67
LAMPIRAN
Hasil Pengolahan Data dalam SPSS
Regression
Descriptive Statistics
Mean Std. Deviation N Jumlah Kelahiran 1800.36 1986.357 22 Jumlah Pasangan Usia
Subur
14274.68 16914.530 22
Jumlah Akseptor KB 10494.36 12268.639 22 Jumlah Puskesmas
Pembantu dan Rumah Bersalin
8.55 6.464 22
Interpretasi :
Pada bagian ini merupakan hasil pilihan options. Dimana terdapat nilai rata-rata
(Mean) dari keempat variabel, nilai Std. Deviation dan jumlah sampel (N).
Sebagai contoh, untuk jumlah kelahiran memiliki rata-rata = 1800,36, Standard
Deviasi = 1986,357, dan jumlah sampel = 22. Demikian juga terhadap data
Correlations
**. Correlation is significant at the 0.01 level (2-tailed).
Interpretasi :
Pada bagian ini dikemukakan hasil perhitungan koefisien korelasi (r) untuk semua
variabel yang dimasukkan dalam perhitungan. Kita dapat membaca satu persatu
69
1. Hubungan/korelasi antara jumlah pasangan usia subur dengan jumlah
kelahiran = 0,995.
2. Hubungan/korelasi antara jumlah akseptor KB dengan jumlah kelahiran =
0,994.
3. Hubungan/korelasi antara jumlah puskesmas pembantu dan rumah bersalin
dengan jumlah kelahiran = 0,889.
Dapat pula kita lihat bagaimana korelasi antara variabel bebas saja, yakni antara
dengan , dengan , dan dengan .
1. Hubungan korelasi antara jumlah pasangan usia subur ( ) dengan jumlah
akseptor KB ( ) = 0,999.
2. Hubungan korelasi antara jumlah pasangan usia subur ( ) dengan jumlah
puskesmas pembantu dan rumah bersalin ( ) = 0.881.
3. Hubungan antara jumlah akseptor KB ( ) dengan jumlah puskesmas
pembantu dan rumah bersalin ( ) = 0,890.
Tingkat signifikansi koefisien Korelasi satu sisi dari output (diukur dari
probabilitas) menghasilkan angka 0,000 atau praktis 0. Karena probabilitas jauh
dibawah 0,05, maka korelasi diantara variabel jumlah kelahiran dengan jumlah
pasangan usia subur, jumlah akseptor KB dan jumlah puskesmas pembantu dan
Variables Entered/Removed
a. All requested variables entered.
Interpretasi :
Bagian ini menjelaskan tentang variabel yang dimasukkan, dimana semua variabel
yang dimasukkan adalah Jumlah Puskesmas Pembantu dan Rumah Bersalin,
Jumlah Pasangan Usia Subur, Jumlah Akseptor KB, sedangkan variabel yang
dikeluarkan (removed) tidak ada.
71
Interpretasi :
Pada bagian ini ditampilkan nilai R, , Adjusted R Square, dan Std. Error of the
Estimate. Dimana nilai Koefisien Determinasi (R Square) sebesar 0,991. ini
merupakan Indeks Determinasi, yakni persentase yang menyumbangkan pengaruh
, , , terhadap Y. sebesar 0,991 menunjukkan pengertian bahwa 99,1%
sumbangan pengaruh (Jumlah Pasangan Usia Subur), (Jumlah Akseptor
KB), (Jumlah Puskesmas Pembantu dan Rumah Bersalin) terhadap Y (Jumlah
Kelahiran), sedangkan sisanya sebesar 0,9% dipengaruhi oleh faktor lain.
Std. Error of the Estimate adalah 205,314. Perhatikan pada analisis sebelumnya,
bahwa standar deviasi jumlah kelahiran adalah 1986,357 yang jauh lebih besar
dari Std. Error of the Estimate. Karena nilainya lebih kecil dari standar deviasi,
maka model regresi lebih bagus dalam bertindak sebagai prediktor jumlah
kelahiran dari pada rata-rata jumlah kelahiran itu sendiri.
ANOVAb
Model Sum of Squares Df Mean Square F Sig.
1 Regression 8.210E7 3 2.737E7 649.202 .000a Residual 758769.894 18 42153.883
Total 8.286E7 21
a. Predictors: (Constant), Jumlah Puskesmas Pembantu dan Rumah Bersalin, Jumlah Pasangan Usia Subur, Jumlah Akseptor KB
Interpretasi :
Pada bagian ini ditampilkan tabel analisis varians (ANOVA). Uji ANOVA
digunakan untuk menguji ada tidaknya pengaruh beberapa variabel independent
terhadap variabel dependen. Dengan demikian sangat tepat diterapkan pada
analisis Multiple Regression. Dapat dijelaskan bahwa nilai F sebesar 649,202
dengan tingkat signifikan 0,000.
a. Dependent Variable: Jumlah Kelahiran
Interpretasi :
Pada bagian ini dikemukakan nilai koefisisen , , , dan . Dari tabel diatas
didapat persamaan perhitungannya sebagai berikut :
73
Angka 1,138 pada Standardized Coefficients (Beta) menunjukkan tingkat korelasi
antara “Jumlah Pasangan Usia Subur” dan “jumlah kelahiran”, angka -0,196 pada
Standardized Coefficients (Beta) menunjukkan tingkat korelasi antara “Jumlah
Akseptor KB” dan “jumlah kelahiran” serta angka 0,060 pada Standardized
Coefficients (Beta) menunjukkan tingkat korelasi antara “Jumlah Puskesmas
Pembantu dan Rumah Bersalin” dan “jumlah kelahiran”.
Residuals Statisticsa
Minimum Maximum Mean Std. Deviation N Predicted Value 150.67 8730.32 1800.36 1977.241 22 Std. Predicted Value -.834 3.505 .000 1.000 22 Standard Error of Predicted
Value
47.166 180.754 80.143 36.063 22
Adjusted Predicted Value 160.78 9222.85 1762.12 1984.637 22
Residual -402.216 363.778 .000 190.084 22
Std. Residual -1.959 1.772 .000 .926 22
Stud. Residual -2.092 3.245 .063 1.238 22
Deleted Residual -709.853 1404.898 38.243 403.355 22 Stud. Deleted Residual -2.336 4.896 .146 1.529 22
Mahal. Distance .154 15.322 2.864 4.058 22
Cook's Distance .000 9.073 .563 1.954 22
Interpretasi :
Pada bagian ini dikemukakan ringkasan hasil-hasil dari “Predicted Value” (nilai
yang diprediksi) yang berupa nilai Minimum, Maksimum, Mean, Std Deviasi dan
N.
66
DAFTAR PUSTAKA
Algifari. 1997. ”Analisis Regresi Cetakan Pertama”. Yogyakarta: BPFE Yogyakarta.
Algifari. 2000. ”Analisis Regresi Cetakan Kedua”. Yogyakarta: BPFE Yogyakarta.
Hasan, M.Iqbal, M.M. 2008. ”Pokok-Pokok Materi Statistika”.Jakarta: Bumi Putra.
Sudjana. 2002. ”Metode Statistika”. Bandung: Tarsito.
Syahri Alhusin, MS. 2003. ”Aplikasi Statistik Praktis dengan SPSS.10 for Windows”. Yogyakarta: GRAHA ILMU.
