PERBANDINGAN
DAN FUZZY DECISION TREE
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM PERBANDINGAN PROBABILISTIC FUZZY DECISION TREE
FUZZY DECISION TREE UNTUK MODEL KLASIFIKASI PADA DATA DIABETES
MUHAMMAD RAFI MUTTAQIN
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2008
PERBANDINGAN PROBABILISTIC FUZZY DECISION TREE
DAN FUZZY DECISION TREE UNTUK MODEL KLASIFIKASI PADA DATA DIABETES
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
MUHAMMAD RAFI MUTTAQIN G64104082
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2008
ABSTRAK
MUHAMMAD RAFI MUTTAQIN. Perbandingan Probabilistic Fuzzy Decision Tree dan Fuzzy Decision Tree untuk Model Klasifikasi pada Data Diabetes. Dibimbing oleh IMAS S. SITANGGANG dan IRMAN HERMADI.
Data yang dikumpulkan oleh rumah sakit sangat banyak dan bervariasi, termasuk juga data pasien yang mengidap penyakit diabetes, akan tetapi data tersebut belum banyak dimanfaatkan secara optimal. Untuk itu diperlukan suatu sistem data mining yang bisa memanfaatkan data tersebut menjadi suatu informasi yang berguna. Sebuah penelitian tentang teknik klasifikasi pada data mining telah dilakukan pada data diabetes suatu rumah sakit dengan metode fuzzy decision tree. Penelitian tersebut menghasilkan 30 buah aturan dengan akurasi 90.69%, pada nilai fuzziness control threshold sebesar 98% dan leaf decision threshold sebesar 3%. Aturan klasifikasi yang mengandung kelas target negatif diabetes sebanyak 29 aturan, sedangkan untuk kelas target positif diabetes sebanyak 1 aturan.
Penelitian ini membandingkan metode probabilistic fuzzy decision tree (PFDT) dan fuzzy decision tree (FDT) pada data yang sama dengan penelitian sebelumnya. Probabilistic fuzzy decision tree merupakan pengembangan dari metode fuzzy decision tree dengan memperbaiki fungsi keanggotaan untuk proses learning dengan menggunakan pendekatan well-defined sample space.
Dari penelitian ini dihasilkan jumlah aturan yang dihasilkan dari FDT lebih banyak dari jumlah aturan dari PFDT, yaitu sebanyak 41 aturan untuk FDT dan 26 aturan untuk PFDT dengan nilai fuzziness control threshold sebesar 98% dan leaf decision threshold sebesar 3%. Nilai akurasi FDT lebih besar dari PFDT yaitu 92.8% untuk FDT dan 90% untuk PFDT dengan nilai fuzziness control threshold sebesar 98% dan leaf decision threshold sebesar 3%.
Kata kunci: klasifikasi, fuzzy decision tree, probabilistic fuzzy decision tree, well-defined sample space
Judul : Perbandingan
Probabilistic Fuzzy Decision Tree
dan
Fuzzy Decision
Tree untuk Model Klasifikasi pada Data Diabetes
Nama : Muhammad Rafi Muttaqin
NIM : G64104082
Menyetujui:
Pembimbing I,
Pembimbing II,
Imas S. Sitanggang, S.Si, M.Kom
Irman Hermadi, S.Kom, M.S
NIP 132206235
NIP 132321422
Mengetahui:
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Dr. Drh. Hasim, DEA
NIP 131578806
RIWAYAT HIDUP
Penulis dilahirkan di Purwakarta pada tanggal 20 Agustus 1987 dari pasangan Busrol Karim dan Heni Yuliati. Penulis merupakan putra ke empat dari empat bersaudara.
Tahun 2004 penulis lulus dari SMA Insan Kamil Bogor dan pada tahun yang sama melanjutkan pendidikan ke Institut Pertanian Bogor (IPB) melalui jalus Seleksi Penerimaan Mahasiswa Baru (SPMB) pada Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.
Pada tanggal 02 Juli 2007 sampai dengan 25 Agustus 2007, penulis melaksanakan Praktik Kerja Lapangan di SMA Insan Kamil Bogor. Penulis ditempatkan di Bagian Teknologi Informasi, SMA Insan Kamil Bogor untuk merancang Sistem Informasi Akademik Berbasis Wireless Application Protocol.
PRAKATA
Alhamdulillahi Rabbil ‘alamin, puji dan syukur penulis panjatkan kepada Allah SWT atas segala curahan rahmat dan karunia-Nya sehingga tugas akhir ini dapat diselesaikan. Tugas akhir ini berjudul Perbandingan Probabilistic Fuzzy Decision Tree dan Fuzzy Decision Tree untuk Model Klasifikasi pada Data Diabetes.
Dalam menyelesaikan tugas akhir ini penulis mendapatkan banyak sekali bantuan, bimbingan dan dorongan dari berbagai pihak. Oleh karena itu, penulis ingin mengucapkan terima kasih kepada semua pihak yang telah membantu dalam penyelesaian tugas akhir ini, antara lain:
1 ABI guruku tercinta yang selalu memberikan doa, nasehat serta dorongan untuk menyelesaikan tugas akhir ini,
2 Kedua orangtua tercinta, mamah Heni Yuliati dan papap Busrol Karim atas do’a, kasih sayang dan dukungannya,
3 Kakak-kakakku tercinta Lina Aliani, Wulan Farhani, dan Rani Rahmani atas segala motivasi dan bantuannya selama proses penyelesaian tugas akhir ini,
4 Ibu Imas S. Sitanggang, S.Si, M.Kom selaku pembimbing pertama atas bimbingan dan arahannya serta dorongannya untuk menyelesaikan tugas akhir ini dengan cepat,
5 Bapak Irman Hermadi, S.Kom, MS selaku pembimbing kedua atas bimbingan dan arahannya selama pengerjaan tugas akhir ini,
6 Ustadz Ahmad,Ustadz Ikhlas, Kak Epul, Kak Hadi, Kak Oi, Kak Hadian, Kak Yusuf, Rizal, Kamal, Yusufa, Afiah dan seluruh Ustadz dan teman di Al-Ihya atas bimbingan, persahabatan, canda, dan bantuan selama ini,
7 David Singo, Reza, dan Maul yang telah bersedia menjadi pembahas pada seminar penulis, 8 Riza, Hasan, Hode, Henry, Welly, Tri yang setia melakukan bimbingan bersama,
9 Noven, Brank, dan teman-teman ILKOM 41 IPB yang telah banyak membantu penulis selama kuliah di IPB
Penulis juga mengucapkan terima kasih kepada semua pihak yang telah membantu selama pengerjaan penyelesaian tugas akhir ini yang tidak dapat disebutkan satu-persatu. Semoga penelitian ini dapat memberi manfaat.
Bogor, Juli 2008
DAFTAR ISI
Halaman DAFTAR TABEL ... vi DAFTAR GAMBAR ... vi DAFTAR LAMPIRAN ... vi PENDAHULUAN Latar Belakang ... 1 Tujuan Penelitian ... 1Ruang Lingkup Penelitian ... 1
Manfaat Penelitian ... 1 TINJAUAN PUSTAKA Data Mining... 1 Klasifikasi ... 2 Fungsi Keanggotaaan ... 2 Himpunan Fuzzy ... 2
Linguistic Variable (Peubah Linguistik)... 2
Linguistic Term ... 3
Sistem Inferensi Fuzzy (Fuzzy Inference System) ... 3
Pohon Keputusan ... 3
Fuzzy Decision Tree (FDT) ... 3
Fuzzy ID3 Decision Tree ... 3
Probabilistic Fuzzy Decision Tree (PFDT) ... 4
Statistical Fuzzy Entropy (SFE) dan Statistical Information Gain ... 4
Threshold ... 4
K-fold Cross Validation ... 5
METODE PENELITIAN Data ... 5
Metode ... 5
Lingkup Pengembangan Sistem ... 5
HASIL DAN PEMBAHASAN Transformasi Data ... 5
Pendekatan Without Well-Defined Sample Space ... 6
Pendekatan Well-Defined Sample Space ... 8
Data Mining... 10
Fase Pembentukan Pohon Keputusan ... 10
Akurasi FDT, PFDT(1), dan PFDT(2) ... 12
Representasi Pengetahuan ... 13
Aturan-Aturan dari FDT ... 13
Aturan-aturan dari PFDT(2) ... 13
KESIMPULAN DAN SARAN Kesimpulan ... 13
Saran ... 13
DAFTAR PUSTAKA ... 13
DAFTAR TABEL
Halaman
1 Kelompok percobaan ... 5
2 Daftar range normal untuk setiap atribut ... 6
3 Rata-rata jumlah aturan FDT ... 10
4 Rata-rata jumlah aturan PFDT(1) ... 10
5 Rata-rata jumlah aturan PFDT(2) ... 10
6 Contoh perbandingan hasil FDT dan PFDT ... 11
7 Rata-rata akurasi FDT ... 12
8 Rata-rata akurasi PFDT(1) ... 12
9 Rata-rata akurasi PFDT(2) ... 12
DAFTAR GAMBAR
Halaman 1 Fungsi keanggotaan trapezoidal. ... 22 Fungsi keanggotaan gaussian. ... 2
3 Diagram alur proses klasifikasi PFDT. ... 6
4 Himpunan fuzzy atribut GLUN untuk FDT. ... 6
5 Himpunan fuzzy atribut GPOST untuk FDT. ... 7
6 Himpunan fuzzy atribut HDL untuk FDT. ... 7
7 Himpunan fuzzy atribut TG untuk FDT. ... 8
8 Himpunan fuzzy atribut GLUN untuk PFDT. ... 8
9 Himpunan fuzzy atribut HDL untuk PFDT. ... 9
10 Himpunan fuzzy atribut HDL untuk PFDT. ... 9
11 Himpunan fuzzy atribut TG untuk PFDT. ... 9
12 Perbandingan rata-rata jumlah aturan untuk nilai sebesar 10%. ... 11
13 Perbandingan rata-rata waktu eksekusi proses training ... 11
14 Perbandingan rata-rata akurasi untuk nilai sebesar 10%. ... 12
15 Akurasi FDT, PFDT(1), dan PFDT(2) untuk nilai sebesar 10%... 12
DAFTAR LAMPIRAN
Halaman 1 Fungsi keanggotaan PFDT(1) ... 162 Jumlah aturan yang dihasilkan FDT, PFDT(1), dan PFDT(2) untuk masing-masing training set ... 17
3 Waktu eksekusi FDT, PFDT(1), dan PFDT(2) untuk masing-masing training set dalam satuan detik ... 20
4 Akurasi aturan FDT, PFDT(1), dan PFDT(2) setelah pengujian dengan menggunakan test set ... 24
5 Aturan-aturan yang dihasilkan dari FDT dengan nilai dan masing-masing 98% dan 3% ... 32
6 Aturan-aturan yang dihasilkan dari PFDT(2) dengan nilai dan masing-masing 98% dan 3% ... 33
PENDAHULUAN
Latar Belakang
Organisasi Kesehatan Dunia (WHO) memperkirakan, bahwa 177 juta penduduk dunia mengidap penyakit diabetes mellitus atau biasa disingkat diabetes. Jumlah ini akan terus meningkat hingga melebihi 300 juta pada tahun 2025. Dr Paul Zimmet, direktur dari International Diabetes Institute (IDI) di Victoria, Australia, meramalkan bahwa diabetes akan menjadi epidemi yang paling dahsyat dalam sejarah manusia.
