Refactoring Object-Relational Database Applications by
Applying Transformation Rules to Develop better
Performance
∗Zahra Davar
†School of Computer Science and Software Engineering University of Wollongong Northfields Ave, Wollongong NSW 2522
Australia
[email protected]
Handoko
‡School of Computer Science and Software Engineering University of Wollongong Northfields Ave, Wollongong NSW 2522
Australia
[email protected]
ABSTRACT
Object-relational database applications implemented in conventional procedural programming languages such as C, C++, and Java along with the embedded statements expressed in the non-procedural pro-gramming languages such as OQL, SQL and XQuery. Therefore, using transformation rules to optimise these applications by bal-ancing the data processing load between the client and the server sides is required. Refactoring object-oriented applications, is one way to preserve output of the application but apply changes on de-sign level. Implementation of object-relational applications with a large amount of procedural code, remains the majority of the data-processing to the client side. This often has catastrophic conse-quences for the performance of the application. Transformation rules need to be applied in an efficient way to come up with opti-mised applications.
This research evaluates whether using transformation rules can be consider as a refactoring technology which can transfer the non-optimise object-relational application to the non-optimise ones. A sys-tematic experimental study was conducted by incorporating trans-formation rules to monitor the number ofBlocks-Readoperations before and after applying the rules. It was concluded that as rules applied in an efficient way, the performance of applications in-creased. Also the efficient way of applying the rules is proposed.
Categories and Subject Descriptors
D.2.8 [Software Engineering]: [performance tunning]
∗(Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee.). For use with SIG-ALTERNATE.CLS. Supported by ACM. †Postgraduate Research Candidate.
‡Postgraduate Research Candidate.
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. iiWAS2014, 4-6 December, 2014, Hanoi, Vietnam.
iiWAS2014Hanoi, Vietnam
Copyright 2014 ACM 978-1-4503-3001-5/14/12 ...$15.00.
General Terms
Refactoring
Keywords
Object-Relational Application; Performance; Transformation Rule; Software Patterns
1.
INTRODUCTION
The performance problem of object-relational applications have received a lot of attention in commercial applications. During the software development, the reconfiguration of an application is a common approach to get the better performance. The restructur-ing of the application, usually depends on the number of changes within the application’s code which have to be made [5]. Restruc-turing the object-relational applications, preserve behaviour of the application thereby change the balance of data-processing.
An application implemented by using an object-oriented lan-guage with non-procedural statements embedded with a relational database as a data storage, consists of four main components. There is the application itself, the database schema, stored data and the object-relational mapping [11]. Refactoring the application can af-fects the database. While relational database system is available on the server side. Object-relational mapping, transform that into classes of objects on the client side [4].
Object-oriented developers tend to write more procedural code to implement an object-relational application, which leaves as much work to the client as possible. This will tend to some major prob-lems. Firstly, process data on the client side, is not as efficient as on the server side as the algorithms which can process the data on the server side are more efficient than the same ones ones on the client side. Secondly, shift object from the server side to the client side is a time consuming operation.
One way to solve these problems and get the better performance of the object-relational applications, is refactoring the source code. This can be done by understanding the structures of an application and reimplement it with more non-procedural code is one solution.
non-procedural code. As a result, faster and more efficient performance of the application is achieved. Theblock-read operations of a set of application is monitored before and after refactoring the applica-tion. Additionally, the paper proposes the optimal way of applying the rules and refactoring the object-relational applications.
In the remainder of this paper a experimental results is presented to show the scale of the problem. Section 2, reviews the existing research on performance tuning of object-relational applications. The transformation rules are presented in section 3. Apply the rules using software patterns is presented in section 4. Section 5 contains the conclusion and suggested future work.
2.