BAB 3
SEJARAH UMUM TEMPAT RISET
3.1 Sejarah Badan Pusat Statistika Provinsi Sumatera Utara
Tahun 1980 ditetapkan Peraturan Pemerintah No.6 Tahun 1980 tentang
Organisasi Badan Pusat Statistik dengan pernyataan bahwa di setiap Provinsi
harus terdapat Kantor Statistik Provinsi . Dengan demikian mulai saat itu kantor
Statistik Provinsi secara resmi ada di seluruh Indonesia, tidak terkecuali di
Provinsi Sumatera Utara. Pada Tahun1998 ditetapkan Keputusan Presiden No.86
Tahun 1998 tentang Badan Pusat Statistik tentang kedudukan, tugas, fungsi,
susunan organisasi dan tata kerja Biro Pusat Statistik. Berdasarkan keputusan
Presiden ini Kantor Statistik Provinsi Sumatera Utara berubah nama menjadi
3.2Visi dan Misi Badan Pusat Statistik Provinsi Sumatera Utara
3.2.1 Visi Badan Pusat Statistik Provinsi Sumatera Utara
Badan Pusat Statistik mempunyai visi menjadikan informasi statistik sebagai
tulang punggung informasi pembangunan nasional dan regional, didukung
Sumber Daya Manusia yang berkualitas, ilmu pengetahuan dan teknologi
informasi yang mutakhir.
3.2.2.Misi Badan Pusat Statistik Provinsi Sumatera Utara
Dalam menuju pembangunan nasional Badan Pusat Statistik mengemban misi
mengarahkan pembangunan statistik pada penyediaan data statistik yang bermutu,
handal, efektif dan efisien, peningkatan kesadaran masyarakat akan arti dan
kegunaan statistik serta pengembanan ilmu pengetahuan statistik.
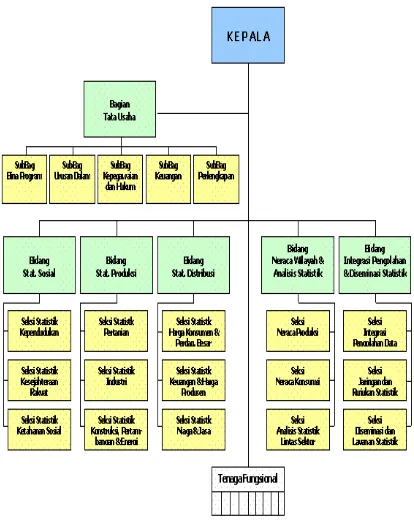
3.3Struktur Organisasi Badan Pusat Statistik Provinsi Sumatera Utara
Setiap perusahaan baik perusahaan pemerintah maupun swasta mempunyai
struktur organisasi, karena perusahaan juga merupakan organisasi. Dimana
organisasi adalah suatu sistem dari aktivitas kerjasama yang terorganisir, yang
Dalam struktur organisasi ditetapkan tugas-tugas, wewenang dan tanggung
jawab setiap orang dalam mencapai tujuan yang telah ditetapkan serta bagaimana
hubungannya yang satu dengan yang lain.
Dengan adanya struktur organisasi perusahaan yang baik, maka dapat
diketahui pembagian tugas antara para pegawai dalam rangka pencapaian tujuan.
Adapun struktur organisasi yang dipakai oleh Badan Pusat Statistik Provinsi
Sumatera Utara adalah :
1. Bagian Tata Usaha/Kepegawaian
2. Bidang Statistik Produksi
3. Bidang Statistik Distribusi
4. Bidang Statistik Kependudukan
5. Bidang Pengolahan, Penyajian dan Pelayanan Statistik
STRUKTUR ORGANISASI BADAN PUSAT STATISTIK PROVINSI
BAB 4
PENGOLAHAN DATA
4.1 Pengambilan Sampel
Dalam penelitian ini, data yang dikumpulkan adalah data mengenai jumlah
kelahiran dan faktor-faktor yang mempengaruhinya, yaitu :
1. Jumlah pasangan usia subur
2. Jumlah akseptor Keluarga Berencana (KB)
3. Jumlah puskesmas pembantu dan rumah bersalin
Untuk memperoleh model yang cocok dalam menduga jumlah kelahiran
berdasarkan faktor-faktor penduga tersebut maka penulis menggunakan analisis
regresi linier dengan satu variabel terikat (dependent variable) dan tiga variabel
bebas (independent variable). Dalam hal ini, jumlah kelahiran sebagai variabel
terikat dan yang menjadi variabel bebas adalah jumlah pasangan usia subur (X ),
jumlah akseptor KB (X ), dan jumlah puskesmas pembantu dan rumah bersalin
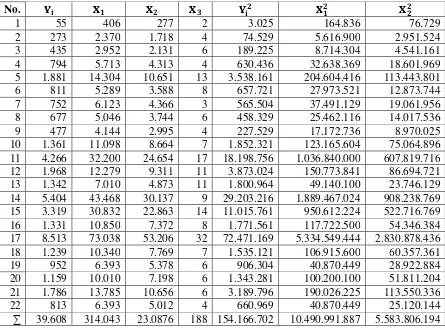
Tabel 4.1 : Data yang akan diolah
( Sumber : Badan Pusat Statistik Provinsi Sumtera Utara)
Keterangan :
Y = Jumlah kelahiran/ jumlah bayi yang lahir (orang)
X = Jumlah pasangan usia subur (pasangan)
X = Jumlah akseptor keluarga berencana (orang)
4.2 Membentuk Persamaan Linier
Dari data di atas akan dibentuk persamaan regresi linier berganda dengan terlebih
dahulu menentukan koefisien-koefisien regresinya. Untuk menentukannya maka
diperlukan jumlah-jumlah variabel seperti pada tabel 3.2 di bawah ini :
Tabel 4.2 Nilai-nilai yang diperlukan untuk menentukan koefisien regresi
No.
Sambungan Tabel 4.2 : 11 289 137.365.200 105.173.964 72.522 793.858.800 547.400 419.118 12 121 24.165.072 18.324.048 21.648 114.329.769 135.069 102.421 13 121 9.407.420 6.539.566 14.762 34.159.730 77.110 53.603 14 81 23.4901.072 162.860.348 48.636 1.309.995.116 391.212 271.233 15 196 102.331.408 75.882.297 46.466 704.912.016 431.648 320.082 16 64 14.441.350 9.812.132 10.648 79.986.200 86.800 58.976 17 1.024 621.772.494 452.942.678 272.416 3.886.059.828 2.337.216 1.702.592 18 49 12.811.260 9.625.791 8.673 80.331.460 72.380 54.383 19 36 6.086.136 5.119.856 5.712 34.381.554 38.358 32.268 20 36 11.601.590 8.342.482 6.954 72.051.980 60.060 43.188 21 36 24.620.010 19.031.616 10.716 146.892.960 82.710 63.936 22 16 5.197.509 4.074.756 3.252 32.041.716 25.572 20.048
∑ 2.484 1.267.487.010 924.547.928 578.087 7.649.634.562 4.707.562 3.454.669
Dari tabel tersebut diperoleh harga-harga sebagai berikut :
Rumus umum persamaan regresi linier berganda dengan tiga variabel bebas yaitu
:
Y = b + b X + b X + b X
Dan diperoleh melalui persamaan-persamaan berikut :
∑Y = nb + b ∑X + b ∑X + b ∑X
∑Y X = b ∑X + b ∑X + b ∑X X + b ∑X X
∑Y X = b ∑X + b ∑X X + b ∑X + b ∑X X
∑Y X = b ∑X + b ∑X X + b ∑X X + b ∑X
Harga-harga yang telah diperoleh disubsitusikan ke dalam bentuk persamaan
tersebut, maka didapatkan :
Setelah persamaan di atas diselesaikan, maka diperoleh nilai
koefisien-koefisien linier bergandanya antara lain :
b = 68,542
b = 0,134
b = -0,032
38
Dari koefisien-koefisien yang diperoleh dibentuk model persamaan regresi linier
berganda :
Ŷ = b + b X + b X + b X
Ŷ = 68,542 + 0,134X − 0,032X + 18,324X
4.3Uji Keberartian Regresi
Sebelum persamaan regresi yang diperoleh digunakan untuk membuat suatu
kesimpulan, maka perlu diadakan suatu pengujian hipotesis mengenai keberartian
model regresi. Perumusan hipotesisnya adalah :
H : β = β = . . . = β = 0
Tidak terdapat pengaruh yang signifikan antara variabel bebas yaitu jumlah
pasangan usia subur, jumlah akseptor keluarga berencana dan jumlah
puskesmas pembantu dan rumah bersalin dengan variabel tak bebas yaitu
jumlah bayi yang lahir.
