IV-1 BAB IV
PENGUMPULAN DAN PENGOLAHAN DATA
Bab ini berisi proses pengumpulan dan pengolahan data yang digunakan dalam penelitian ini. Data yang digunakan dalam penelitian ini adalah data primer, yaitu data yang diperoleh peneliti secara langsung dari responden melalui pengisian kuesioner. Sedangkan pengolahan data dilakukan dengan mengolah hasil dari pengumpulan data dengan menggunakan perhitungan, metode, dan software.
4.1 Pengumpulan Data
Data yang digunakan dalam penelitian ini meliputi data gambaran umum responden dan data primer.
4.1.1 Deskripsi Responden
Responden pada penelitian ini adalah pelanggan Netflix yang melakukan pembayaran pada sistem pembayaran Netflix. Berdasarkan 150 data responden yang didapat dari kuesioner, karakteristik yang diperoleh berdasarkan jenis kelamin, umur, tingkat pendidikan, pekerjaan, penghasilan bulanan, lama penggunaan Netflix, dan tingkat penggunaan Netflix dalam waktu tertentu.
a. Responden berdasarkan jenis kelamin
Dari hasil penyebaran kuesioner, penulis memperoleh data responden berdasarkan jenis kelamin sebagai berikut.
Gambar 4.1 Persentase Responden Berdasarkan Jenis Kelamin Berdasarkan hasil dari 150 responden, dapat dilihat dari Gambar 4.1 bahwa persentase perempuan lebih banyak daripada laki-laki. Sebanyak 92 responden (61,3%) adalah perempuan dan 58 responden (38,7%) adalah laki-laki.
38.7%
61.3%
Laki-Laki Perempuan
IV-2 b. Responden berdasarkan usia
Dari hasil kuesioner, penulis memperoleh data responden berdasarkan usia sebagai berikut.
Gambar 4.2 Persentase Responden Berdasarkan Usia
Berdasarkan hasil dari 150 responden, dapat dilihat dari Gambar 4.2 bahwa persentase terbanyak adalah responden dengan usia 18-25 tahun dengan jumlah 112 orang (74.7%), persentase terbanyak kedua adalah responden dengan usia 26-45 tahun dengan jumlah 36 orang (24%), persentase terbanyak selanjutnya adalah responden dengan usia 12-17 tahun dengan jumlah 2 orang (1,3%), dan usia lebih muda dari 12 tahun dan lebih tua dari 45 tahun mendapat persentase yang sama dan paling rendah yaitu 0% (0 orang).
c. Responden berdasarkan tingkat pendidikan
Dari hasil penyebaran kuesioner, penulis memperoleh data responden berdasarkan tingkat pendidikan sebagai berikut.
Gambar 4.3 Persentase Responden Berdasarkan Tingkat Pendidikan Berdasarkan hasil dari 150 responden, dapat dilihat dari Gambar 4.3 bahwa persentase terbanyak adalah responden dengan tingkat pendidikan Perguruan Tinggi baik S1, S2, atau S3 sebanyak 137 responden (91,3%). Persentase terbanyak selanjutnya adalah responden dengan tingkat pendidikan SMA
1.3
74.7%
24.0%
< 12 Tahun 12-17 Tahun 18-25 Tahun 26-45 Tahun
> 45 Tahun
8.7%
91.3%
SD SMP SMA
Perguruan Tinggi (S1, S2, S3)
IV-3
sebanyak 13 responden (8,7%). Responden dengan tingkat pendidikan setara atau lebih rendah dari SD dan SMP sejumlah 0 responden (0%).
d. Responden berdasarkan pekerjaan
Dari hasil penyebaran kuesioner, penulis memperoleh data responden berdasarkan jenis pekerjaan sebagai berikut.
Gambar 4.4 Persentase Responden Berdasarkan Jenis Pekerjaan Berdasarkan hasil dari 150 responden, dapat dilihat dari Gambar 4.4 bahwa persentase terbanyak adalah responden dengan pekerjaan karyawan sejumlah 77 responden (51,3%). Persentase terbanyak selanjutnya adalah responden dengan pekerjaan pelajar atau mahasiswa sejumlah 56 responden (37,3%).
Persentase terbanyak selanjutnya adalah responden dengan pekerjaan lain selain yang telah disediakan sejumlah 11 responden (7,3%). Responden dengan pekerjaan wirausaha dan ibu rumah tangga memiliki jumlah yang sama masing-masing 3 responden (2%).
e. Responden berdasarkan penghasilan bulanan
Dari hasil penyebaran kuesioner, penulis memperoleh data responden berdasarkan penghasilan bulanan sebagai berikut.
