KLASIFIKASI KEMUNCULAN TITIK PANAS PADA LAHAN
GAMBUT DI SUMATERA DAN KALIMANTAN
MENGGUNAKAN ALGORITME K-NEAREST NEIGHBOR
FITRI KUSUMANINGRUM
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Klasifikasi Kemunculan Titik Panas pada Lahan Gambut di Sumatera dan Kalimantan Menggunakan K-Nearest Neigbor adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Desember 2015
Fitri Kusumaningrum
ABSTRAK
FITRI KUSUMANINGRUM. Klasifikasi Kemunculan Titik Panas pada Lahan Gambut di Sumatera dan Kalimantan Menggunakan Algoritme K-Nearest Neighbor. Di bawah bimbingan IMAS SUKAESIH SITANGGANG.
Data kemunculan titik panas dianalisis menggunakan metode dalam data mining, yaitu K-Nearest Neighbor (KNN). KNN merupakan metode untuk mengklasifikasikan objek berdasarkan data training yang terletak paling dekat dengan objek terdekat. Data yang digunakan adalah data titik panas untuk periode 2001-2014 dan data lahan gambut dari tahun 1990-2002. Hasil penelitian menunjukkan bahwa KNN dapat digunakan untuk mengklasifikasikan kemunculan titik panas di Sumatera dan Kalimantan. Akurasi tertinggi hasil klasifikasi pada dataset di Sumatera adalah 97,04% pada tahun 2007 dengan
dataset di Kalimantan adalah 97.67%. Berdasarkan hasil penelitian dapat disimpulkan bahwa algoritme KNN dapat digunakan untuk memprediksi kemunculan titik panas pada lahan gambut di Sumatera dan Kalimantan.
Kata kunci: kebakaran hutan, klasifikasi, k-Nearest Neighbor, titik panas
ABSTRACT
FITRI KUSUMANINGRUM. Classification of Hotspot Occurences on Peatland in Sumatera and Kalimantan using K-Nearest Neighbor Algorithm. Supervised by IMAS SUKAESIH SITANGGANG.
This research analyzed hotspot occurrences using a method in data mining, namely the K-Nearest Neighbor (KNN). KNN is a method for classifying objects based on the training data that are located to the closest object. The data used in this research are hot-spots for the period of 2001 to 2014 and peatlands data from 1990 to 2002. The results showed that KNN could be used to classify hotspot occurrences in Sumatera and Kalimantan. The highest accuracy classification results using the dataset of Sumatera in 2007 is 97.04% with the number of neighbor (k) of 1. The highest accuracy of classification results using datasets of Kalimantan in 2001, 2003, 2007, and 2011 is 100% with k of 1. In addition, using the dataset of Kalimantan in 2005, the propose method could obtain the accuracy of 100% with the values of k are 1 and 3. The average of classification accuracy results using the dataset of Sumatera and Kalimantan are 94.14% and 97.67%, respectively. It could be concluded that the KNN algorithm could be used to predict hotspots occurrences on peatland in Sumatera and Kalimantan.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
KLASIFIKASI KEMUNCULAN TITIK PANAS PADA LAHAN
GAMBUT DI SUMATERA DAN KALIMANTAN
MENGGUNAKAN ALGORITME K-NEAREST NEIGBOR
FITRI KUSUMANINGRUM
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji :
1 Toto Haryanto, SKom, MSi
Judul Skripsi : Klasifikasi Kemunculan Titik Panas pada Lahan Gambut di Sumatera dan Kalimantan Menggunakan Algoritme K-Nearest Neigbor
Nama : Fitri Kusumaningrum NIM : G64134037
Disetujui oleh
Dr Imas Sukaesih Sitanggang, Ssi, MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, Msi, MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah Subhana wa ta'ala. Shalawat serta salam semoga senantiasa dilimpahkan kepada Nabi Muhammad, keluarganya, sahabatnya, dan kepada kita yang selau berusaha menggapai ridha Allah. Alhamdulillah atas bimbingan dan petunjuk dari Allah Subhana wa ta'ala serta bimbingan dari semua pihak, penyusunan tugas akhir yang berjudul “Klasifikasi Kemunculan Titik Panas pada Lahan Gambut di Sumatera dan Kalimantan Menggunakan Algoritme K-Nearest Neighbor” dapat diselesaikan. Tugas akhir ini tidak mungkin dapat diselesaikan tanpa adanya bantuan dari berbagai pihak. Oleh karena itu, penulis ingin mengucapkan terimakasih dan penghargaan yang setinggi-tingginya kepada:
Bapak, Ibu dan keluarga yang selalu mendoakan, memberi nasihat, kasih sayang, semangat, dan dukungan sehingga penelitian ini bisa diselelsaikan. Ibu Dr Imas Sukaesih Sitanggang, SSi MKom selaku pembimbing yang telah
memberi saran, masukan dan ide-ide dalam penelitian ini.
Bapak Toto Haryanto, SKom MSi dan Bapak Muhammad Asyhar Agmalaro, SSi MKom sebagai penguji.
Teman seperjuangan Elin, Resa, Upi dan Uni yang telah memberikan semangat dan masukan.
Departemen Ilmu Komputer IPB, staf dan dosen yang telah banyak membantu selama masa perkuliahan hingga penelitian.
Wetland Internasional Indonesia yang telah berkenan memberikan data lahan gambut di Sumatera dan Kalimantan.
Semoga penelitian ini bermanfaat.
