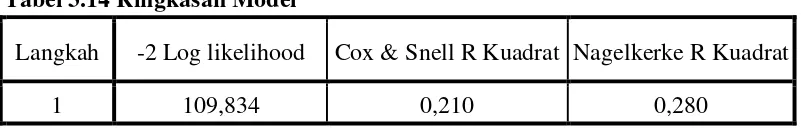ANALISIS FAKTOR RESIKO PENYAKIT RADANG
PARU-PARU DENGAN METODE
REGRESI LOGISTIK
SKRIPSI
SEVENTINA SIAHAAN 110823042
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
MEDAN
ANALISIS FAKTOR RESIKO PENYAKIT RADANG
PARU-PARU DENGAN METODE
REGRESI LOGISTIK
SKRIPSI
Diajukan untuk memenuhi syarat mendapat gelar Sarjana Sains
SEVENTINA SIAHAAN 110823042
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : ANALISIS FAKTOR RESIKO PENYAKIT
RADANG PARU-PARU DENGAN METODE REGRESI LOGISTIK
Kategori : SKRIPSI
Nama : SEVENTINA SIAHAAN
Nomor Induk Mahasiswa : 110823042
Program Studi : SARJANA (S1) MATEMATIKA
Fakultas : MATEMATIKA DAN ILMU PENGETAHUAN
ALAM (FMIPA) UNIVERSITAS SUMATERA UTARA
Diluluskan di
Medan, Februari 2014
Komisi Pembimbing:
Pembimbing 2 Pembimbing 1
Drs. Pengarapen Bangun Drs. Pasukat Sembiring, M.Si NIP. 19560815 198503 1 005 NIP. 19531113 198503 1 002
Diketahui / Disetujui Oleh
Departemen Matematika FMIPA USU
Prof. Dr. Tulus, M. Si
PERNYATAAN
ANALISIS FAKTOR RESIKO PENYAKIT RADANG PARU-PARU DENGAN METODE REGRESI LOGISTIK
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Februari 2014
PENGHARGAAN
Berlimpah puji dan syukur Penulis panjatkan kepada Tuhan Yang Maha Kuasa atas Kasih Karunia-Nya, sehingga skripsi dengan judul “Analisis Faktor Resiko Penyakit Radang Paru–paru dengan Metode Regresi Logistik” ini berhasil diselesaikan.
Ucapan terima kasih saya sampaikan kepada Bapak Drs. Pasukat Sembiring, M. Si, selaku Pembimbing I, Bapak Drs. Pengarapen Bangun, M. Si selaku Pembimbing II pada penyelesaian skripsi ini yang telah membimbing penulis dalam penyempurnaan kajian ini. Penulis juga mengucapkan terima kasih kepada Bapak Drs. Gim Tarigan, M. Si dan Bapak Drs. Partano Siagian, M. Sc sebagai dosen Penguji, atas setiap saran dan masukannya selama pengerjaan skripsi ini. Ucapan terima kasih juga saya ucapkan kepada Ketua dan Sekretaris Departemen Bapak Prof. Dr. Tulus, M. Si dan Ibu Dra. Mardiningsih, M. Si, dan kepada semua Bapak/Ibu Dosen beserta Pegawai pada Departemen Matematika FMIPA USU. Tidak lupa juga ucapan terima kasih saya kepada kedua orang tua saya, M. Siahaaan dan S. Br Nainggolan yang sangat saya cintai yang setia memberi dukungan moril. Serta yang saya sayangi Kakak dan Abang – abang saya sekalian. Terimakasih atas bantuan materi, dorongan dan doanya. Juga untuk sahabat seperjuangan di Ekstensi Matematika Statistika, serta para sahabat yang tidak dapat saya sebutkan satu-persatu, terima kasih atas bantuan dan dorongannya. Semoga Tuhan yang Maha Pengasih yang akan membalasnya.
Medan, Januari 2014 Penulis
ANALISIS FAKTOR RESIKO PENYAKIT RADANG
PARU-PARU DENGAN METODE
REGRESI LOGISTIK
ABSTRAKRegresi logistik adalah bentuk khusus analisis regresi dengan variabel dependen bersifat kategori dan variabel independen bersifat kategori, kontinu, atau gabungan antara keduanya. Tulisan ini menganalisis faktor resiko penyakit radang paru–paru di mana variabel dependennya yang bersifat kategori yaitu terserang radang paru-paru atau tidak. Variabel independennya adalah Jenis kelamin, Usia dan Konsumsi rokok. Dari analisis data diperoleh bahwa variabel independen yang berpengaruh signifikan membentuk model regresi pada penelitian ini adalah variabel Usia dengan nilai signifikansi sebesar 0,032 dengan koefisien regresi sebesar 0,030 dan Konsumsi rokok dengan nilai signifikansi sebesar 0,000 dan koefisien regresi sebesar 1,881. Tingkat akurasi model sebesar 72,9% artinya model regresi yang terbentuk sudah dapat menggambarkan hubungan variabel independen terhadap variabel dependen.
ANALYSIS OF RISK FACTORS PNEUMONIA
WITH LOGISTIC REGRESSION
ABSTRACT
Logistic regression is a special form of regression analysis with the dependent variable and the independent variables are categories are categories, continuous, or a combination of both. This paper analyzed the risk factors for pneumococcal disease in which the dependent variable is the category that is stricken with pneumonia or not. The independent variables were gender, age and cigarette consumption. From the analysis of the data shows that the independent variables have a significant effect on the form of regression models of this study is the variable age with a significance value of 0.032 with a regression coefficient of 0.030 and cigarette consumption with a significance value of 0.000 and a regression coefficient of 1.881. The accuracy rate of 72.9% means that the model regression model that can describe the relationship already established the independent variable on the dependent variable.
