i
CLUSTERINGTINGKAT KEB
DI KABUPAT
Disusun Untuk Memenu
No. NIM
1. AFD 21040117410029
2. AN 21040117410056
3. AND 21040117410020
MAGISTER P
UNI
i
EBUTUHAN SARANA DAN PRASARANA PE
UPATEN PATI PROVINSI JAWA TEGAH
enuhi Tugas Mata Kuliah Metode Analisis Perenc
Oleh Kelompok A-I:
No. Nama NIM
1. FDEN MAHYEDA 21040117410029
2. ANDI RAHMAN 21040117410056
3. NDARIAS KADAM 21040117410020
FAKULTAS TEKNIK
R PEMBANGUNAN WILAYAH DAN KOTA
UNIVERSITAS DIPONEGORO
SEMARANG
2017
i
PERSAMPAHAN
encanaan
No. Nama NIM
1. AFDEN MAHYEDA 21040117410029
2. ANDI RAHMAN 21040117410056
3. ANDARIAS KADAM 21040117410020
DAFTAR ISI
DAFTAR TABEL ...iii
DAFTAR GAMBAR... iv
I. PENDAHULUAN ... 1
I.1 Latar Belakang... 1
I.2 Permasalahan ... 1
I.3 Tujuan Penelitian ... 2
II. DASAR TEORI ... 2
II.1 Analisis Cluster... 2
II.1.1 Hierarchical clustering ... 3
II.1.2 Langkah-langkah analisis cluster ... 4
III. GAMBARAN KASUS ... 5
IV. HASIL DAN ANALISIS... 5
IV.1 Analisis Tahap Pertama ... 5
IV.1.1 Case Processing Summary... 5
IV.1.2 Matrix Proximity... 6
IV.1.3 Average Linkage Between Groups ... 6
IV.1.4 Cluster Membership... 7
IV.1.5 Dendogram... 7
IV.2 Analisis Tahap Kedua ... 8
IV.2.1 Case Prosessing Summary ... 8
IV.2.2 Matrix Proximity... 8
IV.2.3 Average Linkage Between Groups ... 8
IV.2.4 Cluster Membership... 9
IV.2.5 Dendogram... 9
V. KESIMPULAN DAN SARAN ... 10
V.1 KESIMPULAN... 10
V.2 SARAN... 11
iii
DAFTAR TABEL
Tabel III-1 Penilaian Wilayah Timbulan Sampah dan Jumlah Penduduk di Kabupaten Pati ... 5
Tabel IV-1 Tabel Case Processing Summary ... 5
Tabel IV-2 Tabel Proximity Matriks ... 6
Tabel IV-3 Tabel Aggomeration Schedule ... 6
Tabel IV-4 Tabel Cluster Membership ... 7
Tabel IV-5 Gambar Diagram Dendogram ... 7
Tabel IV-6 Tabel Case Processing Summary ... 8
Tabel IV-7 Tabel Proximity Matriks ... 8
Tabel IV-8 Tabel Aggomeration Schedule ... 8
Tabel IV-9 Tabel Cluster Membership ... 9
Tabel IV-10 Gambar Diagram Dendogram ... 9
Tabel V-3 Tabel Clustering Tingkat Kebutuhan Sarana dan Prasarana Sampah di Kabupaten Pati ... 11
Tabel V-1 Tabel Clustering Tahap Pertama ... 10
DAFTAR GAMBAR
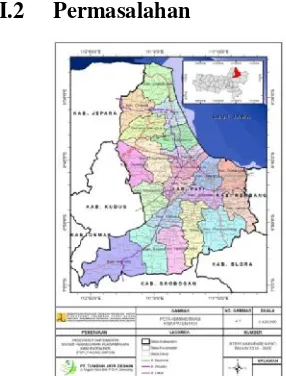
Gambar I-1 Peta Administrasi Kabupaten Pati... 1 Gambar II-1 Dendogram (Steinbach, Karypis, & Kumar 2000)... 4
1
I. PENDAHULUAN
I.1 Latar Belakang
Urbanisasi selalu mendatangkan permasalahan, salah satunya yaitu kerusakan lingkungan dan sampah menjadi bagian dari faktor permasalahan lingkungan tersebut. Jumlah penduduk sebagai nilai wajar dari proses urbanisasi membawa konsekuensi logis terhadap peningkatan jumlah produksi sampah. Jika persoalan ini tidak diikuti dengan kemampuan pengelolaan sampah dan peran serta sadar masyarakat dalam menjaga kebersihan lingkungannya, akan sangat memungkinkan terjadinya pencemaran lingkungan.
Perhatian dunia terhadap penyelesaian permasalahan lingkungan telah lama dilakukan. Pada Tahun 2000, para pemimpin dunia menyepakati tentang 8 tujuan pembagunan global yang spesifik dan terukur yang disebut Millenium Development Goals (MDGs). Pencapaian tujuan dalam MDGs memiliki target waktu hingga 2015. Agenda kedepan untuk melanjutkan MDGs, dikembangkan suatu konsepsi dalam konteks kerangka/agenda pembangunan pasca 2015, yang disebut Sustainable
Development Goals (SDGs). SDG’s 2015 memiliki 17 sasaran yang mencangkup berbagai aspek,
salah satunya dalam bidang sanitasi yaitu di sasaran No. 6: memastikan ketersediaan dan pengelolaan air bersih dan sanitasi yang berkelanjutan.