Bogor, Desember 2015
DAFTAR ISI
Tahapan Klasifikasi menggunakan Algoritme KNN 8
Perhitungan Akurasi 9
Pemilihan Hasil Klasifikasi Terbaik 9
Pemilihan Data Baru 10
Penerapan Hasil Klasifikasi Terbaik 10
Peralatan Penelitian 10
HASIL DAN PEMBAHASAN 10
Pengambilan Data 10
Praproses Data 11
Pembagian Data 18
Tahapan Klasifikasi Menggunakan Algoritme K-Nearest Neigbor 18
Perhitungan Akurasi 19
Pemilihan Hasil Klasifikasi Terbaik 22
Pemilihan Data Baru 22
SIMPULAN DAN SARAN 23
Simpulan 23
Saran 24
DAFTAR PUSTAKA 24
LAMPIRAN 25
DAFTAR TABEL
1 Tingkat kedalaman lahan gambut (Suwanto 2010) 3
2 Atribut dari titik panas 3
3 Luas jenis gambut di Kalimantan 5
4 Luas jenis gambut di Sumatera 6
5 Atribut pada dataset1 15
6 Atribut pada dataset2 15
7 Contoh record tabel dataset2 16
8 Jumlah missing value pada dataset Sumatera dan Kalimantan 17 9 Data hasil konversi dari nominal ke binary dalam bentuk kolom 18 10 Matriks confusion pada dataset Pulau Kalimantan tahun 2010 dengan
nilai k = 13 19
11 Nilai akurasi tertinggi hasil klasifikasi setiap 19 12 Akurasi tertinggi hasil klasifikasi setiap tahun untuk dataset Kalimantan 20
13 Akurasi rata-rata hasil klasifikasi setiap 21
14 Nilai akurasi rata-rata hasil klasifikasi 22
15 Matriks confusion hasil klasifikasi data baru Kalimantan 2015 dengan k
= 1 23
16 Matriks confusion hasil klasifikasi data baru Kalimantan tahun 2015
dengan k = 3 23
DAFTAR GAMBAR
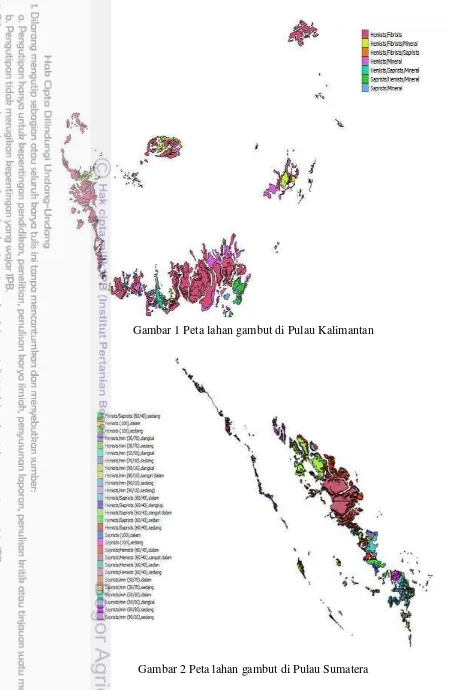
1 Peta lahan gambut di Pulau Kalimantan 4
2 Peta lahan gambut di Pulau Sumatera 4
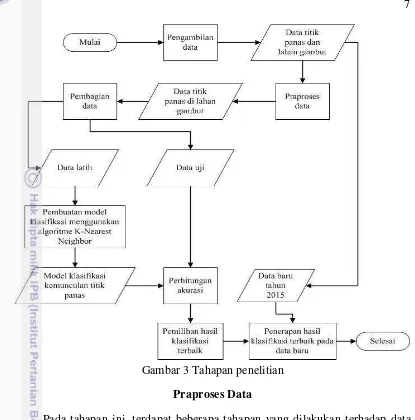
3 Tahapan penelitian 7
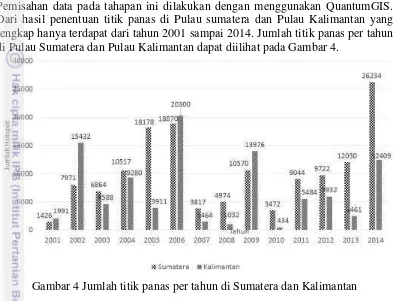
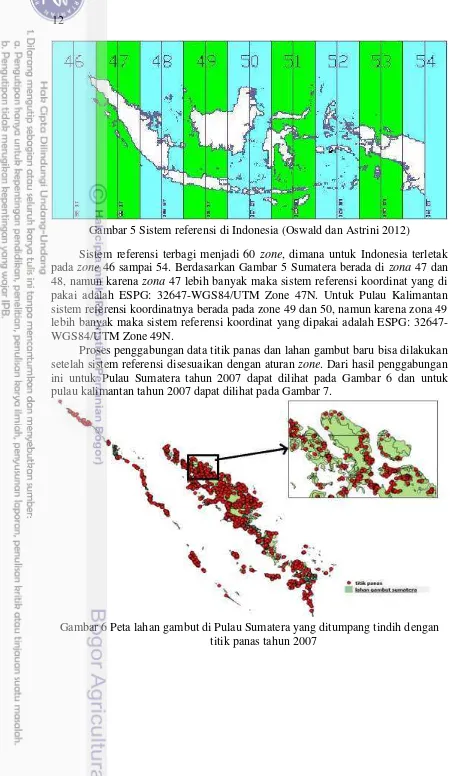
4 Jumlah titik panas per tahun di Sumatera dan Kalimantan 11 5 Sistem referensi di Indonesia (Oswald dan Astrini 2012) 12 6 Peta lahan gambut di Pulau Sumatera yang ditumpang tindih dengan
titik panas tahun 2007 12
7 Peta lahan gambut di Pulau Sumatera yang ditumpang tindih dengan
titik panas tahun 2007 13
8 Data non titik panas pada lahan gambut di Sumatera untuk tahun 2007 14 9 Data non titik panas pada lahan gambut di Kalimantan untuk tahun 2007 14 10 Data hasil konversi dari nominal ke binary dalam format text 17 11 Akurasi hasil klasifikasi untuk dataset akurasi Pulau Sumatera tahun
2010 20
12 Akurasi hasil klasifikasi untuk dataset akurasi Pulau Kalimantan tahun
2003 21
DAFTAR LAMPIRAN
1 Cara kerja KNN 25
4 Akurasi hasil klasifikasi pada dataset Pulau Sumatera tahun 2008 29 5 Akurasi hasil klasifikasi pada dataset Pulau Sumatera tahun 2010 30 6 Akurasi hasil klasifikasi pada dataset Pulau Kalimantan tahun 2001 30 7 Akurasi hasil klasifikasi pada dataset Pulau Kalimantan tahun 2003 31 8 Akurasi hasil klasifikasi pada dataset Pulau Kalimantan tahun 2005 31 9 Akurasi hasil klasifikasi pada dataset Pulau Kalimantan tahun 2007 32 10 Akurasi hasil klasifikasi pada dataset Pulau Kalimantan tahun 2008 32 11 Akurasi hasil klasifikasi pada dataset Pulau Kalimantan tahun 2010 33 12 Akurasi hasil klasifikasi pada dataset Pulau Kalimantan tahun 2011 33 13 Akurasi hasil klasifikasi pada dataset Pulau Kalimantan tahun 2012 34
PENDAHULUAN
Latar Belakang
Indonesia merupakan negara yang memiliki kekayaan alam yang melimpah termasuk diantaranya adalah lahan gambut. Lahan gambut memiliki peranan yang sangat penting dalam menyimpan karbon, dimana kemampuan menyimpan karbon jauh lebih tinggi dibanding lahan mineral. Indonesia memiliki lahan gambut terluas di antara negara tropis, yaitu 20,6 juta hektar atau sekitar 10,8% dari luas daratan di Indonesia, dimana 5,7 juta hektar terdapat di Kalimantan dan 7,2 juta hektar di Sumatera (Wibowo dan Suyatno 1998). Namun sekarang ini, lahan gambut terancam rusak akibat banyaknya kebakaran lahan gambut di Sumatera dan Kalimantan. Kebakaran lahan gambut hampir setiap tahun terjadi. Hal itu menimbulkan masalah baru untuk lingkungan hidup di sekitarnya.
Terjadinya kebakaran lahan gambut dapat dideteksi dengan melihat sebaran titik panas di area lahan gambut tertentu. Sebaran titik panas dapat diperolah dari satelit yang mencatat area tertentu yang dianggap memiliki suhu tinggi. Pemanfaatan data titik panas menjadi informasi yang lebih berguna dapat dilakukan dengan menggunakan teknik data mining karena data mining dapat mengolah data yang cukup besar menjadi pengetahuan. Salah satu metode dalam
data mining adalah K-Nearest Neighbor (KNN). Metode ini dapat mengklasifisikasikan data titik panas ke dalam kelas tertentu berdasarkan jarak kedekatan objek.
