LAMPIRAN I
LAMPIRAN II
LAMPIRAN II
ANALISIS PARAMETER AITEM DENGAN PROGRAM ITEMAN
A. Menyimpan Data dalam Bentuk NotePad/Fixed ASCII
1. Notepad
Alur kerja:
1. Klik Start-Programs-Accessories-Notepad 2. Masukan data
3. Save di local disk (C) satu folder dengan program Iteman 2.Fixed ASCII
Fixed ASCII ini penyimpanan data dari lembar kerja SPSS. Alur kerja:
1. Klik Start-Programs-SPSS 2. Masukan data
B. Membuat Syntax (Control Tile)
Setelah data tersimpan dalam bentuk notepad atau Fixed ASCII di lokal disk C (satu folder dengan program Iteman), buka lagi data tersebut, kemudian masukan syntax (control tile) dengan cara:
1. Baris pertama adalah baris pengontrol yang mendeskripsikan data. 2. Baris kedua adalah daftar kunci jawaban setiap aitem.
3. Baris ketiga adalah daftar jumlah option untuk setiap aitem.
4. Baris keempat adalah daftar aitem yang hendak dianalisis (jika aitem yang akan dianalisis diberi tanda Y (yes), jika tidak diikutkan dalam analisis diberi tanda N (no).
5. Baris kelima dan seterusnya adalah data subjek dan pilihan jawaban subjek. Contoh:
yyyyyyyyyyyyyyyyyyyy [Aitem yang dianalisis ditulis y, jika tidak ditulis n] S0001 BBDCCECEAACDACCEBEAC
S0002 EEDCCCCCDACDBBCEBDDE S0003 BBDDCCBDDCCAABCABEBC S0004 BBEEBACDDADDBBDDDEEC S0005 BBDNCCCADCEEBCCCDNND
………..dst sampai S2011………
Nb: gunakan hurus kecil semua atau kapital semua
Langkah selanjutnya simpan kembali data yang telah dimasukan syntax, misal: WAder.dat (dalam bentuk notepad)
C. Membuka Lembar Kerja ITEMAN
Alur kerja:
2. Ketik cd .. (enter) – cd .. (enter) – cd iteman (enter) – iteman, maka akan muncul:
MicroCAT (tm) Testing System
Copyright (c) 1982, 1984, 1986, 1988 by Assessment Systems Corporation Beta-Test Version--Univ. of Pittsburgh
Item and Test Analysis Program -- ITEMAN (tm) Version 3.00 Enter the name of the input file:
3. Kemudian isilah pertanyaan-pertanyaan yang muncul dilembar kerja iteman, seperti:
Enter the name of the input file: WAder.dat <enter> Enter the name of the output file: outWAder.out <enter>
Do you want the scores written to a file? (Y/N) Y <enter> Enter the name of the score file: SkorWAder.sor <enter>
**ITEMAN ANALYSIS IS COMPLETE**
Kemudian hasil analisis iteman akan tersimpan secara otomatis pada folder Iteman di local disk C sesuai dengan nama yang kita berikan sebelumnya.
Maximum 20.000 Median 12.000 Alpha 0.650 SEM 1.938 Mean P 0.593 Mean Item-Tot. 0.366 Mean Biserial 0.492 Keterangan:
Prop. Correct = indeks kesulitan aitem,
Biser dan Point Biser. = korelasi Biserial dan Korelasi Point Biserial (indeks diskriminasi aitem),
Alt. = alternative/pilihan jawaban,
Prop. Endorsing = proporsi Jawaban pada setiap option Alpha = koefisien reliabilitas
MicroCAT (tm) Testing System
E 0.012 -0.521 -0.149
10 0-10 0.776 0.663 0.476 A 0.776 0.663 0.476
14 0-14 0.620 0.437 0.343 A 0.061 -0.033 -0.016
Copyright (c) 1982, 1984, 1986, 1988 by Assessment Systems Corporation Item and Test Analysis Program -- ITEMAN (tm) Version 3.00
Item Statistics Alternative Statistics
Copyright (c) 1982, 1984, 1986, 1988 by Assessment Systems Corporation Item and Test Analysis Program -- ITEMAN (tm) Version 3.00
Item analysis for data from file warevis.dat Page 5
There were 2011 examinees in the data file.
Minimum 0.000
OUTPUT ANALISIS KORELASI SUBTES RA DENGAN 8 SUBTES
LAINNYA PADA IST DENGAN BANTUAN SPSS VERSI 16
A. Output Validitas Konstrak Subtes WA
Correlations
Zscore(WA) Zscore(SE) Zscore(WA) Pearson Correlation 1 .552**
Sig. (1-tailed) .000
N 2011 2011
Zscore(SE) Pearson Correlation .552** 1 Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(SE) Zscore(AN) Zscore(SE) Pearson Correlation 1 .676**
Sig. (1-tailed) .000
N 2011 2011
Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(SE) Zscore(GEE) Zscore(SE) Pearson Correlation 1 .494**
Sig. (1-tailed) .000
N 2011 2011
Zscore(GEE) Pearson Correlation .494** 1 Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(SE) Zscore(RA) Zscore(SE) Pearson Correlation 1 .544**
Sig. (1-tailed) .000
N 2011 2011
Zscore(RA) Pearson Correlation .544** 1 Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(SE) Zscore(ZR) Zscore(SE) Pearson Correlation 1 .544**
Sig. (1-tailed) .000
N 2011 2011
Zscore(ZR) Pearson Correlation .544** 1 Sig. (1-tailed) .000
Correlations
Zscore(SE) Zscore(ZR) Zscore(SE) Pearson Correlation 1 .544**
Sig. (1-tailed) .000
N 2011 2011
Zscore(ZR) Pearson Correlation .544** 1 Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(SE) Zscore(FA) Zscore(SE) Pearson Correlation 1 .379**
Sig. (1-tailed) .000
N 2011 2011
Zscore(FA) Pearson Correlation .379** 1 Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(SE) Zscore(WU) Zscore(SE) Pearson Correlation 1 .444**
Sig. (1-tailed) .000
N 2011 2011
Zscore(WU) Pearson Correlation .444** 1 Sig. (1-tailed) .000
N 2011 2011
Correlations
Zscore(SE) Zscore(ME) Zscore(SE) Pearson Correlation 1 .635**
Sig. (1-tailed) .000
N 2011 2011
Zscore(ME) Pearson Correlation .635** 1 Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(WA) Zscore(AN) Zscore(WA) Pearson Correlation 1 .579**
Sig. (1-tailed) .000
N 2011 2011
Zscore(AN) Pearson Correlation .579** 1 Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(WA) Zscore(GEE) Zscore(WA) Pearson Correlation 1 .524**
Sig. (1-tailed) .000
N 2011 2011
Zscore(GEE) Pearson Correlation .524** 1 Sig. (1-tailed) .000
N 2011 2011
Correlations
Zscore(WA) Zscore(RA) Zscore(WA) Pearson Correlation 1 .548**
Sig. (1-tailed) .000
N 2011 2011
Zscore(RA) Pearson Correlation .548** 1 Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(WA) Zscore(ZR) Zscore(WA) Pearson Correlation 1 .546**
Sig. (1-tailed) .000
N 2011 2011
Zscore(ZR) Pearson Correlation .546** 1 Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(WA) Zscore(FA) Zscore(WA) Pearson Correlation 1 .379**
Sig. (1-tailed) .000
N 2011 2011
Zscore(FA) Pearson Correlation .379** 1 Sig. (1-tailed) .000
N 2011 2011
Correlations
Zscore(WA) Zscore(WU) Zscore(WA) Pearson Correlation 1 .384**
Sig. (1-tailed) .000
N 2011 2011
Zscore(WU) Pearson Correlation .384** 1 Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(WA) Zscore(ME) Zscore(WA) Pearson Correlation 1 .540**
Sig. (1-tailed) .000
N 2011 2011
Zscore(ME) Pearson Correlation .540** 1 Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(AN) Zscore(GEE) Zscore(AN) Pearson Correlation 1 .509**
Sig. (1-tailed) .000
N 2011 2011
Zscore(GEE) Pearson Correlation .509** 1 Sig. (1-tailed) .000
N 2011 2011
Correlations
Zscore(AN) Zscore(RA) Zscore(AN) Pearson Correlation 1 .604**
Sig. (1-tailed) .000
N 2011 2011
Zscore(RA) Pearson Correlation .604** 1 Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(AN) Zscore(ZR) Zscore(AN) Pearson Correlation 1 .604**
Sig. (1-tailed) .000
N 2011 2011
Zscore(ZR) Pearson Correlation .604** 1 Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(AN) Zscore(FA) Zscore(AN) Pearson Correlation 1 .410**
Sig. (1-tailed) .000
N 2011 2011
Zscore(FA) Pearson Correlation .410** 1 Sig. (1-tailed) .000
N 2011 2011
Correlations
Zscore(AN) Zscore(WU) Zscore(AN) Pearson Correlation 1 .434**
Sig. (1-tailed) .000
N 2011 2011
Zscore(WU) Pearson Correlation .434** 1 Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(AN) Zscore(ME) Zscore(AN) Pearson Correlation 1 .597**
Sig. (1-tailed) .000
N 2011 2011
