6
2.1 Database
Sebuah database sangat erat hubungannya dengan sebuah data, dimana tanpa adanya sebuah data maka sebuah database tidak akan dibutuhkan, arti dari data sendiri menurut Hoffer, Prescott, & Topi (2009, p46) adalah perwakilan penyimpanan dari objek dan kejadian yang memiliki pengertian dan kepentingan dalam lingkungan pengguna, Connolly & Begg(2010, p14) juga mengatakan bahwa data adalah sebuah jembatan antara komponen mesin dan komponen manusia, dijelaskan juga oleh Deliana, Cahya, & Kaisariza(2009, p1) bahwa data adalah kumpulan fakta yang dikumpulkan sebagai hasil pengalaman, observasi, atau percobaan dengan sistem komputer. Dari ketiga definisi diatas maka dapat disimpulkan bahwa data adalah sekumpulan fakta yang terjadi dan memiliki arti bagi pengguna yang dicatat dan disimpan di dalam suatu
record. Didasari oleh definisi mengenai data yang telah dijabarkan diatas, data memiliki
kegunaan yang penting bagi para pengguna dari data itu sendiri, dimana data merupakan fakta-fakta yang terjadi dan dibutuhkan oleh seorang pengguna atau suatu institusi atau organisasi yang akan diolah menjadi informasi dimana informasi yang terolah merupakan informasi yang dibutuhkan oleh para penggunanya. Dengan data yang fiktif atau tidak benar maka informasi yang dihasilkan akan menyesatkan pengguna informasi tersebut. Gambar 2.1 menunjukan contoh dari data client :
dimana data pada tabel Client yang ada pada gambar 2.1 berupa CR76, CR74, dan sebagainya dan data-data tersebut menunjukan atau memberikan informasi bahwa clientNo ‘CR76’ memiliki nama depan’John’ dan nama belakang ‘Kay’ beralamat di ’56 High St.London SW1 4EH’ dan no telponnya ‘0171-774-5632’.
Untuk penyimpanan data dan pengolahannya maka dibutuhkan sebuah database untuk menampung atau menyimpan data. Menurut Connolly & Begg (2010,p54)
Database merupakan sekumpulan data yang saling berelasi, selain itu Connolly & Begg
(2010, p54) juga menjelaskan dengan lebih rinci bahwa Database merupakan sekumpulan data yang berelasi secara logika dan deskripsinya, yang di-desain untuk memenuhi kebutuhan informasi dari sebuah organisasi. Kemudian dari kedua definisi mengenai database diatas dapat disimpulkan bahwa database adalah sekumpulan data yang saling berhubungan dimana data tersebut digunakan oleh sebuah organisasi atau perusahaan dalam melaksanakan proses bisnisnya. Sebuah database memiliki beberapa komponen yakni :
1. Entitas : merupakan sebuah objek yang direpresentasikan pada database 2. Atribut : merupakan karakteristik yang mendeskripsikan objek
3. Hubungan : merupakan hubungan antar entitas
Untuk penjelasan lebih lanjut dan contoh dari entitas,atribut, dan hubungan dapat dilihat pada subbab 2.7.1 mengenai Entity Relationship Diagram.
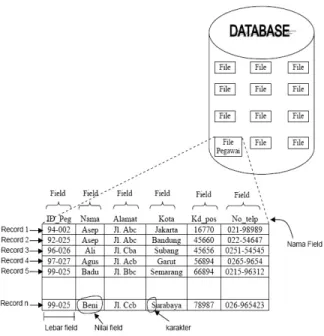
Di dalam suatu database data disimpan ke dalam file-file yang diorganisasikan bedasarkan sebuah schema atau struktur tertentu yang disimpan pada perangkat keras khusus seperti yang tertera pada gambar 2.1 dibawah
Gambar 2. 2 Contoh Database
(Sumber : http://pbsabn.lecture.ub.ac.id/files/2012/05/Untitled5.jpg)
Bedasarkan gambar diatas data yang disimpan dalam sebuah database dinamakan sebuag field, dan kumpulan dari field tersebut dinamakan record, dimana record-record yang ada akan akan disimpan pada sebuah file dan file-file tersebut akan disimpan dalam database. Hirarki data dapat dilihat pada gambar 2.3 :
Gambar 2. 3 Hirarki Data
Dalam melakukan aktivitasnya untuk mendukung kebutuhan informasi perusahaan database memiliki dua jenis konsep dalam pemrosesan data. Kedua konsep dalam pemrosesan data yakni :
1. Online Transaction Processing(OLTP)
Menurut Connolly & Begg(2010,p1199) OLTP merupakan sebuah sistem pemrosesan datayang dirancang secara khusus untuk menangani high transaction dengan transaksi yang merubah data operasional yang digunakan dalam operasi sehari-hari seperti sistem Point Of Sales(POS), pengecekan stok barang, pembuatan invoice. Connolly & Begg(2010,p1199) juga mengatakan pada umumnya Sistem OLTP digunakan untuk menangani transaksi yang dapat diprediksi, berulang-ulang, dan di-update secara instensif(sering dilakukan).
2. Online Analytical Processing(OLAP)
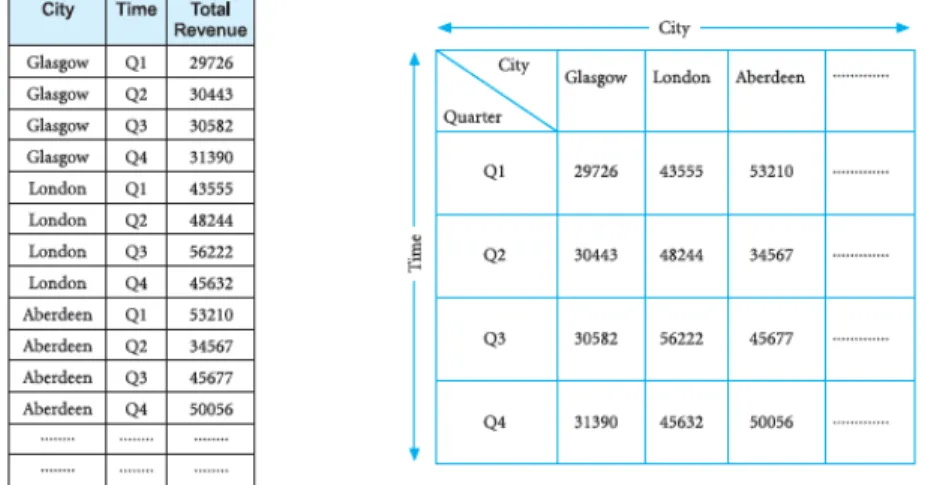
Menurut Connolly & Begg(2010,p1250) OLAP merupakan proses sintetik dinamik, analisa, dan consolidasi dari multi-dimensi data dalam jumlah besar. Dalam penerapannya OLAP memungkinkan seorang pengguna untuk melihat data organisasi dalam bentuk yang dibutuhkan oleh pengguna tersebut, sebagai contoh OLAP digunakan oleh suatu perusahan untuk menampilkan data perbandingan antara penjualan properti antar kota dalam bentuk tabel perbandingan seperti yang ditunjukan pada gambar 2.4
Gambar 2. 4 Tabel tiga kolom, dan (b) matriks dua dimensi (Sumber:Connolly & Begg(2010, p1254)
Seperti yang dapat dilihat pada gambar 2.4 data yang ditampilkan oleh OLAP dapat berbentuk tabel tiga kolom(a) atau matriks dua dimensi(b) sesuai dengan kebutuhan perusahaan dalam melihat data.
2.2 The Database Management System (DBMS)
Menurut Connolly & Begg (2010,p66) DBMS merupakan sebuah perangkat lunak yang berinteraksi antara program aplikasi pengguna dengan database dan memungkinkan seorang pengguna untuk mendefinisikan, membuat, menjaga, dan mengatur data yang ada di dalam database. Seperti yang dikatakan oleh Connolly pada penjelasan DBMS diatas DBMS merupakan sebuah perangkat lunak yang digunakan sebagai perantara antara database dengan pengguna untuk mengatur data yang ada di dalam database.
Dalam penggunaan DBMS, untuk mengakses data yang ada di dalam DBMS pengguna diharuskan menggunakan bahasa query, Bahasa query yang paling umum
adalah SQL lalu menurut Connolly & Begg(2010, p184) SQL dikatakan sebagai sebuah bahasa yang di desain untuk mengubah sebuah input menjadi output yang diinginkan, Sedangkan menurut Ashdown & Kyte (2011, p7-1), SQL merupakan bahasa pemograman tingkat tinggi dimana semua program dan user-nya mengakses Data di dalam database. Lalu dari kedua definisi mengenai SQL yang telah disebutkan dapat ditarik kesimpulan bahwa SQL merupakan sekumpulan perintah yang digunakan oleh
user untuk memanipulasi data yang ada di dalam database, baik menambah, mengubah,
ataupun menghapusnya.
