93
BAB 4
HASIL dan PEMBAHASAN
4.1 Profil Responden
4.1.1 Profil PT Unilever Indonesia Tbk.
Sejak didirikan pada 5 Desember 1933, Unilever Indonesia telah tumbuh menjadi salah satu perusahaan terdepan untuk produk Home and Personal Care serta Foods & Ice Cream di Indonesia. Pada Gambar 4.1 disajikan logo dari Unilever Indonesia.
Gambar 4.1 Logo PT Unilever Indonesia Tbk. Sumber: Laporan Tahunan (Annual Report) 2009 PT Unilever Indonesia Tbk.
Rangkaian Produk Unilever Indonesia mencangkup brand-brand ternama yang disukai di dunia seperti Pepsodent, Lux, Lifebuoy, Dove, Sunsilk, Clear, Rexona, Vaseline, Rinso, Molto, Sunlight, Walls, Blue Band, Royco, Bango, dan lain-lain.
Selama ini, tujuan perusahaan Unilever tetap sama, dimana Unilever bekerja untuk menciptakan masa depan yang lebih baik setiap hari; membuat pelanggan merasa nyaman, berpenampilan baik dan lebih menikmati kehidupan melalui brand dan jasa yang memberikan manfaat untuk mereka maupun orang lain; menginspirasi masyarakat untuk melakukan
tindakan kecil setiap harinya yang bila digabungkan akan membuat perubahan besar bagi dunia; dan senantiasa mengembangkan cara baru dalam berbisnis yang memungkinkan Unilever Indonesia untuk tumbuh sekaligus mengurangi dampak lingkungan.
Saham perseroan pertamakali ditawarkan kepada masyarakat pada tahun 1981 dan tercatat di Bursa Efek Indonesia sejak 11 Januari 1982. Pada akhir tahun 2009, saham perseroan menempati peringkat ketujuh kapitalisasi pasar terbesar di Bursa Efek Indonesia.
Perseroan memiliki dua anak perusahaan : PT Anugrah Lever (dalam likuidasi), kepemilikan Perseroan sebesar 100% (sebelumnya adalah perusahaan patungan untuk pemasaran kecap) yang telah konsolidasi dan PT Technopia Lever, kepemilikan Perseroan sebesar 51%, bergerak di bidang distribusi ekspor, dan impor produk dengan merek Domestos Nomos.
Bagi Unilever, sumber daya manusia adalah pusat dari seluruh aktivitas perseroan. Unilever memberikan prioritas pada mereka dalam pengembangan profesionalisme, keseimbangan kehidupan, dan kemampuan mereka untuk berkontribusi pada perusahaan.
Perseroan mengelola dan mengembangkan bisnis perseroan secara bertanggung jawab dan berkesinambungan. Nilai-nilai dan standar yang Perseroan terapkan terangkum dalam Prinsip Bisnis Kami. Perseroan juga membagi standar dan nilai-nilai tersebut dengan mitra usaha termasuk para pemasok dan distributor.
Perseroan memiliki enam pabrik di Kawasan Industri Jababeka, Cikarang, Bekasi, dan dua pabrik di Kawasan Industri Rungkut, Surabaya, Jawa Timur, dengan kantor pusat di Jakarta. Produk-produk Perseroan berjumlah sekuitar 32 brand utama dan 700 SKU, dipasarkan melalui jaringan yang melibatkan sekitar 370 distributor independen yang menjangkau ratusan ribu toko yang tersebar di seluruh Indonesia. Produk-produk tersebut didistribusikan melalui pusat distribusi milik sendiri, gudang tambahan, depot dan fasilitas distribusi lainnya.
Sebagai perusahaan yang mempunyai tanggung jawab sosial, Unilever Indonesia menjalankan program Corporate Social Responsibility (CSR) yang luas. Keempat pilar program kami adalah Lingkungan, Nutrisi, Higiene dan Pertanian Berkelanjutan. Program CSR termasuk antara lain kampanye Cuci Tangan dnegan Sabun (Lifebuoy), program Edukasi kesehatan Gigi dan Mulut (Pepsodent), program Pelestarian Makanan Tradisional (Bango) serta program Memerangi Kelaparan untuk membantu anak Indonesia yang kekurangan gizi (Blue Band).
Salah satu produk perawatan pribadi (personal care) yang dimiliki Unilever Indonesia adalah Citra yang akan dibahas lebih lanjut pada bagian berikut ini.
4.1.1.1 Merek Citra
Gambar 4.2 Logo Citra
Sumber: Laporan Tahunan (Annual Report) 2009 PT Unilever Indonesia Tbk.
Citra adalah merek lokal di Indonesia yang mempunyai visi untuk menjadi merek perawatan kulit lengkap yang memberikan kecantikan alami secara keseluruhan. Pada tahun 2006, Citra mempunyai dua misi yaitu:
• Misi pertama, Citra menginginkan merek perawatan kulit lengkap yang tercermin dari jajaran produk perawatan kulit Citra yang sudah ada. Untuk perawatan tubuh, Citra memiliki Citra Hand & Body Lotion, Citra Liquid Soap dan Citra Body Scrub. Sementara itu, untuk perawatan wajah, Citra memiliki Citra Hazeline Moisturizer dan Citra Face Cleanser. Citra akan terus menciptakan inovasi strategis yang berkaitan dengan konsumennya.
• Misi kedua, Citra ingin membantu wanita Indonesia menyeimbangkan pikiran dan tubuh mereka. Citra sadar bahwa wanita Indonesia memiliki peran ganda dalam menjalani hidup dan ada permintaan tinggi dari masyarakat untuk wanita ini untuk menjalankan peran mereka. Dengan memiliki keseimbangan pikiran dan tubuh, wanita dapat memainkan peran dengan lebih baik dan hal ini akan membawa ke hubungan harmonis dengan masyarakat. Berdasarkan semua alasan ini, Citra meluncurkan varian wewangian aromaterapi, karena manfaat aromaterapi sudah dikenal luas untuk membantu mengendurkan ketegangan panca indra dan menenangkan pikiran dan tubuh.
Untuk mendukung kedua misi ter sebut di atas, Citra meluncurkan aktivasi Rumah Cantik Citra (RCC). RCC adalah rumah spa untuk merasakan seluruh produk Citra dalam merawat dan mempercantik tubuh dan jiwa.
Citra diketahui sebagai merek kecantikan dengan bahan-bahan alami dari warisan kuat budaya Indonesia, dan telah beredar di Indonesia selama lebih dari 20 tahun. Citra dikenal pertama kali sebagai merek Hand & Body Lotion tetapi beberapa tahun belakangan ini telah memperluas merek ke segmen lain seperti sabun cair, body scrub, pembersih wajah dan pelembab wajah. Konsumen sasaran Citra adalah wanita berusia 15 hingga 35 tahun yang ingin menjadi modern tanpa melupakan norma-norma sosial Indonesia. Mereka juga percaya pada kandungan yang baik untuk merawat kulit mereka yang terdapat dalam produk perawatan kulit alami. Berikut adalah informasi lainnya berkaitan dengan merek Citra.
• Citra telah ada di pasar produk perawatan kulit Indonesia sejak tahun 1984.
• Citra terbuat dari bahan-bahan alami Indonesia dengan warisan kuat budaya Indonesia. • Selama beberapa tahun terakhir, Citra telah mempertahankan posisinya sebagai
Salah satu misi Citra 2006 adalah menjadi Merek Perawatan Kulit Lengkap. Untuk mendukung misi ini, Citra telah meluncurkan berbagai inovasi seperti:
• Pada bulan Februari 2006, Citra meluncurkan kembali varian Citra Hand & Body Lotion (Citra Bengkoang White Lotion, Citra Teh Hijau Beauty Lotion dan Citra Mangir Beauty Lotion) dan meluncurkan Citra Sabun Cair (Citra Bengkoang White Milk Bath dan Citra Teh Hijau Refreshing Bath).
• Inovasi terbaru pada bulan Juli 2006 adalah Citra Body Scrub (Citra Bengkoang White Body Scrub dan Citra Teh Hijau Refreshing Body Scrub) yang secara efektif membersihkan kotoran dari kulit dan melepaskan sel-sel kulit mati yang membuat kulit tampak bersih dan segar.
Citra akan terus melakukan inovasi terhadap produk-produk perawatan kulit dengan meluncurkan produk-produk yang berhubungan dengan wanita Indonesia. Fakta-fakta utama lainnya berkaitan dengan merek Citra, yaitu sebagai berikut.
• Selama beberapa tahun terakhir, nilai dan volume Citra terus tumbuh. Pertumbuhannya didukung oleh inovasi yang berkaitan dengan konsumen Citra.
• Citra yang terus berkomitmen untuk menggali wawasan konsumen dan menciptakan inovasi berdasarkan wawasan telah dianugerahi hadiah ini. Ini tercermin dari berbagai penghargaan yang diraih Citra dalam tiga tahun belakangan ini secara berturut-turut, antara lain Indonesian Best Brand Awards dan Indonesian Consumer Satisfaction Award. • Menurut Majalah SWA, dalam pasar Hand & Body Lotion, Citra memiliki indeks loyalitas
tertinggi. Berdasarkan temuan ini, Citra memperoleh Indonesian Consumer Loyalty Awards pada tahun 2006.
• Pada tahun 2006, Citra meluncurkan Aktivasi Rumah Cantik Citra yang merupakan rumah spa semi permanen untuk merasakan sepenuhnya produk-produk Citra untuk merawat dan mempercantik jiwa.
4.1.2 Kondisi Perusahaan
Kondisi PT Unilever Indonesia Tbk. dari tahun ke tahun semakin mengalami kemajuan, di mana hal ini dapat diamati dari ikhtisar data keuangan penting dari Perseroan untuk lima tahun yang berakhir pada tanggal 31 Desember 2005, 2006, 2007, 2008 dan 2009 yang dijelaskan pada grafik-grafik berikut ini.
Gambar 4.3 Penjualan Bersih (Miliar Rupiah) Tahun 2005-2009 Sumber: Laporan Tahunan (Annual Report) 2009 PT Unilever Indonesia Tbk.
Gambar 4.4 Laba Kotor (Miliar Rupiah) Tahun 2005-2009 Sumber: Laporan Tahunan (Annual Report) 2009 PT Unilever Indonesia Tbk.
Gambar 4.5 Laba Usaha (Miliar Rupiah) Tahun 2005-2009 Sumber: Laporan Tahunan (Annual Report) 2009 PT Unilever Indonesia Tbk.
Gambar 4.6 Laba Bersih (Miliar Rupiah) Tahun 2005-2009 Sumber: Laporan Tahunan (Annual Report) 2009 PT Unilever Indonesia Tbk.
