STATISTIK DESKRIPTIF
PENGERTIAN STATISTIK
DESKRIPTIf
Statistik yang berfungsi untuk mendeskripsikan atau memberi gambaran terhadap obyek yang diteliti melalui data sampel atau populasi, tanpa
Tendensi Central
(letak data)
Sebaran frekuensi yang terpola di
sekitar
nilai yang disebut nilai sentral,
yaitu nilai:
Mean
UKURAN KECENDERUNGAN TENGAH
( TENDENCY CENTRAL)
Tingkat Ukuran
Mode Median Mean
Interval X X X
Ordinal X X
KURVE SIMETRIS
• Apabila dilipat tepat di
tengah-tengahnya maka setengah lipatan bagian kiri akan menutup tepat
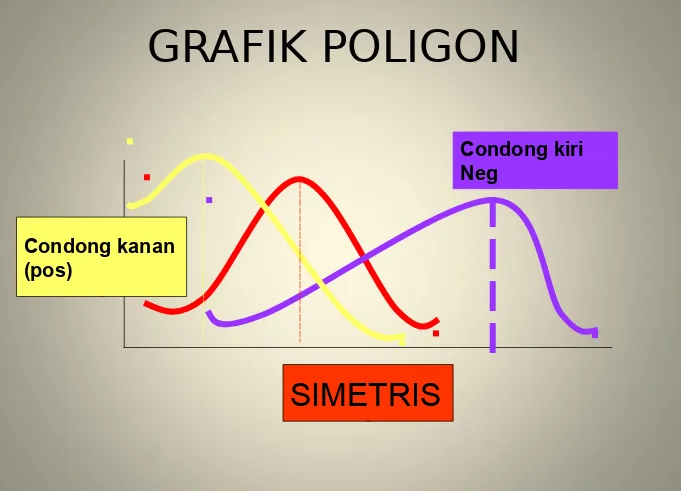
GRAFIK POLIGON
SIMETRIS
Condong kanan (pos)
POLYGON SIMETRIS
POLYGON CONDONG
KEKANAN (Juling Positif)
Mo Med
Mean
POLYGON CONDONG
KEKIRI (Juling Negatif)
KURTOSIS (KELANCIPAN)
f
Fariasi
Sangat
rendah
Variasi
Sangat
besar
SIMETRIS
BEL NORMAL/ NORMAL
BEL LANGSING/ LEPTOKURTIK
f
BEL GEMUK/ PLATKURTIK
f
UKURAN DISPERSI
MERUPAKAN SUATU
METODE ANALISIS YANG DITUJUKAN UNTUK
MENGUKUR BESARNYA PENYIMPANGAN /
PENYEBARAN DARI
Contoh penggunaan
DISPERSI :
DAPAT DIGUNAKAN SEBAGAI PENGUKUR KUALITAS (QUALITY CONTROL) DARI
CONTOH :
•
PT INDOCEMENT YANG SETIAP
HARINYA MENGHASILKAN RATA –
RATA 500.000 ZAK SEMEN @ 40 KG
TIAP ZAKNYA
•
UNTUK MELIHAT PENYIMPANGAN
SAMPEL BERAT/KG KETERANGAN
1 40 KG
TIDAK TERJADI PENYIMPANG
AN
2 40 KG
3 40 KG
5 40 KG
- 40 KG
- 40 KG
KESIMPULAN
• MESIN MASIH
BEKERJA
DENGAN BAIK.
• KARENA
RATA-RATA BERAT
ZAKNYA SESUAI DENGAN
KETENTUAN YANG
SAMPEL BERAT/KG KETERANGAN
1 42,1
TERJADI PENYIMPANG
AN
2 36,8
3 40,2
5 42
-
--
-500 39,2
KESIMPULAN
1. ADA MESIN
YANG BEKERJA TIDAK BAIK.
2. ARTINYA PERLU MENGECEK
KEMBALI MESIN-MESIN YANG
DIGUNAKAN PADA PROSES PRODUKSI
MACAM-MACAM UKURAN
DISPERSI :
1.
RANGE (JANGKAUAN)/ RENTANGAN
2.
DEVIASI RATA-RATA (AVERATE
DEVIATION) DAN MEAN DEVIATION
3.