Perkembangan yang cepat dalam teknologi pengumpulan dan penyimpanan data telah memudahkan suatu organisasi untuk mengumpulkan sejumlah data berukuran besar. Kondisi ini terjadi pada sebuah rumah sakit yang mempunyai beribu-ribu record data pasien dan jenis penyakitnya, misalnya kumpulan data diabetes yang terkait dengan hasil pemeriksaan laboratorium dari pasien rumah sakit. Data diabetes berukuran besar tersebut seringkali dibiarkan menggunung tanpa digunakan secara maksimal.
Data mining merupakan proses ekstraksi informasi atau pola penting dalam basis data berukuran besar (Han & Kamber 2006). Pada penelitian ini akan diterapkan salah satu teknik dalam data mining, yaitu klasifikasi terhadap data diabetes. Klasifikasi merupakan salah satu metode dalam data mining untuk memprediksi label kelas dari suatu record dalam data. Metode yang digunakan dalam penelitian ini yaitu metode klasifikasi dengan probabilistic fuzzy decision tree (PFDT). Penggunaan teknik fuzzy memungkinkan melakukan prediksi suatu objek yang dimiliki oleh lebih dari satu kelas. Dengan menerapkan data mining pada data diabetes diharapkan dapat ditemukan aturan klasifikasi yang dapat digunakan untuk memprediksi potensi seseorang terserang penyakit diabetes. Pada penelitian sebelumnya digunakan metode fuzzy decision tree yang dilakukan oleh Firat Romansyah (2007) dan menghasilkan nilai akurasi yang cukup tinggi yaitu di atas 90%. Metode probabilistic fuzzy decision tree diharapkan dapat meningkatkan nilai akurasi, serta membandingkan hasil klasifikasi dengan metode fuzzy decision tree (FDT).
Tujuan Penelitian
Tujuan penelitian ini adalah:
1 Menerapkan teknik klasifikasi data mining menggunakan metode probabilistic fuzzy decision tree.
2 Membandingkan nilai akurasi antara metode fuzzy decision tree dan probabilistic fuzzy decision tree.
Ruang Lingkup Penelitian
Ruang lingkup penelitian dibatasi pada: 1 Data yang digunakan adalah data
pemeriksaan lab pasien rumah sakit yang meliputi GLUN (Glukosa Darah Puasa), GPOST (Glukosa Darah 2 Jam PP), Tg (Trigliserida), HDL (Kolestrol HDL), serta diagnosa pasien berdasarkan nilai GLUN, GPOST, HDL, dan TG.
2 Teknik yang digunakan adalah salah satu teknik dalam data mining yaitu teknik klasifikasi dengan menggunakan metode decision tree. Untuk menangani ketidakpastian dan ketidaktepatan, pendekatan fuzzy digunakan.
3 Penelitian dilakukan dengan mengimplementasikan Probabilistic Fuzzy ID3 (Iterative Dichotomiser 3) Decision Tree.
Manfaat Penelitian
Penelitian ini diharapkan dapat membuktikan teori yang menyatakan bahwa teknik probabilistic fuzzy decision tree lebih baik nilai akurasinya dibandingkan dengan teknik fuzzy decision tree. Penelitian ini juga diharapkan menjadi dasar untuk memilih teknik apa yang akan digunakan dalam membangun aplikasi data mining yang lebih besar, khususnya untuk teknik klasifikasi.
TINJAUAN PUSTAKA
Data MiningData mining merupakan proses ekstraksi informasi data berukuran besar (Han & Kamber 2006). Dari sudut pandang analisis data, data mining dapat diklasifikasi menjadi dua kategori, yaitu descriptive data mining dan predictive data mining. Descriptive data mining menjelaskan sekumpulan data dalam cara yang lebih ringkas. Ringkasan tersebut menjelaskan sifat-sifat yang menarik dari data. Predictive data mining menganalisis data dengan tujuan mengkonstruksi satu atau sekumpulan model dan melakukan prediksi perilaku dari kumpulan data baru.
d c b a 1 Klasifikasi
Klasifikasi termasuk ke dalam kategori predictive data mining. Klasifikasi adalah proses menemukan model (fungsi) yang menjelaskan dan membedakan kelas-kelas atau konsep, dengan tujuan agar model yang diperoleh dapat digunakan untuk mengetahui kelas atau objek yang memiliki label kelas yang tidak diketahui. Model yang diturunkan didasarkan pada analisis dari data training (Han & Kamber 2006).
Proses klasifikasi dibagi menjadi dua fase yaitu learning dan testing. Pada fase learning, sebagian data yang telah diketahui kelas datanya (training set) digunakan untuk membentuk model. Selanjutnya pada fase testing, model yang sudah terbentuk diuji dengan sebagian data lainnya (test set) untuk mengetahui akurasi dari model tersebut. Jika akurasinya mencukupi maka model tersebut dapat dipakai untuk prediksi kelas data yang belum diketahui (Han & Kamber 2006). Himpunan Fuzzy
Konsep logika fuzzy pertama kali diperkenalkan oleh Prof. Lotfi A Zadeh dari Universitas California pada bulan Juni 1965. Logika fuzzy merupakan generalisasi dari logika klasik yang hanya memiliki dua nilai keanggotaan 0 dan 1. Dalam logika fuzzy nilai kebenaran suatu pernyataan berkisar dari sepenuhnya benar ke sepenuhnya salah. Dengan teori himpunan fuzzy suatu objek dapat menjadi anggota dari banyak himpunan dengan derajat keanggotaan yang berbeda dalam masing-masing himpunan. Derajat keanggotaan menunjukan nilai keanggotaan suatu objek pada suatu himpunan. Nilai keanggotaan ini berkisar antara 0 sampai 1 (Cox 2005).
Fungsi Keanggotaaan
Inti dari himpunan fuzzy adalah fungsi keanggotaan (membership function). Fungsi keanggotaan menggambarkan hubungan antara domain himpunan fuzzy dengan nilai derajat keanggotaan (Cox 2005).
Jika X adalah kumpulan objek yang ditandai secara umum oleh x, maka himpunan fuzzy A pada X didefinisikan sebagai berikut:
(
)
{
x A x x X}
A= ,µ ( ) | ∈
dimana µA(x) adalah fungsi keanggotaan untuk himpunan fuzzy A. Fungsi keanggotaan
memetakan setiap elemen dari X ke nilai derajat keanggotaan (Kantardzic 2003).
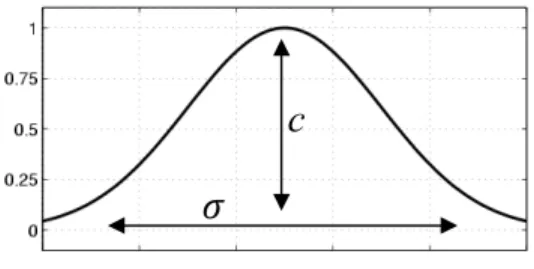
Contoh bentuk fungsi keanggotaan adalah trapezoidal dan gaussian. Fungsi keanggotaan trapezoidal dispesifikasi oleh empat parameter (a, b, c, d) sebagai berikut.
≤ ≤ ≤ − − ≤ ≤ ≤ ≤ − − ≤ = x d d x c c d x d c x b b x a a b a x a x x A ; 0 ; ) /( ) ( ; 1 ; ) /( ) ( ; 0 ) ( µ
Fungsi keanggotaan gaussian dispesifikasikan oleh dua parameter ( dan c ) sebagai berikut.
µ
Ax
=
e
- x-c22σ2
Bentuk fungsi keanggotaan trapezoidal dapat dilihat pada Gambar 1 (Kantardzic 2003). Bentuk fungsi keanggotaan gaussian dapat dilhat pada Gambar 2.
Gambar 1 Fungsi keanggotaan trapezoidal.
Gambar 2 Fungsi keanggotaan gaussian.
Linguistic Variable (Peubah Linguistik) Linguistic variable merupakan peubah verbal yang dapat digunakan untuk memodelkan pemikiran manusia yang diekspresikan dalam bentuk himunan fuzzy. Peubah linguistik dikarakterisasi oleh quintaple (x, T(x), X, G, M) dengan x adalah nama peubah, T(x) adalah kumpulan dari linguistic term, G adalah aturan sintaks, M adalah aturan semantik yang bersesuaian dengan setiap nilai peubah linguistik. Sebagai contoh, jika umur diinterpretasikan sebagai peubah linguistik, maka himpunan dari linguistik term T(umur) menjadi:
c
T(umur) = {sangat muda, muda, tua} Setiap term dalam T(umur) dikarakterisasi oleh himpunan fuzzy, X menunjukkan nilai interval x. Aturan semantik menunjukan fungsi keanggotaan dari setiap nilai pada himpunan linguistic term (Cox 2005).
Linguistic Term
Linguistic term didefinisikan sebagai kumpulan himpunan fuzzy yang didasarkan pada fungsi keanggotaan yang bersesuaian dengan peubah linguistik (Au & Chan 2001).
Jika kumpulan dari record yang terdiri dari kumpulan atribut , dengan
. Atribut dapat berupa atribut numerik atau kategorikal. Untuk setiap record d elemen D, menotasikan nilai i dalam record d untuk atribut . Kumpulan linguistic term dapat didefinisikan pada seluruh domain dari atribut kuantitatif. menotasikan linguistic term yang berasosiasi dengan atribut , sehingga himpunan fuzzy dapat didefinisikan untuk setiap .
