METODE PEMULUSAN (SMOOTHING) EKSPONENSIAL GANDA
(LINIER SATU PARAMETER DARI BROWN) DAN METODE
BOX-JENKINS DALAM MERAMALKAN CURAH HUJAN
DI KOTA MEDAN
SKRIPSI
AFRIDA NINGSIH
110803001
METODE PEMULUSAN (SMOOTHING) EKSPONENSIAL GANDA
(LINIER SATU PARAMETER DARI BROWN) DAN METODE
BOX-JENKINS DALAM MERAMALKAN CURAH HUJAN
DI KOTA MEDAN
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat untuk mencapai gelar Sarjana Sains
AFRIDA NINGSIH
110803001
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
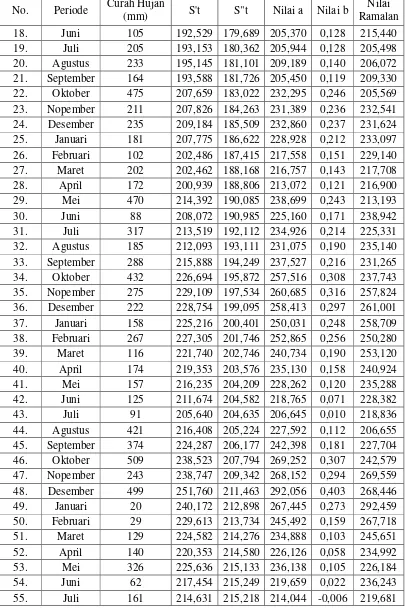
PERSETUJUAN
Judul : Metode Pemulusan (Smoothing) Eksponensial
Ganda (Linier Satu Parameter dari Brown) dan Metode Box-Jenkins dalam Meramalkan Curah Hujan di Kota Medan
Kategori : Skripsi
Nama : Afrida Ningsih
Nomor Induk Mahasiswa : 110803001
Program Studi : Sarjana (S1) Matematika
Departemen : Matematika
Fakultas : Matematika Dan Ilmu Pengetahuan Alam
(FMIPA) Universitas Sumatera Utara
Diluluskan Medan, Mei 2015
Komisi Pembimbing:
Pembimbing 2, Pembimbing 1,
Dr. Faigiziduhu Bu’ulolo, M.Si Dr. Suwarno Ariswoyo, M.Si NIP. 19531218 198003 1 003 NIP. 19500321 198003 1 001
Disetujui oleh
PERNYATAAN
METODE PEMULUSAN (SMOOTHING) EKSPONENSIAL GANDA (LINIER SATU PARAMETER DARI BROWN) DAN METODE
BOX-JENKINS DALAM MERAMALKAN CURAH HUJAN DI KOTA MEDAN
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri. Kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Mei 2015
PENGHARGAAN
Puji dan syukur penulis panjatkan kepada Allah SWT Yang Maha Pemurah dan
Maha Penyayang, dengan limpahan karuniaNya penulis dapat menyelesaikan
penyusunan skripsi ini dengan judul Metode Pemulusan (Smoothing) Eksponensial Ganda (Linier Satu Parameter dari Brown) dan Metode Box-Jenkins
dalam Meramalkan Curah Hujan di Kota Medan
Terima kasih penulis sampaikan kepada Bapak Dr. Suwarno Ariswoyo,
M.Si selaku dosen pembimbing 1 dan Bapak Dr. Faigiziduhu Bu’ulolo, M.Si
selaku dosen pembimbing 2 yang telah meluangkan waktunya selama penulisan
skripsi ini. Terima kasih kepada dosen pembanding penulis Ibu Asima Manurung,
S.Si, M.Si dan Ibu Dr. Elly Rosmaini, M.Si atas kritik dan saran yang
membangun dalam penulisan skripsi penulis. Terima kasih kepada Bapak Prof.
Dr. Tulus, M.Si dan Ibu Dr. Mardiningsih, M.Si selaku Ketua dan Sekretaris
Departemen Matematika FMIPA USU. Terima kasih kepada Bapak Dr. Sutarman,
M.Sc selaku Dekan FMIPA USU, Wakil Dekan FMIPA USU, seluruh Staff dan
Dosen Matematika FMIPA USU, pegawai FMIPA USU serta rekan-rekan kuliah.
Akhirnya tidak terlupakan kepada Ayahanda tercinta H. Syafnal, Ibunda tercinta
Hj. Wirda, serta saudara–saudara penulis yang tersayang Wisnalda, Yenni Afriani,
Yulianisyah, Desmianti, dan Asman serta keluarga dari kedua orang tua yang
selama ini memberikan bantuan dan dorongan yang diperlukan. Semoga Allah
METODE PEMULUSAN (SMOOTHING) EKSPONENSIAL GANDA (LINIER SATU PARAMETER DARI BROWN) DAN METODE
BOX-JENKINS DALAM MERAMALKAN CURAH HUJAN
DI KOTA MEDAN
ABSTRAK
Pada penelitian ini metode yang digunakan dalam meramalkan atau memprediksi curah hujan adalah metode pemulusan (smoothing) eksponensial ganda (linier satu parameter dari Brown) dan metode Box-Jenkins ARIMA. Pada metode pemulusan (smoothing) eksponensial ganda terlebih dahulu mencari nilai pemulusan eksponensial tunggal kemudian membuat pemulusan eksponensial ganda dari nilai yang telah didapat dari pemulusan eksponensial tunggal, selanjutnya mencari nilai a atau penyesuaian nilai tunggal dan menentukan taksiran kecendrungan dari suatu periode waktu ke periode waktu berikutnya yaitu nilai b dan terakhir adalah melakukan peramalan untuk periode berikutnya. Sementara, metode box-jenkins ARIMA terlebih dahulu melakukan differencing. Tujuannya adalah untuk mendapatkan data stasioner dan langkah selanjutnya adalah mengidentifikasi model, estimasi parameter model, melakukan verifikasi parameter model, menentukan model yang lebih baik dengan melihat nilai error terkecil dari model-model yang dipilih sebelumnya dan terakhirya itu melakukan peramalan untuk periode waktu berikutnya. Berdasarkan hasil dari kedua metode peramalan diperoleh nilai SSE dan MSE Brown secara berurut yaitu 977.828.884 dan 16.859,119. Sementara, nilai SSE dan MSE ARIMA secara berurut adalah 665.432 dan 15,475. Sehingga metode yang dipilih dalam penilitian ini adalah metode box-jenkins ARIMA karena nilai error dari metode box-jenkins ARIMA lebih kecil dari pada metode Brown.
DOUBLE EKSPONENTIAL SMOOTHING METHOD (LINIER ONE PARAMETER OF BROWN) AND BOX-JENKINS METHOD IN
PREDICTING RAINFALL IN MEDAN CITY
ABSTRACT
In this research, method that is used in predicting rain pour are double exponential smoothing method (linier one parameter from brown) and Box-Jenkins ARIMA method. In double exponential smoothing is firstly finding a single exponential smoothing of the value that is got from single exponential smoothing, then, finding a value or adaptation of a single value and determining tendency estimation of a period of time to another that is b value and at last is doing prediction for next period. Meanwhile, box-jenkins ARIMA method is firstly doing differencing. It is for getting stationary data and next step is identifying model, estimating parameter of the model, doing verification parameter of the model, determining better model by looking at least error value of previous chosen model and finally making prediction for next period of time. Based on result of both prediction methods is got SSE and MSE brown value consecutively is 977.828.884 and 16.859,119. While SSE and MSE box-jenkins value consecutively is 665.432 and 15,475. So chosen method in this research is box-jenkins ARIMA method because of less error value than brown method.
