PENGELOMPOKAN DOKUMEN TUGAS AKHIR
MAHASISWA PROGRAM S1 ILMU KOMPUTER
BERBASIS
FREQUENT ITEMSET
LUSI MAULINA ERMAN
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Pengelompokan Dokumen Tugas Akhir Mahasiswa Program S1 Ilmu Komputer Berbasis Frequent Itemset adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
LUSI MAULINA ERMAN. Pengelompokan Dokumen Tugas Akhir Mahasiswa Program S1 Ilmu Komputer Berbasis Frequent Itemset. Dibimbing oleh IMAS SUKAESIH SITANGGANG.
Abstrak merupakan bagian dari dokumen tugas akhir memiliki peranan penting dalam menjelaskan keseluruhan dokumen. Kata-kata yang sering muncul dapat dijadikan acuan dalam mengelompokkan dokumen ke dalam kategori-kategori. Tujuan dari penelitian ini adalah menerapkan metode association rule mining menggunakan algoritme ECLAT dalam mencari kombinasi term yang paling sering terjadi dan mengelompokkan dokumen abstrak tugas akhir. Data yang digunakan dalam penelitian ini adalah data abstrak dokumen tugas akhir mahasiswa Program S1 Ilmu Komputer IPB dalam bahasa Inggris dari tahun 2012 hingga 2014. Penelitian ini menggunakan stopwords yang berhubungan dengan istilah Ilmu Komputer yang bersifat umum, menerapkan association rule mining dengan support sebesar 0.1, 0.15, 0.2, 0.25, 0.3, dan 0.35, dan menggunakan clustering K-Means dengan jumlah cluster (k) sebesar 10 karena memiliki nilai sum of squared error (SSE) terendah. Pengelompokan ini membandingkan nilai support, SSE, jumlah anggota, dan nilai evaluasi purity di tiap cluster. Cluster terbaik dihasilkan pada perlakuan data dengan penambahan stopwords dan tanpa penerapan association rule mining, dengan k sebesar 10, nilai SSE sebesar 23 485.03, dan nilai purity sebesar 0.512.
Kata kunci: abstrak, ECLAT, frequent itemset, K-Means, purity
ABSTRACT
LUSI MAULINA ERMAN. Grouping Undergraduate Computer Science Student Final Project Based on Frequent Itemset. Supervised by IMAS SUKAESIH SITANGGANG.
Abstract is a part of document that has an important role in explaining the whole document. Words that frequently appear can be used as a reference in grouping the final project document into categories. The purpose of this study is to apply the method of association rule mining namely ECLAT algorithm to find most common terms combination and to group a collection of abstracts. The data used in this study are documents of final project abstract in English of undergraduate Computer Science student of IPB from 2012 to 2014. This research used stopwords about common Computer Science terminology, applied association rule mining with support of 0.1, 0.15, 0.2, 0.25, 0.3, and 0.35, and used K-Means clustering with number of cluster (k) of 10 because it gives the lowest SSE. This research compared the value of support, SSE, the number of cluster members, and purity value in each cluster. The best clustering result is data with additional stopwords and without applying association rule mining, and with k = 10. The SSE result is 23 485.03, and with purity is 0.512.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
PENGELOMPOKAN DOKUMEN TUGAS AKHIR
MAHASISWA PROGRAM S1 ILMU KOMPUTER
BERBASIS
FREQUENT ITEMSET
LUSI MAULINA ERMAN
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji: 1 Ahmad Ridha, SKom MS
Judul Skripsi : Pengelompokan Dokumen Tugas Akhir Mahasiswa Program S1 Ilmu Komputer Berbasis Frequent Itemset
Nama : Lusi Maulina Erman NIM : G64110032
Disetujui oleh
Dr Imas Sukaesih Sitanggang, SSi MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Alhamdulillah, Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas limpahan rahmat dan segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian ini ialah text mining dengan judul Pengelompokan Dokumen Tugas Akhir Mahasiswa Program S1 Ilmu Komputer Berbasis Frequent Itemset.
Terima kasih penulis ucapkan kepada Mama, Papa, Mbak Pretty, dan keluarga besar yang tidak pernah lelah untuk selalu memberikan doa, dukungan, motivasi agar tetap optimis, dan semangat untuk menyelesaikan penelitian ini. Terima kasih selalu mendukung adik kecilnya ini untuk tetap semangat menyelesaikan penelitian sampai akhir.
Terima kasih penulis ucapkan kepada Ibu Dr Imas Sukaesih Sitanggang, SSi MKom selaku dosen pembimbing skripsi, yang tidak pernah letih untuk memberikan arahan dan masukan serta motivasi untuk menyelesaikan penelitian.
Penulis juga menyampaikan terima kasih kepada:
1 Bapak Ahmad Ridha, SKom MS dan Bapak Hari Agung Adrianto, SKom MSi selaku dosen penguji. Terima kasih atas masukan dan saran dalam pengujian hasil penelitian.
2 Bapak Aziz Kustiyo, SSi MKom dan Ibu Husnul Khotimah, SKomp MKom. Terima kasih atas masukan dan diskusi terkait skripsi penulis.
