6 2.1 Basis Data
Menurut Connolly dan Begg (2005, p15), basis data (database) adalah
kumpulan relasi logikal dari data (dan deskripsi dari data) yang digunakan secara bersama-sama dan didesain untuk memenuhi kebutuhan perusahaan akan informasi. Basis data merupakan katalog sistem (metadata) yang menyediakan deskripsi dari
data sehingga memungkinkan kemandirian data-program (program data independence). Basis data juga dapat dideskripsikan sebagai relasi logikal dari data
yang terdiri dari entitas-entitas, atribut-atribut, dan hubungan dari informasi organisasi atau perusahaan.
Menurut Mannino (2004, p4), basis data adalah kumpulan dari data-data tetap yang saling berhubungan dan dapat digunakan bersamaan.
Beberapa permodelan basis data yang pernah dikenal antara lain :
• Hierarchical Model : mengorganisasikan data dalam bentuk struktur
pohon (tree), yang terdiri atas parent dan child.
• Network Model : seperti Hierarchical Model namun memungkinkan
lebih dari satu parent pada setiap child (mendukung many-to-many). • Relational Model : data diorganisasikan dalam bentuk tabel-tabel. • Object-Relational Model : menambahkan konsep permodelan Class
• Object-Oriented Model : merupakan penggabungan fungsi basis data
ke dalam bahasa permrograman berorientasi objek.
• Semistructured Model : setiap baris data pada model ini memiliki
struktur datanya (schema) masing-masing sehingga tidak ada batas
yang jelas antara data dan strukturnya.
• Associative Model : setiap data terdiri dari item dan link, di mana link
tersebut menjelaskan sumber, tujuan, dan hubungan di antaranya.
• Entity-Attribute-Value (EAV) Data Model : Setiap tabel memiliki 3
kolom yang terdiri dari entitas, atribut, dan nilai.
• Context Model : model ini menggabungkan semua model di atas.
2.2 Model Relasional
2.2.1 Sejarah Model Relasional
Model relasional pertama kali diajukan oleh E. F. Codd pada tahun 1970 dalam penelitiannya yang berjudul “A Relational Model of Data for Shared Data Banks” (Codd, 1970). Model ini lebih diterima dibandingkan model set-oriented yang telah diajukan sebelumnya (Childs, 1968) dan telah menjadi
dasar dari sistem basis data berbagai platform . Inti dari model relasional
adalah sebagai berikut:
- Memungkinkan independensi tingkat tinggi. Artinya aplikasi
tool/alat bantu tidak akan mempengaruhi representasi data
- Untuk menyediakan dasar substansial untuk mengatasi data semantik, konsistensi, dan redudansi, yang pada laporan penelitian E. F. Codd disebut dengan konsep relasi normalisasi yang artinya relasi tersebut tidak boleh ada suatu kelompok perulangan.
- Memungkinkan ekspansi dari set-oriented DML (Data Manipulation Language).
Ketertarikan vendor-vendor besar terhadap model relasional ini terlihat dari tiga proyek yang paling menonjol namun dengan perspektif yang berbeda. Proyek paling pertama dilakukan oleh IBM San Jose’s Reseach Laboratory di California, dimana prototipe dari relasional DBMS System R
dikembangkan pada akhir tahun 1970-an. Proyek ini bertujuan untuk membuktikan kepraktisan model relasional dengan menyediakan implementasi dari struktur data dan operasi. Tujuan lainnya adalah juga untuk membuktikan bahwa model relasional merupakan suatu implementasi dari sumber informasi yang sangat baik seperti manajemen transaksi, kontrol konkurensi, teknik recovery, optimasi query, keamanan data dan
integritasnya, faktor manusia, dan antarmuka pengguna. Proyek ini mempelopori penelitian-penelitian pengembangan prototipe lainnya yang berdasarkan pada model relasional tersebut. Proyek System R memiliki dua
inti pengembangan, yang pertama adalah pengembangan dari struktur bahasa
query yang dinamakan sebagai SQL (Structured Query Language), yang
secara resmi menjadi standar oleh ISO (International Organization for Standarization) dan secara de facto menjadi bahasa standar yang digunakan
untuk relasional DBMS (DataBase Management System). Sedangkan inti
yang kedua adalah menghasilkan berbagai produk DBMS relasional yang dirilis pada akhir 1970-an dan 1980-an, sebagai contoh adalah DB2 dan SQL/DS yang diproduksi oleh IBM dan Oracle yang diproduksi oleh Oracle Corporation.
Proyek yang kedua merupakan hasil pengembangan yang signifikan pada model relasional, yaitu INGRES (Interactive Graphics Retrieval System)
yang dikembangkan oleh University of California di Berkeley pada waktu
yang bersamaan dengan pengembangan proyek System R. Proyek INGRES
terlibat pada pengembangan prototipe RDBMS yang mengfokuskan pada tujuan yang sama dengan proyek System R. Penelitian ini mengawali suatu
versi akademik dari INGRES, dimana yang dikontribusikan untuk apresiasi umum dari konsep relasional dan menghasilkan produk komersial INGRES yang dikeluarkan oleh Relational Technology Inc. (sekarang INGRES 2 dari Computer Associates) dan Intelligent Database Machine dari Brittonlee Inc.
Proyek yang ketiga adalah Peterlee Relational Test Vehicle di IBM UK Scientific Centre, Peterlee (Todd, 1976). Proyek ini lebih berorientasi ke arah
teoritikal dibandingkan proyek System R dan INGRES. Pada prinsipnya,
penelitian ini lebih ditujukan pada proses query, optimasi dan ekstensi
fungsional.
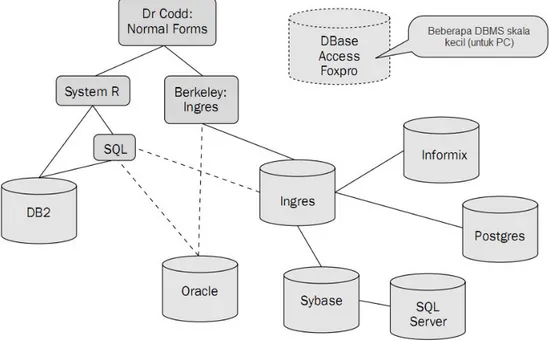
Sistem komersial yang didasarkan pada model relasional mulai semakin berkembang dan bermunculan pada akhir tahun 1970 dan awal tahun 1980. Terdapat ratusan macam produk RDBMS yang dapat digunakan untuk lingkungan mainframe atau PC, walaupun banyak diantaranya tidak
mengikuti definisi dari model relasional tersebut. Beberapa contoh dari RDBMS berbasis PC yaitu Access dan FoxPro yang dikeluarkan oleh Microsoft, Paradox oleh Corel Corporation, InterBase dan BDM oleh Borland, dan yang terakhir adalah R:Base oleh R:Base Technology. Gambar
2.1 menunjukkan arah perkembangan dari model relasional terhadap produk-produk RDBMS.
Gambar 2.1 Sejarah Perkembangan Model Relasional
Seiring dengan kepopuleran dari model relasional, banyak sistem non-relasional yang kini dilengkapi dengan GUI (Graphical User Interface) relasional terlepas dari model yang ada. Computer Associates DBMS yang
merupakan jaringan prinsip dari DBMS telah menjadi CA-IDMS SQL, yang
mendukung view data relasional Pada mainframe DBMS lain, yang
Corporation of America dan ADABAS milik software AG. Beberapa ekstensi
dari model data relasional telah diajukan, sebagai contoh ekstensi pada: - Pengembalian arti data lebih dekat lagi (contohnya Codd, 1979) - Mendukung konsep yang berorientasi objek (contohnya
Stonebraker dan Rowe, 1986)
- Mendukung kemampuan deduktif (contohnya Gardarin dan Valduriez, 1989)
2.2.2 Pengertian Model Relasional
Konsep utama dari model relasional adalah semua data direpresentasikan sebagai sebuah n-relasi secara matematik, di mana n-relasi tersebut adalah subset dari produk Cartesian dari n-domain. Menurut Connolly dan Begg
(2005, p45-46, p71), model relasional didasari oleh suatu konsep relasi matematika, di mana data dan relasi direpresentasikan dengan menggunakan tabel-tabel yang memiliki sejumlah kolom dengan nama-nama yang unik.