Pada penelitian sebelumnya telah dilakukan penelitian mengenai kebakaran hutan oleh Sitanggang (2013). Dalam penelitiannya dibahas mengenai pemodelan kemunculan titik panas dengan metode klasifikasi C4.5, SimpleCart, Naive Bayes,
regresi logistik dan pohon keputusan ID3. Penelitian lain oleh Fernando dan Sitanggang (2014) mengenai klasifikasi data titik panas di Propinsi Riau dengan menggunakan teknik pohon keputusan ID3 dengan akurasi tertinggi yaitu 70.80%. Penelitian ini mengklasifikasi kemunculan titik panas pada lahan gambut di Sumatera dan Kalimantan dengan menggunakan algoritme KNN untuk menentukan kemunculan titik panas dan mengklasifikasikan berdasarkan jarak kedekatan antarobjek pada lahan gambut di Sumatera dan Kalimantan. Hasil klasifikasi ini diharapkan dapat memberikan informasi untuk mencegah kebakaran pada lahan gambut di Sumatera dan Kalimantan.
Perumusan Masalah
Meningkatnya kebakaran lahan gambut menjadi masalah utama dalam penelitian ini. Salah satu upaya untuk mencegah kebakaran lahan gambut adalah dengan menentukan kemunculan titik panas di lahan gambut. Berdasarkan latar belakang dalam penelitian ini, maka perumusan masalah dalam penelitian ini adalah bagaimana mengklasifikasi kemunculan titik panas di lahan gambut di Sumatera dan Kalimantan menggunakan algoritme KNN.
Tujuan Penelitian
2
Manfaat Penelitian
Penelitian ini diharapkan dapat menghasilkan prediksi kemunculan titik panas pada lahan gambut berdasarkan jarak kedekatan objek yang akurat untuk masa yang akan datang sehingga informasi ini dapat digunakan untuk mencegah kebakaran pada lahan gambut.
Ruang Lingkup Penelitian Ruang lingkup dari penelitian ini adalah:
1 Karakteristik yang digunakan untuk data lahan gambut pada penelitian ini terdiri dari jenis lahan gambut, kedalaman lahan gambut dan tutupan lahan. 2 Wilayah kajian pada penelitian ini pada lahan gambut di Sumatera dan
Kalimantan.
3 Penelitian ini menggunakan package class yang sudah disediakan oleh perangkat lunak RStudio.
4 Dataset yang dapat dijalankan untuk Sumatera hanya pada tahun 2001, 2007, 2008, dan 2010. Dataset yang dapat dijalankan untuk Kalimantan hanya pada tahun 2001, 2003, 2005, 2007, 2008, 2010, 2011, 2012, dan 2013.
METODE
Data
Data yang digunakan pada penelitian ini terdiri dari 2 data spasial, yaitu data titik panas Pulau Sumatera dan Pulau Kalimantan dari tanggal 1 Januari 2001 sampai 31 Maret 2015 dan data lahan gambut dari tahun 1990 sampai 2002. Data titik panas diperoleh dari Nasional Aeronautics and Space Administration (NASA) Fire Information for Resource Management (FIRMS) dalam format
shapefile (.shp). Data lahan gambut didapat dari Wetlands International Indonesia Programme (WI–PI) yang berada di Jl. Ahmad Yani No 53 Bogor, Jawa Barat. Menurut Sitanggang et al. (2012) atribut data lahan gambut yang digunakan terdiri dari 3 atribut, yaitu jenis lahan gambut, kedalaman lahan gambut dan tutupan lahan gambut. Berdasarkan tingkat dekomposisi bahan organiknya gambut dibedakan menjadi 3 yaitu fibrists, hemists, dan saprists (Suwanto et al.
2010). Berikut penjelasan mengenai jenis gambut(Suwanto et al. 2010):
1 Fibrists merupakan gambut yang masih muda dengan tingkat pelapukan awal dan lebih dari ¾ bagian volumenya berupa serat kasar, air perasan berwarna bening/jernih.
2 Hemists merupakan gambut yang mempunyai tingkat pelapukan sedang, bagian yang masih berupa serat kasar sekitar 1/4 hingga kurang dari 3/4 bagian, dan air perasan berwarna coklat dan mengandung bahan yang tidak larut.
3 Saprists merupakan gambut yang tingkat pelapukannya sudah lanjut (matang), berupa serat kasar kurang dari 1/4 bagian, dan air perasan berwarna hitam.
3 Kedalaman lahan gambut digunakan untuk melihat tingkat kedalaman lahan gambut tersebut. Kategori tingkat kedalamannya lahan gambut dapat dilihat pada Tabel 1.
Tabel 1 Tingkat kedalaman lahan gambut (Suwanto 2010)
Kedalaman Keterangan
D0 Sangat dangkal/ sangat tipis < 50 cm D1 Dangkal/ tipis 50 - 100 cm
D2 Sedang 100 - 200 cm D3 Dalam/ tebal 200 - 400 cm
D4 Sangat dalam/ sangat tebal > 400 cm
Dari Tabel 1 dapat dilihat bahwa tingkat kedalaman gambut memiliki tingkat ukuran (cm), mulai dari kurang dari 50 cm sampai lebih 400 cm. Untuk atribut data titik panas terdiri dari 12 atribut yang dapat dilihat pada Tabel 2.
Tabel 2 Atribut dari titik panas
No Atribut Tipe
1 Latitude Numerik
2 Longitude Numerik
3 Brightness Numerik
4 Scan Numerik
5 Track Numerik
6 Acq_date Date
7 Acq_time Character varying(5) 8 Satelit Character varying(3) 9 Confidence Integer
10 Version Character varying(1) 11 Brigh_T31 Numerik
12 FRP Numerik
4
Gambar 1 Peta lahan gambut di Pulau Kalimantan
5 Dari Gambar 1 dan Gambar 2 dapat dilihat letak jenis gambut dan letaknya di Pulau Kalimantan dan Sumatera. Lahan gambut di Kalimantan dan Sumatera terdiri dari 2 atau 3 jenis untuk setiap daerahnya. Luas area setiap jenis gambut di Pulau Kalimantan dapat dilihat pada Tabel 3.
Tabel 3 Luas jenis gambut di Kalimantan
No Tipe Gambut Luas (ha)
1 Hemists/Fibrists 4.070.888.40 2 Hemists/Fibrists/Mineral 388.442.91 3 Hemists/Mineral 922.584.25 4 Saprists/Mineral 108.626.03 5 Saprists/Hemists/Mineral 132.833.32 6 Hemists/Saprists/Mineral 133.670.40 7 Hemists/Fibrists/Saprists 3.028.59
Total 5.760.073.90
Tabel 3 menunjukkan luas jenis gambut yang paling luas adalah jenis Hemists/Fibrists dengan luasnya mencapai 4.070.888.40 ha. Hemists/Fibrists maksudnya adalah pada daerah tersebut terdapat jenis Hemist dan Saprist. Luas jenis gambut paling sempit adalah jenis Hemists/Fibrists/Saprists dengan luas 3.028.59 ha. Hemists/Fibrists/Saprists maksudnya adalah pada daerah tersebut terdapat lebih dari 2 jenis lahan gambut, yaitu Hemists, Fibrists, dan Saprists. Luas area setiap jenis gambut di Pulau Sumatera dapat dilihat pada Tabel 4.
