MODUL I
REGRESI LINEAR SEDERHANA
Disusun Oleh :
Kelompok 2
1. Aliffah Aprilya (2070031032)
2. Bazlin Dunyana (2070031093)
3. Muhammad Lukman Hakim (2070031092)
4. Putra F S R Tamnge (2070031038)
5. Ramadhani (2070031027)
6. Wahyu Pratama Sutardji (2070031026)
LABORATORIUM STATISTIKA INDUSTRI PROGRAM STUDI
TEKNIK INDUSTRI UNIVERSITAS UNIVERSITAS
KRISNADWIPAYANA JAKARTA
2021
ii
Lembar Pengesahan
Laporan ini disusun sebagai salah satu syarat kelulusan Laporan Akhir Praktikum Perancangan Sistem Kerja dan Ergonomi Modul 2 “Perbaikan Cara Kerja”.Jurusan Teknik Industri Fakultas Teknik Universitas Krisnadwipayana
Kelompok 2
1. Aliffah Aprilya (2070031093)
2. Bazlin Dunyana (2070031093)
3. Muhammad Lukman Hakim (2070031093)
4. Putra F S R Tamnge (2070031093)
5. Ramadhani (2070031093)
6. Wahyu Pratama Sutardji (2070031093)
Dengan ini telah diperiksa untuk DITERIMA/DITOLAK
Jakarta, 8 Desember 2021
Mengetahui, Menyetujui,
Ka. Lab Teknik Industri Asisten Laboratorium
Aris Abbas, S.T, M.M, M.T M. Chernd Alforbiach
NIDN. 03290565505 NIM. 1970031042
iii
KATA PENGANTAR
Alahamdulillahirabbil ‘Alamin segala puji syukur kita panjatkan kehadirat Allah SWT,Tuhan scmesta alam yang hanya kepada Nyalah kami berserah diri. Dan atas izin dari-Nyalah kami mampu menyusun Makalah yang berjudul "Analisa Regresi Linear Sederhana” ini.
Walaupun demikian, penyusun berusaha dengan semaksimal mungkin demi kesempurnaan penyusunan laporan ini baik dari hasil kegiatan belajar mengajar di sekolah, maupun dalam menunaikan praktik kerja di dunia industri. Saran dan kritik yang sifatnya membangun begitu diharapkan oleh penyusun demi kesempurnaan dalam penulisan laporan berikutnya.
Dalam kesempatan ini, penulis mengucapkan banyak terima kasih kepada semua pihak yang telah membantu dalam penyusunan Laporan Praktik Kerja Industri ini.
Akhir kata, penyusun berharap laporan ini dapat bermanfaat bagi pembaca serta dapat membantu bagi kemajuan serta perkembangan SMK NU Pekalongan.
Saya ucapkan terima kasih banyak kepada semua pihak yang telah membantu, semoga Allah Swt. membalas semua kebaikan kalian. Amiin.
Jakarta, 8 Desember 2021
Kelompok 2
iv
DAFTAR ISI
BAB I ... 1
PENDAHULUAN ... 1
1.1 Maksud dan Tujuan ... 1
1.2 Latar Belakang ... 1
1.3 Perumusan Masalah ... 2
1.4 Pembatasan Masalah ... 2
1.5 Sistematika Pembahasan ... 2
BAB II ... 5
LANDASAN TEORI ... 5
2.1 Pengertian Regresi ... 5
2.2 Model Regresi Linier Sederhana ... 6
2.3 Analisis Regresi Linear Berganda ... 7
2.4 Hubungan Linier Antara Dua Variabel ... 8
2.5 Regresi Dalam Variabel Terikat Data Kualitatif ... 9
BAB III ... 12
PENGUMPULAN DAN PENGOLAHAN DATA ... 12
3.1 Pengumpulan data ... 12
3.2 Pengolahan data ... 13
3.2.1 Menghitung koefisien regresi ... 14
3.2.2 Menghitung jumlah kuadrat total ... 14
3.2.3 Menghitung jumlah kuadrat regresi a ... 14
3.2.4 Menghitung jumlah kuadrat reduksi ... 14
3.2.5 Menghitung jumlah kuadrat regresi b ... 14
3.2.6 Menghitung jumlah kuadrat sisa ... 14
3.2.7 Menghitung uji F ... 15
3.2.8 Menghitung F table. ... 15
3.2.9 Melakukan uji hipotesis. ... 15
3.2.10 Melakukan perhitungan regresi menggunakan software SPSS. ... 16
BAB IV ... 23
ANALISIS ... 23
4.1 Analisis regresi linear sederhana dengan cara manual ... 23
4.2 Analisis regresi linier sederhana menggunakan software SPSS ... 23
v
BAB V ... 24
KESIMPULAN DAN SARAN ... 24
5.1 KESIMPULAN ... 24
5.2 SARAN ... 24
DAFTAR PUSTAKA ... 25
vi
Daftar Gambar
Gambar 3.2.10. 1 tampilan menu awal software spss ... 16
Gambar 3.2.10. 2 tampilan menu new dataset software spss ... 16
Gambar 3.2.10. 3 substitusi data pengamatan kedalam variabel view ... 17
Gambar 3.2.10. 4 substitusi data pengamatan kedalam data view ... 17
Gambar 3.2.10. 5 langkah - angkah menentukan rumus regresi ... 18
Gambar 3.2.10. 6 subtitusi variable ke dalam kolom pengolahan regresi ... 18
Gambar 3.2.10. 7 subtitusi variable ke dalam kolom pengolahan regresi ... 19
1
BAB I
PENDAHULUAN
1.1 Maksud dan Tujuan
Tujuan dari diadakannya praktikum ini adalah : 1. Mengetahui pengertian regresi.
2. Mengetahui metode analisis regresi untuk menentukan hubungan sebab- akibat antara satu variable dengan variabel-variabel lain.
3. Untuk mengetahui cara menganalisis regresi linear sederhana dengan cara manual.
4. Untuk mengetahui cara menganalisis regresi linear sederhana dengan menggunakan SPSS.
Maksud dari diadakannya praktikum :
1. Membuat estimasi rata-rata dan nilai variabel tergantung dengan didasarkan pada nilai variabel bebas.
2. Untuk menguji hipotesis karakteristik dependensi.
3. Meramalkan nilai rata-rata variabel bebas yang didasari nilai variabel bebas diluar jangkauan sample.
1.2 Latar Belakang
Analisis regresi merupakan suatu cara yang dapat digunakan untuk mengetahui hubungan sebuah variabel tak bebas dengan satu atau lebih variabel bebas. Analisis regresi dapat digunakan untuk menganalisis data dan mengambil kesimpulan yang bermakna tentang hubungan ketergantungan variabel terhadap variabel lainnya. Berdasarkan jumlah variabel bebas, analisis regresi linier dibagi menjadi dua macam yaitu, analisis regresi linier sederhana dan analisis regresi linier berganda.
Model regresi dapat diperoleh dengan melakukan estimasi terhadap parameter modelnya. Untuk menduga nilai parameter regresi ini biasanya digunakan Metode Kuadrat Terkecil (MKT). Metode MKT ini diterapkan jika asumsi-asumsi berikut terpenuhi, yaitu asumsi ragam berdistribusi normal,
2
tidak terjadi multikolinieritas, kehomogenan ragam sisaan dan tidak autokorelasi.
Jika terjadi masalah multikolinearitas, maka metode kuadrat terkecil bukan solusi yang terbaik, karena pendugaan koefisien regresi yang dihasilkan tidak stabil dan variansi koefisien regresi menjadi sangat besar. Oleh karena itu diperlukan suatu metode pendugaan alternatif yang memberikan pendugaan yang lebih baik. Salah satu metode untuk mengatasi masalah multikolinearitas yaitu metode regresi ridge, dengan regresi ridge maka koefisien regresi yang dihasilkan lebih stabil dan variansi koefisien regresi lebih kecil[7]. Pada dasarnya metode ini merupakan modifikasi dari metode kuadrat terkecil.
Asumsi yang harus dipenuhi pada metode ini adalah matriks korelasi dari variabel bebas dapat diinverskan dengan menggunakan metode regresi ridge sehingga nilai dugaan koefisien regresi mudah untuk diperoleh
1.3 Perumusan Masalah
Berdasarkan latar belakang, yang menjadi masalah dalam penelitian ini adalah bagaimana menggunakan metode regresi ridge untuk menyelesaikan masalah multikolinearitas.