Tabel 2.1 Tabel Produk
KodeProduk NamaProduk Harga KodeJenisProduk
P0001 Tango 3000 J001
P0002 Sprite 4000 J002
P0003 Fanta 4000 J002
P0004 Rinso 100g 5000 J003
Tabel 2.2 Tabel Jenis Produk
KodeJenisProduk NamaJenisProduk J001 Makanan
J002 Minuman
Sebagai contoh pada Tabel 2.1 diambil satu data misalnya produk ‘Sprite’ dengan kode produk ‘P0002’ memiliki kode jenis produk ‘J002’, di mana pada Tabel 2.2 diketahui bahwa kode produk ‘J002’ merupakan jenis produk ‘Minuman’.
2.2.2.1 Struktur Data Relasional
Komponen-komponen penyusun data relasional : a. Relasi
Relasi merupakan sebuah tabel yang tersusun atas kolom-kolom (columns) dan baris-baris (rows) (Connolly dan Begg,
2005, p72). Sebuah RDBMS berfungsi untuk membantu pengguna melihat basis data dengan tampilan dalam bentuk tabel-tabel. Namun tampilan ini hanya dapat terlihat pada struktur basis data logikal, yaitu pada tingkat eksternal dan tingkat konseptual dari arsitektur ANSI-SPARC, bukan pada stuktur basis data fisikal, di mana pada tahap ini dapat diimplementasikan dengan peyimpanan yang bervariasi.
b. Atribut
Atribut merupakan kolom-kolom pada suatu relasi/tabel (Connolly dan Begg, 2005, p72). Pada model relasional, relasi merupakan informasi tentang objek yang direpresentasikan ke dalam basis data. Sebuah relasi direpresentasikan sebagai tabel 2 dimensi, di mana baris dari tabel berkorespondensi pada
records individual dan kolom dari tabel berkorespondensi
c. Domain
Domain adalah himpunan nilai dari satu atau lebih atribut
(Connolly dan Begg, 2005, p72). Domain terdiri dari 2 bagian
yaitu nama domain (Domain Name) dan definisi domain
(Domain Definition). Nama domain memberikan
keterangan/penjelasan tentang informasi apa yang ada pada atribut tersebut, contohnya atribut SN maka nama domain-nya
adalah Serial Number, menjelaskan bahwa atribut SN berisi
nomor seri suatu produk. Sedangkan definisi domain berisi nilai
apa yang diperbolehkan untuk mengisi atribut tersebut. Contohnya atribut NoTelp dengan nama domain nomor telepon
dan definisi domain adalah character, 12, yang artinya atribut
NoTelp diisi nomor telepon dan hanya boleh diisi tipe data karakter paling banyak 12 karakter.
d. Tuple
Tuple adalah baris pada suatu relasi atau tabel (Connolly
dan Begg, 2005, p73).
e. Degree
Degree adalah banyaknya atribut dalam suatu relasi/tabel
(Connolly dan Begg, 2005, p74). Sebuah relasi yang hanya memiliki satu atribut disebut relasi unary, sedangkan relasi
dengan dua atribut disebut binary, relasi yang memiliki tiga
atribut disebut ternary, dan setelah itu menggunakan n-ary di
f. Cardinality
Cardinality merupakan banyaknya tuple/baris pada suatu
tabel (Connolly dan Begg, 2005, p74). Kardinalitas berubah jika jumlah tuple berubah, misalnya ketika datanya ditambah/dihapus.
g. Basis Data Relasional
Basis Data relasional adalah kumpulan dari relasi yang ternormalisasi dengan nama relasi yang unik.
2.2.2.2 Relasi pada Matematika
Agar dapat lebih memahami tentang relasi maka diperlukan pengkajian ulang dari beberapa konsep relasi pada matematika. Sebagai contoh diberikan dua buah himpunan, D1 dan D2 di mana D1= {2, 4} dan D2= {1, 3, 5}. Produk Cartesian dari kedua himpunan tersebut dapat ditulis D1 × D2, di mana himpunan dari seluruh pasangan yang dihasilkan memiliki urutan elemen pertama adalah anggota dari D1 dan elemen kedua adalah anggota dari D2. Cara alternatif untuk mengkombinasikan elemen ini :
D1 × D2 = {(2, 1), (2, 3), (2, 5), (4, 1), (4, 3), (4, 5)}
Subset dari produk Cartesian ini adalah sebuah relasi. Sebagai contoh relasi A yang merupakan subsetnya, di mana :
R = {(2, 1), (4, 1)}
Jika urutan pasangan yang ada di dalam suatu relasi ingin dispesifikasi maka dapat diberikan beberapa kondisi sebagai seleksi.
Contoh bila ingin didapatkan sebuah relasi R yang berisi pasangan di mana elemen kedua adalah sama dengan 1, maka R dapat ditulis sebagai berikut :
R = {(x, y) | x ∈ D1, y ∈ D2, y = 1}
Contoh lainnya dengan menggunakan himpunan yang sama dapat dibuat juga relasi lain yaitu S, di mana elemen pertama adalah dua kali elemen kedua. Maka S dapat ditulis :
S = {(x, y) | x ∈ D1, y ∈ D2, x = 2y}
Notasi dari relasi tersebut dapat dikembangkan dengan menggunakan 3 buah himpunan. Misalkan terdapat 3 buah himpunan D1, D2, dan D3 maka produk Cartesian-nya dapat ditulis D1 × D2 × D3 dengan urutan himpunannya yaitu elemen pertama dari D1, elemen kedua dari D2, dan elemen ketiga dari D3. Contoh :
D1 = {1, 3} D2 ={2, 4} D3 = {5, 6}
D1 × D2 × D3 = {(1, 2, 5), (1, 2, 6), (1, 4, 5), (1, 4, 6), (3, 2, 5), (3, 2, 6), (3, 4, 5), (3, 4, 6)}
Subset dari produk Cartesian ketiga himpunan tersebut adalah sebuah relasi. Dari ketiga himpunan tersebut, notasi dapat dikembangkan dan dapat disimpulkan untuk relasi umum dengan n-domain. Sebagai contoh terdapat n buah himpunan : D1, D2, D3, ... , Dn, maka produk Cartesian-nya adalah :
D1 × D2 × D3 × ... × Dn = {(d1, d2, ... , dn) | d1 ∈ D1, d2 ∈ D2, ... , dn ∈ Dn}
Setiap subset dari n baris yang berasal dari produk Cartesian di atas adalah sebuah relasi dari n-himpunan.
2.2.2.3 Relasi Basis Data
Berdasarkan konsep basis data tersebut di atas, dapat didefinisikan bahwa skema relasi adalah sebuah nama relasi yang didefinisikan oleh sebuah himpunan pasangan dari atribut dan nama
domain (Connolly, 2005, p76). Misalkan A1, A2, ... , An merupakan
atribut dengan domain D1, D2, ... , Dn. Maka set yang dihasilkan
yaitu {A1 : D1, A2 : D2, ... , An : Dn} adalah sebuah skema relasi . Sebuah relasi R didefinisikan oleh sebuah skema relasi S yang merupakan himpunan pemetaan dari nama atribut dengan domain
yang berkorespondensi dengannya. Jadi relasi R merupakan himpunan dari n-baris :( A1: d1, A2 : d2, ... , An : dn) di mana d1 ∈ D1, d2 ∈ D2, ... , dn ∈ Dn.
Setiap elemen pada n-baris terdiri dari sebuah atribut dan nilai dari atribut tersebut. Pada umumnya, ketika relasi ditulis ke dalam bentuk tabel, maka nama atribut akan ditulis sebagai judul kolom dan menuliskan tuple sebagai baris yang memiliki format (d1, d2, ...
, dn), di mana setiap nilai diambil dari domain yang cocok.
Dengan demikian dapat dikatakan bahwa suatu relasi dalam model relasional adalah suatu subset dari produk Cartesian dari
domain suatu atribut. Sebuah tabel merupakan suatu representasi fisik yang sederhana dari sebuah relasi.
2.2.2.4 Properti dari Relasi
Sebuah relasi memilik properti sebagai berikut :
- Relasi memiliki nama yang berbeda dengan relasi lain pada skema relasional;
- Setiap sel dari relasi mengandung tepat satu nilai tunggal (atomik);
- Setiap atribut memiliki nama yang berbeda; - Nilai dari atribut adalah dari domain yang sama;
- Setiap tuple berbeda-beda, tidak ada tuple yang
terduplikasi;
- Urutan dari atribut tidak berpengaruh;
- Urutan dari tuple tidak berpengaruh secara teori.
(walaupun dalam prakteknya, urutan dari tuple dapat
berpengaruh pada efisiensi pengaksesan tuple.)