6
Tabel 4 Luas jenis gambut di Sumatera
No Tipe Gambut Luas (ha)
1 Hemists/Saprists (60/40), sedang 1.490.145.52 2 Saprists/min (50/50), dangkal 16.859.44 3 Saprists/Hemists (60/40), sedang 18.698.39 4 Saprists/min (30/70), sedang 9.911.10 5 Saprists/min (90/10), sedang 178.408.66
6 Hemists (100), dalam 2.200.51
7 Hemists/Saprists (60/40), dalam 639.263.34
8 Hemists (100), sedang 86.697.37
9 Saprists/min (50/50), dalam 7.748.19
10 Hemists/min(90/10),sangat dalam 30.179.83 11 Hemists/Saprists (60/40), sedang 211.082.31 12 Hemists/min (30/70), dangkal 308.112.73 13 Hemists/Saprists (60/40), sangat dalam 957.561.63 14 Saprists/Hemists (60/40), dalam 553.762.97 15 Saprists/Hemists (60/40), sedang 236.659.27 16 Hemists/min (90/10), dangkal 7.950.21 17 Hemists/Saprists (60/40), dangkal 49.355.05 18 Hemists/min (70/30), sedang 91.797.22 19 Saprists/min (30/70), dalam 12.671.89
20 Hemists/min (90/10), sedang 0.63
21 Hemists/min (50/50), dangkal 2.218.86 22 Saprists/min (50/50), sedang 118.152.46 23 Hemists/min (90/10), sedang 578.525.94 24 Fibrists/Saprists (60/40), sedang 10.721.84 25 Saprists/Hemists (60/40), sangat dalam 1.181.264.70 26 Hemists/min (30/70), sedang 308.958.76
27 Saprists (100), sedang 87.885.62
28 Saprists (100), dalam 35.182.65
Total 7.231.977.09
Tahapan Penelitian
Tahapan yang dilakukan pada penelitian ini dapat dilihat pada Gambar 3. Pengambilan Data
7
Gambar 3 Tahapan penelitian Praproses Data
Pada tahapan ini, terdapat beberapa tahapan yang dilakukan terhadap data titik panas dan data lahan gambut. Pertama yang dilakukan yaitu mendapatkan data titik panas yang lengkap (terdapat titik panas setiap bulannya dalam satu tahun). Kemudian data dipisah per tahunnya untuk setiap pulau. Atribut pada
dataset Sumatera untuk lahan gambut terdiri dari jenis lahan gambut, tutupan lahan dan kedalaman lahan gambut, sedangkan atribut pada dataset Kalimantan hanya terdiri dari jenis lahan gambut dan kedalaman lahan gambut. Perbedaan jumlah atribut tersebut dikarenakan data yang didapat dari Wetland untuk dataset
Kalimantan tidak mencantumkan jenis tutupan lahan. Seleksi Data Titik Panas pada Lahan Gambut
Pada tahapan ini yang dilakukan adalah menentukan data titik panas yang berada di atas lahan gambut. Cara untuk mendapatkannya adalah dengan menggabungkan dengan operasi ST_Within data titik panas Pulau Sumatera dengan data lahan gambut di Pulau Sumatera dan data titik panas di Pulau Kalimantan dengan data lahan gambut di Pulau Kalimantan.
Pembuatan Data Non Titik Panas pada Lahan Gambut
8
gambut. Terdapat beberapa proses untuk mendapatkan data non titik panas yaitu pembuatan buffer, disolve, operasi difference, dan pembangkitan random point. Setelah proses tersebut dilakukan maka data non titik panas sudah didapat.
Pembuatan Dataset untuk Klasifikasi
Setelah didapatkan data titik panas pada lahan gambut dan data bukan titik panas pada lahan gambut. Proses selanjutnya adalah menambahkan kolom baru untuk kelas sebagai identifier yang membedakan antara titik panas dan bukan titik panas. Dari hasil tersebut diambil data titik panas yang confidence-nya ≥ 70 karena dianggap memiliki potensi kebakaran. Barulah kemudian dibuat dataset
yang akan digunakan dalam proses klasifikasi. Membuang Missing Value
Pada tahapan ini yang akan dilakukan adalah mendapatkan jumlah missing value dan presentasenya terhadap jumlah keseluruhan data. Missing value dengan jumlah kurang dari 10% dibuang karena dianggap tidak memiliki mengaruh besar dalam proses klasifikasi.
Konversi Data
Pada tahapan ini dilakukan konversi data yaitu mengubah data dari tipe data
nominal ke dalam bentuk numeric. Proses konversi dilakukan karena untuk klasifikasi menggunakan algoritme KNN, atribut data input harus bersifat numeric
yang dapat diproses, sedangkan data yang didapat masih dalam bentuk nominal. Pembagian Data
Pada tahapan ini dilakukan pembagian data menjadi data latih dan data uji. Metode yang digunakan untuk membagi data adalah metode 10 fold cross validation. Data dibagi secara random ke dalam 10 bagian dengan perbandingan yang sama, kemudian dari setiap bagian terbaik akan menjadi data uji dan 9 bagian lainnya akan menjadi data latih.
Tahapan Klasifikasi menggunakan Algoritme KNN Algoritme KNN
K-Nearest Neighbor (KNN) termasuk kelompok instance-based-learning. Algoritme ini juga merupakan salah satu teknik lazy learning. KNN dilakukan dengan mencari kelompok k objek dalam data training yang paling dekat (mirip) dengan objek pada data baru atau data testing (Wu dan Kumar 2009). Ada banyak cara mengukur jarak kedekatan antara data baru dengan data lama (data training), diantaranya euclidean distance dan manhattan distance. Formula jarak yang paling sering digunakan adalah euclidean distance (Bramer 2007) yaitu:
9 Langkah-langkah dalam Algoritme K-Nearest Neighbor (Bramer 2007): 1 Menentukan parameter k (jumlah tetangga paling dekat).
2 Menghitung kuadrat jarak euclid (query instance) masing-masing objek terhadap data sampel yang diberikan.
3 Kemudian mengurutkan objek-objek tersebut ke dalam kelompok yang mempunyai jarak euclid terkecil.
4 Mengumpulkan kategori Y, dimana Y merupakan class target.
5 Dengan menggunakan kategori Nearest Neighbor yang paling mayoritas maka didapat objek yang diprediksikan.
Tahapan Klasifikasi
Pada tahapan ini, data yang sudah dipraproses dan dibagi diklasifikasi dengan menggunakan algoritme K-Nearest Neighbor. Pembentukan tahapan klasifikasi ini menggunakan bahasa pemrograman R dengan package class. Tahapan klasifikasi yang dilakukan dengan memberikan masukan data yang akan dihitung jarak antar datanya. Kemudian dari hasil semua jarak yang telah dilakukan perhitungan, diurutkan dari yang terbesar ke yang terkecil. Setelah itu menentukan nilai jumlah tetangga terdekat (k). Jika nilai k sudah ditentukan, class
didapat dengan melihat anggota yang paling banyak dari kelas target.
