Large Scale and Big Data Processing and Management pdf pdf
Teks penuh
Gambar

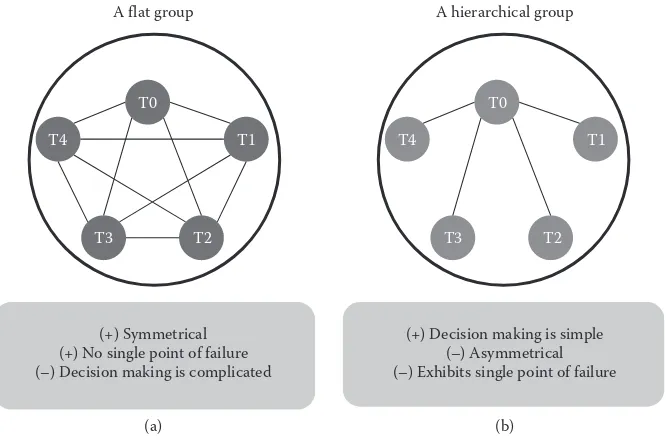
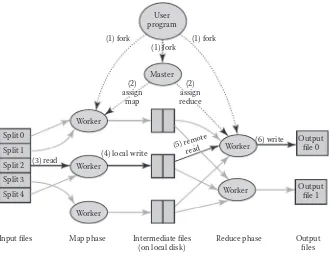
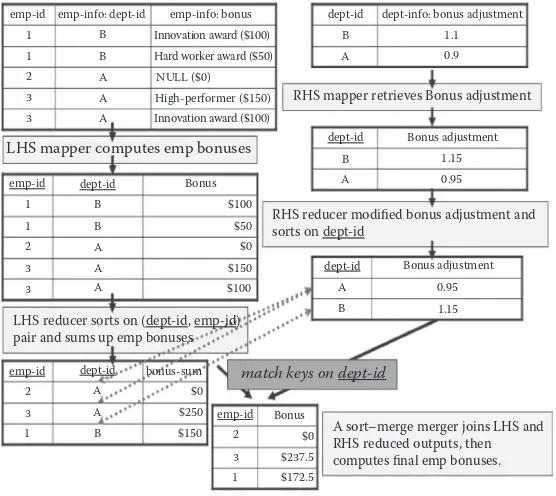
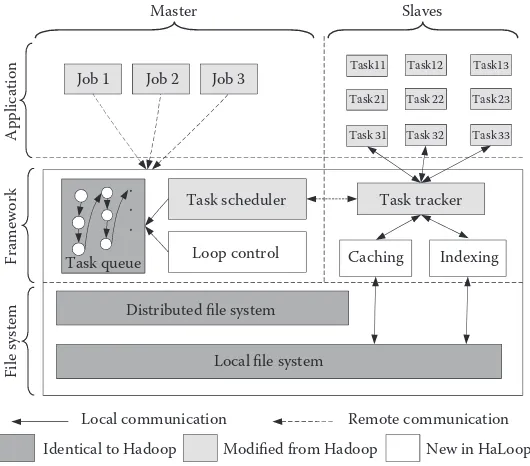
Dokumen terkait
His research interest includes policy-making support system for planning and design using GIS and VR. He is now serving as academic commis- sioner of the City Planning Institute
This chapter demonstrates how to access data—from the Web, in table format, CSV format, and JSON format—and then shape it using the Power Query editor before importing it into
Based on this semantics for the logical formulae without free variables (i.e., the integrity constraints expressed by egds and tgds, and the query inter-schema mappings expressed
If you look at cognitive computing as an analog to the human brain, you need to analyze in context all types of data, from structured data in databases to unstructured data in
A machine learning algorithm trains a model with data; it fits a model over a dataset, so that the model can predict the label for a new observation.. Training a model is a
You might also have noticed that for the mapper option, we have just provided the mapper.py executable name instead of the full S3 path. This is just to demonstrate that you
It describe the optimal solutions using Hadoop cluster, Hadoop Distributed File System HDFS for storage and Map Reduce programming framework for parallel processing to process large
Figure 2: Summary of dead nodes in LEACH and M-TRAC From Figure 3 we can conclude that with the inclusion of CS as a data aggregation scheme, we can reduce the amount of redundant data
