PERBANDINGAN ALGORITME
FEATURE SELECTION
INFORMATION GAIN
DAN
SYMMETRICAL
UNCERTAINTY
PADA DATA KETAHANAN PANGAN
DELKI ABADI
DEPARTEMEN ILMU KOMPUTER
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa skripsi berjudul Perbandingan Algoritme Feature Selection Information Gain dan Symmetrical Uncertainty pada Data Ketahanan Pangan adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Mei 2013
ABSTRAK
DELKI ABADI. Perbandingan Algoritme Feature Selection Information Gain dan Symmetrical Uncertainty pada Data Ketahanan Pangan. Dibimbing oleh Annisa.
Pengelompokan daerah berdasarkan indikator ketahanan pangan sangat penting dilakukan untuk mengambil kebijakan yang tepat dalam hal penentuan sasaran dan pemberian rekomendasi untuk mengatasi masalah kerawanan pangan. Salah satu metode yang dapat digunakan untuk mengelompokkan objek ke dalam kelas-kelas adalah algoritme decision tree. Pada penelitian ini, akan dibangun dua model decision tree. Decision tree pertama menggunakan algoritme seleksi fitur information gain, sedangkan decision tree kedua menggunakan algoritme seleksi fitur symmetrical uncertainty. Kedua metode ini digunakan untuk mengklasifikasikan data indikator ketahanan pangan untuk seluruh kabupaten di Indonesia yang diperoleh dari United Nations World Food Programme dan Dewan Ketahanan Pangan. Kemudian, akurasi kedua metode dibandingkan satu sama lain. Hasil yang diperoleh menunjukkan bahwa akurasi decision tree pertama lebih baik dibandingkan decision tree kedua. Rata-rata akurasi decision tree pertama yaitu 52.02%, sedangkan rata-rata akurasi decision tree kedua yaitu 49.84%.
Kata Kunci: decision tree, information gain, symmetrical uncertainty
ABSTRACT
DELKI ABADI. Comparison of Information Gain and Symmetrical Uncertainty Feature Selection Algorithm in Food security Data. Supervised by ANNISA.
Regional grouping based on indicators of food security is very important to take the proper policy in terms of deciding the targets and providing recommendations for tackling food insecurity. One method that can be used to classify objects into classes is decision tree algorithm. In this research, two decision tree models are constructed. The first decision tree utilizes information gain feature selection algorithm, whereas the second decision tree uses symmetrical uncertainty feature selection algorithm. These methods are used to classify the indicator of food security data from all districts in the provinces of Indonesia, obtained from the United Nations World Food Programme and Food Security Council. Then, the accuracy of both methods are compared. The result showed that the first decision tree is better than the second decision tree. The average accuracy of the first decision tree is 52.02%, while the average accuracy of second decision tree is 49.84%.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Ilmu Komputer
pada
Departemen Ilmu Komputer
PERBANDINGAN ALGORITME
FEATURE SELECTION
INFORMATION GAIN
DAN
SYMMETRICAL
UNCERTAINTY
PADA DATA KETAHANAN PANGAN
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Perbandingan Algoritme Feature Selection Information Gain dan Symmetrical Uncertainty pada Data Ketahanan Pangan
Nama : Delki Abadi NIM : G64104024
Disetujui oleh
Annisa, SKom, MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi, MKom Ketua Departemen Ilmu Komputer
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wata’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Maret 2012 ini ialah seleksi fitur, dengan judul Perbandingan Algoritme Feature Selection Information Gain dan Symmetrical Uncertainty pada Data ketahanan Pangan.
Terima kasih penulis ucapkan kepada Ibu Annisa, SKom, MKom selaku pembimbing yang telah memberikan arahan dan saran selama penelitian ini berlangsung. Ungkapan terima kasih juga disampaikan kepada orangtua, kakak, serta seluruh keluarga atas segala doa dan kasih sayangnya. Ucapan terima kasih juga penulis sampaikan kepada seluruh teman-teman satu bimbingan yang telah membantu dalam penyelesaian penelitian ini.
Penulis menyadari bahwa masih terdapat kekurangan dalam penulisan skripsi ini. Semoga karya ilmiah ini bermanfaat.
Bogor, Mei 2013
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 2
Batasan Penelitian 2
TINJAUAN PUSTAKA 2
Decision Tree 2
Algoritme ID3 2
Seleksi Fitur 3
Entropy, Information Gain, dan Symmetrical Uncertainty 3
K-Fold Cross Validation 4
Overfitting 5
Pruning 5
METODE PENELITIAN 5
Data Indikator Ketahanan Pangan 5
Pembersihan Data 5
Transformasi Data 6
Data Latih dan Data Uji 6
Klasifikasi 8
Pruning 9
Perhitungan Akurasi 9
Lingkungan Pengembangan 10
HASIL DAN PEMBAHASAN 10
Data Indikator Ketahanan Pangan 10
Pembersihan Data 10
Transformasi Data 10
Data Latih dan Data Uji 11
Pruning 14
Perbandingan Akurasi Model 1 dan Model 2 16
KESIMPULAN DAN SARAN 17
Kesimpulan 17
Saran 18
DAFTAR PUSTAKA 18
DAFTAR TABEL
1 Contoh data latih 7
2 Urutan fitur berdasarkan nilai information gain 8
3 Urutan fitur berdasarkan nilai symmetrical uncertainty 8
4 Pembagian data ketahanan pangan 11
5 Pola percobaan 11
6 Akurasi pengujian model 1 12
7 Confusion matrix iterasi kesepuluh pada model 1 12
8 Akurasi pengujian model 2 13
9 Confusion matrix iterasi pertama pada model 2 14
10 Akurasi pengujian setelah dilakukan pruning pada model 1 15 11 Akurasi pengujian setelah dilakukan pruning pada model 2 16 12 Perbandingan akurasi model 1 dan model 2 sebelum dan sesudah
dilakukan pruning 16
DAFTAR GAMBAR
1 Tahapan penelitian 6
2 Decision tree model 1 9
3 Decision tree model 2 9
4 Contoh aturan hasil iterasi kesepuluh pada model 1 13 5 Contoh aturan hasil iterasi pertama pada model 2 14
DAFTAR LAMPIRAN
1 Contoh data sebelum transformasi data 19
2 Interval indikator-indikator data ketahanan pangan 20
PENDAHULUAN
Latar Belakang
Algoritme ID3 merupakan algoritme klasifikasi yang banyak digunakan dalam machine learning. Algoritme ID3 merupakan sebuah metode yang digunakan untuk konstruksi decision tree. Algoritme ID3 menggunakan algoritme seleksi fitur information gain untuk memilih fitur terbaik yang akan digunakan pada decision tree.
