Sistem Pendukung Keputusan
Penyeleksian Calon Siswa SMA Katolik Frateran Podor
dengan Menggunakan Metode Bayesian
Skripsi
Diajukan untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Oleh
Roswita Bulu Masan
075314004
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
Decision Support
System for Candidates Students Selection
Catholic
High School of Frateran
Podor
Using
Bayesian
Methods
A
Thesis
Presented as Partial Fulfillment of the Requirements
To Obtain the Sarjana Komputer Degree
In Study Program of Informatics Engineering
By
Roswita Bulu Masan
075314004
INFORMATICS ENGINEERING STUDY PROGRAM
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
PERNYATAAN KEASLIAN KARYA
Saya menyatakan bahwa skripsi yang saya tulis ini tidak memuat karya atau bagian karya orang lain, kecuali yang telah disebutkan dalam kutipan dan daftar pustaka, sebagaimana layaknya karya ilmiah.
LEMBAR PERNYATAAN PERSETUJUAN
PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN
AKADEMIS
Yang bertanda tangan dibawah ini, saya mahasiswa Universitas Sanata Dharma : Nama : Roswita Bulu Masan
NIM : 075314004
Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan Universitas Sanata Dharma karya ilmiah saya yang berjudul:
“Sistem Pendukung Keputusan Penyeleksian Calon Siswa SMA Katolik Frateran Podor dengan Menggunakan Metode Bayesian”
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan kepada Universitas Sanata Dharma hak untuk menyimpan, mengalihkan dalam bentuk media lain, mengelolanya dalam bentuk pangkalan data, mendistribusikannya secara terbatas, dan mempublikasikannya di internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun memberikan royaliti kepada saya selama tetap mencantumkan nama saya sebagai penulis.
Demikian pernyataan ini saya buat dengan sebenarnya.
Dibuat di Yogyakarta Pada tanggal 24 Juli 2012 Yang menyatakan,
HALAMAN PERSEMBAHAN
Karya ini kupersembahakan bagi:
HALAMAN MOTO
“ Ketika aku berpikir,
aku sedang berjalan menuju kesuksesan ”
KATA PENGANTAR
Puji dan syukur kepada Allah Bapa Yang Maha Kuasa atas semua berkat dan Roh Kudus-Nya yang melimpah, sehingga penulis dapat menyelesaikan Laporan Tugas Akhir ini.
Pada kesempatan ini saya ingin mengucapkan terima kasih kepada pihak – pihak yang telah membantu saya dalam menyelesaikan skripsi ini, baik dalam hal bimbingan, perhatian, kasih sayang, semangat, kritik, dan saran yang telah diberikan. Ucapan terima kasih ini saya sampaikan antara lain kepada :
1. Romo Dr. C. Kuntoro Adi, S.J, M.A, M.Sc selaku Dosen Pembimbing TA yang selalu memberi masukan, mengarahkan, meluangkan waktu serta membimbing penulis sehingga penulis dapat menyelesaikan skripsi ini dengan baik.
2. Ibu PH.Prima Rosa, S.Si., M.Sc., selaku Dekan Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta.
3. Ibu Ridowati Gunawan, S.T., M.T., selaku Dosen Pembimbing Akademik Teknik Informatika Tahun 2007 dan Kepala Program Studi Teknik Informatika.
4. Bapak Eko Hari Parmadi, S.Si., M.Kom. dan Ibu Ridowati Gunawan, S.T., M.T., selaku dosen penguji.
6. Bapa, Mama, Ka Richard, Iman dan Rizky tersayang yang dengan penuh kasih selalu dukungan, kasih sayang dan semangat yang tiada henti sehingga saya dapat menyelesaikan Skripsi ini
7. Bapa Natus dan Mama Lusi yang dengan penuh kasih selalu memberikan dukungan dan semangat kepada penulis.
8. Unu, Itha, Vhien, Tika, San yang selalu memberikan dukungan dan semangat kepada penulis.
9. Teman-teman Teknik Informatika angkatan 2007 untuk kebersamaannya serta motivasi yang diberikan selama penulis menjalani masa studi.
10.Seluruh pihak yang membantu penulis baik secara langsung maupun tidak langsung, yang tidak dapat penulis sebutkan satu persatu.
Saya menyadari masih banyak kekurangan yang terdapat pada laporan ini. Saran dan kritik selalu saya harapkan dari pembaca untuk perbaikan – perbaikan di masa yang akan datang. Akhir kata, saya berharap tulisan ini dapat bermanfaat bagi kemajuan dan perkembangan ilmu pengetahuan dan berbagai pihak pengguna pada umumnya.
Yogyakarta, 24 Juli 2012
ABSTRAKSI
Sistem pendukung keputusan merupakan sistem komputer yang interaktif, yang membantu pengambil keputusan memanfaatkan data dan model untuk menyelesaikan masalah – masalah yang terstruktur.
Penyeleksian calon siswa SMA merupakan salah satu proses dalam penerimaan murid baru disetiap tahun ajaran baru. Penyeleksian yang dilakukan oleh pihak sekolah ini dilakukan sesuai dengan aturan yang telah ditentukan oleh pihak panitia penyeleksian calon siswa SMA ini. Jumlah calon siswa yang mengikuti seleksi tiap tahun mengalami peningkatan, sehingga pihak panitia mengalami kesulitan dalam menentukan calon siswa yang sesuai sebagai siswa SMA Katolik Frateran Podor.
Sistem Pendukung Keputusan ini dikembangkan berdasarkan pertimbangan diatas, sehingga dapat membantu menentukan calon siswa yang sesuai untuk diterima sebagai siswa SMA Katolik Frateran Podor.
Sistem ini menggunakan metode Bayesian karena metode ini memiliki keakuratan yang tinggi dalam menentukan siswa SMA Katolik Frateran Podor yang sesuai kriteria.
ABSTRACT
Decision support system is an interactive computer system, which helps decision makers utilize data and models to finish the structured problems.
Selection of candidates for high school students is one of the processes in the acceptance of new students each school year. Selection is made by the school was conducted in accordance with rules prescribed by the committee for selecting candidates for these high school students. The number of prospective students who follow the selection each year has increased, so that the committee had difficulty in determining the appropriate prospective students in Catholic High School of FrateranPodor.
Decision Support System was developed based on the above considerations, so that students can help determine an appropriate candidate to be accepted students in CatholicHigh School of FrateranPodor.
This system uses a Bayesian method because this method has high accuracy in determining match the criteria students in Catholic High School of FrateranPodor.
The expected result is a system that can determine students in Catholic High School of Frateran Podor in accordance with the requirements set by the organizing committee.