DBMS sendiri dalam penerapannya ke dalam proses bisnis sebuah organisasi/pengguna memiliki beberapa kelemahan dan kelebihan seperti yang dikatakan menurut Connolly&Begg(2010,p77) kelebihan dan kekurangan dari DBMS adalah : 1. Kelebihan
Control of Data redundancy, dengan DBMS maka pengulangan/duplikasi data
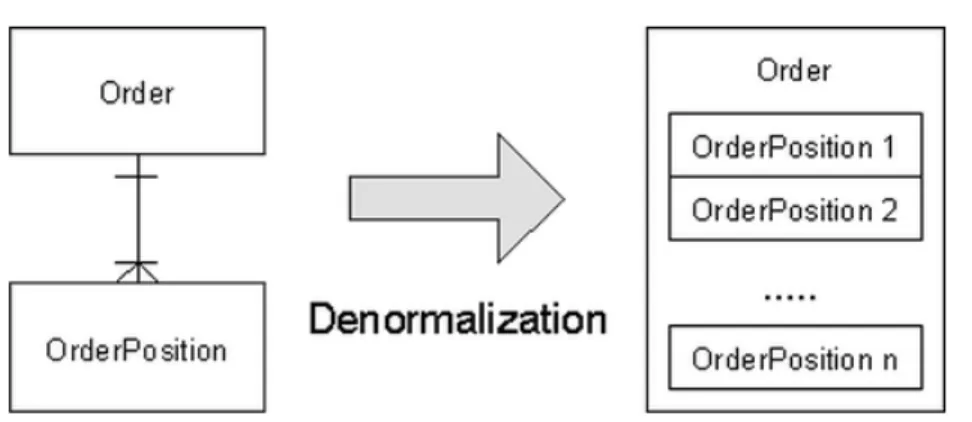
dapat dikendalikan. Pada umumnya pendekatan database akan mengeliminasi data yang berulang/duplikasi sehingga tidak akan ditemukan data yang sama persis, namun dengan digunakannya DBMS maka pengguna dapat mengatur duplikasi data yang terjadi pada database dengan proses denormalisasi. Sebagai contoh :
Gambar 2. 5 Denormalisasi Tabel Order
(http://www.objectarchitects.de/ObjectArchitects/orpatterns/Performance/Denorm alization/index.6.gif)
Dengan dilakukannya proses denormalisasi seperti pada gambar diatas, dimana
orderPosition menjadi terduplikasi pada tabel Order maka kecepatan akses data
akan meningkat.
Data consistency, dengan pengendalian redudansi data seperti yang dijelaskan pada point diatas maka resiko terjadinya ketidak-konsisten-an data dapat dikurangi. Dengan penggunaan DBMS jika data diubah oleh pengguna maka perubahan data yang terjadi dapat dilihat dan dirasakan oleh semua pengguna yang sedang menggunakan data tersebut, DBMS juga mencegah pengguna lain untuk mengakes data yang sedang digunakan oleh pengguna yang lain. Sebagai contoh :
Andi sedang mengakses data gaji pada database dan mengubah nilai gaji Andi dari RP.500.000,- menjadi RP.1.500.000,- maka Badrun sebagai pengguna lain tidak dapat mengubah gaji Andi pada saat yang bersamaan. Setelah Andi selesai mengubah nilai gaji-nya, maka nilai gaji andi yang dilihat badrun pun ikut berubah menjadi RP.1.500.000,-
More information from the same amount of data, dengan terintegrasinya data
yang ada di dalam database maka sebuah organisasi dapat mendapat informasi yang lebih banyak dari data yang sama. Sebagai contoh :
Bagian Sales dari suatu perusahaan mempunyai data penjualan yang berisi ‘kode_Barang, Pemilik_barang’ dan bagian gudang memiliki data gudang yang berisi ‘Kode_barang, Nama_barang’. Dengan terintegrasinya data pada
database maka bagian sales dapat mengakses data gudang untuk mendapatkan
‘nama barang’ begitu pula dengan bagian gudang yang dapat mengakses data ‘pemilik barang’.
Improved security and integrity, dengan pemakaian DBMS maka integritas data
dan keamanan data dapat dijaga, dimana Integritas data dapat ditekankan pada kepastian dan konsistensi data yang pada umumnya integritas data diekspresikan sebagai Constraint. Sedangkan keamanan data mengacu pada proteksi data pada database terhadap pengguna yang tidak memiliki hak(unauthorized user). Tanpa adanya keaman yang kuat integritas data membuat data pada database menjadi mudah dilihat oleh siapa saja, oleh karena itu system keamanan yang ada pada DBMS memungkinakan keamanan data dapat dijamin. System keamanan pada DBMS bisa berupa username dan
password.
2. Kekurangan
Complexity, dikarenakan fungsinya yang beragam macam, maka DBMS
yang menggunakan DBMS haruslah mengerti semua fungsi yang dapat dilakukan oleh DBMS karena penyalahgunaan yang terjadi dalam penggunaan DBMS dapat berakibat fatal bagi sebuah organisasi. Sebagai contoh seorang DBA yang ingin mengubah username dan password seorang pengguna, namun dikarenakan DBA tersebut tidak mengerti sepenuhnya tentang fitur yang ada pada DBMS yang digunakan, DBA tersebut secara tidak sengaja menghapus username dan password pengguna.
Cost, biaya yang harus dikeluarkan dalam menjaga, dan penggunaan DBMS
relative besar dan beraneka ragam tergantung dari kemampuan yang ditawarkannya. Sebagai contoh DBMS untuk 1 orang pengguna mungkin hanya seharga RP. 1 juta sedangkan DBMS untuk sebuah perusahaan besar dengan jumlah pengguna ratusan orang akan memakan biaya sebesar RP. 10 juta. Performance, dengan banyaknya aplikasi yang harus mengakses DBMS secara
bersamaan maka performa database akan menurun karena resource yang ada pada database akan dibagi-bagi ke untuk mengangani setiap aplikasi yang mengakses database tersebut. Sebagai contoh seorang pengguna mengakses ke dalam database untuk penampilan data yang terhitung berlangsung selama 15 detik, namun dengan penggunaan DBMS dimana banyak pengguna dapat mengakses database yang sama dalam waktu yang relatif bersamaan maka waktu yang terhitung untuk penampilan data dari database akan memakan waktu sebesar 60 detik.
Higher impact of a failure, proses centralisasi yang terfokus pada sebuah
DBMS akan meningkatkan resiko yang terjadi apabila terjadi sebuah kerusakan pada salah satu komponen DBMS. Sebagai contoh apabila salah satu komponen DBMS rusak atau mengalami gangguan maka semua operasi yang terjadi akan mengalami hambatan. Sebagai contoh jika salah satu data pada database hilang atau corrupt maka semua data yang terhubung dengan data tersebut menjadi tidak dapat diakses dikarenakan Constraint yang ada pada data tersebut dan mengakibatkan semua operasi bisnis tidak dapat beroperasi sebagaimana mestinya.
Dalam penggunaannya DBMS juga menyediakan tiga fasilitas kepada pengguna DBMS, fasilitas yang diberikan DBMS kepada pengguna adalah DDL, DML, Acces-Control yang akan dibahas lebih lanjut pada subbab 2.2.2 mengenai DDL, subbab 2.2.3 mengenai DMLdan subbab 2.2.4 mengenai Access-Control.
Seperti yang telah dibahas diatas DBMS merupakan software yang dibutuhkan dalam mengatur atau me-manage data yang ada di dalam database, maka dari itu software DBMS yang beredarpun beraneka ragam yakni MS Access, Oracle, SQL Server,dan masih banyak lagi. Oracle yang merupakan salah satu jenis DBMS akan dibahas lebih lebih lanjut pada point 2.2.1.
2.2.1. Oracle
Oracle database merupakan sebuah DBMS yang mendukung SQL, PL/SQL, dan Java dan digunakan untuk menyimpan serta mengambil informasi secara terintegrasi dan komprehensif dalam jumlah yang besar. Seperti yang dikatakan oleh Sthrom
(2011, p1-1), Oracle database merupakan kumpulan dari data yang dianggap sebagai sebuah unit dimana Oracle database dibentuk untuk dapat menangani berbagai tingkat komplektivitas, mulai dari hirarki yang simpel hingga jaringan yang kompleks dengan hubungan multilevel dan menyediakan operating platform yang kokoh dalam mengimplementasikan fitur object-oriented seperti user-defined types, inheritance, dan
polymorphism. Oracle database juga telah melakukan ekstensi terhadap relational model menjadi object-relational model, yang membuatnya cocok untuk menyimpan
permodelan bisnis yang kompleks pada relational database. Disamping itu Oracle
database merupakan database pertama yang didesain untuk enterprise grid computing
yang menyediakan cara untuk mengelola informasi dan aplikasi secara fleksibel dan
cost-effective dimana Enterprise grid computing membuat large pool untuk standar
industri, ruang penyimpanan modular dan server. Oleh karena itu dengan adanya arsitektur ini, setiap sistem baru dapat secara cepat disediakan dari kumpulan komponen maka tidak dibutuhkan workload yang tinggi, dikarenakan kapasitas yang ada dapat ditambahkan atau dialokasikan dari resource pool sesuai yang diinginkan.
