SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
MOCHAMAD INDRA FAIZAL
10110389
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
iii
Asslaamu’alaikum wr.wb,
Alhamdulillahi Rabbil alamiin, segala puji dan syukur kita panjatkan kepada Allah SWT atas berkat, rahmat, taufik dan hidayah-Nya, penyusunan
skripsi yang berjudul “IMPLEMENTASI DATA MINING PADA
PENJUALAN PRODUK DI HUMBLEZING COMPANY
MENGGUNAKAN METODE ASSOCIATION RULE” dapat diselesaikan dengan baik.
Dalam penyusunan laporan tugas akhir ini, penulis menyadari bahwa masih banyak kekurangan dan jauh dari kata sempurna. Namun penulis berharap laporan tugas akhir ini dapat berguna khususnya bagi penulis dan umumnya bagi pembaca. Sesungguhnya banyak sekali pelajaran yang didapatkan penulis dalam proses penulisan skripsi ini, baik dari sisi formal, mental maupun non-formal. Hal tersebut merupakan hal yang sangat dan paling berharga yang merupakan karunia dari Allah SWT dan akan selalu dikenang oleh penulis. Tidak lupa saya mengucapkan terima kasih sebesar-besarnya karena berkat bantuan dan dukungan dari berbagai pihak tugas akhir ini dapat terselesaikan sebagai mana mestinya. Untuk itu saya mengucapkan terimakasih yang sebesar – besarnya kepada :
1. Allah SWT yang selalu memberikan rahmat dan segala kemudahan saat pembuatan tugas akhir ini.
2. Keluarga yang sangat amat saya cinta yakni Orang tua saya Bapak Saepuloh dan Ibu Herni serta kakak dan adik-adik penulis yang telah tulus selalu mendoakan, memberikan dorongan moril dan materil, masukan, perhatian, dukungan sepenuhnya, dan kasih sayang yang tidak ternilai.
3. Ibu Dian Dharmayanti, S.T., M.Kom. selaku pembimbing yang telah mengarahkan dan membimbing penulis dalam proses pengerjaan tugas akhir ini. 4. Bapak Alif Finandhita, S.Kom., M.T. selaku dosen penguji 1 dan Ibu Nelly
iv
menenangkan dan menjadikan lebih percaya diri.
7. Humblezing Company sebagai distro tempat penulis melakukan penelitian, terima kasih telah memberikan kesempatan untuk penulis.
8. Sodara Ridho Khusnul Fadhil selaku Owner dari Humblezing Company yang memberikan ijin untuk melakukan penelitian.
9. Imam Arif S selaku teman yang telah memberikan jalan untuk penulis melakukan penelitian di tempat dia bekerja sehingga akhirnya penulis dapat menyesaikan tugas akhir ini dengan penuh kelancaran.
10. Taufik Hilman, Enjang Rachmat yang berjuang bersama – sama selama beberapa bulan ini dan sangat giat dalam pengerjaan untuk tugas akhir.
11. Rachmat Setiawan, Ferry Andriansyah, Al Yasser, Hadis Muharram, Hegi, Anton, Aldi, Tito, Tania Nur Karlina dan teman-teman dari Cules Unikom yang selalu membuat hari-hari penulis penuh tawa dan kebahagiaan serta selalu memberikan suntikan semangat kepada penulis.
12. Teman – teman kelas IF-9 angkatan 2010 yang telah bersama – sama melawati masa kuliah terima kasih untuk kebersamaan dan asam manis masa-masa kuliah. 13. Teman-teman satu bimbingan. Farlan, Dian kusuma, Resa Tresnadi, Aprisal, dan
lainnya. yang selalu memberikan motivasi dan kebersamaannya serta masukan-masukan untuk penulis agar terus maju menjalani tugas akhir.
14. Pihak – pihak lain yang juga membantu penulis untuk dapat menyelesaikan tugas akhir ini yang tidak dapat disebutkan satu per satu.
v
Bandung, 20 Agustus 2015
vi
ABSTRACT ... ii
KATA PENGANTAR ... iii
DAFTAR ISI ... vi
DAFTAR GAMBAR ... ix
DAFTAR TABEL ... x
DAFTAR SIMBOL ... xii
DAFTAR LAMPIRAN ... xiii
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Identifikasi Masalah ... 2
1.3 Maksud dan Tujuan ... 2
1.4 Batasan Masalah ... 3
1.5 Metodologi Penelitian ... 3
1.5.1 Metode Pengumpulan Data ... 4
1.5.2 Metode Penelitian Data Mining ... 4
1.5.3 Metode Pembangunan Perangkat Lunak ... 6
1.6 Sistematika Penulisan ... 8
BAB 2 TINJAUAN PUSTAKA ... 11
2.1 Profil Perusahaan ... 11
2.1.1 Visi dan Misi Perusahaan ... 11
2.1.2 Struktur Organisasi Perusahaan ... 12
vii
2.2.3 Database Management System (DBMS) ... 16
2.2.4 Data Mining ... 18
2.2.5 Association Rule ... 24
2.2.6 Algoritma FP-Growth ... 26
2.2.7 DFD (Data Flow Diagram) ... 30
2.2.8 Kamus Data (Data Dictionary) ... 32
2.2.9 MySQL ... 32
2.2.10 Microsoft Visual Studio .Net dan C# (Sharp) ... 33
BAB 3 ANALISIS DAN PERANCANGAN SISTEM ... 35
3.1 Analisis Sistem ... 35
3.1.1 Analisis Masalah ... 35
3.1.2 Analisis Penerapan Metode Data Mining... 36
3.2 Analisis Spesifikasi Kebutuhan Perangkat Lunak ... 54
3.2.1 Analisis Kebutuhan Non Fungsional ... 54
3.2.2 Analisis Kebutuhan Fungsional ... 57
3.3 Perancangan Arsitektur ... 69
3.3.1 Perancangan Struktur Menu ... 69
3.3.2 Perancangan Antarmuka ... 70
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM ... 75
4.1 Implementasi Sistem ... 75
4.1.1 Implementasi Perangkat Keras ... 75
viii
4.2.1 Rencana Pengujian ... 77
BAB 5 KESIMPULAN DAN SARAN ... 85
5.1 Kesimpulan ... 85
5.2 Saran ... 85
87
DAFTAR PUSTAKA
[1] Han, J dan Kamber, M., “Data Mining Concept and Technique”, Morgan Kaufmann, 2001.
[2] B. Santoso, “Data Mining: Teknik Pemanfaatan Data Untuk Keperluan
Bisnis”. Yogyakarta: Graha Ilmu, 2007.
[3] A. Dodiet, “Peneliatian Deskriptif”, 2009.
[4] Pete Chapman, Julian Clinton, Randy Kerber, Thomas Khabaza,
Thomas Reinartz, Colin Shearer, and Rüdiger Wirth. “CRISP-DM 1.0 Step-by-step data mining guides”. 2000
[5] Nur ichan. “waterfall dan prototyping”. nurichsan.blog.unsoed.ac.id, November 2010.
[6] Tan, P., dan Steinbach, M., “intoduction to Data Mining”, Addison Wesley, 2006.
[7] Ramon A. Mata Toledeo, Pailine K. Cushman, “Dasar-dasar Database
Relasional”. Jakarta : Airlangga, 2007.
[8] Iko Pramudiono, “Pengantar Data Mining : Menambang Permata
Pengetahuan di Gunung Data”, IlmuKomputer.com, 2003.
[9] J. Santoni, “Implementasi Data Mining Dengan Metode Market Basket Analysis”, Teknologi Informasi dan Pendidikan, vol. 5, p.2, September, 2012.
[10] d. E. T. L. K, “ALGORITMA DATA MINING”. Yogyakarta: Andi, 2009.
[11] D. T. Larose, DATA MINING METHODS AND MODELS, New Jersey: John Wiley & Sons, Inc, 2006.
[12] Han J, Pei, J., Yin, Y. “Mining Frequent Patterns without Candidate
Generation”, 2000.
1
Humblezing Company merupakan salah satu indutri kreatif yang bergerak di bidang fashion brand. Sebagai industri yang berdiri sejak tahun 2010, Humblezing Company telah banyak memasarkan produk dengan berbagai macam design. Jenis produk yang di produksi Humblezing Company sendiri ada beberapa macam diantaranya yaitu jaket, kemeja, baju dan celana. Proses produksinya sendiri dilakukan pada bulan sebelumnya untuk dipasarkan pada bulan berikutnya. Dalam kegiatan penjualannya, Humblezing Company tidak terpaku hanya kepada konsumen yang datang ke toko tetapi juga menerima pesanan secara online. Ini tentunya akan menghasilkan data penjualan yang banyak. Akan tetapi data penjualan tersebut tidak dimanfaatkan untuk dasar pendukung keputusan pemilihan produk sebagai bahan promosi, tidak lain hanya sebagai laporan lalu disimpan sebagai arsip.
