JATISI
Volume 1 Nomor 2
Halaman 123
–
245
Penerapan Metode Forward Chaining untuk Mendeteksi Penyakit THT
Wiwi Verina
Analisis Kinerja Algoritma Fuzzy C-Means dan K-Means pada Data Kemiskinan
Aniq Noviciatie Ulfah, Shofwatul ‘Uyun
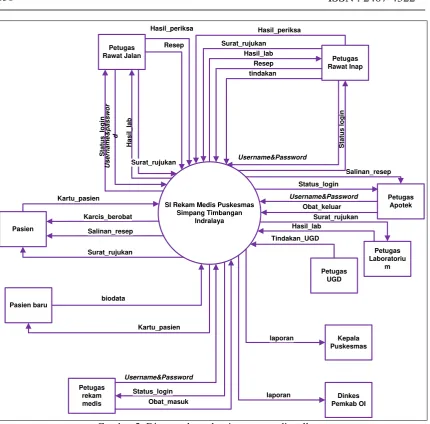
Analisis dan Perancangan Sistem Informasi Rekam Medis Pada Puskesmas Simpang Timbangan
Indralaya
Fransiska Prihatini Sihotang
Sistem Informasi Pemakaian Sparepart Mesin Packing pada PT XYZ
Triana Elizabeth, Stephanie Darmawan H
Perancangan Prototipe Sistem Pemesanan Makanan dan Minuman Menggunakan Mobile Devices
Sandy Kosasi
Perancangan Clinical Information System (CIS) Pada Instalasi Rawat Jalan di Rumah Sakit ABC
Desi Pibriana
Analisis dan Perancangan Iklan Rekrutmen Mahasiswa Baru STMIK Potensi Utama Medan
Soeheri, M.Suyanto, Amir Fatah Sofyan
Perancangan Sistem Informasi Kehadiran Dosen Mengajar pada Universitas XYZ
Arif Yulianto
Implementasi Algoritma Genetika pada Penjadwalan Job Shop
Fithri Selva Jumeilah
Analis, Perancangan, dan Implementasi Sistem Informasi Perhitungan Gaji Berbasis Aktivitas
(Studi Kasus :PT Kembang Djawa Makassar)
VOLUME 1 NOMOR 2, MARET 2015
JURNAL TEKNIK INFORMATIKA DAN SISTEM INFORMASI
(JATISI)
Terbit dua kali setahun pada bulan Maret dan September, Jurnal Teknik Informatika dan
Sistem Informasi (JATISI) merupakan media penyampaian hasil penelitian untuk semua
bidang yang ada pada rumpun teknik informatika dan sistem informasi, diharapkan hasil
penelitian yang ada pada jurnal ini dapat menjadi penghubung antara peneliti dan pihak yang
berkepentingan. ISSN 2407-4322, diterbitkan pertama kali pada tahun 2014
KETUA PENYUNTING
Gasim
DEWAN PENYUNTING
Kudang Boro Seminar
Gasim
Djoko Soetarno
STAF AHLI (MITRA BESTARI)
Achmad Benny Mutiara
Agus Harjoko
Iping Supriana Suwardi
Joko Lianto Buliali
Yani Nurhadryani
TATA USAHA
Yulizar Kasih
Rizani Teguh
Sudiadi
PENANGGUNG JAWAB
Ketua STMIK Global Informatika MDP, Ir. Rusbandi, M.Eng.
PENERBIT
Lembaga Penelitian dan Pengabdian pada Masyarakat (LPPM) STMIK Global Informatika
MDP bekerjasama dengan IndoCEISS (Indonesian Computer, Electronics and
Instrumentation Support Society)
ALAMAT PENYUNTING & TATA USAHA
Gedung STMIK GI MDP, Jalan Rajawali No. 14 Palembang 30113
Telp. 0711-376400, Fax. 0711-376360,
Website : http://jatisi.mdp.ac.id, Email : [email protected]
BERLANGGANAN
DAFTAR ISI
Penerapan Metode Forward Chaining untuk Mendeteksi Penyakit THT
Wiwi Verina
123-138
Analisis Kinerja Algoritma Fuzzy C-Means dan K-Means pada Data
Kemiskinan
Aniq Noviciatie Ulfah,
Shofwatul ‘Uyun
139-148
Analisis dan Perancangan Sistem Informasi Rekam Medis Pada Puskesmas
Simpang Timbangan Indralaya
Fransiska Prihatini Sihotang
149-163
Sistem Informasi Pemakaian Sparepart Mesin Packing pada PT XYZ
Triana Elizabeth, Stephanie Darmawan H
164-174
Perancangan Prototipe Sistem Pemesanan Makanan dan Minuman
Menggunakan Mobile Devices
Sandy Kosasi
175-187
Perancangan Clinical Information System (CIS) Pada Instalasi Rawat Jalan di
Rumah Sakit ABC
Desi Pibriana
188-202
Analisis dan Perancangan Iklan Rekrutmen Mahasiswa Baru STMIK Potensi
Utama Medan
Soeheri, M.Suyanto, Amir Fatah Sofyan
203-213
Perancangan Sistem Informasi Kehadiran Dosen Mengajar pada Universitas
XYZ
Arif Yulianto
214-225
Implementasi Algoritma Genetika pada Penjadwalan Job Shop
Fithri Selva Jumeilah
226-236
Analis, Perancangan, dan Implementasi Sistem Informasi Perhitungan Gaji
Berbasis Aktivitas (Studi Kasus :PT Kembang Djawa Makassar)
Aprizal, Mirfan
237-245
Biodata Penulis
246
Indeks Penyunting/Mitra Bestari
249
Abstrak Volumen 1 Nomor 1
251
Indeks Jurnal Volume 1 Nomor 1
256
Pedoman Penulisan Makalah JATISI
257
Jatisi, Vol. 1 No. 2 Maret 2015 123
Penerapan Metode
Forward
Chaining
untuk Mendeteksi
Penyakit THT
Wiwi Verina
Jurusan Teknik Informatika Universitas Potensi Utama [email protected]
Abstract
Diseases Ear, Nose and Throathas become adisease that issuffered by the world community. ENT disease progression and higher, it is not accompanied by anumber of experts. In this case, an analysis should be doneto speed up the process of diagnosis. The refore it is necessary to use the expert system is a computer application that behaves like an expert. Expert system capable of solving problems that typically can only be solved by an expert using the knowledge base, facts and reasoning techniques. In this analysis using aforward chaining inference engine. In this approach, starting from the information entered and then draws conclusions, tracking the forefind facts in accordance with the IF-THEN rules.Based on the test system accuracy rate forward chaining method to detect ENT disease that is 100%, which according to the data obtained from the ENT specialist to determine disease based on symptoms exist.
Keywords: Expert System, Forward Chaining, Knowledge, THT Diseases, IF-THEN
Abstrak
Penyakit Telinga, Hidung dan Tenggorokan telah menjadi suatu penyakit yang cukup banyak diderita oleh masyarakat dunia. Peningkatan penyakit THT yang semakin tinggi, tidak diiringi oleh jumlah tenaga ahli. Dalam hal ini perlu dilakukan sebuah analisa untuk mempercepat proses diagnosa. Oleh karena itu perlu menggunakan aplikasi sistem pakar yaitu aplikasi komputer yang berprilaku layaknya seorang ahli. Sistem pakar mampu memecahkan masalah yang biasanya hanya dapat dipecahkan oleh seorang pakar dengan menggunakan basis pengetahuan, fakta dan teknik penalaran. Dalam analisa ini menggunakan metode forward chaining sebagai mesin inferensi. Dalam pendekatan ini dimulai dari informasi masukkan dan selanjutnya menggambarkan kesimpulan, pelacakan kedepan mencari fakta yang sesuai dengan aturan IF-THEN. Berdasarkan pengujian sistem tingkat keakurasian metode forward chaining untuk mendeteksi penyakit THT yaitu 100%, dimana sesuai dengan data yang didapat dari pakar THT untuk menentukan penyakit berdasarkan gejala yang ada.
JCCS Vol. x, No. x, July201x : first_page–end_page
1. PENDAHULUAN
aat ini penyakit Telinga Hidung dan Tenggorokan (THT) telah menjadi suatu penyakit yang cukup banyak diderita oleh masyarakat dunia. Peningkatan penyakit THT yang semakin tinggi, tidak diiringi oleh jumlah tenaga ahliyang bertugas melakukan diagnosa atas seorang pasien yang diperkirakan menderita THT. Pasien disini adalah orang yang menerima perhatian atau perawatan kesehatan. Orang ini lebih sering yang mengalami sakit atau terluka dan butuh perawatan ahli medis, walaupun demikian seorang yang pergi ke seorang ahli untuk memeriksa diri rutin juga dapat di sebut sebagai pasien. Pasien juga adalah orang yang pergi ke rumah sakit, klinik atau fasilitas medis lainnya untuk diagnosa atau perawatan.Penyakit THT adalah penyakit yang menyerang sekitar kepala yaitu telinga, hidung dan tenggorokan[1]. Penyakit telinga terdiri dari 11 jenis penyakit, hidung terdiri dari 8 jenis dan penyakit tenggorokan terdiri 17 jenis penyakit[1]. Karena letak penyakit saling berdekatan maka gejala yang timbul hampir sama tetapi yang membedakannya hanya gejala yang spesifik saja. Oleh sebab itu untuk mendiagnosa penyakit ini harus dilakukan dengan secara cermat dan teliti karena memakai pedoman gejala sebagai aturan.