H : Minimal satu parameter koefisien regresi yang ≠ 0
Terdapat pengaruh yang signifikan antara variabel bebas yaitu jumlah
pasangan usia subur, jumlah akseptor keluarga berencana, dan jumlah
puskesmas pembantu dan rumah bersalin dengan variabel tak bebas yaitu
jumlah bayi yang lahir.
Kriteria pengujian hipotesisnya :
Tolak H jika F ≥ F
Untuk menguji model regresi yang terbentuk, diperlukan dua macam
Tabel 4.3 : Nilai-nilai yang diperlukan untuk uji keberartian regresi
40
Sambungan tabel 4.3 :
Ŷ – Ŷ ( -Ŷ)
24.205.892,930 17.833.014,950 11.424,198 150,730 -95,730 9.164,233 3.046.294,223 18.182.778,112 13.404.698,678 6.942,562 404,442 -131,442 17.276,999 2.332.839,678 15.459.578,021 11.419.032,587 3.475,471 505,862 -70,862 5.021,423 1.864.217,860 8.616.165,248 6.220.699,587 4.574,380 769,364 24,636 606,932 1.012.767,769 2.364,112 12.630,587 359,198 1.882,658 -1,658 2,749 6.502,223 8.890.106,839 6.832.905,041 539,653 809,044 1,956 3,826 978.840,405 8.545.926,793 6.424.753,587 5.813,653 804,284 -52,284 2.733,617 1.099.066,314 10.367.165,566 7.583.113,041 2.859,471 734,842 -57,842 3.345,697 1.261.945,860 13.406.575,930 9.924.385,132 6.015,289 601,294 -124,294 15.448,998 1.751.291,314 1.395.718,475 804.195,223 679,017 1.406,694 -45,694 2.087,942 193.040,405 44.197.316,339 34.912.514,314 20.845,835 3.905,922 360,078 129.656,166 6.079.362,678 -334.548,843 -198.374,777 411,471 1.617,540 350,460 122.822,212 28.101,950 3.329.865,975 2.576.628,678 -1.125,074 1.053,510 288,490 83.226,480 210.097,223 105.202.102,975 70.784.918,678 1.638,017 5.093,786 310,214 96.232,726 12.986.195,041 25.144.545,475 18.783.460,950 8.283,471 3.724,950 -405,950 164.795,403 2.306.256,405 1.607.421,112 1.465.523,950 256,017 1.433,130 -102,130 10.430,537 220.302,223 394.456.786,475 286.707.683,405 157.441,835 8.739,410 -226,410 51.261,488 45.059.486,950 2.208.787,293 1.529.920,041 867,562 1.333,762 -94,762 8.979,837 315.129,132 6.686.532,248 4.340.536,860 2.159,471 863,052 88,948 7.911,747 719.720,860 2.735.211,839 2.114.167,769 1.632,562 1.289,490 -130,490 17.027,640 411.347,314 7.033,612 -2.321,686 36,562 1.684,684 101,316 10.264,932 206,314 7.782.086,021 5.413.086,496 4.488,017 838,116 -25,116 630,813 974.886,950 702.095.412,545 508.887.173,091 239.618,636 39.646,566 -38,566 758.932,396 82.857.899,091
Dari tabel tersebut diperoleh nilai-nilai berikut :
JK = b ∑x y + b ∑x y + b ∑x y
= (0,134)(702.095.412,545) + (-0,032)(508.887.173,091) +
(18,324)(239.618,636)
= 94.080.785,281 + (-16.284.389,539) + 4.390.771,893
= 82.187.167,635
42
4.4Koefisien Determinasi
Dari tabel 4.3 dapat dilihat harga ∑y = 82.857.899,091 dan nilai JK
= 82.187.167,635 telah dihitung sebelumnya, maka diperoleh nilai koefisien
determinasi :
Untuk koefisien korelasi ganda digunakan rumus, maka :
R = √R
R = √0,992
R = 0.996
Dari hasil perhitungan diperoleh nilai korelasi (R) yaitu sebesar 0,996 yang
menunjukkan bahwa korelasi antara variabel bebas X dengan variabel tak bebas Y
berhubungan secara positif dengan tingkat yang tinggi. Adapun nilai koefisien
determinasi R diperoleh sebesar 0,992 yang berarti sekitar 99% jumlah kelahiran
dipengaruhi oleh jumlah pasangan usia subur, jumlah akseptor keluarga
berencana, dan jumlah puskesmas pembantu dan rumah bersalin. Sedangkan
sisanya sebesarnya sebesar 100% - 99% = 1% dipengaruhi oleh faktor-faktor yang
4.5 Koefisien Korelasi
4.5.1Perhitungan Korelasi antara Variabel Bebas dan Variabel Terikat
Untuk mengukur besarnya pengaruh variabel bebas terhadap variabel tidak bebas,
maka dari tabel 3. 3 dapat dihitung besar koefisien korelasinya yaitu :
a. Koefisien korelasi antara jumlah kelahiran (Y) dengan jumlah pasangan usia
subur (X ) :
Jumlah pasangan usia subur (X ) berkorelasi sangat tinggi terhadap angka
kelahiran (Y) yaitu sebesar 0,9950836.
b. Koefisien korelasi antara jumlah kelahiran (Y) dengan jumlah pengguna
akseptor keluarga berencana (X ) :
r = ∑ (∑ ) (∑ )
{ ∑ (∑ ) }{ ∑ (∑ ) }
= ( ) ( ) ( ) ( . )
44
Jumlah pengguna akseptor keluarga berencana (X ) berkorelasi sangat
tinggi terhadap angka kelahiran (Y) yaitu sebesar 0,9943711.
c. Koefisien korelasi antara jumlah kelahiran (Y) dengan jumlah puskesmas
pembantu dan rumah bersalin (X ) :
tinggi terhadap angka kelahiran (Y) yaitu sebesar 0,8886716.
4.5.2 Perhitungan Korelasi antara Variabel Bebas
a. Koefisien korelasi antara jumlah pasangan usia subur (X ) dengan jumlah
akseptor keluarga berencana (X ) :
r = ∑ ∑ (∑ ) (∑ )
= ( ) ( . . . ) ( . ) ( . )
Jumlah pasangan usia subur (X ) berkorelasi sangat tinggi terhadap jumlah
akseptor keluarga berencana (X ) yaitu sebesar 0,999098.
b. Koefisien korelasi antara jumlah pasangan usia subur (X ) dengan jumlah
puskesmas pembantu dan rumah bersalin (X ) :
r = ∑ ∑ (∑ ) (∑ )
46
c. Koefisien korelasi antara jumlah akseptor KB (X ) dengan jumlah puskesmas
pembantu dan rumah bersalin (X ) :
pembantu dan rumah bersalin (X ) yaitu sebesar 0,8899714.