Zscore(ME) Pearson Correlation .597** 1 Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(GEE) Zscore(RA) Zscore(GEE) Pearson Correlation 1 .492**
Sig. (1-tailed) .000
N 2011 2011
Zscore(RA) Pearson Correlation .492** 1 Sig. (1-tailed) .000
N 2011 2011
Correlations
Zscore(GEE) Zscore(ZR) Zscore(GEE) Pearson Correlation 1 .490**
Sig. (1-tailed) .000
N 2011 2011
Zscore(ZR) Pearson Correlation .490** 1 Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(GEE) Zscore(FA) Zscore(GEE) Pearson Correlation 1 .348**
Sig. (1-tailed) .000
N 2011 2011
Zscore(FA) Pearson Correlation .348** 1 Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(GEE) Zscore(WU) Zscore(GEE) Pearson Correlation 1 .274**
Sig. (1-tailed) .000
N 2011 2011
Zscore(WU) Pearson Correlation .274** 1 Sig. (1-tailed) .000
N 2011 2011
Correlations
Zscore(GEE) Zscore(ME) Zscore(GEE) Pearson Correlation 1 .466**
Sig. (1-tailed) .000
N 2011 2011
Zscore(ME) Pearson Correlation .466** 1 Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(RA) Zscore(ZR) Zscore(RA) Pearson Correlation 1 .999**
Sig. (1-tailed) .000
N 2011 2011
Zscore(ZR) Pearson Correlation .999** 1 Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(RA) Zscore(FA) Zscore(RA) Pearson Correlation 1 .437**
Sig. (1-tailed) .000
N 2011 2011
Zscore(FA) Pearson Correlation .437** 1 Sig. (1-tailed) .000
N 2011 2011
Correlations
Zscore(RA) Zscore(WU) Zscore(RA) Pearson Correlation 1 .417**
Sig. (1-tailed) .000
N 2011 2011
Zscore(WU) Pearson Correlation .417** 1 Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(RA) Zscore(ME) Zscore(RA) Pearson Correlation 1 .519**
Sig. (1-tailed) .000
N 2011 2011
Zscore(ME) Pearson Correlation .519** 1 Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(ZR) Zscore(FA) Zscore(ZR) Pearson Correlation 1 .436**
Sig. (1-tailed) .000
N 2011 2011
Zscore(FA) Pearson Correlation .436** 1 Sig. (1-tailed) .000
N 2011 2011
Correlations
Zscore(ZR) Zscore(WU) Zscore(ZR) Pearson Correlation 1 .417**
Sig. (1-tailed) .000
N 2011 2011
Zscore(WU) Pearson Correlation .417** 1 Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(ZR) Zscore(ME) Zscore(ZR) Pearson Correlation 1 .518**
Sig. (1-tailed) .000
N 2011 2011
Zscore(ME) Pearson Correlation .518** 1 Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(FA) Zscore(WU) Zscore(FA) Pearson Correlation 1 .390**
Sig. (1-tailed) .000
N 2011 2011
Zscore(WU) Pearson Correlation .390** 1 Sig. (1-tailed) .000
N 2011 2011
Correlations
Zscore(FA) Zscore(ME) Zscore(FA) Pearson Correlation 1 .335**
Sig. (1-tailed) .000
N 2011 2011
Zscore(ME) Pearson Correlation .335** 1 Sig. (1-tailed) .000
N 2011 2011
**. Correlation is significant at the 0.01 level (1-tailed).
Correlations
Zscore(WU) Zscore(ME) Zscore(WU) Pearson Correlation 1 .456**
Sig. (1-tailed) .000
N 2011 2011
Zscore(ME) Pearson Correlation .456** 1 Sig. (1-tailed) .000
N 2011 2011
DAFTAR PUSTAKA
Anastasi, A. & Urbina, S. (2003). Psychological Testing. New Jersey : Prentice- Hall Inc.
Adolf. (2010, Nopember). Analisis Butir Soal dengan Iteman. (27 hal). On-line. Available Email: [email protected]
Azwar, S. (2007). Dasar-dasar psikometri (cetakan VI). Yogyakarta: Pustaka Pelajar.
---. (2004). Metode Penelitian. Yogyakarta : Pustaka pelajar.
---. (2007). Reliabilitas dan validitas. Yogyakarta: Pustaka Pelajar.
---. (2007). Sikap Manusia. Yogyakarta: Pustaka Pelajar.
---. (2005). Tes prestasi: Fungsi pengembangan dan pengukuran prestasi belajar. Yogyakarta: Pustaka Pelajar.
Crocker, L & Algina, J. (2005). Introduction to Classical and Modern Test Theory. Florida : Harcourt Brace Jovanovich College Publishers.
Bawono, Bernadetta A. (2008). Uji Aspek-aspek Psikometrik Subtes Merkaufgaben dari Batterai Intelligenz Structure Test. Skripsi. Jakarta: Unika Atmajaya
Gayatri, Ayu. (2008). Pengujian Validitas dan Reliabilitas Intelligenz Structure Test Subtes Wortauswahl (WA). Skripsi. Jakarta: Unika Atmajaya
Gregory, R.J. (2000). Psychological Testing : History, Principles and Applications. Boston: Allyn & Bacon
Guilford,J.P., B. Fruchter (1978), Fundamental Statistics In Psychology And Education, Tokyo: McGraw-HillKogakusha, Ltd.
Gunarsa, Singgih. (2000). Psikologi Praktis: Anak, Remaja dan Keluarga. BPK Jakarta: Gunung Mulia
Hamidah,. 2000. Uji Validitas dan Reliabilitas Item Tes IST (Intelligenz Strukture Tes). Surabaya: Perpustakaan Universitas Air Langga
Hayet, Brett.K, Evan Heit, & Haruka Swendsen. (2010). Inductive Reasoning. Advanced review: WIREs Cognitive Science
Heit, Evan. (2007). Models of Inductive Reasoning. Cambridge University Press.
Hirzithariqi (2009, November).Biro Psikologi di Indonesia. [On-line serial]. Available E-mail: hirzithariqi.wordpress.com.
Kaplan, R. M. & Saccuzzo, (2005). Psychological testing: Principles, application, and issues (6th ed.). Belmont: Thomson Wadsworth.
Kerlinger, F.N. & Lee.H.B. (2006). Foundation of behavioral Research (Edisi Terjemahan). New York: Hartcourt College Publisher.
Lababa, Junaidi. (2008). Analisis Butir Soal dengan Teori Tes Klasik: Sebuah Pengantar. Volume 5. Iqra’.
Murphy, Kevin R. & Davidshofer, Charles O. (2003). Psychological testing: Principles and application. New Jersey : Prentice-Hall Inc.
Nunnally, Jum C. (2005). Psychometric Theory (2nd ed.). New Delhi: Tata McGraw-Hill Publishing Company Limited.
Reed, Stephen K. (2004). Cognition : Theory and Application (Sixth Edition). United State of America: San Diego University
Stenberg, R.J. (1994). Encyclopedia of Human Intelligence (Jilid 1 & 2). New York: Macmillan
Suryabrata, S. (2005). Pengembangan Alat Ukur Psikologi. Yogyakarta: Andi.
BAB III
METODE PENELITIAN
A. Jenis Penelitian
Penelitian ini merupakan jenis penelitian non-eksperimental, yang artinya penelitian tidak menciptakan atau memanipulasi variabel-variabel tertentu. Menurut Kerlinger (2006), penelitian non-eksperimental adalah penelitian yang tidak melakukan kontrol dan manipulasi terhadap variabel-variabel bebas.
Sesuai dengan tujuan penelitian ini yakni untuk menganalisa karakteristik psikometri pada subtes WA, maka pendekatan yang digunakan adalah pendekatan kuantitatif, yang menekankan pengukuran dengan menggunakan teknik statistika (Kumar, 1996 ). Jika dilihat dari kedalaman analisanya, penelitian ini merupakan penelitian deskriptif, yaitu penelitian yang berusaha menganalisa dan menyajikan secara sistematik dan akurat mengenai fakta dan karakteristik mengenai populasi atau mengenai bidang tertentu (Azwar, 2004)
B. Data Penelitian
Berdasarkan data respon jawaban dari 2011 subjek diketahui 1273 orang berjenis kelamin laki-laki dan 699 orang berjenis kelamin perempuan serta 69 lembar lainnya tidak tercantum identitas jenis kelaminnya.
C. Metode Pengumpulan Data
Metode pengumpulan data pada penelitian ini adalah metode dokumentasi, dengan menggunakan data sekunder sebagai data penelitian. Data diperoleh dari hasil skor IST beberapa perusahaan yang didokumentasikan oleh Biro Fakultas Psikologi Universitas Sumatera Utara.
D. Persiapan dan Pelaksanaan Penelitian
1. Persiapan Izin Penelitian
a. Mengurus surat permohonan untuk melakukan penelitian di bagian administrasi pendidikan Fakultas Psikologi USU yang ditujukan kepada Ketua P3M Fakultas Psikologi USU.
b. Mengajukan surat permohonan izin penelitian kepada Ketua P3M Fakultas Psikologi USU..