Algoritme seleksi fitur information gain yang digunakan pada ID3 menghasilkan pemilihan fitur yang dapat menentukan akurasi dari hasil klasifikasi. Selain information gain, terdapat beberapa algoritme lain yang dapat digunakan untuk memilih fitur terbaik yang akan digunakan pada decision tree seperti symmetrical uncertainty.
Pada penelitian yang dilakukan oleh Hall (1999) dijelaskan bahwa symmetrical uncertainty merupakan bentuk turunan dari information gain. Symmetrical uncertainty digunakan untuk menghilangkan bias pada information gain. Bias pada information gain terjadi karena information gain mendukung fitur dengan kemungkinan nilai yang banyak sehingga fitur dengan kemungkinan nilai yang banyak akan memiliki ukuran information gain yang lebih besar dibanding fitur yang memiliki kemungkinan nilai yang lebih sedikit, bahkan ketika fitur tersebut tidak lebih baik dari fitur lainnya. Untuk itu, symmetrical uncertainty digunakan untuk menormalisasi information gain untuk memastikan semua fitur sebanding atau memiliki efek yang sama.
Hasil dari klasifikasi dapat dilihat dari tingkat akurasi yang dihasilkan. Sering kali model decision tree mengalami masalah overfitting. Overfitting di dalam decision tree menghasilkan suatu keadaan yang lebih kompleks daripada yang dibutuhkan. Hal ini juga membuat tingkat akurasi tidak cukup baik untuk mengklasifikasikan data baru. Oleh karena itu, diperlukan cara untuk meningkatkan akurasi dari model tree yang dihasilkan.
Salah satu metode yang bisa digunakan untuk meningkatkan akurasi dari tree ialah pruning. Pruning bekerja dengan memotong atau memangkas tree. Pruning diharapkan dapat meningkatkan akurasi yang dihasilkan dalam proses klasifikasi.
2
Tujuan Penelitian
Tujuan dari penelitian ini ialah:
1 Menerapkan model klasifikasi decision tree menggunakan algoritme ID3 yang melakukan pemilihan fitur berdasarkan information gain dan algoritme decision tree dengan menggunakan symmetrical uncertainty untuk pemilihan fitur.
2 Membandingkan tingkat akurasi decision tree yang dibangun menggunakan algoritme ID3 dan algoritme decision tree dengan menggunakan symmetrical uncertainty untuk pemilihan fitur.
3 Menerapkan pruning pada decision tree.
Batasan Penelitian
Penelitian ini dibatasi pada pembangunan model decision tree pada data ketahanan pangan menggunakan algoritme ID3 yang melakukan pemilihan fitur berdasarkan information gain dan algoritme decision tree dengan menggunakan symmetrical uncertainty untuk pemilihan fitur, serta penerapan metode pruning untuk meningkatkan akurasi dari model decision tree yang dibangun. Data ketahanan pangan yang digunakan adalah data sekunder berupa indikator-indikator ketahanan pangan untuk seluruh wilayah di Indonesia.
TINJAUAN PUSTAKA
Decision Tree
Decision tree merupakan salah satu metode klasifikasi yang menggunakan representasi struktur pohon. Setiap node pada decision tree merepresentasikan atribut, cabangnya merepresentasikan nilai dari atribut dan daun merepresentasikan kelas. Node paling atas dari decision tree disebut sebagai node akar (Han & Kamber 2001).
Pembentukan decision tree terdiri atas tahap-tahap berikut:
1 Konstruksi tree, yaitu membuat tree yang diawali dengan pembentukan bagian akar, kemudian data terbagi berdasarkan atribut-atribut yang cocok untuk dijadikan node akar.
2 Pemangkasan tree (pruning), yaitu mengidentifikasi dan membuang cabang yang tidak diperlukan pada tree yang telah terbentuk.
3 Pembentukan aturan keputusan, yaitu membuat aturan keputusan dari tree yang telah dibentuk.
Algoritme ID3
3 Strategi pembentukan decision tree dengan algoritme ID3 yaitu (Tan et al. 2006):
1 Tree dimulai sebagai node tunggal (akar) yang merepresentasikan semua data.
2 Sesudah node akar dibentuk, data pada node akar akan diukur dengan information gain untuk memilih atribut yang akan dijadikan atribut pembaginya.
