ANALISA FAKTOR YANG MEMPENGARUHI TINGKAT
KECELAKAAN LALU LINTAS DI KABUPATEN
DELI SERDANG TAHUN 2013
TUGAS AKHIR
MUHAMMAD JONI
112407016
PROGRAM STUDI D3 STATISTIKA
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
ANALISA FAKTOR YANG MEMPENGARUHI TINGKAT
KECELAKAAN LALU LINTAS DI KABUPATEN
DELI SERDANG TAHUN 2013
TUGAS AKHIR
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Ahli Madya
MUHAMMAD JONI
112407016
PROGRAM STUDI D3 STATISTIKA
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : Analisa Faktor Yang Mempengaruhi Tingkat
Kecelakaan Lalu Lintas Di Kabupaten
Deli Serdang Tahun 2013
Kategori : Tugas Akhir
Nama : Muhammad Joni
Nomor Induk Mahasiswa : 112407016
Program Studi : D3 Statistika
Departemen : Matematika
Fakultas : Matematika Dan Ilmu Pengetahuan Alam
Universitas Sumatera Utara
Disetujui di Medan, Juli 2014
Disetujui Oleh:
Program Studi D3 Statistika FMIPA USU
Ketua, Pembimbing
PERNYATAAN
ANALISA FAKTOR YANG MEMPENGARUHI TINGKAT KECELAKAAN LALU LINTAS DI KABUPATEN
DELI SERDANG TAHUN 2013
TUGAS AKHIR
Saya mengakui bahwa Tugas Akhir ini adalah hasil kerja saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Juli 2014
PENGHARGAAN
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Pengasih dan Maha
Penyayang, dengan limpahan karunia-Nya penulis dapat menyelesaikan
penyusunan Tugas Akhir ini dengan judul Analisa Faktor yang Mempengaruhi
Tingkat Kecelakaan Lalu Lintas di Kabupaten Deli Serdang Tahun 2013.
Terima kasih penulis sampaikan kepada Bapak Drs. Gim Tarigan, M.Si
selaku pembimbing yang telah meluangkan waktunya selama penyusunan tugas
akhir ini. Terima kasih kepada Bapak Drs. Faigiziduhu Bu’ulӧlӧ, M.Si dan Bapak
Drs. Suwarno Ariswoyo, M.Si selaku Ketua dan Sekretaris Program Studi D3
Statistika FMIPA USU, Bapak Prof. Dr. Tulus, M.Si dan Ibu Dr. Mardiningsih,
M.Si selaku Ketua dan Sekretaris Departemen Matematika FMIPA USU Medan,
Bapak Dr. Sutarman, M.Sc selaku Dekan FMIPA USU Medan, seluruh staff dan
Dosen Program Studi D3 Statistika FMIPA USU, pegawai FMIPA USU dan
rekan-rekan kuliah. Akhirnya tidak terlupakan kepada Bapak tercinta Sutrisno dan
Ibu tercinta Dra. Halimah dan keluarga yang selama ini memberikan bantuan dan
dorongan yang diperlukan. Semoga Tuhan Yang Maha Esa akan membalasnya.
BAB 3. Gambaran Umum 23 3.6. Kewajiban yang harus ditaati oleh Pengemudi
Kendaraan Bermotor 28
4.5.1. Perhitungan Korelasi Antara Variabel independen
dan Variabel dependen 40
4.5.2. Perhitungan Korelasi Antara Varibel independen 42 4.6. Uji Koefisien Regresi Linier Berganda 44
BAB 5. Implementasi Sistem 50
DAFTAR TABEL
Nomor Judul Halaman
Tabel
4.1. Jumlah Kecelakaan Berdasarkan Faktor Kecelakaan 31 Lalu Lintas di Kabupaten Deli Serdang Tahun 2013
4.2. Nilai-nilai yang diperlukan untuk Membentuk Koefisien 32 Persamaan Regresi Linier Berganda
4.3. Nilai-nilai yang diperlukan untk Uji Keberartian Regresi 36 4.4. Nilai-nilai yang diperlukan untk Uji Koefisien Regresi 45
DAFTAR GAMBAR
Nomor Judul Halaman
Gambar
DAFTAR LAMPIRAN
Nomor Judul Halaman
Lamp
1. Hasil Perhitungan Dari Program SPSS 2. Surat Permohonan Penelitian Tugas Akhir 3. Surat Riset Pengumpulan Data
4. Kartu Bimbingan Tugas Akhir Mahasiswa
BAB 1
PENDAHULUAN
1.1Latar Belakang
Kabupaten Deli Serdang adalah sebuah kabupaten di provinsi Sumatera Utara,
Indonesia. Sekitar tahu
kurang 30 kilometer dari
salah satu daerah dari 25
yang terdapat di Kabupaten Deli Serdang merupakan akses darat yang
menghubungkannya dengan Kabupaten/Kota lain di Sumatera Utara.
Karena sebagai jalan lintas banyak kendaraan bermotor yang beroperasi setiap
harinya, baik itu roda dua atau roda empat. Sementara ruang gerak bagi
kendaraan tersebut semakin berkurang. Dengan kata lain peningkatan sarana
transportasi tidak seimbang dengan ketersediaan prasarananya. Disamping itu,
kurang disiplinnya pengemudi kendaraan bermotor di jalan, akhirnya
menimbulkan persoalan lalu lintas yang berhubungan dengan keselamatan yaitu
Kecelakaan lalu lintas merupakan salah satu penyebab utama kematian
terbesar yang dipengaruhi oleh beberapa faktor seperti jumlah pelanggaran
rambu-rambu lalu lintas yang dilakukan oleh pengemudi, jumlah kendaraan,
dan kondisi jalan. Seberapa besar faktor-faktor tersebut merupakan permasalahan
yang harus diketahui oleh petugas lalu lintas dan Pemerintah Kabupaten Deli
Serdang untuk dapat mengambil tindakan dan keputusan dalam rangka
mengurangi tingkat kecelakaan lalu lintas.
Pengaruh dari faktor-faktor inilah yang akan dianalisa dan juga hubungan
fungsionalnya terhadap tingkat kecelakaan lalu lintas. Bentuk penduga yang
digunakan dalam penulisan ini adalah Persamaan regresi linier berganda antara
jumlah kecelakaan lalu lintas terhadap faktor-faktor yang mempengaruhinya.
Berdasarkan uraian diatas, penulis tertarik untuk melakukan suatu penelitian
untuk menganalisa faktor yang mempengaruhi kecelakaan lalu lintas. Maka
penulis memilih judul Tugas Akhir ini, “ANALISA FAKTOR YANG
MEMPENGARUHI TINGKAT KECELAKAAN LALU LINTAS DI
1.2Identifikasi Masalah
Kecelakaan lalu lintas yang terjadi di kabupaten Deli Serdang mengalami
peningkatan setiap tahunnya, terutama di jalan lintas yang menghubungkan kota
Medan, kabupaten Deli Serdang dan Kabupaten Serdang Bedagai. Hal ini
tentunya tidak terlepas dari faktor-faktor yang mempengaruhi hal tersebut. Yang
menjadi permasalahan dalam tulisan ini adalah menentukan faktor apa yang
paling berpengaruh, dan menetukan seberapa besar faktor tersebut berpengaruh
terhadap tingkat kecelakaan lalu lintas di Kabupaten Deli Serdang.
1.3Ruang Lingkup Permasalahan
Untuk mengarahkan penelitian ini agar tidak menyimpang dari sasaran yang
dituju maka perlu dibuat pembatasan ruang lingkup permasalahan yaitu
menganalisa faktor apa sajakah yang mempengaruhi dan yang paling berpengaruh
terhadap tingkat kecelakaan lalu lintas di Kabupaten Deli Serdang.
1.4Maksud dan Tujuan Penelitian
Maksud dari penelitian ini adalah untuk mengaplikasikan ilmu pengetahuan
Adapun tujuan dilakukan penelitian ini adalah untuk:
1. Untuk mengetahui faktor yang sangat berpengaruh terhadap tingginya
tingkat kecelakaan lalu lintas di kabupaten Deliserdang.
2. Untuk mengetahui seberapa besar faktor-faktor tersebut mempengaruhi
kecelakaan lalu lintas.
3. Untuk menentukan peersamaan linier berganda dari faktor penduga
terjadinya kecelakaan lalu lintas.
1.5Manfaat Penelitian
Adapun manfaat dari penelitian ini adalah:
1. Sebagai bahan pertimbangan bagi pemerintah kabupaten Deli Serdang
dalam perencanaan pembangunan jalan untuk Gerakan Deli Serdang
Membangun.
2. Sebagai informasi tentang faktor-faktor yang mempengaruhi tingkat
kecelakaan lalu lintas di kabupaten Deli Serdang.
3. Sedangkan bagi penulis penelitian ini merupakan penerapan ilmu yang
1.6Tinjauan Pustaka
Ada beberapa defenisi regresi yang dapat dijabarkan yaitu:
1. Persamaan regresi adalah persamaan matematika yang memungkinkan
untuk meramalkan nilai-nilai suatu peubah tak bebas dari nilai-nilai satu
atau lebih peubah bebas.