Fitur-fitur yang dimiliki oleh Oracle hingga versi terbarunya saat ini yaitu Oracle 11g adalah sebagai berikut :
• Adanya data integrity yang memastikan bahwa adanya konsistensi, keakuratan dan kebenaran dari data yang disimpan sehingga user mendapat jaminan bahwa data diterima olehnya merupakan data yang benar-benar berasal dari sumber yang valid. Contohnya jika sudah terdapat user yang memiliki kode karyawan “123” maka tidak boleh terdapat user lain yang memiliki kode yang sama.
• Adanya data concurrency yang menunjukan bahwa data yang ditunjukkan baik data yang berasal dari sumber asal dan duplikasinya memiliki hasil yang sama. • Memiliki fasilitas self-managing database sehingga proses administratif dapat
diotomatisasi dan mempermudah tugas dari DBA dikarenakan adanya
performance diagnostics, dan space and memory management. Dengan fitur ini
maka Oracle juga secara otomatis akan mengirim alert jika ditemukan adanya masalah pada database.
• Menyediakan fasilitas Online backup dan crash recovery apabila database mengalami error.
• Dapat melakukan adaptasi secara otomatis terhadap berbagai kondisi workload dari database server.
• Menyediakan teknologi high-performance bagi data warehousing, OLAP, dan data mining.
• Dapat dengan mudah mengelola keseluruhan siklus hidup dari informasi dalam jumlah besar.
• Memiliki tingkat keamanan data yang tinggi serta terdapat penyesuaian untuk keamanan unique row, auditing, enksripsi data secara transparan, dan pemanggilan secara penuh terhadap data.
• Melindungi data dari server failure, human error, dan mengurangi waktu
downtime yang dibutuhkan.
• Memiliki Enterprise Manager agar pengelolaan database dapat dilakukan dengan mudah.
Disamping kelebihan yang diberikan oleh oracle, oracle sendiri memiliki beberapa kekurangan, kekurangan yang dimilliki oleh Oracle diantaranya sebagai berikut :
• Membutuhkan biaya yang cukup tinggi untuk diimplementasikan terlebih lagi jika user tidak memperhitungkan downtime cost.
• Kompleksitas yang tinggi menyebabkan membutuhkan waktu pembelajaran yang cukup lama bagi user yang ingin mendalami Oracle database secara menyeluruh.
Sebagai sebuah DBMS dengan kompleksitas yang tinggi oracle database memiliki arsitektur tersendiri dimana pada arsitektur tersebut oracle dipecah menjadi dua macam struktur yakni struktur database storage dan struktur database instance dimana akan dijelaskan lebih lanjut pada subbab 2.2.1 poin 1
1. Struktur Database Storage
Gambar 2. 6 Struktur Oracle Database Storage
Menurut Ashdown dan Kyte (2011, p1-8), struktur database storage pada Oracle database dibagi menjadi dua yaitu struktur logical dan physical seperti yang tertera pada Ilustrasi struktur database storage pada gambar 2.6 untuk penjelasan lebih lanjut mengenai struktur database Oracle berikut merupakan penjelasan dari struktur
physical dan logical yang dimiliki oleh Oracle database : a. Struktur Logical Database
Struktur logical database pada Oracle terdiri dari tablespace, data block, extents, dan segment. Dimana dengan adanya struktur ini maka Oracle memiliki fasilitas pengaturan dari disk space yang baik. Untuk penjelasan lebih lanjut mengenai struktur logical dari oracle berikut merupakan komponen-komponen yang terdapat pada struktur
logical oracle database :
• Tablespace
Tablespace merupakan suatu logical storage unit yang terdapat di dalam Oracle database. Tablespace dikatakan logical karena tablespace tersebut tidak terlihat
di file system tempat database tersebut berada. Lalu Setiap tablespace memiliki paling sedikit satu datafile dimana datafile ini secara fisik terletak di file system server dimana setiap datafile hanya dimiliki oleh satu tablespace. Begitu pula setiap table dan index yang tersimpan di Oracle Database, setiap tabel dan
index tersebut dimiliki oleh sebuah tablespace dimana tablespace membangun
suatu “jembatan penghubung” antara Oracle Database dengan filesystem dimana index atau tabel disimpan.
• Data Block
Oracle menyimpan data pada Data Blocks (dapat juga disebut Logical Blocks, Oracle Blocks, atau Pages). dimana satu data blocks akan berhubungan dengan sejumlah spesifik byte dari ruang database fisik di dalam disk.
• Extent
Extent merupakan jumlah spesifik dari data block yang berkesinambungan dimana data tersebut dialokasikan untuk menyimpan tipe tertentu dari suatu informasi.
• Segment
Segment merupakan kumpulan dari extent, dimana masing-masing dialokasikan
untuk struktur data tertentu dan semuanya disimpan pada tablespace yang sama.
b. Struktur Physical Database
Struktur fisikal dari ORACLE database terdiri dari datafiles, control files, redo log
files, archive log files, alert and trace log files, backup files, parameter files. Untuk
pemahaman lebih lanjut mengenai struktur fisik dari database oracle, berikut merupakan penjelasan singkat terhadap struktur fisik database :
• Datafiles
Datafile merupakan file yang terasosiasi dengan tablespace, dimana datafile
hanya bisa dimiliki oleh sebuah tablespace. Dalam pembuatan datafile Oracle biasanya membuat datafile untuk tablespace dengan mengalokasikan jumlah tertentu dari disk space ditambah overhead yang dibutuhkan untuk file header.
Pada saat suatu datafile dibentuk, OS yang menjalankan Oracle bertanggung jawab untuk membersihkan informasi-informasi lama dan authorisasi dari suatu file sebelum dialokasikan ke Oracle dimana Semakin besar ukuran dari suatu
file, maka semakin lama proses authorisasi yang dibutuhkan. Pada umumnya Datafile berisi object-object dari suatu schema.
• Control Files
Control files mengandung data – data mengenai struktur fisik dari database
seperti nama database, nama serta lokasi dari datafile dan redo log file, juga
timestamp dari pembuatan database dimana File-file ini sangat penting bagi database, Jika tidak ada control file, maka user tidak dapat membuka data file
untuk mengakses data – data yang terdapat di dalam database. • Red Log Files
Online Redo Log File bertujuan untuk instance recovery suatu database yang
apabila database mengalami crash dan tidak kehilangan data files, maka
instance dapat melakukan prosedur recovery terhadap database dengan
informasi yang terkandung di dalamnya. • Archive Log Files
Archive log file merupakan catatan historis yang mengandung perubahan data
yang telah terjadi yang dikeluarkan oleh instance, dengan file ini dan backup dari database, user dapat melakukan proses recovery data-data file yang hilang.
Archive log juga memungkinkan adanya recovery dari data files yang telah di restore.
• Parameter Files
Parameter file digunakan untuk menentukan bagaimana suatu instance
dikonfigurasi ketika mulai berjalan. Dimana Pada parameter file terdapat daftar dari sekumpulan configuration parameter bagi instance dan database.
• Alert dan Trace Log Files
Alert Log File dianggap sebagai special trace file, dimana Alert log files merupakan catatan mengenai pesan dan error yang diatur secara kronologis .
Trace log files merupakan file yang berasal dari write server dan background process. dimana ketika internal error ditemukan oleh sebuah proses, maka
proses tersebut akan mencatat error tersebut ke trace file. • Backup Files
Backup File digunakan untuk melakukan pemulihan terhadap database jika database mengalami kegagalan yang dapat disebabkan oleh media failure atau
human error yang menyebabkan original file terhapus. 2. Struktur Oracle Database Instance
Menurut Ashdown dan Kyte (2011,p1-9), Oracle database memiliki memory
structure dan process yang digunakan untuk mengelola dan mengakses database.
sehubungan dengan pernyataan diatas ketika aplikasi terhubung ke Oracle database, maka aplikasi tersebut akan terhubung dengan database instance yang merupakan sebuah kumpulan memori yang berfungsi untuk mengelola file database. lalu Instance akan melayani aplikasi tersebut dengan mengalokasikan area pada memory untuk membentuk memory structures dan proses-proses lainnya. Untuk penjelasan lebih lanjut
mengenai cara kerja oracle database yang terdapat pada gambar 2.6, dibawah ini merupakan komponen – komponen yang terdapat dalam Oracle Instance Structures :
a. Oracle Database Processes
Gambar 2. 7 Struktur Oracle Database Processes
(Sumber : Oracle Database 10g : Administration Workshop I)
Menurut Ashdown dan Kyte (2011, p1-10), Setiap instance yang terdapat di dalam Oracle database memiliki tiga tipe proses seperti yang terlihat pada gambar 2.7, tiga proses tersebut adalah :
• Client Processes
Client processes merupakan proses yang dibentuk dan dikelola untuk
menjalankan kode aplikasi atau Oracle tool. dimana Sebagian besar
environment memiliki komputer yang terpisah bagi client processes.