3 Sebuah cabang dibentuk dari atribut yang dipilih menjadi pembagi dan data akan didistribusikan ke dalam cabang masing-masing.
4 Algoritme ini akan terus menggunakan proses yang sama atau bersifat rekursif untuk dapat membentuk sebuah decision tree. Ketika sebuah atribut telah dipilih menjadi node pembagi atau cabang, atribut tersebut tidak diikutkan lagi dalam penghitungan nilai information gain.
5 Proses pembagian rekursif akan berhenti jika salah satu dari kondisi berikut terpenuhi:
a Semua data dari anak cabang telah termasuk dalam kelas yang sama. b Semua atribut telah dipakai, tetapi masih tersisa data dalam kelas yang
berbeda. Dalam kasus ini, data yang mewakili kelas terbanyak untuk dijadikan label kelas diambil.
c Tidak terdapat data pada anak cabang yang baru. Dalam kasus ini, node daun akan dipilih pada cabang sebelumnya dan diambil data yang mewakili kelas terbanyak untuk dijadikan label kelas.
Seleksi Fitur
Menurut Ramaswami dan Bhaskaran (2009), tujuan utama dari seleksi fitur ialah memilih fitur terbaik dari suatu kumpulan fitur data. Pada decision tree, algoritme seleksi fitur yang digunakan untuk konstruksi decision tree menentukan tingkat akurasi dari decision tree yang dihasilkan. Fitur-fitur yang digunakan pada decision tree merupakan fitur-fitur yang dianggap relevan dalam menentukan kelas target dari suatu objek data.
Entropy, Information Gain, dan Symmetrical Uncertainty
4
Info D = - pi m
i
log2 pi
Info(D) adalah entropi dari D dan pi adalah rasio dari kelas Ci pada himpunan data contoh D.
pi= | Ci,D| | D |
Misalkan himpunan data contoh D dipartisi berdasarkan atribut A yang mempunyai v kemungkinan nilai, {�1,�2,…,��}. Atribut A dapat digunakan
untuk mempartisi himpunan data contoh D menjadi v partisi atau subset,{�1,�2,…,��}, dengan �� merupakan himpunan data contoh D yang
memiliki atribut A dengan nilai ��. Banyaknya informasi yang dibutuhkan untuk mempartisi himpunan data contoh D berdasarkan atribut A dirumuskan sebagai berikut (Han & Kamber 2001):
infoA D = |Dj| |D| v
j=1
x info(Dj)
|Dj|
|D| merupakan rasio dari data dengan atribut j pada himpunan data contoh D. infoA(D) menggambarkan banyaknya informasi yang dibutuhkan untuk mempartisi himpunan data contoh D berdasarkan atribut A. Information gain dirumuskan sebagai berikut (Han & Kamber 2001):
Gain A = info D - info A(D)
Symmetrical uncertainty didapatkan dengan membagi information gain atribut A dengan jumlah dari entropi himpunan data contoh D ditambah dengan entropi dari atribut A (Novakovic et al. 2011).
SU A = Gain (A) info D + info(A)
K-Fold Cross Validation
5 Overfitting
Overfitting merupakan masalah yang sering muncul di dalam upaya klasifikasi. Overfitting di dalam decision tree menghasilkan tree yang lebih kompleks daripada yang dibutuhkan. Gejala yang ditunjukkan di dalam overfitting yaitu memberikan akurasi yang baik pada data latih, namun memberikan akurasi yang buruk pada data uji. Di samping itu, overfitting mengakibatkan semakin besar ukuran dari tree (ditinjau dari jumlah node-nya), justru memberi nilai akurasi yang rendah dalam proses klasifikasi. Pruning merupakan cara yang baik untuk menghindari atau mengatasi overfitting. Setelah pruning, tingkat akurasi dalam proses klasifikasi bisa meningkat (Tan et al. 2006).
Pruning
Pruning (pemangkasan tree) merupakan bagian dari proses pembentukan decision tree. Saat pembentukan decision tree, beberapa node merupakan outlier atau noise. Penerapan pruning pada decision tree dapat mengurangi outlier maupun noise data pada decision tree awal sehingga dapat meningkatkan akurasi pada klasifikasi data (Han & Kamber 2001).
Prinsip pruning terbagi menjadi dua: pre-pruning dan post pruning. Pre-pruning merupakan proses pemangkasan saat tree belum terbentuk secara sempurna, sedangkan post pruning bekerja setelah tree terbentuk dengan sempurna.
METODE PENELITIAN
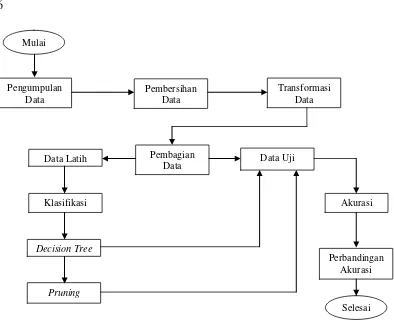
Penelitian ini akan dilakukan dalam beberapa tahap. Tahapan dalam penelitian ini dapat dilihat pada Gambar 1.
Data Indikator Ketahanan Pangan
Data yang akan digunakan pada penelitian ini adalah data indikator ketahanan pangan yang dikumpulkan oleh DKP dan WFP (2009). Pada penelitian ini, data ketahanan pangan untuk seluruh kabupaten di Indonesia digunakan.