1.4 Pembatasan Masalah
Adapun masalah hanya dibatasi pada penggunaan metode regresi ridge dalam mengatasi multikolinaritas kurang sempurna pada faktor-faktor yang mempengaruhi analisis regresi sederhana penggunaaan metode regresi ridge yang dikhususkan untuk mahasiswa sampel kelompok 2 Universitas Krisnadwipayana.
1.5 Sistematika Pembahasan
Sitematika pembahasan dalam penelitian ini terdiri dari lima bab, adapun uraiannya sebagai berikut :
Bab I Pendahuluan : bertujuan untuk memberikan uraian latar belakang masalah, rumusan masalah, tujuan penelitian, manfaat penelitian dan sistematika penulisan.
3
Bab II Landasan Teori : berisi tentang materi-materi berupa defenisi-defenisi, teorema-teorema dan teori-teori terkait, yang akan dijadikan landasan untuk penelitian.
Bab III Metode Penelitian : yang meliputi sumber data, variabel penelitian, dan langkah-langkah dari metode yang digunakan.
Bab IV Hasil dan Pembahasan : yaitu memaparkan hasil-hasil penelitian.
Bab V Penutup : yang memuat simpulan dan saran bagi pengembangan lebih lanjut hasil penelitian ini.
4
Diterima
Pengumpulan Laporan Asintensi 1 dan 2
Praktiku m dimulai
Praktikum Pengumpulan Data Observasi :
1. Data variabel Independent (X)
2. Data Variabel Dependent (Y) Flow Chart :
Ditolak
Seles ai Responsi
5
BAB II
LANDASAN TEORI
2.1 Pengertian Regresi
Regeresi adalah alat yang berfungsi untuk membantu memperkirakan nilai suatu varibel yang tidak diketahui dari satu atau beberapa variabel yang tidak diketahui. Analisis regresi didefinisikan sebagai kajian terhadap hubungan satu variabel yang disebut variabel yang diterangkan (the explaind variabel) atau sering disebut sebagai variabel tergantung, dan variabel tidak tergantung atau variabel bebas. Metode regresi yang sering digunakan yaitu analisis regresi linier dan non linier. Jika variabel tidak bebas bersifat diskrit, analisis linier tidak layak digunakan karena bebebarapa alasan, yaitu :
a. Variabel tidak bebas di dalam metode regresi linier harus bersifat continue
b. Variabel tidak bebas di dalam metode regresi linier harus dapat mengakomodasi nilai negatif Variabel diskrit biasa juga dikatakan salam kategori dan sering juga disebut variabel nominal atau variabel kategorik.
Metode analisis regresi digunakan untuk menghasilkan hubungan antara dua variabel atau lebih dalam bentuk numerik dan untuk bagaimana dua atau lebih peubah saling berkait, dimana telah diketahui variabel lainnya dan variabel mana yang mempengaruhinya. Persamaan regresi ini merupakan persamaan garis yang paling mewakili hubungan antara dua variabel tersebut.
Beberapa asumsi statistik yang diperlukan dalam melakukan analisis regresi adalah :
a. Variabel tak bebas, yaitu fungsi linier dari variabel bebas. Jika hubungan tersebut tidak linier, data sering kali harus ditransformasikan agar menjadi linier.
b. Variabel bebas adalah tetap atau diukur tanpa kesalahan.
c. Tidak ada korelasi antara variabel bebas
6
d. Variansi dari variabel tak bebas terhadap garis regresi adalah sama untuk seluruh nilai variabel tak bebas.
e. Nilai variabel tak bebas harus berdistribusi normal atau mendekati normal.
f. Nilai peubah bebas sebaiknya merupakan besaran yang relative mudah diproyeksikan
2.2 Model Regresi Linier Sederhana
Dalam memperkirakan hubungan antara dua variabel terlebih dahulu membuat asumsi mengenai bentuk hubungan yang dinyatakan dalam fungsi tertentu. Dalam beberapa hal, bisa dicek asumsi tersebut setelah hubungan diperkirakan.
Regresi linier sederhana memiliki fungsi sebagai berikut :
a. Menguji hubungan / korelasi / pengaruh satu variabel bebas terhadap satu variabel terikat.
b. Melakukan prediksi atau estimasi variabel terikat berdasarkan variabel bebasnya.
c. Data yang dianalisis haru berupa data yang berskala interval / rasio.
Fungsi linier, selain mudah interpretasinya, juga dapat digunakan sebagai pendekatan (approximation) atas hubungan yang bukan linier (non linier). Fungsi linier, mempunyai bentuk persamaan sebagai berikut :
Ƴ = A + BX
Dimana A dan B adalah konstanta atau parameter, yang nilainya harus diestimasi. Persamaan Ƴ = A + BX juga bisa ditulis
Y = B0 + B1X1 atau dengan symbol lainnya. Beberapa symbol yang sering digunakan dalam fungsi linier ini adalah :
∆ = delta, symbol pertambahan
∆X = delta X, pertambahan X
∆Y = delta Y, pertambahan Y
7
B = ∆X ∆Y = rata – rata pertambahan Y per 1 unit (satuan) pertambahan X, atau pertambahan X 1 unit akan mengakibatkan pertambahan Y sebesar B.
Y = 2 + 1,5X, A = 2,B = 1,5 artinya kalua X = 0, Y= 2 kalau X bertambah 1 unit, Y bertambah 1,5 unit.
Hubungan di atas merupakan hubungan matematis, secara teoritis, apabila X = 10, Y harus 2 + 1,5 (10) = 17. Tetapi dalam prakteknya tidak demikian, sebab yang mempengaruhi Y bukan hanya X saja melainkan masih ada faktor lain yang tidak dimasukkan dalam persamaan. Faktor – faktor tersebut secara keseluruhan disebut kesalahan pengganggu atau disturbance error. Kesalahan pengganggu tersebutlah yang menyebabkan suatu ramalan sering tidak tepat.
Kesalahan ramalan menyebabkan perencanaan menjadi tidak akurat, sehingga kesalahan tersebut mengakibatkan resiko, dan karenanya harus diusahakan sekecil mungkin. Dalam membuat keputusan, selalu ada resiko yang disebabkan oleh adanya kesalahan. Karena kesalahan itu tidak dapat dihilangkan sama sekali, maka resiko itu berapapun kecilnya selalu ada.
Resiko hanya bisa diperkecil dengan memperkecil kesalahan (minimized error). Dengan 20 memperhitungkan kesalahan pengganggu,ɛ, maka bentuk persamaan fungsi linier diatas menjadi sebagai berikut :
Y = A + BX + ɛ
Dimana : A dan B adalah konstanta yang harus di estimasi. ɛ adalah kesalahan pengganggu (disturbance error)
2.3 Analisis Regresi Linear Berganda
Analisis yang memiliki variabel bebas lebih dari satu disebut analisis regresi linier berganda. Teknik regresi linier berganda digunakan untuk mengetahui ada tidaknya pengaruh signifikan dua atau lebih variabel bebas terhadap variabel terikat (Y).Model regresi linier berganda untuk populasi dapat ditunjukkan sebagai berikut :
Y = (β0 + β1X1 + β2X2 + …. K)
Model regresi linier berganda untuk populasi diatas dapat ditaksir dengan model regresi linier berganda untuk sampel, yaitu :
8
Ŷ = b0 + b1x1 + b2x2 + …. +bkxk dengan :
Ŷ = nilai penduga bagi variabel Y = dugaan bagi parameter konstanta b0 = dugaan bagi parameter konstanta b1, b2,….bk = variabel bebas b1,b2,….bk
2.4 Hubungan Linier Antara Dua Variabel
Salah satu tujuan analisis data ialah untuk memperkirakan / memperhitungkan besarnya efek kuantitatif dari perubahan suatu kejadian terhadap kejadian lainnya. Setiap kebijakan (policy), baik dari pemerintah maupun swasta, selalu dimaksudkan untuk mengadakan perubahan (change).
Sebagai contoh, misalnya pemerintah menambah jumlah pupuk agar produksi padi meningkat, pemerintah menaikkan gaji pegawai negeri agar prestasi kerja mereka meningkat, dll.