3 Yenni Puspitasari, Ihda Husnayain, dan Timotius Devin, terima kasih untuk selalu menyemangati dalam setiap kondisi, saling membantu, mendoakan, dan memotivasi.
4 Keluarga Ilmu Komputer 48, terima kasih untuk persaudaraan yang terjalin selama empat tahun ini dan pelajaran hidup yang diberikan Allah lewat kalian. 5 Rekan-rekan penulis yang tidak dapat disebut satu per satu, terima kasih untuk
segala memori di kampus Institut Pertanian Bogor tercinta.
Semoga segala doa, bantuan, bimbingan, motivasi, dan kebaikan-kebaikan yang telah diberikan kepada penulis akan dihadiahi kebaikan pula oleh Allah subhanahu wa ta’ala.
Akhirnya semoga penulisan karya ilmiah ini bermanfaat dan dapat menambah wawasan kita semua.
DAFTAR ISI
DAFTAR TABEL viii
DAFTAR GAMBAR viii
DAFTAR LAMPIRAN viii
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 2
Data Penelitian 2
Tahapan Penelitian 3
Peralatan Penelitian 6
HASIL DAN PEMBAHASAN 7
Praproses Data 7
Association Rule Mining 8
Clustering K-Means 9
Analisis Cluster Dokumen 9
SIMPULAN DAN SARAN 10
Simpulan 10
Saran 11
DAFTAR PUSTAKA 11
DAFTAR TABEL
1 Contoh dari beberapa stopwords tambahan 7
2 Contoh hasil tahapan stemming 7
3 Variasi dari nilai sparse dan jumlah term yang dihasilkan 8 4 Perbandingan antara penggunaan nilai support dan jumlah term yang
dihasilkan 9
DAFTAR GAMBAR
1 Tahapan penelitian 3
2 Matriks document-term 4
3 Vertikal layout 4
4 Bottom-up traversal (Zaki et al. 1997) 5
5 Pseudocode algoritme ECLAT (Guandong et al. 2010) 5
6 Hasil evaluasi purity 10
DAFTAR LAMPIRAN
1 Label kelas pada data penelitian yang diadopsi dari penelitian Fhattiya
(2014) 13
2 Label kelas pada keseluruhan data dokumen 16
3 Daftar stopwords tambahan yang umum muncul pada dokumen
penelitian bidang Ilmu Komputer 19
4 Nilai SSE per cluster pada perlakuan sebelum dan setelah menerapkan association rule mining dengan variasi nilai support untuk clustering nilai k = 2 hingga 10 untuk data sebelum stopwords tambahan 20 5 Nilai SSE per cluster pada perlakuan sebelum dan setelah menerapkan
PENDAHULUAN
Latar Belakang
Abstrak dalam suatu dokumen tugas akhir memiliki peranan penting dalam menjelaskan keseluruhan dokumen. Kata-kata yang sering muncul dalam abstrak dapat dijadikan acuan dalam mengelompokkan dokumen tugas akhir ke dalam kategori-kategori. Untuk mengelompokkan abstrak ke dalam kategori salah satunya dapat menggunakan text mining.
Salah satu teknik pengelompokan adalah clustering. Menurut Han et al. (2012), clustering adalah proses pengelompokan kumpulan data menjadi beberapa kelompok sehingga objek di dalam satu kelompok memiliki banyak kesamaan dan memiliki banyak perbedaan dengan objek di kelompok lain berdasarkan nilai atribut dari objek tersebut dan dapat juga berupa perhitungan jarak. Pengelompokan kumpulan data tersebut dapat didasari oleh adanya hubungan antar keyword dalam dokumen teks. Hubungan antar keyword dianalisis dengan cara mengumpulkan keyword yang sering muncul secara bersamaan dan menemukan hubungan asosiasi dari suatu itemset (frequent itemset) di antaranya menggunakan teknik association rule mining (Han et al. 2012).
Penelitian sebelumnya dilakukan oleh Subandi (2014) menggunakan Bisecting K-Means dalam melakukan clustering dokumen skripsi berdasarkan abstrak. Data abstrak yang digunakan terdiri atas 78 dokumen abstrak berbahasa Indonesia dan 113 dokumen abstrak berbahasa Inggris. Penelitian ini menerapkan konsep Information Retrieval pada tahap praproses, pembobotan tf-idf pada pemodelan ruang vektor, dan menggunakan ukuran cosine similarity untuk mengukur jarak antar vektor dokumen.
Galang et al. (2012) menggunakan metode Naive Bayes Classifier untuk melakukan proses klasifikasi dan menggunakan metode Keyword-Based Association Analysis yang dikembangkan dari metode Market Based Analysis untuk menggali data menjadi aturan-aturan asosiasi. Aturan-aturan asosiasi yang dihasilkan memberikan informasi asosiasi antar-keyword dari sekumpulan abstrak tugas akhir yang diproses.
Samodra et al. (2009) melakukan penelitian pengklasifikasian dokumen teks berbahasa Indonesia dengan metode Naive Bayes pada sampel dokumen teks yang diambil dari sebuah media massa elektronik berbasis web. Penelitian tersebut menggunakan dua jenis input, yaitu dokumen yang diproses secara langsung dan dokumen yang sudah dihilangkan kata-kata yang tidak penting (stopwords).