EXPERIMENTAL RESULT
In this paper, a set of experiments are presented to show the im-portance of refactoring object-relational applications. To evaluate the performance of the applications before and after refactoring, the total number ofBlocks-Readoperations of the applications is mea-sured and compared. An object-relational application which does theJOINoperation by nested loops is compared with the the refac-tor version of it. TheJOINoutput of the both applications are same. The experiments are conducted using the TPC-H Benchmark database which has 300 MB relational data. The Lucid Lynx Ubuntu system running on 3.33GHz Intel(R), Core(TM)2, Duo CPU with 3.25GB RAM is used to run the applications. The examples were run in Java Persistence API (JPA) format and in the Netbeans 7 environ-ment.
2.1
Join Traversal
Application A, is iterating over two classes of objects, called Lineitemand Supplier. Application A, retrieves all values from l.partsuppin theLineitemclass which has equal values tos.suppkey in theSupplierclass. We performed various experiments for differ-ent sizes of the database on this application and we measured the total number ofBlocks-Readoperations. In all examples, a class Supplierconsists of 3000 objects but a classLineitemvaried be-tween 400,000 objects to 1,800,000 objects.
Application A:
{ Query query1 = em.createQuery
("SELECT s FROM Supplier s",Supplier.class); List list1 = query1.getResultList(); Iterator iterator1= list1.iterator(); while(iterator1.hasNext())
Supplier s= (Supplier)iterator1.next(); Query query2 = em.createQuery
("SELECT l FROM Lineitem l WHERE
l.sSuppkey=
s.sSuppkey",Lineitem.class); List list2 = query2.getResultList(); Iterator iterator2= list2.iterator(); int counter = 0;
if (!list2.isEmpty()) {
while (iterator2.hasNext()) {
Lineitem l=
(Lineitem)iterator2.next(); counter ++;
} }
System.out.println
( item + " " + counter); }
finally{ em.close();
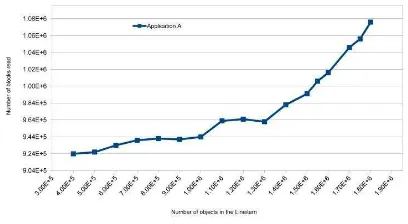
To test the performance of Application A, the total number of Blocks-Readoperations for each time running of the application with different size database is measured. TheBlocks-Read opera-tions were measured by using BSTAT/ESTAT command-lines in-terface tools which could gather instance related performance data. Figure 1, illustrates the total number ofBlocks-Read operations needed to run the Application A with different sizes of theLineitem class. We started running Application A with 400,000 objects in Lineitemand increased the objects up to 1,800,000. The number ofBlocks-Readfor Application A, started from approximately 92 million blocks for 400,000 objects and ended up with almost 108 million blocks for 1,800,000 objects.
Figure 1: Number ofBlocks-Readfor application A
Next, we transformed Application A into Application B. Appli-cation B binds twoSELECT statements into one SELECT state-ment. Application B, which has more OQL statements, reduces the total number of objects transferred from the server side to the client side. By using Application B, the balance of the data-processing is changed and as a result less data-processing shift to the client side and less object transferred from the server side to the client side.
Application B:
{ Query query = (Query) em.createQuery ("SELECT l.sSuppkey,
COUNT(l.sSuppkey) FROM Lineitem l
JOIN Supplier s on l.sSuppkey =
s.sSuppkey", Lineitem.class); List list1 = query.getResultList(); Iterator iterator1= list1.iterator(); while(iterator1.hasNext()){
int counter = 0; if (!list1.isEmpty()) { Lineitem l=
(Lineitem)iterator1.next(); counter ++;
}
System.out.println
( ps_suppkey + " " + counter); }
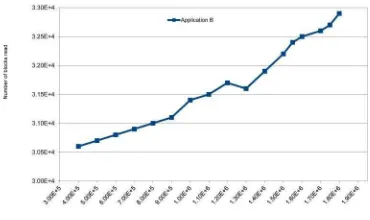
Figure 2, illustrates the total number ofBlocks-Readoperations performed by Application B. The number ofBlocks-Read opera-tions performed by Application B, starts from 30,000 blocks for 400,000 objects in theLineitemclass and increased to almost 32,000 blocks. These results in Figure 1 and Figure 2 show that if we
Figure 2: Number ofBlocks-Readfor application B
change the configuration of the Application A so that only 300MB transmit to the client side instead of 3GB, the number of blocks for read/write will dramatically decrease from 92 million blocks to 30,000 blocks. Therefore, the run-time of the application will increase. This experiment, were run for several other applications and the result was the same.
