COOCURENCE MATRIX (GLCM) DAN SUPPORT VECTOR MACHINE (SVM)
Skripsi
Oleh : Aditya
NIM : 1112091000043
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH JAKARTA
2017 M / 1438 H
(GLCM) DANSUPPORT VECTOR MACHINE (SVM)
Skripsi
Sebagai Salah Satu Syarat untuk Memperoleh Gelar Sarjana Komputer
Oleh : Aditya
NIM : 1112091000043
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH JAKARTA
2017 M / 1438 H
Dengan ini saya menyatakan bahwa :
1. Skripsi ini merupakan hasil karya asli saya yang diajukan untuk memenuhi salah satu persyaratan memperoleh gelar strata 1 di UIN Syarif Hidayatullah Jakarta.
2. Semua sumber yang saya gunakan dalam penulisan ini telah saya cantumkan sesuai dengan ketentuan yang berlaku di UIN Syarif Hidayatullah Jakarta.
3. Jika di kemudian hari terbukti bahwa karya ini bukan hasil karya asli saya atau merupakan hasil jiplakan dari karya orang lain, maka saya bersedia menerima sanksi yang berlaku di UIN Syarif Hidayatullah Jakarta.
Tangerang, 20 Desember 2016
Aditya
(SVM) Skripsi
Sebagai Salah Satu Syarat untuk
Memperoleh Gelar Sarjana Komputer (S.Kom) Oleh:
ADITYA 1112091000043
Menyetujui,
Pembimbing I, Pembimbing II,
Anif Hanifa Setyaningrum, M.Si NIDN. 0410116402
Luh Kesuma Wardhani , M T.
NIP. 19780424 200801 2 022
Mengetahui,
Ketua Program Studi Teknik Informatika
Arini, ST, MT.
NIP. 19760131 200901 2 001
(GLCM) dan Support Vector Machine (SVM)” yang ditulis oleh Aditya , NIM 1112091000043 telah diuji dan dinyatakan lulus dalam sidang munaqasyah Fakultas Sains dan Teknologi UIN Syarif Hidayatullah Jakarta pada 28 Maret 2017. Skripsi ini telah diterima sebagai salah satu syarat memperoleh gelar Sarjana Komputer (S.Kom) pada program Studi Teknik Informatika.
Jakarta, 28 Maret 2017
Tim Penguji Penguji I,
Nurhayati, Ph.D NIP. 19690316 199903 2 002
Penguji I,
Fitri Mintarsih, M.Kom NIP. 19721223 200710 2 004 Tim Pembimbing
Pembimbing I,
Anif Hanifa Setyaningrum, M.Si NIDN. 0410116402
Pembimbing II,
Luh Kesuma Wardhani , M T.
NIP. 19780424 200801 2 022 Mengetahui,
Dekan FST,
Dr. Agus Salim, M.Si NIP. 19720816 199903 1 003
Ketua Program Studi,
Arini, MT
NIP. 19760131 200901 2 001
rahmat-Nya, saya dapat menyelesaikan skirpsi ini. Penulisan skripsi ini dilakukan dalam rangka memenuhi salah satu syarat untuk mencapai gelar Sarjana Komputer Program Studi Teknik Informatika Fakultas Sains dan Teknologi Universitas Islam Negeri Syarif Hidayatullah Jakarta. Saya menyadari bahwa, tanpa bantuan dan bimbingan dari berbagai pihak, dari masa perkuliahan sampai pada penyusunan skripsi ini, sangatlah sulit bagi saya untuk menyelesaikan skripsi ini. Oleh karena itu, saya mengucapkan terima kasih kepada :
1. Bapak Dr. Agus Salim, M. Si, selaku Dekan Fakultas Sains dan Teknologi.
2. Ibu Arini, ST, MT., selaku Ketua Program Studi Teknik Informatika yang selalu memberikan bimbingan bantuan dan Bapak Feri Fahrianto, M. Sc., selaku Sekretaris Program Studi Teknik Informatika.
3. Ibu Anif Hanifa Setianingrum M. Si., selaku Dosen Pembimbing I sekaligus teman debat yang telah meluangkan banyak waktunya untuk membimbing, bertukar pikiran, serta memberikan pandangan-pandangan baru dalam penyelesaian studi saat ini dan di masa yang akan datang.
4. Ibu Luh Kesuma Wardani, MT., selaku Dosen Pembimbing II yang telah memberikan arahan, bimbingan dan motivasi untuk menyelesaikan skripsi ini.
5. Bapak dan Ibu Dosen Fakultas Sains dan Teknologi Universitas Islam Negeri (UIN) Syarif Hidayatullah Jakarta, khususnya pada Program Studi Teknik Informatika yang telah memberikan ilmu pengetahuan yang tidak terhingga banyaknya dan sangat berguna bagi penulis.
6. Orang tua tercinta, Ayahanda Junaedi dan Ibunda Tri Tisngatun, penuh kasih sayang dan perhatian yang tulus, serta dengan penuh kesabaran memberikan dorongan baik moril maupun materil, serta doa yang selalu dipanjatkan demi kesuksesan dan tercapainya cita-cita penulis. Serta adik-
dan mengingatkan seputar akademik, juga partner yang sangat hebat yang berkontribusi besar terhadap terselesaikannya skripsi ini.
8. Amalina Hasyyiati Nur Trivansyah yang selalu memberikan dukungan moral, membantu membenarkan penulisan skripsi ini, dan selalu mendorong penulis untuk bisa menyelesaikan skripsi ini dengan baik.
9. Sahabat-sahabat tercinta, Ahmad Fatoni F.R., Mulkan Arirafly, Ida Bagus Aditya Suryawan, Untung Tri Pamungkas, Putra Triananda, Hasanain Hifni, Rionaldi, dan teman-teman yang tidak dapat disebutkan satu-persatu yang telah membantu, memberikan masukan, semangat dan ilmu serta memotivasi agar selalu melakukan yang terbaik.
10. Seluruh teman-teman TI 2012 atas dukungan, bantuan, dan kerjasama dalam menjalani aktifitas perkuliahan selama kurang lebih 4 tahun.
Semoga dilancarkan penyelesaian skripsinya dan sukses di masa yang akan datang.
11. Teman-teman SMA yang selalu menunggu kabar wisuda dengan sabar, Alirio Saputra, Denny Kristian, Siti Fatimah Anggraini, Angelia Astri Hermatika dan Gatra Astama Wisnu Mukti. Semoga kita semua jadi orang-orang yang berhasil di masyarakat.
12. Seluruh pihak yang baik secara langsung maupun tidak langsung membantu penulis dalam menyelesaikan penyusunan skripsi ini.
Atas bantuan mereka yang sangat berharga, penulis mengucapkan terima kasih.
Tangerang, 20 Desember 2016
Aditya
tangan dibawah ini:
Nama : Aditya
NPM : 1112091000043
Program Studi : Teknik Informatika
Fakultas : Fakultas Sains dan Teknologi Jenis Karya : Skripsi
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Islam NegerSyarif Hidayatullah Jakarta Hak Bebas Royalti Non Eksklusif (Non-exclusive Royalti Free Right) atas karya ilmiah saya yang berjudul :
Identifkasi Kanker Otak pada Citra MRI Menggunakan Metode Principal Component Analysis (PCA), Gray Level Coocurence Matrix (GLCM) dan
Support Vector Machine (SVM)
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Non Eksklusif ini Universitas Islam Negeri Syarif Hidayatullah Jakarta berhak menyimpan, mengalihmedia/formatkan, mengelola dalam bentuk pangkalan data (database), merawat, dan mempublikasikan tugas akhir saya selama tetap mencantumkan nama saya sebagai penulis/pencipta dan sebagai pemilik Hak Cipta.
Demikian pernyataan ini saya buat dengan sebenarnya.
Dibuat di : Tangerang Pada tanggal : 20 Desember 2016
Yang menyatakan
(Aditya)
Metode Principal Component Analysis (PCA), Gray Level Coocurence Matrix (GLCM) dan Support Vector Machine (SVM).
ABSTRAK
Tingkat kematian manusia terhadap penyakit kanker otak sangatlah tinggi.
Laporan National Research Funding pada Juli 2014 menyatakan 1 dari 50 orang di bawah usia 60 tahun mengidap kanker otak dan tingkat kematian akibat penyakit ini mencapai 71%. Pemetaan terhadap gambar MRI kanker otak menggunakan metode Principal Component Analysis (PCA) dan Gray Level Coocurence Matrix (GLCM) menunjukkan suatu pola untuk tingkat keganasan tumor. Pola ini kemudian dapat diklasifikasi berdasarkan tingkat keganasannya menggunakan metode Support Vector Machine (SVM).
Identifikasi kanker otak dilakukan kepada 3 buah sampel yang tergolong sebagai data uji, dan 4 sampel sebagai data latih. Dengan parameter adalah nilai contrast, energy, homogeneity, mean, standard deviation, smoothness, kurtosis, skewness, dan entropy, menghasilkan dua dari tiga sampel uji menghasilkan pengidentifikasian yang benar dengan tingkat akurasi 77% hingga 100%.
Sedangkan satu sampel lainnya menghasilkan pengidentifikasian yang tidak tepat dengan tingkat akurasi 47%
Kata Kunci : Kanker Otak, MRI, Principal Component Analysis (PCA), Gray Level Coocurence Matrix (GLCM) dan Support Vector Machine (SVM).
Daftar Pustaka : 23 (Tahun 2009 – 2015)
Jumlah Halaman : VI BAB + xiii Halaman + 81 Halaman + 22 Gambar + 20 Tabel
Metode Principal Component Analysis (PCA), Gray Level Coocurence Matrix (GLCM) dan Support Vector Machine (SVM).
ABSTRACT
People death rate concerning brain cancer is very high. National Research Funding report on July 2014 described that 1 from 50 people under 60 years old suffered brain cancer and the death rate cause by this desease reach 71%.