DEVIASI STANDARD (STANDARD
RANGE
• RELATIF KASAR
• RANGE KECIL,
BERARTI BAHWA SUATU
DISTRIBUSI MEMILIKI
RANGKAIAN
CONTOH : (1)
KEUNTUNGAN YANG DIPEROLEH 8 TOKO KELONTONG DI JALAN SOLO
TOKO KEUNTUNGAN (Rp)
A 4000
B 5000
C 6000
D 5000
E 4000
F 6000
G 5500
VARIASI RELATIF KECIL
(HOMOGEN)
TOKO KEUNTUN GAN (Rp)
A 4000
B 5000
C 6000
D 5000
E 4000 F 6000
G 5500
DARI DATA DIATAS RATA-RATA
KEUNTUNGAN :
8 500 . 4 500 . 5 000 . 6 000 . 4 000 . 5 000 . 6 000 . 5 000 .4
CONTOH : (2)
KEUNTUNGAN YANG DIPEROLEH 8 TOKO KELONTONG DI JALAN SEMARANG
TOKO KEUNTUNGAN (Rp)
A 1.000
B 9.000
C 5.000
D 4.000
E 6.000
F 5.000
G 9.500
DARI DATA DIATAS
DARI DATA DIATAS
RATA-RATA KEUNTUNGAN :
RATA KEUNTUNGAN :
8 500 500 . 9 000 . 5 000 . 6 000 . 4 000 . 5 000 . 9 000 .
1
VARIASI RELATIF BESAR
(HETEROGEN)
RATA-RATA
000
.
5
N
PERBANDINGAN
PERBANDINGAN
•
KEDUA CONTOH TERSEBUT DIATAS
RATA-RATA SAMA = 5.000
•
TETAPI KEDUA TOKO TERSEBUT
MEMILIKI PERBEDAAN DALAM
PENYEBARANNYA
•
CONTOH (1) RANGE = KECIL =
6.000-4.000 = 2.000 (HOMOGEN)
•
CONTOH (2) RANGE = BESAR =
KESIMPULAN
KESIMPULAN
• RANGE SEMAKIN
MEAN DEVIATION
(DISEBUT DEVIASI RATA-RATA/
AVERAGE DEVIATION)
•
MERUPAKAN PENYEBARAN
DATA ATAU ANGKA-ANGKA
ATAS DASAR JARAK (DEVIASI)
DARI PELBAGAI
RUMUS :
DATA TIDAK BERKELOMPOK
N
X
Xi
MD
N
i
CONTOH :
KEUNTUNGAN YANG DIPEROLEH 5 TOKO KELONTONG
TOKO KEUNTUNGAN (Rp)
A 4.000
B 5.000
C 6.000
D 5.000
E 5.000
N X Xi MD N i 1
Xi X bar
4.000 5.000 1.000
5.000 5.000 0
6.000 5.000 1.000
5.000 5.000 0
5.000 5.000 0
TOTAL 2.000
N
X
Xi
MD
N
i
1 2.000Standar Deviasi
N
x
x
SD
i
Varians
SD
2
Are You Ready !
Buka mulai dari hal IV-1 !!
Mari kita bahas tiap segmen dibawah
ini
OLAP Cubes
Case Summaries
Frekwencies
OLAP Cubes
Menu ini digunakan untuk meringkas data kuantitatif atau data kualitatif secara praktis, yang mencakup banyak variabel, namun tidak dilakukan inferensi
(analisis keputusan) terhadap data melainkan hanya penggambaran/deskripsi saja.
Contoh: Pada kasus yang sama (file berat responden)
kita ingin melihat tinggi badan seseorang berdasarkan
Simulasi 1
Cari deskripsi data dari:
• Jenis kelamin pria;jabatan middle
manajemen
• Jenis kelamin wanita jabatan Low
manajemen
• Tinggi rata-rata terkecil dari kalsifikasi
diatas
• Cari berat minimum untuk pria yang
mempunyai jabatan top manajemen
• Cari berat maksimum untuk wanita yang
Case Summaries
Menyajikan ringkasan suatu variabel (data kuantitatif atau kualitatif) dengan tampilan setiap kasus dengan criteria tertentu
Contoh:
Membuat case summaries dari variabel tinggi
Frequencies
Digunakan untuk membuat table distribusi
frekuensi, dan menghitung nilai – nilai
seperti
mean, median, modus dan juga nilai
tendensi
sentral (kecenderungan terpusat).
