PREDIKSI KECENDERUNGAN KONSUMEN
DALAM MEMILIH JENIS KENDARAAN (RODA EMPAT)
RERDASARKAN SPESIFIKASI KENDARAAN
MENGGUNAKAN
Decision Tree
DENGAN METODE
Gini
Mahbllblll Wathoni
PROGRAM STUD! MATEMATIKA
JURUSAN MIPA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM
negiセriSYARIF IDDAYATULLAH
JAKARTA
PREDIKSI KECENDERUNGAN KONSUMEN
DALAM MEMILIH JENIS KENDARAAN (RODA EMPAT)
BERDASARKAN SPESIFIKASI KEN]JIARAAN
MENGGUNAKAN
Decision Tree
DENGAN METODE
Gini
Oleh:
rvwmuBuL W ATHONI
102094026456
"["l
lJ iセ
Skripsi
Stbagai Salah Salu Syaral untuK Memptrolch Gdar Smjana Sains
Fakultassセゥョウ dan Teknologi
Uniwrsitas Islam Neotri SvarifHidavatullah Jakartab '" . '"
PROGRAM STUDI
MATEMATIKAJURUSAN MIPA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI
SYARIF HlDAYA1ULLAH
JAKA.RTA
Perumpamaan petunjuk dan ilmu
akan ditulis Allah untuk membawanya laksana air hujan
yang sangat lebat menyirami bumi,
diantara tanah (bumi) itu terdapat tanah
yang layak menerima air,
kemudian menumbuhkan pepohonan
dan rerumputan yang banyak.
Ada pula ada tanah yang keras,
sehingga dapat rr.enampung air,
sehingga t'mah semacam ini memberi manfaat kepada manusia.
(H.R. Bukhari dan Muslim dari Abi Musa) Al Fathul Kabir, Jilid
PREDIKSI KECENDERUNGAN KONSUMEN
DALAM MEMILIH JENIS KENDARAAN (RODA EMPAT)
BERDASARKAN SPESIFIKASI KENDARAAN
MENGGUNAKAN
Decision Tree
DENGAN METODE
Gini
Skripsi
Sebagai Salah Satu Syarat untuk Memperoleh Gelar Sarjana Sains
Pada Fakultas Sains dan Teknologi
Universitas Islam Negeri SyarifHidayatuIlah Jakmia
Oleh: Mabbllblll Watboni
102094026467
Menyetujui,
Pembimbin I
TaufikEdySufan 0,M.SeTech NIP. 150377 447
Mengetahui, Kelua Jurusan MIPA
Dr. Agus Salim, M.Si NIP. 150294451
Pembimbing II
/2ft
Dr. Agns Salim, M.SiPROGRAM STUm MATEMATIKA
JURUSAN MIPA FAKULTAS SAINS DAN TEKNOLOGI
UIN SYARIF HIDAYATULLAH JAKARTA
Dengan ini menyatakan bahwa skripsi yang ditulis oleh : Nama
NIM
Program Studi Judul Skripsi
Mahbubul Wathoni 102094026467 Matematika
Prediksi Kecenderungan Konsumen Dalam Memilih Jcnis Kcndaraan (Roda Empai) Bcrdasarkan
Spesifikasi Kendaraan Menggunakan Decision Tree
Dengan MetodeGini.
Dapat diterima sebagai syarat kelulusan untuk memperoleh gelar Sarjana Sains pada Program Studi Matematika Jurusan MIPA, Fakultas Sains dan Teknologi UIN Syarif Hidayatu!lah JakaJta.
Jakarta, 19 Novcmber 2006 Menyetujui,
Dosen Pembimbing
Mcngctahui,
Pembimbing 2
セH[Zz
Dr.Agus Salim,M.SiNIP.. 150294451
Dekan FakultasS,' s dan Teknologi Ketua Jurusan MIPA
PENGESAHAN UJIAN
Skripsi yang berjudul "Prediksi Kecenderungan Konsumen Dalam Memilih Jenis Kendaraan (Roda Empat) Berdasarkan Spes[jikasi Kendaraan Menggunakan Decision Tree Dengan Metode Gini.". Telah dinji dan dinyatakan lulus dalam sidang munaqosyah Fakultas Sains dan Teknologi, Universitas Islam Negeri Syarif Hidayatullah JakaIia, pada had Jum'at 17 November 2006, Skripsi ini telah diterima scbagai salah satu syarat untuk mempcrolch gclar sarjana strata satu (S I) pada Program Studi Matematika Jurusan MIPA,
Jakarta, 19 November 2006
Tim Pcnguji,
Penguji 1
Suherman, M.Si
Pcnguji 2
l'fur Inayah, S.Pd, M.Si
NIP. ISO 326 911
Mcngctahui,
DekaIlfZャォオャャエ。BセQゥGョウ dan Teknologi
PERNYATAAN
DENGAN INI SAYA MENYATAKAN BAHWA SKRIPSI INI BENAR-BENAR HASIL KARYA SENDIRI YANG BELUM PERNAH DIAJUKAN SEBAGAI SKRIPSI ATAU KARYA ILMIAH PADA PERGURUAN TINGGI ATAU LEMBAGA MANAPUN.
Jakarta, 19 November 2006
セセセ
ABSTRACT
The world of business has always been full of competitions. The executors think relentlessly of the way to get survived. Fortunately. in the modem business world, there is valuable data warehouse that could be utilized to generate new knowledge to help the executives in arranging their business strategies. The knowledge generator. which is data mining technology. would be introduced to the readers. This paper presents the business problems to be solved and th,e foundations of data mining: the usage, how data mining works. the tasks, and the popular methods (decision tree. classification.).
The result shows tendency of a consumer to buy heir favorite vehicle in the reality is not influenced by purchasing level of the costomer, but from its this finding Support the hypothesis that Indonesian people do prefer brand than of her factors.
ABSTR-\K
MAHBUBUL WATHONI, Prediksi Kecenderungan Konsumen Oalam Memilih Jenis Kendaraan (Roda Empat) Berdasarkan Spesifikasi Kendaraan Menggunakan
Decision Tree Ocngan Mctodc Gini. (Oi bawah bimbingan TAUFIK EDY
SUTANTO, M.ScTech. dan Dr. AGUS SALIM, M.SL).
Oalam dunia bisnis yang penuh persaingan membuat para pelakunya harus selalu mcmikirkan stratcgi-stratcgi tcrobosan yang dapat mcnjamin kclangsungan bisnis mereka. Salah satu aset utama yang dimiliki oleh perusahaan masa kini adalah data bisnis dalam jumlah yang banyak. Hal ini melahirkan kebutuhan akan adanya teknologi yang dapat memanfaatkannya untuk membangkitkan "pengetahuan-pengetahuan" baru, yang dapat membantu dalam pengaturan strategi bisnis. Teknologi data mining hadir sebagai solusi. Skripsi ini akan mengulas pcrmasalahan bisn;s yang ada dan dasar-dasar desicion tree melalui bahasan kegunaan, cara kerja dan metodologi-metodologi populer pada teknologi ini (pohon keputusan, klasifikasi, regresi), Desicion tree yang digunakan adalah
Classification and Regression Trees.
Dari pengolahan Dat.a PT. OTO MULTIARTA yang merupaksn dat"! dari tahun 2004 sampai 2005 dinyatakan bahwa, kencenderungan seorang konsum.;n ulltuk mcmbcli kcndaraan yang diinginkan tcmyata bukanJah dipcngaruhi olch tingkat pembelian seorang konsumen (harga). Hal ini mcmpertegas dugaan pandangan di masyarakr ptang sifat konsumen di Indonesia.
KATA PENGANTAR
Puja dan puji serta syukur saya panjatkan kehadirat Allah SWT. Atas segala karuniyanya hingga penulis dapat menyelesaikan skripsi ini. Shalawat serta salam keeintaan hanya tereurahkan kepada junjungan Nabi besar Muhammad SA W. Semoga kita semua mendltpatkan syafaatnya baik didunia maupun diakherat kelak. Amin.
Atas izin Allah SWT disertai denga'l usaha yang maksimal penulis dapat menyclesaikan skrips! ini. Meskipun demik!an, !)cnulis s"dar bahwa rlalam mengerjakan skripsi ini p<:nulis banyak dibantu oJeh berbagai pih&k. O!eh karena itl! pada kesempatan ini ;Jenulis ingin mengneapkan terima kasih yang sebGsar-besamya kepada :
I. Bapak Dr. Syopiansyah Jaya Putrlt, M.sis. Dekan Fakultas Sains dan Teknologi.
2. Bapak AgllS Salim. M.Si. Ketua Jurusan MIPA sekaligas dosen pembimbing II dan penasehat akademik penulis. Terima kasih alas nasehat d:m bimbingan selama saya kuliah di Fukultas Sains dan Teknologi Jurusan MIPA Program Studi Matematika.
3. Bapak Taufik Edy Sutanto, M.SeTeeh. Dosen pembimbing I. Penulis mengueapkan terima kasih alas bimbingan yang telah bapak berikan. 4. Ibu Nur Inayah, S.Pd, M.Si. Ketua Prodi Matematika yang telah
5. Seluruh dosen Jurusan MIPA Program Studi Matematika yang sudah mengajarkan ilmu-ilmu yang bermanfaat bagi penulis selama penulis kuliah.
6. Seluruh staf akademik dan Lab Pusat Lab Terpadu Fakukltas Sains dan Teknologi diantaranya Pak Agus Budiono, Pak Aminn, Pak Ade Candra, Pak Edi. Pak Yusuf, Pak Hari Satria, Pak Gunadi, Bu Opah, Mba Fitroh dan semuanya yang tidak dapat penulis ウセ「オエォ。ョ satu-persatu, yang dengan sabar melayani masalah administrasi mahasiswa jオセオウ。ョ MIPA Program Studi Matematika khususnya penulis sendiri.
