PRUNING
PADA
FUZZY DECISION TREE
DALAM
KLASIFIKASI DATA IKLIM DAN TITIK API DI DAERAH
TJILIK RIWUT, PALANGKARAYA, KALIMANTAN SELATAN
AKHMAD AKBAR
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PRUNING
PADA
FUZZY DECISION TREE
DALAM
KLASIFIKASI DATA IKLIM DAN TITIK API DI DAERAH
TJILIK RIWUT, PALANGKARAYA, KALIMANTAN SELATAN
AKHMAD AKBAR
Skripsi
sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
ABSTRACT
AKHMAD AKBAR. Pruning on Fuzzy Decision Tree in Classification of Climatology and Hotspot at Tjilik Riwut, Palangkaraya, South Kalimantan. Supervised by ANNISA.
Forest fire is influenced by several factors, such as humidity, solar radiation intensity, regional temperature, and rainfall. This research aimed at finding the information and knowledge from hotspot and climate data, especially those four attributes. The research data was taken from Tjilik Riwut, Palangkaraya, South Kalimantan in year 2001-2004. Data mining technique used for extracting the information and knowledge is classification using decision tree method. In this research, fuzzy aproach is adapted to solve uncertainty of data. To improve the accuracy of classification process, pruning tree method is utilized. Tree that has the highest accuracy is converted to be the rule. The formed rule shows that the amount of hotspot is inversely proportional with the scale of humidity. This research also proves that pruning process in a tree can improve the accuracy of classification process.
Judul Skripsi : Pruning pada Fuzzy Decision Tree dalam Klasifikasi Data Iklim dan Titik Api di Daerah Tjilik Riwut, Palangkaraya, Kalimantan Selatan
Nama : Akhmad Akbar
NRP : G64063468
Menyetujui:
Pembimbing
Annisa, S.Kom, M.Kom NIP 19790731 200501 2 002
Mengetahui:
Ketua Departemen Ilmu Komputer,
Dr. Ir. Agus Buono, M.Si, M.Kom NIP 19660702 199302 1 001
RIWAYAT HIDUP
Penulis yang dilahirkan di Kediri, Jawa Timur, pada tanggal 9 Juli 1987, merupakan anak ketiga dari tiga bersaudara dengan ayah bernama Slamet Riadi dan Ibu bernama Chadidjah. Pada tahun 2006, penulis lulus dari Sekolah Menengah Atas Negeri 1 Kediri dan diterima di Program Studi Ilmu Komputer, Institut Pertanian Bogor melalui jalur Seleksi Penerimaan Mahasiswa Baru (SPMB).
Selama aktif sebagai mahasiswa, penulis juga aktif di berbagai organisasi, di antaranya: LDK Al Hurriyah IPB, Kesatuan Aksi Mahasiswa Muslim Indonesia Komisariat IPB dan Daerah Bogor, Kaukus Pemuda dan Mahasiswa Demokrasi (KPMD) Bogor, dan beberapa organisasi mahasiswa lainnya. Di samping itu, penulis juga pernah bergabung dengan organisasi pemuda dengan nama Purna Paskibraka Indonesia Daerah Kota Kediri di bidang pembinaan SDM.
PRAKATA
Alhamdulillahi Rabbil ‘alamin. Segala puji dan syukur penulis panjatkan kepada Allah
Subhanahuwata’ala atas limpahan rahmat, kemurahan, dan hidayah-Nya sehingga tugas akhir dengan judul Pruning pada Fuzzy Decision Tree dalam Klasifikasi Data Iklim dan Titik Api di Daerah Tjilik Riwut, Palangkaraya, Kalimantan Selatan dapat diselesaikan. Shalawat serta salam juga penulis ucapkan kepada junjungan Nabi Muhammad Shallalahuwaalaihiwassalam beserta seluruh sahabat dan umatnya hingga akhir zaman.
Penyelesaian tugas akhir ini tidak terlepas dari bantuan beberapa pihak. Oleh karena itu, penulis ingin menyampaikan terima kasih kepada semua pihak yang telah membantu dalam penyelesaian tugas akhir ini, antara lain:
1 Rama dan Umi sebagai motivasi terbesar dan sumber nasihat atas doa, bimbingan, kesabaran, dan keikhlasan mendidik penulis. Hal yang sama juga untuk kedua kakak tercinta dan keponakan-keponakan.
2 Ibu Annisa, S.Kom, M.Kom selaku dosen pembimbing yang selalu memberikan saran dan arahan selama penelitian dan penulisan tugas akhir ini.
3 Bapak Toto Haryanto, S.Kom, M.Si dan Bapak Endang Purnama Giri, S.Kom, M.Kom yang telah bersedia menjadi dosen penguji.
4 Seluruh dosen, staf pengajar, staf tata usaha, hingga cleaning service di Dept. Ilmu Komputer atas bantuan dan pelayanannya.
5 Rekan-rekan mahasiswa bimbingan Ibu Annisa, S.Kom, M.Kom terutama Remarchtito dan Dedek atas bantuan, informasi, saran dan kerjasamanya selama penyelesaian tugas akhir ini.
6 Rekan-rekan yang mengingatkan, membantu dan memberi motivasi dalam penyelesaian tugas akhir, yaitu Rahmat Firdaus, Satriyo, Fitri, Ust. Fendi, Danang, Mas Tulus, Mas Sugi, Cici, Ichi, Iin, Keke, Vida, Kang Jay, Kang Dadan, Arifin, dan Uda Redo.
7 Para ustad yang memberi suplemen rohani dengan sangat optimal dan ikhlas.
8 Rekan-rekan yang rela meminjamkan fasilitasnya untuk penyelesaian tugas akhir ini, yakni Didik Rahmawan, Mas Dito, dan Bang Nizar.
9 Keluarga besar LDK Al Hurriyyah, KAMMI IPB, KAMMI Daerah Bogor, KAMMI Wilayah Megapolitan, PIA Smas’t, dan BKB Nurul Fikri Bogor atas semua dukungannya.
10 Teman-teman Ilmu Komputer angkatan 43 yang tentu tidak bisa disebutkan satu persatu.
Penulis juga mengucapkan terima kasih kepada semua pihak yang telah membantu selama pengerjaan penyelesaian tugas akhir ini yang tidak dapat disebutkan satu-persatu. Semoga penelitian ini dapat memberikan manfaat.
Bogor, Juni 2012
v
DAFTAR ISI
Halaman
DAFTAR TABEL ... ... vi
DAFTAR GAMBAR... ... vi
DAFTAR LAMPIRAN ... ... vi
PENDAHULUAN Latar Belakang ... ... 1
Tujuan ... ... 1
Ruang Lingkup ... ... 1
Manfaat Penelitian ... ... 1
TINJAUAN PUSTAKA Knowledge Data Discovery ... 1
Data Mining... ... 2
Klasifikasi... ... 2
Decision Tree... ... 2
Fuzzy ... ... 2
Fuzzy Decision Tree ... ... 3
Entropy dan Information Gain... 3
Threshold... ... 3
Fuzzy ID3 (FID3) ... 4
Overfitting ... ... 4
Pruning ... ... 4
METODE PENELITIAN Pembersihan Data ... ... 5
Transformasi Data ... ... 5
Aplikasi Teknik Data Mining ... ... 5
Representasi Pengetahuan ... 5
Lingkungan Pengembangan ... ... 6
HASIL DAN PEMBAHASAN Pembersihan data ... ... 6
Transformasi data ... 6
Data Mining ... ... 8
Training ... ... 8
Testing ... ... 10
Pruning ... ... 10
ChiSquare Pruning ... ... 10
Rule Post Pruning... .... 11
KESIMPULAN DAN SARAN Kesimpulan ... ... 12
Saran ... ... 12
DAFTAR PUSTAKA ... ... 12
vi
DAFTAR TABEL
Halaman
1 Contoh persebaran atribut untuk proses pruning chi square... 4
2 Tahapan-tahapan penelitian ... 5
3 Daftar nilai entropy dan information gain ... 9
4 Confusion matrix hasil uji pada tree ... 10
5 Sebaran nilai atribut Curah Hujan ... 10
6 Sebaran nilai atribut Curah Hujan setelah perhitungan ... 10
7 Confusion matrix hasil uji pada tree dengan pruning chi square ... 11
8 Confusion matrix hasil uji pada tree dengan rule post pruning... 11
9 Daftar nilai akurasi tree ... 11
DAFTAR GAMBAR
Halaman 1 Tahap-tahap dalam proses KDD (Han & Kamber 2001) ... 22 Metodologi penelitian ... 5
3 Himpunan fuzzy atribut penyinaran ... 7
4 Himpunan fuzzy atribut temperatur ... 7
5 Himpunan fuzzy atribut curah hujan ... 8
6 Himpunan fuzzy atribut kelembaban ... 8
7 Hasil ekspansi training set berdasarkan atribut Kelembaban ... 9
DAFTAR LAMPIRAN
Halaman 1 Contoh data mentah sebelum pembersihan data ... 152 Contoh data hasil proses pembersihan data ... 17
3 Contoh data hasil proses fuzzyfikasi dan data training ... 18
4 Struktur tree sebelum di-pruning ... 19
5 Struktur tree setelah chi square pruning. ... 20
6 Struktur tree setelah rule post pruning. ... 21
7 Aturan (rule) yang dihasilkan pada tree tanpa pruning. ... 22
8 Aturan yang dihasilkan pada tree dengan metode chi square pruning. ... 23
PENDAHULUAN
Latar BelakangKasus kebakaran hutan di Indonesia merupakan salah satu bencana alam yang sering terjadi. Beberapa faktor cuaca yang mempengaruhinya ialah temperatur, curah hujan, radiasi matahari, kelembaban, stabilitas udara, kecepatan angin dan arah angin secara langsung (Thoha 2001 dalam Dedek 2011).