3.
RELATED WORKS
The approach of processing the integration of complex databases using IIS*Case was proposed in 2006 by Ivan et al. The functional-ity of IIS*Case needs to be extended, however, in order to be able to support the complete development of an information system [10]. In this research, the performance problem of distributed informa-tion systems was not considered as a challenge in integrating the data models. In 2010, the idea of refactoring SQL was presented by Jacobs et al. Their method relied on finding common anti-patterns and techniques [7]. The proposed method was not extensible, how-ever, and not general enough to cover most common queries. Fur-ther research on refactoring was done in 2006 by Michael et al. The success of this approach was its ability to reduce code volume and the number of modules and files needed during maintenance [13]. The main problem, however, is a reduction in performance of the application. This approach is also unable to manage the refactor-ing of the application automatically. Zibran et al (2011). proposed a model for refactoring code clones in the OO source code. This model was useful for estimating the efforts needed for code clone refactoring [19] but it is not applicable for industrial software sys-tems written in other programming languages. Also, a refactoring tool was suggested by Zibran et al. They invented the clone de-tection part of a refactoring system [20]. This research did not consider the performance of the output application in the imple-mentation of their refactoring system. In 2009, Liu et al analysed the relationships among different approaches to software refactor-ing [9]. In this research, however there is no support for resolution orders of software refactoring or for software development. Some transformation rules are proposed in [4], to get the better
perfor-mance of the object-relational applications. The problem with this research is however not having a general pattern to apply the rules on object-relational applications.
S.Agarwal (1995), proposed the idea of using a client-side object cache in order to increase the performance of the application and suggested that the actual performance was greatly dependent on the degree to which the application can take advantage of data stored in the object cache [1]. The problem of this method, however, is that the complexity of the query must be managed so that can return instances of commonly used classes with minimum use of joins. In 2006, P. V Zyl et al. focused on comparing the performance of object databases and object relational mapping tools. This research discussed OR mapping in open source applications [17]. This ap-proach, however, only dealt with one framework and was not tried on the distributed (client-server) or multi-user frameworks which are often used by developers. In 2010, R. Kalantari et al. com-pared the performance of object and OR database systems. Certain factors which system developers need to consider when selecting a database management system for persisting objects were suggested in this research [8] but it was done based on basic query imple-mentation which means that it did not consider complex queries involving two or more objects. This means that it is less than op-timal for todays applications with complex queries. Rahayu et al. discussed the performance evaluation of object-relational transfor-mation methodology. The aim of this research was to clarify the ef-ficiency of the operations on relational tables based on certain OR transformation methodology [15]. The performance of OR trans-formation methodology was also compared with that of the con-ventional relational model. This work, however, did not involve the dynamic parts of the object orientation. Meng et al. proposed a some transformation rules for OO database systems. The rules used in this research were designed to transform the structural part of an OO database schema to an equivalent relational schema [12]. These rules provided a relational view of the OO database schema for relational users. This research is limited, however, to the struc-ture of a relational front end for OO database systems. The idea of translating queries from an SQL into an OQL in an automatic way, were suggested by Mostefaoui et al (1998). Their method was based on graph representations [14]. A formal approach for translating OO database queries into equivalent relational queries was proposed by Yu et al who used the same method as Moste-faoui et al. in [14] [18]. These works, however, did not consider all the possible forms of SQL queries. In addition, the methods suggested were not general enough to be extended to other clauses and they could not address the performance problem of OR appli-cations. Grust et al (2009), developped the FERRY language which was designed as an intermediate language which acts as glue that permits a programming style in which developers access database tables using their programming language’s own syntax and idiom [6]. In 2010 the same authors extended this approach by proposing the FERRY-based LINQ to SQL approach [16]. Both papers were based on compiling the first-order functional programs into SQL which is not an applicable approach in industry. Recently, Chen et al. proposed a framework which can detect and prioritise in-stances of object relational mapping performance anti-patterns [2] and therefore improve the systems response time. This is useful but this approach can detect performance bugs and leaves the de-bugging process for the developer.