Humblezing Company biasa mengkombinasi beberapa jenis produk berbeda untuk dipromosikan dalam jejaring sosial maupun website. Namun banyaknya produk yang dihasilkan membuat Humblezing Company kesulitan dalam menentukan pemilihan produk. Saat ini proses pemilihan produk masih dilakukan secara acak serta berdasarkan produk yang penjualannya tinggi saja, ini kerap kali berdampak pada target yang diinginkan tidak sesuai dengan yang diharapkan, karena tidak semua produk yang dipromosikan diminati oleh konsumen meskipun produk tersebut penjualannya paling tinggi, ini diakibatkan oleh kesalahan dalam pemilihan kombinasi produk.
Association rule bertujuan menunjukan nilai asosiatif antara produk-produk yang dibeli oleh konsumen sehingga terlihatlah sebuah pola berupa produk apa saja yang sering dibeli secara bersamaan dalam sebuah transaksi penjualan. Dengan mengetahui produk apa saja yang sering dibeli secara bersamaan, dapat dibuat sebuah dasar keputusan untuk menentukan produk apa saja yang diminat konsumen untuk dikombinasikan sebagai bahan promosi serta memberikan informasi pola pembelian konsumen[2].
Berdasarkan pertimbangan penjelasan yang telah dipaparkan diatas, maka perlu
dibuat sebuah Aplikasi “Implementasi Data Mining Pada Penjualan Produk Di Humblezing Company Menggunakan Metode Association Rule“ untuk mengatasi permasalahan yang dihadapi oleh Humblezing Company.
1.2 Identifikasi Masalah
Dari penjelasan yang telah dipaparkan dalam latar belakang terdapat masalah yang teridentifikasi yaitu :
Bagaimana membangun Aplikasi untuk mengimplementasikan Data Mining Pada Penjualan Produk Di Humblezing Company menggunakan Metode Association Rule.
1.3 Maksud dan Tujuan
Berdasarkan permasalahan yang diteliti, maka maksud dari penulisan tugas akhir ini adalah untuk membangun Aplikasi Implementasi Data Mining Pada Penjualan Produk Di Humblezing Company menggunakan Metode Association Rule.
Sedangkan tujuan khusus untuk di capai dalam penelitian ini antara lain :
1. Membantu Humblezing Company dalam mengetahui pola penjualan produk dari konsumen.
1.4 Batasan Masalah
Batasan masalah tentunya perlu dalam suatu penelitian karena data mining itu sendiri melibatkan banyak data. Batasan-batasan ini agar masalah lebih terfokus kepada tujuan dan masalah tidak melebar. Batasan masalah yang diterapkan adalah sebagai berikut:
1. Data yang dianalisa merupakan data penjualan produk yang dilakukan Humblezing Company.
2. Algoritma yang digunakan adalah Algoritma FP-Growth dengan menerapkan struktur data tree atau FP-Tree.
3. Aplikasi ini dibangun berbasis desktop.
4. Bahasa pemrograman yang di pakai C# dengan microsoft visual studio 2010 sebagai aplikasi interface system dan database menggunakan MySQL.
5. Metode analisis yang digunakan adalah metode aliran terstruktur dimana tools yang digunakan adalah Data Flow Diagram(DFD) dan Entity Relationship Diagram (ERD).
1.5 Metodologi Penelitian
Metodologi yang digunakan dalam penelitian ini adalah deskriptif[3]. Metode deskriptif merupakan suatu metode penelitian yang bertujuan untuk mendapatkan gambaran yang jelas tentang hal-hal yang dibutuhkan dan berusaha menggambarkan serta menginterpretasi objek yang sesuai dengan fakta secara sistematis, faktual dan akurat.
1.5.1 Metode Pengumpulan Data
Metode yang digunakan dalam penulisan dalam penelitian ini adalah sebagai berikut :
1. Studi Literatur
Studi literatur merupakan pengumpulan data dengan cara mempelajari sumber kepustakaan diantaranya hasil penelitian, jurnal, paper, buku referensi, dan bacaan-bacaan yang ada kaitannya dengan Data Mining, Association Rule, dan Algoritma FP-Growth.
2. Wawancara
Tahap pengumpulan data dengan cara tanya jawab langsung dengan pihak Humblezing Company dan staf terkait permasalahan yang diambil.
1.5.2 Metode Penelitian Data Mining
Gambar 1. 1 Metode CRISP-DM
Berikut ini adalah penjelasan mengenai enam tahap siklus hidup pengembangan data mining berdasarkan gambar di atas :
1. Business Understanding
Tujuan bisnis humblezing company, memasarkan produk secara langsung atau online untuk memenuhi permintaan konsumen. Sedangkan tujuan dari proses mining-nya adalah mengetahui pola penjualan produk yg sering terjual bersama untuk dijadikan dasar dalam penentuan pemilihan kombinasi produk. 2. Data Understanding
Tahap ini dimulai dengan pengumpulan data, sumber data yang didapat dalam penelitian ini merupakan data transaksi penjualan yang terjadi di humblezing company selama bulan Desember 2014. Data yang digunakan dalam proses analisa berupa file excel dengan format *.xlsx.
3. Data Preparation
atribut dan pembersihan data. Atribut dan data yang tidak mengacu pada tujuan data mining akan dihilangkan.
4. Modeling
Dalam tahap ini akan dilakukan pemilihan dan penerapan berbagai teknik pemodelan dan beberapa parameternya akan disesuaikan untuk mendapatkan nilai yang optimal. Pemodelan dilakukan menggunakan metode Association Rule dengan menggunakan algoritma FP-Growth dalam pencarian frekuensi itemset-nya.
5. Evaluation
Pada tahap ini, dilakukan evaluasi terhadap model yang digunakan, apakah dengan Association Rule dengan algoritma FP-Growth cukup efektif dalam mencapai tujuan yang ditetapkan pada tahap business understanding.
6. Deployment
Pada tahap ini, pengetahuan atau informasi yang telah diperoleh akan diatur dan dipresentasikan dalam bentuk tabel yang menunjukan hasil analisa pada data transaksi penjualan.
1.5.3 Metode Pembangunan Perangkat Lunak
Metode yang akan digunakan dalam pembuatan perangkat lunak ini adalah Waterfall. Secara garis besar Waterfall memiliki tahapan sebagai berikut[5] :
1. Analysis
menjadi acuan sistem analis untuk menterjemahkan ke dalam bahasa pemprogram.
2. Design
Proses design akan menerjemahkan syarat kebutuhan ke sebuah perancangan perangkat lunak yang dapat diperkirakan sebelum dibuat coding. Proses ini berfokus pada : struktur data, arsitektur perangkat lunak, representasi interface, dan detail (algoritma) prosedural. Tahapan ini akan menghasilkan dokumen yang disebut software requirment. Dokumen inilah yang akan digunakan proggrammer untuk melakukan aktivitas pembuatan sistemnya. 3. Coding & Testing
Coding merupakan penerjemahan design dalam bahasa yang bisa dikenali oleh komputer. Dilakukan oleh programmer yang akan meterjemahkan transaksi yang diminta oleh user. Tahapan ini lah yang merupakan tahapan secara nyata dalam mengerjakan suatu sistem. Dalam artian penggunaan komputer akan dimaksimalkan dalam tahapan ini. Setelah pengkodean selesai maka akan dilakukan testing terhadap sistem yang telah dibuat tadi. Tujuan testing adalah menemukan kesalahan-kesalahan terhadap sistem tersebut dan kemudian bisa diperbaiki.
4. Implementation
Tahapan ini bisa dikatakan final dalam pembuatan sebuah sistem. Setelah melakukan analisa, design dan pengkodean maka sistem yang sudah jadi akan digunakan oleh user.
5. Maintenance
Analysis
Design
Coding & Testing
Implementation
Maintenance
Gambar 1. 2 Metode Waterfall
1.6 Sistematika Penulisan
Sistematika penulisan tugas akhir ini disusun untuk memberikan gambaran secara umum tentang penelitian yang dijalankan. Sistematika penulisan tugas akhir ini adalah sebagai berikut :
BAB 1 PENDAHULUAN
Bab 1 membahas mengenai latar belakang permasalahan, mengidentifikasi masalah yang dihadapi, menentukan maksud dan tujuan penelitian, dengan diikuti batasan masalah agar penelitian lebih terfokus, menentukan metodologi penelitian yang digunakan, serta sistematika penulisan.
BAB 2 TINJAUAN PUSTAKA
Bab 2 membahas mengenai konsep dasar serta teori-teori yang berkaitan dengan topik penelitian dan hal-hal yang berguna dalam proses analisis permasalahan.
BAB 3 ANALISIS DAN PERANCANGAN SISTEM
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab 4 membahas tentang implementasi dari tahapan-tahapan penting yang telah dilakukan sebelumnya kemudian dilakukan pengujian terhadap kesesuaian sistem dengan tahapan yang telah ditentukan untuk memperlihatkan sejauh mana sistem layak digunakan.