4.1.3 Struktur Perusahaan
Struktur perusahaan Unilever Indonesia didesain supaya keputusan dapat cepat diambil, di mana pada posisi puncak terbagi ke dalam dewan komisaris dan direksi. Kegiatan Perseoran sehari-hari dipimpin Direksi dengan dukungan badan-badan lain termasuk Komite Audit. Direksi bertanggung jawab kepada Dewan Komisaris, yang berperan sebagai badan pengawasan dan pemantauan yang independen sekaligus memberikan masukan kepada Direksi. Sedangkan Dewan Komisaris bertanggung jawab kepada pemegang saham. Badan-badan ini bekerjasama untuk mengendalikan risiko, menjalankan pengawasan, dan menjaga akuntabilitas dalam Unilever Indonesia.
• Dewan Komisaris
Dewan komisaris adalah sebuah dewan yang bertugas untuk melakukan pengawasan dan memberikan nasihat kepada direktur Perseroan terbatas (PT), di mana dewan komisaris terdiri dari 1 Presiden Komisaris dan 3 Komisaris Independen. Peran dan tanggung jawab
Dewan Komisaris, yaitu memantau dan mengawasi kebijakan Direksi dalam menjalankan Perseroan. Dewan Komisaris menerima laporan berkala dari Direksi dan komite lain yang terkait, memberikan nasihat terhadap masalah yang relevan seperti diatur dalam Anggaran Dasar Perseroan. Sebagai tambahan, Dewan Komisaris bertugas untuk melakukan tugas-tugas lain sebagaimana ditentukan oleh Rapat Umum Pemegang Saham Tahunan (RUPST) dari waktu ke waktu. Dewan Komisaris bertanggung jawab kepada pemegang saham pada saat RUPST. Dewan Komisaris selanjutnya diberi wewenang oleh RUPST untuk menunjuk Kantor Akuntan Publik yang terdaftar di Badan Pengawas Pasar Modal dan Lembaga Keuangan (Bapepam-LK) guna mengaudit pembukuan Perseroan; serta menetapkan pembayaran untuk Kantor Akuntan Publik tersebut.
• Direksi
Direksi adalah seseorang yang ditunjuk untuk memimpin Unilever Indonesia. Pada Gambar 4.7 disajikan struktur organisasi direksi tersebut. Peran dan tanggung jawab utama Direksi adalah memimpin dan mengelola Perseroan sesuai dengan tujuan Perseroan dan memanfaatkan, memelihara, dan mengelola aset Perseroan demi kepentingan bisnis Perseoran. Direksi bertanggung jawab kepada Dewan Komisaris. Setelah terpilih, Direksi menerima sebuah dokumen Manual Direksi yang komprehensif dan mendapat penjelasan terperinci mengenai tanggung jawab mereka. Direksi diharapkan untuk terus mengembangkan diri dan keahlian mereka demi Perseroan. Untuk itu, Direksi mengikuti pelatihan dan pendidikan eksekutif yang berkelanjutan terkait dengan bisnis Perseroan, seperti tata kelola perusahaan dan strategi kepemimpinan. Direksi mewakili Perseroan di dalam maupun di luar pengadilan berkaitan dengan semua hal dan permasalahan, yang mengikat pihak Perseroan dengan pihak lain dan sebaliknya, dan untuk melaksanakan semua tugas baik yang menyangkut manajemen maupun permasalahan lain selama masih dalam batas-batas Anggaran Dasar Perseroan.
Gambar 4.7 Struktur Organisasi
4.1.4 Profil Responden yang Menjadi Unit Analisis
Profil responden di dalam penelitian ini dibedakan menurut jenis kelamin, usia, tingkat pendidikan, profesi, dan tingkat pendapatan per bulan. Berikut disajikan penjelasan mengenai karakteristik-karakteristik responden tersebut.
a. Profil Responden Berdasarkan Jenis Kelamin
Dari 200 orang responden, seluruh responden berjenis kelamin wanita (100%), di mana hal tersebut tampak lebih jelas pada Gambar 4.8 berikut ini.
Gambar 4.8 Jenis Kelamin Responden Sumber: Peneliti (2010)
b. Profil Responden Berdasarkan Usia
Dari 200 orang responden, terdapat 15 responden (7%) yang berusia di kurang dari atau sama dengan 20 tahun, 63 responden (31%) yang berusia 21 hingga 25 tahun, 47 responden (23%) yang berusia 26 hingga 30 tahun, 30 responden (15%) yang berusia 31 hingga 35 tahun, 23 responden (12%) yang berusia 36 hingga 40 tahun, 9 responden
100%
Pria Wanita
(5%) yang berusia 41 hingga 45 tahun, 5 responden (3%) yang berusia 46 hingga 50 tahun, 4 responden (2%) yang berusia 51 hingga 55 tahun, 2 responden (1%) yang berusia 56 hingga 60 tahun, dan 2 responden (1%) yang berusia di atas 60 tahun. Untuk itu di dalam penelitian ini, responden terbanyak berada pada kisaran usia 21 hingga 25 tahun, yaitu sebesar 31% dari total responden penelitian dan responden terbanyak kedua berada pada kisaran usia 26 hingga 30 tahun, yaitu sebesar 23% dari total responden penelitian. Untuk lebih jelasnya mengenai usia responden dapat di lihat pada Gambar 4.9 berikut ini.
Gambar 4.9 Usia Responden Sumber: Peneliti (2010)
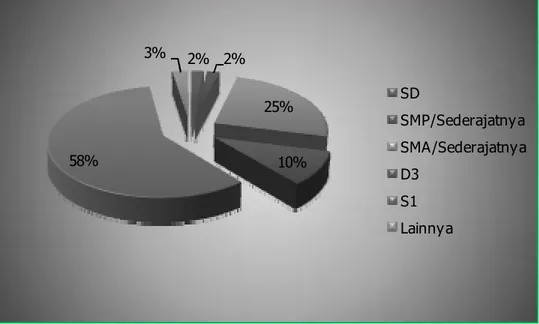
c. Profil Responden Berdasarkan Tingkat Pendidikan
Dari 200 orang responden, terdapat 4 responden (2%) yang sudah meraih tingkat pendidikan SD, 4 responden (2%) yang sudah meraih tingkat pendidikan SMP/sederajatnya, 50 responden (25%) yang sudah meraih tingkat pendidikan
7% 31% 23% 15% 12% 5% 3% 2% 1% 1% < 20 atau = 20 21-25 26-30 31-35 36-40 41-45 46-50 51-55 56-60 > 60
SMA/sederajatnya, 20 responden (10%) yang sudah meraih tingkat pendidikan D3, 117 responden (58%) yang sudah meraih tingkat pendidikan S1, dan 5 responden (3%) yang memberikan jawaban lainnya terhadap tingkat pendidikan yang sudah diraih. Untuk itu di dalam penelitian ini, lebih dari separuh jumlah responden, yaitu sebanyak 58% dari total responden, yang sudah meraih tingkat pendidikan S1. Selain itu, jumlah responden terbanyak kedua, yaitu sebanyak 25% dari total responden, adalah responden yang telah meraih tingkat pendidikan SMA/sederajatnya. Untuk lebih jelasnya mengenai tingkat pendidikan yang sudah diraih oleh responden dapat di lihat pada Gambar 4.10 berikut ini.
Gambar 4.10 Tingkat Pendidikan Responden Sumber: Peneliti (2010)
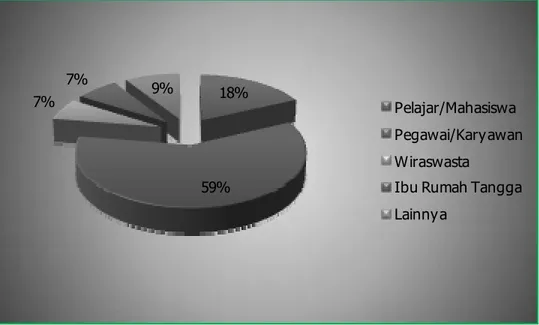
d. Profil Responden Berdasarkan Profesi
Dari 200 orang responden, terdapat 36 responden (18%) yang berprofesi sebagai pelajar atau mahasiswa, 119 responden (59%) yang berprofesi sebagai pegawai atau karyawan, 13 responden (7%) yang berprofesi sebagai wiraswasta, 14 responden (7%) yang
2% 2% 25% 10% 58% 3% SD SMP/Sederajatnya SMA/Sederajatnya D3 S1 Lainnya
berprofesi sebagai ibu rumah tangga, dan 18 responden (9%) yang memberikan jawaban profesi yang lainnya. Untuk itu di dalam penelitian ini, lebih dari separuh jumlah responden, yaitu sebanyak 59% dari total responden, berprofesi sebagai pegawai atau karyawan. Selain itu, jumlah responden terbanyak kedua, yaitu sebanyak 18% dari total responden, adalah responden yang berprofesi sebagai pelajar atau mahasiswa. Untuk lebih jelasnya mengenai profesi responden dapat di lihat pada Gambar 4.11 berikut ini.
Gambar 4.11 Profesi Responden Sumber: Peneliti (2010)
e. Profil Responden Berdasarkan Tingkat Pendapatan Per Bulan
Dari 200 orang responden, terdapat 21 responden (10%) dengan tingkat pendapatan per bulan kurang dari atau sama dengan Rp 1.000.000,00; 74 responden (37%) dengan tingkat pendapatan per bulan Rp 1.000.001,00 hingga Rp 3.000.000,00; 70 responden (35%) dengan tingkat pendapatan per bulan Rp 3.000.001,00 hingga Rp 5.000.000,00; 14 responden (7%) dengan tingkat pendapatan per bulan Rp 5.000.001,00 hingga Rp
18% 59% 7% 7% 9% Pelajar/Mahasiswa Pegawai/Karyawan Wiraswasta
Ibu Rumah Tangga Lainnya
7.000.000,00; 9 responden (5%) dengan tingkat pendapatan per bulan Rp 7.000.001,00 hingga Rp 9.000.000,00; dan 12 responden (6%) dengan tingkat pendapatan per bulan lebih dari Rp 9.000.000,00. Untuk itu di dalam penelitian ini, responden paling banyak, yaitu sebanyak 37%, memiliki tingkat pendapatan per bulan sebesar Rp 1.000.001,00 hingga Rp 3.000.000,00 dan jumlah responden terbanyak kedua, yaitu sebanyak 35%, memiliki tingkat pendapatan per bulan sebesar Rp 3.000.001,00 hingga Rp 5.000.000,00. Untuk lebih jelasnya mengenai tingkat pendapatan per bulan responden dapat di lihat pada Gambar 4.12 berikut ini.
Gambar 4.12 Tingkat Pendapatan Per Bulan Responden Sumber: Peneliti (2010) 10% 37% 35% 7% 5% 6% < Rp 1.000.000,00 atau = Rp 1.000.000,00 Rp 1.000.001,00 - Rp 3.000.000,00 Rp 3.000.001,00 - Rp 5.000.000,00 Rp 5.000.001,00 - Rp 7.000.000,00 Rp 7.000.001,00 - Rp 9.000.000,00 > Rp 9.000.000,00
4.2 Analisis Data 4.2.1 Spesifikasi Model
Pernyataan atau dugaan hipotesis penelitian telah dinyatakan secara rinci pada rancangan uji hipotesis bab 3 bagian 3.7. Untuk itu, peneliti langsung berlanjut ke langkah spesifikasi model berikutnya.