Perencanaan dan pembangunan wilayah merupakan instrumen utama yang digunakan dalam mewujudkan pembangunan yang berkelanjutan. Didalam kegiatan perencanaan wilayah harus melibatkan metode dan analisis yang matang terkait dampak yang akan dihasilkan dari setiap proses pembangunan wilayah. Sehingga, perencanaan menjadi hal penting yang dibutuhkan dalam proses pengambilan kebijakan. Dalam setiap proses perencanaan pun pasti dipengaruhi oleh beberapa faktor yang diantaranya yaitu: faktor internal dan eksternal. Faktor internal biasanya selalu berkaitan dengan aktifitas keruangan seperti ekologi dan ekosistem lingkungannya. Sedangkan faktor eksternal lebih dipengaruhi oleh aktifitas sosial, ekonomi, dan budaya masyarakat. Permasalahan sanitasi khususnya terkait dengan sampah juga tidak pernah terlepas dari faktor-faktor tersebut. Oleh karena itu, penanganan terhadap permasalahan sampah harus segera diselesaikan. Ketersediaan sarana dan prasarana sampah tentunya menjadi faktor utama yang mempengaruhi permasalahan sampah. Banyak sedikitnya ketersediaan sarana dan prasarana sampah tersebut secara signifikan pasti berpengaruh terhadap penyelesaian permasalahan persampahan. Sehingga, perencanaan terkait kebutuhan sarana dan prasarana sampah sangat berpengaruh terhadap proses pengambilan kebijakan.
I.2 Permasalahan
Kabupaten Pati merupakan salah satu Kabupaten di Provinsi Jawa Tengah dengan jumlah penduduk yang padat. Luas wilayah administrasi kabupaten seluas 150.368 hektar dan jumlah penduduk sebesar 1.239.989 jiwa, mempunyai rerata tingkat laju pertumbuhan penduduk sebesar 0,58 pada tahun 2016 (BPS, 2017). Dengan meningkatnya jumlah penduduk di Kabupaten Pati, maka akan berdampak pada tingkat produksi sampah di Kabupaten Pati yang terus meningkat setiap tahunnya. Sarana dan prasarana pengolahan sampah sebagai alat utama yang dibutuhkan untuk mengentaskan permasalahan sampah, membutuhkan perhatian khusus dalam segi anggaran. Kebijakan pemerintah dalam penanganan sampah di daerah urban harus tepat sasaran. Penambahan jumlah sarana dan prasarana sampah harus
mengikuti tren terhadap jumlah penduduk sehingga, permasalahan sampah dapat tertangani dengan baik. Ditinjau dari sarana TPA (Tempat Pemrosesan Akhir Sampah), yaitu: TPA Sukoharjo, TPA Sampok, dan TPA Plosojenar, sementara ini cakupan pelayanan TPA Kabupaten Pati baru dapat melayani 9 dari 21 kecamatan yang ada. Konsentrasi penyediaan sarana dan prasarana sampah pun masih hanya terpusat disekitar Kecamatan Pati khususnya Kota Pati sebagai ibukota Kabupaten Pati. Sehingga, clustering tingkat kebutuhan sarana dan prasarana sampah pada lokasi di luar Kecamatan Pati yang karena permasalahan sampahnya menjadi hal yang penting untuk dianalisis.
I.3 Tujuan Penelitian
Fokus penelitian ini dimaksudkan untuk mengelompokkan tingkat kebutuhan sarana dan prasarana sampah dimasing-masing kecamatan di Kabupaten Pati kedalam cakupan wilayah yang lebih luas berdasarkan pada faktor utama ketersediaan sarana dan prasarana yang ada saat ini terhadap timbulan sampah dan jumlah penduduk. Apakah memang benar bahwa konsentrasi penyediaan sarana dan prasarana sampah masih hanya terfokus pada Kecamatan Pati sebagai ibukota kabupaten. Dengan diketahuinyaclusteringtingkat kebutuhan sarana dan prasarana sampah tersebut, diharapkan dapat digunakan sebagai salah satu alat pengambil kebijakan di lingkungan Pemerintah Kabupaten Pati. Sehingga, solusi dari permasalahan sampah di Kabupaten Pati akan tepat sasaran dan dapat tertanggulangi dengan baik.
II. DASAR TEORI
II.1 Analisis Cluster
Cluster analysis merupakan metode pengelompokan setiap objek ke dalam satu atau lebih
dari satu kelompok, sehingga tiap objek yang berada dalam satu kelompok akan memiliki nilai interaksi yang sama.Clustering analysis bertujuanuntuk membetuk kelompok dengan karakteristik yang sama. (Sharma, 1996). Padaalgoritma clustering, data akan dikelompokkan menjadi
cluster-cluster berdasarkan kemiripan satu data dengan data yang lain. Data yang dikelompokkan dalam
satu clustermemiliki kemiripan yang tinggi, sedangkan antara data pada satu clusterdengan data
pada cluster lainnya memiliki kemiripan yang rendah. Prinsip dari clustering adalah
memaksimalkan kesamaan antaranggota satu kelas dan meminimumkan kesamaan antar kelas/cluster. Banyak algoritma clustering memerlukan fungsi jarak untuk mengukur kemiripan antara data satu dengan yang lain. Sehingga diperlukan normalisasi berbagai jenis atribut yang dimiliki data.Kategori algoritma clustering banyak dikenal salah satunya adalah hierarchical clustering.
Adapun menurut Aldenderfer dan Blashfield (1984) Analisisclusteradalah pengorganisasian kumpulan polakedalamcluster (kelompok-kelompok) berdasar atas kesamaannya. Analisiscluster
digunakan untukmengklasifikasi obyek atau kasus (responden) ke dalam kelompok yang relatif
homogenyang disebutcluster, obyek atau kasus dalam setiap kelompok cenderung mirip satu sama
lain dan berbeda jauh (tidak sama) dengan obyek dari clusterlainnya (Supranto, 2004). Pola-pola dalam suatu cluster akan memiliki kesamaan ciri/sifat daripada pola-pola dalam cluster yang lainnya.