2. Pelaksanaan Penelitian
notepad. Kemudian analisis indeks kesulitan aitem, indeks daya diskriminasi aitem, efektifitas distraktor dan reliabilitas tes akan dilakukan dengan menggunakan program Iteman versi 3.0. Untuk validitas subtes WA, digunakan program SPSS. Selain itu, SPSS juga digunakan untuk melihat indeks daya diskriminasi aitem. Dalam ha ini indeks daya diskriminasi aitem dilihat dengan dua metode, yaitu metode extreme group (menggunakan bantuan proogram SPSS) dan metode korelasi aitem-total (menggunakan bantuan Program Iteman)
E. Program Komputer yang Digunakan
Dalam mengolah data penelitian ini menggunakan alat bantu berupa software program computer, diantaranya:
1. Microsoft Excel diproduksi oleh Microsoft Corp yang diintegrasikan dalam paket Microsoft Office System 2007. Aplikasi ini digunakan untuk proses tabulasi skor subtes WA, yang kemudian akan dipindahkan ke lembar kerja Program Iteman dan program kerja SPSS untuk selnjutnya mempermudah proses analisa karakteristik psikometri yang akan dilakukan. Selain itu, program ini juga digunakan untuk menghitung indeks daya diskriminasi aitem dengan metode extreme-group.
2. SPSS (Statistical Programme for Social Science) versi 16.00.
Digunakan untuk analisa karakteristik psikometri khususnya validitas dan daya diskriminasi aitem pada subtes WA.
Program ini dikembangkan oleh Assesment System Corporation pada tahun 1982. Program ini digunakan untuk menganalisis karakteristik psikometri, mulai dari indeks kesulitan aitem (p), indeks daya diskriminasi aitem (d), efektivitas distraktor dan reliabilitas dari subtes WA.
F. Analisis Data
Penelitian ini menggunakan pendekatan teori skor murni klasik (CTT) dalam menganalisis karakteristik psikometri dari subtes WA. Proses analisis yang dilakukan adalah sebagai berikut:
1. Analisis indeks kesulitan aitem
Secara teoritik dikatakan bahwa p sebenarnya merupakan probabilitas empirik untuk lulus aitem tertentu bagi kelompok subjek tertentu. Analisis indeks kesulitan aitem dilakukan dengan menggunakan Formula 6.
p = ni / N Keterangan:
p = indeks kesulitan aitem
ni = banyaknya subjek yang menjawab aitem dengan benar N = banyaknya subjek yang menjawab aitem.
aitem-aitem dalam subtes WA harus rendah (aitem sulit). Menurut Allen & Yen (dalam Lababa, 2008), suatu aitem yang tergolong sulit adalah aitem yang memiliki nilai p < 0.30.
Proses analisis indeks kesulitan aitem subtes WA ini dilakukan dengan menggunakan bantuan Program Iteman. Data skor subjek yang sudah ditabulasi dengan excel dipindahkan ke dalam lembar kerja SPSS, kemudian disimpan dalam bentuk notepad untuk dianalisis dengan program iteman. Dalam lembar output iteman, indeks kesulitan masing-masing aitem ditunjukkan pada kolom prop. Correct.
2. Analisis indeks diskriminasi aitem
Indeks diskriminasi dilihat untuk mengetahui apakah alat tes mampu membedakan individu-individu yang memang benar-benar memiliki performansi yang baik dan yang tidak. Indeks diskriminasi bergerak dari angka -1 sampai dengan +1, namun yang memiliki arti hanya nilai d yang positif. Semakin harga d mendekati +1, maka semakin bagus aitem tersebut.
Menurut Ebel (dalam Crocker & Algina, 2005) pada Tabel 2, suatu aitem yang memiliki daya diskriminasi yang bagus apabila nilai d ≥ 0.40. Sementara nilai d yang berada pada kisaran 0.30 sampai 0.39 dianggap lumayan bagus dan tidak memerlukan revisi. Dalam penelitian ini, aitem yang baik adalah aitem yang memiliki d ≥ 0.30
perbedaan antara Kelompok Tinggi dan Kelompok Rendah. Proses ini dilakukan dengan bantuan program SPSS. Proses ini diawali dengan memisahkan 27% subjek yang mmemiliki skor tertinggi dan 27% subjek yang memiliki skor terendah.
Sedangkan dengan metode korelasi aitem-total diharapkan dapat melihat kesesuaian fungsi aitem dengan fungsi tes dalam mengungkap perbedaan individual. Proses ini dilakukan dengan menggunakan bantuan program iteman. Langkah yang dilakukan sama dengan analisis indeks kesulitan aitem. Dalam output iteman, indeks daya diskriminasi ditunjukkan pada kolom point Biser. 3. Analisis efektivitas distraktor pada setiap aitem
Efektivitas distraktor dilihat dengan bantuan program iteman dan ditetapkan berdasarkan dua kriteria, yaitu; (a) distraktor dipilih oleh siswa dari Kelompok Rendah, dan (b)pemilih distraktor tersebar relative proporsional pada masing-masing distrakktor yang ada (Azwar, 2007). Artinya, pilihan-pilihan jawaban yang digunakan sebagai penggecoh mayoritas akan dipilih subjek dari Kelompok Rendah dan relatif tersebar pada setiap pilihan.
4. Analisis Reliabilitas subtes WA
Teknik komputasi statistik yang digunakan dalam pendekatan konsistensi internal ini adalah formula Kuder-Richardson (KR’20). KR’20 dapat dikenakan pada data skor dikotomi dari tes yang seolah-olah dibagi-bagi menjadi belahan sebanyak aitemnya. Formula ini dapat digunakan jika aitem dikotomi, jumlah aitem sedikit dan membelahan tes sebanyak jumlah aitem. Formula KR’20 terdapat pada formula 14.
5. Analisis Validitas Konstruk Subtes WA
Validitas konstrak subtes WA dilihat dengan menggunakan matriks validasi berdasarkan pendekatan multitrait-multimethode dimana skor subjek pada subtes WA dikorelasikan dengan masing-masing skor subjek pada 8 subtes IST lainnya, yaitu: Satzergaenzung (SE), Analogien (AN), Gemeinsamkeiten (GE), Rechenaufgaben (RA), Zahlenreinhen (ZR), Figurenauswahl (FA), Wuerfelaufgaben (WU) dan Merkaufgaben (ME).
BAB IV
HASIL DAN PEMBAHASAN
Pada bab 4 ini, akan disajikan hasil analisis karakteristik psikometri subtes WA. Analisis ini didasarkan pada pendekatan CTT dan dalam prosesnya dibantu dengan Program Iteman Version 3,00 MicroCAT (tm) Testing dan Program SPSS versi 16. Selanjutnya hasil yang diperoleh akan dibahas sesuai dengan teori-teori yang sudah dipaparkan pada bab 2.
A. Deskripsi Hasil
1. Analisis Indeks Kesulitan Aitem
Indeks kesulitan aitem menunjukkan proporsi subjek yang menjawab dengan benar pada masing-masing aitem dalam subtes WA. Apabila proporsi subjek yang menjawab benar pada suatu aitem besar, berarti aitem tersebut relatif mudah dan demikian pula sebaliknya.
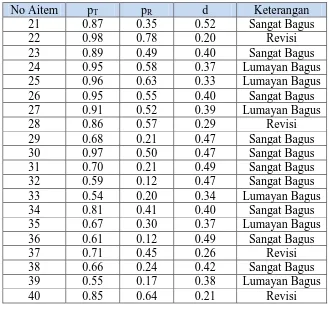
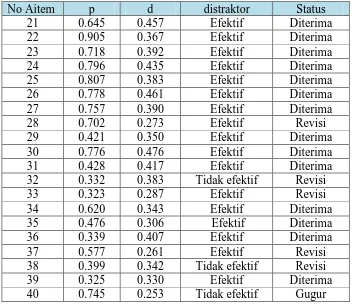
Tabel 3 Indeks kesulitan aitem subtes WA
Keterangan :
p = Indeks Kesukaran Aitem TS = Tidak Sesuai
S = Sesuai
Hasil analisis indeks kesulitan aitem pada Tabel 3 menunjukkan bahwa 11 aitem memiliki tingkat kesulitan kategori sedang dan 9 aitem memiliki tingkat kesulitan kategori mudah, sedangkan kategori sulit tidak ada. Artinya semua aitem dalam subtes WA tidak ada yang sesuai dengan tujuan IST disusun yaitu untuk tujuan seleksi yang diharapkan aitem-aitem dalam subtes WA berkategori Sulit yaitu memiliki nilai p kecil dari 0,3. Secara ringkas hasil analisis aitem berdasarkan nilai p disajikan ada Tabel 4.
Tabel 4 Analisis aitem berdasarkan nila p
2. Analisis Indeks Daya Diskriminasi Aitem
Indeks daya diskriminasi dalam penelitian ini dilihat dengan dua cara yaitu dengan metode extreme group dan metode korelasi aitem-total. Metode extreme group bertujuan untuk melihat discriminating power aitem dalam membedakan
individu-individu yang memiliki trait yang diukur dan yang tidak memiliki. Metode ini dilakukan dengan melibatkan 543 subjek Kelompok Tinggi (27% skor tertinggi dari 2011 subjek) dan 543 subjek Kelompok Rendah (27% skor terendah dari 2011 subjek). Selanjutnya indeks diskriminasi diperoleh dari selisih indeks kesulitan aitem pada subjek Kelompok Tinggi dengan indeks kesulitan aitem pada subjek Kelompok rendah. Sementara nilai indeks kesulitan aitem masing-masing kelompok merupakan nilai rata-rata (mean) pada masing-masing kelompok yang diperoleh dengan bantuan SPSS.