Gambar 4.5 Persentase Responden Berdasarkan Penghasilan Bulanan 37.3%
51.3%
2.0%
2.0% 7.3%
Pelajar/Mahasiswa Karyawan
Wirausaha Ibu rumah tangga Lainnya
26.0%
14.0%
28.0%
24.0%
8.0%
< Rp 1.000.000
Rp 1.000.000 - Rp 2.000.000 Rp 2.000.001 - Rp 5.000.000 Rp 5.000.001 - Rp 10.000.000
> Rp 10.000.000
IV-4
Berdasarkan hasil dari 150 responden, dapat dilihat dari Gambar 4.5 bahwa persentase terbanyak adalah responden dengan penghasilan bulanan Rp 2.000.001 – Rp 5.000.000 dengan jumlah 42 responden (28%). Responden dengan penghasilan bulanan kurang dari Rp 1.000.000 sejumlah 39 responden (26%). Responden dengan penghasilan bulanan Rp 5.000.001 – Rp 10.000.000 sebanyak 36 responden (24%). Responden dengan penghasilan bulanan Rp 1.000.000 – Rp 2.000.000 sebanyak 21 responden (14%). Persentase paling rendah adalah responden dengan penghasilan bulanan lebih dari Rp 10.000.000 sebanyak 12 responden (8%).
f. Responden berdasarkan lama penggunaan Netflix
Dari hasil penyebaran kuesioner, penulis memperoleh data responden berdasarkan lama penggunaan Netflix sebagai berikut.
Gambar 4.6 Persentase Responden Berdasarkan Lama Penggunaan Netflix Berdasarkan hasil dari 150 responden, dapat dilihat dari Gambar 4.6 bahwa persentase terbanyak adalah responden yang telah menggunakan Netflix selama 1-2 tahun sebanyak 50 responden (33,3%). Responden yang sudah menggunakan Netflix selama 3-6 bulan memiliki persentase terbanyak kedua dengan jumlah 33 responden (22%). Responden yang sudah menggunakan Netflix selama lebih dari 2 tahun sejumlah 29 responden (19,3%). Responden yang sudah menggunakan Netflix selama 6-12 bulan sebanyak 25 responden (16,7%). Persentase paling rendah adalah responden yang sudah menggunakan Netflix selama kurang dari 3 bulan sebanyak 13 responden (8,7%).
8.7%
22.0%
16.7%
33.3%
19.3%
< 3 bulan 3 - 6 bulan 6 - 12 bulan 1 - 2 tahun
> 2 tahun
IV-5
g. Responden berdasarkan frekuensi penggunaan Netflix
Dari hasil penyebaran kuesioner, penulis memperoleh data responden berdasarkan frekuensi penggunaan Netflix berikut ini.
Gambar 4.7 Persentase Responden Berdasarkan Frekuensi Penggunaan Netflix
Berdasarkan hasil dari 150 responden, dapat dilihat dari Gambar 4.7 bahwa persentase responden yang menggunakan Netflix hampir setiap hari atau setiap hari sama dengan persentase responden yang menggunakan Netflix beberapa kali dalam seminggu dengan jumlah 65 responden (43,3%). Responden yang menggunakan Netflix beberapa kali dalam sebulan sejumlah 13 responden (8,7%). Persentase paling rendah adalah responden yang menggunakan Netflix lebih jarang dari beberapa kali sebulan dengan jumlah 7 responden (4,7%).
4.2 Pengolahan Data
Pengolahan data dilakukan berdasarkan data-data yang telah diperoleh dari hasil kuesioner 150 responden yang telah dikumpulkan lalu diolah menggunakan software Microsoft Excel yang terdiri dari Rekapitulasi Data Awal Kuesioner, Rekapitulasi Data Skala Likert, Pengembangan Inner Model dan Outer Model, Evaluasi Inner Model dan Outer Model, dan Uji Hubungan Antar Variabel.