DAFTAR ISI
HALAMAN JUDUL ……….…… i
HALAMAN PERSETUJUAN ….……….…… iii
HALAMAN PERGESAHAN …...……….…… iv
PERNYATAAN KEASLIAN KARYA ….…...……….…… v
LEMBAR PERNYATAAN PERSETUJUAN ….………….………….…… vi
HALAMAN PERSESEMBAHAN ….………...……….…… vii
HALAMAN MOTO ………..……….…… viii
KATA PENGANTAR …………..……….…… ix
ABSTRAKSI ….……….…… xi
ABSTRACT……….….…… xii
DAFTAR ISI ……….. xiii
DAFTAR TABEL ………... xx
DAFTAR GAMBAR …...………..………... xxii
BAB I PENDAHULUAN 1.1 Latar Belakang ………..……… 1
1.2 Rumusan Masalah ……… 4
1.3 Tujuan ………..………..…… 4
1.4 Batasan Masalah … ……….. 4
1.5 Luaran yang Diharapkan ………. 5
1.7 Sistematika Penulisan ………. 6
BAB II LANDASAN TEORI 2.1 Sistem Pendukung Keputusan ………. 8
2.1.1 Sistem ……… 8
2.1.2 Model ………. 11
2.1.3 Pengambilan Keputusan ………. 11
2.2 Penambangan Data ( Data Mining ) ………..……. 15
2.3 Metode Naïve Bayesian ………..………...……. 22
2.4 ZK Framework ………..………. 27
2.5 k-fold Cross Validation ………... 27
2.6 Korelasi ……….………... 28
2.7 Tingkat Keakuratan Penggolong….………. 29
BAB III ANALISIS DAN DESAIN 3.1 Analisis Sistem Lama ……….……….………….. 31
3.2 Deskripsi Umum Sistem ……… 33
3.3 Data ……… 36
3.2.1 Pengolahan Data Awal ………..…..….. 36
a. Perbersihan Data (data cleaning) ………... 37
b. Integrasi Data (data integration) …….……….…………. 38
c. Seleksi Data (data selection) .……….… 38
d. Transformasi Data (data transformation)….……..……… 42
3.3 Model Use Case ……… 43
3.3.2 Diagram Use Case ………..………..……… 44
3.3.3 Definisi Use Case ………. 45
3.3.4 Scenario Use Case ……… ..………. 47
a. Login ……….…...………... 47
b. Ganti Aturan ………….………. 48
c. Uji Validasi ………..………. 50
d. Mengolah Data User…..….……… 53
e. Isi Nomor Peserta …...…...……… 54
f. Isi Nilai Tes ………...……… 56
g. Cek Kelengkapan Data…...………... 58
h. Seleksi Calon Siswa ……...……….. 61
i. Cetak Hasil ……… 63
j. Lihat Hasil …….……… 64
k. Cari Data ...……… 66
l. Ganti Password ………..………..……….. 69
m. Input Data ….……….……….. 61
n. Galery ….. ….………..……….. 61
o. Logout ………...……… 63
3.4 Desain Subsistem Manajemen Data ……….………. 73
3.4.1 Diagram Kelas Entity ………....……… 73
3.4.2 Relational Model ……….……….……… . 74
3.5 Desain Subsistem Manajemen Model ….……..……… . 76
3.6.1 Antarmuka Pengguna ……… 79
a. Halaman Login ……….. . 79
b. Halaman Home (Admin) ………... . 80
c. Halaman Ganti Rules ………. 80
d. Halaman Uji Validasi …….……… 81
e. Halaman Mengolah Data User ……… 81
f. Halaman Home (Tim Penyeleksi) ………... 82
g. Isi Nomor Peserta ……… 82
h. Isi Nilai Tes ……….……… 83
i. Halaman Cek Kelengkapan …………..………...…… 84
j. Halaman Seleksi Calon Siswa ……… 85
k. Halaman Lihat Hasil …………...……….. 85
l. Halaman Cetak Hasil ………. 86
m. Halaman Cari Data …………...……… 87
n. Halaman Ganti Password ………. 88
o. Halaman Home (Calon Siswa) ………. 89
p. Halaman Pendaftaran ……… 89
q. Halaman Galery ……… 90
3.7 Desain Proses ……… 90
3.7.1 Diagram Konteks ……….. 90
3.7.2 Diagram Aktivitas ………... 91
3.7.2.1 Diagram Aktivitas Login ………... 92
3.7.2.3 Diagram Aktivitas Uji Validasi ………. 93
3.7.2.4 Diagram Aktivitas Mengolah User ……… 94
3.7.2.5 Diagram Aktivitas Isi Nomor Peserta.……… 95
3.7.2.6 Diagram Aktivitas Isi Nilai Tes …….……… 96
3.7.2.7 Diagram Aktivitas Cek Kelengkapan Data ………… 97
3.7.2.8 Diagram Aktivitas Seleksi Calon Siswa .…………... 98
3.7.2.9 Diagram Aktivitas Cetak Hasil ……….. 99
3.7.2.10 Diagram Aktivitas Lihat Hasil ………..……... 99
3.7.2.11 Diagram Aktivitas Cari Data …..……….. 100
3.7.2.12 Diagram Aktivitas Input Data ………... 100
3.7.2.12 Diagram Aktivitas Galery …..………... 101
3.7.2.14 Diagram Aktivitas Ganti Password ………... 101
3.7.2.15 Diagram Aktivitas Logout ………. 102
3.7.3 Diagram Objek Parsial dan Diagram Sequential ………….... 102
3.7.3.1 Diagram Objek Parsial dan Diagram Sequential Login………. 102
3.7.3.2 Diagram Objek Parsial dan Diagram Sequential Ganti Aturan ………. 104
3.7.3.3 Diagram Objek Parsial dan Diagram Sequential Uji Validasi ……….... 105
Isi Nomor Peserta ……….. 108
3.7.3.6 Diagram Objek Parsial dan Diagram Sequential Isi Nilai Tes……….... 110
3.7.3.7 Diagram Objek Parsial dan Diagram Sequential Cek Kelengkapan Data ……….. 111
3.7.3.8 Diagram Objek Parsial dan Diagram Sequential Seleksi Calon Siswa …….……….. 113
3.7.3.9 Diagram Objek Parsial dan Diagram Sequential Cetak Hasil ………. 114
3.7.3.10 Diagram Objek Parsial dan Diagram Sequential Lihat Hasil ……….. 115
3.7.3.11 Diagram Objek Parsial dan Diagram Sequential Cari Data ………. 117
3.7.3.12 Diagram Objek Parsial dan Diagram Sequential Input Data ……….. 118
3.7.3.13 Diagram Objek Parsial dan Diagram Sequential Ganti Password ……….. 119
3.7.3.14 Diagram Objek Parsial dan Diagram Sequential Logout ……… 121
3.7.4 Daftar Atribut dan Method ………... 122
3.7.4.1 Kelas login ………... 122
3.7.4.2 Kelas siswa ………... 124
3.7.4.4 Kelas rules ………….………... 145
BAB IV IMPLEMENTASI 4.1 Analisa Sistem ………. ………. 164
4.2 Koneksi ke Database ……….……… 169
4.3 Pembuatan Antarmuka (Interface) ……….……… 171
4.5 Implementasi Kelas ……….……… 191
4.5 Analisa Kelebihan dan Kekurangan Sister ……… 225
BAB V KESIMPULAN 5.1 Kesimpulan……….………… 227
DAFTAR TABEL
Tabel 2.1 Tabel Interpretasi Hubungan Korelasi ……..………….... 28
Tabel 2.2 Tabel Confussion Matrix ………….………. 29
Tabel 3.1 Tabel output analisis korelasi untuk 8 tribut dengan menggunakan SPSS ………...…. 39
Tabel 3.2 Tabel rangkuman analisis korelasi untuk 8 atribut …….. ... 40
Tabel 3.3 Tabel output analisis korelasi untuk 4 tribut dengan menggunakan SPSS ……….. 41
Tabel 3.4 Tabel rangkuman analisis korelasi untuk 4 atribut …….. … 41
Tabel 3.5 Transformasi Data Asal Sekolah ………..… 42
Tabel 3.6 Tabel Definisi Use Case ………... 45
Tabel 3.7 Tabel Skenario Use Case Login ………... 47
Tabel 3.8 Tabel Skenario Use Case Ganti Aturan ……… 48
Tabel 3.9 Tabel Skenario Use Case Uji Validasi ……….. 50
Tabel 3.10 Tabel Skenario Use Case Mengolah Data User ……… 52
Tabel 3.11 Tabel Skenario Use Case Isi Nomor Peserta …… ………… 54
Tabel 3.12 Tabel Skenario Use Case Isi Nilai Tes …………..………… 56
Tabel 3.13 Tabel Skenario Use Case Cek Kelengkapan Data ………… 58
Tabel 3.14 Tabel Skenario Use Case Seleksi Calon Siswa ………. 61
Tabel 3.15 Tabel Skenario Use Case Cetak Hasil ………...……… 63
Tabel 3.16 Tabel Skenario Use Case Lihat Hasil ……….……….. 64
Tabel 3.19 Tabel Skenario Use Case Input Data ……… 69
Tabel 3.20 Tabel Skenario Use Case Galery……….. 71
Tabel 3.21 Tabel Skenario Use Case Logout ……….. 72
Tabel 3.22 Tabel Kelas Analisis Login ……….. 103
Tabel 3.23 Tabel Kelas Analisis Ganti Aturan ……….. 104
Tabel 3.24 Tabel Kelas Analisis Uji Validasi ……… 105
Tabel 3.25 Tabel Kelas Analisis Mengolah User ……….….. 107
Tabel 3.26 Tabel Kelas Analisis Isi Nomor Peserta ……….……. 109
Tabel 3.27 Tabel Kelas Analisis Isi Nilai Tes …….……….….. .110
Tabel 3.28 Tabel Kelas Analisis Cek Kelengkapan ………... 111
Tabel 3.29 Tabel Kelas Analisis Seleksi Calon Siswa ………... 113
Tabel 3.30 Tabel Kelas Analisis Cetak Hasil ... 114
Tabel 3.31 Tabel Kelas Analisis Lihat Hasil ... 116
Tabel 3.32 Tabel Kelas Analisis Cari Data ... 117
Tabel 3.33 Tabel Kelas Analisis Input Data ... 118
Tabel 3.34 Tabel Kelas Analisis Ganti Password ... 120
Tabel 3.35 Tabel Kelas Analisis Logout ... 121
Tabel 4.1 Tabel Persentase Keakuratan ... 165
Tabel 4.2 Tabel Persentase Keakuratan ... 166
Tabel 4.3 Tabel Pembagian five-fold cross validation ... 166
Tabel 4.4 Tabel Total Perhitungan ... 167
Tabel 4.5 Tabel Pembagian ten-fold cross validation ... 168
DAFTAR GAMBAR
BAB I
PENDAHULUAN
Pada Bab I ini memaparkan latar belakang, rumusan masalah, tujuan dan manfaat, batasan masalah, metodologi penelitian yang digunakan, luaran yang diharapkan dan kegunaan dari sistem penyeleksian calon siswa yang akan dibangun serta sistematika penulisan.