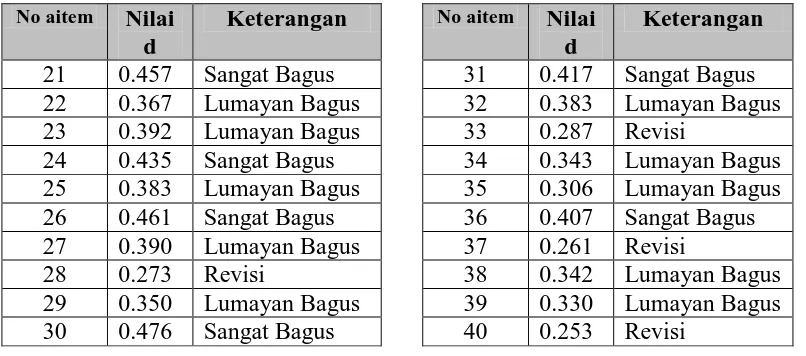
Tabel 5 Indeks Daya Diskriminasi Aitem Subtes WA dengan
pT : Indeks kesulitan pada Kelompok Tinggi
pR : Indeks kesulitan pada Kelompok Rendah
d : Indeks diskriminasi Aitem
Metode kedua yang digunakan untuk melihat daya diskriminasi aitem adalah dengan metode korelasi aitem-total dengan menggunakan bantuan program Iteman Version 3,00 MicroCAT (tm) Testing. Metode korelasi aitem total ini bertujuan untuk melihat kesesuaian fungsi aitem dengan fungsi skala / tes dalam mengungkap perbedaan individu. Korelasi yang semakin tinggi mendekati angka 1 menunjukkan bahwa aitem tersebut mengukur hal yang sama dengan apa yang diukur oleh alat tes. Hasilnya dapat dilihat pada Tabel 6.
Tabel 6 Hasil Analisis Indeks Daya Diskriminasi Aitem Subtes WA dengan
bantuan program Iteman.
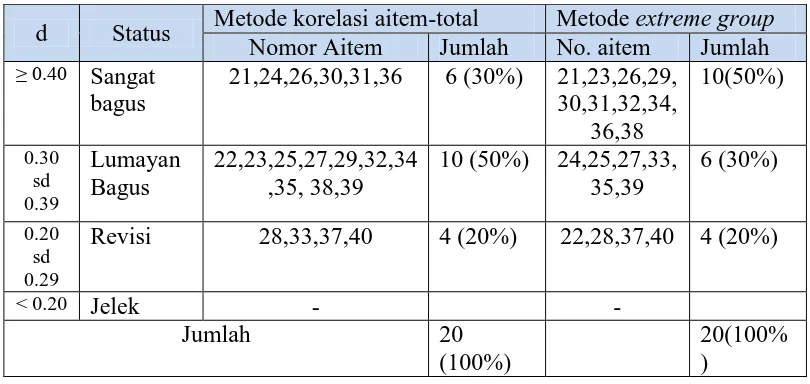
Tabel 7 Analisis aitem berdasarkan nilai d
d Status Metode korelasi aitem-total Metode extreme group Nomor Aitem Jumlah No. aitem Jumlah
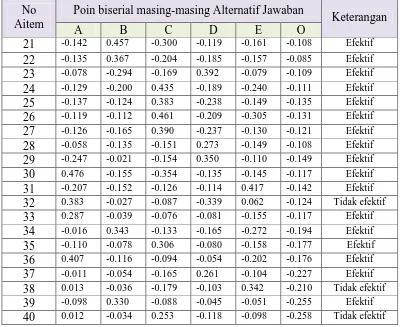
Tabel 8 Efektivitas Distraktor Subtes WA
Hasil analisis efektivitas distraktor pada Tabel 9 menunjukkan bahwa 17 aitem dari 20 aitem memiliki distraktor yang efektif dan 3 lainnya memiliki distraktor yang tidak efektif.
4. Seleksi Aitem Berdasarkan Indeks Kesulitan Aitem, Indeks Daya Diskriminasi Aitem dan Efektivitas Distraktor
diskriminasi dan efektivitas distraktornya. Indeks kesulitan aitem tidak dijadikan patokan karena indeks kesulitan aitem tidak menunjukkan buruk tidaknya suatu aitem. Hasil analisisnya disajikan dalam Tabel 10.
Tabel 9 Seleksi Aitem Subtes WA Berdasarkan Indeks Kesulitan
Aitem, Indeks Daya Diskriminasi Aitem dan Efektivitas Distraktor
No Aitem p d distraktor Status d ≥ 0.30 dan distraktor tidak efektif gugur jika: : d < 0.2 V 0.20 ≤ d < 0.30
5. Analisis Indeks Reliabilitas
Analisis indeks reliabilitas subtes WA dilakukan dengan pendekatan konsistensi internal dengan formula estimasi koefisien reliabilitas KR-20. Formula ini dipilih dengan alasan bahwa indeks kesulitan subtes WA relative bervariasi.
Proses analisis ini dilakukan dengan bantuan program iteman yang relatif sama dengan proses analisis indeks diskriminasi aitem dan indeks kesukaran aitem subtes WA. Indeks reliabilitas subtes WA dengan menggunakan program iteman adalah sebesar α = 0.650
6. Analisis Validitas Konstrak Subtes WA.
Untuk melihat validitas konstrak subtes WA ini, digunakan pendekatan multitrait-multimethod, dimana pendekatan ini akan menguji serentak dua atau lebih trait yang diukur melalui dua atau lebih metode. Pendekatan ini digunakan karena sembilan subtes IST merupakan subtes yang independen dan dapat berdiri sendiri. Melalui pendekatan multitrait-multimethod ini akan dilihat validitas konnvergen dan diskriminan, dimana validitas konvergen ditunjukkan adanya korelasi yang tinggi antara subtes-subtes yang mengukur trait yang sama, dan validitas diskriminan ditunjukkan adanya korelasi yang rendah antara subtes-subtes yang mengukur trait yang berbeda (Azwar, 2007).
menunjukan adanya suatu interkorelasi yang rendah antar subtesnya (r=0.25). (Diktat kuliah IST Universitas Padjajaran, 2008). Artinya bahwa masing-masing subtes dalam IST ini tidak boleh memiliki korelasi yang tinggi satu sama lain atau dengan kata lain tidak boleh saling konvergen antara satu subtes dengan subtes yang lainnya.
Dalam prosedurnya skor subjek pada subtes WA dikorelasikan dengan skor subjek pada delapan subtes IST lainnya, yakni: Satzergaenzung (SE), Analogien (AN), Gemeinsamkeiten (GE), Rechenaufgaben (RA), Zahlenreinhen (ZR), Figurenauswahl (FA), Wuerfelaufgaben (WU) dan Merkaufgaben (ME). Sebelum skor subjek pada subtes WA dikorelasikan dengan skor subjek pada delapan subtes lainnya, terlebih dahulu skor subjek pada semua subtes ditransformasikan ke dalam Z-score (bilangan baku). Hal ini bertujuan untuk menyetarakan metrik, dimana memang salah satu subtes yaitu GE yang diberi skor 0,1 dan 2 memiliki jarak metrik yang berbeda dengan 8 subtes lainnya yang diberi skor 0 dan 1. Untuk nilai Z-score masing-masing subtes dapat dilihat pada Lampiran III.
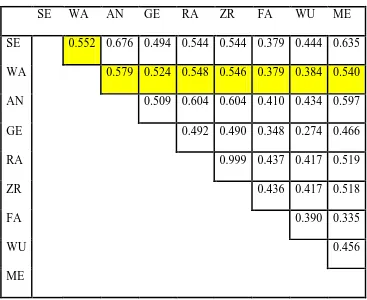
Tabel 10 Matriks validasi multitrait-multimethod subtes pada IST
SE WA AN GE RA ZR FA WU ME
SE 0.552 0.676 0.494 0.544 0.544 0.379 0.444 0.635 WA 0.579 0.524 0.548 0.546 0.379 0.384 0.540
AN 0.509 0.604 0.604 0.410 0.434 0.597
GE 0.492 0.490 0.348 0.274 0.466
RA 0.999 0.437 0.417 0.519
ZR 0.436 0.417 0.518
FA 0.390 0.335
WU 0.456
ME
B. Pembahasan
Berdasarkan deskripsi hasil penelitian di atas, maka akan dibahas tentang karakteristik psikometri Subtes WA pada IST.
1. Analisis Indeks Kesulitan Aitem Subtes WA
Berdasarkan hasil analisis indeks kesulitan aitem pada Tabel 4 diketahui bahwa variasi kesulitan masing-masing aitem pada subtes WA tersebut berada pada kategori mudah dan sedang. Sesuai dengan hasil analisis indeks kesulitan aitem subtes WA, terdapat 11 aitem (55%) dengan kesulitan sedang (0.30<p<0.7) yaitu aitem 21, 29, 31, 32, 33, 34, 35, 36, 37, 38, 39; dan sembilan aitem (45%) dengan kesulitan mudah (p>0.70) yaitu aitem 22, 23, 24, 25, 26, 27, 28, 30, 40.
