58 BAB III
METODE PENELITIAN 3.1 Objek Penelitian
Menurut Nuryaman dan Christina (2015:5) Objek penelitian adalah karakteristik yang melekat pada subjek penelitian, dimana subjek adalah unit analisis atau unit observasi yang akan diteliti. Objek dalam penelitian ini adalah profitabilitas, leverage, dan ukuran perusahaan pada perusahaan manufaktur sektor industri barang konsumsi yang terdaftar di Bursa Efek Indonesia periode 2013 -2017.
3.2 Metode Penelitian
Menurut Darmadi (2013:153) Metode penelitian adalah salah satu cara ilmiah untuk mendapatkan data dengan tujuan kegunaan tertentu. Metodologi penelitian yang digunakan dalam penelitian ini adalah metode penelitian
explanatory dengan menggunakan metode survey. Penelitian explanatoryadalah
penelitian yang bertujuan untuk memperoleh jawaban tentang “bagaimana” dan “mengapa” suatu terjadi fenomena terjadi, serta tujuan penelitian ini untuk menjelaskan atau membuktikan bagaimana hubungan antar variabel penelitian (Nuryaman dan Christina, 2015:6).
3.3 Operasional Variabel
Menurut Nuryaman dan Christina (2015 :42), ada dua tipe variabel dalam penelitian, yaitu :
1. Variabel Independen (Variabel Bebas)
Adalah variabel yang dapat mempengaruhi variabel dependen. Dengan kata lain, perubahan nilai (variance) pada variabel independen dapat menyebabkan perubahan nilai variabel dependen.
2. Variabel Dependen (Variabel Terikat)
Adalah variabel yang dipengaruhi oleh variabel independen. Dengan kata lain, besaran nilai variabel dependen dipengaruhi oleh perubahan nilai variabel independen.
Variabel dalam penelitian ini terdiri dari tiga variabel independen (X) dan satu variabel dependen (Y). Variabel independen dalam penelitian ini adalah profitabilitas (X1), leverage (X2) dan ukuran perusahaan (X3). Sedangkan variabel dependennya adalah penghindaran pajak / tax avoidance (Y). Untuk dapat memahami konsep dan pengukuran variabel-variabel dalam penelitian ini, maka akan disajikan tabel operasional variabel sebagai berikut :
Tabel 3.1
Operasionalisasi Variabel
Variabel Konsep Dimensi Indikator Skala
Profitabilitas (𝑿𝟏)
Profitabilitas merupakan rasio yang menilai kemampuan perusahaan
dalam mendapatkan keuntungan, rasio ini juga memberikan ukuran
tingkat efektifitas manajemen suatu perusahaan. (Kasmir, 2015:196) Return On Asset (ROA) ROA = 𝐸𝐴𝑇 𝑇𝑜𝑡𝑎𝑙 𝐴𝑠𝑠𝑒𝑡 (Kasmir 2015:201) Rasio
Leverage (𝑿𝟐) Leverage adalah rasio
yang digunakan untuk mengukur sejauh mana
aktiva perusahaan dibiayai oleh utang, artinya seberapa besar
beban utang yang ditanggung perusahaan untuk membayar seluruh
kewajibannya baik jangka pendek maupun
jangka panjang. (Kasmir, 2015:151) Debt Equity Rasio (DER) DER = 𝑇𝑜𝑡𝑎𝑙 𝐷𝑒𝑏𝑡 𝐸𝑞𝑢𝑖𝑡𝑦 (Kasmir, 2015:157) Rasio Ukuran Perusahaan (𝑿𝟑) Ukuran perusahaan adalah skala untuk mengklasifikasikan besar
kecilnya perusahaan menurut berbagai cara, antara lain dengan total aset, total penjualan, nilai pasar saham, dan
sebagainya (Hery, 2017:03)
SIZE SIZE = Ln (total asset)
(Hartono, 2013:282)
Penghindaran Pajak (Y)
Penghindaran pajak merupakan upaya menghindari pajak secara legal dan aman bagi Wajib Pajak karena
tidak bertentangan dengan ketentuan perpajakan, di mana metode dan teknik yang
digunakan cenderung memanfaatkan kelemahan-kelemahan
(grey area) yang terdapat dalam
Undang-Undang dan peraturan perpajakan itu sendiri.
(Pohan, 2013:23) Cash Effective Tax Rate (CETR)
Pajak yang dibayarkan Laba Sebelum Pajak
Hanlon dan Heitzman (2010)
Rasio
3.4 Populasi dan Sampel Penelitian 3.4.1 Populasi Penelitian
Menurut Nuryaman dan Christina (2015:101), Populasi menunjukkan seluruh kelompok orang, kejadian atau sesuatu yang menjadi ketertarikan peneliti untuk diinvestigasi. Bisa juga dikatakan bahwa populasi merupakan total kumpulan elemen yang dari kumpulan tersebut akan dibuat kesimpulan. Populasi dalam penelitian ini adalah seluruh perusahaan manufaktur sektor industri barang konsumsi yang terdaftar di Bursa Efek Indonesia (BEI) pada tahun 2013 – 2017.
3.4.2 Sampel Penelitian
Menurut Nuryaman dan Christina (2015:101), Sampel adalah bagian dari populasi, sampel berisi beberapa anggota yang dipilih dari populasi. Teknik penentuan sampel pada penelitian ini adalah non probability sampling. Non
probability samplingadalah teknik sampling yang digunakan jika jumlah
populasinya tidak dapat ditentukan, dan jenis sampel ini tidak dipilih secara acak. Tidak semua unsur atau elemen populasi mempunyai kesempatan yang sama untuk bisa dipilih menjadi objek sampel (Nuryaman dan Christina, 2015:109).
Dalam penelitian ini teknik non probability samplingyang digunakan yaitu
purposive sampling. Purposive sampling adalah teknik pengambilan sampel yang
menganggap bahwa seseorang atau sesuatu tersebut memiliki informasi atau karakteristik yang sesuai dengan keperluan penelitiannya (Nuryaman dan Christina,2015:110). Sampel penelitian diambil dari populasi laporan keuangan perusahaan manufaktur sektor industri barang konsumsi yang terdaftar di Bursa Efek Indonesia (BEI) periode tahun 2013-2017 dengan karakteristik sebagai berikut:
1. Perusahaan manufaktur sektor industri barang konsumsi yang terdaftar di Bursa Efek Indonesia secara berturut-turut untuk periode 2013-2017. 2. Perusahaan manufaktur sektor industri barang konsumsi tersebut telah
menerbitkan laporan keuangan atau laporan tahunan (annual report) lengkap selama tahun 2013-2017.
3. Menampilkan data dan informasi yang digunakan dan dibutuhkan untuk penelitian ini periode 2013-2017.
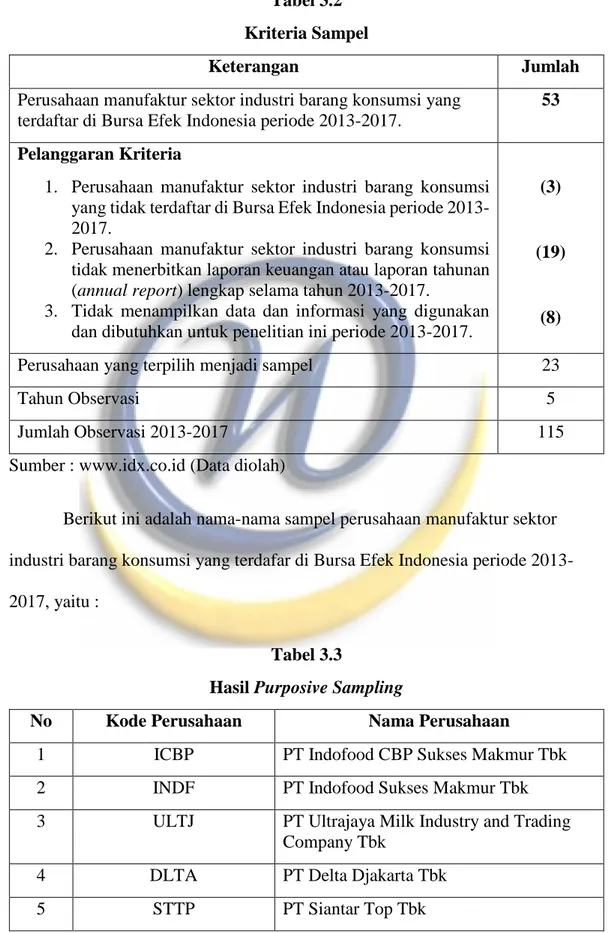
Tabel 3.2 Kriteria Sampel
Keterangan Jumlah
Perusahaan manufaktur sektor industri barang konsumsi yang terdaftar di Bursa Efek Indonesia periode 2013-2017.
53 Pelanggaran Kriteria
1. Perusahaan manufaktur sektor industri barang konsumsi yang tidak terdaftar di Bursa Efek Indonesia periode 2013-2017.
2. Perusahaan manufaktur sektor industri barang konsumsi tidak menerbitkan laporan keuangan atau laporan tahunan (annual report) lengkap selama tahun 2013-2017.
3. Tidak menampilkan data dan informasi yang digunakan dan dibutuhkan untuk penelitian ini periode 2013-2017.
(3)
(19)
(8)
Perusahaan yang terpilih menjadi sampel 23
Tahun Observasi 5
Jumlah Observasi 2013-2017 115
Sumber : www.idx.co.id (Data diolah)
Berikut ini adalah nama-nama sampel perusahaan manufaktur sektor industri barang konsumsi yang terdafar di Bursa Efek Indonesia periode 2013-2017, yaitu :
Tabel 3.3
Hasil Purposive Sampling
No Kode Perusahaan Nama Perusahaan
1 ICBP PT Indofood CBP Sukses Makmur Tbk
2 INDF PT Indofood Sukses Makmur Tbk
3 ULTJ PT Ultrajaya Milk Industry and Trading
Company Tbk
4 DLTA PT Delta Djakarta Tbk
No Kode Perusahaan Nama Perusahaan
6 ADES PT Akasha Wira International Tbk
7 KLBF PT Kalbe Farma Tbk
8 TSPC PT Tempo Scan Pasific Tbk
9 DVLA PT Daya Varia Laboratoria Tbk
10 PYFA PT Pyridam Farma Tbk
11 GGRM PT Gudang Garam Tbk
12 WIIM PT Wismilak Inti Makmur Tbk
13 MYOR PT Mayora Indah Tbk
14 MLBI PT Multi Bintang Indonesia Tbk
15 ROTI PT Nippon Indosari Corporindo
16 SKBM PT Sekar Bumi Tbk
17 CEKA PT Cahaya Kalbar Tbk
18 BUDI PT Budi Starch & Sweetener Tbk
19 SKLT PT Sekar Laut Tbk
20 TCID PT Mandom Indonesia Tbk
21 HMSP PT Handjaya Mandala Sampoerna Tbk
22 UNVR PT Unilever Indonesia Tbk
23 MERK PT Merk Indonesia Tbk
Sumber : www.idx.co.id (Data diolah)
3.5 Teknik Pengumpulan Data
Metode pengumpulan data yang dilakukan oleh penulis pada penelitian ini adalah melalui penelusuran data sekunder dengan kepustakaan dan dokumentasi. Cara pengumpulan data dalam penelitian ini dilakukan dengan cara :
1. Studi Kepustakaan (Library Research)
Penelitian ini dilakukan dengan cara studi kepustakaan, yaitu dengan membaca, mempelajari, dan mengolah literatur-literatur dengan beberapa
sumber kepustakaan, seperti buku, jurnal, majalah-majalah, serta referensi lainnya yang relevan dengan permasalahan yang akan diteliti, dengan tujuan mendapatkan dasar teoritis dan bahan pertimbangan dalam memecahkan masalah yang sedang diteliti.
2. Studi Dokumentasi
Selain data kepustakaan, untuk memperoleh data yang dibutuhkan dalam penelitian ini, penulis mengumpulkan dan mempelajari dokumen dan data yang dibutuhkan. Dokumen yang dimaksud dalam penelitian ini adalah laporan keuangan tahunan yang telah di audit.
Dalam penelitian ini menggunakan data sekunder, dimana data laporan keuangan tahunan perusahaan sektor industri barang konsumsi yang terdaftar di Bursa Efek Indonesia periode 2013-2017. Sumber data ini diperoleh melalui situs resmi www.idnfinancials.com dan www.idx.co.id.
3.6 Sumber Data
Yang dimaksud dengan sumber data dalam penelitian adalah subyek dari mana data dapat diperoleh. Dalam penelitian ini penulis menggunakan :
a. Sumber data sekunder, yaitu data yang langsung dikumpulkan oleh peneliti yang tersusun dalam bentuk dokumen-dokumen. Dalam penelitian ini, laporan keuangan yang dapat di akses pada Bursa Efek Indonesia merupakan sumber data sekunder.
3.7 Disain Penelitian
Dalam menguji variabel-variabel yang digunakan dalam penelitian ini penulis dibantu oleh software statistik yaitu program Eviews 10. Teknik analisis dalam penelitian ini menggunakan metode analisis deskriptif dan analisis regresi berganda.
3.7.1 Statistik Deskriptif
Menurut Ghozali (2013:19), Statistik deskriptif adalah statistik yang memberikan gambaran atau deskripsi suatu data yang dilihat dari rata-rata (mean), standar deviasi, variance, maksimum, minimum, sum, range, kurtoris dan skewness (ketidaksimetrisan distribusi).
Di dalam penelitian ini, penulis akan mendeskripsikan untuk variabel profitabilitas yang diproksikan dengan ROA, leverage yang diproksikan dengan DER, ukuran perusahaan yang diproksikan dengan SIZE, dan penghindaran pajak perusahaan manufaktur sektor industri barang konsumsi yang terdaftar di Bursa Efek Indonesia periode 2013-2017.
3.7.2 Pemilihan Model Regresi Data Panel
Menurut Widarjono (2007:251), untuk mengestimasi parameter model dengan data panel, terdapat tiga teknik yang ditawarkan, yaitu :
1. Common Effect Model, teknik ini merupakan teknik yang paling sederhana untuk mengestimasi parameter model data panel, yaitu dengan mengkombinasikan data cross section dan time series sebagai satu kesatuan
tanpa melihat adanya perbedaan waktu dan individu. Pendekatan yang dipakai pada model ini adalah metode Ordinary Least Square (OLS). 2. Fixed Effect Model, teknik ini mengestimasi data panel dengan
menggunakan variabel dummy untuk menangkap adanya perbedaan intersep. Pendekatan ini didasarkan adanya perbedaan intersep antara perusahaan namun intersepnya sama antar waktu. Model ini juga mengasumsikan bahwa slope tetap antar perusahaan dan antar waktu. Pendekatan yang digunakan pada model ini menggunakan metode Least
Square Dummy Variable (LSDV).
3. Random Effect Model, teknik ini akan mengestimasi data panel dimana variabel gangguan mungkin saling berhubungan antar waktu dan antar individu. Perbedaan antar individu dan antar waktu diakomodasi lewat
error. Karena adanya korelasi antar variabel gangguan maka metode OLS
tidak bisa digunakan sehingga model random effect menggunakan metode
Generalized Least Square (GLS).
Terdapat beberapa cara pengujian yang dapat digunakan untuk menentukan teknik yang paling tepat untuk memilih antara metode-metode tersebut. Pengujian yang dilakukan adalah:
3.7.2.1 Uji Chow (Chow Test)
Uji Chow digunakan untuk menentukan apa yang cocok digunakan untuk model regresi data panel, yaitu antara Common Effect atau Fixed Effect. Adapun dasar pengambilan keputusan dalam Uji Chow adalah sebagai berikut:
- Jika probabilityChi-square >0,05 maka Common Effect lebih baik dari pada
Fixed Effect.
- Jika probabilityChi-square < 0,05 maka Fixed Effect lebih baik dari pada
Common Effect.
Berdasarkan kriteria diatas, jika hasil Uji Chow menunjukan bahwa
Common Effect lebih baik dari Fixed Effect, maka model regresi data panel akan
menggunakan model Pooled Least Square (PLS). Selanjutnya, bila hasil Uji Chow menunjukan bahwa Fixed Effect lebih baik dari pada Common Effect, maka harus dilakukan Uji Hausman untuk menentukan pemilihan motode Fixed Effect atau
Random Effect.
3.7.2.2 Uji Hausman (Hausman Test)
Uji Hausman dilakukan untuk menindaklanjuti Uji Chow ketika hasil Uji
Chow menunjukan bahwa Fixed Effect lebih baik daripada Common Effect, maka
harus dilakukan Uji Hausman untuk menentukan pemilihan metode Fixed Effect atau Random Effect. Adapun dasar pengambilan keputusan dari Uji Hausman adalah sebagai berikut:
- Jika probabilityChi-square > 0,05 maka menggunakan metode Random Effect
Model.
- Jika probabilityChi-square < 0,05 maka menggunakan metode Fixed Effect
3.7.3 Pengujian Asumsi Klasik
Sebelum melakukan regresi terdapat syarat yang harus dilalui yaitu melakukan uji asumsi klasik. Uji asumsi klasik merupakan syarat yang harus dipenuhi agar persamaan regresi dapat dikatakan sebagai persamaan regresi yang baik, maksudnya persamaan regresi yang dihasilkan akan valid jika digunakan untuk memprediksi. Uji asumsi klasik tersebut biasanya sering digunakan pada persamaan regresi berganda. Hal itu didukung oleh pernyataan Santoso (2010:358) yaitu uji asumsi klasik merupakan sebuah model regresi akan digunakan untuk melakukan peramalan, sebuah model yang baik adalah model dengan kesalahan peramalan yang seminimal mungkin. Karena itu, sebuah model sebelum digunakan seharusnya memenuhi berapa asumsi, yang biasa disebut asumsi klasik. Pengujian yang digunakan adalah uji normalitas, uji multikolonieritas, uji heteroskedastisitas, dan uji autokorelasi.
3.7.3.1 Uji Normalitas
Uji normalitas bertujuan untuk mengukur apakah di dalam model regresi variabel pengguna atau residual mempunyai distribusi normal (Ghozali, 2013:160). Model regresi yang baik adalah model regresi yang dimiliki distribusi normal atau mendekati normal, sehingga layak dilakukan pengujian secara statistik terhadap masing-masing variabel. Data yang baik adalah data yang mempunyai pola seperti distribusi normal. Pedoman pengambilan keputusan tentang data tersebut mendekati atau merupakan distribusi normal yang dapat dilihat dari :
a. Bila nilai J-B (Jarque-Bera) tidak signifikan (lebih kecil dari J-B tabel / lebih kecil dari 2), maka data berdistribusi normal.
b. Nilai Sig. Atau signifikan atau probabilitas > 0.05, maka data berdistribusi normal.
3.7.3.2 Uji Multikolinearitas
Uji multikolinearitas bertujuan untuk menguji apakah model regresi ditemukan adanya korelasi antara variabel bebas (variabel independen). Model regresi yang baik seharusnya tidak terjadi korelasi diantara variabel bebas atau independen (Ghozali, 2013:105).
Pengujian multikolinearitas dilihat dari besaran Variance Inflation Factor (VIF)dan Tolerance. Multikolineritas akan terjadi jika nilai VIF > 10 dan nilai
tolerance <0,1. yang berarti tidak ada korelasi antar variabel independen yang nilainya lebih dari 95%. Sedangkan jika nilai VIF < 10 dan nilai tolerance > 0,1 maka dapat disimpulkan bahwa tidak ada multikolinearitas antar variabel independendalam regresi.