DAFTAR ISI
1.4Tinjauan Pustaka 3
1.5Tujuan Penelitian 6
1.6Kontribusi Penelitian 6
1.7Metodologi Penelitian 6
BAB 2 LANDASAN TEORI 10
2.1 Peramalan 10
2.2 Curah Hujan 11
2.3 Metode Deret Berkala 11
2.4 Metode Pemulusan (Smoothing) 12
2.4.1 Pemulusan (Smoothing) Eksponensial Tunggal 12 2.4.2 Pemulusan (Smoothing) Eksponensial Ganda
(Linier Satu Parameter dari Brown) 13
2.4.3 Ketetapan Ramalan Beberapa Kriteria Digunakan
Untuk Menguji 13
2.5 Identifikasi Pola Data 14
2.6 Metodologi Untuk Menganalisis Data Deret Berkala 15
2.7 Metode ARIMA (Autoregressive Integrated Moving Average) 18
2.7.1 Model Autoregressive (AR) 19
2.7.1 Model Moving Average (MA) 20
2.7.3 Model Campuran Autoregressive Moving Average (ARMA) 20 2.7.4 Model Autoregressive Integreted Moving Average (ARIMA) 21
2.8 Model Arima dan Musiman 21
2.9 Estimasi Parameter Model 22
2.10 Verifikasi Parameter Model 22
BAB3 HASIL DAN PEMBAHASAN 25
(Linier Satu Parameter dari Brown) 25 3.1.1 Plot Time Series Curah Hujan Kota Medan 25 3.1.2 Analisa Pemulusan (Smoothing) Eksponensial
Ganda (Linier Satu Parameter dari Brown) 26
3.1.3 Nilai Kesalahan (Galat) 29
3.2Autoregressive Integreted Moving Average (ARIMA) 32 3.2.1 Plot Time Series Curah Hujan Kota Medan 32
3.2.2 Identifikasi Model 35
3.2.3 Estimasi Parameter Model 39
3.2.4 Verifikasi Parameter Model 40
3.2.5 Penentuan Model Yang Lebih Baik 43
3.2.6 Peramalan 43
3.3 Melakukan Perbandingan Hasil Analisis Ramalan 44 3.3.1 Metode Pemulusan (Smoothing) Eksponensial
Ganda (Linier Satu Parameter dari Brown) 44 3.3.2 Metode ARIMA (Autoregressive Integreted
Moving Average) 44 3.4Menetapkan Metode yang Lebih Efektif Berdasarkan
Hasil Peramalan Curah Hujan di Kota Medan 44
BAB 4 KESIMPULAN DAN SARAN 46
4.1 Kesimpulan 46
4.2 Saran 46
DAFTAR PUSTAKA 47
DAFTAR TABEL
Nomor Judul Halaman
Tabel
3.1 Data Curah Hujan Kota Medan 25
3.2 Peramalan Curah Hujan 27
3.3 Nilai Kesalahan 30
3.4 Hasil Nilai Kesalahan 31
3.5 Diffencing Data Curah Hujan Kota Medan 33
3.6 Nilai Keofisien Autokorelasi 35
3.7 Final Estimates of parameters ARIMA (2,1,0)(1,1,0) 40
3.8 Final Estimates of parameters ARIMA (2,1,0)(2,1,0) 40
3.9 Uji Signifikansi Nilai-Nilai Parameter Model ARIMA 42
3.10 Peramalan Curah Hujan Kota Medan 2015 43
3.11 Hasil Nilai Kesalahan dari Brown 44
3.12 Hasil Nilai Kesalahan dari ARIMA 44
DAFTAR GAMBAR
Nomor Judul Halaman
Gambar
3.1 Plot Data Curah Hujan 25
3.2 Plot Ramalan Data Curah Hujan 2015 29
3.3 Plot Data Time Series Curah Hujan 32
3.4 Plot Trend Curah Hujan 33
3.5 Plot Trend Curah Hujan Setelah Pembedaan Pertama 34
3.6 Plot Autokorelasi 38
DAFTAR LAMPIRAN
Nomor Judul Halaman
Lamp
1 Nilai Autokorelasi 49
2 Nilai Autokorelasi Parsial 51
3 Tabel Distribusi t 53
METODE PEMULUSAN (SMOOTHING) EKSPONENSIAL GANDA (LINIER SATU PARAMETER DARI BROWN) DAN METODE
BOX-JENKINS DALAM MERAMALKAN CURAH HUJAN
DI KOTA MEDAN
ABSTRAK
Pada penelitian ini metode yang digunakan dalam meramalkan atau memprediksi curah hujan adalah metode pemulusan (smoothing) eksponensial ganda (linier satu parameter dari Brown) dan metode Box-Jenkins ARIMA. Pada metode pemulusan (smoothing) eksponensial ganda terlebih dahulu mencari nilai pemulusan eksponensial tunggal kemudian membuat pemulusan eksponensial ganda dari nilai yang telah didapat dari pemulusan eksponensial tunggal, selanjutnya mencari nilai a atau penyesuaian nilai tunggal dan menentukan taksiran kecendrungan dari suatu periode waktu ke periode waktu berikutnya yaitu nilai b dan terakhir adalah melakukan peramalan untuk periode berikutnya. Sementara, metode box-jenkins ARIMA terlebih dahulu melakukan differencing. Tujuannya adalah untuk mendapatkan data stasioner dan langkah selanjutnya adalah mengidentifikasi model, estimasi parameter model, melakukan verifikasi parameter model, menentukan model yang lebih baik dengan melihat nilai error terkecil dari model-model yang dipilih sebelumnya dan terakhirya itu melakukan peramalan untuk periode waktu berikutnya. Berdasarkan hasil dari kedua metode peramalan diperoleh nilai SSE dan MSE Brown secara berurut yaitu 977.828.884 dan 16.859,119. Sementara, nilai SSE dan MSE ARIMA secara berurut adalah 665.432 dan 15,475. Sehingga metode yang dipilih dalam penilitian ini adalah metode box-jenkins ARIMA karena nilai error dari metode box-jenkins ARIMA lebih kecil dari pada metode Brown.
DOUBLE EKSPONENTIAL SMOOTHING METHOD (LINIER ONE PARAMETER OF BROWN) AND BOX-JENKINS METHOD IN
PREDICTING RAINFALL IN MEDAN CITY
ABSTRACT
In this research, method that is used in predicting rain pour are double exponential smoothing method (linier one parameter from brown) and Box-Jenkins ARIMA method. In double exponential smoothing is firstly finding a single exponential smoothing of the value that is got from single exponential smoothing, then, finding a value or adaptation of a single value and determining tendency estimation of a period of time to another that is b value and at last is doing prediction for next period. Meanwhile, box-jenkins ARIMA method is firstly doing differencing. It is for getting stationary data and next step is identifying model, estimating parameter of the model, doing verification parameter of the model, determining better model by looking at least error value of previous chosen model and finally making prediction for next period of time. Based on result of both prediction methods is got SSE and MSE brown value consecutively is 977.828.884 and 16.859,119. While SSE and MSE box-jenkins value consecutively is 665.432 and 15,475. So chosen method in this research is box-jenkins ARIMA method because of less error value than brown method.
BAB 1
PENDAHULUAN
1.1Latar Belakang
Di Indonesia sejak tahun enam puluhan telah diterapkan Badan Meteorologi,
Klimatologi, dan Geofisika di Jakarta menjadi suatu direktorat perhubungan
udara. Direktorat BMKG tersebut bertugas mengadakan penelitian dan pelayanan
meteorologi dan geofisika yang salah satu bidangnya adalah iklim. Indonesia
merupakan negara dengan iklim tropis dan memiliki dua musim, musim kemarau
dan musim penghujan. Iklim merupakan kebiasaan alam yang digerakkan oleh
gabungan beberapa unsur yaitu radiasi matahari, temperatur, kelembapan, curah
hujan, tekanan udara dan kecepatan angin.
Curah hujan adalah banyaknya air yang jatuh ke permukaan bumi. Curah
hujan yang terus menerus selama beberapa hari mengakibatkan bencana alam
yang berdampak terhadap manusia, ternak dan tumbuh-tumbuhan, seperti banjir,
badai, kekeringan, dan lain sebagainya. Perkiraan curah hujan sangat besar
dampaknya dan penting untuk diperhatikan dan dipelajari sebaik-baiknya, karena
berpengaruh besar terhadap manusia serta makhluk lainnya.
Peramalan merupakan upaya memperkirakan apa yang terjadi pada masa
mendatang berdasarkan data pada masa lalu. Banyak metode dalam statistika yang
dapat digunakan untuk peramalan suatu deret waktu, seperti metode smoothing,
Box-Jenkins, ekonometrika, regresi fungsi transfer dan sebagainya. Metode-metode tersebut diharapkan dapat mengidentifikasi model yang digunakan untuk
meramalkan kondisi pada waktu yang akan datang sehingga error-nya menjadi seminimal mungkin.
model, dan bila nilai observasi baru tersedia maka dapat menghitung nilai
kesalahan (forcasting error).
Autoregressive Integrated Moving Average (ARIMA) merupakan metode yang secara intensif dikembangkan oleh George Box dan Gwilym Jenkins. ARIMA adalah teknik untuk mencari pola yang paling cocok dari sekelompok
data. Metode ini merupakan gabungan dari metode regresi dan metode
dekomposisi.
Dari uraian di atas, penulis ingin menguraikan penelitian terhadap data
curah hujan pada masa lalu, untuk meramalkan curah hujan pada masa yang akan
datang. Untuk itu penulis mengambil judul “Metode Pemulusan (Smoothing) Eksponensial Ganda (Linier Satu Parameter dari Brown) dan Metode
Box-Jenkins Dalam Meramalkan Curah Hujan di Kota Medan.”
1.2Perumusan Masalah
Yang menjadi perumusan masalah adalah curah hujan yang tinggi di Kota Medan
seringkali mengganggu kegiatan masyarakat Kota Medan. Oleh karena itu,
diperlukan hasil ramalan curah hujan untuk periode mendatang dan memilih salah
satu metode peramalan yang lebih baik dengan menggunakan metode pemulusan
(smoothing) eksponensial ganda (linier satu parameter dari Brown) dan metode
Box-Jenkins berdasarkan hasil nilai error peramalan curah hujan di periode mendatang.
1.3Batasan Masalah
Batasan masalah dalam penelitian ini adalah:
1. Pembuatan model peramalan curah hujan di Kota Medan dengan menggunakan
metode pemulusan (smoothing) eksponensial ganda (linier satu parameter dari
2. Data yang diambil adalah dari BMKG (Badan Meteorologi, Klimatologi dan
Geofisika).