Terdapat empat variabel yang terlibat di dalam penelitian ini, yaitu dijelaskan pada Tabel 4.1. Perlu diingat bahwa pengolahan data dengan LISREL mensyaratkan bahwa, nama variabel manifest (indikator) dan variabel laten harus tidak lebih daripada 8 karakter (Ghozali dan Fuad, 2008, p77). Untuk itu, di dalam tahap ini, peneliti juga memberikan keterangan mengenai singkatan-singkatan yang peneliti gunakan dalam pengolahan data dengan LISREL yang nantinya akan muncul di hasil pengolahan data.
Tabel 4.1 Spesifikasi Kategori Variabel
Variabel Singkatan Kategori Simbol Variabel
Manifest Experiential
Marketing expmark Laten Eksogen Ksi1
ξ
1 13 indikatorCelebrity
Endorsement celeb Laten Eksogen Ksi2
ξ
2 5 indikatorBrand Trust trust Laten Endogen Eta1
η
1 8 indikator Brand Loyalty loyalty Laten Endogen Eta2η
2 3 indikator Sumber: Peneliti (2010)Pada Tabel 4.2 hingga 4.5 dijelaskan mengenai komponen yang termasuk ke dalam indikator-indikator pada Tabel 4.1.
Tabel 4.2 Variabel Manifest Experiential Marketing
Variabel Manifest Simbol Singkatan
Penglihatan X1 SENSE1
Pendengaran X2 SENSE2
Penciuman X3 SENSE3
Perasa X4 SENSE4
Peraba X5 SENSE5
Perasaan batin X6 FEEL1
Emosi X7 FEEL2
Pemikiran konvergen X8 THINK1
Pemikiran divergen X9 THINK2
Pengalaman fisik X10 ACT1
Gaya hidup X11 ACT2
Interaksi X12 ACT3
Menghubungkan orang-orang dengan
sistem sosial yang lebih luas X13 RELATE1
Sumber: Peneliti (2010)
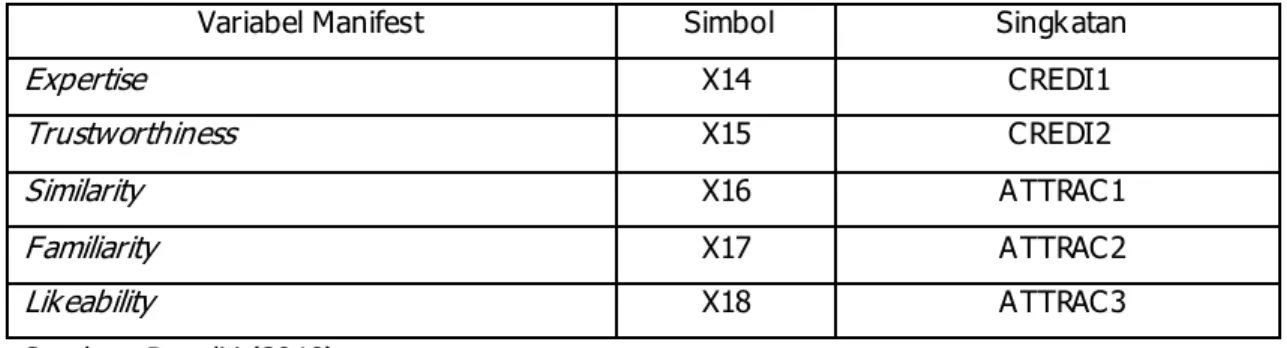
Tabel 4.3 Variabel Manifest Celebrity Endorsement
Variabel Manifest Simbol Singkatan
Expertise X14 CREDI1 Trustworthiness X15 CREDI2 Similarity X16 ATTRAC1 Familiarity X17 ATTRAC2 Likeability X18 ATTRAC3 Sumber: Peneliti (2010)
Tabel 4.4 Variabel Manifest Brand Trust
Variabel Manifest Simbol Singkatan
Kemampuan untuk menepati janji Y1 RELI1
Keinginan untuk menepati janji Y2 RELI2
Kemampuan memuaskan kebutuhan
konsumen Y3 RELI3
Keinginan memuaskan kebutuhan
konsumen Y4 RELI4 Altruism Y5 INTEN1 Honesty Y6 INTEN2 Dependability Y7 INTEN3 Fairness Y8 INTEN4 Sumber: Peneliti (2010)
Tabel 4.5 Variabel Manifest Brand Loyalty
Variabel Manifest Simbol Singkatan Perilaku pembelian ulang, karena
konsumen puas dengan merek tersebut Y9 BEHAV1
Word of mouth Y10 ATTITU1
Kerelaan untuk membayar pada harga
premium Y11 ATTITU2
Sumber: Peneliti (2010)
Berdasarkan hipotesis yang dibentuk diduga adanya hubungan-hubungan struktural berikut ini.
• Variabel experiential marketing memiliki pengaruh langsung yang signifikan terhadap variabel brand trust
• Variabel celebrity endorsement memiliki pengaruh langsung yang signifikan terhadap variabel brand trust
• Variabel brand trust memiliki pengaruh langsung yang signifikan terhadap variabel brand loyalty
• Variabel experiential marketing memiliki pengaruh langsung yang signifikan terhadap variabel brand loyalty
• Variabel celebrity endorsement memiliki pengaruh langsung yang signifikan terhadap variabel brand loyalty
• Variabel experiential marketing memiliki pengaruh tidak langsung yang signifikan terhadap variabel brand loyalty
• Variabel celebrity endorsement memiliki pengaruh tidak langsung yang signifikan terhadap variabel brand loyalty
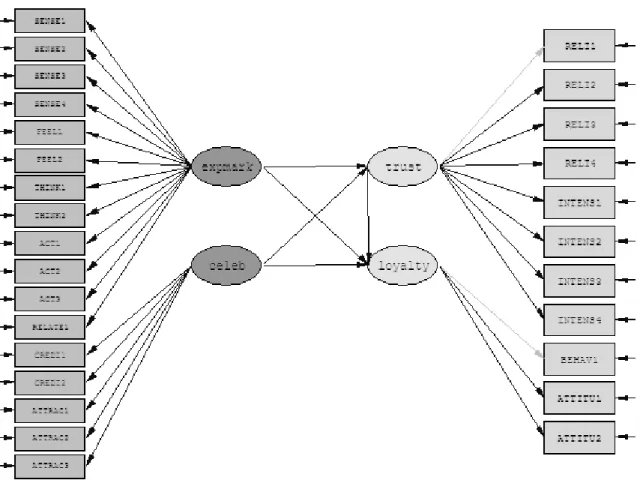
Diagram jalur hubungan antara variabel-variabel laten dan antara variabel laten beserta indikator-indikatornya digambarkan pada Gambar 4.13, di mana hubungan antara variabel-variabel laten tersebut merupakan hubungan recursive, yaitu pola hubungan antarvariabel yang memiliki satu arah (Yamin dan Kurniawan, 2009, p69).
112
Gambar 4.13 Hubungan Antarvariabel Sumber: Peneliti (2010) KSI1 ETA1 ETA2
( )
γ
11( )
β
21 KSI2( )
γ
12( )
ζ
1( )
ζ
2 X6 X7 X8 X9λ
X182 X3 X2 X10 X4δ
4 X11 X5 X1 X12 X13δ
1δ
2δ
3δ
5δ
6δ
7δ
8δ
9δ
10δ
11δ
12δ
13 X15 X16 X14δ
14 X17δ
17δ
16δ
15 X18δ
18 Y2 Y3 Y1 Y4 Y5 Y6 Y7 Y8 Y9 Y10 Y11λ
X172λ
X162λ
X152λ
X142λ
X131λ
X121λ
X111λ
X101λ
X91λ
X81λ
X71λ
X61λ
X51λ
X41λ
X31λ
X21λ
X11ε
1ε
2ε
3ε
4ε
5ε
6ε
7ε
8ε
9ε
10ε
11λ
Y11λ
Y21λ
Y31λ
Y41λ
Y51λ
Y61λ
Y71λ
Y81λ
Y92λ
Y102λ
Y112113
4.2.2 Identifikasi Model
Berdasarkan informasi pada Tabel 4.1 dapat diketahui bahwa total variabel teramati (variabel manifest) yang ada di dalam penelitian ini, yaitu sejumlah 29 variabel teramati (indikator), dengan rincian, yaitu 13 indikator untuk experiential marketing, 5 indikator untuk celebrity endorsement, 8 indikator untuk brand trust, dan 3 indikator untuk brand loyalty.
Berdasarkan pada jumlah variabel teramati tersebut (n = 29), maka jumlah data yang bisa diperoleh untuk pengolahan SEM, yaitu sejumlah 435, yang diperoleh dari perhitungan berikut ini.
Jumlah data = (n x (n + 1))/2 = (29 x (29 +1))/2 = 435
Jumlah data tersebut akan peneliti bandingkan dengan jumlah parameter yang diestimasi. Jumlah parameter yang diestimasi pada penelitian ini, yaitu sejumlah 64 parameter, di mana jumlah tersebut diperoleh dari Parameter Specifications pada output LISREL yang dapat dilihat pada bagian lampiran.
Dengan jumlah data (435) dan jumlah parameter (64), maka jumlah parameter yang diestimasi lebih kecil dari jumlah data yang diketahui, sehingga model di dalam penelitian ini termasuk ke dalam over-identified model atau dengan kata lain, model tersebut tidak termasuk ke dalam model yang under-identified atau unidentified yang memang tidak memiliki penyelesaian yang unik. LISREL secara otomatis juga dapat menampilkan keterangan mengenai model yang under-identified atau unidentified yaitu dengan peringatan adanya degree of freedom yang negatif, sehingga apabila nantinya terjadi respesifikasi model dengan mengeluarkan variabel teramati tertentu atau dengan menambah dan mengurangi suatu hubungan, peneliti tidak akan melakukan perhitungan manual lagi, dan akan langsung memfokuskan pada analisis hasil pengolahan.
4.2.3 Screening Data
Sebelum peneliti melanjutkan ke dalam tahap estimasi model, peneliti terlebih dahulu akan melakukan screening data. Hal ini sesuai dengan yang dinyatakan oleh Ghozali dan Fuad (2008, p65), yaitu “Sebelum melakukan analisis Structural Equation Modeling, sangat dianjurkan untuk melakukan screening data untuk memberikan gambaran mengenai deskriptif data (mean, standar deviasi, dan juga yang terpenting adalah untuk memastikan terpenuhinya asumsi-asumsi SEM seperti normalitas)”.
Skala yang digunakan dalam pengumpulan data merupakan skala ordinal, untuk itu, sebelum screening data dilakukan, peneliti terlebih dahulu akan mengubah data yang semula berskala ordinal menjadi data continuous, dikarenakan peneliti juga ingin menguji asumsi multivariate normality yang akan digunakan dalam penentuan metode estimasi di tahap selanjutnya, di mana pengujian multivariate normality tersebut tidak dapat dilakukan jika data berada dalam skala ordinal. Pengubahan jenis data dilakukan secara otomatis dengan bantuan LISREL 8.70. Berikut adalah ringkasan hasil dari proses screening data.