• Background Processes
Background processes merupakan proses yang berfungsi untuk menggabungkan fungsi-fungsi yang digunakan oleh Oracle database program yang berjalan untuk setiap client process.
• Server Processes
Server processes merupakan proses yang melakukan komunikasi dengan client processes dan berinteraksi dengan Oracle database untuk memenuhi request
yang diterima dari user. b. Instance Memory Structures
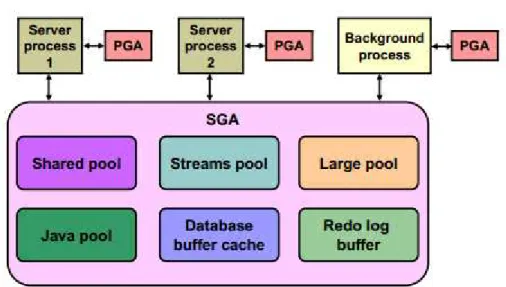
Gambar 2. 8 Oracle Memory Structure
(Sumber : Oracle Database 10g : Administration Workshop I)
Menurut Ashdown dan Kyte (2009,p1-10), Oracle database membuat dan menggunakan memory structures (struktur dapat dilihat pada gambar 2.8) untuk kebutuhan menampung data yang disebar diantara para user serta terdapat private data
areas untuk setiap user yang terhubung. Menurut (Rani, Singh, & Sharma, 2011)
• SGA (System Global Area)
SGA merupakan struktur memori yang dibentuk pada saat instance diinisialisasikan pertama kali, dimana Komponen – komponen yang terdapat pada SGA adalah sebagai berikut :
• Database Buffer Cache
Database buffer cache digunakan untuk menampung data ke dalam memori.
Setiap kali user mengakses data, data tersebut akan ditampung ke dalam buffer
cache dan akan dikelola dengan menggunakan algoritma LRU. Penjelasan lebih
lanjut mengenai buffer cache dapat dilihat pada subbab 2.4 • Redo Log Buffer
Berupa cache redo (digunakan untuk instance recovery) yang digunakan untuk menulis ke redo log files fisik ke dalam disk.
• Shared Pool
Shared pool merupakan wadah yang berisi cache dari beragam construct yang
dapat digunakan secara bersama oleh banyak user. • Large Pool
Large pool merupakan area optional yang menyediakan alokasi memori dalam
jumlah yang besar untuk beberapa proses besar, seperti Oracle backup dan operasi recovery, dan proses server I/O.
• Java Pool
• Streams Pool
Streams pool digunakan untuk menyimpan pesan yang berada pada buffered queue dan menyediakan memori untuk pencatatan proses oracle streams.
• PGA (Program Global Area)
PGA merupakan area pada memori dengan fungsi mengatur informasi bagi
server process yang akan dibentuk pada saat sebuah server process mulai dijalankan.
Dikarenakan setiap server process memiliki PGA tersendiri yang dibentuk ketika proses server mulai berjalan maka akses read beserta write terhadap PGA bersifat eksklusif yaitu hanya kepada server process tersebut. Komponen – komponen yang terdapat pada PGA adalah sebagai berikut :
• Private SQL Area
Private SQL area berfungsi untuk menampung informasi mengenai SQL
statement yang telah diurai dan informasi lainnya yang berhubungan dengan
session untuk melakukan pemrosesan. Ketika server process mengeksekusi
sintaks SQL atau PL/SQL, maka private SQL area akan digunakan untuk menampung nilai bind variable.
• Session Memory
Session memory merupakan yang dialokasikan untuk menampung session variables (misalnya informasi logon) dan informasi lainnya yang terkait
dengan session tersebut. Jika terdapat di dalam shared server, maka session memory tidak bersifat private melainkan bersifat shared.
• SQL Work Area
SQL work area merupakan tempat dimana sekumpulan alokasi khusus dari
memori PGA digunakan untuk operasi yang bersifat memory-intensive yaitu operasi yang menggunakan memori dalam jumlah besar seperti penggunaan
sort-based operator, bitmap merge, dan bitmap create. Ukuran dari SQL work area dapat diatur sesuai dengan kebutuhan pada umumnya semakin
besar ukuran dari work area maka peforma dari operator tertentu akan meningkat namun dengan konsekuensi penggunaan memori yang juga semakin besar.
2.2.2. DDL Statement
DDL statement merupakan sebuah statement yang berfungsi untuk meng-definisikan, mengubah struktur, dan menghapus objek dari dalam database.
Statement DDL mengijinkan pengguna untuk :
• Membuat, mengubah, dan men-drop objects dan struktur database lainnya, termasuk database itu sendiri dan pengguna database. Statement ini dimulai dengan keyword CREATE, ALTER, or DROP.
• Membuang semua Data di dalam object schema tanpa menghilangkan struktur dari object tersebut. Statement ini dijalankan dengan keyword TRUNCATE. • Melakukan proses GRANT dan REVOKE hak aksses dan peran. Statement
ini dijalankan dengan keyword GRANT, REVOKE.
Berikut adalah penjelasan lebih lanjut tentang Statement DDL dan contoh pemakaian serta hasil yang di-munculkan :
1. Create
Syntax Create digunakan apabila pengguna ingin membuat sebuah tabel, schema, view, ataupun index di dalam database. berikut adalah contoh pemakaian syntax Create:
a. Create Schema
“Create Schema” digunakan saat user ingin membuat sebuah schema, format
syntax yang digunakan adalah sebagai berikut :
Dimana Schema name adalah nama dari schema yang ingin dibuat, dan AUTHORIZATIOn merupakan nama dari pembuat schema tersebut, sebagai contoh pemakaian syntax CREATE CHEMA berikut adalah syntax yang digunakan untuk membuat schema “haha” dengan nama pembuat schema “hihi”
b. Create Table
Untuk membuat suatu tabel di dalam database maka pengguna dapat menggunakan syntax Create table dengan format syntax sebagai berikut :
CREATE TABLE table_name (
column_name1 data_type(Length), [NOT NULL] [DEFAULT default option][UNIQUE],
column_name2 data_type(Length), [NOT NULL] [DEFAULT], ………,
column_name n data_type(Length), [NOT NULL] [DEFAULT], CONSTRAINT “Constraint Name” {Condition} Primary Key (column_name),
FOREIGN KEY (Column_name) REFERENCES (table_name) ON DELETE [CASCADE|NO ACTION] ON UPDATE [CASCADE|NO ACTION] )
CREATE SCHEMA haha AUTHORIZATION hihi;
Dimana table_name merupakan nama table yang ingin dibuat, column_name1-2-n merupakan nama-nama kolom yang ingin dibuat, Data_Type merupakan jenis Data yang akan dimasukan pada tiap kolom yang ada, Length merupakan panjang dari tipe data yang diperbolehkan. [NOT NULL] [DEFAULT] [UNIQUE] merupakan alternative penambahan keterangan dari kolom yang dibuat, apabila NOT NULL digunakan maka pada kolom tersebut haruslah memiliki data, opsi DEFAULT akan memberikan ‘Default option’ sebagai data Default apabila pada opsi insert pengguna tidak memasukan nilai pada kolom, opsi [UNIQUE] berguna untuk menentukan apakah data pada kolom tersebut unik atau tidak, CONSTRAINT bisa digunakan sebagai Constraint pada kolom ataupun Constraint pada tabel, apabila digunakan pada kolom maka Constraint tersebut hanya berpengaruh pada kolom yang digunakan, apabila pada tabel maka Constraint tersebut akan berpengaruh pada semua tabel. PRIMARY KEY digunakan untuk menentukan
primary key pada tabel tersebut, sedankan FOREIGN KEY akan menentukan foreign key di tabel tersebut pada opsi ON DELETE dan ON UPDATE foreign key opsi
CASCADE dan NO ACTION merupakan aksi yang dilakukan, CASCADE berarti saat tabel tersebut dihapus maka semua data yang terintegrasi dengan tabel tersebut akan ikut hilang sedangkan pada opsi NO ACTION apabila tabel tersebut dihapus maka semua data yang terintegrasi dengan tabel tersebut akan tetap seperti apa adanya. Berikut adalah contoh pemakaian syntax create table
Pada contoh diatas Constraint yang dipakai berupa Constraint table, dan hasilnya akan menjadi sebagai berikut :
Gambar 2. 9 Tabel Persons
c. Create Index
Penjelasan lebih lanjut mengenai index akan dibahas pada subbab 2.3. berikut merupakan format dari syntax create index :
Dimana “indexName” adalah nama index yang ingin dibuat, table_name adalah nama tabel tempat index akan dibuat dan “Column_name”adalah kolom yang diberikan index. Sebagai contoh syntax dibawah ini akan membuat index001 pada tabel mahasiswa di kolom nama
CREATE INDEX Index_name ON table_name (column_name)
CREATE INDEX idx001 ON Mahasiswa (Nama) CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL, FirstName varchar(255),
Address varchar(255), City varchar(255),
CONSTRAINT pk_PersonID PRIMARY KEY (P_Id) )
d. Create View
“Create View” digunakan saat user ingin membuat sebuah View, format syntax yang digunakan adalah sebagai berikut :
Dimana View_name adalah nama dari View yang ingin dibuat,
New_Column_Name adalah nama kolom yang ingin dibuat, subselect adalah syntax select yang digunakan untuk memasukan data ke dalam view. Sebagai contoh pemakaian syntax CREATE VIEW berikut adalah syntax yang digunakan untuk membuat view “haha” dengan sumber data tabel persons
2. Alter
Syntax ALTER digunakan untuk mengubah struktur tabel yang ada setelah