Pembersihan Data
6
Transformasi Data
Data yang sudah dibersihkan kemudian diubah menjadi bentuk yang tepat untuk di-mining. Information gain dan symmetrical uncertainty merupakan teknik seleksi fitur yang memakai metode scoring untuk nominal ataupun pembobotan atribut kontinu yang didiskretkan menggunakan maksimal entropy sehingga indikator data ketahanan dan kerentanan pangan harus ditransformasikan ke dalam bentuk atribut kategorik. Hal ini merupakan salah satu syarat yang harus dipenuhi dalam penerapan algoritme seleksi fitur information gain dan symmetrical uncertainty. Pada penelitian ini akan dilakukan diskretisasi data menggunakan interval yang sudah ada.
Data Latih dan Data Uji
Setelah tahap transformasi data dilakukan, tahap selanjutnya yaitu pembagian data. Pada tahap ini, data dibagi menjadi data latih dan data uji. Pada penelitian ini digunakan k-fold cross validation untuk menentukan data latih dan data uji.
Pada penelitian ini menggunakan metode 10-fold cross validation. Oleh karena itu, data yang digunakan dibagi menjadi 10 subset secara acak yang
Gambar 1 Tahapan penelitian Mulai
Pengumpulan Data
Pembersihan Data
Transformasi Data
Pembagian
Data Data Uji
Data Latih
Klasifikasi
Decision Tree
Pruning
Akurasi
Perbandingan Akurasi
7 masing-masing subset memiliki jumlah instances yang hampir sama. Pembagian data untuk setiap subset dipilih secara acak.
Pembagian data ini digunakan pada proses iterasi klasifikasi. Iterasi dilakukan sebanyak 10 kali karena penelitian ini menggunakan metode 10-fold cross validation. Pada setiap iterasi, satu subset digunakan untuk pengujian, sedangkan sembilan subset lainnya digunakan untuk pelatihan.
Seleksi Fitur
Penelitian ini menggunakan dua algoritme seleksi fitur dasar yaitu algoritme seleksi fitur information gain dan symmetrical uncertainty. Kedua algoritme ini digunakan untuk mengekspansi tree pada algoritme decision tree. Decision tree hasil kedua algoritme seleksi fitur ini akan dibandingkan akurasinya untuk menentukan algoritme seleksi fitur yang lebih baik. Contoh data latih ditampilkan pada Tabel 1.
Tabel 1 Contoh data latih
Fitur 1 Fitur 2 Fitur 3 Fitur 4 Fitur 5 Kelas
8
Seleksi Fitur Menggunakan Information Gain (IG)
Information gain dihitung untuk setiap fitur dalam data latih. Kemudian, fitur diurutkan berdasarkan nilai information gain dari yang terbesar ke yang terkecil. Fitur yang memiliki nilai information gain tertinggi pada suatu data akan dijadikan node parent untuk node-node selanjutnya pada decision tree. Hasil penghitungan nilai information gain dari setiap fitur berdasarkan data pada Tabel 1 dapat dilihat pada Tabel 2.
Tabel 2 menunjukkan bahwa fitur yang memiliki nilai information gain tertinggi ialah fitur 3 dengan nilai information gain 1.451.
Seleksi Fitur Menggunakan Symmetrical Uncertainty (SU)
Symmetrical uncertainty dihitung untuk setiap fitur dalam data latih. Kemudian, fitur diurutkan berdasarkan nilai symmetrical uncertainty dari yang terbesar ke yang terkecil. Fitur yang memiliki nilai symmetrical uncertainty tertinggi pada suatu data akan dijadikan node parent untuk node-node selanjutnya pada decision tree.
Hasil penghitungan nilai symmetrical uncertainty dari setiap fitur berdasarkan data pada Tabel 1 dapat dilihat pada Tabel 3. Dari Tabel 3 dapat dijelaskan bahwa fitur dengan nilai symmetrical uncertainty tertinggi ialah fitur 3 dengan nilai symmetrical uncertainty 0.640.
Klasifikasi
Pada tahap ini akan dibangun dua model decision tree. Model 1 dibangun menggunakan algoritme decision tree ID3 yang melakukan pemilihan fitur menggunakan algoritme seleksi fitur information gain. Model 2 dibangun menggunakan algoritme decision tree dengan menggunakan algoritme seleksi fitur symmetrical uncertainty untuk pemilihan fitur. Hasil dari tahapan ini berupa aturan klasifikasi yang diperoleh dari decision tree.
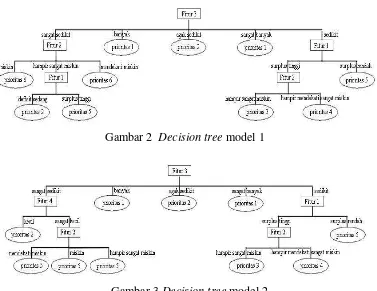
Decision tree model 1 dan model 2 berdasarkan data pada Tabel 1 dapat dilihat pada Gambar 2 dan Gambar 3. Dari Gambar 2 dan Gambar 3 dapat dilihat bahwa decision tree yang dihasilkan memiliki perbedaan. Hal ini menunjukkan bahwa algoritme seleksi fitur yang digunakan untuk memilih fitur pada decision tree mempengaruhi tree yang dihasilkan.