7. Ibu dan Bapak serta Kakak-kakaku yang tercinta juga seluwh kc!uarga besarku yang selalu membcrikan do'a dan scmangat yang tiada hCl1tinya. 8. Teman-te;nan mahasiswa Matematika angkatan 2002 khususnya Andi Nur
Rahman, Hata Maulana, Bambang Ruswandi, M. Farid Fr, Sopirizal, Munaqin. Maya Destia, Haryani Chotijah, Indri, Maya, Cie-eie, Bulan Oktrima dan teman-temanku lainnya yang tidas dapat penulis sebutkan satu persatu.
9. Teman-teman mahasiswa Matemati:,a angkatan 2003, 2004 dan 2005 yang senantiasa memberikan dorongan moril kepada penulis.
Penulis menyadari bahwa masih banyak kelemahan dan kekurangan yang terdapat dalam skripsi ini, yang masih harus diperbaiki. Akhir kata penulis berharap semoga skripsi iili dapat bemlanfaat bagi kita semua.
DAFTARISI
Halaman
HALAMAN JUDUL.. .
KATA PENGANTAR .
DAFTAR lSI .
DAFTAR TABEL .
DAFTAR DIAGRAM .
DAFTAR LAMPlRAN
BAB l. PENDAJ-lULUAN .
1.1. Latar Belakang .
1.2. Perumusan Masalah ..
1.3. Tujuan Penelitian .
1.4. Manfac.t Penclitian ..
1.5. Pembatasan Masalah .
BAB II. KONSEP DAN DEFINISI ..
2.1. Deffinisi Data Mining ..
2.2. Teknik Data Mining ..
2.3. Tahapan Data Mining ..
2.3.1. Association Rule Mining .
ii
iv vii
viii
IX
3
3
3
4
5
5 7 9
2.3.2. Klasifikasi 2.3.2. Regresi 2.3.4 Clustering
10
13 14
2.4. Decision tree '" \5
2.5. Classification and Regression Trees (CART) .. 17
BAB 111. METODOLOGI PENELlTIAN 19
3.1. Pengolahan Data ., 29
3.1.1. Proses Screening Data.... 19
3.2. Data yang diperlukan '" 25
3.3. Pengolahan Data.... 26
3.3.1. Pendeiinisian Masalah 26
3.3.2. Mengerti dan memperkirakan kualitas data. 27 3.3.3. Pengeksplorasian data ,... 27
3.3.4. Pemilihan teknik pennodelan 27
3.3.5. Persiapan data untuk permodelan 28
3.3.6. Evaluasi model... 28 3.4. Proses pengolahan data untuk mengetahui pola yang tersembunyi. 28
BAB IV. ANALISA DAR! SCREENING DATA BASE 30
4.1. Proses Pembentukan Model Untuk Mengetahui Pola Yang
Tersembunyi ,... 30
4.2. Proses pengolahan data 32
4.2.1. Proses model system bahan bakar/fule system... 33
4.2.3. Model kathasil(harga yang dipilih olehkOllsumcn) 43
4.2.4. Modeljkendaraan Genis kendaraan) /... 48
BAB V KESIMPULAN . 53
5.1. Kesimpulan 53
5.2. Saran... 54
DAFTAR PUSTAKA 57
DAFTAR TABEL
'label 3.1. Tgbel32. Tabe: 3.3. 'label 3.4. Tabei4.1. T"beI4.2. 'label 4.3. T?beI4.4.
Halaman
... 21
. 22
. 23
. 24
... 37
. 42
.. 46
DAFTAR DIAGRAM
[image:16.595.85.479.184.553.2]Halaman
Gambar 2.1. 16
Gambar3.1 , 27
Gambar 4.1. 35
Gambar 4.2. 36
Cambar 4.3. 41
Gambar 4.4 _... 44
Gambar 4.5. 45
GamlJar4.6. 49
DAFTAR LAMPIRAN
Halaman
Lampiran I Perubahan ni!ai kategorik harga kendaraan... 58
Lempirc:n 2 Daio. PT. OTO l\1CLTIARTHA 63
BABI
PENDAHULUAN
1.1. Latar Belakang Masalah
memprediksi pelanggan mana yang paling besar kemungkinal1nya untuk mcmbcli scbuah kendaraan roda cmpat dengan karakteristik kcndaraan tertentu.
Pengertian Data Mining digunakan untuk mendefinisikan suatu proses pencari'ln otomatis terhadap infonnasi yang menarik dan berguna dalam suatu basis data yang dititik beratkan pada pencmuan pola yang sulit atau bahkan tidak mungkin dilakukan dengan mekanismequery database standar[2]. Classification Data Mining adalah salah satu tipe Data Mining yang bertujuan untuk menemukan pola k!asifikasi variabel-variabel yang memprediksi suatu variabel target. Pendekatan ini dapat digunakan untuk memprediksi respon konsumen terhadap pengadaan kendaraan roda empat di Perusahaan OTO MT JLTIART!-IA.
A!goritma CART telah I&ma digunakan untuk tujuan raemoentuk suatu
Decision Tree dalam rangka penemuan pola klasifikasi variabel [3]. Learning
sample digunakan untuk membentuk model tree dengan menggunakan algorilmd
oemisah tertentll yang akan memis&hkan learning sample menjadi dua subgmp
(node) ,ceara rekursifatau bertingkat hingga ;neneapai terminal node (leaf).
Mdihat tun,utan dan kebutuhan sumber daya manusia Sallt ini, Perkembangan Data Mining yang ウ。ョセ。エ pesat tidak terlepas dari perkembangan teknologi
infonnasi yang memungkinkan data dalam jllmlah besar dapat terakumlilasi. Sebagai eontoh, PT. OTO MULTIARTHA yang menyimpan data pada setiap penjualan kendaraannya. Database penjualan tersebut adalah sebuah penjualan yang berskala besar, Tetapi pertumbuhan yang pesat dari akllmlilasi data itu telah meneiptakan kondisi yang sering diistilallkan sebagai "rich of data but poor of
aplikasi yang berguna, tidak jarang kumpulan data itu dibiarkan begitu saja S」セォ。ョM。ォ。ョ sebuah kuburan data.
1.2. Perumusan Masalab
Pennasalahan yang akan dikaji dalam penelitian ini adalah :
I. Penearian infonnasi sebanyak mungkin dari data.base PT. OTO. MLTLTlARTHA.
2. Penentuan variabel-variabel prediktor yang sangat berpengaruh dan dapat mempengaruhi variabel target tertentu.
1.3. Tujuan Penelitian
Tujuan pengola;lan database dengan menggunakan pendekatan data mining adalah:
1. Mer.getahui infonnasi-informasi penting yang terkandung dalam kumpulan data di PT. OTO 'I1ULTIARTHA guna mendukung ォ・「ゥェセォ。ョ yang akan diambil perusahaan atau konsumcn.
2. Mengetah:.:i predik'tor-prediktor terpenting ya,lg berpengaruh terhadap suatu variabel target guna mendefinisikan program kerja perusahaan.
1.4. Manfaat Penelitian
baik bagi produsen maupun konsumcn pada umumnya. Dan Icbih khusus lagi digunakan pada?T.eTC' MULTIARTHA.
1.5. Pembatasan Masalah
BABII
DEFINISI DAN KONSEP
2.1. DefinisiDllla Mining
Data Mining (OM) adalah proses yang menggunakan berbagai perangkat
(tools) anal isis data untuk menemukan pola dan hubungan dalam data yang ';1Ungkin dapat cigunakan untuk membuat prediksi yang valid.
Seringkali、。ーセA ditemukan peagertian OM adalah salah satu bidang yang berkembang pesat karena besamya kebutuhan akan nilai tam bah dari database skala besar yang malin banyak terakumulasi sejalan dengan pertumbuhan teknologi infcrmasi [7J.
Oefinisi Uffium dari OM itu sendiri menurut Mohammad Sugeng Haryoro [7] adalah serangkaian proses untuk menggali nilai tam bah berupa pengetahuan IGセョァ sela.na ini tidak diketahui seeara manual dari suatu kumpu!an data. oセャ。ュ review ini, penulis meneoba merangkum perkembangan terakhir dari teknik-teknik OM beserta implikasinya di dunia bisnis. Pengertian miningsendiri berarti usaha untuk mendapatl:an sedikit barang berharga dari sejumlah besar material dasar.
Oleh karena itu OM sebenamya memiliki akar yang panjang dari bidang ilmu seperti kecerdasan buatan (artificial intelligent) [5J, machine learning,
Langkah pcrtama dan paling scdcrhana dalam c1ata mining yaitu menggambarkan data dan menyimpulkan atribut statistik (scperti rata-ra;3 dan standar deviasi), mereview seeara visual menggunakan diagram dan grafik, serta mencari relasi berarti yang potensial antar variabel (misalnya nilai yang sering muncul bersamaan) [10]. Mengumpulkan, meng-eksplor, dan memilih data yang tepat adalah sangat penting.
Menurut [10], pada dasarnya ada empat langkah utama c1alam melakukan data
mining:
I. Mendeskripsikan data, yakni menyimpulkan atribut statistik (seperti rata-rata clan standard deviasi), mereview secara visual menggllnakan grafik dan diagram, serta mencari h!.!bungan-hllbllngan potensial antar variabel (seperti misalnya, nilai-nilai yang seringkali keluar bersamaan).
2. Membangun model perkiraan (predictive model) berdasarkan pada pola-pola yang ditemukan pada langkah sebelumnya.
3. Menguji model di luar sampel asH. Sebllah model yang baik tidak harus sama persis dengan kenyataan sebenarnya (seperti peta bllkanlah rf'presentasi sempurna dari jalan yang sebenamya), akan tetapi bisa meqjadi panduan yang berguna untuk mengerti bisnis kita.
Tapi bisakah kita benar-benar bergantung pada perkiraan kita tersebut? Kita perlu membuk1ikan model perkiraan kita tersebut ke sample pelanggan yang lain dan melihat hasil yang kita dapalkan.
Untuk melakukan hal tersebut diatas maka setidaknya dibutuhkan suatu program yang dapat menampilkan (kalau tidak mendeteksi) pola dan keteraturan dalam data sehingga pola-pola yang kual atau sangat jelas terlihat dapat digunakan untuk melakukan prediksi[ I0].