Harga p yang berada pada titik ekstrem (terlalu sulit atau terlalu mudah) akan mempunyai daya diskriminasi yang kurang baik. Oleh karena itu, umumnya pada penyusunan instrumen tes disarankan untuk menggunakan aitem dengan taraf kesulitan sedang (0,50). Namun Lord (dalam Murphy & Davidshofer, 2003) menyatakan bahwa untuk tes seleksi karyawan, p akan dikatakan baik jika nilai p di bawah 0.30 (aitem sulit).
IST pada khususnya subtes WA merupakan tes inteligensi. Suatu tes inteligensi yang baik seharusnya memiliki variasi tingkat kesulitan aitem mulai dari tingkat kesulitan tinggi, sedang dan rendah (Murphy& Davidshofer, 2003). Pada Tabel 5, terlihat bahwa tidak ada satu pun aitem yang memiliki indeks kesulitan kategori tinggi. Hal ini menunjukkan bahwa subtes WA ini sudah tidak bagus digunakan sebagai salah satu tes inteligensi.
2. Analisis Indeks Daya Diskriminasi Aitem Subtes WA
Berdasarkan hasil analisis indeks daya diskriminasi dengan metode extreme group pada Tabel 5 menunjukkan bahwa 10 aitem memiliki daya diskriminasi sangat bagus yaitu memiliki indeks daya diskriminasi d ≥ 0.40, 6
aitem memiliki daya diskriminasi Lumayan Bagus, yaitu memiliki indeks daya diskriminasi 0,30 – 0,39 dan 4 aitem membutuhkan revisi yaitu aitem yang memiliki nilai indeks daya diskriminasi d < 0,20. Hal ini berarti bahwa 10 aitem mampu membedakan antara Kelompok Tinggi dan Kelompok Rendah dengan sangat bagus, 6 lainnya lumayan bagus, tapi masih perlu peningkatan, sedangkan 4 aitem lainnya masih harus direvisi.
Berdasarkan hasil analisis indeks diskriminasi aitem dengan metode korelasi aitem-total pada Tabel 6 diketahui bahwa terdapat 6 aitem yang dinilai sangat bagus. Masing-masing aitem ini memiliki nilai indeks diskriminasi aitem di atas 0,4. Angka ini mengindikasikan bahwa aitem-aitem ini memiliki kualitas sangat baik dan memiliki kesesuaian fungsi dengan subtes dalam membedakan individu yang memiliki level kompetensi yang diharapkan dan individu yang tidak memilikinya. Dengan kata lain aitem-aitem ini memiliki fungsi yang sama dengan fungsi tes.
Jika dilihat secara keseluruhan, baik dengan mengguunakan metode extreme group maupun dengan metode korelasi aitem-total, dapat dikatakan
bahwa ada 16 butir aitem yang memiliki kualitas baik dan bisa diterima. Sementara itu, ada 4 aitem yang sebenarnya memiliki kualitas buruk. Aitem-aitem ini memiliki nilai indeks diskriminasi relatif rendah, yaitu di bawah 0,3. Hal ini mengindikasikan bahwa aitem-aitem ini tidak mampu menangkap perbedaan antara individu yang memiliki kompetensi yang diharapkan dan individu yang tidak memilikinya. Ke empat aitem tersebut masih mungkin untuk diterima asalkan aitem tersebut direvisi sesuai dengan batasan ukur aitem tersebut.
3. Analisis Efektivitas Distraktor Subtes WA
Efektivits distraktor-distraktor pada suatu aitem dianalisis dari distribusi jawaban terhadap aitem yang bersangkutan pada setiap alternatif yang disediakan. Efektivitas distraktor dilihat dari dua kriteria, yaitu: (a) distraktor dipilih oleh siswa dari Kelompok Rendah, dan (b) pemilih distraktor tersebar relative proporsional pada masing-masing distrakktor yang ada (Azwar, 2005)
Dengan menggunakan bantuan program iteman, efektivitas distraktor dilihat dari nilai point biserial, dimana sebuah aitem dikatakan memiliki distraktor yang efektif apabila alternatif yang menjadi kunci jawaban dipilih lebih banyak dari subjek Kelompok Tinggi (rpbis positif), serta alternative pengecoh lainnya dipilih lebih banyak dari Kelompok Rendah (rpbis negatif).
Ketiga aitem tersebut adalah aitem nomor 32, 38 dan 40. Pada aitem 32, distraktor E dipilih lebih banyak subjek Kelompok Tinggi (rpbis positif), padahal seharusnya sebuah distraktor lebih banyak dipilih subjek dari Kelompok Rendah. Pada aitem 38 dan 40, distraktor A tidak efektif, dimana distraktor ini juga lebih banyak dipilih dari Kelompok Tinggi.
4. Seleksi Aitem Berdasarkan Indeks Kesulitan Aitem, Indeks Daya Diskriminasi Aitem dan Efektivitas Distraktor
Proses analisis ini mencoba melihat aitem-aitem yang baik yaitu aitem yang memiliki parameter indeks daya diskriminasi yang bagus dan distraktor yang efektif. Indeks kesulitan aitem tidak dijadikan sebagai patokan karena taraf kesulitan aitem yang bervariasi memang dibutuhkan ada pada suatu tes inteligensi.
Berdasarkan hasil analisis seleksi yang dilakukan sesuai dengan ketentuan sebagai berikut:
a. Diterima jika: d ≥ 0.30 (Cukup bagus dan bagus sekali) semua distraktor efektif
b. Revisi jika: 0.20 ≤ d < 0.30 dan distraktor efektif d ≥ 0.30 dan distraktor tidak efektif c. gugur jika: : d < 0.2 V 0.20 ≤ d < 0.30
distraktor tidak efektif,
5. Indeks Reliabilitas Subtes WA
Berdasarkan hasil analisis diketahui bahwa nilai koefisien reliabilitas instrument subtes WA pada IST sebesar α = 0.650. Hal ini berarti variasi yang tampak pada skor tes dengan menggunakan instrument tersebut hanya mampu mencerminkan 65% dari variasi yang terjadi pada skor murni subjek yang bersangkutan. Dengan kata lain, 35% variasi skor yang tampak disebabkan oleh eror atau kesalahan.
Menurut Anastasi & Urbina (1997), suatu pengukuran dapat dikatakan reliabel apabila memiliki rentang nilai koefisien reliabilitas antara 0.80-0.90. sedangkan menurut Nunnally (2005), pengukuran dapat dikatakan reliabel jika memiliki koefisien reliabilitas diatas 0.70. Murphy & Davidshofer (2003) mengelompokkan nilai koefisien reliabilitas ke dalam beberapa kelompok nilai, yaitu nilai yang tidak dapat diterima (≤ 0.60), nilai yang rendah (0.61-0.70), nilai moderat (0.71-0.89) dan nilai yang tinggi (≥ 0.90).
Berdasarkan penjelasan tersebut, maka indeks reliabilitas subtes WA yang memiliki nilai sebesar α = 0.650, masih tergolong nilai yang rendah dan belum memuaskan.
6. Analisis Validitas Konstrak Subtes WA
ketika mengkonstraknya. Amthauer menyusun IST sebagai baterai tes yang terdiri dari 9 sub tes. Karakteristik dari baterai tes amthauer menunjukan adanya suatu interkorelasi yang rendah antar subtesnya (r=0.25) (Diktat kuliah IST Universitas Padjajaran, 2008).
Hasil korelasi antara subtes WA dengan kedelapan subtes IST lainnya yang jauh lebih besar dari apa yang seharusnya (0.25) menunjukkan bahwa adanya tumpang tindih mengenai trai-trait yang diukur oleh subtes WA dengan subtes lainnya. Artinya apa yang diukur oleh WA dapat juga terukur oleh subtes lainnya. Selain itu juga, hal ini kemungkinan diakibatkan adanya prroses pembelajaran pada subjek mengenai subtes-subtes yang terdapat dalam IST, mengingat banyaknya alat tes yang mirip dengan IST dijual di pasaran. Sehingga ketika IST ini diujikan pada subjek, maka yang terukur bukan lagi trait yang diharapkan, karena respon subjek merupakan hasil dari persiapan dan pembelajaran yang dilakukan oleh subjek sebelum mengikuti tes.
Demikian juga nilai korelasi antara WA dengan SE, AN, GE dan ME yang cukup signifikan. Hal ini mengindikasikan bahwa konstrak yang diukur dalam subtes WA terukur juga oleh subtes SE, AN, GE dan ME. Subtes-subtes ini juga sama-sama membutuhkan pemahaman bahasa untuk membuat keputusan dalam penyelesaian soal.
Selanjutnya subtes WA berkorelasi dengan FA sebesar 0.379 dan WA berkorelasi dengan WU sebesar 0.384. Menurut Guilford (1978), nilai yang berada diantara 0.20 sampai dengan 0.40 tergolong rendah. Meskipun nilai ini masih lebih besar dari nilai interkorelasi yang ditentukan oleh Amtheuer, namun korelasi yang terjadi tergolong rendah. Artinya memang subtes WA mengukur konstrak yang berbeda dengan WU dan FA, dimana WU mengukur daya bayang ruang dan FA mengukur daya konstraksi.
BAB V
KESIMPULAN DAN SARAN
A. Kesimpulan
Berdasarkan hasil penelitian tentang karakteristik psikometri subtes WA pada IST, maka dapat ditarik beberapa kesimpulan sebagai berikut:
1. Secara umum, indeks kesulitan aitem subtes WA masih belum memuaskan. Mengingat bahwa subtes WA pada IST merupakan alat tes inteligensi maka diharapkan aitem-aitemnya harus memiliki indeks kesulitan yang bervariasi dari mudah, sedang sampai dengan sulit. Berdasarkan hasil analisis, tidak ada satupun aitem yang memiliki taraf kesulitan yang tinggi.