Mapping brain cancer’s MRI image by using Principal Component Analysis (PCA) dan Gray Level Coocurence Matrix (GLCM) will show tumor malignancy rate pattern. This pattern can be classified based on malignancy rate by using Support Vector Machine (SVM) method.
Brain cancer identification use 3 samples which are testing data, and 4 samples as training data. Parameters used for identification are contrast, energy, homogeneity, mean, standard deviation, smoothness, kurtosis, skewness, and entropy value. Two from three testing sample showed true result with 77% until 100% accuracy rate, and another sample show false result with 47% accuracy rate.
Key words : Brain Cancer, MRI, Principal Component Analysis (PCA), Gray Level Coocurence Matrix (GLCM) and Support Vector Machine (SVM).
HALAMAN PERSETUJUAN...iii
PENGESAHAN UJIAN...iv
KATA PENGANTAR...v
HALAMAN PERNYATAAN PERSETUJUAN PUBLIKASI SKRIPSI UNTUK KEPENTINGAN AKADEMIS...vii
ABSTRAK...viii
DAFTAR ISI...x
DAFTAR GAMBAR...xiii
DAFTAR TABEL...xiv
BAB I PENDAHULUAN...1
1.1. Latar Belakang...1
1.2. Tujuan...3
1.3. Manfaat Penelitian...3
1.4. Rumusan Masalah...4
1.5. Batasan Masalah...4
1.6. Metodologi Penelitian...5
1.7. Sistematika Penulisan...5
BAB II LANDASAN TEORI...7
2.1. Kanker Otak...7
2.1.1. Definisi Kanker Otak...7
2.1.2. Definisi Tumor Otak...7
2.1.3. Klasifikasi Tumor Otak...8
2.2. Magnetic Resonance Image (MRI)...8
2.3. Pengolahan Citra...9
2.3.1. Definisi Pengolahan Citra...9
2.3.2. Operasi Pengolahan Citra...10
2.4. Support Vector Machine (SVM)...21
4.2.4. Karakteristik SVM...30
4.2.5. Perbandingan SVM dengan metode lain...31
2.5. Matlab...32
2.6. Metode Simulasi...33
2.6.1. Problem Formulation...33
2.6.2. Conceptual Model...33
2.6.3. Collecting and Analysis of Input/Output Data...34
2.6.4. Modelling...34
2.6.5. Simulation...34
2.6.6. Verification and Validation...34
2.6.7. Experimentation...35
2.6.8. Output Analysis...35
2.7. Metode Pengumpulan Data...35
2.7.1. Observasi...35
2.7.2. Wawancara...35
2.7.3. Studi Pustaka...36
BAB III METODOLOGI PENELITIAN...37
3.1. Metode Pengumpulan Data...37
3.1.1. Wawancara...37
3.1.2. Studi Pustaka...38
3.1.3. Studi Literatur Sejenis...38
3.2. Obyek Penelitian...41
3.3. Sumber Data...41
3.4. Metode Analisis Data...42
3.5. Metode Pemodelan Simulasi...42
3.5.1. Problem Formulation...42
3.5.2. Conceptual Model...42
3.5.3. Collection and Analysis of Input/Output Data...43
3.5.7. Experimentation...44
3.5.8. Output Analysis...45
3.6. Tempat dan Waktu Penelitian...45
3.7. Kerangka Berpikir...45
BAB IV ANALISIS, PERANCANGAN, IMPLEMENTASI DAN PENGUJIAN SISTEM...47
4.1. Deskripsi Data...47
4.2. Pembahasan Hasil Penelitian dengan Menggunakan Metode Simulasi..47
4.2.1. Problem Formulation...47
4.2.2. Conceptual Model...48
4.2.3. Collection and Analysis of Input/Output Data...51
4.2.4. Modelling...53
4.2.5. Simulation...70
BAB V...81
5.1. Verification and Validation...81
5.2. Experimentation...89
5.3. Output Analysis...90
BAB VI...94
6.1. Kesimpulan...94
6.2. Saran...94
DAFTAR PUSTAKA...1
Gambar 4.3 Tampilan Mask...14
Gambar 4.4 Matriks Mask...14
Gambar 4.5 Matriks EDT dari Maks...15
Gambar 4.6 Matriks EDT pada Nilai Ambang antara 1.2 dan -1.2...15
Gambar 4.7 Matriks target <= 0...16
Gambar 4.8 Matriks target > 0...16
Gambar 4.9 Penggabungan Image Sampel dengan Mask...17
Gambar 4.10 Matriks Hasil Penggabungan Image Sampel dengan Mask...18
Gambar 4.11 Nilai Subscript Image Sampel...18
Gambar 4.12 Tumor yang Telah Tersegmentasi...19
Gambar 4.13 Matriks Segmentasi Tumor...19
Gambar 4.14 Antarmuka program simulasi...37
Gambar 4.15 Antarmuka Akuisisi Citra...38
Gambar 4.16 Antarmuka Filtering...39
Gambar 4.17 Antarmuka Segmentasi Tumor...39
Gambar 4.18 Antarmuka Ekstraksi Fitur...40
Gambar 4.19 Antarmuka Identifikasi Kanker...40
Gambar 5.1 Eigen Vector Sampel Uji-1C………..80
Gambar 5 2 Matrix Coocurence Sampel Uji-1C………....81
Gambar 5.3 Eigen Vector Sampel Uji-2C………...83
Gambar 5.4 Matrix Coocurence Sampel Uji-2C………....83
Gambar 5.5 Eigen Vector Sampel Uji-3C………...…...86
Gambar 5.6 Matrix Coocurence Sampel Uji-3C………86
Tabel 2.4 Klasifikasi SVM Biner dengan Metode One-against-all...26
Tabel 2.5 Perbandingan SVM dengan ANN...29
Tabel 4.1 Gambar Sampel Tumor Jinak...11
Tabel 4.2 Gambar Sampel Tumor Ganas...12
Tabel 4.3 Sampel Gambar Data Uji...12
Tabel 4.4 Penghitungan Contrast...20
Tabel 4.5 Penghitungan Energy...22
Tabel 4.6 Penghitungan Homogeneity...24
Tabel 4.7 : Penghitungan Kurtosis...28
Tabel 4.8 Penghitungan Skewness...28
Tabel 4.9 Penghitungan Entropy...29
Tabel 5.1 Range Nilai Data Latih...41
Tabel 5.2 Perbandingan Ekstraksi Sampel Uji-1C...43
Tabel 5.3 Perbandingan Ekstraksi Sampel Uji-2C...45
Tabel 5.4 Perbandingan Ekstraksi Sampel Uji-3C...48
Tabel 5.5 Output GLCM Gambar Sampel...50
Tabel 5.6 Output PCA Gambar Sampel...51
BAB I PENDAHULUAN 1.1. Latar Belakang
Tingkat kematian manusia terhadap penyakit kanker otak sangatlah tinggi. Mengutip laporan National Research Funding mengenai penderita kanker otak pada Juli 2014, 1 dari 50 orang di bawah usia 60 tahun mengidap tumor otak dan tingkat kematian akibat penyakit ini mencapai 71%.
Besarnya tingkat kematian akibat kanker otak, sayangnya tidak diimbangi dengan banyaknya kajian yang dilakukan terhadap penyakit ini.
Masih mengutip laporan National Research Funding, hanya 1% penelitian dikhususkan kepada kanker otak dibandingkan jenis kanker lainnya.
Mengingat tingginya tingkat kematian dan sedikitnya penelitian tentang kanker otak, menjadi penting untuk melakukan kajian terhadap penyakit ini. Salah satu kajian yang bisa diterapkan pada penyakit ini adalah penggunaan teknologi untuk membantu diagnosis (Havaei, 2015 : 2).
Teknologi sudah diterapkan pada diagnosis kanker otak. Salah satu penerapan teknologi untuk mendiagnosis kanker otak adalah dengan menggunakan Magnetc Resonance Image (MRI). MRI dapat membantu memberikan gambaran organ dalam manusia kepada pendiagnosa agar dapat diperiksa lebih lanjut.
Identifikasi kanker otak utamanya digunakan untuk mendiagnosis, memantau pasien, perencanaan pengobatan, perencanaan pembedahan dan perencanaan radioterapi. Pendiagnosa dapat mengidentifikasi kanker otak melalui bentuk serta tekstur tumor pada gambar MRI. Tumor otak kemudian diklasifikasikan menjadi tumor jinak atau tumor ganas. Sebagai tambahan, tumor ganas disebut juga kanker (Havaei, 2015 : 2).
Tumor dapat muncul hampir di mana saja dalam otak. Tumor tidak
memiliki bentuk khusus, dan sering kali sulit untuk dideteksi tepinya.
Secara visual berwarna abu-abu, hampir sama dengan bagian jaringan yang sehat. Karena sulitnya menentukan bagian tumor dengan jaringan otak yang sehat, segmentasi tumor otak pada prakteknya masih dilakukan secara manual. Segmentasi secara manual tidak hanya banyak memakan waktu dan ketelitian, tapi juga bisa memberikan kesan subjektif antara para pendiagnosa yang berbeda, bahkan untuk pendiagnosa yang sama sekalipun akibat faktor inkonsistensi manusia (Havaei, 2015 : 2).
Sistem pengolahan citra yang sudah terotomatisasi untuk mendeteksi kanker otak masih terus dikembangkan. Principal Component Analysis (PCA) merupakan salah satu metode pengolahan citra yang banyak digunakan untuk mendeteksi kanker otak. PCA bekerja dengan cara mencari parameter bentuk dan posisi dari tumor otak. Hasil metode ini adalah sebuah matriks yang sudah merepresentasikan bentuk dan posisi dari tumor (Zulpe, 2012 : 3).
Gray Level Co-Occurrence Matrix adalah sebuah metode statistik untuk menganalisa tekstur citra berdasarkan hubungan spasial antar piksel.
Tekstur diperlukan untuk mendeteksi benjolan yang disebabkan oleh tumor. GLCM juga berisi parameter yang merepresentasikan ukuran dari tumor otak(Muntasa, 2015:186-187).