In this paper, the idea which was presented in [4] is evaluated as a refactoring approach. Also the general pattern for using the rules are presented by real example and symbolic figure.
By using the transformation rules presented in [4], non-optimised versions of the object-relational database applications can be opti-mised to provide the necessary efficiency and high speed. They modified the structure of object-oriented application by using some non-procedural code instead of procedural code. Therefore, ap-plying the transformation rules can consider as a recfactoring of one layer of the object-relational application. The rules modify the application in which filtering conditions are applied on the server side and as a result, not all data will transfer from the server side to the client side. The transformation rule is applied to the non-optimised version of the program which is an input component and the result is an optimised version of the program, which is an out-put component. By using more non-procedural code and changing the configuration of the input component, the output component is implemented. This approach is applied to three different types of the object relational application: filtering, traversal of associations and aggregation [3]. In this paper we present the transformation rule for aggregation application with examples for both input and output component to show how this refactoring process is working.
4.1
Aggregation
The most used implementation of aggregation queries is mod-elled as an input component of this group of applications. In this implementation, developers are using nested SELECT statements to find the appropriate objects for aggregation function from classes of objects. Using two nested SELECT statements to build aggre-gation functions is one of the worst implementations which most object oriented programmers use [3]. This nested loops implemen-tation, takes an object variable from the outer loop and the value of the property of this object will goes to the condition of the other loop as the object on the other side of the association. The aggrega-tion rule is based on finding desired objects in a class and then ap-plying the aggregation function to them. For instance, for counting similar objects from a class of objects, G(x) can be aCOUNT(*)in the input component andCOUNT(Memberi)in the output compo-nent. By using this structure for aggregation queries, all the objects would transfer from the server side to the client side and theClass would be considered as a group of objects.
Assume that G(x) is an aggregation function such as Min, Max, Average and Count.
Assume that WHERE condition can be any condition between mem-bers of class1 and class2.
For instance it can be class1.Memberi=class2.Memberi.
Algorithm 1: Input component
Aggregation with nested loop
1 foreach t in (SELECT MemberiFROM Class 1)do
2 foreach s in (SELECT G(x) FROM Class 2 as RESULT
3 WHERE
4 Class 1.Memberi= Class 2.Memberj)do 5 get x= RESULT P r o c e s s i n g (x)
6 end 7 end
An example of the input component of this rule, is presented as follow:
Algorithm 2:Example/Non-Optimise version
1 foreach t in (SELECT * FROM Department)do 2 foreach s in (SELECT count(*) as TOTAL FROM
Employee
3 WHERE
4 t.Department id = s. Department id)do 5 end
6 Get s Write t
7 end
In the output component of this rule, theGroup by clause is used to group the necessary objects and transfer them to the client side. Therefore, compared to the input component, less objects will transferred from the server side. Any of the aggregation functions can be used instead of G(x). For instance, for counting objects, Count(*)can be used instead of G(x) in the output component.
Algorithm 3: Output component
Counting and grouping objects
1 foreach t in (SELECT Memberi, G(x) as RESULT FROM Class 1Group byMemberiFROM Class 2)do
2 get z = RESULT
3 P r o c e s s i n g< z >
4 end
This rule can make aggregation application run faster. That is because, the output component, includes Group byclause. The Group byclause is used to divide the objects into groups. In the input component withoutGroup by, the entireclassis considered as one group and it takes a lot of time to apply aggregation function to all objects. An example of the output component is presented as follow:
Algorithm 4:Example /Optimise version
1 foreach p in (SELECT count(Department.Department id) as TOTAL
2 FROM Department group by Employee.Department id From Employee
3 WHERE
4 Department.Department id = Employee. Department iddo 5 Write (p)
6 end
Applying this rule to aggregation application which is imple-mented by a developer, is an example of refactoring the aggregation applications. This rule is modifying the control structure of the ap-plication by replacing some procedural part of the apap-plication by non-procedural code.