Hal tersebut menambah beban kerja tenaga ahli yang bertugas melakukan diagnosa atas seorang pasien yang diperkirakan menderita THT sehingga dengan permasalahan seperti ini sangat dibutuhkan sebuah sistem pakar yang dapat membantu dalam pemecahan masalah. Seiring dengan perkembangan teknologi informasi yang semakin pesat segala bidang kehidupan manusia diwarnai dengan penerapan teknologi.
Salah satu wujud nyata dari teknologi ini adalah penerapan sistem komputerisasi sebagai contoh kegiatan pengolahan data dengan menggunakan sistem terkomputerisasi adalah sistem pakar. Sistem Pakar adalah sebuah program aplikasi komputer yang berprilaku layaknya seorang ahli. Aplikasi yang digunakan biasa yaitu membantu mendiagnosa penyakit, kerusakan peralatan dan pengukuran data. Sistem pakar mampu memecahkanmasalah yang biasanya hanya dapat dipecahkan oleh seorang pakar dengan menggunakan pengetahuan, fakta dan teknik penalaran[2].
2. LANDASAN TEORI
2.1 Sistem Pakar
Sistem pakar adalah sistem berbasis komputer yang menggunakan pengetahuan, fakta, dan teknik penalaran dalam memecahkan masalah yang biasanya hanya dapat dipecahkan oleh seorang pakar dalam bidang tersebut[5]. Istilah sistem pakar berasal dari knowlegde-based expert system. Istilah ini muncul karena untuk memecahkan masalah, sistem pakar menggunakan pengetahuan seorang pakar yang dimasukkan kedalam komputer. Seseorang yang bukan pakar menggunakan sistem pakar untuk meningkat kemampuan pemecahan masalah, sedangkan seorang pakar menggunakan sistem pakar untuk knowledge assistant[7].
Sistem pakar adalah suatu program komputer cerdas yang menggunakan
knowledge(pengetahuan) dan prosedur inferensi untuk menyelesaikan masalah yang cukup sulit sehingga membutuhkan seorang yang ahli untuk menyelesaikannya[10]. Pengetahuan adalah sebuah kekuatan yang dapat memecahkan suatu masalah yang kita temui sehari-hari. Sistem pakar adalah program Artificial Intellenge yang menggabungkan pangkalan pengetahuan (knowledge base) dengan sistem inferensi[10]. Kecerdasan buatan atau Artificial Intellenge (AI) dapat didefinisikan sebagai sub bidang pengetahuan komputer yang khusus ditujukan untuk membuat software dan hardware yang sepenuhnya biasa menirukan beberapa fungsi otak manusia. Karena itu diharapkan komputer bisa membantu manusia didalam berbagai masalah yang sangat rumit[10].
Jatisi, Vol. 1 No. 2 Maret 2015 125
2.1.1 Struktur Sistem Pakar
Sistem pakar disusun oleh dua bagian utama, yaitu lingkungan pengembangan (development environment) dan lingkungan konsultas (consultation environment)[3]. Lingkungan pengembangan sistem pakar digunakan untuk memasukan pengetahuan pakar ke dalam lingkungan sistem pakar. Komponen-komponen sistem pakar dalam dua bagian tersebut dapat dilihat pada Gambar 1.
Gambar. 1 Struktur Sistem Pakar
2.2 Forward Chaining
Forward Chaining adalah teknik pencarian yang dimulai dengan fakta yang diketahui, kemudian mencocokkan fakta-fakta tersebut dengan bagian IF dari rules IF-THEN. Bila ada fakta yang cocok dengan bagian IF, maka rule tersebut dieksekusi. Bila sebuah rule dieksekusi, maka sebuah fakta baru (bagian THEN) ditambahkan ke dalam database. Setiap kali pencocokan, dimulai dari rule teratas. Setiap rule hanya boleh dieksekusi sekali saja. Proses pencocokan berhenti bila tidak ada lagi rule yang bisa dieksekusi. Metode pencarian yang digunakan adalah Deptth-Firstf Search(DFS), Breadth-First Search(BFS) atau Best First Search[7]. pendekatan dalam pelacakan dimulai dari informasi masukan dan selanjutnya mencoba menggambarkan kesimpulan, pelacakan kedepan mencari fakta yang sesuai dengan bagian IF dari aturan IF-THEN. Dengan metode forward chaining dari pendekatan dan aturan yang telah dihasilkan dapat ditinjau oleh para ahli untuk diperbaiki atau dimodifikasi untuk memperoleh hasil yang lebih baik[3].
Metode Forward Chaining adalah metode pencarian atau teknik pelacakan ke depan yang dimulai dengan informasi yang ada dan penggabungan rule untuk menghasilkan suatu kesimpulan atau tujuan. Pelacakan maju ini sangat baik jika bekerja dengan permasalahan yang dimulai dengan rekaman informasi awal dan ingin dicapai penyelesaian akhir, karena seluruh proses akan dikerjakan secara berurutan maju. Berikut adalah diagram Forward Chaining secara umum untuk menghasilkan sebuah goal yang dapat dilihat pada Gambar 2[9].
Forward Chaining berarti menggunakan himpunan aturan kondisi-aksi. Dalam metode ini, data digunakan untuk menentukan aturan mana yang akan dijalankan, kemudian aturan tersebut dijalankan. Mungkin proses menambahkan data ke memori kerja. Proses diulang sampai ditemukan suatu hasil. Metode inferensi runut maju cocok digunakan untuk menangani masalah pengendalian (controlling) dan peramalan (prognosis) (Giarattano dan Riley, 1994).
JCCS Vol. x, No. x, July201x : first_page–end_page
Gambar. 2 Forward Chaining
Untuk mempermudah pemahaman mengenai metode ini, akan diberikan ilustrasi kasus pembuatan sistem pakar dengan daftar aturannya sebagai berikut:
R1: Jika Premis 1 Dan Premis 2 Dan Premis 3 Maka Konklusi 1 R2: Jika Premis 1 Dan Premis 3 Dan Premis 4 Maka Konklusi 2 R3: Jika Premis 2 Dan Premis 3 Dan Premis 5 Maka Konklusi 3
R4: Jika Premis 1 Dan Premis 4 Dan Premis 5 Dan Premis 6 Maka Konklusi 4
Penelusuran maju pada kasus ini adalah untuk mengetahui apakah suatu fakta yang dialami oleh pengguna itu termasuk konklusi 1, konklusi 2, konklusi 3, atau konklusi 4 atau bahkan bukan salah satu dari konklusi tersebut, yang artinya sistem belum mampu mengambil kesimpulan karena terbatas aturan. Seandainya user memilih premis 1, premis 2, dan premis 3, maka aturan yang terpilih adalah aturan R1 dengan konklusinya adalah konklusi 1. Seandainya
user memilih premis 1 dan premis 6, maka sistem akan mengarah pada aturan R4 dengan konklusinya adalah konklusi 4, tetapi karena aturan tersebut premisnya adalah premis 1, premis 4, premis 5, dan premis 6, maka premis-premis yang dipilih oleh user tidak cukup untuk mengambil kesimpulan kzonklusi 4 sebagai konklusi terpilih[6].
2.3 Search Engine (Mesin Pencarian)
Pencarian atau pelacakan merupakan salah satu teknik untuk menyelesaikan permasalahan AI. Keberhasilan suatu sistem salah satunya ditentukan oleh kesuksesan dalam pencarian dan percocokan[2].
Metode inferensi yang digunakan dalam penelusuran masalah pada sistem pakar gangguan penyakit umum pada balita ini adalah forward chaining (penelusuran maju), metode
forward chaining adalah strategi pencarian yang memulai proses pencarian dari sekumpulan data atau fakta, dari data-data tersebut dicari suatu kesimpulan yang menjadi solusi dari permasalahan yang dihadapi. Didalam menemukan solusinya dibutuhkan penyelesaian pada setiap tahapan, sebelum tahap yang satu selesai tidak dapat maju ke tahap berikutnya karena hal tersebut dapat berpengaruh dalam pencapaian solusinya[2].
Menurut Tim Penerbit Andi Tahun 2013 ada 3 teknik yang digunakan dalam proses pencarian yaitu [2].
1.
Depth First Search adalah teknik penelusuran data pada node-node secara vertikal dan sudah didefinisikan, misalnya drai kiri ke kanan. Keuntungan pencarian dengan teknik ini adalah bahwa penelusuran masalah dapat digali secara mendalam sampai di temukannya kepastian suatu solusi yang optimal. Kekurangan teknik penelusuran ini adalah membutuhkan waktu yang sangat lama untuk ruang lingkup masalah yang besar.2.
Breadth First Search adalah teknik penelusuran data pada semua node dalam suatu level atau satu tingkatan sebelum ke level atau tingkatan di bawahnya. Keuntungan pencarian dengan teknik ini adalah sama dengan Depth First Search, hanya saja penelusuran dengan teknik ini mempunyai nilai tambah, di mana semua node akan dicek secara menyeluruh pada setiap tingkatan node. Kekurangan teknik penelusuran ini terletakJatisi, Vol. 1 No. 2 Maret 2015 127
pada waktu yang dibutuhkan yang sangat lama apabila solusi berada dalam posisi node
terakhir sehingga menjadi tidak efisien. Kekurangan dalam implementasi juga perlu dipertimbangan, misalnya teknik penelusuran menjadi tidak interaktif antara pemakai dan sistem karena menyebabkan tidak adanya relasi antara suatu topik dengan topik yang lain atau harus melompat dari suatu topik ke topik yang lain sebelumnya topik tersebut selain ditelusuri.
3.
