PENGEMBANGAN MODEL JARINGAN SYARAF TIRUAN
RESILIENT BACKPROPAGATION UNTUK IDENTIFIKASI PEMBICARA
DENGAN PRAPROSES MFCC
Oleh:
NURHADI SUSANTO
G64103059
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2007
PENGEMBANGAN MODEL JARINGAN SYARAF TIRUAN
RESILIENT BACKPROPAGATION UNTUK IDENTIFIKASI PEMBICARA
DENGAN PRAPROSES MFCC
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Oleh :
NURHADI SUSANTO
G64103059
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2007
ABSTRAK
NURHADI SUSANTO. Pengembangan Model Jaringan Syaraf Tiruan Resilient Backpropagation untuk Identifikasi Pembicara dengan Praproses MFCC. Dibimbing oleh AGUS BUONO dan IRMAN HERMADI.
Suara manusia dapat digunakan sebagai sarana identifikasi diri. Dari suara seseorang dapat diambil suatu fitur yang kemudian dimodelkan dan digunakan untuk mengenali seseorang berdasarkan suaranya. Pada penelitian ini, dikembangkan suatu model jaringan syaraf tiruan resilient
backpropagation untuk identifikasi pembicara. Untuk ekstraksi ciri sinyal suara digunakan fitur
MFCC. Jenis identifikasi pembicara pada penelitian ini adalah Closed-Set Identification yang mana suara masukan yang akan dikenali merupakan bagian dari sekumpulan suara pembicara yang telah terdaftar atau diketahui dan kata yang dilatih maupun diujikan telah ditentukan.
Data suara yang digunakan dalam penelitian ini adalah data suara yang diambil secara unguided atau tanpa panduan. Selain itu diamati pula pengaruh noise terhadap akurasi identifikasi dengan cara menambahkan white gaussian noise pada data yang digunakan.
Hasil penelitian ini berupa tingkat akurasi kebenaran dari data yang diujikan. Secara keseluruhan, model terbaik yang dikembangkan menghasilkan nilai akurasi rata-rata sebesar 92,8%. Dengan data yang menggunakan noise 30 dB, nilai akurasi rata-rata yang dihasilkan turun menjadi 71,0% dan dengan data yang menggunakan noise 20 dB, nilai akurasi rata-rata yang dihasilkan turun menjadi 48,3%.
Judul : Pengembangan Model Jaringan Syaraf Tiruan Resilient Backpropagation
untuk Identifikasi Pembicara dengan Praproses MFCC
Nama : Nurhadi Susanto
NRP : G64103059
Menyetujui:
Pembimbing I,
Pembimbing II
Ir. Agus Buono, M.Si., M.Kom.
Irman Hermadi, S.Kom., MS
NIP 132 045 532
NIP 132 321 422
Mengetahui:
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Prof. Dr. Ir. Yonny Koesmaryono, MS
NIP 131 473 999
RIWAYAT HIDUP
Penulis dilahirkan di Tangerang tanggal 7 November 1985, sulung dari lima bersaudara dari pasangan Sunaryoto dan Khasanah. Pada tahun 2000, penulis menuntut ilmu di SMU Negeri 2 Tangerang hingga tahun 2003. Setelah lulus pada tahun 2003 penulis diterima sebagai mahasiswa S1 Departemen Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor melalui jalur SPMB. Pada tahun 2006, penulis melaksanakan kegiatan praktik kerja lapangan di Balai Besar Penelitian dan Pengembangan Teknologi Pertanian (BP2TP), Cimanggu, Bogor.
PRAKATA
Alhamdulillahi Rabbil ‘alamin, puji dan syukur Penulis panjatkan kepada Allah SWT atas
segala curahan rahmat dan karunia-Nya sehingga tugas akhir dengan judul Pengembangan Jaringan Syaraf Tiruan Resilient Backpropagation untuk Identifikasi Pembicara Berbasis Data MFCC ini dapat diselesaikan. Dalam menyelesaikan karya tulis ini penulis mendapatkan banyak sekali bantuan, bimbingan dan dorongan dari berbagai pihak. Oleh karena itu, penulis ingin mengucapkan terima kasih yang sebesar-besarnya kepada semua pihak yang telah membantu kelancaran penelitian ini, antara lain kepada:
1. Orangtuaku tercinta, Bapak Sunaryoto dan Ibunda Khasanah atas segala do’a, kasih sayang, dan dukungan baik dari moril maupun materiil yang telah diberikan selama ini.
2. Adik-adikku tersayang Santi, Peni, Rio dan Ponco yang memberi tambahan motivasi dalam penyelesaian karya tulis ini.
3. Bapak Ir. Agus Bouno, M.Si, M.Komp selaku pembimbing pertama atas bimbingan dan arahannya selama penyusunan karya tulis ini.
4. Bapak Irman Hermadi, S.Kom, MS selaku pembimbing kedua atas bimbingan dan arahannya selama penyusunan karya tulis ini.
5. Abdul Nasrah, seorang teman sekamar terbaik yang selalu memberikan yang terbaik untuk teman-temannya
6. M.Nono Suhartono, Vicky Zilvan, dan Wini Purnamasari, rekan seperjuangan dalam penelitian di bidang speaker recognizing.
7. Dhany, Gemma, Ryan, Inang, Mulyadi, dan Iqbal yang sudah memberikan banyak sekali kenangan selama tinggal bersama.
8. Pandi, Ghoffar, Dona, Mulyadi, Nanik, Vita, Thessy, Yustin, dan seluruh rekan yang telah ikut menymbangkan suranya untuk dijadikan bahan penelitian.
9. Seluruh teman-teman Ilkom 40 yang tidak dapat disebutkan namanya satu-persatu.
Kepada semua pihak lainnya yang telah memberikan kontribusi yang besar selama pengerjaan penelitian ini yang tidak dapat disebutkan satu-persatu, Penulis ucapkan terima kasih banyak. Semoga penelitian ini dapat memberi manfaat.
Bogor, Mei 2007
DAFTAR ISI Halaman DAFTAR GAMBAR ... vi DAFTAR TABEL... vi DAFTAR LAMPIRAN ... vi PENDAHULUAN...1 Latar Belakang ...1 Tujuan...1 Ruang Lingkup...1 Manfaat...1 TINJAUAN PUSTAKA ...1
Jenis Pengenalan Pembicara ...1
Dijitasi Gelombang Suara ...2
Signal to Noise Ratio (SNR) ...2
Ekstraksi Ciri Sinyal Suara ...2
MFCC (Mel-Frequency Cepstrum Coefficients)...3
Resilient Backpropagation ...5
METODOLOGI PENELITIAN...6
Data ...6
Proses Pengenalan Suara...6
Arsitektur Jaringan Syaraf Tiruan ...7
Parameter-parameter Resilient Backpropagation ...7
Lingkungan Pengembangan ...7
HASIL DAN PEMBAHASAN...7
Hasil Pengambilan Data...7
Praproses dengan MFCC ...7
Pengembangan Model Jaringan Syaraf Tiruan...8
Pengambilan Threshold ... 11
Hasil Identikasi Pembicara Model JST Terbaik pada Data Tanpa Noise... 11
KESIMPULAN DAN SARAN... 14
Kesimpulan ... 14
Saran... 14
DAFTAR PUSTAKA... 14
DAFTAR GAMBAR
Halaman
1 Diagram blok dari proses MFCC (Do 1994). ...3
2 Arsitektur JST lapis tunggal...4
3 Grafik fungsi sigmoid biner dengan selang (0,1)...4
4 Arsitektur jaringan propagasi balik (Fu 1994)...5
5 Proses pengenalan pembicara...6
6 Grafik perbandingan nilai akurasi rata-rata terhadap jumlah neuron tersembunyi pada pelatihan dengan data tanpa noise. ...8
7 Grafik perbandingan jumlah epoh rata-rata terhadap jumlah neuron tersembunyi pada pelatihan dengan data tanpa noise. ...9
8 Grafik perbandingan nilai akurasi rata-rata terhadap jumlah neuron tersembunyi pada pelatihan dengan data ber-noise 30 dB. ... 10
9 Grafik perbandingan nilai akurasi rata-rata terhadap jumlah neuron tersembunyi pada pelatihan dengan data ber-noise 20 dB. ... 10
10 Grafik perbandingan nilai akurasi rata-rata terhadap jumlah neuron tersembunyi. ... 11
11 Grafik perbandingan jumlah data suara yang teridentifikasi dengan benar pada data tanpa noise . 13 DAFTAR TABEL Halaman 1 Struktur JST Resilient Backpropagation...7
2 Hasil identifikasi model JST terbaik dari dua puluh data pembicara tanpa threshold ... 12
3 Hasil identifikasi model JST terbaik dari dua puluh data pembicara dengan threshold... 12
4 Hasil identifikasi dua puluh data suara tanpa noise dari pembicara yang tidak ikut serta dalam pelatihan dengan menggunakan threshold ... 14
DAFTAR LAMPIRAN Halaman 1 Algoritma JST RPROP ... 17
2 Hasil Pelatihan dan Pengujian Model JST dari tiga puluh perlakuan jumlah neuron tersembunyi pada data tanpa noise. ... 19
3 Hasil Pelatihan dan Pengujian Model JST dari tiga puluh perlakuan jumlah neuron tersembunyi pada data dengan SNR 30 dB... 21
4 Hasil Pelatihan dan Pengujian Model JST dari tiga puluh perlakuan jumlah neuron tersembunyi pada data dengan SNR 20 dB... 22
PENDAHULUAN Latar Belakang
Suara manusia dapat digunakan sebagai sarana identifikasi diri. Suara yang dihasilkan tersebut diperlakukan sebagai data yang dapat diolah sehingga dapat dimanfaatkan. Sinyal suara yang kontinu dicuplik dengan rentang waktu tertentu sehingga menghasilkan sinyal dijital. Setelah sinyal suara tersebut menjadi sinyal dijital, berbagai perlakuan dapat diterapkan pada data suara tersebut. Salah satu perlakuan yang bermanfaat adalah mengolah data tersebut sedemikian rupa sehingga dapat digunakan untuk mengenali pembicara.