4.2.1 Rekapitulasi Hasil Penilaian Responden
Tahap ini merupakan proses rekapitulasi data skala likert hasil kuesioner dari 150 responden terhadap 11 dimensi yaitu Reliability, Efficiency, Availability,
43.3%
43.3%
8.7%
4.7%
Hampir setiap hari/setiap hari Beberapa kali dalam seminggu Beberapa kali dalam sebulan Lebih jarang lagi
IV-6
Assurance, Security, Site Aesthetics, Easy to Use, Responsiveness, Access, e- Satisfaction, dan e-Loyalty. Dengan ketentuan Skala Likert sebagai berikut:
1. Sangat tidak setuju 2. Tidak setuju 3. Netral 4. Setuju
5. Sangat setuju
Pada data skala likert, dihitung rata-rata pada tiap atribut. Terdapat beberapa kontroversi mengenai skala likert yang termasuk skala ordinal yang tidak bisa dihitung rata-ratanya. Hal tersebut sudah dijelaskan oleh Imam Ghozali (bahwa skala Likert bisa saja diasumsikan sebagai skala data interval sepanjang metode/cara penyusunan pertanyaannya (positif/negatif) bersifat konsisten (Ghozali, 2016).
a. Data Skala Likert variabel e-Service Quality
Data Skala Likert variabel e-Service Quality yang didapatkan dari hasil kuesioner Google Form yang kemudian diolah menggunakan Microsoft Excel dapat dilihat pada Tabel 4.1 sebagai berikut. Data Skala Likert yang lebih lengkap dapat dilihat pada Lampiran 7 sampai Lampiran 13.
Berdasarkan data rekapitulasi skala likert di atas, diketahui nilai rata-rata jawaban pada variabel e-Service Quality untuk masing-masing dimensi.
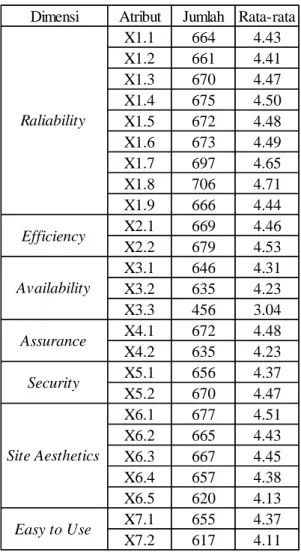
Dimensi Reliability pada atribut 1 memiliki rata-rata sebesar 4,43, atribut 2 sebesar 4,41, atribut 3 sebesar 4,47, atribut 4 sebesar 4,50, atribut 5 sebesar 4,48, atribut 6 sebesar 4,49, atribut 7 sebesar 4,65, atribut 8 sebesar 4,71, dan atribut 9 sebesar 4,44.
Dimensi Efficiency pada atribut 1 memiliki rata-rata sebesar 4,46 dan atribut 2 sebesar 4,53. Dimensi Availability pada atribut 1 memiliki rata-rata sebesar 4,31, atribut 2 sebesar 4,23, dan atribut 3 sebesar 3,04. Dimensi Assurance pada atribut 1 memiliki rata-rata sebesar 4,48 dan atribut 2 sebesar 4,23. Dimensi Security pada atribut 1 memiliki rata-rata sebesar 4,37 dan atribut 2 sebesar 4,47. Dimensi Site Aesthetics pada atribut 1 memiliki rata-rata sebesar 4,51, atribut 2 sebesar 4,43, atribut 3 sebesar 4,45, atribut 4 sebesar 4,38, dan atribut
IV-7
5 sebesar 4,13. Dimensi Easy to Use pada atribut 1 memiliki rata-rata sebesar 4,37 dan atribut 2 sebesar 4,11.
Tabel 4.1 Data Skala Likert Variabel e-Service Quality
b. Data Skala Likert variabel e-Recovery Service Quality
Data Skala Likert variabel e-Recovery Service yang didapatkan dari hasil kuesioner Google Form yang kemudian diolah menggunakan Microsoft Excel dapat dilihat pada tabel 4.2 sebagai berikut. Data Skala Likert yang lebih lengkap dapat dilihat pada Lampiran 14 dan Lampiran 15.
Tabel 4.2 Data Skala Likert variabel e-Recovery Service Quality
Dimensi Atribut Jumlah Rata-rata
X1.1 664 4.43
X1.2 661 4.41
X1.3 670 4.47
X1.4 675 4.50
X1.5 672 4.48
X1.6 673 4.49
X1.7 697 4.65
X1.8 706 4.71
X1.9 666 4.44
X2.1 669 4.46
X2.2 679 4.53
X3.1 646 4.31
X3.2 635 4.23
X3.3 456 3.04
X4.1 672 4.48
X4.2 635 4.23
X5.1 656 4.37
X5.2 670 4.47
X6.1 677 4.51
X6.2 665 4.43
X6.3 667 4.45
X6.4 657 4.38
X6.5 620 4.13
X7.1 655 4.37
X7.2 617 4.11
Easy to Use Site Aesthetics
Security Assurance Availability
Efficiency Raliability
Dimensi Atribut Jumlah Rata-rata
X8.1 459 3.06
X8.2 613 4.09
X8.3 573 3.82
X8.4 520 3.47
X9.1 573 3.82
X9.2 461 3.07
Access Responsiveness
IV-8
Berdasarkan data rekapitulasi skala likert di atas, diketahui nilai rata-rata jawaban tiap atribut pada variabel e-Recovery Service Quality untuk masing- masing dimensi. Dimensi Responsiveness pada atribut 1 memiliki rata-rata sebesar 3,06, atribut 2 sebesar 4,09, atribut 3 sebesar 3,82, dan atribut 4 sebesar 3,47. Dimensi Access pada atribut 1 memiliki rata-rata sebesar 3,82 dan atribut 2 sebesar 3,07.