Setelah data titik panas diubah dalam bentuk binary barulah dapat dilakukan perhitungan jarak antardata. Selanjutnya dijelaskan cara kerja KNN dengan menggunakan 10 record data. Dalam ilustrasi ini data training yang digunakan terdiri dari 6 data titik panas (T) dan 4 data bukan titik panas (F). Data testing
terdiri dari 1 data titik panas. Recorddata training dapat dilihat pada Lampiran 1. Perhitungan Akurasi
Pada tahap ini dilakukan perhitungan nilai akurasi dari hasil klasifikasi menggunakan data uji. Akurasi menunjukkan tingkat kebenaran pengklasifikasian data terhadap kelas yang sebenarnya. Nilai akurasi yang baik adalah yang mendekati 100% dan semakin rendah nilai akurasi maka semakin tinggi kesalahan klasifikasi pada data baru. Nilai akurasi didapat berdasarkan data pengujian terhadap hasil klasifikasi. Untuk menghitung akurasi hasil klasifikasi digunakan rumus sebagai berikut:
�kurasi=∑data yang ∑uji benar diklasifikasidata uji (2)
Pemilihan Hasil Klasifikasi Terbaik
Pada tahapan ini yang dilakukan adalah mendapatkan akurasi hasil klasifikasi untuk dataset Pulau Sumatera dan Kalimantan. Masing-masing dataset
untuk Pulau Kalimantan dan Sumatera dicari nilai akurasi tertingginya. Akurasi tertinggi untuk Pulau Sumatera dan Kalimantan digunakan sebagai data training
10
Pemilihan Data Baru
Pada tahapan ini yang dilakukan adalah memilih data baru yang digunakan sebagai data testing pada proses selanjutnya yaitu penerapan hasil klasifikasi terbaik pada data baru. Data yang digunakan adalah data baru yang belum pernah digunakan pada tahapan klasifikasi. Untuk data baru yang digunakan pada penelitian ini adalah data titik panas dan data non titik panas dari 1 Januari 2015 sampai 31 Maret 2015.
Penerapan Hasil Klasifikasi Terbaik
Pada tahapan ini dilakukan pengujian menggunakan data baru yang digunakan sebagai data testing, dimana data training yang digunakan adalah yang memberikan hasil klasifikasi dengan akurasi tertinggi. Dengan demikian, hasil klasifikasi menggunakan data baru dapat digunakan untuk memprediksi titik panas baru.
Peralatan Penelitian
Perangkat lunak yang digunakan dalam penelitian ini adalah: 1 Sistem operasi Windows 7 Home Basic
2 Bahasa pemrograman R 3.1.3 dengan packages class.
3 Rstudio version 0.98.1102 dengan package class digunakan untuk proses klasifikasi menggunakan algoritme KNN.
4 Quantum GIS 2.6.1 untuk membuat plot data titik panas dan data bukan titik panas pada lahan gambut.
5 Microsoft Excel digunakan untuk mengubah data dalam bentuk text ke dalam bentuk kolom.
6 Weka 3.6.12 digunakan untuk menghilangkan missing value dan mengkonversi data dari nominal ke numeric.
7 PostgreSQL versi 9.1 sebagai sistem manajemen basis data untuk pengolahan kueri data lahan gambut.
8 Notepad ++ digunakan untuk menuliskan kode program untuk dijalankan di R. Spesifikasi perangkat keras dan perangkat lunak yang digunakan untuk penelitian ini adalah sebagai berikut:
11
Praproses Data
Pada tahapan praproses dilakukan pemisahan data titik panas dari tahun 2001 sampai 2015 di Pulau Sumatera dan di Pulau Kalimantan. Pemisahan data yang dimaksud adalah mengambil titik panas yang memiliki data titik panas lengkap atau terdapat titik panas setiap bulannya dalam jangka waktu satu tahun. Pemisahan data pada tahapan ini dilakukan dengan menggunakan QuantumGIS. Dari hasil penentuan titik panas di Pulau sumatera dan Pulau Kalimantan yang lengkap hanya terdapat dari tahun 2001 sampai 2014. Jumlah titik panas per tahun di Pulau Sumatera dan Pulau Kalimantan dapat diilihat pada Gambar 4.
Gambar 4 Jumlah titik panas per tahun di Sumatera dan Kalimantan
Dari Gambar 4 dapat dilihat jumlah titik panas terbanyak untuk kurun waktu 2001 sampai 2014 di Pulau Sumatera terdapat pada tahun 2014, sedangkan di Pulau Kalimantan jumlah titik panas paling banyak terdapat pada tahun 2006. Untuk jumlah titik panas paling sedikit di Pulau Sumatera terdapat di tahun 2001, sedangkan di Pulau Kalimantan terdapat di tahun 2010.
Seleksi Data Titik Panas pada Lahan Gambut
12
Gambar 5 Sistem referensi di Indonesia (Oswald dan Astrini 2012)
Sistem referensi terbagi menjadi 60 zone, dimana untuk Indonesia terletak pada zone 46 sampai 54. Berdasarkan Gambar 5 Sumatera berada di zona 47 dan 48, namun karena zona 47 lebih banyak maka sistem referensi koordinat yang di pakai adalah ESPG: 32647-WGS84/UTM Zone 47N. Untuk Pulau Kalimantan sistem referensi koordinatnya berada pada zone 49 dan 50, namun karena zona 49 lebih banyak maka sistem referensi koordinat yang dipakai adalah ESPG: 32647-WGS84/UTM Zone 49N.
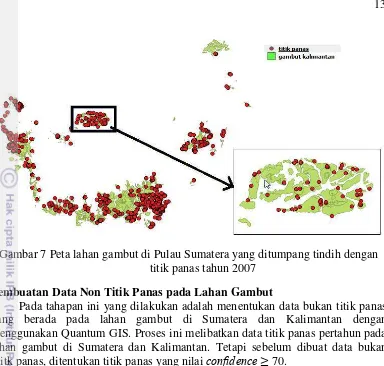
Proses penggabungan data titik panas dan lahan gambut baru bisa dilakukan setelah sistem referensi disesuaikan dengan aturan zone. Dari hasil penggabungan ini untuk Pulau Sumatera tahun 2007 dapat dilihat pada Gambar 6 dan untuk pulau kalimantan tahun 2007 dapat dilihat pada Gambar 7.