3
homogenitas internalyang tinggi dan heterogenitas eksternal yang tinggi. Berbeda dengan teknik
multivariat lainnya, analisis ini tidak mengestimasi set variabel secara empiris sebaliknya menggunakan set variabel yang ditentukan oleh peneliti itu sendiri.
Solusi analisisclusterbersifat tidak unik, anggota clusteruntuk tiap penyelesaian atau solusi tergantung pada beberapa elemen prosedur dan beberapa solusi yang berbeda dapat diperoleh dengan mengubah satu elemen atau lebih. Solusi cluster secara keseluruhan bergantung pada variabel-variabel yang digunakan sebagai dasar untuk menilai kesamaan. Penambahan atau pengurangan variabel-variabel yang relevan datap mempengaruhi substansi hasil analisis cluster.
Secara garis besar analisisclusterdigunakan untuk menjawab pertanyaan-pertanyaan seperti bagaimana mengukur kesamaan, bagaimana membentuk cluster dan berapa banyak cluster atau kelompok yang terbentuk. Tujuan utama analisisclusteradalah mempartisi suatu set objek menjadi dua kelompok atau lebih berdasarkan kesamaan karakteristik khusus yang dimilikinya. Dalam perencanaan sendiri analisis cluster dapat digunakan sebagai alat bantu pengambilan keputusan mengenai di mana sebuah kebijakan akan ditetapkan.
Tiga prinsip dasar dalam analisisclusteryaitu: 1) Pengelompokan atau pemisahan dilakukan berdasarkan prinsip kesamaan (similarity) antar obyek, 2) Kesamaan (similarity) diperoleh dengan cara meminimalkan jarak antar kelompok (within cluster) dan memaksimalkan jarak antar kelompok (between cluster), 3) Pengukuran jarak (distance-type measure) digunakan untuk data yang bersifat matriks, sementara pengukuran kesesuaian (matching-type measure) digunakan pada data yang bersifat kualitatif.
Terdapat dua metode pembetukan cluster, yaitu metode hierarki (hierarchial methods) dan metode partisi (partitioning methods). Perbedaan antara kedua metode tersebut adalah dalam pengalokasian obyek ke dalam kelompok/cluster. Pada metode hierarki, jika suatu obyek dikelompokkan ke dalam suatu cluster, maka obyek tersebut akan tetap berada pada cluster
tersebut, sehingga ketika obyek tersebut dimasukkan ke dalam kelompok lain, maka kelompok/ clusternya juga akan ikut dikelompokkan. Sedangkan pada metode partisi, posisi obyek pada suatu kelompok itu tidak tetap. Artinya, meskipun suatu obyek sudah masuk ke dalam suatu cluster, obyek tersebut dapat mengalami realokasi (pengelompokan kembali) ke dalam cluster yang lain apabila ternyata karakteristik awal pengelompokan tidak akurat.
II.1.1 Hierarchical clustering
Hierarchical clustering merupakan salah satu algoritma clustering yang fungsinya dapat
digunakan untuk meng-clusterdokumen (document clustering). Dari teknikhierarchical clustering, dapat dihasilkan suatu kumpulan partisi yang berurutan, dimana dalam kumpulan tersebut terdapat
cluster-cluster yang mempunyai point-point individu, cluster-cluster ini berbeda di level yang
paling bawah. Selain itu ada jugaclusteryang didalamnya terdapat poin-poin yang dipunyai semua
clusterdidalamnya,clusterini disebutsingle cluster, terletak di level yang paling atas.
Dalam algoritma hierarchical clustering, cluster yang berda di level yang lebih atas
(intermediate level) dari cluster yang lain, dapat diperoleh dengan cara mengkombinasikan dua
buah cluster yang berada pada level dibawahnya (Steinbach, Karypis, & Kumar, 2000). Hasil
keseluruhan dari algoritma hierarchical clusteringsecara grafik dapat digambarkan sebagai pohon, yang disebut dengan dendogram. Pohon ini secara grafik menggambarkan proses penggabungan
dari cluster-cluster yang ada, sehingga menghasilkan cluster dengan level yang lebih tinggi
Gambar II-1 Dendogram (Steinbach, Karypis, & Kumar 2000)
Ada dua metode yang sering diterapkan yaitu agglomerative hierarchical clustering dan
divisive hierarchical clustering. Pada algomerative hierarchical, proses hirarchical clustering
dimulai daricluster-clusteryang mempunyai poin-poin individu yang berada di level paling bawah. Pada setiap langkanya, dilakukan penggabungan berada saling berdekatan atau mempunyai tingkat / sifat kesamaan yang paling tinggi (Steinbach, Karypis, & Kumar, 2000). Pada divisive hierarchical
clustering, proses hierarchical clustering dimulai dari single cluster yang berada di level yang
paling atas. Pada setiap langkanya, dilakukan pemisahan (split) daricluster-clusteryang ada sampai hanya tersisa single cluster dengan masing-masing point individu yang dimilikinya. Dalam kasus ini, harus diputuskan pada setiap langkahnya, cluster mana yang akan dipisah dan bagaimana pemisahan akan dilakukan (Steinbach, Karypis, & Kumar, 2000).
