ABSTRACT
FITRIA YUNINGSIH. Image Searching Using Heuristic Method for Image Retrieval System. Under the supervision of YENI HERDIYENI.
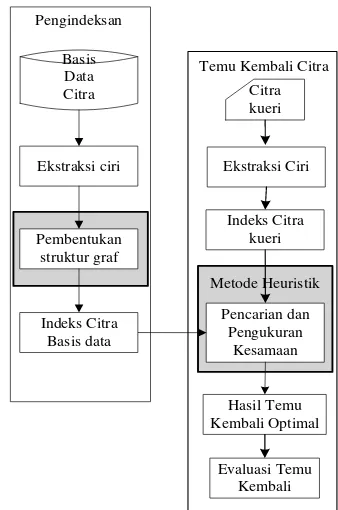
The development of image retrieval system and user demand for a fast and accurate search engine motivates research on finding efficient retrieval methods. Commonly, image searching process works through computing and comparing similarity value between input query and entire database images. This process is not efficient due to time-wasting during computation especially for large database. This research proposes heuristic method for image searching. The basic idea of this research deals with structural database content that reduces searching time. This research implements fitness landscape model. Fitness landscape is kind of directed graph whose labeled vertices and edges. Each node represents an image and each edge represents distance or similarity value of a node to other connected nodes. Similarity value between nodes are computed using combination of three image features, those are color, shape, and texture. Heuristic algorithm moves on these nodes with Breadth-First Search mechanism under certain constraints. Each visited node that fulfills the requirement will be retrieved as searching result. This retrieval result is then evaluated using recall precision parameter to get value of searching effectiveness. This experiment also computes retrieval time for each query. As the result, heuristic method obtains average retrieval time up to nine times faster compared with the non-heuristic one. Hence, this proposed method is promising to be used in image retrieval system because it provides fast image searching.
METODE HEURISTIK UNTUK PENCARIAN CITRA PADA
SISTEM TEMU KEMBALI CITRA
FITRIA YUNINGSIH
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
DAFTAR PUSTAKA
Baeza-Yates R, Ribeiro-Neto R. 1999. Modern Information Retrieval. New York : Addison Wesley
Datta R, Joshi D, Li J, Wang JZ. 2008. Image Retrieval: Ideas, Influences, and Trends of the New Age. ACM Computing Surveys. Grossman DA, Frieder O. 2004. Information
Retrieval Algorithms and Heuristics. Netherlands: Springer.
Jones T. 1995. Evolutionary Algorithms, Fitness Landscapes and Search [dissertation]. http://www.cs.unm.edu/~forrest/dissertation s-and-proposals/terry.pdf [8 April 2009]. Jones T, Forrest S. 1995. Genetic Algorithms
and Heuristic Search.
http://www.cs.unm.edu/~forrest/publications /gahs.pdf [20 November 2008].
Klabbankoh B, Pinngern O. 1999. Applied Genetic Algorithms in Information Retrieval. Bangkok : Faculty of Information Technology King Mongkut, Institute of
Technology Ladkrabang.
http://www.journal.au.edu/ijcim/sep99/02-drouen.pdf[17 Desember 2008].
Pebuardi R. 2008. Pengukuran Kemiripan Citra Berbasis Warna, Bentuk, dan Tekstur Menggunakan Bayesian Network [skripsi]. Bogor: Departemen Ilmu Komputer, Institut Pertanian Bogor.
Pratama F. 2009. Algoritme Genetika untuk Optimasi Pembobotan Fitur pada Temu Kembali Citra [skripsi]. Bogor: Departemen Ilmu Komputer, Institut Pertanian Bogor. Stadler PF. 2001. Fitness Landscape.
http://www.tbi.univie.ac.at/papers/Abstracts/ 01-pfs-004.pdf [26 Mei 2009].
METODE HEURISTIK UNTUK PENCARIAN CITRA PADA
SISTEM TEMU KEMBALI CITRA
FITRIA YUNINGSIH
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
METODE HEURISTIK UNTUK PENCARIAN CITRA PADA
SISTEM TEMU KEMBALI CITRA
FITRIA YUNINGSIH
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
FITRIA YUNINGSIH. Image Searching Using Heuristic Method for Image Retrieval System. Under the supervision of YENI HERDIYENI.
The development of image retrieval system and user demand for a fast and accurate search engine motivates research on finding efficient retrieval methods. Commonly, image searching process works through computing and comparing similarity value between input query and entire database images. This process is not efficient due to time-wasting during computation especially for large database. This research proposes heuristic method for image searching. The basic idea of this research deals with structural database content that reduces searching time. This research implements fitness landscape model. Fitness landscape is kind of directed graph whose labeled vertices and edges. Each node represents an image and each edge represents distance or similarity value of a node to other connected nodes. Similarity value between nodes are computed using combination of three image features, those are color, shape, and texture. Heuristic algorithm moves on these nodes with Breadth-First Search mechanism under certain constraints. Each visited node that fulfills the requirement will be retrieved as searching result. This retrieval result is then evaluated using recall precision parameter to get value of searching effectiveness. This experiment also computes retrieval time for each query. As the result, heuristic method obtains average retrieval time up to nine times faster compared with the non-heuristic one. Hence, this proposed method is promising to be used in image retrieval system because it provides fast image searching.
Judul : Metode Heuristik untuk Pencarian Citra pada Sistem Temu Kembali Citra Nama : Fitria Yuningsih
NIM : G64052644
Menyetujui:
Pembimbing,
Yeni Herdiyeni, S.Si., M.Kom. NIP 197509232000122001
Mengetahui:
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor
Dr. drh. Hasim, DEA. NIP 196103281986011002
PRAKATA
Alhamdulillahirabbil’alamin, segala puji hanya milik Allah SWT, yang tidak henti-hentinya mencurahkan rahmat dan kasih sayang, sehingga tugas akhir berjudul Metode Heuristik untuk Pencarian Citra pada Sistem Temu Kembali Citra dapat diselesaikan dengan baik. Dalam menyelesaikan tugas akhir ini penulis mendapatkan banyak sekali bantuan dan bimbingan dari berbagai pihak, oleh karena itu penulis mengucapkan terima kasih dan penghargaan kepada :
1 Bapak (Alm.), Mama, Mas Udy, Mbak Lita, Mas Teguh, Kak Icha, atas kasih sayang, doa, motivasi dan segala bantuan yang tak ternilai.
2 Ibu Yeni Herdiyeni, S.Si, M.Kom. selaku pembimbing atas bimbingan dan arahan selama pengerjaan tugas akhir ini.
3 Seluruh staf dosen dan karyawan Departemen Ilmu Komputer FMIPA IPB atas segala bimbingan dan bantuannya selama masa perkuliahan Penulis.
4 Mbak Gibtha dan Kak Rizki atas bantuan dan penelitian-penelitiannya.
5 Teman-teman satu bimbingan, Gang CI Berkacamata, Rahmadhani, Ferry Pratama, Muhammad Abi Rafdi, Vera Yunita, Indra Nugraha Abdullah, Dimas Perdana CKP, dan seluruh teman-teman bidang retrieval atas kerjasama dan kebersamaan selama masa pembuatan skripsi.
6 Consistent Team, Medria KDH, Rizqi Baihaqi, M. Abi Rafdi, atas kekompakan serta waktu-waktu yang menyenangkan dan bermanfaat.
7 Ida, Mega, Mirna, Cira, Esti, Windy, Ovie, Ibonk, Regi, Uud, Nano, dan seluruh teman-teman Departemen Ilmu Komputer IPB angkatan 42 yang telah meramaikan hari-hari penulis dengan kebersamaan dan waktu-waktu yang tak terlupakan bersama kalian.
8 Teman-teman kos putri White House sebagai second home Penulis selama kuliah di Departemen Ilmu Komputer IPB.
Penulis juga mengucapkan terima kasih kepada semua pihak yang telah membantu pengerjaan tugas akhir ini yang tidak dapat disebutkan satu per satu. Segala kritik dan saran yang membangun akan diterima untuk perbaikan selanjutnya. Semoga penelitian ini dapat bermanfaat. Terima kasih.
Bogor, Agustus 2009
RIWAYAT HIDUP
Penulis dilahirkan di Jakarta pada tanggal 1 Juni 1987 sebagai anak ketiga dari tiga bersaudara dari ayahanda bernama H. Sugiman (Alm.) dan ibunda bernama Hj. Parini.