2.2. TeknikDataMining
Dengan definisi Data mining (OM) yang luas, acla banyak jenis teknik 。ョセNiゥウ、 yang dapat digolongkan dalam OM. Beberapa teknik yang sering digunakan clalam literatur Data mining (OM) ant'lra lain: Clustering. Cia>sification. Association Rule Mining. Neural NetlVork. Genetic Algorithm dan lain-lain.
Dalam hal ini pcnulis menyajikan pengertian konfigurasi penyimpanan data yang memudahkan pemakai untuk melakukan OM yang umum disebut dengan data warehouse [4].
Data warehouse adalah kumpulan terpadu data perusahaan, yang dapat diakses oleh business managers. administrators. service providers & researchers
l. Pelllbersihan data (Screening data). untuk membuang data yang tidak jelas, dengan demikian data tersebut dapat dikonfirmasi kepada pemberi data
(diem)
2. lntegrasi data(penggabungan data dari beberapa sumber)
3. tイ。ョセヲッイャQャ。ウゥ data (data diubah menjadi bentuk yang sesuai, untuk digunakan dalam metode DM yang dipilih)
4. Aplikasi teknik DM berdasarkan metodenya
5. Evaluasi pola yang ditemukan (untuk menemukan intormasi yang menarik/bemilai)
6. Prtse:ltasi pengetahua:1 (den;;an teknik visualisasi).
2.3. TahapaoData Mining
Tahapan Data Mining digunakan untuk mendefinisikan suatu proses pencarian informasi yang menadk dan berguna dalum suatu dala yang dililik beratkan pada penemuan pola yang sulit atau bahkan tidak mungkin dilakukan dengan mekanismequerystandar. Pada sistem data base dapat digunakan :
2.3.1. Association Rule Mining
Association rule mining adalah teknik mining untuk menemukan aturan assosialif anlar;; sualu kombinasi i!em f6j. (omoh dari aluran assosiatif dad analisa ーセゥャセ「・ャゥ。ョ di SUall< per:lsahaan penjualan mobil adalah dapat diketahui berapa b"sar kemung;"inan (possibility) dan sesecrallg membeli mobil bersamaan dengan asuransinya.
Dengan pellgetailUan oari hai yang 、ゥセエ。^ l"rsebul. pemilik perusahaan penjualan mobil dapat mengatur pengambilan asuransi atau P.1erancang kampanye r:emasaran dengan ヲヲゥ・[ョセォ。ゥ potongan harga untuk sualu mobil tertentu. Penting tidaknya Sl'atu aturan assosiatif dapat diketahui dengan dua parameter support
yaitu persentase dari sualu data.
confidence minimum. Makalah ini membahas perbandingan kinerja dari dua perangkat lunak data mining untuk menemukan pola asosiasi dari suatu basis data. Perangkat lunak yang pertama didasarkan pada metode yang berbasis pada gmf asosiasi, sedang perangkat lunak yang kedua didasarkan pada penempan metode dimensi fraktal, untuk keterangan lebih lanjut tentang hal ini dapat dibaca di [15].
Untuk memperoieh satu set pola asosiasi, pengguna dari kedua perangkat lunak harus mcnspesifikasikan item-item pada masing-masing perangkat lunak. Pada perangkat lunak yang didasarkan pada graf asosiasi, kualitas pola asosiasi yang dieari hanya didasarkan pada p2rameter minimum support dan minimum confidence.Confidence (kepercp.yaMI) dari slietu aturan asosiasi adalah suatu nilai persentase yang menunjukkan bagail1lana atur"n terjadi 。ョエセイ semua kelompok, dan nilai kepercayaan menandai adanya aturan nilai yang lebih tinggi [11].
Meski dari sumber yang sama [11] hasil kaj ian perbandingan terhaclap kinerja dari kcdua perangi<at iunak secara umum dapat disimpulkan bahwa metode dimensi fraktal daflat menghasilkan jum!ah aS0siasi yang jauh lebib banyak dibandingkan metode yang didasarkan pt;da graf asosiasi. Selain itu, waktu komputasi yang diperlukan oleh me/ode Jimensi fi'aklal jauh Iebih kecil dibandingkan dengan me/ode graf asosiasi untuk spesifikasi pola asosiasi yang sama.
2.3.2. Klasifikasi
dipasangkan pada sebuah kelas label tertentu. klasifikasi mcmbentuk sebuah model yang nantinya digunakan untuk melakukan prediksi kelas label pada data baru yang belum pernah ada sebelumnya. Misalnya pada aplikasi email spam filtering, data email dipasangkan pada class label "spam" dan "bukan spam". Kemudian dibentuk sebuah model yang dapat menentukan sebuah email baru. Jadi. dataclassificationmemiliki dua tahap yaitu:
pembentukan model, dan penggunaan model lersebul untuk prediksi kelas label data baru. Model yang dihasilkan biasa disebutclaSSifier. Terdapat banyak sekali leknik dan pendekalan yang digunakan dalam data classification, sebUI saja
decision tree, bayesian classifier, rule-cased classifier, neural lIetwork, support
vector machine (SVMj, associative classification, nearest neighbor, f!.<!netic
algoritl,m, fuzzy logic, dan lain-lain, Dari beberapa istilah ini, kita tahu ballWa
banyak algoritma data classification berasal dari bidang machine learning,
pal/em recognition, danstatisticdengan luj<Jan untuk dapal memperkirakan kelas
dar: suatu objck yang labelnya tidak diketahui. Model itu ウセョ、ゥイゥ bisa bcmpa aluran 'jika-maka", yang berupa decision tree, formula maU,matis atau neural network.
Umumnya salu variabel bersifal sebagai suatu fungsi dari variabel lainnya. Hal inl mengakibatkan nilai dari variabel targel dapat ditentukan dari nilai yang diberikan oleh variabel lainnya yang disebut dengan variabel predihor. Y
merupakan variabel target danX adalah variabel prediktor denganjumlah variabel sebanyakp variabel yang dinotasikan denganXI, ., " Xp • Dalam model prediksi,
adalah hasil prediksi model dan
e
menunjukkan parameter model. Menurut [14] j:ka ;. Fセ。ャ。ィ variabel kategorik maka pemetaan dari X ke Y disebut dengan klasifikasi. Variabel kategorik merupakan variabel yang nilai-nilainya hanya bersifat mengkelas-kelaskan objek yang saling terpisah. Berdasarkan skala pengukurannya, variabel kategorik dapat diklasifikasikan menjadi variabel berskala nominal dan variabel berskala ordinal (16].J. Skala Nominal
Angka-angka yang disajikan pada skala nominal hanya sebagai nama penggolongan. Angka tersebut tidak mengukur besaran telapi hanya sebagai lambang. Disini, angka I tidak lebih besar dad pada 0 「・セゥエャャ pula 0 tidak lebih keeil daripada L Misalkan pemberian kode J pada merek mobil BMW dan 0 pada
merek mobil AUDI tidak berarti bahwa BMW mempunyai nilai satu dan AUDI mempunyai nilai HOI. Angka-angka tersebut ha'lyalah kode untuk membedakan antara BMW dan AUDI, dengan demikian kitajuga bisa menllkar AUDr menjadi
o
dan BMW menjadi I tanpa merubah maknanya.2. Skala Ordinal
tingkatan penjualan , kendaraan murah dibcri angka I, scdang diberi angka 2, mahal diberi angka 3. 、セョ San;;3t mahal diberi angka 4. Penjualan yang berkualitas didapatkan dari penjualan murah, tetapi kualitas p,:njualan dari mahal tidak berarti dua kaJi lebih berkuaJitas dari pada penjualan murah.
2.3.3. Regresi
Perbedaan mendasar antara klasifikasi dengan regresi terletak pada jenis variabel targetnya. Menurut [16] jika variabel targetnya merupakan variabel kategorik maka disebut 、・ョァ。セ klasifikasi namun jika variabel targetnya bempa variabel numerik maka disebut regresi yaitu pemetaan dari X, ..., Xo ke Ydengan
persamaan Y=f(X" ....
xp:e).
p・セウ。ュ。Bョ regresi dapat tcruiri dari satu variabel prediktor dan satu カ。セゥ。エ・ャ tar;;et atau beberapa variabel prediktor dengan satu variabel target, persamaan yang penama disebut persamaan regresi sc:derhana. Contohnya adalah hubungan antara keillarga dengan anggota keJuarga, dalam contoh エ・イウ・「セャエ yang menjadi varia bel target adalah angguta keluarga dan variabel predik'tomya adalah keluarga.
f'ersamaan kedua disebut regresi berganda contohnya adalah hubungan antara variabel prediktor tingkat pendidikan. pendapatan dan jumlah anak terhadap variabel terikat pengeluaran konsumsi keluarga.
hubungan kcdua variabel tcrsebut dapat dituliskan dalam bentuk pcrsamaan berikut:
I'
Y=ao+"'aXL J J
j"'l
...( I)
Dimana
e
=
{ao, ...• ap} adalah parameter dari model persamaan regres!.Jika
.i
= I maka persamaan I disebut dengan persamaan regresi linear sederhana.Jika
.i
>1 maka persamaan 1 disebut dengan persamaan regresi linear berganda.2.3.4. Cluslering
Berbeda dengan associalion I1lle miningdan classificalion dimana kelas data telah ditentukan sebelumnya, cluslering(pengelompokan) banyak digunakan unruk memisahkan dan melakukan pengelompokan data tanpa herdasarkan kelas data pacta suatu variabel target tertentu. cluslering dapat juga dipakai untuk memberikan label pada kelas data yang belum diketahui. Oleh karena itu
cluslerfngsering digolongkan sebagai metode unsupen-ised learning. Prinsip dari
cluslering adalah memaksimalkan kesamaan antar anggota satu kelas dan meminimumkan kesamaan antarkelas/clu3leryang terbentuk[J4].
mcnggabungkan clusler kecil mcnjadi clusler Icbih bcsar clan top-down yang mcmccah chisler besar menjadi clusler yang lebih keci!. Kelemahan [ョ・セッ、・ ini adalah bila salah salu penggabungan/pemecahan dilakukan pada lempal yang salah, lidak dapat diperolehclusteryang optimal [13].
