LAPORAN PRAKTIKUM
MULTIVARIAT
MODUL V
Analisis Faktor dan Analisis
Cluster
Pada Data
Kemiskinan Berdasarkan Dimensi Kualitas Kesehatan
Dan Kualitas Ekonomi di Jawa Tengah
Oleh:
Raras Anasi (1313030055)
Elok Faiqoh (1313030067)
AsistenDosen: Denni Hariyanto
Dosen: Santi Wulan Purnami, M.Si, Ph.D
Program Studi Diploma III Jurusan Statistika Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Teknologi Sepuluh Nopember Surabaya
ABSTRAK
Penduduk miskin adalah penduduk yang memiliki rata-rata pengeluaran perkapita perbulan dibawah garis kemiskinan.Banyak indikator yang digunakan dalam mengindikasi kemiskinan, salah satunya adalah dari segi kesehatan dan ekonomi. Praktikum ini, akan dilakukan analisis cluster pada data kemiskinan berdasarkan dimensi kualitas kesehatan dan kualitas ekonomi. Analisis Cluster merupakan metode pengelompokan dengan dua atau lebih objek yang memiliki kemiripan karakteristik paling dekat.Data yang digunakan adalah data Tugas Akhir Farisca Susiani dengan menggunakan 6 variabel dan diperoleh kesimpulan bahwa Pengujian asumsi dengan melihat boxplot menunjukkan terdapat data yang outlier tetapi diasumsikan tidak terdapat outlier, nilai korelasi antar variabelmenunjukkan tidak ada multiokolinieritas pada data, sedangkan melihat nilai KMO menunjukkan data yang diambil sudah cukup dan dapat digunakan pada analisis klaster. Selain itu, juga diketahui bahwa Variabel penelitian yang berpengaruh terhadap terbentuknya kluster yaitu presentase rumah tangga miskin yang jenis lantai bangunan tempat tinggalnya terbuat dari tanah/kayu berkualitas rendah per kecamatan.
4.3 Analisis Klaster...11 4.2.1 Analisis Cluster Hierarki...13 4.2.2 Analisis ClusterNon-Hierarki...16
BAB V KESIMPULAN DAN SARAN
5.1Kesimpulan...21 5.2 Saran...22
DAFTAR TABEL
Halaman
Tabel 3.1 Variabel Penelitian... 9
Tabel 4.1 Uji Kecukupan Data ...12
Tabel 4.2 Hasil Pengujian Korelasi Variabel Penelitian...12
Tabel 4.3 Pembentukan Dendogram...13
Tabel 4.4 Pengelompokkan Klaster Hierarki Kabupaten/Kota...15
Tabel 4.5 Pusat Klaster...16
Tabel 4.6 Pengelompokkan klaster non Hierarki kabupaten/kota...16
Tabel 4.6 Pengelompokkan klaster non Hierarki kabupaten/kota...16
Tabel 4.7 Rata-rata jarak cluster...18
DAFTAR GAMBAR
Halaman
Gambar 3.1 Diagram Alir...10
Gambar 4.1 Boxplot Outlier pada Variabel Penelitian...11
BAB I
PENDAHULUAN
1.1 Latar Belakang
Peranan statistik dalam kegiatan penelitian banyak sekali. Statistik dapat memberikan teknik-teknik yang tepat dalam pengumpulan, pengklasifikasian dan penyajian data, sehingga hasil-hasil penelitian lebih mudah dimengerti. Statistik dapat memberikan suatu ukuran yang dapat mensifatkan populasi, menyatakan variasi dan memberikan gambaran yang lebih akurat tentang kecenderungan-kecenderungan suatu variabel penelitian. Statistik dapat digunakan sebagai dasar untuk menjelaskan hubungan serta tingkat hubungan antara dua variabel atau lebih. Banyak variabel yang dapat diteliti menggunakan metode dalam statistik, salah satunya yaitu permasalahan tentang kemiskinan (Winarsunu, 2010).
Kemiskinan adalah keadaan tidak berharta, berpenghasilan rendah dan serba kekurangan dalam menjalani kehidupan sehari-hari. Kemiskinan juga bisa diartikan sebagai suatu situasi, baik berupa proses maupun akibat, dimana seseorang tidak mampu untuk berinteraksi dengan lingkungan di sekitarnya untuk memenuhi kebutuhan hidupnya (Ellis, 2014). Banyak indikator yang digunakan dalam mengindikasi kemiskinan, salah satunya adalah dari segi kesehatan dan ekonomi. kemiskinan berdasarkan dimensi kualitas kesehatan dan kualitas ekonomi. Data yang digunakan sebanyak 30 data dengan X1 (presentase tumah tangga miskin yang luas lantai bangunan tempat tinggalnya kurang dari 32 m2), X
miskin yang tidak sanggup membayar biaya pengobatan di puskesmas per kecamatan), dan X6 (Presentase rumah tangga miskin yang menggunakan bahan bakar untuk memasak sehari-hari adalah kayu bakar per kecamatan). Data yang diperoleh selanjutnya dilakukan pengujian asumsi analisis cluster, yaitu deteksi
outlier, uji kecukupan data dan deteksi multikolinearitas.