Indikator kebakaran hutan yang bisa dijadikan acuan adalah jumlah titik api (hotspot). Hotspot merupakan titik-titik di permukaan bumi yang menjadi indikator adanya kebakaran hutan dan lahan. Salah satu cara pencegahan kebakaran hutan yang dapat dilakukan adalah dengan mengetahui hubungan antara faktor cuaca yang ada di suatu wilayah dengan jumlah hotspot yang muncul. Metode klasifikasi dengan menggunakan decision tree
dapat digunakan untuk membuat sebuah
classifier yang berguna untuk melihat pola / hubungan tersebut.
Data iklim dan hotspot sering kali tidak bisa didekati melalui pendekatan crisp (tegas). Hal ini dikarenakan nilai atribut yang sangat berdekatan mampu memberi pengaruh yang berbeda di dalam pembentukan hotspot. Untuk mengatasi hal tersebut, diperlukan pendekatan dengan kaidah fuzzy. Penerapan kaidah fuzzy di dalam suatu decision tree sering dikenal sebagai fuzzy decision tree.
Hasil dari klasifikasi dapat dilihat dari tingkat akurasi yang dihasilkan. Namun, sering kali model decision tree yang dihasilkan mengalami masalah overfitting. Overfitting di dalam decision tree menghasilkan suatu ke-adaan yang lebih kompleks daripada yang diperlukan. Hal ini juga membuat tingkat akurasi yang dihasilkan tidak cukup baik untuk mengklasifikasikan data baru. Oleh karena itu, diperlukan cara untuk meningkatkan akurasi dari model tree yang dihasilkan.
Salah satu metode yang bisa digunakan untuk meningkatkan akurasi dari tree adalah
pruning. Pruning bekerja dengan prinsip memangkas atau menyederhanakan struktur
tree. Pruning diharapkan mampu meningkatkan akurasi yang dihasilkan dalam proses klasifikasi secara signifikan.
Penelitian ini mencoba menemukan hubungan antara faktor-faktor cuaca dengan jumlah hotspot yang dibentuknya menggunakan teknik klasifikasi menggunakan konsep fuzzy
dengan metode decision tree. Untuk meningkatkan akurasi dalam proses klasifikasi,
diterapkan juga metode pruning. Model tree
dengan nilai akurasi tertinggi diharapkan mampu memberikan suatu model atau aturan yang bisa mengklasifikasikan jumlah hotspot
berdasarkan pola pada iklim di daerah tersebut.
Tujuan
Tujuan dari penelitian ini adalah:
1 Menerapkan teknik data mining berupa klasifikasi dengan metode fuzzy decision tree.
2 Menerapkan teknik pruning pada tree.
3 Menemukan aturan klasifikasi pada data titik api (hotspot) sehingga dapat diketahui kelas jumlah hotspot berdasarkan pada pola data iklim di daerah tersebut.
Ruang Lingkup
Ruang lingkup penelitian ini dibatasi pada:
1 Penerapan algoritme ID3 dalam Fuzzy Decision Tree pada data titik api (hotspot) di daerah Tjilik Riwut, Palangkaraya, Kalimantan Selatan.
2 Membangun suatu model klasifikasi untuk mengetahui tingkat potensi kebakaran hutan di daerah terkait. Hal ini meliputi informasi dari atribut temperatur, curah hujan, penyinaran matahari, dan kelembaban
3 Penelitian ini menggunakan teknik data mining yaitu klasifikasi dengan metode
decision tree. Namun, untuk mengatasi adanya ketidaktepatan, pendekatan fuzzy
digunakan sebagai bantuan.
4 Penerapan pruning (pemangkasan) tree
untuk menyederhanakan aturan klasifikasi yang ada.
Manfaat Penelitian
Penelitian ini diharapkan dapat menunjukkan potensi kebakaran hutan berdasarkan jumlah hotspot yang ada sehingga dapat menjadi alat bantu oleh pihak yang berwenang dalam mengantisipasi dan deteksi dini kebakaran hutan.
TINJAUAN PUSTAKA
Knowledge Data Discovery (KDD)
1 Pembersihan Data
Pembersihan terhadap data dilakukan untuk menghilangkan data yang tidak konsisten atau data yang mengandung
noise. 2 Integrasi data
Proses integrasi data dilakukan untuk menggabungkan data dari berbagai sumber.
3 Seleksi data
Proses seleksi data digunakan untuk mengambil data yang relevan digunakan dalam proses analisis.
4 Transformasi data
Proses mentransformasikan atau menggabungkan data ke dalam bentuk yang tepat untuk di-mining.
5 Data mining
Data mining merupakan proses penting yang menerapkan metode-metode cerdas untuk mengekstraksi pola-pola dalam data.
6 Evaluasi pola
Evaluasi pola diperlukan untuk mengidentifikasi beberapa pola yang menarik yang merepresentasikan pengetahuan.
7 Representasi pengetahuan
Penggunaan visualisasi dan teknik representasi untuk menunjukkan pengetahuan hasil penggalian gunung data kepada pengguna.
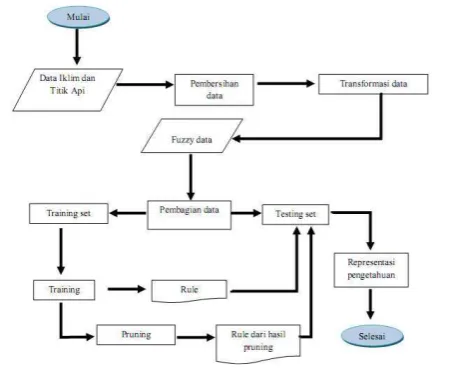
Tahapan di dalam proses KDD akan ditunjukkan oleh Gambar 1.
Gambar 1 Tahap-tahap dalam proses KDD (Han&Kamber 2001).
Data Mining
Data mining merupakan proses ekstraksi informasi data berukuran besar (Han & Kamber
2001). Data mining merupakan kumpulan proses yang mengaplikasikan komputer dan berbagai macam teknik untuk menemukan informasi dari sekumpulan data. Data mining
dibagi menjadi dua kategori besar, yaitu
predictive data mining dan descriptive data mining. Predictive data mining berupaya menganalisis data dengan tujuan membuat suatu model dan memprediksi perilaku dari kumpulan data yang baru. Descriptive data mining lebih pada upaya menjelaskan sekumpulan data dengan ringkas yang menjelaskan sifat-sifat menarik dari data.
Klasifikasi
Klasifikasi adalah suatu cara yang digunakan untuk membedakan objek, kelas, atau konsep pada suatu ruang data. Klasifikasi bertujuan memodelkan suatu fungsi yang dapat digunakan untuk mengetahui kelas dari suatu objek yang kelasnya tidak dikenali.
Proses klasifikasi dibagi menjadi dua, yakni tahap learning dan testing (Han & Kamber 2001). Pada tahap learning, sebagian data yang telah diketahui label kelasnya (training set) digunakan untuk membentuk model. Selanjutnya, pada tahap testing, model yang sudah terbentuk diuji dengan menggunakan sebagian data lain (test set) untuk mengetahui akurasi dari model yang dihasilkan. Jika akurasi yang didapatkan mencukupi, model tersebut dapat dipakai untuk memprediksi kelas data yang belum diketahui.
Decision Tree
Decision tree merupakan suatu pendekatan yang sangat populer dan praktis dalam machine learning untuk menyelesaikan permasalahan klasifikasi. Metode ini digunakan untuk memperkirakan nilai diskret dari fungsi target. Fungsi pembelajaran direpresentasikan oleh sebuah decision tree (Liang 2005).
Decision tree merupakan himpunan aturan IF...THEN. Setiap pathdalam tree dihubungkan dengan sebuah aturan. Premis aturan terdiri atas sekumpulan node yang ditemui, sedangkan kesimpulan aturan terdiri atas kelas yang terhubung dengan leaf dari path (Marsala 1998 dalam Romansyah et al.2009).
