FAK
KLAS
ME
D
KULTAS M
SIFIKASI
ENGGUN
DENGAN E
DEPAR
MATEMA
INSTI
I DOKUM
NAKAN SE
EKSTRAK
NOFEL
RTEMEN
ATIKA DA
ITUT PER
BO
2
MEN BAH
EMANTIC
KSI CIRI
L SAPUTR
ILMU KO
AN ILMU
RTANIAN
OGOR
2012
HASA IND
C SMOOT
CHI-SQU
RA
OMPUTE
U PENGET
N BOGOR
DONESIA
THING
UARE
ER
TAHUAN
R
KLASIFIKASI DOKUMEN BAHASA INDONESIA
MENGGUNAKAN SEMANTIC SMOOTHING
DENGAN EKSTRAKSI CIRI CHI-SQUARE
NOFEL SAPUTRA
Skripsi
sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
NOFEL SAPUTRA. Indonesian Document Classification Using Semantic Smoothing with Chi-square Term Extraction. Supervised by JULIO ADISANTOSO.
One of supervised learning methods for document classification is Naive Bayes classifier. A common problem that often occurs on simple method like naive bayes is data sparsity. This problem especially occurs when the size of training and testing data is too small. Smoothing technique is a method for handling the sparsity problem; one method of smoothing technique is semantic smoothing. This research is intended to implement chi-square term extraction on document classification using semantic smoothing and to compare the classification accuracy rate with previous research. Chi-square term extraction was used to make the classifier work efficiently and to increase classification accuracy. Agriculture Research Journal Document of holticulture domain are used for this research, consisting of three classes.
The average for accuracy of document classification on semantic smoothing with chi-square term extraction is 96%. The results of the classification using semantic smoothing with chi-square Term extraction have been able to classify Agriculture Research Journal Documents in the holticultural domain.
Penguji:
1. Ahmad Ridha, S.Kom, MS
Judul Skripsi : Klasifikasi Dokumen Bahasa Indonesia Menggunakan Semantic Smoothing dengan Ekstraksi Ciri Chi-square
Nama : Nofel Saputra
NRP : G64080071
Menyetujui: Pembimbing
Ir. Julio Adisantoso, M.Kom NIP.19620714 198601 1 002
Mengetahui:
Ketua Departemen Ilmu Komputer
Dr. Ir. Agus Buono, M.Si, M.Kom NIP. 19660702 199302 1 001
KATA PENGANTAR
Segala puji bagi Allah subhanahu wata’ala atas segala limpahan rahmat serta karunia-Nya sehingga penulis mampu menyelesaikan penelitian ini dengan baik. Shalawat dan salam penulis sampaikan kepada Nabi Muhammad shallallahu ‘alaihi wasallam serta kepada keluarganya, sahabatnya, serta para pengikutnya yang selalu berpegang kepada Al-Quran dan As-Sunnah. Penulis juga menyampaikan terima kasih kepada seluruh pihak yang telah berperan dalam penelitian ini, yaitu: 1 Ayahanda Delnof Atri, Ibunda Ellynarti, Adik Gita Dwi Novelia, Farhan Noviandra serta Adelia Safira atas doa, kasih sayang, dukungan, serta motivasi kepada penulis untuk penyelesaian penelitian ini.
2 Bapak Ir. Julio Adisantoso, M.Kom selaku dosen pembimbing tugas akhir yang telah memberi banyak ide, saran, bantuan, serta dukungan sampai selesainya penelitian ini. Bapak Sony Hartono Wijaya, S.Kom, M.Kom selaku dosen pembimbing akademik.
3 Rekan-rekan seperjuangan di Ilmu Komputer IPB angkatan 45 atas segala kebersamaan, bantuan, dukungan, serta kenangan bagi penulis selama menjalani masa studi. Semoga kita bisa berjumpa kembali kelak sebagai orang-orang sukses.
4 Anisa Nur Rahma, Roni Rahmon, Stefanus Eko Susanto, Muhammad Abrar Istiadi dan sahabat lainnya yang telah menjadi mitra dan menemani penulis dalam menjalani kehidupan sebagai mahasiswa.
5 Rekan-rekan satu bimbingan, Susi Handayani, Anita, Putri Dewi P, Fania Rahmania, Meri Marlina, Alfa Nugraha P, Rizky Utama, Meriska Defriani, dan Hafizhia Dhikrul A, telah bersama berjuang dalam mengerjakan tugas akhir mengenai Temu Kembali Informasi.
6 Seluruh staf Departemen Ilmu Komputer IPB yang telah banyak membantu baik selama penelitian maupun perkuliahan.
Penulis berharap penelitian ini dapat memberikan manfaat baik sekarang maupun di masa mendatang.