Agglomerative hierarchical clustering berkerja dengan sederetan dari penggabungan yang
berurutan atau sederetan dari pembagian yang berurutan dan berawal dari objek-objek individual. Jadi pada awalnya banyaknya cluster sama dengan banyaknya objek. Objek-objek yang paling mirip dikelompokkan dan kelompok-kelompok awal ini digabungkan sesuai dengan kemiripannya. Sewaktu kemiripan berkurang, semua sub kelompok digabungkan menjadi satu cluster tunggal. Hasil-hasil dariclusteringdapat disajikan secara grafik dalam bentuk dendrogram. Cabang-cabang dalam pohon menyajikan clusterdan bergabung pada node yang posisinya sepanjang sumbu jarak
(similaritas) menyatakan tingkat dimana penggabungan terjadi.
II.1.2 Langkah-langkah analisis cluster
Langkah-langkah dalam algoritma clustering hirarki agglomerative untuk mengelompokkan N
objek (item/variabel):
1. Mulai denganN cluster, setiap clustermengandung entiti tunggal dan sebuah matriks simetrik dari jarak (similarities)D = {Dik}dengan tipeNxN.
2. Cari matriks jarak untuk pasangan cluster yang terdekat (paling mirip), misalkan jarak antara cluster U dan V yang paling mirip adalah duv.
3. Gabungkan cluster U dan V. Label cluster yang baru dibentuk dengan (UV). Update entries
pada matrik jarak dengan cara :
a. Harpus baris dan kolom yang bersesuaian dengancluster UdanV
b. Tambahan baris dan kolom yang memberikan jarak-jarak antaracluster (UV)dan
cluster-clusteryang
tersisa.
4. Ulangi langkah 2 dan 3 sebanyak (N-1)kali. (Semua objek akan berada dalamcluster tunggal setelah algoritma berakhir). Catat indentitas dari clusteryang digabungkan dan tingkat-tingkat (jarak atausimilaritas) di mana penggabungan terjadi.
Beberapa metode hierarchical clustering yang sering digunakan dibedakan menurut cara mereka untuk menghitung tingkat kemiripan atau jarak antar kelompok. Ada yang menggunakan
ward's linkage, centroid linkage, single linkage, complete linkage, average linkage, median linkage
5
III. GAMBARAN KASUS
Tingkat kebutuhan sarana dan prasarana sampah diasumsikan sebanding dengan jumlah timbulan sampah dan jumlah penduduk. Konsentrasi penyediaan sarana dan prasarana sampah di Kabupaten Pati sementara ini masih terfokus pada Kecamatan Pati khususnya Kota Pati sebagai ibukota kabupaten. Keterbatasan anggaran menjadikan pengambil kebijakan harus berfikir lebih efektif dan efisien terhadap jumlah kebutuhan sarana dan prasarana pengolahan sampah yang akan diberikan pada masing-masing wilayah. Disisi lain, cakupan wilayah adminitrasi yang terlalu luas namun sempit dalam satuan wilayah adminitrasi kecamatan di Kabupaten Pati yaitu sejumlah 21 kecamatan, dirasa membutuhkan gambaran informasi yang lebih spesifik dalam cakupan wilayah yang lebih besar kedalam kelompok administrasi yang lebih sedikit dibandingkan dengan satuan administrasi kecamatan. Sehingga proyeksi tingkat kebutuhan sarana dan prasarana sampah pada tahun rencana lebih didasarkan pada cluster wilayah dengan tingkat kebutuhan sarana dan prasarana yang hierarki terhadap timbulan sampah sebagai entitas pertama dan jumlah penduduk sebagai entitas kedua. Sehingga, tugas ini membahas tentang analisis cluster melalui pendekatan hierarki dengan program SPSS dalam rangka clustering tingkat kebutuhan sarana dan prasarana sampah terhadap timbulan sampah dan jumlah penduduk di Kabupaten Pati Provinsi Jawa Tegah sebagai berikut:
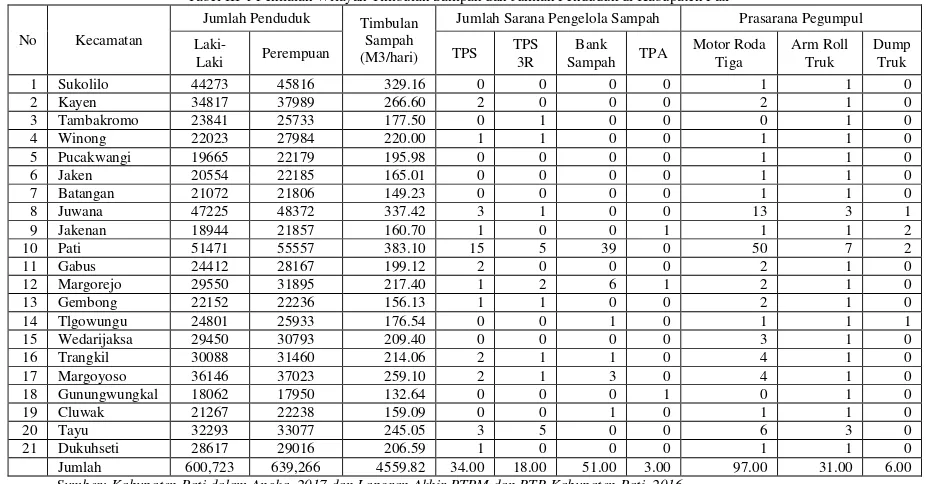
Tabel III-1 Penilaian Wilayah Timbulan Sampah dan Jumlah Penduduk di Kabupaten Pati
No Kecamatan
Jumlah Penduduk Timbulan Sampah (M3/hari)
Jumlah Sarana Pengelola Sampah Prasarana Pegumpul
Laki-18 Gunungwungkal 18062 17950 132.64 0 0 0 1 0 1 0
19 Cluwak 21267 22238 159.09 0 0 1 0 1 1 0
20 Tayu 32293 33077 245.05 3 5 0 0 6 3 0
21 Dukuhseti 28617 29016 206.59 1 0 0 0 1 1 0
Jumlah 600,723 639,266 4559.82 34.00 18.00 51.00 3.00 97.00 31.00 6.00
Sumber: Kabupaten Pati dalam Angka, 2017 dan Laporan Akhir PTPM dan RTR Kabupaten Pati, 2016.