Fuzzy
suatu himpunan tujuan dengan derajat keanggotaan tertentu (Smith 2003).
Secara formal, definisi dari himpunan fuzzy
adalah sebagai berikut:
Jika X merupakan suatu kumpulan objek yang secara umum dilambangkan dengan x, himpun-an fuzzy A pada X merupakan sebuah himpunan dengan formulasi sebagai berikut:
A = {(x, µA (x))| x ɛ X}
Nilai µA (x) disebut sebagai fungsi atau derajat
keanggotaan x dalam A yang memetakan X ke ruang keanggotaan M (Zimmerman 1991 dalam Smith 2003).
Fuzzy Decision Tree
Fuzzy Decision Tree merupakan perluasan ide dari teori klasik tentang proses klasifikasi yang kita kenal sebagai Decision Tree. Node
dari tree dengan derajat satu atau disebut daun (leaf) merupakan label dari konsep klasifikasi, sedangkan node dengan derajat lebih tinggi dibentuk dari sekumpulan aturan menggunakan
operator “OR”, “AND”, dan “NOT” (Rhyne &
Smith 1999 dalam Smith 2003).
Fuzzy Decision Tree memungkinkan untuk menggunakan nilai-nilai numeric-symbolic
selama konstruksi atau saat mengklasifikasikan kasus-kasus baru. Manfaat dari teori himpunan
fuzzy dalam decision tree ialah meningkatkan kemampuan dalam memahami decision tree
ketika menggunakan atribut-atribut kuantitatif. Bahkan dengan penggunaan teknik fuzzy dapat meningkatkan ketahanan saat melakukan klasifikasi kasus-kasus baru (Marsala 1998 dalam Romansyah et al 2009).
Entropy dan Information Gain
Information gain adalah suatu nilai statistik yang digunakan untuk memilih atribut yang akan mengekspansi tree dan menghasilkan node
baru pada algoritme ID3. Suatu entropy
dipergunakan untuk mendefinisikan nilai
information gain. Entropy dirumuskan sebagai berikut: ) ( log * )
( 2 i
N i i
s S P P
H
Pi adalah rasio dari kelas Ci pada himpunan
contoh S = {x1,x2,…,xk}.
S C x P
k
j j i i
1
Untuk menghitung nilai information gain
dari suatu atribut A, digunakan persamaan sebagai berikut:
) ( ) ( | | | | ) ( ) , ( A Values v v v S H S S S H A S Gdengan bobot Wi =
|
|
|
|
S
S
vadalah rasio dari data
dengan atribut v pada himpunan contoh.
Pada fuzzy ID3, fuzzy entropy dirumuskan sebagai berikut: ) ( log * ) ( )
( N 2 i
i i s
f S H S P P
H
Untuk menentukan fuzzy entropy dan
information gain dari suatu atribut A pada algoritme fuzzy ID3 (FID3), digunakan persamaan sebagai berikut:
S S A S H N j ij C i N j ij f
1 log2
) , ( (5) ) , ( * | | | | ) ( )
( H S A
S S S
H S
G f v
N A v
v f
f
Dengan µij adalah nilai keanggotaan dari pola
ke-j untuk kelas ke-i. Hf(S) menunjukkan
entropy dari himpunan S dari data pelatihan pada node. |Sv| adalah ukuran dari subset Sv
Sdari data pelatihan xj dengan atribut v. |S|
menunjukkan ukuran dari himpunan S
(Romansyah et al 2009).
Threshold
Jika proses learning dari FDT dihentikan sampai semua data contoh pada masing-masing
leaf-node menjadi anggota sebuah kelas, akan dihasilkan akurasi yang rendah. Oleh karena itu, untuk meningkatkan akurasinya, proses
learning harus dihentikan lebih awal atau melakukan pemangkasan tree secara umum (Liang 2005). Untuk itu, diberikan 2 (dua) buah
threshold yang harus terpenuhi jika tree akan diekspansi, yaitu:
Fuzziness control threshold (θr)
Jika proporsi himpunan data dari kelas Ck
lebih besar atau sama dengan nilai threshold
θr, ekspansi tree dihentikan. Sebagai contoh:
jika diberikan θr adalah 85%, pada sebuah
sub-dataset rasio dari kelas 1 adalah 90% dan kelas 2 adalah 10%, maka ekspansi tree
dihentikan.
Leaf decision threshold (θn)
Jika banyaknya anggota himpunan data pada suatu node lebih kecil daripada threshold θn, ekspansi tree dihentikan.
memiliki 600 contoh dengan θn adalah 2%.
Jika jumlah data contoh pada sebuah node lebih kecil dari 12 (2% dari 600), ekspansi
tree dihentikan (Romansyah et al. 2009).
Fuzzy ID3 (FID3)
Algoritme ID3 (Iterative Dichotomiser 3) pertama kali dikenalkan oleh Quinlan. Algoritme ini menggunakan teori informasi untuk menentukan atribut yang paling informatif. Namun, ID3 ternyata sangat tidak stabil dalam melakukan penggolongan karena adanya gangguan kecil pada data pelatihan. Logika fuzzy dapat memberikan suatu peningkatan dalam melakukan penggolongan di saat pelatihan. Algoritme fuzzy ID3 merupakan algoritme yang efisien untuk membuat suatu
fuzzy decision tree (Liang 2005).
Overfitting
Overfitting merupakan masalah yang sering muncul di dalam upaya klasifikasi. Overfitting
di dalam decision tree menghasilkan sesuatu yang lebih kompleks daripada yang dibutuhkan. Gejala yang ditunjukkan di dalam overfitting
memberi informasi kebaikan akurasi pada data training, namun memberikan akurasi yang buruk pada data testing. Di samping itu,
overfitting mengakibatkan semakin besar ukuran dari tree (ditinjau dari jumlah node-nya), justru memberi nilai akurasi yang rendah dalam proses klasifikasi. Pruning merupakan cara yang baik untuk menghindari atau mengatasi
overfitting. Pasca pruning tingkat akurasi dalam proses klasifikasi bisa meningkat (Tan et al
2005).
Pruning
Pruning (pemangkasan tree) merupakan bagian dari proses pembentukan decision tree. Saat pembentukan decisiontree, beberapa node merupakan outlier maupun hasil dari noise data. Penerapan pruning pada decision tree dapat mengurangi outlier maupun noise data pada
decision tree awal sehingga dapat meningkatkan akurasi pada klasifikasi data (Han & Kamber 2001 dalam Budi 2010).
Prinsip pruning terbagi menjadi dua: Pre-pruning dan post pruning. Pre-pruning
merupakan proses pemangkasan saat tree belum terbentuk secara sempurna. Salah satu metode
pre-pruning adalah metode chi square. Metode ini menghitung keterkaitan atau hubungan setiap atribut terhadap atribut kelasnya sehingga dapat diketahui apakah atribut yang bersangkutan bisa menjadi classifier yang baik atau tidak.
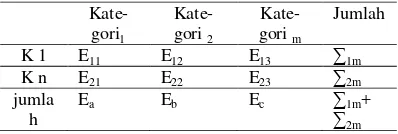
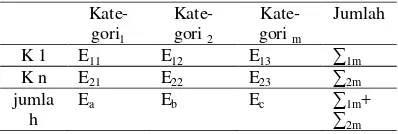
Misalkan didapatkan suatu atribut dengan m
kategori dan n kategori kelas. Langkah awal chi square adalah membentuk tabel sederhana seperti berikut:
Tabel 1 Contoh persebaran atribut untuk proses
pruning chi square
Kate-gori1
Kate-gori 2
Kate- gori m
Jumlah
K 1 E11 E12 E13 ∑1m
K n E21 E22 E23 ∑2m
jumla h
Ea Eb Ec ∑1m+
∑2m Lalu, dengan melihat pada tabel sebaran chi square , X2= {α;(m-1)*(n-1)}
Kemudian, dilakukan perhitungan seperti berikut:
e11 = (∑1m * Ea ) / (∑1m+ ∑2m)
e12 = (∑1m * Eb ) / (∑1m+ ∑2m)
e13 = (∑1m * Ec ) / (∑1m+ ∑2m)
e21 = (∑2m * Ea ) / (∑1m+ ∑2m)
e22 = (∑2m * Eb) / (∑1m+ ∑2m)
e23 = (∑2m * Ec) / (∑1m+ ∑2m)
Berikutnya adalah menghitung nilai X2dari data berikut:
X2hitung= (E11- e11)2 / e11 + (E12- e12)2 / e12 +
(E13- e13)2 / e13 + (E21- e21)2 / e21 +
(E22- e22)
2
/ e22 + (E23- e23)
2 / e23
Kemudian, dibandingkan nilai X2 dengan nilai X2hitung. Jika didapatkan nilai X2hitung yang lebih besar dari X2, atribut yang bersangkutan tidak bisa dihilangkan dalam proses pengembangan tree. Namun, jika nilai X2 hitung lebih kecil dari X2, atribut tersebut bisa diabaikan di dalam proses ekspansi tree.