Penulis masuk SMA Negeri 12 Jakarta pada tahun 2002 dan lulus pada tahun 2005. Pada tahun yang sama, Penulis melanjutkan pendidikan di IPB melalui jalur Ujian Seleksi Masuk IPB (USMI) dan diterima sebagai mahasiswi Program Studi Ilmu Komputer, Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
DAFTAR ISI
Halaman
DAFTAR GAMBAR ... v
PENDAHULUAN Latar Belakang ... 1
Tujuan ... 1
Ruang Lingkup ... 1
TINJAUAN PUSTAKA Content Based Image Retrieval... 1
Heuristik ... 1
Ekstraksi Ciri (Feature Extraction) ... 1
Evolutionary Algorithm ... 1
Fungsi Fitness ... 2
Model Fitness Landscapes ... 2
Algoritme Breadth-First Search (BFS) ... 2
Recall dan Precision ... 2
METODE PENELITIAN Data Penelitian ... 3
Ekstraksi Ciri ... 3
Pembentukan Struktur Graf ... 3
Landscape 1 ... 3
Landscape 2 ... 3
Temu Kembali Citra ... 4
Evaluasi Hasil Temu Kembali ... 4
Spesifikasi Pengembangan ... 5
HASIL DAN PEMBAHASAN Ekstraksi Ciri Citra ... 5
Struktur Graf ... 5
Landscape 1 ... 5
Landscape 2 ... 5
Proses Pencarian ... 6
Hasil Temu Kembali ... 6
Evaluasi Hasil Temu Kembali ... 8
KESIMPULAN DAN SARAN Kesimpulan ... 9
Saran ... 9
DAFTAR PUSTAKA ... 9
DAFTAR GAMBAR
Halaman
1 Ilustrasi algoritme BFS ... 2
2 Metode penelitian ... 3
3 Representasi satu node pada landscape ... 3
4 Ilustrasi pencarian pada landscape 1 ... 4
5 Ilustrasi pencarian pada landscape 2 ... 4
6 Ilustrasi landscape 1 ... 5
7 Ilustrasi landscape 2 ... 5
8 Diagram alur proses penelusuran pada landscape 1 dan landscape 2 ... 6
9 Contoh tampilan utama sistem ... 7
10 Contoh hasil temu kembali ... 7
11 Contoh hasil temu kembali yang kurang relevan ... 8
12 Grafik perbandingan nilai recall dan precision ... 9
PENDAHULUAN
Latar Belakang
Dalam perkembangan media informasi terutama di bidang temu kembali citra dewasa ini, para pengguna membutuhkan mesin pencari yang cepat dengan hasil yang relevan. Oleh karena itu, metode pencarian heuristik diaplikasikan dengan harapan mampu membuat proses pencarian citra menjadi lebih cepat.
Proses pencarian yang umum dilakukan adalah dengan membandingkan citra kueri dengan seluruh citra dalam basis data. Proses ini dilakukan berulang setiap citra kueri diberikan. Hal ini tidak efisien karena proses tersebut cukup membutuhkan waktu terutama pada basis data berukuran besar.
Metode heuristik diterapkan untuk membuat basis data lebih terstruktur. Model struktur basis data tersebut menransformasi isi basis data menjadi graf terhubung. Setiap node graf adalah representasi setiap citra dalam basis data. Antara node satu dengan node lainnya dihubungkan dengan edge yang dilabeli dengan nilai kemiripan dan prediksi kedekatan (Stadler 2001). Model graf ini dalam ruang lingkup
Evolutionary Algorithm (EA) dikenal dengan
fitness landscape (Jones 1995). Prediksi kedekatan dan kemiripan tersebut mempengaruhi posisi antar node. Semakin mirip citra-citra tersebut maka posisinya semakin berdekatan.
Pada saat kueri dimasukkan, pencarian dilakukan dengan cara menelusuri node-node
graf tersebut dengan algoritme pencarian
Breadth-First Search (BFS). Awal pencarian difokuskan untuk mencari citra dalam basis data yang paling relevan dengan kueri. Setelah itu, pencarian berlanjut dengan menelusuri citra-citra lain dengan posisi yang berdekatan dengan citra basis data yang paling relevan tersebut. Hal ini dilakukan karena model struktur graf ini telah memposisikan citra-citra yang mirip saling berdekatan, sehingga ketika citra paling relevan dengan kueri telah ditemukan, maka citra-citra lain yang letaknya berdekatan dengan citra tersebut juga relevan terhadap kueri. Hasil penelusuran kemudian ditampilkan sebagai hasil temu kembali.
Tujuan
Tujuan penelitian ini adalah mengimplementasikan dan menganalisis kinerja metode heuristik pada pencarian citra.
Ruang Lingkup
Ruang lingkup penelitian ini difokuskan pada implementasi pemrograman heuristik pada proses pencarian citra dalam konteks Content Based Image Retrieval (CBIR) berdasarkan fitur warna, bentuk, dan tekstur. Implementasi ini diterapkan pada data sebanyak 1100 citra yang terbagi menjadi 10 kelas, yaitu mobil, singa, matahari terbenam, tekstur, beruang, gajah, tanda panah, pemandangan, reptil, dan pesawat.
TINJAUAN PUSTAKA
Content Based Image Retrieval
Content based imaged retrieval (CBIR) merupakan suatu pendekatan pada temu kembali citra berdasarkan ciri atau informasi yang terkandung di dalam citra seperti warna, bentuk dan tekstur (Han & Ma diacu dalam Pebuardi 2008). Secara umum, proses content based image retrieval (CBIR) dapat dibagi menjadi dua proses utama yaitu pengolahan basis data atau pengindeksan dan temu kembali. Heuristik
Kata heuristik berasal dari bahasa Yunani,
heuriskein, yang berarti mencari atau menemukan. Di dalam mempelajari metode-metode pencarian, kata heuristik diartikan sebagai suatu fungsi yang memberikan suatu nilai berupa biaya perkiraan (estimasi) dari suatu solusi (Suyanto 2007).
Ekstraksi Ciri (Feature Extraction)
Proses ekstraksi ciri adalah salah satu tahap praproses pada sistem CBIR (Datta et al 2008). Informasi visual yang dihasilkan dari ekstraksi ciri sangat bermanfaat untuk analisis dan proses citra selanjutnya. Ekstraksi ciri pada umumnya memanfaatkan komponen informasi pada citra yaitu berdasarkan warna, bentuk dan tekstur. Evolutionary Algorithm
Evolutionary algorithm identik dengan
Evolutionary Programming, Genetic Algorithm, dan Evolution Strategies. Algoritme ini mencari sekumpulan solusi untuk suatu masalah. Solusi awal tersebut digunakan untuk membentuk potensi solusi baru melalui penggunaan operator. Operator yang dimaksud adalah operator genetika seperti mutasi, rekombinasi, dan inversi. Setiap operator yang digunakan membentuk landscape tersendiri (Jones 1995).
Fungsi Fitness
Fungsi fitness adalah ukuran kinerja yang mengevaluasi seberapa bagus suatu solusi. Fungsi ini dapat digunakan untuk mengukur nilai kemiripan antar dua citra. Salah satu fungsi kemiripan yang umum digunakan adalah cosine similarity, formulanya adalah sebagai berikut:
,
dengan
x = vektor citra x, dan y = vektor citra y.
Hasil perhitungan nilai kemiripan berkisar antara 0 sampai 1. Semakin mendekati nilai 1 maka kedua citra tersebut semakin mirip, begitu pula sebaliknya (Klabbankoh & Pinngren 1999).
Model Fitness Landscapes
Model fitness landscape adalah suatu cara untuk memodelkan citra-citra beserta nilai kemiripannya menjadi bentuk graf terhubung. Setiap citra direpresentasikan sebagai sebuah
node pada suatu dimensi ruang (Jones & Forrest 1995). Untuk membentuk landscape diperlukan tiga komponen, yaitu sebagai berikut (Stadler 2001):
1 Memiliki konfigurasi X, yaitu himpunan anggota, atau dalam hal ini citra dalam basis data.
2 Memiliki perkiraan kedekatan atau jarak antar anggota X.
3 Memiliki fungsi kemiripan.
Himpunan citra menjadi node-node pada graf. Fungsi kemiripan dihitung menggunakan persamaan tertentu sehingga dapat mengidentifikasi tingkat kemiripan antar citra. Tingkat kemiripan tersebut digunakan sebagai perkiraan kedekatan antar node. Semakin besar nilai kemiripannya maka posisi dalam graf semakin berdekatan.