BAB 5 KESIMPULAN DAN SARAN
11
Humblezing Company berdiri pada tahun 2010, Humblezing Company beralamat di Jl. Raya Cibereum No. 63 Cimahi Jawa Barat. Humblezing Company merupakan salah satu industri kreatif dibidang fashion brand atau biasa disebut dengan distro. Humblezing Company mendesain dan mengolah produknya sendiri. Mengawali usahanya dari hanya menerima pesanan sampai akhirnya karena ketekunan dan sifat kompetitif sang pemilik(owner) merekapun bisa berinovasi membuat produk sendiri tentu itu adalah sebuah pencapaian yang luar biasa bagi Humblezing.
Teamwork yang baik, kerja keras, terus berinovasi serta jujur lalu didasari filosofi dengan selalu memberikan kualitas dan pelayanan terbaik, humblezing company semakin mendapatkan kepercayaan dari konsumennya. Demi memberikan pelayanan terbaik humblezing company selalu aktif di media sosial, tanpa media sosial humblezing tidak akan mungkin bisa sampai memasarkan produk mereka ke setiap kota di Indonesia.
Karena kualitas produk yang baik dan bagus, Humblezing Company banyak menerima masukan dari konsumen untuk menambah jenis produk yang di produksi. seperti kemeja, jaket, dan baju dengan berbagai macam desain. Oleh karena itu Humblezing Company mampu bersaing dalam bisnis ini hingga sekarang.
2.1.1 Visi dan Misi Perusahaan
2.1.2 Struktur Organisasi Perusahaan
Struktur organisasi perusahaan adalah gambar suatu bagan yang menerangkan posisi dan hierarki struktur kerja pegawai di dalam suatu perusahaan. Untuk struktur organisasi Humblezing Company dapat dilihat pada gambar dibawah ini:
Gambar 2. 1 Struktur Organisasi Humblezing Company 2.1.3 Deskripsi Kerja
a. Owner
Owner bekerja sebagai orang yang bertanggung jawab atas semua tindakan yang diperlukan agar Humblezing Company berjalan lancar, menjalankan program perusahaan untuk mengejar target penjualan.
b. Kepala Produksi
Kepala Produksi bertugas untuk mengontrol kinerja para pekerja, bertugas untuk melaporkan keadaan toko, mulai dari transaksi, keluhan konsumen serta masalah yang ada di toko. Selain itu kepala produksi juga bertugas menentukan bahan-bahan yang dipakai untuk proses produksi dari desain yang baru.
c. Manajer Produksi
d. Marketing
Marketing bekerja memasarkan produk secara online maupun offline, selain itu juga menganalisa dan mengembangkan strategi marketing, melakukan evaluasi untuk memastikan tercapainya target penjualan.
e. Designer
Designer yang membuat desain-desain dari setiap produk yang akan diproduksi. Biasanya designer sendiri di tuntut untuk membuat desain yang cukup banyak sehingga kemudian desain-desain tersebut dipilih oleh owner untuk di produksi
f. Customer Services
CS (Customer Services) bekerja melayani konsumen dari yang datang ke toko maupun secara online dan memberikan informasi terhadap produk yang konsumen minati.
2.2 Landasan Teori
Landasan teori membahas mengenai materi atau teori apa saja yang digunakan sebagai acuan dalam membuat tugas akhir ini. Landasan teori yang diuraikan merupakan hasil studi literatur, baik dari buku, maupun situs internet.
2.2.1 Data
Data adalah fakta atau apapun yang dapat digunakan sebagai input dan menghasilkan informasi[6]. Data adalah kenyataan yang menggambarkan suatu kejadian dan kesatuan kenyataan. Data merupakan suatu istilah yang berbentuk jamak
dari kata “datum” yang berarti fakta atau bagian dari fakta yang mengandung arti yang menghubungkan dengan kenyataan, simbol-simbol, gambar-gambar, kata-kata, angka-angka, huruf-huruf yang menunjukan suatu ide, objek, kondisi dan situasi.
data ibarat bahan mentah yang melalui pengolahannya tertentu lalu menjadi
keterangan (informasi)”.
Kumpulan data yang saling berkaitan, berhubungan yang disimpan secara bersama-sama sedemikian rupa tanpa pengulangan yang tidak perlu, untuk memenuhi berbagai kebutuhan disebut basis data (database). Data-data ini harus
mengandung semua informasi untuk mendukung semua kebutuhan sistem. Proses dasar yang dimiliki oleh database ada empat, yaitu:
1. Pembuatan data-data baru (create database) 2. Penambahan data (insert)
3. Mengubah data (update) 4. Menghapus data (delete)
Database merupakan salah satu komponen yang penting dalam sistem informasi, karena merupakan basis dalam menyediakan informasi pada para pengguna. Database menjadi penting karena munculnya beberapa masalah bila tidak menggunakan data yang terpusat, seperti adanya duplikasi data, hubungan antar data tidak jelas, organisasi data dan update menjadi rumit. Jadi tujuan dari pengaturan data dengan menggunakan database adalah :
a. Menyediakan penyimpanan data untuk dapat digunakan oleh organisasi saat sekarang dan masa yang akan datang.
b. Cara pemasukan data sehingga memudahkan tugas operator dan menyangkut pula waktu yang diperlukan oleh pemakai untuk mendapatkan data serta hak-hak yang dimiliki terhadap data yang ditangani.
c. Pengendalian data untuk setiap siklus agar data selalu up-to-date dan dapat mencerminakan perubahan spesifik yang terjadi di setiap sistem.
d. Pengamanan data terhadap kemungkinan penambahan, modifikasi, pencurian dan gangguan-gangguan lain.
a. DDL (Data Definition Language)
Merupakan bahasa definisi data yang digunakan untuk membuat dan mengelola objek database seperti database, tabel dan view.
b. DML (Data Manipulation Language)
Merupakan bahasa manipulasi data yang digunakan untuk memanipulasi data pada objek database seperti tabel.
c. DCL (Data Control Language)
Merupakan bahasa yang digunakan untuk mengendalikan pengaksesan data.Penyusunan basis data meliputi proses memasukkan data kedalam media penyimpanan data, dan diatur dengan menggunakan perangkat Sistem Manajemen Basis Data (Database Management System / DBMS).
2.2.2 Informasi
Informasi adalah hasil analisis dan sintesis terhadap data. Dengan kata lain, informasi dapat dikatakan sebagai data yang telah diorganisasikan ke dalam bentuk yang sesuai dengan kebutuhan seseorang.
Menurut Encyclopedia of Computer Science and Engineering, banyak ilmuwan di bidang informasi menerima definisi standar bahwa informasi adalah data yang digunakan dalam pengambilan keputusan. Alasanya adalah bahwa informasi bersifat relatif, relatif terhadap situasi, relatif terhadap waktu saat keputusan diambil, juga relatif terhadap pembuat keputusan, dan bahkan juga relatif terhadap latar belakang pengambil keputusan.
Segala sesuatu yang dianggap penting pada suatu waktu bisa saja tidak berguna pada waktu yang lain. Ada kemungkinan pula bahwa sesuatu yang dianggap penting oleh seorang pengambil keputusan tidak dianggap penting bagi orang lain.
2.2.3 Database Management System (DBMS)
“Managemen Sistem Basis Data (Database Management System / DBMS) adalah perangkat lunak yang di desain untuk membantu dalam hal pemeliharaan dan utilitas kumpulan data dalam jumlah besar”.
Sistem Manajemen Basis data (Database Management System) merupakan sistem pengoperasian dan sejumlah data pada komputer. Dengan sistem ini dapat merubah data, memperbaiki data yang salah dan menghapus data yang tidak dapat dipakai. Sistem manajemen database merupakan suatu perluasan software sebelumnya mengenai software pada generasi komputer yang pertama. Dalam hal ini data dan informasi merupakan kesatuan yang saling berhubungan dan berkerja sama yang terdiri dari: peralatan, tenaga pelaksana dan prosedur data. Sehingga pengolahan data ini membentuk sistem pengolahan data. Peralatan dalam hal ini berupa perangakat keras (hardware) yang digunakan, dan prosedur data yaitu berupa perangakat lunak (software) yang digunakan dan dipakai untuk mengalokasikan dalam pembuatan sistem informasi pengolahan database.
1. Hardware
Hardware merupakan sistem komputer aktual yang digunakan untuk menyimpan dan mengakses database. Dalam sebuah organisasi berskala besar, hardware terdiri dari: jaringan dengan sebuah server pusat dan beberapa program client yang berjalan di komputer desktop.
2. Software beserta utility Software adalah DBMS yang aktual. DBMS memungkinkan para user untuk berkomunikasi dengan database. Dengan kata lain DBMS merupakan mediator antara database dengan user. Sebuah database harus memuat seluruh data yang diperlukan oleh sebuah organisasi.
3. Prosedur
Bagian integral dari setiap sistem adalah sekumpulan prosedur yang mengontrol jalannya sistem, yaitu praktik-praktik nyata yang harus diikuti user untuk mendapatkan, memasukkan, menjaga, dan mengambil data. 4. Data
Data adalah jantung dari DBMS. Ada dua jenis data. Pertama, adalah kumpulan informasi yang diperlukan oleh suatu organisasi. Jenis data kedua adalah metadata, yaitu informasi mengenai database.