Berbeda prinsip dengan pre-pruning, post pruning bekerja setelah tree terbentuk dengan sempurna. Salah satu metode dari post pruning
adalah rule post pruning. Metode ini berusaha untuk menyederhanakan rule dengan me-motong antecedent atau leaf pada model tree
dengan prinsip seperti berikut (Mitchell 1997):
1 Infer tree as well as possible.
2 Convert tree to equivalent set of rules. 3 Prune each rule by removing any
4 Sort final rules by their estimated accuracy and consider them in this sequence when classifying.
Metode rule post pruning membutuhkan suatu alat bantu berupa validation set. Validation set merupakan bagian dari training set yang digunakan sebagai objek uji awal dari
rule yang dihasilkan dari proses pruning.
Sebagai contoh, jika didapatkan suatu rule
yang menyatakan R1 = “ If A and B and C Then
D “, metode rule post pruning membuat rule
tersebut menjadi R2 = “If A and B Then D”. Kemudian, R2 diujikan terhadap validation set
dan diperhatikan apakah nilai akurasi yang dihasilkan oleh R2 lebih baik daripada R1. Jika nilai akurasi R2 lebih baik daripada R1, pruning
berhasil dan R2 digunakan. Namun, jika sebaliknya, R2 tidak digunakan.
METODE PENELITIAN
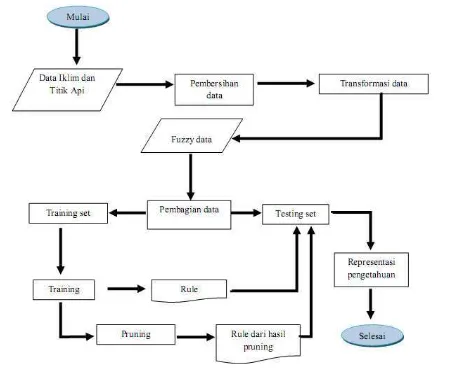
Tahapan yang dilakukan pada penelitian ini dapat dilihat pada Gambar 2. Tahap-tahap yang dilakukan di dalam penelitian ini dijelaskan sebagai berikut:a Pembersihan data
Pembersihan data dilakukan jika terdapat
noise, nilai kosong (null value), atau duplikasi data. Pada tahap ini juga dipilih atribut yang dibutuhkan di dalam proses klasifikasi.
b Transformasi data
Data yang sudah dibersihkan kemudian diubah menjadi bentuk yang tepat untuk
di-mining. Pada proses ini, data iklim dan titik
api sudah ditransformasikan ke dalam bentuk fuzzy.
c Aplikasi teknik data mining
Pada data diterapkan teknik data mining. Untuk menemukan suatu model sistem atau aturan untuk klasifikasi, digunakan metode
fuzzy decision tree. Tahapan pada metode tersebut adalah sebagai berikut:
1 Menentukan banyaknya training dan
testing set yang akan digunakan.
2 Memilih besarnya threshold yang akan digunakan.
3 Membangun fuzzy decision tree dengan algoritme Fuzzy ID3.
4 Menerapkan proses pruning pada tree
yang terbentuk.
d Representasi pengetahuan
Tahap ini merupakan tahap akhir. Pada
Tabel 2 Tahapan-tahapan penelitian Langkah
ke-n Proses Penjelasan
1 Pengadaan data Data iklim dan hotspot siap untuk diolah.
2 Pembersihan data Pemilihan atribut data. Data yang mengandung noise, null value, atau duplikat dibersihkan.
3 Transformasi data Data diubah menjadi bentuk fuzzy.
4 Aplikasi data mining :
a. Pembagian data
b.Menentukan
threshold
c.Membangun
fuzzy decision tree
d.Pruning
e.Testing
Menentukan jumlah training set dan testing set yang akan dipakai.
Menentukan fuzziness control thres-hold (θr ) dan leaf
decision threshold (θn)
Konstruksi fuzzy decision tree dengan algoritme fuzzy ID3.
Menerapkan proses pruning pada tree yang terbentuk. Menguji model tree yang terbentuk menggunakan data uji. 5 Representasi
pengetahuan
tahap ini, pola yang telah ditemukan dipresentasikan ke pengguna dengan teknik visualisasi agar pengguna dapat memahaminya. Deskripsi aturan klasifikasi akan dipresentasikan dalam bentuk aturan logika untuk selanjutnya dievaluasi hasil pengetahuan yang didapatkan.
Setiap tahapan di dalam penelitian ini akan ditunjukkan di dalam Tabel 2.
Lingkungan Pengembangan
Penelitian ini menggunakan perangkat keras dan perangkat lunak dengan spesifikasi sebagai berikut:
1 Perangkat keras
a Intel® Core i3 Processor @ 2.13 GHz.
b Memori DDR2 1 GB. c Harddisk 320 GB. d Keyboard dan mouse.
2 Perangkat lunak
a Windows 7 Professional Edition. b XAMPP versi 1.7.3.
c Microsoft Office 2007. d PHP 5.3.0.
e Notepad++.
HASIL DAN PEMBAHASAN
Pembersihan DataData pada penelitian ini merupakan nilai kuantitatif faktor-faktor cuaca pada daerah Tjilik Riwut, Palangkaraya, Kalimantan Selatan. Pencatatan dilakukan pada tahun 2001-2004 oleh Balai Besar Meteorologi dan Geofisika Wilayah III, Stasiun Meteorologi Tjilik Riwut. Pembersihan data diawali dengan memilih atribut apa saja yang akan dipakai sebagai alat untuk mengklasifikasikan data. Dari data, didapatkan enam atribut, yaitu: temperatur (˚C), curah hujan (mm), penyinaran (%),
kelembaban udara (%), tekanan udara (mb), dan kecepatan angin. Namun, untuk proses klasifikasi pada penelitian ini, atribut tekanan udara dan kecepatan angin tidak diikutsertakan. Hal ini dikarenakan interval antara nilai minimum dan maksimum pada kedua atribut tersebut sangat pendek.
Pada atribut kelembaban udara dan temperatur, diambillah nilai rata-ratanya. Hal ini sebagai representasi keteraturan dari kejadian yang menyangkut kedua atribut tersebut.
Pada tahap ini juga, dipilih record data dengan mempertimbangkan jumlah kelas. Hal
ini penting untuk membuat model sistem yang baik dalam proses klasifikasi. Karena jika terjadi ketidakseimbangan jumlah record kelas target, pemodelan yang dihasilkan akan kurang baik.
Selanjutnya, pembersihan data dilakukan terhadap data yang memiliki nilai kosong dan / atau duplikat. Setelah dilakukan pembersihan terhadap record yang mengandung nilai kosong dan / atau duplikat diperoleh data siap pakai sebanyak 250 record. Contoh hasil dari proses pembersihan data dapat dilihat pada Lampiran 2.
Transformasi Data
Penelitian ini menerapkan salah satu teknik
data mining, yaitu fuzzy decision tree. Oleh karena itu, data yang digunakan harus direpresentasikan ke dalam bentuk fuzzy. Proses diawali dengan membuat fungsi nilai keanggotaan (membership function) pada masing-masing atribut yang dipakai. Hal ini adalah bagian dari penerapan prinsip fuzzy yang menjadi pedoman penelitian.
Pada kasus-kasus tertentu yang menggunakan konsep fuzzy, tidak ditemukan referensi atau pakar yang mampu menjelaskan
range nilai setiap atribut sebagai pedoman pembentukan membership function. Hal ini bisa diatasi dengan cara lain, seperti survey, polling,
atau hasil dari proses learning (Suyanto 2008).
Pada penelitian ini, tidak didapati referensi ataupun pakar yang menjelaskan range nilai setiap atribut. Oleh karena itu, dilakukan eksperimen sebanyak tiga kali sebelum diformulasikan menjadi membership function
pada proses fuzzyfikasi.
Contoh transformasi data ke dalam bentuk
fuzzy pada atribut terpilih ialah sebagai berikut:
Atribut penyinaran matahari
Atribut ini dibagi menjadi 4 kelompok. Rendah (x < 25%), sedang (25% <= x < 50%), tinggi (50% <= x < 75%), dan sangat tinggi (x >= 75%). Dari pembagian itu, dapat ditentukan
membership function dari himpunan fuzzy
rendah, sedang, tinggi, dan sangat tinggi untuk atribut penyinaran matahari seperti berikut:
50
;
0
50
40
;
10
40
40
25
;
1
25
15
;
10
15
15
;
0
)
(
x
x
x
x
x
x
x
x
sedang
75
;
0
75
65
;
10
65
65
50
;
1
50
40
;
10
50
40
;
0
)
(
x
x
x
x
x
x
x
x
tinggi
75
;
1
75
65
;
10
75
65
;
0
)
(
x
x
x
x
x
gi sangatting
Himpunan fuzzy untuk atribut penyinaran mataharidigambarkan melalui kurva berbentuk trapesium seperti pada Gambar 3.