1.2 Rumusan Masalah
Berdasarkan latar belakang yang telah diuraikan, maka rumusan masalah pada penelitian ini adalah sebagai berikut :
1. Bagaimana asumsi yang harus dipenuhi pada analisis cluster yang mencakup deteksi outlier, pemeriksaan kecukupan data dan pemeriksaan multikolinearitas pada data kemiskinan berdasarkan dimensi kualitas kesehatan dan kualitas ekonomi?
2. Bagaimana hasil analisis cluster pada data kemiskinan berdasarkan dimensi kualitas kesehatan dan kualitas ekonomi?
1.3 Tujuan
Berdasarkan rumusan masalah, maka tujuan yang ingin dicapai dari penelitian ini adalah sebagai berikut.
1. Mengetahui asumsi yang harus dipenuhi pada analisis cluster yang mencakup deteksi outlier, pemeriksaan kecukupan data dan pemeriksaan multikolinearitas pada data kemiskinan berdasarkan dimensi kualitas kesehatan dan kualitas ekonomi
1.5 Batasan Masalah
Batasan masalah yang digunakan dalam penelitian ini adalah data yang digunakan harus memenuhi asumsi analisis cluster yaitu tidak ada outlier,
BAB II
TINJAUAN PUSTAKA
2.1 Pendeteksisan Outlier
Outlier merupakan data yang mempunyai nilai jauh di atas atau jauh di bawah rata-rata suatu data (Singgih, 2010). Metode yang digunakan harus berdistribusi normal jika data tidak berdistribusi normal maka hasil analisis dikhawatirkan menjadi bias sedangkan untuk menentukan data tersebut outlier atau bukan maka perlu diuji kemudian dilakukan pemeriksaan dari data yang telah diuji dengan ketentuan -2,5 > X > 2,5 bila melewati dari batas yang telah ditentukan maka dapat dikatakan data mengalami outlier
2.2 Uji Kaiser Meyer Olkin (KMO)
Uji KMO bertujuan untuk mengetahui apakah semua data yang telah terambil telah cukup untuk difaktorkan. Hipotesis dari KMO adalah sebagai berikut :
Hipotesis
Ho : Jumlah data cukup untuk difaktorkan H1 : Jumlah data tidak cukup untuk difaktorkan
Statistik uji :
rij = Koefisien korelasi antara variabel i dan j
aij = Koefisien korelasi parsial antara variabel i dan j
2.3 Uji Bartlett Sphericity
Uji Bartlett ini digunakan untuk mengetahui korelasi antar variabel
prediktor. Variabel
X
i, X
2,
...
, X
p dikatakan bersifat saling bebas (independent)jika matriks korelasi antar variabel membentuk matriks identitas. Untuk menguji kebebasan antar variabel ini dapat dilakukan uji Bartlett sphericity berikut. Hipotesis : bebas. Jika hipotesis ini yang diterima maka penggunanan metode multivariate
tidak layak terutama metode analisis komponen utama dan analisis faktor (Morrison, 2005).
2.4 Analisis Cluster
Cluster analysis adalah analisis statistika yang bertujuan untuk mengelompokkan data sedemikian sehingga data yang berada dalam kelompok yang sama mempunyai sifat yang relatif homogen daripada data yang berada dalam kelompok yang berbeda (Johnson and Wichern, 2007).
Ditinjau dari hal-hal yang dikelompokkan, cluster analysis dibagi menjadi dua macam, yaitu :
1. Pengelompokkan observasi 2. Pengelompokkan variable
Dalam proses penggabungan kelompok selalu diikuti dengan perbaikan matriks jarak. Suatu fungsi disebut jarak jika mempunyai sifat tak negative (dij ≥
0) dan (dij = 0) jika i = j, simetri (dij = dji), panjang salah satu sisi segitiga selalu
lebih kecil atau sama dengan jumlah dua sisi yang lain (dij ≤ dik + djk).
1. Jarak Euclidean
d
(
x, y
)=
√
(
x
−
y
)
'
(
x
−
y
)
(2.3)Sebuah tinjauan cluster analysis dalam penelitian kesehatan psikologi menemukan bahwa pengukuran jarak yang paling umum dalam penelitian adalah jarak Euclidian atau kuadrat jarak Euclidian.