Sementara itu, untuk mengklasifikasikan setiap nilai dari metode PCA dan GLCM, ada beberapa metode yang dapat digunakan, salah satunya Support Vector Machine (SVM). SVM bekerja dengan cara mencari hyperplane (batas keputusan) terbaik yang berfungsi sebagai pemisah dua buah kelas data pada ruang input (Prasetyo, 2012: 118). Salah satu keuntungan dari SVM adalah bahwa kita dapat meningkatkan kinerja dengan memilih kernel yang sesuai (Abe, 2010: 33). Singhal (2015), dalam jurnalnya yang berjudul “A Comparative Study of Two MRI Brain Tumor Classification Techniques” melakukan serangkaian pengujian untuk menentukan tingkat akurasi antara SVM dengan Artificial Neural Network (ANN) dalam klasifikasi jenis tumor otak. Hasil pengujian
tersebut menghasilkan SVM menunjukkan tingkat akurasi yang lebih tinggi dibandingkan ANN.
Penerapan metode Principal Component Analysis (PCA), Gray Level Coocurence Matrix (GLCM) dan Support Vector Machine (SVM) dapat menjadi solusi untuk permasalahan identifikasi tumor pada kanker otak. Kompleksnya fitur pada gambar MRI menimbulkan banyak nilai atribut yang harus didapatkan untuk meningkatkan akurasi pada saat identifikasi kanker. PCA dapat mengakomodir kebutuhan nilai berdasarkan bentuk serta GLCM dapat mengakomodir pemenuhan kebutuhan nilai berdasarkan tingkat keabuan pada gambar MRI. SVM akan melakukan pengujian atau klasifikasi berdasarkan nilai ciri hasil metode PCA dan GLCM guna mengidentifikasi tumor tersebut tergabung dalam kanker atau tidak (Roy, 2012 : 11).
Berdasarkan latar belakang di atas, penulis melakukan penelitian dengan judul “Identifkasi Kanker Otak pada Citra MRI Menggunakan Metode Principal Component Analysis (PCA), Gray Level Coocurence Matrix (GLCM) dan Support Vector Machine (SVM)”.
1.2. Tujuan
Tujuan dilakukannya penelitian ini adalah melakukan identifikasi kanker otak pada citra MRI menggunakan metode Principal Component Analysis (PCA), Gray Level Coocurence Matrix(GLCM) dan Support Vector Machine (SVM).
1.3. Manfaat Penelitian 1. Penulis
Manfaat penelitian ini bagi penulis adalah menerapkan ilmu dan pengetahuan selama kuliah.
2. Universitas
Manfaat penelitian ini bagi Universitas adalah sebagai bahan referensi untuk penelitian selanjutnya.
3. Pembaca
Manfaat penelitian ini bagi pembaca adalah menambah wawasan baru, baik dalam teori diagnosis kanker otak, proses pengolahan citra pada gambar MRI, penggunaan metode PCA dan GLCM untuk ekstraksi fitur dan penggunaan metode SVM untuk identifikasi kanker.
1.4. Rumusan Masalah
Berdasarkan latar belakang masalah yang telah diuraikan sebelumnya, rumusan masalah yang akan dibahas dalam penelitian ini adalah bagaimana mengidentifikasi kanker otak pada citra MRI dengan menggunakan metode Principal Component Analysis (PCA), Gray Level Coocurence Matrix (GLCM) dan Support Vector Machine (SVM)?
1.5. Batasan Masalah
Dalam penelitian ini, penulis membatasi permasalahan dengan batasan sebagai berikut :
1. Masukan dari program dibatasi hanya pada gambar Magnetic Resonance Image (MRI) kanker otak dengan ukuran 256x256 pixel berformat “*.jpg”.
2. MRI kanker otak telah dibedakan berdasarkan jenis tumor jinak (benign) dan ganas (malignant).
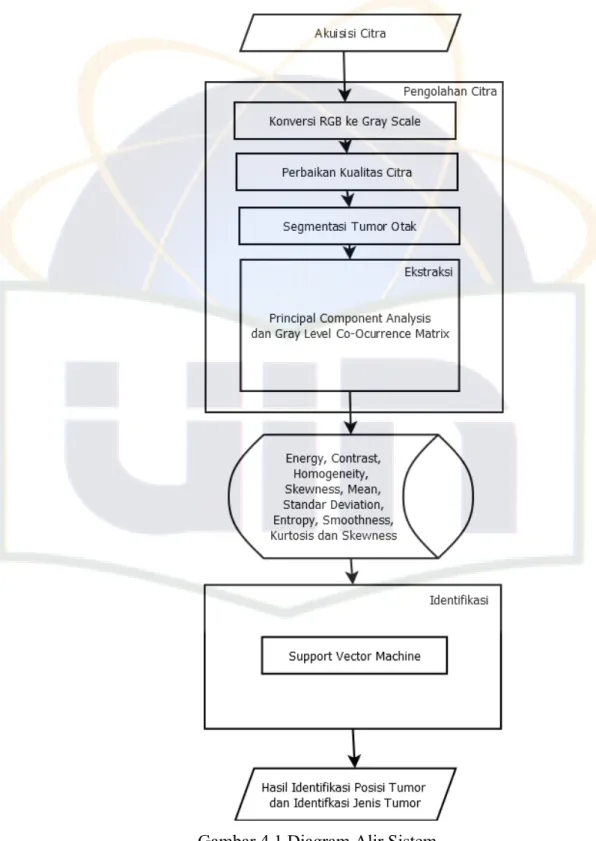
3. Proses ekstraksi dilakukan dengan metode Principal Component Analysis (PCA) dan Gray Level Coocurence Matrix (GLCM).
4. Proses identifikasi dilakukan dengan metode Support Vector Machine (SVM).
5. Bahasa pemrograman yang digunakan adalah MATLAB dengan perangkat lunak bantu MATLAB R2012a.
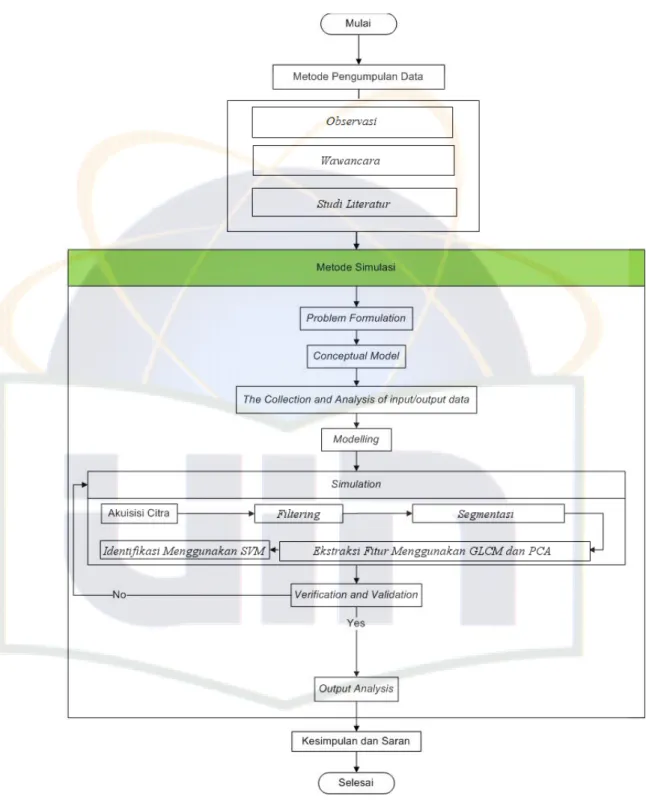
1.6. Metodologi Penelitian
Metode penelitian yang penulis gunakan meliputi : 1.6.1. Metode Pengumpulan Data
1. Observasi 2. Wawancara 3. Studi Pustaka
1.6.2. Metodologi Pengembangan Sistem
Metode yang penulis gunakan dalam pengembangan sistem ialah Metode Simulasi dengan tahapan sebagai berikut :
1. Problem Formulation 2. Conceptual Model
3. Collection and Analysis of Input/Output Data 4. Modelling
5. Simulation
6. Verification and Validation 7. Experimentation
8. Output Analysis 1.7. Sistematika Penulisan
Sistematika penulisan yang digunakan dalam laporan penelitian ini adalah sebagai berikut :
BAB I PENDAHULUAN
Bab ini terdiri dari beberapa sub bab diantaranya latar belakang, rumusan masalah, tujuan penelitian, manfaat penelitian, batasan masalah, metode penelitian dan sistematika penulisan.
BAB II LANDASAN TEORI
Bab ini berisi pembahasan teori-teori dari berbagai referensi yang dijadikan sebagai landasan dan data pendukung dalam penelitian ini.
BAB III METODOLOGI PENELITIAN
Bab ini terdiri dari beberapa sub bab diantaranya metode pengumpulan data, metode pengembangan sistem dan kerangka berpikir penelitian.
BAB IV ANALISIS, PERANCANGAN SISTEM,
IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini berisi penjelasan dari setiap tahapan pengembangan sistem.
BAB V HASIL DAN PEMBAHASAN
Bab ini berisi uraian mengenai proses pengujian sistem serta penjelasan hasil yang didapat setelah pengujian.
BAB VI PENUTUP
Bab ini berisi uraian mengenai kesimpulan yang didapatkan dari hasil penelitian serta saran yang dapat digunakan untuk pengembangan penelitian di masa mendatang.
DAFTAR PUSTAKA LAMPIRAN
BAB II
LANDASAN TEORI
2.1. Kanker Otak
2.1.1.Definisi Kanker Otak
Kanker berarti benjolan patologis pada tubuh yang dapat berwujud dalam beberapa bentuk.
Kanker bukanlah satu penyakit, tetapi beberapa penyakit dengan patogenesis, gambaran klinik, dan penyebab yang berbeda. Kanker ditandai dengan terjadinya pertumbuhan sel yang tidak normal.