4.6 Uji Koefisien Regresi Linier Berganda
Dari hasil perhitungan diperoleh model persamaan regresi linier ganda :
Ŷ= 68,542 + 0,134X - 0,032X + 18,324X
Untuk mengetahui bagaimana keberartian setiap variabel bebas dalam persamaan
regresi tersebut, maka perlu diadakan pengujian tersendiri mengenai
koefisien-koefisien regresinya.
langkahnya adalah sebagai berikut :
1. Hipotesis pengujian :
H : β = 0 ; i=1,2,3
Terdapat pengaruh yang signifikan antara koefisien X , X dan X
H : β ≠ 0 ; i=1,2,3.
Tidak terdapat pengaruh yang signifikan antara koefisien X , X dan X
terhadap Y
Taraf nyata (signifikansi) α = 0,05
2. Kriteria pengujian: jika t > t maka tolak H ; jika t < t maka
terima H
3. Ambil kesimpulan berdasarkan hasil pengujian.
Untuk melakukan pengujian diperlukan rumus :
48
Dari harga-harga tersebut dapat dihitung nilai kekeliruan baku koefisien bi sebagai
= . ,
,
= 77,501
Kemudian didapatkan nilai distribusi student t =
t = ,
memberikan pengaruh yang berarti. Sedangkan jumlah akseptor KB dan jumlah
puskesmas pembantu dan rumah bersalin tidak memberikan pengaruh yang berarti
50
BAB 5
IMPLEMENTASI SISTEM
5.1 Pengertian Implementasi Sistem
Implementasi sistem adalah prosedur yang dilakukan untuk menyelesaikan desain
sistem yang ada dalam desain yang disetujui, menginstal dan memulai sistem atau
sistem yang diperbaiki.
Tahapan implementasi sistem merupakan tahapan penerapan hasil desain
yang tertulis ke dalam programming. Pengolahan data pada tugas akhir ini
menggunakan software yaitu SPSS 17.0 for Windows dalam memperoleh hasil
5.2 Sekilas Tentang Program SPSS
SPSS merupakan salah satu paket program komputer yang digunakan untuk
mengolah data statistik. Banyak program lain yang juga dapat digunakan untuk
olah data statistik, misalnya Microstat, SAS, Minitab, SPSS-2000, MOS, R dan
lain-lain, namun SPSS lebih populer dibandingkan dengan program lainnya.
SPSS merupakan software yang paling populer, dan banyak digunakan sebagai
alat bantu dalam berbagai macam riset, sehingga program ini paling banyak
digunakan di seluruh dunia.
SPSS pertama sekali diperkenalkan oleh tiga mahasiswa Standford
University pada tahun 1968. Tahun 1948 SPSS sebagai software muncul dengan
nama SPSS/PC+ dengan sistem Dos. Lalu sejak tahun 1992 SPSS mengeluarkan
versi Windows. SPSS dengan sistem Windows telah mengeluarkan software
dengan beberapa versi yang berkembang dalam penggunaannya dalam mengolah
data statistika.
SPSS sebelumnya dirancang untuk pengolahan data statistik pada
ilmu-ilmu sosial, sehingga SPSS merupakan singkatan dari Statistical Package for the
Social Science. Namun, dalam perkembangan selanjutnya penggunaan SPSS
diperluas untuk berbagai jenis penggunaan, misalnya untuk proses produksi di
perusahaan, riset ilmu-ilmu sains dan sebagainya. Sehingga kini SPSS menjadi
52
5.3Pengolahan Data dengan SPSS
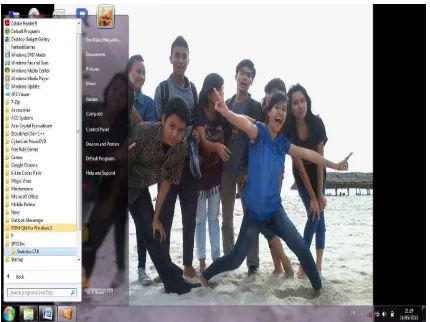
1. Memulai SPSS pada window yaitu sebagai berikut :
1 Pilih menu Start dari Windows 2 Selanjutnya pilih menu Program 3 Pilih Statistics 17.0
Tampilannya adalah sebagai berikut :
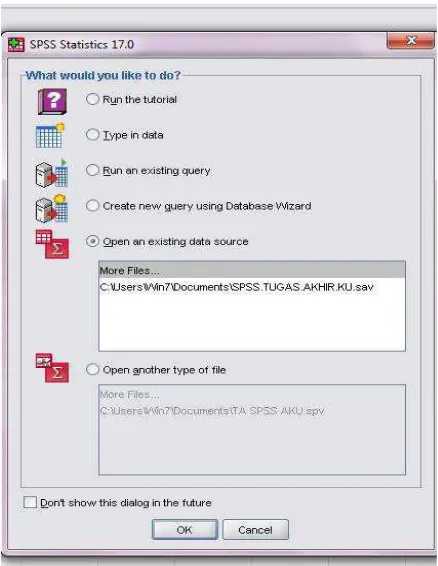
Maka SPSS siap untuk dipergunakan. Jika ingin membuka file, pilih nama file
yang disimpan dan klik Open. Jika akan memulai mendesain variabel dan memasukkan data, pilih Cancel.
Gambar 5.2 Kotak Dialog SPSS for window
2. Memasukan data ke dalam SPSS
SPSS Data Editor mempunyai 2 tipe lingkungan kerja yaitu : Data View dan Variable View. Untuk menyusun defenisi variabel, posisi tampilan SPSS Data Editor harus berada pilih ada “Variable View”. Lakukan dengan mengklik tab sheet Variable View yang berada dibagian kiri bawah atau langsung menekan
54
Tampilannya adalah sebagai berikut :
Gambar 5.3 Tampilan Jendela Variabel View dalam SPSS
Pada tampilan jendela Variabel view terdapat kolom-kolom berikut :
Name : untuk memasukkan nama variabel yang akan diuji
Type : untuk mendefenisikan tipe variabel apakah bersifat numeric atau string
Widht : untuk menuliskan panjang pendek variabel
Decimals : untuk menuliskan jumlah desimal di belakang koma Label : untuk menuliskan label variabel
Values : untuk menuliskan nilai kuantitatif dari variabel yang skala pengukurannya ordinal atau nominal bukan scale
Align : untuk menuliskan rata kanan, kiri atau tengah penempatan teks atau angka di Data view
Measure : untuk menentukan skala pengukuran variabel, misalnya nominal, ordinal atau scale
2.1Pengisian Variabel
Tempatkan pointer pada baris pertama di bawah Name.