DAFTAR ISI
1.2 Perumusan Masalah 3
1.3 Batasan Masalah 3
1.4 Tujuan Penelitian 3
1.5 Kontribusi Penelitian 3
1.6 Tinjauan Pustaka 4
1.7 Metodologi Penelitian 6
Bab 2 Landasan Teori
2.1 Data 8
2.2 Skala Pengukuran Data 8
2.3 Metode Pengumpulan Data 9
2.3.1 Populasi 9
2.3.2 Sampel 10
2.3.3 Teknik Penarikan Sampel 10
2.4 Pengertian Variabel 13
2.5 Macam-macam Rancangan Penelitian dalam Bidang Kesehatan 14
2.6 Pengertian Radang Paru–paru 14
2.7 Pengertian Jenis Kelamin 15
2.8 Pengertian Usia 15
2.9 Konsumsi Rokok 15
2.10 Analisis Regresi 17
2.10.1 Analisis Regresi Logistik 18
2.10.2 Uji Model Persamaan Regresi Logistik 21
2.10.3 Negelkerke R2 21
Bab 3 Pembahasan
3.1 Pengumpulan Data 22
3.1.2 Populasi dan Sampel Penelitian 22
3.2 Pengolahan Data 26
3.2.1 Menguji atau Menilai Kelayakan Model Regresi 26
3.2.2 Menguji Keseluruhan Model 27
3.2.3 Menguji Koefisien Regresi 28
Bab 4 Kesimpulan dan Saran
4.1 Kesimpulan 34
4.2 Saran 35
Daftar pustaka Lampiran
DAFTAR TABEL
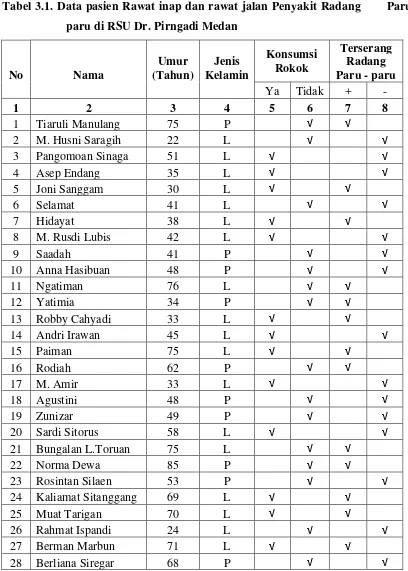
Halaman Tabel 3.1 Data Pasien Rawat Inap dan Rawat Jalan Penyakit
Radang Paru-paru di RSU Dr. Pirngadi Medan 23
Tabel 3.2 Uji Hosmer dan Lemeshow 26
Tabel 3.3 Nilai -2 Log Likehood Awal 27
Tabel 3.4 Nilai -2 Log Likehood Akhir 27
Tabel 3.5 Uji Omnibus dari Model Koefisien 28
Tabel 3.6 Variabel dalam Persamaan 28
Tabel 3.7 Uji Hosmer dan Lemeshow 28
Tabel 3.8 Ringkasan Pengolahan Kasus 29
Tabel 3.9 Pengkodean Variabel Dependen 29
Tabel 3.10 Tabel Klasifikasi 29
Tabel 3.11 Tahapan Iterasi 1 30
Tabel 3.12 Tahapan Iterasi 2 30
Tabel 3.13 Variabel dalam Persamaan 31
DAFTAR GAMBAR
Halaman Gambar 3.1 Grafik antara Variabel Y dengan Variabel X2 32
Gambar 3.2 Grafik antara Variabel Y dengan Variabel X3 32
ANALISIS FAKTOR RESIKO PENYAKIT RADANG
PARU-PARU DENGAN METODE
REGRESI LOGISTIK
ABSTRAKRegresi logistik adalah bentuk khusus analisis regresi dengan variabel dependen bersifat kategori dan variabel independen bersifat kategori, kontinu, atau gabungan antara keduanya. Tulisan ini menganalisis faktor resiko penyakit radang paru–paru di mana variabel dependennya yang bersifat kategori yaitu terserang radang paru-paru atau tidak. Variabel independennya adalah Jenis kelamin, Usia dan Konsumsi rokok. Dari analisis data diperoleh bahwa variabel independen yang berpengaruh signifikan membentuk model regresi pada penelitian ini adalah variabel Usia dengan nilai signifikansi sebesar 0,032 dengan koefisien regresi sebesar 0,030 dan Konsumsi rokok dengan nilai signifikansi sebesar 0,000 dan koefisien regresi sebesar 1,881. Tingkat akurasi model sebesar 72,9% artinya model regresi yang terbentuk sudah dapat menggambarkan hubungan variabel independen terhadap variabel dependen.
ANALYSIS OF RISK FACTORS PNEUMONIA
WITH LOGISTIC REGRESSION
ABSTRACT
Logistic regression is a special form of regression analysis with the dependent variable and the independent variables are categories are categories, continuous, or a combination of both. This paper analyzed the risk factors for pneumococcal disease in which the dependent variable is the category that is stricken with pneumonia or not. The independent variables were gender, age and cigarette consumption. From the analysis of the data shows that the independent variables have a significant effect on the form of regression models of this study is the variable age with a significance value of 0.032 with a regression coefficient of 0.030 and cigarette consumption with a significance value of 0.000 and a regression coefficient of 1.881. The accuracy rate of 72.9% means that the model regression model that can describe the relationship already established the independent variable on the dependent variable.
BAB 1
PENDAHULUAN
1.1Latar Belakang
Radang paru–paru adalah sebuah penyakit pada paru–paru dimana pulmonary alveolus yang bertanggung jawab menyerap oksigen dari atmosfer meradang dan terisi cairan. Berdasarkan data Dinas Kesehatan (Dinkes) Sumut, sepanjang tahun 2012 lalu terdapat 11.326 kasus radang paru–paru (pneumonia) di daerah Sumut. Angka itu tergolong masih cukup tinggi meski turun dibanding tahun sebelumnya yang mencapai 16.130 kasus.
Kepala Bagian Humas Rumah Sakit Umum (RSU) Dr. Pirngadi Medan,
Sebagian besar penyakit yang dipicu oleh rokok dapat dicegah, maka tindakan yang perlu dilakukan oleh pemerintah adalah dengan melindungi masyarakat dari paparan asap rokok melalui upaya pencegahan berbagai penyakit yang dipicu oleh rokok dengan promosi pentingnya lingkungan yang sehat untuk menciptakan keluarga yang bebas dari gangguan radang paru–paru serta menunjang terwujudnya masyarakat yang sehat dan sejahtera. Promosi kesehatan adalah ilmu dan seni membantu masyarakat menjadikan gaya hidup mereka sehat optimal. Kesehatan yang optimal didefinisikan sebagai keseimbangan kesehatan fisik, emosi, sosial, spiritual, dan intelektual. Ini bukan sekedar pengubahan gaya hidup saja, namun berkaitan dengan pengubahan lingkungan yang diharapkan dapat lebih mendukung dalam membuat keputusan yang sehat.
Hair et al (Santoso, 2012) membagi berbagai teknik multivariat dimulai dengan melihat hubungan antar variabel. Untuk mengetahui bagaimana hubungan diantara variabel tersebut dapat dibagi menjadi dua bagian besar yaitu interdependensi dan depedensi. Interdependensi adalah variabel-variabel yang tidak
saling bergantung dengan yang lain. Ciri pentingnya adalah tidak adanya variabel dependen dan variabel independen, semua variabel bersifat independen. Alat analisis yang digunakan adalah analisis faktor, cluster, MDS, dan CA. Sedangkan dependensi adalah variabel-variabel yang saling ketergantungan. Ciri penting dependensi adalah adanya dua jenis variabel yaitu variabel dependen dan variabel independen. Alat analisis yang digunakan adalah regresi berganda, Regresi logistik, analisis diskriminan, SEM, Manova dan korelasi kanonikal.
1.2Perumusan Masalah
Berdasarkan uraian pada latar belakang maka permasalahan yang dibahas penulis adalah seberapa besar faktor resiko berdasarkan jenis kelamin, usia dan konsumsi rokok atau kebiasaan merokok pasien yang terserang radang paru–paru atau tidak terserang.
1.3Batasan Masalah
Untuk mengarahkan pembahasan penulis fokuskan untuk meneliti faktor resiko berdasarkan Jenis Kelamin, Usia dan Konsumsi rokok dengan metode regresi logistik.
1.4Tujuan Penelitian
Tujuan dari penelitian ini adalah untuk menganalisis apakah model yang diteliti sudah baik (sesuai) agar dapat menggambarkan hubungan antara variabel independen; Jenis Kelamin, Usia dan kebiasaan merokok terhadap variabel dependen terserang atau tidaknya seorang pasien.
