PENGKAJIAN PEMBENTUKAN MODEL KLASIFIKASI
DALAM PENGELOMPOKKAN JURUSAN SISWA DI SMA
(Studi Kasus : Siswa SMA Negeri Siau Timur Kabupaten Siau
Tagulandang Biaro Propinsi Sulawesi Utara)
NELDA PONTO
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS
DAN SUMBER INFORMASI
Dengan ini saya menyatakaan bahwa tesis Pengkajian Pembentukan Model Klasifikasi dalam Pengelompokkan Jurusan Siswa di SMA (Studi Kasus : Siswa SMA Negeri Siau Timur kabupaten Siau Tagulandang Biaro Propinsi Sulawesi Utara) adalah karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Bogor, Agustus 2012
Nelda Ponto NIM G152100041
ABSTRACT
NELDA PONTO. Assessment of the Formation of the Classification Model in Student of Senior High School Grouping (Case Study : The students of State Senior High School East Siau, Siau Tagulandang Biaro Regency, North
Sulawesi). Supervised by I MADE SUMERTAJAYA and YENNI ANGRAINI.
Modeling that involve categorical response variables give important role in the classification problem. Statistical analysis is applied to solve this problem are discriminant analysis and multinomial logistic regression. Implementation of both methods against student of senior high school of East Siau data produce multinomial logistic regression as best method for classify the students into Scicence Program, Social Program, and Language Program. Classification accuracy of model from resampling is 88.1% and of model validation from Tagulandang Senior High School is 70.6%. The variables give significantly effect in classification students to Science Program or Language Program are Mathematics, English, Chemistry, and German, whereas, classification students into Social Program or Language Program are Economy, English, German, and History.
Keywords: discriminant analysis, classification, multinomial logistic regression
RINGKASAN
NELDA PONTO. Pengkajian Pembentukan Model Klasifikasi dalam Pengelompokkan Jurusan Siswa di SMA (Studi Kasus : Siswa SMA Negeri Siau Timur Kabupaten Siau Tagulandang Biaro Sulawesi Utara). Dibimbing oleh I MADE SUMERTAJAYA dan YENNI ANGRAINI.
SMA merupakan jenjang pendidikan menengah yang mengutamakan penyiapan siswa untuk melanjutkan pendidikan yang lebih tinggi dengan pengkhususan. Perwujudan pengkhususan tersebut berupa diselenggarakan penjurusan di kelas XI yakni, penjurusan pada Ilmu Pengetahuan Alam (IPA), Ilmu Pengetahuan Sosial (IPS), dan Bahasa.
Program penjurusan pada dasarnya dilakukan untuk membantu para siswa sehingga mereka dapat belajar dengan baik sesuai dengan minat, dan bakatnya. Siswa dalam kegiatan pembelajaran tidak dapat disamakan, dengan demikian setiap siswa sebaiknya ditempatkan pada situasi belajar mengajar yang tepat sesuai dengan kemampuannya masing-masing. Kekurangtepatan dalam penempatan jurusan siswa dapat mengakibatkan prestasi belajar siswa rendah.
Model statistika yang dapat digunakan untuk pengklasifikasian objek dengan melibatkan peubah tak bebas kategori dengan sejumlah peubah bebas kontinu adalah analisis diskriminan dan regresi logistik multinomial. Analisis diskriminan adalah teknik statistika yang dipergunakan untuk mengklasifikasikan objek kedalam kelompok berdasarkan sekumpulan peubah-peubah bebas. Analisis diskriminan juga merupakan suatu analisis dengan tujuan membentuk sejumlah fungsi melalui kombinasi linier peubah-peubah asal, yang dapat digunakan sebagai cara terbaik untuk memisahkan kelompok-kelompok individu. Sedangkan regresi logistik multinomial digunakan untuk memodelkan hubungan antara peubah respon dengan kategori lebih dari dua (polytomous) dengan peubah penjelas kategorik dan atau kontinu. Melalui metode regresi logistik multinomial akan dihasilkan peluang dari masing-masing kategori respon yang akan dijadikan sebagai pedoman pengklasifikasian suatu pengamatan akan masuk dalam respon kategori tertentu berdasarkan nilai peluang terbesar.
Tujuan utama yang ingin dicapai dalam penelitian ini, yaitu (1) menerapkan metode analisis diskriminan dan multinomial logistik untuk klasifikasi, (2) mengevaluasi peubah yang konsisten muncul dari metode analisis diskriminan dan multinomial logistik dengan teknik resampling. Data yang digunakan adalah data sekunder dari dua SMA Negeri di Kabupaten Sitaro yaitu SMA Negeri Tagulandang dan SMA Negeri Siau Timur. Data SMA Negeri Siau Timur digunakan untuk pemodelan, sedangkan yang digunakan untuk validasi model adalah data SMA Negeri Tagulandang. Peubah-peubah yang diamati dalam penelitian ini terdiri 14 peubah numerik, yaitu rataan nilai mata pelajaran Agama, PPKn, Bahasa Indonesia, Bahasa Inggris, Matematika, Fisika, Biologi, Kimia, Sejarah, Geografi, Ekonomi, Sosiologi, TIK, Bahasa Jerman serta 6 peubah kategorik, yaitu : jenis kelamin, pendidikan ayah, pendidikan ibu, pekerjaan ibu, pekerjaan ayah, pendapatan.
logistik multinomial secara keseluruhan adalah sebesar 83.7 persen. Resampling 30 kali menghasilkan metode terbaik adalah regresi logistik multinomial dengan tingkat ketepatan klasifikasi adalah sebesar 88.1%.
Untuk mengelompokkan siswa kedalam jurusan IPA dipengaruhi oleh mata pelajaran Agama, Matematika, Bahasa Inggris, Kimia, Bahasa Jerman dan Pendidikan ayah. Pengelompokkan siswa kedalam jurusan IPS dipengaruhi oleh Bahasa Inggris, Biologi, Sejarah, Geografi, Ekonomi, Bahasa Jerman, dan Jenis kelamin. Validasi model dari SMA Negeri Tagulandang memberikan ketepatan klasifikasi sebesar 70.6%.
© Hak Cipta milik IPB, tahun 2012
Hak Cipta dilindungi Undang-Undang
1. Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumber.
a. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah
b. Pengutipan tidak merugikan kepentingan yang wajar bagi IPB
PENGKAJIAN PEMBENTUKAN MODEL KLASIFIKASI
DALAM PENGELOMPOKKAN JURUSAN SISWA DI SMA
(Studi Kasus : Siswa SMA Negeri Siau Timur Kabupaten Siau
Tagulandang Biaro Propinsi Sulawesi Utara)
NELDA PONTO
Tesis
Sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Program Studi Statistika Terapan
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
Judul Tesis : Pengkajian Pembentukan Model Klasifikasi dalam
Pengelompokkan Jurusan Siswa di SMA (Studi Kasus: Siswa SMA Negeri Siau Timur Kabupaten Siau Tagulandang Biaro Propinsi Sulawesi Utara)
Nama : Nelda Ponto
NRP : G152100041
Disetujui Komisi Pembimbing
Dr. Ir. I Made Sumertajaya, M.Si Ketua
Yenni Angraini, M.Si Anggota
Diketahui,
Ketua Program Studi Statistika
Dr. Ir. Anik Djuraidah, M.S
Dekan Sekolah Pascasarjana
Dr. Ir. Dahrul Syah, M.Sc.Agr
PRAKATA
Puji syukur penulis panjatkan kepada Tuhan Yang Maha Kuasa, atas kasih dan karunia-Nya sehingga karya ilmiah ini dapat diselesaikan. Judul karya ilmiah ini adalah “Pengkajian Pembentukan Model Klasifikasi dalam pengelompokkan Jurusan Siswa di SMA (Studi Kasus: Siswa SMA Negeri Siau Timur Kabupaten Siau Tagulandang Biaro Propinsi Sulawesi Utara)”.
Terima kasih penulis ucapkan kepada Bapak Dr. Ir. I Made Sumertajaya, M.Si selaku ketua komisi pembimbing dan Ibu Yenni Angraini, M.Si selaku anggota komisi pembimbing yang telah banyak memberi saran. Disamping itu, penulis juga mengucapkan terima kasih kepada bapak Dr. Ir. Asep Saefuddin, M.Sc selaku penguji luar komisi pada ujian tesis, serta seluruh staf Program Studi Statistika.
Ungkapan terima kasih juga disampaikan kepada papa (Ferry Ponto), mama (Magdalena. Togelang), kakak-kakakku (Drs. H. Malendes dan T. Ponto, S.Pd), serta seluruh keluarga atas doa, dukungan dan kasih sayangnya. Terima kasih pula kepada teman-teman Statistika dan Statistika Terapan angkatan 2010, 2011 baik S2 maupun S3 atas bantuan dan kebersamaannya selama ini. Semoga karya ilmiah ini dapat bermanfaat.
Bogor, Agustus 2012
RIWAYAT HIDUP
Penulis dilahirkan di Tulusan pada tanggal 17 maret 1979 dari ayah Ferry Ponto dan ibu Magdalena Togelang. Penulis merupakan putri bungsu dari ketiga bersaudara.
Penulis lulus Sekolah Menengah Atas (SMA) Tahun 1997 selanjutnya pada Tahun 1998 di terima sebagai mahasiswa jurusan matematika FMIPA, Universitas Negeri Manado (UNIMA). Penulis memperoleh gelar sarjana pendidikan tahun 2003.
Pada tahun 2005 penulis diangkat menjadi staf pengajar di SMA Negeri Tagulandang dan tahun 2009 dipindahkan ke SMA Negeri Siau Timur. Selanjutnya pada Tahun 2010 penulis diterima di Program Studi Statistika Terapan pada Sekolah Pascasarjana IPB.