Untuk keperluan evaluasi / penilaian sautu kebijaksanaan mungkin ingin diketahui besarnya efek kuantitatif dari perubahan suatu kejadian terhadap kejadian lainnya. Kejadian – kejadian tersebut, untuk keperluan analisis, bisa dinyatakan di dalam perubahan nilai variabel. Untuk analisis dua kejadian (events) digunakan dua variabel x dan y.
Apabila dua variabel X dan Y mempunyai hubungan (korelasi), maka perubahan nilai variabel yang satu akan memepengaruhi nilai variabel lainnya. Hubungan variabel dapat dinyatakan dalam bentuk fungsi, misalnya Y = f (X) → Y = 2 + 1,5X. Apabila bentuk fungsinya sudah diketahui, maka dengan mengetahui nilai dari satu variabel (=X), maka nilai variabel lainnya (=Y) dapat diperkirakan. Data hasil ramalan yang dapat menggambarkan kemampuan untuk waktu yang akan datang, sangat berguna bagi dasar perencanaan.
Untuk membuat ramalan (forecasting) Y dengan menggunakan nilai dari X, maka X dan Y harus mempunyai hubungan yang kuat. Kuat tidaknya
9
hubungan X dan Y diukur dengan suatu nilai, yang disebut koefisien korelasi, sedangkan besarnya pengaruh X terhadap Y, diukur dengan koefisien regresi.
2.5 Regresi Dalam Variabel Terikat Data Kualitatif
Aplikasi data kualitatif sebagai variabel bebas disebut juga dengan variabel dummy. Kasus yang sering dijumpai umumnya adalah kasus data kualitatif yang dapat diterapkan dalam vaariabel terikat. Kasus yang bisa dijadikan contoh yaitu, kemampuan seseorang untuk memiliki sebuah kendaraan di kota yang dipengaruhi oleh jarak, pendapatan. Model yang keduanya menggunakan variabel kualitatif atau kategori terikat dapat dibedakan dalam dua hal yaitu:
1. Regresi model probabilitas linier (linier probability model = LPM)
Model ini digunakan untuk menganalisa variabel dependen yang bersifat kategorik dan variabel independen yang bersifat nonkategorik.
Misalnya kita ingin mengetahui kemungkinan seseorang memiliki rumah (diwakili dengan variabel Yi ) berdasarkan gaji per bulan. Maka persamaannya adalah sebagai berikut :
Yi = 𝑏0 + 𝑏1 Xi +ei Yi
Karena Yi merupakan bilangan biner (berisi 0 dan 1), persamaan tersebut disebut juga linear probability model (LPM). Nilai Yi yang diharapkan tergantung kepada Xi, E(Yi|Xi), dapat diartikan sebagai probabilitas bersyarat (conditional probability) kemungkinan terjadinya Yi tergantung pada Xi, atau Pr(Yi=1|Xi). Dengan demikia, dalam contoh disini, E(Yi|Xi) menunjukkan kemungkinan sebuah keluarga memiliki rumah apabila penghasilannya Xi.
Misalnya diasumsikan E(Hi)=0 untuk mendapatkan estimator tak bias dapat digunakan persamaan berikut ini :
E(Yi|Xi) = bi + b2 X1
10
Bila P1 probabilitas bahwa Yi = 1 (memiliki rumah) dan (1-Pi) adalah probabilitas bahwa Yi=0 (tidak memiliki rumah), variabel Yi memiliki probabilitas Pi + (1-Pi) = 1. Berarti Yi mengikuti distribusi probabilitas Bernoulli.
Dengan persamaan tersebut, probabilitas seseorang untuk memiliki rumah merupakan fungsi linear gaji orang tersebut. Semakin tinggi pendapatan sesorang semakin besar pula kemungkinan orang tersebut memiliki rumah.
Model LPM memiliki karakteristik yang mirip dengan model regresi linear, sehingga metode OLS dapat digunakan pada model LPM ini. Model ini banyak digunakan karena mudah. Namun model ini memiliki kelemahan, diantaranya adalah sebagai berikut :
• Residual tidak berdistribusi normal, karena mengikuti distribusi binomial (distribusi Bernoulli). Sebenarnya kelemahan ini tidak begitu bermasalah, karena akanmenghasilkan estimator yang BLUE.
Apabila datanya semakin banyak, distribusinya juga akan mendekati distribusi normal.
• Varian residual mudah bersifat heteroskedastis, karena
ei berdistribusi binomial. Apabila varian residual tersebut bersifat heteroskedastis, maka estimatornya tidak lagi bersifat BLUE. Untuk menghilangkan masalah ini, dapat diterapkan analisis regresi dengan metode WLS (weighted least square)
• Nilai Prediksi Yi, tidak akan selalu terletak di antara 0 dan 1 seperti pada datanya. Untuk mengatasi hal ini, diperlukan model analisis baru yaitu logit dan probit.
• Nilai koefisien determinasi (R2) tidak lagi mampu menjelaskan kesesuaia garis regresi dengan datanya.
2. Regresi model logistic biner (binary logistic regression model)
11
Analisis regresi logistik biner digunakan untuk menjelaskan hubungan antara variabel respon yang berupa data dikotomik/biner dengan variabel bebas yang berupa data berskala interval dan atau kategorik
Regresi logistik biner (logistic regression) sebenarnya sama dengan analisis regresi berganda, hanya variabel terikatnya
merupakan variabel dummy (0 dan 1). Sebagai contoh, pengaruh beberapa rasio keuangan terhadap keterlambatan penyampaian laporan keuangan. Maka variabel terikatnya adalah 0 jika terlambat dan 1 jika tidak terlambat (tepat). Regresi logistik tidak memerlukan
asumsi normalitas, meskipun screening data outliers tetap dapat dilakukan.
Asumsi-asumsi dalam regresi logistik biner:
• Tidak mengasumsikan hubungan linier antar variabel dependen dan independent
• Variabel dependen harus bersifat dikotomi (2 variabel)
• Variabel independent tidak harus memiliki keragaman yang sama antar kelompok variabel
• Kategori dalam variabel independent harus terpisah satu sama lain atau bersifat eksklusif
• Sampel yang diperlukan dalam jumlah relatif besar, minimum dibutuhkan hingga 50 sampel data untuk sebuah variabel prediktor (bebas).
Tidak seperti regresi linier biasa, regresi logistik biner tidak mengasumsikan hubungan antara variabel independen dan dependen secara linier. Regresi logistik biner merupakan regresi non linier dimana model yang ditentukan akan mengikuti pola kurva .
12
BAB III
PENGUMPULAN DAN PENGOLAHAN DATA
3.1 Pengumpulan data
Pengumpulan data berisikan subtitusi data pengamatan yang telah dikumpulkan pada saat pengamatan.