c. Data Skala Likert variabel e-Satisfaction
Data Skala Likert variabel e-Satisfaction yang didapatkan dari hasil kuesioner Google Form yang kemudian diolah menggunakan Microsoft Excel dapat dilihat pada tabel 4.3 sebagai berikut. Data Skala Likert yang lebih lengkap dapat dilihat pada lampiran 16.
Tabel 4.3 Data Skala Likert variabel e-Satisfaction
Berdasarkan data rekapitulasi skala likert di atas, diketahui nilai rata-rata jawaban tiap atribut pada variabel e-Satisfaction yaitu dimensi e-Satisfaction.
Rata-rata jawaban atribut 1 sebesar 4,29, atribut 2 sebesar 4,21, dan atribut 3 sebesar 4,32.
d. Data Skala Likert variabel e-Loyalty
Data Skala Likert variabel e-Loyalty yang didapatkan dari hasil kuesioner Google Form yang kemudian diolah menggunakan Microsoft Excel dapat dilihat pada tabel 4.4 sebagai berikut. Data Skala Likert yang lebih lengkap dapat dilihat pada lampiran 17.
Tabel 4.4 Data Skala Likert variabel e-Loyalty
Berdasarkan data rekapitulasi skala likert di atas, diketahui nilai rata-rata jawaban tiap atribut pada variabel e-Loyalty yaitu dimensi e-Loyalty. Rata-rata
Dimensi Atribut Jumlah Rata-rata
Y1 643 4.29
Y2 632 4.21
Y3 648 4.32
e-Satisfaction
Dimensi Atribut Jumlah Rata-rata
Z1 613 4.09
Z2 613 4.09
Z3 593 3.95
e-Loyalty
IV-9
jawaban atribut 1 sebesar 4,09, atribut 2 sebesar 4,09, dan atribut 3 sebesar 3,95.
4.2.2 Pengembangan Inner Model dan Outer Model
Tahap ini adalah proses pengembangan Inner Model dan Outer Model berdasarkan model yang sudah disusun. Inner Model atau model struktural adalah model struktural untuk merancang hubungan antar variabel laten pada PLS dengan didasarkan pada hipotesis penelitian. Sedangkan Outer Model atau model pengukuran adalah model pengukuran untuk merancang hubungan variabel laten dengan indikatornya.
Mengingat bahwa hipotesis penelitian adalah menentukan apakah variabel e- Service Quality dan e-Recovery Service Quality berpengaruh terhadap e- Satisfaction dan e-Loyalty, maka dapat ditentukan variabel laten dari hipotesis tersebut. Variabel yang didapatkan adalah e-Service Quality, e-Recovery Service Quality, e-Satisfaction, dan e-Loyalty.
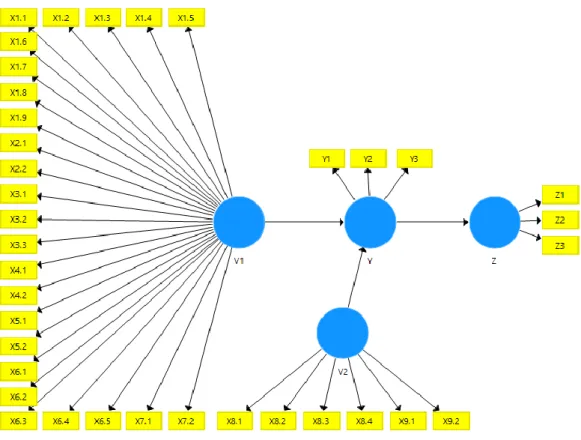
Inner Model dan Outer Model kemudian dikonstruksikan menjadi diagram jalur agar lebih mudah dipahami. Dari pengembangan tersebut, dihasilkan diagram jalur yang dibentuk dalam software SmartPLS versi 3 sebagai berikut.