Bogor, September 2012
RIWAYAT HIDUP
Penulis dilahirkan di Jakarta Pusat, DKI Jakarta pada tanggal 4 Juli 1990. Penulis merupakan anak pertama dari pasangan Delnof Atri dan Ellynarti. Pada tahun 2008, penulis menamatkan pendidikan di SMA Negeri 35 Jakarta. Penulis lulus seleksi masuk Institut Pertanian Bogor (IPB) pada tahun yang sama melalui jalur Undangan Seleksi Masuk IPB dan diterima sebagai mahasiswa di Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.
DAFTAR ISI
Halaman
DAFTAR TABEL ... vi
DAFTAR GAMBAR ... vi
DAFTAR LAMPIRAN ... vi
PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan ... 1
Ruang Lingkup ... 1
METODE PENELITIAN ... 1
Dokumen Penelitian ... 1
I Praproses ... 2
II Ekstraksi Topic Signature ... 3
III Smoothing ... 3
IV Dokumen Uji ... 4
V Evaluasi ... 4
Implementasi ... 4
HASIL DAN PEMBAHASAN ... 4
Tahap I Praproses ... 4
Uji Coba Klasifikasi Dokumen ... 5
Hasil Semantic Smoothing ... 5
KESIMPULAN DAN SARAN ... 8
Kesimpulan ... 8
Saran ... 8
DAFTAR PUSTAKA ... 8
LAMPIRAN ... 10
DAFTAR TABEL
Halaman
1 Kontingensi antara kata terhadap kelas ... 3
2 Nilai kritis untuk taraf nyata α ... 3
3 Confusion matrix (Hammel 2008) ... 4
4 Confusion matrix semantic smoothing ... 6
5 Kinerja semantic smoothing ... 6
6 Confusion matrix SS tanpa dan SS dengan (short document) ... 7
7 Perbandingan hasil SS tanpa dan SS dengan (short document) ... 7
8 Confusion matrix SS tanpa dan SS dengan (long document) ... 7
9 Perbandingan hasil SS tanpa dan SS dengan (long document) ... 8
DAFTAR GAMBAR
Halaman 1 Gambaran umum sistem ... 22 Tingkat kinerja semantic smoothing pada long document dan short document ... 7
3 Tingkat kinerja SS tanpa dan SS dengan (short document) ... 7
DAFTAR LAMPIRAN
Halaman 1 Hasil klasifikasi dokumen uji pada short document ... 10PENDAHULUAN
Latar Belakang
Ilmu pengetahuan dan teknologi dari tahun ke tahun terus berkembang, dimana setiap orang membutuhkan informasi dan berita up to date. Informasi tersebut dapat dikelompokkan atau diklasifikasikan agar terstruktur dan lebih mudah untuk diakses kembali. Salah satu metode yang digunakan untuk mengklasifikasikan informasi adalah Text Classification (Klasifikasi Teks). Klasifikasi dokumen merupakan proses menggolongkan suatu dokumen ke dalam suatu kategori tertentu (Manning et al 2008). Metode klasifikasi dokumen kini telah banyak diketahui diantaranya Naïve Bayes, k-Nearest Neighbor, Support Vector Machines dan Decision Tree. Salah satu metode klasifikasi yang paling mudah diimplementasikan adalah Naïve Bayes Classifier (NBC). Masalah umum yang sering terjadi pada metode NBC adalah adanya sparsity data terutama bila ukuran data latih (training) yang digunakan terlalu kecil. Hal ini biasanya terjadi ketika ada kata-kata atau terms pada dokumen uji yang tidak muncul pada dokumen latih sehingga diperlukan metode smoothing (Ramadhina 2011).
Sebelumnya metode background smoothing telah dilakukan oleh Pramurjadi (2010) dengan akurasi 88.15%. Hasil klasifikasi dengan background smoothing kurang memuaskan karena metode ini tidak memperhatikan keterkaitan kata yang ada di dalam dokumen. Selanjutnya klasifikasi dokumen tersebut diperbaiki oleh Ramadhina (2011) dengan semantic smoothing yang memiliki tingkat akurasi lebih tinggi yaitu 90.22%.
Dalam jangka panjang, dokumen penelitian yang akan terindeks semakin bertambah seiring berjalannya waktu. Kerja yang lebih berat harus dilakukan oleh sistem classifier jika hanya mengandalkan teknik klasifikasi dokumen. Oleh karena itu, salah satu cara untuk meningkatkan kinerja dari sistem klasifikasi adalah dengan menerapkan teknik pemilihan fitur dokumen. Teknik pemilihan fitur memiliki dua tujuan, yaitu mengurangi jumlah kata yang digunakan dan meningkatkan akurasi klasifikasi (Manning et al. 2008). Chi-square merupakan teknik pemilihan fitur dokumen yang sangat efektif untuk memilih kata penciri suatu dokumen
namun tidak menurunkan akurasi sistem klasifikasi (Herawan 2011).