Best First Search adalah penelusuran yang menggunakan pengetahuan akan suatu masalah untuk melakukan panduan pencarian ke arah node tempat di mana solusi berada. Pencarian jenis ini dikenal juga sebagai heuristik. Pendekatan yang dilakukan adalah mencari solusi yang terbaik berdasarkan pengetahuan yang di miliki sehingga penelusuran dapat ditentukan harus bagaimana menggunakan proses terbaik untuk mencari solusi. Keuntungan jenis penelusuran ini adalah mengurangi beban komputasi karena hanya solusi yang memberikan harapan saja yang diuji dan akan berhenti apabila solusi sudah mendekati alternatif yang terbaik.2.4 Telinga, Hidung, dan Tenggorokan
Lokasi dan fungsi telinga, hidung dan tenggorokan (untuk selanjutnya disebut THT) berhubungan erat yang dihubungkan oleh saluran yang dinamakan saluran “Eustachian tube”.
Oleh karena itu infeksi pada hidung dapat menyebar ke tenggorokan dan sebaliknya. Kelainan pada organ-organ tersebut didiagnosis dan diobati oleh dokter spesialis THT[11].
Telinga merupakan organ untuk pendengaran dan keseimbangan, yang terdiri dari telinga luar, telinga tengah, dan telinga dalam. Telinga luar menangkap gelombang suara yang diubah menjadi energi mekanis oleh telinga tengah. Telinga tengah mengubah energi mekanis menjadi gelombang saraf, yang kemudian dihantarkan ke otak. Telinga dalam juga membantu menjaga keseimbangan tubuh [1]
Hidung merupakan organ penciuman dan jalan utama keluar-masuknya udara dari dan ke paru-paru. Hidung juga memberikan tambahan resonansi pada suara dan merupakan tempat bermuaranya sinus paranasalis dan saluran air mata. Hidung bagian atas terdiri dari tulang dan hidung bagian bawah terdiri dari tulang rawan (kartilago). Rongga hidung dilapisi oleh selaput lendir dan pembuluh darah. Sel-sel pada selaput lendir menghasilkan lendir dan memiliki tonjolantonjolan kecil seperti rambut (silia). Hampir seluruh permukaan hidung memiliki silia dan berlendir. Sinus paranasalis tulang di sekitar hidung terdiri dari sinus paranasalis, yang merupakan ruang berongga dengan lubang yang mengarah ke rongga hidung [11].
Tenggorokan (faring) terletak di belakang mulut, di bawah rongga hidung dan diatas kerongkongan dan tabung udara (trakea). Tenggorokan terbagi menjadi tiga bagian, atas, tengah dan bawah. Tenggorokan merupakan saluran berotot tempat jalannya makanan ke kerongkongan dan tempat jalannya udara ke paru-paru. Tenggorokan dilapisi oleh selaput lendir yang terdiri dari sel-sel penghasil lendir dan silia. Tonsil (amandel) terletak di mulut bagian belakang, sedangkan adenoid terletak di rongga hidung bagian belakang. Tonsil dan adenoid
terdiri dari jaringan getah bening dan membantu melawan infeksi. Pada puncak trakea terdapat kotak suara (laring), yang mengandung pita suara dan berfungsi menghasilkan suara. Epiglotis
merupakan suatu lembaran yang terutama terdiri dari kartilago dan terletak di atas serta di depan laring. Selama menelan, epiglotis menutup untuk mencegah masuknya makanan dan cairan ke dalam trakea[11].
3. METODOLOGI PENELITIAN
JCCS Vol. x, No. x, July201x : first_page–end_page
akan dilakukan dalam rangka penyelesaian masalah yang akan dibahas. Adapun kerangka kerja dari penelitian ini dapat disajikan pada Gambar 3.
Gambar 3. Kerangka Kerja Penelitian
Berdasarkan kerangka kerja pada Gambar 3 dimulai dengan mengidentifikasikan masalah yaitu memperhatikan gejala-gejala penyakit THT dan pemilihan akuisisi pengetahuan. Selanjutnya menganalisa masalah dalam melakukan analisa masalah peneliti melakukan beberapa cara dan metode di antaranya metode deskriptif. Pada metode ini data yang akan dikumpulkan, disusun, dikelompokkan, dianalisa sehingga diperoleh beberapa gambaran yang jelas pada masalah penelitian. Kemudian menetapkan tujuan, studi literatur dan mengumpulkan data primer yaitu dengan cara interview dan observasi dengan Pakar THT. Metode yang digunakan dalam pembangunan sistem ini adalah metode forward chaining, yang dimulai dari sekumpulan fakta-fakta tentang gejala-gejala penyakit THT yang telah diamati user sebagai masukan (input) sistem untuk kemudian dilakukan pelacakan sampai tercapainya tujuan akhir berupa kesimpulan. Tahap selanjutnya yaitu desain sistem dimana dari penyusunan basis data, basis pengetahuan, mesin referensi yaitu forward chaining dan perancangan interface dan mulai dengan implementasi sistem. Tahap terakhir yaitu Menguji keakuratan sistem yang sudah dirancang pada basis pengetahuan dan rule sebagai input oleh user untuk hasil konsultasi.
Mengidentifikasi Masalah
Menganalisa Masalah
Menentukan Tujuan
Studi Literatur
Mengumpulkan Data
Menganalisa Metode Forward Chaining
Pengujian Sistem Desain Sistem
Jatisi, Vol. 1 No. 2 Maret 2015 129
4. HASIL DAN PEMBAHASAN
4.1 Arsitektur Sistem
Komponen-komponen yang dibutuhkan dalam sistem tersaji pada Gambar 4.
Gambar. 4 Arsitektur Sistem Pakar Untuk Mendeteksi Penyakit THT
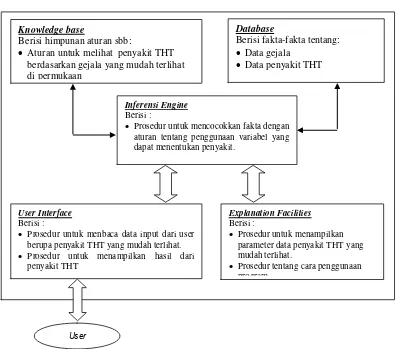
4.2 Basis Pengetahuan(Knowledge Base)
Berdasarkan analisis sistem ini, akan diuraikan tentang analisis permasalahan yang ada dan analisis kebutuhan akan perangkat lunak yang nantinya akan dibuat yaitu membangun aplikasi sistem pakar untuk mendeteksi penyakit THT berdasarkan gejala-gejala yang dirasakan oleh pasien/user. Sistem pakar untuk mendeteksi penyakit THT (Telinga, Hidung dan Tenggorokan) menggunakan metode inferensi runut maju (forward chaining). Pemilihan metode ini didasari karena metode ini cocok diterapkan untuk melakukan diagnosa tentang mendeteksi penyakit THT. Adapun penyakit THT terdiri dari 10 penyakit Telinga, 9 Penyakit Hidung dan 9 Penyakit Tenggorokan. Di mana penyakit THT terdiri dari 57 gejala untuk keseluruhan penyakit THT.
Knowledge base
Berisi himpunan aturan sbb:
Aturan untuk melihat penyakit THT berdasarkan gejala yang mudah terlihat di permukaan
Database
Berisi fakta-fakta tentang: Data gejala
Data penyakit THT
Inferensi Engine
Berisi :
Prosedur untuk mencocokkan fakta dengan aturan tentang penggunaan variabel yang dapat menentukan penyakit.
User Interface
Berisi :
Prosedur untuk menbaca data input dari user berupa penyakit THT yang mudah terlihat.
Prosedur untuk menampilkan hasil dari penyakit THT
Explanation Facilities
Berisi :
Prosedur untuk menampilkan parameter data penyakit THT yang mudah terlihat.
Prosedur tentang cara penggunaan program
Jatisi, Vol. 1 No. 2 Maret 2015 133
4.2.1 Penyajian Fakta
Table 2 adalah sampel data penyajian fakta untuk mendeteksi penyakit THT berdasarkan gejala-gejala. Dimana pada tabel tersebut menjelaskan pengetahuan untuk mengetahui gejala-gejala terhadap penyakit THT.
Tabel . 2 Sampel Data Penyakit THT dengan Gejala-gejala
4.2.2 Penyajian Aturan
Berdasarkan representasi pengetahuan untuk perencanaan mendeteksi penyakit THT maka disusun aturan(rule) yang tersaji pada Tabel 3.
Tabel . 3 Sampel Data Penyakit THT dengan Gejala-gejala
No Aturan (Rule) 1 IFSakit kepala is True
AND Keluar Cairan is True
AND Ada tanda-tanda radang diliang telinga is True THENPenyakit Otitis Eksterna
2 IF Demam is True AND Sakit kepala is True
AND PUS dan di meatus media is True AND Hidung tersumbat is True AND Hidung meler is True
AND Nyeri pipi dibawah mata is True AND Selaput lendir merah dan bengkak is True Then Sinusitis
3 IF Bersin-bersin is True AND Hidung meler is True AND Hidung tersumbat is True AND Lendir di tenggorokan is True Then Renitis Non – Alergika 4 IF Demam is True
AND Sakit kepala is True
AND Nyeri saat berbicara atau menelan is True AND Sakit pada telinga is True
AND Pembengkakan kelenjar getah bening is True AND Tenggorokan gatal is True
AND Adanya tonsil yang membengkak is True AND Suara serak is True
JCCS Vol. x, No. x, July201x : first_page–end_page
Tabel 4 merupakan contoh dari penelusuran metode forward chaining untuk sampel penyakit THT yaitu penyakit farangitis(Radang Tenggorokan). Dimana akan diberikan pertanyaan berupa gejala-gejala dan sistem akan memberikan hasil diagnosa dari hasil konsultasi.