2. Jarak Minkowski
Secara umum, cluster analysis memiliki dua metode, yaitu : 1. Cluster hierarki.
2. Cluster Non-hierarki
2.5 Analisis Cluster Hierarki
Metode ini digunakan untuk mencari struktur pengelompokkan dari objek-objek. Jadi, hasil pengelompokkannya disajikan secara hierarki atau berjenjang. Metode hierarki ini terdiri dari dua cara,yaitu :
a. Agglomerative (penggabungan).
Cara ini digunakan jika masing-masing objek dianggap satu kelompok kemudian antar kelompok yang jaraknya berdekatan bergabung menjadi satu kelompok.
Cara ini dgunakan jika pada awalnya semua objek berada dalam satu gerombol. Setelah itu, sifat paling beda dipisahkan dan membentuk satu gerombol yang lain. Proses tersebut berlanjut sampai semua objek tersebut masing-masing membentuk satu gerombol.
Metode-metode pengelompokkan hierarki dibedakan berdasarkan konsep jarak antar kelompok, penentuan jarak antar kelompok untuk metode-metode tersebut adalah :
1. Metode single linkage
Metode ini mengelompokkan dua objek yang mempunyai jarak terdekat terlebih dahulu. Jarak antar kelompok (u,v) dengan w adalah :
d
(uv)w=
min
{
d
uw,d
vw}
(2.7)
Dimana : d(uv) w = Datakelompok ke (uv) dengan w
duw = Data kelompokke uw
dvw = Data kelompokke vw
2. Metode complete linkage
Metode ini akan mengelompokkan dua objek yang mempunyai jarak terjauh terlebih dahulu. Jarak antar kelompok (u,v) dengan w adalah :
d
(uv)w=
max
{
d
uw,d
vw}
(2.8)
Dimana : d(uv) w = Datakelompok ke (uv) dengan w
duw = Data kelompokke uw
dvw = Data kelompokke vw
3. Metode average linkage
Metode ini akan mengelompokkan objek berdasarkan jarak rata-rata yang didapat dengan melakukan rata-rata semua jarak objek terlebih dahulu. Jarak antar kelompok (u,v) dengan w adalah :
N(uv) = Jumlah semua clusteruv
Nw = Jumlah semua clusterw
Hasil dari analisis Cluster akan disajikan dalam bentuk struktur pohon yang disebut dendogram. Pemotongan dendogram dapat dilakukan pada selisih jarak penggabungan yang terbesar. Akar pohon terdiri dari cluster tunggal yang berisi semua pengamatan, dan daun sesuai dengan pengamatan individu. (Johnson and Wichern, 2007).
2.6 Analisis Cluster Non-Hierarki
Metode non-hierarki digunakan apabila jumlah kelompok yang diinginkan diketahui dan biasanya dipakai untuk mengelompokkan data yang ukurannya besar. Biasanya metode yang dipakai dalam mengcluster data yang berukuran besar yaitu metode K “means”. Algoritma dari metode ini sebagai berikut.
1. Tentukan bersama k (yaitu banyaknya kelompok dan tentukkan juga centroid di tiap kelompok).
2. Hitung jarak antara setiap objek dengan setiap centroid.
3. Hitung kembali rataan (centroid) untuk kelompok yang baru terbentuk. 4. Ulangi langkah kedua sampai tidak ada lagi pemindahan objek antar
kelompok.
Penentuan terakhir suatu objek ke suatu kelompok tertentu tidak tergantung dari K inisial yang pertama kali ditentukan. Perubahan terbesar kemungkinan hanya terjadi pada realokasi yang pertama saja (Johnson and Wichern, 2007).
2.5 Kemiskinan
BAB III
METODOLOGI PENELITIAN
3.1 Sumber Data
Data yang digunakan dalam penelitian ini adalah data sekunder yang diambil dari Tugas Akhir Farisca Susiani dengan NRP 1309100113 di Ruang Baca Jurusan Statistika pada hari Selasa, 17 Maret 2015 pukul 15.00 WIB dengan judul Tugas Akhir “ Penentuan Indikator Kemiskinan Berdasarkan Dimensi Kualitas Kesehatan dan Kualitas Ekonomi Menggunakan Confirmatory Factor Analysis (CFA) dengan Pendekatan Bayesian ”. Data yang digunakan dalam penelitian ini adalah sebanyak 30 data.
3.2 Variabel Penelitian
Dalam penelitian ini yang digunakan sebagai variabel penelitian adalah berikut.