Pramurjadi (2010) dan Ramadhina (2011) menggunakan pembobotan TF.IDF untuk semua kata kecuali stopwords. Pada penelitian ini akan dikembangkan metode semantic smoothing dengan menggunakan ekstraksi ciri (kata) chi-square. Diharapkan penelitian klasifikasi menggunakan semantic smoothing dengan ekstraksi ciri (kata) chi-square dapat lebih meningkatkan tingkat akurasi dan membantu dalam mengelompokkan dokumen bahasa Indonesia. Tujuan
Tujuan penelitian ini adalah:
1 Mengimplementasikan ekstraksi ciri chi-square pada klasifikasi dokumen menggunakan semantic smoothing.
2 Membandingkan tingkat akurasi klasifikasi dengan penelitian Ramadhina (2011). Ruang Lingkup
Ruang lingkup penelitian ini adalah dokumen berbahasa Indonesia di bidang pertanian.
METODE PENELITIAN
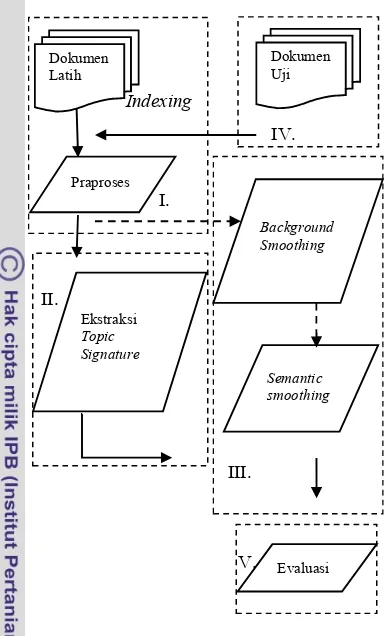
Alur penelitian secara garis besar ditunjukkan pada Gambar 1. Tahapan sistem terdiri atas pengumpulan dokumen, praproses dengan ekstraksi ciri (kata) chi-square, ekstraksi topic signature, semantic smoothing, dan evaluasi hasil klasifikasi.
Metode background smoothing telah dilakukan oleh Pramurjadi (2010) dan selanjutnya background smoothing dikombinasikan dengan semantic smoothing menggunakan pembobotan TF.IDF telah dilakukan oleh Ramadhina (2011). Penelitian ini menggunakan semantic smoothing dengan ekstraksi ciri (kata) chi-square.
Dokumen Penelitian
III. Indexing IV. I. II. V.
Gambar 1 Gambaran umum sistem. Pengujian pada dokumen uji terbagi dua jenis yaitu short document dan long document. Short document merupakan dokumen yang memiliki jumlah kata di bawah 35 kata, sedangkan long document merupakan dokumen yang berisi lebih atau sama dengan 35 kata. Pembagian dokumen tersebut berdasarkan penelitian sebelumnya oleh Ramadhina 2011. Sehingga dapat membandingkan tingkat akurasi klasifikasi dengan penelitian Ramadhina(2011).
I. Praproses
Tahap pertama yang dilakukan dalam praproses adalah pengelompokan dokumen sesuai dengan kelas atau kategori yang ditentukan. Tahap kedua adalah proses indexing yang bertujuan mengekstrak kata dalam dokumen. Pada proses indexing terdapat parsing yaitu memilah dokumen menjadi satuan unit yang kecil berupa kata, dan membuang kata yang sering muncul dan bukan merupakan penciri suatu dokumen yang biasa disebut stopwords. Pada tahapan berikutnya dilakukan ekstraksi ciri (kata) dengan chi-square untuk mendapatkan daftar tokenisasi.
Chi-square ( ) merupakan pengujian hipotesis mengenai perbandingan antara frekuensi sampel yang benar-benar terjadi (kemudian disebut frekuensi observasi) dan frekuensi harapan yang didasarkan atas hipotesis tertentu pada setiap kasus atau data (selanjutnya disebut dengan frekuensi harapan .
Sampel berukuran N diambil dari suatu populasi normal dengan standar deviasi σ. Untuk setiap sampel dihitung nilai
, sehingga diperoleh sebaran sampling untuk yang disebut sebaran chi-square. Sebaran chi-square tergantung pada satu parameter, yaitu derajat bebas (d.f) (Herawan 2011).
Pengaruh antara frekuensi sampel dan frekuensi harapan dapat diuji menggunakan suatu hipotesis H0. Hipotesis nol adalah hipotesis yang menyatakan tidak adanya perbedaan yang signifikan antara frekuensi observasi dan frekuensi harapan. Pengujian hipotesis dilakukan pada taraf nyata tertentu. Taraf nyata yang dimaksud adalah peluang salah menolak hipotesis yang seharusnya benar (Spiegel 2004). Perhitungan nilai chi-square yang digunakan untuk melakukan pengujian perbedaan antara pola frekuensi observasi ( ), dengan frekuensi harapan( ) ditunjukkan pada Persamaan 1.