Sebagian besar dari properti yang dispesifikasikan untuk relasi dihasilkan dari properti dari relasi matematika :
- Ketika kita menderivasikan produk Cartesian dari suatu himpunan dengan sederhana, elemen nilai tunggal seperti
integer, setiap elemen dari setiap baris adalah nilai
tunggal. Sama halnya, setiap sel dari sebuah relasi mengandung tepat satu nilai. Bagaimanapun, sebuah
relasi matematika tidak perlu dinormalisasikan. Namun untuk menyederhanakan model data relasional grup berulang tidak diijinkan.
- Di dalam sebuah relasi, nilai yang mungkin untuk posisi yang diberikan, ditentukan oleh suatu himpunan atau
domain yang telah didefinisikan posisinya. Di dalam
tabel, nilai di setiap kolom harus berasal dari domain
atribut yang sama.
- Di dalam sebuah himpunan, tidak ada elemen yang berulang. Sama halnya pada sebuah relasi, tidak ada
tuple yang berulang.
Walau bagaimanapun, pada relasi matematika, urutan dari elemen-elemen dalam sebuah tuple sangat penting. Sebagai contoh
urutan pasangan (1, 2) berbeda dengan urutan pasangan (2, 1).
2.2.2.5 Relational Keys
Sebagaimana telah dijelaskan sebelumnya, tidak ada tuple
berulang pada sautu relasi. Oleh karena itu, dibutuhkan sesuatu untuk dapat mengidentifikasi satu atau lebih atribut (yang disebut
relationa keys) yang secara unik mengidentifikasikan setiap tuple
a. Superkey
Superkey adalah sebuah atribut, atau himpunan dari
atribut, yang secara unik mengidentifikasi sebuah baris pada suatu relasi (Connolly dan Begg, 2005, p78).
b. Candidate key
Candidate key adalah sebuah superkey yang tidak
layak adalah superkey pada suatu relasi (Connolly dan
Begg, 2005, p78). Sebuah candidate key, K, dari sebuah
relasi R memiliki dua buah properti :
- uniqueness – pada setiap tuple R, nilai dari K
secara unik mengidentifikasi tuple
tersebut.
- irreducibility – tidak ada subset yang tepat dari K
memiliki properti uniqueness. c. Primary key
Primary key adalah candidate key yang dipilih untuk
mengidentifikasi tuple secara unik pada suatu relasi
(Connolly dan Begg, 2005, p79).
d. Foreign key
Foreign key adalah sebuah atribut, atau himpunan dari
atribut, di dalam suatu relasi yang cocok dengan
candidate key dari beberapa relasi (Connolly dan Begg,
2.2.3 Batasan Integritas
Selain struktur, sebuah model data memiliki dua bagian lain, yaitu bagian manipulatif, mendefinisikan tipe-tipe dari operasi yang diperbolehkan untuk data, dan sebuah himpunan dari batasan integritas, yang menjamin keakuratan data.
Sejak setiap atribut memiliki domain yang berasosiasi, ada batasan (yang
disebut batasan domain) yang membentuk batasan pada himpunan nilai yang
diperbolehkan untuk atribut dari relasi tersebut. Ada dua aturan integritas yang penting, yaitu integritas entitas dan dan integritas referensial. Namun agar dapat mengerti kedua aturan integritas tersebut, sebelumnya perlu dipahami terlebih dahulu konsep daripada nulls.
2.2.3.1 Nulls
Menurut Connolly dan Begg (2005, p81), Null
merepresentasikan sebuah nilai untuk sebuah aribut yang tidak diketahui atau tidak dapat diaplikasikan untuk baris tersebut. Bagaimanapun null tidak sama dengan nilai nol atau teks yang
berisi spasi; nol dan spasi adalah nilai, sedangkan null
merepresentasikan absennya suatu nilai. Oleh karena itu, null harus
diperlakukan berbeda dari nilai lainnya.
2.2.3.2 Integritas Entitas (Entity Integrity)
Aturan integritas pertama berlaku untuk primary key dari relasi
key yang berisi null pada relasi dasar. Primary key adalah
pengidentifikasi minimal yang digunakan untuk mengidentifikasi
tuple secara unik. Ini berarti tidak ada subset dari primary key yang
cukup untuk dapat mengidentifikasi tuple secara unik. Apabila
diperbolehkan null untuk bagian mana saja dari primary key, maka
dengan secara tidak langsung menyatakan bahwa tidak semua atribut dibutuhkan untuk membedakan baris yang satu dengan baris yang lain, di mana hal ini bertolak belakang dengan definisi dari
primary key.
2.2.3.3 Integritas referensial (Referential Integrity)
Aturan integritas yang kedua berlaku untuk foreign key.
Integritas referensial adalah jika sebuah foreign key ada di dalam
sebuah relasi, baik nilai foreign key harus cocok dengan nilai candidate key dari beberapa tuple yang ada di dalam relasi home
atau nilai dari foreign key tersebut harus semuanya null (Connolly
dan Begg, 2005, p83).
2.2.3.4 Batasan Umum (General Constraint/Enterprise Constraint) Batasan umum adalah batasan tambahan yang dispesifikasikan oleh pengguna atau administrator basis data dari basis data yang mendefinisikan atau membatasi beberapa aspek dari perusahaan (enterprise) (Connolly dan Begg, 2005, p83).
2.3 Aljabar Relasional dan Kalkulus Relasional
Aljabar relasional adalah bahasa prosedural tingkat tinggi yang dapat digunakan untuk memberi perintah kepada DBMS bagaimana membuat relasi baru dari satu atau lebih relasi pada basis data. Sedangkan kalkulus relasional adalah bahasa nonprosedural yang dapat digunakan untuk memformulasi definisi dari sebuah relasi dalam istilah dari satu atau lebih relasi basis data. Bagaimanapun, secara formal aljabar relasional dan kalkulus relasional adalah sama satu dengan yang lainnya: untuk setiap ekspresi dalam aljbar, ada kesamaan ekspresi dalam kalkulus (begitu juga sebaliknya).
2.3.1 Aljabar Relasional
Aljabar relasional adalah bahasa teoritis dengan operasi-operasi yang bekerja pada satu atau lebih relasi untuk mendefinisikan relasi lainnya dengan tanpa mengubah relasi aslinya (Connolly dan Begg, 2005, p89). Baik operand
maupun hasilnya merupakan relasi, dan juga output dari satu operasi dapat
menjadi input operasi yang lain. Hal ini memungkinkan ekspresi pada aljabar
relasional menjadi bertingkat, sama seperti operasi aritmatik bertingkat.
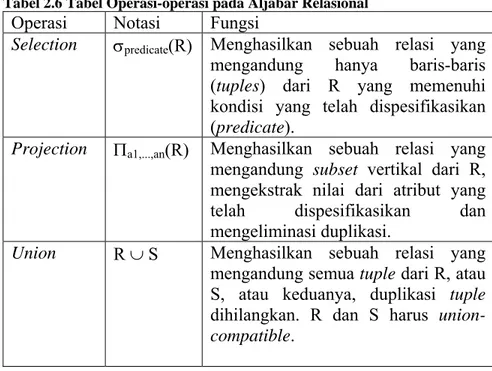
Ada banyak variasi dari operasi yang termasuk ke dalam aljabar relasional. Codd (1972) pada awalnya menawarkan delapan operasi, namun beberapa yang lainnya telah berkembang. Lima operasi fundamental pada aljabar relasional adalah Selection, Projection, Cartesian Product, Union, dan Set difference. Sebagai tambahan ada juga operasi Join, Intersection, dan Division.
2.3.1.1 Operasi Unary
Operasi unary adalah operasi yang hanya beroperasi pada satu
relasi. Operasi Selection dan Projection adalah operasi aljabar
relasional yang termasuk operasi unary.
Operasi Selection (atau Restriction) dinotasikan dengan σpredicate(R), bekerja pada sebuah relasi tunggal R dan mendefinisikan sebuah relasi yang mengandung hanya baris-baris (tuples) dari R yang
memenuhi kondisi yang telah dispesifikasikan (predicate) (Connolly
dan Begg, 2005, p90).
Operasi Projection dinotasikan dengan : Πa1,...,an(R), bekerja pada
sebuah relasi tunggal R dan mendefinisikan sebuah relasi yang mengandung subset vertikal dari R, mengekstrak nilai dari atribut
yang telah dispesifikasikan dan mengeliminasi duplikasi (Connolly dan Begg, 2005, p91).