Tabel 3.1 Variabel Penelitian
X1 Presentase rumah tangga miskin yang luas lantai
bangunan tempat tinggalnya kurang dari 32 m2
X2 Presentase rumah tangga miskin yang jenis lantai
X4 Presentase rumah tangga miskin yang tidak mempunyai
jenis atap dari genteng per kecamatan
X5 Presentase rumah tangga miskin yang tidak sanggup
membayar biaya pengobatan di puskesmas per kecamatan X6 Presentase rumah tangga miskin yang menggunakan
bahan bakar untuk memasak sehari-hari adalah kayu bakar per kecamatan
3.3 Langkah Analisis
Langkah analisis yang dilakukan pada praktikum ini adalah sebagai berikut. 1. Menginputkan pada data kemiskinan berdasarkan dimensi kualitas
kesehatan dan kualitas ekonomi
Uji Kecukupan data
Kesimpulan
Deteksi Multikolinieritas Menginputkan data
Deteksi Outlier
Analisis Cluster
3. Menguji asumsi kecukupan data pada data kemiskinan berdasarkan dimensi kualitas kesehatan dan kualitas ekonomi
4. Menguji asumsi multikolinearitas pada data kemiskinan berdasarkan dimensi kualitas kesehatan dan kualitas ekonomi
5. Melakukan analisis cluster pada data kemiskinan berdasarkan dimensi kualitas kesehatan dan kualitas ekonomi
6. Menginterpretasikan hasil analisis.
7. Melakukan penarikan kesimpulan dan saran
3.4 Diagram Alir
Diagram alir menggambarkan alur perjalanan pembuatan laporan ini, mulai dari perumusan masalah hingga pemberian kesimpulan dan saran. Diagram alir dalam laporan ini adalah sebagai berikut,
Gambar 3.1 Diagram Alir
Ya
BAB IV
ANALISIS DAN PEMBAHASAN
4.1 Pengujian Asumsi Analisis Cluster
Dalam melakukan analisis cluster harus memenuhi beberapa asumsi terlebih dahulu. Berikut adalah pengujian asumsi yang dilakukan.
4.1.1 Pendeteksian Data Outlier
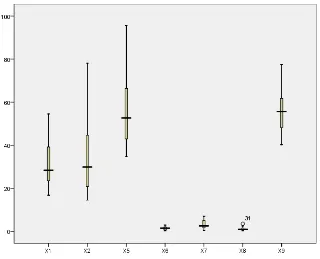
Outlier atau pencilan merupakan data yang mempunyai nilai jauh dibandingkan data-data yang lain dalam satu variabel pengamatan. Data pencilan perlu dideteksi supaya kita dapat mencari tahu sebab-sebab terjadinya outlier pada pengamatan dan variabel tersebut, Berikut adalah hasil deteksi outlier pada data kemiskinan berdasarkan dimensi kualitas kesehatan dan ekonomi di Jawa Tengah.
Gambar 4.1 Boxplot Outlier pada Variabel Penelitian
bahwa terdapat data outlier pada variabel penelitian tetapi pada penelitian ini diasumsikan tidak terdapat data outlier.
4.1.2 Uji Kecukupan Data KMO
Pengujian kecukupan data dapat dilakukan dengan uji KMO. Uji KMO bertujuan untuk mengetahui apakah data kemiskinan berdasarkan dimensi kualitas kesehatan dan ekonomi di Jawa Tengah yang telah terambil cukup untuk dianalisis.
Berdasarkan hasil uji kecukupan KMO diketahui bahwa nilai KMO dari data kemiskinan berdasarkan dimensi kualitas kesehatan dan ekonomi di Jawa Tengah adalah 0,529 atau dapat dikatakan bahwa data sudah cukup karena nilai KMO yaitu 0,529 lebih besar dari 50%, sehingga dapat disimpulkan bahwa data kemiskinan berdasarkan dimensi kualitas kesehatan dan ekonomi di Jawa Tengah cukup untuk dianalisis.
4.1.3 Pendeteksian Multikolinieritas
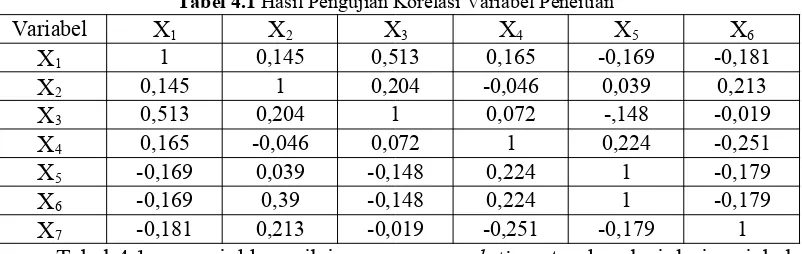
Pengujian multikolinieritas dilakukan untuk mengetahui apakah ada hubungan yang signifikan antar variabel prediktor. Pengujian multikolinieritas dapat dilakukan dengan beberapa cara, salah satunya dengan melihat korelasi antar variabel penelitian. Jika nilai korelasi lebih dari 0,95, maka dapat dikatakan terdapat korelasi antar variabel tersebut. Berikut merupakan pendeteksian multikolinieritas dengan melihat korelasi dari data kemiskinan berdasarkan dimensi kualitas kesehatan dan ekonomi di Jawa Tengah.