Gambar 3 Himpunan fuzzy atribut penyinaran.
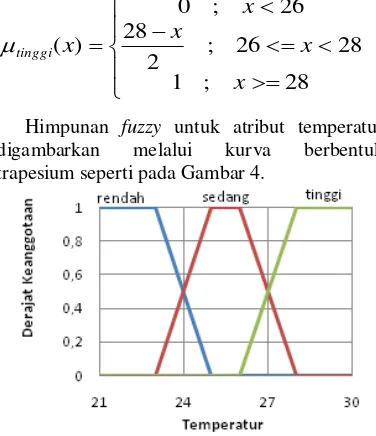
Atribut temperatur
Pada atribut temperatur, dilakukan pem- bagian sebanyak 3 kelompok. Rendah (x < 23
˚C), sedang (23 ˚C <= x < 28 ˚C), dan tinggi (x >= 28 ˚C). Pembagian itu menghasilkan
membership function rendah, sedang, dan tinggi.
25
;
0
25
23
;
2
23
23
;
1
)
(
x
x
x
x
x
rendah
28
;
0
28
26
;
2
26
26
25
;
1
25
23
;
2
25
23
;
0
)
(
x
x
x
x
x
x
x
x
sedang
28
;
1
28
26
;
2
28
26
;
0
)
(
x
x
x
x
x
tinggi
Himpunan fuzzy untuk atribut temperatur digambarkan melalui kurva berbentuk trapesium seperti pada Gambar 4.
Gambar 4 Himpunan fuzzy atribut temperatur.
Atribut curah hujan
Himpunan fuzzy untuk atribut curah hujan digambarkan melalui kurva berbentuk trapesium seperti pada Gambar 5.
Gambar 5 Himpunan fuzzy atribut curah hujan.
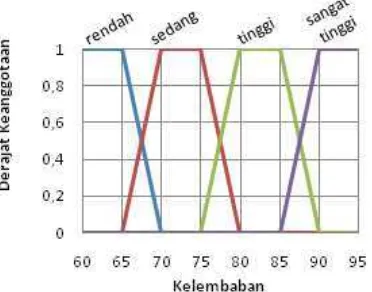
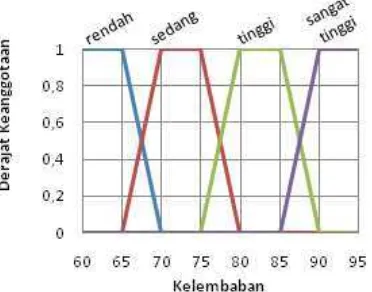
Atribut kelembaban udara
Atribut kelembaban udara dibagi sebanyak 4 kelompok. Rendah (x < 25 %), sedang (25 % <= x < 50 %), tinggi (50 % <= x < 75 %), dan sangat tinggi (x >= 75 %). Pembagian tersebut menghasilkan membership function seperti berikut:
70
;
0
70
65
;
5
65
65
;
1
)
(
x
x
x
x
x
rendah
80
;
0
80
75
;
5
75
75
70
;
1
70
65
;
5
70
65
;
0
)
(
x
x
x
x
x
x
x
x
sedang
90
;
0
90
85
;
5
85
85
80
;
1
80
75
;
5
80
75
;
0
)
(
x
x
x
x
x
x
x
x
tinggi
90
;
1
90
85
;
5
90
85
;
0
)
(
x
x
x
x
x
gi sangatting
Himpunan fuzzy untuk atribut kelembaban udara digambarkan melalui kurva berbentuk trapesium seperti pada Gambar 6.
Gambar 6 Himpunan fuzzy atribut kelembaban.
Atribut hotspot
Atribut hotspot berisi tentang kategori jumlah titik api atau hotspot. Atribut ini merupakan kelas target. Atribut ini diberikan
kode “1” dan “2”. Kelas “1” menunjukkan
bahwa jumlah hotspot sebanyak x ≤ 70. Kelas
“2” menunjukkan jumlah hotspot sebanyak x >
70.
Data atribut temperatur, curah hujan, kelembaban udara, dan penyinaran matahari
kemudian ditransformasikan menjadi bentuk
fuzzy dengan menghitung membership value
berdasarkan membership function pada setiap himpunan atribut. Selanjutnya, nilai yang dipakai di dalam proses pengklasifikasian adalah nilai dari membership value dari masing-masing atribut. Contoh hasil dari proses transformasi dapat dilihat pada Lampiran 3.
Data Mining
Pada tahap ini, dilakukan teknik data mining
menggunakan algoritme FID3 untuk membangun fuzzy decision tree (FDT). Data yang telah ditransformasi dibagi menjadi data latih (training set) dan data uji (test set). Pada penelitian ini, data latih yang digunakan sebanyak 80 % dari keseluruhan (200 record), sedangkan data uji yang digunakan sebanyak 20 % (50 record).
Training
Fase training dilakukan untuk membangun FDT dengan menggunakan algoritme FID3. Tahap training berfungsi untuk memodelkan algoritme yang dipakai dalam proses klasifikasi ini.
mampu merepresentasikan algoritme yang dipakai dengan baik.
Pada contoh training set tersebut, akan diterapkan algoritme fuzzy ID3 untuk mendapatkan model dan aturan klasifikasi. Adapun langkah-langkah pembentukan aturan klasifikasi dengan algoritme fuzzy ID3 adalah sebagai berikut:
1 Membuat root node dari semua data
training yang ada dengan memberi nilai derajat keanggotaan untuk semua record
sama dengan 1.
2 Menghitung fuzzy entropy dan
information gain dari training set yang ada. Hasil perhitungan fuzzy entropy dan
information gain akan ditunjukkan melalui Tabel 3.
Tabel 3 Daftar nilai entropy dan
information gain
Nilai Hasil
Fuzzy Entropy 0.9949
IG Penyinaran (S) 0.0163
IG Temperatur (T) 0.1134
IG Curah Hujan (CH) 0.0449
IG Kelembaban (L) 0.2041
3 Dari hasil perhitungan dipilih nilai
information gain yang terbesar, yaitu atribut Kelembaban. Atribut tersebut akan digunakan untuk mengekspansi tree
sebagai root-node. Namun, pada sub-node berikutnya atribut yang telah digunakan tidak dipakai lagi dalam mengekspansi tree.
4 Data training diekspansi berdasarkan atribut Kelembaban sehingga diperoleh gambar pembentukan tree seperti Gambar 7.
Gambar 7 Hasil ekspansi berdasarkan atribut Kelembaban.
Nilai derajat keanggotaan yang baru masing-masing record pada sub-node diperoleh dari hasil perkalian antara derajat keanggotaan pada root node dan derajat keanggotaan atribut yang digunakan untuk
mengekspansi tree. Misalkan, untuk sub-node dengan nilai atribut rendah, nilai derajat keanggotaan dari data no.73 µl = 0.6
dan derajat keanggotaan dari data no.73 pada root node adalah 1, maka pada node
berikutnya nilai derajat keanggotaannya menjadi
baru
root
node10.60.65 Menghitung proporsi dari setiap kelas yang ada pada tiap-tiap node. Misalkan, untuk sub-node dengan nilai keanggotaan atribut tinggi, proporsi kelasnya adalah:
K1 = 0.7 + 0.5 = 1.2 K2 = 1 + 1 = 2 Proporsi kelas 1
% 5 . 37 % 100 * 2 1 1 K K K
Proporsi kelas 2
% 5 . 62 % 100 * 2 1 2 K K K
6 Pada penelitian ini, digunakan fuzziness control threshold (θr ) sebesar 75% dan
leaf decision threshold (θn) sebesar 3%.
Kedua threshold ini didapatkan dari evaluasi kinerja pada penelitian sebelumnya (Romansyah et al 2009). Kedua threshold ini berfungsi untuk menentukan ekspansi sub-node. Misalkan pada sub-node dengan nilai atribut tinggi. Berdasarkan nilai proporsi kelas 1 (37.5%) dan kelas 2 (62.5%) yang lebih kecil dari θr (75%) dan
banyaknya data atau record pada sub-node tersebut lebih besar dari θn, maka
sub-node tersebut akan terus diekspansi. Lain halnya jika θr yang digunakan
adalah 50%, sub-node tersebut tidak akan diekspansi.
Dari hasil pembentukan tree didapatkan sebanyak 38 rule / aturan yang dapat digunakan untuk mengklasifikasikan suatu data masukan.
Rule yang dihasilkan pada proses training
secara lengkap dapat dilihat pada Lampiran 7.