Algoritme Breadth-First Search (BFS)
Algoritme BFS adalah suatu sitematika pencarian yang dilakukan pada semua node
pada setiap level secara berurutan dari kiri ke kanan. Jika pada satu level belum ditemukan solusi, maka pencarian dilanjutkan pada level berikutnya (Suyanto 2007). Ilustrasi algoritme BFS dapat dilihat pada Gambar 1.
Gambar 1 Ilustrasi algoritme BFS. Recall dan Precision
Recall dan precision merupakan parameter untuk mengukur keefektifan dari hasil temu kembali. Recall menyatakan proporsi materi relevan yang ditemukembalikan terhadap seluruh materi relevan yang ada dalam basis data. Sementara itu, precision menyatakan proporsi materi relevan yang ditemukembalikan terhadap seluruh materi yang ditemukembalikan (Grossman 2006).
Penentuan nilai precision untuk nilai recall
tertentu dihitung dengan interpolasi maksimum dengan aturan berikut (misalnya untuk recall 0 sampai 1 dengan interval 0.1):
,
dengan
rj {0.0, 0.1, …, 1.0}, r0 = 0.0, r1 = 0.1, …, r10=1.0.
Jika tidak semua citra relevan dapat ditemukembalikan maka nilai precision pada
recall yang bersangkutan bernilai 0 (Baeza-Yates & Ribeiro-Neto 1999).
METODE PENELITIAN
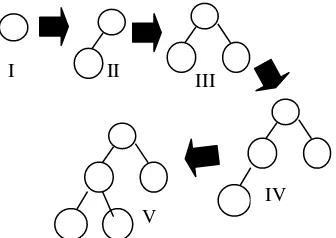
Penelitian ini dilaksanakan dalam beberapa tahap yaitu: (1) ekstraksi citra, (2) proses pembentukan struktur graf, (3) proses pengindeksan dokumen citra, (4) pencarian dan pengukuran kemiripan dengan menggunakan metode heuristik, dan (5) evaluasi hasil temu kembali. Tahap-tahap yang dilakukan pada penelitian diilustrasikan pada Gambar 2.
V III II
I
Basis
Gambar 2 Metode penelitian. Data Penelitian
Data yang digunakan pada penelitian ini terdiri atas 1100 citra berformat TIF yang dikelompokkan secara manual ke dalam 10 kelas, yaitu mobil, singa, matahari terbenam, tekstur, beruang, gajah, tanda panah, pemandangan, reptil, dan pesawat. Setiap citra memiliki ukuran yang bervariasi. Citra didapat dari http://www.fei.edu.br/~psergio/MaterialAu las/Generalist1200.zip. Beberapa contoh citra yang digunakan tertera pada Lampiran 1. Ekstraksi Ciri
Ekstraksi ciri yang digunakan pada penelitian meliputi ekstraksi warna, bentuk, dan tekstur hasil penelitian Pebuardi (2008). Ekstraksi warna menggunakan conventional color histogram (CCH), ekstraksi bentuk menggunakan deteksi tepi Sobel, dan ekstraksi tekstur menggunakan matriks co-occurrence.
Pembentukan Struktur Graf
Tahapan pembentukan struktur graf adalah sebagai berikut.
Landscape 1
Pembentukan landscape ini bertujuan untuk mencari citra dalam basis data yang paling identik dengan citra kueri. Landscape 1 terdiri atas beberapa komponen, yaitu node, edge, dan nilai kemiripan untuk melabeli edge-nya. Tahapan pembuatan landscape ini yaitu:
1 Representasi node
Penelitian ini menggunakan tiga fitur citra, yaitu warna, bentuk, dan tekstur. Oleh karena itu, satu node pada landscape ini adalah satu citra yang direpresentasikan dengan vektor-vektor hasil ekstraksi ketiga fiturnya. Ketiga vektor tersebut terdiri atas vektor warna berisi 162 elemen, vektor bentuk berisi 72 elemen, dan vektor tekstur berisi 7 elemen. Contoh ilustrasi satu node digambarkan pada Gambar 3.
Gambar 3 Representasi satu node pada
landscape.
2 Perhitungan nilai kemiripan
Nilai kemiripan antar citra dalam basis data dihitung menggunakan cosine similarity. Setiap fitur antar dua citra dihitung nilai kemiripannya kemudian dijumlahkan. Perhitungan dilakukan terhadap citra basis data urutan pertama terhadap setiap citra dalam basis data. Hasilnya adalah sebuah matriks berukuran 1×n, dengan n
menunjukkan jumlah citra dalam basis data. Rumus cosine similarity adalah sebagai berikut:
,
dengan
x = vektor citra x,
y = vektor citra y.
Landscape 2
Manfaat landscape 2 dalam pencarian adalah untuk menemukan citra lain yang relevan namun dengan nilai kemiripan yang lebih rendah dibandingkan hasil temuan pada
landscape 1. Dalam landscape ini, setiap node
merepresentasikan satu citra, sedangkan edge -nya merupakan nilai kemiripan hasil perhitungan dengan implementasi pembobotan automatis dengan Algoritme Genetika (GA) sesuai penelitian Pratama (2009). Bobot yang dihasilkan oleh proses GA berubah-ubah karena pembangkitan nilai awal yang dilakukan secara acak. Perbedaan nilai ini tidak terlalu signifikan, namun tetap mempengaruhi nilai akhir
precision yang dihasilkan. Oleh karena itu, perhitungan kemiripan dengan pembobotan
162 elemen warna
72 elemen bentuk
7 elemen tekstur
yang dilakukan dengan GA ini dilakukan beberapa kali dan dilihat hasil yang terbaik. Perhitungan nilai kemiripan dengan pembobotan automatis ini dilakukan terhadap seluruh citra basis data menghasilkan matriks berukuran n×n, dengan n menunjukkan jumlah citra dalam basis data.
Temu Kembali Citra
Proses Heuristik
Pada proses temu kembali, pemberian kueri dilakukan. Kueri citra tersebut melalui proses ekstraksi ciri menghasilkan vektor yang terdiri dari 162 elemenwarna, 72 elemen bentuk, dan 7 elemen tekstur. Node awal untuk proses penelusuran selalu dimulai dari anggota basis data urutan pertama.
Penelusuran bergerak pada dua landscape
yang telah terbentuk. Penjelasannya adalah sebagai berikut:
Landscape 1
Pada landscape ini setiap edge telah memiliki label jarak berupa nilai kemiripan
cosine. Tahapan penelusuran selanjutnya dijelaskan sebagai berikut: nilai kemiripan yang sama dengan c1, maka
node-node citra basis data yang memiliki nilai kemiripan yang sama tersebut dihitung nilai kemiripannya terhadap kueri. Node
yang terpilih adalah node dengan nilai kemiripan tebesar terhadap kueri.
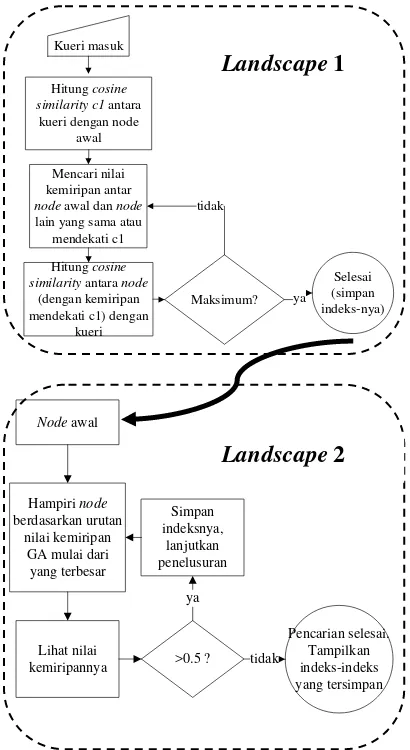
Hasilnya adalah indeks kandidat hasil temu kembali dengan nilai kemiripan tertinggi atau citra dalam basis data yang paling identik dengan kueri. Gambar 4 adalah ilustrasi pencarian pada landscape 1.
Gambar 4 Ilustrasi pencarian pada landscape 1.
Landscape 2
Indeks node awal pada landscape ini adalah indeks node hasil pencarian pada landscape 1. Setiap node pada landscape ini merepresentaskan satu citra dan edge-nya dilabeli nilai kemiripan yang dihitung dengan pembobotan automatis dengan GA. Penelusuran berjalan dengan algoritme berikut:
1 Dari node awal pada landscape 2, berdasarkan urutan nilai kemiripan dari yang paling besar, penelusuran bergerak mengikuti pola BFS.