DAFTAR ISI
Halaman
DAFTAR TABEL ... xii
DAFTAR GAMBAR ... xiii
DAFTAR LAMPIRAN ... xiv
PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan Penelitian ... 3
TINJAUAN PUSTAKA ... 5
Analisis Diskriminan ... 5
Pembentukan Fungsi Diskriminan ... 6
Regresi Logistik Multinomial ... 9
Pengujian Kesesuian Model ... 10
Pereduksian Peubah ... 11
Interpretasi Koefisien... 12
METODOLOGI ... 13
Data Penelitian ... 13
Metode Analisis ... 13
HASIL DAN PEMBAHASAN ... 17
Karakteristik Siswa ... 17
Deskripsi Nilai Rapor Menurut Program Studi ... 19
Analisis Diskriminan ... 20
Analisis Regresi Logistik Multinomial ... 23
Pembangunan Analisis Model Analisis Diskriminan dan Logistik Multinomial dari Hasil Resampling ... 25
Perbandingan Hasil Klasifikasi Analisis Dsikriminan dan Logistik Multinomial ... 28
Penerapan Model Logistik Multinomial ... 29
SIMPULAN DAN SARAN ... 31
Simpulan ... 31
Saran ... 31
DAFTAR PUSTAKA ... 33
DAFTAR TABEL
Halaman
1 Peubah-peubah yang diamati ... 13
2 Distribusi siswa berdasarkan pendidikan orang tua ... 18
3 Nilai rata-rata rapor dan simpangan baku berdasarkan program studi ... 19
4 Nilai-p regresi linier tiap kategori ... 20
5 Koefisien fungsi diskriminan ... 21
6 Nilai rata-rata kelompok ... 22
7 Hasil klasifikasi analisis diskriminan ... 22
8 Analisis logistik multinomial hasil eliminasi langkah mundur ... 23
9 Hasil prediksi logistik multinomial ... 24
10 Fungsi diskriminan ... 24
11 Hasil klasifikasi analisis diskriminan ... 26
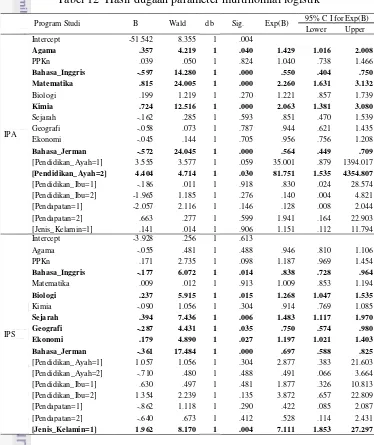
12 Hasil dugaan parameter logistik multinomial... 27
13 Ketepatan klasifikasi model logistik multinomial ... 26
14 Ketepatan klasifikasi ... 28
15 Ilustrasi data siswa ... 29
DAFTAR GAMBAR
Halaman 1 Distribusi siswa berdasarkan jurusan ... 17
2 Distribusi siswa berdasarkan jenis kelamin ... 17
DAFTAR LAMPIRAN
Halaman
1 Pengkodean peubah penjelas kategorik ... 37
2 Hasil analisis logistik multinomial dengan model penuh ... 38
3 Hasil uji asumsi kenormalan ganda ... 39
4 Akar ciri masing-masing fungsi diskriminan ... 41
5 Pengujian Wilks’ Lambda ... 41
6 Peubah-peubah digunakan dalam analisis diskriminan ... 41
7 Jumlah signifikansi peubah-peubah pada analisis logistik multinomial yang dihasilkan dari proses resampling ... 42
8 Jumlah signifikansi peubah-peubah pada analisis diskriminan yang dihasilkan dari proses resampling ... 42
9 Pengklasifikasian objek ke dalam kelompok ... 43
PENDAHULUAN
Latar Belakang
Sekolah Menengah Atas (SMA) merupakan jenjang pendidikan menengah yang mengutamakan penyiapan siswa untuk melanjutkan pendidikan yang lebih tinggi dengan pengkhususan (Depdiknas 2004). Perwujudan pengkhususan tersebut berupa penjurusan. Penjurusan dilakukan pada saat memasuki kelas XI yakni, penjurusan pada Ilmu Pengetahuan Alam (IPA), Ilmu Pengetahuan Sosial (IPS) dan Bahasa.
Penjurusan merupakan upaya strategis dalam memberikan fasilitas kepada siswa untuk menyalurkan bakat, minat dan kemampuan yang dimilikinya yang dianggap paling potensial untuk dikembangkan secara optimal. Sehubungan dengan hal tersebut, maka siswa yang mempunyai kemampuan sains dan ilmu eksakta yang baik biasanya akan memilih jurusan IPA, dan yang memiliki minat pada sosial dan ekonomi akan memilih jurusan IPS, sedangkan yang gemar berbahasa akan memilih jurusan Bahasa (Murniramli 2008). Dengan demikian, karakteristik suatu ilmu menuntut karakteristik yang sama dari yang mempelajarinya. Siswa yang mempelajari suatu ilmu yang sesuai dengan karakteristik kepribadiannya atau minat terhadap suatu ilmu tertentu akan merasa senang ketika mempelajarinya serta faktor kepribadian mempengaruhi secara positif prestasi akademik. Oleh karena itu, penjurusan bukan masalah kecerdasan tetapi juga masalah minat dan bakat siswa (Snow 1986).
mengakibatkan prestasi belajar rendah. Hal ini disebabkan karena adanya perbedaan individual antara siswa disekolah yaitu, meliputi perbedaan kemampuan kognitif, motivasi berprestasi, minat dan kreativitas dan dengan adanya perbedaan individu tersebut, maka fungsi pendidikan tidak hanya dalam proses belajar mengajar tetapi meliputi bimbingan konseling, pemilihan dan penetapan siswa sesuai dengan kapasitas individual yang dimiliki (Snow 1986).
Agar kesalahan dalam pemilihan dan penetapan jurusan di SMA dapat diminimalisasi maka perlu ada upaya dalam mencari model yang terbaik. Beberapa analisis statistik telah banyak dikembangkan untuk membantu menyelesaikan masalah-masalah dalam bidang pendidikan, di antaranya adalah analisis regresi logistik, analisis diskriminan, pohon klasifikasi dan Artificial Neural Network (ANN). Dalam penelitian ini, analisis yang digunakan adalah analisis diskriminan dan regresi logistik multinomial. Menurut Johnson dan Wichern (1998), analisis diskriminan digunakan untuk mengklasifikasikan individu ke dalam salah satu dari dua kelompok atau lebih. Sedangkan regresi logistik multinomial digunakan untuk memodelkan hubungan antara peubah respon dengan kategori lebih dari dua (polytomous) dengan peubah penjelas kategorik dan atau kontinu. Melalui metode regresi logistik multinomial akan dihasilkan peluang dari masing-masing kategori respon yang akan dijadikan sebagai pedoman pengklasifikasian suatu pengamatan akan masuk dalam respon kategori tertentu berdasarkan nilai peluang terbesar (Hosmer DW & Lemeshow S 2000; Gozali 2005).
Penelitian tentang analisis diskriminan dan regresi logistik multinomial banyak dilakukan antara lain oleh, Maulias (2009) klasifikasi penjurusan siswa SMK Negeri 1 Tual Maluku dengan pendekatan analisis diskriminan dan regresi logistik multinomial. Metode klasifikasi menggunakan fungsi diskriminan (Purnomo 2003).
Tujuan Penelitian
Tujuan penelitian ini antara lain :
1. Menerapkan metode analisis diskriminan dan multinomial logistik untuk klasifikasi.
TINJAUAN PUSTAKA
Analisis Diskriminan
Analisis diskriminan (Discriminant Analysis) adalah salah satu metode analisis multivariat yang bertujuan untuk memisahkan beberapa kelompok data yang sudah terkelompokkan dengan cara membentuk fungsi diskriminan (Johnson & Wichern 1998). Untuk melakukan analisis diskriminan ada dua asumsi yang harus diperhatikan (Dillon dan Goldstein 1984) yaitu :
1. Sejumlah � peubah bebas menyebar mengikuti sebaran normal ganda.
2. Matriks peragam berdimensi �� dari peubah-peubah bebas dalam setiap kelompok harus homogen.
Uji sebaran normal ganda dapat dilakukan dengan plot khi-kuadrat (Johnson & Winchern 1998). Setiap vektor pengamatan dihitung jarak Mahalanobisnya dengan persamaan:
Tebaran titik-titik yang membentuk garis lurus menunjukkan kesesuaian pola sebaran 2 terhadap sebaran khi-kuadrat yang berati data berasal dari sebaran normal. Jika asumsi normal ganda tidak terpenuhi maka dapat digunakan analisis diskriminan logistik sebagai solusinya (Cacoullos 1973).
Rencher (2002) menyatakan bahwa uji kehomogenan matriks peragam dilakukan menggunakan uji Box’ M, statistik uji yang digunakan adalah :
Statistik bernilai antara 0 dan 1, jika nilainya mendekati 0, maka telah cukup kehomogenan matriks peragam yang tidak terpenuhi maka analisis yang dapat digunakan adalah analisis diskriminan kuadratik ( Gnanadesikan, R. 1977).
Pembentukan Fungsi Diskriminan
Fungsi diskriminan, menurut Johnson dan Winchern (1998) misalkan terdapat kelompok populasi dengan masing-masing ukuran contoh , = 1,2,…, , vektor peubah acak populasi ke- adalah = 1, 2,…, � , dan baris ke-
adalah maka vektor rataan populasi ke- dapat dinyatakan sebagai berikut:
disusun dengan memaksimalkan rasio antara ragam antar kelompok dengan ragam
Menurut Dillon dan Goldstein (1984), bila didefinisikan adalah banyaknya objek dari kelompok, maka matriks � berukuran �×� berasal dari peubah acak 1, 2,…, � yang bebas linear dengan − �. Sedangkan pangkat
matriks � sama dengan minimum � dan −1, maka matriks �−1� juga berpangkat min(�, −1). Hal ini berarti banyaknya akar ciri yang mungkin diperoleh oleh matriks �−1� adalah min(�, −1), sehingga banyaknya fungsi diskriminan yang dapat dibangun tergantung pada besaran min(�, −1).