Berdasarkan nilai chi-square tersebut dapat diambil suatu keputusan statistik apakah terjadi perbedaan antara pola frekuensi observasi dengan frekuensi harapan. Hipotesis nol (H0) diterima jika nilai perhitungan < nilai kritis pada derajat bebas dan taraf nyata tertentu. Hipotesis nol (H0) ditolak jika nilai perhitungan > nilai kritis pada derajat bebas dan taraf nyata tertentu.
Tabel 1 Tabel kontingensi antara kata terhadap kelas
Kelas
Kelas= 1 Kelas= 0
Kata
Kata= 1 A B
Kata= 0 C D
Perhitungan nilai chi-square berdasarkan tabel kontingensi tersebut disederhanakan menjadi:
(2)
N merupakan jumlah dokumen latih, A merupakan banyaknya dokumen kelas c yang memuat kata t, B merupakan banyaknya dokumen yang tidak berada di c, namun memuat kata t, C merupakan banyaknya dokumen yang berada di kelas c, namun tidak memiliki kata t di dalamnya, serta D merupakan banyaknya dokumen yang bukan merupakan dokumen kelas c dan tidak memuat kata t.
Hipotesis pada penelitian ini antara lain: H0 : kata t sebagai penciri kelas c.
H1 :kata t bukan penciri kelas c.
Pengambilan keputusan dilakukan berdasarkan nilai dari masing-masing kata. Kata yang memiliki nilai di atas nilai kritis pada taraf nyata α adalah kata yang akan dipilih sebagai penciri dokumen. Kata yang dipilih sebagai penciri merupakan kata yang memiliki pengaruh terhadap kelas c. Nilai kritis untuk taraf nyata α ditunjukkan oleh Tabel 2.
Tabel 2 Nilai kritis untuk taraf nyata α pada derajat bebas = 1
α Nilai Kritis
0.100 0.050 0.010 0.005 0.001 2.71 3.84 6.63 7.83 10.83
II Ekstraksi Topic Signature
Ekstraksi topic signature membantu proses pencarian kedekatan semantik berdasarkan frasa itu sendiri dan set dari kata yang mengandung frasa tersebut. Proses pertama yang dilakukan adalah membuat deretan pasangan kata sesuai dengan keterkaitan kata yang ada. Setiap kata yang didapatkan pada proses chi-square dijadikan topic signature yang berisi deretan pasangan kata. Penelitian ini berfokus pada pasangan kata yang terdiri atas dua kata.
Langkah untuk membuat topic signature adalah:
1 Pasangan kata dicari dengan mendapatkan kata unik terlebih dahulu, kata unik yang berarti tidak ada stopword dan tidak ada kata yang sama atau berulang.
2 Semua kata pada dokumen dilakukan segmentasi dua kata yang bertetangga.
Contoh: “masalah utama budidaya cabai” Dari hasil segmentasi kalimat tersebut didapatkan deretan pasangan kata yang terdiri atas: masalah utama, utama budidaya dan budidaya cabai. Terlihat bahwa terdapat 3 pasangan kata sebagai topic signature.
Pasangan kata atau topic signature ini mempengaruhi klasifikasi semantic smoothing karena pasangan kata dokumen yang akan diuji akan mendapatkan nilai peluang yang bergantung pada pasangan kata dari topic signature.
III Smoothing
Metode semantic smoothing dilakukan untuk memudahkan proses klasifikasi dokumen. Semantic smoothing digunakan sebagai parameter kontrol untuk menjadikan hasil klasifikasi menjadi akurat. Proses awal yang dilakukan adalah menghitung peluang berdasarkan kata yang terdapat pada dokumen uji. Proses yang telah dilakukan oleh Pramurjadi (2010) menggunakan formula 3.
b | j ml | | (3)
dengan model kelas unigram dengan pendugaan parameter maximum likelihood adalah ml | , sedangkan b | j merupakan model kelas unigram dengan background smoothing dan | merupakan peluang kata yang ada pada dokumen.
sebagai komponen pengontrol pada pemetaan topic signature sebagai model campuran atau mixture model (Zhou et al. 2007).
Proses berikutnya juga telah dilakukan oleh Ramadhina (2011) menggunakan semantic smoothing dengan menambah perhitungan probability dan perhitungan tiap kata yang ada di korpus semantik menggunakan formula 4.
Ps(t|ci)=(1-λ)Pb(t|ci)+λ P(t|wk)P(wk|ci) (4)
dengan s | j adalah model kelas unigram dengan semantic smoothing dan wk merupakan topic signature, | k merupakan peluang kata dalam dokumen uji yang terdapat dalam topic signature, sedangkan b | j merupakan nilai hasil dari formula background smoothing, dan k| k adalah kata dalam kumpulan topic signature dalam dokumen latih.