2 Dari setiap node yang dikunjungi, dilihat nilai kemiripan antara node awal dengan
node yang sedang dikunjungi, dan hasilnya disimpan sebagai calon hasil temu kembali. 3 Pelusuran dilakukan berdasarkan urutan
nilai kemiripan mulai dari yang terbesar sampai menemukan node dengan nilai kemiripan kurang dari threshold sebesar 0.5. Jika penelusuran menemukan node dengan kriteria tersebut maka pencarian berhenti. Hasil sebelumnya yang telah tersimpan dalam calon hasil temu kembali diurutkan berdasarkan nilai kemiripan mulai dari yang tertinggi. Hasil tersebut kemudian ditampilkan sebagai hasil temu kembali. Gambar 5 menunjukkan ilustrasi pencarian pada landscape 2.
cga= nilai kemiripan dengan pembobotan GA.
Gambar 5 Ilustrasi pencarian pada landscape 2. Evaluasi Hasil Temu Kembali
Pada tahap evaluasi dilakukan penilaian kinerja sistem terhadap sejumlah data pengujian dengan menghitung nilai recall dan precision
untuk menentukan tingkat relevansi hasil temu kembali. Recall adalah perbandingan jumlah citra relevan dan ditemukembalikan dengan jumlah citra relevan dalam basis data. Precision
Spesifikasi Pengembangan
Penelitian ini dilakukan dengan menggunakan spesifikasi perangkat keras dan perangkat lunak sebagai berikut:
Perangkat keras dengan spesifikasi: 1 Prosesor AMD Turion64 X2 2.0 GHz 2 Memori 2,37 GB
3 Harddisk 80 GB
4 Alat input mouse dan keyboard
Perangkat lunak dengan spesifikasi: 1 Microsoft Windows XP Professional SP3 2 MATLAB 7.0.1
HASIL DAN PEMBAHASAN
Pada metode heuristik, proses pengindeksan cukup membutuhkan waktu. Hal ini terjadi karena komputasi pada proses pengindeksan melibatkan seluruh citra dalam basis data untuk membentuk struktur graf. Namun, pada saat temu kembali, yang dilakukan sistem adalah menelusuri nilai-nilai yang telah dihitung tersebut. Oleh sebab itu, minimnya proses komputasi pada saat temu kembali diharapkan mampu mempercepat proses pencarian.
Ekstraksi Ciri Citra
Seluruh citra dalam basis data mengalami proses ekstraksi warna, bentuk, dan tekstur sesuai penelitian Pebuardi (2008). Hasilnya, setiap citra direpresentasikan menjadi vektor warna berisi 162 elemen, vektor bentuk berisi 72 elemen, dan vektor tekstur berisi 7 elemen. Struktur Graf
Landscape 1
Landscape ini memiliki node yang
merepresentasikan satu citra. Setiap citra memiliki tiga vektor yang terdiri dari vektor warna berisi 162 elemen, vektor bentuk berisi 72 elemen, dan vektor tekstur berisi 7 elemen. Edge-nya dilabeli dengan jumlah ketiga nilai kemiripan cosine fiturnya. Semakin besar nilai kemiripannya maka citra semakin identik. Perhitungan nilai kemiripan cosine dilakukan antara citra basis data urutan pertama dengan seluruh citra dalam basis data menghasilkan sebuah matriks berukuran 1×1100 atau sesuai dengan jumlah citra dalam basis data. Hal ini dilakukan karena penelusuran pada landscape 1 selalu dimulai dari citra basis data urutan pertama, sehingga pada saat penelusuran, kemiripan node-node dalam basis data dibandingkan dengan citra urutan pertama
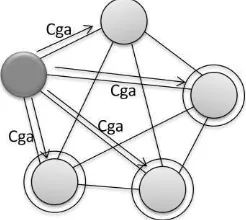
sebagai node awal. Gambar 6 menunjukkan ilustrasi landscape 1.
c = nilai kemiripan cosine.
Gambar 6 Ilustrasi landscape 1.
Komputasi yang dilakukan pada tahap pembentukan landscape ini melibatkan 1100 citra dalam basis data. Waktu yang diperlukan untuk perhitungan kemiripan cosine antar 1100 citra tersebut adalah sekitar 90 detik.
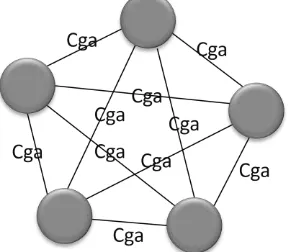
Landscape 2
Landscape ini memiliki node yang
merepresentasikan satu citra. Edge-nya dilabeli dengan nilai kemiripan yang dihitung dengan implementasi pembobotan automatis dengan GA yang dinilai memiliki kinerja yang baik berdasarkan penelitian Pratama (2009). Perhitungan ini menghasilkan sebuah matriks berukuran 1100×1100 sesuai dengan jumlah 1100 citra dalam basis data. Ilustrasi landscape
2 ditunjukkan pada Gambar 7.
cga= nilai kemiripan dengan pembobotan GA.
Gambar 7 Ilustrasi landscape 2.
Pada penelitian ini proses pembobotan dengan GA dilakukan pada saat pengindeksan, yaitu digunakan untuk pembentukan struktur
landscape 2. Nilai bobot yang berubah-ubah tersebut dicoba untuk ditetapkan dengan dilakukan sepuluh kali percobaan dan dipilih yang menghasilkan rata-rata nilai precision
tertinggi. Bobot-bobot tersebut menjadi bobot tetap antar citra dalam basis data. Waktu yang diperlukan untuk komputasi 1100 citra untuk pembentukan landscape ini adalah sekitar 1618 detik.
Proses Pencarian
Proses pencarian bergerak antar node pada graf dengan sistematika BFS. Penelusuran dibatasi dengan threshold sebesar 0.5 dengan asumsi bahwa citra-citra yang mirip akan memiliki nilai kemiripan tinggi.
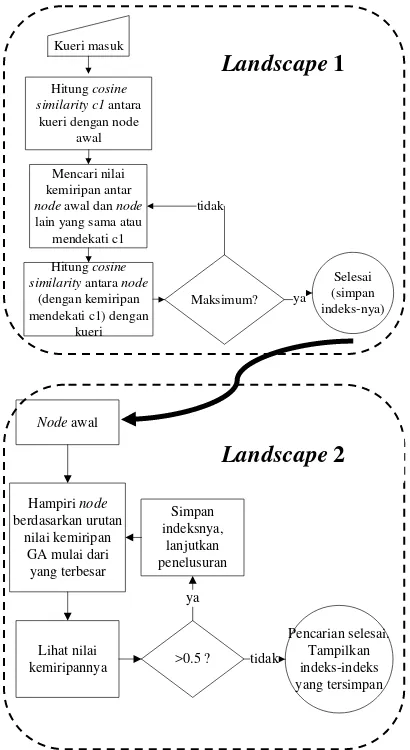
Pada proses penelusuran, kegiatan komputasi minim dilakukan karena pencarian lebih banyak menelusuri angka-angka yang telah dihitung pada tahap pengindeksan. Alur proses pencarian pada dua landscape ini dapat dilihat pada Gambar 8.
Pencarian pertama bergerak pada landscape
1 untuk menemukan citra dalam basis data dengan nilai kemiripan tertinggi atau yang paling identik dengan kueri. Node awal pencarian adalah anggota citra basis data urutan pertama. Selanjutnya, pencarian menuju
landscape 2 untuk menemukan citra lain yang masih relevan dengan kueri namun dengan nilai kemiripan yang lebih rendah dibandingkan hasil pencarian pada landscape 1. Pencarian dimulai pada node awal yang indeksnya merupakan indeks node akhir hasil pencarian pada
landscape 1. Selanjutnya penelusuran dilakukan dengan mencari node tetangga yang memiliki identik berdasarkan urutan nilai kemiripan GA mulai dari yang terbesar. Pencarian akan berhenti dilakukan jika menemukan node
dengan kemiripan kurang dari 0,5. Hasil Temu Kembali
Hasil temu kembali adalah hasil penelusuran graf dengan batasan threshold nilai kemiripan sebesar 0.5. Citra kueri yang digunakan adalah seluruh citra basis data. Rata-rata waktu yang diperlukan untuk setiap proses penelusuran adalah sekitar 0.66 detik. Contoh tampilan utama sistem saat menemukembalikan suatu kueri dapat dilihat pada Gambar 9. Di lain pihak, contoh hasil temu kembali untuk tampilan tersebut terlihat pada Gambar 10. Pada
Gambar 10 terlihat bahwa proses temu kembali berhasil baik dengan menghasilkan 37 citra teratas yang seluruhnya relevan dengan kueri.