(Ronald E Walpole : 340)
2. Analisis regresi adalah hubungan yang didapat dan dinyatakan dalam
bentuk persamaan matematika yang menyatakan hubungan fungsional
antara variabel-variabel.
(Sudjana, 2002 : 310)
3. Persamaan regresi adalah suatu formula matematis yang menunjukkan
hubungan keterkaitan antara satu atau beberapa variabel yang nilainya
sudah diketahui dengan variabel yang nilainya belum diketahui.
(Algifari, 2000 : 2)
1.7Metode Penelitian
Metode yang digunakan penulis dalam melaksanakan penelitian adalah sebagai
berikut:
1. Metode Penelitian Kepustakaan
Metode Penelitian Kepustakaan (Study Literature) yaitu metode
pengumpulan data untuk memperoleh data dan informasi dari
yang bersifat teoritis, serta sumber lainnya yang berhubungan
dengan objek yang diteliti.
2. Metode Pengumpulan Data
Pengumpulan data untuk keperluan penelitian ini, penulis melakukan
dengan menggunakan data sekunder. Data sekunder adalah data
primer yang diperoleh oleh pihak lain yang umumnya disajikan
dalam bentuk tabel-tabel atau diagram.
Data sekunder diperoleh dari Kantor Kepolisian Daerah Sumatera
Utara Direktorat Lalu Lintas.
3. Metode Pengolahan Data
Data dianalisa menggunakan metode regresi linear berganda untuk
melihat persamaan regresi liniernya dan untuk mengetahui hubungan
setiap variabel digunakan analisis kerelasi. Langkah-langkah yang
dilakukan dalam pengolahan data adalah:
1. Megelompokkan data menjadi variabel bebas (X) dan
variabel terikat (Y).
2. Menentukan hubungan antara variabel bebas (X) dengan
variabel terikat (Y) sehingga didapat regresi Y atas X1, X2,
X3, . . . , Xk
3. Uji regresi linier berganda untuk mengetahui besarnya
pengaruh variabel bebas X secara bersama-sama terhadap
variabel terikat Y
4. Uji korelasi untuk mengetahui seberapa besar pengaruh
hubungan variabel-variabel bebas tersebut terhadap variabel
terikat.
5. Uji koefisien-koefisien regresi untuk menguji taraf nyata
koefisien-koefisien regresi yang didapat.
1.8Lokasi Penelitian
Penelitian ataupun pengumpulan data mengenai faktor yang mempengaruhi
tingkat kecelakaan lalu lintas serta data mengenai tingkat kecelakaan lalu lintas itu
sendiri dilaksanakan di Kepolisian Negara Republik Indonesia Daerah Sumatera
Utara Direktorat Lalu Lintas Jl. Putri Hijau No.14 Medan.
1.9Sistematika Penulisan
Adapun sistematika penulisan yang diuraikan penulis antara lain:
BAB 1 : PENDAHULUAN
Bab ini menguraikan tentang latar belakang,
indentifikasi masalah, ruang lingkup permasalahan,
maksud dan tujuan penelitian, manfaat penelitian,
BAB 2 : LANDASAN TEORI
Bab ini menguraikan tentang pengertian regresi
linier berganda, uji regresi linier, uji korelasi, dan uji
koefisien untuk regresi linier berganda.
BAB 3 : GAMBARAN UMUM
Bab ini menjelaskan atau menceritakan tentang
pendefenisian kecelakaan lalu lintas.
BAB 4 : PENGOLAHAN DATA
Bab ini menguraikan proses pengolahan data pada
regresi linier berganda, anlisis korelasi, dan
koefisien kecelakaan lalu lintas.
BAB 5 : IMPLEMENTASI SISTEM
Bab ini menguraikan proses pengolahan data dengan
program yang akan digunakan yaitu SPSS mulai
data input hingga data hasil outputnya yang
membantu dalam menyelesaikan permasalahan
dalam penulisan.
BAB 6 : KESIMPULAN DAN SARAN
Bab ini terdiri atas kesimpulan dan hasil analisa
yang telah dilakukan serta saran berdasarkan
kesimpulan yang diperoleh yang tentunya
bermanfaat bagi pembaca dan pihak yang
BAB 2
LANDASAN TEORI
2.1Pengertian Regresi
Istilah regresi pertama kali diperkenalkan oleh seorang ahli yang bernama Francis
Galton dalam makalah berjudul Regression Towered Mediacraty in Hereditary
Statue. Beliau memperkenalkan model peramalan, penaksiran, atau pendugaan,
dengan penilitiannya terhadap tinggi badan manusia. Galton melakukan suatu
penelitian dimana penelitian tersebut membandingkan antara tinggi anak laki-laki
dan tinggi badan ayahnya. Galton menunjukkan bahwa tinggi badan anak laki-laki
dari ayah yang tinggi setelah beberapa generasi cenderung mundur (Regressed)
pendek cenderung lebih tinggi dari ayahnya, jadi seolah-olah semua anak laki-laki
yang tinggi dan anak laki-laki yang pendek bergerak menuju kerata-rata tinggi
dari seluruh anak laki-laki. Dari uraian tersebut dapat disimpulkan bahwa pada
umumnya tinggi anak mengikuti tinggi orang tuanya.
Regresi pada mulanya bertujuan untuk membuat perkiraan niai suatu
variabel (tinggi badan anak) terhadap variabel yang lain (tinggi badan orang tua).
Pada perkembangan selanjutnya analisis regresi dapat digunakan sebagai alat
untuk membuat perkiraan nilai suatu variabel dengan menggunakan beberapa
variabel lain yang berhubungan dengan variabel tersebut. Jadi analisis regresi
variabel tidak bebas (dependent variable) pada satu atau lebih variabel bebas
(independent variable) yang menerangkan. Dengan tujuan untuk memperkirakan
atau meramalkan nilai rata-rata dari variabel tidak bebas apabila variabel yang
menerangkan sudah diketahui.
2.2Analisis Regresi Linier
Analisis regresi linier merupakan suatu model matematis yang dapat digunakan
dalam pola persamaan yang menyatakan hubungan fungsional antara dua variabel
atau lebih. Analisis regresi linier dapat digunakan untuk dua hal yaitu:
1. Untuk memperoleh suatu persamaan hubungan antara dua variabel
persamaan garis yang dapat disebut persamaan regresi yang dapat
berbentuk linier atau nonlinier.
2. Meramalkan atau menduga nillai dari suatu variabel dalam hubungannya
dengan variabel lain yang diketahui melalui persamaan garis regresinya.
Analisis regresi terdiri dari dua bentuk, yaitu:
1. Analisis Regresi Linier Sederhana
2. Analisis Regresi Linier Berganda
Analisis regresi linier sederhana merupakan bentuk regresi dengan model
yang bertujuan untuk mempelajari hubungan antara dua variabel, yaitu variabel
linier berganda merupakan bentuk regresi dengan model yang memiliki hubungan
antara tiga variabel atau lebih, yaitu sekurang-kurangnya satu variabel dependent
dan dua variabel independent.
Analisis regresi berguna untuk mendapatkan hubungan fungsional antar
dua variabel bebas terhadap variabel tidak bebas atau meramalkan pengaruh
variabel bebas terhadap variabel tidak bebas dalam suatu fenomena yang
kompleks. Jika, X1, X2, ..., Xk adalah variabel-variabel bebas dan Y variabel
terikat, maka terdapat hubungan fungsional antara X dan Y, dimana variasi dari X
akan diiringi pula oleh variasi dari Y. Jika dibuat secara matematis hubungan itu
dapat dijabarkan sebagai berikut:
Dimana: Y= f(X1, X2, ..., Xk, e)
Y adalah variabel dependent (terikat)
X adalah variabel independent (bebas)
e adalah variabel residu (disturbace term)
Berkaitan dengan analisis regresi ini, setidaknya ada empat kegiatan yang
lazim dilaksanakan yaitu:
1. Menguji seberapa besar variasi variabel dependent dapat diterangkan oleh
variasi independent.
2. Mengadakan estimasi terhadap parameter berdasarkan data empiris.
3. Menguji apakah estimasi parameter tersebut signifikan atau tidak.
4. Melihat apakah tanda magnitude dari estimasi parameter cocok dengan
2.2.1 Analisis Regresi Linier Sederhana
Regresi linier sederhana merupakan suatu prosedur yang digunakan untuk
memperkirakan hubungan antara dua variabel dimana hanya terdapat satu variabel
atau peubah bebas X dan satu peubah terikat Y.
Dalam bentuk persamaan, model regresi sederhana adalah:
Y = a + bX (2. 1)
Dimana: Y adalah variabel dependent (terikat)
X adalah variabel independen (bebas)
a adalah penduga bagi intercept (α)
b adalah penduga bagi koefisien regresi (β)
Penggunaan regresi linier sederhana didasarkan pada asumsi diantaranya sebagai
berikut:
1. Model regresi dispesifikasi secara benar. Tidak terdapat bias spesifikasi
dalam model yang digunakan dalam analisis empiris.