2
Perumusan Masalah
Untuk melakukan pencarian dokumen teks yang relevan dari banyak dokumen yang tersimpan secara acak, diperlukan metode yang dapat mengelompokkan dokumen. Dalam penelitian ini dilakukan pengelompokan dokumen tugas akhir mahasiswa Program S1 Ilmu Komputer IPB berdasarkan abstrak dalam bahasa Inggris. Berdasarkan latar belakang yang diuraikan sebelumnya, maka perumusan masalah dalam penelitian ini adalah:
1 Bagaimana penerapan metode association rule mining dengan algoritme ECLAT dalam mencari kombinasi keyword yang paling sering terjadi dari suatu frequent keyword.
2 Bagaimana penerapan teknik clustering K-Means dalam mengelompokkan dokumen abstrak tugas akhir mahasiswa yang mirip.
Tujuan Penelitian
Tujuan dari penelitian ini adalah:
1 Menerapkan metode association rule mining dengan algoritme ECLAT dalam mencari kombinasi keyword yang paling sering terjadi dari suatu frequent keyword dalam dokumen tugas akhir mahasiswa program S1 Ilmu Komputer IPB.
2 Mengelompokkan dokumen teks berdasarkan abstrak tugas akhir mahasiswa program S1 Ilmu Komputer IPB.
Manfaat Penelitian
Manfaat dari penelitian ini adalah mengelompokkan data yang serupa untuk memudahkan proses pencarian informasi yang relevan dengan kebutuhan.
Ruang Lingkup Penelitian
Dataset yang digunakan berupa 346 abstrak dokumen tugas akhir mahasiswa program S1 Ilmu Komputer IPB dalam bahasa Inggris. Pada penelitian ini menggunakan modul text mining dan association rule mining pada bahasa pemrograman R yang tersedia pada package tm dan arules.
METODE
Data Penelitian
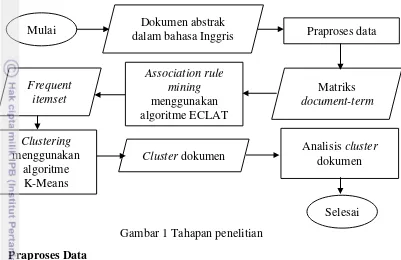
3 Tahapan Penelitian
Tahapan penelitian yang dilakukan dalam pengelompokan dokumen tugas akhir mahasiswa program S1 Ilmu Komputer IPBdapat dilihat pada Gambar 1.
Praproses Data
Tahapan pertama dalam penelitian ini adalah praproses data. Tahap praproses yang dilakukan pada penelitian ini adalah case folding, pembuangan tanda baca dan angka, filtering, pembuangan whitespace, stemming, dan pembuatan matriks document-term.
a Case folding
Case folding adalah mengubah semua huruf dalam dokumen menjadi huruf kecil. Karakter selain huruf dihilangkan dan dianggap delimiter (Feldman dan Sanger 2007). Pada tahap ini semua huruf dalam data abstrak dokumen tugas akhir mahasiswa program S1 Ilmu Komputer IPB diubah menjadi huruf kecil.
b Pembuangan tanda bacadan angka
Pada tahap ini data abstrak yang telah melalui tahap case folding dilakukan pembuangan tanda baca dan pembuangan angka yang terdapat di dalam data abstrak tersebut. Tahap ini bertujuan untuk menghilangkan angka dan tanda baca yang tidak berhubungan dalam melakukan pengelompokan dokumen. c Filtering
Tahap filtering adalah tahap mengambil kata-kata penting. Salah satu algoritme yang dapat digunakan adalah algoritme stoplist (membuang kata yang kurang penting) atau wordlist (menyimpan kata penting). Stoplist/stopwords adalah kata-kata yang tidak deskriptif yang dapat dibuang dalam pendekatan bag-of-words (Feldman dan Sanger 2007). Stopwords yang digunakan pada penelitian ini bersumber dari stopwords dalam bahasa Inggris yang telah tersedia pada package tm di R. Pada tahap ini juga dilakukan penambahan stopwords yang berhubungan dengan istilah ilmu komputer yang bersifat umum.
Cluster dokumen Analisis cluster dokumen
4
d Pembuangan whitespace
Setelah dilakukan tahap filtering, stopwords akan hilang dan menyisakan banyak whitespace pada data abstrak, sehingga dilakukan tahap penghapusan whitespace.
e Stemming
Tahap stemming adalah mengubah kata-kata turunan ke satu representasi yang sama dengan cara menghilangkan semua imbuhan. Idealnya tahap ini menemukan kata dasar (Feldman dan Sanger 2007).
f Pembuatan matriks document-term
Matriks ini memberi informasi frekuensi kemunculan term dalam koleksi dokumen data abstrak. Setiap baris merepresentasikan dokumen data abstrak, sedangkan setiap kolom merepresentasikan term yang ada dalam koleksi dokumen data abstrak. Gambaran mengenai matriks document-term ditunjukkan pada Gambar 2.
Association rule mining bertujuan mencari pola yang sering muncul di antara banyak transaksi. Setiap transaksi terdiri dari beberapa item (Zhang et al. 2003). Kumpulan dari transaksi-transaksi ini disebut dengan itemset. Itemset yang mempunyai item sebanyak k, disebut k-itemset (Zaki 2000).