1.5Kontribusi Penelitian
Beberapa manfaat dari penelitian ini adalah sebagai berikut:
1. Meningkatkan pemahaman aplikasi ilmu statistik khususnya regresi logistik untuk menyusun kebijakan dalam sistem kesehatan.
3. Meningkatkan minat untuk pengembangan riset kebijakan dalam sistem kesehatan yang sangat berguna jadi himbauan untuk masyarakat lebih peduli akan kesehatan lingkungan sekitarnya.
4. Mendorong gerakan masyarakat demi terciptanya rumah bebas asap rokok untuk melindungi perokok pasif.
5. Untuk mendukung Pergub SUMUT No. 35 tahun 2013 tentang kawasan bebas asap rokok.
1.6Tinjauan Pustaka
Regresi logistik adalah suatu model matematik yang digunakan untuk mempelajari hubungan antara satu atau beberapa variabel independen dengan satu variabel dependen yang bersifat dikotomus (binary). Variabel yang bersifat dikotomus adalah variabel yang hanya memiliki dua nilai, misalnya hidup/mati, sakit/sehat, merokok/tidak merokok dan sebagainya. Menurut Hosmer dan Lemeshow (1989)
metode regresi logistik adalah suatu metode analisis statistika yang mendiskripsikan hubungan antara variabel dependen yang memiliki dua kategori dengan variabel independen berskala kategori atau interval maupun numerik. Regresi logistik dapat digunakan untuk memprediksi variabel dependen oleh sebuah atau beberapa variabel independen; untuk menentukan persentase varians dalam variabel dependen yang dapat dijelaskan oleh variabel independen; serta untuk menentukan peringkat
kepentingan relatif variabel independen terhadap variabel dependen.
Persamaan regresi Logistik dengan ‘k’ variabel bebas adalah:
� (��) = 1
1 + �−(��+����+ ����+ … ����)
Keterangan:
i = 1, 2, . . . ,n
b0, b1, . . . bk = koefisien regresi pada model logistik
X1, X2, . . .Xk = variabel independen
Model ini merupakan model peluang suatu kejadian � yang dipengaruhi oleh faktor–faktor �1, �2, . . . ��. Persamaan ini bersifat nonlinier dalam parameter. Tidak
seperti pada regresi linier dengan metode Ordinary Least Squares atau kuadrat terkecil, regresi logistik tidak mengasumsikan hubungan linier antara variabel dependen dengan variabel independen. Akan tetapi, variabel independen memiliki hubungan linear dengan logit variabel dependen. Selanjutnya, untuk menjadikan model tersebut linier proses yang dinamakan logit transformation perlu dilakukan seperti berikut ini:
�� �1−�(���()�
�)�= �0+�1�1+�2�2 + … . . +����
Estimasi koefisien dalam model regresi logistik tidak dapat dilakukan dengan metode Ordinary Least Square atau metode kuadrat terkecil. Metode yang bisa digunakan adalah metode Maximum Likelihood.Regresi logistik membentuk variabel dependen [logit (p(��)/(1-p(��))] yang merupakan kombinasi linier dari variabel independen. Nilai variabel dependen ini kemudian ditransformasikan menjadi probabilitas dengan fungsi logit. Regresi logistik menghasilkan rasio peluang atau biasa disebut odds ratio, yang terkait dengan nilai setiap variabel independen. Ratio peluang (odds ratio) dari suatu kejadian diartikan sebagai peluang hasil yang muncul (p) dibagi dengan peluang suatu kejadian tidak muncul (1 - p). Interpretasi hasil regresi logistik dari variabel independen tidak secara langsung dilihat dari koefisien
yang diketahui pada kurva regresi linier dapat dilihat adanya hubungan linier, peningkatan pada sumbu Y akan diikuti dengan peningkatan pada sumbu X dan sebaliknya. Tetapi pada regresi logistik dengan nilai Y antara 0 dan 1, pendekatan linier tidak bisa digunakan.
Untuk menguji kelayakan model regresi dapat dilihat dari tabel Hosmer and Lemeshow dari hasil olah data. Dan uji hipotesisnya seperti berikut ini: H0: Model sesuai (Model mampu menjelaskan data empiris)
H1: Model tidak sesuai (Model tidak mampu menjelaskan data empiris)
Kriteria Pengujian adalah: H0: ditolak bila probabilitas ≤ 0,05
H0: diterima bila probabilitas > 0,05
1.7Metodologi Penelitian
Metodologi penelitian ini adalah sebagai berikut:
P : Proporsi kasus terhadap populasi, populasi tidak diketahui. Q : 1-P
e : derajat penyimpangan terhadap populasi yang diinginkan.
2. Langkah–langkah pengolahan data adalah seperti berikut ini:
a. Memisahkan variabel ke dalam faktor dependen dan independen b. Menguji model apakah menunjukkan model regresi yang baik.
c. Menilai kelayakan model regresi atau menganalisis seberapa penting variabel independen di dalam model dengan Uji Hosmer and Lemeshow dengan melihat nilai goodness of fit yang diukur dengan nilai chi–square pada tingkat signifikansi 5%.
d. Memperlihatkan tingkat akurasi model dan menguraikan persentase variabel dependen dilihat dari tabel Overall Classification.
e. Membentuk persamaan regresi Logistik dengan bantuan SPSS. f. Menghitung faktor resiko masing–masing pasien secara manual.
g. Membuat kesimpulan apakah model yang diteliti sudah baik (sesuai) sehingga
BAB 2
LANDASAN TEORI
2.1 Data
Data merupakan sejumlah informasi yang dapat memberikan gambaran tentang sesuatu keadaan. Informasi yang diperoleh memberikan keterangan, gambaran, atau fakta mengenai suatu persoalan dalam bentuk kategori, huruf, atau bilangan. Data digunakan untuk menyediakan informasi bagi suatu penelitian, pengukuran kinerja, dasar pembuatan keputusan dan menjawab rasa ingin tahu. Jenis-jenis data berdasarkan cara memperolehnya yaitu:
1. Data primer
Data primer merupakan data yang didapat dari sumber pertama, baik dari individu
atau perseorangan seperti hasil wawancara atau pengisian kuisioner yang biasa dilakukan oleh peneliti. Biasanya data primer, peneliti melakukan observasi sendiri baik di lapangan maupun di laboratorium.
2. Data sekunder
2.2 Skala Pengukuran Data
Pengetahuan mengenai skala pengukuran data sangat penting di dalam statistika. Terdapat empat skala pengukuran data, diurutkan mulai dari tingkatan terendah hingga tertinggi seperti berikut ini:
1. Nominal, tipe data ini digunakan untuk mengklasifikasikan informasi/data. Contoh: Data jenis kelamin yaitu Laki-laki dan Perempuan. Biasanya, saat analisis data tipe seperti ini dilambangkan dengan bilangan numerik. Laki– laki dilambangkan dengan angka 1, sedangkan perempuan dilambangkan dengan angka 2. Tidak berarti angka 1 lebih rendah dari angka 2, hanya melambangkan saja.
2. Ordinal, tipe data ini digunakan untuk mengklasifikasikan serta memiliki tingkatan. Tipe data ordinal lebih tinggi dari nominal karena kemampuannya untuk membentuk tingkatan. Contoh: Jabatan di dalam perusahaan ada karyawan, manager, dan direktur utama. Misal karyawan dilambangkan dengan 1, manager dengan 2 dan direktur utama dengan 3. Pada tipe data ini, angka 1
dianggap lebih rendah dari angka 2 dan seterusnya.