2. Model regresi harus linier dalam parameter.
3. Variabel bebas tidak berkorelasi dengan disturbance term (error).
4. Nilai disturbance term sebesar 0 atau dengan simbol (E (U/X) ) = 0.
5. Varian untuk masing-masing error term (kesalahan) konstan.
6. Jika variabel bebas lebih dari satu, maka antara variabel bebas
(explanatory) tidak ada hubungan yang nyata.
2.2.2 Analisis Regresi Linier Berganda
Analisis regresi linier berganda merupakan analisis regresi yang menjelaskan
hubungan antara peubah respon (variabel terikat) dengan faktor-faktor yang
mempengaruhi lebih dari satu prediktor (variabel bebas). Regresi linier berganda
hampir sama dengan regresi linier sederhana hanya saja pada regresi linier
berganda variabel penduga (variabel bebas) lebih dari satu variabel.
Tujuan analisis regresi linier berganda adalah untuk membuat sebuah
model yang baik (sebuah persamaan perkiraan hubungan Y terhadap
variabel-variabel bebas) yang akan memungkinkan untuk menaksir Y. Untuk
memperkirakan nilai variabel dependen Y, akan lebih baik apabila ikut
memperhitungkan variabel-variabel independen lain yang ikut mempengaruhi
nilai Y, dengan demikian dimiliki hubungan antara satu variabel dependen Y
dengan beberapa variabel lain yang independen X1, X2, dan X3, ..., Xk. Dalam
pembahasan mengenai regresi linier sederhana, simbol yang digunakan untuk
variabel independentnya adalah X. Dalam regresi linier berganda, persamaan
regresinya memiliki lebih dari satu variabel independent maka perlu menambah
tanda bilangan pada setiap variabel tersebut, dalam hal ini X1, X2, ..., Xk.
Secara umum persamaan regresi linier berganda dapat ditulis sebagai berikut:
(Untuk Populasi)
(Untuk Sampel)
Yi = b0 + b1X1i + b2X2i + . . . + bkXk + ԑi (2. 3)
Dimana: i = 1, 2, . . . , n
b0, b1, b2, ..., bk dan ԑadalah pendugaan atas β0, β1, β2,..., βk dan ԑ.
Dalam penelitian ini digunakan empat variabel yang terdiri dari satu
variabel dependent Y dan tiga variabel independent X yaitu: X1, X2, dan X3. Maka
persamaan regresi linier bergandanya adalah:
Ŷ = b0 + b1X1i + b2X2i + b3X3i (2. 4)
Persamaan diatas dapat diselesaikan dengan empat bentuk yaitu:
∑ Yi = b0n + b1 ∑ X1i + b2 ∑X2i + b3∑X3i (2. 5)
∑ YiX1i = b0 ∑ X1i + b1 ∑���� + b2 ∑ X1i X2i + b3∑ X1i X3i (2. 6)
∑ YiX2i = b0 ∑ X2i + b1 ∑ X1i X2i + b2 ∑���� + b3∑ X2i X3i (2. 7)
2.3 Uji Keberartian Regresi
Sebelum persamaan regresi diperoleh digunakan untuk membuat kesimpulan
terlebih dahulu diperiksa setidaknya mengenai kelinieran dan keberartiannya.
Pemeriksaan ini ditempuh melalui pengujian hipotesis. Uji keberartian dilakukan
untuk meyakinkan diri apakah regresi yang didapat berdasarkan penilitian ada
artinya bila dipakai untuk membuat kesimpulan mengenai hubungan sejumlah
peubah yang sedang dipelajari.
Untuk itu diperlukan dua macam jumlah kuadrat (JK) yaitu Jumlah
Kuadrat untuk regresi yang ditulis JKreg dan Jumlah Kuadrat untuk sisa (residu)
yang ditulis JKres.
Jika �1� =�1�− ��1�,�2� =�2�− ��2, … ,�� = ��� − ��� dan �� = �� − �� maka
secara umum jumlah kuadrat-kuadrat tersebut dapat dihitung dari:
JKreg = b1 ∑ �1i yi + b2 ∑ �2i yi + b3 ∑ �3i yi (2. 10)
Dengan derajat kebebasan dk = k
JKres = ∑ (Yi−Ŷi)2 (2. 11)
Dengan derajat kebebasan dk = ( n – k – l ) untuk sampel berukuran n.
Dengan demikian uji keberartian regresi berganda dapat dihitung dengan:
Fhitung = ����� /�
����� /(�−�−�) (2. 12)
Dimana statistik F yang menyebar mengikuti distribusi F dengan derajat
2.4 Pengujian Hipotesis
Pengujian hipotesis dapat didasarkan dengan menggunakan dua hal, yaitu: tingkat
signifikansi atau probabilitas (α) dan tingkat kepercayaan atau confidence interval.
Didasarkan tingkat signifikansi pada umumnya orang menggunakan 0,05. Kisaran
tingkat signifikansi mulai dari 0,01 sampai dengan 0,1. Yang dimaksud dengan
tingkat signifikansi adalah probabilitas menggunakan kesalahan tipe I, yaitu
kesalahan menolak hipotesis ketika hipotesis tersebut benar. Tingkat kepercayaan
pada umumnya ialah sebesar 95%, yang dimaksud dengan tingkat kepercayaan
ialah tingkat dimana sebesar 95% nilai sampel akan mewakili nilai populasi
dimana sampel berasal. Dalam melakukan uji hipotesis terdapat dua hipotesis
yaitu: H0 (hipotesis nol) dan Ha (hipotesis alternatif). H0 bertujuan untuk
memberikan usulan dugaan kemungkinan tidak adanya perbedaan antara
perkiraan penilitian dengan keadaan yang sesungguhnya yang diteliti. Ha
bertujuan memberikan usulan dugaan adanya perbedaan perkiraan dengan
keadaan sesungguhnya yang diteliti.
Pembentukan suatu hipotesis memerlukan teori-teori maupun hasil
penelitian terlebih dahulu sebagai pendukung pernyataan hipotesis yang
diusulkan. Dalam membentuk hipotesis ada beberapa hal yang di pertimbangkan:
1) Hipotesis nol dan hipotesis alternatif yang diusulkan.
2) Penentuan nilai hitung statistik.
3) Daerah penerimaan dan penolakan serta teknik arah pengujian (one tailed
4) Menarik kesimpulan apakah menerima atau menolak hipotesis yang
diusulkan.
Dalam pengujian keberartian regresi, langkah-langkah yang dibutuhkan untuk
pengujian hipotesis ini antara lain:
1) H0: β0= β1= . . . = βk = 0
Tidak terdapat hubungan fungsional yang signifikansi antara variabel
bebas dengan variabel terikat.
Ha : minimal satu parameter koefisien regresi βk yang ≠ 0 terdapat
hubungan fungsional yang signifikansi antara variabel bebas dengan
variabel terikat.
2) Pilih taraf α yang diinginkan.
3) Hitung statistik Fhitung dengan menggunakan persamaan.
4) Nilai Ftabelmenggunakan daftar tabel F dengan taraf signifikansi α.
5) Kriteria pengujian : jika Fhitung≥ Ftabel , maka H0 ditolak dan Ha diterima.
Sebaliknya jika Fhitung≤ Ftabel , maka H0 dan Ha ditolak.
2.5 Koefisien Determinansi
Koefisien determinansi yang disimbolkan dengan R2 bertujuan untuk pengujian regresi linier berganda yang mencakup lebih dari dua variabel adalah untuk
terikat. Nilai R2 dikatakan baik jika berada diatas 0,5 karen nilai R2 berkisar antara 0 dan 1. Pada umumnya model regresi linier berganda dapat dikatakan
layak dipakai untuk penilitian, karena sebagian besar variabel terikat dijelaskan
oleh variabel bebas yang digunakan dalam model.
Koefisien determinansi dapat dihitung dari:
�� =��∑����� + ��∑����� + . . . + ��∑�����
∑( ��− Ȳ� )� (2. 13)
Sehingga rumus umum koefisien determinansi yaitu
�� = ����� ∑�=�� ���
(2.14)
Harga R2 diperoleh sesuai dengan variansi yang dijelaskan oleh masing-masing variabel yang tinggal dalam regresi. Hal ini mengakibatkan variasi yang
dijelaskan penduga hanya disebabkan oleh variabel yang berpengaruh saja.
2.6 Uji Korelasi
Uji korelasi terdiri dari Pearson, Spearman, dan Kendall. Uji korelasi bertujuan
untuk menguji hubungan antara dua variabel yang tidak menunjukkan hubungan
fungsional (berhubungan bukan berarti disebabkan). Uji korelasi tidak
membedakan jenis variabel (tidak ada varaiabel bebas maupun variabel tak
bebas). Keeratan hubungan ini dinyatakan dalam bentuk koefisien korelasi. Jika
menggunakan korelasi Pearson (karena memenuhi asumsi parametrik). Jika
jumlah sampel kurang dari 30 (sampel kecil) dan kondisi data tidak normal maka
sebaiknya menggunakan korelasi Spearman atau Kendall (karena memenuhi
asumsi non-parametrik).