Tabel 2 Urutan fitur berdasarkan nilai information gain
Urutan 1 2 3 4 5
Atribut Fitur 3 Fitur 2 Fitur 4 Fitur 1 Fitur 5 IG 1.451 1.396 1.252 1.114 0.951
Tabel 3 Urutan fitur berdasarkan nilai symmetrical uncertainty
Urutan 1 2 3 4 5
9
Pruning
Pada tahap ini, decision tree yang dihasilkan pada tahap klasifikasi akan dipangkas. Decision tree yang dihasilkan setelah pemangkasan tree akan dilakukan pengujian kembali dengan menggunakan data uji yang sama sebelum dilakukan pemangkasan tree.
Perhitungan Akurasi
Akurasi menunjukkan tingkat kebenaran klasifikasi data terhadap kelas yang sebenarnya. Semakin rendah nilai akurasi, semakin tinggi kesalahan klasifikasi. Tingkat akurasi yang baik adalah tingkat akurasi yang mendekati nilai 100%.
Menurut Han dan Kamber (2001), pengukuran akurasi atau ketepatan model dapat dilakukan dengan menghitung perbandingan jumlah prediksi benar terhadap total seluruh record yang dapat diprediksi (persentase dari data uji yang diprediksi dengan benar oleh model).
Tingkat akurasi dihitung untuk setiap model decision tree yaitu model 1 dan model 2. Akurasi decision tree model 1 dan model 2 dibandingkan untuk mengetahui algoritme seleksi fitur terbaik dalam membangun decision tree pada data ketahanan pangan.
Gambar 2 Decision tree model 1
10
Lingkungan Pengembangan
Penelitian ini menggunakan perangkat keras dan perangkat lunak dengan spesifikasi sebagai berikut:
1 Perangkat keras:
Intel(R) Core(TM) i3 CPU M 330 @2.13 GHz 2.13 GHz.
Memori 2 GB.
Harddisk kapasitas 320 GB. 2 Perangkat lunak:
Windows 7 Ultimate.
XAMPP 1.7.0.
PHP 5.3.8.
HASIL DAN PEMBAHASAN
Data Indikator Ketahanan Pangan
Data sumber yang digunakan pada penelitian ini adalah data indikator ketahanan pangan untuk seluruh kabupaten di Indonesia dengan jumlah record sebanyak 348 baris dan 9 atribut. Atribut-atribut tersebut adalah rasio konsumsi normatif terhadap produksi bersih per kapita, penduduk di bawah garis kemiskinan, desa tanpa akses ke jalan, rumah tangga tanpa akses ke listrik, angka harapan hidup, berat badan balita di bawah standar, perempuan buta huruf, rumah tangga tanpa akses ke air bersih, dan rumah tangga dengan jarak 5 km dari fasilitas kesehatan. Data ini dikelompokkan kedalam enam kelas, yaitu prioritas 1, prioritas 2, prioritas 3, prioritas 4, prioritas 5, dan prioritas 6 (DKP dan WFP 2009). Contoh data dapat dilihat pada Lampiran 1.
Pembersihan Data
Dalam data ketahanan pangan terdapat dua data kabupaten yang tidak lengkap, yaitu Kabupaten Puncak Jaya dan Kabupaten Pegunungan Bintang sehingga data kedua kabupaten tersebut tidak digunakan dalam pembuatan model decision tree. Setelah dilakukan pembersihan data, jumlah data yang digunakan ialah sebanyak 346 record data.
Transformasi Data
11 pangan. Interval indikator-indikator ketahanan pangan dapat dilihat pada Lampiran 2 dan contoh data hasil transformasi data dapat dilihat pada Lampiran 3.
Data Latih dan Data Uji
Setelah tahap transformasi data dilakukan, tahap selanjutnya ialah membagi data menjadi 10 subset. Subset-subset inilah yang akan digunakan pada tahap klasifikasi sebagai data pelatihan dan pengujian. Subset yang terbentuk memiliki jumlah instance yang hampir sama dengan mengabaikan proporsi perbandingan antar kelas. Pembagian data secara keseluruhan dari kesepuluh subset data tersebut disajikan pada Tabel 4.
Klasifikasi
Berdasakan penjelasan pada tahapan penelitian, pada tahap ini akan dibangun 2 model decision tree, yaitu model 1 dan model 2. Setiap model akan dilakukan percobaan sebanyak 10 kali percobaan. Pola percobaan disajikan pada Tabel 5.
Model 1
Model 1 merupakan model decision tree yang dibangun menggunakan algoritme decision tree ID3 yang melakukan pemilihan fitur menggunakan
Tabel 5 Pola percobaan
Iterasi Data Latih Data UJi
1 S2, S3, S4, S5, S6, S7, S8, S9, S10 S1 2 S1, S3, S4, S5, S6, S7, S8, S9, S10 S2 3 S1, S2, S4, S5, S6, S7, S8, S9, S10 S3 4 S1, S2, S3, S5, S6, S7, S8, S9, S10 S4 5 S1, S2, S3, S4, S6, S7, S8 ,S9, S10 S5 6 S1, S2, S3, S4, S5, S7, S8, S9, S10 S6 7 S1, S2, S3, S4, S5, S6, S8, S9, S10 S7 8 S1, S2, S3, S4, S5, S6, S7, S9, S10 S8 9 S1, S2, S3, S4, S5, S6, S7, S8, S10 S9 10 S1, S2, S3, S4, S5, S6, S7, S8, S9 S10 Tabel 4 Pembagian data ketahanan pangan
Subset S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 Total
Jumlah
12
Dari Tabel 6 terlihat bahwa akurasi tertinggi diperoleh pada iterasi kesepuluh dengan nilai akurasi 64.52% dan iterasi terkecil diperoleh pada iterasi ketujuh dengan nilai akurasi 28.57%. Hal ini menunjukkan bahwa tingkat kesalahan pada iterasi ketujuh paling besar dibandingkan iterasi yang lainnya. Hal ini dapat disebabkan instance-instance data yang ada pada subset data uji iterasi ketujuh belum dapat mewakili setiap fitur untuk dapat diklasifikasikan pada kelas tertentu. Kelas-kelas yang salah diklasifikasikan pada iterasi kesepuluh dapat dilihat pada Tabel 7 dan contoh aturan hasil iterasi kesepuluh dapat dilihat pada Gambar 4.