3. Interval, ciri khas dari tipe data ini selain memiliki kemampuan mengklasifikasi dan membentuk tingkatan adalah tidak adanya nilai nol mutlak. Artinya, angka nol yang digunakan bukan berarti tidak ada. Contoh: Derajat suhu. Di dalam skala celcius misalnya, Nol derajat celcius bukan berarti tidak ada suhu. Nol derajat itu memiliki suhu, hanya saja dilambangkan nol.
2. 3 Metode Pengumpulan Data 2.3.1 Populasi
Populasi merupakan keseluruhan unit atau individu dalam ruang lingkup yang ingin diteliti. Menurut Sudjana (2002) Populasi adalah totalitas semua nilai yang mungkin, hasil mengukur atau pengukuran kuantitatif maupun kualitatif mengenai karakteristik tertentu dari semua anggota kumpulan yang lengkap dan jelas yang ingin dipelajari sifat-sifatnya.
2.3.2 Sampel
Sampel adalah sebagian anggota dari populasi yang dipilih dengan menggunakan prosedur tertentu sehingga diharapkan dapat mewakili populasinya. Banyaknya anggota suatu sampel disebut ukuran sampel. Penggunaan sampel dalam suatu penelitian terutama didasarkan pada berbagai pertimbangan seperti karena
ketidakmungkinan mengamati seluruh anggota populasi, pengamatan terhadap seluruh anggota populasi dapat bersifat merusak, menghemat waktu, biaya dan tenaga, mampu memberikan informasi yang lebih menyeluruh dan lebih mendalam.
2.3.3 Teknik Penarikan Sampel
Pemilihan teknik pengambilan sampel merupakan upaya penelitian untuk mendapat sampel yang representatif (mewakili), yang dapat menggambarkan populasinya. Teknik pengambilan sampel secara garis besar terbagi atas dua, yaitu:
Pada tipe pengambilan sampel secara random ini setiap unit populasi mempunyai kesempatan yang sama untuk diambil sebagai sampel. Faktor pemilihan atau penunjukan sampel yang diambil semata-mata karena pertimbangan peneliti akan dihindarkan. Karena jika maka akan mengakibatkan terjadinya bias. Dengan cara random, bias pemilihan dapat diperkecil sekecil mungkin. Ini merupakan salah satu usaha untuk mendapatkan sampel yang representatif.
Selain itu pemilihan sampel dengan cara ini juga memiliki beberapa keuntungan, yaitu derajat kepercayaan terhadap sampel dapat ditentukan, beda penaksiran parameter populasi dengan statistik sampel dapat diperkirakan, serta besar sampel yang akan diambil dapat dihitung secara statistik. Pemilihan sampel dengan teknik sampling random ini mempunyai empat cara, yaitu:
a. Sampel Random Sederhana (Simple Random sampling)
Sampel random sederhana adalah teknik pengambilan sampel secara acak dimana masing-masing subjek atau unit dari populasi memiliki peluang yang sama dan independen (tidak bergantung) untuk terpilih sebagai sampel. Keuntungan dari
teknik ini adalah memungkinkan peneliti mengetahui besarnya sampling error (margin of error) penelitian dan memberikan sampel yang secara rata-rata representatif terhadap populasi. Sedangkan kerugiannya, peneliti harus memiliki daftar (sampling frame) setiap subjek yang ada dalam populasi dan skema sampling random ini membutuhkan perencanaan lebih matang serta biaya yang besar jika populasi besar.
b. Proportionate Stratified Random Sampling
Teknik ini merupakan teknik pengambilan sampel dengan membagi populasi sasaran dalam strata (sub populasi) menurut karakteristik tertentu yang dianggap penting oleh peneliti, status sosio-ekonomi, atau geografis, lalu melakukan pengambilan sampel dari masing-masing strata secara random. Keuntungan dengan teknik ini adalah bahwa kelompok-kelompok dari populasi yang dipandang penting oleh peneliti dapat terwakili secara proporsional.
Cluster sampling adalah teknik pengambilan sampel yang digunakan untuk menentukan sampel bila objek yang akan diteliti atau sumber data sangat luas, misal penduduk dari suatu negara, propinsi, atau kabupaten. Untuk menentukan penduduk mana yang akan dijadikan sumber data, maka pengambilan sampelnya berdasarkan daerah populasi yang telah ditetapkan.
d. Sistematik Sampling
Sistematik sampling menuntut kepada peneliti untuk memilih unsur populasi secara sistematis, yaitu unsur populasi yang bisa dijadikan sampel adalah yang keberapa. Pengambilan sampel ini lebih menekankan pada sistem interval dari hasil proses random. Pengambilan sampel sistematik lebih menghemat waktu dan lebih sederhana. Jika peneliti dihadapkan pada ukuran populasi yang banyak dan tidak memiliki alat pengambil data secara random maka cara pengambilan sampel sistematis dapat digunakan.
2. Teknik Sampling Non-Random (Non Probability Sampling)
Teknik sampling non-random adalah teknik pengambilan sampel yang tidak memberi peluang/kesempatan sama bagi setiap unsur atau anggota populasi untuk dipilih menjadi sampel. Pemilihan sampel dengan teknik sampling nonrandom ini mempunyai empat cara, yaitu:
a. Sampling Purposive
Sampling purposive merupakan teknik pemilihan sampel yang bertujuan untuk mendapatkan subjek-subjek yang memiliki sejumlah karakteristik tertentu, atau mendapatkan kelompok-kelompok penelitian yang sebanding sehingga dapat dianalisis dengan valid.
b. Sampling Kuota
pemilihan sampel peneliti membagi populasi ke dalam kategori, lalu memberikan jatah jumlah subjek untuk masing-masing kategori tersebut.
c. Sampling Kemudahan
Pada pengambilan sampel dengan cara ini, sampel diambil berdasarkan pada ketersediaan elemen dan kemudahan untuk mendapatkannya. Dengan kata lain sampel dipilih/terpilih karena sampel tersebut ada pada tempat dan waktu yang tepat.
d. Snowball Sampling
Snawball sampling atau sampling bola salju adalah teknik penentuan sampel yang mula-mula jumlahnya kecil, kemudian sampel ini disuruh memilih teman-temannya untuk dijadikan sampel sehingga jumlah sampel semakin banyak. Ibarat bola salju yang menggelinding, makin lama semakin besar.
Teknik pengambilan sampel yang dipakai adalah Purposive sampling. Penetapan sampel dengan cara memilih sampel di antara populasi sesuai dengan yang dikehendaki peneliti, sehingga sampel tersebut dapat mewakili karakteristik populasi
yang telah dikenal sebelumnya.
Untuk mendapatkan sampel yang benar-benar mewakili seluruh populasi, maka dalam penelitian ini teknik penentuan jumlah sampel menggunakan rumus pendugaan proporsi sebagai berikut:
P : Proporsi kasus terhadap populasi, populasi tidak diketahui.
