MODUL 1
UJI HIPOTESIS SAMPLE T-TEST 1.1 Tujuan Praktikum
1. Mampu memahami Uji Hipotesis dari parameter rata-rata satu populasi dan dua
populasi
2. Mampu menyelesaikan persoalan Uji Hipotesis rata-rata satu populasi dan dua
populasi menggunakan software SPSS
1.2 Tugas Pratikum
1. Membuat dan mencari dari sumber terpercaya untuk sejumlah data yang akan
diolah kemudian tampilkan dalam bentuk tabel data historis dengan jumlah
data minimal sejumlah 30 data.
2. Melakukan perhitungan Uji Hipotesis Sample t-Test (One Sample t-Test,
Paired Sample t-Test, Independent Sample t-Test) dari sejumlah yang telah
didapat dengan menggunakan software SPSS.
3. Melakukan bahasan dari hasil sejumlah hasil olahan yang didapat hingga
tentukan kesimpulan keputusan yang didapat.
1.3 Latar Belakang
Praktikum ini dilatar belakangi oleh sebuah penugasan yang berbeda pada mata kuliah Statistika Industri yaitu yang judul “Pendidikan Karakter Berbasis Multiple Intelligence” untuk melakukan uji hipotesis sample t-test. Uji hipotesis ini dilakukan untuk mengetahui jumlah kata rata-rata yang dapat dibaca oleh
responden salama 3 menit apakah kata yang dibaca sebanyak 540 kata atau tidak
dalam waktu 3 menit oleh responden tampa diberi treatment, untuk mendapatkan
kesimpulan dari hal tersebut maka dilakukan uji One sampel t-test pada data yang
telah dibaca respondent, data yang dibutuhkan sebanyak 30 sampel. Kemudian
untuk mengetahui perbedaan jumlah kata yang dibaca responden tampa treatment
dan dengan treatment dengan masing-masing waktu selama 3menit apakah ada
berbeda atau tidak maka dilakukan uji hipotesis paired sampel t-test. lalu dilakukan
pengujian yang terakhir yaitu membandingkan antara responden angkatan 2013 dan
waktu 3 menit maka dilakukan uji hipotesis independent sampel t-test untuk
mendapatkan kesimpulan. Dengan adanya praktikum uji hipotesis t-test ini maka
praktikan bisa mengambil keputusan mengenai jumlah perolehan rata-rata kata
selama 3 menit berdasarkan data sudah didapat dengan melakukan pengujian one
sample t-test, paired sample t-test dan independent sample t-test mengunakan
software SPSS.
1.4 Pengolahan Data 1.4.1 Deskripsi Kasus
1.4.1.1. One Sample t-Test
Pada One Sample t-Test im, mahasiswa/responden diberikan jurnal
yang sudah ditentukan oleh asisten laboratorium, yaitu “ Pendidika Karakter Berbasis Multiple Intelligence “ untuk dibaca tampa diberi treatment (membaca biasa) terlebih dahulu selama 3 menit. Setelah itu maka hasilnya
dicatat jumlah kata yang dibaca oleh responden. Data yang dibutuhkan
untuk dijadikan sampel sebanyak 30 responden.
1.4.1.2. Paired Sample t-Test
Data Paired Sample t-Test ini digunakan untuk membandingkan
banyaknya kata yang terbaca oleh responden, baik sebelum dan sesudah
diberi treatment tertentu. Data tampa treatment didapat dari data responden
One Sample t-Test. Kami berikan treatment dan meminta untuk mengulangi
membaca jurnal yang sudah dibaca tersebut. Setelah itu dicatat jumlah kata
yang telah terbaca para responden diberikan treatment, dengan waktu 3
meint yaitu sama dengan waktu yang diberikan pada data One Sample
t-Test.