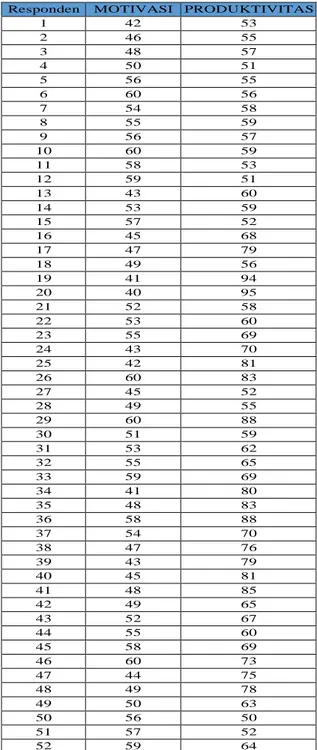
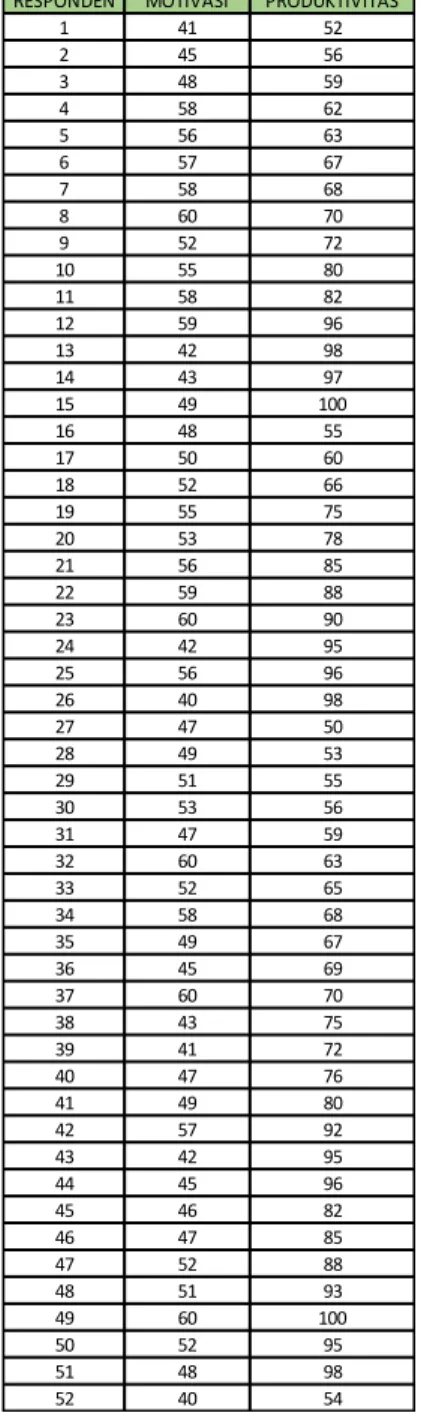
Tabel 3.1. 1 pengumpulan data
Responden MOTIVASI PRODUKTIVITAS
1 42 53
2 46 55
3 48 57
4 50 51
5 56 55
6 60 56
7 54 58
8 55 59
9 56 57
10 60 59
11 58 53
12 59 51
13 43 60
14 53 59
15 57 52
16 45 68
17 47 79
18 49 56
19 41 94
20 40 95
21 52 58
22 53 60
23 55 69
24 43 70
25 42 81
26 60 83
27 45 52
28 49 55
29 60 88
30 51 59
31 53 62
32 55 65
33 59 69
34 41 80
35 48 83
36 58 88
37 54 70
38 47 76
39 43 79
40 45 81
41 48 85
42 49 65
43 52 67
44 55 60
45 58 69
46 60 73
47 44 75
48 49 78
49 50 63
50 56 50
51 57 52
52 59 64
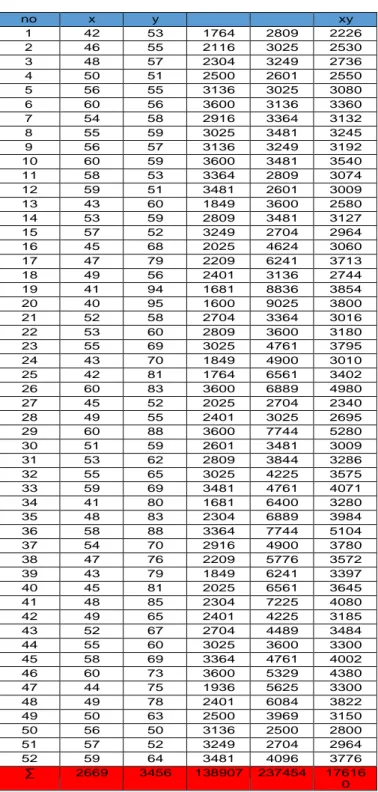
13 3.2 Pengolahan data
Pengolahan data berisikan perhitungan dari data yang ada di lembar pengamatan secara manual dan menggunakan aplikasi SPSS.
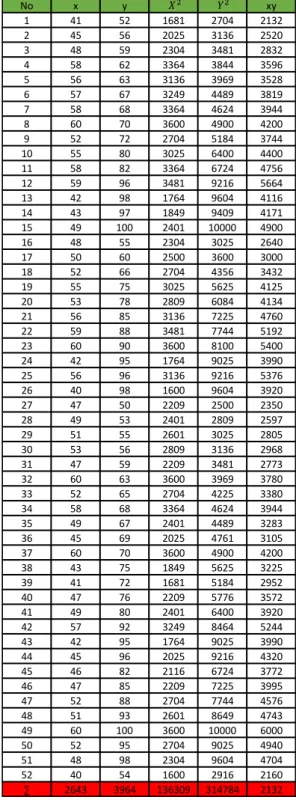
Tabel 3.1. 2 pengolahan data
no x y xy
1 42 53 1764 2809 2226
2 46 55 2116 3025 2530
3 48 57 2304 3249 2736
4 50 51 2500 2601 2550
5 56 55 3136 3025 3080
6 60 56 3600 3136 3360
7 54 58 2916 3364 3132
8 55 59 3025 3481 3245
9 56 57 3136 3249 3192
10 60 59 3600 3481 3540
11 58 53 3364 2809 3074
12 59 51 3481 2601 3009
13 43 60 1849 3600 2580
14 53 59 2809 3481 3127
15 57 52 3249 2704 2964
16 45 68 2025 4624 3060
17 47 79 2209 6241 3713
18 49 56 2401 3136 2744
19 41 94 1681 8836 3854
20 40 95 1600 9025 3800
21 52 58 2704 3364 3016
22 53 60 2809 3600 3180
23 55 69 3025 4761 3795
24 43 70 1849 4900 3010
25 42 81 1764 6561 3402
26 60 83 3600 6889 4980
27 45 52 2025 2704 2340
28 49 55 2401 3025 2695
29 60 88 3600 7744 5280
30 51 59 2601 3481 3009
31 53 62 2809 3844 3286
32 55 65 3025 4225 3575
33 59 69 3481 4761 4071
34 41 80 1681 6400 3280
35 48 83 2304 6889 3984
36 58 88 3364 7744 5104
37 54 70 2916 4900 3780
38 47 76 2209 5776 3572
39 43 79 1849 6241 3397
40 45 81 2025 6561 3645
41 48 85 2304 7225 4080
42 49 65 2401 4225 3185
43 52 67 2704 4489 3484
44 55 60 3025 3600 3300
45 58 69 3364 4761 4002
46 60 73 3600 5329 4380
47 44 75 1936 5625 3300
48 49 78 2401 6084 3822
49 50 63 2500 3969 3150
50 56 50 3136 2500 2800
51 57 52 3249 2704 2964
52 59 64 3481 4096 3776
∑ 2669 3456 138907 237454 17616 0
14 3.2.1 Menghitung koefisien regresi
a = ∑𝑌. ∑𝑋2−∑𝑋 . ∑𝑋𝑌
𝑛. ∑𝑋2−(∑𝑋)2 = (3.456 × 138.907)−( .669 × 176.160) (5 × 138.907)− .6692
b = 𝑛. ∑𝑋𝑌−∑𝑋 . ∑𝑌 𝑛. ∑𝑋2−(∑𝑋)2
= −42238,973
= (5 × 176.160)−( .669 × 3.456) (5 × 138.907)−( .6692)
= −0,639 Persamaan : ′ = 𝑎 + 𝑏
Y’ = −42.238,973+ (−0,639 ) 3.2.2 Menghitung jumlah kuadrat total
𝐽𝐾𝑇 = ∑ = 237.454
3.2.3 Menghitung jumlah kuadrat regresi a 𝐽𝐾𝑎 = (∑𝑌)2
𝑛
(3.456) 2
= 5
= 229.691,076
3.2.4 Menghitung jumlah kuadrat reduksi
𝐽𝐾𝑅= 𝐽𝐾𝑇 - 𝐽𝐾𝑎 = 237.454 - 229.691,076 = 7.762,924 3.2.5 Menghitung jumlah kuadrat regresi b
𝐽𝐾𝑏 = 𝑏 . ∑XY - (∑𝑋.∑𝑌)
𝑛
= −0,639 × 176.160 - (2.669 ×3.456 )
5
= −289.952,086
3.2.6 Menghitung jumlah kuadrat sisa 𝐽𝐾𝑠 = 𝐽𝐾𝑅 − 𝐽𝐾𝑏
= 7762,924 - (−289.952,086)
= 297.715,01
15 1
3.2.7 Menghitung uji F 𝐽𝐾𝑏
𝐹 = 1 𝐽𝐾𝑠 (𝑛
− 2)
−289.952,086
= 297.715,01 (52 − 2)
= −48,696
𝐹ℎ𝑖𝑡𝑢𝑛𝑔 = −48,696
3.2.8 Menghitung F table.
𝑑𝑘𝑝𝑒𝑚𝑏𝑖𝑙𝑎𝑛𝑔 =𝑗𝑢𝑚𝑙𝑎ℎ 𝑣𝑎𝑟𝑖𝑎𝑏𝑒𝑙 𝑏𝑒𝑏𝑎𝑠 = 1 𝑑𝑘𝑝𝑒𝑛𝑦𝑒𝑏𝑢𝑡 = 𝑛 − 2
= 52 − 2
= 50 (menentukan kolom) 𝐹 𝑡𝑎𝑏𝑒𝑙 = 4,03
3.2.9 Melakukan uji hipotesis.
Pernyataan hipotesis :
H0 = Tidak ada pengaruh variabel X (motivasi) terhadap variabel Y (ptoduktivitas).