Tabel 4.1 Hasil Pengujian Korelasi Variabel Peneitian
Variabel X1 X2 X3 X4 X5 X6
4.2 Analisis Cluster
Analisis cluster bertujuan untuk mengelompokkan data kemiskinan berdasarkan dimensi kualitas kesehatan dan ekonomi di Jawa Tengah sehingga data yang berada dalam kelompok yang sama mempunyai sifat yang relatif homogen daripada data yang berada dalam kelompok yang berbeda. Analisis
cluster terdapat dua jenis yaitu hierarki dan non hierarki yang dijelaskan sebagai berikut.
4.2.1 Analisis Cluster Hierarki
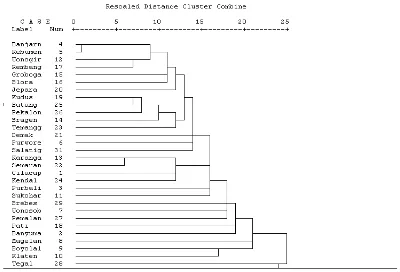
Analisis cluster hierarki dilakukan dimana hasil pengelompokkannya disajikan secara hierarki atau berjenjang. Jumlah cluster yang terbentuk dalam analisis cluster hierarki ini sebanyak 3 cluster dengan jumlah cluster yaitu 2, 3 dan 4. Hasil dan pembahasan analisis cluster hierarki pada data kemiskinan berdasarkan dimensi kualitas kesehatan dan ekonomi di Jawa Tengah dengan langkah awal yaitu membentuk dendogram yang dijelaskan sebagai berikut.
Berdasarkan Gambar 4.2 dapat diperoleh hasil bahwa terdapat beberapa
cluster atau kelompok yang dapat dibentuk sehingga setiap kabupaten/kota yang mempunyai karakteristik yang sama bisa atau memiliki jarak yang berdekatan masuk dalam satu cluster. Kabupaten/kota yang masuk dalam satu anggota cluster
dengan jumlah cluster yang berbeda adalah sebagai berikut.
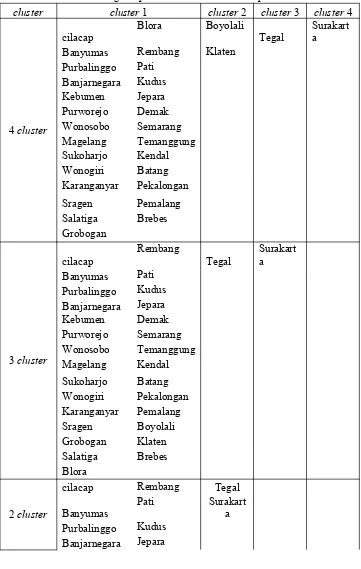
Tabel 4.3 Pengelompokan Cluster Hierarki Kabupaten/Kota
cluster cluster 1 cluster 2 cluster 3 cluster 4
4 cluster
Kebumen Demak Purworejo Semarang Wonosobo Temanggung Magelang Kendal Sukoharjo Batang Wonogiri Pekalongan Karanganyar Pemalang Sragen Salatiga Grobogan Brebes Blora
Berdasarkan Tabel 4.3 dapat diketahui bahwa terdapat cluster sebanyak 2, 3 dan 4 dengan anggota cluster yang berbeda. Pada jumlah cluster 4, kabupaten/kota yang masuk pada cluster 2 yaitu Boyolali dan Klaten, kabupaten/kota yang masuk pada cluster 3 yaitu kabupaten Tegal, kabupaten/kota yang masuk pada cluster 4 yaitu kota Surakarta sedangkan kabupaten/kota lainnya masuk dalam cluster 1. Pada jumlah cluster 3, kabupaten kota yang masuk pada
cluster 2 yaitu kabupaten Tegal, kabupaten/kota yang masuk pada cluster 3 yaitu kota Surakarta sedangkan kabupaten/kota lainnya masuk dalam cluster 1. Pada jumlah cluster 2, kabupaten/kota yang masuk pada cluster 2 yaitu kota Surakarta dan Tegal sedangkan kabupaten/kota lainnya masuk dalam cluster 1.