Dari Gambar 4 dapat dijelaskan bahwa untuk menentukan kelas target dari suatu data, yang pertama kali diperiksa ialah fitur rumah tangga tanpa akses ke listrik. Tahap selanjutnya ialah memeriksa fitur rumah tangga tanpa akses ke air bersih. Misalnya nilai fitur rumah tangga tanpa akses ke air bersih ialah sangat besar (>= 70) maka data dimasukkan ke dalam prioritas 1.
Tabel 6 Akurasi pengujian model 1 Iterasi Akurasi (%)
1 48.57
2 40.00
3 45.71
4 45.71
5 40.00
6 42.86
7 28.57
8 42.86
9 54.29
10 64.52
Rata-rata 45.31
Tabel 7 Confusion matrix iterasi kesepuluh pada model 1
Kelas Prioritas 1 Prioritas 2 Prioritas 3 Prioritas 4 Prioritas 5 Prioritas 6
Prioritas 1 4 0 0 0 0 0
Prioritas 2 0 2 0 0 0 0
Prioritas 3 0 1 3 0 0 0
Prioritas 4 0 0 1 3 1 0
Prioritas 5 0 0 0 1 3 1
13
Model 2
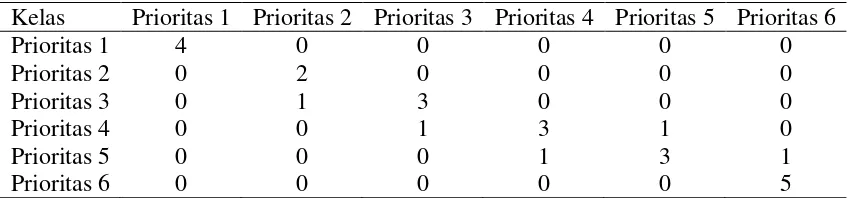
Model 2 merupakan model decision tree yang dibangun menggunakan algoritme decision tree dengan menggunakan algoritme seleksi fitur symmetrical uncertainty untuk pemilihan fitur. Hasil pengujian model 2 dapat dilihat pada Tabel 8.
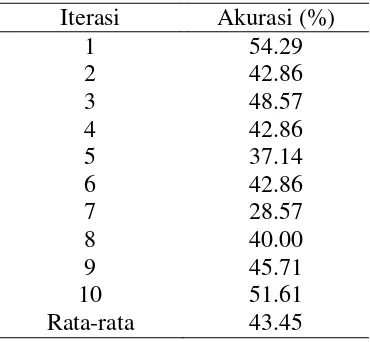
Tabel 8 menunjukkan bahwa akurasi terkecil terdapat pada iterasi ketujuh dengan nilai akurasi 28.57% dan akurasi terbesar terdapat pada iterasi pertama dengan nilai akurasi 54.29%. Kelas-kelas yang salah diklasifikasikan pada iterasi
Gambar 4 Contoh aturan hasil iterasi kesepuluh pada model 1
Tabel 8 Akurasi pengujian model 2 Iterasi Akurasi (%)
1 54.29
2 42.86
3 48.57
4 42.86
5 37.14
6 42.86
7 28.57
8 40.00
9 45.71
10 51.61
14
Dari Gambar 5 dapat dijelaskan bahwa untuk menentukan kelas target dari suatu data, yang pertama kali diperiksa ialah fitur rumah tangga tanpa akses ke listrik. Tahap selanjutnya ialah memeriksa fitur rumah tangga tanpa akses ke air bersih. Misalnya nilai fitur rumah tangga tanpa akses ke air bersih ialah agak besar (50-60) maka data dimasukkan ke dalam prioritas 1.
Pruning
Perlakuan selanjutnya adalah proses pemangkasan tree. Pemangkasan ini bertujuan menyederhanakan struktur tree yang dihasilkan namun dengan tidak mengurangi tingkat akurasi dalam proses klasifikasi.
Pada penelitian ini, dipilih metode post pruning. Sebelum memasuki pruning dengan metode ini, perlu disiapkan validation set. Validation set merupakan bagian dari data latih yang digunakan sebagai evaluasi awal terhadap tree yang terbentuk sebelum diujikan terhadap data uji. Pada penelitian ini, digunakan 60 record validation set.