Berbagai metode dapat dipakai untuk mengolah data suara tadi. Beberapa metode yang pernah digunakan diantaranya model markov tersembunyi (Purnamasari 2006) dan jaringan syaraf tiruan propagasi balik standar (Oktavianto 2004). Penggunaan metode jaringan syaraf tiruan propagasi balik tersebut masih dapat dikembangkan dengan penggunaan metode praproses dan juga penggunaan jaringan syaraf tiruan yang lain dan juga diperlukan kombinasi percobaan yang lebih banyak.
Model jaringan saraf tiruan terinspirasi oleh cara kerja otak manusia. Untuk berpikir, otak manusia mendapat rangsangan dari
neuron-neuron yang terdapat pada indera manusia dan
kemudian hasil rangsangan tersebut diolah sehingga menghasilkan suatu informasi. Pada komputer, rangsangan-rangsangan yang diberikan diibaratkan sebagai masukan dimana masukan tersebut dikalikan dengan suatu nilai, yang dikenal dengan bobot, dan kemudian diolah dengan fungsi aktivasi tertentu untuk menghasilkan suatu keluaran. Pada saat pelatihan, pemasukan tersebut dilakukan berulang-ulang sampai tercapai keluaran seperti yang diinginkan. Dengan metode propagasi balik, keluaran yang diinginkan berusaha dicapai dengan melakukan pembaharuan yang terhadap nilai bobot. Setelah proses pelatihan, diharapkan komputer dapat mengenali suatu masukan baru berdasarkan informasi yang telah diperoleh pada saat pelatihan.
Beberapa modifikasi dari prosedur propagasi balik telah diajukan untuk menambah kecepatan pembelajaran. Martin Riedmiller dan Heinrich Braun telah mengembangkan suatu metode yang disebut Resilient Backpropagation
(Riedmiller & Braun 1993). Metode ini telah terbukti sebagai metode yang memiliki kecepatan pembelajaran yang baik dan juga andal (Saputro 2006).
Tujuan
Penelitian ini bertujuan untuk mengembangkan model jaringan syaraf tiruan
resilient backpropagation untuk mengidentifikasi pembicara pada data yang direkam tanpa pengarahan. Selain itu, dilakukan pula perbandingan tingkat akurasi model untuk suara yang diberi noise dan tanpa noise.
Ruang Lingkup
Ruang lingkup penelitian ini adalah: 1. Penelitian difokuskan pada tahapan
pemodelan identifikasi suara manusia dengan menggunakan jaringan syaraf tiruan dan tidak pada pemrosesan sinyal analog sebagai praproses dari sistem.
2. Model pengenalan dibangun dengan menggunakan jaringan syaraf tiruan model
Multi Layer Preceptron dengan menggunakan
metode pembelajaran resilient backpropagation.
3. Analisis dilakukan untuk pengenalan pembicara tertutup bergantung teks dengan data yang direkam tanpa pengarahan. Uji kinerja dilakukan dengan menghitung tingkat akurasi identifikasi sistem terhadap input yang diberikan.
Manfaat
Penelitian ini diharapkan dapat memberikan informasi mengenai akurasi jaringan syaraf tiruan model Multi Layer Preceptron dengan menggunakan metode pembelajaran resilient
backpropagation untuk identifikasi pembicara.
Di samping itu, diharapkan pula pengaruh noise terhadap nilai akurasi identifikasi dapat diamati. Selanjutnya, diharapkan model yang dihasilkan dapat digunakan untuk mengembangkan sistem identifikasi pembicara yang bersifat tertutup dan bergantung pada teks.
TINJAUAN PUSTAKA Jenis Pengenalan Pembicara
Menurut Campbell (1997), Pengenalan pembicara berdasarkan jenis aplikasinya dibagi menjadi:
1. Identifikasi pembicara adalah proses mengenali seseorang berdasarkan suaranya. Identifikasi pembicara dibagi dua, yaitu:
• Identifikasi tertutup (closed-set identification) yang mana suara masukan
yang akan dikenali merupakan bagian dari sekumpulan suara pembicara yang telah terdaftar atau diketahui.
• Identifikasi terbuka (open-set identification) suara masukan boleh tidak
ada pada kumpulan suara pembicara yang telah terdaftar.
2. Verifikasi pembicara adalah proses menerima atau menolak permintaan identitas dari seseorang berdasarkan suaranya. Berdasarkan teks yang digunakan, pengenalan pembicara dibagi menjadi dua (Campbell 1997):
1. Pengenalan pembicara bergantung teks yang mengharuskan pembicara untuk mengucapkan kata atau kalimat yang sama, baik pada pelatihan maupun pengenalan. 2. Pengenalan pembicara bebas teks yang tidak
mengharuskan pembicara untuk mengucapkan kata atau kalimat yang sama, baik pada pelatihan maupun pengenalan.
Dijitasi Gelombang Suara
Suara adalah sebuah gelombang yang dilewatkan melalui suatu medium dan sampai ke telinga manusia sehingga dapat didengarkan. Medium perantara yang biasa digunakan adalah udara. Gelombang suara merupakan gelombang analog, sehingga untuk dapat diolah dengan peralatan elektronik, gelombang suara harus direpresentasikan dalam bentuk dijital (Boomkamp (2004) dalam Musthofa 2005).
Proses mengubah masukan suara dari gelombang analog menjadi representasi data dijital disebut dijitasi suara. Proses dijitasi suara terdiri dari dua tahap yaitu sampling dan kuantisasi (Jurafsky & Martin 2000). Sampling adalah proses pengambilan nilai setiap jangka waktu tertentu. Nilai ini menyatakan amplitudo volume suara pada saat itu. Hasilnya adalah sebuah vektor yang menyatakan nilai-nilai hasil
sampling. Panjang vektor data ini tergantung
pada panjang atau lamanya suara yang didijitasikan serta sampling rate yang digunakan pada proses dijitasinya. Sampling
rate sendiri adalah banyaknya nilai yang
diambil setiap detik. Sampling rate yang biasa digunakan adalah 8000 Hz dan 16000 Hz (Jurafsky & Martin 2000). Hubungan antara panjang vektor data yang dihasilkan dengan
sampling rate dan panjangnya data suara yang
didijitasikan dapat dinyatakan secara sederhana sebagai berikut:
S = Fs * T
dengan,
S = panjang vektor
Fs = sampling rate yang digunakan (Hertz)
T = panjang suara (detik)
Setelah melalui tahap sampling, proses dijitasi suara selanjutnya adalah kuantisasi yaitu
menyimpan nilai amplitudo ini ke dalam representasi nilai 8 bit atau 16 bit (Jurafsky & Martin 2000).
Signal to Noise Ratio (SNR)
Signal-to-noise ratio (yang biasa disingkat
menjadi SNR atau S/N) adalah suatu konsep yang mendefinisikan perbandingan antara kekuatan sinyal dengan kekuatan noise yang merusak sinyal. Secara sederhana,
signal-to-noise ratio membandingkan level dari sinyal
yang diinginkan (seperti suara piano dalam suatu konser) dengan level dari sinyal yang tidak diinginkan (seperti suara orang yang bercakap-cakap dalam suatu konser). Semakin kecil nilai SNR, semakin tinggi pengaruh noise dalam merusak sinyal asli.
Secara umum, SNR didefinisikan sebagai 2
=
=
noise signal noise signalA
A
P
P
SNR
dengan P adalah rata-rata dari daya (power) dan A adalah akar kuadrat rata-rata dari amplitudo. Pada umumnya, sinyal suara memiliki jangkauan dinamis yang sangat tinggi. Hal ini menyebabkan SNR akan lebih efisien jika diekspresikan dalam skala logarithmic decibel. Pada desibel, SNR didefinisikan sebagai 10 dikali logaritma dari perbandingan daya. Jika sinyal dan noise dihitungdalam impedansi yang sama maka nilai SNR bisa didapatkan dengan
( )
=
noise signalP
P
dB
SNR
10
log
10
=
noise signalA
A
10log
20
sehingga semakin kecil nilai SNR dalam desibel, semakin tinggi pengaruhnya dalam merusak sinyal asli.
Ekstraksi Ciri Sinyal Suara
Sinyal suara merupakan sinyal bervariasi yang diwaktukan dengan lambat atau biasa disebut quasi-stationary (Do 1994). Ketika diamati dalam jangka waktu yang sangat pendek (5 - 100 ms), karakteristiknya hampir sama. Namun, dalam jangka waktu yang panjang (0,2 detik atau lebih) karakteristik sinyal berubah dan merefleksikan perbedaan sinyal suara yang diucapkan. Oleh karena itu, digunakan spektrum waktu pendek (short-time
spectral analysis) untuk mengkarakterisasi
MFCC (Mel-Frequency Cepstrum Coefficients)
MFCC didasarkan pada variasi yang telah diketahui dari jangkauan kritis telinga manusia terhadap frekuensi. Filter dipisahkan secara linear pada frekuensi rendah dan logaritmik pada frekuensi tinggi. Hal ini telah dilakukan untuk menangkap karakteristik penting dari sinyal suara. Tujuan utama MFCC adalah untuk meniru perilaku telinga manusia. Selain itu MFCC telah terbukti bisa menyebutkan variasi dari gelombang suara itu sendiri. Diagram alir dari proses MFCC dapat dilihat pada Gambar 1.