Peranan relatif suatu fungsi diskriminan ke- dalam memisahkan anggota-anggota kelompok diukur dari persentase relatif akar ciri yang berhubungan dengan fungsi diskriminan berikut :
Semua fungsi diskriminan yang terbentuk perlu diuji untuk mengetahui banyaknya fungsi yang dapat menjelaskan perbedaan peubah-peubah penjelas di antara g kelompok (Dillon & Goldstein 1984). Adapun pengujian fungsi diskriminan dapat dilakukan dengan menggunakan statistik V-Barlett melalui pendekatan khi-kuadrat, sebagai berikut :
atau dapat ditulis : untuk menerangkan perbedaan �-peubah diantara -kelompok. Kriteria masuknya individu kedalam kelompok ke- (Gaspersz 1992) bila:
− 2 = ′ − 2 ′ − 2
=1 =1
=1
dengan :
= Vektor skor diskriminan ke-m dari obyek
= Nilai tengah skor diskriminan ke-m dari kelompok ke-i
= Vektor koefisien fungsi diskriminan
= Vektor pengamatan dari objek yang akan dikelompokkan
= Vektor nilai tengah peubah pembeda dari kelompok ke-i
= Banyaknya fungsi diskriminan penggolongan
Statistik kemudian dibandingkan dengan nilai kritis (nilai khi-kuadrat untuk derajat bebas 1 pada taraf tertentu). Jika statistik lebih besar dari nilai kritis berarti persentase hasil klasifikasi yang dihasilkan memiliki kekuatan dalam mengklasifikasikan objek.
Dillon dan Goldstein (1984) menyatakan bahwa dalam menentukan peubah-peubah yang dimasukkan kedalam fungsi diskriminan dapat digunakan analisis diskriminan bertahap (stepwise discriminant). Pada analisis ini diawali dengan fungsi tanpa peubah, fungsi yang terbentuk pada setiap tahap diuji nilai F-parsial untuk setiap peubahnya. Peubah yang memilki nilai F terbesar dimasukkan ke dalam fungsi sedangkan peubah yang memiliki nilai F yang kurang dari 1 tidak akan dimasukkan dalam pembentukan fungsi. Proses akan berhenti bila tidak ada lagi peubah yang dimasukkan atau dikeluarkan.
Regresi Logistik Multinomial
Regresi logistik multinomial merupakan perluasan dari regresi logistik dengan respon biner yang dapat menangani peubah respon dengan kategori lebih dari dua. Hosmer dan Lemeshow (2000) menjelaskan, untuk model regresi dengan peubah respon berskala nominal tiga kategori digunakan kategori peubah hasil Y yang dikode 0, 1, dan 2. Peubah Y terparameterisasi menjadi dua fungsi logit. Sebelumnya perlu ditentukan kategori respon yang digunakan sebagai kategori pembanding terlebih dahulu. Pada umumnya digunakan Y=0 sebagai pembanding. Untuk membentuk fungsi logit, akan dibandingkan Y=1 dan Y=2 terhadap Y=0. Bentuk model regresi yang berupa fungsi peluang dengan p peubah bebas seperti pada persamaan berikut ini:
� = � 0+ 1 1+ 2 2+⋯+ � �
1 + � 0+ 1 1+ 2 2+⋯+ � �
Berdasarkan kedua fungsi logit tersebut maka didapatkan probabilitas respon atau model regresi logistik multinomial dengan peubah respon berskala nominal tiga kategori sebagai berikut (Hosmer dan Lemeshow, 2000).
�0 =
1
1 + � 1 + � 2
�1 =
� 1
1 + � 1 + � 2
�2 =
� 2
1 + � 1 + � 2
Menurut Hosmer dan Lemeshow (2000), dalam menduga model logit dengan peubah responnya berskala kualitatif, teknik pendugaan parameter yang layak digunakan adalah metode kemungkinan maksimum. Prinsip dari metode kemungkinan maksimum memberikan nilai dugaan parameter suatu fungsi kemungkinan. Fungsi kemungkinan yang ingin dimaksimalkan adalah :
= ( =
=1
| )
dengan = banyaknya pengamatan
Pengujian Kesesuaian Model
Pengujian Kesesuaian model dilakukan untuk memeriksa pengaruh peubah-peubah penjelas dalam model. Pengujian dilakukan untuk masing-masing parameter model ( ). Pengujian secara simultan dilakukan dengan menggunakan uji yaitu uji nisbah kemungkinan (likelihood ratio test).
Uji untuk pengujian parameter dengan hipotesis :
0: 1 = 2 =⋯ = � = 0
1: ≠0
Statistik uji yang digunakan adalah statistik uji :
= −2 0
1
dengan : 0 = likelihood tanpa peubah bebas
Jika H0 benar, statistik ini mengikuti sebaran �2 dengan derajat bebas p,
Kriteria keputusan yang diambil adalah menolak 0 jika �2(�) (Hosmer & Lemeshow 2000). Seandainya 0 ditolak, maka selanjutnya dilakukan uji Wald untuk menguji parameter secara parsial. Hipotesis yang diujikan adalah :
0: = 0
1: ≠0, = 1,2,…,�
Sedangkan statistik uji Wald sebagai berikut :
=
�
Statistik uji Wald mengikuti sebaran normal baku, dengan sebagai penduga dan
� sebagai penduga galat baku . Kriteria keputusan adalah menolak 0 jika
2 atau nilai (Hosmer & Lemeshow 2000).
Pereduksian peubah
Pereduksian peubah dalam regresi logistik dikenal dengan analisis regresi logistik bertatar (stepwise logistic regression), dimana langkah yang dilakukan adalah menambah atau menghilangkan peubah penjelas satu persatu dari model sampai diperoleh peubah-peubah yang berpengaruh nyata terhadap model (Hosmer & Lemeshow 2000). Stepwise logistic regression terdiri dari seleksi langkag majudan eliminasi langkah mundur.
Teknik pereduksian peubah penjelas ini telah tersedia dalam paket pengolahan komputer. Dalam penelitian ini metode pereduksian yang digunakan adalah eliminasi langkah mundur.
Interpretasi Koefisien
Setelah diperoleh model terbaik, dilakukan interpretasi koefisien yang diperoleh. Rasio odds dapat juga dipergunakan untuk memudahkan interpretasi model. Rasio odds adalah ukuran asosiasi yang memperkirakan berapa besar kemungkinan peubah-peubah penjelas terhadap peubah respon (Hosmer dan Lemeshow 2000). Rasio odds untuk = terhadap = yang dihitung pada dua nilai (misal = dan = ) adalah :
� , = = = )/ = = )
= = )/ = = )= � −
Sehingga jika − = 1 maka � = �( ).
Ukuran � selalu positif dan umumnya digunakan sebagai pendekatan risiko nisbi (relative risk). Untuk � = 1 berarti bahwa = memiliki risiko yang sama dengan = untuk menghasilkan = . Bila 1 <� <∞ berarti =
memiliki risiko lebih tinggi � kali daripada = , dan sebaliknya untuk 0 <
�< 1. Jika peubah penjelas kontinu maka interpretasi koefisien dugaan tergantung pada unit particular dari peubah penjelas. Untuk peubah penjelas kontinu diperlukan unit perubahan sebesar , maka rasio odds diperoleh dengan
METODOLOGI
Data Penelitian
Data yang digunakan dalam penelitian ini adalah data sekunder yang diambil dari dua SMA di Kabupaten Sitaro yaitu SMA Negeri Tagulandang yang berjumlah 170 siswa dan SMA Negeri Siau Timur yang berjumlah 252 siswa. Peubah yang diambil adalah nilai rataan rapor kelas X dan keterangan pribadi siswa waktu masuk di SMA. Data SMA Negeri Siau Timur Tahun ajaran 2009/2010 dan 2010/2011 digunakan untuk pemodelan. Sedangkan yang digunakan untuk validasi adalah data SMA Negeri Tagulandang. Peubah yang akan digunakan dalam penelitian ini disajikan dalam Tabel 1. Pengkodean untuk peubah dummy dapat dilihat pada Lampiran 1.
Tabel 1 Peubah-peubah yang diamati Peubah
bebas Keterangan
Peubah
bebas Keterangan
X1 Rataan Nilai Agama X11 Rataan Nilai Ekonomi
X2 Rataan Nilai PPKn X12 Rataan Nilai Sosiologi
X3 Rataan Nilai Bhs Indonesia X13 Rataan Nilai TIK
X4 Rataan Nilai Bhs Inggris X14 Rataan Nilai Bhs Jerman
X5 Rataan Nilai Matematika X15 Jenis Kelamin
X6 Rataan Nilai Fisika X16 Pendidikan Ayah
X7 Rataan Nilai Biologi X17 Pendidikan Ibu
X8 Rataan Nilai Kimia X18 Pekerjaan Ayah
X9 Rataan Nilai Sejarah X19 Pekerjaan Ibu
X10 Rataan Nilai Geografi X20 Pendapatan
Metode analisis
Langkah-langkah yang dilakukan dalam penelitian ini adalah sebagai berikut :
Tahap I : Melakukan analisis diskriminan dan multinomial logit
1. Analisis diskriminan a. Uji asumsi diskriminan
2) Menguji kehomogenan matriks peragam gabungan menggunakan uji
Box’M dengan membandingkan signifikansinya terhadap taraf nyata
(α). Jika tidak terpenuhi maka tidak dapat membuat fungsi
diskriminan linear.
b. Melakukan proses diskriminan
1) Mencari fungsi diskriminan bertahap.
2) Menghitung peranan relatif dari fungsi diskriminan yang didapat dengan mengukur menggunakan persentase relatif akar ciri dari fungsi diskriminan yang terbentuk.