IV. HASIL DAN ANALISIS
IV.1 Analisis Tahap Pertama
IV.1.1 Case Processing Summary
Tabel IV-1 Tabel Case Processing Summary
Case Processing Summarya
Cases
Valid Missing Total
N Percent N Percent N Percent
21 100.0 0 .0 21 100.0
Tabel di atas menjelaskan tentang rekap data yang berhasil diolah, serta menunjukkan tidak ada data yang hilang atau tidak dipakai. Jumlah data yang terolah sebanyak 21 variabel dan angka valid 100% menunjukkan semua data teridentifikasi.
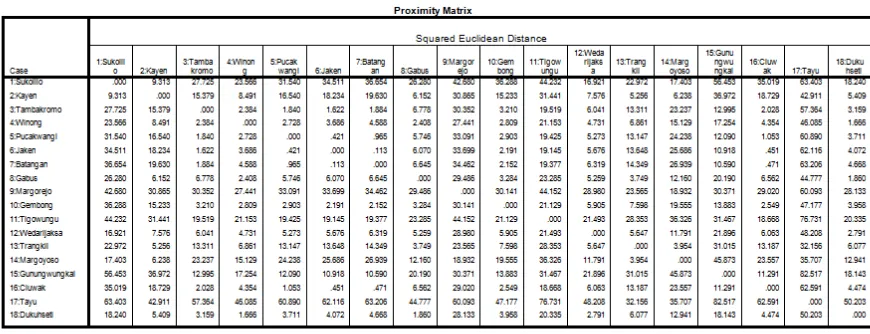
IV.1.2 Matrix Proximity
Tabel IV-2 Tabel Proximity Matriks
Seperti diketahui bahwa langkah pertama pada clustering adalah melakukan pengukuran terhadap kesamaan (similarity) antar variable. Sementara itu, clustering juga memiliki tujuan untuk mengelompokkan variable dengan kemiripan yang sama (similar). Berdasarkan tabel
proximity matrix yang merupakan hasil dari pengolahan dengan software SPSS dan metode
analisis yang digunakan yaitu Avarage Linkage Between Groups, dapat diketahui jarak antar variabel. Semakin dekat jarak antara dua variabel menunjukkan bahwa antara dua variabel tersebut semakin mirip dan dijadikan pada kelompok yang sama.
IV.1.3 Average Linkage Between Groups
Cluster 1 Cluster 2 Cluster 1 Cluster 2
1 6 19 .027 0 0 2
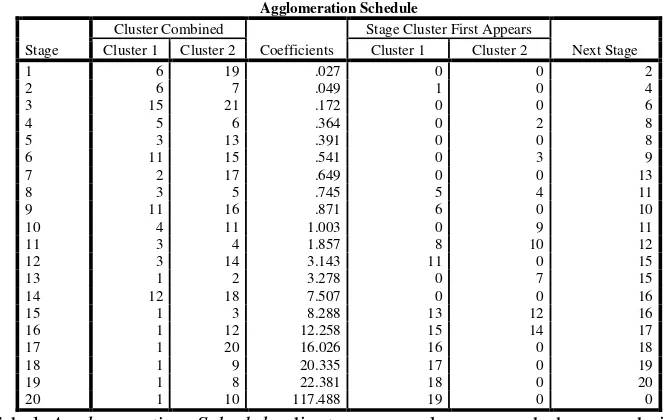
Tabel Agglomeration Schedule di atas merupakan penyederhanaan dari tabel proximity
matrix yang menjabarkan jarak antar obyek yang dijadikan variabel. Tabel di atas merupakan
1:Sukolilo 2:Kayen 1:Sukolilo 0.000 2.890 14.405 11.951 16.426 18.034 19.183 7.181 36.913 104.688 11.759 17.379 18.438 15.939 8.020 8.255 3.667 32.081 18.105 19.185 9.099 2:Kayen 2.890 0.000 5.535 3.873 6.621 7.539 8.287 9.975 25.526 105.587 3.214 11.402 7.630 7.257 1.983 1.807 .649 19.485 7.598 13.915 2.173 3:Tambakr
omo 14.405 5.535 0.000 .601 .856 .741 .882 23.845 18.468 126.421 1.037 9.965 .391 2.896 1.366 1.604 5.128 9.675 .747 12.762 1.106 4:Winong 11.951 3.873 .601 0.000 1.085 1.600 2.082 20.450 19.169 119.048 .714 9.513 1.273 3.527 1.290 1.032 3.673 11.271 1.745 11.381 .976 5:Pucakw
angi 16.426 6.621 .856 1.085 0.000 .225 .517 26.946 17.817 133.010 1.012 12.326 .980 2.948 1.892 3.078 7.190 8.907 .350 17.854 1.483 6:Jaken 18.034 7.539 .741 1.600 .225 0.000 .061 28.613 17.562 135.233 1.188 12.658 .599 2.801 2.114 3.353 7.977 8.277 .027 18.519 1.682 7:Batanga
n 19.183 8.287 .882 2.082 .517 .061 0.000 29.807 17.608 136.761 1.495 13.067 .578 2.925 2.458 3.728 8.648 8.102 .038 19.103 2.001 8:Juwana 7.181 9.975 23.845 20.450 26.946 28.613 29.807 0.000 37.399 65.572 20.288 24.090 27.265 21.174 16.988 14.877 9.435 43.373 28.656 16.808 18.065 9:Jakenan 36.913 25.526 18.468 19.169 17.817 17.562 17.608 37.399 0.000 132.355 18.611 14.959 18.009 10.905 20.135 21.027 25.990 10.104 17.604 36.151 19.464 10:Pati 104.688 105.587 126.421 119.048 133.010 135.233 136.761 65.572 132.355 0.000 119.723 110.756 127.388 120.696 119.309 107.042 97.120 152.161 134.245 82.881 119.763 11:Gabus 11.759 3.214 1.037 .714 1.012 1.188 1.495 20.288 18.611 119.723 0.000 10.675 1.383 2.988 .765 1.012 3.740 10.717 1.240 14.897 .318 12:Margor