2.6.1 Koefisien Korelasi
Koefisien korelasi biasanya disimbolkan dengan r. Nilai koefisien korelasi
merupakan nilai yang digunakan untuk mengukur kekuatan (keeratan) suatu
hubungan antar variabel.
Untuk mencari korelasi antar variabel dapat dirumuskan sebagai berikut:
1. Untuk menghitung koefisien korelasi antara variabel dependen Y dengan
tiga variabel independen X1, X2, X3 yaitu:
�= � ∑X�Y� − (∑ X�)(∑Y�)
�{ � ∑X�2− (∑X�)2} { � ∑Y�2− (∑Y�)2}
(2. 15)
2. Koefisien korelasi antara Y dengan X1
���1 = � ∑
X1�Y� − (∑X1�)(∑Y�)
�{�∑X1�2 − (∑X1�)2} {�∑Y�2− (∑Y�)2}
(2. 16)
3. Koefisien korelasi antara Y dengan X2
���2 = � ∑
X2�Y� − (∑X2�)(∑Y�)
�{�∑X2�2 − (∑X2�)2} {�∑Y�2− (∑Y�)2}
4. Koefisien korelasi antara Y dengan X3
���3 = � ∑
X3�Y� − (∑X3�)(∑Y�)
�{�∑X3�2 − (∑X3�)2} {�∑Y�2− (∑Y�)2}
(2. 18)
Koefisien korelasi memiliki nilai antara -1 hingga +1. Sifat nilai koefisien
korelasi adalah plus (+) atau minus (-) yang menunjukkan arah korelasi. Makna
sifat korelasi yaitu:
1. Tanda positif (+) pada koefisien korelasi menunjukkan hubungan yang
searah (korelasi positif). Artinya jika suatu nilai variabel mengalami
kenaikan maka nilai variabel yang lain juga mengalami kenaikan dan
demikian juga sebaliknya.
2. Tanda negatif (-) pada koefisien korelasi menunjukkan hubungan yang
berlawanan arah (korelasi negatif). Artinya jika suatu nilai variabel
mengalami kenaikan maka nilai variabel yang lain juga mengalami
penurunan dan demikian juga sebaliknya.
Sifat korelasi akan menentukan arah dari korelasi. Keeratan korelasi dapat
dikelompokkan sebagai berikut:
1. 0,00 sampai dengan 0,20 berarti korelasi memiliki keeratan sangat lemah.
2. 0,21 sampai dengan 0,40 berarti korelasi memiliki keeratan lemah.
3. 0,41 sampai dengan 0,70 berarti korelasi memiliki keeratan kuat.
4. 0,71 sampai dengan 0,90 berarti korelasi memiliki keeratan sangat kuat.
5. 0,91 sampai dengan 0,99 berarti korelasi memiliki keeratan sangat kuat
sekali.
Analisis ini bertujuan untuk mengukur kekuatan dan derajat hubungan
antar dua variabel. Derajat hubungan antara dua variabel disebut korelasi
sederhana sedangkan derajat yang berkaitan dengan tiga atau lebih variabel
disebut sebagai korelasi berganda. Korelasi dapat bersifat linier atau nonlinier.
2.7 Uji Korelasi Regresi Linier Berganda
Untuk mengetahui bagaimana keberartian setiap variabel bebas dalam regresi,
perlu diadakan pengujian tersendiri mengenai koefisien-koefisien regresi.
Misalkan populasi memiliki model regresi linier berganda, yaitu:
��,��,��,…,�� = ��+����+����+ … +����
Yang berdasarkan sebuah sampel acak berukuran n ditaksir oleh regresi
berbentuk: Ŷ = b0 + b1X1 + b2X2 + . . . + bkXk
Akan dilakukan pengujian hipotesis dalam bentuk:
H0: β1 = 0, i = 1, 2, ..., k Ha : β2≠ 0, i = 1, 2, ..., k
Untuk menguji hipotesis ini digunakan kekeliruan baku taksiran Sy 1, 2, ..., k
jumlah kuadrat-kuadrat ∑ij2 dengan X�� = X�−X�� dan koefisien korelasi ganda
antara masing-masing variabel independen X dengan variabel dependen Y dalam
Dengan besaran-besaran ini dibentuk kekeliruan baku koefisien b, yakni:
��� = �
s�2 .12…�
�∑x��2�(1− ��2) (2. 19)
Dimana:
��2 .12…� =
∑( Y� − Ȳ�)2 � − � −1
���2 = �(X
��− X��)2
�2 = ����� ∑�=1� � �2
Selanjutnya dihitung statistik:
�� = ���
�� (2. 20)
Dengan kriteria pengujian: jika ��> ������, maka H0 ditolak dan jika ��< ������, maka H0 diterima yang akan berdistribusi t dengan derajat kebebasan
BAB 3
GAMBARAN UMUM
3.1 Pengertian Jalan
Jalan adalah prasarana transportasi darat yang meliputi segala bagian jalan,
termasuk bangunan pelengkap dan perlengkapannya yang diperuntukkan bagi lalu
lintas, yang berada pada permukaan tanah, di atas permukaan tanah, di bawah
permukaan tanah dan atau air, serta di atas permukaan air, kecuali jalan kereta api,
jalan lori, dan jalan kabel (Peraturan Pemerintah Nomor 34 Tahun 2006).
Jalan raya adalah jalur-jalur tanah di atas permukaan bumi yang dibuat
oleh manusia dengan bentuk, ukuran-ukuran dan jenis konstruksinya sehingga
dapat digunakan untuk menyalurkan lalu lintas orang, hewan dan kendaraan yang
mengangkut barang dari suatu tempat ke tempat lainnya dengan mudah dan cepat.
Untuk perencanaan jalan raya yang baik, bentuk geometriknya harus
ditetapkan sedemikian rupa sehingga jalan yang bersangkutan dapat memberikan
pelayanan yang optimal kepada lalu lintas sesuai dengan fungsinya, sebab tujuan
akhir dari perencanaan geometrik ini adalah menghasilkan infrastruktur yang
aman, efisiensi pelayanan arus lalu lintas dan memaksimalkan ratio tingkat
penggunaan biaya juga memberikan rasa aman dan nyaman kepada pengguna
3.2 Klasifikasi Kendaraan
Klasifikasi kendaraan bermotor dalam data didasarkan menurut Peraturan Bina
Marga, yakni perbandingan terhadap satuan mobil penumpang. Penjelasan tentang
jenis kendaraan dapat dilihat sebagai berikut:
1. Mobil penumpang (Passenger car)
Jenis kendaraan pribadi dengan daya angkut lebih kecil dari 12 orang,
termasuk didalamnya jeep, sedan, dan lain-lain.
2. Mobil bus (Bus)
Semua jenis kendaraan penumpang yang daya angkutnya lebih besar dari
12 orang termasuk didalamnya Pick Up.
3. Mobil gerobak (Truck wagon)
Semua jenis truk yang mempunyai roda 4 keatas, termasuk mobil tangki.
4. Sepeda motor (Motor cycle)
Semua jenis kendaraan bermotor beroda 2, seperti Honda, Yamaha,
Kawasaki, Vespa, dan lain-lain.
3.3 Kecelakaan Lalu Lintas di Jalan Raya
Menurut buku Undang-Undang Republik Indonesia Nomor 14 tahun 1992 tentang
Lalu Lintas dan Angkutan Jalan beserta Peraturan Pelaksanaannya PP Nomor 41,
42, 43, dan 44 Tahun 1993 (pada Peraturan Pemerintah Republik Indonesia
peristiwa di jalan yang tidak di sangka-sangka dan tidak disengaja melibatkan
kendaraan yang sedang bergerak dengan atau tanpa pemakai jalan lainnya,
mengakibatkan korban manusia atau kerugian harta benda.
Didalam buku tersebut, korban kecelakaan lalu lintas dibagi menjadi 3
bagian yaitu:
1. Korban Meninggal
Korban meninggal adalah korban yang sudah dipastikan meninggal
sebagai akibat kecelakaan lalu lintas dalam jangka waktu paling lama 3
hari setelah kecelakaan tersebut.
2. Korban Luka Berat
Korban luka berat merupakan korban yang karena luka-lukanya menderita
cacat tetap atau dirawat dalam jangka waktu lebih dari 30 hari sejak
terjadinya kecelakaan.
3. Korban Luka Ringan
Korban luka ringan adalah korban yang tidak termasuk dalam pengertian
korban meninggal dan korban luka berat.
3.4 Jenis dan Bentuk Kecelakaan
Kecelakaan lalu lintas dapat digolongkan atas 3 jenis menurut akibat dari
kecelakaan tersebut yaitu:
2. Kecelakaan dengan korban luka-luka
3. Kecelakaan dengan kerugian dan kerusakan kendaraan.
PT Jasa Marga mengelompokkan jenis tabrakan yang melatar belakangi
terjadinya kecelakaan lalu lintas menjadi:
1. Tabrakan depan-depan
Merupakan jenis tabrakan antara dua kendaraan yang tengah melaju
dimana keduannya saling beradu muka dari arah yang berlawanan, yaitu
bagian depan kendaraan yang satu dengan bagian depan kendaraan
lainnya.