1.1 Latar Belakang
Teknologi Informasi ( information technology ) merupakan bidang yang berkembang pesat dewasa ini. Menurut Martin ( 1999 ), teknologi informasi tidak hanya terbatas pada teknologi komputer ( perangkat keras dan perangkat lunak ) yang akan digunakan untuk memproses dan menyimpan informasi, melainkan juga mencakup teknologi komunikasi untuk mengirim atau menyebarkan informasi. Dari definisi ini, tampak bahwa teknologi informasi tidak hanya terbatas pada teknologi komputer, tetapi juga termasuk teknologi komunikasi.
ComputerBased Information System ( sistem informasi berbasis komputer ) yang salah satunya adalah Sistem Pendukung Keputusan ( decision support system ) adalah suatu sistem informasi komputer yang interaktif yang dapat memberikan alternatif solusi bagi pembuat keputusan. ( Agus 2009 )
tahun perkembangan dan kemajuan teknologi bisa diterapkan pada sarana pengolahan data untuk menangani penyimpanan data-data dan aplikasi. Teknologi tersebut dapat diterapkan untuk mendukung berjalannya kegiatan semua bidang khususnya di bidang pendidikan. Sekolah Menengah Atas ( SMA) merupakan suatu lembaga pendidikan yang mengarahkan siswa ke jenjang perguruan tinggi. Lembaga SMA berusaha untuk menghasilkan lulusan yang baik agar bisa melanjutkan ke universitas yang bermutu dan meningkatkan mutu pendidikan di sekolah.
Indikator peningkatan mutu pendidikan di sekolah dilihat pada setiap komponen pendidikan antara lain: siswa, mutu lulusan, kualitas guru, kepala sekolah, staf sekolah (tenaga administrasi, laboran dan teknisi, tenaga perpustakaan), proses pembelajaran, sarana dan prasarana, pengelolaan sekolah, implementasi kurikulum, sistem penilaian dan komponen-komponen lainnya. Itulah sebabnya penyeleksian calon siswa menjadi bagian integral dalam peningkatan mutu pendidikan SMA. Setelah melewati tahap seleksi, siswa yang memenuhi kriteria diterima sebagai siswa SMA tersebut.
atau sederajat kelas VII sampai IX (semester 1 s.d 5), nilai tes akademik, nilai tes kemampuan bahasa inggris, nilai tes psikologi dan wawancara dikelola secara manual sehingga kadang terjadi kesalahan. Selain itu pemberian skor yang tidak terpaut jauh untuk masing-masing kriteria, menghasilkan banyak skor akhir yang memilki nilai sama (Robert 2010). Hal ini mengakibatkan timbulnya kesulitan dalam proses seleksi.
Sistem pendukung keputusan penyeleksian calon siswa yang akan berusaha dibangun ini, menggunakan metode yang berbeda dibandingkan dengan sistem yang sudah ada. Dari hasil penelitian yang dilakukan, pada sistem lama ini terdapat beberapa kecurangan. Contohnya, siswa yang memiliki nilai UN 23.08, nilai rata-rata Raport 84.4, nilai tes 4 dan lulusan dari salah satu SMP di kota Larantuka. Nilai siswa ini dibawah standar kriteria penerimaan, namun siswa tersebut diterima sebagai siswa SMA Katolik Podor. Hal ini dikarenakan siswa tersebut merupakan keluarga salah satu guru ataupun anak salah satu pejabat daerah.
1.2 Rumusan Masalah
Berdasarkan latar belakang masalah di atas, maka rumusan masalah yang dipaparkan sebagai berikut:
1. Bagaimana metode Bayesian dapat membantu menentukan calon siswa SMA Katolik Frateran Podor dengan tepat?
2. Bagaimana menentukan atribut - atribut yang menjadi persyaratan dalam proses penyeleksian calon siswa SMA Katolik Frateran Podor sehingga dapat menentukan calon siswa yang tepat sesuai kriteria tersebut.
1.3 Tujuan
Tujuan pembuatan aplikasi ini adalah untuk menentukan secara tepat calon siswa yang sesuai dengan kriteria siswa SMA Katolik Frateran Podor, dengan menggunakan metode Bayesian. Hasil yang diperoleh diharapkan memiliki tingkat keakuratan yang tinggi. Dengan demikian, pihak SMA dapat memanfaatkannya dalam peningkatan mutu pendidikan di SMA Katolik Frateran Podor.
1.4 Batasan Masalah
Dalam membangun sistem ini terdapat batasan – batasan masalah sebagai berikut:
1. Sistem yang dibangun menggunakan metode Naïve Bayesian.
3. Data siswa yang digunakan adalah data Penyeleksian Siswa Baru SMA Frateran Podor yang mengikuti proses seleksi. Data siswa yang digunakan tersebut adalah data tahun 2008, 2009 dan 2010.
4. Perubahan rules hanya dilakukan untuk nilai atribut, karena perubahan pada atribut akan merubah keseluruhan sistem.
5. Prasyarat penerimaan siswa tiap tahun diasumsikan tidak mengalami perubahan, karena sistem ini menggunakan data training yang berasal dari data penerimaan siswa sebelumnya.
6. Perangkat lunak yang digunakan untuk membangun sistem ini adalah sistem operasi Microsoft Windows XP profesional SP, bahasa pemrograman Java.
1.5 Luaran yang Diharapkan
Sebuah aplikasi yang mampu membantu pengambilan keputusan penerimaan calon siswa SMA Katolik Frateran Podor, yang memiliki tingkat keakuratan yang cukup tinggi.
1.6 Kegunaan Program
a. Segi Ekonomi
b. Segi Teknologi
Aplikasi ini merupakan sebuah perangkat lunak yang dijalankan di desktop. Dengan memanfaatkan database sebagai penyimpanan data siswa, aplikasi bekerja dengan mengakses data siswa dalam database untuk menentukan data yang memenuhi kriteria agar diterima sebagai siswa di SMA tersebut. Aplikasi ini akan menggunakan bahasa pemrograman Java.
c. Segi Sosial
Aplikasi ini diharapkan dapat membantu pihak sekolah yang bersangkutan untuk memberi keputusan menerima siswa yang benar-benar memenuhi kriteria yang ditentukan.
1.7 Sistematika Penulisan
Bab I. Pendahuluan
Bab ini akan dijelaskan mengenai latar belakang masalah, perumusan masalah, tujuan penelitian, batasan masalah, luaran, keguanaan, metodologi penelitian dan sistematika pembahasan.
Bab II. Landasan Teori
Bab III. Analisis dan Desain
Bab ini akan menjelaskan deskripsi umum sistem, data, use case,
desain database, desain proses, serta desain Graphical User Interface yang akan digunakan.
Bab IV. Implementasi dan Analisa Sistem
Bab ini menjelaskan mengenai implementasi sistem yang berdasarkan pada perancangan sistem pada bab sebelumnya, kemudian analisa hasil yang diperoleh dari sistem yang dibuat serta kelebihan dan kekurangan sistem.
Bab V. Kesimpulan
Bab ini memuat kesimpulan umum yang diperoleh dari pembuatan sistem serta rancangan pengembangan sistem ke depan.
BAB II
LANDASAN TEORI
Pada bab ini akan dipaparkan teori-teori yang mendukung pembuatan Sistem Pendukung Keputusan Penyeleksian Calon Siswa SMA Katolik Frateran Podor dengan menggunakan Metode Bayesian. Teori pendukung tersebut adalah Sistem Pendukung Keputusan, Database, dan Data Mining. Pada bagian Data Mining, akan dijelaskan juga mengenai metode Bayesian sebagai metode yang digunakan dalam sistem.
2.1 Sistem Pendukung Keputusan
2.1.1 Sistem
Sistem ( Turban, Aronson, Liang 2005 ) adalah kumpulan objek seperti orang, sumber daya, konsep, dan prosedur yang dimaksudkan untuk melakukan suatu fungsi yang dapat diidentifikasi atau untuk melayani suatu tujuan.
Struktur Sistem
Menurut Turban et al. (2005) sistem dibagi menjadi tiga bagian berbeda : input, proses, dan output. Bagian-bagian tersebut dikelilingi oleh sebuah lingkaran dan sering melibatkan sebuah mekanisme umpan balik. Selain itu, pengambilan keputusan juga dianggap sebagai bagian dari sistem.
a. Input
b. Proses
Proses adalah semua elemen yang diperlukan untuk mengonversi atau mentransformasikan input ke dalam output.
c. Output
Output adalah produk finis atau konsekuensi yang ada pada sistem. d. Umpan Balik
Ada aliran informasi dari komponen output ke pengambil keputusan berkenaan dengan output atau performa sistem. Berdasarkan output, pengambil keputusan, yang bertindak sebagai kontrol, dapat memutuskan untuk memodifikasi input, proses, atau keduanya. Aliran informasi ini, muncul sebagai closed loop, disebut umpan balik. Pengambilan keputusan membandingkan output dengan output yang diharapkan dan menyesuaikan input dan mungkin proses untuk makin mendekati output target.
e. Lingkungan
Lingkungan sistem terdiri dari beberapa elemen yang ada di luar, dalam hal mereka bukanlan input, output, atau proses. Akan tetapi, mereka mempengaruhi performa sistem dan konsekuensi pencapaian tujuan sistem.
f. Batasan
Batasan dapat berupa fisik atau dapat berupa faktor non-fisik. Sebagai contoh, sistem dapat dibatasi oleh waktu.