Variabel Y
Name : Letakkan kursor di bawah Name, lalu klik ganda pada sel
tersebut kemudian ketik Jlh_Klhrn
Type : Pilih numeric karena berupa angka
Width : Untuk keseragaman ketik 8
Decimal : Ketik 0
Label : Ketik Jumlah kelahiran
Align : Pilih Center
Measure : Pilih scale
Variabel X
Name : Letakkan kursor di bawah Jlh_Klhrn, lalu klik ganda
56
Type : Pilih numeric karena berupa angka
Width : Untuk keseragaman ketik 8
Decimal : Ketik 0
Label : Ketik Jumlah Pasangan Usia Subur
Align : Pilih Center
Measure : Pilih scale
Lakukan seterusnya untuk variabel dan dengan Name dan Label yang sesuai
dengan Variabel yang dimaksudkan, sehingga diperoleh seperti gambar berikut :
2.2Pengisian Data
1. Aktifkan jendela data dengan mengklik Data View
2. Ketikkan data yang sesuai dengan setiap variabel yang telah
didefenisikan pada Variabel View. Tampilannya adalah sebagai berikut :
Gambar 5.5 Tampilan Jendela Pengisian Data View
5.4Pengolahan Data dengan Persamaan Regresi
Langkah-langkahnya adalah sebagai berikut :
1. Tampilkan lembar kerja dimana sudah terdapat data yang akan dianalisis
58
Gambar 5.6 Pilih Analyze,Regression, Linear
3. Setelah itu akan muncul kotak dialog Linear Regression, pada kotak dialog ini akan ditampilkan variabel-variabel yang akan diuji. Masukkan variabel tak
bebas Y (Jumlah kelahiran) pada kotak Dependent, dan variabel bebas X (jumlah pasangan usia subur, jumlah akseptor KB, dan jumlah puskesmas
pembantu dan rumah bersalin) pada kotak Independent seperti gambar berikut :
4. Klik kotak Statistics pada kotak dialog Linear Regression, kemudian aktifkan Estimate, Model fit, Descriptive dan Casewise diagnostics, lalu klik Continue untuk melanjutkan seperti pada gambar berikut :
Gambar 5.8 Kotak dialog Linear Regression : Statistics
60
Gambar 5.9 Kotak dialog Linear Regression : Plots
6. Kemudian klik tombol Options pada kotak dialog Linear Regression sehingga muncul kotak dialog yang baru. Pada Stepping Method Criteria, aktikan Use Probability of F dengan standard error 0,05 oleh karena itu masukkan nilai entry 0,05. Aktifkan include constant in aquation dan Exclude Cases Litwise pada Missing Values seperti gambar berikut :
5.5Pengolahan Data dengan Persamaan Korelasi
Langkah-lagkahnya adalah sebagai berikut :
1. Tampilkan lembar kerja dimana sudah terdapat data yang akan dianalisis
2. Dari menu utama SPSS, klik menu Analyze, lalu pilih sub menu Correlate, dan klik Bivariate seperti gambar berikut :
Gambar 5.11 Pilih Analyze, Correlate, Bivariate
3. Pada kotak dialog Bivariate Correlations akan ditampilkan variabel-variabel yang akan diuji. Pindahkan variabel-variabel tersebut ke dalam kotak
Variables.
62
BAB 6
PENUTUP
6.1 Kesimpulan
Berdasarkan pengolahan data yang telah dilakukan, maka diperoleh beberapa
kesimpulan antara lain :
1. Dengan menggunakan analisis regresi linier berganda diperoleh model
persamaan linier ganda, yaitu :
Ŷ = 68,542 + 0,134X − 0,032X + 18,324X
2. Dari hasil perhitungan koefisien korelasi ganda variabel X , X , X dan
variabel Y, diperoleh korelasi (r) yaitu sebesar 0,996 yang berarti bahwa
variabel X dan variabel Y berhubungan secara positif dengan tingkat yang
tinggi. Adapun nilai koefisien determinasi R = 0,992 yang berarti sekitar
99% jumlah kelahiran dipengaruhi oleh jumlah pasangan usia subur,
jumlah akseptor KB, dan puskesmas pembantu dan rumah bersalin.
64
3. Dari hasil perhitungan koefisien korelasi antara masing-masing variabel
X , X , dan X dengan variabel Y diketahui bahwa faktor yang paling
berpengaruh terhadap tingginya jumlah kelahiran bayi di Kabupaten Deli
Serdang adalah jumlah pasangan usia subur yaitu sebesar 0,995, disusul
dengan jumlah pengguna alat kontrasepsi yaitu sebesar 0,994 dan yang
terakhir adalah puskesmas pembantu dan rumah bersalin yaitu sebesar
0,889.
4. Dari hasil perhitungan distribusi student diketahui koefisisen regresi linier
untuk X signifikan (berarti), sedangkan untuk X dan X tidak signifikan
(tidak berarti). Maka untuk prediksi jumlah kelahiran bayi hanya jumlah
pasangan usia subur saja yang memberikan pengaruh yang berarti,
sedangkan jumlah akseptor KB dan jumlah puskesmas pembantu dan
rumah bersalin tidak memberikan pengaruh yang berarti terhadap jumlah
kelahiran bayi.
6.2 Saran
1. Pemerintah seharusnya membuat suatu kebijakan yang bisa menumbuhkan
kemauan masyarakat untuk memakai alat kontrasepsi karena akan sangat
berpengaruh terhadap jumlah kelahiran.
2. Masyarakat agar senantiasa memperhatikan sarana untuk mendapatkan
pembantu dan rumah bersalin dan ikut serta dalam perencanaan keluarga
BAB 2
LANDASAN TEORI
2.1 Pengertian Regresi
Regresi pertama kali dipergunakan sebagai konsep statistika oleh Sir Francis
Galton (1822 – 1911). Beliau memperkenalkan model peramalan, penaksiran, atau
pendugaan, yang selanjutnya dinamakan regresi yang bertujuan untuk membuat
perkiraan nilai satu variabel (tinggi badan anak) terhadap satu variabel yang lain
(tinggi badan orang tua).
Analisis regresi merupakan salah satu cabang satistika yang banyak
mendapat perhatian dan dipelajari oleh para ilmuwan, baik ilmuwan dibidang
ilmu sosial maupun eksakta. Analisis regresi linier digunakan untuk :
1. Menentukan hubungan fungsional antara variabel bebas (independent)
dengan variabel terikat (dependent).
2. Menelaah hubungan antara dua variabel atau lebih, terutama untuk
menelusuri pola hubungan yang modelnya belum diketahui dengan baik
atau untuk mengetahui bagaimana variasi dari beberapa variabel
independent mempengaruhi variabel dependent dalam suatu fenomena
independent dan Y adalah variabel dependent, maka terdapat hubungan
fungsional antara X dan Y, dimana variasi dari X akan diiringi pula oleh
variasi dari Y.
Jadi prinsip dasar yang harus dipenuhi dalam membangun suatu
persamaan regresi adalah bahwa antara variabel-variabel bebas (independent
variabel) dengan variabel tidak bebas (dependent variabel) memiliki sifat
hubungan sebab akibat (hubungan kausalitas). Variabel dependent adalah variabel
yang nilainya mempengaruhi variabel lain, sedangkan variabel independent adalah
variabel yang nilainya dipengaruhi oleh variabel lain.
2.2 Analisis Regresi Linier Berganda
Dalam regresi berganda, persamaan regresinya memiliki lebih dari satu variabel
bebas. Untuk memperkirakan nilai variabel terikat (dependent variable) kita harus
menghitung variabel-variabel bebas (independent variable) yang
mempengaruhinya. Dengan demikian dimiliki hubungan antara satu variabel
terikat Y dengan beberapa variabel bebas X , X , dan X , . . . , X . Untuk itulah
digunakan regresi linear berganda.
Secara umum persamaan regresi berganda dapat ditulis sebagai berikut :
dengan : X = variabel bebas
Y = variabel terikat
B , B , B , . . . , B = koefisisen regresi
= variabel kesalahan (galat)
Model diatas merupakan model regresi untuk populasi, sedangkan apabila
hanya menarik sebagian berupa sampel dari populasi secara acak, dan tidak
mengetahui regresi populasi, untuk keperluan analisis, variabel bebas akan
dinyatakan dengan , , . . . , (k ≥1) sedangkan variabel terikat dinyatakan
dengan Y. Sehingga model regresi populasi perlu diduga berdasarkan model
regresi sampel berikut :
Y= b + b X + b X + . . . + b X + e dengan : X = variabel bebas
Y = variabel terikat
b , b , b , . . . , b = koefisisen regresi
e = variabel kesalahan (galat)
2.3 Membentuk Persamaan Regresi Linier Berganda
Dalam regresi linier berganda variabel terikat (Y), tergantung kepada dua atau
lebih variabel bebas (X). Dalam penelitian ini, digunakan empat variabel yang
terdiri dari satu variabel bebas Y dan tiga variabel terikat yaitu X , X , dan X .