2. Tabrakan depan-samping
Adalah jenis tabrakan antara dua kendaraan yang tengah melaju dimana
bagian depan kendaraan yang satu menabrak bagian samping kendaraan
lainnya.
3. Tabrakan samping-samping
Merupakan jenis tabrakan antara dua kendaraan yang tengah melaju
dimana bagian samping kendaraan yang satu menabrak bagian yang lain.
4. Tabrakan depan-belakang
Merupakan jenis tabrakan antara dua kendaraan yang tengah melaju
dimana bagian depan kendaraan yang satu menabrak bagian belakang
kendaraan di depannya dan kendaraan tersebut berada pada arah yang
5. Menabrak penyeberang jalan
Adalah jenis tabrakan antara kendaraan yang tengah melaju dan pejalan
kaki yang sedang menyeberang jalan.
6. Tabrakan sendiri
Merupakan jenis tabrakan dimana kendaraan yang tengah melaju
mengalami kecelakaan sendiri atau tunggal.
7. Tabrakan beruntun
Adalah jenis tabrakan dimana kendaraan yang tengah melaju menabrak
mengakibatkan terjadinya kecelakaan yang melibatkan dari dua kendaraan
secara beruntun.
8. Menabrak obyek tetap
Merupakan jenis tabrakan dimana kendaraan yang tengah melaju
menabrak obyek tetap dijalan.
3.5 Faktor Penyebab Kecelakaan Lalu Lintas
Faktor-faktor penyebab kecelakaan terdiri dari: Faktor manusia (pengemudi),
faktor kendaraan, faktor alam, faktor jalan, dan faktor teknologi.
1. Faktor Manusia (pengemudi)
Pelanggaran atau tindakan yang berbahaya oleh pengemudi, seperti
ugal-ugalan, pengemudi dalam kondisi tidak sadar atau terpengaruh alkohol,
2. Faktor Kendaraan
Kendaraan yang digunakan untuk memenuhi standar kendaraan yang baik,
seperti tanpa rem yang baik, tanpa lampu penerangan, tanpa lampu tangan
tanda berbahaya.
3. Faktor Alam
Lingkungan juga dapat menjadi faktor penyebab kecelakaan pada saat
adanya kabut, asap tebal, hujan, genangan air di jalan yang menyebabkan
pengemudi hilang kendali mengemudikan kendaraannya.
4. Faktor Jalan
Jalan yang dilalui kendaraan kurang baik seperti kurangnya lebar badan
jalan sehingga kendaraan melewati jalur lawan atau jalan licin.
5. Faktor Teknologi
Teknologi juga merupakan faktor penyebab kecelakaan, misalnya pada
saat mengendarai sering sekali pengemudi menggunakan handphone, ini
menyebabkan pengemudi kurang berkonsentrasi dalam mengemudi.
3.6 Kewajiban yang harus ditaati oleh Pengemudi Kendaraan Bermotor
Kewajiban yang harus ditaati oleh Pengguna Kendaraan Bermotor antara lain:
1. Pengemudi kendaraan bermotor yang terlibat peristiwa kecelakaan lalu
lintas wajib:
a. Menghentikan kendaraannya,
c. Melaporkan kecelakaan tersebut pada Pejabat Kepolisian Negara
Republik Indonesia terdekat.
2. Apabila pengemudi kendaraan bermotor sebagaiman dimaksud pada no.1
oleh karena keadaan memaksa tidak dapat melaksanakan ketentuan
sebagaimana dimaksudkan pada no.1 huruf a dan b, kepadanya tetap
diwajibkan melaporkan diri kepada Pejabat Kepolisian Negara Republik
Indonesia terdekat.
3. Pengemudi kendaraan bermotor bertanggung jawab atas kerugian yang
diderita oleh penumpang atau pemilik barang atau pihak ketiga, yang
timbul karena kelalaian atau kesalahan pengemudi dalam mengemudikan
kendaraan bermotor, (dikutip dari Undang-Undang Republik Indonesia
No. 14 Tahun 1992 tentang Lalu Lintas dan Angkutan Jalan Beserta
peraturan pelaksanaannya PP No. 41, 42, 43, dan 44 tahun 1993 halaman
BAB 4
PENGOLAHAN DATA
4.1 Data yang diperoleh
Data merupakan alat untuk pengambilan keputusan dalam memecahkan suatu
persoalan. Salah satu kegunaan data adalah untuk memberikan informasi
mengenai gambaran tentang suatu keadaan permasalahan.
Untuk membahas dan memecahkan permasalahan tentang faktor-faktor
yang mempengaruhi kecelakaan lalu lintas, maka penulis mengumpulkan data
yang berhubungan dengan permasalahan tersebut. Data yang akan dianalisis
dalam tugas akhir ini adalah data sekunder yang dikumpulkan dari Kepolisian
Negara Republik Indonesia Daerah Sumatera Utara Direktorat Lalu Lintas Resort
Deli Serdang mengenai jumlah kecelakaan lalu lintas di Kabupaten Deli Serdang
beserta faktor-faktor yang mempengaruhinya.
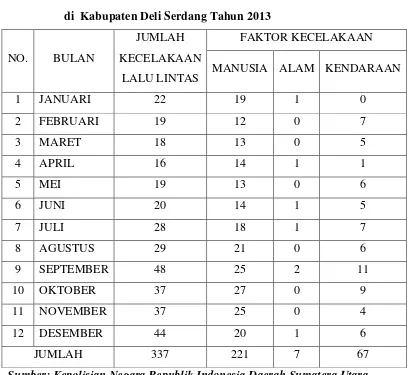
Tabel 4.1: Jumlah Kecelakaan Berdasarkan Faktor Kecelakaan Lalu Lintas
di Kabupaten Deli Serdang Tahun 2013
NO. BULAN
JUMLAH
KECELAKAAN
LALU LINTAS
FAKTOR KECELAKAAN
MANUSIA ALAM KENDARAAN
1 JANUARI 22 19 1 0
Sumber: Kepolisian Negara Republik Indonesia Daerah Sumatera Utara Direktorat Lalu Lintas Resort Deli Serdan
Untuk memperoleh model yang cocok dalam menduga tingkat kecelakaan
lalu lintas berdasarkan faktor-faktor penduga tersebut maka penulis menggunakan
analisis regresi dengan 1 variabel terikat (dependent variable) dan 3 variabel
bebas (independent variable).
Keterangan:
Yi : Jumlah kecelakaan lalu lintas
X1i : Jumlah kecelakaan lalu lintas karena Manusia
X2i : Jumlah kecelakaan lalu lintas karena Alam
4.2 Persamaan Regresi Linier Berganda
Sebelum membentuk persamaan regresi linier berganda maka terlebih dahulu
menghitung koefisien-koefisien regresinya. Koefisien-koefisien regresinya dapat
dicari berdasarkan tabel 4.1
Persamaan regresinya adalah:
Ŷ = b0 + b1X1 + b2X2 + b3X3
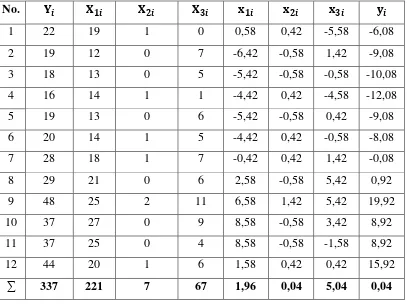
Tabel 4.2 Nilai-Nilai Yang Diperlukan Untuk Membentuk Koefisien
sambungan tabel 4.2
Dari tabel tersebut diperoleh harga-harga sebagai berikut:
Rumus umum persamaan regresi linier berganda dengan tiga variabel bebas yaitu:
Ŷ = b0 + b1X1i + b2X2i + b3X3i (4. 1)
Dan diperoleh melalui persamaan-persamaan berikut:
∑ Yi = b0n + b1 ∑ X1i + b2 ∑X2i + b3∑X3i (4. 2)
∑ YiX1i = b0 ∑ X1i + b1 ∑ X21i + b2 ∑ X1i X2i + b3∑ X1i X3i (4. 3)
∑ YiX2i = b0 ∑ X2i + b1 ∑ X1i X2i + b2 ∑ X2i2 + b3∑ X2i X3i (4. 4)
∑ YiX3i = b0∑ X3i + b1 ∑ X1i X3i + b2 ∑ X2i X3i + b3∑ X3i2 (4. 5)
Harga-harga yang telah diperoleh disubstitusikan kedalam bentuk persamaan
tersebut maka didapatkan:
337 = b0 12 + b1 221 + b2 7 + b3 67
6748 = b0 221 + b1 4379 + b2 135 + b3 1301
226 = b0 7 + b1 135 + b2 9 + b3 41
2096 = b0 67 + b1 1301 + b2 41 + b3 475
Setelah selesai mensubstitusikan persamaan di atas, maka didapat
koefisien-koefisien regresi linier berganda sebagai berikut:
b0 = -6,771
b1 = 1,441
b2 = 3,773
b3 = 1,095
Dari koefisien-koefisien yang diperoleh dibentuklah model persamaan regresi
linier berganda:
Ŷ = b0 + b1X1i + b2X2i + b3X3i (4. 6)
Ŷ = -6,771 + 1,441 X1 + 3,773 X2 + 1,095 X3
4.3 Uji Keberartian Regresi
Sebelum persamaan regresi yang diperoleh digunakan untuk membuat kesimpulan
terlebih dahulu diperiksa setidak-tidaknya mengenai kelinieran dan
keberartiannya. Perumusan hipotesisnya adalah:
H0: β0= β1= . . . = βk = 0
Tidak terdapat hubungan fungsional yang signifikan antara variabel independen
yaitu manusia, alam dan kendaraan dengan variabel dependent yaitu jumlah
kecelakaan.