Batasan sebuah sistem informasi biasanya ditentukan dengan mempersempit lingkup sistem untuk mempermudah analisis. Dengan kata lin, batasan sebuah sistem pendukung keputusan adalah desain. Batasan dikaitkan dengan konsep sistem tertutup dan terbuka (closed system dan open system).
(Turban, et al. 2009)
Sistem Tertutup dan Sistem Terbuka
Sistem tertutup mencerminkan tingkat independensi sistem. Sistem tertutup sama sekali independen, sedangkan sistem terbuka sangat tergantung pada lingkungannya. Sistem terbuka menerima input dari lingkungan dan dapat mengirim output kepada lingkungan.
Ketika menentukan dampak keputusan pada sebuah sistem terbuka, harus ditentukan hubungan sistem dengan lingkungan dan dengan sistem lainnya. Pada sistem tertutup, tidak perlu dilakukan hal tersebut karena sistem dianggap diisolasi. Sistem pendukung keputusan berusaha berhubungan dengan sistem-sistem yang cukup terbuka. (Turban et al. 2005)
Efektifitas dan Efisiensi Sistem
berkaitan dengan output sebuah sistem. Efektivitas adalah melakukan sesuatu yang benar.
b. Efisiensi adalah ukuran pemakaian input (sumber daya) untuk mencapai output. Efisiensi adalah melakukan sesuatu dengan benar. (Turban et al. 2005)
2.1.2 Model
Karakteristik utama sebuah sistem pendukung keputusan adalah inklusi pada sedikitnya satu model. Model merupakan representasi atau abstraksi sederhana dari realitas. Model dapat merepresentasikan sistem atau masalah dengan berbagai tingkatan abstraksi, (Turban, et al. 2009).
2.1.3 Pengambilan Keputusan
Pengambilan keputusan adalah sebuah proses memilih tindakan (di antara berbagai alternatif) untuk mencapai suatu tujuan atau beberapa tujuan.
Sistem Pendukung Keputusan merupakan sistem komputer yang interaktif, yang membantu pengambil keputusan memanfaatkan data dan model untuk menyelesaikan masalah-masalah yang terstruktur (Irfan, 2002).
komputer yang adaptif, fleksibel, dan interaktif yang digunakan untuk memecahkan masalah-masalah tidak terstruktur sehingga meningkatkan nilai keputusan yang diambil.
Sistem Pendukung Keputusan juga digunakan untuk membantu manajeman dalam memecahkan masalah yang dihadapi ( McLeod 1998 ). Selain itu, dapat didefinisikan sebagai sebuah sistem penghasil informasi spesifik yang ditujukan untuk memecahkan suatu masalah tertentu yang harus dipecahkan oleh manajer pada berbagai tingkatan.
Sistem Pendukung Keputusan juga dapat diartikan sebagai suatu sistem informasi berbasis komputer yang menghasilkan berbagai alternatif keputusan untuk membantu manajemen dalam menangani berbagi permasalahan yang terstruktur ataupun tidak terstruktur dengan menggunakan model atau data.
Tujuan dari Sistem Pendukung Keputusan yang dikemukakan oleh Keen dan Scoot dalam buku Sistem Informasi Manajemen (McLeod 1998) adalah :
a. Membantu organisasi membuat sebuah keputusan untuk memecahkan masalah semiterstruktur.
b. Mendukung penilaian organisasi, dan tidak bermaksud menggantikan. c. Meningkatkan efektifitas pengambilan keputusan organisasi daripada
Tahap-tahap Pengambilan Keputusan
Ada beberapa tahap pengambilan keputusan seperti yang dikemukakan oleh Agus, 2009 dibawah ini :
a. Tahap Penelusuran (Intelligence Phase)
Suatu tahap dimana seseorang dalam rangka pengambilan keputusan untuk permasalahan yang dihadapi, terdiri dari aktivitas penelusuran, pendeteksian serta proses pengenalan masalah. Data masukan diperoleh, diuji dalam rangka mengidentifikasi masalah. b. Tahap Perancangan (Design Phase)
Tahap proses pengambil keputusan setelah tahap intelligence
meliputi proses untuk mengerti masalah, menurunkan solusi dan menguji kelayakan solusi. Aktivitas yang biasanya dilakukan seperti menemukan, mengembangkan dan menganalisa alternatif tindakan yang dapat dilakukan.
c. Tahap Pilihan (Choice Phase)
Pada tahap ini dilakukan proses pemilihan diantara berbagai alternatif tindakan yang mungkin dijalankan. Hasil pemilihan tersebut kemudian diimplementasikan dalam proses pengambilan keputusan. d. Tahap Implementasi (Implementation Phase)
Komponen-Komponen Sistem pendukung Keputusan
Sistem Pendukung Keputusan dapat terdiri dari subsistem sebagai berikut: a. Subsistem manajemen data
Subsistem manajemen data memasukkan satu database yang berisi data yang relevan untuk situasi dan dikelola oleh perangkat lunak yang disebut sistem manajemen database ( DBMS ). Subsistem manajemen data dapat diinterkoneksikan dengan data warehouse
perusahaan, suatu repositori untuk data perusahaan yang relevan untuk pengambilan keputusan.
b. Subsistem manajemen model
Merupakan paket perangkat lunak yang memasukkan model keuangan, statistik, ilmu manajemen, atau model kuantitatif lainnya yang memberikan kapabbilitas analitik dan manajemen perangkat lunak yang tepat. Bahasa-bahasa pemodelan untuk membangun model-model kustom juga dimasukkan. Perangkat lunak ini sering disebut sistem manajemen basis model ( MBMS ).
c. Susbsistem antarmuka pengguna
Pengguna berkomunikasi dengan dan memerintahkan sistem pendukung keputusan melalui subsistem ini. Pengguna adalah bagian yang dipertimbangkan dari sistem.
d. Subsistem manajemen berbasis-pengetahuan
berinteligensi untuk memperbesar pengetahuan pengambil keputusan. Subsistem ini dapat diinterkoneksikan dengan repositori pengetahuan perusahaan yang terkadang disebut basis pengetahuan organisasional.
Berdasarkan keterangan di atas, sebuah sistem pendukung keputusan harus mencangkup tiga komponen yakni DBMS, MBMS, dan antarmuka pengguna. Sedangkan subsistem manajemen berbasis pengetahuan adalah opsional, namun dapat memberikan banyak manfaat karena memberikan inteligensi bagi tiga komponen utama tersebut. (Turban, et al. 2009)
2.2 Penambangan Data ( Data Mining )
Istilah penggalian data ( data mining ) merupakan proses pencarian informasi yang bernilai di basis data yang besar, gudang data, atau data mart. Alat penggalian data mengidentifikasi pola yang sebelumnya tersembunyi dalam satu langkah.( Turban, et al. 2005 )
Beberapa pengertian penambangan data menurut sejumlah penulis adalah : 1. Definisi sederhana dari penambangan data adalah ekstraksi informasi
atau pola yang penting atau menarik dari data yang ada di database yang besar. ( Yudho, 2003 )
Dari pengertian di atas, dapat diartikan bahwa penambangan data sebagai proses pengambilan pola atau informasi pada data dalam jumlah besar yang tersimpan dalam database.
Penambangan data dapat menjalankan fungsi-fungsi berikut: a. Deskripsi
Pola dan trend data sering dideskripsikan. Deskripsi tersebut sangat membantu dalam menjelaskan pola dan trend yang terjadi. Model data mining harus setransparan mungkin, dimana hasilnya dapat mendeskripsikan pola dengan jelas.
b. Estimasi
Estimasi mirip dengan klasifikasi kecuali variabel target-nya numerik ketimbang kategorikal. Model yang dibangun menggunakan
record yang lengkap, yang menyediakan nilai variabel target dan
predictor. Untuk observasi yang baru, estimasi nilai variabel target ditentukan, berdasarkan nilai-nilai predictor.
c. Prediksi
Sasaran pada tugas ini adalah memprediksikan nilai atribut tertentu berdasarkan nilai atribut yang lain. Atribut yang diprediksi dikenal sebagai target atau variabel yang tergantung pada variabel lain, atribut yang digunakan selama membuat prediksi dikenal sebagai penjelasan ( explanatory ) atau variabel yang bebas.