Y = b + b X + b X + b X
Koefisien-koefisien , , , dapat dihitung dengan menggunakan
persamaaan :
∑Y = nb + b ∑X + b ∑X + b ∑X
∑Y X = b ∑X + b ∑X + b ∑X X + b ∑X X
∑Y X = b ∑X + b ∑X X + b ∑X + b ∑X X
∑Y X = b ∑X + b ∑X X + b ∑X X + b ∑X
Harga-harga , , , didapat dengan menggunakan persamaan diatas dengan
metode eliminasi atau subsitusi.
2.4 Uji Keberartian Regresi
Sebelum persamaan regresi yang diperoleh digunakan untuk membuat kesimpulan
terlebih dahulu diperiksa setidak-tidaknya mengenai keliniearan dan
keberartiannya. Pemeriksaan ini ditempuh melalui pengujian hipotesis. Uji
keberartian dilakukan untuk meyakinkan diri apakah regresi yang didapat
berdasarkan penelitian ada artinya bila dipakai untuk membuat kesimpulan
mengenai hubungan sejumlah peubah yang sedang dipelajari.
Untuk itu diperlukan dua jenis jumlah kuadrat (JK) yaitu Jumlah Kuadrat
untuk regresi yang ditulis dan Jumlah Kuadrat untuk sisa (residu) yang
Jika x = X - X 1, x = X - X2, . . . , x = X - Xk dan y = Y - Y i maka
secara umum jumlah kuadrat-kuadrat tersebut dapat dihitung dari :
JK = b ∑x y + b ∑x y + . . . + b ∑x y
JK = ∑( Y - Ŷ)
Dengan demikian uji keberartian regresi berganda dapat dihitung dengan :
F = /
/ ( )
2.5 Pengujian Hipotesis
Pengujian hipotesis merupakan salah satu tujuan yang akan dibuktikan dalam
penelitian. Pengujian hipotesis dapat didasarkan dengan menggunakan dua hal,
yaitu: tingkat signifikansi atau probabilitas (α) dan tingkat kepercayaan atau
confidence interval. Didasarkan tingkat signifikansi pada umumnya orang
menggunakan 0,05. Kisaran tingkat signifikansi mulai dari 0,01 sampai dengan
0,1. Yang dimaksud dengan tingkat signifikansi adalah probabilitas melakukan
kesalahan tipe I, yaitu kesalahan menolak hipotesis ketika hipotesis tersebut
benar. Tingkat kepercayaan pada umumnya ialah sebesar 95%, yang dimaksud
dengan tingkat kepercayaan ialah tingkat dimana sebesar 95% nilai sampel akan
mewakili nilai populasi dimana sampel berasal. Dalam melakukan uji hipotesis
terdapat dua hipotesis, yaitu: (hipotesis nol) dan (hipotesis alternatif).
bertujuan untuk memberikan usulan dugaan kemungkinan tidak adanya perbedaan
bertujuan memberikan usulan dugaan adanya perbedaan perkiraan dengan
keadaan sesungguhnya yang diteliti.
Pembentukan suatu hipotesis memerlukan teori-teori maupun hasil
penelitian terlebih dahulu sebagai pendukung pernyataan hipotesis yang
diusulkan. Dalam membentuk hipotesis ada beberapa hal yang dipertimbangkan :
1) Hipotesis nol dan hipotesis alternatif yang diusulkan
2) Daerah penerimaan dan penolakan serta teknik arah pengujian (one tailed
atau two tailed)
3) Penentuan nilai hitung statistik
4) Menarik kesimpulan apakah menerima atau menolak hipotesis yang
diusulkan
Dalam uji keberartian regresi, langkah-langkah yang dibutuhkan untuk
pengujian hipotesis ini antara lain :
1) : = = . . . = = 0
Tidak terdapat hubungan fungsional yang signifikan antara variabel bebas
dengan variabel tak bebas.
: Minimal satu parameter koefisien regresi yang ≠ 0
Terdapat hubungan fungsional yang signifikan antara variabel bebas
dengan variabel tak bebas
2)Pilih taraf α yang diinginkan
3)Hitung statistik dengan menggunakan persamaan
= ( ) ( ) ,( )
5)Kriteria pengujian : jika ≥ , maka ditolak dan
diterima. Sebaliknya Jika < , maka diterima dan
ditolak.
2.6 Koefisien Determinasi
Koefisien determinasi yang disimbolkan dengan bertujuan untuk mengetahui
seberapa besar kemampuan variabel independen menjelaskan variabel dependen.
Nilai dikatakan baik jika berada di atas 0,5 karena nilai berkisar antara 0
dan 1. Pada umumnya model regresi linier berganda dapat dikatakan layak dipakai
untuk penelitian, karena sebagian besar variabel dependen dijelaskan oleh variabel
independen yang digunakan dalam model.
Koefisien determinasi dapat dihitung dari :
=
Sehingga rumus umum koefisien determinasi yaitu :
Harga diperoleh sesuai dengan variansi yang dijelaskan oleh masing-masing
variabel yang tinggal dalam regresi. Hal ini mengakibatkan variasi yang
dijelaskan penduga hanya disebabkan oleh variabel yang berpengaruh saja.
2.7 Koefisien Korelasi
Nilai koefisien korelasi merupakan nilai yang digunakan untuk mengukur
kekuatan (keeratan) suatu hubungan antara variabel. Koefisien korelasi biasanya
disimbolkan dengan r.
Koefisien korelasi dapat dirumuskan sebagai berikut :
r = ∑ (∑ ) (∑ )
{ ∑ (∑ ) }{ ∑ (∑ ) }
Untuk menghitung koefisien korelasi antara variabel tak bebas Y dengan
tiga variabel bebas X1, X2, X3 yaitu :
1. Koefisien korelasi antara Y dengan X1
= ∑ (∑ ) (∑ )
{ ∑ (∑ ) }{ ∑ (∑ ) }
= ∑ (∑ ) (∑ )
{ ∑ (∑ ) }{ ∑ (∑ ) }
3. Koefisien korelasi antara Y dengan X3
= ∑ (∑ ) (∑ )
{ ∑ (∑ ) }{ ∑ (∑ ) }
Koefisien korelasi memiliki nilai antara -1 hingga +1. Sifat nilai koefisien
korelasi adalah plus (+) atau minus (-) yang menunjukan arah korelasi. Makna
sifat korelasi:
1.Korelasi positif (+) berarti jika variabel mengalami kenaikan maka variabel
juga mengalami kenaikan atau jika variabel mengalami kenaikan maka
variabel X1 juga mengalami kenaikan
2.Korelasi negatif (-) berarti jika variabel mengalami kenaikan maka variabel
akan mengalami penurunan, atau jika variabel mengalami kenaikan
maka variabel akan mengalami penurunan
Sifat korelasi akan menentukan arah dari korelasi. Interpretasi harga r akan
Tabel 2.1 Interpretasi Koefisien Korelasi Nilai r
R Interpretasi
0 Tidak berkorelasi
0,01 – 0,20 Sangat rendah
0,21 – 0,40 Rendah
0,41 – 0,60 Agak rendah
0,61 – 0,80 Cukup
0,81 – 0,99 Tinggi
1 Sangat tinggi
2.8 Uji Koefisien Regresi Linier Berganda
Untuk mengetahui bagaimana keberartian setiap variabel bebas dalam regresi,
perlu diadakan pengujian tersendiri mengenai koefisien-koefisien regresi.