Pada metode post pruning, model tree dipotong dari bagian bawah tree. Subtree yang dipotong akan diganti dengan sebuah node akar. Node akar akan diberi label dengan kelas yang sering muncul. Setelah dilakukan pemotongan
Gambar 5 Contoh aturan hasil iterasi pertama pada model 2 Tabel 9 Confusion matrix iterasi pertama pada model 2
Kelas Prioritas 1 Prioritas 2 Prioritas 3 Prioritas 4 Prioritas 5 Prioritas 6
Prioritas 1 1 0 1 0 0 0
Prioritas 2 0 1 0 1 0 0
Prioritas 3 0 0 0 0 0 0
Prioritas 4 1 0 0 4 2 1
Prioritas 5 0 0 1 4 5 1
15 sebuah subtree, tree akan diujikan terhadap validation set. Jika tree yang dihasilkan meningkatkan akurasi pada validation set, tree tersebut akan digunakan dan jika tidak, tree tersebut tidak digunakan. Proses ini akan terus dilakukan sampai tidak ada lagi tree yang dapat meningkatkan akurasi pada validation set.
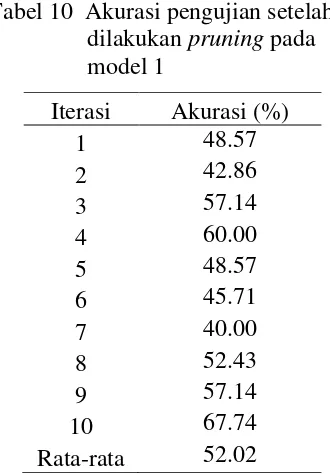
Pruning pada Model 1
Pada tahap ini, pruning dilakukan terhadap decision tree yang dihasilkan pada model 1. Akurasi setelah dilakukan pruning pada model 1 disajikan pada Tabel 10.
Setelah dilakukan pruning pada model 1, akurasi mengalami kenaikan cukup baik. Dari Tabel 10 terlihat bahwa umumnya akurasi pada setiap iterasi mengalami kenaikan. Akurasi tertinggi didapat pada iterasi kesepuluh dengan nilai akurasi 67.74% dan iterasi terkecil didapat pada iterasi ketujuh dengan nilai akurasi 40.00%. Rata-rata akurasi sebelum dan sesudah dilakukan pruning pada model 1 secara berurutan ialah 45.31% dan 52.02%.
Pruning pada Model 2
Pada tahap ini, pruning dilakukan terhadap decision tree yang dihasilkan pada model 2. Akurasi setelah dilakukan pruning pada model 2 disajikan pada Tabel 11.
Setelah dilakukan pruning pada model 2, akurasi juga mengalami kenaikan cukup baik. Dari Tabel 11 terlihat bahwa akurasi pada setiap iterasi mengalami kenaikan. Akurasi tertinggi didapat pada iterasi kesepuluh dengan nilai akurasi 61.29% dan iterasi terkecil didapat pada iterasi ketujuh dengan nilai akurasi 37.14%. Rata-rata akurasi sebelum dan sesudah dilakukan pruning pada model 2 secara berurutan ialah 43.45% dan 49.84%.
Tabel 10 Akurasi pengujian setelah dilakukan pruning pada model 1
Iterasi Akurasi (%)
1 48.57
2 42.86
3 57.14
4 60.00
5 48.57
6 45.71
7 40.00
8 52.43
9 57.14
10 67.74
16
Perbandingan Akurasi Model 1 dan Model 2
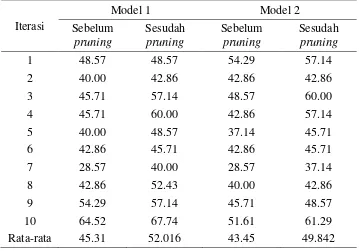
Tujuan dilakukan perbandingan akurasi model 1 dan model 2 ialah untuk menentukan algoritme seleksi fitur yang paling baik digunakan dalam membangun decision tree untuk menentukan daerah yang tahan atau rawan pangan. Perbandingan akurasi model 1 dan model 2 sebelum dan sesudah dilakukan pruning dapat dilihat pada Tabel 12.
Tabel 12 Perbandingan akurasi model 1 dan model 2 sebelum dan sesudah dilakukan pruning
17
Tabel 12 menunjukkan bahwa sebelum dilakukan pruning rata-rata akurasi model 1 lebih tinggi dibandingkan rata-rata akurasi model 2. Rata-rata akurasi model 1 dan model 2 sebelum dilakukan pruning ialah 45.31% dan 43.45%. Model 1 mencapai akurasi maksimal dengan nilai akurasi 64.52%, sedangkan akurasi maksimal yang dicapai pada model 2 ialah 54.29%. Berdasarkan rata-rata akurasi dan nilai akurasi maksimal yang didapatkan pada model 1 dan model 2 sebelum dilakukan pruning, dapat dijelaskan bahwa model 1 lebih baik dibandingkan model 2.
Secara keseluruhan, kedua model decision tree mengalami peningkatan akurasi setelah dilakukan pruning. Rata-rata akurasi model 1 dan model 2 sesudah dilakukan pruning secara berurutan ialah 52.02% dan 49.84%. Hal ini menunjukkan bahwa decision tree yang terbentuk sebelum dilakukan pruning mengalami suatu gejala overfitting. Hal ini terbukti dengan meningkatnya akurasi pada kedua model decision tree sesudah dilakukan pruning. Oleh karena itu, tree yang mengalami overfitting perlu dipangkas. Dari hasil penelitian, dapat diketahui bahwa proses pruning bisa meningkatkan hasil akurasi.