2.3.1.2 Operasi Set
Operasi Selection dan Projection mengekstrak informasi dari
hanya satu relasi. Operasi Set beroperasi dari lebih dari satu relasi untuk menghasilkan relasi lain. Operasi yang termasuk Operasi Set adalah Union, Set difference, Intersection, dan Cartesian product.
Operasi Union dari dua buah relasi R dan S dinotasikan dengan :
R ∪ S, mendefinisikan sebuah relasi yang mengandung semua tuple
dan Begg, 2005, p92). R dan S harus union-compatible: memiliki
jumlah atribut yang sama dengan atribut yang berkorespondensi memiliki domain yang sama.
Operasi Set difference dari dua buah relasi R dan S dinotasikan
dengan : R – S, mendefinisikan sebuah relasi yang terdiri dari baris-baris (tuples) yang ada di dalam relasi R, tetapi tidak dalam relasi S
(Connolly dan Begg, 2005, p92). R dan S harus union-compatible.
Operasi Intersection dari dua buah relasi R dan S dinotasikan
dengan : R ∩ S, mendefinisikan sebuah relasi yang terdiri dari himpunan seluruh tuple yang ada di dalam relasi R dan S (Connolly
dan Begg, 2005, p93). R dan S harus union-compatible.
Operasi Cartesian product dari dua buah relasi R dan S
dinotasikan dengan : R × S, mendefinisikan sebuah relasi yang merupakan hasil dari penggabungan setiap tuple dari relasi R dengan
setiap tuple dari relasi S (Connolly dan Begg, 2005, p93).
2.3.1.3 Operasi Join
Pada umumnya, yang diperlukan hanya kombinasi dari Cartesian product yang memenuhi kondisi tertentu dan sehingga biasanya
digunakan operasi join daripada operasi Cartesian product. Operasi join, yang mengkombinasikan dua relasi untuk membentuk sebuah
relasi baru, adalah satu dari operasi yang penting pada aljabar relasional. Join adalah operasi turunan dari Cartesian product, sama
dengan melakukan sebuah operasi Selection, menggunakan predicate
dari join sebagai rumus Selection, melalui Cartesian product dari
relasi dua operand. Join adalah operasi yang paling sulit
diimplementasikan pada RDBMS dan merupakan salah satu alasan sistem relasional memiliki problem masalah intrinsik. Ada beberapa bentuk dari operasi Join, masing-masing memiliki perbedaan,
beberapa di antaranya lebih berguna daripada yang lainnya :
• Theta join (θ-join)
Operasi Theta join dinotasikan dengan R ⋈F S,
mendefinisikan sebuah relasi yang mengandung baris-baris (tuples) yang memenuhi predicate F dari Cartesian product dari R dan S. predicate F terbentuk dari R.ai θ S.bi
mana θ dapat merupakan operator perbandingan (< , ≤ , > ,
≥ , = , ≠) (Connolly dan Begg, 2005, p96). Theta join
dapat ditulis dalam bentuk operasi Selection dasar dan Cartesian product :
R ⋈F S = σF(R×S)
Sama seperti Cartesian product, degree dari Thetajoin
adalah jumlah dari degree operan relasi R dan S. • Equijoin
Operasi Equijoin adalah operasi Theta join di mana predicate F hanya mengandung operator sama dengan (=).
• Natural join
Natural join dinotasikan dengan : R ⋈ S, adalah Equijoin dari dua relasi R dan S ke semua atribut umum
x. Satu kejadian dari setiap atribut umum dihilangkan dari hasil (Connolly dan Begg, 2005, p96).
Operasi Natural join melakukan Equijoin ke semua
atribut pada kedua relasi yang memiliki nama yang sama.
Degree dari Natural join adalah jumlah degree dari relasi
R dan S dikurangi jumlah atribut x.
• Outer join
Outer join dinotasikan dengan : R ⋊ S, adalah join di
mana baris-baris (tuples) dari R yang tidak memiliki nilai
yang cocok dengan atribut umum dari S ikut dimasukkan ke dalam relasi hasil. Nilai yang hilang pada relasi kedua diisi null (Connolly dan Begg, 2005, p97).
Outer join menjadi sangat luas tersedia pada sistem
relasional dan merupakan operator yang telah dispesifikasikan pada standar SQL. Keuntungan dari Outer join adalah tidak ada informasi yang hilang, yaitu
baris-baris yang menjadi hilang apabila menggunakan operasi
• Semijoin
Operasi Semijoin dinotasikan dengan : R⊳FS,
mendefinisikan sebuah relasi yang mengandung baris-baris dari R yang berpartisipasi dalam operasi join relasi R
dengan S (Connolly dan Begg, 2005, p98). Keuntungan dari Semijoin yaitu mengurangi jumlah tuple yang perlu
ditangani untuk membentuk join. • Natural Semijoin
Operasi Natural Semijoin dinotasikan dengan R ⋉ S,
merupakan operasi gabungan antara operasi Natural join
dan Semijoin. Operasi ini mendefinisikan sebuah relasi
yang merupakan hasil proyeksi dari semua atribut relasi R setelah melakukan operasi Natural join dari relasi R dan S:
R ⋉ S = ΠaR1,aR2,...,aRn (R ⋈ S). Contoh :
Tabel 2.3 Tabel Staff
KdStaff Nama Umur Kota
S1 Irvan 22 Jakarta
S2 Nahar 25 Jakarta S3 Suwanto 23 Bandung
Tabel 2.4 Tabel Kota
Kota Jakarta Surabaya
Tabel 2.5 Tabel Staff ⋉Kota
KdStaff Nama Umur Kota S1 Irvan 22 Jakarta
2.3.1.4 Operasi Division
Operasi Division mendefinisikan sebuah relasi ke atribut C yang
mengandung himpunan dari baris-baris dari R yang cocok dengan kombinasi dari setiap baris dalam S (Connolly dan Begg, 2005, p99). Operasi Division dinotasikan dengan : R÷S .Operasi Division juga
dapat dituliskan dalam operasi dasar: T1 ← ΠC(R)
T2 ← ΠC((S × T1) – R) T ← T1 - T2
2.3.1.5 Operasi Aggregation dan Grouping
Operasi Aggregation menerapkan daftar fungsi agregasi, AL, ke
relasi R untuk mendefinisikan sebuah relasi melalui daftar agregasi. AL mengandung satu atau lebih pasangan (<fungsi agregasi>, <atribut>) (Connolly dan Begg, 2005, p100). Operasi aggregation
dinotasikan dengan : ℑAL(R) . Fungsi agregasi utama yaitu :
• COUNT – mengembalikan banyak nilai pada atribut yang berasosiasi.
• SUM – mengembalikan jumlah dari nilai pada atribut yang berasosiasi.
• AVG – mengembalikan rata-rata dari nilai pada atribut yang berasosiasi.
• MIN – mengembalikan nilai terkecil pada atribut yang berasosiasi.
• MAX – mengembalikan nilai terbesar pada atribut yang berasosiasi.
Operasi Grouping mengelompokkan baris-baris dari relasi R
dengan atribut grouping, GA, dan kemudian mengaplikasikan daftar
fungsi agregasi AL untuk mendefinisikan relasi baru. AL mengandung satu atau lebih pasangan (<fungsi agregasi>, <atribut>). Relasi hasil mengandung atribut grouping, GA, sesuai
dengan hasil dari setiap fungsi agregasi (Connolly dan Begg, 2005, p101). Operasi Grouping dinotasikan dengan : GAℑAL(R)
2.3.1.6 Rangkuman Operasi Aljabar Relasional
Operasi-operasi aljabar relasional terangkum dalam Tabel 2.6
Tabel 2.6 Tabel Operasi-operasi pada Aljabar Relasional
Operasi Notasi Fungsi
Selection σpredicate(R) Menghasilkan sebuah relasi yang
mengandung hanya baris-baris (tuples) dari R yang memenuhi
kondisi yang telah dispesifikasikan (predicate).
Projection Πa1,...,an(R) Menghasilkan sebuah relasi yang mengandung subset vertikal dari R,
mengekstrak nilai dari atribut yang telah dispesifikasikan dan mengeliminasi duplikasi.
Union R ∪ S Menghasilkan sebuah relasi yang mengandung semua tuple dari R, atau
S, atau keduanya, duplikasi tuple
dihilangkan. R dan S harus union-compatible.
Set difference
R - S Menghasilkan sebuah relasi yang terdiri dari baris-baris (tuples) yang
ada di dalam relasi R, tetapi tidak dalam relasi S. R dan S harus union-compatible.
Intersection R ∩ S Menghasilkan sebuah relasi yang
terdiri dari himpunan seluruh tuple
yang ada di dalam relasi R dan S. R dan S harus union-compatible.