3. Data yang diolah adalah data curah hujan tahun 2010-2014 di Kota Medan.
4. Hasil ramalan dalam penelitian ini diarahkan untuk satu tahun mendatang.
1.4Tinjauan Pustaka
Lerbin R. Aritonang R dalam bukunya “Peramalan Bisnis” (2002) menyatakan
eksponensial ganda linier satu parameter Brown adalah teknik yang digunakan untuk data runtut waktu yang memiliki komponen trend yang linier, jika
parameternya (∝) tidak mendekati nol, pengaruh proses awalnya secara cepat
menjadi kurang berarti begitu waktu berlalu. Jika parameternya mendekati nol,
proses awalnya dapat berperan penting untuk beberapa periode.
Sedangkan Metode ARIMA Box-Jenkins mengemukakan bahwa data yang dianalisa dalam model ARIMA Box-Jenkins adalah data yang bersifat stasioner, yaitu data yang mempunyai rata-rata dan variansi yang konstan dari periode ke
periode.
Spyros Makridakis dalam bukunya berjudul “Metode Dan Aplikasi
Peramalan” (1992) menyatakan bahwa metode pemulusan (smoothing) eksponensial dijelaskan sekelompok metode yang menunjukkan pembobotan
menurun secara eksponensial terhadap nilai observasi yang lebih tua.
ARIMA Box-Jenkins mengemukakan bahwa hal yang penting dalam analisa deret berkala adalah koefisien autokorelasi yang menunjukkan hubungan
antara suatu data deret berkala dengan deret berkala itu sendiri pada suatu
keterlambatan waktu (time lag) k periode. Autokorelasi untuk time lag dapat dicari dengan notasi sebagai berikut:
=meandari data aktual
= dataaktualpadaperiodet dengan lag k
Model Box-Jenkins (ARIMA) dibagi ke dalam tiga kelompok yaitu model
Autoregressive (AR), Moving Average (MA), dan model campuran
Autoregressive Moving Average (ARIMA) yang mempunyai karakteristik dari dua model pertama.
1. Model Autoregressive (AR)
Bentuk umum model Autoregressive dengan ordo p (AR (p)) atau model ARIMA (p,0,0) dinyatakan sebagai berikut:
= ′+ + + ⋯ + +
di mana:
′ = suatu konstanta
= nilaipengamatanperiode ke-p
= parameter Autoregressiveke-p = nilaikesalahanpadasaat t
, = parameter-parameter moving average
= nilai kesalahan pada saat t-q
3. Model Campuran
a. Proses ARMA
Model umum untuk campuran proses AR (p) murni dan MA (q) murni, misalnya ARMA (p,q) dinyatakan sebagai berikut:
= ′+ + + ⋯ + − − − ⋯ − +
b. Proses ARIMA
Apabila non stasioneritas ditambah pada campuran proses ARMA, maka
= ′+ + + ⋯ + + − − − ⋯ −
Hal yang perlu diperhatikan adalah bahwa kebanyakan deret berkala
bersifat nonstasioner dan bahwa aspek-aspek AR dan MA dari model ARIMA
hanya berkenaan dengan deret berkala yang stasioner. Stasioneritas berarti tidak
terdapat pertumbuhan atau penurunan pada data.Data secara kasarnya harus
horizontal sepanjang sumbu waktu. Suatu deret waktu yang tidak stasioner harus
diubah menjadi data stasioner dengan melakukan differencing. Yang dimaksud dengan differencing adalah menghitung perubahan atau selisih nilai observasi. Nilai selisih yang diperoleh dicek lagi apakah stasioner atau tidak. Jika belum
stasioner maka dilakukan differencing lagi. Jika varians tidak stasioner, maka dilakukan transformasi logaritma.
Sedangkan dengan metode peramalan pemulusan (smoothing) eksponensial ganda (linier satu parameter dari Brown) persamaan yang digunakan sebagai berikut:
′ = ∝ + (1−∝) ′
" = ∝ ′ + (1−∝) ′
di mana:
′ = nilai pemulusan eksponensial tunggal
" = nilai pemulusan eksponensial ganda
∝ = parameter pemulusan eksponensial yang besarnya 0 < α < 1
1.5Tujuan Penelitian
Adapun tujuan dari penelitian ini adalah meramalkan curah hujan di Kota Medan
untuk tahun 2015 dengan metode peramalan pemulusan (smoothing) eksponensial ganda (linier satu parameter dari Brown) dan metode Box-Jenkins serta pemilihan metode peramalan berdasarkan nilai errror hasil peramalan.
1.6Kontribusi Penelitian
Kontribusi dari penelitian ini adalah sebagai berikut:
1. Dapat menjadi suatu bahan masukan atau sebagai pertimbangan yang berguna
bagi BMKG dalam mengambil suatu kebijaksanaan.
2. Membantu penulis dalam menerapkan ilmu dan pengetahuan yang didapat
selama masa perkuliahan kedalam dunia nyata.
3. Dapat digunakan sebagai tambahan informasi dan referensi bacaan untuk
mahasiswa matematika, terlebih bagi mahasiswa yang akan melakukan
penelitian dalam peramalan.
1.7Metodologi Penelitian
Dalam penelitian ini tahapan-tahapan yang dilakukan sebagai berikut:
1. Mengumpulkan data curah hujan dari BMKG.
2. Penelusuran referensi ini bersumber dari buku, jurnal maupun penelitian yang
telah ada sebelumnya mengenai hal-hal yang berhubungan dengan metode
3. Menganalisis data menggunakan metode pemulusan (smoothing) eksponensial ganda
Mulai
Membuat Pemulusan (Smoothing) Ekponensial
Tunggal
Membuat Pemulusan (Smoothing) Eksponensial Ganda
Penyesuaian Nilai Tunggal (Nilai a)
Menentukan Taksiran Kecenderungan dari Periode
Waktu ke Periode Waktu Berikutnya (Nilai b)
Melakukan Peramalan
Selesa Pengumpulan
4. Menganalisa data menggunakan metode Box-Jenkins
Selesa Mulai
• Membuat Time Series Plot
• Membuat Plot ACF dan PACF
Data Sudah
Melakukan
Differencing
Identifikasi Model
Estimasi Parameter Model
Verifikasi Parameter Model
Penentuan Model
Melakukan Peramalan Pengumpulan
Data
Tidak
4. Melakukan perbandingan hasil analisis ramalan dengan menggunakan metode
pemulusan (smoothing) eksponensial ganda (linier satu parameter dari Brown) dan metode Box-jenkins berdasarkan hasil nilai error peramalan curah hujan. 5. Menetapkan metode yang lebih efektif berdasarkan hasil peramalan curah
hujan di Kota Medan.
BAB 2
LANDASAN TEORI
2.1 Peramalan
Peramalan digunakanan sebagai acuan pencegah yang mendasari suatu keputusan
untuk yang akan datang dalam upaya meminimalis kendala atau memaksimalkan
pengembangan baik dalam dunia usaha, peramalan cuaca dan sebagainya. Dalam
keefektifannya haruslah suatu peramalan tersebut adalah hasil dari proses
perhitungan yang sistematis. Dalam statistika, peramalan sangat bergantung pada
data histori.
Secara ilmiah metode peramalan dapat diklasifikasikan dalam dua
kelompok yaitu metode kualitatif dan metode kuantitatif. Metode peramalan
kualitatif lebih mengandalkan intuisi manusia dari pada penggunaan data historis
yang dimiliki. Metode ini banyak digunakan dalam banyak pengambilan
keputusan sehari-hari. Dalam hal ini ramalan dikatakan baik atau tidak bergantung
dari banyak hal antara lain pengalaman, perkiraan, dan pengetahuan yang didapat.
Metode peramalan kuantitatif merupakan peramalan yang didasarkan pada
data-data variabel yang bersangkutan di masa sebelumnya. Metode ini
menggunakan analisis statistik dan tanpa intuisi atau penilaian subyektif orang
yang melakukan peramalan. Menurut Makridakis dkk. (1992), peramalan dengan
menggunakan metode kuantitatif dapat diterapkan apabila terdapat tiga kondisi
berikut:
1. Tersedia informasi tentang masa lalu,
2. Informasi tersebut dapat dikuantitatifkan dalam bentuk data numerik,
3. Dapat diasumsikan bahwa beberapa aspek pola masa lalu akan terus
2.2 Curah Hujan
Curah hujan adalah banyaknya air yang jatuh ke permukaan bumi. Satuan yang
digunakan adalah millimeter per jam (mm/jam). Dalam meteorologi butiran hujan
dengan diameter lebih dari 0,5 mm disebut hujan dan diameter antara 0,1-0,5 mm
disebut gerimis. Semakin besar butiran hujan maka akan semakin besar pula
kecepatan jatuhnya. Ketelitian alat ukur curah hujan adalah 1/10 mm. Pembacaan
dilakukan satu kali dalam sehari dan dicatat sebagai curah hujan hari terdahulu
(Suyono,1985).
Curah hujan di suatu daerah tidak sama dengan curah hujan di daerah lain.
Ada suatu daerah yang pada akhir tahun hujannya mulai meningkat tinggi dan
mencapai puncaknya dan pertengahan tahun mencapai titik terendahnya.