Dalam klasifikasi, variabel target-nya merupakan kategorikal. Model data mining memeriksa set record yang besar, tiap record
mempunyai informasi variabel target dan set input atau variabel
predictor.
e. Clustering
Clustering merupakan pengelompokkan record, observasi, atau kasus ke dalam kelas-kelas objek yang mirip. Clustering berbeda dengan klasifikasi dimana dalam clustering tidak terdapat variabel target. Clustering mencoba menyegmentasi seluruh set data ke dalam
subgroup atau cluster yang relatif homogen, dimana kemiripan antar
record dalam cluster dimasikimasi dan kemiripan record di luar
cluster diminimasi. f. Asosiasi
Asosiasi merupakan suatu tugas untuk menemukan atribut-atribut yang “terjadi” bersamaan. Tugas asosiasi mencoba untuk menemukan aturan untuk mengkuantifikasi hubungan antara dua atau lebih atribut. Aturan asosiasi berbentuk “If antecedent, then consequent”, bersama-sama dengan ukuran support dan confidence
yang berhubungan dengan aturan.
Proses Penambangan Data
tahap dari proses KDD yang mempergunakan analisa data dan penggunaan algoritma, sehingga menghasilkan pola-pola khusus dalam basis data yang besar.
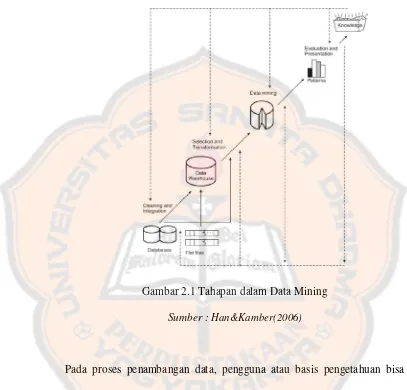
Berikut ini merupakan langkah-langkah dalam membangun penambangan data (Han&Kamber, 2006):
1. Pembersihan data ( data cleaning )
Proses ini dilakukan untuk membuang data noice dan yang tidak konsisten akan dihapus. Langkah pertama yang dilakukan dalam proses pembersihan data adalah mendeteksi ketidakcocokan. Ketidakcocokan tersebut dapat disebabkan oleh beberapa factor antara lain adanya kesalahan petugas ketika memasukkan data, kemungkinan adanya kesalahan yang disengaja dan adanya data yang tidak sesuai. 2. Integrasi data ( data integration )
Pada proses ini akan dilakukan penggabungan data. Data digabungkan dari beberapa tempat penyimpanan akan digabungkan ke dalam satu tempat penyimpanan data yang koheren.
3. Seleksi data ( data selection )
yang antara satu atribut dengan atribut yang lainnya tidak saling mempengaruhi.
4. Transformasi data ( data transformation )
Pada proses ini data ditransformasikan ke dalam bentuk yang tepat untuk di-mining. Yang termasuk dalam proses transformasi data adalah penghalusan ( smooting ) yaitu proses menghilangkan noise
yang ada pada data, generalisasi ( generalization ) yaitu mengganti data primitive atau data level rendah menjadi data level tinggi, normalisasi ( normalization ) yaitu mengemas data atribut ke dalam skala yang kecil, dan konstruksi atribut atau fitur ( attribute construction atau feature construction ) yaitu mengkonstruksi dan menambahkan atribut baru untuk membantu dalam proses penambangan.
5. Penambangan data ( data mining )
Pada proses ini akan diaplikasikan metode yang tepat untuk mengekstrak pola data.
6. Evaluasi pola ( pattern evaluation )
Proses ini dilakukan untuk mengidentifikasi pola yang benar dan menarik. Pola tersebut akan direpresentasikan dalam bentuk pengetahuan berdasarkan beberapa pengukuran yang penting.
7. Presentasi pengetahuan ( knowledge presentation )
Tahapan tersebut dapat diilustrasikan kedalam gambar berikut :
Gambar 2.1 Tahapan dalam Data Mining
Sumber:Han&Kamber(2006)
Pada proses penambangan data, pengguna atau basis pengetahuan bisa dilibatkan. Dalam proses di atas, penambangan data hanya terdapat dalam satu langkah. Penambangan data ini merupakan proses yang sangat penting karena dalam proses ini bisa ditemukan pola yang nantinya akan dievaluasi.
penambangan prediktif adalah menampilkan kesimpulan dari data yang sekarang ada untuk membuat sebuah prediksi.
Jenis pola yang dapat diketahui dari penambangan data salah satunya adalah klasifikasi dan prediksi. Klasifikasi merupakan model yang dibangun untuk memprediksi label-label kategorikal yang direpresentasikan dengan nilai diskrit. Prediksi numerik merupakan model yang dibangun untuk memprediksi fungsi nilai yang kontinyu (continuous-valued function) ataupun nilai yang terurut (ordered value). Klasifikasi dan prediksi angka ini merupakan jenis permasalahan prediksi (Han&Kamber, 2006).
Klasifikasi data terdiri dari dua proses. Pada proses pertama, classifier
membangun gambaran konsep atau kelas data yang telah ditentukan sebelumnya. Langkah ini dinamakan langkah pembelajaran (learning) atau fase pelatihan. Pada fase pelatihan ini, algoritma klasifikasi yang diterapkan akan membangun sebuah
classifier. Caranya adalah dengan belajar dari sekumpulan data pelatihan yang diambil dari tuple basis data. Karena label kelas dari setiap tuple pelatihan sudah tersedia maka fase ini juga dikenal dengan sebutan fase supervised learning.
Salah satu cara penyelesaian masalah-masalah yang berkaitan dengan klasifikasi adalah dengan menggunakan teorema naïve Bayesian.
2.3 Metode Naive Bayesian
Teorema Bayesian mengungkapkan bahwa hasil probabilitas posterior sebanding dengan hasil perkalian antara likelihood dengan probababilitas prior. Probabilitas posterior adalah probabilitas bersyarat dari sebuah hipotesis jika diberikan data. Likelihood adalah probabilitas bersyarat dari sebuah data jika diberikan hipotesis. Probabilitas prior adalah probabilitas bahwa hipotesis itu benar sebelum data terlihat.
Misalkan X adalah tuple data dan H adalah hipotesis. Untuk masalah klasifikasi, akan ditentukan P(H|X), yaitu probabilitas bersyarat di mana probabilitas hipotesis H ditentukan oleh data X. P(H|X) adalah probabilitas
posterior dari kondisi H terhadap X. P(X|H) adalah probabilitas posterior dari X
berdasarkan H. P(H) adalah probabilitas prior dari H. P(X) adalah probabilitas
prior dari X. Kalkulasi dari probabilitas-probabilitas tersebut sebagai berikut :
P(H|X)= ( | ) ( )( ) ……….………(2.1)
Keterangan:
X himpunan data pelatihan. H hipotesis.
P(H) probabilitas prior dari hipotesis H yaitu probabilitas bahwa hipotesis H bernilai benar sebelum data X muncul.
P(X) probabilitas dari data X.
P(X|H) probabilitas bersyarat dari X yang berasal dari hipotesis H, dan biasa disebut dengan likelihood.
likelihood ini mudah dihitung ketika memberikan nilai 1 saat X dan H konsisten, dan memberikan nilai 0 saat X dan H tidak konsisten.
Naïve Bayesian adalah penggolong yang bersifat statistik. Penggolong
NaïveBayesian dapat memprediksi probabilitas kelas. Penggolong naïve Bayesian
didasarkan pada asumsi bahwa kehadiran atau keberadaan fitur tertentu dari sebuah kelas tidak berhubungan dengan kehadiran atau keberadaan fitur lainnya. Artinya, atribut dari sebuah kelas adalah independen dengan nilai atribut lainnya. Rumusnya adalah:
P(H|x)= ( | ) ( | ) … ( | ) ( )
( ) ………(2.2)
Keterangan:
X himpunan data pelatihan.
H hipotesis.
hipotesis H setelah data X
muncul.
P(H) probabilitas prior dari
hipotesis H sebelum X
muncul.
P(X) probabilitas dari data X. P(H)
mempunyai nilai yang sama dengan kelas yang lain atau
irrelevant.
( | ) ( | ) … ( | ) ( ) probabilitas dari , , untuk hipotesis H, biasa disebut dengan likelihood.
Penggolong Naïve Bayesian bekerja seperti berikut :
1. Anggap D adalah kumpulan data pelatihan dari tuple dan D berhubungan dengan label kelas.
2. Andaikan ada m kelas, C1, C2, … , Cm. Jika disediakan tuple X,
penggolong Naïve Bayesian memprediksi X ke dalam kelas yang mempunyai probabilitas posterior tertinggi. Maka penggolong
Naïve Bayesian memprediksi tuple X termasuk ke dalam kelas Ci
jika dan hanya jika
Dengan demikian P(Ci|X) akan dimaksimalkan. Kelas Ci untuk setiap P(Ci|X) yang dimaksimalkan dinamakan maximum posteriori hypothesis.