Himpunan fuzzy , didefinisikan sebagai: dom !"#$"$ " jika diskret %dom !"#$" $" jika kontinu untuk semua &' (), dengan dom & &.
Derajat keanggotaan dari nilai &'dom dengan beberapa linguistic term dinotasikan oleh *"#.
Sistem Inferensi Fuzzy (Fuzzy Inference System)
Sistem inferensi fuzzy adalah suatu framework yang didasarkan pada konsep himpunan fuzzy, fuzzy if-then rules, dan fuzzy reasoning. Salah satu metode inferensi fuzzy yang paling umum digunakan adalah metode sistem inferensi fuzzy Mamdani. Struktur dasar dari sistem inferensi fuzzy terdiri dari tiga komponen yaitu (Jang et al 1997): 1 basis aturan, terdiri dari aturan-aturan
fuzzy,
2 basis data / kamus data, mendefinisikan fungsi keanggotaan yang digunakan pada aturan fuzzy, dan
3 mekanisme penalaran, melakukan proses inferensi pada aturan dan fakta yang
diberikan untuk memperoleh output atau kesimpulan.
Pohon Keputusan
Pohon keputusan merupakan suatu pendekatan yang sangat populer dan praktis dalam machine learning untuk menyelesaikan permasalah klasifikasi. Metode ini digunakan untuk memperkirakan nilai diskret dari fungsi target, yang mana fungsi pembelajaran direpresentasikan oleh sebuah pohon keputusan (Liang 2005).
Pohon keputtusan sama dengan satu himpunan aturan IF…THEN. Setiap path dalam tree dihubungkan dengan sebuah aturan, yang mana premis terdiri dari sekumpulan node-node yang ditemui, dan kesimpulan dari aturan terdiri dari kelas yang terhubung dengan leaf dari path (Marsala 1998).
Fuzzy Decision Tree (FDT)
Fuzzy decision tree memungkinkan untuk menggunakan nilai-nilai numeric-symbolic selama konstruksi atau saat mengklarifikasikan kasus-kasus baru. Manfaat dari teori himpunan fuzzy dalam decision tree ialah meningkatkan kemampuan dalam memahami decision tree ketika menggunakan atribut-atribut kuantitatif. Bahkan, dengan menggunakan teknik fuzzy dapat meningkatkan ketahanan saat dilakukan klasifikasi kasus-kasus baru (Marsala 1998).
Fuzzy ID3 Decision Tree
Saat ini ID3 (Iterative Dichotomiser 3) adalah algoritme yang paling banyak digunakan untuk membuat suatu decision tree. Algoritme ini pertama kali diperkenalkan oleh Quinlan, menggunakan teori informasi untuk menentukan atribut mana yang paling informatif, namun ID3 sangat tidak stabil dalam melakukan penggolongan berkenaan dengan gangguan kecil pada data latihan. Logika fuzzy dapat memberikan suatu peningkatan untuk dalam melakukan penggolongan pada saat pelatihan (Liang 2005).
Algoritme fuzzy ID3 merupakan algoritme yang efisien untuk membuat suatu fuzzy decision tree. Algoritme fuzzy ID3 adalah sebagai berikut (Liang 2005):
1. Create a Root node that has a
set of fuzzy data with
2. If a node t with a fuzzy set of data D satisfies the following conditions, then it is a leaf node and assigned by the class name.
• The proportion of a class Ck
is greater than or equal to Өx, r Ci
D
D
θ
≥
|
|
|
|
• the number of a data set is less than θn
• there are no attributes for
more classifications
3. If a node D does no satisfy the
above conditions, then it is not a leaf-node. And an new
sub-node is generated as
follow:
• For Ai’s (i=1,…, L) calculate
the information gain, and
select the test attribute Amax
that maximizes them.
• Divide D into fuzzy subset D1
, ..., Dm according to Amax ,
where the membership value of the data in Dj is the product
of the membership value in D and the value of Fmax,j of the
value of Amax in D.
• Generate new nodes t1 , …, tm
for fuzzy subsets D1 , ... ,
Dm and label the fuzzy sets
Fmax,j to edges that connect
between the nodes tj and t
• Replace D by Dj (j=1, 2, …,
m) and repeat from 2
recursively.
Probabilistic Fuzzy Decision Tree (PFDT) Probabilistic fuzzy decision tree merupakan metode pengembangan dari metode sebelumnya yaitu fuzzy decision tree. Metode PFDT memperbaiki fungsi keanggotaan untuk proses learning pada metode FDT. Dengan adanya perbaikan pada membership function maka diharapkan nilai akurasi yang diperoleh oleh metode PFDT lebih tinggi dibandingkan metode FDT.
Algoritme probabilistic fuzzy ID3 adalah sebagai berikut (Liang 2005):
1.Create a Root node that has a
set of fuzzy data with
membership value 1 that fits the
condition of well-defined sample
space.
2.Execute the fuzzy ID3 algorithm from step 2 to end
Statistical Fuzzy Entropy (SFE) dan
Statistical Information Gain
Information gain adalah suatu nilai statistik yang digunakan untuk memilih atribut yang akan mengekspansi tree dan menghasilkan node baru pada algoritme ID3. Suatu entropy dipergunakan untuk mendefinisikan nilai information gain. Entropy dirumuskan sebagai berikut:
+,- ./5$ $01234/$ (1) dengan /$ adalah rasio dari kelas Ci pada
himpunan contoh S = {x1,x2,...,xk}.
/
$ 67'89 :7;<
= (2)
Untuk menghitung nilai information gain digunakan persamaan sebagai berikut:
>- ? +- .'ValuesA@="@=@@+- (3)
dengan bobot B$ @="@=@@ adalah rasio dari data dengan atribut v pada himpunan contoh.
Pada probabilistic fuzzy ID3, statistical fuzzy entropy (SFE) dirumuskan sebagai berikut:
C,D. 8GLE F*AGH 1234FEI*AGHJKK (4)
/? *$ AH$MH$ EI*AHJ (5)
Setelah SFE diterapkan pada algoritme probabilistic fuzzy ID3 (PFID3) maka didapatkan statistical fuzzy decision tree. Untuk menentukan statistical fuzzy information gain dari statistical information gain dilakukan penggantian entropy menggunakan rumus berikut:
>- ? +,D- .$@=@=@9@+,D-$ (6) Untuk meyakinkan kondisi dari well-defined sample space, jumlah dari membership function harus sama dengan 1. Jika jumlah membership function sama dengan 1, maka kita telah memperbaiki membership function dari algoritme fuzzy ID3.
Threshold
Jika pada proses learning dari FDT dihentikan sampai semua data contoh pada masing-masing leaf-node menjadi anggota sebuah kelas, akan dihasilkan akurasi yang
rendah. Oleh karena itu untuk meningkatkan akurasinya, proses learning harus dihentikan lebih awal atau melakukan pemotongan tree secara umum. Untuk itu diberikan 2 (dua) buah threshold yang harus dipenuhi jika tree akan diekspansi, yaitu:
Fuzziness control threshold (FCT) / Jika proporsi dari himpunan data dari kelas Ck lebih besar atau sama dengan nilai
threshold , maka hentikan ekspansi tree. Sebagai contoh: jika pada sebuah sub-dataset rasio dari kelas 1 adalah 90%, maka kelas 2 adalah 10% dan adalah 85%, maka hentikan ekspansi tree. Leaf decision threshold (LDT) /
Jika banyaknya anggota himpunan data pada suatu node lebih kecil dari threshold
, hentikan ekspansi tree. Sebagai contoh: sebuah himpunan data memiliki 600 contoh dengan adalah 2%. Jika jumlah data contoh pada sebuah node lebih kecil dari 12 (2% dari 600), maka hentikan ekspansi tree.
K-fold Cross Validation
K-fold cross validation dilakukan untuk membagi training set dan test set. K-fold cross validation mengulang k-kali untuk membagi sebuah himpunan contoh secara acak menjadi k subset yang paling bebas, setiap ulangan disisakan satu subset untuk pengujian dan subset lainnya untuk pelatihan (Fu 1994).
METODE PENELITIAN
Data
Penelitian ini menggunakan data diabetes yang merupakan hasil pemeriksaan laboratorium pasien dari sebuah rumah sakit. Data hasil pemeriksaan lab pasien yang digunakan dalam penelitian ini meliputi GLUN (Glukosa Darah Puasa), GPOST (Glukosa Darah 2 Jam Pasca Puasa), HDL (Kolesterol HDL), TG (Trigliserida), serta diagnosa pasien berdasarkan nilai GLUN, GPOST, HDL dan TG. Nilai GLUN, GPOST, HDL, TG dinyatakan dalam satuan Mg/DL. Diagnosa pasien ditransformasi menjadi dua kategori, yaitu negatif diabetes yang direpresentasikan dengan angka 1 dan positif diabetes yang direpresentasikan dengan angka 2. Total data yang digunakan dalam penelitian ini berjumlah 290 record.
Metode
Tahapan penelitian yang digunakan dapat dilihat pada Gambar 3. Proses pembersihan
data tidak dilakukan, karena tahapan ini telah dilakukan pada penelitian sebelumnya. Dalam penelitian ini, percobaan dibagi ke dalam tiga kelompok seperti dalam Tabel 1.
Lingkup Pengembangan Sistem
Perangkat keras yang digunakan berupa notebook dengan spesifikasi:
• processor: Intel Core 2 Duo 2.0 GHz, • memori: 1 GB, dan
• harddisk: 120 GB.
Perangkat lunak yang digunakan yaitu: • sistem operasi: Window XP,
• Matlab 7.0.1 sebagai bahasa pemrograman, dan
• Microsoft Excel 2007 sebagai tempat penyimpanan data.