H1 : Minimal satu parameter koefisien regresi βk yang ≠ 0 terdapat hubungan
fungsional yang signifikan antara variabel independent yaitu manusia, alam, dan
kendaraan dengan variabel dependent yaitu jumlah kecelakaan.
Kriteria pengujian : jika Fhitung≥ Ftabel , maka H0 ditolak dan H1 diterima.
Untuk menguji model regresi yang terbentuk, diperlukan dua macam
jumlah kuadrat (JK) yaitu JK untuk regresi (JKreg) dan JK untuk sisa (JKres) yang
akan didapatkan setelah mengetahui nilai-nilai:
X1�= X1�−X�1 X3� = X3�− X�3
X2�= X2�−X�2 y� = Y� −Y�
Nilai �1, �2, �3, dan y diperoleh dari tabel 4.3 berikut:
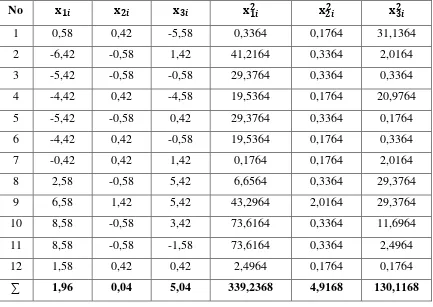
Tabel 4.3 : Nilai-Nilai Yang Diperoleh Untuk Uji Keberartian Regresi
Sambungan tabel 4.3
∑ 559,4232 29,4168 219,0168 336,985 0,015 198,66234 1324,917
Dimana:
Dari tabel tersebut diperoleh nilai-nilai berikut:
∑x1iyi = 559,4232
∑x2iyi = 29,4168
∑x3iyi = 219,0168
Sehingga diperoleh dua macam jumlah kuadrat-kuadrat yakni JKreg dan JKres
sebagai berikut:
JKreg = b1∑x1iyi + b2∑x2iyi + b3∑x3iyi (4. 7)
= (1,441)(559,4232) + (3,773)(29,4168) + (1,095)(219,0168)
= 806,12883 + 110,98959 + 239,8234
= 1156,9418
JKres = ∑(Y� − Y�)2 (4. 8)
= 198,66234
Jadi Fhitung dapat dicari dengan:
Fhitung = JK���/�
Untuk Ftabel, yaitu nilai statistik F jika dilihat dari tabel distribusi F dengan
derajat kebebasan pembilang V1 = k dan penyebut V2 = n-k-1, dan α = 5% = 0,05
Dengan demikian dapat dilihat bahwa nilai Fhitung (15,53) > Ftabel (4,07),
maka H0 ditolak dan H1 diterima. Hal ini berarti persamaan linier berganda Y atas
X1, X2, X3 bersifat nyata yang berarti bahwa jumlah kecelakaan lalu lintas yang
diakibatkan oleh faktor manusia, alam, dan kendaraan secara bersama-sama
berpengaruh terhadap terjadinya tingkat kecelakaan lalu lintas (perhitungan dapat
dilihat pada output SPSS di lampiran 1 tabel anova).
4.4 Koefisien Determinansi
Dari tabel 4.3 dapat dilihat harga ∑�2=1324,917 dan nilai JKreg =1156,9418 telah
dihitung sebelumnya, maka diperoleh nilai koefisien determinansi:
R2 = JK���
Untuk koefisien korelasi ganda maka:
R =√R2
R =√0,8732183
Dari hasil perhitungan diperoleh nilai korelasi (R) yaitu sebesar 0,934
yang menunjukkan bahwa korelasi antara variabel bebas X dengan variabel tak
bebas Y berhubungan secara positif dengan tingkat yang tinggi. Adapun nilai
koefisien determinasi R2 diperoleh sebesar 0,8732183 yang berarti sekitar 87% tingkat kecelakaan lalu lintas dipengaruhi oleh faktor manusia, alam, dan
kendaraan. Sedangkan sisanya 100% - 87% = 13% dipengaruhi oleh faktor-faktor
lain (perhitungan dapat dilihat pada output SPSS di lampiran 1 tabel Model
Summary).
4.5 Koefisiensi Korelasi
4.5.1 Perhitungan Korelasi Antara Variabel Independent dan Variabel
Dependent
Untuk mengukur besarnya pengaruh variabel independent terhadap variabel
dependent, maka dari tabel 4.2 dapat dihitung besar koefisien korelasinya yaitu:
1. Koefisien korelasi antara tingkat kecelakaan lalu lintas (Y) dengan jumlah
kecelakaan lalu lintas yang disebabkan oleh faktor manusia (X1).
���1= �∑
�{52548−48841}{129468−113569
= 6499
= 6499 7677,24
= 0,847
2. Koefisien korelasi antara tingkat kecelakaan lalu lintas (Y) dengan jumlah
kecelakaan lalu lintas yang disebabkan oleh faktor alam (X2).
���2 = �∑
3. Koefisien korelasi antara tingkat kecelakaan lalu lintas (Y) dengan jumlah
kecelakaan lalu lintas yang disebabkan oleh faktor kendaraan (X3).
���3 = �∑
�{5700−4489}{129468−113569}
= 2573
= 2573 4388,62
= 0,586
4.5.2 Perhitungan Korelasi Antara Variabel independent
1. Koefisien korelasi antara jumlah faktor manusia (X1) dengan jumlah faktor
alam (X2):
2. Koefisien korelasi antara jumlah faktor manusia (X1) dengan jumlah faktor
= 15612−14807
�{52548−48841}{5700−4489}
= 805
√4489177
= 805
2118,77
= 0,380
3. Koefisien korelasi antara jumlah faktor alam (X2) dengan jumlah faktor
kendaraan (X3):
Dari perhitungan koefisien korelasi baik antara variabel independent terhadap
variabel dependent maupun antara sesama variabel bebas diperoleh kesimpulan
1. ���1= 0,847 ; variabel X1 berkorelasi sangat kuat terhadap variabel Y
2. ���2= 0,364 ; variabel X2 berkorelasi lemah terhadap variabel Y
3. ���3= 0,586 ; variabel X3 berkorelasi kuat terhadap variabel Y
4. �12 = 0,156 ; variabel X1 berkorelasi sangat lemah terhadap variabel X2
5. �13 = 0,380 ; variabel X1 berkorelasi lemah terhadap variabel X3
6. �23 = 0,086 ; variabel X2 berkorelasi sangat lemah terhadap variabel X3
(perhitungan dapat dilihat pada output SPSS di lampiran 1 tabel Correlations).
4.6 Uji Koefisien Regresi Linier Berganda
Dari hasil perhitungan diperoleh model persamaan regresi linier berganda:
Ŷ = -6,771 + 1,441 X1 + 3,773 X2 + 1,095 X3
Untuk mengetahui bagaimana keberartian setiap variabel bebas dalam persamaan
regresi tersebut, maka perlu diadakan pengujian tersendiri mengenai
koefisien-koefisien regresinya.