4.2.2 Analisis Cluster Non Hierarki
Analisis cluster non hierarki dilakukan apabila jumlah kelompok yang diinginkan diketahui dan biasanya dipakai untuk mengelompokkan data yang ukurannya besar. Metode ini dimulai dengan menentukan terlebih dahulu jumlah
cluster yang diinginkan, dalam kasus ini jumlah cluster yang diinginkan adalah 2. Hasil dan pembahasan analisis cluster non hierarki pada data kemiskinan berdasarkan dimensi kualitas kesehatan dan ekonomi di Jawa Tengah dengan langkah awal menentukan pusat cluster adalah sebagai berikut.
Variabel Cluster
Tabel 4.4 menunjukkan bahwa pusat cluster pada variabel X1 yaitu (43,94 : 34,95), pusat cluster pada variabel X2 berada pada koordinat (78,10 ; 17,71), pusat cluster pada variabel X3 berada pada koordinat (52,10 ; 95,70), pusat
cluster pada variabel X4 berada pada koordinat (1,98 ; 2,50), pusat cluster pada variabel X5 berada pada koordinat (5,83 ; 1,92) dan pusat cluster pada variabel X6 berada pada koordinat (57,82 ; 49,08). Langkah selanjutnya adalah menentukan jarak setiap kabupaten/kota ke pusat cluster kemudian mengelompokkannya berdasarkan jarak yang paling dekat dengan pusat cluster
sehingga diperoleh pengelompokan cluster dengan iterasi sebanyak 4 sebagai berikut.
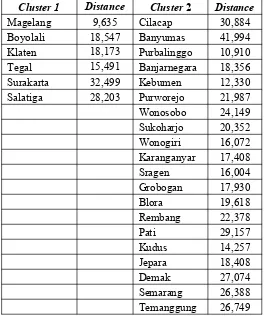
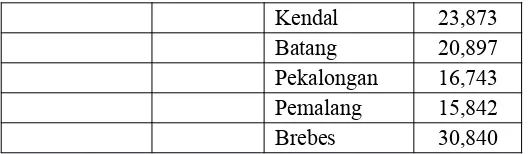
Tabel 4.5 Pengelompokan Cluster Non Hierarki Kabupaten/Kota
Cluster 1 Distance Cluster 2 Distance
Kendal 23,873
Batang 20,897
Pekalongan 16,743 Pemalang 15,842
Brebes 30,840
Berdasarkan Tabel 4.5 dapat diketahui bahwa cluster yang terbentuk sesuai yang diinginkan sebanyak 2. Kabupaten/kota yang masuk dalam cluster 1 yaitu Magelang, Boyolali, Klaten, Pemalang, Tegal, Surakarta, dan Salatiga sedangkan kabupaten/kota lainnya masuk dalam cluster 2.
Dalam pengelompokan cluster perlu diketahui rata-rata pusat cluster yang paling besar untuk mengetahui cluster yang memiliki jarak paling jauh. Hasil dan pembahasannya adalah sebagai berikut.
Tabel 4.6 Rata-Rata jarak Cluster
variabel Cluster
Berdasarkan Tabel 4.6 menunjukkan bahwa pada variabel X1, X2, X3,X5, dan X6 memiliki rata-rata jarak cluster paling besar pada cluster 1 sedangkan variabel X4 memiliki rata-rata jarak cluster paling besar pada cluster 2 sehingga dapat dikatakan bahwa cluster 1 memiliki rata-rata jarak antar cluster paling besar dibanding cluster 2. Langkah selanjutnya yaitu analisis ANOVA untuk mengetahui variabel apa saja yang berpengaruh signifikan terhadap pembentukan
cluster pada data kemiskinan berdasarkan dimensi kualitas kesehatan dan ekonomi di Jawa Tengah. Hasil dan pembahasannya dalah sebagai berikut.