Association rule mining akan menghasilkan aturan berbentuk X→Y untuk menentukan seberapa besar hubungan antara X dan Y. Aturan ini memerlukan dua ukuran, yakni support dan confidence. Support merupakan kemungkinan X dan Y muncul bersamaan, sedangkan confidence merupakan kemungkinan munculnya Y ketika X juga muncul (Han et al. 2012). Akan tetapi, penelitian ini hanya mencari itemset dengan menggunakan ukuran support yang dinotasikan menurut Han et al. (2012):
Support X→Y =P X Y =jumlah transaksi yang mengandung X dan Yjumlah transaksi 1
Algoritme ECLAT merupakan salah satu algoritme association rule mining untuk mencari frequent itemset dalam sebuah kumpulan data (dataset). Sebuah dataset terdiri atas beberapa item diikuti oleh tid-list. Setiap item dinyatakan dalam tabel tid-list secara vertikal membentuk vertikal layout (Zaki et al. 1997) yang ditunjukkan pada Gambar 3.
5 Algoritme ECLAT membangkitkan kandidatnya dengan pencarian depth-first dan menggunakan titik potong tid-list antar-item (Borgelt 2003). Pendekatan titik potong yang digunakan algoritme ECLAT adalah pendekatan bottom-up traversal yang ditunjukkan pada Gambar 4.
Gambar 4 Bottom-up traversal (Zaki et al. 1997)
Pseudocode algoritme ECLAT ditunjukkan pada Gambar 5. Pada pseudocode ini yang dimaksud dengan atom adalah term.
Algorithm 1: ECLAT – Frequent Itemset Mining Input: A transaction database D,
A user specified threshold minsup
A set of atoms of a sublattice S
Output: Frequent itemsets F
Procedure:
Gambar 5 Pseudocode algoritme ECLAT (Guandong et al. 2010) Clustering K-Means
Masukan pada tahapan ini berupa data hasil dari pengurangan dimensi matriks document term setelah dijalankan algoritme ECLAT dan nilai k. Algoritme K-Means sebagai berikut (Han et al. 2012):
1 Pilih sebanyak k objek dari set data sebagai pusat cluster (centroid) secara acak.
2 Ulangi hingga tidak ada perubahan cluster atau hingga masa/epoch yang ditentukan:
6
b Perbaharui nilai rataan cluster (centroid) pada setiap cluster.
Untuk menentukan nilai k terbaik digunakan fungsi sum of squared error (SSE). Dengan mengetahui nilai SSE dari tiap nilai k maka dapat diketahui clustering yang menghasilkan nilai kesamaan atau kemiripan terbaik. Clustering yang memiliki nilai SSE terkecil adalah clustering dengan hasil terbaik. SSE didefinisikan sebagai berikut (Han et al. 2012):
SSE= ∑ ∑dist(ci, p)2
x∈Ci
k
i=1
(2)
dengan k adalah jumlah kelas, p adalah objek data, Ci adalah objek dalam cluster i, ciadalah centroid atau titik pusat cluster i, dan dist adalah fungsi jarak, yaitu jarak
Euclidean.
Analisis cluster dokumen
Tahapan ini menganalisis hasil clustering dokumen menggunakan algoritme K-Means. Evaluasi purity digunakan untuk mengukur kualitas clustering yang dihasilkan. Menurut Manning et al. (2009), purity merupakan salah satu ukuran untuk mengukur kualitas clustering berbasis external criterion. External criterion adalah metode untuk mengevaluasi seberapa baik hasil clustering dengan menggunakan sekumpulan kelas acuan sebagai wakil penilaian pengguna. Kelas acuan ini diperoleh dari hasil penilaian manusia. Label kelas pada penelitian ini diadopsi dari penelitian Fhattiya (2014) yang dapat dilihat pada Lampiran 1. Label kelas pada keseluruhan data dapat dilihat pada Lampiran 2. Persamaan 3 memperlihatkan formula untuk menghitung purity (Manning et al. 2009). Semakin besar nilai purity (semakin mendekati 1), semakin baik kualitas cluster.
purity Ω, K =N1∑max
j |ωk∩cj|
k
(3)
dengan Ω={ω1,ω2,…,ωk} adalah kumpulan cluster, K={c1,c2,…,cj} adalah kumpulan kelas acuan, N adalah jumlah dokumen, ωk adalah kumpulan objek pada cluster ωk, dan cj adalah kumpulan objek pada kumpulan kelas acuan cj.