2.4. Decision tree
Decision tree melakukan partisi terhadap learning sample yaitu kumpulan data terdahulu sebelum dikelaskan unluk semlla observasi menjadi bagian yang lebih kecil [12]. Setiap partisi hanya didasarkan pada variabe! lunggal yang dipilih dari learning sample.AlgoritmaClass!{Jcalion And Regression Tree(CART) akan mencari variabel dan semua nilai yang mungkin bertujuan untuk menjadi pemisah terbaik. Proses pemisahan tersebut dilakukan pada setiap hasil pembagian data atau node padatreenya.
Decision Iree adalah cara merepresentasikan kumpulan aturan yang mengacu ke suatu nilai atau kelas[12]. Misalnya kita bisa mengklasifikasikan
SU8(U proposal pinjaman uang memiliki resiko baik atau buruk dengan menelusuri
Income>
$40,000
N/
Gセウ
High Debat
y・ウOセセッ
Job>
5 Years
y・セno
Good Risk
Bad Risk
Bad Risk
Good Risk
GambaI' 2.1 Decision tree sederhana untuk menentukan resiko pengaman oieh
cusfomer
Komponen pertama adalah simpul top decision, atau simpul rOOI, yang ュ・ョ・ョエオセ。ョ test yang akan dijalankan. Simpul rOOT dalam cantoh ini adalah
"income> $40.000". Hasi! dari tes ini menyebabkan tree terpecah menjadi dua cabang, clengan tiap cabang mepresentasikan satu dari jawaban yang mungkin. Dalam kasus in!, jawabannya adalah "ya" dan "tidak", sehingga kita mendapatkan dua cahang.
Bergantung pada algoritma yang digunakan. Tiap simpul bisa memiliki dua atau lebih cabang. Misalnya, CARf akan meng-generate hanya dua cabang pada tiap simpul. Treeseperti inl disebut binmy tree.Ketika lebih dad dua cabang diperbolehkan maka disebut sebagaimllltiway tree.
ini, scorang manager, yang bcrtanggungja\\ab untuk memutuskan apakah scorang konsumen dapat membeli sebuah kendaraan dengan prediksi memiliki resiko kredit yang baik atau buruk.
Model decision tree umum digunakan dalam data mining untuk menelaah data dan menginduksi tree dan aturan yang akan digunakan untuk membuat prediksi. Sejumlah algoritma yang berbeda bisa digunakan untuk membanguntree di antaranya adalah CHAID(Chi squared Automatic Interactin Detection), CART
(Classification and Regression Trees), Questdan CS.O.
Decision tree 「・セォ・ュ「。ョァ melalui pemecahan iteratif dari data ke dalam grup-gi'UP diskrit, yang tujuannya adalah untuk memaksimalkan 'Jarak" antara grup padaエゥセー pemecahan.
Contoh yang kim gunakan pada penelitian ini sederhana. Tree ini mudah untuk dimclIgcrti dan d;jnielpretasikan. Akan tetapi, tree bisa menjadi sangat kompleks. Sebagai contoh kompleksi!us suatu tree yang diturunkan dari database d'cngan イ。エオセ。ョ atrib:.Jt dan カ。セゥ。「・A respon dcngan lusinan kelas input. Tree
sej)crti ini akan sangat sulit untuk dimengerti, meskipun tiap path dari tree
lJiasanya dapat dimengerti. Dalam hat ini decision tree bisa rnenjelaskan prediksinya, yang merupakan keuntungan penting. Akan tetapi, kejelasan ini bisa jadi menyesatkan.
2.5 ClassificationandRegression Trees (CARl)
Clas.I'lication And Regression Tree (CART) adalah metodologi klasitikasi yang menggunakan data terdahulu untuk membangun decision tree. Kemudian
Dalam membangun decision free, Classification And Regressio/l Tree
(CART) menggunakan learning sample yaitu kumpulan dat, terdahulu sebelum dikelaskan untuk semua observasL
CART merupakan alat decisio/l tree yang baik untuk data mining, pemodelan prediksi dan pengolahan datI. CART seeara otomatis mencari pola-pola dan hubungan yang pe:1ting yairu membuka struktur yang tersembunyi meskipun datI yang digunakan memiliki kompleksitas tinggi. Metodologi CART dike;)a] sebagai parrisi binary rekursif Binary karena proses pemode!an melibatkan pe;nba8ia'1 kumpulan datI mer:jadi dua subgroup (atau /lode).
BABIH
METODOLOGI PENELITIAN
3.1. Pengolaban Data
3.1.1. ProsesScreening Data
Screening data adalah sebuah proses yang dilakukan untuk mengetahui
terdapat nilai yang hilang (missing value), kesalahan ketik, Wilier, penentuan
variabel yang akan digunakan, dan sebagainya. Terkadang dalal11 melakukan proses
screening data, transfarmasi data dilakukan c:ntuk merubah data bemilai numerik,
menjadi kategorik.
Pada pembentukan model, learnjag sample yang digunakan ahn dipisah
menjadi menjadi ciua subgmp (node) secara rekm-sif atau bertingkat hingga mencapai
lerminal node (lcu/) dCllgan rl'enggiJuakan algcritma pemisah tcrtentu[7]. Dalam
peneliti8.n ini algoritma p.emisah yang akan diballas adalah aturan pemisahGini (Gini
splitTing rule)yang digunakan dalamclasstfication tree.
Pertumbuhan Iree dari learning sample akan menghasilkan level suatu tree
yang paling besar atau disebut dengan tinggi tree. Dibandingkan dengan model tree
yang lainnya tree tersebut memiliki jumlah terminal node yang paling banyak. Tree
paling besar seperti ini disebut dengan maksimumtree.
Database saat ini baleh jadi berkembang menjadi sangat besar secara cepat ke
informasi-informasi tersel11bunyi yang sangat penting atau menjadi penting pada saat
dibutuhkan. Hal ini sulitnya l11enel11ukan sebuah jarum dalam tUl11pukan jerami?
Dalal11 hal ini dapat kita katakan bahwa semua data belum berarti infonnasi.
Pengolahan sebuah data terlebih dahulu haruslah melalui proses screening
data agar dapat diketahui variabel-variabel mana saja yang memiliki missing value.
[17
J
Penggunaan SPSS untuk melakukan screening dab agar data tersebut dapat diolah kedalam program CART (Classification dan Regression Trees).
Penggunaan SPSSuntuk melakukan screening data agar data tersebut dapat cii
lakukan dalam mcngolah kc dalam program CART (Classification dun Regression
Trees). Dari data tersebut akan diketahui variabel-variabel apa saja yang berpengaruh
terhadap data yang ada, antara lain (tabel 3.2, 3.3, dan 3.4)
Tabel 3.1. Contoh data yang akan di screening dengan mengglmakan sofwere SPSS
rnrkmobi!
I
bbakarI
sidI
bpinll jkendara Qセャッォイョ・S lOIS;I
ー。ョセ lebarlting! berat ljmesinl rriltsubl 98S turbo tv,,/(1 h.lchba f','.o'd flont 959 11'), , ).<-",":1 G53 50 29J5 01"1(:rrul';utll
go,
Eld four s&ljan f'Nd front 963 17:24 654 52 2365 oticrnitsubl 985 std fout' S!?;d8n f,Yd front 9E.3 172,4 G54 52 2405 ohc
r(ll!subl (las turbo four sedan f'Nd front 96.3 1724 65.4 52 2403 DilL:
t"flitsubl gas std four sedan fyd ftont 9E3 172.4 G54 52 2403 ohc
nl5san gas std t1.I>l(1 sedan ヲセGe ...d flem! YセQNU 165.3 636 55 188'3 ohc
t"llss.;n dl8B81 std tv·)!) sl?:dan f·yd front 945 166.3 GO:' 0.... L. 55 ;'017 uhe:
n15Sf:!1l gas 5td tlNO sedan f'Nd front sNセ .5 1G53 l33.o 55 1916 ohc:
nlSSCin gas std four ウセ、。ョ f·/o.'d front 94.5 155,3 133.8 b'=' 1938 ohc:
ョャセLsXョ gas e,td fOUl \I"'lagon f'Afd front 945 171J2 63.a 54 2024 ohc
nissan 9as std tv.JD s8dan fvvd front 945 1&5.3 6-) ':--'... 55 195·1 c.hc
fH:·San gas e,td tlJVO halo:hba f'Nd front 94.5 165.6 r-'r,J').O Uセゥ 2028 ahc:
nl·::·Sdtl gd'; s,:d f,)lIl" s8dan fNd front 945 1£,5.3 133 :3 5f, 197·1 ,:,h(;
Data yang akan digunakan untuk discreening dengan menggunabn sonvere
SPSS [16], memiliki 24 variabel diantaranya adalah Madein (pembuatan kendaraan).
MrYJDobil (merek mobil), Bbakar (Bahan baker), Eksmcsin (pcnggunaan mcs;n).
Bpintu (banyaknya nintu), Jkendara (jenis kendaraan), K.rit (kriteria mesin),
lッォョャ・セゥョ (likasi mesin), Jmes;;] (jenis mesial, Cylinder (banyaknya cylinder).
Sbbfsyst (sistem bahan bakar full system), ャGセ。エィ。ウゥャ (kategorik nilai harga), l'e;ljuala
(kategorik dari laku), Laku (normalisasi penjualan), Umesin (ukuran mesin), Symbol
(symbol), Torsi (jarak/torsi rada), Panjang (panjang body kendaraan), Lebar (lebar
body KenJaraan), Tinggi (tinggi body kendarqan), Berat (berat kendaraan), Rasio
(rasio kompresi mesin), Hp (tenaga kudalbhp), Harga (harga jual kendaraan). Dalam
proses screening akan dilakukan uji frekwensi, untuk mengetahui nilai yang hilang
(missing Valuc).Hasil dari proscs scrccning data tcrscbut dapat dilihat pada tabcl3.2,
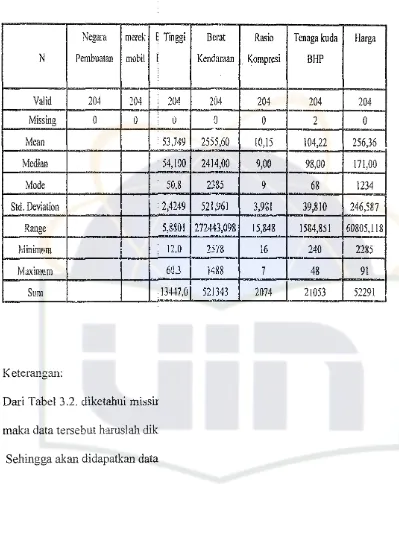
Tabel 3.2. Hasil Screening Peng
naga kuda Harga
BHP
204 204
2 0
104,22 256,36
98,00 171,00
68 1234
39,810 246,587
1584,851 60805,118
2&0
I
228548 91
-21053 5229!.-.