Cartesian product
R × S Menghasilkan sebuah relasi yang merupakan hasil dari penggabungan setiap tuple dari relasi R dengan
setiap tuple dari relasi S.
Theta join σF(R×S) Menghasilkan sebuah relasi yang
mengandung baris-baris (tuples) yang
memenuhi predicate F dari Cartesian product dari R dan S.
Equijoin σF(R×S) Menghasilkan sebuah relasi yang mengandung baris-baris (tuples) yang
memenuhi predicate F (yang hanya
mengandung operator perbandingan sama dengan) dari Cartesian product
dari R dan S.
Natural join
R ⋈ S Equijoin dari dua relasi R dan S ke
semua atribut umum x. Satu kejadian dari setiap atribut umum dihilangkan dari hasil.
(Left) Outer join
R ⋊ S Sebuah join di mana baris-baris
(tuples) dari R yang tidak memiliki
nilai yang cocok dengan atribut umum dari S ikut dimasukkan ke dalam relasi hasil.
Semijoin R⊳FS Menghasilkan sebuah relasi yang mengandung baris-baris dari R yang berpartisipasi dalam operasi Join
relasi R dengan S.
Natural Semijoin
R ⋉ S mendefinisikan sebuah relasi yang merupakan hasil proyeksi dari semua atribut relasi R setelah melakukan operasi Natural join dari relasi R dan
S.
Division R ÷ S Menghasilkan sebuah relasi ke atribut
C yang mengandung himpunan dari baris-baris dari R yang cocok dengan kombinasi dari setiap baris dalam S.
Aggregate ℑAL(R) Menerapkan daftar fungsi agregasi, AL, ke relasi R untuk mendefinisikan sebuah relasi melalui daftar agregasi. AL mengandung satu atau lebih pasangan (<fungsi agregasi>, <atribut>).
Grouping GAℑAL(R) Mengelompokkan baris-baris dari relasi R dengan atribut grouping, GA,
dan kemudian mengaplikasikan daftar fungsi agregasi AL untuk mendefinisikan relasi baru. AL mengandung satu atau lebih pasangan (<fungsi agregasi>, <atribut>). Relasi hasil mengandung atribut
grouping, GA, sesuai dengan hasil
dari setiap fungsi agregasi.
2.3.2 Kalkulus Relasional
Kalkulus relasional adalah bahasa non-prosedural yang menggunakan
predicate. Kalkulus relasional tidak ada hubungannya dengan diferensial dan
kalkulus integral pada matematika, tetapi namanya diambil dari sebuah cabang dari logika simbolik yang disebut predicate calculus. Ketika
diimplementasikan ke basis data, ada dua bentuk dari kalkulus relasional yaitu kalkulus relasional tuple dan kalkulus relasional domain.
2.3.2.1 Kalkulus Relasional Tuple
Kalkulus relasional tuple bertujuan untuk menemukan baris-baris
untuk yang predicate-nya bernilai benar (true). Kalkulus ini
berdasarkan pada penggunaan variabel tuple. Variabel tuple adalah
sebuah variabel yang meliputi suatu relasi: yaitu suatu variabel yang di mana nilai yang diijinkan adalah baris-baris dari relasi. Contoh:
- Menspesifikasikan variabel tuple S sebagai relasi Staff:
Staff(S)
- Menemukan himpunan dari seluruh tuple S sehingga F(S) adalah benar:
{S | F(S)}
- Menemukan detil dari seluruh staff yang mempunyai pendapatan lebih dari 10000:
{S | Staff(S) ∧ S.Salary > 10000}
- Menemukan atribut tertentu, seperti pendapatan: {S.Salary | Staff(S) ∧ S.Salary > 10000}
Ada 2 quantifier yang dapat digunakan untuk mengetahui berapa
banyak instance yang diterapkan predicate :
o Extensial quantifier∃ (‘ada’)
o Universal quantifier∀ (‘untuk semua’)
2.3.2.2 Kalkulus Relasional Domain
Pada kalkulus relasional domain, juga digunakan variabel seperti
halnya pada kalkulus relasional tuple, namun pada kalkulus relasional domain menggunakann domain, bukan tuple. Ekspresi dalam kalkulus
relasional domain memiliki bentuk umum :
2.4 Structured Query Language (SQL)
Menurut Richards (1996) , SQL adalah suatu bahasa non prosedural yang dirancang secara spesifik untuk operasi pengaksesan data pada struktur basis data relasional yang sudah dinormalisasi. Dengan menggunakan SQL dapat dibuat stuktur-struktur basis data dan relasi antara tabel-tabelnya. Operasi pengaksesan data meliputi penyisipan data (insert), pengubahan data (update), pemilihan data
(select), dan penghapusan data (delete).
Menurut James & Paul (1999, p4), SQL adalah sebuah alat (tool) yang
digunakan untuk mengorganisasikan, mengatur, dan mengambil data yang disimpan pada sebuah basis data di dalam komputer atau dengan kata lain adalah sebuah bahasa komputer yang digunakan untuk berinteraksi dengan basis data. 2.4.1 Sejarah SQL
Sejarah dari bahasa SQL dimulai dengan paper pertama dari Dr. Ted
Codd pada tahun 1970 tentang model relasional dan dasar-dasar secara matematikanya. Hasil pekerjaan Dr. Codd tersebut memicu IBM sebagai yang pertama untuk melakukan penelitian tentang pengembangan dari sistem basis data relasional yang pertama, yang disebut System R, dan aplikasi pemograman antar mukanya, yang disebut sebagai SEQUEL (Structured English Query Language).
SEQUEL pada awalnya dikembangkan dan diimplementasikan pada tahun 1974-1975 dan direvisi pada tahun 1977. Menyadari akan signifikansi dari pengembangan ini, sebuah proyek basis data dari pemerintah Amerika Serikat mulai dikembangkan pada tahun 1977. Akronim SEQUEL kemudian pada akhirnya diganti menjadi SQL karena “SEQUEL”
merupakan sebuah merek dagang dari perusahaan penyedia pesawat terbang Hawker Siddeley yang berdomisili di Inggris. Pada tahun 1978, ANSI (American National Standards Institute) mengesahkan proyek bahasa basis
data SQL, yang dimana hal ini kemudian memicu penetapan standar awal bagi bahasa SQL.
Berdasarkan dari hasil pengembangan awal oleh ANSI dan IBM untuk SQL, ISO (International Standardization Organization) kemudian bekerja
sama dengan ANSI untuk memulai proses standarisasi dari basis data tersebut pada tahun 1979. Pada tahun 1982-1983, pengembangan ini dilanjutkan dengan sebuah keputusan untuk memecah standarisasi ini menjadi dua bagian yaitu NDL dan SQL. Pengembangan akan standarisasi ini dilanjutkan hingga pada tahun 1986, ANSI merilis standar bagi bahasa NDL dan juga standar bagi SQL. Lalu pada tahun berikutnya oleh ISO dengan standar bagi SQL.
Berkaitan dengan pengembangan dari standar SQL tersebut, juga dimulai pengembangan untuk dilakukan pengujian untuk menguji hasil dari penggunaan SQL agar dapat beroperasi sesuai dengan standar. Hasil pengembangan ini adalah berupa pemuliaan dan pembersihan dari bahasa SQL. Standar SQL-89 kemudian akhirnya dirilis dan bersamaan dengan dirilisnya spesifikasi FIPS (Federal Information Processing Standard) yaitu
FIPS 127-1. NIST (National Institute of Standards and Technology)
mengembangkan paket pengujian untuk menguji validitas dari SQL-89 tersebut sehingga akhirnya mengawali evolusi dari SQL-89 menjadi standar SQL-92. Seiring dengan perubahan terhadap bahasa awalnya, SQL
Committee, di bawah bimbingan ANSI dan ISO, kemudian melakukan
perombakan besar-besaran terhadap bahasa SQL pada tahun 1992. Revisi tersebut, yang disebut SQL-3, kemudian dijadikan sebagai rancangan standar bagi SQL-99.
Pengembangan selanjutnya lalu pada tahun 2003, dengan mendukung penggunaan XML (eXtensible Markup Language) sebagai fitur utamanya,
kemudian standar SQL-2003 dirilis. ISO kemudian menetapkan penggunaan data-data SQL dalam bentuk XML hingga memungkinkan aplikasi untuk diintegrasikan ke dalam kode SQL, yaitu dengan menggunakan XQuery sebagai bahasa kuery XML yang dipublikasikan oleh W3C (World Wide Web Consortium). Fitur ini kemudian menjadi fitur utama pada standar
SQL-2006. Standar selanjutnya yaitu SQL-2008 merupakan sebuah revisi kecil dengan menambahkan beberapa fungsi tambahan, seperti penggunaan
triggerINSTEAD OF dan statementTRUNCATE.