13
Gambar 7 Peta lahan gambut di Pulau Sumatera yang ditumpang tindih dengan titik panas tahun 2007
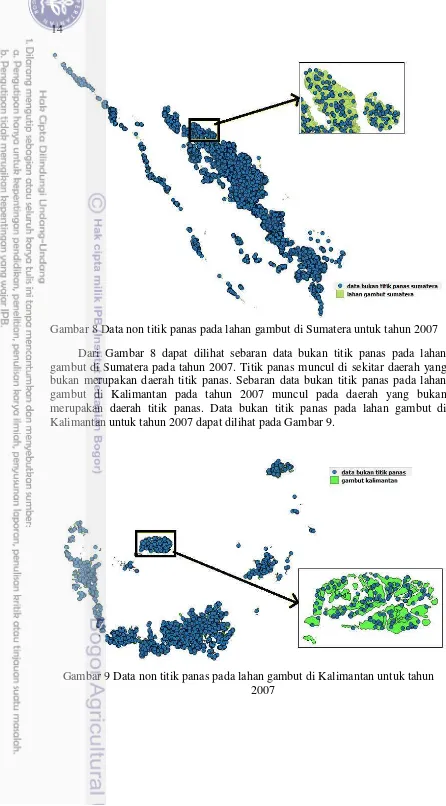
Pembuatan Data Non Titik Panas pada Lahan Gambut
Pada tahapan ini yang dilakukan adalah menentukan data bukan titik panas yang berada pada lahan gambut di Sumatera dan Kalimantan dengan menggunakan Quantum GIS. Proses ini melibatkan data titik panas pertahun pada lahan gambut di Sumatera dan Kalimantan. Tetapi sebelum dibuat data bukan tititk panas, ditentukan titik panas yang nilai confidence ≥ 70.
Langkah pertama adalah membuat tabel baru yang terdiri dari gid, the geom,
longitude, latitude, acq date, confidence, dan kelas yang berisi titik panas dengan
confidence ≥ 70. Nilai confidence yang digunakan adalah diatas ≥ 70, karena titik panas demikian memiliki potensi tinggi sebagai indikator kebakaran hutan dan lahan.
14
Gambar 8 Data non titik panas pada lahan gambut di Sumatera untuk tahun 2007 Dari Gambar 8 dapat dilihat sebaran data bukan titik panas pada lahan gambut di Sumatera pada tahun 2007. Titik panas muncul di sekitar daerah yang bukan merupakan daerah titik panas. Sebaran data bukan titik panas pada lahan gambut di Kalimantan pada tahun 2007 muncul pada daerah yang bukan merupakan daerah titik panas. Data bukan titik panas pada lahan gambut di Kalimantan untuk tahun 2007 dapat dilihat pada Gambar 9.
15 Pembuatan Dataset
Setelah didapatkan data titik panas pada lahan gambut dan data bukan titik panas pada lahan gambut. Proses selanjutnya adalah menambahkan kolom baru untuk kelas. Pada atribut kelas data titik panas per tahun diberikan isian T atau
True dan untuk data bukan titik panas pada gambut akan diisikan F atau False. Proses ini dilakukan menggunakan PostgresSQL.
Dari proses ini didapat tabel baru yang diberi nama target. Proses ini masih dilakukan menggunakan PostgresSQL. Dari data titik panas dengan confidence≥ 70 selanjutnya akan dibuat dataset1 dan dataset2 menggunakan PostgresSQL. Adapun untuk dataset1 berisi data dari tabel lahan gambut dan data target. Atribut data yang ada di dataset1 dapat dilihat pada Tabel 5.
Tabel 5 Atribut pada dataset1
No Atribut Tipe
1 Gid Big integer
2 Gid2 Integer
3 The geom Geometri(point)
4 Confidence Integer
5 Legend Character varying(42) 6 Landuse Character varying(60) 7 Ketebalan Character varying(16)
Dataset1 digunakan untuk menyimpan informasi yang lebih lengkap yang dapat digunakan untuk melihat letak dari objek dalam peta lahan gambut menggunakan Quantum GIS. Untuk proses klasifikasi di R dibuat dataset2 yang diambil dari data target dan data gambut. Atribut pada dataset2 dapat dilihat pada Tabel 6.
Tabel 6 Atribut pada dataset2
No Atribut Tipe
1 Legend Character varying(42) 2 Landuse Character varying(60) 3 Ketebalan Character varying(16)
4 Kelas Character
Atribut pada Tabel 6 ini hanya untuk Pulau Sumatera, sedangkan untuk Pulau Kalimantan hanya terdiri dari legend, ketebalan dan kelas. Atribut landuse
16
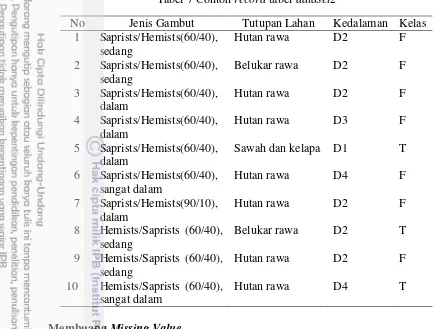
Tabel 7 Contoh record tabel dataset2
No Jenis Gambut Tutupan Lahan Kedalaman Kelas 1 Saprists/Hemists(60/40),
8 Hemists/Saprists (60/40), sedang
Belukar rawa D2 T
9 Hemists/Saprists (60/40), sedang
Hutan rawa D2 F
10 Hemists/Saprists (60/40), sangat dalam
Hutan rawa D4 T
Membuang Missing Value
Pada tahapan ini ditentukan jumlah missing value. Untuk melihat jumlah
missing value digunakan Weka. Setelah didapat missing value, kemudian menghitung presentase jumlah missing value terhadap data keseluruhan. Jika
missing value tidak lebih dari 10%, maka missing value tersebut dibuang dari
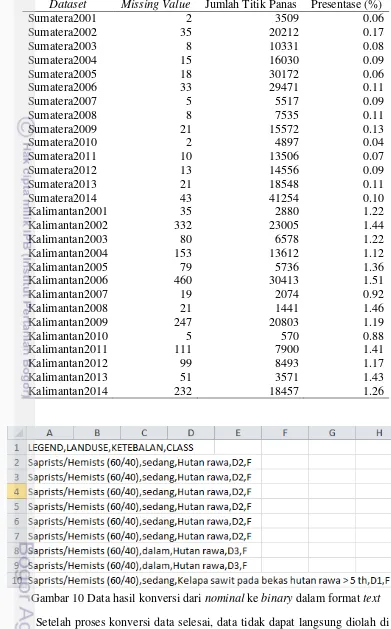
dataset karena dianggap tidak memiliki pengaruh yang cukup besar dalam proses klasifikasi. Jumlah missing value di Pulau Sumatera dan Pulau Kalimantan dapat dilihat pada Tabel 8.