IV Dokumen Uji
Setelah didapatkan peluang tiap kata dari dokumen uji berdasarkan topic signature dan kelas pada dokumen latih, proses dilanjutkan dengan menghitung peluang tiap kelas terhadap dokumen uji. Dokumen uji yang digunakan berupa short document dan long document.
V Evaluasi
Evaluasi hasil dari klasifikasi dokumen dilakukan untuk mengetahui tingkat keakurasian klasifikasi semantic smoothing dengan ekstraksi ciri chi-square. Evaluasi dilakukan pada hasil kelas untuk data uji yang terbagi menjadi short document dan long document. Selanjutnya, hasil klasifikasi dokumen antara semantic smoothing tanpa chi-square dan semantic smoothing dengan chi-square dibandingkan.
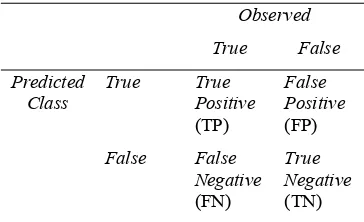
Tabel 3 merupakan sebuah confusion matrix, yakni tabel yang terdiri atas banyaknya baris data uji yang diprediksi benar dan tidak benar oleh model klasifikasi yang digunakan untuk menentukan kinerja suatu model klasifikasi.
Perbandingan hasil kedua metode tersebut dengan melakukan pengukuran kesamaan menggunakan recall, precision, F-1 , tabel confusion matrix dan tingkat akurasi.
Recall = TP / (TP + FN) Precision = TP / (TP + FP)
Tabel 3. Confusion matrix (Hammel 2008) Observed True False Predicted Class True True Positive (TP) False Positive (FP) False False Negative (FN) True Negative (TN)
Recall merupakan evaluasi untuk mengetahui tingkat keberhasilan kinerja user dalam observasi yang telah dilakukan. Recall dinyatakan dalam jumlah pengenalan entitas bernilai benar dibagi jumlah entitas yang dikenali sistem. Precision adalah tingkat ketepatan hasil klasifikasi dan jumlah keseluruhan pengenalan yang dilakukan sistem.
Akurasi
F-measure (F1) adalah nilai yang lebih dipengaruhi kinerja sistem dibandingkan dengan user. Akurasi dari klasifikasi dapat diperoleh dari penjumlahan true positif dan true negatif dibagi total untuk melihat kinerja secara keseluruhan.
Implementasi
Lingkungan implementasi yang digunakan adalah sebagai berikut:
Perangkat Lunak
Perangkat lunak yang digunakan antara lain:
1 Sistem operasi Windows 7
Professional;
2 Microsoft Excel untuk mengolah data;
3 PHP sebagai bahasa pemrograman. Perangkat keras:
1 Prosesor Intel Core i5 2.26 GHz 2 RAM 2.00 GB
3 Harddisk 500GB
HASIL DAN PEMBAHASAN
Tahap I Praproses
1 Kelas Ekofisiologi dan Agronomi; 2 Kelas Pemuliaan dan Teknologi
Benih;
3 Kelas Proteksi (Hama dan Penyakit). Keseluruhan dokumen kelas yang berjumlah 249 terbagi menjadi 174 dokumen latih dan 75 dokumen uji. Dokumen yang akan diuji terbagi dalam dua jenis, yaitu long document dan short document. Dalam praproses dilakukan penentuan kata stopwords yang disesuaikan dengan kebutuhan penelitian.
Selanjutnya dilakukan proses pemilihan fitur menggunakan chi-square. Setelah didapatkan hasil pemilihan fitur, dilakukan. pembobotan TF IDF pada setiap term. Kata-kata yang terpilih oleh chi-square akan menjadi penciri suatu kelas.
Taraf nyata α (kesalahan jenis 1) merupakan kesalahan yang dibuat pada waktu menguji hipotesis, menolak H0 padahal H0 benar. Taraf nyata yang digunakan pada penelitian ini adalah 0.05 agar peluang kesalahan sebesar 5%. Bila dibandingkan dengan taraf nyata 0.01, dari segi jumlah kata lebih sedikit dan waktu proses lebih cepat daripada taraf nyata 0.05. Namun dari segi kinerja taraf nyata 0.05 lebih baik daripada taraf nyata 0.01.
Pemilihan kata dilakukan pada taraf nyata 0.05 (Tabel 1). Berdasarkan teori terpenuhinya hipotesis, taraf nyata 0.05 dapat diartikan bahwa kriteria kata yang dipilih adalah kata yang memiliki nilai di atas 3.84. Hasil dari tahapan ini pada dokumen latih adalah:
1 Kelas Ekofisiologi dan Agronomi terdapat 178 kata unik
2 Kelas Pemuliaan dan Teknologi Benih terdapat 198 kata unik
3 Kelas Proteksi (Hama dan Penyakit) 148 kata unik.
Kata “organik, dracaena” merupakan salah satu contoh kata yang hanya terdapat pada kelas ekofisiologi. Kata “diaklimatisasi” merupakan salah satu contoh kata yang hanya terdapat pada kelas pemuliaan. Sedangkan kata “entomopatogen” merupakan salah satu contoh kata yang hanya terdapat pada kelas proteksi.