Sesudah dilakukan pruning, model 1 mencapai akurasi maksimal dengan nilai akurasi 67.74%. Jumlah node dan aturan yang dibutuhkan model 1 untuk mencapai akurasi maksimal ialah 119 node dan 102 aturan, sedangkan model 2 membutuhkan 129 node dan 110 aturan untuk mencapai akurasi maksimal yaitu 61.29%. Berdasarkan jumlah node dan aturan yang dibutuhkan untuk mencapai akurasi maksimal terlihat bahwa model 1 lebik baik dibandingkan dengan model 2.
Model 1 dan model 2 membutuhkan 8 fitur untuk mencapai akurasi maksimal. Fitur yang tidak digunakan model 1 dan model 2 untuk mencapai nilai maksimal adalah fitur rumah tangga dengan jarak 5 km dari fasilitas kesehatan.
KESIMPULAN DAN SARAN
Kesimpulan
Algoritme ID3 merupakan sebuah metode yang digunakan untuk konstruksi decision tree. Algoritme ID3 mengkonstruksi decision tree berdasarkan ukuran information gain. Information gain merupakan salah satu algoritme seleksi fitur yang digunakan untuk memilih fitur terbaik. Selain information gain, terdapat beberapa algoritme lain yang dapat digunakan untuk memilih fitur terbaik yang akan digunakan pada decision tree seperti symmetrical uncertainty. Algoritme seleksi fitur yang digunakan pada decision tree dapat menentukan akurasi dari decision tree yang dibangun.
18
menggunakan algoritme ID3 lebih baik dalam menentukan daerah yang tahan atau rawan pangan di Indonesia jika dibandingkan dengan algoritme decision tree menggunakan ukuran symmetrical uncertainty untuk pemilihan fitur.
Hal ini menunjukkan bahwa bias pada information gain tidak terjadi pada data yang memiliki perbedaan kemungkinan nilai pada setiap fiturnya tidak terlalu besar. Dengan demikian, information gain tidak perlu dinormalisasi menggunakan symmetrical uncertainty. Maksimal kemungkinan nilai pada fitur data ketahanan pangan ialah 6 kemungkinan, sedangkan minimal kemungkinan nilai fitur ialah 4 kemungkinan.
Saran
Penelitian ini masih memiliki beberapa kekurangan yang dapat diperbaiki pada penelitian selanjutnya. Beberapa saran tersebut di antaranya:
1 Menggunakan algoritme seleksi fitur yang lain sehingga bisa dibandingkan algoritme seleksi fitur yang paling baik.
2 Menggunakan data yang memiliki perbedaan kemungkinan nilai fitur yang besar agar perbedaan akurasi dapat dilihat perbedaanya.
3 Menggunakan algoritme klasifikasi yang lain agar perbedaan akurasi dari kedua algoritme seleksi fitur dapat dilihat perbedaannya.
DAFTAR PUSTAKA
[DKP dan WFP] Dewan Ketahanan Pangan dan World Food Programme. 2009. Peta Ketahanan dan Kerawanan Pangan Indonesia. Jakarta: Dewan Ketahanan Pangan, Departemen Pertanian RI.
Fu L. 1994. Neural Network in Computers Intelligence. Singapura: McGraw-Hill. Hall MA. 1999. Feature selection for discrete and numeric class machine learning
[internet]. [diacu 2013 April 7]. Tersedia dari: http: //www.cs.waikato.ac.nz/ ml/publications/1999/99MH-Feature-Select.pdf.
Han J, Kamber M. 2001. Data Mining Concepts & Techniques. San Fransisco: Morgan Kaufman.
Novakovic J, Strbac P, Bulatovic D. 2011. Toward optimal feature selection using rangking methods and classification algorithms. Yugoslav Journal of
Operations Research. 21(1):119-135.
Ramaswami M, Bhaskaran R. 2009. A study on feature selection techniques in educational data mining. Journal of Computing. 1(1):7-11.
19 Lampiran 1 Contoh data sebelum transformasi data
20
Lampiran 2 Interval indikator-indikator data ketahanan pangan
Indikator Nilai awal Kelas
Rasio Konsumsi Normatif Per Kapita terhadap Produksi Bersih Serealia
< 0.50 Surplus Tinggi 0.50 - 0.75 Surplus Sedang 0.75 - 1.00 Surplus Rendah 1.00 - 1.25 Defisit Rendah 1.25 - 1.50 Defisit Sedang >= 1.50 Defisit Tinggi
Penduduk Hidup di Bawah Garis Kemiskinan
0 - 10 Hampir Mendekati Miskin 10.00 - 15.00 Hampir Miskin
15 - 20 Miskin
20 - 25 Hampir Mendekati Sangat Miskin
25 - 35 Hampir Sangat Miskin >= 35 Sangat Miskin
Rumah Tangga tanpa Akses ke Listrik
Desa tanpa Akses ke Jalan
21 Lampiran 2 Lanjutan
Indikator Nilai awal Kelas
Berat Badan Balita di Bawah Standar
< 10 Baik
10 - 20 Kurang
20 - 30 Buruk
>= 30 Sangat Buruk
Rumah Tangga dengan Jarak 5 KM dari Fasilitas Kesehatan
< 20 Sangat Kecil
20 - 30 Kecil
30 - 40 Agak Kecil
40 - 50 Agak Tinggi
50 - 60 Tinggi
>= 60 Sangat Tinggi
Rumah Tangga tanpa Akses ke Air Bersih
< 30 Sangat Sedikit
30 - 40 Sedikit
40 - 50 Agak Sedikit
50 - 60 Agak Besar
60 - 70 Besar
22
Lampiran 3 Contoh data hasil transformasi data
23