Tabel . 4 Sampel Penelusuran Penyakit Farangitis
No Aturan (Rule)
1 IF Demam is True AND Sakit kepala is True
AND Nyeri saat berbicara atau menelan is True AND Sakit pada telinga is True
AND Pembengkakan kelenjar getah bening is True AND Tenggorokan gatal is True
AND Adanya tonsil yang membengkak is True AND Suara serak is True
Then Farangitis (Radang Tenggorokan)
Proses penelusuran forward chaining dapat dilihat sebagai berikut :
1. IF G1 Then G2 2. IF G2 Then G3 3. IF G3 Then G6 4. IF G6 Then G8 5. IF G8Then G12 6. IF G12 Then G20 7. IF G20 Then G21 GOAL : 9. IF G22 THEN P22
Penyakit farangitis didapat melalui proses 9 rule, dimana penelurusan pertama itu dieksekusi apabila fakta sudah cocok dengan aturan bagian IF pada bagian IF-THEN. Kemudian data tersebut menghasilkan fakta baru dibagian Then yang akan disimpan kedatabase. Proses penelusuran dilakukan dari rule pertama dan tidak ada pengulangan eksekusi. Proses eksekusi akan berhenti apabila tidak ada lagi data yang sesuai dan akan mengeluarkan kesimpulan berdasarkan pencocokan fakta.
5. HASIL DAN PENGUJIAN SISTEM
Berikut adalah tampilan Form halaman utama user adalah beranda utama untuk user
dimana pada beranda utama ini sekilas tentang pengetahuan tentang penyakit THT (Telinga, Hidung dan Tenggorokan). Pada form beranda ini ada pilihan Beranda, Buat Akun, Konsultasi dan Ubah Data. Dapat dilihat pada Gambar 5.
Setelah user selesai membuat akun dan login, kemudian user akan memilih menu
konsultasi. Di mana pada menu ini akan ditampilkan pertanyaan-pertanyaan kepada user
berdasarkan rule yang sudah ditentukan. Pertanyaan berupa gejala-gejala penyakit THT dan
user harus menjawab pertanyaan yang disediakan sistem. Kemudian user akan mendapatkan hasil dari jawaban tersebut berupa penyakit yang dialami berdasarkan gejala-gejala yang dipilih. Pada form konsultasi penyakit ini pertanyaan berupa “Ya” dan “Tidak” seperti terlihat pada
Jatisi, Vol. 1 No. 2 Maret 2015 135
Gambar 5 Tampilan Halaman Sistem Pakar Mendeteksi Penyakit THT
Gambar 6 Tampilan Halaman Konsultasi
Setelah selesai user menjawab pertanyaan maka akan keluar jawaban daripertanyan-pertanyaan yang dijawab oleh user. Kemudian user juga bisa mencetak hasil dari diognosa penyakit THT tersebut yang tersaji pada Gambar 7 dan 8.
JCCS Vol. x, No. x, July201x : first_page–end_page
Halaman tampilan hasil dari konsultasi merupakan hasil diagnosa dari pertanyaan yang dijawab oleh user yaitu berupa gejala-gejala yang di alami oleh user. Pada halama tersebut memberikan informasi penyakit apa yang diderita kemudian bagaimana pengobatannya.
Gambar 8 Tampilan Laporan Hasil Konsultasi
Pada halaman tampilan laporan hasil konsultasi (Gambar 8) yaitu hasil dari konsultasi dan kemudian sistem memberikan riwayat konsultasi dimana user dapat mencetak laporan dari konsultasi tersebut.
Pengujian Sistem
Pengujian sistem dilakukan dengan cara menjawab pertanyaan Ya atau Tidak yang diajukan sistem melalu interfaceformberdasarkan gejala penyakit THT.
1. Pengujian sistem1 untuk Penyakit Farangitis(Radang Tenggorokan)
Tabel 5 adalah hasil dari jawaban interface mendeteksi penyakit THT(Telinga, Hidung dan Tenggorokan).
Tabel.5 Pengujian Penyakit Farangitis (Radang Tenggorokan) Nama : Wiwi Verina
Konsultasi
Pertanyaan Jawaban
1. Apakah anda demam ? Ya
2.Apakah Anda Mengalami Gejala Nyeri Saat Bicara atau Menelan ? Ya 3. Apakah Anda Mengalami Gejala Sakit Pada Telinga ? Ya 4. Apakah Anda Mengalami Gejala Pembengkakan Kelenjar Getah Bening ? Ya 5. Apakah Anda Mengalami Gejala Adanya tonsil yang membengkak ? Ya 5. Apakah Anda Mengalami Gejala Suara Serak ? Ya 6. Apakah Anda Mengalami Gejala Tenggorokan Gatal ? Ya 7. Apakah Anda Mengalami Gejala Sakit Kepala ? Ya
Penyakit Yang Diderita
Faringitis (Radang Tenggorokan)
Pengertian : Faringitis adalah peradangan yang terjadi di tenggorokan (faring). Faringitis biasanya disebabkan oleh infeksi virus, dan lebih jarang oleh bakteri
Pada Tabel 5 setelah diinput jawaban berdasarkan gejala-gejala penyakit THT pada program sistem pakar didapatkan terkena penyakit Farangitis. Hal ini disebabkan karena dari item-item pertanyaan lebih mengarah kepada rule yang ada sesuai dengan penyakit Farangitis.
2. Pengujian sistem2 untuk Penyakit Sinusitis
Jatisi, Vol. 1 No. 2 Maret 2015 137
Tabel 6 Pengujian Penyakit Sinuisitis
Nama : Wiwi Verina
Konsultasi
Pertanyaan Jawaban
1. Apakah anda demam ? Ya 2.Apakah Anda Mengalami Gejala Nyeri Saat Bicara atau Menelan ? Tidak 3. Apakah Anda Mengalami Gejala Sakit Pada Telinga ? Tidak 4. Apakah anda mengalami Sakit Kepala Ya 5. Apakah anda mengalami Hidung Tersumbat ? Ya 6. Apakah Anda Mengalami Gejala Pus dan Di meatus media ? Ya 7. Apakah Anda Mengalami Gejala Hidung Meler ? Ya 8.Apakah Anda Mengalami Gejala Nyeri Pipi di Bagian Bawah ? Ya
Penyakit Yang Diderita
Sinusitis
Pengertian : Sinusitis adalah suatu peradangan pada sinus yang terjadi karena
alergi atau infeksi virus, bakteri maupun jamur. Sinusitis bisa terjadi pada salah satu dari keempat sinus yang ada (maksilaris, etmoidalis, frontalis atau sfenoidalis)
Pada Table 6 setelah di input jawaban berdasarkan gejala-gejala penyakit THT pada program sistem pakar didapatkan terkena penyakit Sinusitis. Hal ini disebabkan karena dari item-item pertanyaan lebih mengarah kepada rule yang ada sesuai dengan penyakit Sinusitis.
6. KESIMPULAN DAN SARAN
6.1 Kesimpulan
Berdasarkan penelitian dan pembahasan yang dilakukan, maka dapat disimpulkan beberapa hal sebagai berikut :
1. Setelah dilakukan pengujian dengan menggunakan beberapa data uji, aplikasi sistem pakar yang dirancang dapat mendeteksi penyakit THT(Telinga, Hidung dan Tenggorokan) dari input data gejala yang dimasukkan dan memberikan hasil sesuai dengan jawaban pakar THT.
2. Metode forward chaining digunakan untuk melakukan penelusuran untuk mendapatkan hasil penyakit THT(Telinga, Hidung dan Tenggorokan). Dengan demikian hasil dari penelurusan metode forward chaining di dapat 75 rule untuk menentukan penyakit THT berdasarkan gejala-gejala yang di input user.
6.2 Saran
Sebagai akhir dari penelitian ini, kami ingin menyampaikan saran-saran yang mungkin bermanfaat bagi siapa saja yang berminat untuk menggunakan sistem ini
1. Diharapkan dengan dikembangkan sistem pakar ini, jumlah rule-rule yang digunakan agar lebih banyak lagi sehingga untuk hasil diagnosa bisa mendapatkan hasil yang lebih baik lagi.
2. Untuk mendapakan hasil diagnosa yang lebih akurat dan lebih mendekati kebenaran sebaiknya diterapkan metoda-metoda statistik atau metoda sistem pengambilan keputusan lainnya.
JCCS Vol. x, No. x, July201x : first_page–end_page
DAFTAR PUSTAKA
[1] Arsyad et al (2007), “Buku Bahan Ajar Telinga, Hidung dan Tenggorokan”, Fakultas Kedokteran Universitas Indonesia Yogyakarta :Andi Offset.
[2] Desiani, Anita dan Arhami M. 2006. Konsep Kecerdasan Buatan. Yogyakarta: Andi Offset.
[3] Deefa (2012), “Expert System For Car Troubleshooting”, International Journal For Research In Science & Advanced Technologies, Issue-I, Volume-I, 046-049
[4] Ginanjar Wiro Sasmito, Bayu Surarso dan Aris Sugiharo (2011), “Application Expert System of Forward Chaining And The Rule Based Reasoning For Simulation Diagnose
Pest and Disease Red Onion and Chili Plant”, Proceedings of the 1 International Conference on Information Systems For Business Competitiveness(ICISBC)
[5] Ivo Randi MS, Zaenal Wafa dan Ruri Hartika Jhon(2013), “ Perancangan Sistem Pakar
Untuk Mendiagnosa Penyakit Kanker Serviks Dengan Metode Forward Chaining”,Jurnal Sarjana Teknik Informatika 09101152630035.
[6] Kusrini (2006), “Sistem Pakar Teori dan Aplikasi”, Yogyakarta :Andi Offset.
[7] Kusrini (2008), “Aplikasi Sistem Pakar”, Yogyakarta : Andi Offset.