Testing
Setelah didapatkan model tree secara lengkap, tree kemudian diubah menjadi rule. Langkah berikutnya adalah menguji akurasi dari model tree tersebut. Setiap record data dimasukkan kepada model tree yang sudah terbentuk. Pada penelitian ini, diujikan 50
record data yang sudah disiapkan pada testing set. Akurasi yang didapatkan dari proses
testing ditunjukkan pada Tabel 4.
Nilai akurasi yang didapatkan adalah seperti berikut: 0 3 8 39 0 39
x 100 % = 78 %
Pruning
Perlakuan selanjutnya adalah proses memangkas tree yang disebut dengan pruning.
Pemangkasan ini bertujuan menyederhanakan
rule atau struktur tree yang dihasilkan namun dengan tidak merusak atau mengurangi tingkat akurasi dalam proses klasifikasi.
Secara garis besar, ada dua kaidah pruning.
Pertama, kaidah pre-pruning. Pada kaidah ini, dilakukan pemangkasan sebelum tree terbentuk secara sempurna. Salah satu metode yang menerapkan kaidah ini adalah metode chi-square. Pada metode chi-square, atribut-atribut yang sudah ditentukan sebagai classifier
kemudian dihitung keterkaitannya terhadap atribut kelas yang dimaksud. Di akhir perhitungan, akan didapatkan atribut mana yang bisa dihilangkan atau diabaikan dalam proses klasifikasi.
Kedua, kaidah post pruning. Berbeda dengan sebelumnya, kaidah ini diterapkan pada model tree yang secara sempurna telah terbentuk. Pada penelitian ini, dipilih metode
rule post pruning. Pada metode rule post pruning, model tree diubah ke dalam bentuk
rule. Kemudian, dari setiap rule dilakukan proses penghapusan anteseden dari rule yang menyebabkan penurunan akurasi pada
validation set yang telah ditentukan. Kemudian, langkah berikutnya adalah pengurutan rule
berdasarkan nilai akurasi rule yang terbesar.
Pre-pruning dengan metode chi-square
Pada tahap ini, dilakukan dulu perhi-tungan keterkaitan hubungan antara atribut-atribut yang ada dengan atribut-atribut kelas. Sebagai contoh, hasil perhitungan hubungan atribut Curah Hujan (CH) dengan atribut kelas dapat dilihat pada Tabel 5.
α = 0.05
X2{0.05; (2-1)*(4-1)}={0.05;3} = 7.815 (dilihat dari tabel sebaran chi-square
Walpole 1993)
e11 = (109)*(185)/200 = 100.825
e12 = (109)*(7)/200 = 3.815
e13 = (109)*(5)/200 = 2.725
e14 = (109)*(3)/200 = 1.635
e21 = (91)*(185)/200 = 84.175
e22 = (91)*(7)/200 = 3.185
e23 = (91)*(5)/200 = 2.275
e24 =(91)*(3)/200 = 1.365
Kemudian, nilai setiap elemen perhitungan dimasukkan lagi dalam tabel seperti pada Tabel 6.
Berikutnya, dilakukan operasi matematika terhadap nilai awal dan nilai akhir seperti berikut:
X2 = (96-100.825)2 /100.825 + (7-3.815)2/ 3.815 + (3-2.275)2/2.275 +
(3-1.635)2/1.635 + (89-84.175)2/84.175
+ (0-3.185)2/3.185 + (2-2.275)2 /
2.275 + (0-1.365)2 / 1.365
= 8.92
Tabel 5 Sebaran nilai atribut Curah Hujan
rendah sedang tinggi
sangat
tinggi jumlah
K 1 96 7 3 3 109
K 2 89 0 2 0 91
jumlah 185 7 5 3 200
Tabel 4 Confusion matrix hasil uji pada tree
Prediksi
Kel.1 Kel.2
Aktual Kel.1 39 8
Kel.2 3 0
Tabel 6 Sebaran nilai atribut Curah Hujan setelah perhitungan
rendah sedang tinggi
sangat
tinggi jumlah
K 1 100.825 3.815 2.725 1.635 109
K 2 84.175 3.185 2.275 1.365 91
Tabel 7 Confusion matrix hasil uji pada tree
dengan pruning chi square
Prediksi
Kel.1 Kel.2
Aktual Kel.1 40 7
Kel.2 3 0
Tabel 8 Confusion matrix hasil uji pada tree
dengan rule post pruning
Prediksi
Kel.1 Kel.2
Aktual Kel.1 Kel.2 39 3 8 0
Tampak pada hasil perhitungan bahwa
X2dari hasil hitung lebih besar dari X2dari tabel sehingga atribut Curah Hujan (CH) tidak bisa diabaikan atau dihilangkan dalam proses klasifikasi.
Dari proses perhitungan seluruh atribut yang menjadi classifier dalam penelitian ini, didapatkan kesimpulan bahwa atribut yang bisa diabaikan atau dihilangkan dalam proses klasifikasi adalah atribut Penyinaran (S). Langkah selanjutnya adalah dilakukan pengembangan model tree tanpa menyertakan atribut tersebut.
Dari proses pruning dengan metode chi-square, didapatkan 17 rule. Rule yang di-hasilkan pada proses pruning dengan chi square secara lengkap dapat dilihat pada Lampiran 8. Hasil dari pruning dengan me-tode chi-square kemudian diuji dengan
testing set. Data uji atau testing set sebanyak 50 record diujicobakan terhadap tree yang terbentuk. Hasil akurasi pada metode chi square pruning dapat dilihat pada Tabel 7.
Nilai akurasi yang didapatkan adalah seperti berikut: 0 3 7 40 0 40
x 100 % = 80 %
Post pruning dengan metode rule post
Sebelum memasuki pruning dengan metode ini, perlu disiapkan validation set. Validation set merupakan bagian dari
training set yang digunakan sebagai evaluasi awal terhadap rule yang terbentuk sebelum pada akhirnya diujikan terhadap testing set.
Pada penelitian ini, disiapkan 25 record validation set.
Pruning dilakukan terhadap rule yang sudah terbentuk pada tree sebelum dipangkas. Kemudian, anteseden di-hilangkan satu per satu dengan tetap melihat tingkat akurasinya. Berikutnya adalah memberi peringkat terhadap rule yang terbentuk bergantung pada nilai akurasi terbesar di dalam mengklasifikasikan
validation set. Hasilnya adalah didapatkan 26 rule dengan nilai akurasi terbesar sebesar 100 % pada rule“If L tinggi AND T tinggi
AND CH sedang THEN Kelas 1.” dan nilai
akurasi terkecil sebesar 85.7 % pada rule“If
L tinggi AND T sedang AND S rendah
THEN Kelas 1”. Hasil pruning dengan
metode rule post pruning kemudian diujikan terhadap testing set. Hasil akurasi pada metode rule post pruning dapat dilihat pada Tabel 8.
Nilai akurasi yang didapatkan adalah seperti berikut: 0 3 8 39 0 39
x 100 % = 78 %
Perbandingan akurasi dari model tree
sebelum dan sesudah mendapat perlakuan
pruning akan ditunjukkan oleh Tabel 9.
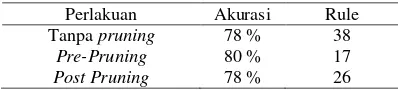
Tabel 9 Daftar nilai akurasi tree
Perlakuan Akurasi Rule
Tanpa pruning 78 % 38
Pre-Pruning 80 % 17
Post Pruning 78 % 26
Nilai akurasi pada tiap-tiap perlakuan pada Tabel 9 menunjukkan bahwa tree yang terbentuk pada awal ekspansi (tree tanpa
pruning) mengalami suatu gejala overfitting.
Hal ini terbukti dengan kondisi ukuran tree
yang besar ataupun rule yang kompleks, justru tidak memberikan nilai akurasi yang baik dalam proses klasifikasi. Karenanya, tree dengan gejala overfitting perlu di-prune. Dari hasil penelitian, dapat diketahui bahwa proses
pruning bisa meningkatkan tingkat akurasi secara signifikan.
Dari ketiga perlakuan di atas, terlihat bahwa
tree dengan perlakuan pre-pruning chi square
menghasilkan nilai akurasi terbesar dibanding-kan dengan tree tanpa proses pruning dan tree
dengan perlakuan rule post pruning sehingga hasil akhir dari penelitian ini didapatkan 17 aturan / rule yang bisa mengklasifikasikan jumlah hotspot berdasarkan pada pola nilai atribut data iklim yang dipakai dengan akurasi sebesar 80 %.
tanpa pruning, didapatkan 38 rule, sedangkan pada tree dengan perlakuan rule post pruning
didapatkan rule sebanyak 26 buah. Dengan rule post pruning, tree dapat dipahami dengan lebih mudah dan ringkas.