H1 = Ada pengaruh variabel X (motivasi) terhadap variabel Y (ptoduktivitas).
Jika 𝐹ℎ𝑖𝑡𝑢𝑛𝑔 ≤ 𝐹𝑡𝑎𝑏𝑒𝑙 maka H0 Diterima Jika 𝐹ℎ𝑖𝑡𝑢𝑛𝑔 > 𝐹𝑡𝑎𝑏𝑒𝑙 maka H0 Ditolak
Terlihat dari hasil di atas, F hitung lebih kecil daripada F table (−48,696 ≤ 4,03 ). Maka dapat disimpulkan bahwa produktivitas tidak terpengaruh oleh motivasi.
16
3.2.10 Melakukan perhitungan regresi menggunakan software SPSS.
Berikut Langkah – Langkah mengaplikasikan software SPSS.
1. Buka Software SPSS lalu akan ada tampilan menu sebagai berikut, lalu klik new dataset.
Gambar 3.2.10. 1 tampilan menu awal software spss
Gambar 3.2.10. 2 tampilan menu new dataset software spss
17
2. Lalu klik variable view, kemuadian subtitusi variabel X dan Y ke dalam kolom tersebut
Gambar 3.2.10. 3 substitusi data pengamatan kedalam variabel view
3. Lalu subtitusi data yang ada di lembar pengamatan ke dalam data view
Gambar 3.2.10. 4 substitusi data pengamatan kedalam data view
18
4. Lalu klik analyze dan pilih regression lalu pilih linear
Gambar 3.2.10. 5 langkah - angkah menentukan rumus regresi
5. Lalu pindahkan variabel X dan variable Y ke kolom variable lalu Klik OK untuk menampilkan hasil pengolahan data yang telah diprogram
Gambar 3.2.10. 6 subtitusi variable ke dalam kolom pengolahan regresi
19
Gambar 3.2.10. 7 subtitusi variable ke dalam kolom pengolahan regresi
3.2.11 Kesimpulan hasil pengolahan data yang telah diprogram
3.2.11.1 Tabel Variabels Entered/Removed Variables Entered/Removeda
Model Variables Entered Variables Removed Method
1 MOTIVASIb . Enter
a. Dependent Variable: PRODUKTIVITAS b. All requested variables entered.
Di dalam metode enter ini berisikan hasil subtitusi variable view ke dalam langkah awal proses yang ada di dalam pemrograman SPSS. Tabel ini menunjukkan bahwa variabel yang sudah dimasukkan ke dalam kolom pengolahan regresi telah sukses terinput.
20 3.2.11.2 Tabel Model Summary
Model Summary
Model R R Square Adjusted R Square
Std. Error of the Estimate
1 .318a .101 .083 11.81389
a. Predictors: (Constant), MOTIVASI
Di dalam metode summary ini berisikan perhitungan seberapa besar persentase variable bebas mempengaruhi variable tak bebas.
Dari table di atas menunjukkan tingkat persentase pengaruh variable X dengan variable Y sebesar 10,1 %
3.2.11.3 Tabel Anova
ANOVAa
Sum of
Squares df Mean Square F Sig.
1 Regression 784.518 1 784.518 5.621 .022b
Residual 6978.405 50 139.568
Total 7762.923 51
a. Dependent Variable: PRODUKTIVITAS b. Predictors: (Constant), MOTIVASI
Jika nilai signifikansi 0,00 < 0,05 maka ada pengaruh variabel X dengan variabel Y. Begitupula sebaliknya. Jika nilai signifikansi 0,00 > 0,05 maka tidak ada pengaruh variabel X dengan variabel Y.
Dikarenakan nilai signifikansinya 0,022 < 0,05, maka dapat disimpulkan bahwa adanya pengaruh antara variabel X dengan variabel Y.
3.2.11.4 Tabel Coefficients
Coefficientsa
Model
Unstandardized Coefficients
Standardized
Coefficients t Sig.
21
B Std. Error Beta
1 (Constant) 99.310 13.951 7.118 .000
MOTIVASI -.640 .270 -.318 -2.371 .022
a. Dependent Variable: PRODUKTIVITAS
𝐻0 = Tidak ada pengaruh varibel X (motivasi) terhadap variable Y (produktivitas)
𝐻1 = Ada pengaruh varibel X (motivasi) terhadap variable Y (produktivitas)
Apabila 𝑇ℎ𝑖𝑡𝑢𝑛𝑔 > 𝑇𝑡𝑎𝑏𝑒𝑙 maka, variable X mempengaruhi variabel Y Apabila 𝑇ℎ𝑖𝑡𝑢𝑛𝑔 ≤ 𝑇𝑡𝑎𝑏𝑒𝑙 maka, variable X tidak mempengaruhi variabel Y
Menghitung 𝑇𝑡𝑎𝑏𝑒𝑙 :
𝛼 = 0,05
= 0,025 (menentukan baris) 𝑑𝑓 = 𝑛 − 𝑘 − 1 = 52 − 1 − 1
= 50 (menentukan kolom) 𝑇𝑡𝑎𝑏𝑒𝑙 : 2,008
Dikarenakan nilai 𝑇ℎ𝑖𝑡𝑢𝑛𝑔 = -2,371 ≤ 𝑇𝑡𝑎𝑏𝑒𝑙 = 2,008 dapat disimpulkan bahwa 𝐻1 ditolak dan 𝐻0 diterima, yang berarti tidak ada pengaruh antara variable X (motivasi) dengan variable Y (produktivitas).
22 Kurva 3.2.10. 1
Dari grafik tersebut dapat disimpulkan bahwa ada pengaruh ke arah negatif dan positif antara variabel X terhadap variabel Y.
Area Tidak Berpengaruh
-5 -4 -3 -2 -1 0 1 2 3
Area Berpengar uh ke Arah Negatif
Area Berpengaruh
Ke Arah Positif T hitung : -
T table : - T table :
23
BAB IV
ANALISIS
4.1 Analisis regresi linear sederhana dengan cara manual
Dasar pengambilan keputusan dalam uji regresi linear sederhana dapat mengacu pada perbandingan nilai 𝐹ℎ𝑖𝑡𝑢𝑛𝑔 𝑑𝑎𝑛 𝐹𝑡𝑎𝑏𝑒𝑙. Nilai 𝐹ℎ𝑖𝑡𝑢𝑛𝑔 diperoleh dari uji F dengan taraf uji nyata 5%. Nilai uji F diperoleh dari rumus :
𝐽𝐾𝑏
𝐹 = 1 𝐽𝐾𝑠 (𝑛
− 2)
Dari hasil uji F diperoleh nilai 𝐹ℎ𝑖𝑡𝑢𝑛𝑔 sebesar -48,696. Dan 𝐹𝑡𝑎𝑏𝑒𝑙 diperoleh 4,03 . Maka dapat disimpulkan bahwa produktivitas tidak terpengaruh oleh motivasi.
4.2 Analisis regresi linier sederhana menggunakan software SPSS
Pada hasil analisis regresi linier sederhana menggunakan aplikasi SPSS diperoleh nilai signifikasi sebesar 0,022. Jika nilai signifikansi 0,00 < 0,05 maka ada pengaruh variabel X dengan variabel Y. Begitupula sebaliknya. Jika nilai signifikansi 0,00 > 0,05 maka tidak ada pengaruh variabel X dengan variabel Y. Dikarenakan nilai signifikansinya 0,022 < 0,05, maka dapat disimpulkan bahwa ada pengaruh antara variabel X dengan variabel Y.
Selain itu, analisis regresi linier sederhana dengan menggunakan software SPSS juga diperoleh hasil uji T. Apabila 𝑇ℎ𝑖𝑡𝑢𝑛𝑔 > 𝑇𝑡𝑎𝑏𝑒𝑙 maka, variable X mempengaruhi variabel Y begitu pula sebaliknya. Apabila 𝑇ℎ𝑖𝑡𝑢𝑛𝑔 ≤ 𝑇𝑡𝑎𝑏𝑒𝑙 maka, variable X tidak mempengaruhi variabel Y.