Berdasarkan teorema Bayes adalah :
( | ) = ( | ) ( )
( ) ……….( 2.4 )
3. Selama P(X) konstan untuk semua kelas maka hanya P(X|Ci)P(Ci) yang dimaksimalkan. Jika kelas probabilitas prior tidak diketahui, maka kelas - kelas tersebut diasumsikan sama, yaitu
P(C1) = P(C2) = … = P(Cm), oleh karena itu P(X|Ci) akan dimaksimalkan. Jika tidak, P(X|Ci)P(Ci) yang akan dimaksimalkan 4. Misalkan data terdiri dari banyak atribut. Untuk mengurangi kerumitan komputasi dalam mengevaluasi P(X|Ci), naïve mengasumsikan ada class conditional independence. Maka,
P(X|Ci) = ∏ ( | )……..………..(2.5)
= ( | ) × ( | ) × … × ( | )………(2.6) xkmerujuk pada nilai atribut Ak untuk tuple X. Untuk setiap atribut, akan dicek apakah atribut tersebut adalah atribut kategorikal atau atribut yang nilainya kontinyu. Sebagai contoh, untuk menghitung P(X|Ci), perlu dipertimbangkan hal berikut ini :
untuk Ak, dibagi dengan |Ci, D|, |Ci, D| adalah jumlah tuple
pada kelas Ci dalam D.
P(Xk | Ci) = |Xki|/ Nci………..………(2.7)
Keterangan
P(Xk|Ci) probabilitas likelihood dari atribut Xk dalam kelas Ci
Xki jumlah atribut Xk yang termasuk dalam kelas Ci
Nci jumlah Ci
b. Jika Ak adalah atribut yang nilainya kontinyu, maka perhitungan menjadi lebih rumit karena melibatkan distribusi
Gaussian dengan mean μ dan standar deviasi σ. Rumusnya adalah sebagai berikut:
g( , , ) =
√
( )
………..(2.8)
maka,
P(Xk|Ci) = ( , , )…………..………..(2.9) Keterangan:
P(Xk|Ci) probabilitas likelihood dari atribut dalam kelas Ci.
Xk nilai atribut Xk
5. Untuk memprediksi label kelas X, P(X|Ci)P(Ci) perlu dievaluasi untuk setiap kelas Ci. Penggolong naïve Bayesian memprediksi label kelas tuple X adalah Ci jika dan hanya jika P(X|Ci)P(Ci) >
P(X|Cj)P(Cj) untuk 1≤ j ≤ m, j ≠ i. Dengan kata lain, prediksi suatu label kelas adalah kelas Ciuntuk P(X|Ci)P(Ci) adalah maksimum. (Han&Kamber, 2006).
2.4 ZK Framework
Hubungan ZK dengan java yaitu secara garis besar ZK merupakan script yang digunakan untuk mengelola interface program, di dalamnya berisi kode untuk view data. Sedangkan java adalah mesin/bahasa yang digunakan untuk mengolah dan mengontrol data yang akan ditampilkan ke ZK atau sebaliknya dari
ZK data diolah dengan java dan disimpan ke database menggunakan spring. Jadi
ZK berada di atasnya java yang berfungsi sebagai layer presentasi data.
2.5 k-fold Cross Validation
Cross Validation adalah salah satu metode yang bisa digunakan untuk mengukur kinerja dari sebuah model prediktif. Dalam k-fold Cross Validation, data akan dipartisi secara acak ke dalam k partisi, D1, D2, …Dk, masing-masing D mempunyai jumlah yang sama. Jika salah satu partisi digunakan sebagai data uji, maka partisi lainnya digunakan sebagai data pelatihan.
2.6 Korelasi
Analisis korelasi digunakan untuk memilih atribut yang akan digunakan untuk perhitungan. Hal ini diperlukan karena dalam metode Naïve Bayesian diperlukan atribut yang independen sehingga dengan analisis korelasi dapat diketahui atribut yang sifatnya independen satu dengan yang lain.
Analisis korelasi merupakan salah satu dari metode statistik. Metode ini digunakan untuk menyelidiki hubungan antara dua buah variabel atau antar set variabel. Nilai korelasi berkisar antara -1 hingga 1. Nilai korelasi -1 berarti bahwa hubungan antara dua variabel adalah hubungan negatif sempurna. Nilai korelasi 0 berarti bahwa hubungan antara dua variabel dapat diabaikan atau dengan kata lain tidak ada hubungan antara dua variabel. Niali korelasi 1 berarti bahwa terdapat hubungan positif sempurna antara dua variabel. (Sofyan Yamin, 2009)
Interpretasi dari besarnya nilai korelasi antara variable dapat diklasifikasikan sebagai berikut:
Tabel 2.1 Tabel Interpretasi Hubungan Korelasi Besar Korelasi Hubungan Korelasi
0,00 – 0,09 Hubungan korelasinya diabaikan 0,10 – 0,29 Hubungan korelasi rendah 0,30 – 0,49 Hubungan korelasi moderat 0,50 – 0,70 Hubungan korelasi sedang
2.7 Tingkat Keakuratan Penggolong
Keakuratan penggolong dapat diukur dari data uji. Keakuratan penggolong (jika diberikan data uji) adalah persentasi dari dari tuple data uji yang telah diprediksi dengan benar oleh penggolong.
Confusion matrix adalah alat yang berguna untuk menganalisis sebagus apa sebuah penggolong dapat mengenal tuple dari kelas-kelas yang berbeda. Jika ada m kelas, maka confusion matrix adalah tabel yang berukuran m x m. CMij
adalah inputan pada baris m yang pertama dan kolom m yang pertama. CMij
menunjukkan jumlah tuple dari kelas i yang sudah dilabeli oleh penggolong sebagai kelas j.
Tabel 2.2 Tabel Confussion Matrix
C1 C2
Kelas yang sebenarnya
C1
Benar positif
Salah negatif C2
Salah positif
Benar positif
Jika diberikan dua kelas, ada terminologi tuple positif dan tuple negatif. Benar positif merujuk pada tuple positif yang dilabeli oleh penggolong secara benar. Benar negatif merujuk pada tuple negatif yang dilabeli oleh penggolong secara benar. Salah positif merujuk pada tuple negatif yang dilabeli dengan tidak benar. Maka, Salah negatif merujuk pada tuple positif yang dilebeli dengan tidak benar. Sensitivitas juga merujuk pada angka benar positif. Angka benar positif
adalah ukuran dari tuple positif yang diidentifikasi dengan benar. Spesifikasi (specificity) merujuk pada angka benar negatif. Angka benar negatif adalah ukuran dari tuple negatif yang diidentifikasi dengan benar. Sebagai tambahan, diperlukan perhitungan ketelitian (precision) untuk mendapatkan persentasi dari
tuple yang dilabeli sebagai ‘a’ yang sebenarnya adalah ‘a’.
sensitivity = _ ……….……… (2.10)
specifity = _ ……….……… (2.11)
precision = _
_ _ ……….……… (2.12)
Keterangan:
t_pos : Jumlah benar positif
pos : Jumlah tuple positif
t_neg : Jumlah benar negatif
neg : Jumlah tuple negatif
f_pos : Jumlah salah positif
Dengan demikian untuk menghitung keakuratan sebuah penggolong adalah:
Accuracy = sensitivity + specifity
………....(2.13)
BAB III
ANALISA DAN DESAIN
Bab ini menjelaskan mengenai desain atau gambaran sistem yang akan dibuat dan dikembangkan, mulai dari diagram use case, desain subsistem manajemen data, desain subsistem manajemen dialog, desain subsistem manajemen model dan desain proses.
3.1. Analisis Sistem Lama
Setiap tahun SMAK Frateran Podor melakukan penerimaan calon siswa baru melalui tes masuk. Proses penyeleksian calon siswa yang telah dilaksanakan oleh tim penyeleksi SMAK Frateran Podor selama ini masih dilakukan secara manual. Tim penyeksi belum memiliki sistem yang telah terkomputerisasi yang digunakan secara khusus yang membantu tim penyeleksi dalam melakukan perhitungan untuk menentukan siswa yang akan diterima. Selain itu, data hasil proses penyeleksian yang diserahkan oleh tim penyeksi ke sekretariat masih berupa dokumen fisik.