Gambar 1 Diagram blok dari proses MFCC (Do 1994).
Penjelasan tiap tahapan pada proses MFCC sebagai berikut (Do 1994):
1. Frame Blocking. Pada tahap ini sinyal suara (continous speech) dibagi ke dalam
frame-frame. Tiap frame terdiri dari N sample.
2. Windowing. Proses selanjutnya adalah melakukan windowing pada tiap frame untuk meminimalkan diskontinuitas sinyal pada awal dan akhir tiap frame. Konsepnya adalah meminimisasi distorsi spektral dengan menggunakan window untuk memperkecil sinyal hingga mendekati nol pada awal dan akhir tiap frame. Jika window didefinisikan sebagai w(n), 0 ≤ n ≤ N-1, dengan N adalah banyaknya sampel tiap frame, maka hasil dari windowing adalah sinyal dengan persamaan:
Yt(n) = x1(n)w(n), 0 ≤ n ≤ N-1 Pada umumnya, window yang digunakan adalah hamming window, dengan persamaan: w(n)=0.54-0.46cos(2πn/N-1), 0 ≤ n ≤ N-1 3. Fast Fourier Transform (FFT). Tahap ini
mengkonversi tiap frame dengan N sampel dari time domain menjadi frequency domain. FFT adalah suatu algoritma untuk mengimplementasikan Discrete Fourier Transform (DFT) yang didefinisikan pada
himpunan N sampel {xn} sebagai berikut: ∑− = = − − = 1 0 , 0,1,2,..., 1 / 2 N k n N N jkn e k x n X π
j digunakan untuk menotasikan unit imajiner, yaitu j= −1. Secara umum Xn adalah bilangan kompleks. Barisan {Xn} yang
dihasilkan diartikan sebagai berikut: frekuensi nol berkorespondensi dengan n = 0, frekuensi positif 0 < f < Fs/2
berkorespondensi dengan nilai 1 ≤ n ≤ N/2-1, sedangkan frekuensi negatif –Fs/2 < f < 0
berkorespondensi dengan N/2+1 < n < N-1. Dalam hal ini Fs adalah sampling frequency. Hasil yang didapatkan dalam tahap ini biasa disebut dengan spektrum sinyal atau
periodogram.
4. Mel-frequency Wrapping. Studi psikofisik menunjukkan bahwa persepsi manusia terhadap frekuensi sinyal suara tidak berupa skala linier. Oleh karena itu, untuk setiap nada dengan frekuensi aktual f (dalam Hertz), tinggi subjektifnya diukur dengan skala ‘mel’. Skala mel-frequency adalah selang frekuensi di bawah 1000 Hz dan selang logaritmik untuk frekuensi di atas 1000 Hz, sehingga pendekatan berikut dapat digunakan untuk menghitung mel-frequency untuk frekuensi f dalam Hz:
Mel(f) = 2595*log10(1+f/700).
5. Cepstrum. Langkah terakhir, konversikan log
mel spectrum ke domain waktu. Hasilnya
disebut mel frequency cepstrum coefficients. Representasi cepstral spektrum suara merupakan representasi properti spektral lokal yang baik dari suatu sinyal untuk analisis frame. Mel spectrum coefficients (dan logaritmanya) berupa bilangan riil, sehingga dapat dikonversikan ke domain waktu dengan menggunakan Discrete Cosine
Transform (DCT).
Jaringan Syaraf Tiruan (JST)
Jaringan Syaraf Tiruan (JST) merupakan suatu sistem pemroses informasi yang memiliki persamaan secara umum dengan cara kerja jaringan syaraf biologi (Fausett 1994). Metode komputasional dari JST diinspirasikan oleh cara kerja sel-sel otak manusia. Untuk berpikir, otak manusia mendapat rangsangan dari
neuron-neuron yang terdapat pada indera manusia,
kemudian hasil rangsangan tersebut diolah sehingga menghasilkan suatu informasi. Pada komputer, rangsangan yang diberikan diumpamakan sebagai masukan dimana masukan tersebut dikalikan dengan suatu nilai dan kemudian diolah dengan fungsi tertentu untuk menghasilkan suatu keluaran. Pada saat pelatihan, pemasukan tersebut dilakukan berulang-ulang hingga dicapai keluaran seperti
yang diinginkan. Setelah proses pelatihan, diharapkan komputer dapat mengenali suatu masukan baru berdasarkan data-data yang telah diberikan pada saat pelatihan.
Menurut Fausett (1994), suatu JST dicirikan oleh tiga hal sebagai berikut:
1. Arsitektur jaringan syaraf tiruan
Arsitektur jaringan ialah pengaturan neuron dalam suatu lapisan, pola hubungan dalam lapisan dan di antara lapisan. Dalam JST,
neuron-neuron diatur dalam sebuah lapisan
(layer). Ada 3 tipe lapisan, yaitu lapisan input, lapisan tersembunyi (hidden layer) dan lapisan output. Jaringan neuron dikelompokkan sebagai lapis tunggal (single
layer) yang terdiri atas lapisan input dan
output, dan lapis banyak (multiple layer) yang terdiri atas lapisan input, lapisan tersembunyi, dan lapisan output. Ilustrasi JST lapis tunggal dapat dilihat dalam Gambar 2. Pada Gambar 2, pr
melambangkan masukan untuk tiap neuron ke-r pada lapisan input, wr melambangkan
bobot dari neuron ke-r pada lapisan input ke neuron output, dan b melambangkan bias. Jumlah dari seluruh masukan untuk neuron output, yang dilambangkan sebagai n, kemudian dihitung dengan fungsi aktivasi f untuk menghasilkan keluaran dari neuron tersebut yang dilambangkan sebagai a.
Gambar 2 Arsitektur JST lapis tunggal. 2. Metode pembelajaran untuk penentuan
pembobot koneksi.
Metode pembelajaran digunakan untuk menentukan nilai pembobot yang akan digunakan pada saat pengujian. Ada dua tipe pembelajaran, yaitu dengan pengarahan (supervised learning) dan tanpa pengarahan (unsupervised learning). Sedangkan metode pembelajaran JST, di antaranya: perceptron, Aturan Delta (Adaline/Madaline), Propagasi Balik, Self Organizing Map (SOM), dan
Learning Vector Quantization (LVQ) .
3. Fungsi aktivasi yang digunakan.
Fungsi aktivasi merupakan fungsi yang menentukan level aktivasi, yaitu keadaan internal sebuah neuron dalam JST. Keluaran aktivasi ini biasanya dikirim sebagai sinyal ke neuron lainnya. Contoh fungsi aktivasi ialah fungsi identitas fungsi tangga biner (binary step function), fungsi tangga bipolar, fungsi sigmoid biner dan fungsi sigmoid bipolar.
JST Propagasi Balik Standar
Menurut Fu (1994), jaringan propagasi balik (propagation network) merupakan jaringan umpan maju berlapis banyak (multilayer
feedforward network). Aturan pembelajaran
propagasi balik disebut backpropagation yang merupakan jenis dari teknik gradient descent dengan backward error (gradient) propagation. Fungsi aktivasi yang digunakan dalam propagasi balik ialah fungsi sigmoid. Hal ini disebabkan karena dalam jaringan propagasi balik fungsi aktivasi yang digunakan harus kontinu, dapat didiferensialkan, dan monoton naik (Fausett 1994). Salah satu fungsi aktivasi yang paling banyak digunakan ialah sigmoid biner, yang memiliki selang [0, 1] dan didefinisikan sebagai: ) exp( 1 1 ) ( 1 x x f − + = ... (1) Dengan turunannya )] ( 1 1 )[ ( 1 ) ( ' 1 x f x f x f = − ... (2) Grafik untuk fungsi sigmoid biner dapat diihat dalam Gambar 3 dengan n sebagai masukan dan a sebagai keluaran dari neuron tersebut.
Gambar 3 Grafik fungsi sigmoid biner dengan selang (0,1).
Jaringan ini menggunakan metode pembelajaran dengan pengarahan (supervised
learning). Cara kerja JST diawali dengan
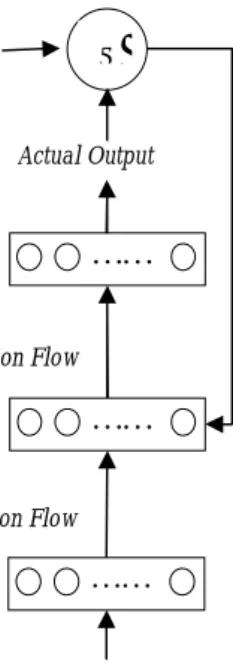
inisialisasi pembobot dan bias. Pemilihan metode inisialisasi pembobot dan bias berpengaruh pada kecepatan JST dalam mencapai kekonvergenan (Fausett, 1994). Jaringan propagasi balik ditunjukkan dalam Gambar 4. n a wr w3 w1 w2 pr p3 p2 p1 Σ b f
Gambar 4 Arsitektur jaringan propagasi balik (Fu 1994).