Hipotesis :
H1 : β1 ≠ 0 (Presentase rumah tangga miskin yang luas lantai bangunan tempat tinggalnya kurang dari 32 m2 berpengaruh signifikan terhadap pembentukan cluster)
2. H0 : β2 = 0 (Presentase rumah tangga miskin yang jenis lantai bangunan tempat tinggalnya terbuat dari tanah/kayu berkualitas rendah per kecamatan tidak berpengaruh signifikan terhadap pembentukan cluster)
H1 : β2 ≠ 0 (Presentase rumah tangga miskin yang jenis lantai bangunan tempat tinggalnya terbuat dari tanah/kayu berkualitas rendah per kecamatan berpengaruh signifikan terhadap pembentukan cluster)
3. H0 : β3 = 0 (Presentase rumah tangga miskin yang sumber air minumnya berasal dari sumur/mata air tidak terlindung/sungai per kecamatan tidak berpengaruh signifikan terhadap pembentukan cluster)
H1 : β3 ≠ 0 (Jumlah Presentase rumah tangga miskin yang sumber air minumnya berasal dari sumur/mata air tidak terlindung/sungai per kecamatan berpengaruh signifikan terhadap pembentukan cluster)
4. H0 : β4 = 0 (Presentase rumah tangga miskin yang tidak mempunyai jenis
5. H0 : β5 = 0 (Presentase rumah tangga miskin yang tidak sanggup membayar biaya pengobatan di puskesmas per kecamatan tidak berpengaruh signifikan terhadap pembentukan cluster)
H1 : β5 ≠ 0 (Presentase rumah tangga miskin yang tidak sanggup membayar biaya pengobatan di puskesmas per kecamatan berpengaruh signifikan terhadap pembentukan cluster)
H1 : β5 ≠ 0 (Presentase rumah tangga miskin yang menggunakan bahan bakar untuk memasak sehari-hari adalah kayu bakar per kecamatan berpengaruh signifikan terhadap pembentukan cluster)
Taraf signifikan : α = 0,05
Daerah kritis : Tolak H0 jika P-value < α Statistik uji :
Tabel 4.7 ANOVA
Variabel F P-value
X1 0,154 0,698
X2 114,097 0,000
X3 0,949 0,338
X4 0,153 0,699
X5 0,005 0,946
X6 3,746 0,063
BAB V
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Kesimpulan yang dapat diambil dari analisis cluster pada penelitian mengenai data kemiskinan berdasarkan dimensi kualitas kesehatan dan ekonomi di Jawa Tengah adalah sebagai berikut.
1. Pengujian asumsi dengan melihat boxplot menunjukkan terdapat data yang
outlier tetapi diasumsikan tidak terdapat outlier, nilai korelasi antar variabel menunjukkan tidak ada multiokolinieritas pada data, sedangkan melihat nilai KMO menunjukkan data yang diambil sudah cukup dan dapat digunakan pada analisis cluster.
2. Analisis cluster hierarki menunjukkan pada jumlah cluster 4, kabupaten/kota yang masuk pada cluster 2 yaitu Boyolali dan Klaten, kabupaten/kota yang masuk pada cluster 3 yaitu kabupaten Tegal, kabupaten/kota yang masuk pada cluster 4 yaitu kota Surakarta sedangkan kabupaten/kota lainnya masuk dalam cluster 1. Pada jumlah cluster 3, kabupaten kota yang masuk pada cluster 2 yaitu kabupaten Tegal, kabupaten/kota yang masuk pada cluster 3 yaitu kota Surakarta sedangkan kabupaten/kota lainnya masuk dalam cluster 1. Pada jumlah cluster 2, kabupaten/kota yang masuk pada cluster 2 yaitu kota Surakarta dan Tegal sedangkan kabupaten/kota lainnya masuk dalam cluster 1. Analisis cluster
non hierarki menunjukkan bahwa Kabupaten/kota yang masuk dalam
5.2 Saran
DAFTAR PUSTAKA
Ellin, 2014. Kemiskinan.file:///E:/Pengertian%20Kemiskinan%20Menurut %20Para%20Ahli%20_%20 Dilihatya.htm Diakses pada tanggal 7 Mei 2015.
Johnson, R. A., & Wichern, D. 2007. Applied Multivariate Statistical Analysis. New Jersey: Prentice Hall.
Morrison, D. F. 2005. Multivariate Statistical Methods Fourth Edition. The Wharton School University of Pennsylvania.
Rencher, A. R. 2002. Methods of Multivariate Analysis Second Edition. John Wiley & Sons, Inc. New York
Santoso, Singgih. 2010. Statistik Multivariat, Jakarta : PT. Gramedia.
Winarsunu, Tulus.2010.Statistik Dalam Penelitian Psikologi Dan Pendidikan.