3.7.3.3 Uji Heteroskedastisitas
Heteroskedastisitas merupakan keadaan di mana faktor penggangu (error) tidak konstan. Menurut Ghozali (2013:139) uji heteroskedastisitas bertujuan untuk menguji apakah dalam model regresi terjadi ketidaksamaan varian dari residual satu pengamatan ke pengamatan lain. Jika varian dari residual suatu pengamatan ke pengamatan lain tetap, maka disebut homoskedastisitas, sedangkan jika variannya berbeda disebut heteroskedastisitas. Penelitian ini menggunakan Uji Glejser, yaitu dengan mengusulkan untuk meregres nilai absolut residual terhadap variabel
independen (Gujarati,2003) dalam Ghozali (2013:142). Prosedur pengujian dilakukan dengan hipotesis sebagai berikut :
• H0 : Tidak ada heteroskedastisitas • Ha : Ada heteroskedastisitas
Jika pengujian menghasilkan nilai lebih besar dari 0,05 (5%) maka persamaan regresi tidak mengandung heteroskedastisitas, dan sebaliknya jika pengujian menghasilkan nilai lebih kecil dari 0,05 (5%) maka persamaan regresi mengandung heteroskedastisitas.
3.7.3.4 Uji Autokorelasi
Menurut Ghozali (2013:137) Uji autokorelasi memiliki tujuan menguji apakah dalam model regresi linear ada korelasi antara kesalahan penganggu pada periode t dengan kesalahan pengganggu pada periode t-1 (sebelumnya). Autokorelasi muncul karena observasi yang berurutan sepanjang waktu berkaitan satu sama lainnya. Model regresi yang baik adalah regresi yang bebas dari autokorelasi.
Salah satu cara yang dapat digunakan untuk mendeteksi ada atau tidaknya autokorelasi adalah uji Durbin-Waston (DW test). Uji Durbin-Waston (DW test) hanya digunakan untuk autokorelasi tingkat satu (first order autocorrelation) dan mensyaratkan adanya intercept (konstanta) dalam model regresi dan tidak ada variabel lagi di antara variabel independen (Ghozali, 2013:138).Hipotesis yang akan diuji adalah :
H0 : tidak ada autokorelasi (r = 0) Ha : ada autokorelasi (r ≠ 0)
Pengambilan keputusan ada tidaknya autokorelasi :
Hipotesis nol Keputusan Jika
Tidak ada autokorelasi positif Tidak ada autokorelasi positif Tidak ada korelasi negatif Tidak ada korelasi negatif Tidak ada autokorelasi, Positif atau negatif Tolak No desicison Tolak No desicision Tidak ditolak 0 < d < dl dl ≤ d ≤ du 4 – dl < d < 4 4 – du ≤ d ≤ 4 – dl du < d < 4 – du
3.7.4 Analisis Regresi Linear Berganda
Analisis regresi linier berganda adalah teknik analisis yang digunakan untuk meramal bagaimana keadaan atau pengaruh variabel independen terhadap variabel dependen dan menunjukkan arah hubungan antara variabel dependen dengan independen (Ghozali, 2013:96). Analisis ini untuk memprediksi nilai dari variabel dependenapabila nilai variabel independen mengalami kenaikan atau penurunan dan untuk mengetahui arah hubungan antara variabel independen dengan variabel dependen apakah masing-masing variabel independenberhubungan positif atau negatif. Dalam penelitian ini terdapat satu variabel terikat (Y) dan tiga variabel bebas.
Persamaan regresi linear berganda yang ditetapkan sebagai berikut : Y = a + 𝐛𝟏𝐗𝟏 + 𝐛𝟐𝐗𝟐 + 𝐛𝟑𝐗𝟑 + e Keterangan : Y : Penghindaran Pajak a : Konstanta b : Koefisien Regresi X1 : Profitabilitas X2 : Leverage X3 : Ukuran Perusahaan e : Standar error 3.8 Pengujian Hipotesis
3.8.1 Pengujian Secara Parsial (Uji t)
Menurut Ghozali (2013:98) Uji statistik t pada dasarnya menunjukkan seberapa jauh pengaruh satu variabel independen secara individual dalam menerangkan variabel dependen. Langkah-langkah pengujian menggunakan Uji t adalah sebagai berikut:
a. Menentukan tingkat signifikan sebesar α = 5%
Tingkat signifikan 0,05 atau 5% artinya kemungkinan besar hasil penarikan kesimpulan memiliki probabilitas 95% dan toleransi 5% b. Kriteria Pengambilan Keputusan
1. 𝐻0 diterima jika nilai thitung ≤ ttabel atau nilai sig > α 2. 𝐻0 ditolak jika nilai thitung ≥ ttabel atau nilai sig < α
Nilai ttabel di dapat dari: df = n-k-1
Keterangan:
n : menyatakan jumlah observasi
k : menyatakan variabel independen
Bila hasil pengujian statistik menunjukkan bahwa H0 ditolak artinya terdapat pengaruh yang signifikan secara parsial dari variabel independen terhadap variabel dependen, tetapi bila hasil pengujian statistik menunjukkan bahwa H0 diterima artinya tidak terdapat pengaruh yang signifikan secara parsial dari variabel independen terhadap variabel dependen. Dalam penelitian ini pengujian hipotesis statistik untuk mengguji ada tidaknya pengaruh antara variabel independen (X) yaitu Profitabilitas (X1), Leverage (X2) dan Ukuran Perusahaan (X3) terhadap Penghindaran Pajak (Y).
3.8.2 Pengujian Secara Simultan (Uji F)
Menurut Ghozali (2013:98) Uji statistik F pada dasarnya menunjukkan apakah semua variabel independen yang dimasukkan dalam model mempunyai pengaruh secara besama-sama terhadap variabel terikat. Langkah-langkah pengujian dengan Uji F adalah sebagai berikut:
a. Menentukan taraf nyata signifikan penelitian sebesar a = 5%
Taraf nyata signifikansi penelitian 0,05 (5%) artinya kemungkinan besar hasil penarikan kesimpulan memiliki probabilitas 95% atau toleransi kesalahan 5%.
b. Kriteria Pengambilan Keputusan
2. H0diterima jika Fhitung<Ftabel atau nilai sig >𝛼
Nilai Ftabel didapat dari:
df1 (pembilang) menyatakan Jumlah variabel independen (k) df2 (penyebut) menyatakan n-k-1
Bila hasil pengujian statistik menunjukkan bahwa H0 ditolak artinya terdapat pengaruh yang signifikan secara simultan dari variabel indepeden terhadap variabel dependen, tetapi bila hasil pengujian statistik menunjukkan bahwa H0 diterima artinya tidak terdapat pengaruh yang signifikan secara simultan dari variabel independen terhadap variabel dependen.
3.9 Uji Koefisien Determinasi (𝐑𝟐)
Pada intinya koefisien determinasi (R2) mengukur sebarapa jauh kemampuan model dalam menerangkan variasi variabel dependen (Ghozali, 2013:97). Koefisien determinasi merupakan ukuran untuk mengetahui kesesuaian atau ketetapan antara nilai dugaan atau garis regresi dengan data sampel. Besarnya koefisien determinasi dapat dihitung dengan menggunakan rumus sebagai berikut:
Kd = 𝒓𝟐 x 100% Keterangan :
Kd : Koefisiensi determinasi 𝑟2 : Koefisien korelasi
Kriteria untuk analisis koefisien determinasi adalah :
a. Jika Kd mendeteksi nol (0), maka pengaruh variabel independen terhadap variabel dependen lemah.
b. Jika Kd mendeteksi satu (1), maka pengaruh variabel independen terhadap variabel dependen kuat.
3.10 Penetapan Tingkat Signifikansi (α)
Tingkat signifikansi yang digunakan α = 5% atau 0,05. Karena menggunakan tingkat signifikansi sebesar 5% paling umum digunakan untuk penelitian dan dianggap cukup menyediakan hubungan antara variabel-variabel yang diteliti. Tingkat signifikan 0,05 pun memiliki arti kemungkinan besar dari hasil penarikan kesimpulan mempunyai probabilitas 95% atau toleransi kesalahan sebesar 5%.