Peralatan Penelitian
Penelitian ini menggunakan perangkat keras dan perangkat lunak. Perangkat keras berupa komputer personal dengan spesifikasi sebagai berikut:
• Processor Intel Core i3-3217U
• RAM 2 GB • 460 GB HD
Adapun perangkat lunak yang digunakan sebagai berikut:
• Sistem operasi Windows 8.1 Single Language
7
HASIL DAN PEMBAHASAN
Praproses Data
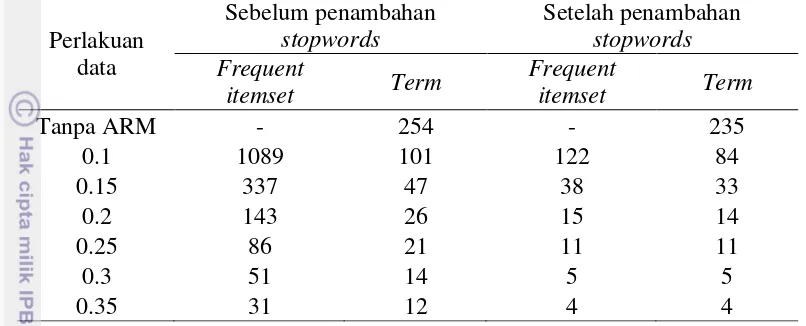
Penelitian ini menggunakan data abstrak dokumen tugas akhir sebanyak 346 dokumen dalam format fail PDF. Sebelum melakukan tahap praproses data, data dengan format fail PDF diubah menjadi format fail txtdengan cara copy–paste secara manual. Tahap praproses data terdiri dari 6 tahap, yaitu case folding, pembuangan tanda baca dan angka, filtering, pembuangan whitespace, stemming, dan pembuatan matriks document-term. Tahap pertama adalah case folding. Tahap ini perlu dilakukan untuk mempermudah tahap praproses selanjutnya tanpa memperhatikan huruf kapital atau tidaknya kata. Tahap kedua adalah pembuangan tanda baca dan angka. Selanjutnya, tahapan ketiga adalah tahap filtering. Pada tahap ini dilakukan penambahan stopwords yang berhubungan dengan istilah ilmu komputer yang bersifat umum. Contoh dari beberapa stopwords tambahan ditunjukkan pada Tabel 1. Daftar stopwords tambahan secara lengkap dapat dilihat pada Lampiran 3.
Tabel 1 Contoh dari beberapa stopwords tambahan Daftar stopwords tambahan
accuracy algorithm application
Setelah dilakukan tahap filtering, stopwords akan hilang dan menyisakan banyak whitespace, sehingga perlu dilakukan tahap penghapusan whitespace. Tahap selanjutnya adalah stemming, yaitu penghilangan imbuhan yang terdapat di dalam data abstrak untuk menghasilkan kata dasar. Pada tahap ini tidak semua kata dasar dihasilkan dalam bentuk yang sempurna. Beberapa kata yang dihasilkan berubah menjadi kata yang tidak terdapat di dalam kamus bahasa Inggris seperti yang ditunjukkan pada Tabel 2. Namun, hasil dari tahap stemming yang demikian tidak terlalu berpengaruh di dalam tahap analisis asosiasi dan clustering. Semua data abstrak yang memiliki kata-kata yang sama akan dilakukan pemotongan imbuhan dengan hasil yang sama sehingga tahap analisis asosiasi dan clustering dapat dijalankan.
Tabel 2 Contoh hasil tahapan stemming
Sebelum tahap stemming Setelah tahap stemming
temporal tempor
analyze analyz
queries queri
8
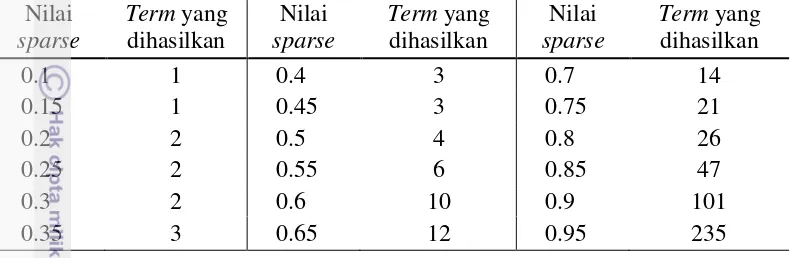
Nilai ini dinilai cukup baik dari nilai sparse yang lain, karena menyisakan jumlah term yang cukup banyak. Hal ini bertujuan untuk mendapatkan term dengan variasi yang banyak sebagai masukan pada tahap asosiasi. Variasi dari nilai sparse dan jumlah term yang dihasilkan dapat dilihat pada Tabel 3.
Tabel 3 Variasi dari nilai sparse dan jumlah term yang dihasilkan Nilai dihasilkan menggunakan fungsi removeSparseTerm() di R. Fungsi ini membuang term yang jarang muncul di dalam dataset. Term yang muncul hanya satu atau dua kali cenderung memakai banyak komputasi sumber daya tanpa menambahkan sesuatu yang berguna untuk analisis. Oleh karena itu, dapat dilakukan reduksi ukuran dimensi matriks document-term tanpa mengurangi banyak informasi yang berguna di dalam matriks tersebut. Fungsi removeSparseTerm() dijalankan pada kode program berikut:
1 dm <- DocumentTermMatrix(docs) 2 dm <- removeSparseTerms(dm, 0.95)
Parameter sparse sebesar 0.95 menunjukkan bahwa term yang dihilangkan adalah yang term yang banyak muncul dengan frekuensi 0 di dalam matriks document-term yang dihitung pada 95% dokumen.