Sel-sel kanker tumbuh dengan tanpa kontrol dan tanpa tujuan yang jelas. Pertumbuhan ini akan mendesak dan merusak pertumbuhan sel- sel normal. Sel normal tumbuh dengan suatu tujuan tertentu membentuk jaringan tubuh dan mengganti jaringan yang rusak. Pertumbuhan sel-sel kanker akan menyebabkan jaringan menjadi besar yang disebut sebagai tumor.
Sel-sel kanker yang tumbuh dengan cepat ini akan menyusup dan menyebar ke jaringan sekitarnya melalui pembuluh darah dan pembuluh getah bening. Penjalarannya ke jaringan lain disebut sebagai metastatis (Bustan, 2015 : 181).
2.1.2. Definisi Tumor Otak
Tumor merupakan istilah umum yang dipakai untuk semua bentuk pembengkakan atau benjolan pada tubuh. Namun tumor biasanya dipakai untuk menyatakan benjolan abnormal akibat pertumbuhan jaringan baru. Tumor secara khusus dipakai pula untuk pengganti nama kanker jinak, sementara istilah kanker dimaksudkan sebagai suatu
‘tumor’ ganas. Dengan demikian dapat disebutkan bahwa semua benjolan adalah tumor, tetapi tidak semua tumor itu adalah kanker (Bustan, 2015 : 181).
2.1.3. Klasifikasi Tumor Otak
Menurut Bustan (2015, hal. 182), tumor secara garis besar diklasifikasikan menjadi tumor jinak (benign) dan tumor ganas (malignant). Tabel 2.1 menunjukkan perbandingan karakteristik tumor jinak dan tumor ganas.
Tabel 2.1 Karakteristik Jenis Tumor
Tumor Jinak (Benign) Tumor Ganas (Malignant) 1. Sering disebut tumor
2. Tidak menyebar
3. Tidak mengancam hidup 4. Dapat dioperasi baik 5. Pertumbuhannya lambat 6. Beberapa gambaran mitosis 7. Tumbuh ekspansif
8. Encapsulation biasanya ada
1. Disebut kanker 2. Sering metastatis 3. Kematian tinggi 4. Sulit operasi 5. Tumbuh cepat
6. Banyak gambaran mitosis 7. Tumbuh infiltratif
8. Pseudoencapsulation 2.2. Magnetic Resonance Image (MRI)
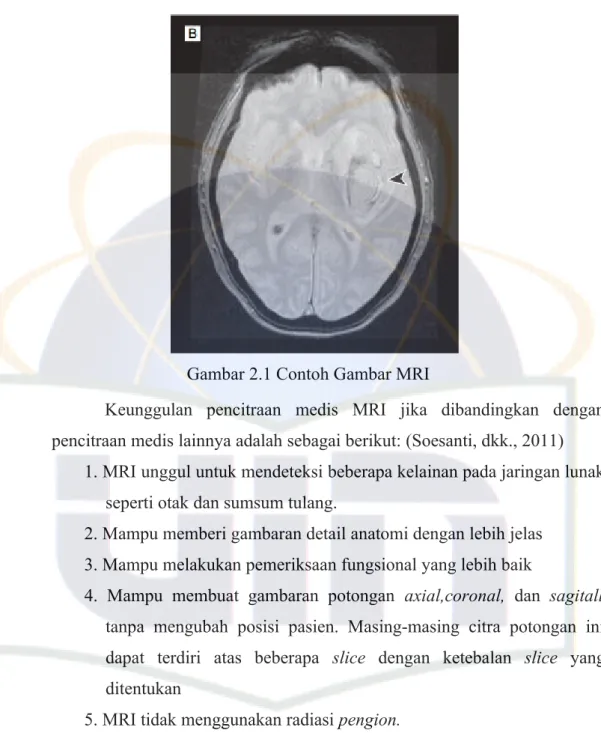
Magnetic Resonance Imaging (MRI) adalah suatu teknik pencitraan medis dalam pemeriksaan diagnostik radiologi, yang menghasilkan rekaman citra potongan penampang tubuh atau organ manusia dengan menggunakan medan magnet dan resonansi getaran terhadap inti atom hidrogen. Teknologi ini memanfaatkan sifat atom hidrogen, dikarenakan pada sebagian besar tubuh manusia terdapat atom hidrogen. Dapat juga dikatakan bahwa MRI merupakan alat diagnostik atau alat pemeriksaan radiologi berteknologi tinggi, yang menggunakan medan magnet yang besar, frequensi radio tertentu dan seperangkat detektor dan pengolahan data untuk menghasilkan gambaran potongan-potongan anatomi tubuh manusia. Dengan pencitraan MRI dapat dihasilkan potongan atau irisan (slice) melintang atau tegak sesuai dengan kebutuhan. Berikut merupakan contoh gambar MRI:
Gambar 2.1 Contoh Gambar MRI
Keunggulan pencitraan medis MRI jika dibandingkan dengan pencitraan medis lainnya adalah sebagai berikut: (Soesanti, dkk., 2011)
1. MRI unggul untuk mendeteksi beberapa kelainan pada jaringan lunak seperti otak dan sumsum tulang.
2. Mampu memberi gambaran detail anatomi dengan lebih jelas 3. Mampu melakukan pemeriksaan fungsional yang lebih baik
4. Mampu membuat gambaran potongan axial,coronal, dan sagitall tanpa mengubah posisi pasien. Masing-masing citra potongan ini dapat terdiri atas beberapa slice dengan ketebalan slice yang ditentukan
5. MRI tidak menggunakan radiasi pengion.
2.3. Pengolahan Citra
2.3.1. Definisi Pengolahan Citra
Menurut Kadir & Susanto (2013: 2), pengolahan citra adalah istilah umum untuk berbagai teknik yang keberadaannya untuk memanipulasi dan memodifikasi citra dengan berbagai cara. Sedangkan pengolahan citra digital merupakan pemrosesan gambar berdimensi-dua melalui
komputer digital. Pengolahan citra digital dapat juga diartikan sebagai penggunaan algoritma komputer untuk melakukan pemrosesan citra pada citra digital (Nitasha, et al., 2012: 1).
Operasi pengolahan citra dapat dibagi menjadi tiga kategori utama: kompresi citra, peningkatan kualitas dan restorasi citra, serta segmentasi citra (Nitasha, dkk., 2012: 1).
Kompresi citra berarti mengurangi jumlah data yang diperlukan untuk mewakili citra. Selanjutnya, perbaikan (enhancement) dan restorasi citra merupakan teknik peningkatan kualitas citra yang terdegradasi akibat proses transformasi citra yang diubah dari satu bentuk ke bentuk lainnya, seperti digitalisasi, transmisi, scanning, dan proses lain yang mengakibatkan degradasi pada output citra. Perbaikan citra meningkatkan kualitas citra untuk penglihatan manusia, menghapus citra kabur (blur) dan noise, meningkatkan kontras dan menampilkan detail merupakan operasi tambahan pada enhancement.
Sedangkan segmentasi yaitu membagi citra ke daerah dan obyek-obyek penyusunnya (Nitasha, dkk., 2012: 1).
2.3.2. Operasi Pengolahan Citra
Operasi-operasi yang dilakukan di dalam pengolahan citra banyak ragamnya. Namun, secara umum, operasi pengolahan citra dapat diklasifikasikan dalam beberapa jenis sebagai berikut :
2.3.2.1. Gray Scale
Dalam prakteknya, gambar gray scale terkadang disebut gambar hitam dan putih, namun secara teknis keduanya berbeda. Gambar hitam dan putih, juga dikenal dengan sebutan halftone, terdiri dari murni warna hitam dan putih (dua warna).
Sedangkan pada jenis gray scale hanya terdapat warna abu-abu (satu warna).
Warna abu-abu memiliki intensitas atau nilai red (R), green (G), dan blue (B) yang sama. Red (R), green(G), dan blue (B) memiliki batas nilai dari 0 sampai 255 untuk tipe bilangan desimal, atau 00000000 sampai 11111111 untuk tipe bilangan biner. Jadi untuk setiap pixel dari model RGB pada gambar gray scale bernilai sama, R = G = B. Tingkat kecerahan dari warna abu-abu tergantung dari nilai RGB. Semakin tinggi nilai RGB, semakin cerah gambar.
Dalam penelitian ini, gambar MRI yang berbentuk RGB dikonversikan menjadi gray scale. Hal ini dilakukan untuk mempercepat waktu komputasi karena informasi pada setiap pixel yang dimiliki gambar gray scale lebih kecil dari gambar RGB (Gopinath, 2012 : 29).
2.3.2.2. Perbaikan Kualitas Citra
Secara terminologi perbaikan kualitas citra merupakan kumpulan operasi pemrosesan gambar yang merubah sebuah gambar agar lebih mudah dikenali oleh manusia. Contoh operasi yang dimaksud meliputi penyebaran kontras dan penyamaan histogram (Fisher, 2014 : 129).
Metode perbaikan kualitas citra yang digunakan pada penelitian ini adalah High Pass Filter.
a. High Pass Filter
High Pass Filter(HPF) akan menyaring berdasarkan frekuensi. HPF akan melewatkan frekuensi bernilai tinggi dan menjaga atau melakukan block terhadap frekuensi bernilai rendah. Mask dari HPF bisa berbobot positif maupun negatif.