[8] Sutojo, T dkk (2011), “Kecerdasan Buatan”, Yogyakarta : Andi Offset.
[9] Tati Harihayati dan Luthfi Kurnia (2013), “Sistem Pakar Mendiagnosa Penyakit Umum Yang Sering Diderita Balita Berbasis Web Di Dinas Kesehatan Kota Bandung ”,Jurnal Komputer dan Informatika (KOMPUTA) Edisi I Volume I Maret 2012
[10] Wisnu Yudho Untoro (2009),” Penerapan Metode Forward Chaining Pada Penjadwalan Mata Kuliah”, Jurnal Matematika dan Komputer Indonesia Vol. 1, No.2.
[11] Wenny Widia Astuti, Dini Destiani dan Dhami Johar Damiri (2012), “Aplikasi Sistem
Pakar Deteksi Dini Pada Penyakit Tuberkulosis”, ISSN : 2302-7339 Vol. 09 No. 06 2012
Jatisi, Vol. 1 No. 2 Maret 2015 139
Analisis Kinerja Algoritma
Fuzzy C-Means
dan
K
-Means
pada Data Kemiskinan
Aniq Noviciatie Ulfah*1, Shofwatul ‘Uyun2
1,2Program Studi Teknik Informatika Universitas Islam Negeri Sunan Kalijaga
Jl. Marsda Adisucipto No.1 Yogyakarta 55281 Telp (0274) 519739, fax (0274) 540971
e-mail: *1[email protected], 2[email protected]
Abstrak
Salah satu upaya untuk mewujudkan program pemerintah Kabupaten Gunungkidul dalam rangka untuk pengentasan kemiskinan adalah dengan melakukan pendataan data kemiskinan warganya. Pemerintah telah merumuskan pendataan dengan melakukan pembobotan terhadap 15 indikator kedalam 3 kelompok. Banyaknya data dan indikator yang harus digunakan tentunya akan menimbulkan kesulitan dalam pelaksanaannya, tidak efektif dan kurang obyektif. Oleh karena itu diperlukan otomatisasi dalam proses clustering data kemiskinan. Penelitian ini bertujuan untuk menganalisis kinerja antara algoritma FCM dan K-means yang diimplementasikan pada data kemiskinan di Desa Girijati Purwosari menjadi 3 cluster. Beberapa tahapan yang harus dilakukan sebelum dilakukan clustering, terebih dahulu dilakukan prapengolahan yaitu data cleaning dan data transformation untuk selanjutnya dilakukan clustering menggunakan kedua algoritma tersebut. Hasil perhitungan digunakan untuk membandingkan antara algoritma FCM dengan K-Means. Kesesuaian data antara algoritma FCM dengan perhitungan indikator kemiskinan di Desa Girijati sebesar 50% dan untuk algoritma K-Means sebesar 83,33%. Algoritma K-Means lebih tepat digunakan pada pengelompokan data kemiskinan berdasarkan ketiga kriteria kemiskinan dibandingkan algoritma FCM.
Kata kunci—Clustering, Data Kemiskinan, FuzzyC-Means, K-Means.
Abstract
One of the local government of Gunungkidul efforts to realize program in order to alleviate poverty is to perform the data collection poverty of its citizens. The local government of Gunungkidul has formulated a collection by weighting against 15 indicators into three groups. The amount of data and indicators to be used will certainly lead to difficulties in implementation, ineffective and less objective. Therefore we need automation in the process of clustering data on poverty. This study aims to analyze the performance of the FCM algorithm and K-means are implemented in the data on poverty in Girijati Purwosari village into 3 clusters. Some of the steps that must be done prior to clustering, first performed pretreatment includes data cleaning and data transformation for clustering is then performed using the second algorithm. The suitability of data between FCM algorithm and the calculation of poverty indicators in the Girijati village is 50 % and for the K - Means algorithm is 83.33 % . Therefore, K- Means algorithm is more appropriately used in data classification of poverty based on the three criteria of poverty, beside FCM algorithm.
1. PENDAHULUAN
emiskinan di Yogyakarta menurut Badan Pusat Statistik (BPS) pada tahun 2012 tertinggi se-Jawa melebihi DKI Jakarta, Banten dan Jawa Tengah yang mencapai 15,88 persen sedangkan tingkat kemiskinan masyarakat Jawa Tengah hanya mencapai 14,98 persen, Jawa Timur 13,08 persen, Jawa Barat 9,89 persen, Banten 5,71 persen dan DKI jakarta hanya 3,7 persen [1]. Sebagai upaya pengentasan kemiskinan pemerintahan Kabupaten Gunungkidul membuat suatu penanggulangan kemiskinan dengan membuat rumusan yaitu membuat indikator-indikator kemiskinan serta mengklasifikasikannya kedalam tiga kategori yaitu keluarga tidak miskin, keluarga miskin dan keluarga sangat miskin berdasarkan 15 indikator kemiskinan [2]. Pendataan kemiskinan dilakukan secara berjenjang mulai dari tinggat RT, Pedukuhan, Desa, Kecamatan, sampai pada tingkat Kabupaten. Desa Girijati yang teletak di Kabupaten Gunungkidul merupakan bagian dari pendataan kemiskinan yang dilakukan oleh BAPPEDA Kabupaten Gunungkidul. Untuk mempermudah pengklusteran diperlukan suatu sistem yang dapat mengkluster data kemiskinan tersebut. Beberapa penelitian telah melakukan kajian terhadap beberapa algoritma clustering, antara lain K-Means oleh [3,4,5] yang menyatakan bahwa algoritma dari K-Means memiliki waktu proses yang lebih cepat dari pada
hierarchical clustering (jika k kecil) dengan jumlah variabel yang besar dan menghasilkan
cluster yang lebih rapat. Fuzzy C-means juga telah dianalisis kinerjanya oleh [6,7,8] bahwa algoritma FCM memiliki waktu proses lebih cepat dibandingkan Agglomerative Hierarchical Clustering dan hasil clustering lebih mudah untuk diinterpretasikan.
Oleh karena itu pada penelitin ini menggunakan algoritma Fuzzy C-Means dan K-Meansuntuk mengkluster data kemiskinan menjadi tiga kategori dengan 15 indikator yang diperoleh dari 10 aspek kemiskinan menurut BAPPEDA yaitu aspek penghasilan, aspek pangan, aspek sandang, aspek papan, aspek air bersih, aspek kesehatan, aspek pendidikan, aspek kekayaan, aspek penerangan dan aspek jumlah jiwa. Indikator-indikator tersebut digunakan sebagai variabel dari clustering data kemiskinan tersebut. Kedua algoritma tersebut digunakan untuk membagi data kedalam beberapa kelompok (grup atau kluster atau segmen) yang tiap kluster dapat ditempati beberapa anggota bersama-sama. Setiap objek dilewatkan pada grup yang paling mirip dengannya. Kedua algoritma tersebut merupakan algoritma unsupervised learning dimana data yang diolah tidak memerlukan pembelajaran terlebih dahulu.
2. DATA DAN METODE PENELITIAN
Data yang digunakan pada penelitian ini diambil dari data keluarga sejahtera Desa Girijati, Purwosari, Gunungkidul dengan 15 indikator kemiskinan yang terbagi menjadi 10 aspek [9], antara lain : penghasilan, pangan, sandang, papan, air bersih, kesehatan, pendidikan, kekayaan, penerangan dan jumlah jiwa. Untuk memperkuat analisis data juga dilakukan wawancara dengan Bapak Joko Hardiyanto selaku KASUBID Statistik, Bapak Sungkem selaku KASI KESOS Kecamatan Purwosari dan Bapak Budi Suryono selaku kepala Desa Girijati terkait sasaran pendataan kemiskinan, kriteria, indikator kemiskinan dan perhitungan data-data kemiskinan. Penelitian ini bertujuan untuk melakukan clustering data kemiskinan menggunakan algoritma FCM dan k-means clustering serta menganalisis kinerja untuk kedua algoritma tersebut. Untuk mengukur kinerja dari kedua algoritma tersebut dilakukan dengan membandingkannya dengan hasil klasifikasi yang dilakukan secara manual berdasarkan 15 indikator kemiskinan menurut BAPPEDA tahun 2008. Penelitian ini terdiri dari beberapa tahapan, antara lain : prapengolahan, proses clustering dan perbandingan hasil clustering.
2.1 Prapengolahan
Data yang diperoleh masih dalam bentuk Microsoftaccess serta masih terdapat data-data yang tidak terisi dengan lengkap, oleh karena itu perlu dilakukan prapengolahan terlebih dahulu
Jatisi, Vol. 1 No. 2 Maret 2015 141
sebelum data dikluster. Data diubah menjadi data yang ber-extensi .sql yang berisi beberapa tabel yang berhubungan dengan program Pendataan Ketenagakerjaan Gunungkidul. Selanjutnya dibuat satu tabel lagi yang berisi data-data yang berhubungan dengan proses perhitungan clustering data kemiskinan yaitu id, Nomerator, nama KK dan 15 indikator kemiskinan. Untuk kepentingan clustering data harus dalam bentuk numerik atau angka, sehingga semua data harus dikonversi terlebih dahulu, selain itu kelimabelas indikator yang digunakan pada penelitian ini perlu dilakukan data cleaning dan data transformation. Salah satu contoh data sebelum dilakukan perubahan kedalam bentuk numeris ditunjukkan pada Tabel 1.
Tabel 1. Contoh salah satu data indikator kemiskinan yang dilakukan perubahan bentuk dari frase ke numeris
No Aspek Kriteria Numerisasi 1 Pangan Berapa kali makan dalam sehari seluruh keluarga
a) Kurang dari 2 kali b) Dua kali atau lebih
1 2 2 Pangan Konsumsi daging/susu/telor/ikan/ayam dalam
seminggu seluruh anggota keluarga
Setelah dilakukan prapengolahan, format data kemiskinan yang sudah siap untuk diolah ditunjukkan pada Tabel 2.