5.
APPLY THE RULES USING SOFTWARE
PATTERNS
An input component of any transformation rule is a non-optimised version of object-relational application. The application, is written by an object-oriented developer who prefers to iterate over classes of objects. To use the transformation rules, we need to have the in-put components based on what most application programmers use. The transformation rules presented in [4], can only apply to the ap-plications which are consistent with the special software patterns.
the inner most loop of the application. The results of the inner loop must be calculated and pass to the outer loops. OV is an object variable which can store the result of each loop and pass it to the next loop.
For instance, if the case is :
FILTERING(FILTERING(A JOIN B) ANTIJOIN (C JOIN D))
Then the template for the application must implement in the fol-lowing ways:
FILTERING { ANTIJOIN {
FILTERING { JOIN (A,B) {
} RESULT OV1 } RESULT OV2
JOIN (C,D) { } RESULT OV3 } RESULT OV4 } RESULT OV5
== OR, it can be done as follow ==
JOIN (A,B) { } RESULT OV1
FILTERING (OV1) { } RESULT OV2
JOIN (C,D) { } RESULT OV3
ANTIJOIN (OV2, OV3) { } RESULT OV4
FILTERING (OV4) { } RESULT OV5
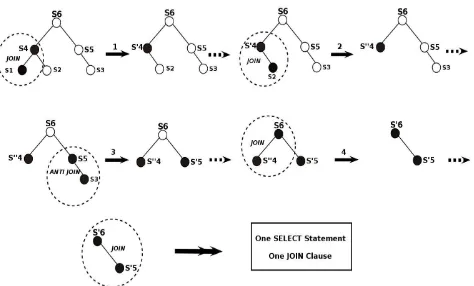
The following figure illustrates the symbolic tree of the object relational application. This tree has three levels. Both join and anti-join patterns are applied to the tree. The patterns must start to apply from the inner nodes. In this tree, each two pairs of nodes will be transferred into one node. Generally this tree presents the process of applying the patterns step by step. Each level includes two nodes and each node represents a SELECT statement which is a part of the object relational application. The join template is ap-plied for the nodes on the left side of the main branch. On the right branch the anti-join template is applied.(The patterns are presented in [3]).
Figure 3: Apply patterns symbolically on an application step by step
The outermost SELECT statement is shown as ’S’ and all other SELECT statements in the branches are shown as ’s’. Applying the templates has to be started from the two innermost SELECT state-ments. In the end, there will be only one SELECT statement. This new SELECT statement should be used in the join/anti-join clause with the other innermost SELECT statements. This symbolic figure shows how refactoring an object-relational application can modify the control structure of the application.
6.
CONCLUSION AND FUTURE WORK
This paper evaluate one of the refactoring approaches to get the better performance of object-relational applications by using the transformation rules. Also, it presents an efficient way to apply the rules to object-relational application. Using this approach, speed up the process of recognising the input component from the appli-cation and as a result getting better performance of the appliappli-cation by applying the appropriate rule. Future work will be implement-ing a refactorimplement-ing tool which can automatically restructure of the object-relational applications to get the better performance of the application.
7.
ACKNOWLEDGMENTS
The authors wish to gratefully acknowledge the help of Dr.Janusz Getta to developing the main idea presented in this paper.
8.
REFERENCES
[1] S. Agarwal. Architecting object applications for high performance with relational databases. InIn OOPSLA Workshop on Object Database Behavior, Benchmarks, and Performance. Persistence Software, Inc, 1995.
[2] T.-H. Chen, W. Shang, Z. M. Jiang, A. E. Hassan, M. Nasser, and P. Flora. Detecting performance anti-patterns for applications developed using object-relational mapping. In Proceedings of the 36th International Conference on Software Engineering, ICSE 2014, pages 1001–1012, New York, NY, USA, 2014. ACM.