Pada pelatihan JST propagasi balik terdapat tiga tahapan, yaitu pelatihan input yang bersifat umpan maju, penghitungan galat, dan penyesuaian pembobot. Secara umum cara kerja JST propagasi balik ada beberapa langkah. Pertama, pola input dan target dimasukkan ke dalam jaringan. Selanjutnya pola input ini akan berubah sesuai dengan propagasi pola tersebut ke lapisan-lapisan berikutnya hingga menghasilkan output. Output ini akan dibandingkan dengan target. Apabila dari hasil perbandingan ini dihasilkan nilai yang sama, proses pembelajaran akan berhenti. Tetapi apabila berbeda, maka jaringan mengubah pembobot yang ada pada hubungan antar
neuron dengan suatu aturan tertentu agar nilai
output lebih mendekati nilai target.
Proses pengubahan pembobot adalah dengan cara mempropagasikan kembali nilai korelasi galat output jaringan ke lapisan-lapisan sebelumnya (propagasi balik). Kemudian dari lapisan input, pola akan diproses lagi untuk mengubah nilai pembobot, hingga akhirnya memperoleh output jaringan baru. Proses ini dilakukan berulang-ulang sampai diperoleh nilai yang sama atau minimal sesuai dengan galat yang diinginkan. Proses perubahan pembobot inilah yang disebut proses pembelajaran.
Inisialisasi Pembobot Nguyen-Widrow
Inisialisasi pembobot dari neuron input ke
neuron tersembunyi bertujuan untuk meningkatkan kemampuan neuron-neuron
tersembunyi untuk melakukan pembelajaran. Hal ini dilakukan dengan mendistribusikan pembobot dan bias awal sedemikian rupa sehingga dapat meningkatkan kemampuan lapisan tersembunyi dalam melakukan proses pembelajaran. Inisialisasi Nguyen-Widrow didefinisikan sebagai persamaan berikut (Fausett 1994):
- Hitung harga faktor penskalaan β
n
p
17
.
0
=
β
... (3) dimana: β = faktor penskalaann = jumlah neuron lapisan input p = jumlah neuron lapisan tersembunyi - Untuk setiap unit tersembunyi (j=1, 2,... ,p):
- Hitung vij (lama) yaitu bilangan acak
diantara -0.5 dan 0.5 (atau diantara -γ dan +γ). Pembaharuan pembobot vij
(lama) menjadi vij baru yaitu:
) ( ) ( ) ( lama v lama v baru v j ij ij β = ... (4) - Tetapkan bias.
vij = Pembobot pada bias bernilai antara
-β dan β.
Resilient Backpropagation
Resilient backpropagation atau biasa disingkat RPROP adalah salah satu algoritma yang digunakan untuk mempercapat laju pembelajaran pada pelatihan jaringan syaraf tiruan propagasi balik. RPROP melakukan penyesuaian nilai bobot secara langsung berdasarkan informasi dari gradien lokalnya.
Untuk melakukannya, pada tiap nilai bobot diberikan suatu nilai perubahan bobot individual yang secara personal menentukan besarnya perubahan bobot. Nilai perubahan ini terus berubah selama proses pembelajaran berdasarkan pada pengamatan lokalnya terhadap fungsi galatnya (Riedmiller dan Braun, 1993).
Secara sederhana, algoritma ini menggunakan tanda turunan untuk menentukan arah perbaikan bobot-bobot. Besarnya perubahan setiap bobot ditentukan oleh suatu faktor yang diatur pada parameter yang disebut
delt_inc dan delt_dec. Apabila gradien fungsi error berubah tanda dari satu iterasi ke iterasi
berikutnya, maka bobot akan berkurang sebesar
delt_dec. Sebaliknya apabila gradien error tidak
berubah tanda dari satu iterasi ke iterasi berikutnya, maka bobot akan berkurang sebesar
delt_inc. Apabila gradien error sama dengan 0
maka perubahan sama dengan perubahan bobot sebelumnya. Pada awal iterasi, besarnya
Σ Backward Error Propagation OUTPUT LAYER HIDDEN LAYER INPUT LAYER Input Actual Output Forward Information Flow
K
K
Forward Information Flow Target OutputK
K
K Kperubahan bobot diinisalisasikan dengan parameter delta0. Besarnya perubahan tidak boleh melebihi batas maksimum yang terdapat pada parameter deltamax, apabila perubahan bobot melebihi batas maksimum perubahan bobot, maka perubahan bobot akan ditentukan sama dengan maksimum perubahan bobot (Mathworks, 1999). Untuk lebih jelasnya algoritma RPROP disajikan pada Lampiran 1.
METODOLOGI PENELITIAN Data
Data yang digunakan pada penelitian ini adalah gelombang suara yang telah didijitasi dan direkam dari 10 pembicara, yaitu 5 pembicara laki-laki dan 5 pembicara perempuan dengan rentang usia 20-25 tahun. Masing-masing pembicara diambil suaranya dalam jangka waktu yang sama dan tanpa pengarahan (unguided). Yang dimaksud tanpa pengarahan adalah pembicara dapat menggunakan cara pengucapan, intonasi, dan logat apapun pada saat merekam data. Setiap suara dicuplik dengan sampling rate 16000 Hz dan kemudian dikuantisasi dengan ke dalam representasi 16 bit. Pemilihan sampling rate 16000 Hz didasarkan pada pengetahuan bahwa sampling
rate di atas 10000 Hz dapat meminimalkan efek aliasing pada konversi dari analog menjadi
dijital (Jurafsky & Martin 2000).
Jenis identifikasi pembicara yang dilakukan bersifat bergantung pada teks, maka kata yang diucapkan baik untuk pelatihan maupun pengujian telah ditentukan yaitu “komputer”. Kata tersebut diucapkan sebanyak 60 kali oleh tiap pembicara, sehingga terdapat 600 file data. Di samping itu, diperlukan juga data yang memiliki noise dengan jumlah yang sama untuk mengetahui pengaruh noise terhadap akurasi.
Selanjutnya untuk melihat keakuratan model JST yang dibangun terhadap identifikasi tertutup, digunakan 50 data suara dari 10 pembicara lainnya. Sama seperti pengambilan data suara sebelumnya, 5 pembicara laki-laki dan 5 pembicara perempuan dengan rentang usia 20-25 tahun diambil suaranya dalam jangka waktu yang sama dan tanpa pengarahan Masing-masing pembicara mengucapkan kata yang sama, yaitu “komputer”, sebanyak lima kali. Data suara yang dihasilkan dari proses ini selanjutnya disebut sebagai data non model.
Proses Pengenalan Suara
Proses pengenalan suara dalam penelitian ini secara umum terdiri dari 4 tahap yaitu: (1) Tahap Input Data:
Pada tahap ini dilakukan pengumpulan data dengan cara merekam data dan menyimpannya dalam bentuk file berekstensi WAV.
(2) Tahap Pra-proses:
Proses pereduksian dan analisis fitur dari data dengan menggunakan Mel-Frequency
Ceptrum Coeffisien.
(3) Tahap Pelatihan Jaringan Syaraf Tiruan Metode pelatihan yang digunakan adalah
resilient backpropagation dengan tipe supervised learning.
(4) Tahap Pengujian Jaringan Syaraf Tiruan Model jaringan syaraf tiruan yang terbentuk dari hasil pelatihan diuji dengan data uji kemudian diukur akurasinya. Diagram proses ditunjukkan pada Gambar 5.
Gambar 5 Proses pengenalan pembicara Data suara terlebih dahulu dikonversikan ke dalam bentuk vektor kemudian dilakukan praproses dengan MFCC pada data tersebut. Selanjutnya semua data untuk pelatihan digabungkan menjadi suatu matriks data input
yang akan digunakan sebagai input dari jaringan syaraf tiruan.
Hasil dari pelatihan yang berupa suatu model jaringan syaraf tiruan dengan bobot yang telah sesuai digunakan untuk tahap pengujian dan akhirnya diperoleh hasil pengujian berupa tingkat keakuratan terhadap data suara yang akan dikenal.
Arsitektur Jaringan Syaraf Tiruan
Arsitektur JST Propagasi Balik yang digunakan adalah arsitektur multilayer perceptron dengan satu hidden layer. Jumlah neuron input disesuaikan dengan hasil pereduksian dengan MFCC. Jumlah neuron
hidden dibagi menjadi tiga puluh perlakuan
yakni 10 sampai 300 dengan increment 10. Sedangkan jumlah neuron output disesuaikan dengan target pembicara. Inisialisasi yang digunakan adalah Nguyen-Widrow dengan alasan laju pembelajaran yang lebih baik (Fausett 1994). Struktur JST Resilient Backpropagation dapat dilihat pada Tabel 1.
Tabel 1 Struktur JST Resilient Backpropagation Karakteristik Spesifikasi Arsitektur
Jumlah neuron input Jumlah neuron hidden
Jumlah neuron output Inisialisasi bobot Fungsi Pembelajaran Fungsi aktivasi Toleransi galat 1 hidden layer Dimensi hasil MFCC 10 sampai 300 dengan increment 10 10 (Definisi target) Nguyen-Widrow Resilient Backpropagation Log-sigmoid 0.0001 Parameter-parameter Resilient Backpropagation
Walaupun pada resilient backpropagation ada banyak parameter yang dapat diatur, tetapi sebagian besar dari parameter-parameter tersebut dapat digunakan dengan nilai yang diatur secara default. Hal ini disebabkan karena variasi nilai dari parameter-parameter tersebut tidak terlalu mempengaruhi waktu yang dibutuhkan untuk pelatihan (Riedmiller dan Braun, 1993).