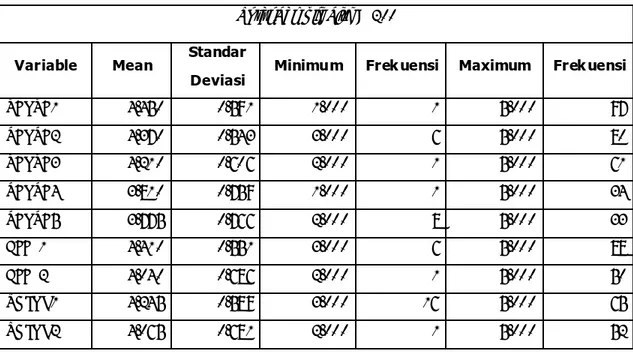
Tabel 4.6 Univariate Summary Statistics for Continuous Variables Total Sample Size = 200
Variable Mean Standar
Deviasi Minimum Frekuensi Maximum Frekuensi
SENSE1 4.450 0.591 1.000 1 5.000 97 SENSE2 4.370 0.543 3.000 6 5.000 80 SENSE3 4.210 0.606 2.000 1 5.000 61 SENSE4 3.810 0.759 1.000 1 5.000 34 SENSE5 3.775 0.766 2.000 8 5.000 33 FEEL1 4.410 0.551 3.000 6 5.000 88 FEEL2 4.040 0.686 2.000 1 5.000 50 THINK1 4.245 0.589 3.000 16 5.000 65 THINK2 4.065 0.681 2.000 1 5.000 52
Variable Mean Standar
Deviasi Minimum Frekuensi Maximum Frekuensi
ACT1 4.185 0.602 2.000 1 5.000 57 ACT2 4.240 0.674 2.000 2 5.000 73 ACT3 4.330 0.550 3.000 8 5.000 74 RELATE1 3.625 0.746 2.000 9 5.000 23 CREDI1 3.905 0.734 1.000 1 5.000 39 CREDI2 3.800 0.673 2.000 1 5.000 28 ATTRAC1 3.720 0.724 2.000 4 5.000 28 ATTRAC2 3.600 0.750 1.000 1 5.000 22 ATTRAC3 3.805 0.728 1.000 1 5.000 29 RELI1 3.825 0.653 3.000 63 5.000 28 RELI2 3.920 0.613 3.000 46 5.000 30 RELI3 3.860 0.688 3.000 63 5.000 35 RELI4 3.820 0.678 2.000 1 5.000 30 INTENS1 3.970 0.657 2.000 1 5.000 39 INTENS2 3.935 0.619 3.000 45 5.000 32 INTENS3 3.715 0.668 2.000 3 5.000 21 INTENS4 3.795 0.620 2.000 1 5.000 21 BEHAV1 3.900 0.750 1.000 1 5.000 42 ATTITU1 4.070 0.630 2.000 1 5.000 46 ATTITU2 3.630 0.822 1.000 1 5.000 26 Sumber: Peneliti (2010)
Menurut Yamin dan Kurniawan (2009, p23), salah satu fungsi dari screening data adalah untuk memeriksa ulang apakah terdapat kesalahan pengetikan data yang di-input atau apakah terdapat missing value (responden tidak memilih salah satu dari sebuah item pertanyaan).
Dari Tabel 4.6 dapat diketahui bahwa jumlah sample yang digunakan di dalam penelitian ini berjumlah 200 sample. Selain itu, di dalam output hasil screening data tidak (Lanjutan Tabel 4.6)
ditemukan adanya keterangan number of missing values yang berarti bahwa tidak ada data yang hilang dalam proses pemasukan data.
Skala Likert yang digunakan dalam penelitian ini terdiri dari lima jenis kategori, yaitu sangat tidak setuju (1), tidak setuju (2), biasa atau netral (3), setuju (4), dan sangat setuju (5). Berarti nilai minimum yang mungkin muncul atas tanggapan terhadap masing-masing indikator, yaitu sebesar 1 dan nilai maksimum yang mungkin muncul adalah sebesar 5.
Dengan melihat nilai minimum dan maksimum pada Tabel 4.6, dapat diamati bahwa tidak ada nilai ekstrim yang tidak masuk akal atau dengan kata lain tidak terdeteksi adanya outliers pada penelitian ini.
Tabel 4.7 Test of Multivariate Normality for Continuous Variables Skewness and Kurtosis
Chi-Square P-Value 392.764 0.000 Sumber: Peneliti (2010)
Menurut Ghozali dan Fuad (2008, p67), asumsi multivariate normality jauh lebih penting daripada univariate normality. Multivariate normality menunjukkan bahwa data tidak normal secara simultan. Berikut adalah pengujian multivariate normality berdasarkan pada informasi p-value di Tabel 4.7.
• Dasar Pengambilan Keputusan
Jika P-Value Skewness dan Kurtosis > 0.05, maka data normal secara simultan Jika P-Value Skewness dan Kurtosis < 0.05, maka data tidak normal secara simultan • Keputusan
P-Value Skewness dan Kurtosis = 0.000 < 0.05, maka data tidak normal secara simultan, sehingga data di dalam penelitian ini tidak memenuhi asumsi multivariate normality.
4.2.4 Estimasi Model
Berdasarkan pada terpenuhi atau tidaknya asumsi multivariate normality, karena data tidak normal secara simultan dan telah diubah ke dalam bentuk kontinu, maka metode estimasi yang digunakan adalah Robust Maximum Likelihood.
4.2.5 Uji Kecocokan Keseluruhan Model
Pada bagian ini, peneliti akan menggunakan informasi tingkat kecocokan yang bisa diterima pada suatu model yang terdapat di Tabel 3.7. Khusus untuk penilaian statistic chi-square, menurut Hu et al. (Ghozali dan Fuad, 2008, p258) hanya Satorra-Bentler Scaled Chi-Square yang menghasilkan estimasi chi-square yang paling valid, berapapun jumlah sampel, dan pada penggunaan data yang tidak normal. Untuk itu nilai statistic chi-square yang akan digunakan dalam uji kecocokan keseluruhan model adalah Satorra-Bentler Scaled Chi-Square. Pada Tabel 4.8 disajikan hasil untuk uji kecocokan model keseluruhan.
Tabel 4.8 Uji Kecocokan Keseluruhan Model 1 Ukuran
Derajat Kecocokan
Tingkat Kecocokan Yang Bisa Diterima Pada Suatu Model Keputusan Statistic Chi-square
⎟
⎠
⎞
⎜
⎝
⎛
χ
2Dasar Pengambilan Keputusan P > 0.05 Æ model fit
Tidak Fit
Hasil Pengolahan
Satorra-Bentler Scaled Chi-Square (P = 0.0) Goodness of Fit
Index (GFI)
Dasar Pengambilan Keputusan GFI = 1 Æ perfect fit
0,90 < GFI < 1 Æ good fit 0.80 < GFI < 0.90 Æ marginal fit 0 Æ poor fit
Tidak Fit
Hasil Pengolahan
Ukuran Derajat Kecocokan
Tingkat Kecocokan Yang Bisa Diterima Pada Suatu Model
Keputusan
Root Mean Square
Residual (RMR)
Dasar Pengambilan Keputusan Standardized RMR < 0.05 Æ good fit
Tidak Fit Hasil Pengolahan Standardized RMR = 0.070 Root Mean Square Error of Approximation (RMSEA)
Dasar Pengambilan Keputusan RMSEA < 0.05 Æ close fit 0.05 < RMSEA < 0.08 Æ good fit 0.08 < RMSEA < 0.10 Æ marginal fit RMSEA > 0.10 Æ poor fit
Good fit
Hasil Pengolahan
Root Mean Square Error of Approximation (RMSEA) = 0.065 Expected Cross
Validation Index (ECVI)
Dasar Pengambilan Keputusan
ECVI < ECVI for Saturated Model Æ model fit
Fit
Hasil Pengolahan
Expected Cross-Validation Index (ECVI) = 4.07 ECVI for Saturated Model = 4.37
Dasar Pengambilan Keputusan
ECVI < ECVI for Independence Model Æ model fit
Fit
Hasil Pengolahan
Expected Cross-Validation Index (ECVI) = 4.07 ECVI for Independence Model = 45.64
Adjusted Goodness of Fit Index (AGFI)
Dasar Pengambilan Keputusan AGFI = 1 Æ perfect fit
0,90 < AGFI < 1 Æ good fit 0.80 < AGFI < 0.90 Æ marginal fit (nilai AGFI berkisar antara 0 sampai 1)
Tidak Fit
Hasil Pengolahan
Adjusted Goodness of Fit Index (AGFI) = 0.75 (Lanjutan Tabel 4.8)
Ukuran Derajat Kecocokan
Tingkat Kecocokan Yang Bisa Diterima Pada Suatu Model
Keputusan
Tucker-Lewis Index atau Non-Normed Fit Index (TLI atau NNFI)
Dasar Pengambilan Keputusan TLI > 0.90 Æ good fit.