Association Rule Mining
Tahapan ini melakukan pencarian frequent itemset dalam matriks document-term menggunakan algoritme ECLAT yang tersedia pada package arules yang dijalankan pada fungsi eclat() sebagai berikut:
1 library(arules)
2 fsets <- eclat(dm, parameter = list(support = 0.35)) 3 x <- as(items(fsets),"list")
4 x
9 sedikit frequent itemset yang dihasilkan. Pada support sebesar 0.35 menghasilkan 31 frequent itemset yang dikombinasikan dari 12 term. Hal ini dikarenakan nilai support mencari kemunculan frequent itemset yang muncul sebanyak 35% di dalam keseluruhan term yang tersedia pada matriks document-term.
Clustering K-Means
Pada tahap ini dilakukan clustering menggunakan K-Means. Masukan dari tahap ini adalah matriks document-term yang dihasilkan sebelum dan setelah melalui tahap asosiasi. Nilai SSE untuk setiap perlakuan untuk clustering nilai k=2 hingga 10 ditampilkan pada Lampiran 4 dan 5. Nilai SSE terkecil yang dihasilkan pada setiap perlakuan adalah dengan nilai k sebesar 10. Oleh sebab itu, fungsi K-Means diberi masukan k sebesar 10. Sebelum menjalankan fungsi kmeans() diperlukan pemilihan angka pada fungsi set.seed(). Fungsi ini bertujuan untuk menentukan bagaimana penghasil bilangan acak harus diinisialisasi (seeded) sehingga mendapatkan hasil yang tetap walaupun kode program dijalankan terus-menerus. Pada penelitian ini nilai seed yang digunakan adalah 346, 122, 300, 255, dan 50. Pemilihan nilai pada fungsi set.seed() ini dapat dijadikan bahan koreksi untuk penelitian selanjutnya dan sebagai batasan dalam perbandingan clustering dokumen. Untuk mengevaluasi hasil clustering, perhitungan evaluasi purity dilakukan pada tahap selanjutnya yaitu tahap analisis cluster dokumen.
Analisis Cluster Dokumen
10
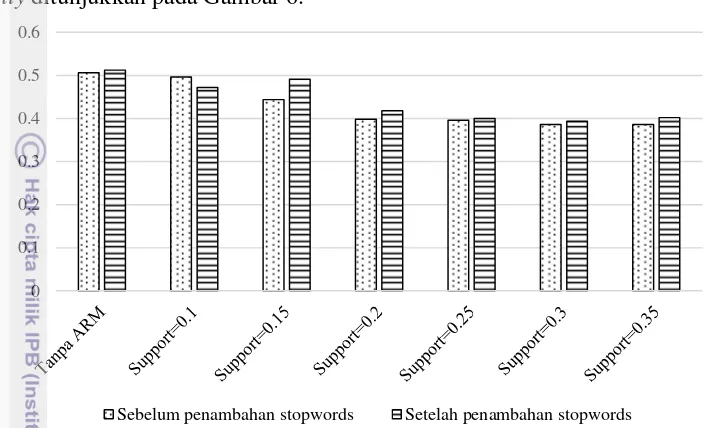
merupakan rataan dari nilai purity hasil pada tahap clustering K-Means menggunakan nilai seed yang telah disebutkan diatas. Rincian nilai purity pada setiap nilai seed dapat dilihat pada Lampiran 6. Hasil dari perhitungan evaluasi purity ditunjukkan pada Gambar 6.
Gambar 6 Hasil evaluasi purity
Gambar 6 menunjukkan bahwa nilai evaluasi purity yang dihasilkan pada setiap perlakuan data memiliki perbedaan nilai yang tidak signifikan, yaitu berkisar antara 0.386 sampai 0.512. Hal ini berarti bahwa penggunaan ARM tidak memberikan hasil cluster yang lebih baik dibandingkan dengan tanpa penggunaan ARM jika dilihat dari nilai evaluasi purity yang dihasilkan. Meskipun pada nilai SSE, data yang menggunakan ARM memiliki nilai SSE yang terendah diantara semua perlakuan data.
Penambahan stopwords yang berhubungan dengan istilah ilmu komputer yang bersifat umum juga tidak memberikan hasil cluster yang lebih baik dibandingkan dengan data sebelum penambahan stopwords jika dilihat dari nilai evaluasi purity yang dihasilkan. Meskipun pada nilai SSE untuk data setelah penambahan stopwords memiliki nilai SSE yang lebih rendah dibandingkan dengan data sebelum penambahan stopwords.
SIMPULAN DAN SARAN
Simpulan
Kesimpulan dari hasil penelitian ini adalah pengelompokan dokumen tugas akhir berdasarkan abstrak dapat dilakukan dengan melakukan analisis asosiasi pada term yang sering muncul di dalam abstrak. Penelitian ini menerapkan association rule mining dengan support sebesar 0.1, 0.15, 0.2, 0.25, 0.3, dan 0.35. Clustering dilakukan menggunakan clustering K-Means dengan jumlah cluster (k) sebesar 10
0 0.1 0.2 0.3 0.4 0.5 0.6
11 karena memiliki nilai sum of squared error (SSE) terendah. Pengelompokan ini membandingkan nilai support, SSE, jumlah anggota dan nilai evaluasi purity di tiap cluster. Cluster terbaik dihasilkan pada data dengan penambahan stopwords dan tanpa penerapan association rule mining, dengan k sebesar 10, nilai SSE sebesar 23 485.03, dan nilai purity sebesar 0.512.