Berikut merupakan matriks mask pada HPF:
−1 2 −1
0 0 0
1 −2 1
Proses filter menggunakan metode HPF diawali dengan menjumlahkan matriks gambar dengan matriks mask. Hasil penjumlahan tersebut kemudian dijumlahkan kembali dengan nilai ambang. Berikut rumus dari HPF:
HPF = p(i,j) + mask + t
t = nilai ambang (2.1)
HPF akan menghilangkan gangguan(noise) berintensitas kecil dan berguna dalam menekankan intensitas transisi, seperti sisi luar tumor otak (Roy, dkk, 2012 : 6).
b. Perbandingan Metode Perbaikan Kualitas Citra
Menurut Anush dan Ayush (2015 : 95), dalam penelitiannya mengenai perbandingan performa teknik perbaikan kualitas citra, antara High Pass Filter(HPF) dengan Gausian Filter(GF), HPF menghasilkan tingkat ketajaman yang lebih tinggi dibandingkan GF dalam melakukan perbaikan kualitas citra pada gambar CT dan MRI otak.Di bawah disajikan tabel perbandingan dari pengujian berupa nilai Mean Square Error (MSE). Semakin kecil nilai MSE, semakin bagus performa yang dihasilkan.
Tabel 2.2 Perbandingan Performa HPF dengan GF
Frekuensi Gausian Filter High Pass Filter
D0=10 716,9992 2,5023e+03
D0=20 449,4283 2,5023r+03
D0=30 317,5338 2,5023+e03
D0=40 242,7772 2,5023+e03
D0=50 194,6673 2,5023+e03
2.3.2.3. Segmentasi Citra
Segmentasi citra merupakan proses yang ditujukan untuk mendapatkan objek-objek yang terkandung di dalam citra atau membagi citra ke dalam beberapa daerah dengan setiap objek atau daerah memiliki kemiripan atribut. Pada citra yang mengandung hanya satu objek, objek dibedakan dari latar belakangnya (Kadir & Susanto, 2013:336).
2.3.2.4. Ekstraksi Fitur
Ekstraksi fitur dilakukan untuk mendapatkan nilai ciri dari sebuah citra. Berikut dijabarkan proses dan metode yang digunakan pada proses ekstraksi citra:
A. Proses Ekstraksi Fitur
Proses Ekstraksi fitur yang digunakan sebagai ciri dalam pengenalan suatu objek juga dapat dilakukan dengan menganalis tekstur objek. Tekstur objek dapat direpresentasikan dengan menggunakan persamaan matematika, sehingga hasil dari analisa tekstur dapat diukur dan dibandingkan dengan objek lainnya dalam proses pengenalan (Muntasa, 2015:181).
Fitur-fitur suatu objek mempunyai peran penting untuk berbagai aplikasi berikut (Kadir & Susanto, 2013:
472) :
1. Pencarian citra: Fitur dipakai untuk mencari objek- objek tertentu yang berada di dalam database.
2. Penyederhanaan dan hampiran bentuk: Bentuk objek dapat dinyatakan dengan representasi yang lebih ringkas.
3. Pengenalan dan klasifikasi: Sejumlah fitur dipakai untuk menentukan jenis objek.
B. Gray Level Coocirrence Matrikx (GLCM)
Analisa tekstur objek berbasis statistik juga dapat menggunakan Gray Level Co-Occurence Matrix atau sering disebut sebagai GLCM. GLCM dibentuk dengan mempertimbangkan lokasi piksel-piksel yang saling berdekatan (d) dan sudut antara lokasi piksel yang saling berdekatan (θ) (Muntasa, 2015:186-187).
Hasil perhitungan GLCM, selanjutnya dapat digunakan untuk menghitung nilai fitur-fitur sebagai representasi tekstur objek. Adapun fitur yang dapat digunakan untuk memperoleh ciri tekstur dari suatu objek diantaranya adalah:
1. Angular Second Moment Feature (ASM Feature), fungsinya mengukur keseragaman piksel dalam suatu citra.
Energy/ASM=
∑
i
∑
j
{
p(i , j)}
2 (2.2)2. Contrast Feature, fungsinya mengukur tingkat variasi tingkat keabuan antara piksel referensi dan tetangganya.
Contrast=
∑
k
k2[
∑
i
∑
j
p(i, j)]
|i−j|=k
(2.3)
3. Inverse Different Moment (IDM) Feature, fitur ini digunakan untuk mengukur tingkat homoginitas lokal dari citra (Muntasa, 2015:188-191).
IDM/Homogeneity=
∑
i
∑
j
p(i , j) 1+(i−j)
(2.4)
C. Principal Component Analysis (PCA)
Principal Component Analysis (PCA) menangani serangkaian gambar yang memiliki korelasi tertentu.
Kapanpun kita memiliki banyak sample data vektor yang menampilkan derajat korelasi yang besar antar satu sama lain, kita dapat menggunakan PCA sebagai metode ekstraksi fitur. PCA juga dignakan sebagai distribusi statistikal dari sample yang sama yang biasanya digunakan sebagai sample data latih (Solomon dan Breckon, 2011 : 247).
Hasil perhitungan PCA, selanjutnya dapat digunakan untuk menghitung nilai fitur-fitur sebagai representasi tekstur objek. Adapun fitur yang dapat digunakan untuk memperoleh ciri tekstur dari suatu objek diantaranya adalah:
1. Mean
Mean atau rata-rata merupakan jumlah dari seluruh nilai data dibagi dengan banyaknya data. Fungsinya mengukur nilai rata-rata dari setiap pixel (Abdurahman, 2011 : 95).
Mean(μ)=
∑
i
∑
j
p(i , j) ij
(2.5)
Dimana : i = baris j = kolom
p(i,j) = nilai matriks gambar 2. Standard Deviation
Standard Deviation adalah akar dari jumlah kuadrat selisih nilai observasi dengan rata-rata hitung dibagi banyaknya observasi (Abdurahman, 2011 : 102).
σ=
√ ∑
i∑
j (p(i , j)i . j− μ)2Dimana : i = baris j = kolom
p(i,j) = nilai matriks gambar
(2.6)
3. Smoothness
Nilai smoothness digunakan pada image processing untuk merepresentasikan nilai maksimum dari kualitas gambar berdasarkan tingkat kecerahan tertentu (Polzehl Jorg dan Karsten Tabelow, 2007:1).
Smoothness=1−
(
1+∑
1p(i , j))
Dimana : i = baris j = kolom
(2.7)
p(i,j) = nilai matriks gambar 4. Kurtosis
Kurtosis didefinisikan sebagai penghitungan standarisasi populasi ke empat dari nilai rata-rata. Kurtosis dapat menangkap bentuk-bentuk gradien atau lengkungan dengan menangkap pergerakan massa yang tidak terpengaruh oleh varians (DeCarlo T. Lawrence, 1997:292).
Kurt[x]=
∑ [
(x − μ)4] ( ∑ [
(x − μ)2])
2Dimana :
x = nilai matriks gambar
(2.8)
5. Skewness
Tidak jauh berbeda dengan kurtosis, skewness digunakan untuk menangkap bentuk-bentuk gradien. Perbedaan skewness terhadap kurtosis ada pada tahap standarisasi.
Skewness menghitung standarisasi populasi ke tiga dari nilai rata-rata (Ho D. Andrew dan Carol C. Yu, 2016:7).
γ1=
∑ [
(x − μ)3] ( ∑ [
(x − μ)2])
3 2
Dimana :
(2.9)
6. Entropy
Metode entropy dapat menghitung bobot-bobot berdasarkan karakteristik data pada kriteria, semakin tinggi variasi antar data pada kriteria maka bobot kriteria tersebut makin tinggi
atau semakin penting. Penelitian ini menggunakan kriteria bentuk (Jamila, 2011).
Entropy=−
∑
i
p
(
xi)
.log2p(
xi)
Dimana : i = baris
= nilai matriks gambar ke-i
(2.10)
2.4.Support Vector Machine (SVM)
Menurut Widodo, et al. (2013: 107), Support Vector Machine (SVM) merupakan metode klasifikasi jenis terpandu (supervised) karena ketika proses pelatihan, diperlukan target pembelajaran tertentu. SVM muncul pertama kali pada tahun 1992 oleh Vladimir Vapnik bersama rekannya Bernhard Boser dan Isabelle Guyon. Ide dasar SVM adalah memaksimalkan batas hyperplane (maximal margin hyperplane) seperti yang diilustrasikan pada Gambar 2.2.
Gambar 2.2 (a) Decision Boundary yang Mungkin (b) Decision Boundary dengan Margin Maksimal
(Sumber: Prasetyo, 2012: 118)
Konsep klasifikasi dengan SVM dapat dijelaskan secara sederhana sebagai usaha untuk mencari hyperplane terbaik yang berfungsi sebagai pemisah dua buah kelas data pada ruang input. Hyperplane (batas
keputusan) pemisah terbaik antara kedua kelas dapat ditemukan dengan mengukur margin hyperplane tersebut dan mencari titik maksimalnya.
Margin adalah jarak antara hyperplane tersebut dengan data terdekat dari masing-masing kelas. Data yang paling dekat ini disebut support vector.
Garis solid pada Gambar 2.2(b) sebelah kanan menunjukkan hyperplane yang terbaik yaitu yang terletak tepat pada tengah-tengah kedua kelas, sedangkan data lingkaran dan bujur sangkar yang dilewati garis batas margin (garis putus-putus) adalah support vector. Usaha untuk mencari lokasi hyperplane ini merupakan inti dari proses pelatihan pada SVM (Prasetyo, 2012: 118).
4.2.1. SVM Linear
Kasus data yang terpisah secara linear adalah kasus yang termudah. Misalnya kita memiliki data yang terdiri dari kelas orang yang membeli komputer dan yang tidak membeli komputer (Xi,Yi), (X2,Y2), ..., (X|D|,Y|D|). Data tersebut kita beri notasi X dan kelasnya adalah y dimana yi hanya memiliki dua kemungkinan yakni +1 atau -1 (Widodo, et al., 2013: 108).
Gambar 2.3 Data yang Terpisah Secara Linear
SVM memecahkan masalah klasifikasi dengan mencari hyperplane marjinal maksimum dimana ada jumlah tak terbatas hyperplanes yang harus dicari mana yang terbaik. Secara intuitif, hyperplane dengan margin yang lebih besar lebih akurat dalam mengklasifikasikan data dibanding margin yang lebih kecil. Inilah
sebabnya mengapa (selama pembelajaran), SVM mencari hyperplane dengan margin terbesar, dikenal dengan istilah Maximum Marginal Hyperplane (MMH). Untuk definisi margin, kita dapat mengatakan bahwa jarak terpendek dari hyperplane ke satu sisi margin adalah sama dengan jarak terpendek dari hyperplane yang ke sisi lain dari margin, dimana “sisi” dari margin sejajar dengan hyperplane tersebut (Widodo, et al., 2013:
109).