Dari ketiga perlakuan di atas, didapatkan juga suatu ruleyang konstan, yaitu “If L rendah
THEN Kelas 2” dan “If L sangat tinggi THEN
Kelas 1”. Kedua rule ini menyatakan bahwa
tingkat kelembaban suatu daerah berbanding terbalik dengan jumlah hotspot yang dihasilkan di daerah tersebut. Rule yang serupa didapatkan dari hasil penelitian sebelumnya (Apriyani 2011). Di antaranya ialah “If Kelembaban tinggi
Then Jumlah Hotspot sedikit” dengan nilai
confidence sebesar 89,29%. Dengan kata lain, semakin rendah nilai kelembaban menghasilkan jumlah hotspot yang semakin banyak. Sebaliknya, semakin tinggi nilai kelembaban di suatu daerah akan menghasilkan jumlah hotspot
yang semakin sedikit.
KESIMPULAN DAN SARAN
Kesimpulan
Dari percobaan yang dilakukan terhadap data iklim dan titik api didapatkan beberapa kesimpulan sebagai berikut:
1 Algoritme FID3 dapat diterapkan pada proses klasifikasi jumlah titik api (hotspot) berdasarkan nilai atribut data iklim.
2 Didapatkan model aturan (rule) yang bisa digunakan untuk memprediksi jumlah titik api berdasarkan atribut-atribut yang telah disertakan.
3 Dari aturan yang dihasilkan, dapat diketahui suatu hubungan jumlah hotspot
yang terbentuk berbanding terbalik dengan tingkat kelembaban udara yang mempengaruhinya.
4 Melalui penelitian ini, ditunjukkan bahwa proses pruning bisa meningkatkan akurasi tree dalam upaya klasifikasi atau mereduksi jumlah rule
yang terbentuk namun tetap dengan akurasi yang sama.
Saran
Pada penelitian ini, masih terdapat beberapa kekurangan yang bisa diperbaiki pada penelitian selanjutnya. Beberapa saran yang dapat dilakukan antara lain:
1 Memperhitungkan variabel luasan daerah yang diteliti atau menggunakan tambahan data spasial.
2 Menambah atribut yang menjadi
classifier.
3 Menggunakan bantuan konsep clustering
di dalam penyusunan membership function.
4 Sistem yang dipakai mampu menampilkan hasil klasifikasi dari ketiga perlakuan tree sehingga pengguna mam-pu melakukan perbandingan dari hasil ketiga perlakuan tree.
DAFTAR PUSTAKA
Apriyani D. 2011. Fuzzy association rules mining pada data klimatologi dan jumlah
hotspot di Kalimantan Tengah dan Kalimantan Selatan [skripsi]. Bogor: Fakultas Matematika dan Ilmi Pengetahuan Alam, Institut Pertanian Bogor.
Budi M, Karyadin R, Hartono SW. 2010. Perbandingan algoritme pruning pada
decision tree yang dikembangkan dengan algoritme CART. Jurnal Ilmiah Ilmu Komputer 15(2): 7-13.
Kamber M, Han J. 2001. Data Mining Concepts & Techniques. San Fransisco: Morgan Kaufman.
Liang G. 2005. A Comparative Study of Three Decision Tree algorithms: ID3, Fuzzy ID3, and Probabilistic Fuzzy ID3. Rotterdam: Informatics & Economics Erasmus University Rotterdam.
Marsala C. 1998. Application of Fuzzy Rule Induction to data Mining. Paris: University Pierre et Marie Curie.
Mitchell TM. 1997. Machine Learning.
Houston: McGraw Hill.
Rhyne RD, Smith JF. 1999. A Resource Manager for Distributed Resources: Fuzzy Decision Trees and Genetic Optimization.
Las Vegas: CSREA Press.
Romansyah F, Sitanggang IS, Nurdiati S. 2009.
Fuzzy decision tree dengan algoritme ID3 pada data diabetes. Internetworking Indonesia Journal 1(2) : 2-13.
Smith JF. 2003. Fuzzy Logic Resource Manager: Evolving Fuzzy Decision Tree Structure that Adapts in Real-Time.
Washington: Naval Research.
Suyanto. 2008. Soft Computing: Membangun Mesin ber-IQ Tinggi. Bandung: Informatika.
Tan S, Kumar P, Steinbach M. 2005.
Thoha AS. 2008. Penggunaan data hotspot
untuk monitoring kebakaran hutan dan lahan di Indonesia. http://repository.usu.ac.id/ bitstream/123456789/919/1/132259563(1).p df. [5 Jul 2012].
Walpole R.E. 1993. Pengantar Statistika. Rahmat F, penerjemah. Jakarta: Gramedia Pustaka Utama. Terjemahan dari:
Introduction of Statistics.
Lampiran 2 Contoh data hasil proses pembersihan data
ID
Temperatur
Curah Hujan
Penyinaran
Kelembaban Kelas
1
27 2 81 831
2
26 2 33 911
3
25 17 28 911
4
26 11 71 871
5
26 5 51 871
6
24 56 0 911
7
27 17 66 831
8
25 1 28 911
9
26 8 92 851
10
26 18 75 851
11
25 34 0 961
12
26 81 76 871
Lampiran 3 Contoh data hasil proses fuzzyfikasi dan data training
ID Sinar MF rend ah
MF seda ng
MF tinggi
MF sangat tinggi
Tem perat ur
MF ren dah
MF sed ang
MF tinggi
Cura h hujan
MF ren dah
MF sed ang
MF tin ggi
MF sanga t tinggi
Kele mbab an
MF ren dah
MF sed ang
MF tinggi
MF sangat tinggi
Kelas
hotspot
1 81 0 0 0 1 27 0 0,2 0,8 2 1 0 0 0 83 0 0 0 1 1
2 33 0 1 0 0 26 0 0,1 0,9 2 1 0 0 0 91 0 0 0 1 1
3 28 0 1 0 0 25 0 1 0 17 0,3 0,7 0 0 91 0 0 0 1 1
4 71 0 0 0,6 0,4 26 0 0,1 0,9 11 0,9 0,1 0 0 87 0 0 0 1 1
5 51 0 0 1 0 26 0 0,1 0,9 5 1 0 0 0 87 0 0 0 1 1
6 0 1 0 0 0 24 0 1 0 56 0 0 1 0 91 0 0 0 1 1
7 66 0 0 0,1 0,9 27 0 0,2 0,8 17 0,3 0,7 0 0 83 0 0 0 1 1
8 28 0 1 0 0 25 0 1 0 1 1 0 0 0 91 0 0 0 1 1
9 92 0 0 0 1 26 0 0,1 0,9 8 1 0 0 0 85 0 0 0 1 1
Lampiran 5 Struktur tree setelah chi square pruning.
Lampiran 6 Struktur tree setelah rule post pruning.
Lampiran 7 Aturan (rule) yang dihasilkan pada tree tanpa pruning.
1. If L rendah THEN Kelas 2.
2. If L sedang AND CH rendah AND T rendah THEN Kelas 1.
3. If L sedang AND CH rendah AND T sedang AND S rendah THEN Kelas 1.
4. If L sedang AND CH rendah AND T sedang AND S sedang THEN Kelas 2.
5. If L sedang AND CH rendah AND T sedang AND S tinggi THEN Kelas 1.
6. If L sedang AND CH rendah AND T sedang AND S sangat tinggi THEN Kelas 1.
7. If L sedang AND CH rendah AND T tinggi AND S rendah THEN Kelas 1.
8. If L sedang AND CH rendah AND T tinggi AND S sedang THEN Kelas 2.
9. If L sedang AND CH rendah AND T tinggi AND S tinggi THEN Kelas 1.
10. If L sedang AND CH rendah AND T tinggi AND S sangat tinggi THEN Kelas 1.
11. If L sedang AND CH sedang THEN Kelas 1.
12. If L sedang AND CH tinggi THEN Kelas 1.
13. If L sedang AND CH sangat tinggi THEN Kelas 1.
14. If L tinggi AND T rendah THEN Kelas 1.
15. If L tinggi AND T sedang AND S rendah AND CH rendah THEN Kelas 1.
16. If L tinggi AND T sedang AND S rendah AND CH sedang THEN Kelas 1.
17. If L tinggi AND T sedang AND S rendah AND CH tinggi THEN Kelas 1.
18. If L tinggi AND T sedang AND S rendah AND CH sangat tinggi THEN Kelas 1.
19. If L tinggi AND T sedang AND S sedang AND CH rendah THEN Kelas 1.
20. If L tinggi AND T sedang AND S sedang AND CH sedang THEN Kelas 1.
21. If L tinggi AND T sedang AND S sedang AND CH tinggi THEN Kelas 1.
22. If L tinggi AND T sedang AND S sedang AND CH sangat tinggi THEN Kelas 1.
23. If L tinggi AND T sedang AND S tinggi AND CH rendah THEN Kelas 1.
24. If L tinggi AND T sedang AND S tinggi AND CH sedang THEN Kelas 1.
25. If L tinggi AND T sedang AND S tinggi AND CH tinggi THEN Kelas 1.
26. If L tinggi AND T sedang AND S tinggi AND CH sangat tinggi THEN Kelas 1.
27. If L tinggi AND T sedang AND S sangat tinggi AND CH rendah THEN Kelas 1.
28. If L tinggi AND T sedang AND S sangat tinggi AND CH sedang THEN Kelas 1.
29. If L tinggi AND T sedang AND S sangat tinggi AND CH tinggi THEN Kelas 1.
30. If L tinggi AND T sedang AND S sangat tinggi AND CH sangat tinggi THEN Kelas 1.
31. If L tinggi AND T tinggi AND CH rendah AND S rendah THEN Kelas 1.
32. If L tinggi AND T tinggi AND CH rendah AND S sedang THEN Kelas 2.
33. If L tinggi AND T tinggi AND CH rendah AND S tinggi THEN Kelas 1.
34. If L tinggi AND T tinggi AND CH rendah AND S sangat tinggi THEN Kelas 1.
35. If L tinggi AND T tinggi AND CH sedang THEN Kelas 1.
36. If L tinggi AND T tinggi AND CH tinggi THEN Kelas 1.
37. If L tinggi AND T tinggi AND CH sangat tinggi THEN Kelas 1.
Lampiran 8 Aturan yang dihasilkan pada tree dengan metode chi square pruning.