V1 Y
V2
Z
Gambar 4.8 Diagram Jalur Inner Model
Dari Gambar 4.8, dapat diketahui bahwa Inner Model telah disusun berdasarkan hipotesis penelitian. Variabel V1 atau e-Service Quality dan V2 atau e-Recovery Service Quality ditentukan apakah keduanya berpengaruh terhadap Y atau e-Satisfaction. Kemudian Y atau e-Satisfaction ditentukan apakah berpengaruh terhadap Z atau e-Loyalty.
Keterangan:
V1 = e-Service Quality
V2 = e-Recovery Service Quality Y = e-Satisfaction
Z = e-Loyalty
IV-10
Sedangkan Outer Model dikontruksi menjadi diagram jalur seperti gambar berikut. Diagram jalur dibentuk berdasarkan hipotesis penelitian dan model kerja yang sudah disusun. Outer Model akan memberikan spesifikasi hubungan antara variabel laten dan indikatornya.
Gambar 4.9 Diagram Jalur Outer Model
Dari Gambar 4.9, dapat dilihat bagaimana indikator menjadi bagian dari variabel laten. Indikator-indikator tersebut adalah 11 dimensi yang digunakan dalam penelitian ini yaitu Reliability, Efficiency, Availability, Assurance, Security, Site Aesthetics, Easy to Use, Responsiveness, Access, e-Satisfaction, dan e-Loyalty.
Dimensi Reliability, Efficiency, Availability, Assurance, Security, Site Aesthetics, dan Easy to Use adalah bagian dari variabel V1 yaitu e-Service Quality. Dimensi Responsiveness dan Access adalah bagian dari variabel V2 yaitu e-Recovery Service Quality. Dimensi e-Satisfaction adalah satu-satunya dimensi dalam variabel e- Satisfaction. Dimensi e-Loyalty juga menjadi satu-satunya dimensi dalam variabel e-Loyalty.
Diagram jalur tersebut digunakan sebagai landasan perhitungan dalam proses pengolahan data kuesioner untuk menentukan apakah e-Service Quality dan e- Recovery Service Quality berpengaruh terhadap e-Satisfaction dan e-Loyalty.
IV-11 4.2.3 Evaluasi Inner Model dan Outer Model
Tahap ini adalah tahap evaluasi Inner Model dan Outer Model yang sudah dibentuk. Evaluasi dilakukan dengan menguji Inner Model dan Outer Model melalui proses PLS Algorithm pada menu Calculate. Setelah dilakukan operasi tersebut, akan muncul berbagai hasil operasi. Beberapa dari hasil operasi tersebut diperiksa untuk mengevaluasi Inner Model dan Outer Model.
a. Outer Loading
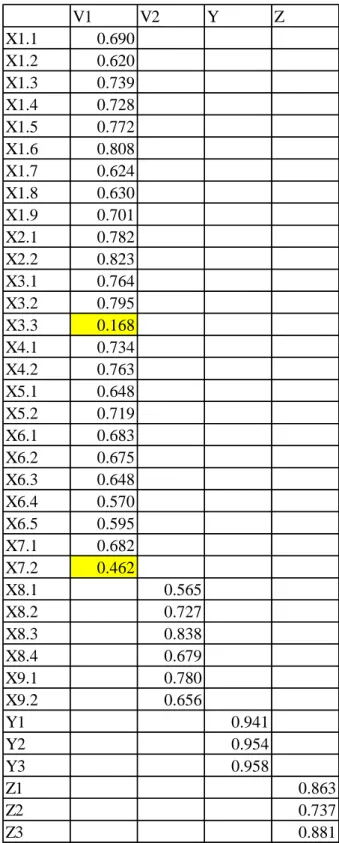
Saat hasil Outer Loading dipilih, muncul nilai loading factor dari seluruh indikator sebagai berikut. Hair, dkk (1994) menyatakan bahwa indikator yang memiliki nilai loading factor di atas 0,5 dianggap valid. Sedangkan apabila nilai loading factor di bawah 0,5 maka indikator dianggap tidak valid.
Dapat dilihat pada Tabel 4.5 bahwa terdapat beberapa indikator yang memiliki nilai loading factor di bawah 0,5. Hal tersebut menunjukkan bahwa indikator tersebut tidak valid. Untuk itu, indikator yang bernilai di bawah 0,5 dihapus untuk diproses selanjutnya. Sehingga indikator X3.3 dan indikator X7.2 dihapus.