24
BAB V
KESIMPULAN DAN SARAN
5.1 KESIMPULAN
Hasil model persamaan regresi dapat dipergunakan sebagai pedoman untuk memprediksi hubungan antar variabel diluar data yang dijadikan sampel dalam suatu populasi. Uji regresi linier sederhana seperti uji signifikan dengan uji-t sangat membantu untuk mengetahui pengaruh secara kualitas dan kuantitas satu variabel bebas terhadap variable tak bebas.
Metode analisis regresi ini sangat dibutuhkan di berbagai bidang, baik di bidang sains, sosial, industri maupun bisnis. Dalam makalah ini akan diuraikan masalah regresi yaitu regrsi linear sebagai pengukur hubungan antara dua variabel.
Maka dari hasil di atas, dapat dilihat bahwa hasil perhitungan dengan menggunakan cara manual sama dengan hasil perhitungan dengan SPSS.
Perbedaan nilai dibelakang koma dapat diterima, karena hal ini terkait dengan tingkat ketelitian.
5.2 SARAN
Dalam melakukan analisis Regresi terlebih dahulu harus diketahui apakah variabel-variabel yang akan diregresikan, itu merupakan regresi linear maupun regresi non linear, karena hal ini akan menctukan teknik analisa regresi mana yang akan dipergunakan dalam menganalisis data.
Untuk mengetahui apakah variabel-variabel yang akan diregresiakn apakah itu regresi linear atau non linear ada beberapa metode yang dapat digunakan, yaitu metode tangan bebas menggunakan diagram sebagai bahan pertimbangan merupakan cara yang paling sederhana untuk menentukan suatu variabel regresi linear dan regresi non linear.
25
DAFTAR PUSTAKA
https://www.spssindonesia.com/2017/03/uji-analisis-regresi-linear-sederhana.html https://www.scribd.com/document/106316867/Laporan-Hasil-Penelitian-
Praktikum-Regresi-Sederhana
https://www.scribd.com/document/388724481/Makalah-Regresi-Linier-Sederhana https://duwiconsultant.blogspot.com/2011/11/analisis-regresi-linier-
sederhana.html
LAMPIRAN
26
LAPORAN PRAKTIKUM STATISTIK MODUL II
KORELASI LINIER SEDERHANA
Kelompok 2
1. Badzlin Dunyana (2070031093)
2. Muhammad Lukman Hakim (2070031092)
3. Fajar sidik Rumlan Tamnge (2070031038)
4. Wahyu Pratama Sutardji (2070031028)
5. Alifah Aprilya (2070031032)
6. Ramadhani (2070031023)
LABORATORIUM STATISTIKA INDUSTRI
PROGRAM STUDI TEKNIK INDUSTRI
UNIVERSITAS KRISNADWIPAYANA JAKARTA
i
LEMBAR PENGESAHAN
Laporan ini disusun sebagai salah satu syarat kelulusan Laporan Akhir Praktikum Statistik Modul 2 “Korelasi Linier Sederhana”. Jurusan Teknik Industri Fakultas Teknik Universitas Krisnadwipayana.
Kelompok 2
1. Badzlin Dunyana (2070031093) 2. Muhammad Lukman Hakim (2070031092) 3. Fajar sidik Rumlan Tamnge (2070031038) 4. Wahyu Pratama Sutardji (2070031028) 5. Alifah Aprilya (2070031032) 6. Ramadhani (2070031023)
Dengan ini telah diperiksa untuk DITERIMA/DITOLAK Jakarta, 3 Desember 2021
Menyetujui, Menyetujui, KALAB Teknik Indutri Asisten Laboratorium
Statistik Teknik Industri
Aries Abbas, S.T, M.M, M.T Amallia Aindina Fitri
NIDN: 03290565505 NIM: 1970031040
ii
KATA PENGANTAR
Puji syukur kami panjatkan kepada Tuhan yang maha Esa, yang telah memberikan rahmat-Nya kepada kami untuk menyelesaikan Laporan Akhir Praktikum Statistika modul 2 "Korelasi Linier Sederhana"
Kami juga ingin mengucapkan terima kasih yang dalam dan tulus kepada
semua pihak yang telah terlibat dalam penyusunan Laporan Akhir Praktikum Statistika modul 2 " Korelasi Linier Sederhana " yang kami buat.
Kami sadar bahwa penyusunan laporan praktikum ini jauh dari kata baik.
maka dari itu, kami mengharapkan saran dan kritik dari pembaca guna meperbaiki di kesempatan berikutnya.
Demikian kami sampaikan, semoga laporan akhir praktikum ini dapat bermanfaat bagi pembaca
Jakarta, 3 Desember 2021
Kelompok 2
iii
DAFTAR ISI
LEMBAR PENGESAHAN ... i KATA PENGANTAR ... ii DAFTAR ISI ... iii DAFTAR GAMBAR ... iv BAB I ... 6 PENDAHULUAN ... 6 1.1. ... Maksud dan Tujuan
6
1.2. ... Latar Belakang Masalah 6
1.3. ... Perumusan Masalah 7
1.4. ... Pembatasan Masalah 7
1.5. ... Sistematika Pembahasan 8
BAB II ... 11 LANDASAN TEORI ... 11 2.1 Korelasi Linier Sederhana ... 11 2.2 Pola Hubungan Antara 2 Variabel ... 12 BAB III ... 19
iv
PENGUMPULAN DAN PENGOLAHAN DATA ... 19 3.1. ... Pengumpulan Data.
19
3.2. ... Pengolahan data.
20
BAB IV ... 27 ANALISIS ... 27 4.1. ... Korelasi linier sederhana
27
4.1.1. ... Analisis korelasi linier sederhana 27
4.1.2. ... Analisis korelasi linier sederhana menggunakan software SPSS 27
BAB V ... 27 KESIMPULAN DAN SARAN ... 28 5.1. Kesimpulan ... 28 5.2. Saran ... 28 BAB VI ... 28 DAFTAR PUSTAKA ... 29
DAFTAR GAMBAR
Gambar 3.2.6. 1 tampilan awal SPSS ...23 Gambar 3.2.6. 2 mengisi kolom yang telah ditentukan...23 Gambar 3.2.6. 3 memasukan data ...24 Gambar 3.2.6. 4 pilih Corralate ...24 Gambar 3.2.6. 5 mengatur Bivariate Correlations ...24 Gambar 3.2.6. 6 hasil penghitungan SPSS ...25
v
DAFTAR TABEL
Tabel 3.1. 1 Tabel Pedoman Kriteria Korelasi ... 13 Tabel 3.1. 2 Tabel Pengolahan Data ... 19 Tabel 3.1. 3 Tabel Pengolahan Data ... 20
6
BAB I
PENDAHULUAN
1.1.Maksud dan Tujuan
Maksud dan tujuan dari penulisan laporan akhir ini adalah untuk mengetahui ukuran kekuatan hubungan dua variabel dan juga untuk dapat mengetahui bentuk hubungan antar dua variabel tersebut dengan hasil yang sifatnya kuantitaif. Kekuatan hubungan antara dua variabel yang dimaksud disini adalah apakah hubungan tersebut ERAT, LEMAH, ataupun TIDAK ERAT sedangkan bentuk hubungannya adalah apakah bentuk korelasinya Linier Positif ataupunLinier Negatif.
1.2.Latar Belakang Masalah
Analisis korelasi sederhana (Bivariate Correlation) digunakan untuk mengetahui keeratan hubungan antara dua variabel dan untuk mengetahui arah hubungan yang terjadi. Koefisien korelasi sederhana. menunjukkan seberapa besar hubungan yang terjadi antara dua variabel. Dalam SPSS ada tiga metode korelasi sederhana (bivariate correlation) diantaranya Pearson Correlation, dan Spearman Correlation. Pearson Correlation digunakan untuk data berskala interval atau rasio, dan Spearman Correlation lebih cocok untuk data berskala ordinal.