Sebaliknya, di daerah lain pada akhir tahun hujannya mencapai titik terendah,
sedangkan pada pertengahan tahun mencapai titik tertinggi (Suyono,1985).
Rata-rata curah hujan di Indonesia untuk setiap tahunnya tidak sama.
Namun masih tergolong cukup banyak, yaitu rata-rata 2000-3000 mm/tahun.
Curah hujan menurut BMKG dibagi menjadi empat kelompok, yaitu:
1. Curah hujan rendah: 0-20 mm, 21-50 mm, 51-100 mm.
2. Curah hujan menengah: 101-150 mm, 151-200 mm, 201-300 mm.
3. Curah hujan tinggi: 301-400 mm.
4. Curah hujan sangat tinggi: 401-500 mm, >500 mm.
2.3 Metode Deret Berkala
Data berkala (Time Series) adalah data yang dikumpulkan dari waktu ke waktu untuk memberikan gambaran tentang perkembangan suatu kegiatan dari waktu ke
Sedangkan data deret berkala adalah serangkaian nilai-nilai variabel yang
disusun berdasarkan waktu. Pada analisis data deret berkala ada empat komponen
salah satunya adalah variasi musim. Variasi musim merupakan gerakan suatu
deret berkala yang diklasifikasikan kedalam periode kurang dari satu tahun seperti
kwartalan, bulanan atau harian, atau gerakan periodik yang berulang
(Kustituanto,1984).
Data sebuah deret berkala dapat mempunyai atau tidak variasi musim, oleh
karena itu perlu dilakukan identifikasi terlebih dahulu untuk mengetahui apakah
deret tersebut mempunyai variasi musim atau tidak sebelum dilakukan
perhitungan. Metode yang paling sederhana untuk mengetahui adanya variasi
musim adalah dengan melihat pola yang ada pada plot time series. Pola variasi musim dapat diklasifikasikan dalam dua bentuk yakni spesifik dan tipical. Pola spesifik menunjukkan variasi musim dalam periode misalnya kwartalan.
Sedangkan pola tipical menunjukkan rata-rata variasi musim dalam sejumlah periode seperti lima tahunan.
2.4 Metode Pemulusan (Smoothing)
Metode pemulusan (smoothing) adalah suatu metode peramalan dengan melakukan penghalusan terhadap masa lalu, yaitu dengan mengambil rata-rata
dari nilai beberapa tahun untuk menaksir nilai pada beberapa tahun ke depan.
2.4.1 Pemulusan (Smoothing) Eksonensial Tunggal
Teknik eksponensial tunggal linier satu parameter digunakan dengan menetapkan
bobot tertentu atas data yang tersedia dan berdasarkan bobot itu akan diketahui
pula bobot atas hasil peramalan sebelumnya. Penentuan besarnya bobot yang
2.4.2 Pemulusan (Smoothing) Eksponensial Ganda (Linier Satu Parameter dari Brown)
Metode ini merupakan metode linier yang dikemukakan oleh Brown. Dasar pemikiran dari metode pemulusan (smoothing) eksponensial ganda (linier satu parameter dari Brown) adalah sama dengan rata-rata bergerak linier karena dua nilai pemulusan tunggal dan ganda ketinggalan dari data sebenarnya. Persamaan
yang dipakai dalam penggunaan smoothing eksponensial ganda (linier satu parameter dari Brown) adalah sebagai berikut:
′
= Nilai pemulusan eksponensial tunggal " = Nilai pemulusan eksponensial ganda
∝ = Parameter pemulusan eksponensial yang besarnya 0 < α < 1
! , # = Konstanta pemulusan
$ % = hasil peramalan untuk periode ke depan yang diramalkan
2.4.3 Ketetapan Ramalan Beberapa Kriteria Digunakan Untuk Menguji
1. MSE (Mean Square Error) atau Rata-Rata Kesalahan Kuadrat
' ( = ∑ )*
+
,
kesalahan peramalan yang besar karena kesalahan-kesalahan itu
dikuadratkan.
2. SSE (Sum of Square Error) atau Jumlah Kuadrat Kesalahan
( = ∑, - 2.7
Sedangkan SSE menyatakan jumlah kuadrat penyimpangan, yang biasa disebut jumlah kuadrat kesalahan (sum of square for error). SSE diperoleh dengan cara mengkuadratkan kesalahan dan kemudian menjumlahkan seluruh
kesalahan. Dimana semakin kecil nilai SSE, maka semakin baik hasil ramalan.
di mana:
= $ ( kesalahan pada periode ke t ) = data aktual pada periode ke t $ = nilai ramalan pada periode ke t . = banyaknya periode waktu
2.5 Identifikasi Pola Data
Salah satu langkah penting dalam melakukan suatu metode peramalan yang
terbaik dengan mengidentifikasi pola data. Berapa komponen yang mungkin
terkandung dalam suatu deret waktu adalah sebagai berikut:
1. Kompenan trend ditunjukkan dengan adanya peningkatan atau penurunan
dalam satu periode.
2. Komponen musiman ditunjukkan dengan pola berulang dari waktu ke waktu.
Variasi musiman biasanya timbul karena adanya pengaruh cuaca suatu musim
2.6 Metodologi Untuk Menganalisis Data Deret Berkala
1. Plot Data
Langkah pertama yang baik untuk menghasilkan data deret berkala adalah
memplot data tersebut secara grafis yang bermanfaat untuk memplot berbagai
versi data dan melihat plot data tersebut stasioner atau tidak dari data yang
ingin diramalkan.
2. Stasioner dan Nonstasioner
Model ARIMA yang perlu diperhatikan adalah bahwa kebanyakan deret
berkala bersifat nonstasioner dan bahwa aspek-aspek Autoregressive (AR) dan Moving Average (MA) dari model ARIMA hanya berkenaan dengan deret berkala stasioner. Stasioneritas berarti tidak mengalami pertumbuhan
atau penurunan pada data. Data secara kasarnya harus horizontal sepanjang
sumbu waktu. Dengan kata lain, fluktuasi data berada pada suatu nilai
rata-rata yang konstan, tidak tergantung pada waktu, dan varians dari fluktuasi
tersebut tetap konstan setiap waktu.
Kestasioneritasan data dapat diperiksa dengan analisis autokorelasi
dan autokorelasi parsial. Autokorelasi-autokorelasi dari data yang stasioner
mengecil secara drastis membentuk garis lengkung kearah nol setelah periode
kedua dan ketiga. Jadi apabila autokorelasi pada periode satu, dua ataupun
ketiga tergolong signifikan sedangkan autokorelasi pada periode lainnya tidak
signifikan maka data tersebut bersifat stasioner.
Menurut Box-Jenkins data deret berkala yang tidak stasioner dapat ditransformasikan menjadi data yang stasioner dengan melakukan proses
pembedaan (differencing) pada data aktual. Pembedaan orde pertama dari data aktual dapat dinyatakan sebagai berikut:
/ = − ; untuk t = 2,3,...,N 2.8
Notasi yang sangat bermanfaat dalam metode pembedaan adalah operator
tersebut dua periode ke belakang sebagai berikut:
0(0 ) = 0 = 2.11
Apabila suatu deret berkala tidak stasioner maka data tersebut dapat dibuat
lebih mendekati stasioner dengan melakukan pembedaan pertama dari deret
data dan persamaannya adalah sebagai berikut:
′= − 2.12
Pembedaan orde pertama
′ =
2− 0 = (1 − 0) 2.13
Pembedaan pertama dinyatakan oleh (1 − 0). Sama halnya apabila
pembedaanorde kedua (yaitu pembedaan pertama dari pembedaan pertama
sebelumnya)harus dihitung, maka:
Identifikasi model berkaitan dengan penentuan orde pada ARIMA. Oleh
karena itu, identifikasi model dilakukan setelah melakukan analisis deret
berkala untuk mengetahui adanya autokorelasi dan kestasioneran data
pembedaan. Jika data tidak stasioner dalam hal varians maka dapat dilakukan
transformasi dan jika data tidak stasioner dalam rata-rata maka dapat
dilakukan pembedaan. Langkah pertama yang baik untuk menganalisis data
deret berkala adalah dengan membuat plot data time series terlebih dahulu. Hal ini bermanfaat untuk mengetahui adanya trend dan pengaruh musiman pada data tersebut. Langkah selanjutnya adalah menganalisis koefisien
autokorelasi dan koefisien autokorelasi parsialnya dengan tujuan mengetahui
kestasioneran data dalam rata-rata dan dari plot ACF, PACF tersebut dapat
diidentifikasi orde model ARMAnya.
5. Keofisien Autokorelasi
Secara matematis rumus untuk koefisien autokorelasi dapat dituliskan dengan
rumus seperti pada persamaan sebagai berikut:
=∑645789(3* 3)(3*45 3)
Apabila merupakan fungsi atas waktu, maka hubungan autokorelasi
dengan lagnya dinamakan fungsi autokorelasi (Autocorrelation Function) sering disebut ACF dan dinotasikan oleh:
: =∑645789(3* 3)(3*45 3)
∑6789(3* 3)+ 2.16
Konsepsi lain pada autokorelasi adalah autokorelasi parsial (Partial Autocorrelation Funcition) sering disebut PAFC. Seperti halnya autokorelasi yang merupakan fungsi atas lagnya, yang hubungannya dinamakan
autokorelasi (ACF), autokorelasi parsial juga merupakan fungsi atas lagnya,
Dengan n adalah banyaknya data. Ini berarti bahwa 95% dari seluruh
koefisien korelasi berdasarkan sampel harus terletak didalam daerah nilai
tengah ditambah atau dikurangi 1,96 kali kesalahan standar (Makridakis,
1992).