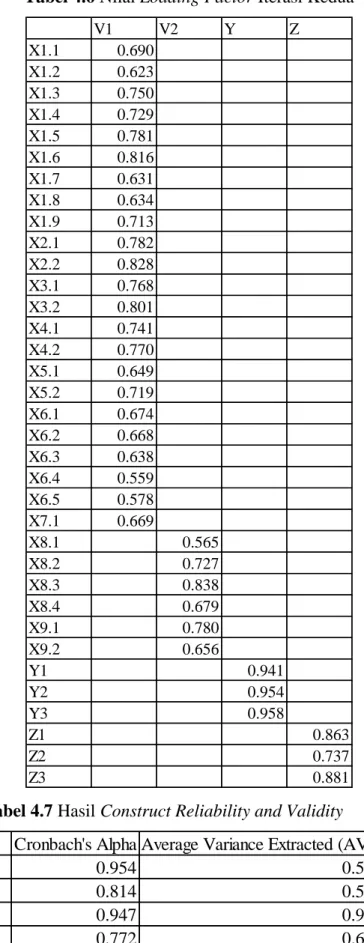
Didapatkan hasil dari proses PLS Algorithm kedua sebagai berikut pada Tabel 4.6 setelah indikator yang tidak valid dihapus. Nampak bahwa seluruh indikator sudah memiliki nilai loading factor di atas 0,5 yang berarti seluruh indikator sudah dianggap valid.
b. Construct Reliability and Validity
Saat hasil Construct Reliability and Validity dipilih, maka muncul hasil perhitungan menurut berbagai metode. Metode yang dipilih adalah cornbach’s alpha. Suatu indikator dikatakan reliabel atau tidak reliabel, apabila hasil α >
0,60 maka disebut reliabel. Sedangkan jika hasil α < 0,60 maka dianggap tidak reliabel (Sugiyono, 2010).
Dari Tabel 4.7, dapat dilihat bahwa seluruh indikator memiliki nilai cronbach’s alpha lebih besar dari 0,6 sehingga seluruh indikator dianggap reliabel.
Sedangkan dapat dilihat pula pada Tabel 4.7 bahwa seluruh variabel sudah memiliki Average Variance Extracted (AVE) dengan nilai di atas 0,5 sehingga seluruh variabel dianggap valid.
IV-12
Tabel 4.5 Nilai Loading Factor Iterasi Awal
V1 V2 Y Z
X1.1 0.690
X1.2 0.620
X1.3 0.739
X1.4 0.728
X1.5 0.772
X1.6 0.808
X1.7 0.624
X1.8 0.630
X1.9 0.701
X2.1 0.782
X2.2 0.823
X3.1 0.764
X3.2 0.795
X3.3 0.168
X4.1 0.734
X4.2 0.763
X5.1 0.648
X5.2 0.719
X6.1 0.683
X6.2 0.675
X6.3 0.648
X6.4 0.570
X6.5 0.595
X7.1 0.682
X7.2 0.462
X8.1 0.565
X8.2 0.727
X8.3 0.838
X8.4 0.679
X9.1 0.780
X9.2 0.656
Y1 0.941
Y2 0.954
Y3 0.958
Z1 0.863
Z2 0.737
Z3 0.881
IV-13
Tabel 4.6 Nilai Loading Factor Iterasi Kedua
Tabel 4.7 Hasil Construct Reliability and Validity
V1 V2 Y Z
X1.1 0.690
X1.2 0.623
X1.3 0.750
X1.4 0.729
X1.5 0.781
X1.6 0.816
X1.7 0.631
X1.8 0.634
X1.9 0.713
X2.1 0.782
X2.2 0.828
X3.1 0.768
X3.2 0.801
X4.1 0.741
X4.2 0.770
X5.1 0.649
X5.2 0.719
X6.1 0.674
X6.2 0.668
X6.3 0.638
X6.4 0.559
X6.5 0.578
X7.1 0.669
X8.1 0.565
X8.2 0.727
X8.3 0.838
X8.4 0.679
X9.1 0.780
X9.2 0.656
Y1 0.941
Y2 0.954
Y3 0.958
Z1 0.863
Z2 0.737
Z3 0.881
Cronbach's Alpha Average Variance Extracted (AVE)
V1 0.954 0.502
V2 0.814 0.508
Y 0.947 0.904
Z 0.772 0.688
IV-14 4.2.4 Uji Hubungan Antar Variabel
Tahap ini adalah tahap untuk menguji hubungan antar variabel. Variabel yang diuji adalah variabel e-Service Quality, e- Recovery Service Quality, e-Satisfaction, dan e-Loyalty.
