sama dengan nol, sebab secara manusiawi kita tidak mungkin mengukur panjang komponen tersebut “tepat” = 164 cm. Oleh karena itu dalam variabel random kontinu perhitungan kemungkinan biasanya digunakan dalam bentuk interval seperti misalnya P(a < X < b), P(X c) atau P(X>c) dan lain sebagainya.
P(a < X < b) menyatakan besarnya kemungkinan harga X berada diantara a dan b, P(X c) menyatakan besarnya kemungkinan harga X lebih besar atau sama dengan c.
Lihat Gambar 2.3. berikut ini
f(x) f(x)
a b x c x (a) P(a < X < b) (b) P(X c)
Gambar 2.3. Besarnya kemungkinan pada distribusi kontinu
Besarnya kemungkinan harga x berada diantara a dan b adalah merupakan luas dibawah kurva f(x) yang dibatasi oleh harga X=a dan X=b. Berdasarkan teori kalkulus, luas daerah tersebut adalah sama dengan :
P(a < X < b) =
ba
dx x
f( ) ... (2.32.)
Oleh karena fungsi ini adalah fungsi kemungkinan maka nilai seluruh fungsi kemungkinan adalah sama dengan 1. Jadi nilai integral untuk semua harga X dari suatu fungsi kemungkinan adalah sama dengan 1.
1 ) (x
f ... (2.33.)
Fungsi kemungkinan kontinu dari variabel random X diatas sering disebut dengan istilah fungsi padat kemungkinan atau “probability density function” (pdf). Fungsi kemungkinan kontinu mempunyai sifat sebagai berikut :
1. f(x 0) untuk semua xR ; R=bilangan riil.
2.
1 ) (x dx f
3. P(a < X < b) =
ba
dx x f( )
Contoh 2.21.
Misalkan kesalahan didalam temperatur reaksi untuk suatu eksperimen di sebuah laboratorium industri (dalam oC) merupakan variabel random kontinu X yang mempunyai fungsi sebagai berikut :
1 2 3
2untuk x x
f(x) =
0 untuk harga x yang lain
a. Buktikan fungsi diatas adalah merupakan fungsi kemungkinan.
b. Jika a. terbukti, hitunglah P(0 < X < 1) Jawab :
Distribusi kumulatif F(x) untuk variabel random kontinu X dengan fungsi padat kemungkinan f(x) adalah :
F(x) = P(X x) =
x
dt t
f( ) untuk - < x < ... (2.34.)
Dari definisi diatas kita dapat menuliskan dua macam hasil, yakni : 1. P(a < X < b) = F(b) – F(a)
2. f(x) = dx
x dF( )
jika turunan dari x memang ada.
Contoh 2.22.
Untuk soal Contoh 2.21, tentukan F(x) dan gunakan hasilnya untuk menghitung nilai kemungkinan P(0 < X < 1).
Jawab :
2.6.2.1. Distribusi Eksponensial.
Distribusi ekspoensial biasanya digunakan didalam analisis reliabilitas, yakni menerangkan waktu kerusakan atau umur suatu peralatan. Fungsi padat kemungkinan dari distribusi eksponensial adalah :
f(x) = e-x untuk x 0 ... (2.35.)
dengan adalah menyatakan laju kerusakan (misal 1/10.000 jam). Gambar 3. dibawah ini menujukkan pdf dari distribusi eksponensial tersebut.
f(x)
X Gambar 2.4. Fungsi Padat Kemungkinan Eksponensial
Nilai rata-rata dan varian dari variabel random eksponensial adalah :
=
1 dan 2 = 12
... (2.36.)
Perhatikan bahwa nilai rata-rata dan simpangan baku dari distribusi eksponensial adalah sama.
Fungsi kemungkinan kumulatif dari distribusi eksponensial adalah :
F(x) = P(X x) = e dt
x
t 0 = 1 – e-t ... (2.37.)
Gambar dari fugsi kumulatif exponensial adalah sebagai berikut : f(x)
X Gambar 2.5. Fungsi Kumulatif Eksponensial
Distribusi eksponensial mempunyai sifat “memoryless”, yakni kemungkinan umur suatu komponen melebihi (s+t) satuan waktu, jika komponen tersebut telah melewati umur t satuan waktu adalah sama dengan kemungkinan umur komponentersebut melebihi s satuan waktu. Secara matematik sifat ini ditulis sebagai berikut :
P(X > s+t / X>t) = P(X > s) ... (2.38.) untuk semua s dan t 0
Contoh 2.23.