-1.96 (1/√=) ≤ +1.96 (1/ √=) 2.18
6. Koefisien Autokorelasi Parsial
Autokorelasi parsial digunakan untuk mengukur tingkat keeratan (association) antara dan pengaruh dari time-lag 1,2,3,... dan seterusnya sampai k-1 dianggap terpisah. Satu-satunya tujuan di dalam analisis deret berkala adalah
untuk membantu menetapkan model ARIMA yang tepat untuk peramalan.
2.7 Metode ARIMA (Autoregressive Integrated Moving Average)
Model ARIMA (Autoregresive Integrated Moving Average) merupakan metode yang secara intensif dikembangkan oleh Goerge Box Dan Jenkins. Metode ARIMA berbeda dengan metode peramalan lain karena tidak mensyaratkan suatu
pola data tertentu supaya model dapat bekera dengan baik. Metode ARIMA akan
bekerja dengan baik apabila data deret berkala yang dipergunaknan besifat
dependent atau berhubungan satu sama lain secara statistik.
Secara umum model arima dirumuskan dengan notasi sebagai berikut:
ARIMA (p,d,q)
di mana:
P menunjukkan orde atau derajat autoregressive (AR) D menunjukkan orde atau derajat differencing
Q menunjukkan orde atau derajat moving average (MA)
Model box-jenkins dikelompokkan menjadi tiga kelompok: 1. Model autoregressive
2. Model moving average
2.7.1 Model Autoregressive (AR)
Model AR menunjukkan nilai prediksi variabel dependen hanya merupakan
fungsi linear dari sejumlah aktual sebelumnya. Misalnya nilai variabel
dipenden hanya dipengaruhi oleh nilai variabel tersebut satu periode
sebeumnya maka model ini disebut model Autoregressive tingkat pertama. Model ini dapat ditulis sebagai berikut :
= ′+ + + ⋯ + + 2.19
dimana:
′ = Suatu konstanta
= Nilai pengamatan periode ke-p = Parameter Autoregressive ke-p
= Nilai kesalahan pada saat t
Persamaan umum model autoregressive (AR) dengan orde p juga dapat ditulis sebagai berikut:
B1 − 0 − 0 − ⋯ − 0 C = ′
+ 2.20
Dalam hal ini B menyatakan operator penggerak mundur.
Model AR menunjukkan bahwa nilai prediksi variabel hanya merupakan fungsi
linear dari sejumlah aktual sebelumnya (Makridakis, 1992).
2.7.2 Model Moving Average (MA)
Model MA mempunyai orde (D), sehingga model tersebut biasanya dituliskan
sebagai MA(D). Model MA ini menyatakan bahwa nilai prediksi variabel
dependen hanya dipengaruhi oleh nilai residual sebelumnya atau tiap-tiap
dimana:
′ = suatu konstanta
, = parameter-parameter moving average
= nilai kesalahan pada saat t-q
Dengan menggunakan operator penggerak mundur model rataan bergerak dari
persamaan (2.21) dapat ditulis sebagai berikut: = ′
+ (1 − 0 − 0 − ⋯ − 0 ) 2.22
Dalam hal ini B menyatakan operator penggerak mundur.
2.7.3 Model campuran Autoregressive Moving Average (ARMA)
Apabila suatu deret waktu tanpa proses differencing (d=0) dinotasikan dengan model ARIMA (p,0,q). Model ini dinamakan dengan model autoregressive moving average berorde (p,q). Secara singkat bentuk umum model proses
autoregressive orde p dan berorde (p,q) adalah sebagai berikut: = ′
+ + + ⋯ + − − − ⋯ − 2.23
+
Dengan operator penggerak mundur proses ARMA (p,q) sebagai berikut:
B1 − 0 − 0 − ⋯ − 0 C = ′+ B1 − 0 − 0 − ⋯ − 0 C
2.24
2.7.4 Model Autoregressive Integrated Moving Average (ARIMA)
Apabila data deret waktu tidak stasioner, model box-jenkins ini disebut model
Autoregressive Integrated Moving Average (ARIMA). Jika F menyatakan banyaknya proses differencing, maka bentuk umum model ARIMA (p,d,q) yang mengkombinasikan model autoregressive berorde p dengan model moving average berorde q ditulis dengan ARIMA (p,d,q) adalah sebagai berikut:
= ′+ + + ⋯ + + − −
2 G−2− ⋯ 2.25
Atau dengan operator penggerak mundur model ARIMA (p,d,q) dapat ditulis sebagai berikut:
B1 − 0 − 0 − ⋯ − 0 C/ = ′+ B1 − 0 − 0 − ⋯ − 0 C
2.26
Dalam hal ini / menyatakan bahwa deret waktu sudah di differencing. Dengan menotasikan ′ sebagai berikut:
′
= (1 − − − ⋯ − ) H′ 2.27
Dengan H′ adalah rata-rata dari data waktu yang sudah di differencing.
2.8 Model Arima dan Musiman
Musiman didefinisikan sebagai suatu pola data yang berulang-ulang dalam selang
waktu tetap. Untuk data stasioner faktor musiman dapat ditentukan dengan
mengidentifikasikan koefisien autokorelasi pada dua atau tiga time-lag yang berbeda nyata dari nol. Autokorelasi secara signifikan berbeda dari nol
menyatakan adanya satu pola dalam data. Untuk mengenali adanya faktor
musiman, dapat dilihat dari autokorelasi yang tinggi. Secara umum notasi ARIMA
faktor musiman adalah:
ARIMA (p,d,q)(P,D,Q)I
di mana:
(p,d,q) = Bagian yang tidak musiman dari model
(P,D,Q) = Bagian musiman dari model
S = Jumlah periode per musim
Model ARIMA (1,1,1)(1,1,1) yang mengandung faktor musiman adalah sebagai
berikut:
(1 − 0)(1 − 0 )(1 − 0)(1 − 0 ) (1 − 0)(1 −Ɵ 0 ) 2.28
di mana:
(1 − 0) = MA(1) tidak musiman (1 −Ɵ 0 ) = MA(1) musiman
2.9 Estimasi Parameter Model
Tahap selanjutnya dilakukan estimasi parameter model untuk mencari parameter
estimasi yang paling efisien untuk model. Estimasi parameter dilakukan dengan
menetapkan model awal parameter (koefisien model) denganbantuan analisis
regresi linier untuk mencari nilai konstanta dan koefisien regresi dari model.
Dalam mencari nilai etimasi model ARIMA ini sangat rumit sehingga digunakan
bantuan program komputer software Minitab.
2.10 Verifikasi Parameter Model
Langkah ini dilakukan untuk memeriksa apakah model ARIMA yang dipilih
cukup cocok untuk data. Verifikasi dilakukan dengan menggunakan uji
distribusi t. Adapun verifikasi yang dilakukan terhadap parameter-parameter
model ARIMA sebagai berikut:
GJ- K L =I) )I -%MI- M;M%) );)I -%MI- M;M%) ); 2.29
Dengan kriteria keputusan H0 ditolak jika:
NGJ- K LN > GP
+,
2.30
1. QR: ∅ = 0 (nilai parameter ∅ tidak signifikan) Q : ∅ ≠ 0 (nilai parameter ∅ signifikan)
Selanjutnya adalah menghitung nilai GJ- K Ldengan rumus sebagai berikut:
GJ- K L = ∅9 V
WX(∅9) 2.31
di mana:
∅V = Koefisien parameter ∅
Nilai parameter dikatakan signifikan apabila nilaiNGJ- K LN > GMY)Z. Artinya,
QR ditolak dan Q diterima. Sebaliknya, jika nilai NGJ- K LN < GMY)Z maka QR
diterima dan Q ditolak.
2. QR: ∅ = 0 (nilai parameter ∅ tidak signifikan) Q : ∅ ≠ 0 (nilai parameter ∅ signifikan)
Selanjutnya adalah menghitung nilai GJ- K L dengan rumus sebagai berikut:
GJ- K L = ∅+ V
WX(∅+) 2.32
di mana:
∅V = Koefisien parameter ∅
((∅ ) = Standard Error koefisien parameter ∅
Nilai parameter dikatakan signifikan apabila nilaiNGJ- K LN > GMY)Z. Artinya,
QR ditolak dan Q diterima. Sebaliknya, jika nilai NGJ- K LN < GMY)Z maka QR
diterima dan Q ditolak.
3. QR: ∅\ = 0 (nilai parameter ∅\ tidak signifikan) Q : ∅\ ≠ 0 (nilai parameter ∅\ signifikan)
Selanjutnya adalah menghitung nilai GJ- K L dengan rumus sebagai berikut:
GJ- K L = ∅]
diterima dan Q ditolak.
Setelah model ditemukan, maka parameter dari model harus diestimasi.