Hitung cosine similarity c1 antara kueri dengan node
awal
Mencari nilai kemiripan antar
node awal dan node
lain yang sama atau mendekati c1
Hitung cosine similarity antara node
(dengan kemiripan
Gambar 8 Diagram alur proses penelusuran. Contoh hasil temu kembali yang kurang relevan tertera pada Gambar 11. Pada gambar tersebut terlihat hanya ditemukan dua citra yang relevan, sedangkan selainnya adalah citra-citra dari kelas lain namun dengan nilai kemiripan yang besar terhadap kueri. Ini menunjukkan bahwa antar citra dalam satu kelas belum tentu memiliki nilai kemiripan tinggi. Hal ini berkaitan dengan perhitungan nilai kemiripan yang sangat dipengaruhi oleh kualitas ekstraksi ciri. Dengan kata lain, pada beberapa citra, ekstraksi ciri yang digunakan kurang mencirikan citra tertentu untuk masuk ke kelasnya.
Landscape
1
Gambar 9 Contoh tampilan utama sistem.
Gambar 10 Contoh hasil temu kembali.
Jumlah citra yang ditemukan
Gambar 11 Contoh hasil temu kembali yang kurang relevan.
Evaluasi Hasil Temu Kembali
Evaluasi dilakukan menggunakan perhitungan recall dan precision. Perhitungan nilai recall dan precision ini melibatkan seluruh citra dalam basis data sebagai kueri. Nilai recall
yang digunakan adalah 0, 0.1, 0.2, 0.3, …, 1.
Penentuan nilai precision pada recall tersebut menggunakan interpolasi maksimum dengan aturan
, dengan
rj {0.0, 0.1, …, 1.0}, r0 = 0.0, r1 = 0.1, …, r10=1.0.
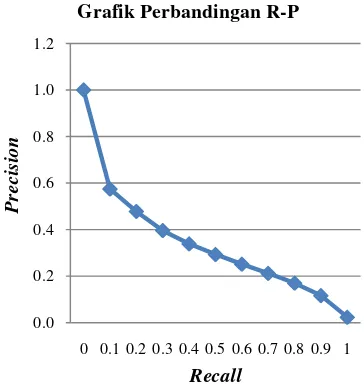
Nilai precision yang ditampilkan pada Tabel 1 adalah hasil rataan nilai precision dari keseluruhan kueri. Grafik perbandingan nilai
recall dan precision dapat dilihat pada Gambar 12. Pada nilai recall 0 dan 0.1, precision yang dihasilkan masih di atas 0.5 walaupun penurunannya cukup signifikan. Hal ini berarti rata-rata pada sejumlah hasil temu kembali yang teratas, lebih dari setengahnya merupakan citra yang relevan terhadap kueri. Pada nilai recall
selanjutnya, precision yang dihasilkan kurang dari 0.5 namun dengan penurunan yang tidak signifikan.
Tabel 1 Rataan precision temu kembali.
Recall Precision
0 1.0000
0.1 0.5746
0.2 0.4779
0.3 0.3957
0.4 0.3385
0.5 0.2929
0.6 0.2511
0.7 0.2116
0.8 0.1697
0.9 0.1159
1 0.0231
Rataan 0.3501
Gambar 12 Grafik perbandingan nilai recall dan
precision.
KESIMPULAN DAN SARAN Kesimpulan
Metode heuristik berhasil
diimplementasikan dan mampu menghasilkan
temu kembali 8.89 kali lebih cepat dibandingkan dengan sistem tanpa implementasi heuristik. Kinerja metode heuristik ini dapat berjalan lebih baik jika nilai kemiripan yang dihasilkan antar citra baik, artinya nilai tersebut mampu mencirikan citra-citra yang memang berada pada kelas yang sama.
Saran
Model heuristik dengan landscape ini sangat bergantung pada nilai kemiripan antar citra, dan nilai kemiripan ini sangat dipengaruhi oleh kualitas ekstraksi ciri. Penelitian selanjutnya dapat mengimplementasikan teknik ekstraksi ciri lain yang lebih mencirikan antar satu citra dengan citra lainnya terutama untuk fitur bentuk dan tekstur. Selain itu, penghitungan nilai kemiripan dengan menggabungkan ketiga fitur juga merupakan tantangan yang masih dapat terus dicarikan solusi. Di sisi lain, pengimplementasian model heuristik lain masih mungkin untuk hasil yang lebih optimal.
Gambar 13 Grafik perbandingan waktu temu kembali. 0.0
113 141 169 197 225 253 281 309 337 365 393 421 449 477 505 533 561 589 617 645 673 701 729 757 785 813 841 869 897 925 953 981
1009 1037 1065 1093
Grafik perbandingan waktu temu kembali
DAFTAR PUSTAKA
Baeza-Yates R, Ribeiro-Neto R. 1999. Modern Information Retrieval. New York : Addison Wesley
Datta R, Joshi D, Li J, Wang JZ. 2008. Image Retrieval: Ideas, Influences, and Trends of the New Age. ACM Computing Surveys. Grossman DA, Frieder O. 2004. Information
Retrieval Algorithms and Heuristics. Netherlands: Springer.
Jones T. 1995. Evolutionary Algorithms, Fitness Landscapes and Search [dissertation]. http://www.cs.unm.edu/~forrest/dissertation s-and-proposals/terry.pdf [8 April 2009]. Jones T, Forrest S. 1995. Genetic Algorithms
and Heuristic Search.
http://www.cs.unm.edu/~forrest/publications /gahs.pdf [20 November 2008].
Klabbankoh B, Pinngern O. 1999. Applied Genetic Algorithms in Information Retrieval. Bangkok : Faculty of Information Technology King Mongkut, Institute of
Technology Ladkrabang.
http://www.journal.au.edu/ijcim/sep99/02-drouen.pdf[17 Desember 2008].
Pebuardi R. 2008. Pengukuran Kemiripan Citra Berbasis Warna, Bentuk, dan Tekstur Menggunakan Bayesian Network [skripsi]. Bogor: Departemen Ilmu Komputer, Institut Pertanian Bogor.
Pratama F. 2009. Algoritme Genetika untuk Optimasi Pembobotan Fitur pada Temu Kembali Citra [skripsi]. Bogor: Departemen Ilmu Komputer, Institut Pertanian Bogor. Stadler PF. 2001. Fitness Landscape.
http://www.tbi.univie.ac.at/papers/Abstracts/ 01-pfs-004.pdf [26 Mei 2009].
Lampiran 1 Contoh citra yang digunakan untuk masing-masing kelas 1. Kelas mobil
Citra 2 Citra20 Citra 43 Citra 66
Citra 96 Citra 109 Citra 135 Citra 164
2. Kelas singa
Citra 179 Citra 192 Citra 206 Citra 181
Citra 216 Citra 252 Citra 263 Citra 279
3. Kelas matahari terbenam
Citra 280 Citra 279 Citra 323 Citra 317
Citra 329 Citra 342 Citra 344 Citra 375
4. Kelas tekstur
Citra 386 Citra 400 Citra 418 Citra 430
Citra 465 Citra 494 Citra 506 Citra 545
5. Kelas beruang
Lanjutan
Citra 611 Citra 617 Citra 620 Citra 654
6. Kelas gajah
Citra 659 Citra 678 Citra 684 Citra 691
Citra 705 Citra 720 Citra 738 Citra 754
7. Kelas tanda panah
Citra 760 Citra 764 Citra 774 Citra 789
Citra 793 Citra 795
Citra 797 Citra 800
8. Kelas pemandangan
Citra 804 Citra 823 Citra 847 Citra 861
Citra 868 Citra 880 Citra 899 Citra 933
9. Kelas reptil
Lanjutan
Citra 965 Citra 937 Citra 988 Citra 994
10.Kelas pesawat
Citra 1006 Citra1023 Citra 1027 Citra 1030
Spesifikasi Pengembangan
Penelitian ini dilakukan dengan menggunakan spesifikasi perangkat keras dan perangkat lunak sebagai berikut:
Perangkat keras dengan spesifikasi: 1 Prosesor AMD Turion64 X2 2.0 GHz 2 Memori 2,37 GB
3 Harddisk 80 GB
4 Alat input mouse dan keyboard
Perangkat lunak dengan spesifikasi: 1 Microsoft Windows XP Professional SP3 2 MATLAB 7.0.1
HASIL DAN PEMBAHASAN
Pada metode heuristik, proses pengindeksan cukup membutuhkan waktu. Hal ini terjadi karena komputasi pada proses pengindeksan melibatkan seluruh citra dalam basis data untuk membentuk struktur graf. Namun, pada saat temu kembali, yang dilakukan sistem adalah menelusuri nilai-nilai yang telah dihitung tersebut. Oleh sebab itu, minimnya proses komputasi pada saat temu kembali diharapkan mampu mempercepat proses pencarian.