2. Berdasarkan hasil analisis indeks daya diskriminasi aitem subtes WA, aitem-aitem yang memiliki kualitas yang baik serta mampu menangkap perbedaan individu yang memiliki tingkat kompetensi baik dan tidak baik berjumlah 16 aitem. Ke 16 aitem ini memiliki indeks daya diskriminasi sangat bagus dan lumayan bagus, sehingga tidak membutuhkan revisi.
3. Berdasarkan hasil analisis efektifitas distraktor pada aitem subtes WA, 17 dari 20 aitem memiliki distraktor yang efektif, dalam arti distraktor tersebut berfungsi sebagaimana mestinya.
4. Secara keseluruhan dari hasil analisis gabungan karakteristik psikometri yang dilakukan terhadap subtes WA menunjukkan bahwa 14 aitem dapat diterima, 5 aitem membutuhkan revisi dan 1 sisanya dianggap gugur.
5. Instrumen subtes WA pada IST yang mengukur kemampuan berpikir induktif
6. Berdasarkan analisis validitas konstrak Subtes WA pada IST diketahui bahwa subtes ini sudah tidak valid.
B. Saran
Berdasarkan hasil penelitian tentang karakteristik psikometri subtes WA pada IST, maka disarankan beberapa hal yang berkaitan dengan penggunaan subtes WA pada masa yang akan datang, sebagai berikut:
1. Jika dilihat dari hasil analisis aitem subtes WA, maka diharapkan adanya perbaikan terhadap beberapa aitem dengan memperhatikan tingkat kesulitan, indeks daya diskriminasi serta distraktor yang digunakan.
2. Untuk peneliti selanjutnya, disarankan untuk mengkorelasikan dengan alat tes lain diluar IST, misalnya dengan TIKI atau CFIT, supaya hasil yang diperoleh lebih kaya dan mendalam khususnya mengenai validitas diskriminan.
3. Selain itu, peneliti selanjutnya juga diharapkan untuk meneliti secara kualitatif, karena dalam penelitian ini, peneliti masih terfokus secara kuantitatif.
4. Untuk para tenaga akademisi, khususnya bidang psikometri Fakultas Psikologi Universitas Sumatera Utara, supaya mempertimbangkan melakukan revisi dan adaptasi terhadap IST supaya menjadi alat tes yang valid dan reliabel di lingkungan Fakultas Psikologi.
6. Selain itu, P3M juga diharapkan agar hati-hati saat memeriksa setiap lembar jawaban peserta tes, karena selama dalam proses penelitian ini juga dijumpai beberapa lembar jawaban yang salah koreksi. Tentu hal ini dapat merugikan peserta tes.
BAB II
TINJAUAN PUSTAKA
Menurut Azwar (2007) bahwa teori pengukuran dapat dibahas dari tiga macam pendekatan secara umum, yaitu (a) pendekatan teori skor murni klasikal (classical score theory), (b) pendekatan teori skor murni kuat (strong true-score theory) dan (c) pendekatan latent-trait theory.
Teori murni kuat mempunyai pandangan yang mirip dengan teori skor-murni klasikal mengenai nilai harapan skor tampak yang merupakan skor skor-murni, akan tetapi dalam teori skor murni kuat terdapat asumsi-asumsi tambahan mengenai probabilitas skor-tampak yang akan diperoleh seorang subjek yang merupakan skor-murni tertentu sehingga dengan asumsi-asumsi tersebut kelayakan teori skor-murni kuat bagi data tertentu, dapat diuji.
Sedangkan latent-trait theory berasumsi bahwa aspek performansi terpenting pada suatu tes dapat ditunjukkan oleh kedudukan seorang subjek pada suatu latent-trait yang berupa karakteristik psikologis yang tidak tampak. Berbeda dengan teori skor murni kuat, walaupun asumsi bahwa nilai harapan skor tampak pada teori latent-trait juga merupakan skor murni, pada umumnya tidak terdapat hubungan linear antara skor-murni dengan latent-trait sehingga nilai harapan skor tampak tidak sama dengan nilai latent-trait.
eror standar yang bervariasi sesuai dengan level skor murni atau latent-traitnya. Menurut kedua teori tersebut, eror standar tidak terpengaruh oleh distribusi skor subjek.
Penelitian ini akan menggunakan pendekatan pendekatan teori skor murni klasikal dalam proses analisis yang dilakukan, denga pertimbangan bahwa teori ini lebih praktis dalam menerangkan masalah reliabilitas dan validitas. Selain itu juga pemahamannya yang tidak menuntut pengetahuan yang terlalu dalam mengenai beberapa fungsi distribusi statistik dan model-model matematiknya.
E. Classical True-score Theory
1. Pengertian Classical True-score Theory
Classical True-score Theory (selanjutnya disebut dengan CTT) merupakan pendekatan yang telah berhasil meletakkan dasar-dasar konsepsi reliabilitas pada dekade-dekade yang telah lalu dan memiliki kontribusi yang sangat besar dalam pengembangan formula-formula reliabilitas. Pendekatan ini juga memiliki nilai praktis yang tinggi dalam menerangkan masalah validitas dan reliabilitas (Azwar, 2004)
2. Asumsi-asumsi dalam Classical True-score Theory
Sebelum membahas asumsi-asumsi dalam CTT, perlu diketahui bahwa asumsi-asumsi tersebut merupakan hubungan matematis dari skor tampak (X), skor murni (T), dan eror pengukuran (E). Skor tampak merupakan angka yang
menunjukkan nilai performansi subjek pada suatu pengukuran, yang tidak lain
merupakan nilai total dari jawaban subjek dalam tes tersebut. Skor murni dijelaskan
sebagai angka performansi.
Adapun sumsi-asumsi dalam CTT (dalam Azwar, 2007) adalah sebagai berikut:
Asumsi 1 :
X = T + E (1)
Asumsi ini menjelaskan bahwa sifat aditif berlaku pada hubungan antara skor tampak, skor muni, dan eror. Skor tampak (X) merupakan jumlah skor murni (T) dan eror (E)
Asumsi 2:
ε(X) = T (2)
Asumsi ini menyatakan bahwa skor murni merupakan nilai harapan dari skor tampaknya. Jadi, T merupakan harga rata-rata distribusi teoretik skor tampak apabila orang yang sama dikenai tes yang sama berulangkali dengan asumsi pengulangan tes itu dilakukan tidak terbatas banyaknya dan setiap pengulangan tes adalah independen satu sama lain.
Asumsi 3:
Asumsi ini menyatakan bahwa bagi populasi subjek yang dikenai tes, distribusi eror pengukuran dan distribusi skor murni tidak berkorelasi. Implikasinya, skor murni yang tinggi tidak selalu berarti mengandung eror yang selalu positif ataupun selalu negatif (Azwar, 2007).
Asumsi 4:
= 0 (4)
Asumsi ini menyatakan bahwa dalam eror pada dua tes ( yang dimaksud untuk mengukur hal yang sama) tidak saling berkorelasi. Asumsi ini akan tidak terpenuhi sekiranya skor tampak dipengaruhi kondisi testing, seperti misalnya kelelahan, Practice effect, suasana hati, atau factor-faktor dari lingkungan (Suryabrata, 2005).
Asumsi 5 :
= 0 (5)
Jika ada dua tes yang dimaksudkan untuk mengukur atribut yang sama, maka eror pada tes pertama tidak berkorelasi dengan skor-skor murni pada tes kedua.
Asumsi 6
Jika ada dua tes yang dimaksudkan untuk mengukur atribut yang sama membunyai skot tampak X dan X’ yang memenuhi asumsi 1 sampai 5, dan jika
untuk setiap populasi subjek T = T’ serta varians eror kedua tes tersebut sama,
Asumsi 7
Jika ada dua tes yang dimaksudkan untuk mengukur atribut yang sama membunyai skot tampak X dan X’ yang memenuhi asumsi 1 sampai 5, dan jika
untuk setiap populasi subjek T1 = T2 + C. Dengan C sebagai suatu bilangan konstan, maka kedua tes tersebut dapat disebut sebagai tes yang setara (equivalent test).
B. Analisis Karakteristik Psikometri
Sebuah instrument tes merupakan sekumpulan aitem yang disusun sedemikian rupa, baik berupa pertanyaan maupun pernyataan mengenai suatu hal yang hendak diukur (Azwar, 2007). Proses analisis terhadap karakteristik psikometri dari suatu instrument tes ditujukan untuk memilih aitem-aitem yang layak dan mengetahui kelayakan instrument tersebut. Jadi proses analisis dapat dilakukan untuk merancang sebuah instrumen tes yang baru atau menguji instrument yang sudah ada. Proses analisis tersebut secara sederhana meliputi dua cara, yaitu:
Tahap kedua adalah prosedur seleksi aitem berdasarkan data empiris dengan melakukan analisis kuantitatif terhadap parameter-parameter aitem. Parameter-parameter yang dimaksud meliputi indeks diskriminasi aitem dan indeks kesulitan aitem, analisis efektivitas distraktor, analisis reliabilitas, serta analisis validitas dari instrumen tersebut (Crocker & Algina, 2005).