Berdasarkan hasil penelitian tersebut, pada penelitian ini digunakan nilai default pada parameter-parameter yang diperlukan. Nilai
delta0 yang digunakan adalah 0,1. Nilai deltamax dan deltamin masing-masing sebesar
50 dan 0,1. Sedangkan untuk parameter delt_inc dan delt_dec digunakan nilai 1,2 dan 0,5.
Lingkungan Pengembangan
Program diimplementasikan menggunakan perangkat lunak Matlab 7.0.1 Pemilihan perangkat lunak ini dilakukan dengan mempertimbangkan kemudahan dalam pengolahan matriks, penghitungan statistika dan jaringan syaraf tiruan propagasi balik. Sedangkan sistem operasi yang digunakan ialah Microsoft Windows XP Professional.
Perangkat keras yang digunakan dalam penelitian ini ialah komputer personal dengan
processor AMD Sempron 2600+, RAM DDR
512 MB, dan harddisk dengan kapasitas 80 GB.
HASIL DAN PEMBAHASAN Hasil Pengambilan Data
Data suara yang digunakan direkam menggunakan fungsi wavrecord pada Matlab, dan disimpan menjadi file berekstensi WAV dengan fungsi wavwrite. Setiap pembicara mengucapkan kata “komputer” sebanyak 60 kali sehingga didapat 600 data suara. Setiap suara direkam selama 1 detik tanpa pengarahan (unguided) dengan sampling rate 16000 Hz dan kemudian dikuantisasi dengan ke dalam representasi 16 bit, sehingga masing-masing menghasilkan ukuran file 31,25 KB.
Untuk mendapatkan data yang memiliki
noise, data yang telah dikumpulkan sebelumnya
disalin sebanyak dua kali kemudian ditambahkan white gaussian noise masing-masing dengan SNR 30 dB dan 20 dB. Setelah tahapan ini selesai dilakukan, didapatkan tiga tipe data suara yaitu: data tanpa noise, data dengan SNR 30 dB, dan data dengan SNR 20 dB dengan jumlah 600 data suara untuk tiap tipenya. Selanjutnya data yang telah dikumpulkan tadi dibagi menjadi dua kelompok dengan perbandingan 2:1 untuk tiap pembicara. Kelompok pertama, sebanyak 400 data suara, akan digunakan sebagai data latih dan kelompok kedua, sebanyak 200 data suara digunakan sebagai data uji. Data non model didapatkan dengan cara yang sama.
Praproses dengan MFCC
Data suara yang dihasilkan dari proses yang dijelaskan di atas memiliki ukuran yang cukup besar. Sampling rate 16000 Hz dan waktu perekaman 1 detik membuat matriks yang dihasilkan untuk tiap suara berukuran 16000 × 1 sehingga dianggap terlalu besar jika dilakukan pelatihan dan pengujian secara langsung. Untuk mengatasi masalah tersebut, data suara yang telah dikumpulkan tadi direduksi terlebih
dahulu dengan menggunakan Mel-Frequency
Cepstrum Coefficients (MFCC). Dengan MFCC, data suara yang telah dikumpulkan direduksi dengan cara dilakukan segmentasi dan kemudian diambil beberapa koefisien dari tiap segmen tersebut yang dianggap mewakili keseluruhan segmen. Hasil dari MFCC adalah matriks ceptrum coefficients dengan ukuran m × n, dengan n adalah banyaknya segmen dan m adalah jumlah koefisien dari tiap segmen tersebut.
Pada penelitian ini, digunakan fungsi dari
Auditory Toolbox yang dikembangkan oleh
Slanley pada tahun 1998. Setiap data suara akan dibagi menjadi segmen berukuran masing-masing 30 ms dengan overlap 50% sehingga menghasilkan 66 segmen. Dari tiap segmen tersebut diambil 13 koefisien sehingga setelah melewati tahap praproses tiap datum suara akan menjadi sebuah matriks dengan ukuran 13 × 66. Matriks inilah yang selanjutnya digunakan sebagai data untuk melakukan pelatihan dan pengujian pada jaringan syaraf tiruan yang dibangun.
Pengembangan Model Jaringan Syaraf Tiruan
Tiga puluh perlakuan yang berbeda dalam jumlah neuron tersembunyi mengakibatkan perlu dibangunnya sepuluh model jaringan syaraf tiruan yang berbeda dengan tiap model mewakili satu jenis perlakuan. Tiga puluh model tadi kemudian dilatih dan diuji untuk mendapatkan model dengan nilai akurasi yang optimal. Pelatihan dan pengujian yang dilakukan pada tiap model dilakukan sebanyak lima kali karena pada saat inisialisasi bobot digunakan bilangan random sehingga tiap kali ulangan dihasilkan nilai akurasi yang berbeda. Nilai akurasi yang didapat kemudian dihitung rata-ratanya untuk mendapatkan nilai akurasi rata-rata yang digunakan sebagai pembanding
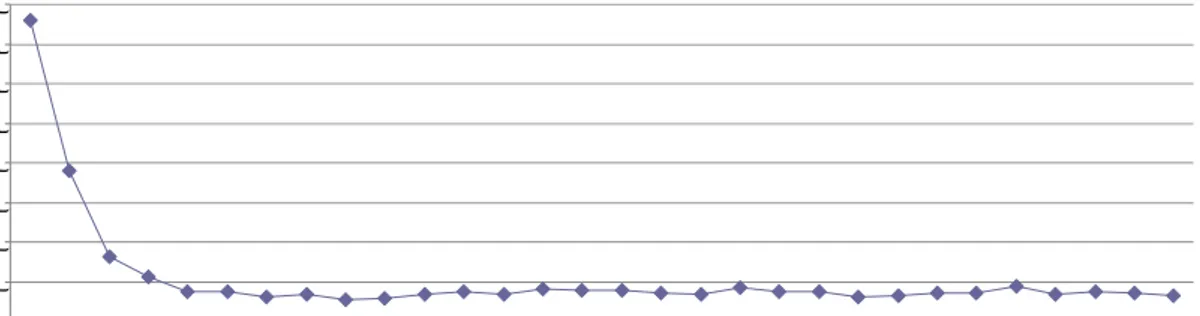
dalam mencari nilai akurasi yang optimal. Grafik akurasi rata-rata dari tiap model pada pelatihan dengan data tanpa noise diperlihatkan pada Gambar 6 dan dijabarkan dengan lebih jelas pada Lampiran 2.
Dari hasil penelitian, akurasi rata-rata optimal yang dicapai adalah 92.8% yang didapatkan dari model dengan seratus neuron tersembunyi. Di sisi lain, akurasi rata-rata terendah yang dicapai adalah 58,6% yang didapat pada model dengan sepuluh neuron tersembunyi. Dari Gambar 6 juga dapat dilihat bahwa nilai dari akurasi rata-rata yang dihasilkan oleh model JST dengan sepuluh
neuron tersembunyi sampai dengan seratus neuron tersembunyi secara umum bergerak naik
seiring bertambahnya jumlah neuron. Tetapi setelah jumlah neuron tersembunyi melebihi seratus, akurasi rata-rata yang dihasilkan berfluktuasi dengan ragam yang kecil di sekitar nilai tertentu.
Perubahan akurasi rata-rata dari model sampai dengan seratus neuron tersembunyi sangat mungkin disebabkan oleh pengaruh banyaknya jumlah bobot yang digunakan sebagai koefisien dalam proses perhitungan dari tiap neuron. Tiap nilai bobot berpengaruh besar dalam menentukan keluaran dari kesuluruhan model JST yang dibuat. Nilai bobot ini selalu diperbaharui pada tiap iterasi. Dengan lebih banyak bobot yang dapat diperbaharui, nilai bobot yang disimpan dapat lebih tepat sehingga menghasilkan perhitungan yang lebih akurat. Jumlah neuron tersembunyi yang lebih banyak juga membuat keluaran dari hidden layer menjadi lebih banyak. Keluaran dari hidden
layer digunakan sebagai nilai masukan pada output layer. Hal ini menyebabkan perhitungan
yang dilakukan pada output layer menjadi lebih akurat karena masukan yang didapatnya lebih banyak dan dengan bobot yang lebih tepat. Perbandingan Akurasi Rata-rata Terhadap Jumlah Neuron Tersembunyi
0 10 20 30 40 50 60 70 80 90 100 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 270 280 290 300 jumlah neuron tersembunyi
ak urasi r at a-rata
Gambar 6 Grafik perbandingan nilai akurasi rata-rata terhadap jumlah neuron tersembunyi pada pelatihan dengan data tanpa noise.
Namun setelah jumlah neuron tersembunyi melewati angka seratus neuron, nilai akurasi rata-rata cenderung konvergen. Dari fakta tersebut dapat disimpulkan bahwa nilai akurasi maksimal yang bisa dicapai oleh model JST untuk data yang dimasukkan telah dicapai sehingga akurasi yang dihasilkan oleh tiap model JST cenderung konvergen.