Ekstraksi Ciri Citra
Seluruh citra dalam basis data mengalami proses ekstraksi warna, bentuk, dan tekstur sesuai penelitian Pebuardi (2008). Hasilnya, setiap citra direpresentasikan menjadi vektor warna berisi 162 elemen, vektor bentuk berisi 72 elemen, dan vektor tekstur berisi 7 elemen. Struktur Graf
Landscape 1
Landscape ini memiliki node yang
merepresentasikan satu citra. Setiap citra memiliki tiga vektor yang terdiri dari vektor warna berisi 162 elemen, vektor bentuk berisi 72 elemen, dan vektor tekstur berisi 7 elemen. Edge-nya dilabeli dengan jumlah ketiga nilai kemiripan cosine fiturnya. Semakin besar nilai kemiripannya maka citra semakin identik. Perhitungan nilai kemiripan cosine dilakukan antara citra basis data urutan pertama dengan seluruh citra dalam basis data menghasilkan sebuah matriks berukuran 1×1100 atau sesuai dengan jumlah citra dalam basis data. Hal ini dilakukan karena penelusuran pada landscape 1 selalu dimulai dari citra basis data urutan pertama, sehingga pada saat penelusuran, kemiripan node-node dalam basis data dibandingkan dengan citra urutan pertama
sebagai node awal. Gambar 6 menunjukkan ilustrasi landscape 1.
c = nilai kemiripan cosine.
Gambar 6 Ilustrasi landscape 1.
Komputasi yang dilakukan pada tahap pembentukan landscape ini melibatkan 1100 citra dalam basis data. Waktu yang diperlukan untuk perhitungan kemiripan cosine antar 1100 citra tersebut adalah sekitar 90 detik.
Landscape 2
Landscape ini memiliki node yang
merepresentasikan satu citra. Edge-nya dilabeli dengan nilai kemiripan yang dihitung dengan implementasi pembobotan automatis dengan GA yang dinilai memiliki kinerja yang baik berdasarkan penelitian Pratama (2009). Perhitungan ini menghasilkan sebuah matriks berukuran 1100×1100 sesuai dengan jumlah 1100 citra dalam basis data. Ilustrasi landscape
2 ditunjukkan pada Gambar 7.
cga= nilai kemiripan dengan pembobotan GA.
Gambar 7 Ilustrasi landscape 2.
Pada penelitian ini proses pembobotan dengan GA dilakukan pada saat pengindeksan, yaitu digunakan untuk pembentukan struktur
landscape 2. Nilai bobot yang berubah-ubah tersebut dicoba untuk ditetapkan dengan dilakukan sepuluh kali percobaan dan dipilih yang menghasilkan rata-rata nilai precision
tertinggi. Bobot-bobot tersebut menjadi bobot tetap antar citra dalam basis data. Waktu yang diperlukan untuk komputasi 1100 citra untuk pembentukan landscape ini adalah sekitar 1618 detik.
Proses Pencarian
Proses pencarian bergerak antar node pada graf dengan sistematika BFS. Penelusuran dibatasi dengan threshold sebesar 0.5 dengan asumsi bahwa citra-citra yang mirip akan memiliki nilai kemiripan tinggi.
Pada proses penelusuran, kegiatan komputasi minim dilakukan karena pencarian lebih banyak menelusuri angka-angka yang telah dihitung pada tahap pengindeksan. Alur proses pencarian pada dua landscape ini dapat dilihat pada Gambar 8.
Pencarian pertama bergerak pada landscape
1 untuk menemukan citra dalam basis data dengan nilai kemiripan tertinggi atau yang paling identik dengan kueri. Node awal pencarian adalah anggota citra basis data urutan pertama. Selanjutnya, pencarian menuju
landscape 2 untuk menemukan citra lain yang masih relevan dengan kueri namun dengan nilai kemiripan yang lebih rendah dibandingkan hasil pencarian pada landscape 1. Pencarian dimulai pada node awal yang indeksnya merupakan indeks node akhir hasil pencarian pada
landscape 1. Selanjutnya penelusuran dilakukan dengan mencari node tetangga yang memiliki identik berdasarkan urutan nilai kemiripan GA mulai dari yang terbesar. Pencarian akan berhenti dilakukan jika menemukan node
dengan kemiripan kurang dari 0,5. Hasil Temu Kembali
Hasil temu kembali adalah hasil penelusuran graf dengan batasan threshold nilai kemiripan sebesar 0.5. Citra kueri yang digunakan adalah seluruh citra basis data. Rata-rata waktu yang diperlukan untuk setiap proses penelusuran adalah sekitar 0.66 detik. Contoh tampilan utama sistem saat menemukembalikan suatu kueri dapat dilihat pada Gambar 9. Di lain pihak, contoh hasil temu kembali untuk tampilan tersebut terlihat pada Gambar 10. Pada
Gambar 10 terlihat bahwa proses temu kembali berhasil baik dengan menghasilkan 37 citra teratas yang seluruhnya relevan dengan kueri.
Hitung cosine similarity c1 antara kueri dengan node
awal
Mencari nilai kemiripan antar
node awal dan node
lain yang sama atau mendekati c1
Hitung cosine similarity antara node
(dengan kemiripan
Gambar 8 Diagram alur proses penelusuran. Contoh hasil temu kembali yang kurang relevan tertera pada Gambar 11. Pada gambar tersebut terlihat hanya ditemukan dua citra yang relevan, sedangkan selainnya adalah citra-citra dari kelas lain namun dengan nilai kemiripan yang besar terhadap kueri. Ini menunjukkan bahwa antar citra dalam satu kelas belum tentu memiliki nilai kemiripan tinggi. Hal ini berkaitan dengan perhitungan nilai kemiripan yang sangat dipengaruhi oleh kualitas ekstraksi ciri. Dengan kata lain, pada beberapa citra, ekstraksi ciri yang digunakan kurang mencirikan citra tertentu untuk masuk ke kelasnya.
Landscape
1
Gambar 9 Contoh tampilan utama sistem.
Gambar 10 Contoh hasil temu kembali.
Jumlah citra yang ditemukan
Gambar 11 Contoh hasil temu kembali yang kurang relevan.
Evaluasi Hasil Temu Kembali
Evaluasi dilakukan menggunakan perhitungan recall dan precision. Perhitungan nilai recall dan precision ini melibatkan seluruh citra dalam basis data sebagai kueri. Nilai recall
yang digunakan adalah 0, 0.1, 0.2, 0.3, …, 1.
Penentuan nilai precision pada recall tersebut menggunakan interpolasi maksimum dengan aturan
, dengan
rj {0.0, 0.1, …, 1.0}, r0 = 0.0, r1 = 0.1, …, r10=1.0.
Nilai precision yang ditampilkan pada Tabel 1 adalah hasil rataan nilai precision dari keseluruhan kueri. Grafik perbandingan nilai
recall dan precision dapat dilihat pada Gambar 12. Pada nilai recall 0 dan 0.1, precision yang dihasilkan masih di atas 0.5 walaupun penurunannya cukup signifikan. Hal ini berarti rata-rata pada sejumlah hasil temu kembali yang teratas, lebih dari setengahnya merupakan citra yang relevan terhadap kueri. Pada nilai recall
selanjutnya, precision yang dihasilkan kurang dari 0.5 namun dengan penurunan yang tidak signifikan.
Tabel 1 Rataan precision temu kembali.
Recall Precision
0 1.0000
0.1 0.5746
0.2 0.4779
0.3 0.3957
0.4 0.3385
0.5 0.2929
0.6 0.2511
0.7 0.2116
0.8 0.1697
0.9 0.1159
1 0.0231
Rataan 0.3501
Gambar 12 Grafik perbandingan nilai recall dan
precision.
KESIMPULAN DAN SARAN Kesimpulan
Metode heuristik berhasil
diimplementasikan dan mampu menghasilkan
temu kembali 8.89 kali lebih cepat dibandingkan dengan sistem tanpa implementasi heuristik. Kinerja metode heuristik ini dapat berjalan lebih baik jika nilai kemiripan yang dihasilkan antar citra baik, artinya nilai tersebut mampu mencirikan citra-citra yang memang berada pada kelas yang sama.