Q : 1-P
2. 4 Pengertian Variabel
Variabel merupakan objek yang berbentuk apa saja yang ditentukan oleh peneliti dengan tujuan untuk memperoleh informasi agar bisa ditarik suatu kesimpulan. Secara teori, definisi variabel penelitian adalah merupakan suatu objek atau sifat atau atribut atau nilai dari orang atau kegiatan yang mempunyai bermacam-macam variasi antara satu dengan yang lainnya yang ditetapkan oleh peneliti dengan tujuan untuk dicari dan ditarik kesimpulan. Adapun tipe-tipe variabel terbagi atas:
1. Variabel Bebas
Variabel bebas ataupun variabel independen merupakan variabel stimulus atau variabel yang memepengaruhi variabel lain. Variabel bebas merupakan yang variabilitasnya diukur atau dipilih oleh peneliti untuk menentukan hubungannya dengan suatu gejala yang diobservasi.
2. Variabel Terikat
Variabel terikat atau variabel dependen merupakan variabel yang memberikan reaksi atau respon jika dihubungkan dengan variabel bebas. Variabel dependen
adalah variabel yang variabilitasnya diamati dan diukur untuk menentukan pengaruh yang disebabkan oleh variabel bebas.
2.5 Macam–Macam Rancangan Penelitian dalam Bidang Kesehatan
Secara garis besar, penelitian dalam bidang kesehatan dapat dibagi berdasarkan beberapa aspek sebagai berikut:
1. Berdasarkan tujuan, penelitian kesehatan dapat dibagi menjadi penelitian eksploratif, penelitian deskriptif, penelitian analitik (prospektif dan retrospektif) dan penelitian eksperimental.
3. Berdasarkan keterlibatan peneliti dapat dikelompokkan menjadi penelitian observasional dan penelitian intervensional.
Konsep penelitian ini adalah penelitian Cross Sectional. Penelitian cross sectional mempelajari dinamika hubungan antara faktor resiko dengan efeknya. Faktor resiko dengan efeknya diobservasi pada saat yang sama. Artinya subjek penelitian diobservasi hanya satu kali saja dan faktor resiko dengan efeknya dicatat sesuai kondisi atau status pada saat observasi. Faktor resiko pada penelitian ini adalah Jenis Kelamin, Usia dan Konsumsi rokok, dan efeknya adalah penyakit radang paru-paru.
2. 6 Pengertian Radang Paru-paru
Radang paru-paru atau pneumonia adalah sebuah penyakit pada paru-paru di mana pulmonary alveolus yang berfungsi menyerap oksigen meradang dan terisi oleh
cairan. Radang paru-paru dapat disebabkan oleh beberapa penyebab, termasuk infeksi oleh bakteria, virus, jamur, atau parasit. Radang paru-paru yang disebabkan oleh bakteri biasanya diakibatkan oleh bakteri streptococcus dan mycoplasma pneumonia. Radang paru-paru dapat juga disebabkan oleh kepedihan zat-zat kimia atau cedera jasmani pada paru atau sebagai akibat dari penyakit lainnya, seperti kanker paru-paru atau berlebihan minum alkohol.
2. 7 Pengertian Jenis Kelamin
Jenis kelamin sex) adalah kelas atau kelompok yang terbentuk dalam suatu merupakan suatu akibat dari seringkali dijadikan penciri bagi masing-masing jenis kelamin. Laki-laki yaitu seorang yang memiliki kemaluan dan identitasnya laki-laki. Perempuan yaitu seorang yang memiliki kemaluan dan identitasya perempuan.
2. 8 Pengertian Usia
Usia adalah rentang kehidupan yang diukur dengan tahun, dihitung mulai saat dilahirkan sampai saat berulang tahun. Istilah usia dapat diartikan juga dengan
lamanya keberadaan seseorang diukur dalam satuan waktu di pandang dari segi kronologik, individu normal yang memperlihatkan derajat perkembangan anatomis dan fisiologik sama. Atau usia adalah lama waktu hidup atau ada (sejak dilahirkan atau diadakan).
2. 9 Konsumsi Rokok
Jenis bahan kimia tersebut terdiri dari 400 bahan beracun dan 40 dari bahan tersebut yang bisa berakumulasi dalam tubuh dan dapat menyebabkan penyakit. Perokok dapat dikategorikan menjadi dua kategori yaitu:
1. Perokok aktif
Perokok Aktif adalah seseorang yang dengan sengaja menghisap lintingan atau gulungan tembakau yang dibungkus biasanya dengan kertas, daun, dan kulit jagung. Secara langsung mereka juga menghirup asap rokok yang mereka hembuskan dari mulut mereka. Tujuan mereka merokok pada umumnya adalah untuk menghangatkan badan mereka dari suhu yang dingin. Tapi seiring perjalanan waktu pemanfaatan rokok disalahartikan, sekarang rokok dianggap sebagai suatu sarana untuk pembuktian jati diri bahwa mereka yang merokok adalah ”keren”.
2. Perokok Pasif
Perokok Pasif adalah seseorang atau sekelompok orang yang menghirup asap rokok orang lain. Telah terbukti bahwa perokok pasif mengalami risiko gangguan kesehatan yang sama seperti perokok aktif, yaitu orang yang menghirup asap
rokoknya sendiri.
Beberapa bahan–bahan rokok yang berbahaya bagi kesehatan yaitu:
8. dengan unsur-unsur tertentu.
9.
mayat.
10.
semut. Zat ini juga digunakan sebagai zat pembuat plastik dan pestisida.
11.
12.
buangan mobil dan motor.
Berikut beberapa masalah lain yang dapat timbul akibat bahaya rokok terhadap paru-paru :
1. Perokok mempunyai fungsi paru-paru yang lebih rendah dibandingkan dengan mereka yang bukan perokok.
2. Merokok mengurangi pertumbuhan paru-paru.
3. Merokok sejak usia dini akan meningkatkan resiko untuk terkena kanker
paru-paru. Untuk penyakit lain karena rokok maka resikonya juga akan semakin meningkat apabila terus merokok.
2. 10 Analisis Regresi
Analisis regresi adalah teknik statistika yang berguna untuk memeriksa dan memodelkan hubungan diantara variabel-variabel. Analisis regresi dapat digunakan untuk dua hal pokok, yaitu :
b. Untuk menaksir suatu variabel yang disebut variabel tak bebas (terikat) dengan variabel lain yang disebut variabel bebas berdasarkan hubungan yang ditunjukkan persamaan regresi tersebut.
Berdasarkan amatan dan analisis data, penyelesaian regresi ini dapat berupa persamaan linier maupun nonlinier. Oleh karena itu analisis regresi ini terbagi atas regresi linier dan regresi nonlinier. Yang termasuk ke dalam regresi linier adalah regresi linier sederhana, regresi linier berganda, dan sebagainya. Ssedangkan yang termasuk regresi nonlinier adalah regresi model parabola kuadratik, model parabola kubik, model eksponen, model geometrik, regresi logistik, dan sebagainya.
2.10.1 Analisis Regresi Logistik
Model regresi merupakan komponen penting dalam beberapa analisis data dengan menggambarkan hubungan antara variabel respon dan satu atau beberapa variabel penjelas. Pada umumnya analisis regresi digunakan untuk menganalisis data dengan
variabel respon berupa data kuantitatif. Akan tetapi sering juga ditemui kasus dengan variabel responnya bersifat kualitatif/kategori. Untuk mengatasi masalah tersebut maka dapat digunakan model regresi logistik.