ejo 17.379 11.402 9.965 9.513 12.326 12.658 13.067 24.090 14.959 110.756 10.675 0.000 11.139 13.429 10.202 8.710 9.623 7.507 12.509 15.144 10.201 13:Gembo
ng 18.438 7.630 .391 1.273 .980 .599 .578 27.265 18.009 127.388 1.383 11.139 0.000 3.293 2.536 2.473 7.060 8.855 .577 13.870 1.967 14:Tlgowu
ngu 15.939 7.257 2.896 3.527 2.948 2.801 2.925 21.174 10.905 120.696 2.988 13.429 3.293 0.000 3.187 4.264 7.602 11.807 2.761 18.965 2.985 15:Wedarij
aksa 8.020 1.983 1.366 1.290 1.892 2.114 2.458 16.988 20.135 119.309 .765 10.202 2.536 3.187 0.000 .868 2.416 12.316 2.112 14.626 .172 16:Trangki
l 8.255 1.807 1.604 1.032 3.078 3.353 3.728 14.877 21.027 107.042 1.012 8.710 2.473 4.264 .868 0.000 1.236 13.733 3.325 9.660 .734 17:Margoy
oso 3.667 .649 5.128 3.673 7.190 7.977 8.648 9.435 25.990 97.120 3.740 9.623 7.060 7.602 2.416 1.236 0.000 19.835 7.913 9.841 2.654 18:Gunun
gwungkal 32.081 19.485 9.675 11.271 8.907 8.277 8.102 43.373 10.104 152.161 10.717 7.507 8.855 11.807 12.316 13.733 19.835 0.000 8.261 29.650 11.606 19:Cluwak
18.105 7.598 .747 1.745 .350 .027 .038 28.656 17.604 134.245 1.240 12.509 .577 2.761 2.112 3.325 7.913 8.261 0.000 18.565 1.687 20:Tayu 19.185 13.915 12.762 11.381 17.854 18.519 19.103 16.808 36.151 82.881 14.897 15.144 13.870 18.965 14.626 9.660 9.841 29.650 18.565 0.000 14.508 21:Dukuh
seti 9.099 2.173 1.106 .976 1.483 1.682 2.001 18.065 19.464 119.763 .318 10.201 1.967 2.985 .172 .734 2.654 11.606 1.687 14.508 0.000 Squared Euclidean Distance
Proximity Matrix
7
hasil pengelompokan variabel berdasarkan hierarki dengan cara mengelompokkan variabel dengan jarak terdekat. Pengelompokan bertingkat dilakukan satu persatu sehingga menghasilkan cluster yang banyak. Pengelompokan ini didasarkan pada jarak antar variabel, yaitu variabel dengan jarak yang paling dekat mempunyai peluang untuk berada dalam satu cluster. Selain itu, dari tabel agglomeration schedule di atas juga dapat menginformasikan tentang pembagian
cluster. Jika dilihat dari kolom cluster combined, variabel yang menjadi satu kelompok dengan variabel nomor 1 (Sukolilo) yaitu Kayen, Tambakromo, Margorejo, dan Tayu.
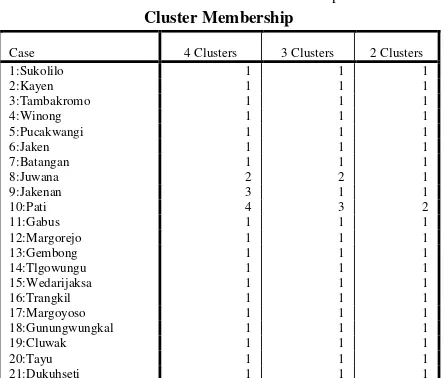
IV.1.4 Cluster Membership
Tabel IV-4 Tabel Cluster Membership Cluster Membership
Case 4 Clusters 3 Clusters 2 Clusters
1:Sukolilo 1 1 1
Data dari 21 variabel yang telah dimasukkan dan dianalisis dapat dikeompokkan menjadi 2 kelompok, 3 kelompok, dan 4 kelompok. Dari tabel disamping dapat dilihat bahwa konsentrasi penyediaan sarana dan prasarana sampah memang masih hanya terkonsentrasi di Kecamatan Pati diikuti dengan Kecamatan Juwana dan Kecamatan Jakenan sedangkan penyediaan sarana dan prasarana diluar Kecamatan Pati masih kurang perhatian. Sehingga, hipotesis awal tentang pernyataan konsentrasi penyediaan sarana dan prasarana sampah yang masih terfokus pada Kecamatan Pati adalah benar.