Tabel 1 Kelompok percobaan Kelompok Algoritme yang digunakan Fungsi Keanggotaan FDT Fuzzy ID3 s-shaped, gaussian, p-shaped PFDT(1) Probabilistic Fuzzy ID3 triangle, trapezoid PFDT(2) Probabilistic Fuzzy ID3 s-shaped, gaussian, p-shaped
HASIL DAN PEMBAHASAN
Data yang digunakan dalam penelitian ini menggunakan data dari penelitian sebelumnya (Romansyah 2007). Data ini terdiri dari 6 buah kolom yaitu, no.RM (nomor rekam medis/MRN), GLUN, GPOST, HDL, TG dan diagutama (hasil pemeriksaan lab / diagnosis). Transformasi Data
Pada penelitian ini, teknik data mining yang digunakan adalah fuzzy decision tree (FDT) dan probabilistic fuzzy decision tree (PFDT), oleh karena itu data yang digunakan harus direpresentasikan ke dalam bentuk himpunan fuzzy. Dari 5 (lima) atribut yang digunakan pada penelitian ini 4 diantaranya merupakan atribut yang kontinu, yaitu GLUN, GPOST, HDL, dan TG. Berdasarkan hasil laboratorium range normal untuk atribut GLUN, GPOST, HDL, dan TG diperlihatkan pada Tabel 2.
Tabel 2 Daftar range normal untuk setiap atribut Kode Pemeriksaan Satuan Nilai Normal GLUN Mg/DL 70 – 100 GPOST Mg/DL 100 – 140 HDL Mg/DL 40 – 60 TG Mg/DL 50 – 150
Gambar 3 Diagram alur proses klasifikasi PFDT.
Atribut-atribut pada Tabel 2 ditransformasikan ke dalam himpunan fuzzy dengan menggunakan dua pendekatan yaitu dengan pendekatan well-defined sample space dan without well-defined sample space. Fungsi keanggotaan dibuat menggunakan toolbox fuzzy dalam Matlab 7.0.1. Fungsi keanggotaan untuk penelitian sebelumnya dapat dilihat pada Lampiran 1 (Romansyah 2007).
Pendekatan Without Well-Defined Sample Space
Dalam pendekatan without well-defined sample space jumlah derajat keanggotaan suatu objek dalam setiap himpunan fuzzy adalah tidak sama dengan 1. Berikut adalah bentuk-bentuk himpunan fuzzy untuk setiap atribut.
Atribut GLUN
Atribut GLUN dibagi menjadi 4 kelompok atau linguistic term, yaitu rendah (GLUN < 70 mg/DL), sedang (70 mg/DL <= GLUN < 110 mg/DL), tinggi (110 mg/DL <= GLUN < 140 mg/DL), dan sangat tinggi (GLUN >= 140 mg/DL) (Herwanto 2006). Dari pembagian itu dapat ditentukan membership function dari himpunan fuzzy rendah, sedang, tinggi, dan sangat tinggi untuk atribut GLUN yaitu:
Himpunan fuzzy untuk linguistic term rendah menggunakan kurva z-shaped, untuk linguistic term sedang dan tinggi menggunakan kurva Gaussian sedangkan untuk linguistic term sangat tinggi menggunakan kurva s-shaped. Gambar 4 menunjukkan himpunan fuzzy untuk atribut GLUN.
Gambar 4 Himpunan fuzzy atribut GLUN untuk FDT.
Atribut GPOST
Atribut GPOST dibagi menjadi 4 kelompok atau linguistic term, yaitu rendah (GPOST < 100 mg/DL), sedang (100 mg/DL <= GPOST < 140 mg/DL), tinggi (140 mg/DL <= GPOST < 200 mg/DL), dan sangat tinggi (GPOST >= 200 mg/DL) (Herwanto 2006). rendah sedang tinggi sangatTinggi
*rendahx ;x ≤65 1-2Nx-65 10 O 2 ;65≤x≤70 2N75-x 10 O 2 ;70≤x≤75 0 ;x≥75 *sedangH
e
-6PQR S 2σ2 *tinggiHe
-6P4T S 2σ2 *,UVUWX$VV$H YZ H [ \] ^ NH . \]Y O4Z \] [ H [ _Y . ^ N`] . HY O4Z _Y [ H [ _] YZ H a _]Dari pembagian itu dapat ditentukan membership function dari himpunan fuzzy rendah, sedang, tinggi, dan sangat tinggi untuk atribut GPOST yaitu:
Himpunan fuzzy untuk linguistic term rendah menggunakan kurva z-shaped, untuk linguistic term sedang dan tinggi menggunakan kurva Gaussian sedangkan untuk linguistic term sangat tinggi menggunakan kurva s-shaped. Gambar 5 menunjukkan himpunan fuzzy untuk atribut GPOST.
Gambar 5 Himpunan fuzzy atribut GPOST untuk FDT.
Atribut HDL
Atribut HDL dibagi menjadi 3 kelompok atau linguistic term, yaitu rendah (HDL < 40 mg/DL), sedang (40 mg/DL <= HDL < 60 mg/DL), dan tinggi (HDL >= 60 mg/DL) (Herwanto 2006). Dari pembagian itu dapat ditentukan membership function dari himpunan fuzzy rendah, sedang, dan tinggi untuk atribut HDL yaitu:
Himpunan fuzzy untuk linguistic term rendah menggunakan kurva z-shaped, untuk linguistic term sedang menggunakan kurva Gaussian sedangkan untuk linguistic term tinggi menggunakan kurva s-shaped. Gambar 6 menunjukkan himpunan fuzzy untuk atribut HDL.
Gambar 6 Himpunan fuzzy atribut HDL untuk FDT.
Atribut TG
Atribut TG dibagi menjadi 3 kelompok atau linguistic term, yaitu rendah (TG < 50 mg/DL), sedang (50 mg/DL <= TG < 150 mg/DL), dan tinggi (TG >= 150 mg/DL) (Herwanto 2006). Dari pembagian itu dapat ditentukan membership function dari himpunan fuzzy rendah, sedang, dan tinggi untuk atribut TG yaitu:
Himpunan fuzzy untuk linguistic term rendah menggunakan kurva z-shaped, untuk linguistic term sedang menggunakan kurva Gaussian sedangkan untuk linguistic term tinggi menggunakan kurva s-shaped. Gambar
*bcUdH Z H [ \] . ^ NH . \]Y O4Z \] [ H [ _Y ^ N_] . HY O4Z _Y [ H [ _] YZ H a _] *,bcUVH
e
P6fTR S 4gS *W$VV$H YZ H [ ]] ^ NH . h]Y O4Z ]] [ H [ hY . ^ Nh] . HY O4Z hY [ H [ h] YZ H a h] *bcUdH Z H [ _] . ^ NH . _]Y O4Z _] [ H [ ]Y ^ N]] . HY O4Z ]Y [ H [ ]] YZ H a ]] *,bcUVHe
f6fRR S 4gS *W$VV$H YZH [ _] ^ NH . _]Y O4Z _] [ H [ ]Y . ^ N]] . HY O4Z ]Y [ H [ ]] YZ H a ]]rendah sedang tinggi
rendah sedang tinggi sangatTinggi
*bcUdH Z H [ i] . ^ NH . i]Y O4Z i] [ H [ YY ^ NY] . HY O4Z YY [ H [ Y] YZH a Y] *,bcUVH
e
f6P4R S 4gS *W$VV$He
f6fjR S 4gS *,UVUWX$VV$H YZ H [ i] ^ NH . ^Y]Y O4Z i] [ H [ ^YY. ^ N^Y] . HY O4Z ^YY [ H [ ^Y] YZ H a ^Y]
*W$VV$H YZH [ \] ^ NH . \].\] O4Z \] [ H [ ]^k] . ^ N`Y . H\] O4Z ]^k] [ H [ `Y . ^ NH . `Y\] O4Z `Y [ H [ l`k] ^ N^Y] . H\] O4Z l`k] [ H [ ^Y] YZ H a ^Y]
7 menunjukkan himpunan fuzzy untuk atribut TG.
Gambar 7 Himpunan fuzzy atribut TG untuk FDT.
Pendekatan Well-Defined Sample Space
Dalam pendekatan well-defined sample space jumlah derajat keanggotaan suatu objek dalam setiap himpunan fuzzy adalah sama dengan 1. Berikut adalah bentuk-bentuk himpunan fuzzy untuk setiap atribut.
Atribut GLUN
Atribut GLUN dibagi menjadi 4 kelompok atau linguistic term, yaitu rendah, sedang, tinggi, dan sangat tinggi (Herwanto 2006). Dari pembagian itu dapat ditentukan membership function dari himpunan fuzzy rendah, sedang, tinggi, dan sangat tinggi untuk atribut GLUN yaitu:
Himpunan fuzzy untuk linguistic term rendah menggunakan kurva z-shaped, linguistic term sedang dan tinggi menggunakan kurva phi-shaped, dan untuk linguistic term sangat tinggi menggunakan kurva s-shaped. Gambar 8 menunjukkan himpunan fuzzy untuk atribut GLUN.
Gambar 8 Himpunan fuzzy atribut GLUN untuk PFDT.
Atribut GPOST
Atribut GPOST dibagi menjadi 4 kelompok atau linguistic term, yaitu rendah, sedang, tinggi, dan sangat tinggi (Herwanto 2006). Dari pembagian itu dapat ditentukan membership function dari himpunan fuzzy rendah, sedang, tinggi, dan sangat tinggi untuk atribut GPOST yaitu:
*bcUdH Z H [ h] . ^ NH . h]Y O4Z h] [ H [ `Y ^ N`] . HY O4Z `Y [ H [ `] YZH a `] *W$VV$H YZ H [ Y] ^ NH . Y].^Y O4Z Y] [ H [ ] . ^ N^] . H^Y O4Z ] [ H [ ^] . ^ NH . ^]^Y O4Z ^] [ H [ \] ^ N_] . H^Y O4Z \] [ H [ _] YZ H a _] *,UVUWX$VV$H YZ H [ \] ^ NH . \]Y O4Z \] [ H [ _Y . ^ N`] . HY O4Z _Y [ H [ _] YZH a _] *bcUdH Z H [ i] . ^ NH . i]Y O4Z i] [ H [ YY ^ NY] . HY O4Z YY [ H [ Y] YZ H a Y] *,UVUWX$VV$H YZ H [ i] ^ NH . ^Y]Y O4Z i] [ H [ ^YY
. ^ N^Y] . HY O4Z ^YY [ H [ ^Y] YZH a ^Y] *,bcUVH YZ H [ i] ^ NH . i].^] O4Z i] [ H [ Y`k] . ^ N^Y . H^] O4Z Y`k] [ H [ ^Y . ^ NH . ^Y^] O4Z ^Y [ H [ \^k] ^ N_] . H^] O4Z \^k] [ H [ _] YZ H a _]
rendah sedang tinggi sangatTinggi rendah sedang tinggi
*,bcUVH YZ H [ h] ^ NH . h].^] O4Z h] [ H [ ``k] . ^ NiY . H^] O4Z ``k] [ H [ iY . ^ NH . iY^] O4Z iY [ H [ Y^k] ^ N] . H^] O4Z Y^k] [ H [ ] YZ H a ]
*,bcUVH YZ H [ _] ^ NH . _].]] O4Z _] [ H [ `^k] . ^ NYY . H]] O4Z `^k] [ H [ YY . ^ NH . YY]] O4Z YY [ H [ ^`k] ^ N]] . H]] O4Z ^`k] [ H [ ]] YZH a ]] *,bcUVH YZ H [ \] ^ NH . \].] O4Z \] [ H [ _^k] . ^ N]Y . H] O4Z _^k] [ H [ ]Y . ^ NH . ]Y] O4Z ]Y [ H [ ]`k] ^ Nh] . H] O4Z ]`k] [ H [ h] YZH a h]
Himpunan fuzzy untuk linguistic term rendah menggunakan kurva z-shaped, linguistic term sedang dan tinggi menggunakan kurva phi-shaped, dan untuk linguistic term sangat tinggi menggunakan kurva s-shaped. Gambar 9 menunjukkan himpunan fuzzy untuk atribut GPOST.