Saran
Model heuristik dengan landscape ini sangat bergantung pada nilai kemiripan antar citra, dan nilai kemiripan ini sangat dipengaruhi oleh kualitas ekstraksi ciri. Penelitian selanjutnya dapat mengimplementasikan teknik ekstraksi ciri lain yang lebih mencirikan antar satu citra dengan citra lainnya terutama untuk fitur bentuk dan tekstur. Selain itu, penghitungan nilai kemiripan dengan menggabungkan ketiga fitur juga merupakan tantangan yang masih dapat terus dicarikan solusi. Di sisi lain, pengimplementasian model heuristik lain masih mungkin untuk hasil yang lebih optimal.
Gambar 13 Grafik perbandingan waktu temu kembali. 0.0
113 141 169 197 225 253 281 309 337 365 393 421 449 477 505 533 561 589 617 645 673 701 729 757 785 813 841 869 897 925 953 981
1009 1037 1065 1093
Grafik perbandingan waktu temu kembali
Lampiran 1 Contoh citra yang digunakan untuk masing-masing kelas 1. Kelas mobil
Citra 2 Citra20 Citra 43 Citra 66
Citra 96 Citra 109 Citra 135 Citra 164
2. Kelas singa
Citra 179 Citra 192 Citra 206 Citra 181
Citra 216 Citra 252 Citra 263 Citra 279
3. Kelas matahari terbenam
Citra 280 Citra 279 Citra 323 Citra 317
Citra 329 Citra 342 Citra 344 Citra 375
4. Kelas tekstur
Citra 386 Citra 400 Citra 418 Citra 430
Citra 465 Citra 494 Citra 506 Citra 545
5. Kelas beruang
Lanjutan
Citra 611 Citra 617 Citra 620 Citra 654
6. Kelas gajah
Citra 659 Citra 678 Citra 684 Citra 691
Citra 705 Citra 720 Citra 738 Citra 754
7. Kelas tanda panah
Citra 760 Citra 764 Citra 774 Citra 789
Citra 793 Citra 795
Citra 797 Citra 800
8. Kelas pemandangan
Citra 804 Citra 823 Citra 847 Citra 861
Citra 868 Citra 880 Citra 899 Citra 933
9. Kelas reptil
Lanjutan
Citra 965 Citra 937 Citra 988 Citra 994
10.Kelas pesawat
Citra 1006 Citra1023 Citra 1027 Citra 1030
PENDAHULUAN
Latar Belakang
Dalam perkembangan media informasi terutama di bidang temu kembali citra dewasa ini, para pengguna membutuhkan mesin pencari yang cepat dengan hasil yang relevan. Oleh karena itu, metode pencarian heuristik diaplikasikan dengan harapan mampu membuat proses pencarian citra menjadi lebih cepat.
Proses pencarian yang umum dilakukan adalah dengan membandingkan citra kueri dengan seluruh citra dalam basis data. Proses ini dilakukan berulang setiap citra kueri diberikan. Hal ini tidak efisien karena proses tersebut cukup membutuhkan waktu terutama pada basis data berukuran besar.
Metode heuristik diterapkan untuk membuat basis data lebih terstruktur. Model struktur basis data tersebut menransformasi isi basis data menjadi graf terhubung. Setiap node graf adalah representasi setiap citra dalam basis data. Antara node satu dengan node lainnya dihubungkan dengan edge yang dilabeli dengan nilai kemiripan dan prediksi kedekatan (Stadler 2001). Model graf ini dalam ruang lingkup
Evolutionary Algorithm (EA) dikenal dengan
fitness landscape (Jones 1995). Prediksi kedekatan dan kemiripan tersebut mempengaruhi posisi antar node. Semakin mirip citra-citra tersebut maka posisinya semakin berdekatan.
Pada saat kueri dimasukkan, pencarian dilakukan dengan cara menelusuri node-node
graf tersebut dengan algoritme pencarian
Breadth-First Search (BFS). Awal pencarian difokuskan untuk mencari citra dalam basis data yang paling relevan dengan kueri. Setelah itu, pencarian berlanjut dengan menelusuri citra-citra lain dengan posisi yang berdekatan dengan citra basis data yang paling relevan tersebut. Hal ini dilakukan karena model struktur graf ini telah memposisikan citra-citra yang mirip saling berdekatan, sehingga ketika citra paling relevan dengan kueri telah ditemukan, maka citra-citra lain yang letaknya berdekatan dengan citra tersebut juga relevan terhadap kueri. Hasil penelusuran kemudian ditampilkan sebagai hasil temu kembali.
Tujuan
Tujuan penelitian ini adalah mengimplementasikan dan menganalisis kinerja metode heuristik pada pencarian citra.
Ruang Lingkup
Ruang lingkup penelitian ini difokuskan pada implementasi pemrograman heuristik pada proses pencarian citra dalam konteks Content Based Image Retrieval (CBIR) berdasarkan fitur warna, bentuk, dan tekstur. Implementasi ini diterapkan pada data sebanyak 1100 citra yang terbagi menjadi 10 kelas, yaitu mobil, singa, matahari terbenam, tekstur, beruang, gajah, tanda panah, pemandangan, reptil, dan pesawat.
TINJAUAN PUSTAKA
Content Based Image Retrieval
Content based imaged retrieval (CBIR) merupakan suatu pendekatan pada temu kembali citra berdasarkan ciri atau informasi yang terkandung di dalam citra seperti warna, bentuk dan tekstur (Han & Ma diacu dalam Pebuardi 2008). Secara umum, proses content based image retrieval (CBIR) dapat dibagi menjadi dua proses utama yaitu pengolahan basis data atau pengindeksan dan temu kembali. Heuristik
Kata heuristik berasal dari bahasa Yunani,
heuriskein, yang berarti mencari atau menemukan. Di dalam mempelajari metode-metode pencarian, kata heuristik diartikan sebagai suatu fungsi yang memberikan suatu nilai berupa biaya perkiraan (estimasi) dari suatu solusi (Suyanto 2007).
Ekstraksi Ciri (Feature Extraction)
Proses ekstraksi ciri adalah salah satu tahap praproses pada sistem CBIR (Datta et al 2008). Informasi visual yang dihasilkan dari ekstraksi ciri sangat bermanfaat untuk analisis dan proses citra selanjutnya. Ekstraksi ciri pada umumnya memanfaatkan komponen informasi pada citra yaitu berdasarkan warna, bentuk dan tekstur. Evolutionary Algorithm
Evolutionary algorithm identik dengan
Evolutionary Programming, Genetic Algorithm, dan Evolution Strategies. Algoritme ini mencari sekumpulan solusi untuk suatu masalah. Solusi awal tersebut digunakan untuk membentuk potensi solusi baru melalui penggunaan operator. Operator yang dimaksud adalah operator genetika seperti mutasi, rekombinasi, dan inversi. Setiap operator yang digunakan membentuk landscape tersendiri (Jones 1995).
Fungsi Fitness
Fungsi fitness adalah ukuran kinerja yang mengevaluasi seberapa bagus suatu solusi. Fungsi ini dapat digunakan untuk mengukur nilai kemiripan antar dua citra. Salah satu fungsi kemiripan yang umum digunakan adalah cosine similarity, formulanya adalah sebagai berikut:
,
dengan
x = vektor citra x, dan y = vektor citra y.
Hasil perhitungan nilai kemiripan berkisar antara 0 sampai 1. Semakin mendekati nilai 1 maka kedua citra tersebut semakin mirip, begitu pula sebaliknya (Klabbankoh & Pinngren 1999).
Model Fitness Landscapes
Model fitness landscape adalah suatu cara untuk memodelkan citra-citra beserta nilai kemiripannya menjadi bentuk graf terhubung. Setiap citra direpresentasikan sebagai sebuah
node pada suatu dimensi ruang (Jones & Forrest 1995). Untuk membentuk landscape diperlukan tiga komponen, yaitu sebagai berikut (Stadler 2001):
1 Memiliki konfigurasi X, yaitu himpunan anggota, atau dalam hal ini citra dalam basis data.
2 Memiliki perkiraan kedekatan atau jarak antar anggota X.
3 Memiliki fungsi kemiripan.
Himpunan citra menjadi node-node pada graf. Fungsi kemiripan dihitung menggunakan persamaan tertentu sehingga dapat mengidentifikasi tingkat kemiripan antar citra. Tingkat kemiripan tersebut digunakan sebagai perkiraan kedekatan antar node. Semakin besar nilai kemiripannya maka posisi dalam graf semakin berdekatan.