3) Menguji keterandalan fungsi diskriminan dengan uji V-Bartlett yang menggunakan pendekatan khi-kuadrat.
4) Menghitung ketepatan klasifikasi fungsi diskriminan.
5) Menguji keterandalan hasil klasifikasi dari proses analisis diskriminan dengan statistik .
2. Analisis multinomial logit
a. Membentuk fungsi logit dari peubah penjelas, yang mana transformasi logit yang digunakan adalah :
� ( )
� ( ) = 0 + 1 1 + . . . + � �
b. Menyelesaikan dugaan parameter dengan metode Kemungkinan Maksimum.
c. Melakukan pengujian parameter dengan statistik uji-G untuk melihat peran seluruh peubah penjelas di dalam model secara simultan.
d. Melakukan pengujian parameter secara parsial dengan statistik uji Wald untuk melihat pengaruh masing-masing peubah penjelas terhadap peubah respon.
e. Melakukan interpretasi koefisien model regresi logistik multinomial dengan Rasio odds.
f. Menghitung ketepatan klasifikasi model logistik.
Tahap II : Mengevaluasi model klasifikasi dengan resampling
contoh berukuran sama dengan data awal. Hal ini bertujuan untuk melihat kekonsistenan peubah-peubah yang signifikan terhadap jurusan siswa di SMA. Konsistensi peubah-peubah tersebut akan digunakan sebagai pertimbangan untuk memilih peubah bebas dalam membangun model klasifikasi pengelompokan jurusan siswa di SMA.
2. Pada setiap resampling, data yang terambil kemudian dianalisis menggunakan analisis logistik multinomial dan analisis diskriminan. Dengan demikian, akan diperoleh masing-masing 30 model untuk model logistik multinomial dan model diskriminan.
3. Mengidentifikasi peubah-peubah yang signifikan untuk masing-masing model. Peubah yang signifikan pada 10 model logistik multinomial atau lebih akan digunakan untuk membangun model klasifikasi, demikian pula halnya untuk model diskriminan.
4. Melakukan analisis logistik multinomial dan analisis diskriminan terhadap data awal, dengan peubah bebas yang terpilih pada langkah 3.
5. Mengevaluasi model logistik multinomial dan analisis diskriminan yang diperoleh pada langkah 4 dengan melihat ketepatan klasifikasi masing-masing model.
6. Memilih model klasifikasi terbaik berdasarkan hasil pada langkah 5. Model yang terbaik adalah model yang memiliki tingkat klasifikasi paling tinggi.
Tahap III : Melakukan validasi terhadap model terbaik
HASIL DAN PEMBAHASAN
Karakteristik Siswa
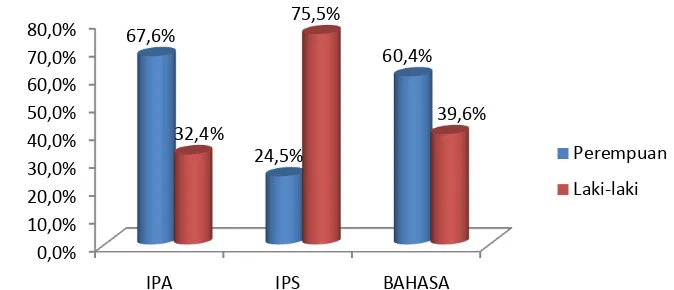
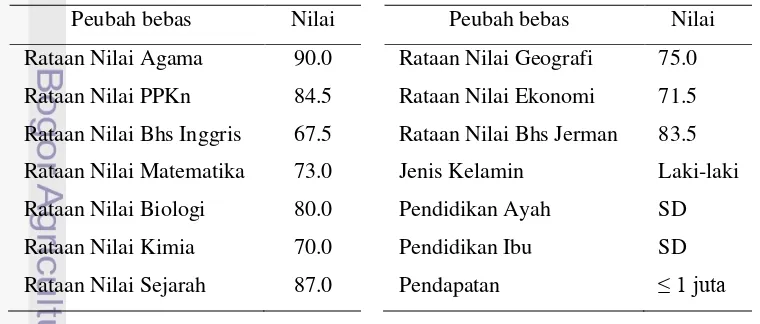
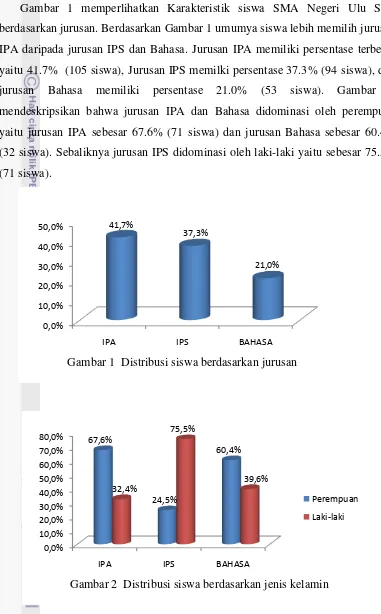
Gambar 1 memperlihatkan Karakteristik siswa SMA Negeri Ulu Siau berdasarkan jurusan. Berdasarkan Gambar 1 umumya siswa lebih memilih jurusan IPA daripada jurusan IPS dan Bahasa. Jurusan IPA memiliki persentase terbesar yaitu 41.7% (105 siswa), Jurusan IPS memilki persentase 37.3% (94 siswa), dan jurusan Bahasa memiliki persentase 21.0% (53 siswa). Gambar 2 mendeskripsikan bahwa jurusan IPA dan Bahasa didominasi oleh perempuan yaitu jurusan IPA sebesar 67.6% (71 siswa) dan jurusan Bahasa sebesar 60.4% (32 siswa). Sebaliknya jurusan IPS didominasi oleh laki-laki yaitu sebesar 75.5% (71 siswa).
Gambar 2 Distribusi siswa berdasarkan jenis kelamin Perempuan
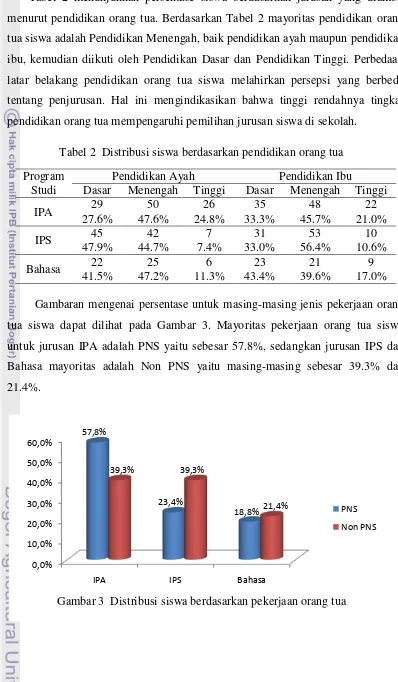
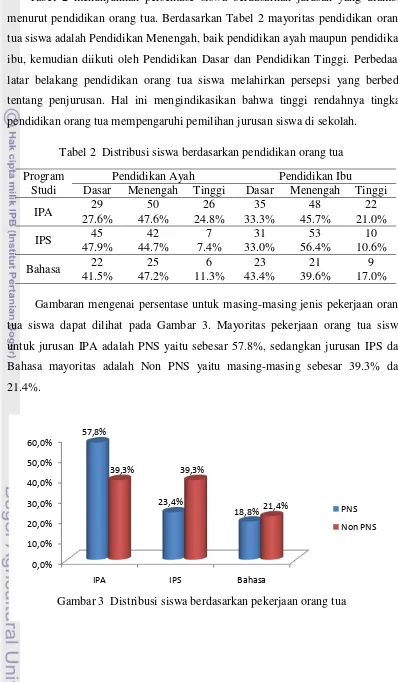
Tabel 2 menunjukkan persentase siswa berdasarkan jurusan yang diambil menurut pendidikan orang tua. Berdasarkan Tabel 2 mayoritas pendidikan orang tua siswa adalah Pendidikan Menengah, baik pendidikan ayah maupun pendidikan ibu, kemudian diikuti oleh Pendidikan Dasar dan Pendidikan Tinggi. Perbedaan latar belakang pendidikan orang tua siswa melahirkan persepsi yang berbeda tentang penjurusan. Hal ini mengindikasikan bahwa tinggi rendahnya tingkat pendidikan orang tua mempengaruhi pemilihan jurusan siswa di sekolah.
Tabel 2 Distribusi siswa berdasarkan pendidikan orang tua
Program Studi
Pendidikan Ayah Pendidikan Ibu
Dasar Menengah Tinggi Dasar Menengah Tinggi
IPA 29 50 26 35 48 22
Gambaran mengenai persentase untuk masing-masing jenis pekerjaan orang tua siswa dapat dilihat pada Gambar 3. Mayoritas pekerjaan orang tua siswa
Gambar 3 Distribusi siswa berdasarkan pekerjaan orang tua PNS
Deskripsi Nilai Rapor Menurut Program Studi
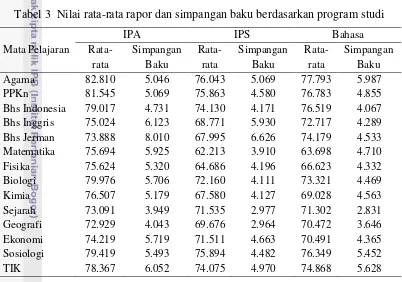
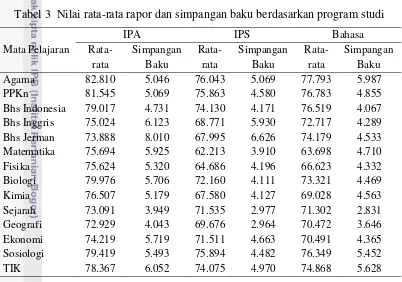
Berdasarkan laporan hasil prestasi belajar siswa SMA Negeri Siau Timur, diperoleh nilai rata-rata kelas dan simpangan baku untuk setiap mata pelajaran (Tabel 3). Mata pelajaran yang menjadi ciri khas program studi IPA adalah Matematika, Fisika, Kimia, Biologi. Pelajaran ciri khas program studi IPS adalah Sejarah, Ekonomi, Sosiologi, Geografi dan pelajaran ciri khas program studi Bahasa adalah Bahasa Indonesia, Bahasa Inggris, Bahasa Jerman.