1.4.1.3. Independent Sample t-Test
Data Independent Sample t-Test ini bertujuan untuk membandingkan
rata-rata dari dua kelompok yang berbeda, yaitu jumlah kata yang dibaca
responden angkatan 2013 dan responden angkatan 2014. Data ini diperoleh
dari data Paired Sample t-Test yang diberi treatmen. Data tersebut
dibandingkan anatara responden angkatan 2013 dan responden angkatan
responden angkatan 2013 lalu dicari rata-ratanya dibandingkan rata-rata
responden responden angkatan 2014 dengan mengunakan waktu yang sama
yaitu 3 menit.
1.4.1.4. sumber dan jenis treatment
Jenis treatment yang dibeikan kepara para responden yaitu metode
skimming dan metod scanning. Metode ini dianggap seabagai metode yang
paling efektif untuk memahami dan mengetahui isi jurnal yang dibaca
dengan cepat dan tepat, mangkannya metode ini yang dipilih untuk
diberikan kepada respondent. Diambil dari sumber internet pada website
http://www.lpmmarhaenubk.com/2014/06/teknik-membaca-cepat-skimming-dan.html pada 07/11/2015 pada pukul 12:51 PM.
1.4.2 Tabel Data Historis 1.4.2.1. One Sample t-Test
4 saelendra adi saputra 14522327 678
5 syayyid lukman 14522283 735
6 aditya nanda 13522281 667
7 jufrizal 13522201 650
8 azhar basyir 13522279 701
9 novia purwitasari 13521185 693
10 nadhya chairiza fitri 13521106 787
11 derry sundana 14522263 704
12 riyan prasetyo 14521297 688
13 giyan setyowati 14521289 749
20 hario s 13521125 653
21 wahyu sulistyawan 13521223 677
22 wari sandi 14525071 841
23 muhammad farid abdurrahman 14525074 601
24 rian nur adiyatama 14525062 739
25 mhd hamzah fansuri 14525101 605
26 shinichi 14525071 748
27 ulil fawaaid 13525064 705
28 muhammad wahyu putra 13525056 665
29 muhamad zulkarnain 13525063 732
30 ahmad faza farkhani 13525048 678
1.4.2.2. Paired Sample t-Test
Tabel 2. Paired Sample t-Test
20 hario s 653 866
1.4.2.3. Independent Sample t-Test
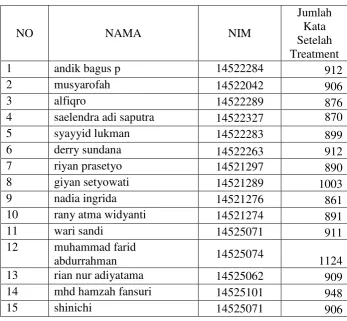
Tabel 3. Independent Sample t-Test kelompok 1 (angkatan 2014)
NO NAMA NIM
4 saelendra adi saputra 14522327 870
5 syayyid lukman 14522283 899
6 derry sundana 14522263 912
7 riyan prasetyo 14521297 890
8 giyan setyowati 14521289 1003
9 nadia ingrida 14521276 861
10 rany atma widyanti 14521274 891
11 wari sandi 14525071 911
12 muhammad farid
abdurrahman 14525074 1124
13 rian nur adiyatama 14525062 909
14 mhd hamzah fansuri 14525101 948
15 shinichi 14525071 906
NO NAMA NIM Jumlah Kata Setelah Treatment
1 aditya nanda 13522281 877
2 jufrizal 13522201 901
3 azhar basyir 13522279 930
4 novia purwitasari 13521185 881
5 nadhya chairiza fitri 13521106 922
6 sapta hadi kesuma 13521226 943
7 risky andi 13521119 870
8 sawaludin 13521118 978
9 erika dwi yosiana 13521206 1012
10 hario s 13521125 866
11 wahyu sulistyawan 13521223 1007
12 ulil fawaaid 13525064 993
13 muhammad wahyu
putra 13525056 871
14 muhamad zulkarnain 13525063 971
15 ahmad faza farkhani 13525048 889
1.4.3 menentukan Ho dan Ha, tingkat probabilitas kesalahan (p), dan kriteria pengujian
1.4.3.1. One Sample t-Test
a. Ho dan Ha
Ho = Jumlah kata rata-rata yang dibaca responden tanpa
treatment adalah 540 selama 3 menit.
Ha = Jumlah kata rata-rata yang dibaca responden tanpa
treatment bukan 540 selama 3 menit.
b. Tingkat Probabilitas Kesalahan (α) = 0,05
c. Kriteria Pengujian
Jika signifikansi < 0,05 berarti Ho ditolak, maka Jumlah
rata-rata kata yang dibaca responden tanpa treatment bukan 540
selama 3 menit.
Jika signifikansi > 0,05 berarti Ho diterima, maka Jumlah
rata-rata kata yang dibaca responden tanpa treatment adalah 540
selama 3 menit adalah 540.
a.Ho dan Ha
Ho = Tidak ada perbedaan rata – rata jumlah kata yang dibaca
selama 3 menit sebelum dan sesudah diberi treatment.
Ha = Ada perbedaan rata – rata jumlah kata yang dibaca selama
3 menit sebelum dan sesudah diberi treatment.
b.Tingkat Probabilitas Kesalahan (α) = 0,05
c.Kriteria Pengujian
Jika signifikansi < 0,05 berarti Ho ditolak, maka ada perbedaan
rata – rata jumlah kata yang dibaca selama 3 menit sebelum dan
sesudah diberi treatment.
Jika signifikansi > 0,05 berarti Ho diterima, maka tidak ada
perbedaan rata – rata jumlah kata yang dibaca selama 3 menit
sebelum dan sesudah diberi treatment.
1.4.3.3. Independent Sample t-Test
a. Ho dan Ha
Ho = Tidak ada perbedaan rata – rata jumlah kata yang dibaca
selama 3 menit dengan treatment antara kelompok 1 dan
kelompok 2.
Ha = Ada perbedaan rata – rata jumlah kata yang dibaca selama
3 menit dengan treatment antara kelompok 1 dan kelompok 2.
b. Tingkat Probabilitas Kesalahan (α) = 0,05
c. Kriteria Pengujian
Jika signifikansi < 0,05 berarti Ho ditolak, maka ada perbedaan
rata – rata jumlah kata yang dibaca selama 3 menit dengan
treatment antara kelompok 1 dan kelompok 2.
Jika signifikansi > 0,05 berarti Ho diterima, maka tidak ada
perbedaan rata – rata jumlah kata yang dibaca selama 3 menit
dengan treatment antara kelompok 1 dan kelompok 2.
1.4.4 Cara Kerja
1. One Sample t-Test
1.Tampilan pertama SPSS, klik variabel view pada bagian bawah
Gambar 1. Tampilan utama pada SPSS
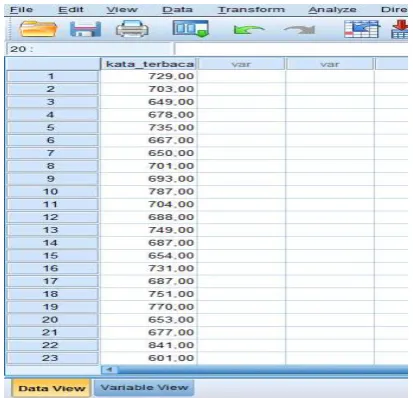
2. Pada kolom Nama diisi kata_terbaca, pada label diisi kata terbaca dan measure diisi nominal karna mencari nilai bilngan.
Gambar 2. Tampilan pada menu variabel view
Gambar 3. Penyimputan data ke dalam SPSS
4. Menu analyse > descriptive statistics > explore maka akan tampil seperti dibawah ini.
Gambar 4.langkah menu explore
5. Pada tampilan Explore, maka data yang ada diruas kiri dipindah
Gambar 5. Jendela One Sample Shapiro Wilk dan
Explore : Statistics
6. Klik plot akan tampil seperti dibawah ini pada boxplots pilih factor levels together, descriptive pilih stem-and-leaf dan centang normality plots with tests > continue,
Gambar 6. Jendela Explore : Plots
Gambar 7. Hasil Test of Normality
Hipotesis :
Ho : Sampel mewakili seluruh populasi.