Ada beberapa kata yang sama, seperti kata “dilakukan” terdapat pada kelas ekofisiologi dan pemuliaan, namun pada kelas proteksi tidak ada. Kata “hama” terdapat pada kelas
pemuliaan dan proteksi, namun pada kelas ekofisiologi tidak ada.
Tiap kata unik yang didapatkan pada hasil chi-square dibuat menjadi pasangan kata untuk daftar topic signature. Misal contoh kata yang didapatkan pada kelas ekofisiologi seperti meningkatkan, organik dan perlakuan. Kata tersebut masing-masing dipasangkan menjadi list pasangan kata yaitu meningkatkan organik, meningkatkan perlakuan, organik meningkatkan, organik perlakuan, perlakuan meningkatkan, dan perlakuan organik.
Setelah dilakukan proses ekstraksi topic signature, didapatkan
1 Kelas Ekofisiologi dan Agronomi terdapat 31142 pasangan kata.
2 Kelas Pemuliaan dan Teknologi Benih terdapat 38805 pasangan kata 3 Kelas Proteksi (Hama dan Penyakit)
21321 pasangan kata.
Total jumlah pasangan kata yang menjadi topic signature adalah 89853 pasangan kata.
Uji Coba Klasifikasi Dokumen
Uji coba dilakukan pada dokumen uji yang terdiri atas long document dan short document. Parameter pengontrol yang terdapat pada formula semantic smoothing yaitu λ= 0.1 sampai dengan 0.9 digunakan untuk mengatur komposisi antara semantic smoothing dan background smoothing seperti yang terdapat pada formula (2) dan (3). Semakin besar nilai parameter pengontrol menjadikan nilai peluang yang dihasilkan juga meningkat. Hasil Semantic smoothing
Hasil klasifikasi semantic smoothing (SS) untuk kelas Ekofisiologi dan Agronomi (a), kelas Pemuliaan dan Teknologi Benih (b), serta kelas Proteksi Hama dan Penyakit (c) berupa confusion matrix.
Pada long document, pasangan kata banyak yang sama dengan topic signature namun dokumen uji yang salah masuk ke dalam kelasnya karena nilai peluang yang dihasilkan pada kelasnya lebih kecil dari nilai peluang di luar kelasnya. Nilai peluang yang kecil bisa mengakibatkan kurang maksimalnya pengklasifikasian.
Tabel 4 Confusion matrix semantic smoothing Short Document
TRUE FALSE
TRUE 69 6
FALSE 6 144
Long Document
TRUE FALSE
TRUE 72 3
TRUE 3 147
Confusion matrix ini didapatkan dari hasil pengujian tiap kelas yang terdapat pada Lampiran 1 dan Lampiran 2. Terlihat bahwa hasil klasifikasi pada long document lebih besar dibandingkan dengan hasil short document.
Tabel 5 Kinerja semantic smoothing
Short Document
Rec Prec F-1 Akurasi
SS (%) 92 92 92 94.67
Long Document
Rec Prec F-1 Akurasi
SS (%) 96 96 96 97.33
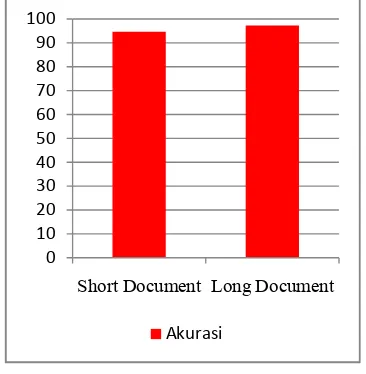
Recall dan precision yang dihasilkan long document adalah 96% sedangkan pada short document sebesar 92%. Hal ini menunjukkan bahwa ketepatan dan pengenalan hasil klasifikasi sistem long document lebih baik daripada short document.
F-1 yang dihasilkan long document adalah 96% lebih tinggi daripada short document hanya 92%. Hal ini menunjukkan kinerja sistem klasifikasi terhadap long document lebih baik daripada short document.
Akurasi yang didapatkan untuk dokumen uji short document adalah 94% dan dokumen uji long document adalah 97%. Pada
penelitian ini didapatkan hasil short document lebih rendah, karena sedikitnya pasangan kata yang sama dengan topic signature.