Te
Negara merek Tinggi Berat Rasio
N Pembuatan mobil Kendaraan Kompresi
Valid 204 204 204 204 204
Missing 0 0 u 0 0
Mean 53,749 2555,60 10,15
Median 54,100 2414,00 9,00
Mode 50,8 2385 9
Std. Deviation 2,4249 521,%1 3,961
Range 5,8801 272443,098 15,848
Minimum II 12.0 2578 16
Maximum 60,3 1488 7
Sum 13447.0 521343 2074
Keterangan:
Dari Tabel 3.2. diketahui missir
maka data tersebut haruslah dik
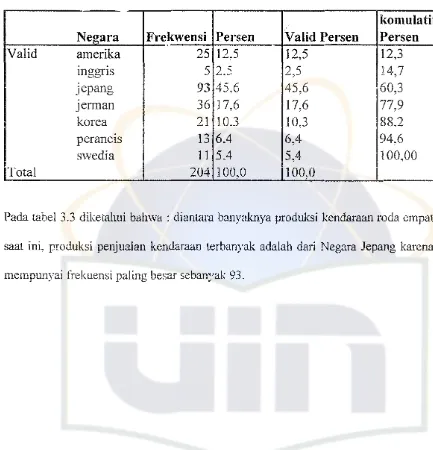
Tabel 3.3. Produksi Pembuatan kendaraan berdasarkan negara pell1produksi
komulatif
Negara
Frekwensi Persen
Valid I1ersen
Persen
Valid amerika
25 12.5
12.5
12,3
mggns
5 2.5
2,5
14,7
jepang
93
45,6
45,6
60,3
Jennan
36 17.6
17,6
779
,
korea
21 10.3
10.3
88.2
perancIs
13 6.4
6,4
94,6
swedia
11
5,45,4
100,00
Total
204 100,0
100,0
Pada tabel 3.3 diketahui bahwa : dianlara banyaknya produksi kel1daraan roda empat
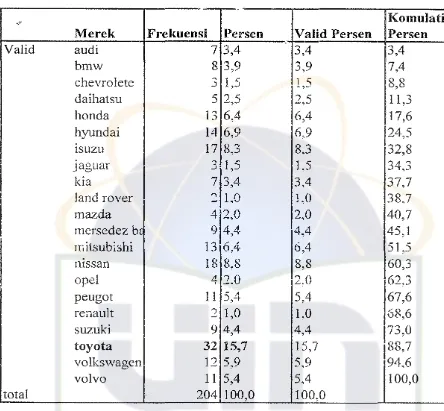
Tabel 3.4. Banyaknya konsumen memilih kendaraan berdasarkan merek
.,'-
Komulatif
Merek
Frekuensi
Persen
Valid Persen
Persen
Valid
audi
7 3,4
3,43,4
bmw
8 3,9
3,9
7,4
chevrolete
3 1,5
1,5
8,8
daihatsu
5 2,5
2,5
11,3
honda
13 6,4
6,4
17,6
hyundai
14 6,9
6,9
124,5
lSUZU
17
8,3
8,332,8
jaguar
3
1,51,5
34,3kia
7 3,4
3,4
37,7
I
land rover
"
LO
1,038,7
mazda
42,0
2,0
40,7
mersedez
「セ9 4,4
4,4
45,1
mitsubishi
13 6,4
6,4
51,5
nissan
18 8,8
8,8
60,3
opel
4 2.0
2.0
62.3
peugot
115,4
5,4
67,6
reilault
')1,0
1,0
68,6
suzuki
9
4,4 4,473,0
toyota
32 15,7
15,7
188,7
volkswagen
12 5,9
5,9
セ
volvo
115,4
5,4
100,0
total
204 100,0
100,0
Dari TabeJ 3.4. dapat diketahui banyaknya penjualan didominasi oleh kendaraan
3.2. Data yangdipcrlukan
Penelitian ini menggunakan data sekllnder yang diperoleh dari PT. OTO
MULTIARTHA, data yang diambil pada tahun 2004 tersebut memiliki 22 variabel,
204 record.
Dalam pengolahan data, metode gini digllnakan untuk lI1engolah dan mencari
informasi dengan indeks gini yang didefinisikan sebagai gini ( t )=
L:
Pi(I - Pi) ,dimana p, adalah frekuensi relatif (ditentukan dengan membagi juml<:h kelas
pengamatan dengall total j umlah pellgamatan) dari kelas i pada node t, dan node t
ュ・ョuャセオォォ。ョ parent node amuchild node yang memisahkan data. Indeks gini adalah
penguKur impurity untuk node maksimum yang diberikan ketika semua pengamatan
didistribusikan ke semua kelas. Secara umum, aturan pemisahan gini berusaha untuk
mencari kategOli homogenitas yang paling besar dalam data dan mengiso!asikannya
dari sisa data. Sub barisan node kemudian dipisahkan dengan cam yang sarna sampai
tidak mnngkin nntuk dibagi [8].
Menurut [9] Indeksginiuntuk nilai variabel target binary yaitu
i
(t
)
=2.
P(lit).
p(211)
Dimana:
t adalah node pohon.
P
V
It)
adalah probaiIitas dari kelas ke-j pada nodet.i(s,1)
=
i(t)- PI .i(tl)- P,.i(l,)dimana PI' P,merupakan pecahan kasus dalam leaf kiri (kanan),
3.3. Pengolahan Data
Dalam melakukan proses data mining ada beberapa tahap yaitu :
3.3.1. Pcndctinisian masalah
Pendefinisian masalah sangatlah penting karena kita dapat melakukan
penggalian data untuk mencari informasi yang penting dan dapat mengetahui
suatu pC!TIlasalahannya contoh :
1. 'v1en.:ntukan bauyaknya prediktor yang dapat mempengaruhi target.
2. Memilih kelas mana saja yang dapat mempengaruhi dari informasi tersebut.
3. Menentukan metvde yang digunak:m dalanl pengo!a.'1:m data, metode yang
digunakan dalam penelitian ini adalah metodegilli.
4. !'lasil yang diperoleh dari pengolahan data berupa Classification Tree, dan
dapat ciijelaskan menurut kelas-kelasnya,contoh dari Classification Tree
Gambar 3.1. Contoh Tree Classification
3.3.2. Mengerti dan memperkirakan kualitas data
Data yang didapat harus dimengerti dan dipahami terlebih dahulu agar dapat
melakukan langkah selanjutnya serta memperkirakan kualitas data yang
dlperoleh agar hasil infoITllasi yang akan didapatkan menjadi baik
3.3.3. f・ョァ・セセウーャッイ。ウゥ。ョ daw
Pencarian kemungkinan terdapatnya hubungan-hubungan yang saling
berpengaruh antar variabe!. Variabel yang secara teod saling berhubungan
dapat digunakan untuk memperoJeh infoffi1asi sebanyak-banyal!.nya dari data
yang digunakan.
3.3.4. Pemilihan teknik pemodelan
Teknik data mining yang akan digunakan adalah tc!mik berdasarkan decission
3.3.5. Persiapan data dan pembentukan model
Persiapan data yang dilakukan meliputi pembersihan data (membuang data
yang tidak konsisten), deskripsi masing-masing varia be!, integrasi data
(penggabungan data dari berbagai swnber), transformasi data (clata diubah
menjacli bentuk yang sesuai untuk di analisa). Moclel dapat dibangun setelah
dilakukan persiapan data yang akan digunakan, maka langkah selanjutnya
adalah membangun sebuah model untuk mengetahui tingkat ketepatannya
3.3.6. Evaluasi model
Model yang kurang infonnutif harus die.,/aluasi kembali agar didapatkan
model ycng lebih infoffilatif dan mortel-model yang telah dihasilkan dapat
、ゥォッュ「ゥョ。セゥォ。エャ sehingga mendapatkan informasi yang kbi h baik lagi.
3.4. Proses pengolahan data untuk meilgetahui palayangtersembunyi
Stlatu perusahaan dapat menerapkan aplikasi yang menjanjikan
kCWlggulan kompetitif melalui pengelolaan pelangilan yang lebih baik.
Penerapan teknologi infonnasi (TI) di sebuah perusahaan penjualan kendaraan
telah menjadi kebutuhan mutlak penerapannya, tidak hanya untuk komunikasi
dan transaksi, melaillkanjuga untuk pemasaran. Dalam menentukan informasi
pelanggan untuk tingkat layanan yang pantas diberikan, serta menawarkan
produk yang sesuai.
Kita telah mengetahui bahwa data mentah (raw data) biasanya tidak
dianalisa. Kita perlu mengekstrak pola dad data mentah tersebut dengan
teknik data mining. Banyak instansi / perusahaan di dunia telah menggunakan
data mining untuk mencari dan menarik kesimpulan dari data yang mereka
miliki. Berikut beberapa contoh aplikasi data mining:
•
Perusahaan pemasaran menggunakan data sejarah respon pembelianterhadap suatu tawaran produk yang dapat membangun model untuk
memperkirakan pelanggan potensial yang akan eli raih dengan metode
ーセョ。キ。イ。ョ tertentu [18].
•
• Agen pemerintah menyaring elatil transaksi keuangan untuk mendctcksi
money launctering elan vnye!undupan obat terlarang (18].
Dalam tahapan 、ゥ。ァョッウゥセL para fisikawan membangun
expert system
berdasar1.:an b"nyalz pcrcJbaan yang tcbh dilakukan [! 8].