1. Indeks Kesulitan Aitem
a. Pengertian Indeks Kesulitan Aitem
Indeks kesulitan aitem yang biasanya disimbolkan dengan huruf p merupakan rasio antara penjawab aitem dengan benar dan banyaknya penjawab aitem. Secara teoritik dikatakan bahwa p sebenarnya merupakan probabilitas empirik untuk lulus aitem tertentu bagi kelompok subjek tertentu. Secara matematis diformulaikan sebagai berikut:
p = ni / N (6)
Keterangan:
p = indeks kesulitan aitem
ni = banyaknya subjek yang menjawab aitem dengan benar
N = banyaknya subjek yang menjawab aitem
aitem-aitem dalam tes secara sistematis, dengan menempatkan aitem-aitem-aitem-aitem berdasarkan tingkat kesukarannya, mulai dari aitem yang paling mudah hingga yang paling sulit. Sehingga pola penyusunan aitem-aitem dalam tes dimulai dari aitem dengan harga p yang paling tinggi hingga aitem dengan harga p yang paling rendah. b. Analisis Indeks Kesulitan Aitem
Nilai p yang semakin tinggi menunjukkan bahwa aitem yang bersangkutan semakin mudah. Nilai p berkisar dari 0 sampai dengan angka 1. Apabila sebuah aitem sedemikian sukarnya, sehingga tidak seorang subjek pun dapat menjawab dengan benar, maka harga p = 0, sedangkan apabila suatu aitem sedemikian mudahnya sehingga seluruh subjek dapat menjawab dengan benar, maka harga p = 1. Aitem yang terlalu mudah atau terlalu sulit biasanya tidak akan banyak berguna dalam membedakan subjek yang menguasai bahan pelajaran dan mereka yang tidak (Azwar, 2007).
Pada umumnya harga p yang berada disekitar 0,50 dianggap yang terbaik. Menurut Azwar (2007), harga p terbaik adalah yang sesuai yang sesuai dengan tujuan tes yang bersangkutan. Misalnya kadang-kadang dikehendaki harga p < 0,50 (aitemnya lebih sulit) apabila aitem aitem itu dimaksudkan sebagai bagian dari suatu tes yang digunakan dalam prosedur seleksi guna memilih sebagian kecil saja dari antara pelamar. Tidak jarang pula sebuah tes prestasi perlu disusun dengan memasukkan banyak aitem yang taraf kesulitannya rendah (p tinggi) dengan tujuan untuk evaluasi formatif.
Oleh karena itu, umumnya pada penyusunan instrumen tes disarankan untuk menggunakan aitem dengan taraf kesulitan sedang (0,50). Namun Lord (dalam Murphy & Davidshofer, 2003) menyatakan bahwa untuk tes seleksi karyawan, p akan dikatakan baik jika nilai p mendekati 0,2.
Allen & Yen (dalam Lababa, 2008) mengkategorikan nilai p sebagai berikut:
Tabel 1 Kategori Tingkat Kesulitan aitem
No P Kategori
1 p<0,3 Sulit
2 0,3 p 0,7 Sedang
3 p>0,7 Mudah
Ada beberapa hal yang perlu dipahami mengenai indeks kesulitan aitem ini, diantaranya pertama adalah bahwa harga p dari suatu aitem menunjukkan taraf kesulitan aitem tersebut bagi kelompok yang bersangkutan, yaitu kelompok yang menjadi dasar dalam menghitung p itu sendiri (Azwar, 2005). Artinya harga p suatu aitem akan berbeda apabila dihitung pada kelompok siswa yang berbeda. Kedua bahwa besarnya harga p yang kita hitung merupakan indek kesulitan aitem
bagi seluruh kelompok yang bersangkutan, bukan indeks kesulitan bagi masing-masing individu dalam kelompok. Artinya harga p yang dihitung dalam kelompok hanya merupakan rata-rata indeks kesulitan bagi seluruh individu dalam kelompok tersebut.
2. Indeks Daya Diskriminasi Aitem
a. Pengertian Indeks Diskriminasi Aitem.
Indeks daya diskriminasi aitem atau sering disebut dengan daya beda aitem merupakan parameter yang paling penting dalam tes psikologi yang menunjukkan sejauh mana aitem mampu membedakan antara individu atau kelompok individu yang memiliki dan yang tidak memiliki atribut yang diukur (Azwar, 2005). Artinya bahwa aitem yang memiliki daya beda yang tinggi harus memiliki skor yang tinggi pada individu yang memiliki atribut yang diukur dan skor yang rendah pada individu yang tidak memiliki atribut yang diukur.
Indeks diskriminasi aitem (d) secara sederhana didefinisikan sebagai perbedaan proporsi penjawab aitem dengan benar antara Kelompok Tinggi dengan Kelompok Rendah.
Secara matematis diformulasikan sebagai berikut:
(7) Keterangan:
d : Indeks diskriminasi Aitem
niT : jumlah subjek penjawab dengan benar dari Kelompok Tinggi nT : Jumlah subjek Kelompok Tinggi
niR : jumlah subjek penjawab dengan benar dari Kelompok Rendah
nR : Jumlah subjek Kelompok Rendah
-
(8)
Keterangan :
= Indeks kesulitan pada Kelompok Tinggi = Indeks kesulitan pada Kelompok Rendah
Dalam skala sikap, sebuah aitem dikatakan memiliki daya beda tinggi jika aitem tersebut mampu membedakan antara subjek yang bersikap positif dan subjek yang bersifat negatif. Sedangkan untuk sebuah tes inteligensi, sebuah aitem dikatakan memiliki daya beda tinggi jika aitem tersebut mampu membedakan subjek yang memiliki kemampuan tinggi (Kelompok Tinggi) dan subjek yang memiliki kemampuan rendah (Kelompok Rendah). Artinya suatu aitem tersebut haruslah dijawab dengan benar oleh semua atau sebagian besar subjek Kelompok Tinggi dan tidak dapat dijawab dengan benar oleh semua atau sebagian besar subjek Kelompok Rendah (Azwar, 2007).
b. Analisis Indeks Diskriminasi Aitem
Menurut Murphy dan Davidshofer (2003), jika suatu tes dan satu aitem mengukur hal yang sama, maka diharapkan bahwa orang yang mengerjakan tes dengan baik akan menjawab aitem tersebut dengan benar, dan orang yang mengerjakan tes dengan buruk menjawab aitem tersebut dengan salah. Dengan kata lain, aitem yang memiliki daya diskriminasi yang baik mampu membedakan antara orang yang mengerjakan tes dengan baik dan orang yang mengerjakan tes dengan buruk.
Daya diskriminasi maksimal tercapai apabila seuruh subjek Kelompok Tinggi dapat menjawab dengan benar ( ), sedangkan seluruh subjek Kelompok Rendah tidak seorang pun yang dapat menjawab dengan benar ( ). Dalam hal ini, harga indeks diskriminasi d = 1-0=1.
Harga d yang berada disekitar 0 menunjukkan bahwa aitem yang bersangkutan memiliki daya diskriminasi yang rendah, sedangkan harga d yang negative menunjukkan bahwa aitem yang bersanngkutan tidak ada gunanya sama sekali, bahkan memberikan informasi yang menyesatkan.
Indeks diskriminasi yang ideal yang ideal adalah yang sebesar mungkin mendekati angka 1. Semakin besar indeks kemsukaran aitem (semakin mendekati angka 1) berarti aitem tersebut semakin mampu membedakan antara subjek yang menguasai bahan yang diujikan dan dan subjek yang tidak menguasai.
Menurut Thorndike (dalam Azwar, 2005) bahwa dalam proses seleksi aitem, aitem-aitem yang memiliki nilai diskriminasi di atas 0,50 akan langsung dianggap baik sedangkan aitem-aitem dengan indeks diskriminasi di bawah 0,20 dapat langsung dibuang dan dianggap jelek. Sementara menurut Ebel (dalam Azwar, 2005) terdapat suatu panduan dalam evaluasi indeks diskriminasi aitem, yaitu:
Tabel 2 Evaluasi Indeks Daya Diskriminasi Aitem
Indeks Daya Beda Evaluasi 0,40 Sangat bagus
0,30 – 0,39 Lumayan bagus, tidak membutuhkan revisi 0,20 – 0,29 Belum memuaskan, perlu direvisi
Menurut Murphy dan Davidshofer (2003), ada tiga statistik yang dapat digunakan untuk mengukur daya diskriminasi suatu aitem, yaitu:
1. Method of Extreme Group
Metode ini biasanya dugunakan untuk indeks diskriminasi pada kelompok besar. Diskriminasi aitem dapat dihitung dengan cara membagi kelompok menjadi dua, Upper group (Kelompok Tinggi) yakni kelompok yang memiliki skor yang tinggi (25-35 % nilai tertinggi didalam kelompok) dan lower group (Kelompok Rendah) yakni kelompok yang memiliki nilai yang rendah (25-35 % nilai terendah dalam kelompok). Aitem yang memiliki indeks diskriminasi yang baik akan dijawab benar oleh Kelompok Tinggi dan dijawab salah oleh Kelompok Rendah. 2. Korelasi Aitem-Total
Parameter daya beda aitem yang berupa koefisien korelasi aitem-total memperlihatkan kesesuaian fungsi aitem dengan fungsi skala / tes dalam mengungkap perbedaan individual. Besarnya koefisien korelasi aitem-total bergerak 0 sampai dengan 1,00. Semakin baik daya diskriminasi aitem, maka koefisien korelasi semakin mendekati angka 1,00.