Proses pengujian dibantu dengan menggunakan program SmartPLS versi 3.
Proses running dilakukan tahap Bootstraping untuk menguji pengaruh variabel e- Service Quality terhadap e-Satisfaction, pengaruh variabel e-Recovery Service Quality terhadap e-Satisfactin, dan pengaruh variabel e-Satisfaction terhadap e- Loyalty. PLS Bootstraping berfungsi untuk menampilkan uji regresi berganda dengan menampilkan output t dan nilai koefisien masing-masing.
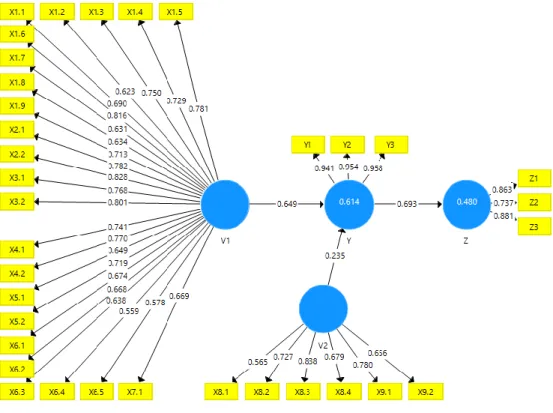
Gambar 4.10 Model Jalur Hasil Analisis Regresi (Koefisien)
Bootstrapping adalah prosedur statistik dengan cara mengubah data dari sampel yang kita peroleh dan melakukan replikasi dari data sampel tersebut (resampling) secara acak untuk diperoleh data simulasi baru. Prosedur ini dapat digunakan untuk menghitung standar error, interval kepercayaan, dan melakukan pengujian hipotesis untuk berbagai jenis analisis statistik (Akhtar, 2020).
Hasil output nilai koefisien pada model regresi setelah proses running data dapat dilihat pada Gambar 4.10.
IV-15
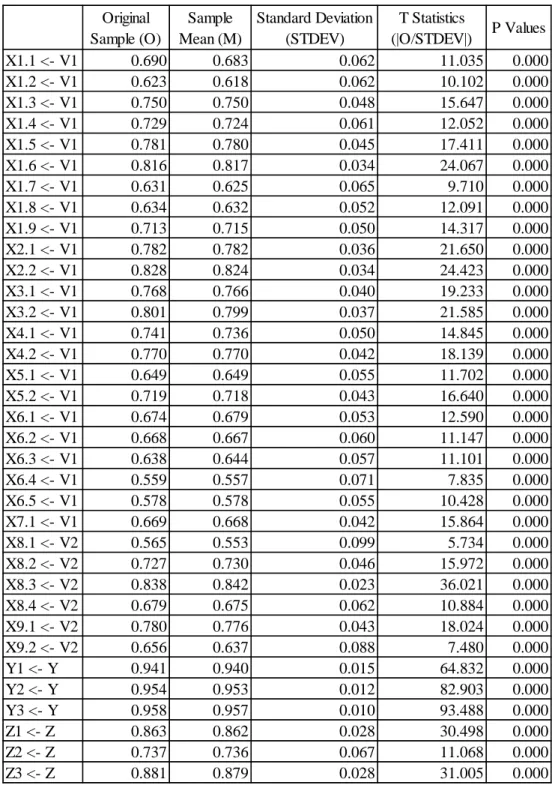
Setelah diperoleh output nilai koefisen pada model analisis regresi di atas, kemudian diperoleh hasil PLS bootstraping untuk menampilkan uji analisis regresi dengan menampilkan output t-test seperti yang terlihat pada Tabel 4.8.
Dengan tingkat signifikansi (α) yang digunakan sebesar 5% (0,05). Hasil uji analisis regresi berganda untuk nilai signifikansi (P-Value) dapat dilihat pada output Tabel 4.8.
Persamaan Regresi sebagai berikut:
𝑌 = 0,614 + 0,649𝑋1 + 0,235𝑋2 + 𝑒 (7) 𝑍 = 0,48 + 0,693𝑌 + 𝑒 (8) Berdasarkan Tabel 4.9, hasil hipotesis pada variabel e-Service Quality terhadap e-Satisfaction menghasilkan nilai signifikansi sebesar 0,000 < 0,05. Kemudian variabel e-Recovery Service Quality terhadap e-Satisfaction menghasilkan nilai signifikansi sebesar 0,000 < 0,05. Pada variabel e-Satisfaction terhadap e-Loyalty terdapat hasil nilai signifikansi sebesar 0,000 < 0,05.