Diketahui umur battery sebuah “video game” mempunyai nilai rata-rata 500 jam.
Kerusakan dari battery tersebut diketahui bersifat random dan dapat digambarkan dengan distribusi eksponensial. Hitunglah :
a. Kemungkinan battery tersebut paling sedikit akan berumur 600 jam b. Kemungkinan battery akan berumur dalam kurun waktu 200 jam c. Kemungkinan battery akan berumur antara 300 dan 600 jam d. Simpangan baku dari umur battery
e. Jika diketahui bahwa battery tersebut telah berhasil dioperasikan sampai dengan 300 jam. Berapa kemungkinan battery tersebut akan dapat dioperasikan paling sedikit 500 jam ?
Jawab :
a. = 500 jam, maka : = 1/500 jam
Misal X = variabel random yang menyatakan umur battery, maka : P(X > 600) = 1 – P(X 600) = 1- (1- e-(1/500)600) = e-1,2 = 0,301 b. P(X 200) = 1 – e-(1/500)200
= 1 – e-0,04
= 0,330
c. P(300 X 600) = F(600) – F(300)
= (1 – e-(1/500)600) – (1 – e-(1/500)300) = e-(1/500)300 – e-(1/500)600
= e-0,6 – e-1,2 = 0,248 d. σ = 1/λ = 500 jam
e. P(X>500/X>300) = P(X>200) = 1 – P(X 200) = 1 – 0,330 = 0,670 2.6.2.2. Distribusi Normal.
Distribusi normal (distribusi Gaussian) adalah distribusi simetris yang berbentuk
“lonceng” dan merupakan distribusi yang menggambarkan “outcome” dari berbagai eksperimen, proses maupun fenomena yang lain. Fungsi padat kemungkinan dan fungsi distribusi kontinu dari distribusi normal adalah sebagai berikut :
f(x) =
2
2 2 /
1
x
e untuk - < x <
... (2.39.) P(- < X < xo) = F(xo) =
2 2 / 1
2
1
xo x
e
Oleh karena f(x) dalam persamaan (31) sulit diintegralkan, maka persamaan ini jarang langsung digunakan, dan sebagai gantinya digunakan sebuah tabel yang dinamakan Tabel Normal Standar (Lihat Lampiran ...) Tabel Normal Standar didasarkan pada distribusi normal yang mempunyai nilai rata-rata = 0 dan simpangan
baku = 1. Oleh karena nilai-nilai yang diperoleh dari eksperimen tidak selalu menghasilkan nilai rata-rata = 0 dan simpangan baku = 1, maka nilai x dari eksperimen tersebut harus dikonversikan ke nilai standar z dengan menggunakan persamaan sebagai berkut :
z =
x ... (2.40.)
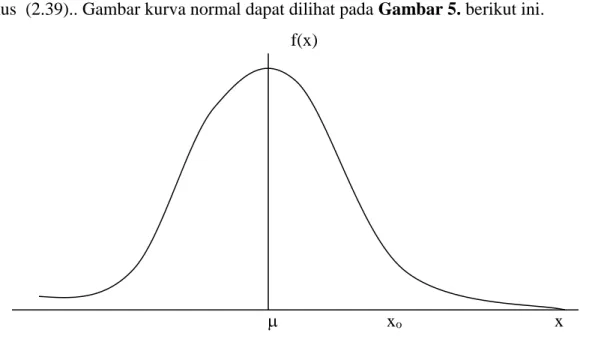
Angka-angka dalam Tabel Normal Standar di Lampiran ... adalah menunjukkan nilai kemungkinan suatu harga z berada diantara -~ s/d z yang nilainya diperoleh dari rumus (2.39).. Gambar kurva normal dapat dilihat pada Gambar 5. berikut ini.
f(x)
xo x
Gambar 2.6. Distribusi Normal
Contoh 2.24.
Masa m dari suatu produk berdistribusi normal dengan nilai rata-rata 66 kg dan simpangan baku 5 kg. Hitunglah :
a. Berapa % kira-kira produk yang mempunyai masa kurang dari 72 kg ? b. Berapa % kira-kira produk yang mempunyai masa lebih dari 72 kg. ? c. Berapa % kira-kira produk yang mempunyai masa diantara 61 dan 72 kg ?