0.80 < TLI < 0.90 Æ marginal fit
(nilai TLI/NNFI berkisar antara 0 sampai 1)
Good fit
Hasil Pengolahan
Non-Normed Fit Index (NNFI) = 0.96 Normed Fit
Index (NFI)
Dasar Pengambilan Keputusan NFI > 0.90 Æ good fit
0.80 < NFI < 0.90 Æ marginal fit (nilai NFI berkisar antara 0 sampai 1)
Good fit
Hasil Pengolahan
Normed Fit Index (NFI) = 0.92 Relative Fit
Index (RFI)
Dasar Pengambilan Keputusan RFI > 0.90 Æ good fit
0.80 < RFI < 0.90 Æ marginal fit (nilai RFI berkisar antara 0 sampai 1)
Good fit
Hasil Pengolahan
Relative Fit Index (RFI) = 0.92 Incremental Fit
Index (IFI)
Dasar Pengambilan Keputusan IFI > 0.90 Æ good fit
0.80 < IFI < 0.90 Æ marginal fit (nilai IFI berkisar antara 0 sampai 1)
Good fit
Hasil Pengolahan
Incremental Fit Index (IFI) = 0.96 (Lanjutan Tabel 4.8)
Ukuran Derajat Kecocokan
Tingkat Kecocokan Yang Bisa Diterima Pada Suatu Model
Keputusan
Comparative Fit Index (CFI)
Dasar Pengambilan Keputusan CFI > 0.90 Æ good fit
0.80 < CFI < 0.90 Æ marginal fit (nilai CFI berkisar antara 0 sampai 1)
Good fit
Hasil Pengolahan
Comparative Fit Index (CFI) = 0.96 Normed
Chi-Square
Dasar Pengambilan Keputusan 1.0 < (X2/df) < 5.0 Æmodel fit Fit Hasil Pengolahan 682.31/371 = 1.839 Akaike Information Criterion (AIC)
Dasar Pengambilan Keputusan AIC < Saturated AIC Æ model fit
Fit
Hasil Pengolahan Model AIC = 810.31 Saturated AIC = 870.00 Dasar Pengambilan Keputusan AIC < Independence AIC Æ model fit
Fit Hasil Pengolahan Model AIC = 810.31 Independence AIC = 9082.92 Consistent Akaike Information Criterion (CAIC)
Dasar Pengambilan Keputusan CAIC < Saturated CAIC Æ model fit
Fit
Hasil Pengolahan Model CAIC = 1085.40 Saturated CAIC = 2739.77 (Lanjutan Tabel 4.8)
Ukuran Derajat Kecocokan
Tingkat Kecocokan Yang Bisa Diterima Pada Suatu Model Keputusan Consistent Akaike Information Criterion (CAIC)
Dasar Pengambilan Keputusan
CAIC < Independence CAIC Æ model fit
Fit
Hasil Pengolahan Model CAIC = 1085.40
Independence CAIC = 9207.57 Critical N (CN) Dasar Pengambilan Keputusan
CN > 200 Æ model fit
Tidak Fit
Hasil Pengolahan Critical N (CN) = 128.54 Sumber: Peneliti (2010)
Berdasarkan pada informasi pada Tabel 4.8, dapat diamati bahwa terdapat 5 ukuran GOF yang menunjukkan kecocokan yang tidak fit dan 13 ukuran GOF menunjukkan kecocokan yang fit. Sebagian besar ukuran kecocokan tersebut menunjukkan hasil yang fit, sehingga dapat dikatakan bahwa kecocokan keseluruhan model adalah baik dan peneliti dapat melanjutkan ke tahap selanjutnya. Namun sebelum itu, kecocokan keseluruhan model ini sebenarnya masih bisa ditingkatkan dengan memanfaatkan informasi yang ada di Modification Index, seperti tampak pada Gambar 4.14.
Gambar 4.14 Modification Index Sumber: Peneliti (2010)
Pada Gambar 4.14 dapat diketahui bahwa modifikasi yang mungkin dilakukan antara lain, yaitu (1) menjadikan indikator ATTRAC1 yang merupakan indikator dari variabel laten celebrity endorsement sekaligus juga menjadi indikator dari variabel laten experiential marketing, (2) menjadikan indikator RELATE1 yang merupakan indikator dari variabel laten experiential marketing sekaligus juga menjadi indikator dari variabel laten celebrity endorsement, (3) menjadikan indikator INTENS4 yang merupakan indikator dari variabel laten brand trust sekaligus juga menjadi indikator dari variabel laten brand loyalty, dan (4) menambahkan hubungan di antara kesalahan pengukuran antara indikator-indikator tertentu seperti yang disarankan di gambar. Untuk melakukan modifikasi tersebut, Ghozali dan Fuad (2008, p339) menyatakan bahwa apapun modifikasi yang dilakukan harus sesuai dan dapat
dipertanggung jawabkan sesuai dengan teori”, dan peneliti tidak menemukan adanya teori yang mendukung untuk diberlakukannya modifikasi-modifikasi tersebut. Lagipula, sebagian besar ukuran GOF telah menyatakan bahwa model ini fit dan model ini pun dibangun atas berbagai teori dasar yang cukup kuat. Hal ini sesuai dengan salah satu konsensus yang ada di antara para peneliti yang dipantau oleh Bollen dan Long (Wijanto, 2008, pp49-50), yaitu bahwa “Petunjuk terbaik dalam menilai kecocokan model adalah teori substantif yang kuat. Jika model hanya menunjukkan atau mewakili teori substantif yang tidak kuat, dan meskipun model mempunyai kecocokan yang sangat baik, agak sukar bagi kita untuk menilai model tersebut”. Untuk itulah peneliti tidak mengadakan modifikasi yang disarankan oleh output Modification Index dan melanjutkan ke tahap berikutnya, yaitu uji kecocokan model pengukuran.
4.2.6 Uji Kecocokan Model Pengukuran
Evaluasi pada uji kecocokan model pengukuran terdiri dari evaluasi terhadap validitas dari model pengukuran dan evaluasi terhadap reliabilitas dari model pengukuran. Sebelum melakukan uji reliabilitas, peneliti terlebih dahulu akan melakukan uji validitas, dikarenakan indikator yang tidak valid akan dikeluarkan dari model.
Terdapat dua jenis penilaian agar suatu variabel dikatakan mempunyai validitas yang baik, yaitu dengan berdasarkan pada nilai t muatan faktor dan muatan faktor standar. Suatu variabel dikatakan mempunyai validitas yang baik, jika:
(1) Nilai t muatan faktornya lebih besar dari nilai kritis (>1.96). Nilai kritis sebesar 1.96 diperoleh dari nilai t tabel dengan level signifikansi 5% dan jumlah sampel 200.
(2) Muatan faktor standarnya (standardized factor loadings) lebih besar atau sama dengan 0.70 (Rigdon dan Ferguson) atau muatan faktor standarnya > 0.50 (Igrabia, et al.).
Memang terdapat dua pandangan mengenai nilai minimal untuk muatan faktor standar, namun sepengamatan peneliti, masih banyak referensi yang menggunakan nilai minimal sebesar 0.50. Untuk itu di dalam penelitian ini, peneliti akan menggunakan standar nilai minimal ter sebut. Sehingga, dasar pengambilan keputusan untuk pengujian validitas pada tahap ini, yaitu suatu variabel dikatakan mempunyai validitas yang baik dengan berdasarkan pada dua kriteria, yaitu jika:
(1) Nilai t muatan faktor > 1,96 dan (2) Muatan faktor standar > 0.50
Pada Tabel 4.9 disajikan informasi mengenai nilai t, muatan faktor standar/ standardized factor loadings (SFL), dan juga kesimpulan mengenai validitas dari masing-masing variabel teramati berkaitan dengan variabel laten mereka masing-masing-masing-masing.
Tabel 4.9 Uji Validitas (1) Var. Laten Var. Teramati Experiential Marketing (expmark) Celebrity endorsement (celeb) Brand Trust (trust) Brand Loyalty (loyalty) Kesimpulan Validitas
SFL Nilai t SFL Nilai t SFL Nilai t SFL Nilai t
SENSE1 0.45 7.46 - - - - - - Kurang Baik
SENSE2 0.61 10.69 - - - - - - Baik
SENSE3 0.69 11.60 - - - - - - Baik
SENSE4 0.46 6.55 - - - - - - Kurang Baik
SENSE5 0.40 5.51 - - - - - - Kurang Baik
FEEL1 0.57 9.52 - - - - - - Baik FEEL2 0.68 12.10 - - - - - - Baik THINK1 0.72 12.99 - - - - - - Baik THINK2 0.62 10.20 - - - - - - Baik ACT1 0.52 8.69 - - - - - - Baik ACT2 0.66 11.63 - - - - - - Baik ACT3 0.52 8.54 - - - - - - Baik RELATE1 0.52 7.63 - - - - - - Baik CREDI1 - - 0.74 12.98 - - - - Baik CREDI2 - - 0.65 9.01 - - - - Baik
Var. Laten Var. Teramati Experiential Marketing (expmark) Celebrity endorsement (celeb) Brand Trust (trust) Brand Loyalty (loyalty) Kesimpulan Validitas
SFL Nilai t SFL Nilai t SFL Nilai t SFL Nilai t
ATTRAC1 - - 0.69 12.20 - - - - Baik ATTRAC2 - - 0.83 14.03 - - - - Baik ATTRAC3 - - 0.70 9.27 - - - - Baik RELI1 - - - - 0.80 * - - Baik RELI2 - - - - 0.79 13.86 - - Baik RELI3 - - - - 0.84 14.09 - - Baik RELI4 - - - - 0.86 16.72 - - Baik INTENS1 - - - - 0.68 11.00 - - Baik INTENS2 - - - - 0.67 9.97 - - Baik INTENS3 - - - - 0.65 10.15 - - Baik INTENS4 - - - - 0.67 9.22 - - Baik BEHAV1 - - - - - - 0.80 * Baik ATTITU1 - - - - - - 0.78 11.12 Baik ATTITU2 - - - - - - 0.58 7.74 Baik
Pada Tabel 4.9 terdapat tanda (*), di mana maksud dari tanda tersebut adalah ditetapkan secara default oleh LISREL, yaitu nilai t tidak diestimasi. Dapat diamati bahwa seluruh variabel teramati memiliki nilai t muatan faktor lebih besar dari 1,96 sehingga memenuhi satu kriteria untuk dinyatakan memiliki validitas yang baik. Namun untuk muatan faktor standar, terdapat 3 variabel teramati yang tidak valid, karena muatan faktor standarnya lebih kecil dibanding 0.5. Ketiga variabel teramati tersebut adalah SENSE1, SENSE4, dan SENSE5. Sehingga di dalam model penelitian ini, variabel laten yang seluruh variabel teramatinya memiliki validitas yang baik, karena telah memenuhi dua kriteria validitas yang baik, adalah variabel laten celebrity endorsement, brand trust, dan brand Sumber: Peneliti (2010)
loyalty. Berbeda dengan variabel laten experiential marketing yang memiliki beberapa variabel teramati yang kurang baik dari segi validitas, di mana adanya ukuran validitas yang kurang baik dari beberapa variabel teramatinya tersebut akan dapat memengaruhi reliabilitas dari variabel laten experiential marketing tersebut menjadi tidak reliabel.
4.2.7 Respesifikasi Model (A)
Berdasarkan pada hasil uji validitas pada Tabel 4.9, variabel teramati SENSE1, SENSE4, dan SENSE5 tidak memenuhi salah satu syarat yang harus dipenuhi agar suatu variabel teramati bisa dikatakan memiliki validitas yang baik, maka SENSE1, SENSE4, dan SENSE5 seharusnya dikeluarkan dari model di penelitian ini. Namun, ketiganya tidak perlu dikeluarkan sekaligus, karena ketika satu indikator dikeluarkan dari model, maka nilai muatan faktor standar dan nilai t dari indikator-indikator lain yang masih berada di dalam model penelitian akan ikut berubah, dan untuk itu ada kemungkinan indikator yang semula tidak valid dapat menjadi valid, walaupun hal tersebut tidak selalu terjadi. Indikator yang pertama kali akan dikeluarkan dari model adalah indikator dengan nilai muatan faktor standar terkecil, yaitu SENSE5 dengan muatan faktor standar sebesar 0.40. Dengan dikeluarkannya indikator tersebut, maka model di penelitian ini menjadi seperti apa yang ditampilkan pada Gambar 4.15. Pada gambar tersebut dapat diamati bahwa variabel laten experiential marketing yang pada model awal memiliki 13 buah variabel teramati, kini variabel teramatinya menjadi 12 buah, karena dikeluarkannya SENSE5 dari penelitian.