Sebuah data digunakan sebagai pencarian dari pengolahE!ll dengan
menggunaka.!1 programCART Dalam sebmIt data, akan dikelahui banyaknya
variansi konsumen lliltuk memiiih sebuah kenelaraan foda empat. Set;ap
konsumen memiliki selcra yang berbeela-beda diantaranya, didapatkan sebuah
pengklasifikasian, dimana variabel target akan dipengaruhi oleh beberapa
variable prediktor. Dalam algoritma diutas tersebut kita akan mengetahui
prediktor-prediktor mana yang sangat mempengaruhi variable target. Dalam
pengolahan data akan di dapatkan hasil dar! sebuah variable target, dimana
variable targetnya aelalah merek kendaraan dimana konsumen biasanya
BABIV
ANALISA DARI SCREENING DATA BASE
4.1. Proses Pembentukan Model Untuk Mengetahui Po12, Yang Tersembunyi
Data yang akan diguanakan adalah data dari PT. OTO Multiaratha yang
diambil atau di kalkulasikan dari penjualan pada tahun 2004 sanlpai dengan 2005.
Data tersebut mempunyai 24 variabel dimana banyaknya reeord/kasus ada sebanyak
204 kasus.
Data yang akan diolah memiliki 24 vari:::bel Jiantaranya 14 variabel kategorik
(string) dan 10variabel numerik. Keterang.'n lengkap tentang ','ariabel y11fig ada dapat
dilihat pada Tabel lampiran 3.
Di dalam variabel harga Yi\ag bcmilai fiUiGErik akan dirubah menjadi
kategorik agar lebih mudah untuk melakukan uji sebuah model. Dalamュ・ョァァuャセ。ォ。ョ
metode CART nilai y:wg numerik Jirubaf] menjaJi kategorik agar dapat
dik1asifil:asikan dengan baik, dan Japat memberkian suatu informasi yang dapat
memberikan kepuasan kepada konsumen. Dalanl menentukan perubahan numerik
menjadi kategorik, kami menggunakan metode Quartit, dirnana dalam merubah
vari'.lbel harga tersebut dibutuhkan metode Quartil agar nilai numerik dapat dirubah
menjadi nilai kategorik. Jumlah record dari harga akan dibagi menjadi empat yaitu
QI, Q2, dan Q3. Dengan WI kami kategorikan sebagai interval harga murah, W2
record dari variabel harga terdiri dari 204 nilai numerik, akan diubah menjadi 4 nilai
kategorik interval.
Da!am melakukan screening data diketahui banyaknya record dari harga tersebut
adalah 204 data. Unluk menentukan QI, Q2, dan Q3 akan kila gunakan rumus :
[I]
[I]
[I
I
セョMf
-·n-F
セョMfN4 ' 4 2 4 .,
Q,
=
セ
+
c
.r,
,
Q,
=
L,
+
c
j,
,
Q
3=
L3+
C.f,
セ
Keterangan :
: 1.2,3
Li :tepi bawah kelas !martil bawah
Qi
n : ukuran data (jumlah frekwensi)
f, : trekwemi pada interval kclas kuarti! bawah
Qi
fi : frekwensi kumulatif sebt'lum kdas kuartil bawah Qi
Nilai dari
Q
tersebut akan di gunakan untuk menentukan batasan WI, W2, W3, danW4. yang mcnghasilkan:
WI
=
91 sampai dengan 138 juta=
MmahW2= 140 san1pai dengan 170 juta = Sedang
W3
=
172 sampm dengan 275 juta=
MahalDalam proses perubahan nilai harga dari nUl11erik l11enjadi kategorik ini akan
mel11permudah dalal11 proses pengolahan data l11enggunakan Program CART,
terutama dalam pembentuk.:n mode!
Classijica/wn /ree-nya.
4.2. Proses Pengolahan Data
Dalam menentukan suatu variabel target, peneliti biasanya menean-ean
variabel mana saja yang baik dan dapat dial11bil infonnasi yang sebanyak banyaknya
untuk dapat diketahui variabel target tersebut dipengaruhi oleh variabel variabel lain
(prediktor) mau tidak . Variabe! target dapat dipengaruhi oleh variabel prediktor dan
dapat menentukan infonnasi apa saja yang dihasilkan dari modd tersebut.
Pada 24 variabel dari tabel lan:piran 3 tersebut, banyak variabel yang kurang
tepat unmk dijadikan variabe! target, karena variabe! o:argd banyak yang tidak
berhubungan seeara teuri dengan variabel predlktomya. maka hanya almn diambil
bebe,aprr v::aiabel saJa untuk Jijadikan sebagai target yang dapat diambil
informasinya.
Diantara 24 variabel target tersebut yang haik untuk diambil infonnasinya
adalah variabel
Sis/em Bahan Bakor/Fuel Sis/em, laku(banyaknya yang /erjual),
Ka/hasi(harga yang dipilih aleh konsumen), Jkendaraan(jenis kendaraan)
karenauntuk mengurangi hubungan antara variabel target dan prediktor.
Dalam proses pengolahan data terdapat empat target diantaranya model dari
oleh konsumen), Jkendaraan (jenis kendaraan yang banyak di beli oleh konsumen)
akan dilakukan proses pembuatan model, agar didapat infonnasi yang sesuai,
4.2.1. Proses Pemodelan Sistem Bahan Bakar/Fuel System
Dalam model yang pertama, dapat kita jadikan Sistem Bahan Bakar/Fuel
System menjadi variabel target dan prediktomya yang mempengaruhi variabel target
adalah Panjang, Lebar, Ukuran mesin, Torsi, Tinggi, Rasio, Hp (house power), Berat
jcnis kcndaraan tcrscbut.
Dalam pengolahan Model yang pertama, akan kita gunakan metode Gini.
Dalam meclentubn model, dapat diketahui setiap System Bahan BakarlFuel System
kendaraan mcmpunyai prediksi bennacam-macam, diantaranya :
• disel,
• ecGS (ECCS, Multi-Point Fuel Injection),
" en
(Electronic fuel inje..:tioin),• msi (Multipoint Sequeutial Injection),
• feem (Fully Electronic Engine Management),
• hpcrdit (High Pressure Common Rail Direct Injectioll Turbo Diesel) ,
• icimulti, ifis (Electronic Fuel Injection System),
• micpro (Electronically (Microprocessor) Controlled Direct Diesel Injection),
• mpfi (Multi Port fuel Injection),
.. pgmfi (Programmed Fuel Injection),
.. Mi (Mechanical Injection),
Dari tree di bawah ini akan di(-00
._._---_._
...._._.__
...-
MM⦅N⦅セ Terminal" Node 29 W=5.000 -N(;j';:e""'5---LEBAR W=23000 N=23 Node 6 :INGGI W= 14.000 N= 14 Terminai", T8rrdnalNode 1 Node 2 W=8000 W=6.000
ZjijャZiャセ
_*
Terminal Node 3 W=9.000-_._
__
.Nod< Node 20
UMESI BERAT
W=10 W=65.000
N=' N=65
. _ - - - - -
. _-N Node 24
TOI RASIO
W' W=31.000
セ N=SNQセ セセ
Terll1lnai'-Noel-e
25 !---_.- Node':!]Node4 JMESIN 3CRAT
W=2.000N=13.000 W= 18.000
N=13 N=18
-I_.-
"t1Ode26-
"NOde28-l'erminalTORSI TORSI Node 27 iO W= 12.000 W= 17.000 W= 1.000
J
N=12-!!..=.E-
セTerminal Terminal Terminal Terminal
iセッ、・ 23 Node 24 Node 25 Node 26 W=4.000 W=8.000W=15.000W=2.000
F
TIfIIIII
. . .
Terminal Nvde28 W= 10000
'1IIF
Dalanl node 1 dapat dilihat m( kecii
Dalam oktimaml tree, terbentt'eda-beda
Hal tersebut dipengaruhi oleh Gambar 4.1. yang akan mempengaruhi gains chart dari
nilai rata rata 10 % data, maka akan diketahui 100 % dari kelasnya
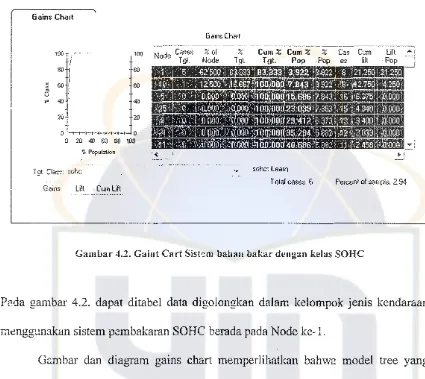
Gaim: Chart
I tOO
"
20
Gains Lift Cum Lift
sohc: learn
[image:53.595.66.491.141.520.2]Tot<i! cases:6 Percen( of :>arnple: 2.94
Gambar 4.2. Gaint Cart Sistem bahan bakar dengan kelas SOHC
fセ、。 gambar 4.2. dapat ditabel data digolongkan dalam kelompok jenis kendarlian
wenggunakan sistemーセュ「。ォ。イ。ョ SOHC berada pada Node ke-l,
G::mbar dan diagram gains chart mell1perlihatkan bahw2. model tree yang
dihasilkan l11el11iliki persentase kUl11ulatif kelas target lebih besar dari pada persentase
kumulatif dari populasinya sehingga model tree inidapat dikatakan suatu model yang
IIIIIIIIII
llIIlIIli
IIIIIIII
1Il1I11
IIIII]
IIIIl
III]
IIHal tersebut dipengaruhi oleh variabel yang mempengaruhi target dibawah ini (Tabel
4.1.) :
Tabe! 4.1. Val"iabcl Importance dad Sistcm Bahan Balmr
TORSI
100,00
1111111111]111111]1111
Ui'vlESIN
89,28
IIII]]IIII]I]II;]III;I
EERAT
82,76
111]1]1111]1]]]1111111
LEBAR
80.8 ]
]1]1111111111111111111
TINGGI
1
75,28
1111111]111]11111111111
RASia
73,00
IIII111l]IIIIIIIIIIIII
panセang
QセYL
19
1:IIIIIIIIIIIIIIIIIII]1
HP
64,79
1111111!!11111111111]1
Vanabel prediktor yang memp"ngaruhi variabe! target
'.'ariabel yang sangat mempengaruh dari variabel target adalah torsi, dimana dalam
target sistem bahan bal,:3r, torsi sangatlah berpengaruh dalam menentukan tipe bahan
「。ャセ。イ yar.g layak digun2.kal1. dU!:lm sebuM! kel1.daraan.