Terdapat dua cara mendasarkan yang dapat digunakan untuk pendugaan terhadap
2. Perbaikan secar iteratif yaitu dengan cara memilih taksiran awal dan
kemudian membiarkan program komputer untuk memperhalus penaksiran
BAB 3
HASIL DAN PEMBAHASAN
3.1 Pemulusan (Smoothing) Eksponensial Ganda (Linier Satu Perameter dari Brown)
3.1.1 Plot Time Series Curah Hujan Kota Medan
Adapun data yang akan dianalisa dalam penelitian ini adalah data curah hujan
pada tahun 2010-2014 di Kota Medan.
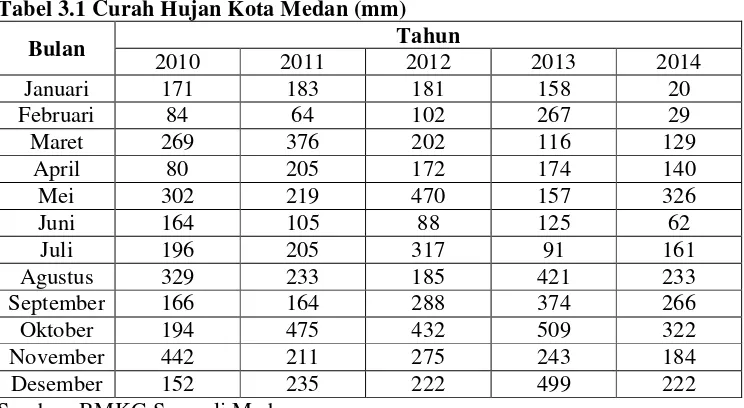
Tabel 3.1 Curah Hujan Kota Medan (mm)
Bulan Tahun
2010 2011 2012 2013 2014
Januari 171 183 181 158 20
Februari 84 64 102 267 29
Maret 269 376 202 116 129
April 80 205 172 174 140
Mei 302 219 470 157 326
Juni 164 105 88 125 62
Juli 196 205 317 91 161
Agustus 329 233 185 421 233
September 166 164 288 374 266
Oktober 194 475 432 509 322
November 442 211 275 243 184
Desember 152 235 222 499 222
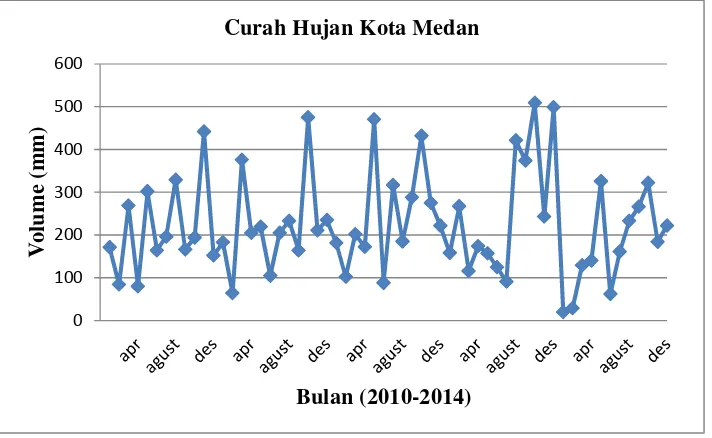
Plot data curah hujan di Kota Medan pada tahun 2010-2014 dapat dilihat pada gambar 3.1
Gambar 3.1 Plot Data Curah Hujan
Bentuk pola data curah hujan pada gambar (3.1) merupakan data musiman,
dimana pola data musiman yang menunjukkan perubahan yang berulang-ulang
secara periode dalam deret waktu.
3.1.2 Analisis Pemulusan Eksponensial Ganda (Linier Satu Parameter dari Brown)
Pola pemulusan ekponensial tunggal dilakukan peramalan dangan satu kali
penghalusan saja. Sedangkan pada metode Brown ini dilakukan dua kali penghalusan dan kemudian dilakukan peramalan. Jika parameter pemulusan α
tidak mendekati nol, pengaruh dari proses inisialisasi dengan cepat menjadi
kurang berarti dengan berlalunya waktu. Tetapi, jika α mendakati nol prosesnya
inisialisasi tersebut dapat menjadi lebih berarti dari data yang sebenarnya.
Maka dari analisis yang telah dilakukan, penulis akan menentukan
parameter α-nya adalah α = 0,01 dan 0,05, karena dari hasil analisis nilai error
terkecil berada pada α = 0,01 dan 0,05. Untuk mencari perhitungan pemulusan
a. Perhitungan Eksponensial Tunggal
e. Peramalan untuk. bulan ke-62 atau periode ke-2 (m=2)
$ % = !G+# & 3.5
$dR = 212,592 + 0,176(2)
$dR = 212,944
Demikian seterus.nya untuk periode-periode selanjutnya dan dapat dilihat pada
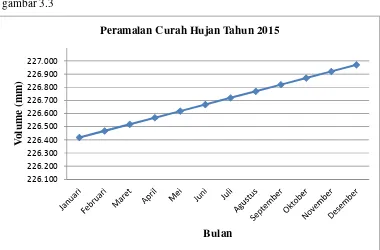
Plot data curah hujan di Kota Medan dengan parameter ∝ = 0,01 dapat dilihat pada gambar 3.2
Gambar 3.2 Plot Ramalan Data Curah Hujan 2015
Bentuk ramalan pola data curah hujan pada gambar (3.2) merupakan pola data
yang linier.
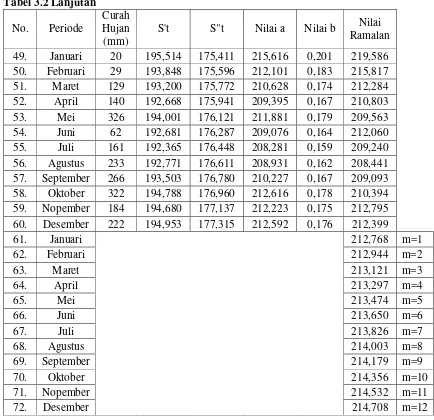
Tabel 3.3 Peramalan Curah Hujan (mm) parameter ∝ = f, fh
Tabel 3.3 Lanjutan
Plot data curah hujan di Kota Medan dengan parameter ∝ = 0,05 dapat dilihat
gambar 3.3
Gambar 3.3 Plot Ramalan Data Curah Hujan 2015
3.1.3 Nilai kesalahan (Galat)
Sebelum mencari nilai kesalah tersebut, terlebih dahulu data dibuat dalam bentuk
tabel yaitu sebagai berikut:
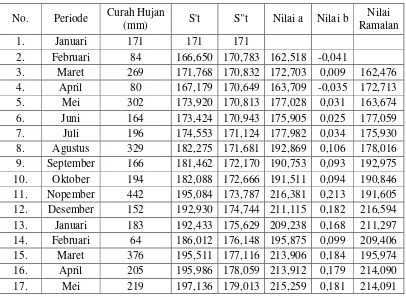
Tabel 3.4 Nilai Kesalahan dengan parameter ∝= f, fg
Tabel 3.4 Lanjutan
Jumlah 13386 1868,704 898162,300 5369,262
Keterangan:
Selanjutnya, mencari nilai SSE dan MSE dengan cara sebagai berikut:
Berikut adalah nilai kesalahan metode Brown untuk nilai ∝ = 0,05.
Tabel 3.5 Nilai Kesalahan dengan parameter ∝= f, fh
Tabel 3.5 Lanjutan
Keterangan:
= $ (kesalahan pada periode ke-t) = kesalahan pada periode ke-t dipangkatkan | | = absolut nilai kesalahaan
Untuk lebih jelas perbandingan nilai SSE dan MSE dari kedua parameter yakni 0,01 dan 0,05 dapat dilihat pada tabel 3.6.
Tabel 3.6 Hasil Nilai Kesalahan
Parameter SSE MSE
0,01 898.162,3 15.485,557
0,05 908.119,486 15.657,233
Dimana untuk mendapatkan nilai-nilai pada tabel (3.4) dipakai = = 58, karena
perhitungan nilai galat dimulai pada bulan maret tahun 2010.
Berdasarkan teori-teori sebelumnya, ramalan yang baik adalah ramalan
yang mempunyai nilai galat (kesalahan) yang paling kecil, dimana hal itu
dilakukan dengan adanya pencocokan suatu model ramalan dengan parameter
tertentu dengan data historis yang ada. Semakin kecil nilai MSE dan SSE maka dapat dikatakan peramalan semakin mendekati akurasi yang baik.
3.2 Autoregressive Integrated Moving Average (ARIMA)
3.2.1 Plot Time Series Curah Hujan Kota Medan
Langkah pertama dalam melakukan peramalan dengan metode ARIMA yang
Gambar 3.4 Plot Data Time Series Curah Hujan (mm)
Langkah selanjutnya adalah membuat plot analisis trend data curah hujan kota Medan. Tujuannya adalah untuk melihat kestasioneran data. Di bawah ini adalah
plot analisis trend data curah hujan Kota Medan.