Gambar 4.15 Respesifikasi Model (A) Sumber: Peneliti (2010)
Dengan adanya model penelitian yang baru seperti yang tampak di Gambar 4.15, maka nilai uji kecocokan keseluruhan juga memiliki kemungkinan untuk berubah, baik pada sebagian atau seluruh ukuran penilaian yang tersedia. Pada Tabel 4.10 ditampilkan hasil uji kecocokan keseluruhan untuk model penelitian pada Gambar 4.15. Pada tabel tersebut dapat diamati bahwa hasil keputusan mengenai uji kecocokan keseluruhan adalah sama dengan hasil keputusan uji kecocokan keseluruhan pada model penelitian sebelum direspifikasi. Walaupun dari segi keputusan terdapat hasil yang sama, yaitu terdapat 5 ukuran GOF yang menunjukkan kecocokan yang tidak fit dan 13 ukuran GOF menunjukkan kecocokan yang fit,
namun dari segi angka hasil pengolahan terdapat beberapa perbedaan, yaitu tampak pada ukuran derajat kecocokan Root Mean Square Error of Approximation (RMSEA), Expected Cross-Validation Index (ECVI), Normed Fit Index (NFI), Normed Chi-Square, Akaike Information Criterion (AIC), Consistent Akaike Information Criterion (CAIC), dan Critical N (CN), hanya saja angka hasil pengolahan tersebut masih terdapat pada daerah keputusan yang sama sehingga hasil keputusannya pun sama. Karena sebagian besar ukuran kecocokan tersebut menunjukkan hasil yang fit, sehingga dapat dikatakan bahwa kecocokan keseluruhan model adalah baik dan peneliti dapat melanjutkan ke tahap selanjutnya.
Tabel 4.10 Uji Kecocokan Keseluruhan 2 (A) Ukuran
Derajat Kecocokan
Tingkat Kecocokan Yang Bisa Diterima Pada Suatu Model Keputusan Statistic Chi-square
⎟
⎠
⎞
⎜
⎝
⎛
χ
2Dasar Pengambilan Keputusan P > 0.05 Æ model fit
Tidak Fit
Hasil Pengolahan
Satorra-Bentler Scaled Chi-Square (P = 0.0) Goodness of Fit
Index (GFI)
Dasar Pengambilan Keputusan GFI = 1 Æ perfect fit
0,90 < GFI < 1 Æ good fit 0.80 < GFI < 0.90 Æ marginal fit 0 Æ poor fit
Tidak Fit
Hasil Pengolahan
Goodness of Fit Index (GFI) = 0.79 Root Mean
Square
Residual (RMR)
Dasar Pengambilan Keputusan Standardized RMR < 0.05 Æ good fit
Tidak Fit
Hasil Pengolahan
Ukuran Derajat Kecocokan
Tingkat Kecocokan Yang Bisa Diterima Pada Suatu Model Keputusan Root Mean Square Error of Approximation (RMSEA)
Dasar Pengambilan Keputusan RMSEA < 0.05 Æ close fit 0.05 < RMSEA < 0.08 Æ good fit 0.08 < RMSEA < 0.10 Æ marginal fit RMSEA > 0.10 Æ poor fit
Good fit
Hasil Pengolahan
Root Mean Square Error of Approximation (RMSEA) = 0.066 Expected Cross
Validation Index (ECVI)
Dasar Pengambilan Keputusan
ECVI < ECVI for Saturated Model Æ model fit
Fit
Hasil Pengolahan
Expected Cross-Validation Index (ECVI) = 3.85 ECVI for Saturated Model = 4.08
Dasar Pengambilan Keputusan
ECVI < ECVI for Independence Model Æ model fit
Fit
Hasil Pengolahan
Expected Cross-Validation Index (ECVI) = 3.85 ECVI for Independence Model = 44.16
Adjusted Goodness of Fit Index (AGFI)
Dasar Pengambilan Keputusan AGFI = 1 Æ perfect fit
0,90 < AGFI < 1 Æ good fit 0.80 < AGFI < 0.90 Æ marginal fit (nilai AGFI berkisar antara 0 sampai 1)
Tidak Fit
Hasil Pengolahan
Adjusted Goodness of Fit Index (AGFI) = 0.75 (Lanjutan Tabel 4.10)
Ukuran Derajat Kecocokan
Tingkat Kecocokan Yang Bisa Diterima Pada Suatu Model
Keputusan
Tucker-Lewis Index atau Non-Normed Fit Index (TLI atau NNFI)
Dasar Pengambilan Keputusan TLI > 0.90 Æ good fit.
0.80 < TLI < 0.90 Æ marginal fit
(nilai TLI/NNFI berkisar antara 0 sampai 1)
Good fit
Hasil Pengolahan
Non-Normed Fit Index (NNFI) = 0.96 Normed Fit
Index (NFI)
Dasar Pengambilan Keputusan NFI > 0.90 Æ good fit
0.80 < NFI < 0.90 Æ marginal fit (nilai NFI berkisar antara 0 sampai 1)
Good fit
Hasil Pengolahan
Normed Fit Index (NFI) = 0.93 Relative Fit
Index (RFI)
Dasar Pengambilan Keputusan RFI > 0.90 Æ good fit
0.80 < RFI < 0.90 Æ marginal fit (nilai RFI berkisar antara 0 sampai 1)
Good fit
Hasil Pengolahan
Relative Fit Index (RFI) = 0.92 Incremental Fit
Index (IFI)
Dasar Pengambilan Keputusan IFI > 0.90 Æ good fit
0.80 < IFI < 0.90 Æ marginal fit (nilai IFI berkisar antara 0 sampai 1)
Good fit
Hasil Pengolahan
Incremental Fit Index (IFI) = 0.96 (Lanjutan Tabel 4.10)
Ukuran Derajat Kecocokan
Tingkat Kecocokan Yang Bisa Diterima Pada Suatu Model
Keputusan
Comparative Fit Index (CFI)
Dasar Pengambilan Keputusan CFI > 0.90 Æ good fit
0.80 < CFI < 0.90 Æ marginal fit (nilai CFI berkisar antara 0 sampai 1)
Good fit
Hasil Pengolahan
Comparative Fit Index (CFI) = 0.96 Normed
Chi-Square
Dasar Pengambilan Keputusan 1.0 < (X2/df) < 5.0 Æmodel fit Fit Hasil Pengolahan 641.21/344 = 1.864 Akaike Information Criterion (AIC)
Dasar Pengambilan Keputusan AIC < Saturated AIC Æ model fit
Fit
Hasil Pengolahan Model AIC = 765.21 Saturated AIC = 812.00 Dasar Pengambilan Keputusan AIC < Independence AIC Æ model fit
Fit Hasil Pengolahan Model AIC = 765.21 Independence AIC = 8788.63 Consistent Akaike Information Criterion (CAIC)
Dasar Pengambilan Keputusan CAIC < Saturated CAIC Æ model fit
Fit
Hasil Pengolahan Model CAIC = 1031.71 Saturated CAIC = 2557.12 (Lanjutan Tabel 4.10)
Ukuran Derajat Kecocokan
Tingkat Kecocokan Yang Bisa Diterima Pada Suatu Model Keputusan Consistent Akaike Information Criterion (CAIC)
Dasar Pengambilan Keputusan
CAIC < Independence CAIC Æ model fit
Fit
Hasil Pengolahan Model CAIC = 1031.71
Independence CAIC = 8908.98 Critical N (CN) Dasar Pengambilan Keputusan
CN > 200 Æ model fit
Tidak Fit
Hasil Pengolahan Critical N (CN) = 127.61 Sumber: Peneliti (2010)
Sebenarnya setelah uji kecocokan keseluruhan selesai, tahap selanjutnya yang akan dilakukan peneliti, adalah uji kecocokan model pengukuran. Namun, sebenarnya uji kecocokan model keseluruhan yang ada pada Tabel 4.10 belum selesai. Dengan meninjau kembali informasi yang tersedia di Tabel 3.7 mengenai rangkuman kriteria uji kecocokan, maka terdapat dua kategori besar penilaian, yaitu penilaian untuk tingkat kecocokan yang bisa diterima pada suatu model dan untuk perbandingan antarmodel, di mana pada Tabel 4.10 tersebut baru memperhitungkan tingkat kecocokan yang bisa diterima pada suatu model. Untuk itu, peneliti juga akan melakukan uji kecocokan untuk perbandingan antarmodel, guna membandingkan antara model awal sebelum respesifikasi dengan hasil respesifikasi model (A), di mana hasil uji kecocokan tersebut ditampilkan pada Tabel 4.11. (Lanjutan Tabel 4.10)
Tabel 4.11 Uji Kecocokan Keseluruhan 2 (B) Ukuran Derajat Kecocokan Dasar Pengambilan Keputusan Model Awal Respesifikasi Model (A) Keputusan Statistic Chi-square
⎟
⎠
⎞
⎜
⎝
⎛
χ
2 Nilaiχ
2 semakin kecil semakin baik682.31 641.21 Lebih baik Non-Centrality Parameter (NCP) Semakin kecil semakin baik 311.31 297.21 Lebih baik
Scaled NCP (SNCP) Semakin kecil semakin baik
1.55655 1.48605 Lebih baik
Goodness of Fit Index (GFI)
Nilai lebih tinggi adalah lebih baik
0.79 0.79 Tidak mengalami perubahan Expected Cross Validation Index (ECVI) Semakin kecil semakin baik 4.07 3.85 Lebih baik Adjusted Goodness of Fit Index (AGFI)
Nilai lebih tinggi adalah lebih baik
0.75 0.75 Tidak mengalami
perubahan Tucker-Lewis Index
atau Non-Normed Fit Index (TLI atau NNFI)
Nilai lebih tinggi adalah lebih baik
0.96 0.96 Tidak mengalami
perubahan
Normed Fit Index (NFI)
Nilai lebih tinggi adalah lebih baik
0.92 0.93 Lebih baik
Relative Fit Index (RFI)
Nilai lebih tinggi adalah lebih baik
0.92 0.92 Tidak mengalami
perubahan Incremental Fit
Index (IFI)
Nilai lebih tinggi adalah lebih baik
0.96 0.96 Tidak mengalami
perubahan Comparative Fit
Index (CFI)
Nilai lebih tinggi adalah lebih baik
0.96 0.96 Tidak mengalami
perubahan Parsimonious
Normed Fit Index (PNFI)
Nilai PNFI tinggi adalah lebih baik
0.84 0.84 Tidak mengalami
Ukuran Derajat Kecocokan Dasar Pengambilan Keputusan Model Awal Respesifikasi Model (A) Keputusan Parsimonious Goodness of Fit (PGFI)
Nilai PGFI yang lebih tinggi adalah lebih baik
(Nilai PGFI berkisar antara 0 dengan 1)
0.67 0.67 Tidak mengalami
perubahan
Akaike Information Criterion (AIC)
Nilai AIC positif lebih kecil adalah lebih baik
810.31 765.21 Lebih baik
Consistent Akaike Information Criterion (CAIC)
Nilai positif yang lebih kecil adalah lebih baik
1085.40 1031.71 Lebih baik
Sumber: Peneliti (2010)
Untuk hasil Scaled NCP (SNCP), tidak diperoleh dari output LISREL, melainkan dari perhitungan berikut ini.