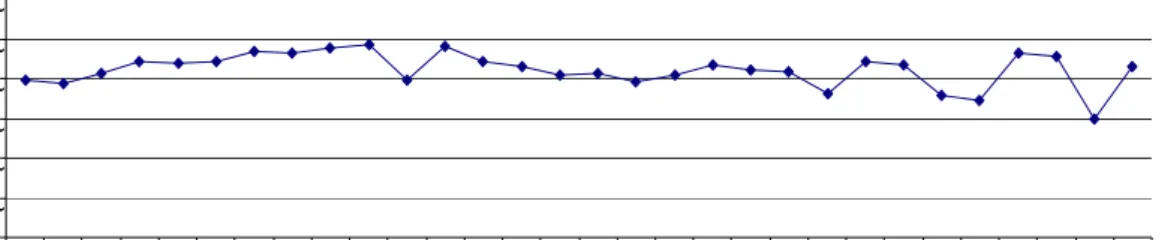
Pada Gambar 7 ditampilkan jumlah epoh rata-rata yang dibutuhkan untuk mencapai nilai galat yang dikehendaki pada saat pelatihan untuk tiap model JST. Dari nilai-nilai yang ditampilkan, terlihat bahwa perilaku dari jumlah epoh rata-rata yang dibutuhkan untuk mencapai nilai galat yang diinginkan kurang lebih mirip dengan perilaku dari nilai akurasi rata-rata yang dihasilkan oleh model JST. Sampai dengan sembilan puluh neuron tersembunyi, jumlah epoh rata-rata yang dibutuhkan untuk mencapai nilai galat yang dikehendaki menurun seiring dengan pertambahan jumlah neuron
tersembunyi.
Penurunan jumlah epoh yang dibutuhkan seiring dengan pertambahan jumlah neuron ini terkait erat dengan alasan terjadinya kenaikan nilai akurasi rata-rata seiring dengan kenaikan jumlah neuron tersembunyi. Perhitungan yang lebih akurat di output layer menyebabkan keluaran dari keseluruhan model JST menjadi lebih akurat sehingga galat yang didapat sudah cukup mendekati target. Banyaknya bobot yang dapat diperbaharui juga mengakibatkan nilai bobot yang disimpan dapat lebih tepat sehingga jumlah iterasi yang diperlukan untuk untuk mencapai nilai galat yang dikehendaki tidak terlalu banyak. Keterkaitan ini dikuatkan dengan kenyataan bahwa nilai akurasi rata-rata
cenderung meningkat seiring dengan semakin turunnya jumlah epoh rata-rata dari model pada model JST dengan jumlah neuron tersembunyi kurang dari seratus.
Selanjutnya, setelah jumlah neuron
tersembunyi melebihi seratus, jumlah epoh yang dibutuhkan untuk mencapai nilai galat yang dikehendaki berfluktuasi menuju suatu nilai tertentu, mirip dengan yang terjadi pada nilai akurasi yang dihasilkan tiap model JST. Dari Fakta ini dapat disimpulkan pula bahwa nilai epoh minimum yang dibutuhkan untuk mencapai nilai galat yang dikehendaki telah tercapai sehingga selanjutnya epoh yang dibutuhkan cenderung tidak terlalu berubah untuk tiap penambahan jumlah neuron
tersembunyi. Kemudian apabila diamati, terlihat bahwa nilai akurasi rata-rata yang tinggi didapat dari model yang dilatih dengan jumlah epoh yang relatif kecil. Fakta tersebut memperkuat analisis bahwa nilai akurasi yang dihasilkan oleh tiap model JST berkaitan erat dengan jumlah epoh yang dibutuhkan untuk mencapai nilai galat yang dikehendaki karena alasan seperti yang telah dijelaskan sebelumnya.
Untuk melihat perilaku dari model JST yang dibangun terhadap data yang diberi noise, dilakukan pelatihan dan pengujian model JST dengan arsitektur yang sama dengan data yang memiliki noise. Pada Gambar 8 ditampilkan akurasi rata-rata yang dihasilkan dari pelatihan dan pengujian model JST pada data dengan SNR 30 dB. Hasil pelatihan dan pengujian model JST dari tiga puluh perlakuan jumlah
neuron tersembunyi pada data dengan SNR
30 dB dijabarkan dengan lebih jelas pada Lampiran 3.
Perbandingan Epoh Rata-rata Terhadap Jumlah Neuron Tersembunyi
0 100 200 300 400 500 600 700 800 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 270 280 290 300 jumlah neuron tersembunyi
e p o h rata -r at a
Gambar 7 Grafik perbandingan jumlah epoh rata-rata terhadap jumlah neuron tersembunyi pada pelatihan dengan data tanpa noise.
Perbandingan Akurasi Terhadap Jumlah Neuron Tersembunyi pada Data dengan SNR 30dB 0 10 20 30 40 50 60 70 80 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 270 280 290 300 jumlah neuron tersembunyi
aku ras i r at a-rat a
Gambar 8 Grafik perbandingan nilai akurasi rata-rata terhadap jumlah neuron tersembunyi pada pelatihan dengan data SNR 30 dB.
Dari hasil penelitian, nilai akurasi rata-rata terbaik adalah 71% yang dihasilkan dari model JST dengan 200 neuron tersembunyi. Sementara itu, nilai akurasi rata-rata terendah kembali dihasilkan dari model dengan dengan jumlah lapisan neuron tersedikit, yaitu sepuluh. Di samping itu juga terlihat bahwa sampai dengan lima puluh neuron tersembunyi, nilai akurasi rata-rata cenderung naik seiring dengan pertambahan jumlah neuron tersembunyi. Setelah itu, nilai akurasi yang dihasilkan kembali berfluktuasi menuju suatu nilai. Dari perilaku ini dapat disimpulkan bahwa dengan model JST yang dibangun, untuk data dengan SNR 30 dB nilai akurasi maksimal yang dapat dicapai tidak dapat lebih baik lagi.
Hasil yang didapat dari pelatihan dan pengujian model JST dengan arsitektur yang sama pada data yang dengan SNR 20dB juga memperlihatkan perilaku yang mirip. Akurasi rata-rata yang dihasilkan oleh tiap model JST tersebut diperlihatkan pada Gambar 9. Hasil pelatihan dan pengujian model JST dari tiga puluh perlakuan jumlah neuron tersembunyi pada data dengan SNR 20 dB dijabarkan dengan lebih jelas pada Lampiran 4.
Pada Gambar 9 sekali lagi terlihat bahwa akurasi yang dihasilkan cenderung naik sampai suatu titik lalu kemudian berfluktuasi menuju suatu nilai. Bahkan kali ini fluktuasi hampir terlihat dari awal karena nilai akurasi rata-rata yang dihasilkan oleh tiap model JST hampir tidak menunjukkan peningkatan yang terlalu berarti. Nilai akurasi rata-rata yang dihasilkan dari model JST dengan jumlah neuron tersedikit, dalam hal ini sepuluh, hanya berbeda beberapa persen dari nilai akurasi rata-rata yang dihasilkan oleh model JST dengan tiga ratus neuron tersembunyi. Dari fakta tersebut dapat disimpulkan bahwa untuk data dengan noise yang cukup besar, jumlah neuron tersembunyi tidak terlalu berpengaruh dalam meningkatkan nilai akurasi rata-rata.
Selanjutnya, untuk melihat pengaruh dari
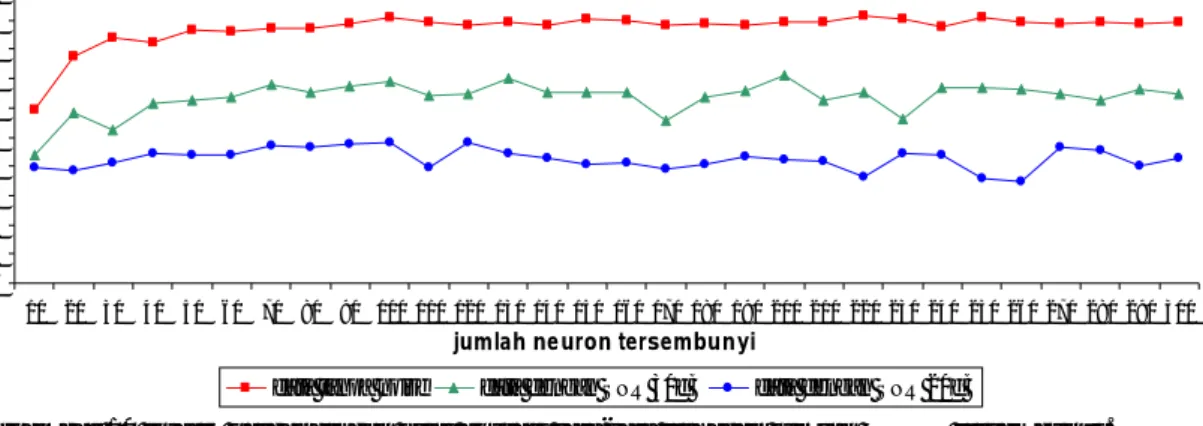
noise terhadap nilai akurasi dilakukan perbandingan nilai akurasi rata-rata yang dihasilkan dari tiap jenis data. Gambar 10 menampilkan perbandingan langsung dari akurasi rata-rata yang dihasilkan tiap model JST yang dilatih dan diuji dengan tipe data yang berbeda.