Pada variabel sistem bahan bakar, variabel yang sangat mempengaruh dari
variabel target tersebut adalah torsi, dimuna dalam taiget sistem bahan bakar, torsi
sangatlah berpengaruh dalam menentukan tipe bahan bakar yang akan digunakan
dalam sebuah kendaraan. Dari jenis mesin SOHC cenclerung digunakan untuk
kendaraan-kendaraan yang bersilinder keell untuk mengirit pasokan bahan bakar yang
Penentuan node tersebut akan menghasilkan number of cases dari sistem
bahan bakar Sohc adalah 8, sedangkan presentage of datanya :lama engan 3.9% dan
castnya adalah 1.0000
/*Rules for terminal node 1*/
if
(
RASIO <= 22.85 &&
PANJANG <= 175.65&&
UMESIN <= 91.5 &8.-LEBAR <=04.1 &&
TINGGI <= 51.4
)
{
terminalNode = -I:
class= sohc: probClass J= 0: probCJass2= 0, dイッ「cャ。セウS = 0; probC!ass4= 0; probClass5= 0; proLClasSI)= 0; p,obClass7 = 0, probClass8 = 0; probCJass9= 0.375: probClass 10= 0; probCJass J J= 0; probClass12= 0; probClass13= 0.625; probClass14= 0;
}
Alur dari algoritma yang digunakan untuk mendapatkan informasi dari jenis mesin
SOHC yaitu:
Jika sebuah kendaraan memiJiki rasio kurang dari 22.85 em dan panjang kurang dari
175.65 em dan ukuran mesin kurang dari 91.5 em dan lebar kurang dari 64.1 em
dengan tinggi kurang dari 51.4 em maka jenis kendaraan tersebut eenderung beJjenis
SOIle.
Sebuah mobil dikatakan efisien apabila mempunyai tenaga mesin yang baik
dan mel71iJiki sistem pembakaran yang tidak boros. maka jenis sistem bahan bakar
SOHC akan lebih banyak didomiamsi oieh kendaraan keeil dengan yang memiliki ee
(kapasitas ュ・セゥョI dihawah ;500 saja. Maka akan dapat diketahui banyaknya
kendaraan yang menggunakan Eystem bahan bakar SOHC adalah kendaraan yang
memiliki ee (kdpasitas IT'.;;sia) keciJ atau digunakan untuk k;;ndaraan yang memiJiki
body ramping (sedang) dengan meJihat dari segi kapasita5nya. Banyaknya jenis
kenda,aaD yaDg mendominasi sistem bahan bakar SOHC adalah jenis minibus dan
sedan.
4.2.2. Model Laku (banyaknya yang terjual)
Dalam pengolahan data dari model Laku (banyaknya yang terjual), dapat kita
jadikan bahwa Laku (banyaknya kendaraan yang teJjual pada tahun 2004) menjadi
power), Kathasil (harga yang banyak diambil oleh konsumen), Sbbfsyst ( sistem
bahan bakar), Jkendaraan (Jerus kendaraan), dan merek mobil kendaraan.
Dalam proses pemilihan variable akan dicari informasi yang menyatakan
bahwa banyaknya kendaraan yang ada saat
ini
bukanya dipengaruhi oleh harga, tetapibanyaknya kendaraan yang digunakan oleh konsumen dilihat dari segi merek.
Dalam menggunakan program CART jenis tree yang akan digunakan dalam
menentukan model data tersebut adalah Regresi dimana nilai dari カ。iセ。「・ャ target
tersebut adalah bemilai numerik. Daiam pengolahan model laku, kami akan
menggunakan metode Gini .
Dalam menentukan model regresi, dapat dikelu)1Ui setiap variabel target dari
Laku memiliki nilai diantaranya mean dan median, tetapi yang akan kami tentukan
Dari tree di bawah ini akan didapatkan informasi bahwa : nセ、・ 14 MRWDBllf PJJg"16S.SO W=16.ooii 11= 16 thde 10 r-.P.fMDBll$ a[セB 144.370 '011=6400{) N=&4 fセBG[Gセャ kg·llEj"8% wBセINッッ{L N' 48
=-,J=---,__
L..., __,--'
._.1_,
TellTlInal iIIMni.1Jl IIlemo.'\3l
l1od\'13" Node14 ,1thj;;15 i
W,,-4illl(l It/=l1!lfj{l ;i\f:(=HOD'
,_....⦅セ __; :_' m_C'
イNZZhBセG UセMMQ⦅
, '.. '
.J_
H? Te'1Ti<'.at Tem.icl<!' i -1•.,,11".1Alg" BS-W: I"'de 4 !! Ilrm. 5 : _ Uode 6 I tbd,; 7 hadeS
wAセ[UQセG
!
wBZセセN⦅G イNw⦅ᄋG⦅QVセj ZwBャセ⦅ Aセセ⦅セ⦅ゥ w=lID)ivrヲQセbicj
ゥa\セ] 1l::.fJ!)D
,セセB 'lAJ)j)
:, \4<',fA
セG^、セR ,
1<8»,109:1.$
f'¥G=lOi.f';W
'61'lro.lM)
N·l00
\;:;;-
Nセ UW,,3He H
" k'Q'QQセWIT
£00 W=!-4itX>
Ii=54
iィMセT
iセ
1-;;;;;;;
QiNセヲQNQPbAT Hi
I"'
ktg: 1017Sg
イLアセュャ !ajセZ QSGjFァセ
11'1=3<).000 .... '161«
IW=44.ooo
tlon 1<=16 1l=44
GMセ
セUQ
I
IWd" 7 セMN[[[[MG._L
__ ...J__rI
HHP
I
He HI Twra T5mU,.1,m,
Atg=I%'.i'w
I
I
PorO=1l717S 1AtO "Qw⦅QTセ Uxi"セ iwZjセ 10I'"
'or"2flJ))
I
W: 1&.000 セATNd」サ[ "i'2.lA); iN'1301\1 , IN·H"2)
i
No 18 1<=14 - - -,
Mセ
jTim
: Um
GQZZセTD
GanJbar 4.3. Tree model .!...aku
Dari tree tersebut akan didapatkan terminal node sebanyak 14, akan dilihat infonnasi
apa saja yang akan diketahui di dalam node tersebut.
Dari tree tFrsebut, optimum tree terminal node sebanyak 14 buah, dan dapat
Hal tersebut dipengaruhi oleh variabel yang mempengaruhi target dibawah ini (Tabel
[image:59.595.57.479.164.658.2]4.2.) :
Tabel 4.2. Variabcllmporianec Lalm
-MRKMOBIL$
100,00
1111]11111]111111111]11111111
HP
74,74
IIIIIIIIIIIIIIIIIIIIIIIII]
SBBFSYST$
47,49
IIJIJIIIIlIIIII
KATHASIU
9,91
II!
JK.ENDA.
..R.A$
3,70
T!Oad Tabcl diatas variabel Importance yang sangat mempengamhi adalah merck mobil dan hp (house powel')
Dari tabel diatas, yang paling mempengaruhi variabe! target adalah merek
mobil, in; memperkuat dugaan di mastarakat bahwa orang indonesia cenderung
membeli kcndaraan bcrdasarkanウセ「オ。ィ :r.crck bu.'<:an dari scgi harga atau yang
Jai:1-lain.
/*Ru!es for terminal nude 14*/
if
( (
MRKMOI3IL$
=
audiII
MRKMOBIL$
==
peugot) )
{
terminalNode
=
-14; mean= 161Dalam penjualan kendaraan ternyata audi atau peugot, mempengaruhi rata-rata
per1iualan di tahun 2004.
Berdasarkan dua merek kendaraan tersebut yairu audi atau peugot, banyaknya
kendaraan yang diminati oleh konsumen rata-rata pada tahun 2004 adalah merek
kendaraan audi atau peugot, tetapi bukanlah rata-rata konsumen membeli merek
kendaraan tersebut. Akan dapat informasi yang berharga dari model laku, bahwa
kecendrungan konsumen untuk memilih kendaraan audi atau peugot yang rata-rata
mempcngaruhi pcnjualan di tahun 2004 sangatlah mcnguntungkan bagi produscn
kendaraan tersebut. tetapi bukanlah kendaraan terbanyak yang di gunakan oleh
konsumcn pada tahun 2004, hanya saja merek kendaraan tersebut yang
mcmpcngarulli pcnjualan rata rata pada tahun 2004.
4.2.3. Model Kathasil (Harga yang dipilih uleh konsuillcn)
Dalarn pengolahan model ketiga dari data tersebut, dapat kita jadikan Kathasil
Gumlah atau harga yang terjual) menjadi variabel target, karena dapat diketahui
banyaknya kendaraan yang teIjual dengan hcrga yang murah, sedang, mahal, dan
sangat mahal. Prediktornya yang mempengaruhi variabel target adalah Bbakar
(bahan bakar), rnrkmobil(merek mobil) sbbfsyst (sistem bahan bakar),
bpintu(banyaknya Pintu), JkcndaraanGensi kendaraan), Hp (house power) kendaraan
tipe tree Klasifikasi. Dalam pengolahan Model Kathasil (Harga yang dipilih oleh
konsumen) kita mengunakan metode Gini.
DaJam menentukan kelas untuk data yang ban;, Kathasil dan penjualan
kendaraan mempunyai prediksi bennacam macam dari murah, sedang, mahal, dan
sangat mahal. Dari tree di bawah ini akan didapatkan informasi bahwa :
- I " " "H'¥M06U
,;Y·20HW
lセGセ
i riooe2 .,----.--'=:=
QLセBアkmPヲヲゥND
i
GwセQWHh^oo
N· IlD
;.p'%d():
I
w.17.lJiXji
11_17
MゥセMGMtセ
!o::oe3 エセT
-" ..セセNイIIj ゥwセ|SiIyj
[image:61.595.76.477.207.542.2]Uii!IIIIIIllIJ!",.'1iW .'