Langka-langkahnya adalah sebagai berikut:
1. Hipotesis Pengujian
H0: β1 = 0 ; i = 1, 2, ..., k
Terdapat pengaruh yang signifikan antara koefisien X1, X2, dan X3
terhadap Y
H1: β1≠ 0 ; i = 1, 2, ..., k
Tidak terdapat pengaruh yang signifikan antara koefisien X1, X2, dan X3
2. Taraf nyata (signifikansi) α = 0,05
3. Dengan kriteria penguji: jika t� > t�����, maka tolak H0 dan jika t� < t�����, maka terima H0
4. Ambil kesimpulan berdasarkan hasil pengujian
Tabel 4.4: Nilai-nilai yang diperlukan untuk Uji Koefisien Regresi Linier
Dari tabel tersebut diperoleh nilai-nilai berikut:
∑x1�2 = 339,2368
∑x2�2 = 4,9168
∑x3�2 = 130,1168
Untuk melakukan pengujian diperlukan rumus:
�12 = 0,156
�13 = 0,380
�23= 0,086
Dari harga-harga tersebut dapat dihitung nilai kekeliruan baku koefisien bi sebagai
Kemudian didapatkan nilai distribusi student
Maka dari perhitungan thitung di atas diperoleh:
t1 > ttabel maka H0 ditolak ; t1 (5,259) > ttabel (2,31)
t2 < ttabel maka H0 diterima ; t2 (1,553) < ttabel (2,31)
t3 > ttabel maka H0 ditolak ; t3 (2,499) > ttabel (2,31)
Dari ketiga koefisien regresi tersebut menunjukkan bahwa variabel X1 (manusia)
dan X3 (kendaraan) memberikan pengaruh yang berarti terhadap tingkat
kecelakaan lalu lintas, sedangkan variabel X2 (alam) tidak memberikan pengaruh
yang berarti terhadap tingkat kecelakaan lalu lintas (perhitungan dapat dilihat
BAB 5
IMPLEMENTASI SISTEM
5.1 Pengertian Implementasi Sistem
Implementasi sistem adalah tahapan hasil desain tertulis kedalam programming
dengan menggunakan perangkat lunak (software) sebagai implementasi ataupun
prosedur untuk menyelesaikan desain sistem, yang mana dalam hal ini
implementasi sistem digunakan untuk menganalisa data-data yang dianggap
mempengaruhi tingkat kecelakaan lalu lintas di Kabupaten Deliserdang tahun
2013.
Adapun implementasi yang digunakan untuk menganalisa hubungan
ataupun pengaruh tingkat kecelakaan lalu lintas adalah SPSS. Diharapkan dengan
menggunakan SPSS ini dapat meningkatkan pengetahuan dan kemampuan dalam
hal:
1. Pemahaman elemen dari lembar kerja SPSS
2. Pendayagunaan fasilitas SPSS
3. Menganalisa data dan lembar kerja
5.2 Peranan Komputer dalam Statistika
Komputer memegang peranan yang sangat penting dalam statistika. Komputer
bekerja secara efisien dalam pengolahan data mempunyai karakteristik yaitu:
1. Jumlah Input yang besar
Jumlah input yang besar akan dapat diolah komputer dengan mudah
semudah kita mengolah data yang jumlahnya sedikit sehingga komputer
akan dapat bekerja secara efisien pada pengolahan data dengan
menggunakan input yang besar.
2. Diperlukan kecepatan tinggi
Komputer dapat melakukan proses pengolahan jumlah data yang besar
dalam waktu yang singkat. Jumlah data yang besar dan sedikit akan sama
cepatnya diolah komputer, yang membedakannya hanya pada proses
pemasukkan data saja.
3. Diperlukan kecepatan yang tinggi
Komputer yang telah terprogram dengan benar akan melakukan proses
pengolahan yang tepat. Kesalahan informasi yang mungkin dihasilkan
hanya terjadi pada proses pemasukkan data saja.
4. Pengolahan hal yang kompleks
Hubungan antar fenomena yang kompleks akan dapat dipecahkan dengan
menggunakan komputer dalam waktu yang tepat dan cepat.
SPSS sebagai software statistik, pertama kali dibuat tahun 1968 oleh tiga
SPSS yang tadinya ditujukan bagi pengolahan data statistik untuk ilmu sosial
(SPSS saat itu adalah singkatan dari Statistical Package for the Social Sciences),
sekarang diperluas untuk melayani berbagai user, seperti untuk proses produksi
dipabrik, riset ilmu-ilmu sains dan lainnya. Sehingga sekarang kepanjangan SPSS
adalah Statistical Product and Services Solutions. Kelebihan program ini adalah
kita dapat melakukan secara lebih cepat semua perhitungan statistik dari yang
sederhana sampai yang rumit sekalipun yang jika kita lakukan secara manual akan
memakan waktu yang lebh lama.
5.3 Pengolahan Data dengan SPSS
1. Memulai SPSS pada Window yaitu sebagai berikut:
1. Pilih dan tekan tombol start dari keyboard
2. Pilih SPSS inc, PASW Statistic 17
Maka SPSS siap untuk dipergunakan. Jika ingin membuka file, pilih nama
file yang disimpan dan klik open. Jika akan memulai mendesain variabel dan akan
memasukkan data, pilih cancel.
2. Memasukkan data kedalam SPSS
SPSS Data Editor mempunyai 2 tipe lingkungan kerja yaitu: Data View dan
Variabel View. Untuk menyusun definisi variabel, posisi tampilan SPSS Data
Editor pilih variabel View. Lakukan dengan mengklik tab Sheet variabel view
yang berada di bagian kiri bawah atau langsung menekan Ctrl+T. Tampilan
variabel view juga dapat dimunculkan dari View lalu pilih Variabel.
Pada tampilan jendela Variabel View terdapat kolom-kolom berikut:
Name : untuk memasukkan nama variabel yang akan diuji
Type : untuk mendefenisikan tipe apakah bersifat numeric atau
string
Width : untuk menuliskan panjang pendek variabel
Decimal : untuk menuliskan jumlah decimal dibelakang koma
Label : untuk menuliskan label variabel
Values : untuk menuliskan nilai kuantitatif dari variabel yang skala
pengukurannya ordinal atau nominal bukan scale
Missing : untuk menuliskan ada tidaknya jawaban kosong
Columns : untuk menuliskan lebar kolom
Align : untuk menuliskan rata kanan, kiri, atau tengah
penempatan teks atau angka di Data View
Measure : untuk menentukan skala pengukuran variabel, misalnya
nominal, ordinal, atau scale
Gambar 5.3 Tampilan Pemasukkan Data Pada Icon Data View
5.4 Pengolahan Data dengan Persamaan Regresi
Langkah-langkahnya adalah sebagai berikut:
1. Dari menu utama SPSS, klik menu Analayze, lalu pilih sub menu
Gambar 5.4 Pilih Analyze, Regression, Linear
2. Setelah itu akan muncul kotak dialog Linear Regression, pada kotak dialog
ini akan ditampilkan variabel-variabel yang akan diuji. Masukkan variabel
tak bebas Y (jumlah kecelakaan lalu lintas) pada kotak Dependent, dan
variabel bebas X (manusia, alam, kendaraan) pada kotak Independent
seperti gambar berikut:
3. Klik kotak Statistic pada kotak dialog Linear Regression, kemudian
aktifkan Estimate, Model fit, Descriptive dan Casewise diagnostics, lalu
klik continue untuk melanjutkan seperti pada gambar berikut:
Gambar 5.6 Kotak Dialog Linear Regression: Statistics
4. Selanjutnya klik kotak Plots pada kotak dialog Linear Regression untuk
membuat grafik, isi kolom Y dengan pilihan SRESID dan kolom X dengan
ZPRED, kemudian klik Next. Isi kolom Y dengan ZPRED dan kolom X
dengan DEPENDENT. Pada Standardizes Residual Plots, aktifkan
Histogram dan Normal Probability Plot. Lalu klik Continue untuk
Gambar 5.7 Kotak Dialog Linear Regression: Plots
5. Kemudian klik tombol Options pada kotak dialog Linear Regression
sehingga muncul kotak dialog yang baru. Pada Stepping Method Criteria,
aktifkan Use Probability of F dengan standard error 0,05 oleh karena itu
masukkan nilai entry 0,05. Aktifkan include in aquation dan Exclude
Gambar 5.8 Kotak Dialog Linear Regression: Options
6. Selanjutnya klik Ok pada kotak dialog Linear Regression.
5.5 Pengolahan Data dengan Persamaan Korelasi
Langkah-langkahnya adalah sebagai berikut:
1. Dari menu utama SPSS, klik menu Analyze, lalu pilih sub menu Correlate
Gambar 5.9 Pilih Analyze, Correlate, Bivariate
2. Pada kotak dialog Bivariate Correlations akan ditampilkan
variabel-variabel yang akan diuji. Pindahkan variabel-variabel-variabel-variabel tersebut kedalam
kotak variabels.
3. Pada kolom Correlations Coefficients aktifkan Pearson, pada kolom Test
of Significant aktifkan Two-Tailed dan Flag Significant Correlations, lalu
BAB 6
KESIMPULAN DAN SARAN
6.1 Kesimpulan
Berdasarkan pengolahan data yang telah dilakukan, maka diperoleh beberapa
kesimpulan antara lain:
1. Dengan menggunakan analisis regresi linier berganda diperoleh model
persamaan linier ganda yaitu:
Ŷ = -6,771 + 1,441 X1 + 3,773 X2 + 1,095 X3 atau dengan kata lain jumlah
kecelakaan lalu lintas = -6,771 + 1,441 faktor kecelakaan manusia + 3,773
faktor kecelakaan pengaruh alam + 1,095 faktor kecelakaan kendaraan.
2. Dengan taraf kepercayaan α = 0,05 ; derajat kebebasan (degree of
independent) dkpembilang= 3 dan dkpenyebut =� − � − � = 12-3-1 = 8,
diperoleh Ftabel = 4,07 dan dari perhitungan diperoleh Fhitung = 15,53.