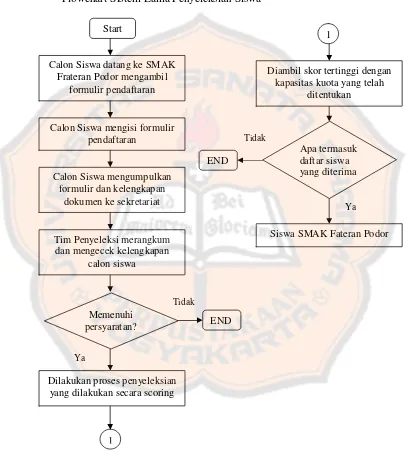
Sistem lama penyeleksian calon siswa SMAK Frateran Podor dapat dilihat seperti pada gambar 3.1:
Flowchart Sistem Lama Penyeleksian Siswa
Gambar 3.1 Flowchart Sistem Lama Penyeleksian Siswa
Start
Calon Siswa datang ke SMAK Frateran Podor mengambil
formulir pendaftaran
Calon Siswa mengisi formulir pendaftaran yang dilakukan secara scoring
END
Tidak
Ya
1
1
Diambil skor tertinggi dengan kapasitas kuota yang telah
ditentukan
Dari gambar 3.1 dapat diketahui proses penyeleksian secara manual yang telah dilaksanakan oleh tim penyeleksi adalah sebagai berikut:
1. Siswa mendaftar dengan mengisikan formulir pendaftaran, kemudian mengumpulkannya pada tim penyeleksi serta melengkapi dokumen persyaratan sebagai ketentuan yang telah ditetapkan oleh tim penyeleksi.
2. Petugas merangkum data calon siswa tersebut ( seperti : data diri, data orang tua, data akademik ) kemudian mengecek kelengkapan dokumen calon siswa.
3. Setelah semua data dirangkum dan dicek, data diolah sesuai dengan kebutuhan penyeleksian tersebut. Dalam mengolah data tersebut ada patokan yang digunakan untuk menentukan siswa yang diterima.
3.2. Deskripsi Umum Sistem
Sistem yang akan dibangun ini merupakan sistem yang digunakan untuk menggantikan sistem manual yang telah dijalankan oleh pihak tim penyeleksi selama ini dalam menentukan siswa yang akan diterima. Sistem yang akan dibangun ini diusahakan agar mampu melakukan proses penyeleksian mulai dari proses entri data, publikasi, cari data, sorting data, pembuatan keputusan, serta uji validitas.
dikembangkan dengan menggunakan MySQL sebagai Database Management System, Java sebagai bahasa pemrogramannya dan ZK sebagai frameworknya.
Keputusan yang diambil dari sistem yang akan dibangun bertujuan untuk menentukan siswa yang akan diterima sesuai dengan ketentuan yang telah ditetapkan oleh tim penyeleksi SMAK Frateran Podor. Sistem ini juga membantu proses seleksi agar lebih cepat dan tidak ada kecurangan.
Flowchart Sistem Baru Penyeleksian Siswa
Gambar 3.2 Flowchart Sistem Baru Penyeleksian Siswa
Start
Calon Siswa mengisi form pendaftaran pada komputer nomor peserta dan nilai tes
Tim Penyeleksi mengecek kelengkapan calon siswa dan mengisikan status kelengkapan
Siswa SMAK Fateran Podor
Dari gambar 3.3 dapat diketahui proses penyeleksian pada sistem baru yang telah dilaksanakan oleh tim penyeleksi adalah sebagai berikut:
1. Siswa mendaftar dengan mengisikan form pendaftaran, kemudian mengumpulkan dokumen persyaratan sebagai ketentuan yang telah ditetapkan pada tim penyeleksi.
2. Tim Penyeleksi mengisikan nomor peserta, nilai tes kemudian mengecek kelengkapan dokumen calon siswa dan mengisikan status kelengkapan.
3. Setelah itu, tim penyeleksi melakukan proses perhitungan yang dilakukan dengan menggunakan Bayesian.
4. Siswa dapat mengecek pengumuman penerimaan siswa.
3.2. Data
3.2.1. Pengolahan Data Awal
Nilai Tes Masuk dan Asal SMP.
Data tahun 2008 memuat 262 calon siswa yang mendaftar, dengan rincian: - Sebanyak 203 siswa yang diterima
- Sebanyak 59 siswa yang tidak diterima
Data tahun 2009 mencakup 283 calon siswa yang mendaftar, dengan rincian: - Sebanyak 206 siswa yang diterima
- Sebanyak 77 siswa yang tidak diterima
Dalam tahun 2010 terdapat sebanyak 273 calon siswa yang mendaftar, dengan rincian:
- Sebanyak 205 siswa yang diterima - Sebanyak 78 siswa yang tidak diterima
Beberapa langkah awal pre-pocessing sebagai berikut: a. Pembersihan Data ( data cleaning )
Pembersihan data merupakan tahap awal dalam data mining.
Pada data mentah, terdapat beberapa record yang mempunyai data yang tidak lengkap (missing value). Pada proses pembersihan data,
record yang mempunyai data yang tidak lengkaptersebut dihapus. Pada data tahun 2008 sebanyak 17 record yang dihapus, pada tahun 2009 sebanyak 10 record yang di hapus, dan pada tahun 2010 sebanyak 12 record yang di hapus.
Pada tahap ini dilakukan penggabungan data antara tahun 2008, 2009 dan 2010. Data mentah yang diterima dalam bentuk fisik dan terpisah untuk setiap tahun. Data tersebut dijadikan satu dokumen berformat .xls.
c. Seleksi Data ( data selection )
Data yang sudah diintegrasikan kemudian diseleksi. Pada tahap ini, dipilih atribut –atribut yang menjadi kriteria penerimaan siswa serta relevan untuk dilakukan proses penambangn data.
Data mentah yang diperoleh memiliki atribut – atribut sebagai berikut : Nomor, Nama, No. Telepon, Tempat Tanggal Lahir, Alamat Asal, Alamat di Larantuka, Nama Orang Tua ( Ayah dan Ibu ), Pekerjaan Orang Tua ( Ayah dan Ibu ), Nilai UN, Nilai Raport semester 1 sampai dengan 5, Nilai Tes, dan Asal SMP.
Pada proses ini juga dilakukan analisis korelasi untuk analisis variabel dengan menggunakan aplikasi SPSS. Analisis korelasi dilakukan untuk memastikan apakah 8 atribut yang digunakan untuk penambangan data bersifat independen satu sama lain. Artinya, antara atribut satu dengan atribut yang lain tidak saling mempengaruhi.
Berikut ini adalah hasil analisis korelasi untuk 8 atribut yaitu Nilai UN, Nilai semester 1, Nilai Semester 2, Nilai Semester 3, Nilai Semester 4, Nilai Semester 5, Nilai Tes, Asal SMP.
Tabel 3.1 Tabel output analisis korelasi untuk 8 tribut dengan menggunakan SPSS
**. Correlation is significant at the 0.01 level (2-tailed).
Dari tabel 3.1 dapat dilihat bahwa ada beberapa atribut yang mempunyai hubungan korelasi dengan atribut lain. Berikut rangkuman analisisnya.
Tabel 3.2 Tabel rangkuman analisis korelasi untuk 8 atribut
ATRIBUT
Nilai Semester 1, Nilai Semester 2, Nilai Semester 3, Nilai Semester 4, Nilai Semester
5.
Nilai Semester 1
Nilai Test, Asal SMP
Nilai UN, Nilai Semester 2, Nilai Semester 3, Nilai Semester 4, Nilai Semester 5.
Nilai Semester 2
Nilai Tes Nilai UN, Nilai Semester 1, Nilai Semester 3, Nilai Semester 4, Nilai Semester 5, Asal SMP.
Nilai
Semester 3
Asal SMP Nilai UN, Nilai Semester 1, Nilai Semester 2,
Nilai Semester 4, Nilai Semester 5, Nilai Tes.
Nilai
Semester 4
Nilai Tes, Asal
SMP
Nilai UN, Nilai Semester 1, Nilai Semester 2,
Nilai Semester 3, Nilai Semester 5.
Nilai
Semester 5
Nilai Tes, Asal
SMP
Nilai UN, Nilai Semester 1, Nilai Semester 2,
Nilai Semester 3, Nilai Semester 4.
Nilai Test Nilai UN, Asal SMP
Nilai Semester 1, Nilai Semester 2, Nilai Semester 3, Nilai Semester 4, Nilai semester 5.
Asal SMP Nilai UN, Nilai Tes
Nilai Semester 1, Nilai Semester 2, Nilai Semester 3, Nilai Semester 4, Nilai semester 5.
Berikut ini adalah hasil analisis korelasi untuk 4 atribut yaitu Nilai UN, Rata – rata Nilai Raport, Nilai Tes, Asal SMP.