Gambar 3.5 Plot Trend Curah Hujan (mm)
Berdasarkan gambar 3.5 dapat dilihat bahwa garis trend belum sejajar dengan sumbu x sehingga dapat dikatakan data belum stasioner dalam rata-rata dan varians. Oleh karena itu, dilakukan differencing. Data differencing dapat dilihat pada tabel 3.7.
Trend Analysis Plot for Curah Hujan Kota Medan
Year
Tabel 3.7 Differencing Data Curah Hujan Kota Medan
j = data pembedaan pertama
Untuk plot trend data curah hujan kota Medan dapat dilihat pada gambar 3.6.
Gambar 3.6 Plot Trend Curah Hujan (mm) Setelah Pembedaan Pertama
Berdasarkan gambar 3.6 plot trend curah hujan setelah pembedaan pertama terlihat bahwa data sudah stasioner (rata-rata dan variansinya konstan).
3.2.2 Identifikasi Model
Dalam mengidentifikasi model ARIMA, nilai yang harus lebih dahulu dicari
adalah nilai Autocorrelation Function (ACF) dan nilai Partial Autocorrelation Function (PACF) Untuk mencari nilai koefisien autokorelasi dan autokorelasi parsial dapat dilakukan sebagai berikut:
=,∑, 3.8
l = ∑, ( − ) × (j9)
Sehingga untuk nilai koefisien autokorelasi 1 dan 2 adalah:
=ll
Perhitungan untuk mencari koefisien autokorelasi juga dapat dibuat dalam bentuk
Tabel 3.8 Lanjutan
Jumlah 51 1752229 -1069147 500158,8
Rata-rata
= Data Curah Hujan kota Medan setelah differencing pertama j = − di mana = 0 dan t = 2, 3, 4, …, 60
j9= merupakan nilai dari j di mana nilai j = j( \)9, j \= j( n)9, j n= j( t)9, dan seterusnya,
j+= merupakan nilai dari j di mana nilai j = j( n)+, j \= j( t)+, j n= j( d)+, dan seterusnya,
Dalam memilih berapa p dan q dapat dibantu dengan mengamati pola fungsi
autocorrelation dan partial autocorrelation (correlogram) dari data time series
yang sudah stasioner, Model Box-Jenkins terdiri dari (Gaynor & Patrick, 1994):
a. Jika ACF terpotong (cut off) setelah lag 1 atau 2; lag musiman tidak signifikan dan PACF perlahan-lahan menghilang (dies down) maka diperoleh model non seasonal MA (q = 1 atau 2)
b. Jika ACF terpotong (cut off) setelah lag musiman L, lag non musiman tidak signifikan dan PACF perlahan-lahan menghilang (dies down) maka diperoleh model seasonal MA (Q = 1)
c. Jika ACF terpotong setelah lag musiman L; lag non musiman terpotong (cut off) setelah lag 1 dan 2 maka diperoleh model non seasonal-seasonal MA (q = 1 atau 2, Q = 1)
d. Jika ACF perlahan-lahan menghilang (dies down) dan PACF terpotong (cut off) setelah lag 1 atau 2, lag musiman tidak signifikan maka diperoleh model non seasonal AR (p =1 atau 2),
e. Jika ACF perlahan-lahan menghilang (dies down) dan PACF terpotong (cut off) setelah lag musiman L, lag non musiman tidak signifikan maka diperoleh model seasonal AR (P=1)
f. Jika ACF perlahan-lahan menghilang (dies down) dan PACF terpotong (cut off) setelah lag musiman L dan non musiman terpotong (cut off) setelah lag 1 atau 2 maka diperoleh model non seasonal dan seasonal AR (p = 1 atau 2 dan P = 1)
g. Jika ACF dan PACF perlahan-lahan menghilang (dies down) maka diperoleh
lampiran 1, Setelah mendapat nilai koefisien autokorelasi maka selanjutnya adalah
membuat plot autokorelasi. Hasil plot autokorelasi dapat dilihat pada gambar 3.7.
Gambar 3.7 Plot Autokorelasi
Selanjutnya adalah mencari nilai koefisien autokorelasi parsial dengan rumus
sebagai berikut: ∅ = = −0,61016, ∅ =;+ ;9+
;9+ =
R, ut R,\v
R,\v = −0,138
Untuk autokorelasi parsial selanjutnya dapat dilihat pada lampiran 2, Berikut
adalah hasil plot autokorelasi parsial:
Dari gambar 3.7 plot autokorelasi (ACF) dan gambar 3.8 plot autokorelasi
parsial (PACF) menunjukkan bahwa pola ACF cenderung terpotong (cut off) pada lag 1 dan 2 sementara pola PACF cenderung perlahan-lahan menghilang
(dies down) sehingga estimasi yang diperoleh adalah model ARIMA (1,1,0) (1,1,0)12 dan (2,1,0) (1,1,0)12.
Model pertama yang ditetapkan adalah ARIMA (1,1,0) (1,1,0)12 dengan bentuk
model persamaan sebagai berikut:
(1 − ∅ 0 )(1 − Φ 0 ) = (1 − 0) 3.12
Model kedua adalah ARIMA (2,1,0) (1,1,0)12 dengan bentuk model persamaan
sebagai berikut:
(1 − ∅ 0 − ∅ 0 )(1 − Φ 0 ) = (1 − 0) 3.13
3.2.3 Estimasi Parameter Model
Model ARIMA yang ditetapkan ada dua yaitu ARIMA (1,1,0) (1,1,0)12 dan (2,1,0)
(1,1,0)12 maka tahap selanjutnya adalah melakukan estimasi terhadap parameter
kedua model. Dalam mencari nilai estimasi parameter model ARIMA ini sangat
rumit sehingga digunakan bantuan program komputer yaitu software Minitab 17,0. Berikut adalah estimasi parameter-parameter untuk model ARIMA (1,1,0)
(1,1,0)12:
Tabel 3.9 Final Estimates of Parameters ARIMA (1,1,0) (1,1,0)12
Parameter Koefisien SE Koefisien T P
∅ -0,6174 0,1191 -5,18 0,000
Φ -0,9128 0,1245 -7,33 0,000
Sumber: Minitab 17.0
Nilai-nilai parameter yang diperoleh yakni dengan nilai ∅ = −0,6174,
dan Φ = −0,9128 Sedangkan untuk model ARIMA (2,1,0) (1,1,0)12 adalah:
Berdasarkan tabel 3.10 diperoleh bahwa nilai-nilai parameter ∅ = −0,8616,
∅ = −0,3951, dan Φ = 0,9331.
3.2.4 Verifikasi Parameter Model
Setelah mendapatkan nilai-nilai parameter dari kedua model ARIMA maka
langkah selanjutnya adalah melakukan verifikasi terhadap parameter-parameter
kedua model ARIMA tersebut dengan menggunakan uji distribusi t.
Adapun verifikasi yang dilakukan terhadap parameter-parameter model
ARIMA (1,1,0) (1,1,0)12 yaitu:
4. QR: ∅ = 0 (nilai parameter ∅ tidak signifikan)
Q : ∅ ≠ 0 (nilai parameter ∅ signifikan)
Selanjutnya adalah menghitung nilai GJ- K Ldengan rumus sebagai berikut:
GJ- K L= ∅9
V
WX(∅9) 3.12
GJ- K L=−0,61740,1191 = −5,18
Keterangan:
∅V = Koefisien parameter ∅
((∅ ) = Standard Error koefisien parameter ∅
Nilai parameter dikatakan signifikan apabila nilaiNGJ- K LN > GMY)Z. Artinya,
QR ditolak dan Q diterima. Sebaliknya, jika nilai NGJ- K LN < GMY)Z maka QR
diterima dan Q ditolak. Ketika nilai x = 1% dan jumlah data curah hujan
kota Medan sebanyak 60 (= = 60) maka diperoleh nilai
GMY)Z ( %; ) = 2,391 ( lampiran 3) sehingga dapat ditarik kesimpulan
bahwa nilaiNGJ- K LN = 5,18 > GMY)Z ( %; ) = 2,391, Dengan kata lain, QR
ditolak dan Q diterima atau parameter ∅ signifikan.
5. QR: Φ = 0 (nilai parameter Φ tidak signifikan)
Q : Φ ≠ 0 (nilai parameter Φ signifikan)
GJ- K L= {|9+
ΦV = Koefisien parameter Φ
((Φ ) = Standard Error koefisien parameter Φ
Nilai parameter dikatakan signifikan apabila nilaiNGJ- K LN > GMY)Z. Artinya,
QR ditolak dan Q diterima. Sebaliknya, jika nilai NGJ- K LN < GMY)Z maka QR
diterima dan Q ditolak. Ketika nilai x = 1% dan jumlah data curah hujan
kota Medan sebanyak 60 (= = 60) maka diperoleh nilai GMY)Z ( %; )=
2,3931 (lampiran 3) sehingga dapat ditarik kesimpulan bahwa
nilaiNGJ- K LN = 7,33 > GMY)Z ( %;tc)= 2,3931. Dengan kata lain, QR ditolak
dan Q diterima atau parameter Φ signifikan. Cara lain adalah melihat
perbandingan nilai signifikansi yang digunakan yaitu 1% dengan nilai
probability. Apabilai nilai p lebih kecil dari nilai signifikansi yang digunakan maka dapat dikatakan bahwa parameter signifikan. Sebaliknya, apabila nilai p
lebih besar dari nilai signifikansi yang digunakan maka parameter tidak
signifikan. Dari hasil olahan data dengan software Minitab (lampiran 4) diperoleh nilai } = 0,000 < 0,01 sehingga parameter Φ signifikan.