Gambar 9 Himpunan fuzzy atribut HDL untuk PFDT.
Atribut HDL
Atribut HDL dibagi menjadi 3 kelompok atau linguistic term, yaitu rendah, sedang, dan tinggi (Herwanto 2006). Dari pembagian itu dapat ditentukan membership function dari himpunan fuzzy rendah, sedang, dan tinggi untuk atribut HDL yaitu:
Himpunan fuzzy untuk linguistic term rendah menggunakan kurva z-shaped, linguistic term sedang menggunakan kurva phi-shaped, dan untuk linguistic term tinggi menggunakan kurva s-shaped. Gambar 10 menunjukkan himpunan fuzzy untuk atribut HDL.
Gambar 10 Himpunan fuzzy atribut HDL untuk PFDT.
Atribut TG
Atribut TG dibagi menjadi 3 kelompok atau linguistic term, yaitu rendah, sedang, dan tinggi (Herwanto 2006). Dari pembagian itu dapat ditentukan membership function dari himpunan fuzzy rendah, sedang, dan tinggi untuk atribut TG yaitu:
Himpunan fuzzy untuk linguistic term rendah menggunakan kurva z-shaped, linguistic term sedang menggunakan kurva phi-shaped, dan untuk linguistic term tinggi menggunakan kurva s-shaped. Gambar 11 menunjukkan himpunan fuzzy untuk atribut TG.
Gambar 11 Himpunan fuzzy atribut TG untuk PFDT. *W$VV$H YZ H [ ]] ^ NH . h]Y O4Z ]] [ H [ hY . ^ Nh] . HY O4Z hY [ H [ h] YZ H a h] *bcUdH Z H [ \] . ^ NH . \]Y O4Z \] [ H [ _Y ^ N_] . HY O4Z _Y [ H [ _] YZ H a _] *bcUdH Z H [ _] . ^ NH . _]Y O4Z _] [ H [ ]Y ^ N]] . HY O4Z ]Y [ H [ ]] YZ H a ]] *W$VV$H YZH [ _] ^ NH . _]Y O4Z _] [ H [ ]Y . ^ N]] . HY O4Z ]Y [ H [ ]] YZ H a ]]
rendah sedang tinggi sangatTinggi
rendah sedang tinggi
Atribut Diagnosis
Atribut Diagnosis selanjutnya akan disebut sebagai CLASS, direpresentasikan oleh dua buah peubah linguistik yaitu “negatif diabetes” dan “positif diabetes”. Kedua linguistic term-nya didefinisikan sebagai berikut:
“negatif diabetes” = 0 “positif diabetes” = 1
Untuk atribut diagnosis ini tidak ada perbedaan antara FDT dan PFDT.
Nilai setiap record atribut GLUN, GPOST, HDL, dan TG kemudian akan ditransformasi ke dalam bentuk himpunan fuzzy dengan menggunakan program Matlab. Nilai-nilai dari atribut CLASS yang awalnya berisi hasil diagnosis laboratorium akan ditransformasikan menjadi 2 (dua) kategori saja, yaitu negatif diabetes yang direpresentasikan dengan angka 1, dan positif diabetes yang direpresentasikan dengan angka 2.
Data Mining
Pada tahap ini dilakukan teknik data mining menggunakan algoritma FID3 untuk membangun fuzzy decision tree (FDT) dan algoritma PFID3 untuk membangun probabilistic fuzzy decision tree (PFDT). Proses data mining ini dilakukan dengan menggunakan program Matlab 7.0.1 yang telah dibuat oleh peneliti sebelumnya (Romansyah 2007). Program untuk membangun PFDT ini sama dengan program untuk membangun FDT karena tidak ada perbedaan coding antara FDT dan PFDT. Training set dan testing set yang digunakan sama persis dengan penelitian sebelumnya, hal ini bertujuan membandingkan hasil antara penelitian sebelumnya (PFDT(1)), FDT, dan PFDT(2). Untuk selanjutnya hasil penelitian sebelumnya dituliskan dengan PFDT(1), sedangkan PFDT(2) untuk penelitian saat ini. Perbedaan PFDT(1) dengan PFDT(2) adalah PFDT(1) menggunakan fungsi membership function dengan kurva berbentuk trapesium sedangkan PFDT(2) menggunakan z-shaped, phi-shaped, dan s-shaped (Liang 2005). • Fase Pembentukan Pohon Keputusan
Fase training dilakukan untuk membangun FDT dan PFDT dengan algoritma FID3 dan PFID3. Proses training dilakukan sama dengan proses training yang dilakukan pada penelitian sebelumnya (Romansyah 2007).
Proses training dilakukan sebanyak 480 kali, untuk masing-masing metode (FDT dan
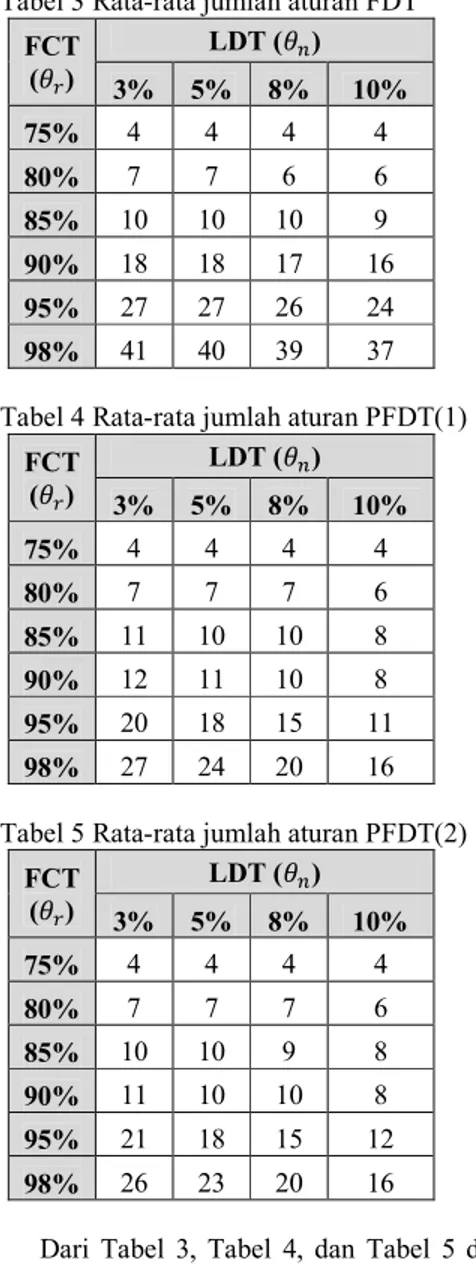
PFDT) sebanyak 240 kali. Untuk tiap training set, proses training dilakukan sebanyak 24 kali, dengan mengubah nilai sebanyak 6 kali yaitu 75%, 80%, 85%, 90%, 95%, dan 98%, dan untuk masing-masing nilai yang sama diberikan nilai yang berbeda-beda yaitu 3%, 5%, 8%, dan 10%. Jumlah aturan dan waktu eksekusi untuk masing-masing training set secara keseluruhan dapat dilihat pada Lampiran 2 dan Lampiran 3 secara berturut-turut. Perbandingan rata-rata jumlah aturan yang dihasilkan pada proses training dan waktu eksekusi yang dibutuhkan dapat dilihat pada Tabel 3, Tabel 4, dan Tabel 5. Tabel 3 Rata-rata jumlah aturan FDT
FCT () LDT () 3% 5% 8% 10% 75% 4 4 4 4 80% 7 7 6 6 85% 10 10 10 9 90% 18 18 17 16 95% 27 27 26 24 98% 41 40 39 37
Tabel 4 Rata-rata jumlah aturan PFDT(1) FCT () LDT () 3% 5% 8% 10% 75% 4 4 4 4 80% 7 7 7 6 85% 11 10 10 8 90% 12 11 10 8 95% 20 18 15 11 98% 27 24 20 16
Tabel 5 Rata-rata jumlah aturan PFDT(2) FCT () LDT () 3% 5% 8% 10% 75% 4 4 4 4 80% 7 7 7 6 85% 10 10 9 8 90% 11 10 10 8 95% 21 18 15 12 98% 26 23 20 16
Dari Tabel 3, Tabel 4, dan Tabel 5 dapat dilihat perbandingan rata-rata jumlah aturan yang dihasilkan oleh masing-masing metode. Hasil PFDT(1) dan PFDT(2) tidak mengalami perubahan yang siginifikan dalam jumlah
aturan, sedangkan jika dibandingkan dengan hasil FDT terdapat perbedaan rata-rata jumlah aturan yang cukup mencolok. Hal ini disebabkan pada training set FDT, jumlah nilai dari membership function tidak sama dengan satu, sedangkan pada PFDT jumlah nilai dari membership function untuk masing-masing atribut sama dengan satu. Hal ini berimplikasi pada proses ekspansi dalam pembentukan tree yang menghasilkan aturan. Proses ekspansi ini juga dipengaruhi oleh leaf decision threshold (). Pada kasus ini, training set PFDT memiliki beberapa nilai linguistic term sama dengan nol, sedangkan pada FDT dapat memiliki sebuah nilai yang bernilai nol pada PFDT. Contoh perbedaan hasil FDT dan PFDT pada training set 30 dan 33 dapat dilihat pada Tabel 6. Perbedaan hasil ini menyebabkan jumlah data yang tersisa pada FDT menjadi lebih banyak dibandingkan dengan PFDT. Jika jumlah record dalam suatu node lebih banyak, maka kemungkinan besar program melakukan ekspansi node tersebut karena tidak memenuhi leaf decision threshold ().