Jawab :
2.7. TEORI SAMPLING 2.7.1. Teorema Batas Sentral :
Pengukuran sampel yang berukuran n yang diambil dari suatu populasi yang mempunyai nilai rata-rata dan simpangan baku adalah merupakan konsep umum dari suatu eksperimen. Rata-rata X adalah salah satu parameter ukur yang dapat diambil dari eksperimen tersebut. Eksperimen ini dapat diulang sebanyak k kali sehingga didapatkan kumpulan nilai rata-rata X1, X2, X3 ... Xk. Kumpulan k bilangan ini menggambarkan sebuah sampel dari distribusi rata-rata. Rata-rata dari rata-rata yang biasa dinotasikan dengan x dan simpangan baku sampel yang dinotasikan dengan x
akan dapat dihitung dari eksperimen tersebut.
Teorema batas sentral mendefinisikan rata-rata dari rata-rata sampel diatas.
Teorema ini dapat dinyatakan dalam berbagai cara, tapi unsur yang penting ddalam teorema tersebut adalah sebagai berikut :
a. Kumpulan dari rata-rata Xi akan berdistribusi normal walaupun populasi dimana Xi tersebut diambil tidak berdistribusi normal.
b. x (yakni rata-rata dari rata-rata) harganya akan mendekati rata-rata populasi dan simpangan baku sampel, yakni x harganya lebih kecil dari simpangan baku populasi .
x =
x = n
... (2.41.)
Contoh 2.25.
Sebuah “tabung” hasil produksi perusahaan “ABC” mempunyai umur rata-rata 800 jam dan simpangan baku 60 jam. Sebuah sampel dengan ukuran 16 diambil dari hasil produksi tersebut.
Hitunglah berapa kemungkinannya umur rata-rata dari sampel tersebut : a. Berada diantara 790 dan 810 jam
b. Kurang dari 785 jam c. Lebih dari 820 jam d. Antara 770 dan 830 jam.
Jawab :
2.7.2. Tingkat Keyakinan dan Resiko Kesalahan Hasil Eksperimen.
Dalam Contoh 2.25. tampak bahwa berdasarkan teorema batas sentral, informasi mengenai suatu sampel yang diambil dari suatu populasi dapat diperoleh dari populasi tersebut dengan assumsi bahwa nilai parameter dari populasi tadi diketahui.
Dalam praktek yang dilakukan dapat sebaliknya, yakni bagaimana informasi mengenai suatu populasi dapat diperoleh dari sampel random yang diambil dari populasi tersebut.
Sampel dari suatu hasil eksperimen jarang sekali dapat menggambarkan kebenaran keadaan populasi secara 100%. Jadi pada umumnya para peneliti dapat menerima kenyataan bahwa hasil eksperimennya mungkin mengandung kesalahan. Untuk mengurangi kemungkinan kesalahan ini maka eksperimen tersebut dapat diulang-ulang hingga dapat diperoleh tingkat keyakinan tertentu terhadap kebenaran hasil eksperimen tersebut.
Jika hasil eksperimen mempunyai kemungkinan salah 5%, maka tingkat keyakinan bahwa hasil eksperimen tersebut benar adalah 95%. Tingkat keyakinan yang lain misalnya adalah 90%, 99% dan sebagainya. Tingkat keyakinan ini biasa dinotasikan dengan “C”, sedangkan resiko kesalahan dengan “”.
2.8. PERKIRAAN TERHADAP PARAMETER POPULASI ()
Berdasarkan teorema batas sentral yang sudah diuraikan didepan maka sampel rata-rata berukuran n yang diambil dari populasi normal dengan nilai rata-rata dan simpangan baku akan berdisrtribusi normal dengan : x = dan x =
n
.
Jadi kemungkinan bahwa suatu harga rata-rata x akan melebihi suatu harga L adalah :
P(X > L) = P
n Z L
... (2.42.)
Lihat Gambar 2.7. berikut ini :
L
Gambar 2.7. Kemungkinan suatu harga X melebihi L
Atau kemungkinan bahwa suatu harga x berada diantara dua harga, katakanlah Batas Bawah (LCL) dan Batas Atas (UCL) adalah :
P(LCL < X < UCL) = P
n z UCL
n LCL
... (2.43.)
Lihat Gambar 2.8. dibawah ini.
LCL UCL
Gambar 2.8. Kemungkinan harga X berada diantara UCL dan LCL.