• N adalah jumlah data yang valid adalah
20 buah
• Mean atau rata-rata tinggi responden
adalah 166,29 cm dengan standar error sebesar 2,84 cm;
• Hal ini bisa ditafsirkan rentang rata-rata
usia karyawan terletak pada 3 standar error of mean; yaitu: 166,29 cm +/- (3 x 2,84 cm)
174.81
166.29
157.77
Batas atas rentang rata-rata usia
Median sebesar 165,55 cm
Median = Persentil 50 menunjukan
Standar deviasi
adalah
12,69 cm
Varians
= Kuadrat dari standar
deviasi bernilai 161,15
Hal ini menunjukan
rentang usia
karyawan
terletak tiga standar
deviasi yaitu 166,29 cm +/- (3 x
12,69cm)
204.33
166.29
128.22
Batas atas rentang usia
Ukuran skewness/kemencengan terhadap bentuk normal adalah
0,134; teori menyebutkan jika skewness bernilai positif maka
maka bentuk kurva positif dan data lebih tersebar pada kurva
sebelah kanan; skewness bernilai negative sebaliknya
Mo=
Med=165
teori:
•Jika nilai nilai kurtosis sama dengan nol maka dikatakan
kurva normal (mesokurtik)
•Jika > 3 dikatakan kurva diatas kurva normal (leptokurtic)
•Jika < 3 dikatakan kurva dibawah kurva normal
(platikurtik).
Kurtosis
Leptokurtik
Mesokurtik
Hasil Kortusis
Ukuran kurtosis/penyebaran terhadap distribusi
normal bernilai -0,795 maka Jika -0,795 < 3
maka dikatakan kurva dibawah kurva normal
(platikurtik).
Gambaran Kurva
+
Range adalah data maksimum dikurangi
data minimum adalah 44,66 cm
Angka Persentil mengandung arti;
• 10% rata-rata tinggi dibawah 146,54 cm • 25% rata-rata tinggi dibawah 155,58 cm • 50% persentil adalah nilai median;
Simulasi 2
Buat pembuktian kurva dengan
pendekatan
skewness
dan
kurtosis
untuk data variabel tinggi
(caranya: Pada
gambar 4-6
aktifkan
histogram
dan
with normal curve
)
Buat analisis model
frekuensi
untuk
DESCRIPTIVE
Memberikan gambaran tentang suatu
data baik itu data kualitatif ataupun data
kuantitatif seperti
mean, standar
CONTOH
•
Buat deskripsi data variabel tinggi !
•
Buat deskripsi data variabel berat!
•
Untuk hasil variabel berat, apakah
data dapat dikatakan normal atau
apakah ada data yang terlalu jauh
(outlier atau exstrim) dari nilai
Z Scores
• Melihat nilai mana saja yang menyimpang jauh
(outlier) dari nilai mean
• Pada Tab-Sheet data view muncul variabel baru
dengan nama Zberat;
• Untuk data normal nilai Z akan terletak antara
-1,96 dan -1,96 pada taraf signifikan 5%;
• Maka jika kita melihat data Zberat responden
EXPLORE
Melakukan deskripsi data dan
mengujinya; data yang digunakan bisa
berupa data kuantitatif dan atau data
Output test of normality
• Konsepnya nilai sig./signifikansi atau
probalitas < 0,05 distribusi adalah tidak normal dan sebaliknya;
• Seperti untuk pengujian kolmogorov
smirnov pada jabatan low manajemen
mempunyai nilai signifikan sebesar 0.200 ( > 0.05) yang menyatakan bahwa distribusi data normal
Distribusi
Simulasi 3
(Kasus data tiap kelas)
• Tentukan variabel yang di pilih!!!
• Berapa nilai mean;modus;median?
• Berapa nilai standar error of mean dan
Standar deviasi?
• Berapa nilai Persentil 25; 50; dan 95
• Apa arti persentil 95
• Apa hubungan antara median dengan
persentil 50
• Berapa Rentang Rata-rata kasus tersebut,
jelaskan artinya?
• Berapa Rentang kasus tersebut, jelaskan
lanjutan1
• Teori menyebutkan bahwa kurva normal
jika kisaran nilai mean=modus=median; bentuklah kurva normal tersebut secara skematis!
• Berapa nilai skewness nya, bagaimana
kemungkinan bentuk kurvanya, serta dimana kemungkinan posisi nilai mean, median modus?
• Berapa nilai kurtosisnya!, bagaimana
kemungkinan bentuk kurvanya
• Apakah dari kasus tersebut ada data yang
Lanjutan2
•
Apakah dari kasus tersebut ada data
yang extrim (diluarbatas/outlier)
•
Jika ada data yang “outlier”, apa
yang harus kita lakukan!