Untuk mencari parameter dari model ARIMA (2,1,0) (1,1,0)12 dapat
dilakukan dengan cara yang sama. Dalam hal ini, signifikansi yang digunakan
sebesar 0,05 (5%). Dari hasil olahan data dengan software Minitab
(lampiran 4) diperoleh nilai p dari ∅ , ∅ dan Φ masing-masing adalah 0,000, 0,010 dan 0,000. Artinya ketiga parameter dapat dikatakan signifikan
Tabel 3.11 Uji Signifikansi Nilai-Nilai Parameter Model ARIMA (1,1,0) (1,1,0)12 dan ARIMA (2,1,0) (1,1,0)12
Model ARIMA Parameter Koefisien P Keputusan
(`1,1,0) (1,1,0)12 ∅ -0,6174 0,000 Signifikan
Berdasarkan hasil verifikasi nilai-nilai parameter dari model ARIMA (1,1,0)
(1,1,0)12 dan ARIMA (2,1,0) (1,1,0)12 dapat dibuat persamaan dari ke dua model
tersebut sebagai berikut :
Persamaan Model ARIMA (1,1,0) (1,1,0)12
(1 − ∅ 0 )(1 − Φ 0 ) = (1 − 0)
(1 − 0,6174)0 )(1 − (−0,91280 ) = (1 − 0) (1 + 0,61740 )(1 + 0,91280 ) = (1 − 0)
Sedangkan persamaan model ARIMA (2,1,0) (1,1,0)12
(1 − ∅ 0 − ∅ 0 )(1 − Φ 0 ) = (1 − 0)
(1 − (−0,8616)0 − (−0,3951)0 )(1 − (−0,9331)0 ) = (1 − 0) (1 + 0,86160 + 0,39510 )(1 + 0,93310 ) = (1 − 0)
3.2.6 Peramalan
Dengan menggunakan program komputer yaitu Minitab 17,0 dapat diperoleh
peramalan untuk 12 periode ke depan yang disajikan dalam bentuk tabel.
Peramalan yang ditampilkan adalah peramalan dengan tingkat signifikansi 0,01
dan 0,05. Berikut adalah hasil peramalan curah hujan kota Medan Tahun 2015
Tabel 3.12 Peramalan Curah Hujan Kota Medan Tahun 2015 (mm)
Februari 202,998 190,191
Maret 56,634 53,272
April 118,333 93,355
Mei 111,368 99,584
Juni 61,010 45,430
Juli 34,594 18,074
Agustus 341,712 331,216
September 299,065 285,954
Oktober 425,937 414,465
November 169,009 155,339
Desember 404,428 394,527
3.2.7 Melakukan perbandingan hasil analisis ramalan
Berikut adalah perbandingan peramalan curah hujan Kota Medan tahun 2015 yang
disajikan dalam bentuk tabel:
Tabel 3.14 Peramalan Curah Hujan (mm) Kota Medan Tahun 2015
Bulan
Metode Pemulusan
Eksponensial Metode Box-Jenkins
∝ =0,01 ∝ =0,05 ∝ =0,01 ∝ =0,05
Januari 212,768 226,417 79,397 55,096
Februari 212,944 226,468 202,998 190,191
Maret 213,121 226,518 56,634 53,272
April 213,297 226,568 118,333 93,355
Mei 213,474 226,619 111,368 99,584
Juni 213,65 226,669 61,010 45,43
Juli 213,826 226,719 34,594 18,074
Agustus 214,003 226,769 341,712 331,216
September 214,179 226,82 299,065 285,954
Oktober 214,356 226,87 425,937 414,465
Nopember 214,532 226,92 169,009 155,339
Sehingga dapat dikatakan bahwa keakurasian peramalan dengan metode
ARIMA lebih baik dari pada Metode pemulusan (smoothing) eksponensial ganda (linier satu parameter dari Brown). Hal ini juga didukung dari bentuk pola data yang dihasilkan dari kedua metode tersebut, di mana hasil plot data
peramalan ARIMA tidak jauh berbeda dengan bentuk atau pola data
sebelumnya. Sementara, hasil plot data dari pemulusan (smoothing) ekponensial ganda sangat berbeda, karena hasil pola data dari metode
BAB 4
KESIMPULAN DAN SARAN
4.1 Kesimpulan
Berdasarkan hasil pembahasan diketahui bahwa :
1. Peramalan metode pemulusan eksponensial ganda (linier satu parameter
dari Brown) dengan ∝= 0,01 menghasilkan nilai kesalahan (galat) SSE = 898,162,3 dan MSE = 15,485,557.
2. Peramalan metode pemulusan eksponensial ganda (linier satu parameter
dari Brown) dengan ∝= 0,05 menghasilkan nilai kesalahan (galat) SSE = 908,119,486 dan MSE = 15,657,233.
3. Peramalan Box-Jenkins dengan ∝= 0,01 menghasilkan nilai kesalahan (galat) SSE = 773,399 dan MSE = 17,577.
4. Peramalan Box-Jenkins dengan ∝= 0,05 menghasilkan nilai kesalahan (galat) SSE = 665,432 dan MSE = 15,475.
Dalam penelitian ini dapat disimpulkan bahwa metode pemulusan eksponensial
ganda (linier satu parametr dari Brown) tidak sesuai dengan data curah hujan karena metode pemulusan eksponensial tidak memperhatikan bentuk musiman
pola data curah hujan sementara metode Box-Jenkins dapat digunakan dalam meramalkan curah hujan karena metode Box-Jenkins memperhatikan bentuk atau pola musiman dari data curah hujan. Adapun model Box-Jenkins yang layak digunakan (lebih baik) dalam meramalkan curah hujan tahun 2015 adalah model
4.2 Saran
Saran yang dapat diberikan berdasarkan penelitian ini adalah sebelum melakukan
peramalan sebaiknya penelitian terlebih dahulu melihat bentuk atau pola data
yang akan diteliti dan kemudian memilih metode peramalan sesuai dengan bentuk
DAFTAR PUSTAKA
Aritonang, Lerbin. 2002. Peramalan Bisnis. Edisi 1. Jakarta: Ghalia Indonesia
Arga. 1984. Analisa Runtun Waktu Teori & Aplikasi. Yogyakarta: BPEF
Firdaus. Muhammad. 2011. Ekonometrika Suatu Pendekatan Aplikatif. Edisi 2. Jakarta: PT Bumi Aksara
Gaynor, PE and Kirkpatrick RC. 1994. Introduction to Time Series Modelling and Forcesting in Business and Economics. Mc Grow Hill, Singapore.
Kustituanto, Bambang. 1984. Statistik Analisis Runtun Waktu Dan Regresi Korelasi. Yogyakarta: BPEF
Lubis, Edyan Syahputra. 2009. Aplikasi Metode Pemulusan Eksponensial Ganda Dari Brown Untuk Peramalan Produksi Kelapa Sawit Pada PT.Perkebunan Nusantara III Tahun 2010 dan 2011. Medan: Universitas Sumatera Utara.
Manurung, Alder Haymans. 1990. Teknik Peramalan Bisnis Dan Ekonomi. Jakarta:
Rineka Cipta.
Makridakis, S, dkk. 1992. Metode Dan Aplikasi Peramalan. Jilid 1. Edisi kedua. Jakarta: Erlangga.
Panjaitan, Lukas. 2012. peramalan Hasil Produksi Aluminium Batangan Pada PT Inalum Dengan Metode Arima. Medan: Universitas Sumatera Utara.
Rara, Dyah. 2014. Model Fungsi Transfer Bivariat Untuk Meramalkan Curah Hujan di Kabupaten Deli Serdang. Medan : Universitas Sumatera Utara.
LAMPIRAN
Lampiran 1
Autocorrelations
Series: Curah_Hujan
Lag Autocorrelation Std. Errora
Lanjutan Lampiran 1 Tabel Autokorelasi
Lag Autocorrelation Std. Errora Box-Ljung Statistic
Value df Sig.b
a. The underlying process assumed is independence (white noise).
Lanjutan lampiran 2 tabel autokorelasi parsial
Lag Partial
Autocorrelation Std. Error
37 -.035 .130
38 -.001 .130
39 -.010 .130
40 -.012 .130
41 .004 .130
42 -.054 .130
43 -.002 .130
44 -.096 .130
45 .023 .130
46 .071 .130
47 .023 .130
48 -.009 .130
49 -.035 .130
50 -.072 .130
51 .080 .130
52 -.022 .130
53 -.085 .130
54 .048 .130
55 -.060 .130
56 -.050 .130
Lampiran 4
Differencing: 1 regular, 1 seasonal of order 12 Number of observations: Original series 60, after differencing 47
Number of observations: Original series 60, after differencing 47
Residuals: SS = 665432 (backforecasts excluded) MS = 15475 DF = 43
Modified Box-Pierce (Ljung-Box) Chi-Square statistic