Dalam praktek seringkali persoalan diatas dibalik, yakni diberikan nilai kemungkinannya (tingkat keyakinan C) kemudian ditanyakan nilai-nilai batas dari X yakni UCL dan LCL. Jika harga C diberikan, maka harga z yang bersesuaian dengan nilai C tersebut dapat dicari pada Tabel Normal Standar (Lampiran ...), dan kemudian nilai LCL dan UCL dapat dihitung sebagai berikut :
LCL = X - Z/2
n
UCL = X + Z/2
n
... (2.44.)
Dengan =100% - C dan harga Z/2 dapat dilihat pada Tabel. Lihat Gambar 2.9. berikut ini.
C = 100% -
/2 /2
- Z/2 Z/2
Gambar 2.9. Perhitungan LCL dan UCL dengan diketahui C
Jadi perkiraan harga dapat disimpulkan sebagai berikut :
Jika x adalah rata-rata sampel random berukuran n yang diambil dari suatu populasi dengan varian 2 diketahui maka dengan tingkat keyakinan sebesar C = 100% -
harga diperkirakan akan berada pada interval : x - z/2
n z x n
/2
Contoh 2.26.
Berat rata-rata dari 200 bantalan peluru yang diambil dari hasil produksi mesin
“X” adalah 0,824 Newton. Jika dimisalkan simpangan baku populasi diketahui sebesar 0,042 Newton, dengan tingkat keyakinan 95% tentukanlah interval perkiraan harga rata- rata berat bantalan peluru yang diproduksi oleh mesin “X” tersebut.
Jawab :
Bagaimana kalau varian populasi harganya tidak diketahui ? Jika varian populasi tidak diketahui maka harga varian populasi 2 dapat didekati dengan harga varian sampel s2 asalkan ukuran sampel tersebut cukup besar (n > 30). Varian sampel s2 dihitung dengan menggunakan rumus (2.23.) dan selanjutnya LCL dan UCL dihitung dengan rumus sebagai berikut :
LCL = X - Z/2
n s
; UCL = X + Z/2
n
s ... (2.45.)
Contoh 2.27.
Berikut adalah sampel panjang produk “X” hasil produksi Perusahaan “ABC”
yang diukur dalam mm.
138 164 150 132 144 125 149 157 146 158 140 147 136 148 152 144 168 126 138 176 163 139 154 165 146 173 142 147 135 153 140 135 161 145 135 142 150 156 145 128
Jika diasumsikan panjang produk “X” berdistribusi normal, tentukan interval perkiraan rata-rata panjang produk “X” tersebut dengan tingkat keyakinan 95%.
Jawab :
2.9. UJI HIPOTESIS.
Uji hipotesis adalah prosedur yang akan menjawab pertanyaan : Apakah data ini berasal dari distribusi “x” ? Distribusi “x” dalam hal ini menggambarkan suatu distribusi dengan ciri atau spesifikasi tertentu. Spesifikasi suatu distribusi ditentukan oleh parameter-parameter dari distribusi tersebut.
Ada beberapa macam ujit hipotesis, hal ini bergantung kepada distribusi parameter yang dievaluasi. Ujit hipotesis yang paling sederhana adalah menentukan apakah nilai rata-rata yang diperoleh dari n ulangan eksperimen adalah berasal dari suatu populasi yang mempunyai nilai rata-rata dan simpangan baku . Contoh aplikasi praktis dari pertanyaan semacam ini misalnya adalah :
Apakah proses manufaktur yang ada sekarang ini telah mengalami perubahan ?
Jawaban dari pertanyan ini tidak dapat langsung dijawab dengan pasti “ya” atau
“tidak”, tapi jawaban tersebut akan diberikan dengan menggunakan tingkat keyakinan dan resiko kesalahan tertentu. Sebagaimana telah diutarakan didepan, tingkat keyakinan ini biasa dinotasikan dengan C, sedangkan resiko kesalahan dengan , keduanya dinyatakan dalam %.
Berikut adalah prosedur yang digunakan untuk menentukan apakah nilai rata-rata dari n pengukuran adalah berasal dari suatu populasi yang telah diketahui.
Langkah 1 :
Assumsikan sampling random yang dilakukan adalah berasal dari populasi yang berdistribusi normal.
Langkah 2 :
Tetapkan tingkat keyakinan yang digunakan.
Langkah 3 :
Tetapkan uji hipotesis yang akan dilakukan, yakni uji satu sisi atau uji dua sisi. Uji hipotesis satu sisi dilakukan apabila nilai rata-rata yang akan diuji hanya mempunyai satu kemungkinan arah perubahan yakni naik atau turun. Sedangkan uji dua sisi dilakukan apabila perubahan nilai rata-rata yang diuji dapat berubah dengan dua arah yakni dapat turun atau naik.