Perbandingan Akurasi Terhadap Jumlah Neuron Tersembunyi Pada Data dengan SNR 20 dB
0 10 20 30 40 50 60 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 270 280 290 300 jumlah neuron tersembunyi
a k ur a si rat a -r at a
Gambar 9 Grafik perbandingan nilai akurasi rata-rata terhadap jumlah neuron tersembunyi pada data dengan SNR 20 dB
Perbandingan Nilai Akurasi Rata-rata Terhadap Jumlah Neuron Tersembunyi pada Berbagai Data
0 10 20 30 40 50 60 70 80 90 100 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 270 280 290 300 jumlah neuron tersembunyi
a ku ra s i rata -rat a
data tanpa noise data dengan SNR 30dB data dengan SNR 20dB
Gambar 10 Grafik perbandingan nilai akurasi rata-rata terhadap jumlah neuron tersembunyi. Dari gambar, terlihat bahwa nilai akurasi
rata-rata dari tiap model JST yang dilatih dan diuji dengan data tanpa noise selalu lebih besar dibandingkan dengan nilai akurasi rata-rata dari tiap model JST yang dilatih dan diuji dengan data yang diberi noise. Di samping itu, terlihat pula bahwa data dengan noise yang lebih buruk, dalam hal ini 20 dB, menghasilkan nilai akurasi rata-rata yang lebih buruk pula bila dibandingkan dengan model yang dilatih dan diuji dengan data yang diberi noise 30 dB. Hal ini memberikan kesimpulan bahwa nilai akurasi akan lebih baik jika data yang digunakan dalam pelatihan dan pengujian lebih baik.
Dari grafik juga terlihat bahwa konvergensi dari tiap data tidak sama. Dari grafik terlihat bahwa data tanpa noise konvergensi terjadi pada saat jumlah neuron tersembunyi telah melewati angka seratus, sedangkan pada data dengan
noise 30 dB konvergensi sudah terjadi pada saat
jumlah neuron tersembunyi masih tujuh puluh. Bahkan pada data dengan noise 20 dB konvergensi hampir terlihat dari awal. Di samping itu, dari grafik dapat terlihat pula bahwa kemiringan dari garis yang menyatakan akurasi rata-rata cenderung meningkat jika data yang digunakan lebih baik. Dari fakta tersebut dapat disimpulkan bahwa jika digunakan data yang guided maka akurasi yang didapat akan jauh lebih baik.
Pengambilan Threshold
Dengan model JST yang optimal, dilakukan pengambilan nilai threshold untuk tiap pembicara. Threshold tersebut digunakan pada saat identifikasi untuk melakukan seleksi yang lebih akurat dari hasil identifikasi setiap suara. Nilai threshold dari tiap pembicara berfungsi sebagai ambang batas nilai keluaran yang
diterima untuk dapat diidentifikasikan sebagai pembicara tersebut. Data threshold diambil dengan menjadikan data latih sebagai data uji. Keluaran yang diidentifikasi dengan benar dari model JST kemudian disimpan dalam suatu matriks. Dari matriks tersebut kemudian diambil nilai keluaran minimal untuk tiap pembicara. Nilai keluaran minimal tersebut adalah nilai yang digunakan sebagai threshold untuk tiap pembicara (Ho, 1998).
Hasil Identikasi Pembicara Model JST Terbaik pada Data Tanpa Noise
Identifikasi dilakukan dengan menjadikan data uji sebagai masukan untuk model JST yang telah selesai dilatih. Keluaran dari tiap neuron di ouput layer model JST tersebut kemudian dicari nilai maksimalnya. Nilai maksimal tersebut menunjukkan identifikasi pembicara dari data suara yang dimasukkan. Hasil identifikasi pembicara untuk dua puluh data tanpa noise dan tidak menggunakan threshold ditampilkan pada Tabel 2.
Dari Tabel 2 dapat dilihat bahwa pembicara yang dapat diidentikasi dengan benar seluruhnya adalah pembicara 1, pembicara 2, pembicara 5, dan pembicara 8. Di samping itu, dapat dilihat juga bahwa pembicara yang paling sedikit diidentifikasi dengan benar adalah pembicara 9. Pada pembicara tersebut, data uji yang dapat diidentifikasi dengan benar hanya tujuh belas data atau 85% sedangkan sisanya dua data uji diidentifikasi sebagai suara pembicara 6 dan satu diidentikasi sebagai suara pembicara 7. Dari data, dapat dihitung akurasi identifikasi dari model JST tersebut untuk seluruh pembicara adalah 96 %.
Tabel 2 Hasil identifikasi model JST terbaik dari dua puluh data pembicara tanpa threshold Diidentifikasi Sebagai Pembicara
Pembicara 1 2 3 4 5 6 7 8 9 10 Persentase 1 20 100 % 2 20 100 % 3 19 1 95 % 4 19 1 95 % 5 20 100 % 6 19 1 95 % 7 19 1 95 % 8 20 100 % 9 2 1 17 85 % 10 1 19 95 %
Ada dua alasan yang dapat menjelaskan terjadinya perilaku tersebut. Pertama, model JST yang dibangun kurang dapat membedakan dengan baik suara pembicara 6, pembicara 7, dan pembicara 9. Hal ini mungkin disebabkan karena pada pelatihan, galat target yang digunakan kurang kecil sehingga pelatihan belum optimal. Alasan kedua adalah data suara yang digunakan pada pelatihan atau pengujian dari pembicara 6, pembicara 7, dan pembicara 9 kurang lebih mirip. Pada Tabel 2 juga terlihat bahwa ada dua data suara dari pembicara lain yang teridentifikasi sebagai data suara pembicara 5. Data suara itu adalah data suara milik pembicara pembicara 3 dan satu suara milik pembicara 4. Sementara di lain pihak, seluruh data uji dari pembicara 5 diidentifikasi dengan benar. Perilaku ini menguatkan alasan bahwa data yang digunakan pada pelatihan dan pengujian kurang lebih mirip sehingga model JST yang dibangun dengan arsitektur yang direncanakan belum dapat mengidentifikasi dengan baik.
Selanjutnya, pada proses identifikasi ditambahkan satu tahapan lagi. Kali ini setelah
ditemukan nilai maksimal dari keluaran model JST, dilakukan pembandingan terhadap nilai
threshold dari pembicara tersebut. Sebuah data
suara yang diuji diidentifikasi sebagai suara salah seorang pembicara hanya jika nilai maksimal keluaran dari model JST, yang menyatakan bahwa data tersebut suara dari salah seorang pembicara, lebih besar dari nilai
threshold. Apabila nilai maksimal yang
ditemukan masih lebih kecil dari pada nilai
threshold maka data suara tersebut tidak
dikategorikan sebagai satu pun pembicara. Dengan penambahan tahap threshold dalam proses identifikasi, model JST yang dibangun menjadi lebih “hati-hati” dalam mengidentifikasi suatu suara. Hasil identifikasi pembicara untuk dua puluh data pengujian tanpa noise dengan menggunakan threshold ditampilkan pada Tabel 3. Pada tabel tersebut ditambahkan satu pembicara baru yaitu pembicara 0. Pembicara ini ditambahkan dengan maksud untuk menampung data suara yang hasil identifikasinya lebih kecil daripada nilai threshold.
Tabel 3 Hasil identifikasi model JST terbaik dari dua puluh data pembicara dengan threshold Diidentifikasi Sebagai Pembicara
Pembicara 0 1 2 3 4 5 6 7 8 9 10 Persentase 1 4 16 80 % 2 3 17 85 % 3 2 18 90 % 4 7 13 65 % 5 1 19 95 % 6 1 19 95 % 7 7 13 65 % 8 6 14 70 % 9 3 17 85 % 10 1 19 95 %
Dari Tabel 3 dapat dilihat bahwa setelah ditambahkan threshold tidak ada lagi data suara dari satu pembicara yang teridentifikasi sebagai pembicara lain. Tapi di lain pihak dapat dilihat juga bahwa tidak ada lagi data suara yang seluruhnya diidentifikasi dengan benar. Jumlah data suara yang teridentifikasi dengan benar terbanyak hanya sembilan belas data yaitu data suara dari pembicara 5, pembicara 6, dan pembicara 10. Satu data suara dari masing-masing pembicara tadi dikenali sebagai pembicara 0 yang berarti bahwa nilai keluaran model JST untuk data tersebut lebih kecil dari nilai thresholdnya.
Jumlah data suara yang teridentifikasi dengan benar terendah terjadi pada pembicara 4 dan pembicara 7, yaitu tiga belas data suara atau hanya 65 % dari seluruh data suara yang diujikan. Jumlah data suara teridentifikasi dengan benar yang rendah juga terjadi pada pembicara 8. Dari dua puluh data yang diujikan, hanya empat belas data yang diidentifikasi dengan benar.
Bila dibandingkan dengan identifikasi tanpa threshold, jumlah data suara yang teridentifikasi dengan benar pada identifikasi dengan threshold secara umum mengalami penurunan yang cukup drastis. Hal ini dapat dilihat dengan jelas dalam grafik perbandingan jumlah data suara yang teridentifikasi dengan benar pada Gambar 11.
0 5 10 15 20 25 1 2 3 4 5 6 7 8 9 10 Pembicara J um lah t e ri d en ti fi k as i b e na r
identifikasi tanpa threshold identifikasi dengan threshold
Keterangan :
threshold
threshold
Gambar 11 Grafik perbandingan jumlah data suara yang teridentifikasi dengan benar pada
data tanpa noise
Dari grafik terlihat bahwa pada identifikasi tanpa threshold jumlah data suara yang dikenali dengan benar secara umum mengalami penurunan dibandingkan dengan identifikasi
tanpa threshold. Nilai akurasi keseluruhan pun turun menjadi hanya 82.5%. Hal ini disebabkan karena hasil keluaran dari model JST untuk data suara tersebut masih lebih kecil dari nilai
threshold pembicara yang bersangkutan. Keadaaan tersebut mengakibatkan data suara yang diujikan tadi dianggap bukan merupakan suara dari pembicara yang bersangkutan dan kemudian diklasifikasikan sebagai data suara pembicara 0.