5. Pengguna (User)
Ada sejumlah user yang dapat mengakses atau mengambil data sesuai dengan kebutuhan penggunaan aplikasi-aplikasi dan interface yang disediakan oleh DBMS, antara lain adalah :
a. Database administrator adalah orang atau group yang bertanggungjawab mengimplementasikan sistem database di dalam suatu organisasi.
b. Enduser adalah orang yang berada di depan workstation dan berinteraksi secara langsung dengan sistem.
2.2.3.1Data Pada database dan Hubungannya
Ada 3 jenis data pada sistem database, yaitu[7]:
1. Data operasional dari suatu organisasi, berupa data yang tersimpan dalam basis data
2. Data masukan (input data), data dari luar sistem yang dimasukan melalui peralatan input (keyboard), yang dapat merubah data operasional.
3. Data keluaran (output data), berupa laporan melalui peralatan output sebagai hasil dari dalam sistem yang mengakses data operasional.
2.2.3.2Keuntungan dan Kerugian Pemakaian Sistem Database
Keuntungan[7]:
1. Terpeliharanya keselarasan data
2. Data dapat dipakai secara bersama-sama.
3. Memudahkan penerapan standarisaasi dan batas-batas pengamanan.
4. Terpeliharanya keseimbangan atas perbedaan kebutuhan data dari setiap aplikasi.
5. Program /data independent. Kerugian:
1. Mahal dalam implementasinya. 2. Rumit/kompleks.
3. Penganan proses recovery backup sulit.
4. Kerusakan pada sistem basis data dapat mempengaruhi.
2.2.4 DataMining
Data Mining adalah salah satu bidang yang berkembang pesat karena besarnya kebutuhan akan nilai tambah dari database skala besar yang makin banyak terakumulasi sejalan dengan pertumbuhan teknologi informasi. Defisini umum dari data mining itu sendiri adalah serangkaian proses untuk menggali nilai tambah berupa pengatahuan yang selama ini tidak diketahui secara manual dari suatu kumpulan data[8].
Data mining terutama digunakan untuk mencari pengetahuan yang terdapat dalam database yang besar sehingga sering disebut Knowledge Discovery in Databases (KDD). Proses pencarian pengetahuan ini menggunakan berbagai teknik-teknik pembelajaran komputer (machine learning) untuk menganalisis dan mengekstraksikannya. Proses pencarian bersifat iteratif dan interaktif untuk menemukan pola atau model yang sahih, baru, bermanfaat, dan dimengerti.
2.2.4.1Metode-Metode Data Mining
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat dilakukan, yaitu[11]:
1. Deskripsi
Terkadang peneliti dan analis secara sederhana ingin mencoba mencari cara untuk menggambarkan pola dan kecenderungan yang terdapat dalam data. Sebagai contoh, petugas pengumpulan suara mungkin tidak dapat mengumpulkan keterangan atau fakta bahwa siapa yang tidak cukup profesional akan sedikit didukung dalam pemilihan presiden. deskripsi dari pola dan kecenderungan sering memberikan kemungkinan penjelesan untuk suatu pola atau kecenderungan.
2. Estimasi
pada pasien rumah sakit berdasarkan umur pasien, jenis kelamin, indeks berat badan, dan level sodium darah. Hubungan antara tekanan darah sistolik dan nilai variabel prediksi dalam proses pembelajaran akan menghasilkan model estimasi. Model estimasi yang dihasilkan dapat digunakan untuk kasus baru lainnya.
3. Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada dimasa mendatang. Contoh prediksi dalam bisnis dan penelitian adalah :
a. Prediksi harga beras dalam tiga bulan yang akan datang.
b. Prediksi persentase kenaikan kecelakaan lalu lintas tahun depan jika batas bawah dinaikan.
4. Klasifikasi
Dalam klasifikasi, terdapat target variabel kategori. sebagai contoh, penggolongan pendapatan dapat dipisahkan dalam tiga kategori yaitu: pendapatan tinggi, pendapatan sedang, dan pendapatan rendah. Contoh lain klasifikasi dalam bisnis dan penelitian adalah :
a. Menentukan apakah suatu transaksi kartu kredit merupakan transaksi yang curang atau bukan.
b. Mendiagnosis penyakit seorang pasien untuk mendapatkan termasuk kategori penyakit apa.
5. Pengklusteran
variabel target. Akan tetapi, algoritma pengklusteran mencoba untuk melakukan pembagian terhadap keselurahan data menjadi kelompok-kelompok yang memiliki kemiripan (homogen), yang mana kemiripan record dalam suatu kelompok akan bernilai maksimal, sedangkan kemiripan dengan record dalam kelompok lain akan bernilai minimal. Contoh pengklusteran dalam bisnis dan penelitian adalah :
a. Mendapatkan kelompok-kelompok konsumen untuk target pemasaran dari suatu produk sebuah perusahaan yang tidak memiliki dana pemasaran yang besar.
b. Untuk tujuan audit akuntansi, yaitu melakukan pemisahan terhadap perilaku finansial dalam baik maupun mencurigakan.
6. Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang pasar. Contoh asosiasi dalam bisnis dan penelitian adalah : a. Meneliti jumlah pelanggan dari perusahaan telekomunikasi seluler yang
diharapkan untuk memberikan respon positif terhadap penawaran upgrade layanan yang diberikan.
b. Menemukan barang dalam supermarket yang dibeli secara bersamaan dan barang yang tidak pernah dibeli secara bersamaan.
2.2.4.2Cross-Industry Standard Process For Data Mining (CRISP-DM)
yang ada tersebut bersifat adaptif. Fase berikutnya dalam urutan bergantung kepada keluaran dari fase sebelumnya. Hubungan antarfase digambarkan dengan panah. Sebagai contoh, jika proses berada pada fase modelling. Berdasar pada perilaku dan karakteristik model, proses mungkin harus kembali kepada fase data preparation untuk perbaikan lebih lanjut terhadap data atau berpindah maju kepada fase evaluation. Gambar berikut menjelaskan tentang siklus hidup pengembangan data mining yang telah ditetapkan dalam CRISP-DM[4].
Gambar 2. 2 Metode CRISP-DM
Berikut ini adalah penjelasan mengenai enam tahap siklus hidup pengembangan data mining berdasarkan gambar di atas :
1. Business Understanding
2. Data Understanding
Tahap ini dimulai dengan pengumpulan data yang kemudian akan dilanjutkan dengan proses untuk mendapatkan pemahaman yang mendalam tentang data, mengidentifikasi masalah kualitas data, atau untuk mendeteksi adanya bagian yang menarik dari data yang dapat digunakan untuk hipotesa untuk informasi yang tersembunyi.
3. Data Preparation
Tahap ini meliputi semua kegiatan untuk membangun dataset akhir (data yang akan diproses pada tahap pemodelan/modeling) dari data mentah. Tahap ini dapat diulang beberapa kali. Pada tahap ini juga mencakup pemilihan tabel, record, dan atribut-atribut data, termasuk proses pembersihan dan transformasi data untuk kemudian dijadikan masukan dalam tahap pemodelan (modeling). 4. Modeling
Dalam tahap ini akan dilakukan pemilihan dan penerapan berbagai teknik pemodelan dan beberapa parameternya akan disesuaikan untuk mendapatkan nilai yang optimal. Secara khusus, ada beberapa teknik berbeda yang dapat diterapkan untuk masalah data mining yang sama. Di pihak lain ada teknik pemodelan yang membutuhan format data khusus. Sehingga pada tahap ini masih memungkinan kembali ke tahap sebelumnya.
5. Evaluation
6. Deployment
Pada tahap ini, pengetahuan atau informasi yang telah diperoleh akan diatur dan dipresentasikan dalam bentuk khusus sehingga dapat digunakan oleh pengguna. Tahap deployment dapat berupa pembuatan laporan sederhana atau mengimplementasikan proses data mining yang berulang dalam perusahaan. Dalam banyak kasus, tahap deployment melibatkan konsumen, di samping analis data, karena sangat penting bagi konsumen untuk memahami tindakan apa yang harus dilakukan untuk menggunakan model yang telah dibuat.
2.2.5 Association Rule
Assocation rule adalah salah satu teknik utama atau prosedur dalam Market Basket Analysis untuk mencari hubungan antar-item dalam suatu data-set dan menampilkan bentuk association rule[2]. Association rule (aturan asosiasi) akan menemukan pola tertentu untuk mengasosiasikan data yang satu dengan data yang lain. Untuk mencari association rule dari suatu kumpulan data, tahap pertama yang harus dilakukan adalah mencari frequent itemset terlebih dahulu. Frequent itemset adalah sekumpulan item yang sering muncul secara bersamaan. Setelah semua pola frequent itemset ditemukan, barulah mencari aturan assosiatif atau aturan keterkaitan yang memenuhi syarat yang telah ditentukan[9].