Langkah 4 :
Gunakan tabel normal standar untuk menentukan nilai z sesuai dengan tingkat keyakinan dan jumlah sisi uji hipotesis yang diambil.
Langkah 5 :
Hitung nilai variable normal standar yang diperoleh dari hasil eksperimen; yakni z’; dengan rumus :
z’ = n X
Langkah 6 :
Jika z’ z, maka nilai rata-rata yang diperoleh dari hasil eksperimen disimpulkan berasal dari distribusi yang berbeda. Kesimpulan ini diambil dengan tingkat keyakinan sebesar C seperti yang sudah ditetapkan pada langkah 2.
Contoh 2.28.
Jika dioperasikan dengan benar maka sebuah pabrik kimia akan dapat menghasilkan produksi dengan kecepatan yang berdistribusi normal dengan nilai rata-rata 880 ton/hari dan simpangan baku 21 ton/hari. Sebuah eksperimen yang dilakukan secara berurutan selama 50 hari ternyata memberikan nilai rata-rata output produksi pabrik tersebut adalah 871 ton/hari.
Pertanyaan :
Dengan tingkat keyakinan 95%, tentukan apakah pabrik kimia tersebut telah dioperasikan dengan benar ?
Jawab : Langkah 1 :
Diketahui kecepatan produksi pabrik tersebut memang berdistribusi normal.
Langkah 2 :
Diambil C=95%
Langkah 3 :
Test hipotesis yang diambil adalah dua sisi, karena hasil produksi pabrik dapat dibawah atau diatas nilai rata-rata.
Langkah 4 :
= 100% - 95% = 5% = 0,05
Jadi : /2 = 0,05/2 = 0,025. Dari tabel normal standar diperoleh : z(1)/2 = z(1)0,025 = -1,96
z(2)/2 = +1,96 Langkah 5 :
z’ =
50 21
880 871
= -3,03
Langkah 6 :
Oleh karena z’ < z(1)/2 maka disimpulkan bahwa statistic hasil eksperimen adalah berasal dari distribusi yang berbeda. Dengan lain perkataan pabrik telah dioperasikan secara tidak benar.
Contoh 2.29.
Sebuah pabrik perlengkapan olah raga telah mengembangkan suatu “bahan” untuk membuat salah satu perlengkapan olah raga tersebut. Dinyatakan oleh pabrik tersebut bahwa bahan ini mempunyai kekuatan dapat menahan beban seberat 8 kg dengan simpangan baku 0,5 kg.
Dari sample sebanyak 50 unit yang diambil ternyata hasil pengujiannya memberikan nilai rata-rata kekuatan sebesar 7,8 kg. Dengan tingkat keyakinan sebesar 99%, tentukan apakah pernyataan pabrik tersebut dapat dianggap benar ?
Jawab : Langkah 1 :
Diassumsikan nilai kekuatan bahan tersebut berdistribusi normal.
Langkah 2 :
Diambil C = 99%
Langkah 3 :
Uji hipotesis adalah dua sisi, sebab hasil produksi bahan tersebut kekuatannya dapat diatas atau dibawah nilai rata-rata. Ujit hipotesis dua sisi ini dapat dinyatakan dalam bentuk sebagai berikut :
Ho : = 8 Ha : 8
Langkah 4 :
= 100% - 99% = 1% = 0,01
/2 = 0,01/2 = 0,005
Jadi : z(1)/2 = -2,57 dan z(2)/2 = +2,57
Dengan diketahuinya harga z(1)/2 dan z(2)/2 maka dapat digambarkan daerah penerimaan dan penolakan Ho sebagai berikut :
Daerah penerimaan Ho
Daerah penolakan Ho Daerah penolakan Ho
z(1)/2 z(2)/2
Langkah 5 : z’ =
n X
=
50 5 , 0
8 8 ,
7
= -2,828
Langkah 6 :
Karena z’ < z(1)/2 (z’ berada pada daerah penolakan) maka disimpulkan sample ini berasal dari distribusi yang lain. Jadi dengan tingkat kepercayaan 99% disimpulkan bahwa pernyataan pabrik yang mengatakan bahwa rata-rata kekuatan bahan = 8 kg adalah tidak benar. Dengan lain perkataan Ho ditolak.
--- o ---