Sebuah hyperplane dapat ditulis sebagai W . X+b=0 (2.12)
Di mana W adalah vektor bobot, yaitu, W = {w1, w2, ..., wn}, X adalah jumlah atribut, dan b adalah skalar yang sering disebut sebagai bias. Jika b sebagai bobot tambahan, w0, kita dapat menulis ulang hyperplane pemisah sebagai
w0+w1x1+w2x2=0 (2.13)
Gambar 2.4 (a) Margin Kecil (b) Margin Besar
Dengan demikian, setiap titik yang terletak di atas hyperplane pemisah memenuhi :
w0+w1x1+w2x2>0 (2.14)
Demikian pula, setiap titik yang terletak di bawah hyperplane pemisah memenuhi :
(a) (b)
w0+w1x1+w2x2<0 (2.15)
Bobot dapat disesuaikan sehingga hyperplanes dapat mendefinisikan “sisi” dari margin yang ditulis sebagai :
H1:w0+w1x1+w2x2≥1 untuk yi = +1 (2.16) H1:w0+w1x1+w2x2≤1 untuk yi = -1 (2.17)
Artinya, setiap tupel yang jatuh pada atau di atas H1 milik kelas +1, dan setiap tuple yang jatuh pada atau di bawah H2 milik kelas -1 (Widodo, et al., 2013: 110).
Nilai bobot (w) dapat dicari dengan menggunakan rumus : Support Vector= 1
Standar deviation∗data+mean (2.18) 4.2.2. SVM Nonlinear
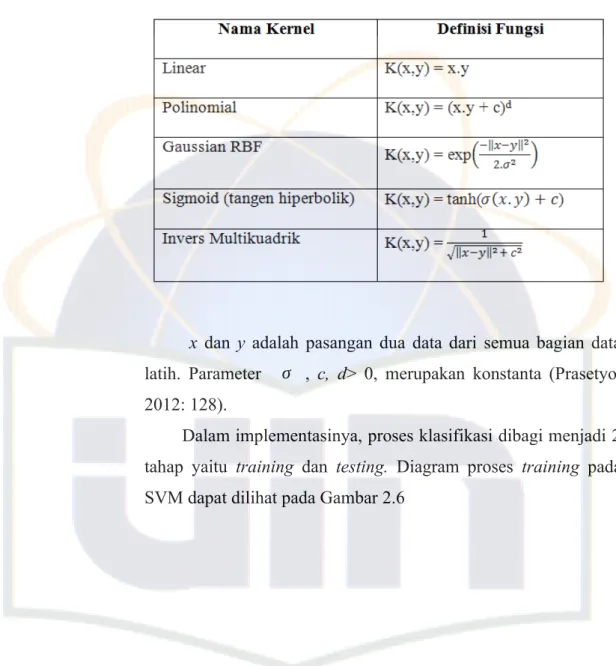
Untuk data yang distribusi kelasnya tidak linear biasanya digunakan pendekatan kernel pada fitur data awal set data. Kernel dapat didefinisikan sebagai suatu fungsi yang memetakan fitur data dari dimensi awal (rendah) ke fitur lain yang berdimensi lebih tinggi (bahkan jauh lebih tinggi). Pendekatan ini berbeda dengan metode klasifikasi pada umumnya yang justru mengurangi dimensi awal untuk menyederhanakan proses komputasi dan memberikan akurasi prediksi yang lebih baik (Prasetyo, 2012: 126) .
Gambar 2.5 Dimensi Data (a) Dalam Fitur Dimensi Rendah (b) Dalam Fitur Dimensi Tinggi
Algoritma pemetaan kernel ditunjukkan sebagai berikut : Φ : Dq Dr
x Φ(x)
Φ merupakan fungsi kernel yang digunakan untuk pemetaan, D merupakan data latih, q merupakan set fitur dalam satu data yang lama, dan r merupakan set fitur yang baru sebagai hasil pemetaan untuk setiap data latih. Sementara x merupakan data latih, dimana x1, x2, ..., xnϵDq merupakan fitur-fitur yang akan dipetakan ke fitur berdimensi tinggi r, jadi untuk set data yang digunakan sebagai pelatihan dengan algoritma yang ada dari dimensi fitur yang lama D ke dimensi baru r (Prasetyo, 2012: 127).
Untuk pilihan fungsi kernel yang banyak digunakan dalam aplikasi, dapat dilihat pada Tabel berikut.
(a) (b)
Tabel 2.3 Fungsi Kernel
x dan y adalah pasangan dua data dari semua bagian data latih. Parameter σ , c, d> 0, merupakan konstanta (Prasetyo, 2012: 128).
Dalam implementasinya, proses klasifikasi dibagi menjadi 2 tahap yaitu training dan testing. Diagram proses training pada SVM dapat dilihat pada Gambar 2.6
Gambar 2.6 Diagram Alir Training SVM
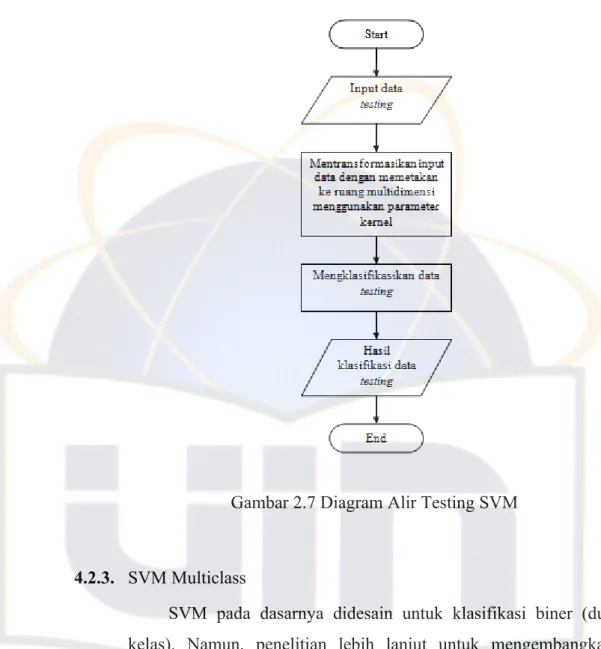
sedangkan diagram alir proses testing pada SVM dapat dilihat pada Gambar 2.7.
Gambar 2.7 Diagram Alir Testing SVM
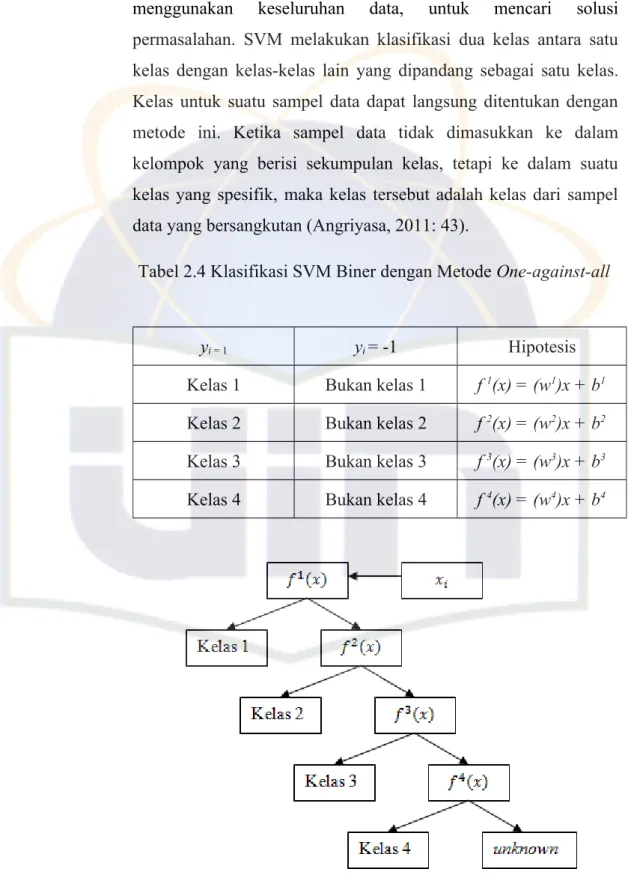
4.2.3. SVM Multiclass
SVM pada dasarnya didesain untuk klasifikasi biner (dua kelas). Namun, penelitian lebih lanjut untuk mengembangkan SVM sehingga bisa mengklasifikasi data yang memiliki lebih dari dua kelas, terus dilakukan. Ada dua pilihan untuk mengimplementasikan multiclass SVM yaitu dengan menggabungkan beberapa SVM biner atau menggabungkan semua data yang terdiri dari beberapa kelas ke dalam sebuah bentuk permasalahan optimasi. Namun, pada pendekatan yang kedua permasalahan optimasi yang harus diselesaikan jauh lebih rumit.
Pada Tugas Akhir ini, pendekatan multiclass SVM yang penulis gunakan adalah metode klasifikasi “one-against-all”. Pada metode ini, dibangun k buah model SVM biner, dengan kadalah
banyak kelas. Setiap model klasifikasi ke-i dilatih dengan menggunakan keseluruhan data, untuk mencari solusi permasalahan. SVM melakukan klasifikasi dua kelas antara satu kelas dengan kelas-kelas lain yang dipandang sebagai satu kelas.
Kelas untuk suatu sampel data dapat langsung ditentukan dengan metode ini. Ketika sampel data tidak dimasukkan ke dalam kelompok yang berisi sekumpulan kelas, tetapi ke dalam suatu kelas yang spesifik, maka kelas tersebut adalah kelas dari sampel data yang bersangkutan (Angriyasa, 2011: 43).