Saran
Penelitian ini masih memiliki kekurangan yaitu kurang optimalnya proses pada tahapan clustering dokumen dilihat dari nilai SSE yang masih tinggi dan nilai purity yang belum mendekati 1. Saran untuk penelitian selanjutnya adalah dapat menggunakan algoritme lain yang dapat menggabungkan tahapan asosiasi dan clustering dokumen. Selain itu dapat dilakukan penambahan stopwords yang lebih lengkap dan menggunakan varian dari algoritme K-Means untuk clustering dokumen.
DAFTAR PUSTAKA
Borgelt C. 2003. Efficient implementations of Apriori and ECLAT. Di dalam: Zaki MJ, Goethals B, editor. Proceedings of the Workshop on Frequent Itemset Mining Implementations (FIMI-03); 2003 Nov 19; Melbourne, Florida, Amerika Serikat. Aachen (DE): CEUR-WS. hlm 26-34.
Feldman R, Sanger J. 2007. The Text Mining Handbook. Cambridge (UK): Cambridge University Press.
Fhattiya, SR. 2014. Pembangunan Data Warehouse dan Aplikasi OLAP untuk Memantau Prestasi Mahasiswa Program Studi S1 Ilmu Komputer IPB [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Galang A, Indra R, Ramadani, Warman A. 2012. Pencarian dan Penentuan Buku Referensi Tugas Akhir Matakuliah dengan Metode Naive Bayes Classifier dan Association Rule. Yogyakarta (ID): Universitas Islam Indonesia.
Guandong X, Yanchun Z, Lin L. 2010. Web Mining and Social Networking: Techniques and Applications. New York (US): Springe Science & Business Media.
Han J, Kamber M, Pei J. 2012. Data Mining Concepts and Techniques. 3rd Edition. Waltham (US): Morgan Kaufmann Publisher.
Manning CD, Raghavan P, Schutze H. 2009. An Introduction to Information Retrieval. Cambridge (UK): Cambridge University Press.
Samodra J, Sumpeno S, Hariadi M. 2009. Klasifikasi Dokumen Teks Berbahasa Indonesia dengan Menggunakan Naive Bayes. Surabaya (ID): Institut Teknologi Surabaya.
Subandi, NA. 2014. Clustering Dokumen Skripsi Berdasarkan Abstrak Dengan Menggunakan Bisecting K-Means [skripsi]. Bogor (ID): Institut Pertanian Bogor.
12
Zaki MJ. 2000. Generating non-redundant Association Rules. Di dalam: Ramakrishnari R, Stolfo S, Bayardo R, Parsa I, editor. The Second Annual International Conference on Knowledge Discovery in Data; 2000 Agu 20-23; Boston, Amerika Serikat. New York (US): ACM. hlm 34-43.
13 Lampiran 1 Label kelas pada data penelitian yang diadopsi dari penelitian Fhattiya
(2014)
Topik Label
DNA secuencing error correction BI (Bioinformatika) DNA sequence assembly BI (Bioinformatika) Dynamic programming BI (Bioinformatika) Graph algorithm BI (Bioinformatika) Metagenome fragment binning BI (Bioinformatika) Network pharmacology BI (Bioinformatika) SNP identification BI (Bioinformatika) Artificial intelligence CI (Computer Intelligent) Computational intelligence CI (Computer Intelligent) Computer vision CI (Computer Intelligent) Decision support system CI (Computer Intelligent) Expert system CI (Computer Intelligent) Fuzzy system CI (Computer Intelligent) Genetic algorithm CI (Computer Intelligent) Genetic algorithm CI (Computer Intelligent) Haar wavelet CI (Computer Intelligent) Image processing CI (Computer Intelligent) Machine learning CI (Computer Intelligent) Neural network CI (Computer Intelligent) Pattern recognition CI (Computer Intelligent) Pemrosesan suara CI (Computer Intelligent)
PNN CI (Computer Intelligent)
Prediction CI (Computer Intelligent)
Semantic web CI (Computer Intelligent)
SOM CI (Computer Intelligent)
Speech recognition CI (Computer Intelligent)
SVM CI (Computer Intelligent)
Associaton rule mining DM (Data Mining)
Clustering DM (Data Mining)
Data warehouse DM (Data Mining)
Deteksi pencilan DM (Data Mining)
Klasifikasi DM (Data Mining)
OLAP DM (Data Mining)
Sequantial pattern mining DM (Data Mining) Spatial data mining DM (Data Mining) Spatio temporal data mining DM (Data Mining)
Text mining DM (Data Mining)
Web mining DM (Data Mining)
14 Lanjutan
Topik Label
Document clustering IR (Information Retrieval) Expert system IR (Information Retrieval)
IDF IR (Information Retrieval)
Indexing IR (Information Retrieval)
Information retrieval IR (Information Retrieval) Jaringan syaraf tiruan IR (Information Retrieval) Knowledge graph IR (Information Retrieval)
Kompresi IR (Information Retrieval)
Learning management system IR (Information Retrieval)
Naive bayes IR (Information Retrieval)