Ha : Sampel tidak mewakili seluruh populasi.
Kesimpulan :
Dari uji normalis pada SPSS didapat kan hasilya bahwa nilai
kolmogorov-smirnov signigikan (sig) adalah 200 atau
probabilitas lebih dari 0,05 maka Ho diterima berarti sampel
mewakili seluruh sampel.
1.4.4.2 Perhitungan Menggunakan SPSS
Sebelum mengolah data menggunakan SPSS terlebih dahulu
menbuat nama datanya
1. Klik variable view pada sebelah kiri bawah jendela SPSS dan
pada menu Name klik 2 kali lalu ketik nama seperti dibawah ini.
Gambar 8. Variabel View
2. Masukkan data yang ada di miscrosoft excel pada data view
Gambar 9. Penyimputan data ke dalam SPSS
3. Pilih Analyze untuk memulai t-Test, pada submenu pilih
Compare Means kemudian pilih One Sample t-Test.
Gambar 10. One Sample t-Test
4. Maka akan muncul jendela One Sample t-Test. Pindahkan variable kata_terbaca ke Test Variable(s) dengan mengklik
tanda panah ke kanan dan isikan Test Value dengan t hitung
Gambar 11. Jendela One Sample t-Test
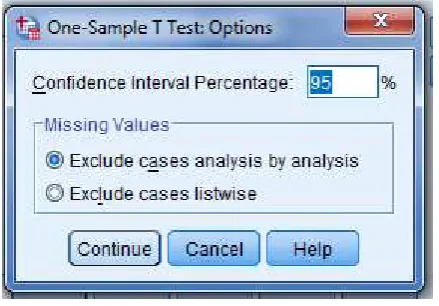
5. Klik Option kemudian akan muncul jendela seperti dibawah ini.
Isi confidence interval percentage sebesar 95%.
Gambar 12. Jendela Option
6. Klik Continue kemudian Ok, maka akan muncul tabel seperti
Gambar 13. Hasil One Sample t-Test
2. Paired Sample t-Test
1.4.4.3 Uji Normalitas
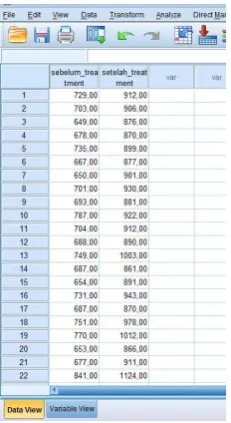
1. Klik File > New > Data, maka SPSS akan membuat jendela baru,
klik Name 2 kali lalu ketik nama sebelum_treatment pada baris 1
dan setelah_treatment pada baris 2, jangan lupa measure pilih
nominal kedua-duanya.
Gambar 14. Tampilan menu variabel view
Gambar 15. Penginputan data pada SPSS
3. klik menu Analyze, lalu submenu Descriptive Statistics. pilih
Explore, lalu akan muncul kotak dialog seperti gambar dibawah
ini. Pindahkan semua variable ke kotak Dependent List dengan
meng-klik tanda panah ke kanan,
Gambar 16. Jendela One Sample Shapiro Wilk
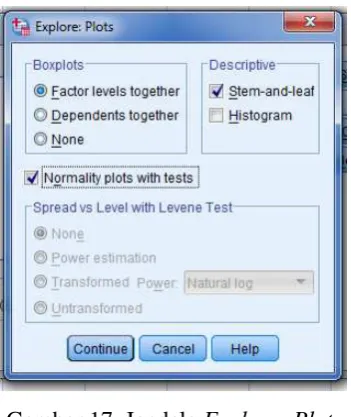
4. Klik Plots dan akan muncul kotak dialog seperti dibawah ini,
centang sesuai pada gambar lalu klik continue. Lalu Ok pada
Gambar 17. Jendela Explore: Plots
5. Setelah diklik Ok Maka akan tampil seperti dibawah ini.
Gambar 18. Tests of Normality
Hipotesis :
Ho : Sampel mewakili seluruh populasi.