Terlihat bahwa hasil klasifikasi pada long document lebih baik dibandingkan dengan short document, karena long document memiliki banyaknya pasangan kata yang sama dengan topic signature. Rata-rata akurasi kinerja semantic smoothing dengan ekstraksi ciri chi-square adalah 94% dengan adanya pengukuran pada long document dan short document.
Gambar 2 Tingkat kinerja semantic smoothing pada long document dan short document.
Gambar 3 Tingkat kinerja SS tanpa dan SS dengan (short document).
0 10 20 30 40 50 60 70 80 90 100
Short Document Long Document Akurasi 0 10 20 30 40 50 60 70 80 90 100 recall prec
ison f‐
1 ak urasi Tingkat Kiner ja (%)
SS tanpa Chi‐square
Tabel 6 Confusion matrix SS tanpa dan SS dengan (short document)
SS tanpa Chi-square
TRUE FALSE
TRUE 64 11
FALSE 11 139
SS dengan Chi-square
TRUE FALSE
TRUE 69 6
FALSE 6 144
Tabel 7 Perbandingan hasil SS tanpa dan SS dengan (short document)
SS tanpa
Chi-square
SS dengan
Chi-square
Recall 85.33% 92,00%
Precison 85.33% 92,00%
F-1 85.33% 92,00%
Akurasi 90.22% 94,67%
Terlihat bahwa recall dan precision short document yang dihasilkan semantic smoothing dengan chi-square adalah 92% sedangkan pada semantic smoothing tanpa chi-square sebesar 85,33%. Hal ini menunjukkan bahwa ketepatan dan pengenalan hasil klasifikasi sistem semantic smoothing dengan chi-square lebih baik daripada semantic smoothing tanpa chi-square.
F-1 short document yang dihasilkan semantic smoothing dengan chi-square adalah 92% lebih tinggi daripada semantic smoothing tanpa chi-square yang hanya sebesar 85.33%. Hal ini menunjukkan kinerja sistem klasifikasi terhadap semantic smoothing dengan chi-square lebih baik daripada semantic smoothing tanpa chi-square.
Perbandingan hasil klasifikasi semantic smoothing tanpa dan semantic smoothing dengan dilihat pada Tabel 7 yaitu pengukuran hasil tingkat kinerja kedua metode tersebut untuk short document. Hasil klasifikasi pada short document menggunakan metode semantic smoothing dengan chi-square lebih baik. Terjadi peningkatan akurasi antara hasil semantic smoothing tanpa
chi-square dan metode semantic smoothing dengan chi-square.
Tabel 8 merupakan perbandingan confusion matrix dari semantic smoothing tanpa chi-square dan semantic smoothing dengan chi-square pada long document. Hasil klasifikasi semantic smoothing tanpa chi-square adalah 70 dokumen uji yang sesuai dengan kelas, sedangkan hasil klasifikasi dari semantic smoothing dengan chi-square menghasilkan 72 dokumen uji yang sesuai dengan kelas.
Tabel 8 Confusion matrix SS tanpa dan SS dengan (long document)
Semantic tanpa Chi-square
TRUE FALSE
TRUE 70 5
FALSE 5 145
Semantic dengan Chi-square
TRUE FALSE
TRUE 72 3
FALSE 3 147
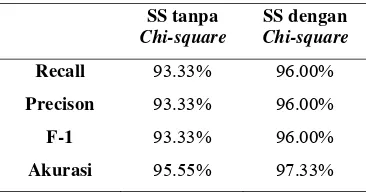
Perhitungan confusion matrix tersebut menghasilkan pengukuran kinerja yang diberikan pada Tabel 9. Tingkat akurasi pada semantic smoothing dengan chi-square lebih tinggi dengan nilai 97.33% dibandingkan dengan tingkat akurasi semantic smoothing tanpa chi-square yaitu 95.55%.
Terlihat bahwa recall dan precision long document yang dihasilkan semantic smoothing dengan chi-square adalah 96% sedangkan pada semantic smoothing tanpa chi-square sebesar 93.33%.
Tabel 9. Perbandingan hasil SS tanpa dan SS dengan (long document)
SS tanpa
Chi-square
SS dengan
Chi-square
Recall 93.33% 96.00%
Precison 93.33% 96.00%
F-1 93.33% 96.00%
Akurasi 95.55% 97.33%
F-1 long document yang dihasilkan semantic smoothing dengan chi-square adalah 96% lebih tinggi daripada semantic smoothing tanpa chi-square hanya 93.33%. Hal ini menunjukkan kinerja sistem klasifikasi terhadap semantic smoothing dengan chi-square lebih baik daripada semantic smoothing tanpa chi-square.
Seperti yang terlihat pada Tabel 7 dan Tabel 9, hasil klasifikasi semantic smoothing dengan chi-square lebih baik dibandingkan dengan hasil klasifikasi semantic smoothing tanpa chi-square. Hal ini membuktikan bahwa ekstraksi ciri chi-square dan keterkaitan kata yang ada pada dokumen dapat mempengaruhi klasifikasi dokumen.