1. If L rendah THEN Kelas 2.
2. If L sedang AND CH rendah AND T rendah THEN Kelas 1.
3. If L sedang AND CH rendah AND T sedang THEN Kelas 1.
4. If L sedang AND CH rendah AND T tinggi THEN Kelas 1.
5. If L sedang AND CH sedang THEN Kelas 1.
6. If L sedang AND CH tinggi THEN Kelas 1.
7. If L sedang AND CH sangat tinggi THEN Kelas 1.
8. If L tinggi AND T rendah THEN Kelas 1.
9. If L tinggi AND T sedang AND CH rendah THEN Kelas 1.
10.If L tinggi AND T sedang AND CH sedang THEN Kelas 1.
11.If L tinggi AND T sedang AND CH tinggi THEN Kelas 1.
12.If L tinggi AND T sedang AND CH sangat tinggi THEN Kelas 1.
13.If L tinggi AND T tinggi AND CH rendah THEN Kelas 1.
14.If L tinggi AND T tinggi AND CH sedang THEN Kelas 1.
15.If L tinggi AND T tinggi AND CH tinggi THEN Kelas 1.
16.If L tinggi AND T tinggi AND CH sangat tinggi THEN Kelas 1.
Lampiran 9 Aturan yang dihasilkan pada tree dengan metode rule post pruning.
1.If L rendah THEN Kelas 2.
2.If L sedang AND CH rendah AND T rendah THEN Kelas 1.
3.If L sedang AND CH rendah AND T sedang AND S rendah THEN Kelas 1.
4.If L sedang AND CH rendah AND T sedang AND S sedang THEN Kelas 2.
5.If L sedang AND CH rendah AND T sedang AND S tinggi THEN Kelas 1.
6.If L sedang AND CH rendah AND T sedang AND S sangat tinggi THEN Kelas 1.
7.If L sedang AND CH rendah AND T tinggi AND S rendah THEN Kelas 1.
8.If L sedang AND CH rendah AND T tinggi AND S sedang THEN Kelas 2.
9.If L sedang AND CH rendah AND T tinggi AND S tinggi THEN Kelas 1.
10.If L sedang AND CH rendah AND T tinggi AND S sangat tinggi THEN Kelas 1.
11. If L sedang AND CH sedang THEN Kelas 1.
12.If L sedang AND CH tinggi THEN Kelas 1.
13. If L sedang AND CH sangat tinggi THEN Kelas 1.
14. If L tinggi AND T rendah THEN Kelas 1.
15. If L tinggi AND T sedang AND S rendah THEN Kelas 1.
16. If L tinggi AND T sedang AND S sedang THEN Kelas 1.
17. If L tinggi AND T sedang AND S tinggi THEN Kelas 1.
18. If L tinggi AND T sedang AND S sangat tinggi THEN Kelas 1.
19. If L tinggi AND T tinggi AND CH rendah AND S rendah THEN Kelas 1.
20. If L tinggi AND T tinggi AND CH rendah AND S sedang THEN Kelas 2.
21. If L tinggi AND T tinggi AND CH rendah AND S tinggi THEN Kelas 1.
22. If L tinggi AND T tinggi AND CH rendah AND S sangat tinggi THEN Kelas 1.
23. If L tinggi AND T tinggi AND CH sedang THEN Kelas 1.
24. If L tinggi AND T tinggi AND CH tinggi THEN Kelas 1.
25. If L tinggi AND T tinggi AND CH sangat tinggi THEN Kelas 1.
ABSTRACT
AKHMAD AKBAR. Pruning on Fuzzy Decision Tree in Classification of Climatology and Hotspot at Tjilik Riwut, Palangkaraya, South Kalimantan. Supervised by ANNISA.
Forest fire is influenced by several factors, such as humidity, solar radiation intensity, regional temperature, and rainfall. This research aimed at finding the information and knowledge from hotspot and climate data, especially those four attributes. The research data was taken from Tjilik Riwut, Palangkaraya, South Kalimantan in year 2001-2004. Data mining technique used for extracting the information and knowledge is classification using decision tree method. In this research, fuzzy aproach is adapted to solve uncertainty of data. To improve the accuracy of classification process, pruning tree method is utilized. Tree that has the highest accuracy is converted to be the rule. The formed rule shows that the amount of hotspot is inversely proportional with the scale of humidity. This research also proves that pruning process in a tree can improve the accuracy of classification process.
PENDAHULUAN
Latar BelakangKasus kebakaran hutan di Indonesia merupakan salah satu bencana alam yang sering terjadi. Beberapa faktor cuaca yang mempengaruhinya ialah temperatur, curah hujan, radiasi matahari, kelembaban, stabilitas udara, kecepatan angin dan arah angin secara langsung (Thoha 2001 dalam Dedek 2011).
Indikator kebakaran hutan yang bisa dijadikan acuan adalah jumlah titik api (hotspot). Hotspot merupakan titik-titik di permukaan bumi yang menjadi indikator adanya kebakaran hutan dan lahan. Salah satu cara pencegahan kebakaran hutan yang dapat dilakukan adalah dengan mengetahui hubungan antara faktor cuaca yang ada di suatu wilayah dengan jumlah hotspot yang muncul. Metode klasifikasi dengan menggunakan decision tree
dapat digunakan untuk membuat sebuah
classifier yang berguna untuk melihat pola / hubungan tersebut.
Data iklim dan hotspot sering kali tidak bisa didekati melalui pendekatan crisp (tegas). Hal ini dikarenakan nilai atribut yang sangat berdekatan mampu memberi pengaruh yang berbeda di dalam pembentukan hotspot. Untuk mengatasi hal tersebut, diperlukan pendekatan dengan kaidah fuzzy. Penerapan kaidah fuzzy di dalam suatu decision tree sering dikenal sebagai fuzzy decision tree.
Hasil dari klasifikasi dapat dilihat dari tingkat akurasi yang dihasilkan. Namun, sering kali model decision tree yang dihasilkan mengalami masalah overfitting. Overfitting di dalam decision tree menghasilkan suatu ke-adaan yang lebih kompleks daripada yang diperlukan. Hal ini juga membuat tingkat akurasi yang dihasilkan tidak cukup baik untuk mengklasifikasikan data baru. Oleh karena itu, diperlukan cara untuk meningkatkan akurasi dari model tree yang dihasilkan.
Salah satu metode yang bisa digunakan untuk meningkatkan akurasi dari tree adalah
pruning. Pruning bekerja dengan prinsip memangkas atau menyederhanakan struktur
tree. Pruning diharapkan mampu meningkatkan akurasi yang dihasilkan dalam proses klasifikasi secara signifikan.
Penelitian ini mencoba menemukan hubungan antara faktor-faktor cuaca dengan jumlah hotspot yang dibentuknya menggunakan teknik klasifikasi menggunakan konsep fuzzy
dengan metode decision tree. Untuk meningkatkan akurasi dalam proses klasifikasi,
diterapkan juga metode pruning. Model tree
dengan nilai akurasi tertinggi diharapkan mampu memberikan suatu model atau aturan yang bisa mengklasifikasikan jumlah hotspot
berdasarkan pola pada iklim di daerah tersebut.
Tujuan
Tujuan dari penelitian ini adalah:
1 Menerapkan teknik data mining berupa klasifikasi dengan metode fuzzy decision tree.
2 Menerapkan teknik pruning pada tree.
3 Menemukan aturan klasifikasi pada data titik api (hotspot) sehingga dapat diketahui kelas jumlah hotspot berdasarkan pada pola data iklim di daerah tersebut.
Ruang Lingkup
Ruang lingkup penelitian ini dibatasi pada:
1 Penerapan algoritme ID3 dalam Fuzzy Decision T