Misalkan populasi memiliki model regresi linier berganda :
. . … = + + + . . . +
yang berdasarkan sebuah sampel acak berukuran n ditaksir oleh regresi berbentuk
:
Ŷ = b + b X + b X + . . . + b X
Akan dilakukan pengujian hipotesis dalam bentuk :
H : = 0, i = 1, 2, . . ., k
Untuk menguji hipotesis ini digunakan kekeliruan baku taksiran sy.12...k,
jumlah kaudrat-kuadrat ∑ dengan = - Xj dan koefisien korelasi ganda
antara masing-masing variabel bebas X dengan variabel tak bebas Y dalam regresi
yaitu .
Dengan besaran-besaran ini dibentuk kekeliruan baku koefisien yakni :
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Masalah kelahiran dewasa ini merupakan masalah penting yang perlu mendapat
perhatian dan pembahasan yang serius karena dapat mempengaruhi pertumbuhan
penduduk. Bila hal ini tidak cepat ditanggapi, maka hukum Malthus yang
berbunyi “Penduduk yang bertambah menurut deret hitung” akan membawa
malapetaka. Pertumbuhan penduduk yang tidak terkendali, cepat dan tidak
seimbang akan mengakibatkan terjadinya tekanan-tekanan yang berat pada sektor
penyediaan pangan, sandang, perumahan, lapangan kerja, fasilitas kesehatan,
pendidikan, pengangkutan, perhubungan ,dan sebagainya. Karena semakin tinggi
pertumbuhan penduduk maka akan semakin meningkat juga pertumbuhan
kebutuhan manusia.
Fertilisasi adalah jumlah kelahiran hidup yang dipunyai oleh seorang
mengurangi laju pertumbuhan penduduk. Hal ini sangat berpengaruh terhadap
kesejahteraan penduduk yang merupakan tujuan penting yang ingin dicapai oleh
setiap Negara. Di kabupaten atau kota yang masih mempunyai tingkat fertilitas
tinggi atau yang KB-nya kurang berhasil, jumlah bayi yang lahir tiap tahunnya
akan lebih banyak dibandingkan dengan kabupaten atau kota yang program
KB-nya berhasil menurunkan tingkat fertilitas.Untuk mencapai tujuan tersebut maka
pemerintah berusaha membuat suatu kebijakan–kebijakan yang penting dan
berusaha memenuhi sarana dan fasilitas yang menunjang kesejahteraan penduduk.
Kebijakan-kebijakan atau usaha ini dilakukan oleh pemerintah harus
diikuti dengan peran serta masyarakat untuk mendukung tujuan tersebut.
Pengetahuan tentang kependudukan, fertilitas atau kelahiran, dan KB serta
indikator-indikatornya sangat penting diketahui oleh masyarakat luas, para
penentu kebijakan dan perancang program untuk merencanakan pembangunan
sosial terutama kesejahteraan ibu dan anak dan merangsang timbulnya kesadaran
dan membina tingkah laku yang bertanggungjawab terhadap masalah
kependudukan. Dengan adanya kesadaran masyarakat dan perhatian untuk ikut
serta dalam mewujudkan kesejahteraan penduduk maka pemerintah dan
masyarakat secara bersama-sama telah berusaha menanggulangi masalah
pertumbuhan penduduk. Misalnya dengan peran serta penduduk untuk
menurunkan tingkat fertilitas (kelahiran) dengan melaksanakan program keluarga
berencana (KB). Selain program keluarga berencana (KB), jumlah pasangan usia
subur dan jumlah sarana kesehatan seperti puskesmas pembantu dan rumah
Berdasarkan hal diatas, penulis ingin mengetahui bagaimankah respon
masyarakat dalam penurunan fertilitas (jumlah kelahiran). Sejauh manakah
masyarakat memperhatikan faktor-faktor yang mempengaruhi jumlah kelahiran.
Variabel manakah yang sangat kuat mempengaruhi tingkat kelahiran dan keeratan
hubungan antara variable-variabel yang mempengaruhi terhadap jumlah kelahiran.
Untuk itu penulis mengambil judul tulisan “FAKTOR-FAKTOR YANG
MEMPENGRUHI JUMLAH KELAHIRANDI KABUPATEN DELI SERDANG
TAHUN 2011.
1.2 Identifikasi Masalah
Jika jumlah kelahiran tinggi maka pertumbuhan penduduk meningkat, sebaliknya
jika jumlah kelahiran rendah maka pertumbuhan penduduk menurun. Banyak
faktor yang mempengaruhi peningkatan dan penurunan jumlah kelahiran. Dalam
penelitian ini data yang dianalisi adalah data sekunder tentang jumlah kelahiran
pada tahun 2011 di kabupaten Deli Serdang dan penulis membatasi faktor-faktor
yang mempengaruhinya yaitu jumlah Pasangan Usia Subur (PUS), jumlah
akseptor KB dan jumlah sarana kesehatan (puskesmas pembantu dan rumah
1.3Tujuan Penelitian
Tujuan dilakukannya penelitian ini adalah :
1. Untuk menentukan persamaan regresi linier bergandanya.
2. Untuk mengetahui seberapa besar faktor-faktor tersebut mempengaruhi
jumlah kelahiran.
3. Untuk mengetahui apakah secara signifikan terdapat korelasi positif
antara jumlah kelahiran dengan jumlah pasangan usia subur, jumlah
akseptor KB dan jumlah sarana kesehatan ( puskesmas pembantu dan
rumah bersalin ).
1.4Manfaat Penelitian
Manfaat yang diambil dari penelitian ini adalah :
1. Memberikan masukan yang dapat menjadi bahan pertimbangan bagi
pemerintah dan pihak-pihak terkait untuk menanggulangi peningkatan
jumlah kelahiran.
2. Sebagai sarana meningkatkan pengetahuan dan wawasan penulis dalam
1.5Metodologi Penelitian
Metode yang digunakan penulis dalam melakukan penelitian ini antara lain :
1. Metode Penelitian Kepustakaan ( Study Literatur )
Suatu cara penelitian yang digunakan untuk memperoleh data atau informasi
dari perpustakaan yaitu dengan membaca buku-buku, referensi,
bahan-bahan yang bersifat teoritis yang berhubungan dengan objek yang diteliti
sehingga membantu penulis dalam menyelesaikan Tugas Akhir ini.
2. Metode Pengumpulan Data
Untuk mengumpulkan data dalam pelaksanaan riset ini, penulis
menggunakan data sekunder yang terdapat di Badan Pusat Statistik Provinsi
Sumatera Utara. Data sekunder tersebut adalah data yang diperoleh dan
dirangkum ulang berdasarkan data yang telah tersedia dan disusun oleh
Badan Pusat Statistik (BPS) Provinsi Sumatera Utara. Data yang
dikumpulkan tersebut kemudian diatur/disusun dan disajikan dalam bentuk
tabel yang berisi angka-angka yang diperlukan, dengan tujuan untuk
1.6Tempat Riset
Pengumpulan data mengenai faktor-faktor yang mempengaruhi jumlah kelahiran
itu sendiri dilaksanakan di Badan Pusat Statistik (BPS) Provinsi Sumatera Utara
Jl. Asrama No. 179, Medan.
1.7Sistematika Penulisan
Tugas akhir ini dibuat dengan beberapa bab, dimana masing-masing bab terdiri
dari beberapa subbab. Hal ini dilakukan untuk mempermudah penulis pada
khususnya dan pembaca pada umumnya dalam memahami isi dari tugas akhir ini.
Adapun penyususnan tugas akhir ini dibagi dalam 5 bab, yaitu :
Bab 1 : Pendahuluan
Dalam bab ini terdapat penjelasan mengenai latar
belakang, identifikasi masalah, tujuan penelitian,
manfaat penelitian, metodologi penelitian, tempat riset
dan sistematika penulisannya.