Pada dasarnya regresi logistik sama dengan analisis diskriminan, perbedaan ada pada jenis data dari variabel dependen. Jika pada analisis diskriminan variabel dependen adalah data rasio, maka pada regresi logistik variabel dependen adalah data nominal. Data nominal di sini lebih khusus adalah data binary. Dengan demikian, tujuan regresi logistik adalah pembuatan sebuah model regresi untuk memprediksi besar variabel dependen yang berupa variabel binary dengan menggunakan data variabel independen yang sudah diketahaui besarnya.
Regresi logistik biner adalah salah satu metode statistika yang sering digunakan untuk mengklasifikasikan sejumlah pengamatan dengan respon biner ke dalam beberapa kelompok berdasarkan satu atau lebih variabel prediktor. Melalui metode ini akan dihasilkan peluang dari masing-masing kategori respon yang akan dijadikan sebagai pedoman pengklasifikasian dan suatu pengamatan akan masuk kedalam respon kategori tertentu berdasarkan nilai peluang yang terbesar.
Pada Regresi logistik biner (dikotomus), variabel responnya mempunyai dua kategori. Fenomena dimana variabel responnya dua (bivariat) dan masing-masing berkategorikan biner, dapat dianalisis mengunakan regresi logistik biner bivariat, dengan asumsi antar peubah respon biner terdapat dependensi. Regresi logistik cukup baik dan sering digunakan.
Regresi logistik memiliki beberapa keuntungan dibandingkan regresi lainnya, yaitu:
1. Regresi logistik tidak memiliki asumsi normalitas atas variabel bebas yang digunakan dalam model. Artinya variabel penjelas tidak harus memiliki distribusi normal, linier, maupun memiliki varian yang sama dalam setiap group.
3. Regresi logistik amat bermanfaat digunakan apabila distribusi respon atas variabel terikat diharapkan non linier dengan satu atau lebih variabel bebas.
Bentuk umum regresi logistik tersebut adalah:
p(x
i) =
1ln� π (x)
1− π (x)� = (b0+ b1X1+ b2X2+ … bkXk)
ln �1−pp(xi)
(xi)�= (b0+ b1X1 + b2X2+ … bkXk) (3)
Dengan, � (��) = Probabilitas terjadinya peristiwa pada kelompok ke-i e = Basis dari logaritma natural;≈ 2,71828
i = 1, 2, . . . ,n
b0, b1, . . . bk = Koefisien regresi pada model logistik
X1, X2, . . .Xk = Variabel independen
2.10.2 Uji Model Persamaan Regresi Logistik
Uji ini sering disebut juga sebagai uji ketepatan model. Uji ini digunakan untuk mengatahui apakah model regresi logistik sudah sesuai dengan data observasi yang diperoleh. Untuk menilai ketepatan model regresi logistik dalam penelitian ini diukur dengan nilai chi square dengan uji Hosmer dan Lemeshow. Pengujian ini akan melihat nilai goodness of fit test yang diukur dengan nilai chi square pada tingkat
signifikansi, dimana tingkat signifikansi pada penelitian ini adalah 5%.
Uji Hosmer dan Lemeshow ini disebut juga uji t yaitu uji signifikansi konstanta dan setiap variabel independen. Kriteria Statistiknya dapat dilihat dari tabel Hosmer and Lemeshow dari hasil olah data.
Uji hipotesis: H0: Model sesuai (Model mampu menjelaskan data empiris)
H1: Model tidak sesuai (Model tidak mampu menjelaskan data empiris)
Kriteria Pengujian: H0: ditolak bila probabilitas ≤ 0,05
2.10.3 Negelkerke atau Korelasi Determinasi (R2)
BAB 3
PEMBAHASAN
3.1Pengumpulan Data 3.1.1 Sumber Data
Data yang digunakan dalam penelitian ini adalah data sekunder yaitu data yang sudah tersedia dari data rekam medis RSU. Dr. Pringadi Medan sehingga peneliti tinggal mengumpulkan dan mengolah data tersebut.
3.1.2 Populasi dan Sampel Penelitian
Populasi adalah keseluruhan objek penelitian. Dalam penelitian ini, populasinya adalah seluruh pasien yang berobat selama bulan Desember 2013 di Rawat Inap Ruang Flamboyan dan Poly Paru RSU Dr. Pirngadi Medan. Jumlah sampel minimum yang diambil ditentukan dengan menggunakan rumus:
�
=
��/22 .�.�
�2
Keterangan:
n : Jumlah sampel
��/2 : Nilai Z pada interval keyakinan (95% atau 1,96)
P : ditetapkan 50% karena populasi tidak diketahui Q : P adalah 0,5 sehingga Q = 1 – 0,5
e : 10% atau 0,1 Sehingga
�
=
1,962.0,5 .0,5Jadi dari hasil perhitungan di atas, diperoleh sampel yang diteliti sebanyak 96 orang yaitu data berikut ini:
67 Rajali 52 L √ √
3.2 Pengolahan Data
3.2.1 Menguji atau menilai Kelayakan Model regresi
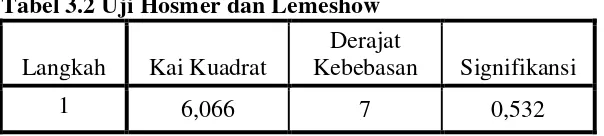
Tabel 3.2 Uji Hosmer dan Lemeshow
Langkah Kai Kuadrat
Derajat
Kebebasan Signifikansi
1 6,066 7 0,532
Hipotesis : H0: Model sesuai (Model mampu menjelaskan data empiris)
H1: Model tidak sesuai (Model tidak mampu menjelaskan data empiris)
Kriteria Pengujian: H0: ditolak bila probabilitas ≤ 0,05
H0: diterima bila probabilitas > 0,05
Untuk menguji apakah koefisien regresi layak atau tidak digunakan berdasarkan Tabel 3.2 Uji Hosmer dan Lemeshow atau goodnees and fit test statistik dan dapat diuraikan seperti berikut ini:
a. Berdasarkan pengujian nilai statistik uji Hosmer dan Lemeshow atau goodnees and fit test statistiksebesar 6,066 dengan probabilitas 0,532 nilai ini jauh di atas 0,05. Dengan demikian dapat disimpulkan bahwa model tersebut sesuai dan dapat diterima. Model mampu menjelaskan data empiris yang artinya tidak terdapat perbedaan antara model dengan data sehingga model dapat memprediksi nilai observasinya.
b. Jika nilai Hosmer and Lemeshow ≤ 0,05 artinya ada perbedaan signifikan antara model dengan observasinya sehingga goodnees and fit test statistik tidak baik, yang artinya model tidak dapat memprediksi nilai observasinya.
3.2.2 Menguji Keseluruhan Model
Tabel 3.3 Nilai -2 Log Likehood Awal
Iterasi -2 Log likelihood
Koefisien
Konstanta
Langkah 1 1 132,417 0,167
2 132,417 0,167
a. Konstanta termasuk dalam model. b. Nilai -2 Log Likelihood Awal: 132,417
c. Estimasi dihentikan pada iterasi nomor 2 karena nilai parameter lebih kecil dari 0,001.