2.4.2 Elemen-elemen SQL 2.4.2.1 Statements
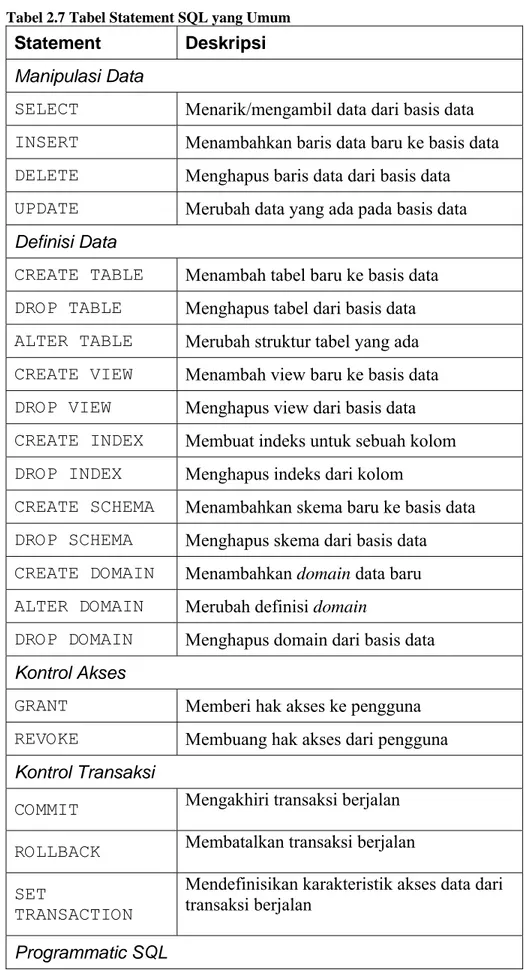
Bagian utama dari bahasa SQL terdiri atas sekitar 40 statement yang
ditampilkan secara ringkas pada Tabel 2.7. Setiap statement tersebut akan
meminta aksi-aksi atau respon-respon yang spesifik dari DBMS, misalnya seperti membuat sebuah tabel baru, mengambil data, atau menambahkan data baru ke dalam basis data. Setiap statement SQL
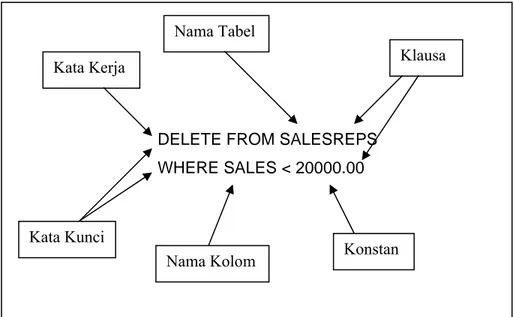
memiliki bentuk umum yang sama, seperti diilustrasikan pada Gambar 2.2.
Setiap statement SQL dimulai dengan sebuah ‘kata kerja’, sebuah
kata kunci yang menjabarkan apa yang dilakukan oleh statement tersebut.
CREATE, INSERT, DELETE, dan COMMIT adalah kata kerja yang umum. Statement dilanjutkan dengan satu atau lebih clause (klausa).
Sebuah klausa dapat menjelaskan tentang data yang mana yang dikenakan pekerjaan oleh statement atau menjelaskan lebih detil tentang
apa yang statement tersebut lakukan. Setiap klausa juga dimulai dengan
sebuah kata kunci, misalnya WHERE, FROM, INTO, dan HAVING. Beberapa klausa sifatnya tambahan atau opsional, namun beberapa ada yang diharuskan. Struktur spesifik dan isi dari klausa tersebut akan bervariasi dari satu klausa dengan klausa lainnya. Banyak klausa yang mengandung nama kolom ataupun nama tabel, beberapa bahkan dapat mengandung tambahan kata kunci, konstan, maupun expressions.
Gambar 2.2 Struktur dari Statement SQL
DELETE FROM SALESREPS WHERE SALES < 20000.00
Nama Tabel Kata Kerja
Kata Kunci
Nama Kolom Konstan Klausa
Tabel 2.7 Tabel Statement SQL yang Umum
Statement Deskripsi Manipulasi Data
SELECT Menarik/mengambil data dari basis data INSERT Menambahkan baris data baru ke basis data DELETE Menghapus baris data dari basis data UPDATE Merubah data yang ada pada basis data Definisi Data
CREATE TABLE Menambah tabel baru ke basis data DROP TABLE Menghapus tabel dari basis data ALTER TABLE Merubah struktur tabel yang ada CREATE VIEW Menambah view baru ke basis data DROP VIEW Menghapus view dari basis data CREATE INDEX Membuat indeks untuk sebuah kolom DROP INDEX Menghapus indeks dari kolom
CREATE SCHEMA Menambahkan skema baru ke basis data DROP SCHEMA Menghapus skema dari basis data CREATE DOMAIN Menambahkan domain data baru
ALTER DOMAIN Merubah definisi domain
DROP DOMAIN Menghapus domain dari basis data Kontrol Akses
GRANT Memberi hak akses ke pengguna REVOKE Membuang hak akses dari pengguna Kontrol Transaksi
COMMIT Mengakhiri transaksi berjalan ROLLBACK Membatalkan transaksi berjalan SET
TRANSACTION
Mendefinisikan karakteristik akses data dari transaksi berjalan
DECLARE Mendefinisikan sebuah kursor untuk query
EXPLAIN Mendiskripsikan rencana akses data untuk
query
OPEN Membuka kursor untuk mengambil hasil
query
FETCH Mengambil satu baris dari hasil query
CLOSE Menutup kursor
PREPARE Menyiapkan sebuah eksekusi yang dinamis statement SQL untuk EXECUTE Mengeksekusi sebuah dinamis statement SQL secara DESCRIBE Mendeskripsikan sebuah prepared query
2.4.2.2 Names
Setiap objek pada sebuah basis data berbasiskan SQL diidentifikasikan dengan cara memberikan nama-nama yang unik. Nama-nama tersebut yang akan digunakan pada statement SQL untuk
mengidentifikasikan objek basis data yang mana yang harus dikenakan pekerjaan oleh statement. Nama-nama objek yang paling fundamental
pada sebuah basis data relasional adalah nama tabel (yang mengidentifikasikan tabel), nama kolom (yang mengidentifikasikan kolom), dan nama pengguna / user names (yang mengidentifikasikan
pengguna dari basis data).
Standar ANSI/ISO yang pertama menspesifikasikan bahwa nama-nama pada SQL harus terdiri atas 1 hingga 18 karakter, harus dimulai dengan huruf, dan tidak boleh mengandung spasi ataupun karakter-karakter khusus. Lalu pada standar SQL-2 maksimum karakter-karakter meningkat hingga 128 karakter. Dalam prakteknya, nama-nama yang didukung oleh
produk-produk DBMS berbasiskan SQL sangat bervariasi. Misalnya DB2 yang membatasi nama pengguna hanya hingga 8 karakter namun memperbolehkan penggunaan nama kolom dan nama tabel yang lebih panjang.
2.4.2.3 Tipe Data
Standar ANSI/ISO bagi SQL menspesifikasikan berbagai macam tipe data yang dapat disimpan pada basis data yang berbasiskan SQL dan dimanipulasikan oleh bahasa SQL.
Beberapa tipe data tersebut di antara lain :
• Integer (bilangan bulat)
• Decimal Numbers (bilangan pecahan)
• Floating Point Numbers (bilangan pecahan dengan presisi lebih
baik)
• Fixed-length Character Strings (kalimat dengan panjang tetap) • Variable-length character strings (kalimat dengan panjang
dinamis)
• Money amounts (seperti floating point namun lebih dikhusukan
untuk menyimpan data-data nilai uang)
• Dates and times (tanggal dan waktu)
• Boolean data (nilai logikal, TRUE atau FALSE)
• Long text (kalimat yang panjang, hingga 32.000 sampai 65.000
• Unstructured byte streams (untuk penyimpanan data-data file,
misalnya seperti file gambar dan video)
• Asian characters (untuk penggunaan karakter-karakter khusus,
misalnya seperti Kanji, mendukung fixed-length maupun variable-length strings)
2.4.2.4 Constants
Dalam beberapa statement SQL sebuah nilai data numerik, karakter
ataupun tanggal harus dapat diekspresikan dalam bentuk teks. Contoh seperti dalam statement INSERT berikut :
Gambar 2.3 Contoh Query Pengunaan Constants
Standar ANSI/ISO bagi SQL menspesifikasikan format bagi nilai-nilai konstan bagi berbagai jenis tipe data sebagai berikut :
• Numeric Constants
Ditulis seperti angka desimal biasa, dengan tambahan tanda plus atau minus yang sifatnya opsional.