Kopi susu [support = 2%, confidence = 60%]
Association rule diperlukan suatu variabel ukuran yang ditentukan sendiri oleh user untuk menentukan batasan sejauh mana atau sebanyak apa output yang diinginkan user. Support dan Confidence adalah sebuah ukuran kepercayaan dan kegunaan suatu pola yang telah ditemukan. Nilai support 2% menunjukkan bahwa keseluruhan dari total transaksi konsumen membeli kopi dan susu secara bersamaan yaitu sebanyak 2%. Sedangkan confidence 60% menunjukkan bila konsumen membeli kopi dan pasti membeli susu sebesar 60%. Association rule memiliki dua tahap pengerjaan, yaitu:
1. Mencari kombinasi yang paling sering terjadi dari suatu itemset.
2. Mendefinisikan condition dan result (untuk conditional association rule). Dalam menentukan suatu associaiton rule, terdapat suatu interestingness measure (ukuran kepercayaan) yang didaapt dari hasil pengolahan data dengan perhitungan tertentu. Umumnya ada dua ukuran, yaitu :
1. Support : suatu ukuran yang menunjukkan seberapa besar tingkat dominasi suatu item/itemset dari keseluruhan transaksi. Ukuran ini menentukan apakah suatu item/itemset layak untuk dicari confidence-nya (misal, dari keseluruhan transaksi yang ada, seberapa besar tingkat dominasi suatu item yang menunjukkan bahwa item A dan item B dibeli bersamaan).
disebut sebagai interesting rule atau strong rule. Metodologi dasar analisis asosiasi terbagi menjadi dua tahap[2] :
1. Analisis pola frekuensi tinggi
Tahap ini mencari kombinasi item yang memenuhi syarat minimum dari nilai support dalam database. Nilai support sebuah item diperoleh dengan rumus berikut.
Persamaan (2-1)
Sementara itu, nilai support dari 2 item diperoleh dari rumus berikut.
Persamaan (2-2)
Persamaan (2-3)
2. Pembentukan aturan asosiasi
Setelah semua pola frekuensi tinggi ditemukan, kemudian mencari aturan asosiatif yang memenuhi syarat minimum untuk confidence dengan menghitung confidence aturan assosiatif A -> B dari support pola frekuensi tinggi A dan B, menggunakan rumus :
| Persamaan (2-4)
2.2.6 Algoritma FP-Growth
Algoritma FP-Growth merupakan pengembangan dari algoritma Apriori. Sehingga kekurangan dari algortima Apriori diperbaiki oleh algoritma FP-Growth.
Frequent Pattern Growth (FP-Growth) adalah salah satu alternatif algoritma yang digunakan untuk menentukan himpunan data yang paling sering muncul dalam sebuah kumpulan data.
dilakukan karena FP-Growth menggunakan konsep pembangunan tree dalam pencarian frequent itemset. Hal ini yang menyebabkan algortima FP-Growth lebih cepat dari algortima Apriori.
Karakteristik algoritma FP-Growth adalah struktur data yang digunakan adalah tree yang disebut dengan FP-Tree. Dengan menggunakan FP-Tree, algortima FP-Growth dapat langsung mengekstrak frequent itemset dari FP-Tree.
Penggalian itemset yang frequent dengan menggunakan algortima FP-Growth akan dilakukan dengan cara membangkitkan struktur data FP-Tree. Metode FP-Growth dapat dibagi menjadi 3 tahapan utama yaitu[12]:
a. Tahap pembangkitan Conditional pattern base. b. Tahap pembangkitan conditional FP-Tree c. Tahap pencarian frequent itemset
Algoritma FP-Growth menggunakan struktur data FP-Tree. Informasi yang disimpan sebuah node FP-Tree: Item, Index parent, Support, dan Next (Pointer). Ketika selesai membuat FP-Tree, kita tidak begitu saja bisa mendapatkan frequent itemset yang terdapat dalam dataset. Suatu kombinasi itemset bisa saja berada di beberapa path yang berbeda. Untuk mendapatkan suatu pattern dalam FP-Growth langkah yang lebih mudah adalah mencari arah dari ujung suatu path, kemudian kita mencari mulai dari header untuk item di ujung tersebut, barulah kemudian dibuat berdasarkan tiap node berisi item tersebut dicari arah path node ke atas. Hal ini tentu lebih cepat dari pada up-down karena pointer langsung yang dimiliki tiap node adalah pointer ke parent. Path yang dieksplorasi hanyalah path-path yang memiliki node yang sedang dicari. Jadi dalam struktur FP-Tree ada link dari suatu item ke path-path yang memiliki item tersebut, sehingga ketika dibutuhkan pencarian pattern-pattern untuk suatu item tertentu, hanya mencari dari path-path tersebut saja. Berikut adalah tahapan-tahapan dari algoritma FP-Growth[13]:
1. Membuat Harder Item
mendapatkan item dan nilai support-nya, maka item yang tidak frequent dibuang dan item diurutkan berdasarkan nilai support-nya. Header untuk item, disiapkan pada suatu array tertentu dan ditambahkan ketika membuat FP-Tree. 2. Membuat FP-Tree
FP-Tree dibangun dengan mencari item sesuai urutan pada item yang frequent. Data transaksi tidak perlu diurutkan, dan untuk tiap item yang ditemukan bisa langsung dimasukkan ke dalam FP-Tree. Sesudah membuat root, tiap item yang ditemukan dimasukkan berdasarkan path pada FP-Tree. Jika item yang ditemukan sudah ada, maka nilai support item tersebut yang ditambahkan. Namun jika path belum ada, maka dibuat node baru untuk melengkapi path baru pada FP-Tree tersebut. Hal ini dilakukan selama item pada transaksi masih ada yang qualified, artinya memenuhi nilai minimum support. Jadi, item-item yang ditemukan dalam transaksi akan berurutan memanjang ke bawah. Dalam struktur FP-Tree, diterapkan alur path dari child hingga ke root. Jadi, suatu path utuh dalam FP-Tree adalah dari child terbawah hingga ke root. Tiap node pada FP Tree memiliki pointer ke parent, sehingga pencarian harus dimulai dari bawah.
3. Pattern Extraction
Pattern extraction dilakukan berdasarkan keterlibatan item pada suatu path. Di setiap path, diperiksa semua kombinasi yang mungkin dimana item tersebut terlibat. Di iterasi berikutnya dilakukan dengan melibatkan item berikutnya, tanpa melibatkan item sebelumnya, sehingga pattern yang sama tidak akan ditemukan dua kali pada path yang sama. Bila item pertama suatu hasil kombinasi bukan item terakhir (sebelum root), maka kombinasi itemset tersebut masih bisa dikembangkan lagi.
4. Memasukkan setiap pattern yang ditemukan ke dalam PatternTree
PatternTree. Setiap node di PatternTree merepresentasikan dan menyimpan frekuensi suatu pattern. PatternTree terdiri atas PatternTreeNode yang menyimpan nilai item, nilai support dan dilengkapi dengan dua pointer yaitu untuk horisontal dan vertikal.
Gambar 2. 3 Pattern Tree
Misalnya pada node d:1 di atas, berarti terdapat pattern a-c-d bernilai support 1. Kemudian bila ada pattern a-c-d lagi bernilai support n yang ditemukan dari FP-Tree maka nilai support 1 tersebut menjadi n+1. Contoh hasil lengkap dari PatternTree tersebut:
a. a:5 menggambarkan bahwa ada Pattern a sebanyak 5 b. b:4 menggambarkan bahwa ada Pattern a-b sebanyak 4 c. c:4 menggambarkan bahwa ada Pattern a-b-c sebanyak 4 d. d:3 menggambarkan bahwa ada Pattern a-b-c-d sebanyak 3 e. c:2 menggambarkan bahwa ada Pattern a-c sebanyak 2 f. d:1 menggambarkan bahwa ada Pattern a-c-d sebanyak 1 g. d:3 menggambarkan bahwa ada Pattern a-d sebanyak 3 5. Mengurutkan dan Menyeleksi Pattern
Struktur data-struktur data yang digunakan dalam algoritma FP-Growth adalah FP-Tree yang tersusun dari FPTNode, PatternTree yang terdiri dari PatternTreeNode,dan juga FItemset. FP-Tree adalah struktur tree yang menyimpan item-item yang telah ditemukan pada saat membaca data. Kemudian FP-Tree ini terdiri atas FPTNode yang membentuk suatu path untuk dicari terdapat pattern apa saja pada path tersebut. FPTNode adalah node pada FP-Tree yang menyimpan informasi item pada node, nilai support, pointer ke parent, dan pointer ke node berikutnya yang mempunyai item yang sama (next). PatternTree adalah struktur untuk menyimpan semua pattern yang ditemukan pada FP-Tree. FItemset menyimpan frequent itemset yang telah ditemukan. Format ini digunakan terutama bila ingin menghasilkan rule, untuk membandingkan suatu frequent itemset dengan subset-nya, akan lebih mudah dengan struktur seperti ini daripada mengolah frequent itemset masih dalam bentuk tree.
2.2.7 DFD (Data Flow Diagram)
DFD adalah suatu model logika data atau proses yang dibuat untuk menggambarkan dari mana asal data dan kemana tujuan data yang keluar dari sistem, dimana data disimpan, proses apa yang menghasilkan data tersebut dan interaksi antara data yang tersimpan dan proses yang dikenakan pada data tersebut.