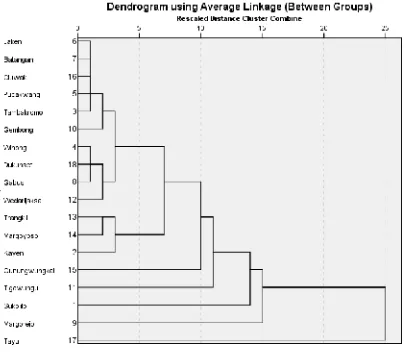
IV.1.5 Dendogram
Dendogram merupakan
pendiagraman cluster membership. Berdasarkan dendogram di atas, kita dapat mengetahui keanggotaan setiap kelompok atau cluster berdasarkan hierarki atau tingkatannya. Dari tabel hasil analisis, terlihat adanya kesenjangan ketersediaan sarana dan prasarana yang signifikan antar
kecamatan. Khususnya Kecamatan
Pati, kemudian diikuti dengan
wilayah selain tiga kecamatan tersebut secara tidak langsung tertutupi. Sehingga, dibutuhkan analisis lebih lanjut untuk memetakan persebaran kelompok wilayah dengan tingkat kebutuhan sarana dan prasarana persampahan diluar Kecamatan Pati, Kecamatan Juwana, dan Kecamatan Jenaken agar didapatkan informasi yang lebih detail.
IV.2 Analisis Tahap Kedua
IV.2.1 Case Prosessing Summary
Tabel IV-6 Tabel Case Processing Summary
Case Processing Summarya
Cases
Valid Missing Total
N Percent N Percent N Percent
18 100.0% 0 0.0% 18 100.0%
a. Squared Euclidean Distance used
Tabel di atas menggambarkan bahwa rekap data yang berhasil diolah dan tidak ada data yang hilang atau tidak dipakai. Jumlah data yang terolah sebanyak 18 variabel dan angka valid 100% menunjukkan semua data teridentifikasi.
IV.2.2 Matrix Proximity
Tabel IV-7 Tabel Proximity Matriks
Berdasarkan tabel proximity matrix yang merupakan hasil dari pengolahan dengan software SPSS dan metode analisis yang digunakan yaitu Avarage Linkage Between Groups, dapat diketahui jarak antar variabel. Semakin dekat jarak antara dua variabel menunjukkan bahwa antara dua variabel tersebut semakin mirip dan dijadikan pada kelompok yang sama.
IV.2.3 Average Linkage Between Groups Cluster 1 Cluster 2 Cluster 1 Cluster 2
9
Berdasarkan tabel agglomeration schedule di atas diinformasikan mengenai pembagian
cluster kedalam beberapa kelompok. Jika dilihat dari kolom cluster combined, variabel yang
menjadi satu kelompok dengan variabel nomor 4 (Kecamatan Winong) yaitu Kecamatan Dukuhseti, Kecamatan Gabus, dan Kecamatan Wedarijaksa.
IV.2.4 Cluster Membership
Tabel IV-9 Tabel Cluster Membership
Cluster Membership
Case 4 Clusters 3 Clusters 2 Clusters
1:Sukolilo 1 1 1
Data dari 21 kecamatan yang telah diolah pada tahap pertama mengindikasikan bahwa terjadi ketimpangan sarana dan prasarana sehingga pada tahap kedua ini hanya kecamatan dengan tingkat kebutuhan sangat tinggi yaitu sebanyak 18 kecamatan saja yang diambil. Data dari 18 kecamatan yang telah dimasukkan dan dianalisis dapat dikelompokkan menjadi 2 kelompok, 3 kelompok, dan 4 kelompok. Dari tabel disamping dapat dilihat bahwa untuk 4 cluster terlihat wilayah dengan tingkat kebutuhan sarana dan prasarana persampahan sangat tinggi yaitu Kecamatan Sukolilo. Sedangkan, wilayah dengan tingkat kebutuhan sarana dan prasarana persampahan yang rendah yaitu Kecamatan Tayu. Kecamatan Margorejo memiliki tingkat kebutuhan sarana dan prasarana persampahan yang sedang dan untuk 15 kecamatan lainnya berkebutuhan yang tinggi.
IV.2.5 Dendogram
Dendogram merupakan pendiagraman cluster membership. Berdasarkan dendogram di atas, kita dapat mengetahui keanggotaan setiap kelompok atau cluster berdasarkan hierarki atau tingkatannya.
V. KESIMPULAN DAN SARAN
V.1 KESIMPULAN
Berdasarkan tujuan analisis yaitu mengelompokkan wilayah berdasarkan tingkat kebutuhan sarana dan prasarana sampah terhadap timbulan sampah yang belum tertanggulangi dan jumlah penduduk di Kabupaten Pati, maka telah diperoleh 4 kelompok dan sangat terlihat bahwa konsentrasi kategori cluster masih hanya terfokus di Kecamatan Pati, Kecamatan Juwana, dan Kecamatan Jakenan. Ketimpangan tersebut belum dapat memberikan informasi yang tajam terkait tingkat kebutuhan sarana dan prasarana sampah di Kabupaten Pati. Sehingga diputuskan untuk mengeluarkan 3 wilayah kecamatan tersebut untuk mendapatkan informasi cluster yang lebih detail. Proses pengeluaran 3 wilayah kecamatan tersebut tidak serta merta membuang informasi datanya, namun dikelompokkan kedalam satu cluster baru yaitu cluster 5 dengan kategori tingkat kebutuhan yang sangat rendah.