Tabel 3.4 Nilai -2 Log Likehood Akhir
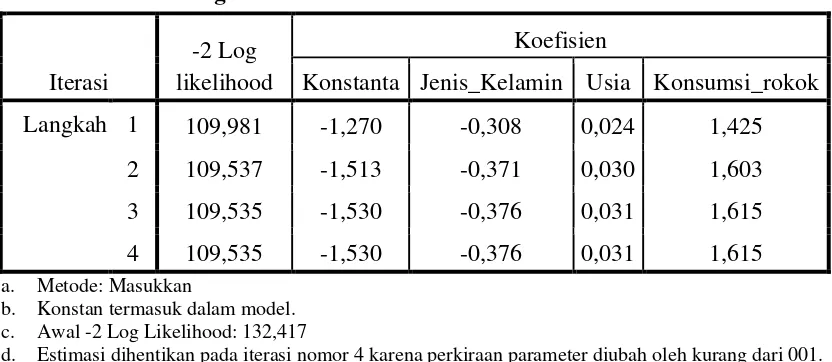
Iterasi
-2 Log likelihood
Koefisien
Konstanta Jenis_Kelamin Usia Konsumsi_rokok
Langkah 1 109,981 -1,270 -0,308 0,024 1,425
2 109,537 -1,513 -0,371 0,030 1,603 3 109,535 -1,530 -0,376 0,031 1,615
4 109,535 -1,530 -0,376 0,031 1,615
a. Metode: Masukkan
b. Konstan termasuk dalam model. c. Awal -2 Log Likelihood: 132,417
d. Estimasi dihentikan pada iterasi nomor 4 karena perkiraan parameter diubah oleh kurang dari 001.
Perhatikan angka -2 Log likelihood, di mana pada table 3.3nNilai Log
Statistik -2 Log Likehood dapat juga digunakan untuk menentukan jika variabel bebas ditambahkan ke dalam model apakah secara signifikan memperbaiki model yang sesuai. Selisih antara -2LogLikehood sebelum dan sesudah ditambah variabel bebas adalah sebesar 22,882 dengan derajat kebebasan 3, dan angka ini signifikan secara statistik dapat dibuktikan berdasarkan dari Tabel 3.5.
Table 3.5 Uji Omnibus dari Model Koefisien
Kai Kuadrat
3.2.3 Menguji Koefisien Regresi Tabel 3.6 Variabel dalam Persamaan
b S.E. Wald
Derajat
kebebasan Signifikansi Exp(b)
Langkah 1 Jenis_Kelamin -0,376 0,683 0,303 1 0,582 0,687
Usia 0,031 0,014 4,805 1 0,028 1,031 Konsumsi_rokok 1,615 0,671 5,788 1 0,016 5,029
Konstanta -1,530 1,310 1,365 1 0,243 0,216
a. Variabel: Jenis_Kelamin, Usia, Konsumsi_rokok.
Dari Tabel 3.6 di atas diperoleh bahwa variabel Usia (X2) dan variabel
konsumsi rokok (X3) yang signifikan secara statistik, terlihat dari angka Signifikansi
(X2) 0,028 < 0,05 dan angka signifikansi (X3) 0,016 < 0,05. Sedangkan variabel Jenis
kelamin (X1) mempunyai angka signifikansi di atas 0,05 yaitu sebesar 0,582. Maka
(X3). Langkah-langkah yang dilakukan sama dengan proses pembentukan model
regresi binary yang pertama dan hasil yang diperoleh adalah sebagai berikut:
Tabel 3.7 Uji Hosmer dan Lemeshow
Langkah Kai Kuadrat Derajat Kebebasan Signifikansi
1 8,067 7 0,327
Perhatikan nilai signifikansi dari Tabel 3.7, terlihat angka probabilitas adalah 0,327 > 0,05. Hal ini berarti model regresi binary kedua layak juga dipakai untuk analisis selanjutnya, karena tidak ada perbedaan yang nyata antara klasifikasi yang diprediksi dengan klasifikasi yang diamati.
Tabel 3.8 Ringkasan Pengolahan Kasus
Kasus yang tertimbang N Persentase Kasus yang dipilih Masuk dalam Analisis
96 100,0
Kasus yang tinggal 0 0,0
Total 96 100,0
Kasus yang tidak dipilih 0 0,0
Total 96 100,0
a. Lihat tabel klasifikasi untuk jumlah total kasus.
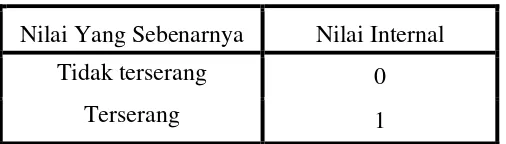
Tabel 3.9 Pengkodean Variabel Dependen
Nilai Yang Sebenarnya Nilai Internal
Tidak terserang 0
Terserang 1
Berdasarkan Tabel 3.8 dan Tabel 3.9 dapat dilihat bahwa:
Tabel 3.10 Tabel Klasifikasi
Langkah 1 Terserang_atau_tidak Tidak terserang 31 13 70,5
Terserang 13 39 75,0
Persentase Keseluruhan 72,9
Dari Tabel 3.10 diperoleh tingkat akurasi model adalah 72,9%. Tabel klasifikasi ini digunakan untuk menunjukkan seberapa baik hasil prediksi dan ukuran akurasi model. Model yang baik mempunyai tingkat akurasi yang tinggi. Angka 72,9% merupakan angka yang cukup baik. Dari tabel di atas, dari 52 (13+39) pasien yang terserang radang paru–paru, baris pengamatan diprediksi oleh model 13 pasien tidak terserang radang paru–paru dan 39 pasien yang terserang radang paru-paru. Dari 44 (31+13) pasien yang tidak terserang radang paru baris pengamatandiprediksi oleh model 13 pasien terserang radang paru–paru dan 31 pasien yang tidak terserang radang paru-paru.
Tabel 3.11 Tahapan Iterasi
Iterasi -2 Log likelihood Koefisien Konstanta
Langkah 0 1 132,417 0,167
2 132,417 0,167
a. Metode: Masukkan
b. Konstan termasuk dalam model. c. Awal -2 Log Likelihood: 132417
Tabel 3.12 Tahapan Iterasi
Iterasi -2 Log likelihood
Koefisien
Konstanta Usia Konsumsi_rokok
Langkah 1 1 110,262 -1,765 0,024 1,648
2 109,836 -2,104 0,029 1,867
3 109,834 -2,127 0,030 1,881
4 109,834 -2,127 0,030 1,881
a. Metode: Masukkan
b. Konstan termasuk dalam model. c. Awal -2 Log Likelihood: 132417
d. Estimasi dihentikan pada iterasi nomor 4 karena nilai parameter lebih kecil dari, 001.
Nilai -2 Log Likehood yang diperoleh setelah proses regresi binary kedua yang mana hanya memasukkan variabel bebas Usia (X2) dan Konsumsi rokok (X3)
dapat terlihat dari Tabel 3.11 dan Tabel 3.12 dengan nilai -2Log likehood 132,417 dan 109,834. Angka -2Log Likehood masih tetap turun. Penurunan ini menunjukkan model regresi tetap baik. Dan setelah dilakukan analisis data dengan model regresi yang telah diulang diperoleh koefisien regresi dari Tabel 3.13.