tabel tersebut dibuat, untuk mengubah sebuah tabel ada 6 tipe dari ALTER TABLE yang dapat digunakan yaitu :
Menambah kolom
Menghapus kolom
Manambah Constraint Menghapus Constraint
Menambah DEFAULT pada kolom Menghapus DEFAULT pada kolom
CREATE VIEW haha
AS SELECT * FROM persons;
CREATE VIEW view_name [New_Column_name 1, New_Column_name 2,…., New_Column_name n]
Bentuk syntax umum dari Alter adalah sebagai berikut
Dibawah ini akan dijelaskan lebih lanjut mengenai syntax ALTER TABLE dan contohnya :
a. Menambah kolom pada table Format :
Dimana table_name adalah nama table yang ingin diubah, column_name adalah nama kolom yang ingin ditambahkan, dan datatype adalah jenis Data dari kolom yang baru dan length adalah panjang dari tipe data pada kolom. Contoh Pemakaian syntax ALTER TABLE untuk menambahkan kolom DateofBirth pada tabel persons adalah sebagai berikut :
Maka Hasil yang akan diperoleh dengan penambahan kolom “DateofBirth” adalah seperti gambar berikut :
ALTER TABLE table_name
ADD column_name datatype(length);
ALTER TABLE Persons ADD DateOfBirth date;
ALTER TABLE table_name
{[ADD [COLUMN] column_name datatype(length) [NOT NULL][UNIQUE][DEFAULT default_option]] |
[DROP [COLUMN] column_name [RESTRICT|CASCADE]] | [ADD CONSTRAINT “constraint_name” Constraint Definition] | [DROP CONSTRAINT “constraint_name” [RESTRICT|CASCADE]] | [ALTER [COLUMN] SET DEFAULT defaultoption] |
[ALTER [COLUMN] DROP DEFAULT] }
Gambar 2. 10 Tabel Persons Beserta Datanya-Altered b. Menghapus kolom pada table
Untuk menghapus kolom dari sebuah tabel maka format dari Syntax ALTER TABLE yang digunakan adalah sebagai berikut:
Dimana table_name adalah nama table yang ingin diubah, column_name adalah nama kolom yang ingin dihapus. Sebagai contoh, untuk menghapus kolom DateofBirth dari tabel persons seperti yang ditampilkan pada gambar 2.10 diatas adalah sebagai berikut
Maka hasil dari penghapusan kolom DateofBirth dapat dilihat pada gambar 2.11 dibawah ini :
Gambar 2. 11 Tabel Persons Beserta Datanya-Altered 2
c. Menambah Constraint pada table
Untuk menambahkan sebuah Constraint pada kolom P_id maka format syntax ALTER TABLE yang dapat digunakan adalah
ALTER TABLE table_name DROP COLUMN column_name;
ALTER TABLE Persons DROP COLUMN DateOfBirth;
Dimana table_name adalah nama tabel yang ingin ditambahkan Constraint, dan Constraint_name adalah nama Constraint yang ingin ditambahkan, berikut adalah contoh penambahan Constraint pk_PersonID pada tabel Persons :
d. Menghapus Constraint pada table
Untuk menghapus sebuah Constraint pada kolom P_id maka format syntax ALTER TABLE yang dapat digunakan adalah
Dimana table_name adalah nama tabel yang ingin dihapus Constraint-nya, dan Constraint_name adalah nama Constraint yang ingin dihapus, berikut adalah contoh penghapusan Constraint pk_PersonID pada tabel Persons
e. Menambah Default pada kolom table
Untuk menambahkan default pada kolom dalam sebuah tabel maka format syntax yang dapat digunakan adalah sebagai berikut:
ALTER TABLE table_name
DROP CONSTRAINT constraint_name;
ALTER TABLE Persons
DROPCONSTRAINT pk_PersonID ; ALTER TABLE table_name
ADD CONSTRAINT constraint_name;
ALTER TABLE table_name
ALTER column_name SET DEFAULT default_option; ALTER TABLE Persons
Dimana table_name adalah nama table yang ingin diubah, column_name adalah nama kolom yang ingin ditambahkan Default, dan Default_option adalah opsi Default yang ingin ditambahkan. Contoh Pemakaian syntax Alter Table untuk men-set Default pada kolom “Address” pada tabel persons adalah sebagai berikut :
f. Menghapus Default pada kolom table
Untuk menghapus Default dari kolom sebuah tabel maka format dari Syntax ALTER TABLE yang digunakan adalah sebagai berikut:
Dimana table_name adalah nama table yang ingin diubah dancolumn_name adalah nama kolom yang ingin dihapus Default-nya. Contoh Pemakaian syntax ALTER TABLE untuk menghapus Default kolom “Address” pada tabel persons adalah sebagai berikut :
3. Drop
Syntax drop digunakan oleh user untuk menghapus object yang ada di dalam
database seperti table, schema, index, constraint, view, syntax drop ini dapat digunakan
dengan format sebagai berikut ALTER TABLE Persons
ALTER Address SET DEFAULT “Homeless”;
ALTER TABLE table_name
ALTER column_name DROP DEFAULT;
ALTER TABLE Persons
a. Drop Schema
“Drop Schema” digunakan saat user ingin menghapus sebuah schema, format
syntax yang digunakan adalah sebagai berikut :
Dimana Schema name adalah nama dari schema yang ingin dihapus, dan RESTRICT|CASCADE merupakan jenis pen-delete-an dimana jika RESTRICT dipilih maka SCHEMA yang mau dihapus haruslah kosong apabila tidak kosong maka proses penghapusan akan gagal, sedangkan pada CASCADE operasi penghapusan akan dijalankan walaupun SCHEMA masih memiliki isi(tidak kosong) jika pengguna tidak menetapkan RESTRICT atau CASCADE maka Default dari DROP SCHEMA adalah RESTRICT. Sebagai contoh pemakaian syntax DROP SCHEMA berikut adalah syntax yang digunakan untuk menghapus schema “haha” dengan asumsi bahwa pada SCHEMA “haha” sudah kosong
b. DropTable
“Drop Table” digunakan saat user ingin menghapus sebuah Table, format
syntax yang digunakan adalah sebagai berikut :
DROP [TABLE,VIEW, CONSTRAINT, SCHEMA, INDEX] “ObjectName” RESTRICT|CASCADE
[WHERE condition]
DROP TABLE table_name [RESTRICT|CASCADE] DROP SCHEMA haha;
Dimana Table_name adalah nama dari tabel yang ingin dihapus, dan
RESTRICT|CASCADE merupakan jenis pen-delete-an dimana jika RESTRICT dipilih maka TABLE yang mau dihapus tidak boleh memiliki objek apapun yang bergantung pada tabel yang ingin digapus, sedangkan pada CASCADE operasi penghapusan akan dijalankan dan menghapusTABLE dan objek lain yang
bergantung pada tabel tersebut. Jika pengguna tidak menetapkan RESTRICT atau CASCADE maka Default dari DROP TABLE adalah RESTRICT. Sebagai contoh pemakaian syntax DROP TABLE berikut adalah syntax yang digunakan untuk menghapus tabel “haha” dengan asumsi bahwa pada tabel tidak ada objek yang bergantung pada tabel “haha”
c. Drop View
“Drop View” digunakan saat user ingin menghapus sebuah View, format syntax yang digunakan adalah sebagai berikut :
DimanaView_name adalah nama dari View yang ingin dihapus, dan
RESTRICT|CASCADE merupakan jenis pen-delete-an dimana jika RESTRICT dipilih maka view yang mau dihapus tidak boleh memiliki objek apapun yang bergantung pada view yang ingin digapus, sedangkan pada CASCADE operasi penghapusan akan dijalankan dan menghapus VIEW dan objek lain yang bergantung pada tabel tersebut. Jika pengguna tidak menetapkan RESTRICT atau CASCADE maka Default dari DROP VIEW adalah RESTRICT. Sebagai contoh pemakaian
DROP VIEW view_name [RESTRICT|CASCADE] DROP TABLE haha;
syntax DROP VIEW berikut adalah syntax yang digunakan untuk menghapus view “haha” dengan asumsi bahwa pada view tidak ada objek yang bergantung pada view “haha” :
d. Drop Index
Syntax ini digunakan untuk menghapus index yang ada, penjelasan lebih lanjut mengenai index akan dibahas pada subbab2.3. berikut merupakan format dari syntax Drop index :
Dimana “indexName” adalah nama index yang ingin dibuat, sebagai contoh syntax dibawah ini akan menghapus index001 :
4. Grant
Syntax grant ini dipakai untuk memberikan akses atau hak khusus atas objek
dari database ke pada user tertentu, pada umumnya syntax grant ini dipakai untuk memberikan user tertentu sebuah akses atas suatu objek milik user lainnya. format yang dipakai dalam pembuatan syntax grant adalah sebagai berikut :
DROP INDEX Index_name ON table_name (column_name)
DROP INDEX idx001; DROP VIEW haha;
GRANT “Privilege1, Privilege2,…., Privilegen” | ALL PRIVILEGES ON “object Name”
TO “User Name”|PUBLIC [WITH GRANT OPTION];
Dimana “ Privilege” yang dimaksud adalah hak khusus yang ingin diberikan kepada
user seperti
SELECT
Fungsi dari privilege select akan memberikan user tertentu hak akses untuk
mengambil/ menampilkan data dari tabel tertentu, sebagai contoh user Andi sebagai pemilik tabel persons, memberikan hak kepada user badrun untuk menampilkan (dengan perintah select) data atas tabel persons miliknya
UPDATE
Fungsi dari privilege update akan memberikan user tertentu hak akses untuk
melakukan update data pada tabel tertentu, sebagai contoh user Andi sebagai pemilik tabel persons, memberikan hak kepada user badrun untuk mengubah data di tabel persons miliknya.