Tabel 3 Nilai rata-rata rapor dan simpangan baku berdasarkan program studi
Mata Pelajaran
Analisis Diskriminan
Analisis Diskriminan dimaksudkan untuk mengetahui sejauh mana peubah-peubah tersebut dapat menentukan kelompok jurusan siswa dan peubah-peubah mana yang menjadi penciri utama sebagai pembeda kelompok jurusan siswa di SMA. Peubah penciri yang akan diamati adalah Rataan nilai mata pelajaran Kelas X ( meliputi : Agama, PPKn, Bahasa Indonesia, Bahasa Inggris, Matematika, Fisika, Biologi, Kimia, Sejarah, Geografi, Ekonomi, Sosiologi, Teknologi Informasi dan Komunikasi (TIK), Bahasa Jerman), Jenis kelamin, Pendidikan ayah, Pendidikan ibu, Pekerjaan ayah, Pekerjaan ibu, dan Pendapatan orang tua.
Pemeriksaan Asumsi Dasar Diskriminan a. Asumsi kenormalan ganda
Hasil plot quantil khi-kuadrat terlihat polanya mengikuti trend linier baik untuk kelompok IPA, IPS maupun Bahasa (Lampiran 3). Kelinieran tersebut terlihat dari hubungan regresi linier antara jarak dan khi-kuadrat yang nyata pada taraf = 0.05, seperti yang terlihat pada Tabel 4.
Tabel 4 Nilai-p regresi linier tiap kategori Jurusan Siswa Nilai-p
IPA IPS Bahasa
.0001 .0001 .0001
Hasil tersebut menunjukkan bahwa hipotesis kenormalan ganda pada analisis diskriminan terpenuhi.
b. Asumsi kehomogenan ragam
sebesar 0.073 > = 0.05, maka asumsi kehomogenan matriks peragam peubah penjelas terpenuhi. Selanjutnya akan dilakukan analisis diskriminan.
Pembentukan Fungsi diskriminan
Fungsi diskriminan dibentuk dengan menggunakan metode stepwise discriminant. Tabel 5 menunjukkan bahwa terdapat 5 peubah penjelas yang cukup mewakili dalam melihat perbedaan antara kelompok IPA, IPS dan Bahasa. Kelima peubah itu adalah Bahasa Inggris, Fisika Kimia, Ekonomi dan TIK.
Tabel 5 Koefisien fungsi diskriminan
Peubah Fungsi
1 2
Bahasa Inggris -.028 .214
Fisika .219 -.023
Kimia .084 -.051
Ekonomi -.038 -.189
TIK -.060 .030
(Constant) -11.933 1.141
Peubah bertanda positif, artinya setiap kenaikan satu satuan nilai peubah maka akan memberikan skor yang makin tinggi bagi fungsi diskriminan. Sedangkan peubah bertanda negatif, artinya setiap kenaikan satu satuan nilai peubah maka akan memberikan skor yang makin rendah bagi fungsi diskriminan. Peranan relatif suatu fungsi diskriminan dalam memisahkan anggota-anggota kelompok diukur dari persentase relatif akar ciri yang berhubungan dengan fungsi diskriminan itu. Dengan memperhatikan akar ciri pada Lampiran 4, terlihat fungsi pertama adalah 92.5 dan fungsi kedua adalah 7.5, artinya persentase relatif yang dapat dijelaskan oleh fungsi diskriminan pertama adalah 92.5%, sedangkan sisanya sebesar 7.5 dijelaskan oleh fungsi diskriminan kedua.
masih bersifat nyata secara statistik, dengan demikian diskriminan kedua masih diperlukan untuk menerangkan perbedaan peubah.
Dari fungsi diskriminan yang terbentuk melalui analisis diskriminan bertahap, lalu dilakukan pengklasifikasian. Pengklasifikasian suatu objek pengamatan baru pada fungsi diskriminan linier, dilakukan dengan mengacu pada konsep jarak bahwa pengklasifikasian suatu objek x dipilih dari jarak objek pengamatan x terhadap vektor rataanya yang terdekat/terkecil pada masing-masing jurusan. Rata-rata kelompok (group centroids) dari jurusan siswa mempunyai nilai yang besarnya berbeda, yaitu dapat dilihat pada Tabel 6. Secara umum keseluruhan proses pengklasifikasian dengan menggunakan fungsi diskriminan dapat dilihat pada Lampiran 9.
Tabel 6 Nilai Rata-rata Kelompok Jurusan Siswa Fungsi
1 2
IPA 1.433 -.053
IPS -1.177 -.302
Bahasa -.751 .641
Ketepatan Klasifikasi Fungsi Diskriminan
Pengklasifikasian kelompok asal siswa menunjukkan bahwa 76.2% siswa yang diteliti dapat diklasifikasikan dengan benar ke dalam jurusannya sedang sisanya mengalami salah klasifikasi. Tabel 7 menunjukkan bahwa siswa IPA terklasifikasi dengan benar ke dalam jurusannya sebesar 83.8%, siswa IPS 73.4% dan siswa Bahasa 66.0%. Hal ini menunjukkan bahwa, 16.2% siswa IPA, 26.6% siswa IPS, dan 34% siswa Bahasa terklasifikasikan ke jurusan lain.
Tabel 7 Hasil klasifikasi analisis diskriminan Observasi Prediksi (%)
IPA IPS Bahasa Benar
IPA 88 7 10 83.8%
IPS 4 69 21 73.4%
Bahasa 4 14 35 66.0%
Statistik Q dari hasil klasifikasi kebenaran yang sebesar 76.2% adalah 208.3 dan nilai kritis �0.05(1)2 adalah 3.84. Terlihat statistik Q lebih besar dari nilai kritis sehingga klasifikasi kebenaran yang didapat sebesar 76.2%, secara statistik sudah baik.
Analisis Regresi Logistik Multinomial
Hasil pendugaan model penuh dengan melibatkan 20 peubah penjelas menghasilkan nilai G sebesar 399.939 dan nilai p= 0.000 < 0.05, sehingga dapat ditarik kesimpulan bahwa ada satu atau lebih peubah penjelas yang berpengaruh terhadap pengelompokkan jurusan siswa di SMA. Hasil dari pendugaan model penuh ini dapat dilihat pada Lampiran 2. Selanjutnya, dilakukan pemilihan peubah yang signifikan dengan menggunakan eliminasi langkah mundur. Hasil setelah seleksi dapat dilihat pada Tabel 8.
Tabel 8 Analisis multinomial logistik hasil eliminasi langkah mundur
1 =−32.094 + 0.212 1 − 0.417 4 + 0.708 5 + 0.561 8 − 0.070 9−
0.031 11 − 0.483 14 − 0.328 15
2 =−4.707 + 0.070 1 − 0.147 4 + 0.047 5 + 0.011 8 − 0.222 9−
0.166 11 − 0.307 14 − 0.047 15
Interpretasi model regresi logistik multinomial akan lebih mudah dilihat dari
nilai rasio oddsnya. Jika suatu peubah memiliki nilai koefisien yang bertanda positif maka nilai rasio odds diatas satu, sedangkan nilai koefisien yang bertanda negatif maka nilai rasio odds dibawah satu.
Pada model pertama terdapat lima peubah penjelas yang signifikan. Interpretasinya adalah setiap bertambahnya satu nilai pada pelajaran Bahasa Jerman maka akan menurunkan peluang siswa masuk ke jurusan IPA menjadi 0.617 kali dibandingkan ke jurusan Bahasa. Setiap bertambahnya satu nilai pada pelajaran Kimia maka akan meningkatkan peluang siswa masuk ke jurusan IPA sebesar 1.752 kali dibandingkan ke jurusan Bahasa. Setiap bertambahnya satu nilai Bahasa Inggris maka akan menurunkan peluang siswa masuk ke jurusan IPA sebesar 0.659 kali dibandingkan ke jurusan Bahasa. Untuk nilai odds Agama sebesar 1.236, artinya siswa lebih cenderung memilih jurusan IPA sebesar 1.236 dibanding Bahasa Setiap bertambahnya satu nilai pada pelajaran Matematika maka akan meningkatkan peluang siswa masuk ke jurusan IPA sebesar 2.030 kali dibanding ke jurusan Bahasa.
Evaluasi Kebaikan Model
Menurut Hosmer dan Lemeshow (1989) salah satu ukuran kebaikan model adalah jika memiliki peluang kesalahan klasifikasi yang minimal. Ketepatan dan kesalahan klasifikasi dapat dilihat dalam tabel klasifikasi.
Tabel 9 Hasil prediksi multinomial logistik Observasi Prediksi (%)
IPA IPS Bahasa Benar
IPA 100 4 1 95.2%
IPS 6 75 13 79.8%
Bahasa 3 14 36 67.9%
% Keseluruhan 83.7%
Berdasarkan Tabel 9 diperoleh total ketepatan klasifikasi analisis regresi logistik multinomial sebesar 83.7 %. Artinya model logistik multinomial mampu mengklasifikasikan siswa ke dalam jurusannya dengan benar sebesar 83.7% dari total siswa keseluruhan. Untuk masing-masing jurusan, model logistik mampu mengklasifikasikan siswa IPA dengan benar sebesar 95.2%, siswa IPS 79.8%, dan siswa Bahasa 67.9%. Hal ini menunjukkan bahwa 4.8% siswa IPA, 20.2% siswa IPS, dan 32.1% siswa Bahasa terklasifikasikan ke jurusan lain.