Tabel 2. Contoh data hasil proses prapengolahan dan siap untuk dilakukan clustering No Nomerator Indikator
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1 764042 900000 2 2 3 1 3 2 1 2 3 4 3 2 3 3 2 764043 450000 2 2 3 1 3 2 1 2 3 4 3 2 3 2
2.2 Proses Clustering
Penelitian ini menggunakan dua algoritma clustering dengan dua pendekatan yang berbeda, yaitu pendekatan hard dan fuzzy clustering yang akan dijelaskan lebih detail pada subbab 2.2.1. dan 2.2.2.
2.2.1 Fuzzy C-Means (FCM)Clustering
Algoritma FCM telah dikenalkan oleh [10] dan merupakan metode clustering dengan pendekatan fuzzy, artinya setiap data yang dicluster memungkinkan menjadi anggota lebih dari satu cluster. Konsep dasar FCM adalah menentukan pusat cluster, pada kondisi awal pusat
cluster ini masih belum akurat dan setiap data memiliki derajat keanggotaan untuk tiap-tiap
cluster. Dengan cara memperbaiki pusat cluster dan nilai keanggotaan tiap data secara berulang untuk mendapatkan posisi pusat cluster yang tepat berdasarkan pada minimisasi fungsi obyektif yang menggambarkan jarak dari titik data yang diberikan ke pusat cluster.
μik= [∑ (Xij−Vkj)
[1] Input data yang akan dicluster X, berupa matriks berukuran n x m (n = jumlah sampel data, m = atribut setiap data). Xij = data sampel ke-i (i = 1,2,3…,n), atribut ke-j (j = 1,2,3,…,m). [2] Tentukan : jumlah cluster (c),pangkat (w), maksimum iterasi (MaxIter), error terkecil yang
diharapkan (ξ), fungsi objektif awal (P0 = 0) dan iterasi awal (t=1).
[3] Bangkitkan bilangan random μik , dimana i=1,2,3,…,n; k=1,2,….,c; sebagai elemen -elemen matriks partisi awal U.
[4] Hitung pusat cluster ke-k dengan persamaan (1)
[5] Hitung fungsi obyektif pada iterasi ke–t, Pt atau dengan cara menghitung hasil maksimal dari selisih matriks partisi akhir-dikurangi matriks partisi awal menggunakan persamaan (2)
[6] Hitung perubahan matriks partisi dengan persamaan (3) [7] Cek kondisi berhenti :
a. Jika (|Pt-Pt-1| <ξ ) atau ( t > MaxIter) maka berhenti. b. Jika tidak : t=t+1, ulangi langkah ke -4.
Contoh hasil clustering menggunakan algoritma FCM dengan 5 kali iterasi dan 3
cluster ditunjukkan pada Tabel 3 Perubahan kluster pada FCM didasarkan pada derajat keanggotaan yang terbesar. Jika derajat keanggotaan terbesar terletak pada kolom pertama, hal itu menunjukkan bahwa data tersebut termasuk ke dalam cluster pertama, begitu seterusnya. Sebagai contoh pada data pertama di Tabel 3 yang memiliki derajat keanggotaan untuk kluster 1, 2 dan 3 adalah 0.26661900, 0.19149878 dan 0.07512022, sehingga data tersebut masuk dalam kluster yang pertama. Dalam FCM satu data dapat masuk dalam lebih dari satu cluster,
sehingga kemungkinan satu KK bisa di kategorikan dalam dua atau tiga kriteria kemiskinan dengan nilai keanggotaan yang dapat digunakan sebagai pembeda antara anggota cluster yang satu dengan yang lain.
Tabel 3. Contoh hasil perhitungan menggunakan algoritma FCM
Derajat keanggotaan
Max Cluster
C1 C2 C3 1 2 3
0.26661900 0.19149878 0.07512022 0.26661900 * 0.86809009 0.07904618 0.78904391 0.86809009 *
0.18817855 0.21732199 0.02914245 0.21732199 *
0.55897680 0.05708580 0.61606260 0.61606260 * 0.25794736 0.24453871 0.50248607 0.50248607 * 0.75466121 0.10686331 0.86152452 0.86152452 *
2.2.2 K-Means Clustering
Jatisi, Vol. 1 No. 2 Maret 2015 143
Algoritma k-means clustering :
[1] Inisialisasi cluster centroid 𝜇1, 𝜇2, … , 𝜇𝑘 𝜖 𝑅𝑛 secara random [2] Repeat until convergence :
{
fori , 𝑐(𝑖)≔ arg𝑚𝑖𝑛𝑗||𝑥(𝑖)− 𝜇𝑗||2
for j , 𝜇𝑗≔∑𝑚𝑖=1∑𝑚1{𝑐1{𝑐(𝑖)(𝑖)=𝑗}𝑥=𝑗}(𝑖) 𝑖=1
}
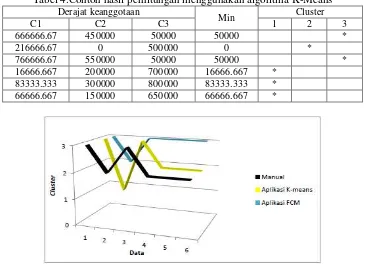
Contoh hasil perhitungan menggunakan algoritma K-Means ditunjukkan pada Tabel 4. Contoh hasil akhir dengan 5 kali iterasi dan 3 cluster ditunjukkan pada Tabel 4.Perubahan kluster pada clustering menggunakan K-Means didasarkan pada derajat keanggotaan yang terkecil. Jika derajat keanggotaan terkecil terletak pada kolom pertama, hal ini menunjukkan bahwa data tersebut masuk ke dalam cluster pertama, begitu seterusnya. Sebagai contoh data pertama pada Tabel 4menunjukkan bahwa derajat keanggotaan untuk kluster 1, 2 dan 3 adalah 666666.67, 450000 dan 50000 maka data satu tersebut masuk dalam cluster yang ke-3.
2.3 Perbandingan Hasil Clustering
Hasil clustering menggunakan agoritma FCM dan K-means selanjutnya dibandingkan dengan hasil clustering yang dilakukan secara manual berdasarkan beberapa indikator yang telah digunakan oleh pemerintah sesuai BAPPAEDA tahun 2008 yang ditunjukkan pada Gambar 1. Gambar 1 menunjukkan hasil perbandingan perhitungan menggunakan algoritma FCM ditunjukkan dengan warna biru ,K-Means dengan warna kuning dan perhitungan Manual dengan warna hitam. Perhitungan manual dengan perhitungan menggunakan algoritma FCM memiliki kesesuaian sebesar 50% dan hasil perhitungan manual dengan perhitungan algoritma
K-Means sebesar 83,33%.
Tabel 4.Contoh hasil perhitungan menggunakan algoritma K-Means
Derajat keanggotaan
Min Cluster
C1 C2 C3 1 2 3
666666.67 450000 50000 50000 *
216666.67 0 500000 0 *
766666.67 550000 50000 50000 *
16666.667 200000 700000 16666.667 * 83333.333 300000 800000 83333.333 * 66666.667 150000 650000 66666.667 *
3. HASIL DAN PEMBAHASAN
Penelitian ini mengunakan 9 skenario untuk pengujian algoritma FCM dan 7 skenario untuk pengujian algoritma K-Means. Pengujian kedua algoritma tersebut menggunakan data kemiskinan desa Girijati, Purwosari, Gunungkidul pada tahun 2009, 2010, 2012 dan 2013. Jumlah data dari masing-masing tahun adalah 347, 13,16 dan 23.
3.1. Fuzzy C-Means
Pengujian menggunakan algoritma FCM menggunakan 3 parameter yaitu maksimal iterasi, pangkat dan epsilon. Secara umum skenario-skenario pengujian ditunjukan pada Tabel 5.
Tabel 5.Ringkasan Skenario untuk Algoritma FCM
Skenario Maksimal Iterasi Pangkat Epsilon
1 50 2 10-5
2 100 2 10-5
3 250 2 10-5
4 500 2 10-5
5 1000 2 10-5
6 50 5 10-5
7 100 5 10-5
8 50 100 10-5
9 100 100 10-5
3.1.1. Skenario 1 – 5
Percobaan dengan sKenario 1 sampai dengan 5 dilakukan untuk mengetahui pengaruh banyaknya iterasi dan data dengan waktu yang dibutuhkan sistem untuk mengolah data dan nilai
epsilon.Begitu juga semakin banyak data dan maksimal iterasi maka semakin tinggi nilai
epsilon-nya. Hasil percobaan ditunjukkan pada Gambar 2 (a) dan (b), dapat dilihat bahwa semakin banyak data dan jumlah iterasi maka akan mempengaruhi waktu yang diperlukan untuk proses perhitungan algoritma FCM. Dapat dilihat juga bahwa untuk kesemua pengujian maksimal iterasinya sama dengan inisialisasi iterasi awal, hal ini menunjukan bahwa proses berhenti dikarenakan sudah mencapai batas maksimal iterasi yang ditentukan diawal bukan karena nilai epsilonnya. Percobaan hanya dilakukan mencapai maksimal iterasi 1000 saja, ini dikarenakan hasil yang diperoleh semakin jauh dari yang diharapkan. Hal ini dapat dilihat dari data yang diperoleh bahwa pusat kluster yang nantinya akan dijadikan acuan sebagai kriteria tidak sesuai dari masing - masing indikator dan efisiensi waktu. Hasil untuk pusat kluster masih jauh dari yang diharapkan, Hal ini terjadi karena data yang ada pada kriteria 2 – 14 kurang bervariasi.