Tabel 6 Contoh perbandingan hasil FDT dan PFDT Derajat Keanggotaan No. Data Training Nilai Atribut GLUN FDT PFDT Rendah 30 262 0 0 33 130 0 0 Sedang 30 262 8.09E-11 0 33 130 0.284572 0 Tinggi 30 262 3.96E-07 0 33 130 0.980555 1 Sangat Tinggi 30 262 1 1 33 130 0 0
Jika diamati dengan seksama pada Tabel 3, 4, dan 5, walaupun nilai LDT () ditingkatkan, jumlah aturan yang dihasilkan tidak mengalami penurunan yang signifikan. Berdasarkan pengamatan yang dilakukan pada penelitian sebelumnya, ternyata karakteristik data pada training set yang digunakan tidak terlalu berbeda, pada saat terjadi ekspansi tree data tidak akan terlalu menyebar, karenanya jumlah data yang ada pada sub-node tidak berbeda jauh dengan jumlah data yang ada pada root-node. Dengan adanya situasi yang demikian, syarat untuk menghentikan ekspansi tree yaitu jumlah data atau record pada sub-node harus lebih kecil dari nilai sulit untuk tercapai.
Nilai yang terlalu rendah dan atau yang terlalu tinggi akan menghasilkan tree dengan ukuran yang kecil sehingga jumlah aturan yang dihasilkan juga sangat sedikit. Hal
ini terjadi karena tree yang sedang dibangun mengalami pemangkasan (pruning) pada saat model masih mempelajari struktur dari training set. Sebaliknya, nilai yang terlalu tinggi dan atau yang terlalu rendah kadang kala akan menyebabkan FDT dan PFDT berperilaku seperti decision tree biasa yang tidak memerlukan adanya threshold sehingga menghasilkan tree dengan ukuran sangat besar dan jumlah aturan yang juga sangat banyak, karena tree akan terus diekspansi sampai leaf-node terdalam.
Gambar 12 Perbandingan rata-rata jumlah aturan untuk nilai sebesar 10%.
Gambar 12 menunjukkan perbandingan rata-rata jumlah aturan yang dihasilkan oleh FDT, PFDT(1), dan PFDT(2) pada proses training untuk LDT () 10%. Dapat terlihat bahwa dalam semua metode yang metode yang digunakan semakin tinggi nilai akan menyebabkan jumlah aturan yang dihasilkan juga meningkat dan peningkatan yang signifikan terjadi pada FDT.
Gambar 13 Perbandingan rata-rata waktu eksekusi proses training untuk nilai sebesar 10%.
Dari Gambar 12 dan Gambar 13, dapat disimpulkan bahwa, semakin tinggi nilai yang digunakan akan menghasilkan jumlah aturan yang semakin banyak sehingga waktu yang dibutuhkan untuk menghasilkan aturan-aturan tersebut juga meningkat. Hal ini terjadi karena proses yang harus dilakukan untuk membangun tree semakin banyak.
Dari Tabel 3, Tabel 4, dan Tabel 5 dapat dilihat bahwa untuk nilai FCT () sebesar 98% dan LDT () sebesar 3% dapat
disimpulkan bahwa rata-rata jumlah aturan yang dihasilkan oleh FDT dan PFDT jauh berbeda. Rata-rata aturan yang dihasilkan FDT sebanyak 41 aturan, PFDT(1) sebanyak 27 aturan, dan PFDT(2) sebanyak 26 aturan. • Akurasi FDT, PFDT(1), dan PFDT(2)
Untuk mengukur tingkat akurasi dari model yang dihasilkan pada fase training, proses testing dilakukan sebanyak 480 kali, masing-masing 240 kali untuk model FDT dan PFDT(2). Proses testing dilakukan dengan cara memasukkan aturan yang diperoleh dari proses training ke dalam sebuah FIS Mamdani untuk menentukan kelas dari masing-masing record dan test set. Untuk satu kali proses training dilakukan satu kali proses testing. Hasil proses testing secara keseluruhan dari masing-masing model dapat dilihat pada Lampiran 4.
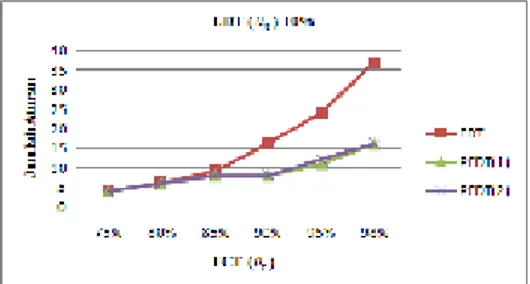
Gambar 14 Perbandingan rata-rata akurasi untuk nilai sebesar 10%. Dengan melihat Gambar 14 dapat disimpulkan bahwa nilai akurasi pada metode FDT dan PFDT tidak jauh berbeda untuk kasus ini. Hal ini dikarenakan data training dan testing yang digunakan terlalu seragam. Training set yang digunakan mayoritas (90%) merupakan kelas negatif diabetes, sehingga aturan yang dihasilkan hanya memiliki keluaran kelas negatif diabetes. Apabila aturan yang dihasilkan semuanya memiliki kelas negatif diabetes, maka ketika melakukan proses testing akan menghasilkan keluaran yang seragam yaitu negatif diabetes. Perbandingan evaluasi kinerja dari algoritma FID3 dan PFID3 pada nilai dan yang berbeda dapat dilihat pada Tabel 7, Tabel 8, dan Tabel 9. Gambar 15 menunjukkan perbandingan rata-rata akurasi FDT, PFDT(1), dan PFDT(2) untuk 10%.
Dari Tabel 7, Tabel 8, Tabel 9, dan Gambar 15 dapat disimpulkan bahwa nilai akurasi pada masing-masing metode tidak jauh berbeda. Akurasi algoritma FID3 dan PFID3 mengalami penurunan jika nilai semakin besar dan atau nilai semakin kecil,
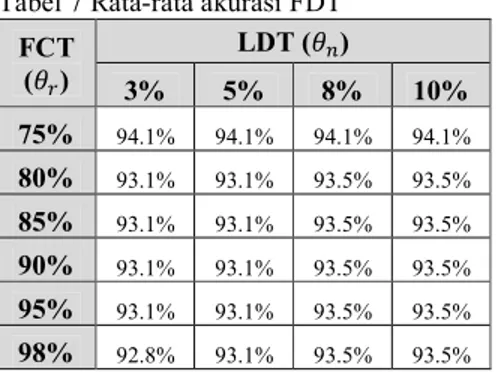
walaupun penurunan yang terjadi tidaklah signifikan sehingga masih dapat ditoleransi. Tabel 7 Rata-rata akurasi FDT
FCT () LDT () 3% 5% 8% 10% 75% 94.1% 94.1% 94.1% 94.1% 80% 93.1% 93.1% 93.5% 93.5% 85% 93.1% 93.1% 93.5% 93.5% 90% 93.1% 93.1% 93.5% 93.5% 95% 93.1% 93.1% 93.5% 93.5% 98% 92.8% 93.1% 93.5% 93.5% Tabel 8 Rata-rata akurasi PFDT(1)
FCT () LDT () 3% 5% 8% 10% 75% 94.14% 94.14% 94.15% 94.15% 80% 92.07% 92.07% 93.45% 93.45% 85% 92.07% 92.07% 93.45% 93.45% 90% 92.07% 92.07% 93.45% 93.45% 95% 90.69% 91.73% 93.10% 93.45% 98% 90.69% 91.73% 93.10% 93.45% Tabel 9 Rata-rata akurasi PFDT(2)
FCT () LDT () 3% 5% 8% 10% 75% 94.14% 94.14% 94.14% 94.14% 80% 92.07% 92.07% 93.45% 93.45% 85% 92.07% 92.07% 93.45% 93.45% 90% 92.07% 92.07% 93.45% 93.45% 95% 90.00% 91.72% 93.10% 93.45% 98% 90.00% 91.72% 93.10% 93.45%
Gambar 15 Akurasi FDT, PFDT(1), dan PFDT(2) untuk nilai sebesar 10%.
Dari Tabel 7, Tabel 8, dan Tabel 9 juga dapat dilihat untuk nilai FCT () sebesar 98% dan LDT () sebesar 3% dapat disimpulkan bahwa rata-rata akurasi FDT lebih besar dari PFDT walaupun tidak terlalu
jauh berbeda. Rata-rata akurasi untuk FDT sebesar 92.8%, PFDT(1) sebesar 90.69%, dan PFDT(2) sebesar 90%.
Representasi Pengetahuan
Model hasil proses training digunakan untuk mengetahui label kelas pada data yang baru. Model tersebut dipilih berdasarkan 3 (tiga) kriteria berikut yang diurutkan berdasarkan prioritas (Romansyah 2007): 1 Model yang mencakup semua kelas target
yang mungkin muncul dalam test set, dalam penelitian ini kelas target yang mungkin muncul yaitu kelas target 1 (negatif diabetes) dan kelas 2 (positif diabetes).
2 Model dengan akurasi yang tinggi, semakin tinggi akurasinya maka semakin baik model tersebut.
3 Model dengan jumlah aturan yang paling banyak.
Berdasarkan kriteria tersebut maka model yang dipilih adalah hasil training dengan nilai
dan masing-masing 98% dan 3 % dari pasangan training set dan test set ke-8 untuk FDT dan ke-10 untuk PFDT(2).
• Aturan-Aturan dari FDT
Terdapat 46 aturan yang dihasilkan dari FDT, dimana hanya 1 aturan yang mengandung kelas target positif diabetes. Model yang dihasilkan dapat dilihat pada Lampiran 5.
• Aturan-aturan dari PFDT(2)
Terdapat 30 aturan yang dihasilkan PFDT(2), dimana hanya 1 aturan yang mengandung kelas target positif diabetes. Model yang dihasilkan dapat dilihat pada Lampiran 6.