Setelah mendapatkan hasil regresi didapatkan nilai R2 (Koefisien determinasi) pada variabel e-Satisfaction adalah 0,609 dan pada variabel e-Loyalty adalah 0,477.
Artinya bahwa pada variabel e-Satisfaction, kemampuan variabel bebas dalam menjelaskan variansi dari variabel terikatnya adalah sebesar 60,9%. Sehingga 39,1% variansi variabel terikat dijelaskan oleh faktor lain. Sedangkan pada variabel e-Loyalty, kemampuan variabel bebas dalam menjelaskan variansi dari variabel terikatnya adalah sebesar 47,7%. Sehingga 52,3% variansi variabel terikat dijelaskan faktor lain.
Pada Tabel 4.9, terdapat nilai Original Sample (O) dan Sample Mean (m) yang artinya adalah besarnya nilai koefisien pengaruh dari konstruk independen terhadap konstruk dependen. Original Sample berasal dari perhitungan nilai awal (sampel awal). Sample Mean berasal dari hasil perhitungan sampel pada proses Bootstrapping. Nilai Original Sample digunakan untuk melihat arah dari pengujian hipotesis. Apabila Original Sample menunjukkan nilai positif, maka arahnya positif. Sebaliknya, apabila Original Sample bernilai negatif maka arahnya negatif (Zunianto, 2017).
IV-16
Tabel 4.8 Model jalur hasil analisis regresi (T-Test)
Tabel 4.9 Hasil uji regresi berganda
Original Sample (O)
Sample Mean (M)
Standard Deviation (STDEV)
T Statistics
(|O/STDEV|) P Values
X1.1 <- V1 0.690 0.683 0.062 11.035 0.000
X1.2 <- V1 0.623 0.618 0.062 10.102 0.000
X1.3 <- V1 0.750 0.750 0.048 15.647 0.000
X1.4 <- V1 0.729 0.724 0.061 12.052 0.000
X1.5 <- V1 0.781 0.780 0.045 17.411 0.000
X1.6 <- V1 0.816 0.817 0.034 24.067 0.000
X1.7 <- V1 0.631 0.625 0.065 9.710 0.000
X1.8 <- V1 0.634 0.632 0.052 12.091 0.000
X1.9 <- V1 0.713 0.715 0.050 14.317 0.000
X2.1 <- V1 0.782 0.782 0.036 21.650 0.000
X2.2 <- V1 0.828 0.824 0.034 24.423 0.000
X3.1 <- V1 0.768 0.766 0.040 19.233 0.000
X3.2 <- V1 0.801 0.799 0.037 21.585 0.000
X4.1 <- V1 0.741 0.736 0.050 14.845 0.000
X4.2 <- V1 0.770 0.770 0.042 18.139 0.000
X5.1 <- V1 0.649 0.649 0.055 11.702 0.000
X5.2 <- V1 0.719 0.718 0.043 16.640 0.000
X6.1 <- V1 0.674 0.679 0.053 12.590 0.000
X6.2 <- V1 0.668 0.667 0.060 11.147 0.000
X6.3 <- V1 0.638 0.644 0.057 11.101 0.000
X6.4 <- V1 0.559 0.557 0.071 7.835 0.000
X6.5 <- V1 0.578 0.578 0.055 10.428 0.000
X7.1 <- V1 0.669 0.668 0.042 15.864 0.000
X8.1 <- V2 0.565 0.553 0.099 5.734 0.000
X8.2 <- V2 0.727 0.730 0.046 15.972 0.000
X8.3 <- V2 0.838 0.842 0.023 36.021 0.000
X8.4 <- V2 0.679 0.675 0.062 10.884 0.000
X9.1 <- V2 0.780 0.776 0.043 18.024 0.000
X9.2 <- V2 0.656 0.637 0.088 7.480 0.000
Y1 <- Y 0.941 0.940 0.015 64.832 0.000
Y2 <- Y 0.954 0.953 0.012 82.903 0.000
Y3 <- Y 0.958 0.957 0.010 93.488 0.000
Z1 <- Z 0.863 0.862 0.028 30.498 0.000
Z2 <- Z 0.737 0.736 0.067 11.068 0.000
Z3 <- Z 0.881 0.879 0.028 31.005 0.000
Original Sample (O)
Sample Mean (M)
Standard Deviation (STDEV)
T Statistics
(|O/STDEV|) P Values
V1 -> Y 0.649 0.649 0.052 12.569 0.000
V2 -> Y 0.235 0.239 0.052 4.508 0.000
Y -> Z 0.693 0.701 0.049 14.033 0.000