(a) (b)
Jatisi, Vol. 1 No. 2 Maret 2015 145
3.1.2. Skenario 1, 6 dan 8
Percobaan dengan sKenario 1, 6 dan 8 dilakukan untuk mengetahui pengaruh parameter pangkat terhadap waktu yang dibutuhkan sistem untuk mengolah data dan nilai epsilon. Hasil clustering yang ditunjukkan pada Gambar 3 (a) dan (b)menunjukkan bahwa banyaknya pangkat kurang mempengaruhi waktu yang diperlukan untuk proses perhitungan yang dilakukan. Hal ini dilihat pada nilai pangkat 5 mengalami penurunan waktu yang diperlukan, akan tetapi pada pangkat 100 waktu yang diperlukan bertambah kembali. Hal ini kemungkinan terjadi karena pengaruh nilai random untuk partisi awal. Nilai random partisi awal juga sangat berpanguruh terhadap banyaknya iterasi, hal itu disebabkan nilai dari fungsi objektif dapat berubah sesuai nilai partisi awal.
(a) (b)
Gambar 3. Hasil clustering terkait waktu yang dibutuhkan oleh system dengan parameter pangkat dengan maksimal iterasi 50 (a) dan 100 (b)
Berdasarkan dari Gambar 3 (a) dan (b)menunjukkan bahwa nilai pangkat kurang mempengaruhi waktu yang diperlukan untuk menyelesaikan proses perhitungan pada algoritma FCM.
3.1.3. Skenario 1, 6 dan 8
Percobaan dengan skenario 1, 2, 6, 7, 8 dan 9 dilakukan untuk mengetahui pengaruh banyak data, iterasi dan pangkat dengan waktu yang dibutuhkan sistem untuk mengolah data dan nilai epsilon. Dari Gambar 4 (a) dapat dilihat bahwa parameter pangkat mempengaruhi nilai epsilon akhir. Semakin tinggi pangkat maka nilai epsilon semakin besar dan semakin jauh dari nilai epsilon awal yang ditetapkan. Begitu juga untuk hasil clustering dengan maksimal iterasi 100 menunjukkan bahwa parameter pangkat berpengaruh terhadap nilai akhir epsilon
yang ditunjukkan pada Gambar 4 (b).
(a) (b)
Semakin banyak data dan jumlah iterasi maka akan mempengaruhi waktu yang diperlukan untuk proses perhitungan algoritma FCM. Semakin banyak data dan maksimal iterasi maka semakin tinggi nilai epsilon-nya. Dari sekian percobaan yang dilakukan, data - data pada proses pengujian belum mencapai pada hasil yang diinginkan. Hal ini dikarenakan beberapa faktor yang mempengaruhinya antara lain proses perhitungan dipaksa berhenti berdasarkan maksimal iterasi yang telah ditentukan, bukan karena nilai epsilon yang ditentukan sehingga kemungkinan data dapat berpindah kluster masih bisa terjadi. Dari penjelasan – penjelasa di atas maka dapat disimpulkan bahwa algortima Fuzzy C-Means kurang sesuai untuk clustering data kemiskinan di Desa Girijati, mengingat hasil yang diperoleh masih jauh dari harapan. Algortima
Fuzzy C-Means tidak sesuai untuk data Kemiskinan di Kabupaten Gunungkidul disebabkan data yang kurang bervariasi. Pengaruh inisialisasi pangkat dan maksimal iterasi berpengaruh pada waktu yang diperlukan untuk proses perhitungan menggunakan algoritma Fuzzy C-Means.
3.2. K-Means
Data yang digunakan untuk pengujian algoritma K-Means adalah data kemiskinan di Kabupaten Gunungkidul pada tahun 2009, 2010, 2012 dan 2013 dengan banyak data adalah 347, 13, 16 dan 23. Parameter untuk skenario – skenario ditunjukan pada Tabel 6.
Tabel 6. Ringkasan Skenario untuk Algoritma K-Means Skenario Maksimal
Iterasi
Threshold
2009 2010 2011 2012
1 25 10-5 10-5 10-5 10-5
2 50 10-5 10-5 10-5 10-5
3 100 10-5 10-5 10-5 10-5
4 25 10-5 10-5 10-5 10-5
5 100 10-5 10-5 10-5 10-5
6 25 1,37 x 108 1,53 x 106 7,15 x 106 6,51 x 106
7 100 1,37 x 108 1,53 x 106 7,15 x 106 6,51 x 106
3.2.1. Skenario 1-3
Percobaan dengan skenario 1 – 3 dilakukan untuk mengetahui pengaruh banyak iterasi dan data dengan waktu yang dibutuhkan sistem untuk mengolsssah data. Gambar 5 (a) menunjukkan banyaknya iterasi dan data yang mempengaruhi waktu untuk menyelesaikan proses perhitungan algoritma K-Means. Semakin banyak iterasi maka semakin lama juga waktu yang diperlukan. Dari Gambar 5 (b) dapat disimpulkan bahwa banyaknya iterasi tidak berpengaruh pada nilai epsilon akhir. Hal ini terjadi karena nilai epsilon dari percobaan yang dilakukan sama untuk semua percobaan yang dilakukan. Kemungkinan ini terjadi karena pada iterasi 25 kebawah perhitungannya sudah berhenti. Karena nilai epsilon awal terlalu kecil proses tetap berjalan sampai maksimal iterasi terpenuhi.
(a) (b)
Jatisi, Vol. 1 No. 2 Maret 2015 147
3.1.1. Skenario 6 Dan 7
Dari permasalahan di atas maka penulis meneliti sampai iterasi keberapakah proses perhitungan berhenti. Maka percobaan skenario 6 dan 7 dilakukan untuk mengetahui iterasi berapa proses perhitungan berhenti, sehingga penelitian ini mencoba untuk melakukan perhitungan dengan menggunakan maksimal iterasi adalah 50 dan threshold adalah 1,37 x 108 untuk tahun 2009, 1,55 x 106 untuk tahun 2010, 7,15 x 106 untuk tahun 2012, dan 6,51 x 106 untuk tahun 2013.
Tabel 7. Hasil Iterasi Terakhir pada Algoritma K-Means
dengan Parameter Maksimal Iterasi 50
Tahun Iterasi akhir
2009 12
2010 4
2011 3
2012 9
Tabel 7 menunjukkan bahwa proses berhenti pada iterasi ke-12 untuk tahun 2009, pada tahun 2010 berhenti pada iterasi ke-4, pada tahun 2012 berhenti pada iterasi ke-312, pada tahun 2013 berhenti pada iterasi ke-9. Percobaan dilakukan juga untuk mengetahui pengaruh nilai
random objek cluster awal terhadap lama waktu dan hasil yang diperoleh. Hasil percobaan pada skenario 4, 5 dan 7 menunjukkan bahwa nilai random sedikit berpengaruh terhadap waktu dan maksimal iterasi yang diperlukan, akan tetapi tidak berpengaruh terhadap hasil yang diperoleh.
Berdasarkan hasil pengujian yang sudah dilakukan dengan skenario-skenario yang sudah ditentukan didapatkan hasil bahwa beberapa parameter saling mempengaruhi hasil yang diperoleh. Seperti halnya percobaan pada algortima Fuzzy C-Means bahwa banyak data dan inisialisasi maksimal iterasi awal dapat mempengaruhi lama waktu proses perhitungan, semakin besar data dan maksimal iterasi awal maka akan semakin lama waktu yang diperlukan.
4. KESIMPULAN
Berdasarkan hasil analisa dan pembahasan, diperoleh kesimpulan sebagai berikut : 1. Data kemiskinan di Desa Girijati, Purwosari, Gunungkidul, Yogyakarta memiiki data yang
kurang bervariasi untuk kelima belas indikatornya, hal itu menyebabkan hasil clustering menjadi sensitif terhadap perubahan nilai parameter. Dari percobaan yang dilakukan, waktu clustering yang diperlukan algoritma FCM relatif lebih lama serta membutuhkan iterasi lebih banyak dibandingkan dengan algoritma K-Means. Algoritma FCM lebih cocok diterapkan pada data yang lebih variatif.
2. Pengujian dilakukan dengan membandingkan hasil clustering kedua algoritma tersebut dengan pengelompokan berdasarkan aturan BAPPEDA 2008. Hasil clustering menggunakan algoritma FCM memiliki tingkat akurasi hanya 50%, sedangkan untuk algoritma K-means memiliki tingkat akurasi lebih baik yaitu 83.33%.
DAFTAR PUSTAKA
[1] Republika, 2013, Republika Online. http://www.republika.co.id/berita/nasional/jawa-tengah-diy-nasional/13/01/02/mfzoyv-tingkat-kemiskinan-di-diy-tertinggi-sejawa
[diakses tanggal 26 November 2013].
[3] Kardi dalam Susanto, A.R., 2013, Sistem Pendukung Keputusan Pengadaan Buku Perpustakaan STIKOM Surabaya Menggunakan Metode K-Means Clustering. Makalah TA. Surabaya, STIKOM Surabaya.
[4] Helmiah, 2013, Sisitem Pendukung Keputusan untuk Pengkatogorian IPK dan Llama Studi Alumni Menggunakan Metode K-Means. Skripsi, Yogyakarta: UII Teknik Informatika.