LAMPIRAN
Lampiran 1 Data Penelitian
No Kecamatan X1 X2 X3 X4 X5 X6
1 Cilacap 43,63 28,67 82,2 1,53 2,74 62,51
2 Banyumas 34,95 17,71 95,7 2,5 1,92 49,08
3 Purbalingga 35,95 17,35 52,7 2,7 5,54 54,94
4 Banjarnegara 24,49 14,48 44,9 1,5 4,62 59,18
5 Kebumen 22,47 23,37 52,5 1,35 4,51 60,59
6 Purworejo 25,91 46,05 48,2 1,87 2,54 48,79
7 Wonosobo 16,79 29,84 36,6 2,9 3,77 55,71
8 Magelang 35,82 63,66 70 2,76 1,65 61,02
9 Boyolali 37,47 66,6 67,4 2,3 6,98 44,71
10 Klaten 43,94 78,1 52,1 1,98 5,83 57,82
11 Sukoharjo 43,31 23,45 42,4 1,8 1,7 64,21
12 Wonogiri 26,57 22,06 50,3 0,98 2,54 67,49
13 Karanganyar 46,54 27,1 56,9 2,55 2,4 44,89
14 Sragen 25,82 15,82 65,2 0,65 2,7 54,03
15 Grobogan 27,99 43,14 51,6 1,84 6,12 57,62
16 Blora 18,11 32,19 43,4 1,54 5,62 48,94
17 Rembang 20 23,8 42,2 0,75 0,87 67,33
18 Pati 39,66 36,78 79 0,78 5,43 43,41
19 Kudus 26,39 20,01 52,7 0,45 2,67 42,76
20 Jepara 37,22 15,82 64,1 0,88 0,89 64,11
21 Demak 26,77 18,57 34,9 0,65 6,01 68,83
22 Semarang 48,71 37,57 70,9 2,6 1,65 47,66
23 Temanggung 21,43 18,06 34,7 1,95 1,99 43,05
24 Kendal 46,23 21,68 72,8 1,5 2,35 49,1
25 Batang 20,93 31,57 41 0,78 1,83 44,14
26 Pekalongan 28,34 36,62 42,2 0,58 1,55 53,61
27 Pemalang 20,35 62,76 56 0,48 6,02 58,74
28 Tegal 20,81 68,49 63,4 0,98 0,39 69,66
29 Brebes 54,5 38,51 65,4 0,47 1,45 40,23
30 Surakarta 37,8 77,36 88 0,23 0,41 77,46
31 Salatiga 38,71 57,7 36,2 0,53 0,55 60,86
Correlations
X1 X2 X5 X6 X7 X9
X1 Pearson Correlation 1 .145 .513** .165 -.169 -.181
Sig. (2-tailed) .437 .003 .374 .362 .331
N 31 31 31 31 31 31
X2 Pearson Correlation .145 1 .204 -.046 .039 .213
Sig. (2-tailed) .437 .271 .805 .835 .249
N 31 31 31 31 31 31
X5 Pearson Correlation .513** .204 1 .072 -.148 -.019
Sig. (2-tailed) .003 .271 .699 .428 .919
N 31 31 31 31 31 31
X6 Pearson Correlation .165 -.046 .072 1 .224 -.251
Sig. (2-tailed) .374 .805 .699 .226 .174
N 31 31 31 31 31 31
X7 Pearson Correlation -.169 .039 -.148 .224 1 -.179
Sig. (2-tailed) .362 .835 .428 .226 .336
N 31 31 31 31 31 31
X9 Pearson Correlation -.181 .213 -.019 -.251 -.179 1
Sig. (2-tailed) .331 .249 .919 .174 .336
N 31 31 31 31 31 31
**. Correlation is significant at the 0.01 level (2-tailed).
Lampiran 3 Uji Kecukupan Data KMO
KMO and Bartlett's Test
Kaiser-Meyer-Olkin Measure of Sampling Adequacy. .529
Bartlett's Test of Sphericity Approx. Chi-Square 18.476
df 15
Lampiran 4 Pengelompokkan Cluster
Cluster 1 Cluster 2 Cluster 1 Cluster 2
Lampiran 5 Pengelompokan Cluster
Cluster Membership
Case 4 Clusters 3 Clusters 2 Clusters
* * * * * * * * * * * * * * * * * * * H I E R A R C H I C A L C L U S T
Initial Cluster Centers
Cluster
1 2
X1 43.94 34.95
X2 78.10 17.71
X3 52.10 95.70
X4 1.98 2.50
X5 5.83 1.92
X6 57.82 49.08
Lampiran 7 Interaksi
Iteration Historya
Iteration
Change in Cluster Centers
1 2
1 30.502 36.695
2 10.329 4.192
3 3.196 .866
4 2.702 .853
5 3.709 .956
Lampiran 9 Final Cluster Centers K-Means
Final Cluster Centers
Cluster
1 2
X1 33.56 31.78
X2 67.81 26.68
X3 61.87 55.10
X4 1.32 1.46
X5 3.12 3.06
X6 61.47 53.84
Lampiran 10 ANOVA Variabel Penelitian
ANOVA
Cluster Error
F Sig.
Mean Square df Mean Square df
X1 17.124 1 111.178 29 .154 .698
X2 9169.655 1 80.367 29 114.097 .000
X3 248.184 1 261.427 29 .949 .338
X4 .106 1 .692 29 .153 .699
X5 .019 1 4.127 29 .005 .946
X6 315.090 1 84.123 29 3.746 .063