• Scaled NCP (SNCP) = NCP/n, di mana n = jumlah sample • Scaled NCP (SNCP) model awal = 311.31/200 = 1.55655
• Scaled NCP (SNCP) respesifikasi model (A) = 297.21/200 = 1.48605
Dengan membandingkan antara model awal penelitian dengan hasil respesifikasi model (A) pada Tabel 4.11, maka terdapat 7 ukuran derajat kecocokan yang memberikan keputusan bahwa hasil respesifikasi model (A) dari segi ukuran derajat kecocokan menunjukkan hasil yang lebih baik (lebih fit) dibandingkan model sebelumnya. Hal ini sesuai dengan teori bahwa terdapat beberapa alasan kenapa suatu model memiliki fit yang buruk, salah satunya, yaitu adanya specification error. Specification error timbul bisa disebabkan oleh beberapa penyebab, salah satunya adalah adanya indikator yang tidak valid dan (Lanjutan Tabel 4.11)
memiliki reliabilitas yang kurang (Ghozali dan Fuad, 2008, pp339-340). Karena sebagian besar hasil uji kecocokan keseluruhan dari hasil respesifikasi model (A) adalah baik (fit) dan hasil respesifikasi model (A) ini juga lebih baik dibandingkan model penelitian awal, maka kecocokan keseluruhan model adalah baik dan peneliti dapat melanjutkan ke tahap selanjutnya, yaitu uji kecocokan model pengukuran.
Seperti yang telah dijelaskan sebelumnya bahwa uji kecocokan model pengukuran terdiri dari uji validitas dan uji reliabilitas. Namun sebelum uji reliabilitas dilakukan, peneliti harus memastikan bahwa seluruh variabel teramati telah baik dari segi validitas. Pada Tabel 4.12 ditampilkan hasil uji validitas untuk model penelitian hasil respesifikasi model (A).
Dasar pengambilan keputusan untuk pengujian validitas pada tahap ini, yaitu suatu variabel dikatakan mempunyai validitas yang baik dengan berdasarkan pada dua kriteria, yaitu jika:
(1) Nilai t muatan faktor > 1,96 (2) Muatan faktor standar > 0.50
Tabel 4.12 Uji Validitas (2) Var. Laten Var. Teramati Experiential Marketing (expmark) Celebrity endorsement (celeb) Brand Trust (trust) Brand Loyalty (loyalty) Kesimpulan Validitas
SFL Nilai t SFL Nilai t SFL Nilai t SFL Nilai t
SENSE1 0.44 7.49 - - - - - - Kurang Baik
SENSE2 0.62 10.85 - - - - - - Baik
SENSE3 0.70 11.52 - - - - - - Baik
SENSE4 0.45 6.35 - - - - - - Kurang Baik
FEEL1 0.56 9.13 - - - - - - Baik
FEEL2 0.68 11.98 - - - - - - Baik
THINK1 0.73 13.06 - - - - - - Baik
Var. Laten Var. Teramati Experiential Marketing (expmark) Celebrity endorsement (celeb) Brand Trust (trust) Brand Loyalty (loyalty) Kesimpulan Validitas
SFL Nilai t SFL Nilai t SFL Nilai t SFL Nilai t
ACT1 0.53 8.69 - - - - - - Baik ACT2 0.66 11.64 - - - - - - Baik ACT3 0.52 8.48 - - - - - - Baik RELATE1 0.52 7.49 - - - - - - Baik CREDI1 - - 0.74 12.98 - - - - Baik CREDI2 - - 0.65 9.01 - - - - Baik ATTRAC1 - - 0.69 12.21 - - - - Baik ATTRAC2 - - 0.83 14.04 - - - - Baik ATTRAC3 - - 0.70 9.27 - - - - Baik RELI1 - - - - 0.80 * - - Baik RELI2 - - - - 0.79 13.85 - - Baik RELI3 - - - - 0.84 14.09 - - Baik RELI4 - - - - 0.86 16.72 - - Baik INTENS1 - - - - 0.68 10.99 - - Baik INTENS2 - - - - 0.67 9.97 - - Baik INTENS3 - - - - 0.65 10.15 - - Baik INTENS4 - - - - 0.67 9.22 - - Baik BEHAV1 - - - - - - 0.80 * Baik ATTITU1 - - - - - - 0.78 11.11 Baik ATTITU2 - - - - - - 0.58 7.74 Baik
Pada Tabel 4.12 terdapat tanda (*), di mana maksud dari tanda tersebut adalah ditetapkan secara default oleh LISREL, yaitu nilai t tidak diestimasi. Dapat diamati bahwa seluruh variabel teramati memiliki nilai t muatan faktor lebih besar dari 1,96 sehingga memenuhi satu kriteria untuk dinyatakan memiliki validitas yang baik. Namun untuk muatan Sumber: Peneliti (2010)
faktor standar atau standardized factor loadings (SFL), terdapat 2 variabel teramati yang tidak valid, karena muatan faktor standarnya lebih kecil dibanding 0.5. Kedua variabel teramati tersebut adalah SENSE1 dan SENSE4. Sehingga di dalam model penelitian ini, variabel laten yang seluruh variabel teramatinya memiliki validitas yang baik, karena telah memenuhi dua kriteria validitas yang baik, adalah variabel laten celebrity endorsement, brand trust, dan brand loyalty.
4.2.8 Respesifikasi Model (B)
Berdasarkan pada hasil uji validitas pada Tabel 4.12, variabel teramati SENSE1 dan SENSE4 tidak memenuhi salah satu syarat yang harus dipenuhi agar suatu variabel teramati bisa dikatakan memiliki validitas yang baik, maka SENSE1 dan SENSE4 seharusnya dikeluarkan dari model di penelitian ini. Namun, keduanya tidak perlu dikeluarkan sekaligus, karena seperti yang telah dinyatakan sebelumnya bahwa ketika satu indikator dikeluarkan dari model, maka nilai muatan faktor standar dan nilai t dari indikator-indikator lain yang masih berada di dalam model penelitian akan ikut berubah, dan untuk itu ada kemungkinan indikator yang semula tidak valid dapat menjadi valid, walaupun hal tersebut tidak selalu terjadi. Indikator yang pertama kali akan dikeluarkan dari model adalah indikator dengan nilai muatan faktor standar terkecil, yaitu SENSE1 dengan muatan faktor standar sebesar 0.44. Dengan dikeluarkannya indikator tersebut, maka model di penelitian ini menjadi seperti apa yang ditampilkan pada Gambar 4.16. Pada gambar tersebut dapat diamati bahwa variabel laten experiential marketing yang pada respesifikasi model (A) memiliki 12 buah variabel teramati, kini variabel teramatinya menjadi 11 buah, karena dikeluarkannya SENSE1 dari model penelitian.
Gambar 4.16 Respesifikasi Model (B) Sumber: Peneliti (2010)
Dengan adanya model penelitian yang baru seperti yang tampak di Gambar 4.16, maka nilai uji kecocokan keseluruhan juga memiliki kemungkinan untuk berubah, baik pada sebagian atau seluruh ukuran penilaian yang tersedia. Pada Tabel 4.13 ditampilkan hasil uji kecocokan keseluruhan untuk model penelitian pada Gambar 4.16. Pada tabel tersebut dapat diamati bahwa hasil keputusan mengenai uji kecocokan keseluruhan hasil respesifikasi model (B) adalah sama dengan hasil keputusan uji kecocokan keseluruhan pada respesifikasi model (A). Walaupun dari segi keputusan terdapat hasil yang sama, yaitu terdapat 5 ukuran GOF yang menunjukkan kecocokan yang tidak fit dan 13 ukuran GOF menunjukkan kecocokan yang fit, namun dari segi angka hasil pengolahan terdapat beberapa perbedaan, yaitu
tampak pada ukuran derajat kecocokan Root Mean Square Residual (RMR), Root Mean Square Error of Approximation (RMSEA), Expected Cross Validation Index (ECVI), Normed Chi-Square, Akaike Information Criterion (AIC), Consistent Akaike Information Criterion (CAIC), dan Critical N (CN), hanya saja angka hasil pengolahan tersebut masih terdapat pada daerah keputusan yang sama sehingga hasil keputusannya pun sama.
Tabel 4.13 Uji Kecocokan Keseluruhan 3 (A) Ukuran
Derajat Kecocokan
Tingkat Kecocokan Yang Bisa Diterima Pada Suatu Model Keputusan Statistic Chi-square
⎟
⎠
⎞
⎜
⎝
⎛
χ
2Dasar Pengambilan Keputusan P > 0.05 Æ model fit
Tidak Fit
Hasil Pengolahan
Satorra-Bentler Scaled Chi-Square (P = 0.0) Goodness of Fit
Index (GFI)
Dasar Pengambilan Keputusan GFI = 1 Æ perfect fit
0,90 < GFI < 1 Æ good fit 0.80 < GFI < 0.90 Æ marginal fit 0 Æ poor fit
Tidak Fit
Hasil Pengolahan
Goodness of Fit Index (GFI) = 0.79 Root Mean
Square
Residual (RMR)
Dasar Pengambilan Keputusan Standardized RMR < 0.05 Æ good fit
Tidak Fit Hasil Pengolahan Standardized RMR = 0.071 Root Mean Square Error of Approximation (RMSEA)
Dasar Pengambilan Keputusan RMSEA < 0.05 Æ close fit 0.05 < RMSEA < 0.08 Æ good fit 0.08 < RMSEA < 0.10 Æ marginal fit RMSEA > 0.10 Æ poor fit
Good fit
Hasil Pengolahan
Ukuran Derajat Kecocokan
Tingkat Kecocokan Yang Bisa Diterima Pada Suatu Model
Keputusan
Expected Cross Validation Index (ECVI)
Dasar Pengambilan Keputusan
ECVI < ECVI for Saturated Model Æ model fit
Fit
Hasil Pengolahan
Expected Cross-Validation Index (ECVI) = 3.69 ECVI for Saturated Model = 3.80
Dasar Pengambilan Keputusan
ECVI < ECVI for Independence Model Æ model fit
Fit
Hasil Pengolahan
Expected Cross-Validation Index (ECVI) = 3.69 ECVI for Independence Model = 42.79
Adjusted Goodness of Fit Index (AGFI)
Dasar Pengambilan Keputusan AGFI = 1 Æ perfect fit
0,90 < AGFI < 1 Æ good fit 0.80 < AGFI < 0.90 Æ marginal fit (nilai AGFI berkisar antara 0 sampai 1)
Tidak Fit
Hasil Pengolahan
Adjusted Goodness of Fit Index (AGFI) = 0.75 Tucker-Lewis
Index atau Non-Normed Fit Index (TLI atau NNFI)
Dasar Pengambilan Keputusan TLI > 0.90 Æ good fit.