[5] Pamungkas, A., 2010, Perbandingan Distance Space Manhattan(Cityblock) dengan Ecludiean pada Algoritma K-Means Clustering Studi Kasus : Data Balita di Wilayah Kecamatan Melati, Sleman. Skripsi, Yogyakarta, AKAKOM Sekolah Tinggi Manajemen Informatika dan Komputer
[6] Susilowati, R., 2012, Clustering Data Pasien Menggunakan Fuzzy C-Means dan Aglomerative Hierarchical Clustering. Skripsi, Yogyakarta, UIN Sunan Kalijaga Teknik Informatika
[7] Pebrianto, R., 2011, Aplikasi Clustering Dengan Menggunakan Metode Fuzzy C-Means.
Skripsi, Yogyakarta, UII Teknik Informatika.
[8] Pahri, A.N.I., 2012, Pengelompokan Uji Laboratorium sebagai Penunjang Diagnosa Demam Berdarah Menggunakan Fuzzy C-Means. Skripsi, Yogyakarta, UII Teknik Informatika.
[9] BPS, 2011, Kemiskinan dan Ketimbangan Pendapatan : Pengukuran, Relevasi dan Pemanfaatan. In Nasional, D.S.K., ed. Workshop Evaluasi Data Podes. Bandung, BPS.
[10] Bezdek, J. C., Ehrlich, R., & Full, W. (1984). FCM: The fuzzy c-means clustering algorithm. Computers & Geosciences, 10(2), 191-203.
Jatisi, Vol. 1 No. 2 Maret 2015 149
Analisis dan Perancangan Sistem Informasi Rekam Medis
Pada Puskesmas Simpang Timbangan Indralaya
Fransiska Prihatini Sihotang STMIK MDP Palembang
Abstrak
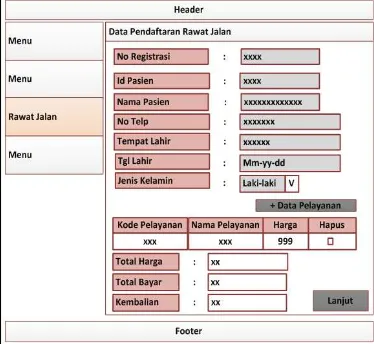
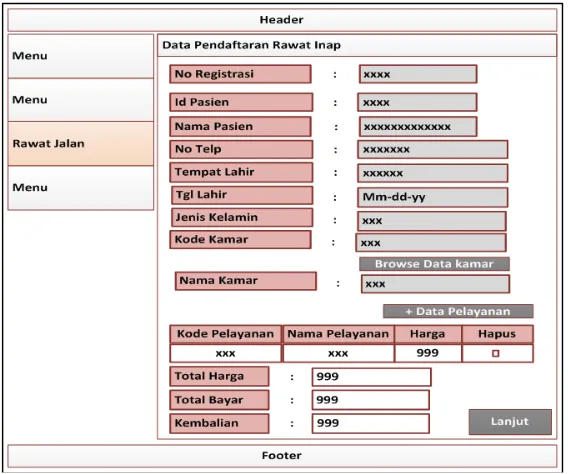
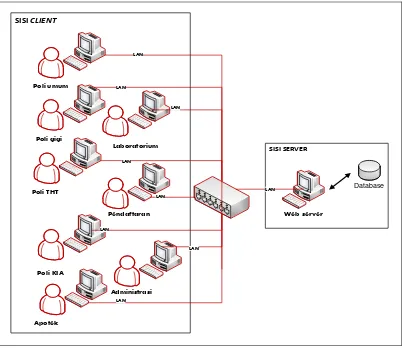
Rekam medis adalah berkas yang berisikan catatan dan dokumen tentang identitas pasien, pemeriksaan, pengobatan, tindakan dan pelayanan lain yang telah diberikan kepada pasien. Berkas rekam medis dibutuhkan pihak manajemen untuk merencanakan, mengendalikan, dan mengevaluasi mutu pelayanan. Puskesmas adalah unit pelaksana teknis dari Dinas Kesehatan Kabupaten/Kota yang bertanggung jawab menyelenggarakan pembangunan kesehatan di satu atau sebagian wilayah kecamatan. Pelayanan di puskesmas cukup kompleks mulai dari kegiatan pelayanan rawat jalan, rawat inap, pemeriksaan laboratorium, dan apotek. Tujuan dari penelitian ini adalah merancang sebuah sistem informasi rekam medis yang terintegrasi pada puskesmas Simpang Timbangan Indralaya sehingga dapat memperbaiki sistem yang lama. Pengembangan sistem menggunakan metodologi FAST, pengumpulan data menggunakan wawancara, observasi, dan studi literatur. Hasil penelitian ini adalah rancangan sistem informasi rekam medis Puskesmas Simpang Timbangan Indralaya yang terdiri dari pelayanan rawat inap, pelayanan rawat jalan, pengelolaan laboratorium, pengelolaan apotek, dan pembuatan laporan rekam medis. Rancangan yang dihasilkan berupa DFD, ERD, diagram dekomposisi, rancangan antar muka aplikasi, rancangan laporan, dan rancangan arsitektur jaringan.
Kata kunci—Sistem Informasi, rekam medis, puskesmas, FAST, prototyping
Abstract
Medical record is a file containing records and documents about the patient’s identity, examination, treatment, medical action, and other services that have been administered to patients. Management need a medical record file for planning, controlling, and evaluating the quality of care. Puskesmas (local medical center) is a technical unit of the District/City Health Office held responsible for health development in one or some districts. Puskesmas has a fairly complex service such as outpatient services, inpatient, laboratory tests, and pharmacy. The purpose of this research is to design an integrated medical record information systems at Puskesmas Simpang Timbangan Indralaya to repair the old system. This study used FAST as system development, and to colect the data used interview, observation, and literature study. The results of this study is the design of medical record information system on Puskesmas Simpang Timbangan Indralaya consisting of inpatient services, outpatient services, laboratory management, pharmacy management, and medical reports. The design is generated in the form of DFD, ERD, decomposition diagrams, application design interface, report design, and network architecture design.
1. PENDAHULUAN
ekam medis adalah berkas yang berisikan catatan dan dokumen tentang identitas pasien, pemeriksaan, pengobatan, tindakan dan pelayanan lain yang telah diberikan kepada pasien[1]. Informasi yang dihasilkan oleh sebuah sistem rekam medis sangat dibutuhkan untuk pengobatan pasien, peningkatan kualitas pelayanan, pendidikan, dan penelitian. Selain itu pemerintah juga mewajibkan setiap tenaga kesehatan membuat rekam medis dan akan dikenakan sanksi jika tidak membuatnya[2].
Puskesmas Simpang Timbangan Indralaya menggunakan komputer dengan memanfaatkan program Microsoft Office Word dan Microsoft Office Excel terbatas pada pembuatan laporan, sedangkan kegiatan pendaftaran pasien, pencatatan pemeriksaan, pemberian obat, sampai pasien pulang masih berupa lembaran-lembaran kertas. Hal tersebut sering menimbulkan masalah dalam penyajian data pasien, pembuatan laporan, dan memberikan pelayanan terhadap pasien.Contoh kasus yang sering terjadi dalam pendataan pasien adalah ketika pasien kehilangan atau lupa membawa kartu pasien. Petugas harus mencari kembali data pasien tersebut dan jika tidak ditemukan akan dilakukan pendataan ulang sehingga terjadi duplikasi data tanpa mengetahui riwayat medis pasien sebelumnya. Hal tersebut merugikan puskesmas karena membutuhkan waktu yang lama untuk penyajian data, tidak akuratnya laporan tentang rekam medis di puskesmas tersebut sehingga menyulitkan pengambilan keputusan oleh pihak manajemen, dan mengurangi kualitas pelayanan terhadap pasien.
Untuk mengatasi masalah tersebut, perlu digunakan komputer dan sistem basis data yang baik sebagai alat bantu dalam mengelola data rekam medis menjadi suatu sistem informasi yang berguna bagi perkembangan puskesmas di masa yang akan datang.Dengan program berbasis komputer pada rekam medis, diharapkan kinerja Puskesmas Simpang Timbangan Indralaya dapat ditingkatkan, sehingga kualitas dan mutu pelayanan menjadi meningkat.
Tujuan dari penelitian ini adalah mengidentifikasi dan menganalisis masalah pencatatan dan penyimpanan rekam medis, merancang proses bisnis baru dalam sebuah sistem informasi rekam medis yang terintegrasi pada puskesmas Simpang Timbangan Indralaya sehingga dapat memperbaiki sistem yang lama.Penelitian ini diharapkan dapat mempermudah penyajian informasi rekam medis, meningkatkan konsistensi data rekam medis sehingga laporan yang dihasilkan lebih akurat dan mempermudah pengambilan keputusan oleh pihak manajemen, dan meningkatkan mutu pelayanan Puskesmas Simpang Timbangan Indralaya.
2. METODE PENELITIAN
Bagian ini berisi tentang metode dan dasar teori yang digunakan pada tulisan ini.
2.1 Pengumpulan Data
Penulis memperoleh data primer dengan melakukan wawancara, observasi, dan memberikan kuisioner. Wawancara dilakukan kepada beberapa narasumber dari Puskesmas Simpang Timbangan Indralaya. Wawancara dilakukan secara langsung dan tidak langsung. Secara langsung dilakukan dengan tatap muka, sedangkan secara tidak langsung dilakukan melalui media telekomunikasi seperti telepon dan percakapan online.Teknik observasi dilakukan untuk mengetahui secara langsung proses bisnis yang terjadi pada Puskesmas Simpang Timbangan Indralaya.Penulis juga melakukan studi literatur untuk memperkaya pengetahuan terkait rekam medis.
2.2 Rekam Medis
Rekam medis adalah berkas yang berisikan catatan dan dokumen tentang identitas pasien, pemeriksaan, pengobatan, tindakan dan pelayanan lain yang telah diberikan kepada pasien[1]. Isi rekam medis harus memuat beberapa hal sebagai berikut[3]: