BAB IV
ANALISIS DAN EVALUASI
4.1. Analisis
dan
Evaluasi
Pada bab ini akan dijabarkan secara rinci bagaimana langkah – langkah yang dilakukan untuk melakukan analisis dan evaluasi dari pengujian sistem. Dalam melakukan pengujian dan evaluasi, terdapat tujuh langkah utama yaitu :
Gambar 4.1. Langkah analisis dan evaluasi
1. Pengujian performansi sistem sebelum melakukan implementasi MV. 2. Simulasi proses seleksi MV dengan menggunakan aplikasi prototipe. 3. Pengujian performansi sistem setelah melakukan implementasi MV. 4. Melakukan estimasi analisis biaya yang dikeluarkan untuk
implementasi MV pada sistem.
5. Melakukan analisis manfaat yang didapatkan setelah implementasi MV dengan menggunakan metode gap analysis.
6. Melakukan evaluasi perbandingan biaya dan manfaat untuk mendapatkan hasil evaluasi dari solusi yang ditawarkan.
7. Melakukan evaluasi prototype aplikasi seleksi MV
Dalam melakukan pengujian, peneliti menggunakan dua buah data sampel pada tabel fact dengan ukuran sebesar 1.25G dan 11.05G, hal ini dikarenakan adanya limitasi untuk mendapatkan data tepat sebesar 1G dan 10G sesuai dengan rekomendasi dari TPC-H (TPC, 2011). Untuk melakukan simulasi proses seleksi MV pada aplikasi prototype diperlukan query workload sebagai data sampel dengan beberapa pertimbangan dalam melakukan pemilihan sampel, yaitu :
1. Query untuk mendapatkan laporan pendapatan berdasarkan jenis trafik dan jenis charging adalah paling sering digunakan. Parameter query
yang sering digunakan sebagai predicate adalah jenis charging yang berelasi dengan akses ke facebook (Q3 dan Q4)dan jenis trafik yang berelasi dengan akses data GPRS (Q7 dan Q8).
2. Laporan pendapatan harian adalah laporan yang paling penting karena untuk melihat performa jaringan dan pendapatan setiap harinya (Q1-Q8).
3. Sistem DWS yang digunakan dalam penelitian hanya mencakup area region Jawa Timur dan sekitarnya, sehingga parameter yang pilih adalah area Surabaya (Q2 dan Q4) dan Malang (Q6 dan Q8) karena area ini mempunyai jumlah pelanggan dan jumlah trafik paling tinggi diantara kota lainnya.
Berikut ini adalah data sampel yang digunakan yang terdiri dari delapan jenis query.
Tabel 4.1 Query Workload untuk Uji Coba
ID Teks Query Frek
Q1 select wftd.FINANCIAL_DATE_KEY, sdtf.branch,
wccd.CH_CATEGORY_NAME ,sum(sdtf.DURATION), sum(sdtf.FREE_DURATION),
sum(sdtf.NUMBER_OF_TRANSACTIONS),sum(sdtf.TOTAL_COST), sum(sdtf.VOLUME) from sdm_daily_traffic_facts sdtf,
wh_charging_categories_dim wccd, wh_financials_time_dim wftd where sdtf.CH_CATEGORY_ID = wccd.CH_CATEGORY_ID and sdtf.FINANCIAL_DATE_KEY = wftd.FINANCIAL_DATE_KEY and wftd.FINANCIAL_DATE_KEY = 20111220000 group by wftd.FINANCIAL_DATE_KEY, sdtf.branch, wccd.CH_CATEGORY_NAME order by wftd.FINANCIAL_DATE_KEY, sdtf.branch, wccd.CH_CATEGORY_NAME 2
Q2 select wftd.FINANCIAL_DATE_KEY, sdtf.branch,
wccd.CH_CATEGORY_NAME ,sum(sdtf.DURATION), sum(sdtf.FREE_DURATION),
sum(sdtf.NUMBER_OF_TRANSACTIONS),sum(sdtf.TOTAL_COST), sum(sdtf.VOLUME) from sdm_daily_traffic_facts sdtf,
wh_charging_categories_dim wccd, wh_financials_time_dim wftd where sdtf.CH_CATEGORY_ID = wccd.CH_CATEGORY_ID and sdtf.FINANCIAL_DATE_KEY = wftd.FINANCIAL_DATE_KEY and wftd.FINANCIAL_DATE_KEY = 20111220000 and sdtf.branch = 'Surabaya' group by wftd.FINANCIAL_DATE_KEY, sdtf.branch, wccd.CH_CATEGORY_NAME order by
wftd.FINANCIAL_DATE_KEY, sdtf.branch, wccd.CH_CATEGORY_NAME
1
Q3 select wftd.FINANCIAL_DATE_KEY, sdtf.branch,
wccd.CH_CATEGORY_NAME ,sum(sdtf.DURATION), sum(sdtf.FREE_DURATION),
sum(sdtf.NUMBER_OF_TRANSACTIONS),sum(sdtf.TOTAL_COST), sum(sdtf.VOLUME) from sdm_daily_traffic_facts sdtf,
wh_charging_categories_dim wccd, wh_financials_time_dim wftd where sdtf.CH_CATEGORY_ID = wccd.CH_CATEGORY_ID and sdtf.FINANCIAL_DATE_KEY = wftd.FINANCIAL_DATE_KEY and wftd.FINANCIAL_DATE_KEY = 20111220000 and
wccd.ch_category_name LIKE 'Facebook%' group by wftd.FINANCIAL_DATE_KEY, sdtf.branch, wccd.CH_CATEGORY_NAME order by wftd.FINANCIAL_DATE_KEY, sdtf.branch, wccd.CH_CATEGORY_NAME
2
Q4 select wftd.FINANCIAL_DATE_KEY, sdtf.branch,
wccd.CH_CATEGORY_NAME ,sum(sdtf.DURATION), sum(sdtf.FREE_DURATION),
sum(sdtf.NUMBER_OF_TRANSACTIONS),sum(sdtf.TOTAL_COST), sum(sdtf.VOLUME) from sdm_daily_traffic_facts sdtf,
wh_charging_categories_dim wccd, wh_financials_time_dim wftd where sdtf.CH_CATEGORY_ID = wccd.CH_CATEGORY_ID and sdtf.FINANCIAL_DATE_KEY = wftd.FINANCIAL_DATE_KEY and wftd.FINANCIAL_DATE_KEY = 20111220000 and sdtf.branch = 'Surabaya' and wccd.ch_category_name LIKE 'Facebook%' group by wftd.FINANCIAL_DATE_KEY, sdtf.branch,
wccd.CH_CATEGORY_NAME order by wftd.FINANCIAL_DATE_KEY, sdtf.branch, wccd.CH_CATEGORY_NAME
Q5 select wftd.FINANCIAL_DATE_KEY, sdtf.branch,
wttd.TELE_SERVICE_NAME ,sum(sdtf.DURATION), sum(sdtf.FREE_DURATION),
sum(sdtf.NUMBER_OF_TRANSACTIONS),sum(sdtf.TOTAL_COST), sum(sdtf.VOLUME) from sdm_daily_traffic_facts sdtf,
wh_traffic_types_dim wttd, wh_financials_time_dim wftd where sdtf.TRAFFIC_TYPE_ID = wttd.TRAFFIC_TYPE_ID and
sdtf.FINANCIAL_DATE_KEY = wftd.FINANCIAL_DATE_KEY and wftd.FINANCIAL_DATE_KEY = 20111220000 group by wftd.FINANCIAL_DATE_KEY, sdtf.branch, wttd.TELE_SERVICE_NAME order by wftd.FINANCIAL_DATE_KEY, sdtf.branch, wttd.TELE_SERVICE_NAME 1
Q6 select wftd.FINANCIAL_DATE_KEY, sdtf.branch,
wttd.TELE_SERVICE_NAME ,sum(sdtf.DURATION), sum(sdtf.FREE_DURATION),
sum(sdtf.NUMBER_OF_TRANSACTIONS),sum(sdtf.TOTAL_COST), sum(sdtf.VOLUME) from sdm_daily_traffic_facts sdtf,
wh_traffic_types_dim wttd, wh_financials_time_dim wftd where sdtf.TRAFFIC_TYPE_ID = wttd.TRAFFIC_TYPE_ID and
sdtf.FINANCIAL_DATE_KEY = wftd.FINANCIAL_DATE_KEY and wftd.FINANCIAL_DATE_KEY = 20111220000 and sdtf.branch = 'Malang' group by wftd.FINANCIAL_DATE_KEY, sdtf.branch, wttd.TELE_SERVICE_NAME order by
wftd.FINANCIAL_DATE_KEY, sdtf.branch, wttd.TELE_SERVICE_NAME
2
Q7 select wftd.FINANCIAL_DATE_KEY, sdtf.branch,
wttd.TELE_SERVICE_NAME ,sum(sdtf.DURATION), sum(sdtf.FREE_DURATION),
sum(sdtf.NUMBER_OF_TRANSACTIONS),sum(sdtf.TOTAL_COST), sum(sdtf.VOLUME) from sdm_daily_traffic_facts sdtf,
wh_traffic_types_dim wttd, wh_financials_time_dim wftd where sdtf.TRAFFIC_TYPE_ID = wttd.TRAFFIC_TYPE_ID and
sdtf.FINANCIAL_DATE_KEY = wftd.FINANCIAL_DATE_KEY and wftd.FINANCIAL_DATE_KEY = 20111220000 and wttd.TELE_SERVICE_NAME = 'GPRS' group by wftd.FINANCIAL_DATE_KEY, sdtf.branch, wttd.TELE_SERVICE_NAME order by wftd.FINANCIAL_DATE_KEY, sdtf.branch, wttd.TELE_SERVICE_NAME 1
Q8 select wftd.FINANCIAL_DATE_KEY, sdtf.branch,
wttd.TELE_SERVICE_NAME ,sum(sdtf.DURATION), sum(sdtf.FREE_DURATION),
sum(sdtf.NUMBER_OF_TRANSACTIONS),sum(sdtf.TOTAL_COST), sum(sdtf.VOLUME) from sdm_daily_traffic_facts sdtf,
wh_traffic_types_dim wttd, wh_financials_time_dim wftd where sdtf.TRAFFIC_TYPE_ID = wttd.TRAFFIC_TYPE_ID and
sdtf.FINANCIAL_DATE_KEY = wftd.FINANCIAL_DATE_KEY and wftd.FINANCIAL_DATE_KEY = 20111220000 and sdtf.branch = 'Malang' and wttd.TELE_SERVICE_NAME = 'GPRS' group by wftd.FINANCIAL_DATE_KEY, sdtf.branch,
wttd.TELE_SERVICE_NAME order by wftd.FINANCIAL_DATE_KEY, sdtf.branch, wttd.TELE_SERVICE_NAME
4.2. Performansi
Sistem tanpa MV
Melakukan pengujian performansi pada sistem sebelum diimplementasi MV merupakan langkah pertama dalam langkah – langkah uji coba. Masing – masing data sampel dari query workload dijalankan sebanyak empat kali untuk mendapatkan hasil yang lebih akurat, kemudian hasil akhirnya diambil dari nilai rata – ratanya. Terdapat dua parameter indikator yang akan diukur dalam pengujian ini yaitu nilai waktu respon dan nilai estimasi biaya dalam satuan blok. Hasil dari pengujian ini nantinya akan dibandingkan dengan sistem setelah diimplementasi MV. Berikut ini adalah hasil rata – rata dari pengujian data sampel :
Tabel 4.2. Hasil Pengujian Sistem tanpa MV
ID Ukuran Waktu Respon (s) Query Cost (block)
Q1 1.25G 28.7175 35838 11.05G 296.5385 328704 Q2 1.25G 28.0765 36697 11.05G 285.9955 336896 Q3 1.25G 0.51375 10213 11.05G 2.8255 77369 Q4 1.25G 0.161 10207 11.05G 0.26575 77320 Q5 1.25G 28.38025 35838 11.05G 294.05975 328704
Q6 1.25G 28.49275 37292 11.05G 281.7285 336896 Q7 1.25G 28.41225 35836 11.05G 287.07575 328704 Q8 1.25G 28.20775 36689 11.05G 275.28575 336896
Berdasarkan hasil pengujian diatas terlihat bahwa kenaikan waktu respon
query dan biaya query processing secara umum adalah linier karena hasil query plan yang didapatkan adalah full table scan. Namun meskipun terdapat kenaikan linier, hasil akhirnya tidak selalu merupakan nilai kelipatan dari hasil sebelumnya. Sebagai contoh rasio perbandingan ukuran antara sampel data pertama dan kedua adalah 8.9, namun rasio perbandingan waktu respon query secara umum antara sampel data pertama dan kedua berada pada kisaran 9.7 hingga 10.3 kali. Begitu juga dengan rasio perbandingan biaya query processing ada pada kisaran 9 – 9.2 kali. Rasio hasil pada Q3 dan Q4 relatif kecil karena pada kedua query tersebut
query plan yang digunakan adalah menggunakan index dan tidak full table scan, sehingga perbandingan hanya sebesar 1-5 kali. Hal tersebut juga dibuktikan dengan biaya query processing yang lebil kecil dibandingkan query yang lain. Jadi kesimpulannya adalah tanpa menggunakan MV maka performansi akan turun secara linier dan penggunaan index bisa memperkecil rasio penurunan performansi.
Tabel 4.3. Rasio Perbandingan 2 Ukuran Sampel
ID Waktu Respon Query Cost
Q1 10.32605554 9.171940398 Q2 10.18629459 9.180477968 Q3 5.499756691 7.575540977 Q4 1.650621118 7.575193495 Q5 10.36142212 9.171940398 Q6 9.887725825 9.034001931 Q7 10.10394284 9.172452283 Q8 9.759223972 9.182479762
4.3. Simulasi Prototype Seleksi MV
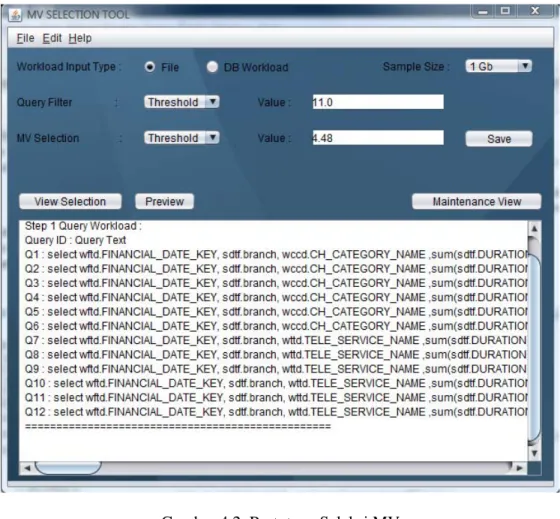
Pada bagian ini akan digambarkan bagaimana proses seleksi MV berdasarkan input query workload. Berikut adalah gambar aplikasi prototype
seleksi MV dan informasi penggunaannya :
Gambar 4.2. Prototype Seleksi MV
Dari gambar di atas, berikut adalah penjelasan dari masing – masing widget : 1. Workload Input Type digunakan untuk memilih apakah pengguna ingin
menggunakan input dari file teks atau langsung mengambil informasi dari database.
2. Sample Size adalah pilihan besaran tabel fact yang digunakan dalam proses seleksi.
3. Query Filter digunakan untuk memilih input query yang masuk dalam kriteria. Pilihan ada dua yaitu berdasarkan nilai threshold atau Top-N.
Nilai masing – masing parameter bisa dikonfigurasi pada bagian value.
4. MV Selection digunakan untuk memilih kandidat MVyang masuk dalam kriteria. Pilihan ada dua yaitu berdasarkan nilai threshold atau Top-N.
Nilai masing – masing parameter bisa dikonfigurasi pada bagian value.
5. Save digunakan untuk menyimpan perubahan konfigurasi 6. View Selection digunakan untuk melakukan proses seleksi MV
berdasarkan konfigurasi yang telah ditetapkan.
7. Preview digunakan untuk melihat hasil proses seleksi MV secara langkah per langkah.
8. Maintanance MV digunakan untuk memberikan laporan penggunaan MV kepada pengguna berdasarkan tingkat penggunaan dan kapasitas storage
Dengan konfigurasi seperti pada gambar di atas dan ketika proses dijalankan maka pada langkah pertama adalah melakukan seleksi query – query
mana yang terseleksi dan tidak. Dengan menggunakan asumsi nilai threshold (Φ)
= 11, maka dari input yang ada berikut adalah hasil dari proses seleksi query : Tabel 4.4. Hasil Proses Seleksi Query
ID Frekuensi Ukuran (byte) Bobot
Q1 2 206016 10.849 Q2 1 206016 12.235 Q3 2 1554 5.962 Q4 1 1554 7.348 Q5 1 13542 9.513 Q6 2 8631804 14.585 Q7 1 888 6.789 Q8 2 4350090 13.899
Selanjutnya dari query yang terseleksi (bobot < 11), masing – masing akan diekstrak atribut yang terdapat pada conditional clause (CC). Pada masing – masing CC akan dicari attribut yang benar – benar unik atau disebut Distinc CC. Di bawah ini adalah tabel representasi CC pada query – query yang telah terseleksi. Tabel 4.5. Representasi CC ID CC CC Text DCC Q1 CC1 sdtf.CH_CATEGORY_ID = wccd.CH_CATEGORY_ID DCC7 CC2 sdtf.FINANCIAL_DATE_KEY= wftd.FINANCIAL_DATE_KEY DCC5 CC3 wftd.FINANCIAL_DATE_KEY = 20111220000 DCC4 Q3 CC1 sdtf.CH_CATEGORY_ID = wccd.CH_CATEGORY_ID DCC7 CC2 sdtf.FINANCIAL_DATE_KEY = wftd.FINANCIAL_DATE_KEY DCC5 CC3 wftd.FINANCIAL_DATE_KEY = 20111220000 DCC4 CC4 Wccd.CH_CATEGORY_NAME LIKE 'Facebook%' DCC1
Q4
CC1 sdtf.CH_CATEGORY_ID = wccd.CH_CATEGORY_ID DCC7 CC2 sdtf.FINANCIAL_DATE_KEY = wftd.FINANCIAL_DATE_KEY DCC5 CC3 wftd.FINANCIAL_DATE_KEY = 20111220000 DCC4 CC4 sdtf.BRANCH = 'Surabaya' DCC2 CC5 Wccd. CH_CATEGORY_NAME LIKE 'Facebook%' DCC1
Q5 CC1 sdtf.TRAFFIC_TYPE_ID = wttd.TRAFFIC_TYPE_ID DCC3 CC2 sdtf.FINANCIAL_DATE_KEY = wftd.FINANCIAL_DATE_KEY DCC5 CC3 wftd.FINANCIAL_DATE_KEY = 20111220000 DCC4 Q7 CC1 sdtf.TRAFFIC_TYPE_ID = wttd.TRAFFIC_TYPE_ID DCC3 CC2 sdtf.FINANCIAL_DATE_KEY = wftd.FINANCIAL_DATE_KEY DCC5 CC3 wftd.FINANCIAL_DATE_KEY = 20111220000 DCC4 CC4 wttd.TELE_SERVICE_NAME = 'GPRS' DCC6
Langkah selanjutnya untuk mendapatkan kandidat MV adalah dengan cara menghitung bobot masing – masing DCC. Jika nilai bobot tidak melebihi nilai
threshold, dalam hal ini diasumsikan threshold < 4.48, maka berikut ini hasil dari proses seleksi DCC.
Tabel 4.6. Hasil Seleksi DCC
ID Frekuensi Ukuran (byte) Bobot
DCC1 2 3892548 4.499
DCC2 1 300665256 5.618
DCC3 2 38921484 4.471
DCC5 5 19965792 2.654
DCC6 1 973248 5.888
DCC7 5 901995768 2.447
Setelah semua DCC terpilih maka selanjutnya atribut – atribut tersebut disusun kembali menjadi query semula. Hasil inilah nantinya yang akan digunakan untuk implementasi MV pada sistem. Dari hasil DCC yang terpilih, berikut ini adalah MV yang akan diimplementasi.
4.4. Performansi Sistem dengan MV
Setelah MV hasil dari proses seleksi telah diimplementasi di dalam sistem, maka langkah selanjutnya adalah melakukan pengujian performansi sistem setelah implementasi MV. Skenario dan parameter indikator yang digunakan adalah sama dengan pengujian pada sistem tanpa MV. Berikut ini adalah hasil dari waktu respon dan biaya query :
Tabel 4.7. Hasil Pengujian dengan MV
ID Ukuran Waktu Respon (s) Query Cost (block)
Q1 1.25G 0.19575 4 11.05G 0.189 4 Q2 1.25G 0.1475 4 11.05G 0.2115 4 Q3 1.25G 0.22075 4 11.05G 0.19125 3
Q4 1.25G 0.1535 4 11.05G 0.185 3 Q5 1.25G 0.14775 4 11.05G 0.2205 4 Q6 1.25G 0.14575 4 11.05G 0.17325 4 Q7 1.25G 0.21125 2 11.05G 0.1815 4 Q8 1.25G 0.1495 1 11.05G 0.14975 3
Berdasarkan hasil pengujian diatas terlihat bahwa kenaikan waktu respon
query dan biaya query processing adalah tidak linier meskipun hasil query plan
yang didapatkan adalah full table scan. Sebagai contoh rasio perbandingan ukuran antara sampel data pertama dan kedua adalah 8.9, namun rasio perbandingan waktu respon query secara umum antara sampel data pertama dan kedua berada pada kisaran 0.8 hingga 1.4 kali. Begitu juga dengan rasio perbandingan biaya
query processing ada pada kisaran 1 – 3 kali. Rasio hasil pada Q3 dan Q4 juga tidak selalu linier meskipun kedua query tersebut query plan yang digunakan adalah menggunakan index dan tidak full table scan. Bahkan biaya query processing pada data 11.05G lebih kecil daripada data 1.25G. Jadi kesimpulan yang bisa didapatkan adalah pada MV tidak terdapat efek penurunan performansi yang cukup signifikan antara jumlah data yang lebih besar dan penggunaan index
atau tidak.
Tabel 4.9. Rasio Perbandingan 2 Ukuran Sampel
ID Waktu Respon Query Cost
Q1 0.965517241 1 Q2 1.433898305 1 Q3 0.866364666 0.75 Q4 1.205211726 0.75 Q5 1.492385787 1 Q6 1.188679245 1 Q7 0.859171598 2 Q8 1.001672241 3
4.5. Analysis
Biaya
Dalam melakukan investasi pengembangan sebuah sistem, biaya merupakan faktor penting yang harus diperhatikan. Begitu juga ketika perusahaan akan melakukan implementasi aplikasi pemilihan MV. Perhitungan biaya investasi yang harus dikeluarkan untuk biaya hardware, software dan biaya lain seperti biaya pengembangan, biaya operasional dll. Berikut ini adalah biaya – biaya yang diperlukan untuk pengembangan, implementasi dan operasional.
1. Biaya Pengembangan
Dalam perhitungan biaya akan digunakan model COCOMO II dengan sub model level prototype. Karena dalam pengembangan hanya dihasilkan output berupa prototype yang sudah bisa diujikan dan hanya dibutuhkan tim yang kecil dan tentunya masing – masing anggota memiliki kompenten yang sangat baik tentang database dan
programming. Berikut ini adalah koefisien daripada prototype yang akan dibangun.
• Terdapat 1 tampilan GUI dengan tingkat kerumitan simpel
• Report yang digunakan hanya 2 yaitu 1 report hasil seleksi MV dan 1 report untuk hasil maintenance MV. Tingkat kerumitan dari masing – masing report adalah simpel.
• Modul yang digunakan ada 6 modul yaitu modul input query set, query selection, MV selection, QP and MV cost
calculation, final recommendation and MV maintenance.
• Asumsi tingkat produktivitas dari developer menggunakan nilai nominal yaitu 13.
Sehingga dengan input koefisien diatas maka akan didapatkan jumlah
object-points dari prototype dibawah ini :
• 1 GUI simpel x 1 = 1
• 2 Report simple x 1 = 2
• 6 modul x 10 = 60
Total 63
Hasil perhitungan estimasi usaha yang diperlukan adalah sebagai berikut :
PM = NOP / PROD
= 63 / 13
= 5 PM
Dengan asumsi gaji seorang programmer adalah 7.000.000 (Kelly, 2011), maka total estimasi biaya pengembangan yang diperlukan adalah 7 jt x 5 bulan = 35 jt.
2. Biaya Operasional
Biaya operasional adalah biaya yang dihitung setelah aplikasi tersebut sudah dipakai termasuk biaya untuk melakukan monitor aplikasi. Diasumsikan untuk melakukan aktivitas operasional dan maintenance
adalah personel yang sama dengan tim OAM aplikasi DWS, maka biaya ini bisa dihilangkan.
3. Biaya Hardware
Karena implementasi MV membutuhkan disk untuk meyimpan data hasil aggregasi, maka perlu diperhitungkan biaya yang harus dikeluarkan untuk setiap byte yang digunakan. Diasumsikan besarnya
kapasitas yang dibutuhkan untuk menyimpan data MV adalah sebesar kapasitas yang dibutuhkan oleh tabel – tabel fact maka total kapasitas MV adalah : 12 tabel fact x 24Gb = 288 Gb. Dengan asumsi bahwa pada sistem DWH kebutuhan hardware media penyimpanan masih mencukupi, maka biaya ini bisa dihilangkan.
4.6. Analisis
Manfaat
Sebuah perbaikan yang dilakukan pasti akan menghasilkan manfaat terhadap perusahaan baik yang dapat diukur secara langsung ataupun tidak. Sehingga perlu dilakukan analisis manfaat terhadap implementasi MV dengan apa yang telah dihasilkan dalam pengujian. Analisis manfaat ini akan digunakan untuk melakukan analisa terhadap sistem yang belum mengimplementasikan MV dan sistem yang telah mengimplementasikan MV, di mana metode akan yang digunakan adalah metode gap analysis. Terdapat dua buah parameter indikator yang akan digunakan dalam melakukan perbandingan yaitu :
1. Biaya Query Processing
Berdasarkan hasil pengujian pada sistem sebelum dan sesudah diimplementasi MV, tabel berikut akan menggambarkan perbandingan hasil keduanya.
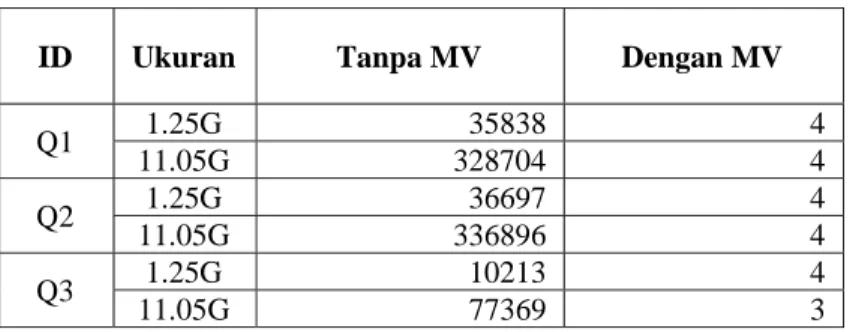
Tabel 4.7. Perbandingan Biaya Query Processing
ID Ukuran Tanpa MV Dengan MV
Q1 1.25G 35838 4 11.05G 328704 4 Q2 1.25G 36697 4 11.05G 336896 4 Q3 1.25G 10213 4 11.05G 77369 3
Q4 1.25G 10207 4 11.05G 77320 3 Q5 1.25G 35838 4 11.05G 328704 4 Q6 1.25G 37292 4 11.05G 336896 4 Q7 1.25G 35836 2 11.05G 328704 4 Q8 1.25G 36689 1 11.05G 336896 3
Dapat dianalisis dari tabel diatas bahwa dengan menggunakan MV maka biaya query processing dapat diturunkan hingga skala faktor ribuan. Selain itu pada sistem dengan menggunakan MV, biaya query processing relatif sama artinya tidak terlalu terpengaruh oleh besaran data yang dibaca. Sedangkan pada sistem tanpa MV terlihat bahwa kenaikan linier terjadi. Dari hasil analisis tersebut dapat disimpulkan bahwa implementasi MV memberikan manfaat :
a. Menghasilkan biaya query processing yang lebih rendah hingga ribuan kali lipat
b. Biaya query processing tidak terpengaruh oleh besaran data, sehingga sangat cocok dengan sistem DWH yang memiliki data sangat besar
c. Memberikan efisiensi penggunaan processor ketika melakukan proses komputasi data seperti query , aggregation dll
d. Dapat menggunakan utilisasi processor untuk proses aplikasi yang lain dalam 1 sistem.
Berikut ditampilkan grafik perbandingan biaya query processing
terjadi gap yang sangat besar dalam artian efek implementasi MV memberikan peningkatan performansi yang sangat signifikan.
1 10 100 1000 10000 100000 Biaya (blok) Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8 Query ID Biaya Query Processing - 1.25G
Tanpa MV Dengan MV 1 10 100 1000 10000 100000 1000000 Biaya (blok) Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8 Query ID Biaya Query Processing - 11.05G
Tanpa MV Dengan MV
Grafik 4.1. Perbandingan Biaya Query Processing
2. Waktu Respon Query
Berdasarkan hasil pengujian pada sistem sebelum dan sesudah diimplementasi MV, tabel berikut akan menggambarkan perbandingan
hasil keduanya dalam hal waktu respon query dalam satuan detik (second).
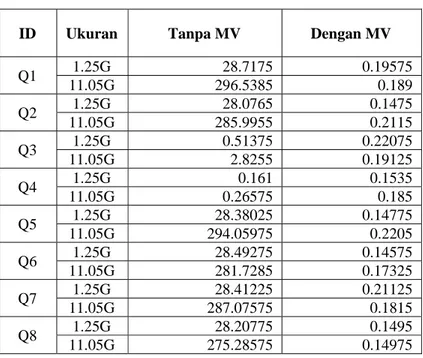
Tabel 4.8. Perbandingan Waktu Respon Query
ID Ukuran Tanpa MV Dengan MV
Q1 1.25G 28.7175 0.19575 11.05G 296.5385 0.189 Q2 1.25G 28.0765 0.1475 11.05G 285.9955 0.2115 Q3 1.25G 0.51375 0.22075 11.05G 2.8255 0.19125 Q4 1.25G 0.161 0.1535 11.05G 0.26575 0.185 Q5 1.25G 28.38025 0.14775 11.05G 294.05975 0.2205 Q6 1.25G 28.49275 0.14575 11.05G 281.7285 0.17325 Q7 1.25G 28.41225 0.21125 11.05G 287.07575 0.1815 Q8 1.25G 28.20775 0.1495 11.05G 275.28575 0.14975
Dapat dianalisis dari tabel diatas bahwa dengan menggunakan MV maka waktu respon query meningkat sangat signifikan hingga rata – rata dengan skala faktor 150 keatas. Selain itu pada sistem dengan menggunakan MV, waktu respon query relatif sama artinya tidak terlalu terpengaruh oleh besaran data yang dibaca. Sedangkan pada sistem tanpa MV terlihat bahwa kenaikan linier terjadi. Dari hasil analisis tersebut dapat disimpulkan bahwa implementasi MV memberikan manfaat :
b. Waktu respon query relatif sama untuk ukuran data yang lebih besar, hanya memberikan kenaikan sebesar 1-1.5 kali untuk data 1.25G dengan 11.05G.
c. Hasil report dapat disediakan lebih cepat dari sebelumnya. d. Membantu meningkatkan efisiensi operasional karyawan dalam
perusahaan, sehingga waktu kerja dapat digunakan untuk aktivitas operasional yang lain.
Berikut ditampilkan grafik perbandingan waktu respon query antara sebelum dan sesudah implementasi MV. Terlihat bahwa terjadi gap
yang sangat besar dalam artian efek implementasi MV memberikan peningkatan performansi yang sangat signifikan. Dapat dilihat bahwa rata – rata kecepatan waktu respon query dari sampel data di bawah 1 detik. Hal ini akan memberikan pengalaman baru kepada user ketika sedang melakukan proses retrieval data.
0.1 1 10 100 Waktu (detik) Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8 Query ID Waktu Respon Query - 1.25G
Tanpa MV Dengan MV
0.1 1 10 100 1000 Waktu (detik) Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8 Query ID Waktu Respon Query - 11.05G
Tanpa MV Dengan MV
Grafik 4.2. Perbandingan Waktu Respon Query
4.7. Analysis Biaya dan Manfaat
Berdasarkan hasil analisis biaya dan manfaat di atas, maka dapat digambarkan metrik perbandingan antara sistem sebelum dan sesudah menggunakan MV dalam dua bagian yaitu analisis perbandingan biaya dan analisis perbandingan manfaat.
4.7.1. Analisis Perbandingan Biaya
Berikut adalah tabel metrik perbandingan biaya antara aplikasi DWS tanpa dan dengan menggunakan MV.
Tabel 4.9. Metrik Biaya
No Indikator Tanpa MV Dengan
MV
1 Biaya Pengembangan (rupiah) 0 35.000.000
2 Biaya Operasional tambahan per tahun (rupiah) 0 0
Terlihat bahwa dalam implementasi MV hanya dibutuhkan biaya pengembangan prototype senilai 35 juta rupiah. Sedangkan untuk tambahan biaya operasional tidak perlu biaya karena dapat menggunakan resource yang ada yaitu staf operation and maintenance dan para DBA perusahaan. Karena implementasi MV bisa menggunakan sisa kapasitas storage yang masih ada maka tidak diperlukan biaya tambahan untuk meningkatkan kapasitas storage.
4.7.2. Analisis Perbandingan Manfaat
Berikut adalah tabel metrik perbandingan manfaat antara aplikasi DWS tanpa dan dengan menggunakan MV.
Tabel 4.10. Metrik Manfaat
No Indikator Tanpa MV Dengan
MV
1 Biaya per Query Processing (blok) 29826.25 3.375
2 Waktu Respon per Query (detik) 21.37 0.17
Terlihat bahwa secara tangible, manfaat yang diperoleh jauh lebih besar karena memberikan biaya query processing per query yang jauh lebih rendah dan juga meningkatkan waktu respon per query. Impak dari manfaat tangible tersebut akan memberikan banyak mafaat intangble yaitu :
1. Memberikan efisiensi penggunaan processor ketika melakukan proses komputasi data seperti query , aggregation dll, sehingga utilitasi sistem bisa digunakan untuk proses – proses lain.
2. Dengan waktu respon query yang lebih cepat maka secara langsung akan memberikan manfaat yaitu report akan dihasilkan lebih cepat dan lebih tepat waktu. Sehingga akan membantu tim assurance untuk menganalisis dan memberikan rekomendasi berdasarkan hasil report lebih cepat.
3. Jika waktu respon query lebih cepat maka akan meningkatkan efisiensi jam kerja pegawai, sehingga waktu yang ada bisa diutilisasi untuk pekerjaan yang lain.
4. Operational efficient akan terwujud dengan sistem yang bekerja lebih optimal dan jam kerja yang lebih efisien.