Dari Tabel 8 dapat dilihat jumlah missing value tertinggi pada dataset
Kalimantan2006 yaitu 460, namun jumlah tersebut hanya 1.51% dibandingkan jumlah datanya yang mencapai 30413. Presentase tertinggi missing value adalah 1.46% dan nilai ini tidak lebih dari 10%, jadi semua missing value dihilangkan. Konversi Data
Sebelum dataset diolah di R dengan menggunakan model klasifikasi
menggunakan algoritme K-Nearest Neighbor diperlukan konversi data, karena KNN hanya bisa memproses data bertipe numeric sedangkan atribut dalam
17 Tabel 8 Jumlah missing value pada dataset Sumatera dan Kalimantan
Dataset Missing Value Jumlah Titik Panas Presentase (%)
Sumatera2001 2 3509 0.06
Kalimantan2002 332 23005 1.44
Kalimantan2003 80 6578 1.22
Kalimantan2004 153 13612 1.12
Kalimantan2005 79 5736 1.36
Kalimantan2006 460 30413 1.51
Kalimantan2007 19 2074 0.92
Kalimantan2008 21 1441 1.46
Kalimantan2009 247 20803 1.19
Kalimantan2010 5 570 0.88
Kalimantan2011 111 7900 1.41
Kalimantan2012 99 8493 1.17
Kalimantan2013 51 3571 1.43
Kalimantan2014 232 18457 1.26
Gambar 10 Data hasil konversi dari nominal ke binary dalam format text
18
kolom, sehingga atribut tersebut di dalam R terbaca menjadi 2 kolom. Hal tersebut sangat fatal karena menimbulkan pergeseran data yang berakibat timbul data kosong. Apabila itu terjadi, data menjadi tidak akurat lagi. Solusi yang dilakukan yaitu dataset yang sebelumnya dipisahkan dengan koma (,) bukan dalam bentuk kolom diolah dengan Microsoft Excel agar terpisah dengan baik. Pemisahan
dataset ini menggunakan fasilitas yang disediakan oleh Microsoft Excel untuk mengubah text ke dalam bentuk kolom. Contoh dataset yang telah diolah di Microsoft Excel dapat dilihat pada Tabel 9.
Tabel 9 Data hasil konversi dari nominal ke binary dalam bentuk kolom No Legend= Saprists/Hemists (60/40),
sedang
Legend= Saprists/Hemists (60/40), dalam
Dari hasil pemisahan data menggunakan Microsoft Excel yang telah dilakukan harus dilakukan pengecekan ulang. Hal ini dilakukan untuk memastikan data telah sesuai untuk diproses di tahap selanjutnya.
Pembagian Data
Pembagian data pada pengolahan data di R menggunakan 10 fold cross validation. Dengan demikian, 10% dari data akan dijadikan sebagai data uji dan 90% bagian data akan dijadikan data latih. Adapun keseluruhan data dibagi menjadi 10 bagian, kemudian dari setiap bagian menjadi data uji dan 9 bagian lainnya akan menjadi data latih.
19 Tabel 10 Matriks confusion pada dataset Pulau Kalimantan tahun 2010 dengan
nilai k = 13
Kelas Hasil Prediksi Kelas Aktual
False True
menyatakan data bukan titik panas.
Matriks confusion ini selanjutnya akan digunakan untuk menghitung nilai akurasi hasil tahapan klasifikasi dengan menggunakan KNN. Namun untuk mendapatkan hasil tahapan klasifikasi menggunakan algoritme KNN ini tidak semua data dapat diolah oleh packages class pada R karena untuk Pulau Sumatera tahun 2002 sampai 2006, 2009, dan 2011 sampai 2014 memiliki jumlah atribut yang sangat banyak. Untuk dataset Pulau Kalimantan tahun 2002, 2004, 2006, 2009, dan 2014 tidak dapat diolah di R karena jumlah data yang terlalu banyak.
Perhitungan Akurasi
Pada tahapan ini dihitung nilai akurasi dari hasil tahapan klasifikasi untuk setiap nilai k. Untuk menghitung nilai akurasi digunakan rumus akurasi pada persamaan 2.
Dengan menggunakan nilai hasil tahapan klasifikasi menggunakan algoritme KNN yang telah dihasilkan pada proses klasifikasi, selanjutnya dihitung nilai akurasinya. Berdasarkan Tabel 10 akurasi hasil klasifikasi dengan KNN dengan k = 13 adalah
Akurasi=115+21+9+127115+127 =88.97% (3)
Perhitungan akurasi dilakukan untuk semua dataset dan semua nilai k. Akurasi tertinggi untuk dataset setiap tahunnya untuk Pulau Sumatera dapat dilihat pada Tabel 11.
Tabel 11 Nilai akurasi tertinggi hasil klasifikasi setiap tahun untuk dataset Sumatera
Dataset Nilai k Terbaik Akurasi (%)
Sumatera2001 1 99.14
Sumatera2007 1 99.10
Sumatera2008 1 98.48
20
Berdasarkan Tabel 11 akurasi yang diperoleh selisihnya tidak terlalu berbeda jauh. Akurasi tertinggi untuk Pulau Sumatera adalah pada Sumatera2010 untuk nilai k = 1. Grafik akurasi untuk dataset Sumatera2010 dapat dilihat pada Gambar 12, sedangkan untuk grafik dataset Sumatera lainnya dapat dilihat pada Lampiran 2 sampai Lampiran 5.
Gambar 11 Akurasi hasil klasifikasi untuk dataset akurasi Pulau Sumatera tahun 2010
Dari Gambar 11 dapat dilihat akurasi hasil klasifikasi untuk nilai k = 1 sampai k = 19 yang cenderung menurun. Jumlah tetangga (k) = 1 memiliki akurasi tertinggi untuk dataset Sumatera, jadi untuk pengujian dengan menggunakan
dataset Sumatera 2010 menggunakan jumlah tetangga (k) = 1. Akurasi tertinggi hasil klasifikasi untuk dataset setiap tahunnya di Pulau Kalimantan dapat dilihat pada Tabel 12.
Tabel 12 Akurasi tertinggi hasil klasifikasi setiap tahun untuk dataset Kalimantan
Dataset Nilai k Tertinggi Akurasi (%)
Kalimantan2001 1 100.00
Kalimantan2003 1 100.00
Kalimantan2005 1 100.00
Kalimantan2005 3 100.00
Kalimantan2007 1 100.00
Kalimantan2008 1 99.87
Kalimantan2010 1 99.26
Kalimantan2011 1 100.00
Kalimantan2012 1 99.98
Kalimantan2013 1 99.95
21 1, dataset Kalimantan2003 dengan k = 1, dataset Kalimantan2005 dengan nilai k = 1, dan 3, Kalimantan2007 dengan k = 1, dan Kalimantan2011 dengan k = 1. Grafik akurasi untuk jumlah tetangga k = 1 sampai k = 19 untuk dataset Kalimantan 2005 dapat dilihat pada Gambar 12, sedangkan untuk grafik dataset
Kalimantan lainnya dapat dilihat pada Lampiran 6 sampai Lampiran 14.
Gambar 12 Akurasi hasil klasifikasi untuk dataset akurasi Pulau Kalimantan tahun 2003
Dari Gambar 12 menunjukkan jumlah tetangga (k) = 1 memiliki akurasi tertinggi. Untuk nilai k = 3 sampai k = 19 akurasi cenderung menurun. Walaupun pada k = 7 mengalami kenaikan tetapi kenaikannya tidak lebih tinggi dari akurasi hasil klasifikasi dengan k = 1. Akurasi rata-rata hasil klasifikasi pada dataset
Pulau Sumatera setiap tahun dapat dilihat pada Tabel 13.