DFD sering digunakan untuk menggambarkan suatu sistem yang telah ada atau sistem baru yang akan dikembangkan secara logika tanpa mempertimbangkan lingkungan fisik dimana data tersebut mengalir atau dimana data tersebut akan disimpan.
DFD merupakan alat yang digunakan pada metodologi pengembangan sistem yang terstruktur. Kelebihan utama pendekatan aliran data, yaitu :
a. Kebebasan dari menjalankan implementasi dalam teknis sebuah sistem. b. Pemahaman lebih jauh mengenai keterkaitan satu dama lain dalam sistem
c. Mengkomunikasikan pengetahuan sistem yang ada dengan user melalui diagram aliran data.
d. Menganalisa sistem yang diajukan untuk menentukan apakah data-data dan proses yang diperlukan sudah ditetapkan.
Selain kelebihan utama DFD sendiri memiliki kelebihan tambahan lainnya, yaitu sebagai berikut:
1. Dapat digunakan sebagai suatu perangkat untuk berinteraksi dengan user. 2. Memungkinkan pengalisis menggambarkan setiap komponen yang
digunakan dalam diagram.
3. Membedakan sistem dari lingkungannya dengan menempatkan batas-batasnya.
4. Dapat digunakan sebagai latihan yang bermanfaat bagi pengalisis, sehingga memahami dengan lebih baik keterkaitan satu sama lain dalam sistem dan subsistem.
DFD terdiri dari context diagram dan diagram rinci (DFD Levelled). Context diagram berfungsi memetakan model lingkungan (menggambarkan hubungan antara entitas luar, masukan dan keluaran sistem), yang direpresentasikan dengan lingkaran tunggal yang mewakili keseluruhan sistem. DFD levelled menggambarkan sistem sebagai jaringan kerja antara fungsi yang berhubungan satu sama lain dengan aliran dan penyimpanan data, model ini hanya memodelkan sistem dari sudut pandang fungsi.
diturunkan/dirinci lagi dikatakan primitif secara fungsional dan disebut sebagai proses primitif.
2.2.8 Kamus Data (Data Dictionary)
Merupakan tempat penyimpanan dari elemen-elemen yang berada dalam satu sistem. Kamus data mempunyai fungsi yang sama dalam pemodelan sistem dan juga berfungsi membantu pelaku sistem untuk mengerti aplikasi secara detail, dan me-reorganisasi semua elemen data yang digunakan dalam sistem sehingga pemakai dan penganalisa sistem punya dasar pengertian yang sama tentang masukan, keluaran, penyimpanan dan proses.
2.2.9 MySQL
SQL ( Structured Query Language ) adalah bahasa standar yang digunakan untuk mengakses server database. Semenjak tahun 70-an bahasa ini telah dikembangkan oleh IBM, yang kemudian diikuti dengan adanya Oracle, Informix dan Sybase. Dengan menggunakan SQL, proses akses database menjadi lebih user-friendly dibandingkan dengan misalnya dBase ataupun Clipper yang masih menggunakan perintah-perintah pemrograman murni.
kelemahan ini perlu digabung dengan bahasa pemrograman semisal Pascal. MySQL sering digunakan sebagai SQL server karena berbagai kelebihannya, antara lain :
1. Sintaksnya lebih mudah dipahami dan tidak terlalu rumit. 2. Source MySQL dapat diperoleh dengan mudah dan gratis. 3. Pengaksesan database dapat dilakukan dengan mudah.
2.2.10 Microsoft Visual Studio .Net dan C# (Sharp)
Visual studio .Net adalah sekumpulan alat pengembangan software yang diperuntukkan bagi .Net platform. Microsoft Visual Studio merupakan sebuah perangkat lunak lengkap (suite) yang dapat digunakan untuk melakukan pengembangan aplikasi, baik itu aplikasi bisnis, aplikasi personal, ataupun komponen aplikasinya, dalam bentuk aplikasi console, aplikasi Windows, ataupun aplikasi Web. Microsoft Visual Studio dapat digunakan untuk mengembangkan aplikasi dalam native code (dalam bentuk bahasa mesin yang berjalan di atas Windows) ataupun managed code (dalam bentuk Microsoft Intermediate Language di atas .NET Framework).
Bahasa C# adalah sebuah bahasa pemrograman yang bersifat general-purpose, berorientasi objek, yang dapat digunakan untuk membuat program di atas arsitektur Microsoft .NET Framework. Bahasa C# ini memiliki kemiripan dengan
bahasa Ja a, C dan C (selengkapnya dapat dilihat pada Sejarah Bahasa C#).
ahasa pemrograman ini dikembangkan oleh sebuah tim pengembang di icrosoft yang dipimpin oleh Anders Hejlsberg, seorang yang telah lama malang melintang di dunia pengembangan bahasa pemrograman karena memang ialah yang membuat Borland Turbo Pascal, Borland Delphi, dan juga Microsoft J++.
Kini, C# telah distandarisasi oleh European Computer Manufacturer Association ( C ) dan juga International Organization for Standardization ( SO)
35
Analisis sistem adalah pengurain dari suatu sistem informasi yang utuh kedalam bagian-bagian komponennya dengan maksud untuk mengidentifikasi dan mengevaluasi permasalahan, kesempatan, hambatan yang terjadi dan kebutuhan yang diharapkan sehingga dapat diusulkan perbaikan. Tahap analisis sistem merupakan tahapan yang sangat kritis dan penting, karena kesalahan di dalam tahap ini akan menyebabkan juga kesalahan di tahap selanjutnya. Tugas utama analisis sistem dalam tahap ini adalah menemukan kelemahan-kelemahan dari sistem yang berjalan sehingga dapat diusulkan perbaikannya. Dalam analisis sistem ini meliputi beberapa bagian, yaitu :
1. Analisis Masalah
2. Analisis Penerapan Metode Data Mining
3. Analisis Spesifikasi Kebutuhan Perangkat Lunak 4. Analisis Kebutuhan Non-Fungsional
5. Analisis Kebutuhan Fungsional
3.1.1 Analisis Masalah
Adapun analisis masalah hasil wawancara dengan pihak Humblezing Company adalah sebagai berikut :
1. Banyaknya jenis produk yang dihasilkan membuat pihak Humblezing Company sulit untuk menemukan kombinasi produk sebagai bahan untuk promosi.
2. Pemilihan produk masih dilakukan secara acak produk serta berdasarkan yang penjualannya tinggi saja, ini kerap kali berdampak pada target yang diinginkan tidak sesuai dengan harapan. ini diakibatkan oleh kesalahan dalam pemilihan kombinasi produk.
lanjut untuk dijadikan dasar dalam mengambil sebuah keputusan pemilihan produk yang akan dikombinasikan.
3.1.2 Analisis Penerapan Metode Data Mining
Berdasarkan tahapan-tahapan yang terdapat dalam CRIPS-DM, maka dalam penelitian data mining ini terdapat beberapa tahapan sebagai berikut:
3.1.2.1Pemahaman Bisnis (Business Understanding)
Tahapan ini merupakan tahapan awal pada kerangka kerja CRISP-DM. Tahap ini bertujuan untuk memahami tujuan dan kebutuhan dari sudut pandang bisnis Humblezing Company. Dalam tahapan ini ada beberapa tahapan lainnya, yaitu :
1. Tujuan Bisnis
Memasarkan produk secara langsung maupun online kepada konsumen merupakan proses bisnis dari Humblezing Company. Tujuannya adalah untuk memenuhi permintaan konsumen sehingga dapat meningkatkan pendapatan.
2. Penentuan Sasaran Data Mining
Tujuan dari penerapan data mining pada penjualan produk ini adalah untuk mengetahui bagaimana pola penjualan produk dan produk apa saja yang sering dibeli secara bersamaan oleh konsumen untuk dijadikan dasar dalam penentuan kombinasi produk.
3.1.2.2Pemahaman Data (Data Understanding)
Sumber data yang didapat dalam penelitian ini merupakan data transaksi yang terjadi di Humblezing Company selama bulan Desember tahun 2014. Data yang digunakan dalam proses analisis berupa file Excel dengan format *.xlsx yang terdapat 150 transaksi penjualan didalamnya. Untuk lebih jelas data dapat dilihat pada tabel D-1 yang terdapat pada lampiran D. Terdapat beberapa atribut dalam data transaksi penjualan ini antara lain yaitu:
4. nama 5. alamat 6. kota 7. no Hp 8. produk 9. size 10.qty 11.via
12.transfer time 13.bank
14.harga 15.atas nama 16.ongkos kirim 17.discount.
Adapun detail informasi mengenai data transaksi penjualan yang digunakan dapat dilihat dalam tabel 3.1 dibawah ini :
3.1.2.3Persiapan Data (Data Preparation)
Dalam proses persiapan data ini akan dilakukan preprocessing terhadap data yang digunakan. Terdapat beberapa tahapan yang harus dilakukan, yaitu :
1. Pemilihan Data
Karena penelitian ini bertujuan untuk mengetahui pola pembelian produk oleh konsumen yang harus dilihat dari setiap transaksinya maka data yang dipakai adalah data penjualan yang memliki format .xlsx (file Microsoft excel), yang akan di simpan ke dalam sebuah database agar proses pengolahan data menjadi lebih mudah.