Pertimbangan semantic smoothing dalam klasifikasi salah satunya adalah keterkaitan kata dan pemilihan topic signature. Pemilihan topic signature berasal dari ekstraksi ciri (kata) chi-quare sehingga setiap kelas memiliki kata sebagai penciri masing-masing kelas. Hal ini membuat akurasi semantic smoothing dengan chi-square menjadi lebih baik dibandingkan dengan semantic smoothing tanpa chi-square. Sistem klasifikasi ini bergantung pada dokumen yang digunakan sehingga sistem ini hanya untuk dokumen pertanian
KESIMPULAN DAN SARAN
Kesimpulan
Semantic smoothing merupakan teknik smoothing yang mengandalkan topic signature dan keterkaitan kata. Selain itu juga ekstraksi ciri chi-square menambah keakurasian semantic smoothing dalam pengklasifikasian dokumen. Hasil yang didapatkan dari penelitian ini adalah tingkat akurasi semantic smoothing cukup tinggi. Hal ini juga dipengaruhi oleh dokumen pertanian yang masing-masing dokumen memiliki kata yang relatif sama. Akurasi yang didapatkan metode semantic smoothing dengan chi-square lebih tinggi dibandingkan dengan hasil yang didapatkan semantic smoothing tanpa chi-square.
Kinerja metode semantic smoothing dengan chi-square menghasilkan akurasi lebih tinggi pada long document yaitu 97.33% dibandingkan dengan short document dengan nilai akurasi 94.67% karena banyaknya kata yang terdapat pada dokumen uji cukup mempengaruhi nilai peluang yang akan digunakan untuk klasifikasi. Semantic smoothing dengan ekstraksi ciri chi-square
menghasilkan akurasi dengan rata-rata 96%. Hasil klasifikasi semantic smoothing dipengaruhi oleh keterkaitan kata atau pasangan kata yang ada pada dokumen latih dan dokumen uji serta pemilihan kata pada proses chi-square .
Saran
Perlu dilakukan penelitian untuk menentukan topic signature yang lebih baik yaitu dengan mengambil tiga pasangan kata atau lebih serta dapat dilakukan analisis lebih dalam untuk topic signature dan pengetahuan mengenai semantik. Klasifikasi selanjutnya dapat menggunakan penggabungan metode semantic smoothing dengan metode klasifikasi lainnya agar mendapatkan akurasi yang lebih baik.
DAFTAR PUSTAKA
Hammel L. 2008. Model Assessment with ROC Curves. The Encyclopedia of Data Warehousing and Mining. Ed ke-2. Idea Group Publisher.
Herawan Y. 2011. Pengembangan Indexing spatio-temporal pada database spatiotemporal dengan konsep event-based spatiotemporal data model [skripsi]. Bogor: Departemen Ilmu Komputer Institut Pertanian Bogor.
Manning CD, Raghavan P, Schutze H. 2008. Introduction to Information Retrieval. Cambridge: Cambridge University Press. Pramurjadi A. 2010. Klasifikasi dokumen
menggunakan background smoothing [skripsi]. Bogor: Departemen Ilmu Komputer, Institut Pertanian Bogor.
Ramadhina A. 2011. Klasifikasi dokumen bahasa Indonesia menggunakan semantic smoothing [skripsi]. Bogor: Departemen Ilmu Komputer Institut Pertanian Bogor. Zhou X, Zhang X, Hu X. 2008. Semantic
Lampiran 1 Hasil klasifikasi dokumen uji pada short document
Class a b c
Fisiologi dan agronomi a 23 0 1
Pemuliaan dan tek. benih b 1 22 0
Proteksi c 1 3 24
Pemuliaan & Tek. Benih
b a+c
b 22 1
a+c 3 49 Recall b = 88,00% Prec b = 95,65% F-1 b = 89,71% Akurasi b= 94,67% Fisiologi &
Agronomi
a b+c
a 23 1
b+c 2 49 Recall a = 92,00% Prec a = 95,83% F-1 a = 93,88% Akurasi a= 96,00%
Proteksi (Hama & Penyakit
c a+b
c 24 4
Lampiran 2 Hasil klasifikasi dokumen uji pada long document
Class a b c
Fisiologi dan agronomi a 25 3 0
Pemuliaan dan tek. benih b 0 22 0
Proteksi c 0 0 25
Fisiologi & Agronomi
a b+c
a 25 3
b+c 0 47 Recall a = 100% Prec a = 89,29% F-1 a = 94,34% Akurasi a= 96,00%
Pemuliaan & Tek. Benih
b a+c
b 22 0
a+c 3 50 Recall b = 88,00% Prec b = 100% F-1 b = 93,62% Akurasi b= 96,00%
Proteksi (Hama & Penyakit
c a+b
c 25 0