Pembangunan Analisis Model Diskriminan dan Logistik Multinomial dari
Hasil Resampling
Analisis Diskriminan
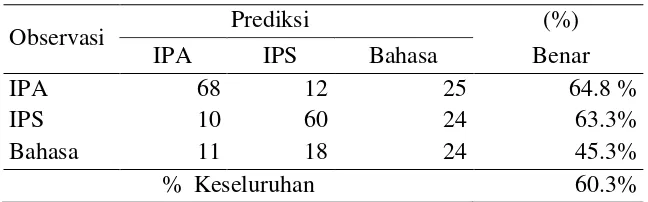
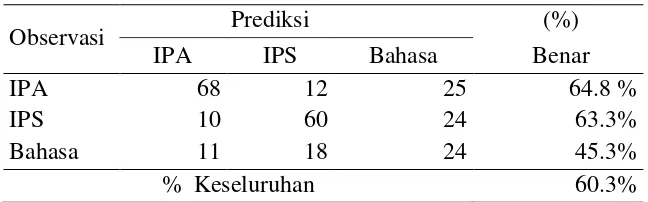
Penentuan peubah penjelas berdasarkan kekonsistenan yang diperoleh melalui resampling menghasilkan tiga peubah penjelas yang berpengaruh terhadap pengelompokkan jurusan siswa. Peubah-peubah tersebut adalah Bahasa Indonesia, Biologi dan Sosiologi (Tabel 10). Tingkat ketepatan klasifikasi yang dihasilkan dari model analisis diskriminan adalah 60.3% (Tabel 11).
Tabel 10 Fungsi Diskriminan
Peubah Fungsi
1 2
Bahasa Indonesia .055 .269
Biologi .187 -.117
Sosiologi -.023 -.081
(Constant) -16.616 -5.462
Tabel 11 Hasil Klasifikasi Analisis Diskriminan
Observasi Prediksi (%)
IPA IPS Bahasa Benar
IPA 68 12 25 64.8 %
IPS 10 60 24 63.3%
Bahasa 11 18 24 45.3%
% Keseluruhan 60.3%
Analisis Regresi Logistik Multinomial
Hasil pemodelan regresi logistik multinomial menunjukkan bahwa dari empat mata pelajaran yang menjadi ciri khas jurusan IPA, ternyata hanya Matematika dan Kimia yang berpengaruh nyata. Hal ini disebabkan oleh korelasi yang cukup kuat antar mata pelajaran. Lampiran 10 menunjukkan bahwa mata pelajaran Fisika memiliki korelasi sebesar 0.823 terhadap Matematika, sementara mata pelajaran Biologi memiliki korelasi sebesar 0.769 terhadap Kimia. Artinya, kemampuan siswa untuk mata pelajaran Fisika dan Biologi sudah tercermin melalui mata pelajaran Matematika dan Kimia.
Tabel 12 Hasil dugaan parameter multinomial logistik
Model klasifikasi yang disusun menggunakan analisis regresi logistik multinomial memiliki tingkat ketepatan klasifikasi sebesar 88.1% (Tabel 13). Ketepatan klasifikasi model ini lebih tinggi jika dibandingkan dengan model sebelum dilakukan resampling. Hal ini berarti bahwa model logistik multinomial cukup baik dalam mengklasifikasikan siswa ke dalam jurusannya dengan tepat sebanyak 88.1% dari total siswa.
Tabel 13 Ketepatan Klasifikasi Model Logistik multinomial
Observasi Prediksi (%)
IPA IPS Bahasa Benar
IPA 99 5 1 94.3%
IPS 4 83 7 88.3%
Bahasa 2 11 40 75.5%
% Keseluruhan 88.1%
Perbandingan Hasil Klasifikasi Analisis Diskriminan dan Logistik
Multinomial
Perbandingan hasil klasifikasi analisis diskriminan dan regresi logistik multinomial dalam mengklasifikasi siswa ke dalam jurusan IPA, IPS, dan Bahasa dapat dilihat dari tingkat ketepatan klasifikasi. Semakin besar persentase ketepatan klasifikasi suatu model maka semakin baik dan akurat model tersebut dalam mengklasifikasi jurusan siswa.
Tabel 14 Ketepatan klasifikasi
Model Model Sebelum Resampling (%)
Model Sesudah Resampling
(%)
Analisis Diskriminan 76.2 60.3
Regresi Logistik Multinomial 83.7 88.1
sebelum resampling, dan 60.3% pada model sesudah resampling. Hal ini menunjukkan bahwa regresi logistik multinomial mampu memberikan tingkat ketepatan klasifikasi yang lebih tinggi dibandingkan model analisis diskriminan. Dengan demikian, regresi logistik multinomial merupakan model terbaik yang dapat digunakan untuk menduga siswa memilih jurusan di SMA. Bentuk persamaan logistik multinomial adalah :
1 =−51.542 + 0.357 1 + 0.039 2− 0.597 4 + 0.815 5 + 0.199 7+
0.724 8 − 0.162 9 − 0.058 10− 0.045 11−0.572 14+ 0.141 15+
3.555 16(1)+ 4.404 16(2)−0.186 17(1)−1.965 17(2)−2.057 20(1)+ 0.663 20(2)
2 =−3.928 − 0.055 1 + 0.171 2 − 0.177 4 + 0.009 5 + 0.237 7 −
0.090 8 + 0.394 9 − 0.287 10+ 0.179 11−0.361 14+ 1.962 15+ 1.057 16(1)− 0.710 16(2) + 0.630 17(1)+ 1.354 17(2)−0.862 20(1)+ 0.640 20(2)
Penerapan Model Logistik multinomial
Nilai peluang pada Tabel 13 memberikan informasi mengenai penerapan model logistik multinomial dalam mengelompokkan jurusan siswa di SMA Negeri Tagulandang Kabupaten Siau Tagulandang Biaro. Peluang seorang siswa untuk masuk ke dalam kategori jurusan tertentu dapat dihitung berdasarkan ilustrasi data pada Tabel 15.
Tabel 15 Ilustrasi data siswa
Peubah bebas Nilai Peubah bebas Nilai
Rataan Nilai Agama 90.0 Rataan Nilai Geografi 75.0
Rataan Nilai PPKn 84.5 Rataan Nilai Ekonomi 71.5
Rataan Nilai Bhs Inggris 67.5 Rataan Nilai Bhs Jerman 83.5
Rataan Nilai Matematika 73.0 Jenis Kelamin Laki-laki
Rataan Nilai Biologi 80.0 Pendidikan Ayah SD
Rataan Nilai Kimia 70.0 Pendidikan Ibu SD
Sehingga dapat dihitung nilai untuk model logit pertama, yaitu:
dan nilai untuk model logit kedua, yaitu:
g2 x =−3.928−0.055 90 + 0.171 84.5 −0.177 67.5 + 0.009 73 +
0.237 80 −0.090 70 + 0.394 87 −0.287 75 + 0.179 71.5 − 0.361 83.5 + 1.962 1 + 1.057 1 −0.710 0 + 0.630 1 + 1.354 0 −0.862 1 −0.640(0)
g2 x = 5.136
Hasil dari model logit dimasukkan ke fungsi peluang, sebagai berikut :
P Y = 0x = π0 x = 1 siswa masuk ke kategori kedua. Hasil perhitungan lengkap untuk model logistik multinomial dari data siswa SMA Negeri Tagulandang disajikan pada Tabel 16. Ketepatan klasifikasi yang diperoleh model tersebut adalah 70.6%, artinya sebanyak 70.6% siswa SMA Negeri Tagulandang dapat diklasifikasikan dengan benar ke dalam kejurusannya masing-masing. Hal ini menunjukkan bahwa kemampuan model sudah cukup baik dalam mengelompokan siswa ke dalam jurusannya.
SIMPULAN DAN SARAN
SIMPULAN
Penerapan analisis diskriminan dan regresi logistik multinomial dalam mengelompokkan siswa SMA Negeri Siau Timur memberikan ketepatan klasifikasi masing-masing sebesar 76.2% dan 83.7%. Berdasarkan penentuan peubah dari proses resampling sebanyak 30 kali, diperoleh model terbaik yaitu regresi logistik multinomial dengan tingkat ketepatan klasifikasi sebesar 88.1%.
Pengelompokkan siswa ke dalam jurusan IPA atau Bahasa dipengaruhi oleh mata pelajaran Matematika, Bahasa Inggris, Kimia, dan Bahasa Jerman. Pengelompokkan siswa ke dalam jurusan IPS atau Bahasa dipengaruhi oleh mata pelajaran Ekonomi, Bahasa Inggris, Bahasa Jerman, dan Sejarah. Validasi model yang dilakukan dengan menggunakan data SMA Negeri Tagulandang memberikan ketepatan klasifikasi sebesar 70.6%. Hal ini menunjukkan bahwa kemampuan model regresi logistik multinomial sudah cukup baik dalam mengelompokan siswa ke dalam jurusannya.
SARAN
Penelitian lanjutan dapat dilakukan untuk studi kasus dengan mengambil sampel yang berbeda. Peneliti berikutnya dapat melakukan penelitian tentang penjurusan, apakah benar nilai Biologi merupakan salah satu penentu untuk jurusan IPS sebagaimana penulis temukan pada penelitian ini.
DAFTAR PUSTAKA
Andanawari AG. 2010. Faktor-Faktor yang Mempengaruhi Minat Siswa Melanjutkan Pendidikan ke Perguruan Tinggi dengan Menggunakan Regresi Logistik. [tesis] Bogor. Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Cacoullos T. 1973. Discriminant Analysis and Applications. New York and London: Academic Press.
Depdiknas. 2004. Pedoman Umum Pengembangan Penilaian. Departemen Pendidikan Nasional.
Dillon W, Goldstein M. 1984. Multivariate Analysis. New York: Wiley.
Garson. 2010. Logistic Regression: Statnotes. North Carolina State University.
http://faculty.chass.ncsu.edu/garson/PA765/Logistic.htm/ [31 Januari 2012].