INSERT [ColumnName1, ColumnName2,….,ColumnName n]
Fungsi dari privilege insert akan memberikan user tertentu hak akses untuk
melakukan insert data pada tabel tertentu, sebagai contoh user Andi sebagai pemilik tabel persons, memberikan hak kepada user badrun untuk menambahkan kolom dengan nama “keluarga” di tabel persons miliknya. DELETE [ColumnName1, ColumnName2,….,ColumnName n]
Fungsi dari privilege delete akan memberikan user tertentu hak akses untuk
melakukan penghapusan terhadap tabel tertentu, sebagai contoh user Andi sebagai pemilik tabel persons, memberikan hak kepada user badrun untuk menghapus kolom dengan nama “DateOfBirth” di tabel persons miliknya.
REFERENCE [ColumnName1, ColumnName2,….,ColumnName n]
Fungsi dari privilege reference akan memberikan user tertentu hak akses untuk
melakukan referensi atas suatu kolom tertentu, untuk penjelasan lebih lanjut mengenai reference silahkan lihat subbab 2.2.2 poin 1 tentang create table pada bagian constraint.
dan “ object name´ adalah nama table,view, objek lainnya dimana user mendapat hak khusus dan dapat menjalankan hak khususnya, ´user name´ adalah user id yang akan diberikan hak khusus apabila memakai PUBLIC maka semua user yang ada akan mendapat hak khusus yang sudah di deklarasikan atas objek tersebut, dan WITH GRANT OPTION berguna apabila user yang diberikan hak atas object tersebut diperbolehkan untuk memberikan hak kepada user lain, sebagai contoh dibawah ini seorang DBA akan memberikan hak SELECT atas table mahasiswa kepada User andi.
Contoh diatas berarti DBA tersebut memberikan hak “SELECT” atas tabel “mahasiswa” kepada user “andi” dimana user “andi” dapat memberikan privileges tertentu kepada user lain.
5. Revoke
Syntax revoke ini akan mencabut privileges dari user tertentu sesuai yang telah
diberikan pada syntax GRANT. Bentuk pemakaian syntax revoke adalah sebagai berikut GRANT SELECT ON mahasiswa TO andi
WITH GRANT OPTION;
REVOKE [GRANT OPTION FOR] ““Privilege1, Privilege2,…., Privilege n” | ALL PRIVILEGES, ON “Object Name”
Dimana “ Privilege” yang dimaksud adalah hak khusus yang ingin diberikan kepada user seperti yang telah dijelaskan pada syntax grant diatas, GRANT OPTION FOR digunakan untuk mencabut hak yang telah diberikan WITH GRANT OPTION pada syntax grant diatas,“ object name´ adalah nama table,view, objek lainnya dimana
user mendapat hak khusus dan dapat menjalankan hak khususnya, ´user name´ adalah user id yang akan diberikan hak khusus apabila memakai PUBLIC maka semua user
yang ada akan mendapat hak khusus yang sudah di deklarasikan atas objek tersebut, dan CASCADE atau RESTRICT memili fungsi sama seperti pada syntax drop yang telah dijelaskan pada subbab 2.2.2 poin 3.
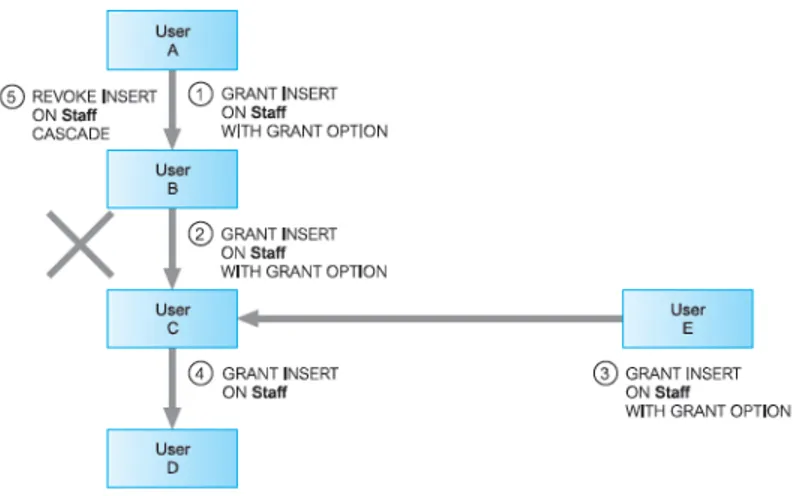
Gambar 2. 12 Ilustrasi Syntax REVOKE
Dalam contoh dibawah ini DBA akan mencabut hak SELECT atas table
mahasiswa dari user Andi.
2.2.3. DML Statement
DML Statement merupakan statement SQL yang digunakan untuk
menambahkan, mengubah, menghapus, dan menampilkan data yang ada di dalam
database. Untuk lebih jelasnya DML Statement mengijinkan pengguna untuk :
• Menampilkan Data dari satu atau lebih table. Hal ini dilakukan dengan Syntax SELECT.
• Menambahkan baris Data baru ke dalam table atau view. Hal ini dilakukan dengan Syntax INSERT.
• Mengubah nilai dari suatu Data pada table atau view. Hal ini dilakukan dengan Syntax UPDATE.
• Menghilangkan baris Data dari table atau view. Hal ini dilakukan dengan
Syntax DELETE.
Sebagai penjelasan lebih lanjut mengenai format DML Statement dan pemakaiannya, maka semua contoh yang digunakan akan merujuk pada gambar 2.13 yang menunjukan tabel persons dan order.
1. Select
Syntax ini digunakan untuk menampilkan data dari 1 atau lebih tabel dari dalam
database. untuk menampilkan data dari 1 tabel maka akan digunakan syntax select
dengan format syntax seperti di bawah ini
Dimana dalam syntax select pengguna dapat memilih untuk menampilkan data dengan distinct(menampilkan data tanpa ada redudansi/duplikasi) sehingga data yang ditampilkan berupa unique, column name adalah nama-nama kolom yang ingin di tampilkan datanya. Lalu ‘FROM’ merujuk kepada nama tabel sumber data yang ingin ditampilkan, table_name adalah nama sumber table yang ingn ditampilkan. Setelah pengguna menentukan data yang ingin ditampilkan dan tabel asal data, maka pengguna juga dapat mengatur data-data yang ditampilkan dengan syntax WHERE, GROUP BY, ORDER BY, dimana syntax WHERE berguna sebagai Filter terhadap data-data yang ingin ditampilkan, syntax GROUP BY digunakan apabila syntax select memiliki data agregat yang berupa hasil perhitungan, dan ORDER BY digunakan untuk mensortir data. Contoh penggunaan syntax select :
Contoh dibawah User akan menampilkan seluruh data dari table persons
SELECT [DISTINCT] column_name1,column_name2,column_name n [AS newColumnName] FROM table_name [alias]
[WHERE Condition] [GROUP BY Condition] [ORDER BY Condition]
Gambar 2. 14 Tabel Persons beserta datanya 2
Sedangkan untuk menampilkan data lebih dari satu tabel maka syntax join, atau
Cartesian product dapat digunakan. Untuk penjelasan lebih lanjut mengenai syntax join
dan Cartesian product akan dibahas pada poin a&b.
a. Join
Join merupakan query yang bertujuan untuk menggabungkan baris Data dari dua
atau lebih table atau view. Dimana Join biasanya memiliki paling sedikit satu kondisi
join yang terletak pada klausa WHERE dimana kondisi join tersebut akan
membandingkan dua kolom dari table yang berbeda sebelum dilakukan penggabungan. Dalam penggunaannya syntax join memiliki dua jenis join yang dapat digunakan pengguna dalam melakukan penggabungan dua tabel atau lebih, jenis-jenis join yang dapat digunakan oleh pengguna adalah INNER JOIN, dan OUTER JOIN. Untuk contoh dan penjelasan lebih lanjut mengenai syntax Join semua contoh penggunaan syntax join yang akan dibahas lanjut pada seksi (i) dan (ii) dibawah ini akan didasari pada tabel
persons dan order seperti yang tertera pada Gambar2.14 diatas
i. INNER JOIN
Inner Join merupakan salah satu jenis join dimana baris Data yang
dikembalikan hanya baris yang memenuhi syarat pada kondisi join. Syntax INNER JOIN dapat digunakan dengan format sebagai berikut
Dimana Column_name merupakan nama colom yang akan digabung,
table_name adalah nama table yang akan digabungkan, table_name1.column_name = table_name2.column_name adalah syarat penggabungannya.