Ha : Sampel tidak mewakili seluruh populasi.
Kesimpulan :
Dari uji normalis pada SPSS didapat kan hasilya bahwa nilai
kolmogorov-smirnov signigikan (sig) pada kata_sebelum_trearment
adalah 200 atau probabilitas lebih dari 0,05 maka Ho diterima berarti
sampel berdistribusi normal. signigikan (sig) pada
kata_setelah_trearment adalah 0.01 atau probabilitas kurang dari 0,05
1.4.4.4 Perhitungan Menggunakan SPSS
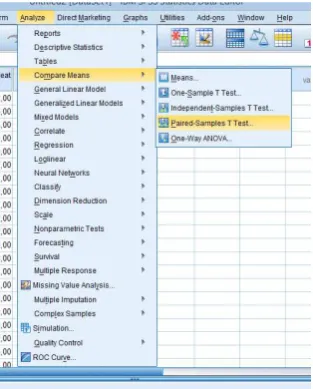
1. Klik menu Analyze > Compare Means > Paired-Sample t-Test
seperti pada gambar dibawah ini.
Gambar 19. Langkah untuk analyze Paired Sample t-Test 2. Pada tampilan Paired Sample t-Test pindahkan
kata_sebelum_treatment dan kata_setelah_treatment ke paired
variables dengan mengklik tanda panah yang ada
ditengah-tengah.
Gambar 20. Jendela Paired Sample t-Test
3. Klik Option kemudian akan muncul jendela seperti dibawah ini.
Gambar 21. Jendela Paired Sample
t-Test : Options
4. Klik Ok untuk mengetahui hasilnya
Gambar 22. Jendela Paired
Sample Statistics
Dari hasil output dapat diketahui bahwa nilai rata – rata jumlah
kata yang dibaca sebelum dan sesudah treatment masing –
masing 701,9 dan 924,3 dengan jumlah data (responden) adalah
30 orang.
Gambar 23. Jendela Paired Sample Correlations
1.4.4.5 Uji Normalitas
1. Klik File > New > Data. Maka dibuatlah data seperti dibawah ini,
pada data kelompok klik Value labels ketik
Value : 1, Labels : angkatan 2013 > Add
Value : 2, Labels : angkatan 2014 > Add > Ok.
Gambar 24. Jendela variabel view dan jendela value labels
2. Data diinputkan dari microsoft excel dengan kode yang dibuat
sebelumnya pada microsoft excel maka akan muncul seperti
dibawah ini, untuk mengecek kebenaran kodenya maka klik
submenu value labels seperti warna kuning dibawah ini maka
Gambar 25. Penginputan data ke data view pada SPSS
3. Klik menu Analyze > descriptive statisitcs > explore seperti pada
Gambar 26.langkah menu explore
2. Maka akan tampil dialog seperti dibawah ini
Gambar 27. Menu explore
3. Pimdahkan data yang ada diruas kiri keruas kanan dengan
mengunakan tanda panah yang ada pada masing-masing tabel.
Untuk data jumlah_kata dipindah ke descriptive list dan data
Gambar 28. Jendela explore setelah data dipindah.
4. Klik Plots dan akan muncul kotak dialog seperti dibawah ini,
centang sesuai pada gambar lalu klik continue.
Gambar 29. Jendela explore : Plots
5. Klik Ok maka akan tampil tabel seperti dibawah ini.
Hipotesis :
Ho : Sampel mewakili seluruh populasi.
Ha : Sampel tidak mewakili seluruh populasi.
Kesimpulan :
Dari uji normalis pada SPSS didapat kan hasilya bahwa nilai
kolmogorov-smirnov signigikan (sig) pada jumlah kata adalah 0,001
atau probabilitas kurang dari 0,05 maka Ho ditolak mak sampel
berdistribusi tidak normal berarti sampel tidak mewakili seluruh
sampel.