Pada bab ini akan dibahas analisis korelasi sederhana dengan metode Pearson atau sering disebut Product Moment Pearson. Nilai korelasi (r) berkisar antara 1 sampai -1, nilai semakin mendekati 1 atau -1 berarti hubungan antara dua variabel semakin kuat, sebaliknya nilai mendekati 0 berarti hubungan antara dua variabel semakin lemah. Nilai positif menunjukkan hubungan searah (X naik maka Y naik) dan nilai negatif menunjukkan hubungan terbalik (X naik maka Y turun). Menurut Sugiyono (2007) pedoman untuk memberikan interpretasi koefisien korelasi sebagai berikut:
0,00 - 0,199 = sangat rendah 0,20 - 0,399 = rendah 0,40 - 0,599 = sedang 0,60 - 0,799 = kuat
7 0,80 - 1,000 = sangat kuat
1.3.Perumusan Masalah
1. Apa itu korelasi linier sederhana?
2. Bagaimana cara pengolahan data korelasi linier sederhana?
3. Bagaimana cara pengolahan data korelasi linier sederhana dengan menggunakan software SPSS?
1.4.Pembatasan Masalah
Berdasarkan latar belakang diatas agar tidak terjadi pembiasan atau perluasan masalah, maka penyusunan laporan akhir modul 2 ini membatsi masalah sebagai berikut:
1. menjelaskan mengenai teori-teori tentang Korelasi Linier Sederhana 2. menjelaskan mengenai urutan langkah-langkah dalam memecahkan 3. masalah dalam pengumpulan data pengelolahan data koefisien linier
sederhana menggunakan rumus manual maupun Software SPSS
8 1.5.Sistematika Pembahasan
Flow Chart :
Praktikum dimulai
Praktikum Pengumpulan Data Observasi :
1. Data Atribut 2. Data Variabel
Asintensi 1 dan 2
Pengumpulan Laporan
Responsi
Selesai
Ditolak
Diterima
9
Untuk menyusun Lapoan ini secara sistematis, maka penulis menyusun sistematika Laporan sebagai Berikut :
BAB I LANDASAN PENDAHULUAN
Pada BAB ini menjelaskan mengenai maksud dan tujuan, latar belakang masalah, perumusan masalah, batasan masalah, dan Sistematika Penulisan.
BAB II LANDASAN TEORI
Pada BAB ini menjelaskan mengenai teori-teori tentang Korelasi Linier Sederhana
BAB III PEGOLAHAN DATA
Pada BAB ini menjelaskan mengenai urutan langkah-langkah dalam memecahkan masalah dalam pengumpulan data pengelolahan data.
BAB IV ANALISIS
Di bab ini praktikan menjelaskan secara ringkas dan sistematis aktivitas yang terdiri dari serangkaian kegiatan seperti; mengurai. membedakan, dan memilah sesuatu untuk dikelompokkan kembali menurut kriteria tertentu dan kemudian dicari kaitannya lalu ditafsirkan maknanya.
BAB V KESIMPIULAN DAN SARAN
Di bab ini menjelaskan kesimpulan dari hasil penulisan dan saran-saran yang diberikan praktikan berkaitan dengan penulisan laporan praktikum dari proses praktikum dan penulisan laporan yang sudah dilaksanakan.
BAB VI (DAFTAR PUSTAKA)
Di bab ini praktikan menguraikan daftar yang berisi nama penulis, judul tulisan, penerbit, identitas penerbit dan tahun terbit dari sebuah buku atau kajian lain yang digunakan sebagai sumber atau rujukan bagi praktikan dalam menyusun laporan akhir praktikum.
10
11
BAB II
LANDASAN TEORI
2.1 Korelasi Linier Sederhana
Korelasi Sederhana merupakan suatu Teknik Statistik yang dipergunakan untuk mengukur kekuatan hubungan 2 Variabel dan juga untuk dapat mengetahui bentuk hubungan antara 2 Variabel tersebut dengan hasil yang sifatnya kuantitatif.
Kekuatan hubungan antara 2 variabel yang dimaksud disini adalah apakah hubungan tersebut ERAT, LEMAH, ataupun TIDAK ERAT sedangkan bentuk hubungannya adalah apakah bentuk korelasinya Linear Positif ataupun Linear Negatif.
Disamping Korelasi, Diagram Tebar (Scatter Diagram) sebenarnya juga dapat mempelajari hubungan 2 variabel dengan cara menggambarkan hubungan tersebut dalam bentuk grafik. Tetapi Diagram tebar hanya dapat memperkirakan kecenderungan hubungan tersebut apakah Linear Positif, Linear Negatif ataupun tidak memiliki Korelasi Linear. Kelemahan Diagram Tebar adalah tidak dapat menunjukkan secara tepat dan juga tidak dapat memberikan angka Kuantitas tentang kekuatan hubungan antara 2 variabel yang dikaji tersebut.
Kekuatan Hubungan antara 2 Variabel biasanya disebut dengan Koefisien Korelasi dan dilambangkan dengan symbol “r”. Nilai Koefisian r akan selalu berada di antara -1 sampai +1.
Perlu diingat :
Koefisien Korelasi akan selalu berada di dalam Range -1 ≤ r ≤ +1
Jika ditemukan perhitungan diluar Range tersebut, berarti telah terjadi kesalahan perhitungan dan harus di koreksi terhadap perhitungan tersebut.
Rumus Pearson Product Moment
Koefisien Korelasi Sederhana disebut juga dengan Koefisien Korelasi Pearson karena rumus perhitungan Koefisien korelasi sederhana ini dikemukakan oleh Karl Pearson yaitu seorang ahli Matematika yang berasal dari Inggris.
12
Rumus yang dipergunakan untuk menghitung Koefisien Korelasi Sederhana adalah sebagai berikut :
(Rumus ini disebut juga dengan Pearson Product Moment)
r = nΣxy – (Σx) (Σy) . √{nΣx² – (Σx)²} {nΣy2 – (Σy)2}
Dimana :
n = Banyaknya Pasangan data X dan Y Σx = Total Jumlah dari Variabel X Σy = Total Jumlah dari Variabel Y
Σx2= Kuadrat dari Total Jumlah Variabel X Σy2= Kuadrat dari Total Jumlah Variabel Y
Σxy= Hasil Perkalian dari Total Jumlah Variabel X dan Variabel Y 2.2 Pola Hubungan Antara 2 Variabel
Pola / Bentuk Hubungan antara 2 Variabel :
1. Korelasi Linear Positif (+1)
Perubahan salah satu Nilai Variabel diikuti perubahan Nilai Variabel yang lainnya secara teratur dengan arah yang sama. Jika Nilai Variabel X mengalami kenaikan, maka Variabel Y akan ikut naik. Jika Nilai Variabel X mengalami penurunan, maka Variabel Y akan ikut turun.
Apabila Nilai Koefisien Korelasi mendekati +1 (positif Satu) berarti pasangan data Variabel X dan Variabel Y memiliki Korelasi Linear Positif yang kuat/Erat.
2. Korelasi Linear Negatif (-1)
Perubahan salah satu Nilai Variabel diikuti perubahan Nilai Variabel yang lainnya secara teratur dengan arah yang berlawanan. Jika Nilai Variabel X mengalami
13
kenaikan, maka Variabel Y akan turun. Jika Nilai Variabel X mengalami penurunan, maka Nilai Variabel Y akan naik.
Apabila Nilai Koefisien Korelasi mendekati -1 (Negatif Satu) maka hal ini menunjukan pasangan data Variabel X dan Variabel Y memiliki Korelasi Linear Negatif yang kuat/erat.
3. Tidak Berkorelasi (0)
Kenaikan Nilai Variabel yang satunya kadang-kadang diikut dengan penurunan Variabel lainnya atau kadang-kadang diikuti dengan kenaikan Variable yang lainnya. Arah hubungannya tidak teratur, kadang-kadang searah, kadang-kadang berlawanan.
Apabila Nilai Koefisien Korelasi mendekati 0 (Nol) berarti pasangan data Variabel X dan Variabel Y memiliki korelasi yang sangat lemah atau berkemungkinan tidak berkorelasi.
Ketiga Pola atau bentuk hubungan tersebut jika di gambarkan ke dalam Scatter Diagram (Diagram tebar) adalah sebagai berikut :
Tabel tentang Pedoman umum dalam menentukan Kriteria Korelasi :
Tabel 3.1. 1 Tabel Pedoman Kriteria Korelasi
r Kriteria Hubungan
0 Tidak ada Korelasi
0 – 0.5 Korelasi Lemah
14
0.5 – 0.8 Korelasi sedang 0.8 – 1 Korelasi Kuat / erat
1 Korelasi Sempurna
Contoh Penggunaan Analisis Korelasi di Produksi :
1. Apakah ada hubungan antara suhu ruangan dengan jumlah cacat Produksi?
2. Apakah ada hubungan antara lamanya waktu kerusakan mesin dengan jumlah cacat produksi?
3. Apakah ada hubungan antara jumlah Jam lembur dengan tingkat absensi?
Analisis korelasi merupakan studi pembahasan tentang derajad keeratan hubungan antar variabel yang dinyatakan dengan nilai koefisien korelasi. Hubungan antara variabel tersebut dapat bersifat bersifat positif dan negatif. Dalam analisis korelasi sebenarnya tidak ada istilah variabel independent (X) dan variabel dependent (Y).