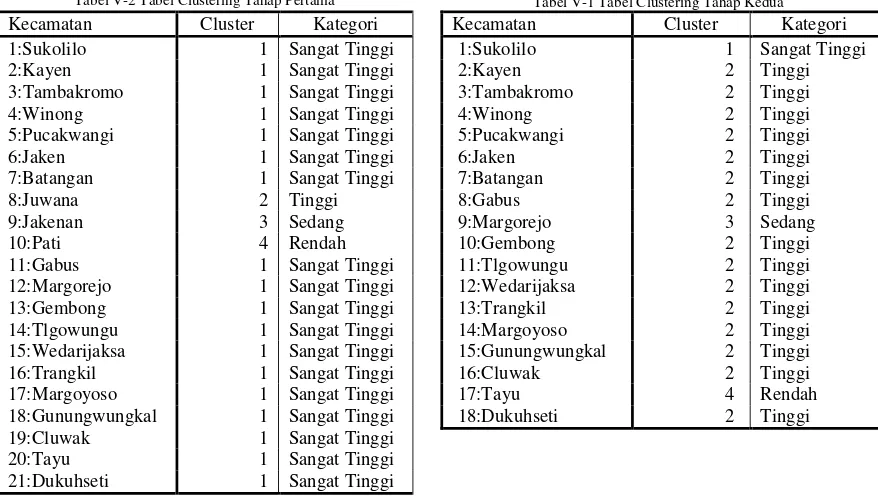
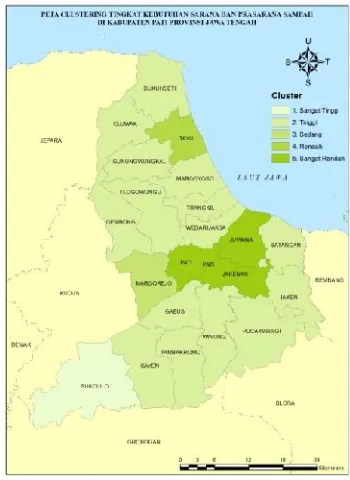
Dari hasil clustering yang telah terbentuk, dapat disimpulkan bahwa memang konsentrasi ketersediaan sarana dan prasaran sampah adalah benar masih hanya terfokus di sekitar kota pati sesuai hipotesis awal seperti tersaji pada gambar V-1. Oleh karena itu, lokasi sebaran tingkat kebutuhan sarana dan prasarana sampah relatif linear terhadap jarak dari pusat kota pati dengan kriteria yang tertinggi adalah yaitu kecamatan yang terjauh dari pusat kota. Hal yang perlu diingat bahwa, hasil dari analisis cluster terbatas pada pengelompokan saja, sehingga mengenai pengategorian dilakukan dengan analisis yang lebih lanjut. Berikut pengelompokan kecamatan di Kabupaten Pati berdasarkan tingkat kebutuhan sarana dan prasarana sampah terhadap timbulan sampah dan jumlah penduduk:
11
Tabel V-3 Tabel Clustering Tingkat Kebutuhan Sarana dan Prasarana Sampah di Kabupaten Pati
Kecamatan Cluster Kategori
1:Sukolilo 1 Sangat Tinggi
2:Kayen 2 Tinggi
3:Tambakromo 2 Tinggi
4:Winong 2 Tinggi
5:Pucakwangi 2 Tinggi
6:Jaken 2 Tinggi
7:Batangan 2 Tinggi
8:Gembong 2 Tinggi
9:Gabus 2 Tinggi
10:Tlgowungu 2 Tinggi
11:Wedarijaksa 2 Tinggi
12:Trangkil 2 Tinggi
13:Margoyoso 2 Tinggi
14:Gunungwungkal 2 Tinggi
15:Cluwak 2 Tinggi
16:Dukuhseti 2 Tinggi
17:Margorejo 3 Sedang
18:Tayu 4 Rendah
19:Juwana 5 Sangat Rendah
20:Jakenan 5 Sangat Rendah
21:Pati 5 Sangat Rendah
V.2 SARAN
Dari simpulan diatas, disarankan untuk menggunakan pengelompokkan ulang dengan mengeluarkan obyek Kecamatan Pati, Kecamatan Juwan, dan Kecamatan Jakenan yang memiliki ketimpangan sangat tinggi kemudian menjadikan tiga kecamatan tersebut menjadi kelompok baru dengan kategori tingkat kebutuhan sangat rendah. Hal ini dilakukan agar clustering dapat memberikan informasi yang lebih detail dalam proses pengambilan kebijakan. Sehingga, direkomendasikan untuk memberikan penambahan jumlah sarana dan prasarana sampah di kecamatan dengan kriteria tingkat kebutuhan sangat tinggi yaitu Kecamatan Sukolilo.
DAFTAR PUSTAKA
Aldenderfer, M. S., & Blashfi eld, R. K. 1984.Cluster analysis. Beverly Hills, CA : Sage.
J. Supranto. 2004.Analisis Multivariat: Arti dan Interpretasi.Jakarta : PT. Asdi Mahasatya.
Kabupaten Pati Dalam Angka 2017. Badan Pusat Statistik Kabupaten Pati, 2017.
Laporan Akhir Fasilitasi Perencanaan Teknis dan Manajemen Persampahan (PTMP) dan Rencana
Teknis Rinci (RTR) Sistem Penanganan Persampahan Kabupaten Pati. Dinas Persampahan
Kabupaten Pati, 2016.
Sharma, Shubash. 1996.Applied Multivariate Techniques.Canada : John Wiley and Sons, Inc.