Contoh : 21, -375, 2000.00, +497500.8778 • String Constants
Ditulis dengan diapit oleh karakter kutip satu (‘...’). Contoh : ‘Jones, John J.’, ‘New York’, ‘Western’
INSERT INTO SALESREPS ( EMPL_NUM, NAME, QUOTA, HIRE_DATE, SALES) VAL, ‘Dennis Irving’,
• Date and Time Constants
Ditulis seperti String Constants, namun dengan format yang
bervariasi dari satu DBMS ke DBMS lainnya. Contoh pada SQL Server :
‘March 15, 1990’, ‘Mar 15 1990’, ‘3/15/1990’, • Symbolic Constants
Konstan khusus yang mengembalikan nilai-nilai yang diatur oleh DBMS secara bervariasi.
Contoh : CURRENT_DATE, GETDATE()
2.4.2.5 Expressions
Expresssions digunakan pada bahasa SQL untuk menghitung
nilai-nilai yang didapatkan dari basis data dan untuk menghitung nilai-nilai-nilai-nilai yang digunakan pada pencarian di basis data.
Gambar 2.4 Contoh Query Penggunaan Expressions
Standar ANSI/ISO untuk SQL menspesifikasikan 4 jenis operasi aritmatik yang dapat digunakan pada expression :
• Penambahan (A + B)
• Pengurangan (A - B)
• Perkalian (A * B)
• Pembagian (A / B)
SELECT CITY, TARGET, SALES, (SALES/TARGET) * 100 FROM OFFICES
2.4.2.6 Fungsi Built-in
Merupakan fungsi-fungsi khusus yang sudah disediakan oleh DBMS dan bervariasi antar satu DBMS dengan DBMS lainnya.
Misalnya salah satu fungsi built-in pada DB2 yaitu MONTH() dan YEAR() yang membutuhkan tipe data DATE sebagai input dan
mengembalikan nilai integer yaitu bulan dan tahun dari nilai tersebut.
Contoh :
Gambar 2.5 Contoh Fungsi Built-in
2.4.2.7 NULL Values
Sebuah basis data merupakan sebuah permodelan dari situasi dunian nyata, sehingga sebagian data dapat ditemukan hilang, tidak dikenal, ataupun tidak cocok.
SQL mendukung mekanisme data yang hilang ataupun tidak dikenal tersebut secara eksplisit melalui konsep nilai null. Sebuah nilai null
adalah sebuah indikator yang memberitahu SQL (dan penggunanya) bahwa data tersebut hilang dan tak cocok. Tetapi nilai NULL tersebut bukanlah nilai data yang sebenarnya seperti 0, 473.83, ‘Sam Clark’. Melainkan hanya sebuah sinyal dan pertanda bahwa nilai data tersebut hilang dan tidak dikenal.
SELECT NAME, MONTH(HIRE_DATE) FROM SALESREPS
2.5 Statement SELECT
Statement SELECT atau perintah SELECT digunakan untuk menarik/mengambil
data dari basis data dan mengembalikannya dalam bentuk hasil query. Record atau
baris data yang diambil didapatkan dari satu buah tabel atau lebih dan di tampilkan dalam bentuk result set.
Contoh query dan hasilnya :
Tampilkan data kantor penjualan dengan target dan nilai penjualannya
Gambar 2.6 Contoh Query SELECT dan Tampilan Hasilnya
Untuk query-query yang simpel, statement SELECT SQL yang digunakan masih
cenderung sama. Namun ketika kebutuhan menjadi semakin kompleks, maka semakin banyak fitur-fitur dari statement SELECT yang harus digunakan untuk
menjawab query secara akurat.
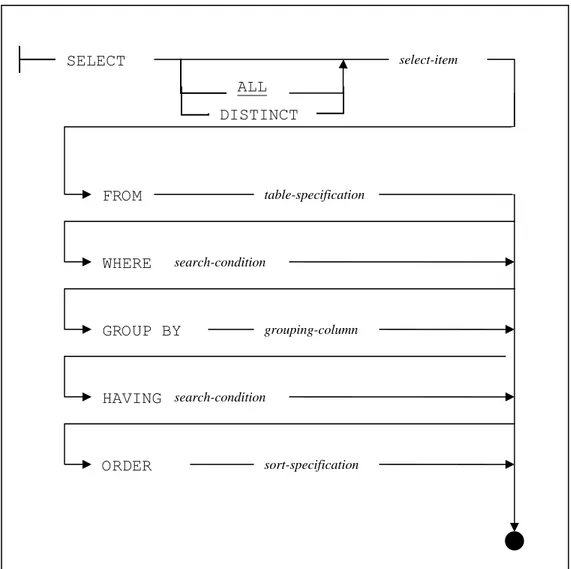
Gambar 2.3 menampilkan bentuk penuh dari statement SELECTyang terdiri atas
6 klausa. Klausa SELECT dan FROM diharuskan ada, sedangkan untuk 4 klausa lainnya sifatnya opsional.
SELECT CITY, TARGET, SALES FROM OFFICES CITY TARGET SALES - --- ---Denver 300,000.00 186,042.00 New York 575,000.00 692,637.00 Chicago 800,000.00 735,042.00
Gambar 2.7 Diagram Sintaksis Statement SELECT
2.5.1 Klausa SELECT
Klausa SELECT adalah klausa yang mengawali statement SELECT.
Klausa SELECT melampirkan dengan menspesifikasikan keseluruhan data
item yang ingin ditampilkan oleh statement SELECT. Item yang dimaksud
dapat berupa kolom dari tabel pada basis data atau merupakan kolom-kolom hasil perhitungan yang dilakukan oleh query yang ditulis dengan
dipisahkan oleh tanda koma. SELECT ALL DISTINCT FROM WHERE GROUP BY HAVING ORDER select-item table-specification search-condition grouping-column search-condition sort-specification
Setiap item yang ditampilkan akan menghasilkan satu kolom secara
satuan (single) pada hasil query (query results) dengan berurutan dari kiri ke
kanan.
SELECT item dapat berupa : • Nama kolom
Mengidentifikasikan sebuah kolom dari table yang dispesifikasikan pada klausa FROM. Ketika sebuah nama kolom ada pada SELECT
item, maka SQL akan mengambil nilai pada kolom tersebut dan
menempatkannya pada baris yang bersangkutan pada query results. • Konstan
Menspesifikasikan bahwa nilai konstan yang sama akan ditampilkan pada semua baris pada query results.
• SQL Expression
Mengindikasikan bahwa SQL harus mengkalkulasikan terlebih dahulu untuk nilai-nilai yang akan ditempatkan pada query results,
dengan format yang sudah dispesifikasikan oleh expression.
2.5.2 Klausa FROM
Klausa FROM terdiri atas kata kunci FROM diikuti dengan urutan dari tabel yang dispesifikasikan dan dipisahkan oleh tanda koma. Setiap spesifikasi tabel akan dikenal sebagai tabel yang mengandung data yang akan diambil oleh query.
Tabel-tabel tersebut disebut sebagai sumber tabel (source tables) dari query (dan juga dari statement SELECT-nya) karena semua merupakan
sumber dari semua data yang ada pada query results.
2.5.3 Klausa WHERE
Klausa WHERE merupakan tanda bagi SQL untuk menyertakan hanya sebagian baris data dari keseluruhan data pada query results. Sebuah kondisi
pencarian (search condition) digunakan untuk menspesifikasikan baris-baris
yang diinginkan. 2.5.4 Klausa GROUP BY
Klausa GROUP BY menspesifikasikan sebuah summary dari query.
Selain menghasilkan satu baris data pada query results untuk setiap baris data
pada database, sebuah summary query akan mengelompokan menjadi satu
bagi baris-baris data yang memiliki kesamaan dan kemudian menghasilkan sebuah baris summary ke query results untuk setiap grup.
2.5.5 Klausa HAVING
Klausa HAVING memberitahu SQL untuk mengikutsertakan hanya beberapa grup yang dihasilkan oleh klausa GROUP BY dalam query results.