KESIMPULAN DAN SARAN
Kesimpulan
Dari berbagai percobaan yang dilakukan dengan menggunakan data training dan testing yang sama dengan penelitian sebelumya, dapat disimpulkan bahwa pembentukan pohon keputusan dengan menggunakan algoritma FID3 dengan pendekatan tanpa well-defined sample space pada fungsi keanggotaan dan algoritma PFID3 dengan pendekatan well-defined sample space memiliki jumlah aturan yang berbeda.
Jumlah aturan yang dihasilkan FDT lebih banyak dari jumlah aturan PFDT. Untuk nilai
FCT () sebesar 98% dan LDT () sebesar 3%, jumlah rata-rata aturan yang dihasilkan FDT sebanyak 41 aturan, PFDT(1) sebanyak 27 aturan, dan PFDT(2) sebanyak 26 aturan. Nilai akurasi FDT lebih besar dari PFDT denagn rata-rata akurasi FDT sebesar 92.8%, PFDT(1) sebesar 90.69%, dan PFDT(2) sebesar 90%. Hal ini disebabkan karena adanya perbedaan jumlah aturan yang dihasilkan oleh FDT lebih banyak dari PFDT(1) dan PFDT(2) sehingga nilai akurasi yang memiliki jumlah aturan yang banyak akan mempunyai nilai akurasi yang lebih besar.
Saran
Pada penelitian ini masih terdapat beberapa kekurangan yang dapat diperbaiki pada penelitian selanjutnya. Pada penelitian ini, data yang digunakan kurang representatif karena jumlah data yang positif diabetes hanya 17 record, sedangkan yang negatif diabetes sebanyak 273 record. Dengan data yang ada, belum dapat dinyatakan bahwa PFDT tidak lebih baik dibandingkan dengan FDT. Pada penelitian selanjutnya diharapkan menggunakan data yang lebih representatif dengan perbandingan jumlah data yang positif dan negatif diabetes yang sama besar, sehingga aturan klasifikasi yang dihasilkan memiliki akurasi yang lebih baik lagi.
DAFTAR PUSTAKA
Cox E. 2005. Fuzzy Modeling and Genetic Algorithms for Data Mining and Exploration. USA: Academic Press. Han J, Kamber M. 2001. Data Mining:
Concepts and Techniques. USA: Academic Press.
Herwanto. 2006. Pengembangan Sistem Data Mining untuk Diagnosis Penyakit Diabetes Menggunakan Algoritme Classification Based Association [Tesis]. Bogor. Departemen Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor.
Jang JSR, Sun CT, Mizutani Eiji. 1997. Neuro-Fuzzy and Soft Computing. London: Prentice-Hall International, Inc.
Kantardzic M. 2003. Data Mining: Concepts, Models, Methods, and Algorithms. Wiley-Interscience.
Liang G. 2005. A Comparative Study of Three Decision Tree Algorithms: ID3, Fuzzy ID3 and Probabilistic Fuzzy ID3. Informatic & Economics Eramus University Rotterdam. Rotterdam, the Nederlands.
Marsala C. 1998. Application of Fuzzy Rule Induction to Data Mining. France: University Pierre et Marie Curie. Romansyah. 2007. Penerapan Aturan
Klasifikasi Menggunakan Fuzzy Decision Tree dengan Algoritme ID3 pada Data Diabetes [Skripsi]. Bogor. Departemen Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor.
*,bcUVH YZ H m \] H . \] Y Z \] [ H m _] Z _] [ H m ]] H . h] .Y Z ]] [ H m h] YZ H a h] Lampiran 1 Fungsi keanggotaan PFDT(1) GLUN GPOST HDL *,bcUVH YZ H m h] H . h] Y Z h] [ H m `] Z `] [ H m Y] H . ] .Y Z Y] [ H m ] YZ H a ] *bcUdH Z H m h] H . `] .Y Z h] [ H m `] YZ H a `] *W$VV$H YZ H m Y] H . Y] Y Z Y] [ H m ] Z ] [ H m \] H . _] .Y Z \] [ H m _] YZ H a _] *,UVUWX$VV$H YZ H m \] H . \] Y Z \] [ H m _] Z H a _] *bcUdH Z H m i] H . Y] .Y Z i] [ H m Y] YZ H a Y] *,bcUVH YZ H m i] H . i] Y Z i] [ H m Y] Z Y] [ H m \] H . _] .Y Z \] [ H m _] YZ H a _] *W$VV$H YZ H m \] H . \] Y Z \] [ H m _] Z _] [ H m i] H . _] .Y Z i] [ H m ^Y] YZ H a ^Y] *,UVUWX$VV$H YZ H m i] H . i] Y Z i] [ H m ^Y] Z H a ^Y] *bcUdH Z H m \] H . _] .Y Z \] [ H m _] YZ H a _] *W$VV$H YZ H m ]] H . ]] Y Z ]] [ H m h] Z H a h]
Lanjutan TG
Lampiran 2 Jumlah aturan yang dihasilkan FDT, PFDT(1), dan PFDT(2) untuk masing-masing training set
• FDT
Training set ke-1
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 4 4 4 4 85% 12 12 12 10 90% 20 20 20 18 95% 30 30 30 28 98% 47 46 46 40
Training set ke-2
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 4 4 4 4 85% 4 4 4 4 90% 4 4 4 4 95% 9 9 7 7 98% 9 9 7 7
Training set ke-3
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 4 4 4 4 85% 4 4 4 4 90% 18 18 16 16 95% 29 29 27 25 98% 41 41 39 37
Training set ke-4
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 4 4 4 4 85% 12 12 12 10 90% 20 20 20 18 95% 29 29 29 27 98% 44 43 43 39 *bcUdH Z H m _] H . ]] .Y Z _] [ H m ]] YZ H a ]] *,bcUVH YZ H m _] H . _] Y Z _] [ H m ]] Z ]] [ H m _] H . ]] .Y Z _] [ H m ]] YZ H a ]] *W$VV$H YZ H m _] H . _] Y Z _] [ H m ]] Z H a ]]
Lanjutan
Training set ke-5
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 4 4 4 4 85% 12 12 12 10 90% 18 18 18 16 95% 29 29 29 27 98% 45 45 45 43
Training set ke-6
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 4 4 4 4 85% 12 12 10 10 90% 18 18 16 16 95% 29 29 27 25 98% 45 45 43 41
Training set ke-7
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 10 10 8 8 85% 12 12 10 10 90% 20 20 18 18 95% 29 29 27 25 98% 44 43 41 39
Training set ke-8
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 12 12 12 10 85% 12 12 12 10 90% 20 20 20 18 95% 29 29 29 27 98% 46 45 45 39
Training set ke-9
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 12 12 12 10 85% 12 12 12 10 90% 20 20 20 18 95% 29 29 29 27 98% 44 43 43 41
Training set ke-10
LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 10 10 8 8 85% 12 12 10 10 90% 20 20 18 18 95% 29 29 27 25 98% 44 43 41 39 • PFDT(1)
Training set ke-1
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 4 4 4 4 85% 12 11 11 10 90% 12 11 11 10 95% 21 18 16 12 98% 29 26 23 18
Training set ke-2
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 4 4 4 4 85% 4 4 4 4 90% 4 4 4 4 95% 9 9 7 7 98% 9 9 7 7
Lanjutan
Training set ke-3
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 4 4 4 4 85% 4 4 4 4 90% 13 11 11 9 95% 23 18 16 12 98% 23 18 16 12
Training set ke-4
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 4 4 4 4 85% 12 11 11 10 90% 15 12 11 10 95% 21 16 15 12 98% 29 24 22 19
Training set ke-5
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 4 4 4 4 85% 12 12 12 8 90% 15 13 12 8 95% 22 19 17 11 98% 30 27 24 18
Training set ke-6
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 4 4 4 4 85% 13 12 10 8 90% 13 12 11 8 95% 23 22 16 11 98% 31 31 23 18
Training set ke-7
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 10 10 8 8 85% 13 12 10 8 90% 13 12 10 8 95% 21 17 14 10 98% 29 25 22 17
Training set ke-8
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 11 11 11 9 85% 11 11 11 9 90% 11 11 11 9 95% 21 21 15 12 98% 29 29 22 18
Training set ke-9
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 12 12 12 8 85% 12 12 12 8 90% 12 12 12 8 95% 21 19 16 10 98% 29 27 23 17
Training set ke-10
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 12 12 10 8 85% 12 12 10 8 90% 15 13 10 8 95% 22 19 16 11 98% 30 27 22 18
Lanjutan • PFDT(2)
Training set ke-1
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 9 9 9 9 85% 11 10 10 9 90% 11 10 10 9 95% 24 21 17 16 98% 24 21 17 16
Training set ke-2
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 4 4 4 4 85% 4 4 4 4 90% 4 4 4 4 95% 9 9 7 7 98% 9 9 7 7
Training set ke-3
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 4 4 4 4 85% 4 4 4 4 90% 12 10 10 9 95% 23 18 16 12 98% 23 18 16 12
Training set ke-4