Karena pada dasarnya hubungan antara variabel independent dengan variabel dependent, akan bermakna sama dengan hubungan variabel dependent dengan variabel independent. Namun demikian dalam prakteknya banyak kita jumpai peneliti memberikan nama untuk hubungan variabel independent dengan variabel dependent. Hal ini bukan sebuah masalah, sebab penamaan tersebut tujuan sebenarnya hanya sebagal alat bantu saja supaya pembaca lebih mudah memahami arah hubungan yang ingin disampaikan oleh peneliti dalam penelitiannya.
Derajad hubungan biasanya dinyatakan dengan huruf "r" atau disebut juga dengan koefisien korelasi sampel yang merupakan penduga bagi koefisien populasi.
Sedangkan r2 atau r square disebut dengan koefisien determinasi (koefisien penentu). Kekuatan korelasi linear antara variabel yang dihubungkan dapat disajikan dengan r x y
Formula tersebut disebut merupakan formula koefisien korelasi momen produk (product moment karl pearson). Dalam penelitian analisis korelasi bivariate pearson digunakan untuk menguji hubungan antara dua varaibel yang
15
menggunakan data berkala rasio atau interval. Sementara untuk data ordinal pakal Uji Korelasi Rank Spearman
Peryaratan dalam Analisis Korelasi Bivariate Pearson
Ada beberapa persyaratan atau asumsi dasar yang harus terpenuhi ketika kita hendak memakal analisis korelasi bivariate pearson untuk menguji hipotesis penelitian kita.
1. Data penelitian untuk masing-masing variabel setidak-tidaknya berskala rasio atau interval (yaltu data yang berbentuk angka sesungguhnya atau data metrik (data kuantitatif). Namun demikian analisis ini bisa juga dipakai untuk data kuesioner dengan skala likert.
2. Data untuk masing-masing variabel yang dihubungkan berdistribusi normal.
3. Terdapat hubungan yang linear antar variabel penelitian.
Arti Angka Korelasi (Pearson Correlations)
Koefisien korelasi atau Pearson Correlations memiliki nilai paling kecil -1 dan paling besar 1.
1. Berkenaan dengan besaran angka ini, jika 0 maka artinya tidak ada korelasi sama sekali sementara jika korelasi 1 berarti ada korelasi sempurna. Hal ini menunjukkan bahwa semakin nilai pearson correlations mendekati 1 atau -1 maka hubungan antara dua variabel adalah semakin kuat. Sebaliknya, jika nilai r atau pearson correlations mendekati 0 berarti hubungan dua variabel menjadi semakin lemah. Sebenarnya tidak ada ketentuan yang benar-benar tepat mengenai apakah angka korelasi tertentu menunjukkan tingkat korelasi yang tinggi atau lemah. Namun, hal berikut ini dapat kita dijadikan pedoman sederhana bahwa jika angka korelasi di atas 0,5 maka menunjukkan korelasi yang cukup kuat sedangkan jika di bawah 0,5 maka menunjukkan korelasi yang lemah.
16
2. Selain besarnya korelasi, tanda korelasi juga berpengaruh pada penafsiran hasil dalam analisis Ini. Dimana, tanda negatif (-) pada tabel output SPSS menunjukkan adanya arah yang berlawanan, sedangkan tanda…
nilai r hitung (Pearson Correlations) dengan nilai r tabel product moment. Ketiga adalah dengan melihat tanda bintang (*) yang terdapat pada output program SPSS.
1. Berdasarkan Nilal Signifikansi Sig. (2-tailed): Jika nilai Sig. (2-talled) < 0,05 maka terdapat korelasi antar variabel yang dihubungkan. Sebaliknya jika nilai Sig.
(2-tailed) > 0,05 maka tidak terdapat korelasi.
2. Berdasarkan Nilai r hitung (Pearson Correlations): Jika nilal r hitung > r tabel maka ada korelasi antar variabel. Sebaliknya jika nilai r hitung < r tabel maka artinya tidak ada korelasi antar variabel.
3. Berdasarkan Tanda Bintang (*) yang diberikan SPSS: Jika terdapat tanda bintang (*) pada nilai pearson correlation maka antara variabel yang di analisis terjadi korelasi. Sebaliknya jika tidak terdapat tanda bintang pada nilai pearson correlation maka antara variabel yang di analisis tidak terjadi korelasi.
Catatan: Tanda bintang satu (*) menujukkan korelasi pada signifikansi 1% atau 0,01. Sedangkan tanda bintang dua (**) menunjukkan korelasi pada signifikansi 5% atau 0,05.
Untuk lebih jelas, kita langsung praktekkan saja cara melakukan analisis korelasi bivariate pearson dengan program SPSS. Misalkan saya ingin menguji apakah ada hubungan yang signifikan antara Motivasi dan Minat dengan Prestasi belajar siswa.
Adapun detail data penelitiannya dapat anda lihat di bawah ini.
17
1. Buka program SPSS, klik Variable View. Selanjutnya, pada bagian Name tulis saja X1, X2 dan Y, pada Decimals ubah semua menjadi angka 0, pada bagian Label tuliskan Motivasi, Minat dan Prestasi. Pada bagian Measure ganti menjadi Scale
2. Setelah itu, klik Data View, dan masukkan data Motivasi (X1), Minat (X2) dan Prestasi (Y) yang sudah dipersiapkan tadi ke program SPSS.
3. Selanjutnya, dari menu utama SPSS, pilih menu Analyze, lalu klik Correlate, dan klik Bivariate
4. Muncul kotak dialog dengan nama "Bivariate Correlations". Masukkan variabel Motivasi (X1), Minat (X2) dan Prestasi (Y) pada kotak Variables:.
Selanjutnya, pada kolom "Correlation Coefficient" pilih Pearson, lalu untuk kolom "Test of Significant” pilih Two-tailed, dan centang pada Flag Significant Correlations, terakhir klik Ok untuk mengakhiri perintah.
Setelah selasai, maka akan muncul tampilan output SPSS "Correlations" tinggal kita interpretasikan saja.
Interpretasi Analisis Korelasi Bivariate Pearson
Berdasarkan tabel output di atas, kita akan melakukan pernarikan kesimpulan dengan merujuk pada ke-3 dasar pengambilan keputusan dalam analisis korelasi bivariate pearson di atas.
1. Berdasarkan Nilai Signifikansi Sig. (2-tailed): Dari tabel output di atas diketahul nilal Sig. (2-talled) antara Motivasi (X1) dengan Prestasi (Y) adalah sebesar 0,002< 0,05, yang berarti terdapat korelasi yang signifikan antara variabel Motivasi dengan variabel Prestasi. Selanjutnya, hubungan antara Minat (X2) dengan Prestasi (Y) memiliki nilai Sig. (2-talled) sebesar 0,000 < 0,05, yang berarti terdapat korelasi yang signifikan antara variabel Minat dengan variabel Prestasi.
18
2. Berdasarkan Nilai r hitung (Pearson Correlations): Diketahui nilai r hitung untuk hubungan Motivasi (X1) dengan Prestasi (Y) adalah sebesar adalah sebesar 0,796 >r tabel 0,576, maka dapat disimpulkan bahwa ada hubungan atau korelasi antara variabel Motivasi dengan variabel Presta…
3. Berdasarkan Tanda Bintang () SPSS: Dari output di atas diketahui bahwa nilai Pearson Correlation antara masing-masing variabel yang dihubungkan mempunyai dua tanda bintang (*), ini berarti terdapat korelasi antara variabel yang dihubungkan dengan taraf signifikansi 1%.
Demikian pembahasan mengenai cara melakukan analisis korelasi bivariate pearson dengan SPSS. Jika artikel ini bermanfaat silahkan anda dibagikan ke media sosial anda supaya ilmu ini dapat berguna bagi banyak orang yang belum mengetahuinya.