[3] Z. Davar and J. Getta. Performance optimisation of object-relational database applications in client-server environments. InICSEA 2014 - Proceedings of the Ninth International Conference on Software Engineering Advances- Nice, France, 2014.
systems. InICEIS 2014 - Proceedings of the 16th
International Conference on Enterprise Information Systems, Volume 1, Lisbon, Portugal, 27-30 April, 2014, pages 201–208, 2014.
[5] M. Fowler.Refactoring: Improving the Design of Existing Code. Addison-Wesley Longman Publishing Co., Inc., Boston, MA, USA, 1999.
[6] T. Grust, M. Mayr, J. Rittinger, and T. Schreiber. Ferry: Database-supported program execution. InProceedings of the 2009 ACM SIGMOD International Conference on Management of Data, SIGMOD ’09, pages 1063–1066, New York, NY, USA, 2009. ACM.
[7] j. Jacobs and Associates.Refactoring Common SQL Performance Anti-Patterns. LLC, 2010.
[8] R. Kalantari and C. H. Bryant. Comparing the performance of object and object relational database systems on objects of varying complexity. InProceedings of the 27th British National Conference on Data Security and Security Data, BNCOD’10, pages 72–83, Berlin, Heidelberg, 2012. Springer-Verlag.
[9] H. Liu, L. Yang, Z. Niu, Z. Ma, and W. Shao. Facilitating software refactoring with appropriate resolution order of bad smells. InProceedings of the the 7th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on The Foundations of Software Engineering, ESEC/FSE ’09, pages 265–268, New York, NY, USA, 2009. ACM.
[10] I. Lukovi, S. Risti, P. Mogin, and J. Pavievi. Database schema integration process a methodology and aspects of its applying. InSad Journal of Mathematics (Formerly Review of Research, Faculty of Science, Mathematic Series), Novi Sad, 2006, Accepted for publishing, 2006.
[11] R. K. Macek, O. Application and relational database co-refactoring. computer science and information systems. ACM Trans. Program. Lang. Syst., 11(2):503524, 2014. [12] W. Meng, C. T. Yu, W. Kim, G. Wang, T. Pham, and S. Dao.
Construction of a relational front-end for object-oriented database systems. InICDE, pages 476–483. IEEE Computer Society, 1993.
[13] M. Mortensen, S. Ghosh, and J. Bieman. Aspect-oriented refactoring of legacy applications: An evaluation, 2010. [14] A. Mostefaoui and J. Kouloumdjian. Translating relational
queries to object-oriented queries according to odmg-93. In W. Litwin, T. Morzy, and G. Vossen, editors,ADBIS, volume 1475 ofLecture Notes in Computer Science, pages 328–338. Springer, 1998.
[15] J. W. Rahayu, E. Chang, T. S. Dillon, and D. Taniar. Performance evaluation of the object-relational transformation methodology.Data Knowl. Eng., 38(3):265–300, 2001.
[16] T. Schreiber, S. Bonetti, T. Grust, M. Mayr, and J. Rittinger. Thirteen new players in the team: A ferry-based linq to sql provider.PVLDB, 3(2):1549–1552, 2010.
[17] P. van Zyl, D. G. Kourie, and A. Boake. Comparing the performance of object databases and orm tools. In
Proceedings of the 2006 Annual Research Conference of the South African Institute of Computer Scientists and
Information Technologists on IT Research in Developing Countries, SAICSIT ’06, pages 1–11, Republic of South Africa, 2006. South African Institute for Computer Scientists and Information Technologists.
[18] C. Yu, Y. Zhang, W. Meng, W. Kim, G. Wang, T. Pham, and
S. Dao. Translation of object-oriented queries to relational queries. InIn: Proc. of the 11th Int. Conf. on Data Engineering, pages 90–97, 1995.
[19] M. F. Zibran and C. K. Roy. A constraint programming approach to conflict-aware optimal scheduling of prioritized code clone refactoring. InProceedings of the 2011 IEEE 11th International Working Conference on Source Code Analysis and Manipulation, SCAM ’11, pages 105–114, Washington, DC, USA, 2011. IEEE Computer Society. [20] M. F. Zibran and C. K. Roy. Towards flexible code clone