Statistics authors titles recent submissions
Teks penuh
Gambar
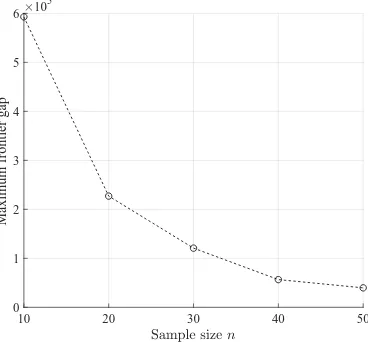
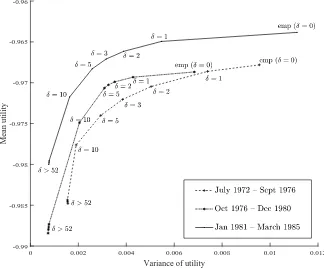
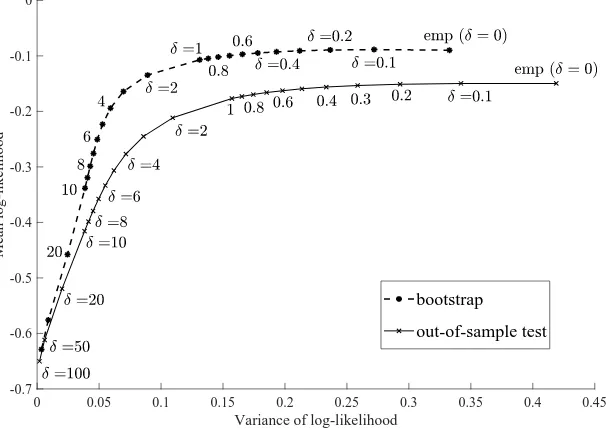
![Figure 1.1. Simulated mean reward—usual practice for calibration.the investor’s utility function values is taken over 50 bootstrap samples, attainingthe maximum atselection (ii) consists ofdata set at [34], and the average of the log-likelihood (y-axis) is](https://thumb-ap.123doks.com/thumbv2/123dok/2118373.1609601/3.612.95.520.76.241/simulated-practice-calibration-bootstrap-attainingthe-atselection-consists-likelihood.webp)




Garis besar
Dokumen terkait
Here we investigate the application of deep learning using convolutional neural networks (CNNs) for the task of fracture detection, and present the first large scale study where a
b) We now compare GPLVM+SVM and GPDNN, e.g. the latent space classifier and its corresponding LSAN. The results are shown in Figure 4b. We observe that for all datasets except Spam,
Table 1: Simulated coverage probabilities (CP) and average lengths (AL) of 95% confidence intervals from the proposed exact (EX) method, the restricted maximum likelihood (REML)
In the ordinal regression model, we trained with soft thresholds since we needed the model to be differentiable end to end. In the post-hoc model, we searched threshold space in
1) In order that any algorithm works for the semi-supervised classification problem the initial training sample D n (whose size does not need to tend to infinity) must be well
In doing so, we introduce the basic meaning and relevance of the judgment to regard a sequence of quantities exchangeably, and we show how the fundamental theorem of probability can
The better performance of moncord over space, concord and glasso is largely due to the fact that mconcord is designed for multivariate network, and treating the precision matrix
(c) Using Log-rank splitting criteria described in previous section, a node is split using the single predictor that maximizes the survival differences between daughter nodes..