2. Pemilihan Atribut
Proses yang kedua adalah pemilihan atribut. Proses ini dilakukan untuk menghilangkan beberapa atribut yang tidak penting agar proses mining menjadi lebih cepat. Mengacu pada tujuan penelitian, maka atribut yang digunakan adalah Kode dan Produk yang bertujuan untuk menyeleksi data apa saja yang relevan dan diperlukan database untuk keperluan analisa. Hasil pemilihan atribut dapat dilihat pada tabel D-2 pada lampiran D.
3. Pembersihan Data
Proses ini dilakukan untuk membersihkan data yang tidak relevan berdasarkan aturan yang diterapkan dalam memenuhi tujuan proses mining. Mencari pola pembelian serta memberi informasi tentang pemilihan produk untuk dikombinasikan sebagai bahan promosi. Maka aturan yang digunakan jika dalam satu transaksi hanya terdapat satu item produk maka transaksi tersebut akan dibersihkan dari data. Berikut proses pembersihan data:
a. Yang pertama dilakukan adalah memindai setiap transaksi pada tabel D-2 pada lampiran D.
b. Jika transaksi tersebut mengandung lebih dari satu item produk maka akan dimasukan dalam proses selanjutnya.
Untuk hasil dari proses pembersihan data dapat dilihat pada tabel D-3 pada lampiran D.
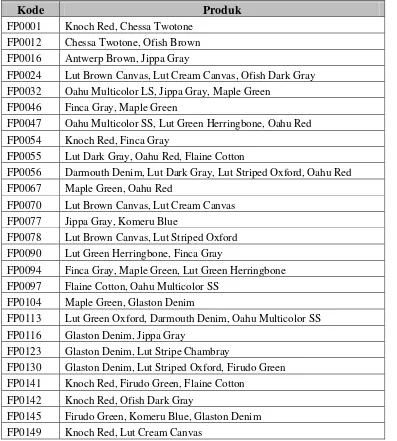
Setelah preprocessing dilakukan dan data transaksi penjualan telah sesuai dengan kebutuhan proses mining. Proses selanjutnya setiap produk pada data hasil preprocessing pada tabel D-3 akan digabungkan berdasarkan kode agar lebih sederhana untuk mempermudah pembacaan. Data dapat dilihat pada tabel 3.2:
Tabel 3.2 Penyederhanaan Data Penjualan
Kode Produk
FP0001 Knoch Red, Chessa Twotone FP0012 Chessa Twotone, Ofish Brown FP0016 Antwerp Brown, Jippa Gray
FP0024 Lut Brown Canvas, Lut Cream Canvas, Ofish Dark Gray FP0032 Oahu Multicolor LS, Jippa Gray, Maple Green
FP0046 Finca Gray, Maple Green
FP0047 Oahu Multicolor SS, Lut Green Herringbone, Oahu Red FP0054 Knoch Red, Finca Gray
FP0055 Lut Dark Gray, Oahu Red, Flaine Cotton
FP0056 Darmouth Denim, Lut Dark Gray, Lut Striped Oxford, Oahu Red FP0067 Maple Green, Oahu Red
FP0070 Lut Brown Canvas, Lut Cream Canvas FP0077 Jippa Gray, Komeru Blue
FP0078 Lut Brown Canvas, Lut Striped Oxford FP0090 Lut Green Herringbone, Finca Gray
FP0094 Finca Gray, Maple Green, Lut Green Herringbone FP0097 Flaine Cotton, Oahu Multicolor SS
FP0104 Maple Green, Glaston Denim
FP0113 Lut Green Oxford, Darmouth Denim, Oahu Multicolor SS FP0116 Glaston Denim, Jippa Gray
FP0123 Glaston Denim, Lut Stripe Chambray
FP0130 Glaston Denim, Lut Striped Oxford, Firudo Green FP0141 Knoch Red, Firudo Green, Flaine Cotton
FP0142 Knoch Red, Ofish Dark Gray
3.1.2.4Pemodelan (Modeling)
Merupakan tahapan penerapan suatu metode yang digunakan terhadap masalah yang ada di Humblezing Company. Pemodelan ini dilakukan dengan menggunakan metode Association Rule. Metode ini memiliki dua tahapan pengerjaan yaitu :
1. Mencari Frequent Itemset
2. Menghasilkan rule (generate rule)
Dalam tahap pencarian frequent itemset algoritma yang akan digunakan adalah fp-growth. Algoritma ini memiliki dasar pengetahuan mengenai frequent itemset yang telah diketahui sebelumnya untuk memproses informasi lebih lanjut. Dalam algoritma Fp-growth terdapat tiga tahapan penting, namun sebelum masuk pada tahapan untuk mempermudah pembentukan frequent itemset akan dilakukan pengkodean terhadap produk yang terdapat pada data yang sudah siap digunakan untuk proses mining, proses pengkodean ini berdasarkan inisial setiap produk yang terdapat pada transaksi, contoh Knoch Red maka akan menjadi KR. berikut adalah pengkodean dari setiap produk dapat dilihat pada tabel dibawah ini:
Tabel 3.3 Hasil Pengkodean Produk
Produk Kode Produk
Knoch Red KR
Chessa Twotone CT
Ofish Brown OB
Oahu Multicolor LS OML
Maple Green MG
Finca Gray FGY
Oahu Multicolor SS OMS
Lut Green Herringbone LGH
Produk Kode Produk
Oahu Red OR
Komeru Blue KB
Lut Striped Oxford LSO
Darmouth Denim DD
Flaine Cotton FC
Glaston Denim GD
Firudo Green FG
Lut Stripe Chambray LSC
Lut Dark Gray LDG
Setelah dilakukan pengkodean terhadap setiap produk maka selanjutnya masuk pada tiga tahapan penting algoritma Fp-growth. Tahapan-tahapannya adalah sebagai berikut :
1. Pembangkitan Fp-tree
Fp-tree adalah struktur data yang digunakan oleh algortima Fp-growth dalam penentuan frequent itemset. Kelebihan dari Fp-tree adalah hanya memerlukan dua kali pemindaian data transaksi yang terbukti sangat efisien. Data yang digunakan dalam tahapan ini adalah data pada tabel 3.2 yang telah dilakukan pengkodean pada setiap produknya untuk memudahkan saat pembuatan tree bisa dilihat pada tabel berikut :
Tabel 3.4 Hasil Pengkodean Penyederhaan Data Penjualan
a. Selanjutnya dicari frekuensi kemunculan dari setiap produk dari data transaksi penjualan untuk melihat produk mana saja yang dapat di proses dalam tahap selanjutnya, untuk frekuensi kemunculan produk bisa dilihat pada tabel 3.5 di bawah ini:
Tabel 3.5 Frekuensi Kemunculan Setiap Produk Produk Frekuensi
KR 5
CT 2
OB 1
AB 1
JG 4
LBC 3
LCC 3
ODG 2
OMLS 1
MG 5
FGY 4
OMSS 3
LGH 3
OR 4
KB 2
LSO 3
DD 2
FC 3
GD 5
FG 3
LSC 1
LDG 2
b. Setelah frekuensi dari setiap produk diketahui maka selanjutnya adalah menentukan minimum support. Minimum support yang digunakan dalam contoh kasus ini adalah 2 yang di dapat dari perhitungan
. Maka saat dilakukan
pemindaian jika terdapat produk yang kemunculannya ≤ 2 akan dihapus. Berikut data yang sudah dihapus dapat dilihat pada tabel 3.6:
Tabel 3.6 Penghapusan Data Tidak Frequent Produk Frekuensi
KR 5
CT 2
JG 4
LBC 3
LCC 3
ODG 2
MG 5
FGY 4
OMSS 3
LGH 3
OR 4
KB 2
LSO 3
DD 2
FC 3
GD 5
FG 3
LDG 2
KR akan diberikan priority 1 dan FGY priority 2. Hasil dari pengurutan dan penentuan priority dapat dilihat pada tabel berikut :
Tabel 3.7 Pengurutan Berdasarkan Frekuensi dan Penentuan Priority
Produk Frekuensi Priority
KR 5 1
d. Setelah priority didapatkan, selanjutnya kemunculan produk pada tabel 3.4 akan dilakukan pengecekan setiap transaksi untuk diurutkan berdasarkan priority dari masing-masing produk, contoh: sebelum diurutkan produk pada transaksi kode FP0032 adalah JG dan MG setelah dilakukan pengecekan priority kedua produk tersebut maka kemunculan produk menjadi MG dan JG karena MG memiliki priority lebih awal dibanding JG. Berikut adalah hasil dari pengurutan data dapat dilihat pada tabel di bawah ini :
Tabel 3.8 Hasil Pengurutan Data Kode Produk(ordered item)
Kode Produk(Ordered item)
FP0054 KR, FGY FP0055 OR, FC, LDG
FP0056 OR, LSO, DD, LDG FP0067 MG, OR
FP0070 LBC, LCC FP0077 JG, KB FP0078 LBC, LSO FP0090 FGY, LGH FP0094 MG, FGY, LGH FP0097 OMSS, FC FP0104 MG, GD FP0113 OMSS, DD FP0116 GD, JG FP0123 GD
FP0130 GD, LSO, FG FP0141 KR, FC, FG FP0142 KR, ODG FP0145 GD, FG, KB FP0149 KR, LCC
e. Setelah mendapatkan data yang sesuai, selanjutnya setiap transaksi penjualan yang terdapat pada tabel 3.8 akan bangkitkan dengan struktur data fp-tree. Berikut adalah penerapan struktur data fp-tree : - Transaksi dengan kode FP0001: KR, CT. Diberikan support count 1 dan dua node dengan KR sebagai parent dan CT sebagai child.