Seperti klausa WHERE, klausa HAVING diguakan untuk sebuah kondisi pencarian untuk menspesifikasikan grup-grup tertentu yang ingin ditampilkan.
2.5.6 Klausa ORDER BY
Klausa ORDER BY mengurutkan query results berdasarkan satu atau
lebih kolom yang ada pada data. Jika klausa ORDER BY tidak digunakan pada statement SELECT , maka query results-nya tidak akan diurutkan.
2.6 Kompleksitas Algoritma
Seorang programmer atau system analyst paling tidak harus memiliki dasar
untuk menganalisis algoritma. Analisis algoritma sangat membantu di dalam meningkatkan efisiensi program. Kecanggihan suatu program bukan dilihat dari tampilan program, tetapi berdasarkan efisiensi algoritma yang terdapat didalam program tersebut.
Pembuatan program komputer tidak terlepas dari algoritma, apalagi jika program yang dibuat sangat kompleks. Program dapat dibuat dengan mengabaikan algoritma, namun tidak heran bila seandainya ada pengembang lain yang dapat membuat program seperti program tersebut namun memiliki akses yang lebih cepat dan memakai resource memori yang sangat sedikit.
Analisis algoritma adalah bahasan utama dalam ilmu komputer. Dalam menguji suatu algoritma, dibutuhkan beberapa kriteria untuk mengukur efisiensi algoritma.
Notasi O (Big O)
Misalkan 4 program yang mengurutkan n bilangan dengan fungsi yang menyatakan sejumlah langkah yang dijumlahkan masing-masing program untuk sorting n bilangan :
Bila n = 4 maka f1 (n) = 4, f2 (n) = f3 (n) = 16 dan f4 (n) = 24 sedangkan untuk n = 100, program ketiga akan memerlukan 21000 langkah.
Dalam analisis sebuah algoritma biasanya yang dijadikan ukuran adalah operasi aljabar seperti penjumlahan, pengurangan, perkalian dan pembagian, proses pengulangan (looping / iterasi), proses pengurutan (sorting) dan proses pencarian
(searching).
2.7 Teknik Kompilasi
Kompilator (compiler) adalah sebuah program yang membaca suatu program
yang ditulis dalam suatu bahasa sumber (source language) dan menterjemahkannya
ke dalam suatu bahasa sasaran (target language).
Proses kompilasi dapat digambarkan melalui sebuah kotak hitam (black box)
berikut :
program sumber Æ kompilator Æ bahasa sasaran
pesan-pesan kesalahan
(error messages)
Proses kompilasi dikelompokkan ke dalam dua kelompok besar :
1. Analisa : program sumber dipecah-pecah dan dibentuk menjadi bentuk antara (intermediaterepresentation)
2. Sintesa : membangun program sasaran yang diinginkan dari bentuk antara
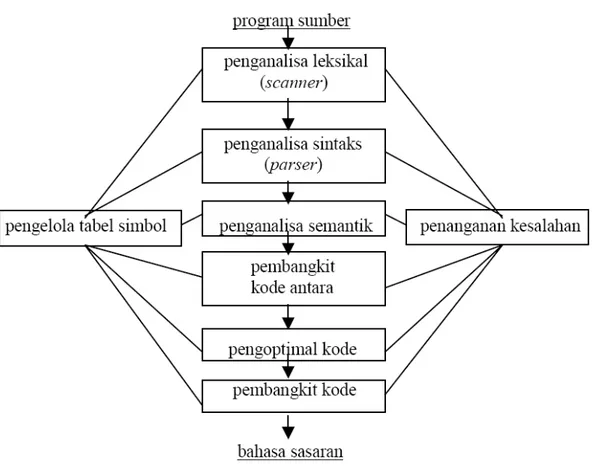
Fase-fase proses sebuah kompilasi adalah sebagai berikut :
Gambar 2.9 Fase-Fase Proses Kompilasi
Program sumber merupakan rangkaian karakter. Berikut ini hal-hal yang dilakukan oleh setiap fase pada proses kompilasi terhadap program sumber tersebut :
1. Penganalisa leksikal : membaca program sumber, karakter demi karakter. Sederetan (satu atau lebih) karakter dikelompokkan menjadi satu kesatuan mengacu kepada pola kesatuan kelompok karakter (token) yang
ditentukan dalam bahasa sumber. Kelompok karakter yang membentuk sebuah token dinamakan lexeme untuk token tersebut. Setiap token yang
dihasilkan disimpan di dalam tabel simbol. Sederetan karakter yang tidak mengikuti pola token akan dilaporkan sebagai token tak dikenal
2. Penganalisa sintaksis : memeriksa kesesuaian pola deretan token dengan
aturan sintaks yang ditentukan dalam bahasa sumber. Sederetan token
yang tidak mengikuti aturan sintaks akan dilaporkan sebagai kesalahan sintaks (syntax error). Secara logika deretan token yang bersesuaian
dengan sintaksis tertentu akan dinyatakan sebagai parse tree.
3. Penganalisa semantik : memeriksa token dan ekspresi dari
batasan-batasan yang ditetapkan. Batasan-batasan-batasan tersebut misalnya : a. panjang maksimum token identifier adalah 8 karakter,
b. panjang maksimum ekspresi tunggal adalah 80 karakter, c. nilai bilangan bulat adalah -32768 s/d 32767,
d. operasi aritmatika harus melibatkan operand-operand bertipe sama.
4. Pembangkit kode antara : membangkitkan kode antara (intermediate code) berdasarkan parse tree. Parse tree selanjutnya diterjemahkan oleh
suatu penerjemah yang dinamakan penerjemah berdasarkan sintaksis (syntax-directed translator). Hasil penerjemahan ini biasanya merupakan
perintah tiga alamat (three-address code) yang merupakan representasi
program untuk suatu mesin abstrak. Perintah tiga alamat bisa berbentuk
quadruples (op, arg1, arg2, result), tripels (op, arg1, arg2). Ekspresi
dengan satu argumen dinyatakan dengan menetapkan arg2 dengan - (strip, dash).
5. Pengoptimasi kode : melakukan optimasi (penghematan space dan waktu
komputasi), jika mungkin, terhadap kode antara.
6. Pembangkit kode : membangkitkan kode dalam bahasa target tertentu (misalnya bahasa mesin).
Grammar
Grammar adalah sebuah alat untuk mendefinisikan bahasa secara rekursif.
Definisi konseptual :
Grammar adalah sebuah sistem matematis yang dapat mendefinisikan
bahasa. Dan bahasa yang didefinisikan oleh grammar ini awalnya berupa himpunan string.
Definisi formal :
Sebuah grammar G memiliki 4 properti (VN, VT, S, θ) dengan VN
adalah himpunan berhingga non-terminal, VT adalah himpunan berhingga terminal, salah salah satu anggota VN yang dijadikan start symbol, dan θ
adalah himpunan berhingga production yang berbentuk α→β
(dimana α adalah salah satu simbol dari himpunan VN dan β berbentuk rangkaian terminal dan/atau non-terminal).
Misal terdapat sebuah grammar G = (VN, VT, S, φ) untuk pembentukan identifier pada bahasa pemrograman, seperti berikut :
Sub-himpunan nonterminal : VN= {I, L, D}
Sub-himpunan terminal :
VT= {a, b, c, …, z, 0, 1, 2, …, 9} Sub-himpunan start symbol :
S = I
Sub-himpunan production :
φ = {I →L, I →IL, I →ID, L →a, L →b, …, L →z, D →0, D →1, D →2, …, D →9}
Grammar untuk pembentukan identifier tersebut dapat pula
diekspresikan/dituliskan/ dinyatakan dalam bentuk lain seperti berikut : I →LL →aD →0
I →ILL →bD →1 I →ID……L →zD →9
Atau secara singkat dapat ditulis : I →L | IL | ID
L →a | b | … | z D →0 | 1 | … | 9
Sintaks bahasa pemrograman umumnya dinyatakan melalui grammar,
yang secara garis besar dibagi menjadi 2 kelas utama, yaitu :
• Backus-Naur Form • Chomsky Normal Form
Backus-Naur Form
Non-terminal ditulis <non-terminal> Terminal ditulis terminal
Simbol “ →”ditulis ::=
Contoh:
Grammar bahasa Pascal pertama kali ditulis oleh Niclaus Wirth
menggunakan format BNF.
<identifier>::= <letter> | <identifier> <letter> | <identifier> <digit>
<letter>::= a | b | c | … | z <digit>::= 0 | 1 | 2 | … | 9