Phonetic search IR (Information Retrieval) Query expansion IR (Information Retrieval) Question answering system IR (Information Retrieval)
Recall IR (Information Retrieval)
Recognition IR (Information Retrieval)
Segmentation IR (Information Retrieval) Semantic indexing IR (Information Retrieval) Semantic smoothing IR (Information Retrieval) Shortest path IR (Information Retrieval) Sistem informasi IR (Information Retrieval) Speling correction IR (Information Retrieval) Text summarization IR (Information Retrieval)
Arduino NCC (Net Centric Computing)
Dynamic tagging NCC (Net Centric Computing)
E-voting NCC (Net Centric Computing)
Hexapod NCC (Net Centric Computing)
HTTP NCC (Net Centric Computing)
Keamanan jaringan NCC (Net Centric Computing)
Kriptografi NCC (Net Centric Computing)
Obstacle Avoidance NCC (Net Centric Computing) Operating system NCC (Net Centric Computing)
Parallel NCC (Net Centric Computing)
Peer-to-peer NCC (Net Centric Computing)
RSA algorithm NCC (Net Centric Computing) Security service NCC (Net Centric Computing) Spatial query NCC (Net Centric Computing) Steganography NCC (Net Centric Computing) Vector space model NCC (Net Centric Computing)
Watermarking NCC (Net Centric Computing)
16
Lampiran 2 Label kelas pada keseluruhan data dokumen
Dokumen Label Dokumen Label Dokumen Label
17 Lanjutan
Dokumen Label Dokumen Label Dokumen Label
18 Lanjutan
Dokumen Label Dokumen Label Dokumen Label
19 Lampiran 3 Daftar stopwords tambahan yang umum muncul pada dokumen
penelitian bidang Ilmu Komputer
accuracy format optimal source
algorithm formula output summary
application function perform system
base generate power technique
browser implement previous technology
calculate input problem tool
code installation process transfer
compile measure program unit
computer method provide use
develop model purpose utility
environment need require research
execute operate research
20
Lampiran 4 Nilai SSE per cluster pada perlakuan sebelum dan setelah menerapkan association rule mining dengan variasi nilai support untuk clustering nilai k = 2 hingga 10 untuk data sebelum stopwords tambahan
Cluster Tanpa ARM
Dengan ARM
Support=0.1 Support=0.15 Support=0.2
SSE SSE SSE SSE
2 37 661.83 23 945.74 16 412.27 11 978.67 3 36 102.99 22 443.63 15 236.37 10 892.25 4 35 309.91 21 291.61 14 323.41 10 081.78 5 33 830.94 20 526.93 13 500.62 9 705.03 6 32 480.46 19 933.67 13 112.95 9 378.82 7 31 957.78 19 553.91 12 879.49 9 191.54 8 31 453.25 18 925.99 12 578.40 8 924.36 9 30 978.34 19 012.29 12 275.59 8 620.80 10 30 585.11 18 697.45 12 007.40 8 378.81
Cluster Support=0.25 Support=0.3 Support=0.35
SSE SSE SSE
21 Lampiran 5 Nilai SSE per cluster pada perlakuan sebelum dan setelah menerapkan association rule mining dengan variasi nilai support untuk clustering nilai k = 2 hingga 10 untuk data setelah stopwords tambahan
Cluster Tanpa ARM
Dengan ARM
Support=0.1 Support=0.15 Support=0.2
SSE SSE SSE SSE
2 30 210.49 16 768.03 8 926.56 4 742.36 3 28 691.95 15 426.97 7 891.57 4 298.89 4 27 204.97 14 045.59 7 471.23 3 861.14 5 26 521.00 13 654.75 6 924.07 3 585.73 6 26 127.89 13 025.02 6 747.42 3 441.56 7 25 491.91 12 867.32 6 476.48 3 313.45 8 24 324.59 12 591.26 6 077.16 2 959.85 9 23 853.45 11 936.77 5 964.55 2 826.84 10 23 485.03 11 575.35 5 728.71 2 748.30
Cluster Support=0.25 Support=0.3 Support=0.35
SSE SSE SSE
22
Lampiran 6 Hasil evaluasi purity pada seed 346, 122, 300, 255, dan 50
Seed 346 122 300
Penambahan stopwords Sebelum Sesudah Sebelum Sesudah Sebelum Sesudah Tanpa ARM 0.483 0.474 0.520 0.534 0.523 0.485
ARM dengan support
0.1 0.465 0.488 0.500 0.468 0.486 0.465 0.15 0.445 0.480 0.456 0.502 0.421 0.485 0.2 0.408 0.410 0.387 0.413 0.378 0.419 0.25 0.402 0.399 0.398 0.401 0.381 0.401 0.3 0.402 0.375 0.393 0.404 0.375 0.395 0.35 0.408 0.390 0.369 0.395 0.375 0.421
Seed 255 50
Penambahan stopwords Sebelum Sesudah Sebelum Sesudah Tanpa ARM 0.517 0.537 0.488 0.531
ARM dengan support
23
RIWAYAT HIDUP
Penulis lahir di Kota Jambi pada 22 Agustus 1994. Penulis merupakan putri kedua dari dua bersaudara pasangan Erman dan Krisnawati. Penulis menamatkan sekolah menengah di SMAN1 Kota Jambi pada tahun 2011 dan kemudian melanjutkan pendidikan di Institut Pertanian Bogor pada tahun yang sama melalui jalur SNMPTN Undangan.