Penurunan jumlah data suara teridentifikasi dengan benar yang cukup drastis ini kemungkinan disebabkan oleh dua hal. Pertama, data dan model JST yang digunakan masih kurang baik. Model yang masih kurang baik menyebabkan identifikasi kurang baik, yang digambarkan dengan nilai maksimal keluaran dari model yang kurang besar. Nilai maksimal keluaran yang kurang besar ini mengakibatkan data suara yang diujikan diangap bukan suara pembicara yang bersangkutan karena nilainya lebih kecil dari threshold. Kemungkinan kedua adalah kurang baiknya nilai threshold itu sendiri. Jika nilai threshold yang diambil terlalu besar, maka akan banyak data suara yang tidak teridentifikasi karena nilai maksimalnya lebih kecil dari threshold.
Untuk mengamati ketepatan nilai threshold yang dipakai dilakukan pengujian model JST dengan data suara dari pembicara yang tidak ikut serta dalam pelatihan model JST. Idealnya, seluruh data yang diuji akan dikenali sebagai pembicara 0 karena pembicara tidak ikut dalam pelatihan. Hasil identifikasi dua puluh data suara tanpa noise dari pembicara yang tidak ikut serta dalam pelatihan dan dengan menggunakan
threshold ditampilkan pada Tabel 4.
Pada Tabel 4 terlihat bahwa secara umum model JST dan threshold yang digunakan sudah dapat mengenali data suara tanpa noise dari pembicara yang tidak ikut serta dalam pelatihan dengan baik. Kesalahan hanya terjadi pada pembicara non model 1. Pada pembicara non model 1 ada satu data suara yang dikenali sebagai pembicara 4. Dari sini kita dapat menyimpulkan bahwa threshold yang digunakan tidak terlalu tinggi sehingga masih ada satu data suara dari pembicara yang tidak ikut serta dalam pelatihan yang dikenali sebagai pembicara 4, yang ikut serta dalam pelatihan. Dengan demikian dapat disimpulkan bahwa penyebab turunnya nilai akurasi rata-rata setelah penerapan nilai threshold adalah data dan model jaringan syaraf tiruan yang digunakan untuk identifikasi pembicara tidak cukup baik.
Tabel 4 Hasil identifikasi dua puluh data suara tanpa noise dari pembicara yang tidak ikut serta dalam pelatihan dengan menggunakan threshold
Diidentifikasi Sebagai Pembicara Pembicara Non model 0 1 2 3 4 5 6 7 8 9 10 Persentase 1 4 0 1 80 2 5 0 100 3 5 0 100 4 5 0 100 5 5 0 100 6 5 0 100 7 5 0 100 8 5 0 100 9 5 0 100 10 5 0 100
KESIMPULAN DAN SARAN Kesimpulan
Dari penelitian yang telah dilakukan, dapat disimpulkan bahwa model jaringan syaraf tiruan resilient backpropagation dapat digunakan untuk identifikasi pembicara pada data yang direkam tanpa pengarahan. Dari tiga puluh model yang dibangun, nilai akurasi rata-rata terbaik didapatkan dari model dengan seratus neuron tersembunyi yaitu sebesar 92,8%. Nilai akurasi rata-rata terendah didapatkan dari model dengan sepuluh neuron tersembunyi, yaitu 58,6%.
Pada data yang diberi noise, nilai akurasi rata-rata mengalami penurunan dibandingkan dengan data yang tanpa noise. Model jaringan syaraf tiruan yang dilatih dengan menggunakan data dengan SNR 30 dB hanya mampu menghasilkan nilai akurasi rata-rata terbaik 71,0% yang didapat dari model dengan dua ratus neuron tersembunyi. Di samping itu, data dengan noise yang lebih besar juga menghasilkan nilai akurasi rata-rata yang lebih buruk. Model jaringan syaraf tiruan yang dilatih menggunakan data dengan SNR 20 dB hanya mampu menghasilkan nilai akurasi rata-rata terbaik 48,3% yang didapat dari model dengan seratus neuron tersembunyi.
Saran
Untuk penelitian selanjutnya, tingkat akurasi dapat dinaikkan dengan beberapa cara berikut:
1. Menambahkan beberapa lapisan tersembunyi untuk melihat pengaruh banyaknya lapisan tersembunyi terhadap nilai akurasi.
2. Menggabungkan metode JST dengan beberapa metode lain yang telah diketahui dapat digunakan untuk melakukan identifikasi pembicara sehingga nilai akurasi dapat ditingkatkan.
3. Menambahkan tahap untuk menghilangkan atau mengurangi noise dari data suara yang digunakan.
DAFTAR PUSTAKA
Campbell, Jr JP. 1997. Speaker Recognition:
A Tutorial.Proceeding IEEE.
85:1437-1461.
Do MN. 1994. Digital Signal Processing
Mini-Project: An Automatic Speaker Recognition System. Audio Visual Communications Laboratory, Swiss Federal Institute of Technology,
Laussanne, Switzerland.
http://lcavwww.epfl.ch/~minhdo/asr_proje ct.pdf [12 Juli 2006].
Fausett L. 1994. Fundamentals of Neural
Network. New York: Prentice Hall.
Fu LM. 1994. Neural Networks in Computer
Intelligence. Singapore: Mc Graw-Hill.
Ho, CE. 1998. Speaker Recognition System. CNS 248 - Spring 1998 Project Report. Jurafsky D, dan Martin JH. 2000. Speech and
Language Processing An Introduction to Natural Language Processing, Computational Linguistic, and Speech Recognition. New Jersey: Prentice Hall.
Mathworks Inc. 1999. Neural Network for
Use With Matlab. Natick: The Mathworks
Inc.
Musthofa. 2005. Pencarian Pola Data Audio
dalam Interval Tertentu Menggunakan Jaringan Syaraf Tiruan Recurrent
[Skripsi]. Bogor: Departemen Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor.
Oktavianto, B. 2004. Pengenalan Pembicara
dengan Jaringan Syaraf Tiruan Propagasi Balik [Skripsi]. Bogor: Departemen Ilmu
Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor.
Purnamasari, W. 2006. Pengembangan Model
Markov Tersembunyi untuk Identifikasi Pembicara [Skripsi]. Bogor: Departemen
Ilmu Komputer, Fakultus Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Saputro, DW. 2006. Pengenalan Karakter
Tulisan Tangan dengan Menggunakan Jaringan Syaraf Tiruan Propagasi Balik Resilient [Skripsi]. Bogor: Departemen
Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor.
Slanley M. 1998. Auditory Toolbox. Interval Research Corporation, Palo Alto. http://rv14.ecn.purdue.edu/~malcolm/inter val/1998-010/). [4 Juni 2006].
Lampiran 1 Algoritma JSTRPROP
Langkah 0. Inisialisasi bobot
Langkah 1. Selama syarat henti salah, lakukan langkah 2-9
Langkah 2. Untuk setiap pasangan pelatihan (masukan dan target), lakukan langkah 3-8
Langkah 3. Setiap unit masukan (Xi, i=1, …,n) menerima sinyal masukan xi dan meneruskannya ke seluruh unit pada lapisan diatasnya (hidden unit).
Langkah 4. Setiap unit tersembunyi (Zj, j=1, …,p) menghitung total sinyal masukan terbobot,
∑
= + = n i ij i j j v xv in z 1 0 _ ,lalu menghitung sinyal keluarannya dengan fungsi aktivasi,
(
j)
j f z in
z = _ ,
dan mengirimkan sinyal ini ke seluruh unit pada lapisan atasnya (lapisan output).
Langkah 5. Setiap unit output (Yk, k=1, …,m) menghitung total sinyal masukan terbobot,
∑
= + = p j jk j k k w x w in y 1 0 _ ,lalu menghitung sinyal keluaran dengan fungsi aktivasi,
(
k)
k f y in
y = _
Langkah 6. Setiap unit output (Yk, k=1, …, m) menerima sebuah pola target yang sesuai dengan pola masukan pelatihannya. Unit tersebut menghitung informasi kesalahan,
(
k k) (
k)
k t y f y_in ' − = δ j k jk δ z ϕ2 = k k δ β2 = ) ( 2 2 2jk ϕ jk ϕ jk old ϕϕ = ∗ ) ( 2 2 2k β k β k old ββ = ∗kemudian menghitung koreksi bobot (digunakan untuk mengubah wjk nanti),
∆ ∆ ∆ = ∆ ); ( ); ( * ); ( * old w old w FT old w FN w jk jk jk jk 0 2 0 2 0 2 = < > jk jk jk ϕϕ ϕϕ ϕϕ
(
, max)
min w delta wjk = ∆ jk ∆ ∆ ∆ − = ∆ ; 0 ; ; jk jk jk w w w 0 2 0 2 0 2 = < > jk jk jk ϕ ϕ ϕhitung juga koreksi bias (yang nantinya akan digunakan untuk memperbaiki nilai b2k)
∆ ∆ ∆ = ∆ ); ( 2 ); ( 2 * ); ( 2 * 2 old b old b FT old b FN b k k k k