Tabel 13 Akurasi rata-rata hasil klasifikasi setiap tahun untuk dataset Pulau Sumatera
Dataset Akurasi (%)
Sumatera2001 93.67
Sumatera2007 97.33
Sumatera2008 92.72
Sumatera2010 97.10
Rata-rata 95.20
22
Tabel 14 Nilai akurasi rata-rata hasil klasifikasi setiap tahun untuk dataset Pulau Kalimantan
Dataset Akurasi (%)
Nilai akurasi tertinggi untuk Pulau Kalimantan adalah 99.79% pada dataset Kalimantan2012. Akurasi rata-rata hasil klasifikasi keseluruhan untuk Pulau Kalimantan adalah sebesar 98.66%.
Pemilihan Hasil Klasifikasi Terbaik
Setelah dilakukan klasifikasi menggunakan algoritme KNN dan dihitung nilai akurasinya maka didapat hasil klasifikasi dengan akurasi tertinggi. Untuk Pulau Sumatera akurasi tertinggi pada dataset pada tahun 2010 dengan nilai k = 1. Akurasi tertinggi hasil klasifikasi untuk Pulau Kalimantan pada dataset tahun 2001, 2007, dan 2011 dengan nilai k = 1, sedangkan dataset tahun 2005 pada k = 1 dan k = 3.
Pemilihan Data Baru
Pada tahapan ini yang dilakukan adalah memilih data baru yang akan digunakan sebagai data testing. Untuk data baru yang digunakan pada penelitian ini adalah data titik panas dan data non titik panas dari 1 Januari 2015 sampai 31 Maret 2015.
Penerapan Hasil Klasifikasi Terbaik
Pada tahapan ini, dilakukan pengujian pada hasil klasifikasi menggunakan data titik panas pada tahun 2015 yang akan digunakan sebagai data testing dan
dataset Kalimantan tahun 2005 sebagai data training. Penggunaan dataset
23
Tabel 15 Matriks confusion hasil klasifikasi data baru Kalimantan 2015 dengan k = 1
Kelas Prediksi Kelas Aktual
False True
False 76 1
True 0 23
Tabel 16 Matriks confusion hasil klasifikasi data baru Kalimantan tahun 2015 dengan k = 3
Kelas Prediksi Kelas Aktual
False True
False 76 1
True 0 23
Matriks confusion untuk k = 1 dan k = 3 menghasilkan nilai yang sama. Klasifikasi menggunakan KNN menunjukan dapat mengklasifikasikan data dengan kelas true (titik panas) ke kelas true (titik panas) dan dapat mengklasifikasikan data dengan kelas false (bukan titik panas) ke kelas false
(bukan titik panas). Berdasarkan Tabel 15 dan Tabel 16 akurasi hasil klasifikasi dengan k = 1 dan k = 3 adalah
Akurasi=76+1+0+2376+23 =99% (5) Akurasi hasil klasifikasi menggunakan KNN untuk dataset Kalimantan2005 yang dijadikan data training dan data titik panas tahun 2015 sebagai data testing
adalah 99%, untuk jumlah tetangga terdekat (k) = 1 dan (k) = 3. Hasil klasifikasi tertinggi untuk Pulau Sumatera tidak dapat digunakan sebagai data training
menggunakan data baru tahun 2015 karena proses klasifikasi pada dataset tersebut tidak dapat dilakukan di R.
SIMPULAN DAN SARAN
Simpulan
24
Saran
Untuk penelitian selanjutnya, dapat dikembangkan aplikasi berbasis web untuk memudahkan pengguna sehingga dapat diperoleh nilai akurasi yang dapat diketahui secara cepat.
DAFTAR PUSTAKA
Bramer M. 2007. Principles of Data Mining. London(UK): Springer.
Fernando V, Sitanggang IS. 2014. Klasifikasi data spasial untuk kemunculan hotspot di Provinsi Riau menggunakan algoritme ID3. Integrasi Sains MIPA untuk Mengatasi Masalah Pangan, Energi, Kesehatan, Reklamasi, dan Lingkungan; 09-11 Mei 2014. Bogor, Indonesia. Bogor (ID): SEMIRATA, hlm 428-436. ISBN: 978-602-70491-0-9.
Oswald P, Astrini R. 2012. Tutorial QuantumGIS Tingkat Dasar Versi 1.8.0 Lisboa. Mataram (ID): GIZ Decentralization as Contribution to Good Governance (DeCGG).
Sitanggang IS, Yaakob R, Mustapha N, Ainuddin AN. 2012. Application of classification algorithms in data mining for hotspots occurrence prediction in Riau Province Indonesia dalam: JATIT 43(2): 214-221. ISSN: 1992-8645. Sitanggang IS. 2013. Penggunaan teknik data mining dalam pemodelan resiko
terjadinya kebakaran hutan. Peran Teknologi Informasi dalam Menghadapi Pasar Global China-ASEAN 2015. Bogor, Indonesia. Bogor (ID): HIPI, pp. 55–62. ISBN: 978-602-95366-1-4.
Suwanto A, Maas A, Sutaryo D, Wijaya DY, Sartono D, Achsani H, Komarsa, Hastuti S, Soli TI. Profil Ekosistem Gambut di Indonesia. Jakarta (ID).
25 Lampiran 1 Cara kerja KNN
Record data training Pulau Kalimantan.
26 Lanjutan
Hitungan jarak kedekatan dengan menggunakan euclidean distance: 1. Jarak data testing ke D1
euclidean=√(1-1)2+(0-0)2+..+(0-0)2=√2=1.41 2. Jarak data testing ke D2
euclidean=√(1-1)2+(0-0)2+..+(0-0)2=√2=1.41 3. Jarak data testing ke D3
euclidean=√(1-1)2+(0-0)2+..+(0-0)2=√2=1.41 4. Jarak data testing ke D4
euclidean=√(0-1)2+(1-0)2+..+(0-0)2=√4=2 5. Jarak data testing ke D5
euclidean=√(0-1)2+(1-0)2+..+(0-0)2=√4=2 6. Jarak data testing ke D6
euclidean=√(0-1)2+(0-0)2+..+(0-0)2=√2=1.41 7. Jarak data testing ke D7
euclidean=√(0-1)2+(0-0)2+..+(0-0)2=√4=2 8. Jarak data testing ke D8
euclidean=√(0-1)2+(1-0)2+..+(0-0)2=√4=2 9. Jarak data testing ke D9
euclidean=√(0-1)2+(0-0)2+..+(0-0)2=√4=2 10.Jarak data testing ke D10
27
28 Lanjutan Ilustrasi KNN
Kelas untuk nilai k = 1 sampai k = 9
K 1 3 5 7 9
Kelas T T T T T
29 Lampiran 3 Akurasi hasil klasifikasi pada dataset Pulau Sumatera tahun 2007
30
Lampiran 5 Akurasi hasil klasifikasi pada dataset Pulau Sumatera tahun 2010
31 Lampiran 7 Akurasi hasil klasifikasi pada dataset Pulau Kalimantan tahun 2003
32
Lampiran 9 Akurasi hasil klasifikasi pada dataset Pulau Kalimantan tahun 2007
33 Lampiran 11 Akurasi hasil klasifikasi pada dataset Pulau Kalimantan tahun 2010
34
Lampiran 13 Akurasi hasil klasifikasi pada dataset Pulau Kalimantan tahun 2012
35