Tabel 2.4 Klasifikasi SVM Biner dengan Metode One-against-all
yi = 1 yi = -1 Hipotesis
Kelas 1 Bukan kelas 1 f 1(x) = (w1)x + b1 Kelas 2 Bukan kelas 2 f 2(x) = (w2)x + b2 Kelas 3 Bukan kelas 3 f 3(x) = (w3)x + b3 Kelas 4 Bukan kelas 4 f 4(x) = (w4)x + b4
Gambar 2.8 Contoh Klasifikasi dengan Metode One-against-all
4.2.4. Karakteristik SVM
Menurut Prasetyo (2012:150), karakteristik klasifikasi SVM dapat diringkas menjadi seperti berikut :
1. SVM merupakan teknik klasifikasi yang semi-eager lerner karena selain memerlukan proses pelatihan, SVM juga menyimpan sebagian kecil data latih untuk digunakan kembali pada saat proses prediksi.
2. SVM selalu memberikan model yang sama dan solusi dengan margin maksimal.
3. Proses pelatihan yang dilakukan oleh SVM tidak sebanyak ANN, tetapi sering kali memberikan kinerja yang lebih baik daripada ANN.
4. Tidak membutuhkan pemilihan parameter-parameter seperti pada ANN. SVM hanya menentukan fungsi kernel yang harus digunakan (untuk kasus data yang distribusi kelasnya tidak dapat dipisahkan secara linear).
5. SVM membutuhkan komputasi pelatihan dan prediksi yang rumit karena dimensi data yang digunakan dalam proses pelatihan dan prediksi lebih besar daripada dimensi yang sesungguhnya.
6. Untuk set data berjumlah besar, SVM membutuhkan memori yang sangat besar untuk alokasi matriks kernel yang digunakan.
7. Penggunaan matriks kernel mempunyai keuntungan lain, yaitu kinerja set data dengan dimensi besar tetapi jumlah datanya sedikit akan lebih cepat karena ukuran data pada dimensi baru berkurang banyak.
4.2.5. Perbandingan SVM dengan metode lain
Selain SVM sebagai metode yang bersifat terawasi (supervised), terdapat metode lain yang memiliki sifat yang sama.
Artificial Neural Network (ANN) merupakan salah satunya.
ANN adalah paradigma pemrosesan informasi yang diilhami dari bagaimana sistem saraf bekerja. ANN terbentuk dari sejumlah elemen proses yang saling terhubung bekerja serentak untuk memecahkan masalah dengan spesifikasi tertentu.
Sama halnya dengan SVM yang bersifat terawasi (supervised), ANN juga melakukan pelatihan terhadap data atau informasi. Oleh karena itu, ANN dapat dikatakan sebagai pembanding yang tepat bagi SVM, sebagai metode yang sama- sama bersifat terawasi.
Singhal (2015), dalam journalnya yang berjudul “A Comparative Study of Two MRI Brain Tumor Classification Techniques” melakukan serangkaian pengujian untuk menentukan tingkat akurasi antara SVM dengan ANN dalam klasifikasi jenis tumor otak. Berikut adalah tabel perbandingan hasil dari pengujian tersebut.
Tabel 2.5 Perbandingan SVM dengan ANN Metode Persentasi Kebenaran
dalam Klasifikasi
Persentasi Kesalahan dalam Klasifikasi
SVM 96,77% 3,22%
ANN 58,33% 41,67%
2.5. Matlab
Menurut Solomon & Breckon (2011: xii), matlab merupakan bahasa pemrograman dengan sekumpulan toolbox perangkat lunak khusus. Matlab digunakan sebagai bahasa pemrograman standard industri dalam komputasi
ilmiah dan digunakan di seluruh dunia dalam sektor keilmuan, teknik, industri, dan pendidikan.
Script atau kode yang digunakan oleh Matlab dapat dikategorikan sebagai bahasa pemrograman tingkat tinggi. Kode dan fungsinya merupakan campuran Bahasa Inggris dan notasi Matematika, seperti “print this” atau
“if x<5 do something”. Program yang ditulis dalam bahasa pemrograman tingkat tinggi harus diterjemahkan terlebih dahulu menjadi bahasa mesin sebelum komputer dapat benar-benar mengeksekusi urutan instruksi kode dalam program.
Matlab menggunakan sistem interpreter sebagai penerjemah dan pengekesekusi kode. Interpreter akan mentranslasikan dan mengeksekusi kode ke bahasa mesin— baris demi baris. Matlab menggunakan apa yang disebut sebagai M-files sebagai wadah untuk penulisan kode Matlab. Sebuah atau kumpulan M-files akan membentuk sebuah program (Attaway,2013:
75).
2.6. Metode Simulasi
Simulasi adalah proses implementasi model menjadi program komputer (software) atau rangkaian elektronik dan mengeksekusi software tersebut sedemikian rupa sehingga perilakunya menirukan atau menyerupai sistem nyata (realitas) tertentu untuk tujuan mempelajari perilaku (behaviour) sistem, pelatihan (training), atau permainan (gaming) yang melibatkan sistem nyata (realitas). Jadi, simulasi adalah proses merancang model dari suatu sistem yang sebenarnya, mengadakan percobaan-ercobaan terhadap model tersebut dan mengevaluasi hasil percobaan tersebut (Sriadi, 2009).
Berikut ini merupakan gambaran langkah-langkah penting dalam simulasi (Madani et al, 2012) :
2.6.1.Problem Formulation
Proses mendefinisikan masalah yang dilakukan untuk menentukan tujuan dari simulasi berbeda dari proses mendefinisikan masalah dalam teknik analisa lainnya. Pada intinya, proses mendefinisikan masalah dalam simulasi mencakup spesifikasi tujuan untuk diteliti.
2.6.2.Conceptual Model
Langkah ini terdiri dari rangkaian deskripsi dari struktur dan perilaku sistem dan mengidentifikasi semua obyek dengan atribut. Kita juga harus menentukan variabel, bagaimana mereka berhubungan, dan mana yang penting untuk penelitian. Pada langkah ini, aspek-aspek kunci dari persyaratan dijelaskan. Selama definisi model konseptual, kita perlu mengungkapkan fitur yang penting penting.
2.6.3.Collecting and Analysis of Input/Output Data
Pada fase ini, kita harus mempelajari sistem untuk memperoleh data input / output. Untuk melakukannya, kita harus mengamati dan mengumpulkan atribut yang dipilih pada fase sebelumnya. Ketika entitas sistem yang dipelajari, kita mencoba untuk mengasosiasikan mereka dengan nilai waktu. Akhirnya, kita harus memutuskan mana atribut yang yang akan dipakai dalam sebuah simulasi.
2.6.4.Modelling
Pada tahap pemodelan, kita harus membangun representasi rinci dari sistem berdasarkan model konseptual dan data input / output dikumpulkan. Model ini dibangun dengan mendefinisikan objek, atribut, dan metode menggunakan paradigma yang dipilih. Setelah menyelesaikan definisi ini, kita harus mencoba untuk membangun struktur awal dari model.
2.6.5.Simulation
Selama tahap simulasi, kita harus memilih mekanisme untuk menerapkan model (dalam banyak kasus menggunakan komputer dan bahasa pemrograman yang memadai dan alat-alat), dan model simulasi dibangun. Selama langkah ini, mungkin perlu untuk mendefinisikan algoritma simulasi dan menerjemahkannya ke dalam program komputer.
2.6.6.Verification and Validation
Selama langkah-langkah sebelumnya, tiga model yang berbeda yang dibangun: model konseptual (spesifikasi), model sistem (desain), dan model simulasi (executable program). Kita perlu untuk memverifikasi dan memvalidasi model ini. Verifikasi terkait dengan konsistensi internal antara tiga. Validasi difokuskan pada korespondensi antara model dan realitas : Apakah hasil simulasi konsisten dengan sistem yang dianalisis? Apakah kita membangun model yang tepat?
Berdasarkan hasil yang diperoleh selama tahap ini, model dan implementasinya mungkin perlu dilakukan penyempurnaan.
2.6.7.Output Analysis
Pada tahap analisa hasil, output simulasi dianalisis untuk memahami perilaku sistem. Pada tahap ini, alat visualisasi dapat digunakan untuk membantu dengan proses. Tujuan dari visualisasi adalah untuk memberikan pemahaman yang lebih dalam sistem nyata yang sedang diselidiki.
2.7. Metode Pengumpulan Data 2.7.1. Observasi
Observasi adalah melakukan pengamatan secara langsung ke obyek penelitian untuk melihat dari dekat kegiatan yang dilakukan.
Kemudian, obyek penelitian bersifat perilaku, tindakan manusia, dan
fenomena alam (kejadian yang ada di alam sekitar), proses kerja, dan penggunaan responden kecil. Observasi atau pengamatan merupakan suatu teknik atau cara mengumpulkan data dengan jalan mengadakan pengamatan terhadap kegiatan yang sedang berlangsung (Guritno, 2011:134).
2.7.2. Wawancara
Wawancara adalah suatu cara pengumpulan data yang digunakan untuk memperoleh informasi langsung dari sumbernya.
Wawancara digunakan bila ingin mengetahui hal-hal dari responden secara lebih mendalam serta jumlah responden sedikit (Guritno, 2011:131).
2.7.3. Studi Pustaka
Studi pustaka merupakan langkah awal dalam metode pengumpulan data. Studi pustaka merupakan metode pengumpulan data yang diarahkan kepada pencarian data dan informasi melalui dokumen- dokumen, baik dokumen tertulis, foto-foto, gambar, maupun dokumen elektronik yang dapat mendukung dalam proses penulisan (Sugiyono, 2013:83).