0.80 < TLI < 0.90 Æ marginal fit
(nilai TLI/NNFI berkisar antara 0 sampai 1)
Good fit
Hasil Pengolahan
Non-Normed Fit Index (NNFI) = 0.96 Normed Fit
Index (NFI)
Dasar Pengambilan Keputusan NFI > 0.90 Æ good fit
0.80 < NFI < 0.90 Æ marginal fit (nilai NFI berkisar antara 0 sampai 1)
Good fit
Hasil Pengolahan
Normed Fit Index (NFI) = 0.93 (Lanjutan Tabel 4.13)
Ukuran Derajat Kecocokan
Tingkat Kecocokan Yang Bisa Diterima Pada Suatu Model
Keputusan
Relative Fit Index (RFI)
Dasar Pengambilan Keputusan RFI > 0.90 Æ good fit
0.80 < RFI < 0.90 Æ marginal fit (nilai RFI berkisar antara 0 sampai 1)
Good fit
Hasil Pengolahan
Relative Fit Index (RFI) = 0.92 Incremental Fit
Index (IFI)
Dasar Pengambilan Keputusan IFI > 0.90 Æ good fit
0.80 < IFI < 0.90 Æ marginal fit (nilai IFI berkisar antara 0 sampai 1)
Good fit
Hasil Pengolahan
Incremental Fit Index (IFI) = 0.96 Comparative Fit
Index (CFI)
Dasar Pengambilan Keputusan CFI > 0.90 Æ good fit
0.80 < CFI < 0.90 Æ marginal fit (nilai CFI berkisar antara 0 sampai 1)
Good fit
Hasil Pengolahan
Comparative Fit Index (CFI) = 0.96 Normed
Chi-Square
Dasar Pengambilan Keputusan 1.0 < (X2/df) < 5.0 Æmodel fit Fit Hasil Pengolahan 613.66/318 = 1.930 Akaike Information Criterion (AIC)
Dasar Pengambilan Keputusan AIC < Saturated AIC Æ model fit
Fit
Hasil Pengolahan Model AIC = 733.66 Saturated AIC = 756.00 (Lanjutan Tabel 4.13)
Ukuran Derajat Kecocokan
Tingkat Kecocokan Yang Bisa Diterima Pada Suatu Model
Keputusan
Akaike Information Criterion (AIC)
Dasar Pengambilan Keputusan AIC < Independence AIC Æ model fit
Fit Hasil Pengolahan Model AIC = 733.66 Independence AIC = 8515.11 Consistent Akaike Information Criterion (CAIC)
Dasar Pengambilan Keputusan CAIC < Saturated CAIC Æ model fit
Fit
Hasil Pengolahan Model CAIC = 991.56 Saturated CAIC = 2380.76 Dasar Pengambilan Keputusan
CAIC < Independence CAIC Æ model fit
Fit
Hasil Pengolahan Model CAIC = 991.56
Independence CAIC = 8631.16 Critical N (CN) Dasar Pengambilan Keputusan
CN > 200 Æ model fit
Tidak Fit
Hasil Pengolahan Critical N (CN) = 124.10 Sumber: Peneliti (2010)
Seperti yang telah dijelaskan pada respesifikasi model (A) bahwa uji kecocokan model keseluruhan, seperti yang terdapat pada Tabel 4.13 belum selesai. Uji kecocokan model keseluruhan yang harus dilakukan selanjutnya adalah perbandingan antarmodel, di mana pada Tabel 4.13 tersebut baru memperhitungkan tingkat kecocokan yang bisa diterima pada suatu model. Untuk itu, langkah selanjutnya adalah melakukan uji kecocokan keseluruhan untuk perbandingan antarmodel yang dijelaskan pada Tabel 4.14.
Tabel 4.14 Uji Kecocokan Keseluruhan 3 (B) Ukuran Derajat Kecocokan Dasar Pengambilan Keputusan Respesifikasi Model (A) Respesifikasi Model (B) Keputusan Statistic Chi-square
⎟
⎠
⎞
⎜
⎝
⎛
χ
2 Nilaiχ
2 semakin kecil semakin baik641.21 613.66 Lebih baik Non-Centrality Parameter (NCP) Semakin kecil semakin baik 297.21 295.66 Lebih baik
Scaled NCP (SNCP) Semakin kecil semakin baik
1.48605 1.4783 Lebih baik
Goodness of Fit Index (GFI)
Nilai lebih tinggi adalah lebih baik
0.79 0.79 Tidak mengalami perubahan Expected Cross Validation Index (ECVI) Semakin kecil semakin baik 3.85 3.69 Lebih baik Adjusted Goodness of Fit Index (AGFI)
Nilai lebih tinggi adalah lebih baik
0.75 0.75 Tidak mengalami
perubahan Tucker-Lewis Index
atau Non-Normed Fit Index (TLI atau NNFI)
Nilai lebih tinggi adalah lebih baik
0.96 0.96 Tidak mengalami
perubahan
Normed Fit Index (NFI)
Nilai lebih tinggi adalah lebih baik
0.93 0.93 Tidak mengalami
perubahan Relative Fit Index
(RFI)
Nilai lebih tinggi adalah lebih baik
0.92 0.92 Tidak mengalami
perubahan Incremental Fit
Index (IFI)
Nilai lebih tinggi adalah lebih baik
0.96 0.96 Tidak mengalami
perubahan Comparative Fit
Index (CFI)
Nilai lebih tinggi adalah lebih baik
0.96 0.96 Tidak mengalami
perubahan Parsimonious
Normed Fit Index (PNFI)
Nilai PNFI tinggi adalah lebih baik
0.84 0.84 Tidak mengalami
Ukuran Derajat Kecocokan Dasar Pengambilan Keputusan Respesifikasi Model (A) Respesifikasi Model (B) Keputusan Parsimonious Goodness of Fit (PGFI)
Nilai PGFI yang lebih tinggi adalah lebih baik (Nilai PGFI berkisar antara 0 dengan 1) 0.67 0.67 Tidak mengalami perubahan Akaike Information Criterion (AIC)
Nilai AIC positif lebih kecil adalah lebih baik
765.21 733.66 Lebih baik
Consistent Akaike Information Criterion (CAIC)
Nilai positif yang lebih kecil adalah lebih baik
1031.71 991.56 Lebih baik
Sumber: Peneliti (2010)
Untuk hasil Scaled NCP (SNCP), tidak diperoleh dari output LISREL, melainkan dari perhitungan berikut ini.
• Scaled NCP (SNCP) = NCP/n, di mana n = jumlah sample
• Scaled NCP (SNCP) respesifikasi model (B) = 295.66/200 = 1.4783
Dengan membandingkan antara hasil respesifikasi model (A) dengan hasil respesifikasi model (B) pada Tabel 4.14, maka terdapat 6 ukuran derajat kecocokan yang memberikan keputusan bahwa hasil respesifikasi model (B) dari segi ukuran derajat kecocokan menunjukkan hasil yang lebih baik (lebih fit) dibandingkan model sebelumnya. Karena sebagian besar hasil uji kecocokan keseluruhan dari hasil respesifikasi model (B) adalah baik (fit) dan hasil respesifikasi model (B) ini juga lebih baik dibandingkan hasil (Lanjutan Tabel 4.14)
respesifikasi model (A), maka kecocokan keseluruhan model adalah baik dan peneliti dapat melanjutkan ke tahap selanjutnya, yaitu uji kecocokan model pengukuran.
Sebelum melakukan uji reliabilitas, peneliti harus memastikan terlebih dahulu bahwa seluruh variabel teramati telah baik dari segi validitas. Pada Tabel 4.15 ditampilkan hasil uji validitas untuk model penelitian hasil respesifikasi model (B).
Dasar pengambilan keputusan untuk pengujian validitas pada tahap ini, yaitu suatu variabel dikatakan mempunyai validitas yang baik dengan berdasarkan pada dua kriteria, yaitu jika:
(1) Nilai t muatan faktor > 1,96 (2) Muatan faktor standar > 0.50
Tabel 4.15 Uji Validitas (3) Var. Laten Var. Teramati Experiential Marketing (expmark) Celebrity endorsement (celeb) Brand Trust (trust) Brand Loyalty (loyalty) Kesimpulan Validitas
SFL Nilai t SFL Nilai t SFL Nilai t SFL Nilai t
SENSE2 0.62 10.56 - - - - - - Baik
SENSE3 0.70 11.44 - - - - - - Baik
SENSE4 0.44 6.24 - - - - - - Kurang Baik
FEEL1 0.55 8.99 - - - - - - Baik FEEL2 0.68 11.95 - - - - - - Baik THINK1 0.74 13.32 - - - - - - Baik THINK2 0.63 10.33 - - - - - - Baik ACT1 0.52 8.58 - - - - - - Baik ACT2 0.66 11.51 - - - - - - Baik ACT3 0.51 8.30 - - - - - - Baik RELATE1 0.52 7.49 - - - - - - Baik CREDI1 - - 0.74 12.98 - - - - Baik CREDI2 - - 0.65 9.01 - - - - Baik
Var. Laten Var. Teramati Experiential Marketing (expmark) Celebrity endorsement (celeb) Brand Trust (trust) Brand Loyalty (loyalty) Kesimpulan Validitas
SFL Nilai t SFL Nilai t SFL Nilai t SFL Nilai t
ATTRAC1 - - 0.69 12.22 - - - - Baik ATTRAC2 - - 0.83 14.04 - - - - Baik ATTRAC3 - - 0.70 9.27 - - - - Baik RELI1 - - - - 0.80 * - - Baik RELI2 - - - - 0.79 13.87 - - Baik RELI3 - - - - 0.84 14.11 - - Baik RELI4 - - - - 0.86 16.74 - - Baik INTENS1 - - - - 0.68 11.00 - - Baik INTENS2 - - - - 0.67 9.97 - - Baik INTENS3 - - - - 0.65 10.15 - - Baik INTENS4 - - - - 0.67 9.22 - - Baik BEHAV1 - - - - - - 0.80 * Baik ATTITU1 - - - - - - 0.78 11.09 Baik ATTITU2 - - - - - - 0.58 7.75 Baik
Pada Tabel 4.15 terdapat tanda (*), di mana maksud dari tanda tersebut adalah ditetapkan secara default oleh LISREL, yaitu nilai t tidak diestimasi. Dapat diamati bahwa seluruh variabel teramati memiliki nilai t muatan faktor lebih besar dari 1,96 sehingga memenuhi satu kriteria untuk dinyatakan memiliki validitas yang baik.
Namun untuk muatan faktor standar atau standardized factor loadings (SFL), terdapat 1 variabel teramati yang tidak valid, karena muatan faktor standarnya lebih kecil dibanding 0.5. Variabel teramati tersebut adalah SENSE4. Sehingga di dalam model penelitian ini, variabel laten yang seluruh variabel teramatinya memiliki validitas yang baik, Sumber: Peneliti (2010)