Bab 2 : Landasan Teori
Pada bab ini diuraikan tentang pengertian regresi,
analisis regresi linier berganda, membentuk persamaan
pengujian hipotesis, koefisisen determinasi, koefisien
korelasi, uji koefisien regresi linier berganda.
Bab 3 : Sejarah Umum Tempat Riset
Bab ini diuraikan tentang sejarah badan pusat statistika
provinsi Sumatera Utara, visi dan misi badan pusat
statistika provinsi Sumataera Utara, struktur organisasi
badan pusat statistika provinsi Sumatera Utara.
. Bab 4 : Pengolahan Data
Bab ini diuraikan tentang pengambilan sampel,
pembentukan persamaan linier berganda, uji
keberartian regresi, koefisien determinasi, koefisien
korelasi dan uji koefisien regresi linier berganda.
Bab5 : Implementasi Sistem
Dalam bab ini diuraikan tentang proses pengolahan
data dengan program yang akan digunakan yaitu SPSS
mulai dari input data hingga hasil outputnya yang
membantu dalam menyelesaikan permasalahan dalam
Bab 6 : Kesimpulan dan Saran
Pada bab ini penulis memberikan beberapa kesimpulan
dan saran kepada pembaca sesuai hasil analisa yang
telah diperoleh.
FAKTOR-FAKTOR YANG MEMPENGARUHI JUMLAH KELAHIRAN DI KABUPATEN DELI SERDANG TAHUN 2011
TUGAS AKHIR
DENGSI LESMANA SILITONGA 102407007
PROGRAM STUDI DIPLOMA 3 STATISTIKA
DEPARTEMEN MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
FAKTOR-FAKTOR YANG MEMPENGARUHI JUMLAH KELAHIRAN DI KABUPATEN DELI SERDANG TAHUN 2011
Diajukan untuk melengkapi Tugas Akhir dan memenuhi syarat mencapai gelar Ahli Madya
TUGAS AKHIR
DENGSI LESMANA SILITONGA 102407007
PROGRAM STUDI DIPLOMA 3 STATISTIKA
DEPARTEMEN MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : FAKTOR-FAKTOR YANG MEMPENGARUHI
JUMLAH KELAHIRAN DI KABUPATEN DELI SERDANG TAHUN 2011
Kategori : TUGAS AKHIR
Nama : DENGSI LESMANA SILITONGA
Nomor Induk Mahasiswa : 102407007
Program Studi : D3 STATISTIKA
Departemen : MATEMATIKA
Fakultas : MATEMATIKA DAN ILMU PENGETAHUAN
ALAM (FMIPA) UNIVERSITAS SUMATERA UTARA
Diluluskan di
Medan, Juni 2013
Diketahui oleh
Departemen Matematika FMIPA USU
Ketua, Pembimbing
Prof. Dr. Tulus, M.Si Asima Manurung, S.Si, M.Si
PERNYATAAN
FAKTOR-FAKTOR YANG MEMPENGARUHI JUMLAH
KELAHIRAN DI KABUPATEN DELI SERDANG TAHUN
2011
TUGAS AKHIR
Saya mengakui bahwa Tugas Akhir ini adalah hasil kerja saya sendiri, kecuali
beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Juni 2013
DENGSI LESMANA SILITONGA
PENGHARGAAN
Puji dan syukur Penulis panjatkan kepada Tuhan Yang Maha Pemurah dan Maha
Penyayang, dengan limpah karunia-Nya Penulis dapat menyususn Tugas Akhir ini
dengan judul Faktor- Faktor yang Mempengaruhi Jumlah Kelahiran di Kabupaten
Deli Serdang Tahun 2011.
Terima kasih penulis sampaikan kepada Ibu Asima Manurung,S.Si, M.Si
selaku pembimbing yang telah meluangkan waktunya selama penyusunan tugas
akhir ini. Terima kasih kepada bapak Drs. Faigiziduhu Bu’ulolo, M.Si dan Bapak
Drs. Suwarno Ariswoyo, M.Si selaku ketua dan sekretaris Program Studi D3
Statistika FMIPA USU, Bapak Prof. Dr. Tulus dan Ibu Dra. Mardiningsi, M.Si
selaku ketua dan sekretaris Departemen Matematika FMIPA USU Medan, Bapak
Dr. Sutarman, M.Sc selaku Dekan FMIPA USU Medan, seluruh staf dan Dosen
Program Studi D3 Statistika FMIPA USU, pegawai FMIPA USU dan rekan-
rekan kuliah. Akhirnya tidak terlupakan kepada Bapak Madaris Silitonga, Ibu
Paida Sihombing dan keluarga yang selama ini memberikan bantuan dan
DAFTAR ISI
1.2Identifikasi Masalah 3
1.3Tujuan Penelitian 4
1.4Manfaat Penelitian 4
1.5Metodologi Penelitian 6
1.6Tempat Riset 6
1.7Sistematika Penulisan 6
BAB 2 LANDASAN TEORI
2.1Pengertian Regresi 9
2.2Analisis Regresi Linier Berganda 10
2.3Membentuk Persamaan Regresi Linier Berganda 11
2.4Uji Keberartian Regresi 12
2.5Pengujian Hipotesis 13
2.6Koefisien Determinasi 15
2.7Koefisien Korelasi 16
2.8Uji Koefisien Regresi Linier Berganda 18
BAB 3 SEJARAH UMUM TEMPAT RISET
BAB 4 PENGOLAHAN DATA
4.1 Pengambilan Sampel 24
4.2 Membentuk Persamaan Linier 26
4.3 Uji Keberartian Regresi 29
4.4 Koefisien Determinasi 33
4.5 Koefisien Korelasi 34
3.5.1 Perhitungan Korelasi antara Variabel Bebas dan Variabel Terikat 34 3.5.2 Perhitungan Korelasi antara Variabel Bebas 35 4.6 Uji Koefisien Regresi Linier Berganda 35
BAB 5 IMPLEMENTASI SISTEM
5.1Pengertian Implementasi Sistem 41
5.2Sekilas Tentang Program SPSS 42
5.3Pengolahan Data dengan SPSS 43
5.4Pengolahan Data dengan Persamaan Regresi 48 5.5Pengolahan Data dengan Persamaan Korelasi 52
BAB 6 KESIMPULAN DAN SARAN
6.1Kesimpulan 54
6.2Saran 56
DAFTAR TABEL
Halaman Tabel 2.1 Interpretasi Koefisien Korelasi Nilai r 18
Tabel 4.1 Data yang akan diolah 20
Tabel 4.2 Nilai-nilai yang diperlukan untuk menentukan koefisien regresi 26
DAFTAR GAMBAR
Halaman Gambar 3.1 Struktur Organisasi Badan Pusat Provinsi Sumatera Utara 23
Gambar 5.1 Tampilan Pengaktifan SPSS 17.0 43
Gambar 5.2 Kotak Dialog SPSS for window 44
Gambar 5.3 Tampilan Jendela Variabel View dalam SPSS 45
Gambar 5.4 Tampilan Jendela Pengisian Variabel View 47
Gambar 5.5 Tampilan Jendela Pengisian Data View 48
Gambar 5.6 Pilih Analyze,Regression, Linear 49
Gambar 5.7 Kotak Dialog Linier Regression 49
Gambar 5.8 Kotak dialog Linear Regression : Statistics 50
Gambar 5.9 Kotak dialog Linear Regression : Plots 51
Gambar 5.10 Kotak dialog Linear Regression : Options 51
Gambar 5.11 Pilih Analyze, Correlate, Bivariate 52