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 4 4 4 4 85% 12 11 11 10 90% 12 11 11 10 95% 21 16 15 12 98% 29 24 22 18
Training set kelima
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 4 4 4 4 85% 11 11 11 10 90% 11 11 11 10 95% 21 18 16 13 98% 29 26 23 20
Training set ke-6
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 4 4 4 4 85% 13 12 10 8 90% 13 12 10 8 95% 23 21 16 11 98% 31 29 23 18
Training set ke-7
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 11 10 8 8 85% 13 12 10 8 90% 13 12 10 8 95% 21 17 14 10 98% 29 25 22 17
Training set ke-8
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 10 10 10 9 85% 11 11 11 9 90% 11 11 11 9 95% 21 21 15 12 98% 29 29 22 18
Lanjutan
Training set ke-9
FCT LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 11 10 10 9 85% 12 11 11 9 90% 12 11 11 9 95% 21 18 15 11 98% 29 26 22 18
Training set ke-10
LDT 3% 5% 8% 10% 75% 4 4 4 4 80% 12 12 10 8 85% 12 12 10 8 90% 12 12 10 8 95% 22 19 15 11 98% 30 27 22 18
Lampiran 3 Waktu eksekusi FDT, PFDT(1), dan PFDT(2) untuk masing-masing training set dalam satuan detik
• FDT
Training set ke-1
FCT LDT 3% 5% 8% 10% 75% 1.032 0.125 1.938 0.141 80% 0.110 0.094 0.094 0.093 85% 0.656 0.250 0.250 0.219 90% 0.422 0.422 0.438 0.390 95% 0.703 0.687 0.687 0.656 98% 1.219 1.172 1.187 1.031
Training set ke-2
FCT LDT 3% 5% 8% 10% 75% 0.094 0.094 0.094 0.094 80% 0.094 0.094 0.094 0.078 85% 0.094 0.094 0.094 0.078 90% 0.093 0.094 0.078 0.094 95% 0.235 0.172 0.140 0.141 98% 0.172 0.187 0.156 0.172
Training set ke3
FCT LDT 3% 5% 8% 10% 75% 0.094 0.094 0.078 0.093 80% 0.093 0.093 0.094 0.094 85% 0.094 0.094 0.094 0.093 90% 0.359 0.360 0.328 0.328 95% 0.641 0.640 0.609 0.547 98% 1.015 1.000 0.969 0.875
Training set ke-4
FCT LDT 3% 5% 8% 10% 75% 0.516 0.093 0.093 0.093 80% 0.094 0.094 0.109 0.093 85% 0.281 0.234 0.250 0.203 90% 0.453 0.422 0.437 0.391 95% 0.687 0.656 0.857 0.610 98% 1.031 1.015 1.031 0.937
Training set ke-5
FCT LDT 3% 5% 8% 10% 75% 0.094 0.078 0.094 0.094 80% 0.078 0.078 0.078 0.093 85% 0.250 0.219 0.218 0.203 90% 0.375 0.343 0.375 0.328 95% 0.609 0.640 0.641 0.594 98% 1.093 1.062 1.094 1.031
Training set ke-6
FCT LDT 3% 5% 8% 10% 75% 0.703 0.093 0.094 0.094 80% 0.093 0.093 0.094 0.094 85% 0.281 0.234 0.188 0.203 90% 0.360 0.359 0.313 0.313 95% 0.625 0.640 0.593 0.547 98% 1.094 1.093 1.031 0.969
Lanjutan
Training set ke-7
FCT LDT 3% 5% 8% 10% 75% 0.093 0.094 0.094 0.094 80% 0.203 0.203 0.172 0.156 85% 0.219 0.234 0.203 0.204 90% 0.407 0.391 0.359 0.357 95% 0.656 0.640 0.579 0.547 98% 1.094 1.031 0.984 0.938
Training set ke-8
FCT LDT 3% 5% 8% 10% 75% 0.094 0.094 0.094 0.109 80% 0.234 0.250 0.235 0.204 85% 0.250 0.250 0.234 0.204 90% 0.406 0.406 0.406 0.375 95% 0.672 0.640 0.641 0.594 98% 1.391 1.109 1.093 0.969
Training set ke-9
FCT LDT 3% 5% 8% 10% 75% 0.109 0.094 0.094 0.094 80% 0.234 0.234 0.235 0.203 85% 0.234 0.250 0.250 0.219 90% 0.437 0.422 0.422 0.406 95% 0.627 0.672 0.672 0.609 98% 1.125 1.078 1.093 1.031
Training set ke-10
FCT LDT 3% 5% 8% 10% 75% 0.094 0.094 0.110 0.094 80% 0.265 0.204 0.172 0.156 85% 0.234 0.234 0.203 0.203 90% 0.422 0.406 0.375 0.360 95% 0.641 0.641 0.594 0.562 98% 1.094 1.063 1.000 0.937 • PFDT(1)
Training set ke-1
FCT LDT 3% 5% 8% 10% 75% 0.125 0.125 0.110 0.109 80% 0.109 0.125 0.125 0.140 85% 0.390 0.390 0.344 0.329 90% 0.391 0.359 0.359 0.328 95% 0.719 0.610 0.562 0.406 98% 1.063 0.937 0.813 0.640
Training set ke-2
FCT LDT 3% 5% 8% 10% 75% 0.125 0.125 0.125 0.141 80% 0.141 0.125 0.141 0.125 85% 0.125 0.125 0.125 0.125 90% 0.140 0.109 0.125 0.125 95% 0.312 0.282 0.253 0.219 98% 0.312 0.297 0.218 0.203
Training set ke-3
FCT LDT 3% 5% 8% 10% 75% 0.110 0.125 0.125 0.125 80% 0.141 0.141 0.125 0.109 85% 0.125 0.109 0.141 0.141 90% 0.422 0.375 0.344 0.282 95% 0.797 0.609 0.532 0.406 98% 0.781 0.609 0.516 0.375
Training set ke-4
FCT LDT 3% 5% 8% 10% 75% 0.140 0.141 0.125 0.141 80% 0.125 0.141 0.156 0.125 85% 0.391 0.359 0.359 0.328 90% 0.500 0.407 0.360 0.328 95% 0.734 0.547 0.500 0.391 98% 1.046 0.829 0.750 0.593
Lanjutan
Training set ke-5
FCT LDT 3% 5% 8% 10% 75% 0.109 0.125 0.141 0.140 80% 0.141 0.110 0.125 0.125 85% 0.391 0.391 0.391 0.250 90% 0.484 0.437 0.391 0.250 95% 0.766 0.625 0.593 0.359 98% 1.094 0.938 0.969 0.610
Training set ke-6
FCT LDT 3% 5% 8% 10% 75% 0.125 0.125 0.125 0.125 80% 0.125 0.125 0.141 0.141 85% 0.438 0.406 0.344 0.250 90% 0.437 0.390 0.313 0.266 95% 0.828 0.719 0.531 0.375 98% 1.109 1.047 0.797 0.609
Training set ke-7
FCT LDT 3% 5% 8% 10% 75% 0.141 0.140 0.110 0.110 80% 0.313 0.328 0.250 0.256 85% 0.422 0.406 0.328 0.234 90% 0.421 0.390 0.328 0.282 95% 0.907 0.578 0.451 0.328 98% 1.047 0.906 0.765 0.609
Training set ke-8
FCT LDT 3% 5% 8% 10% 75% 0.125 0.125 0.109 0.141 80% 0.438 0.375 0.344 0.281 85% 0.359 0.375 0.359 0.266 90% 0.344 0.343 0.360 0.282 95% 0.672 0.703 0.485 0.390 98% 1.047 1.031 0.734 0.609
Training set ke-9
FCT LDT 3% 5% 8% 10% 75% 0.125 0.125 0.109 0.109 80% 0.391 0.391 0.390 0.265 85% 0.390 0.406 0.375 0.250 90% 0.390 0.375 0.375 0.250 95% 0.703 0.625 0.515 0.312 98% 0.985 0.906 0.797 0.563
Training set ke-10
FCT LDT 3% 5% 8% 10% 75% 0.125 0.125 0.125 0.125 80% 0.469 0.406 0.344 0.266 85% 0.407 0.375 0.313 0.265 90% 0.515 0.422 0.328 0.250 95% 0.735 0.641 0.500 0.375 98% 1.062 0.922 0.765 0.625 • PFDT(2)
Training set ke-1
FCT LDT 3% 5% 8% 10% 75% 0.734 0.078 0.078 0.079 80% 0.25 0.172 0.171 0.172 85% 0.203 0.187 0.187 0.172 90% 0.203 0.187 0.187 0.172 95% 0.5 0.407 0.312 0.297 98% 0.5 0.406 0.328 0.297
Training set ke-2
FCT LDT 3% 5% 8% 10% 75% 0.078 0.078 0.078 0.078 80% 0.078 0.078 0.079 0.079 85% 0.078 0.078 0.078 0.078 90% 0.079 0.062 0.078 0.079 95% 0.172 0.156 0.125 0.141 98% 0.157 0.172 0.156 0.125
Lanjutan
Training set ke-3
FCT LDT 3% 5% 8% 10% 75% 0.188 0.078 0.078 0.078 80% 0.11 0.079 0.078 0.078 85% 0.093 0.078 0.078 0.078 90% 0.235 0.219 0.188 0.172 95% 0.485 0.334 0.313 0.234 98% 0.438 0.359 0.312 0.219
Training set ke-4
FCT LDT 3% 5% 8% 10% 75% 0.078 0.063 0.078 0.078 80% 0.078 0.063 0.093 0.079 85% 0.281 0.203 0.203 0.172 90% 0.219 0.188 0.203 0.187 95% 0.406 0.312 0.282 0.219 98% 0.578 0.484 0.421 0.344
Training set ke-5
FCT LDT 3% 5% 8% 10% 75% 0.078 0.078 0.078 0.078 80% 0.078 0.079 0.078 0.062 85% 0.219 0.203 0.234 0.187 90% 0.218 0.203 0.219 0.203 95% 0.406 0.375 0.297 0.25 98% 0.609 0.531 0.469 0.391
Training set ke-6
FCT LDT 3% 5% 8% 10% 75% 0.078 0.063 0.093 0.078 80% 0.078 0.063 0.094 0.078 85% 0.25 0.234 0.203 0.156 90% 0.266 0.234 0.187 0.157 95% 0.453 0.422 0.312 0.203 98% 0.656 0.652 0.453 0.359
Training set ke-7
FCT LDT 3% 5% 8% 10% 75% 0.078 0.078 0.062 0.078 80% 0.281 0.188 0.157 0.156 85% 0.235 0.234 0.172 0.141 90% 0.235 0.219 0.171 0.141 95% 0.407 0.312 0.25 0.187 98% 0.594 0.484 0.438 0.328
Training set ke-8
FCT LDT 3% 5% 8% 10% 75% 0.063 0.063 0.078 0.078 80% 0.188 0.172 0.187 0.156 85% 0.218 0.188 0.187 0.156 90% 0.187 0.203 0.203 0.172 95% 0.422 0.407 0.281 0.235 98% 0.594 0.609 0.437 0.328
Training set ke-9
FCT LDT 3% 5% 8% 10% 75% 0.078 0.078 0.063 0.078 80% 0.203 0.187 0.187 0.156 85% 0.218 0.203 0.203 0.156 90% 0.219 0.203 0.188 0.156 95% 0.39 0.328 0.265 0.204 98% 0.578 0.515 0.422 0.344
Training set ke-10
FCT LDT 3% 5% 8% 10% 75% 0.079 0.078 0.078 0.078 80% 0.219 0.203 0.172 0.157 85% 0.218 0.219 0.187 0.156 90% 0.219 0.219 0.187 0.141 95% 0.422 0.375 0.281 0.188 98% 0.625 0.547 0.437 0.359