r
pbis=
[(Mi – Mx)/Sx] / √[p/(1-p)](9)
Keterangan :
rpb : Korelasi point biserial
Mi :Mean skor X dari seluruh subjek yang mendapat angka 1 pada variabel dikotomi i
Mx : Mean skor dari seluruh subjek Sx :Standard deviasi skor X
P :Proporsi subjek yang mendapat angka 1 pada variabel dikotomi
3. Korelasi Inter-Aitem
Pengujian terhadap korelasi inter-aitem dapat membantu kita mengetahui mengapa beberapa aitem gagal membedakan anatara subjek yang bekerja dengan baik (Kelompok Tinggi) dan yang bekerja dengan buruk (Kelompok Rendah) (Murphy dan Davidshofer, 2003)
Korelasi inter-aitem yang bernilai rendah dapat memiliki dua arti, kemungkinan pertama adalah aitem tidak mengukur hal yang sama dengan tes, sehingga aitem harus dibuang atau dibuat ulang, kemungkinan kedua adalah aitem memang mengukur atribut yang berbeda dengan tes dikarenakan tes memang disusun untuk mengukur dua atribut yang berbeda.
3. Efektivitas Distraktor
Efektivits distraktor-distraktor pada suatu aitem dianalisis dari distribusi jawaban terhadap aitem yang bersangkutan pada setiap alternatif yang disediakan. Efektivitas distraktor diperiksa untuk melihat apakah semua distraktor atau semua pilihan jawaban yang bukan kunci telah berfungsi sebagaimana mestinya, yaitu apakah distraktor-distraktor tersebut telah dipilih lebih banyak (atau semua) siswa Kelompok Rendah sedangkan siswa dari Kelompok Tinggi hanya sedikit (atau tidak ada) yang memilihnya.
Efektivitas distraktor dilihat dari dua kriteria, yaitu: (a) distraktor dipilih oleh siswa dari Kelompok Rendah, dan (b) pemilih distraktor tersebar relative proporsional pada masing-masing distrakktor yang ada (Azwar, 2005)
4. Reliabilitas
a. Pengertian Reliabilitas
Reliabilitas merupakan penerjemahan dari kata reliability yang berasal dari dua kata yaitu rely dan ability, dimana rely memilliki arti percaya atau mempercayakan sedangkan ability memiliki arti kemampuan. Ada banyak istilah yang digunakan untuk menyatakan reliabilitas, seperti keterpercayaan, keterandalan, keajegan, kestabilan, konsistensi dan sebagainya, namun pada intinya konsep reliabilitas memiliki makna: sejauh mana hasil suatu tes/ pengukuran dapat dipercaya (Azwar, 2007)
”a reliability term refers to the degree to which individuals deviation
scores, or z-scores, remain relatively consistent over repeated
administration of the same test or alternate test forms”.
Reliabilitas suatu tes ditunjukkan oleh taraf konsistensi skor yang diperoleh para subjek yang diukur dengan alat yang sama atau minimal setara, dalam kondisi yang berbeda (Suryabrata, 2005). Konsepsi mengenai reliabilitas berkaitan dengan derajat konsistensi antara dua perangkat skor tes, maka formula reliabilitas selalu dinyatakan dalam bentuk koefisien korelasi (Azwar, 2007). Menurut Gregory (2000), reliabilitas dalam pengukuran psikologis menunjukkan atribut konsistensi dari pengukuran itu sendiri. Hanya sedikit dari pengukuran behavioral yang benar-benar reliabel, dan reliabilitas itu sendiri bersifat kontinum.
Berdasarkan beberapa definisi di atas, dapat disimpulkan bahwa reliabilitas pada dasarnya merupakan ketetapan atau derajat konsistensi performansi relative dari individu yang dikenai tes ketika diberikan tes yang sama secara berulang atau tes yang parallel.
adalah kondisi yang tidak sesuai atau tidak relevan dengan maksud tes (Anastasi & Urbina, 1997). Ada dua jenis error yang sering terjadi, yaitu:
1) Systematic error yaitu kecenderungan individu untuk memperoleh skor yang tinggi semua atau rendah semua. Sifat eror ini selalu konstan. Sumbernya adalah karakteristik fisik individu, proses tes/ tes yang tidak berkaitan dengan konstruk yang ingin diukkur. Misalnya alat ukur rusak, gangguan pendengaran, gangguan penglihatan, dll.
2) Unsystematic error (random error), yaitu kecenderungan individu memperoleh skor yang tidak tetap, terkadang baik, terkadang buruk. Error ini bersifat random. Ada berbagai hal yang dapat menimbulkan random error, antara lain kelelahan memori subjek dan naik turunnya
suasana hati, dll.
b. Jenis-jenis Pendekatan Estimasi Reliabilitas
Estimasi terhadap tingginya reliabilitas dapat dilakukan melalui berbagai metode pendekatan, dimana masing-masing metode pendekatan dikembangkan sesuai dengan sifat dan fungsi alat ukur yang bersangkutan dengan mempertimbangkan segi-segi praktisnya (Azwar, 2007)
Menurut Azwar (2007), secara tradisional terdapat tiga macam pendekatan reliabilitas yaitu :
1) Pendekatan Tes Ulang (tes-retest)
dengan tenggang waktu tertentu. Asumsinya adalah bahwa suatu tes yang reliable tentu akan menghasilkan skor tampak yang relative sama apabila dikenakan dua kali pada waktu yang berbeda. Semakin besar variasi perbedaan skor subjek antara kedua pengenaan tes, berarti semakin sulit untuk mempercayai bahwa tes itu memberikan hasil ukur yang konsisten (Azwar, 2007)
Dalam prakteknya, pendekatan ini memiliki keterbatasan yaitu kurang praktis dalam pelaksanaan tes sebanyak dua kali, dan besarnya kemungkinan terjadi efek bawaan (carry-over effects) dari satu pengenaan tes ke pengenaan te syang kedua. Artinya dalam hal ini besar kemungkinan terjadinya proses pembelajaran bagi subjek dan hal ini akan mempengaruhi terhadapa skor hasil tes yang kedua kalinya.
2) Pendekatan Bentuk-Paralel (alternate-forms)
Pendekatan bentuk paralel merupakan pengenaan dua bentuk tes pararel dalam waktu yang bersamaan pada satu kelompok subjek. Jadi pendekatan ini hanya dapat dilakukan apabila tersedia dua bentuk instrumen yang dapat dianggap memenuhi asumsi parallel. Salah satu indicator terpenuhinya asumsi paralel adalah setaranya korelasi antara skor kedua instrument tersebut dengan skor suatu ukuran lain.
Tentu saja untuk dapat paralel kedua bentuk instrumen harus disusun dengan tujuan mengukur objek psikologis yang sama, berdasarkan blue-Print (pola-rancangan) yang sama dan spesifikasi yang sama pula.
pendekatan ini juga memiliki kelebihan, yaitu dapat menghilangkan kemungkinan terjadinya efek bawaan.
3) Pendekatan Konsistensi Internal (Internal-Consistency)
Pendekatan konsistensi internal dilakukan dengan menggunakan satu bentuk tes yang dikenakan hanya sekali saja pada sekelompok subjek (single-trial administration). Pendekatan ini mengatasi kelemahan pada pendekatan tes-retest dan alternate-forms.
Pendekatan reliabilitas konsistensi internal bertujuan untuk melihat konsistensi antar-aitem atau antar bagian dalam tes itu sendiri. Untuk itu, setelah skor setiap aitem diperoleh dari sekelompok subjek, tes dibagi menjadi beberapa belahan, bisa dua belahan, tiga belahan dan bahkan belahan sebanyak aitem. Membelah tes prinsipnya adalah mengusahakan agar antar belahan memiliki jumlah aitem sama banyak, taraf kesulitan seimbang, isi sebanding, dan memenuhi ciri-ciri paralel .
1. Spearman-Brown
Formula komputasi Spearman-Brown merupakan formula koreksi terhadap koefisien korelasi antara dua bagian tes dan dirumuskan sebagai berikut (Azwar, 2005):
S-B
= r
xx’=
(10)Keterangan:
rxx’ = Koefisien reliabilitas Spearman-Brown r1.2 = Koefisien korelasu antara dua belahan
Formula ini dapat digunakan jika aitem dikotomi ataupun politomi, pembelahan tes dilakukan dengan cara gasal-genap dan matched-random subtes dan menghasilkan dua bagian yang paralel satu sama lain dan korelasi antara kedua belahan paralel tersebut cukup tinggi.
2. Rulon
Rulon (1939) mempersoalkan reliabilitas tes yang dibelah menjadi dua belahan. Jika sekiranya belahan tersebut setara maka secara teori skor subjek pada perangkat belahan pertama dan skor perangkat belahan kedua akan sama. Jika skor-skor pada kedua perangkat itu tidak sama, maka itu terjadi karena kesalahan/kekeliruan pengukuran. Berdasarkan atas pemikiran ini maka diusulkan rumus reliabilitas tes sebagai berikut (Suryabrata, 2005):