1.4.4.6 Perhitungan Menggunakan SPSS
1. Pada jendela data view dilakukan langkah-langkah seperti pada
gambar dibawah ini.
Gambar 31. Langkah untuk independent sampel t-tests.
2. Maka akan tampil dialog seperti dibawah ini pindahkan data yang
ada diruas kiri keruas kanan dengan mengunakan tanda panah. Test
Gambar 32. Jendela Independent
Sample Correlations
3. Pada grouping variable diklik maka akan tampil seperti dibawah ini.
Menu Define groups pada group 1 diisi 1 dan group 2 diisi 2. Lalu
continue
Gambar 33. Jendela Define Groups
4. Kemudian kik Ok maka data akan menampilkan hasilnya.
Gambar 34. Jendela Group Statistics
Dari data tersebut dapat diambil kesimpulan bahwa rata-rata jumlah
kata angkatan 2013 dan angkatan 2014 masing-masing 927,4 dan
Gambar 35. Jendela Independent Sample Test
1.4.5 Hasil dan Analisis Output SPSS 1.4.5.1. One Sample t-Test
Gambar 36. Jendela One Sample Statistics
Dari hasil tersebut diketahui bahwa nilai sing 0,000 ( sig.(2-tailed))
yang artinya 0,00 < 0,05 berarti Ho ditolak maka jumlah kata rata-rata
yanag dibaca oles responden tampa treatment dalam 3 menit bukan 540
kata.
Gambar 37. Jendela Paired Sample Statistics
Gambar 38. Jendela Paired Sample Correlations
Dari hasil pengujian diketahu bawha sig. (2-tailed) < 0,05 maka Ho di
tolak, maka dapat disimpulkan bawha rata-rata jumlah kata yang dibaca
responden selama 3 menit tidak sama dengan dengan rata-rata jumlah
kata yang dibaca setelah dikasih treatment dengan mengunakan waktru
yang sama.
1.4.5.3. Independent Sample t-Test
Gambar 32. Jendela Independent Sample Test
Dari hasil pengujian diketahui bawha sig. (2-tailed)
>
0,05 yaitu 0,775 >perbedaan rata-rata jumlah kata yang dibaca selama 3 menit dengan diberi
treatment kepada masing-masing kelompok.
1.4.6 Kesimpulan dibandingkan, maka t hitung SPSS berada diluar angka – angka perhitungan t
tabel. Sehingga Ho ditolak. Karena Sig. (2-tailed) <0,05 maka Ho ditolak.
Oleh karna itu diambil disimpulkan bahwa jumlah kata rata-rata yang
dibaca oleh responden tanpa treatment selama 3 menit bukan 540 kata.
b. Paired Sample t-Test
Dari tabel kedua diperoleh nilai t hitung SPSS sebesar -30,499 sedangkan
nilai −��
2,� dan � �2,� adalah -2,045. Jika dibandingkan, maka nilai t hitung < t tabel, sehingga Ho ditolak. Selain itu, Sig.(2-tailed) diperoleh sebesar
0,000 berarti <0,05 maka Ho ditolak.
Oleh karna itu diambil disimpulkan bahwa ada perbedaan rata – rata
jumlah kata yang dibaca selama 3 menit oleh responden sebelum dan sesudah
diberi treatment.
c. Independent Sample t-Test
Dari output kedua diperoleh nilai t hitung SPSS sebesar 0.284
sedangkan nilai −��
2,� dan ��2,� adalah -2,048. Jika dibandingkan, maka nilai t hitung > t tabel, sehingga Ho diterima. Selain itu, Sig.(2-tailed)
diperoleh sebesar 0,775 berarti > 0,05 maka Ho diterima.
Oleh karna itu diambil disimpulkan bahwa tidak ada perbedaan rata –
rata jumlah kata yang dibaca selama 3 menit dengan treatment antara