Tabel 3.3 Tabel output analisis korelasi untuk 4 tribut dengan menggunakan SPSS
Correlations
NILAI_UN RATA_RATA NILAI_TES ASAL_SMP
NILAI_UN Pearson Correlation 1 .296** -.021 -.054
**. Correlation is significant at the 0.01 level (2-tailed).
Tabel 3.4 Tabel rangkuman analisis korelasi untuk 4 atribut
ATRIBUT INDEPENDEN
TERHADAP ATRIBUT
BERKORELASI DENGAN
ATRIBUT
Nilai UN Nilai Tes, Asal SMP Rata-rata Nilai Raport
Rata-rata
Nilai Raport
Nilai Test, Asal SMP Nilai UN
Nilai Tes Nilai UN, Rata-rata Nilai
Raport, Asal SMP
-
Asal SMP Nilai UN, Rata-rata Nilai
Raport, Nilai Tes
Berdasarkan tabel korelasi Pearson dengan menggunakan SPSS di atas, maka diperoleh kriteria yang dapat digunakan untuk penerimaan siswa SMAK Frateran Podor adalah Nilai UN, Nilai Tes, Rata-rata Nilai Raport dan Asal SMP.
d. Transformasi Data ( data transformation )
Pada tahap transformasi data, data Nilai UN, Rata-rata Nilai Raport, Nilai Tes dan Asal SMP akan dikategorikan sesuai dengan keputusan pihak SMAK Frateran Podor. Berikut kategorinya:
Nilai UN
Nilai UN dikategorikan menjadi 2 kategori yaitu nilai UN ≥ 24 dan nilai UN < 24
Rata-rata Nilai Raport
Rata-rata Nilai Raport dikategorikan menjadi 2 kategori yaitu nilai UN ≥ 84 dan nilai UN < 84
Nilai Tes
Nilai Tes dikategorikan menjadi 2 kategori yaitu nilai tes ≥ 7 dan nilai tes < 7
Asal Sekolah
Asal sekolah dikategorikan menjadi 4 kategori yaitu: Tabel 3.5 Transformasi Data Asal Sekolah
Asal SMP Klasifikasi
SMPK Mater Inviolata, SMPK Gabriel, SMP Ratu Damai
SMP Negeri Larantuka, SMP Negeri Adonara, SMP
Darius
Wilayah 2
SMP Negeri Solor, SMP Negeri Lembata, SMP Negeri
Tanjung Bunga
Wilayah 3
SMPK Frateran Maumere, SMPK Giovanni Kupang,
dan SMP lain di luar Flores Timur
Wilayah 4
3.3. Model Use Case
Use Case Diagram secara grafis mendeskripsikan siapa yang akan menggunakan sistem dan melalui cara apa pengguna ( user ) mengharapkan interaksi dengan sistem tersebut. Use Case secara naratif digunakan secara tekstual untuk menggambarkan sekuensi langkah – langkah dari setiap interaksi.
3.3.1. Aktor dalam Use Case
Ada tiga aktor yang berperan menjalankan Sistem Pendukung Keputusan Penyeleksian Calon Siswa ini, yaitu:
1. Admin
Aktor yang berperan dalam mengubah aturan dan password user lain yang ada dalam sistem. Jika ada aturan yang berubah dam sistem maka admin dapat merubahnya dengan membuat aturan baru.
2. Tim Penyeleksi
3. Calon Siswa
Aktor yang berperan dalam melihat hasil keputusan penerimaan siswa dan memasukkan data ke sistem.
3.3.2. Diagram Use Case
Gambar 3.3. Diagram Use Case
Tim
<< depends on >> << depends on >>
Cari Data
<< depends on >>
Ganti Password Lihat Hasil
3.3.3. Definisi Use Case
Tabel 3.6 Tabel Definisi Use Case
Kode Use Case Deskripsi
UC-01-01 Login Aktor : Admin, Tim Penyeleksi dan calon siswa
Deskripsi : Aktor dapat melakukan autentifikasi
user dengan memasukkan Password dan User
name untuk dapat masuk ke sistem
UC-01-02 Ganti Aturan Aktor : Admin
Deskripsi : Aktor dapat menghapus aturan lama dan
menggantikannya dengan aturan baru.
UC-01-03 Uji Validasi Aktor : Admin
Deskripsi : Aktor dapat melakukan uji validasi
keseluruhan sistem ( menggunakan data training )
dengan k-fold cross validation.
UC-01-04 Mengolah
Data User
Aktor : Admin
Deskripsi : Aktor dapat mengganti password login
yang lama dengan password yang baru dan
menambah user baru.
UC-01-05 Isi Nomor
Peserta
Aktor : Tim Penyeleksi
Deskripsi : Aktor dapat mengisikan nomor peserta
sesuai data pendaftaran yang telah diisikan siswa.
UC-01-06 Isi Nilai Tes Aktor : Tim Penyeleksi
Deskripsi : Aktor dapat mengisikan nilai tes calon
siswa.
Kelengkapan
Data
Deskripsi : Aktor dapat melengkapi atau mengedit
data calon siswa yang telah disimpan dalam sistem.
UC-01-08 Seleksi
Calon Siswa
Aktor : Tim Penyeleksi
Deskripsi : Aktor dapat melakukan perhitungan
untuk penyeleksian calon siswa dengan
menggunakan metode Bayesian.
UC-01-09 Cetak Hasil Aktor : Tim Penyeleksi
Deskripsi : Aktor dapat mencetak hasil
penyeleksian calon siswa.
UC-01-10 Lihat Hasil Aktor : Tim Penyeleksi, Calon Siswa
Deskripsi : Aktor dapat melihat hasil penyeleksian
siswa yang ditampilkan dalaam bentuk tabel.
UC-01-11 Cari Data Aktor : Tim Penyeleksi
Deskripsi : Aktor dapat mencari data siswa
berdasarkan nomor dan nama.
UC-01-12 Ganti
Password
Aktor : Tim Penyeleksi
Deskripsi : Aktor dapat menganti password lama
dengan password yang baru
UC-01-13 Input Data Aktor : Calon siswa
Deskripsi : Aktor dapat mengisikan data – data pada
form yang disediakan.
UC-01-14 Galery Aktor : Calon Siswa
Deskripsi : Aktor dapat melihat foto-foto yang ada
pada halaman galery
Deskripsi : Aktor keluar dari sistem.
3.3.4. Scenario Use Case
a. Login
Pengarang : Roswita Bulu Masan Tanggal : 9 November 2011 Versi :
Tabel 3.7 Tabel Skenario Use Case Login
Nama Use Case Login Jenis Use Case:
Persyaratan Bisnis Use Case ID UC-01-01
Prioritas Tinggi
Sumber -
Aktor Bisnis Primer
Tim Penyeleksi, Admin dan calon siswa
Aktor
Pendukung Lain -
Stakeholder lain yang
berhubungan -
Deskripsi Use case ini mendeskripsikan suatu kejadian yang dilakukan oleh tim penyeleksi, admin dan calon siswa. Penyeleksi menginputkan password dan user name ke sistem mengautentifikasi ke data base.
Prakondisi Aktor sudah masuk dalam halaman utama
Pemicu -
Langkah Umum Kegiatan Aktor Respon Sistem Langkah 1 : Aktor
Langkah 3 : Aktor memasukkan user name dan password
Langkah 4 : Aktor mengklik tombol login
Langkah 2 : Sistem merespon dengan menampilkan
halaman login.
Langkah 5 : Sistem
mengautentifikasi password dan user name (apakah sesuai dengan data yang disimpan di data base)
Langkah 6 : Sistem
menampilkan halaman utama actor
Langkah alternative
Langkah 7 : Jika verifikasi username dan password tidak sesuai maka sistem akan menampilkan pesan error dan kembali ke halaman login
Kesimpulan Use case ini berakhir jika sistem sudah penampilkan halaman utama actor.
b. Ganti Aturan
Pengarang : Roswita Bulu Masan Tanggal : 9 November 2011
Versi :
Tabel 3.8 Tabel Skenario Use Case Ganti Aturan Nama Use Case Ganti Aturan Jenis Use Case:
Prioritas Tinggi
Deskripsi Use case ini digunakan untuk menghapus aturan lama dan mengantikannya dengan aturan baru untuk proses
perhitungan.
Prakondisi Penyeleksi sudah login sebagai admin
Pemicu Aktor diharuskan melakukan login terlebih dahulu sebelum mengganti aturan
Langkah Umum Kegiatan Aktor Respon Sistem Langkah 1 : Aktor
memilih menu ganti rules
Langkah 3 : Aktor menekan tombol Proses Ganti Aturan
Lagkah 5 : Aktor menyetujui permintaan
Langkah 2 : Sistem merespon dengan menampilkan
halaman ganti rules
konfirmasi
Langkah 6: Sistem
menghapus aturan yang ada di dalam database ,
memproses perhitungan probabilitas tiap atribut dan menampilkan hasilnya. Langkah
alternative
Langkah 9 : Jika aktor menolak permintaan konfirmasi dari sitem maka sistem akan menampilkan pesan bahwa data tidak jadi dirubah.
Kesimpulan Use case ini berakhir jika sistem sudah menampilkan hasil pergantian aturan.
c. Uji Validasi
Pengarang : Roswita Bulu Masan Tanggal : 9 November 2011 Versi :
Tabel 3.9 Tabel Skenario Use Case Uji Validasi Nama Use Case Uji Validasi Jenis Use Case:
Persyaratan Bisnis