Tabel 3.13 Variabel dalam Persamaan
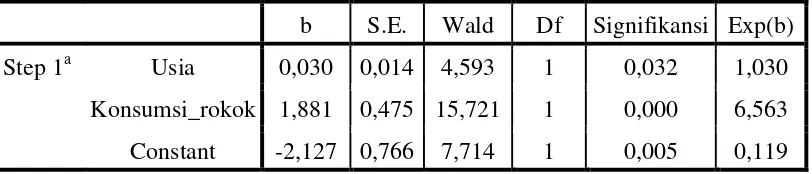
b S.E. Wald Df Signifikansi Exp(b) Step 1a Usia 0,030 0,014 4,593 1 0,032 1,030
Konsumsi_rokok 1,881 0,475 15,721 1 0,000 6,563 Constant -2,127 0,766 7,714 1 0,005 0,119 a. Variabel: Usia, Konsumsi_rokok, masukkan langkah satu 1
Dari koefisien yang diperoleh dari Table 3.13 maka diperoleh model persamaan regresi sebagai berikut ini:
� (��) = 1
Dari hasil olah data dan dari persamaan regresi logistik yang terbentuk, maka dapat diperoleh prediksi probabilitas setiap responden. Penulis mengambil responden pertama sebagai salah satu contoh seperti berikut ini:
� (�1) = 1
1 + 2,7183−[−�,���+�,��(��)+�,���(�)]
� (�1) = 1
1 + 2,7183−[−�,���+�,��(��)+�,���(�)]
� (�1) = 1
1 + 2,7183−[−�,���+��,�]
� (�1) = 1
1 + 2,7183−[��,���]
� (�1) = 1
1 + 1,419251536.10(−�)
� (�1) = 1
1 + 0,000000001419251536
p (x1) = 1
1,000000001
p (x1) = 0,999999999
Gambar 3.1 Grafik antara Variabel Y dengan Variabel X2
Dari Gambar 3.1 Grafik antara variabel Y dengan variabel Usia (X2) dapat
dilihat bahwa semakin tua seorang pasien akan semakin besar atau meningkat resiko untuk terserang radang paru-paru.
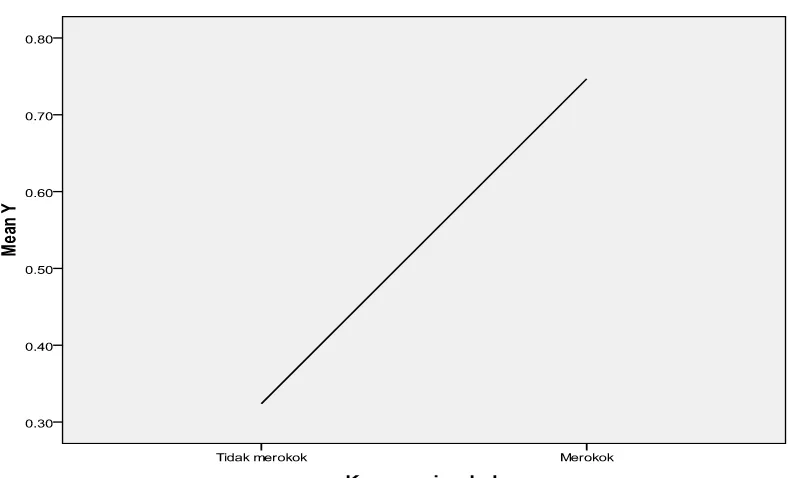
Dari Gambar 3.2 Grafik antara variabel Y dengan variabel Komsumsi rokok (X3)
dapat dilihat bahwa baik perokok aktif maupun perokok pasif akan semakin besar atau meningkat resiko untuk terserang radang paru-paru jika semakin sering terpapar asap rokok.
Tabel 3.14 Ringkasan Model
Langkah -2 Log likelihood Cox & Snell R Kuadrat Nagelkerke R Kuadrat
1 109,834 0,210 0,280
Estimasi dihentikan pada iterasi nomor 4 karena nilai parameter lebih kecil dari 0,001.
BAB 4
KESIMPULAN DAN SARAN
4.1 Kesimpulan
Berdasarkan hasil penelitian penulis di RSUD Dr. Pirngadi Medan, maka dapat disimpulkan:
1. Berdasarkan hasil olah data, persamaan regresi logistik yang diperoleh adalah:
� (��) = 1
1 + �−[−�,���+( �,�����+�,�����]
2. Variabel Usia (X2) dan Konsumsi rokok (X3) berpengaruh secara signifikan
membentuk model regresi logistik pada penelitian ini sedangkan variabel Jenis Kelamin (X1) tidak berpengaruh secara signifikan artinya faktor resiko penyakit
radang paru-paru berdasarkan jenis kelamin tidak mempengaruhi model regresi logistik yang terbentuk.
3. Faktor resiko terbesar yang mempengaruhi penyakit radang paru-paru adalah variabel Konsumsi rokok (X3) terlihat dari angka koefisien regresi sebesar 1,881
artinya baik perokok aktif maupun perokok pasif tetapi yang semakin sering terpapar asap rokok sangat beresiko tinggi terserang penyakit radang paru-paru. 4. Angka koefisien regresi variabel Usia (X2) sebesar 0,030 artinya tua maupun
muda mempunyai resiko terkena dampak dari paparan asap rokok yang merupakan faktor resiko terbesar penyakit radang paru-paru.
4.2Saran
1. Semua pihak sangat diharapkan lebih memperhatikan PERGU SUMUT No. 35 tentang kawasan bebas asap rokok agar benar–benar tercipta kawasan yang sehat bagi setiap masyarakat sehingga masyarakat semakin sehat dan sejahtera. 2. Semua pihak diharapkan dapat saling mendukung dalam membuat keputusan
yang sehat dalam kehidupan sehari–hari sehingga menjadi gaya hidup dalam bermasyarakat.
DAFTAR PUSTAKA
Damodar N. Gujarati and Dawn C. Porter. 2012. Dasar–dasar Ekonometrika. Jakarta: Salemba Empat.
David W. Hosmer and Stanley Lemeshow. 1989. Applied Logistic Regression. United States of America : Jhon Wiley & Sons, Inc.
Eko Budiarto. 2003. Metodologi Penelitian Kedokteran. Jakarta : Penerbit Buku Kedokteran EGC.
Jonathan Sarwono. 2013. Statistik Multivariat, Aplikasi untuk Riset Skripsi. Yogyakarta : CV Andi.
Singgih Santoso. 2012. Aplikasi SPSS pada Statistik Multivariat. Jakarta: PT. Elexmedia Komputindo.
Sofyan Yamin, Lien A. Rachmach dan Heri Kurniawaan. 2011. Regresi dan Korelasi dalam Genggaman Anda. Jakarta : Salemba Empat.
Sudjana. 1992. Metode Statistika. Bandung : Tarsito.
Sugiarto dkk. 2001. Teknik Sampling. Jakarta : PT. Gramedia Pustaka Utama
Sugiyono. 2006. Statistika untuk Penelitian. Bandung: CV Alfabeta.
Yasril dan Heru Subaris Kasjono. 2009. Analisis Multivariat untuk Penelitian Kesehatan. Yogjakarta : Mitra Cendekia.