BAB III
METODOLOGI PENELITIAN
Pada bab ini akan dibahas metodologi penelitian yang digunakan dalam penyusunan skripsi ini. Metodologi penelitian yang digunakan terbagi menjadi dua yaitu metode pengumpulan data dan metode pengembangan sistem dengan penjelasan sebagai berikut :
3.1. Metode Pengumpulan Data
Metode pengumpulan data yang penulis gunakan untuk mendapatkan informasi sebagai acuan dalam penelitian ini antara lain :
3.1.1. Wawancara
Pada tahap awal perancangan aplikasi ini, terlebih dahulu dilakukan wawancara dengan pihak terkait (dalam hal ini pakar radiologi) untuk mendapatkan informasi yang dibutuhkan mengenai permasalahan dan kebutuhan aplikasi yang akan dirancang. Wawancara ini dilakukan dengan cara berdiskusi dengan pakar radiologi diantaranya, BapakAgus Surjaselaku Kepala Bagian Radiologi RSPAD Gatot Soebroto pada tanggal 9 Agustus 2016 bertempat di kantor pusat radiologi RSPAD Gatot Soebroto.
Berikut informasi yang dapat dikumpulkan berdasarkan wawancara yang telah penulis lakukan:
a. Pengetahuan radiologi secara umum, memuat tentang apa itu radiologi, bagaimana menerapkan ilmu radiologi untuk mendeteksi kondisi organ dalam tubuh, bagaimana penerapannya, dan lain-lain.
b. Ilmu radiologi untuk melihat kondisi organ dalamtubuh manusia dalam penelitian ini dikhususkan pada otak, baik dalam keadaan normal ataupun jika terdapat gangguan.
c. Sample organ dalam otak yang memiliki tumor.
Hasil wawancara dapat dilihat di lampiran 1.
3.1.2. Studi Pustaka
Pada tahapan ini, dilakukan pengumpulan referensi yang relevan dengan objek yang akan diteliti. Sumber referensi berasal dari buku, jurnal, dan buku elektronik. Dari studi pustaka yang telah peneliti lakukan, berikut ini hal-hal penting yang didapatkan:
a. Pengetahuan mengenai tumor dan kanker otak manusia.
b. Pengetahuan mengenai pengolahan citra digital.
c. Pengetahuan mengenai ekstraksi fitur.
d. Pengetahuan mengenai Principal Component Analysis (PCA).
e. Pengetahuan mengenai Gray Level Coocurence Matrix (GLCM).
f. Pengetahuan mengenai klasifikasi.
g. Pengetahuan mengenai Support Vector Machine (SVM).
h. Pengetahuan mengenai metode Simulasi.
i. Pengetahuan mengenai metode pengujian sistem.
1.1.1. Studi Literatur Sejenis
Penulis melakukan studi literatur sejenis untuk mengetahui kelebihan serta kekurangan terhadap penelitian sebelumnya guna dijadikan referensi pada penelitian ini. Berikut ini adalah perbandingan penelitian literatur sejenis dilihat dari beberapa aspek :
Literatur Referensi 1 Referensi 2 Referensi 3 Referensi 4 Referensi 5 Judul,
Tahun, dan Instansi
Kumar, D.
Dhilip, dkk.
“Brain Tumour Image
Segmentation Using
Matlab”.Internati onal Journal for Innovative
Research in
Science &
Technology, vol.
1 Issue 12, May 2015.
Sotaninejad, dkk.
2014. “Brain Tumour Grading in Different MRI Protocols using
SVM on
Statistical Features”.
London : School of Computer Science,
University of Lincoln.
Zulpe, Nitish, dan Vrushsen Pawar. “GLCM Textural
Features for Brain Tumor Classification”.
IJCSI
International
Journal of
Computer Science Issues, vol. 9, issue 3, no. 3, May 2012.
Liton Chandra
Paul dan
Abdulla Al Sumam. 2012.
“Face Recognition Using Principal Component Analysis Method”.
University of Engineering and Technology : Rajshahi.
Ada dan Rajneet Kaur. 2013.
“Feature Extraction and Principal Component Analysis for Lung Cancer Detection in CT scan Images”.
Sri Guru Granth Sahib World University : Punjap India.
Metode Threshold
Segmentation dan Support Vector
Support Vector Machine, Super Pixel
Gray Level Coocurence Matrix
Principal Component Analysis
Gray Level Coocurence Matrix dan Principal
Region of Interest.
C Means dan Support Vector Machine (SVM).
Analysis
Nilai Pembeda
Penggunaan metode
segmentasi yang berbeda
menggunakan Threshold Segmentation
Penggunaan metode
segmentasi yang berbedamengguna kan Super Pixel Segmentation dan metode ekstraksi fitur yang berbeda menggunakan Region of Interest.
Menggunakan metode Fuzzy C Means dalam proses
segmentasi.
Tidak
mensegmentasi daerah wajah.
Penggunaan CT Scan sebagai masukan.
Lingkup Sistem
Desktop, dibangun menggunakan
- Desktop,
dibangun menggunakan
Desktop, dibangun menggunakan
Desktop, dibangun menggunakan
pemrograman Matlab.
Pemrograman Matlab.
Pemrograman Matlab.
Pemrograman Matlab.
Kelebihan Mengidentifikasi tumor jinak dan tumor ganas.
- Dapat
mengidentifik asi tingkat keganasan tumor berdasarkan WHO grading.
- Berdasarkan percobaan, tingkat akurasi minimalnya adalah 80%.
Tingkat akurasi minimal 95%.
Dapat dengan baik mengenali pola wajah.
Dapat mendeteksi kanker paru- paru dengan baik
Kekurangan - Tidak ada tingkat akurasi dari
- Tidak
menjabarkan proses
Pengenalan wajah belum bisa real time.
Deteksi kanker masih pada kanker paru-
klasifikasi.
- Tidak dijabarkan metode ekstraksi fiturnya.
- Threshold segmentation tidak hanya mengsegment asi bagian tumor.
tumor. diuji pada
kanker yang lain.
3.2. Obyek Penelitian
Obyek penelitian ini adalah pasien-pasien penderita tumor otak. Baik tumor otak jinak maupun tumor otak ganas. Obyek penelitian ini didapatkan melalui sumber daya milik Rumah Sakit Pusat Angkatan Darat Gatot Soebroto.
3.3. Sumber Data
Data yang digunakan dalam penelitian ini berupa gambar Magnetic Resonance Image (MRI) dari otak pasien penderita tumor otak. Gambar MRI yang diteliti terbagi menjadi dua kelompok, tumor ganas dan tumor jinak.
Total data yang didapatkan berjumlah 6 buah. Data diberikan oleh bagian radiologi RSPAD Gatot Soebroto melalui izin penelitian dari UIN Syarif Hidayatullah Jakarta dan RSPAD Gatot Soebroto. Surat keterangan izin penilitian terlampir pada bagian lampiran.
3.4. Metode Analisis Data
Support Vector Machine (SVM) merupakan suatu metode pengelompokan kumpulan data yang mampu melakukan perbandingan data baru dengan data kelompok yang telah terbentuk. Dalam melakukan analisa data dilakukan beberapa tahap antara lain sebagai berikut:
Tahap 1: melakukan pengumpulan sampel berupa gambar MRI dari pasien pengidap tumor.
Tahap 2 : melakukan pengolahan citra (image procesing) dengan menggunakan metode Principal Component Analysis (PCA), Gray Level Coocurence Matrix (GLCM) dan SVM berdasarkan sampel gambar MRI dengan menggunakan MATLAB.
3.5. Metode Pemodelan Simulasi
Metodologi yang digunakan dalam penelitian ini adalah Metode Pemodelan Simulasi. Adapun tahapan dari metode simulasi adalah sebagai berikut :
3.5.1.Problem Formulation
Proses simulasi dimulai dengan masalah praktis yang memerlukan pemecahan atau pemahaman. Pada tahap ini peneliti mengidentifikasi masalah dengan melihat data penelitian berupa gambar MRI otak tepatnya pada bagian tumornya. Suatu tumor dikatakan kanker bila bersifat ganas. Hal ini antara lain ditandai dengan ukuran dan tekstur dari tumor tersebut. Semakin besar ukuran dan semakin beragam tekstur dari tumor, semakin ganas tumor tersebut. Pendekatan PCA, GLCM, dan SVM akan memetakan gambar MRI ini menjadi bentuk matematika untuk menemukan ciri sehingga jenis tumor dapat diidentifikasi.
3.5.2.Conceptual Model
Tahap ini mendeskripsikan pemodelan yang dilakukan ketika proses matematis untuk mengidentifikasi kanker berjalan. Pada bagian ini akan dijelaskan langkah demi langkah jalannya identifikasi berlangsung.
Mulai dari memilih sampel, melakukan serangkaian pengolahan citra, mengambil nilai ciri sampel, hingga identifikasi sampel berdasarkan ciri.
3.5.3.Collection and Analysis of Input/Output Data
Pada tahap ini pembelajaran terhadap sistem untuk mendapatkan data input dan output mutlak untuk dilakukan. Hal ini dilakukan dengan mengumpulkan dan mengamati atribut-atribut yang telah ditentukan.
Ketika entitas data uji telah dipelajari, maka dilakukan perbandingan data sampel yang telah tersimpan sebelumnya untuk mengetahui
golongan dari data uji. Isu penting lainnya pada tahap ini adalah pemilihan ukuran sampel yang valid secara statistik dan format data yang dapat diproses komputer. Ukuran dan format data dibuat secara seragam agar perbandingan bisa berjalan dengan baik. Analisis dari data-data ini, secara matematis akan dimodelkan oleh algoritma PCA, GLCM, dan SVM.
3.5.4.Modelling
Pada tahap pemodelan, kita harus membangun representasi yang rinci dari sistem berdasarkan model konseptual dan input/output data yang dikumpulkan. Model ini dibangun dengan mendefinisikan objek, atribut, dan metode menggunakan paradigma yang dipilih seperti metode pemodelan matematika, algoritma dan metode model simulasi.
Pada tahap ini spesifikasi model dibuat, termasuk set persamaan yang mendefinisikan struktur. Setelah menyelesaikan definisi ini, kita harus membangun struktur awal model.
3.5.5.Simulation
Pad