Contoh Penggunaan syntax INNER JOIN yang akan menggabungkan tabel persons dan orders adalah sebagai berikut:
Dan Hasil dari penggabungan syntax join tabel persons dan orders adalah :
Gambar 2. 15 Hasil Join Tabel Persons dan Order 2
ii. OUTER JOIN
Outer Join merupakan syntax join dimana Data yang ditampilkan merupakan
data yang memenuhi syarat dan semua Data dari salah satu table, walaupun pada table lainnya tidak terdapat Data yang sama, untuk penjelasan lebih lanjut dibawah ini akan dibahas mengenai tiga jenis Syntax outer join yaitu :
SELECT column_name1,column_name2,column_name n FROM table_name1
INNER JOIN table_name2
ON table_name1.column_name=table_name2.column_name
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo FROM Persons
INNER JOIN Orders
ON Persons.P_Id=Orders.P_Id ORDER BY Persons.LastName
LEFT JOIN
LEFT JOIN merupakan outer join yang akan mengembalikan semua baris Data
yang terdapat pada tabel pertama (tabel pertama akan dianggap menjadi sisi sebelah “kiri”). Format dari Syntax LEFT JOIN dalam penggunaanya adalah sebagai berikut:
Dimana Column_name merupakan nama-nama kolom yang akan digabung,
table_name adalah nama table yang akan digabungkan,
table_name1.column_name=table_name2.column_name adalah syarat penggabungannya. Sebagai contoh penggunaan LEFT JOIN yang akan menggabungkan tabel persons dan tabel orders maka bentuk syntax yang akan digunakan adalah sebagai berikut :
Dari penggunaan syntax left join diatas maka data yang dihasilkan adalah seperti pada gambar 2.16 dibawah ini.:
Gambar 2. 16 Hasil Left Join Tabel Persons dan Order
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo FROM Persons
LEFT JOIN Orders
ON Persons.P_Id=Orders.P_Id ORDER BY Persons.LastName
SELECT column_name1,column_name2,column_name n FROM table_name1
LEFT JOIN table_name2
RIGHT JOIN
RIGHT JOIN merupakan outer join yang akan mengembalikan semua baris
Data yang terdapat pada tabel kedua (tabel pertama akan dianggap menjadi sisi sebelah “kanan”). Format dari Syntax LEFT JOIN dalam penggunaanya adalah sebagai berikut:
Dimana Column_name merupakan nama-nama kolom yang akan digabung,
table_name adalah nama table yang akan digabungkan, table_name1.column_name = table_name2.column_name adalah syarat penggabungannya. Sebagai contoh penggunaan RIGHT JOIN yang akan menggabungkan tabel persons dan tabel orders maka bentuk syntax yang akan digunakan adalah sebagai berikut :
Dari penggunaan syntax right join diatas maka data yang dihasilkan adalah seperti pada gambar 2.17 dibawah ini.:
Gambar 2. 17 Hasil right Join Tabel Persons dan Order
SELECT column_name1,column_name2,column_name n FROM table_name1
RIGHT JOIN table_name2
ON table_name1.column_name=table_name2.column_name
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo FROM Persons
RIGHT JOIN Orders
ON Persons.P_Id=Orders.P_Id ORDER BY Persons.LastName
FULL OUTER JOIN
FULL OUTER JOIN merupakan outer join yang memadukan LEFT JOIN
dengan RIGHT JOIN sehingga baris Data yang akan dikembalikan dapat berasal dari sisi sebelah “kiri” table maupun sebelah “kanan” table. Format dari Syntax Full Outer Join dalam penggunaanya adalah sebagai berikut:
DImana Column_name = nama colom yang akan digabung, table_name adalah nama table yang akan digabungkan, table_name1.column_name =
table_name2.column_name adalah syarat penggabungannya. Sebagai contoh penggunaan FULL OUTER JOIN yang akan menggabungkan tabel persons dan tabel orders maka bentuk syntax yang akan digunakan adalah sebagai berikut :
Dari penggunaan syntax Full Outer join diatas maka data yang dihasilkan adalah seperti pada gambar 2.18 dibawah ini.:
Gambar 2. 18 Hasil Full Join Tabel Persons dan Order
SELECT column_name1,column_name2,column_name n FROM table_name1
FULL JOIN table_name2
ON table_name1.column_name=table_name2.column_name
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo FROM Persons
FULL JOIN Orders
ON Persons.P_Id=Orders.P_Id ORDER BY Persons.LastName
b. Cartesian Product
Cartesian product merupakan Top join dimana semua Data ditampilkan dari
masing-masing table dikarenakan tidak menggunakan kondisi penggabungan pada syntax join. Cartesian Product ini dapat digunakan dengan format :
Dari syntax diatas “Table 1”, “Table 2”, “Table n” merupakan Cartesian product Contoh :
c. Subquery
Subquery merupakan Statement SELECT yang bersifat nested di dalam SQL Statement lainnya. Subquery berguna ketika ada banyak query yang harus dieksekusi
untuk memecahkan satu masalah. Subquery ini dapat digunakan dengan format :
Sebagai Contoh penggunaan subquery adalah sebagai berikut:
SELECT “Column Name 1”, “Column Name 2”,….., “Column Name n” FROM “Table 1”, “Table 2”, “Table n”
SELECT * FROM EMPLOYEE, DEPARTMENT
SELECT “Column Name 1”, “Column Name 2”,….., “Column Name n” FROM “Table Name”
WHERE “Condition” IN (
SELECT “Column Name” FROM “Table Name” WHERE “Condition” );
SELECT first_name, last_name FROM employees WHERE department_id
IN (SELECT department_id FROM departments WHERE location_id = 1800);
d. Exists & IN
Penggunaan Syntax exists akan mengecek apakah sebuah row itu eksis atau tidak bedasarkan syarat yang ditentukan. Dan dianjurkan digunakan ketika terjadi komparasi atas satu kolom dengan kolom lainnya. Bentuk pemakaian syntax Exists adalah sebagai berikut :
Dimana column name adalah nama kolom yang data-datanya ingin dijadikan sebagai persyaratan, dan table_name adalah nama sumber table yang ingn ditampilkan dan condition adalah syarat pemanggilan, berikut merupakan contoh penggunaan syntax exists yang mengacu pada gambar 2.12 untuk menampilkan data persons dimana data yang ditampilkan merupakan data yang memiliki LastName “hansen” atau “peter”
Bedasarkan query exists diatas maka gambar 2.19 merupakan hasil dari query exists
Gambar 2. 19 Tabel Persons – Exists
Dan Penggunaan Syntax IN juga akan mengecek apakah sebuah row itu eksis atau tidak bedasarkan syarat yang ditentukan. Berikut merupakan format yang dipakai dalam menggunakan syntax In:
SELECT “Column Name 1”, “Column Name 2”,….., “Column Name n” FROM table_name
WHERE column_name EXISTS (SELECT ‘COLUMN_NAME1, COLUMN_NAME1,…, COLUMN_NAME n ’ FROM ‘TABLE_NAME’ WHERE ‘Condition’)
SELECT *
FROM persons
WHERE EXISTS (SELECT LastName FROM persons WHERE LastName =’Hansen’ or LastName=’Peter’ )
Dimana column name adalah nama kolom yang ingin di tampilkan data-datanya, dan table_name adalah nama sumber table yang ingn ditampilkan dan
value adalah syarat pemanggilan. Dibawah ini merupakan contoh penggunaan syntax in
untuk menampilkan data persons dimana data yang ditampilkan merupakan data yang memiliki LastName “hansen” atau “peter”
Dari sytax in diatas maka Hasil dari query In adalah seperti yang ditampilkan pada gambar 2.20 :
Gambar 2. 20 Tabel Persons – In e. Group By & Distinct
Syntax Distinct digunakan untuk menampilkan satu (Non-Duplikasi) baris Data dari
sebuah tabel. Berikut merupakan bentuk dari syntax distinct :
Dimana column name adalah nama kolom yang ingin di tampilkan data-datanya, dan table_name adalah nama sumber table yang ingn ditampilkan. Contoh Penggunaan
SELECT DISTINCT column_name FROM table_name
SELECT “Column Name 1”, “Column Name 2”,….., “Column Name n”) FROM table_name
WHERE column_name IN (value1,value2,...)