Algoritme Breadth-First Search (BFS)
Algoritme BFS adalah suatu sitematika pencarian yang dilakukan pada semua node
pada setiap level secara berurutan dari kiri ke kanan. Jika pada satu level belum ditemukan solusi, maka pencarian dilanjutkan pada level berikutnya (Suyanto 2007). Ilustrasi algoritme BFS dapat dilihat pada Gambar 1.
Gambar 1 Ilustrasi algoritme BFS. Recall dan Precision
Recall dan precision merupakan parameter untuk mengukur keefektifan dari hasil temu kembali. Recall menyatakan proporsi materi relevan yang ditemukembalikan terhadap seluruh materi relevan yang ada dalam basis data. Sementara itu, precision menyatakan proporsi materi relevan yang ditemukembalikan terhadap seluruh materi yang ditemukembalikan (Grossman 2006).
Penentuan nilai precision untuk nilai recall
tertentu dihitung dengan interpolasi maksimum dengan aturan berikut (misalnya untuk recall 0 sampai 1 dengan interval 0.1):
,
dengan
rj {0.0, 0.1, …, 1.0}, r0 = 0.0, r1 = 0.1, …, r10=1.0.
Jika tidak semua citra relevan dapat ditemukembalikan maka nilai precision pada
recall yang bersangkutan bernilai 0 (Baeza-Yates & Ribeiro-Neto 1999).
METODE PENELITIAN
Penelitian ini dilaksanakan dalam beberapa tahap yaitu: (1) ekstraksi citra, (2) proses pembentukan struktur graf, (3) proses pengindeksan dokumen citra, (4) pencarian dan pengukuran kemiripan dengan menggunakan metode heuristik, dan (5) evaluasi hasil temu kembali. Tahap-tahap yang dilakukan pada penelitian diilustrasikan pada Gambar 2.
V III II
I
Basis
Gambar 2 Metode penelitian. Data Penelitian
Data yang digunakan pada penelitian ini terdiri atas 1100 citra berformat TIF yang dikelompokkan secara manual ke dalam 10 kelas, yaitu mobil, singa, matahari terbenam, tekstur, beruang, gajah, tanda panah, pemandangan, reptil, dan pesawat. Setiap citra memiliki ukuran yang bervariasi. Citra didapat dari http://www.fei.edu.br/~psergio/MaterialAu las/Generalist1200.zip. Beberapa contoh citra yang digunakan tertera pada Lampiran 1. Ekstraksi Ciri
Ekstraksi ciri yang digunakan pada penelitian meliputi ekstraksi warna, bentuk, dan tekstur hasil penelitian Pebuardi (2008). Ekstraksi warna menggunakan conventional color histogram (CCH), ekstraksi bentuk menggunakan deteksi tepi Sobel, dan ekstraksi tekstur menggunakan matriks co-occurrence.
Pembentukan Struktur Graf
Tahapan pembentukan struktur graf adalah sebagai berikut.
Landscape 1
Pembentukan landscape ini bertujuan untuk mencari citra dalam basis data yang paling identik dengan citra kueri. Landscape 1 terdiri atas beberapa komponen, yaitu node, edge, dan nilai kemiripan untuk melabeli edge-nya. Tahapan pembuatan landscape ini yaitu:
1 Representasi node
Penelitian ini menggunakan tiga fitur citra, yaitu warna, bentuk, dan tekstur. Oleh karena itu, satu node pada landscape ini adalah satu citra yang direpresentasikan dengan vektor-vektor hasil ekstraksi ketiga fiturnya. Ketiga vektor tersebut terdiri atas vektor warna berisi 162 elemen, vektor bentuk berisi 72 elemen, dan vektor tekstur berisi 7 elemen. Contoh ilustrasi satu node digambarkan pada Gambar 3.
Gambar 3 Representasi satu node pada
landscape.
2 Perhitungan nilai kemiripan
Nilai kemiripan antar citra dalam basis data dihitung menggunakan cosine similarity. Setiap fitur antar dua citra dihitung nilai kemiripannya kemudian dijumlahkan. Perhitungan dilakukan terhadap citra basis data urutan pertama terhadap setiap citra dalam basis data. Hasilnya adalah sebuah matriks berukuran 1×n, dengan n
menunjukkan jumlah citra dalam basis data. Rumus cosine similarity adalah sebagai berikut:
,
dengan
x = vektor citra x,
y = vektor citra y.
Landscape 2
Manfaat landscape 2 dalam pencarian adalah untuk menemukan citra lain yang relevan namun dengan nilai kemiripan yang lebih rendah dibandingkan hasil temuan pada
landscape 1. Dalam landscape ini, setiap node
merepresentasikan satu citra, sedangkan edge -nya merupakan nilai kemiripan hasil perhitungan dengan implementasi pembobotan automatis dengan Algoritme Genetika (GA) sesuai penelitian Pratama (2009). Bobot yang dihasilkan oleh proses GA berubah-ubah karena pembangkitan nilai awal yang dilakukan secara acak. Perbedaan nilai ini tidak terlalu signifikan, namun tetap mempengaruhi nilai akhir
precision yang dihasilkan. Oleh karena itu, perhitungan kemiripan dengan pembobotan
162 elemen warna
72 elemen bentuk
7 elemen tekstur
yang dilakukan dengan GA ini dilakukan beberapa kali dan dilihat hasil yang terbaik. Perhitungan nilai kemiripan dengan pembobotan automatis ini dilakukan terhadap seluruh citra basis data menghasilkan matriks berukuran n×n, dengan n menunjukkan jumlah citra dalam basis data.
Temu Kembali Citra
Proses Heuristik
Pada proses temu kembali, pemberian kueri dilakukan. Kueri citra tersebut melalui proses ekstraksi ciri menghasilkan vektor yang terdiri dari 162 elemenwarna, 72 elemen bentuk, dan 7 elemen tekstur. Node awal untuk proses penelusuran selalu dimulai dari anggota basis data urutan pertama.
Penelusuran bergerak pada dua landscape
yang telah terbentuk. Penjelasannya adalah sebagai berikut:
Landscape 1
Pada landscape ini setiap edge telah memiliki label jarak berupa nilai kemiripan
cosine. Tahapan penelusuran selanjutnya dijelaskan sebagai berikut: nilai kemiripan yang sama dengan c1, maka
node-node citra basis data yang memiliki nilai kemiripan yang sama tersebut dihitung nilai kemiripannya terhadap kueri. Node
yang terpilih adalah node dengan nilai kemiripan tebesar terhadap kueri.
Hasilnya adalah indeks kandidat hasil temu kembali dengan nilai kemiripan tertinggi atau citra dalam basis data yang paling identik dengan kueri. Gambar 4 adalah ilustrasi pencarian pada landscape 1.
Gambar 4 Ilustrasi pencarian pada landscape 1.
Landscape 2
Indeks node awal pada landscape ini adalah indeks node hasil pencarian pada landscape 1. Setiap node pada landscape ini merepresentaskan satu citra dan edge-nya dilabeli nilai kemiripan yang dihitung dengan pembobotan automatis dengan GA. Penelusuran berjalan dengan algoritme berikut:
1 Dari node awal pada landscape 2, berdasarkan urutan nilai kemiripan dari yang paling besar, penelusuran bergerak mengikuti pola BFS.
2 Dari setiap node yang dikunjungi, dilihat nilai kemiripan antara node awal dengan
node yang sedang dikunjungi, dan hasilnya disimpan sebagai calon hasil temu kembali. 3 Pelusuran dilakukan berdasarkan urutan
nilai kemiripan mulai dari yang terbesar sampai menemukan node dengan nilai kemiripan kurang dari threshold sebesar 0.5. Jika penelusuran menemukan node dengan kriteria tersebut maka pencarian berhenti. Hasil sebelumnya yang telah tersimpan dalam calon hasil temu kembali diurutkan berdasarkan nilai kemiripan mulai dari yang tertinggi. Hasil tersebut kemudian ditampilkan sebagai hasil temu kembali. Gambar 5 menunjukkan ilustrasi pencarian pada landscape 2.
cga= nilai kemiripan dengan pembobotan GA.
Gambar 5 Ilustrasi pencarian pada landscape 2. Evaluasi Hasil Temu Kembali
Pada tahap evaluasi dilakukan penilaian kinerja sistem terhadap sejumlah data pengujian dengan menghitung nilai recall dan precision
untuk menentukan tingkat relevansi hasil temu kembali. Recall adalah perbandingan jumlah citra relevan dan ditemukembalikan dengan jumlah citra relevan dalam basis data. Precision