Null
KR : 1
CT : 1
- Untuk transaksi kedua FP0012: CT. Ini akan disimpan pada lintasan (path) yang berbeda karena produk pada transaksinya berbeda. Dengan diberi support count-nya 1.
Null
KR : 1
CT : 1
CT : 1
Gambar 3. 2 FP-Tree Transaksi Kode FP0012
- Untuk transaksi kedua FP0016: JG. Ini akan di simpan pada lintasan (path) yang berbeda karena produk pada transaksinya berbeda. Dengan diberi support count-nya 1
Null
KR : 1
CT : 1
CT : 1 JG : 1
Gambar 3. 3 FP-Tree Transaksi Kode FP0016
Null
KR : 1
CT : 1
CT : 1 JG : 1 LBC : 1
LCC : 1
ODG : 1
Gambar 3. 4 FP-Tree Transaksi Kode FP0024
- Untuk transaksi dengan kode FP0032: MG, JG. Meskipun JG sudah ada tetapi JG dalam transaksi ini memiliki induk node. Maka akan disimpan pada lintasan (path) berbeda dengan memiliki dua node yang masing-masingnya diberi support count 1.
Null
KR : 1
CT : 1
CT : 1 JG : 1 LBC : 1
LCC : 1
ODG : 1
JG : 1 MG : 1
Gambar 3. 5 FP-Tree Transaksi Kode FP0032
Null
Gambar 3. 6 FP-Tree Transaksi Kode FP0149
Setelah tahapan pembangkitan FP-Tree dari sekumpulan data transaksi penjualan, maka selanjutnya algoritma Fp-Growth akan melakukan pembangkitan conditional pattern base dan pembangkitan conditional fp-tree dari setiap produk untuk mencari frequent itemset yang berakhiran suffix dengan menggunakan pendekatan divide and conquer. Pendekatan divide and conquer berperan untuk memecahkan problem menjadi subproblem yang lebih kecil.
2. Pembangkitan conditional pattern base
b. Kedua, pengecekan nilai support count produk-produk diatas sebelum akhirnya dibangkitkan. Jika nilai support count ≥2 sesuai yang telah ditentukan di awal analisis, maka bangkitkan lintasan (path) itemset-nya. Untuk melihat kondisi tree setiap produk pada conditional pattern base dapat dilihat pada lampiran E. Berikut adalah conditional pattern base dari setiap produk:
Tabel 3. 9 Conditional Pattern Base
Produk Conditional Pattern Base LDG {OR,LSO,DD:1},{OR,FC:1} DD {OR,LSO:1},{OMSS:1} KB {GD, FG:1},{JG:1} ODG {LBC,LCC:1},{KR:1} FG {GD,LSO:1},{KR,FC:1},
{GD:1}
LGH {OR,OMSS:1},{MG,FGY:1}, {FGY:1}
CT {KR:1},{Null}
FC {OMSS:1},{OR:1},{KR:1} LSO {GD:1},{OR:1},{LBC:1} OMSS {OR:1},{Null}
LCC {LBC:2}, {KR:1} OR {MG:1},{Null}
FGY {MG:2},{KR:1},{Null} JG {GD:1},{MG:1},{Null} GD {MG:1},{Null}
LBC {Null} MG {Null} KR {Null}
3. Pembangkitan conditional Fp-Tree
- Pembangkitan conditional Fp-tree untuk produk LDG. Conditional pattern base dari LDG adalah {OR, LSO, DD: 1}, {OR, FC: 1}. Setelah diakumulasikan support count dari produk LDG memenuhi syarat minimum support yaitu ≥ 2. Tetapi LSO, DD, FC dalam lintasan ini di hapus karena tidak memenuhi syarat minimum. Maka conditional FP-Tree LDG :
Null
OR : 2
Null
Conditional Fp-Tree LDG : {OR: 2} Conditional Fp-Tree {OR,LDG: 2}
Gambar 3. 7 Conditional FP-Tree Untuk Produk LDG
- Pembangkitan conditional FP-Tree produk FG. Dengan conditional pattern base {GD,LSO:1},{KR,FC:1},{GD:1}. Setelah di akumulasi support count dari FG memenuhi syarat minimum supportyaitu ≥ 2. Produk KR, FC, LSO akan dihapus karena tidak memenuhi syarat minimum. Berikut adalah conditional FP-Tree dari FG :
Null
GD : 2
Conditional FP-Tree FG : {GD: 2}
Null
Conditional FP-Tree {GD,FG: 2}
Gambar 3. 8 Conditional FP-Tree untuk Produk FG
Null
FGY:2
Conditional FP-Tree LGH : {FGY: 2}
Null
Conditional FP-Tree {FGY,LGH: 2}
Gambar 3. 9 Conditional FP-Tree untuk Produk LGH
- Conditional FP-Tree selanjutnya adalah produk LCC dengan conditional pattern base {LBC: 2}, {KR: 1}. LCC memenuhi syarat minimum support karena support count≥ 2. Produk KR dihapus dari lintasan karena tidak memenuhi syarat minimum. Berikut adalah conditional FP-Tree dari LCC adalah :
Null
LBC:2
Conditional FP-Tree LCC : {LBC:2}
Null
Conditional FP-Tree {LBC,LCC: 2}
Gambar 3. 10 Conditional FP-Tree untuk Produk LCC
Null
MG : 2
Null
Conditional Fp-Tree FGY: {MG: 2} Conditional Fp-Tree {MG,FGY: 2}
Gambar 3. 11 Conditional FP-Tree Untuk Produk FGY
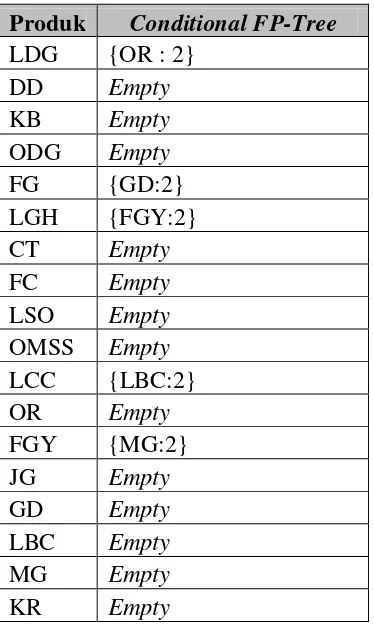
4. Setelah selesai membangkitkan conditional FP-Tree produk yang memenuhi syarat miniumum support, maka selanjutnya akan dilakukan pencarian frekuensi itemset. Agar lebih mudah membaca maka hasil dari conditional FP-Tree akan dimasukkan ke dalam bentuk tabel. Berikut adalah conditional FP-Tree :
Tabel 3. 10 Conditional FP-Tree Produk Conditional FP-Tree LDG {OR : 2}
DD Empty KB Empty ODG Empty
FG {GD:2}
LGH {FGY:2} CT Empty FC Empty LSO Empty OMSS Empty LCC {LBC:2} OR Empty
FGY {MG:2}
Hasil conditional FP-Tree pada tabel diatas menunjukan bahwa ada 5 frekuensi itemset yang ditemukan dengan akhiran (suffix) yang akan diproses pada tahapan selanjutnya. Untuk frekuensi itemset bisa dilihat pada tabel berikut :
Tabel 3. 11 Frekuensi Itemset (suffix)
Suffix Frekuensi Itemset LDG {LDG}, {OR,LDG} FG {FG}, {GD,FG} LGH {LGH}, {FGY,LGH} LCC {LCC}, {LBC,LCC} FGY {FGY}, {MG,FGY} 5. Generate Rule
Dari hasil frekuensi itemset disaat akan di-generate untuk mendapatkan rule dengan minimum support=2 dan minimum confidence=60% dengan masing-masing itemset dikombinasikan dengan itemset yang lain. Untuk mengetahui itemset mana saja yang termasuk rule maka akan dilakukan perhitungan minimum confidence dari setiap itemset dengan rumus persamaan (2.2) yang terdapat pada bab 2. Hasil dari perhitungan bisa dilihat dibawah ini:
Tabel 3. 12 Hasil Perhitungan Confidence