SELECT * FROM Persons
dari syntax distinct untuk menampilkan data “city” dari tabel persons yang terdapat pada gambar 2.12 adalah sebagai demikian
Bedasarkan syntax distinct diatas maka hasil yang diberikan adalah seperti yang tertera pada gambar 2.21:
Gambar 2. 21 Tabel Persons-Distinct
Dan untuk pemakaian Syntax group by bentuk dasar dari syntax group by adalah sebagai demikian :
Dimana column name adalah nama kolom yang ingin di tampilkan data-datanya, dan table_name adalah nama sumber table yang ingn ditampilkan. Berikut merupakan penggunaan syntax group by untuk menampilkan data Nim, Nama, Alamat dikelompokan bedasarkan Nim, Nama, Alamat
Bedasarkan query group by diatas maka hasil yang didapat dari peng-eksekusian query adalah sebagai demikian :
SELECT DISTINCT City FROM Persons
SELECT ‘COLUMN_NAME’ FROM ‘TABLE_NAME’
GROUP BY ‘COLUMN_NAME’
SELECT Nim, Nama, Alamat FROM ‘Mahasiswa’
Gambar 2. 22 Tabel Persons-Group By
2. Insert
Untuk menambahkan data kedalam sebuah database maka pengguna dapat menggunakan kedalam sebuah database maka pengguna dapat menggunakan syntax
insert. Syntax insert dapat digunakan untuk menambahkan data kedalam sebuah table
dengan format seperti yang terdapat dibawah ini.
Dimana table_name adalah nama table yang ingin diinput datanya dan value berupa nilai-nilai dari data yang ingin dimasukan. Sebagai contoh gambar 2.23 merupakan table persons sebelum dilakukan perintah insert
Gambar 2. 23 Tabel Persons beserta datanya 3
Dan berikut merupakan syntax insert yang akan memasukan data ke dalam table persons INSERT INTO table_name
VALUES (value1, value2, value n,...)
INSERT INTO Persons
Setelah proses insert selesai maka tabel persons akan berubah menjadi seperti gambar 2.24 :
Gambar 2. 24 Tabel Persons Beserta Datanya – Inserted
3. Update
Untuk merubah data yang terdapat dalam database maka pengguna dapat menggunakan syntax update. Syntax update dapat digunakan untuk mengubah data kedalam sebuah table dengan format sebagai berikut:
Dimana table_name adalah nama tabel yang ingin di-update column1-2 adalah nama kolom yang ingin diupdate, value1-2 adalah nilai dari updatenya, some_column dan some_value adalah syarat kolom dannilai dari yang akan diubah. Sebagai contoh pemakaian syntax update, berikut adalah table persons :
Gambar 2. 25 Tabel Persons Beserta Datanya 4
UPDATE table_name
SET column1=value, column2=value2, column n=value n ,... WHERE some_column=some_value
Lalu berikut adalah syntax Update yang digunakan untuk mengubah data ‘Jakob’
Setelah proses update selesai maka hasil dari syntax update adalah sebagai berikut
Gambar 2. 26 Tabel Persons Beserta Datanya - Updated
4. Delete
Untuk menghapus data dari dalam database, maka pengguna dapat menggunakan syntax delete. Syntax delete dapat digunakan untuk menghapus data dari sebuah table dengan format sebagai berikut :
Dimana table_name adalah nama table yang ada, some_column dan some_value adalah syarat kolom dannilai dari yang akan dihapus datanya. Sebagai contoh pemakaian syntax delete berikut adalah tabel persons beserta datanya sebelum dilakukan perintah Delete
Gambar 2. 27 Tabel Persons Beserta Datanya 5
UPDATE Persons
SET Address='Nissestien 67', City='Sandnes'
WHERE LastName='Tjessem' AND FirstName='Jakob'
DELETE FROM table_name WHERE some_column=some_value
Dan untuk menghapus ‘Johan’ dengan P_ID=4, Berikut adalah contoh syntax delete yang digunakan
Setelah syntax delete dijalankan dengan sukses maka data yang dihasilkan akan menjadi seperti gambar 2.28 :
Gambar 2. 28 Tabel Persons Beserta Datanya - Deleted
2.2.4. Access-Control
Menurut Connolly & Begg (2010,p66), Salah satu fitur lainnya yang disediakan DBMS dalam mengelola database adalah Kontrol-akses, dimana control-akses menyediakan :
Security System
Fasilitas dari DBMS ini dapat digunakan untuk melindungi data-data yang ada di dalam database dengan menolak user tanpa ijin untuk mengakses database, contoh dari sistem keamanan adalah username dan password.
Intergrity System
Fasilitas dari DBMS ini berupa system integrasi data yang akan mengatur konsistensi Data yg tersimpan, sehingga data yang ada di dalam database menjadi terintegrasi satu dengan yang lainnya
Concurency Control System
Fasilitas DBMS ini berguna untuk memungkin pembagian akses ke database sehingga pengguna yang dapat mengakses database tidak selalu bergantung pada DBA.
Recovery Control System
Fasilitas DBMS ini merupakan system yang akan menyimpan keadaan konsisten database sebelum terjadi kerusakan sehingga mempermudah proses
recovery pada saat data/database itu sendiri mengalami kegagalan.
User-accessible catalog
Fasilitas DBMS ini berguna untuk menyimpan deskripsi dari Data yang ada di dalam database yang akan mempermudah pengguna dalam mengenali data yang ada di dalam database.
2.3 Index
Menurut Ashdown & Kyte (2011, p61), Index adalah sebuah struktur optional yang diasosiasikan dengan table atau table cluster yang dapat mempercepat akses Data. sedangkan menurut Connolly & Begg(2010,p242) index adalah sebuah struktur yang menyediakan percepatan akses kepada sebuah baris dalam tabel didasari pada nilai dari satu atau lebih kolom. Dari ke dua definisi diatas dapat ditarik kesimpulan bahwa index adalah sebuah struktur yang digunakan untuk mempercepat akses data dan didasari dari sebuah nilai. Oleh karena itu dengan jika suatu tabel dengan jumlah data yang besar tidak menggunakan Index, maka database harus melakukan full table scan dalam
mencari nilai yang akan menyebabkan waktu akan semakin bertambah seiring dengan meningkatnya volume Data. index memiliki dua karakteristik sebagai berikut :
1. Usability
Index dapat berupa usable ataupun unusable, dimana suatu unusable index tidak
diatur oleh operasi DML dan diabaikan oleh optimizer sehingga meningkatkan peforma bulk loads yaitu kejadian dimana dilakukannya proses entry data dalam jumlah besar ke dalam tabel dimana jika index sedang dalam kondisi usable dapat memperlambat proses entry data tersebut. Selain itu penggunaan
Unusable Index dan Index partitions tidak mengkonsumsi space dan ketika suatu Index dibuat menjadi unusable, database akan melakukan proses drop pada Index Segment.
2. Visibility
Index dapat berupa visible atau invisible, dimana suatu invisible Index akan diatur
oleh operasi DML dan tidak digunakan secara default oleh optimizer. Selain itu suatu invisible Index merupakan suatu alternatif untuk membuat Index tersebut menjadi unusable atau men-drop nya. Kemudian, Invisible Index sangat berguna untuk melakukan testing terhadap suatu Index sebelum Index tersebut di drop atau digunakan secara temporer tanpa mengganggu kinerja aplikasi.
1. B-Tree Index
Gambar 2. 29 B-Tree Index (Sumber : Oracle Database Concepts 11g Release 2) B-Tree merupakan singkatan dari balanced trees, dan merupakan jenis index
yang paling sering dipakai dimana B-tree index merupakan sederetan nilai terurut yang dibagi dalam jarak nilai tertentu. Lalu B-tree juga memberikan performa pengambilan sejumlah baris query yang sangat baik.
Berikut adalah Jenis-jenis B-Tree index : a. Index-Organized Tables
Gambar 2. 30 Index-Organized Tables (Sumber : learningdrop.com)
Index-Organized Tables merupakan tabel yang disimpan di dalam variasi
struktur B-Tree Index. Index-organized tables terlihat seperti tabel pada umumnya dengan primary key index yang terdapat pada satu atau lebih atribut miliknya. Namun, jika pada tabel biasa terdapat dua ruang penyimpanan yang harus dikelola (ruang penyimpanan untuk tabel itu sendiri dan untuk B-Tree index), pada index-organized
tables seluruh atribut yang ada pada tabel tersebut disimpan sebagai index sehingga
hanya cukup mengelola satu B-Tree index yang mengandung primary key beserta atribut-atribut yang lain. Jadi dapat dikatakan bahwa selain berperan sebagai tabel yang menyimpan baris data pada umumnya, tabel tersebut juga berperan sebagai index. Sebagai contoh, terlihat pada gambar 2.29 terdapat ilustrasi perbedaan antara tabel yang menggunakan index biasa dengan index-organized tables. Pada index biasa, setiap data dari atribut memiliki rowid yang berfungsi sebagai pointer kepada lokasi dari data yang ada pada tabel yang bersangkutan sedangkan pada index-organized tables, tidak