Gaspersz V. 1992. Teknik Analisis dalam Penelitian Percobaan. Ed ke-1. Tarsito Bandung.
Ghozali. 2006. Aplikasi Analisis Multivariate dengan program SPSS. Universitas Diponegoro.
Gnanadesikan R. 1977. Methods for Statistical Data Analysis of Multivariate Observations. New York: John Wiley & Sons.
Hair JF, Anderson RE, Tatham RL, Black WC. 1995. Multivariate Data Analysis with Readings. New Jersey: Prentice-Hall.
Hosmer DW, Lemeshow S. 2000. Applied Logistic Regression. New York: John Wiley & Sons.
Johnson RA, Wichern DW. 1998. Applied Multivariate Statistical Analysis Ed ke-4. New Jersey: Hall.
Maulias SS. 2009. Klasifikasi Penjurusan Siswa SMK Negeri 1 Tual Maluku Tenggara dengan Pendekatan Analisis Diskriminan dan regresi Logistik Multinomial. [tesis]. Surabaya. Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Teknologi Sepuluh Nopember.
Morrison DF. 1990. Multivariate Statistical Methods Ed ke-3. McGraw-Hill Publishing Company.
Purnomo H. 2003. Metode Klasifikasi Menggunakan Fungsi Diskriminan. [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Rencher AC. 2002. Methods of Multivariate Analysis. New York: Wiley.
Sharma S. 1996. Applied Multivariate Techniques. New York. John Wiley & Sons.
Snow RE. 1986. Individual Differences and the Design Of Educational Programs in Journal Of Psychology.
Lampiran 1 Pengkodean peubah penjelas kategorik 1. Peubah Jenis Kelamin (JK)
Jenis Kelamin (1)
Laki-Laki 1
Perempuan 0
2. Peubah Pendidikan Ayah (PDDK_A)
Pendidikan Ayah (1) (2)
Pendidikan Dasar 1 0
Menengah 0 1
PT 0 0
3. Peubah Pendidikan Ibu (PDDK_I)
Pendidikan Ibu (1) (2)
Pendidikan Dasar 1 0
Menengah 0 1
PT 0 0
4. Peubah Pekerjaan Ayah (PKRJ_A)
Pekerjaan Ayah (1)
PNS 1
Non PNS 0
5. Peubah Pekerjaan Ibu (PKRJ_I)
Pekerjaan Ibu (1)
PNS 1
Non PNS 0
6. Peubah Pendapatan Orang Tua per Bulan (PDT)
Pendidikan Ibu (1) (2)
<= 1 juta 1 0
1 juta – 3 juta 0 1
Lampiran 3 Hasil Uji Asumsi Kenormalan Ganda
Lampiran 3 Hasil Uji Asumsi Kenormalan Ganda
c. Jurusan Bahasa
0 ˆ
Lampiran 4 Akar ciri masing-masing fungsi diskriminan
Fungsi Akar ciri % Keragaman Akumulasi % Korelasi kanonik
1 1.510a 92.5 92.5 .776
2 .123a 7.5 100.0 .331
a. First 2 canonical discriminant functions were used in the analysis.
Tes Fungsi Wilks' Lambda Chi-square db Sig.
1 .355 255.949 10 .000
2 .890 28.685 4 .000
Lampiran 6 Peubah-peubah yang digunakan dalam analisis diskriminan
Wilks' Lambda F df1 df2 Sig.
Agama .741 43.475 2 249 .000
PPKn .766 37.939 2 249 .000
Bahasa Indonesia .802 30.720 2 249 .000
Bahasa Inggris .806 29.975 2 249 .000
Fisika .459 146.728 2 249 .000
Biologi .638 70.549 2 249 .000
Kimia .554 100.363 2 249 .000
Geografi .851 21.741 2 249 .000
Ekonomi .913 11.935 2 249 .000
Sosiologi .904 13.283 2 249 .000
TIK .885 16.128 2 249 .000
Lampiran 7 Jumlah signifikansi peubah-peubah pada analisis logistik multinomial yang dihasilkan dari proses resampling
1
Lampiran 8 Jumlah signifikansi peubah-peubah pada analisis diskriminan yang dihasilkan dari proses resampling
Lampiran 9 Pengklasifikasian obyek ke dalam kelompok
No. amatan Kelompok asal
Kelompok tertinggi Kelompok tertinggi kedua Skor Diskriminan
Lampiran 9 Pengklasifikasian obyek ke dalam kelompok
No. amatan Kelompok asal
Kelompok tertinggi Kelompok tertinggi kedua Skor Diskriminan
Lampiran 9 Pengklasifikasian obyek ke dalam kelompok
No. amatan Kelompok asal
Kelompok tertinggi Kelompok tertinggi kedua Skor Diskriminan
Prediksi kelompok
P(D>d | G=g)
P(G=g | D=d) Jarak kuadrat Mahalanobis
Lampiran 9 Pengklasifikasian obyek ke dalam kelompok
No. amatan Kelompok asal
Kelompok tertinggi Kelompok tertinggi kedua Skor Diskriminan
Prediksi kelompok
P(D>d | G=g)
P(G=g | D=d) Jarak kuadrat Mahalanobis
Lampiran 9 Pengklasifikasian obyek ke dalam kelompok
No. amatan Kelompok asal
Kelompok tertinggi Kelompok tertinggi kedua Skor Diskriminan
Prediksi kelompok
P(D>d | G=g)
P(G=g | D=d) Jarak kuadrat Mahalanobis
Lampiran 9 Pengklasifikasian obyek ke dalam kelompok
No. amatan Kelompok asal
Kelompok tertinggi Kelompok tertinggi kedua Skor Diskriminan
Prediksi kelompok
P(D>d | G=g)
P(G=g | D=d) Jarak kuadrat Mahalanobis
Lampiran 9 Pengklasifikasian obyek ke dalam kelompok
No. amatan Kelompok asal
Kelompok tertinggi Kelompok tertinggi kedua Skor Diskriminan
Prediksi kelompok
P(D>d | G=g)
P(G=g | D=d) Jarak kuadrat Mahalanobis
Lampiran 9 Pengklasifikasian obyek ke dalam kelompok
No. amatan Kelompok asal
Kelompok tertinggi Kelompok tertinggi kedua Skor Diskriminan
Prediksi kelompok
P(D>d | G=g)
P(G=g | D=d) Jarak kuadrat Mahalanobis
Lampiran 9 Pengklasifikasian obyek ke dalam kelompok
No. amatan Kelompok asal
Kelompok tertinggi Kelompok tertinggi kedua Skor Diskriminan
Prediksi kelompok
P(D>d | G=g)
P(G=g | D=d) Jarak kuadrat Mahalanobis
ke Centroid Kelompok
P(G=g | D=d)
Jarak kuadrat Mahalanobis ke
Centroid Fungsi 1 Fungsi 2 p df
asal 247 3 3 .575 2 .496 1.108 1 .333 1.904 .297 .731
248 3 3 .964 2 .602 .073 2 .374 1.026 -1.015 .697
249 3 1** .998 2 .913 .003 3 .059 5.468 1.467 -.099
250 3 3 .698 2 .536 .720 1 .246 2.277 .097 .648
251 3 3 .599 2 .503 1.026 1 .317 1.953 .259 .705
252 3 3 .824 2 .514 .386 2 .342 1.199 -.248 .276
** klasifikasi berbeda
Lampiran 10 Korelasi Antar Mata Pelajaran
Agama PPKn Bhs
Indonesia
Bhs
Inggris
Matematika Fisika Biologi Kimia Sejarah Geografi Ekonomi Sosiologi TIK Bhs
Jerman
Agama 1 .809 .561 .479 .607 .678 .616 .609 .408 .456 .460 .541 .595 .458
PPKn .809 1 .649 .563 .649 .672 .668 .598 .458 .534 .520 .623 .642 .397
Bhs Indonesia .561 .649 1 .688 .612 .606 .598 .587 .393 .553 .546 .539 .433 .346
Bhs Inggris .479 .563 .688 1 .656 .637 .586 .569 .411 .549 .583 .517 .430 .343
Matematika .607 .649 .612 .656 1 .823 .718 .728 .424 .535 .544 .487 .525 .409
Fisika .678 .672 .606 .637 .823 1 .762 .789 .460 .590 .536 .559 .620 .379
Biologi .616 .668 .598 .586 .718 .762 1 .769 .498 .563 .505 .538 .567 .441
Kimia .609 .598 .587 .569 .728 .789 .769 1 .501 .559 .421 .539 .516 .444
Sejarah .408 .458 .393 .411 .424 .460 .498 .501 1 .729 .408 .535 .468 .305
Geografi .456 .534 .553 .549 .535 .590 .563 .559 .729 1 .488 .624 .550 .231
Ekonomi .460 .520 .546 .583 .544 .536 .505 .421 .408 .488 1 .496 .481 .203
Sosiologi .541 .623 .539 .517 .487 .559 .538 .539 .535 .624 .496 1 .571 .309
TIK .595 .642 .433 .430 .525 .620 .567 .516 .468 .550 .481 .571 1 .323
Bhs Jerman .458 .397 .346 .343 .409 .379 .441 .444 .305 .231 .203 .309 .323 1
Mata Pelajaran
IPA IPS Bahasa
Sig Rata-Rata Std . Deviasi Rata-Rata Std . Deviasi Rata-Rata Std . Deviasi
Agama 82.8095 5.04612 76.0426 5.06870 77.7925 5.98671 .000
PPKn 81.5453 5.06939 75.8626 4.57991 76.7830 4.85512 .000
Bahasa Indonesia 79.0167 4.73089 74.1303 4.17087 76.5189 4.06671 .000
Bahasa Inggris 75.0238 6.12270 68.7713 5.93034 72.7170 4.28942 .000
matematika 75.6938 5.92463 62.2128 3.91044 63.6983 4.71028 .000
Fisika 75.6238 5.32040 64.6862 4.19548 66.6226 4.33224 .000
Biologi 79.9762 5.70610 72.1596 4.11084 73.3208 4.46901 .000
Kimia 76.5071 5.17860 67.5798 4.12721 69.0283 4.56304 .000
Sejarah 73.0905 3.94906 71.5346 2.97675 71.3019 2.83070 .001
Geografi 72.9286 4.04329 69.6755 2.96436 70.4717 3.64588 .000
Ekonomi 74.2190 5.71895 71.5106 4.66267 70.4906 4.36495 .000
Sosiologi 79.4190 5.49262 75.8936 4.48227 76.3491 5.45223 .000
TIK 78.3667 6.05157 74.0745 4.97032 74.8679 5.62801 .000
ABSTRACT
NELDA PONTO. Assessment of the Formation of the Classification Model in Student of Senior High School Grouping (Case Study : The students of State Senior High School East Siau, Siau Tagulandang Biaro Regency, North
Sulawesi). Supervised by I MADE SUMERTAJAYA and YENNI ANGRAINI.