Maka Fhitung (15,53) > Ftabel (4,07), maka H0 ditolak dan Ha diterima.
Hal ini berarti persamaan linier berganda Y atas X1, X2, X3 bersifat nyata
faktor manusia, alam, kendaraan secara bersama-sama mempengaruhi
terjadinya tingkat kecelakaan lalu lintas di Kabupaten Deli Serdang.
3. Dari perhitungan diperoleh nilai korelasi (R) yaitu sebesar 0,934 yang
berarti bahwa korelasi antara variabel independent X dengan variabel
dependent Y berhubungan secara positif dengan tingkat yang tinggi.
Adapun nilai koefisien determinasi R2 diperoleh sebesar 0,8732183 yang berarti sekitar 87% tingkat kecelakaan lalu lintas dipengaruhi oleh faktor
manusia, alam, dan kendaraan. Sedangkan sisanya sebesar 100% - 87% =
13% dipengaruhi oleh faktor-faktor lain.
4. Dari perhitungan koefisien korelasi antara masing-masing variabel X1, X2,
X3 dengan variabel Y diperoleh:
1. Hubungan antara tingkat kecelakaan lalu lintas dengan faktor manusia
adalah sebesar 0,847
2. Hubungan antara tingkat kecelakaan lalu lintas dengan faktor alam
adalah sebesar 0,364
3. Hubungan antara tingkat kecelakaan lalu lintas dengan faktor
kendaraan adalah sebesar 0,586
Maka faktor yang paling berpengaruhi terhadap tingginya tingkat
kecelakaan lalu lintas di Kabupaten Deli Serdang adalah faktor manusia
5. Dari hasil perhitungan untuk taraf nyata α = 0,05 dan derajat kebebasan dk
= (n-k-1) = (12-3-1) = 8 dari tabel distribusi student t diperoleh ttabel =
t(n−k−1,α/2) = t(12−3−1,0,025) = 2,31.
Maka dari perhitungan thitung di peroleh:
t1 > ttabel maka H0 ditolak ; t1 (5,259) > ttabel (2,31)
t2 < ttabel maka H0 diterima ; t2 (1,553) < ttabel (2,31)
t3 > ttabel maka H0 ditolak ; t3 (2,499) > ttabel (2,31)
Dari ketiga koefisien regresi tersebut menunjukkan bahwa variabel X1
(manusia) dan X3 (kendaraan) memberikan pengaruh yang berarti terhadap
tingkat kecelakaan lalu lintas, sedangkan variabel X2 (alam) tidak
memberikan pengaruh yang berarti terhadap tingkat kecelakaan lalu lintas.
6.2 Saran
Dari analisa dan kesimpulan yang telah di dapat, ada beberapa saran yang penulis
dapat berikan, yang mungkin bisa membantu masyarakat maupun pemerintah
dalam mengendalikan tingkat kecelakaan lalu lintas di Kabupaten Deli Serdang
adalah sebagai berikut:
1. Kecelakaan lalu lintas merupakan suatu peristiwa di jalan yang tidak
disangka-sangka maka, masyarakat Kabupaten Deli Serdang sebaiknya
kendaraan bermotor baik roda empat maupun roda dua untuk mengurangi
terjadinya kecelakaan lalu lintas.
2. Bagi pihak pemerintah Kabupaten Deli Serdang seperti pihak Satuan lalu
lintas dan dinas Perhubungan hendaklah lebih memperhatikan
faktor-faktor yang menyebabkan tingginya tingkat kecelakaan lalu lintas agar
bisa mengambil kebijakan untuk mengurangi kecelakaan lalu lintas
tersebut demi keselamatan masyarakat dan untuk mengurangi tingkat
kematian di Kabupaten Deli Serdang yang disebabkan oleh kecelakaan
DAFTAR PUSTAKA
Algifari. 2000. Analisa Regresi Teori, Kasus dan Solusi, Edisi Kedua.
Yogyakarta: BPFE.
Hartono. 2004. Satistika untuk Penelitian. Yogyakarta: Lembaga Studi Filsafat,
Kemasyarakatan, Kependidikan dan Perempuan (LSFK2P).
Hartono. 2008. Analisis Data Statistika dan Penelitian dengan SPSS 16.
Pekanbaru: Zanafa
Kantor Kepolisian Negara Republik Indonesia Daerah Sumatera Utara Direktorat
Lalu Lintas. 2014. Anatomi Laka Lantas Polres Deli Serdang Laporan
Tahunan: Januari sd Desember 2013. Deli Serdang: Ditlantas Polres Deli
Serdang
Sudjana. 2002. Metoda Statistika Edisi ke-6. Bandung: Tarsito
Suharjo, Bambang. 2008. Analisis Regresi Terapan dengan SPSS. Graha Ilmu.
Yogyakarta.
Sutarman, Marpongahtun, dkk. 2013. Panduan Tatacara Penulisan Tugas Akhir
Edisi kedua. Medan: Fakultas Matematika dan Ilmu Pengetahuan Alam
Unuversitas Sumatera Utara.
Walpole, E. Ronald. 1995. Pengantar Statistika Edisi ke-3. Jakarta: Gramedia.
Pustaka Utama.
Yamin, Sofyan., Rachmach, Lien, A., dan Kurniawan, Heri. 2011. Regresi dan
Korelasi Dalam Genggaman Anda. Salemba Empat. Jakarta.
LAMPIRAN
Regression
Descriptive Statistics
Mean Std. Deviation N
Jumlah Kecelakaan 28.08 10.975 12
Manusia 18.42 5.299 12
Alam .58 .669 12
Kendaraan 5.58 3.029 12
Correlations
Jumlah
Kecelakaan Manusia Alam Kendaraan
Pearson Correlation Jumlah Kecelakaan 1.000 .847 .364 .586
Manusia .847 1.000 .156 .380
Alam .364 .156 1.000 .086
Kendaraan .586 .380 .086 1.000
Sig. (1-tailed) Jumlah Kecelakaan . .000 .122 .023
Manusia .000 . .314 .112
Alam .122 .314 . .395
N Jumlah Kecelakaan 12 12 12 12
a. All requested variables entered.
Model Summaryb
a. Predictors: (Constant), Kendaraan, Alam, Manusia
ANOVAb
Model Sum of Squares df Mean Square F Sig.
1 Regression 1126.254 3 375.418 15.118 .001a
Residual 198.662 8 24.833
Total 1324.917 11
a. Predictors: (Constant), Kendaraan, Alam, Manusia
b. Dependent Variable: Jumlah Kecelakaan
Coefficientsa
Model
Unstandardized Coefficients
Standardized
Coefficients
B Std. Error Beta t Sig.
1 (Constant) -6.771 5.503 -1.230 .253
Manusia 1.441 .309 .696 4.659 .002
Alam 3.773 2.276 .230 1.658 .136
Kendaraan 1.095 .537 .302 2.041 .076
Casewise Diagnosticsa
Case
Number Std. Residual
Jumlah
Kecelakaan Predicted Value Residual
1 -.478 22 24.38 -2.382
2 .163 19 18.19 .813
3 .113 18 17.44 .562
4 -.456 16 18.27 -2.272
5 .094 19 18.53 .467
6 -.532 20 22.65 -2.652
7 -.523 28 30.61 -2.606
8 -.213 29 30.06 -1.061
9 -.170 48 48.85 -.847
10 -1.002 37 41.99 -4.993
11 .675 37 33.64 3.365
12 2.329 44 32.39 11.607
Residuals Statisticsa
Minimum Maximum Mean Std. Deviation N
Predicted Value 17.44 48.85 28.08 10.119 12
Std. Predicted Value -1.052 2.052 .000 1.000 12
Standard Error of Predicted
Value
1.744 4.283 2.785 .756 12
Adjusted Predicted Value 17.27 51.24 28.66 10.935 12
Residual -4.993 11.607 .000 4.250 12
Std. Residual -1.002 2.329 .000 .853 12
Stud. Residual -1.378 2.486 -.045 .979 12
Deleted Residual -9.443 13.226 -.580 5.763 12
Stud. Deleted Residual -1.476 4.878 .155 1.596 12
Mahal. Distance .430 7.209 2.750 1.981 12
Cook's Distance .001 .423 .090 .126 12
Centered Leverage Value .039 .655 .250 .180 12
Correlations
Correlations
Manusia Alam Kendaraan
Jumlah
Kecelakaan
Manusia Pearson Correlation 1 .156 .380 .847**
Sig. (2-tailed) .628 .223 .001
N 12 12 12 12
Alam Pearson Correlation .156 1 .086 .364
Sig. (2-tailed) .628 .790 .244
N 12 12 12 12
Kendaraan Pearson Correlation .380 .086 1 .586*
Sig. (2-tailed) .223 .790 .045
N 12 12 12 12
Jumlah Kecelakaan Pearson Correlation .847** .364 .586* 1
Sig. (2-tailed) .001 .244 .045
N 12 12 12 12
**. Correlation is significant at the 0.01 level (2-tailed).