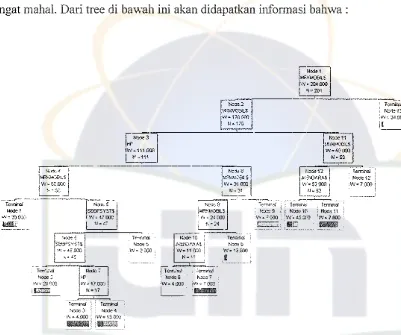
Gambar 4.4. Tree model Kathasil
GtセMZ
Ncde12 i
[キセ UffJ
!
Tcm.nrn N:;>je13
W·34.ooo
II
Pada gambar tree diatas dapat dilihat bahwa node ke-13 memiliki model yang
menyatakan model penjualan kendaraan untuk menengah ke atas.
Da!am menentukan optimum tree, dapat terbentuk jumlah terminal node
ciri yang berbeda-beda. Tem1inal node 13 dapat menyatakan bahwa node tersebut
dapat diklasifikasikan sebagai variabel sangat mahal.
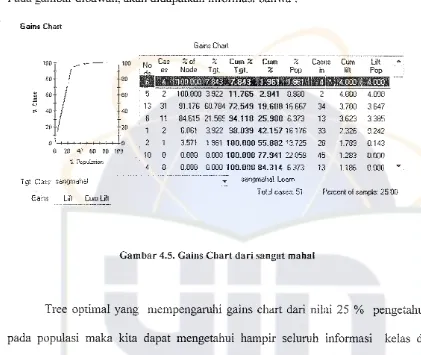
Pada gambar dibawah, a1:an didapatkan informasi bahwa :
Gains Chart
Gains C!'latt
No Cas_0 %of % Cum%" Cum % Cases Cum Lift
'"
Node Tgt Tgt % Pop In iセ PopaEM..
i.nI.JI• •,:tP-.UijU'iiWfii
1.1.1• •1.1.1115 2 100.000 3.922 11.765 2.941 09S0 2 4.000 4.oaO
13 31 91176 6078472.549 19.60B 16667 34 3700 3.647
8 11 84.615 21.56,94.118 25.980 6373 13 3623 3.385
1 2 6861 3922 38.039 42.15716176 33 2.326 0.242
2 1 3.571 1961 100.000 55.B82 '3.725 28 1.789 0143
10 0 0000 0000 100.000 77.941 22059 45 1.283 0000
4 0 0.000 0.000100.00084.314 6373 13 1.186 0.000
Tgt.(:3$$:sangmahal
Gai:>$ Lift CumLift
sengmahal: Learn
[image:62.595.57.478.161.516.2]TッャセQ cases:51
Gambar 4.5. Gains Chart dari sangat mahal
Percent of sample: 25,00
Tree optimal yang mempengaruhi gains chart dari nilai 25 % pengetahmn
pada populasi maka kita dapat mengetahui harnpir seluruh informasi kelas dari
variabel target tersebut. Dari Gambar 4.5. dinyatakan bahwa dengan setiap note yang
akan mendekati nilai 100 akan diartikan sebagai jumlah dari peminat penjualan
kendaraan yang sangat mahal tersebut sangat tinggi, lain pula apabila note itu
semakin mendekati garis horizontal maka makna yang akan didapatkan adalahjumlah
dari peminat penjualan kendaraan yang sangat mahal yang diminati oleh konsumen
biasa saja atau tidak sarna sekali mengalami perubahan dalam penjualan dari merek
Hal tersebut dipengaruhi oleh variabel yang mempengaruhi target dibawah ini
(TabeI4.3.) :
Tabcl 4.3. Varia bel ImportanceKathasi!
MRKMOBIL$
100,00
1111111111111111111
SBBFSYST$
50,22
111111111111111111
HP
42,68
IIIIIIIIIIIIIII
JKENDARA$
35,54
IIIIIIllIll
BBAKAR$
1,39
BPINTU$
0,00
Daftar variabel yang mempengaruhi variabel target
V8riabel yang sfulgat bcrpengaruh adalah merck mobil, dimana pada target kathasil
dapat diketahui bahwa merck menenentuan harga dari mobil, karena pada suatu
pembelian kendaraan, biasanya seorang konsumen cendrung membeli kendaraan
bcrdasarkan lIlcrck.
Pada Kathasil (harga penjualan) kendaraan roda empat biasanya produsen
menentukan harga yang akan di beli oleh konsumen. Sebuah kendaraan dilihat dari
sistem bahan bakamya dan Hp (house power) karena dari dna variabel tersebntlah
sebuah kendaraan dapat dijual dengan beberapa tipe harga.
/*Rules for terminal node 13
*/
if (
(
MRKMOBIL$
=
jaguarII
MRKMOBIL$ == land rover
Ii
MRKMOBIL$
=
mercedes-benzII
MRKMOBIL$= volkswagon
)
)
{
terminalNode= -13:
class = sangmahal; probClassl = 0.0882353; probClass2= 0;
probClass3 = 0.91 1765;
probClass4= 0; }
Dari model ini sm;gat veriabel karena tidak berIawanan dengan kenyataan
bahwa, rnei·ek kendaraan BMW, JAGUAR, LAND ROVER, MERCEDEZ BANZ,
"tau YOLKSW.,\GON adalah merek bn:iaraan dengan harga yang sangat mahal dan
jcn" kenduraan terscbut banyak diminati oleh kalangan atas.
Alur clari mls yang digunakan untuk mendapatkan informasi
dan
data penjualan kendaraan yaitu :Bahwa biasanya scbuab mobil yang dijual kcp"saran dcngan katcgori
penjualan yang sangat mahal akan ditentukan oleh merek kendaraan seperti BMW,
JAGUAR, LAND ROVER., MERCEDEZ BANZ, atau YOLKSWAGON. Maka akan
diketabui banyaknya kendaraan yang dijua! kepasaran dengan harga yang sangat
mahal dengan menggunakan system bahan bakar yang lebih bagus dan memiliki HP
4.2.4. Model Jkendaraan (j"nis kendaraan)
Dalam pengolahan model jkendaraan (jenis kendaraan) dapat diketahui
bahwa jenis kendaraan banyak mempengaruhi pendualan dari data tersebut, dapat kita
jadikanjkendaraan (jenis kendaraan) sebagai variabel target dan predik'tomya yang
mempengaruhi variabel target adalah Madein (buatan dari negara), Mrkmobil (merek
mobil), Bbakar (bahan bakar), Eksmesin (menggunakan ke:cepatan standar atau
turbo), Bpintu (banydcnya pintu), Ktit (kritcria mcsin), Kokl'1esin (lokasi mcsin),
Jmesin Genis mesin). Cylinder ( ba;1yaknya cylinder) sbbftyst (sistem bahan bakar),
Katha5il (Penjaalan), Umesin (ukuran mesin), Torsi (jarak antara mesin dengan
rada) Panjang(p::'Dang mobil),Lebar (khar mobil), Tinggi(tinggi kendaraan), Berat
(berat kepdaraa;1), Rasia (pcrbandingan bhdaraan), Hp (house power), Penjualan
kendaraan tersebut.
Dalam jenis tree yang aka.'1 digunakan dalarn mcnggunakan data tersebut
adalah trce rjpe KlasifIkasi, Daiam pengolahan Jkendaraan (ienis kendaraan) akan
Pada gambar dibawah, akan didapatkan informasi bahwa
Nooe 1
s{jdヲsyDセD
W·2l)4.(J."(,
IhX>l
GambaI' 4.6. Tree model jen's kendaraan
Dalam Tree, dapat terbentuk jumlah term;l.a; node sebanyak ; 4 buah, Pada Gambar
4.6. ciapat dinyatakan bahwa setiap kelas memiliki ciri yang berbeda-beda. Suatu
me1'ek l:endara£i.f1 dapat diketahui Lefbed::t jikaォ・ョ、N。イセBQ tersebut、ゥ「オ。セ 、・ョァセョ jenis
)'ang berbe<1a. Pada tenninal node 5 menyatakan bahwa node tersebut
Pada gambar dibawah, akan didapatkan informasi bahwa :
Gains Chart
Gains Chart
100
/" 100
".
No Care,
Node%01 Tgt% Cum%: Cum"Tgt. Pop Pop% Cases'"
Cumlift PopLift80 I 80 ャiBョェャャュAャゥゥGセᄋゥセエNicZAャェャNimZ`ゥ
iWMmmt
I
セ 60
I
60 5 2 66667 6.452 12.903 2.451 1.471 3 5.265 4.387u 40
I
6 2 66.667 6.452 19.355 3.922 1.471 3 4.935 4.387
,.
402 15 62.500 413.387 67.742 15.686 11,765 24 4.319 4.113
20, 20 8 3 30000 9677 77.419 20.5R8 4.902 10 3.760 1.974
+
0' 0 14 3 23077 9.677 87.097 26.961 6.373 13 323D 15'19
0 2D 40
"
SO 1003 4 8000 12.903 100.000 51.471 24.510 50 1.943 0.526
1.Population
4 D 0000 0000 100.00086.765 35.294 72 1.153 OJ)OO
.
⦅NセMMセMセN⦅セMM -⦅NセM NMセMMMGM
suv; Learn Tgl Oa$"s:: suv
Total cases; 31 Pelcent ofsample:1520
[image:67.595.57.480.114.517.2]Gains Lift CUfnLift
Gambar 4.7. Gains chart dad Sport Utility Vehicle (SUV)
Dalam glan chart Gambar 4,7. dapat dilihat bahwa jenis kendaraan Sport Utility
Vehicle (SUV) adalah tipe kendaraan yang cukup banyak di ambil oleh konsumen,
karena 20 % dari jumlah populasi d3patュセキ。ォゥャゥ 90 % jumlah dan kelasnya.
Dapat dilihat bahwa setiap peminat kendaraan Sport Utility Vehicle (SUV)
tersebut cukup banyak peminatnya. Jenis kendaraan SUV tersebut banyak digunakan
oleh