Modeling that involve categorical response variables give important role in the classification problem. Statistical analysis is applied to solve this problem are discriminant analysis and multinomial logistic regression. Implementation of both methods against student of senior high school of East Siau data produce multinomial logistic regression as best method for classify the students into Scicence Program, Social Program, and Language Program. Classification accuracy of model from resampling is 88.1% and of model validation from Tagulandang Senior High School is 70.6%. The variables give significantly effect in classification students to Science Program or Language Program are Mathematics, English, Chemistry, and German, whereas, classification students into Social Program or Language Program are Economy, English, German, and History.
Keywords: discriminant analysis, classification, multinomial logistic regression
RINGKASAN
NELDA PONTO. Pengkajian Pembentukan Model Klasifikasi dalam Pengelompokkan Jurusan Siswa di SMA (Studi Kasus : Siswa SMA Negeri Siau Timur Kabupaten Siau Tagulandang Biaro Sulawesi Utara). Dibimbing oleh I MADE SUMERTAJAYA dan YENNI ANGRAINI.
SMA merupakan jenjang pendidikan menengah yang mengutamakan penyiapan siswa untuk melanjutkan pendidikan yang lebih tinggi dengan pengkhususan. Perwujudan pengkhususan tersebut berupa diselenggarakan penjurusan di kelas XI yakni, penjurusan pada Ilmu Pengetahuan Alam (IPA), Ilmu Pengetahuan Sosial (IPS), dan Bahasa.
Program penjurusan pada dasarnya dilakukan untuk membantu para siswa sehingga mereka dapat belajar dengan baik sesuai dengan minat, dan bakatnya. Siswa dalam kegiatan pembelajaran tidak dapat disamakan, dengan demikian setiap siswa sebaiknya ditempatkan pada situasi belajar mengajar yang tepat sesuai dengan kemampuannya masing-masing. Kekurangtepatan dalam penempatan jurusan siswa dapat mengakibatkan prestasi belajar siswa rendah.
Model statistika yang dapat digunakan untuk pengklasifikasian objek dengan melibatkan peubah tak bebas kategori dengan sejumlah peubah bebas kontinu adalah analisis diskriminan dan regresi logistik multinomial. Analisis diskriminan adalah teknik statistika yang dipergunakan untuk mengklasifikasikan objek kedalam kelompok berdasarkan sekumpulan peubah-peubah bebas. Analisis diskriminan juga merupakan suatu analisis dengan tujuan membentuk sejumlah fungsi melalui kombinasi linier peubah-peubah asal, yang dapat digunakan sebagai cara terbaik untuk memisahkan kelompok-kelompok individu. Sedangkan regresi logistik multinomial digunakan untuk memodelkan hubungan antara peubah respon dengan kategori lebih dari dua (polytomous) dengan peubah penjelas kategorik dan atau kontinu. Melalui metode regresi logistik multinomial akan dihasilkan peluang dari masing-masing kategori respon yang akan dijadikan sebagai pedoman pengklasifikasian suatu pengamatan akan masuk dalam respon kategori tertentu berdasarkan nilai peluang terbesar.
Tujuan utama yang ingin dicapai dalam penelitian ini, yaitu (1) menerapkan metode analisis diskriminan dan multinomial logistik untuk klasifikasi, (2) mengevaluasi peubah yang konsisten muncul dari metode analisis diskriminan dan multinomial logistik dengan teknik resampling. Data yang digunakan adalah data sekunder dari dua SMA Negeri di Kabupaten Sitaro yaitu SMA Negeri Tagulandang dan SMA Negeri Siau Timur. Data SMA Negeri Siau Timur digunakan untuk pemodelan, sedangkan yang digunakan untuk validasi model adalah data SMA Negeri Tagulandang. Peubah-peubah yang diamati dalam penelitian ini terdiri 14 peubah numerik, yaitu rataan nilai mata pelajaran Agama, PPKn, Bahasa Indonesia, Bahasa Inggris, Matematika, Fisika, Biologi, Kimia, Sejarah, Geografi, Ekonomi, Sosiologi, TIK, Bahasa Jerman serta 6 peubah kategorik, yaitu : jenis kelamin, pendidikan ayah, pendidikan ibu, pekerjaan ibu, pekerjaan ayah, pendapatan.
logistik multinomial secara keseluruhan adalah sebesar 83.7 persen. Resampling 30 kali menghasilkan metode terbaik adalah regresi logistik multinomial dengan tingkat ketepatan klasifikasi adalah sebesar 88.1%.
Untuk mengelompokkan siswa kedalam jurusan IPA dipengaruhi oleh mata pelajaran Agama, Matematika, Bahasa Inggris, Kimia, Bahasa Jerman dan Pendidikan ayah. Pengelompokkan siswa kedalam jurusan IPS dipengaruhi oleh Bahasa Inggris, Biologi, Sejarah, Geografi, Ekonomi, Bahasa Jerman, dan Jenis kelamin. Validasi model dari SMA Negeri Tagulandang memberikan ketepatan klasifikasi sebesar 70.6%.
PENDAHULUAN
Latar Belakang
Sekolah Menengah Atas (SMA) merupakan jenjang pendidikan menengah yang mengutamakan penyiapan siswa untuk melanjutkan pendidikan yang lebih tinggi dengan pengkhususan (Depdiknas 2004). Perwujudan pengkhususan tersebut berupa penjurusan. Penjurusan dilakukan pada saat memasuki kelas XI yakni, penjurusan pada Ilmu Pengetahuan Alam (IPA), Ilmu Pengetahuan Sosial (IPS) dan Bahasa.
Penjurusan merupakan upaya strategis dalam memberikan fasilitas kepada siswa untuk menyalurkan bakat, minat dan kemampuan yang dimilikinya yang dianggap paling potensial untuk dikembangkan secara optimal. Sehubungan dengan hal tersebut, maka siswa yang mempunyai kemampuan sains dan ilmu eksakta yang baik biasanya akan memilih jurusan IPA, dan yang memiliki minat pada sosial dan ekonomi akan memilih jurusan IPS, sedangkan yang gemar berbahasa akan memilih jurusan Bahasa (Murniramli 2008). Dengan demikian, karakteristik suatu ilmu menuntut karakteristik yang sama dari yang mempelajarinya. Siswa yang mempelajari suatu ilmu yang sesuai dengan karakteristik kepribadiannya atau minat terhadap suatu ilmu tertentu akan merasa senang ketika mempelajarinya serta faktor kepribadian mempengaruhi secara positif prestasi akademik. Oleh karena itu, penjurusan bukan masalah kecerdasan tetapi juga masalah minat dan bakat siswa (Snow 1986).
mengakibatkan prestasi belajar rendah. Hal ini disebabkan karena adanya perbedaan individual antara siswa disekolah yaitu, meliputi perbedaan kemampuan kognitif, motivasi berprestasi, minat dan kreativitas dan dengan adanya perbedaan individu tersebut, maka fungsi pendidikan tidak hanya dalam proses belajar mengajar tetapi meliputi bimbingan konseling, pemilihan dan penetapan siswa sesuai dengan kapasitas individual yang dimiliki (Snow 1986).
Agar kesalahan dalam pemilihan dan penetapan jurusan di SMA dapat diminimalisasi maka perlu ada upaya dalam mencari model yang terbaik. Beberapa analisis statistik telah banyak dikembangkan untuk membantu menyelesaikan masalah-masalah dalam bidang pendidikan, di antaranya adalah analisis regresi logistik, analisis diskriminan, pohon klasifikasi dan Artificial Neural Network (ANN). Dalam penelitian ini, analisis yang digunakan adalah analisis diskriminan dan regresi logistik multinomial. Menurut Johnson dan Wichern (1998), analisis diskriminan digunakan untuk mengklasifikasikan individu ke dalam salah satu dari dua kelompok atau lebih. Sedangkan regresi logistik multinomial digunakan untuk memodelkan hubungan antara peubah respon dengan kategori lebih dari dua (polytomous) dengan peubah penjelas kategorik dan atau kontinu. Melalui metode regresi logistik multinomial akan dihasilkan peluang dari masing-masing kategori respon yang akan dijadikan sebagai pedoman pengklasifikasian suatu pengamatan akan masuk dalam respon kategori tertentu berdasarkan nilai peluang terbesar (Hosmer DW & Lemeshow S 2000; Gozali 2005).
Penelitian tentang analisis diskriminan dan regresi logistik multinomial banyak dilakukan antara lain oleh, Maulias (2009) klasifikasi penjurusan siswa SMK Negeri 1 Tual Maluku dengan pendekatan analisis diskriminan dan regresi logistik multinomial. Metode klasifikasi menggunakan fungsi diskriminan (Purnomo 2003).
Tujuan Penelitian
Tujuan penelitian ini antara lain :
1. Menerapkan metode analisis diskriminan dan multinomial logistik untuk klasifikasi.