ABSTRAK
BAYU ALFIANSYAH. Diskretisasi Peubah Credit Scoring Model Menggunakan Metode Entropi dan Khi Kuadrat. Di bawah bimbingan BAGUS SARTONO dan AJI HAMIM WIGENA.
Credit scoring model telah banyak digunakan oleh berbagai organisasi finansial berdasarkan pada informasi data historis yang dimiliki perusahaan tersebut. Masalah yang sering muncul ialah model yang biasa digunakan hanya bisa menerima data dengan skala diskret. Selain itu pada data-data yang sangat besar (data-database perusahaan) terkadang sangat rentan terhadap pencilan, dan tidak konsisten. Salah satu cara untuk mengatasi hal ini adalah melakukan data pre-processing dengan melakukan diskretisasi atau biasa disebut binning. Dari sekian banyak metode diskretisasi, peneliti membandingkan metode entropi dan khi kuadrat terhadap data kredit konsumtif sebuah bank. Secara umum, untuk data kredit konsumtif pada penelitian ini, kategori yang didapatkan dari metode entropi lebih banyak daripada metode khi kuadrat.
DISKRETISASI PEUBAH
CREDIT SCORING MODEL
MENGGUNAKAN
METODE ENTROPI DAN KHI KUADRAT
BAYU ALFIANSYAH
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
DISKRETISASI PEUBAH
CREDIT SCORING MODEL
MENGGUNAKAN
METODE ENTROPI DAN KHI KUADRAT
BAYU ALFIANSYAH
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRAK
BAYU ALFIANSYAH. Diskretisasi Peubah Credit Scoring Model Menggunakan Metode Entropi dan Khi Kuadrat. Di bawah bimbingan BAGUS SARTONO dan AJI HAMIM WIGENA.
Credit scoring model telah banyak digunakan oleh berbagai organisasi finansial berdasarkan pada informasi data historis yang dimiliki perusahaan tersebut. Masalah yang sering muncul ialah model yang biasa digunakan hanya bisa menerima data dengan skala diskret. Selain itu pada data-data yang sangat besar (data-database perusahaan) terkadang sangat rentan terhadap pencilan, dan tidak konsisten. Salah satu cara untuk mengatasi hal ini adalah melakukan data pre-processing dengan melakukan diskretisasi atau biasa disebut binning. Dari sekian banyak metode diskretisasi, peneliti membandingkan metode entropi dan khi kuadrat terhadap data kredit konsumtif sebuah bank. Secara umum, untuk data kredit konsumtif pada penelitian ini, kategori yang didapatkan dari metode entropi lebih banyak daripada metode khi kuadrat.
DISKRETISASI PEUBAH
CREDIT SCORING MODEL
MENGGUNAKAN METODE ENTROPI DAN KHI KUADRAT
BAYU ALFIANSYAH
G14103012
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Sains pada
Departemen Statistika
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Judul : Diskretisasi Peubah
Credit Scoring Model
Menggunakan Metode
Entropi dan Khi Kuadrat
Nama
: Bayu Alfiansyah
NRP :
G14103012
Menyetujui :
Pembimbing I,
Bagus Sartono, M.Si
NIP. 132 311 923
Pembimbing II,
Dr. Ir. Aji Hamim Wigena, M.Sc
NIP. 130 605 236
Mengetahui :
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Dr. Drh. Hasim, DEA
NIP. 131 578 806
PRAKATA
Alhamdulillahirabbil’alamin, segala puji dan syukur penulis haturkan kehadirat Allah SWT atas segala karunia-Nya sehingga penulis dapat menyelesaikan karya ilmiah ini. Shalawat serta salam semoga selalu tercurahkan kepada Rasulullah SAW, keluarga, sahabat, dan umatnya hingga akhir zaman.
Karya ilmiah ini berjudul “Diskretisasi Peubah Credit Scoring Model Menggunakan Metode Entropi dan Khi Kuadrat “. Penelitian ini membahas dan membandingkan hasil dari dua metode transformasi data kuantitatif menjadi kualitatif (proses diskretisasi) terhadap peubah pembentuk credit scoring model.
Terima kasih penulis ucapkan kepada semua pihak yang telah membantu dalam penyelesaian karya ilmiah ini, terutama kepada :
• Bapak Bagus Sartono, M.Si dan bapak Dr. Ir. Aji Hamim Wigena, M.Sc, atas semua kesabaran beliau dalam membimbing. Mohon dimaaafkan jika selama ini banyak mengecewakan Pak Bagus dan Pak Aji.
• Seluruh dosen pengajar Departemen Statistika IPB atas ilmu bermanfaat yang telah diberikan selama penulis mengikuti perkuliahan di Departemen Statistika IPB.
• Ibu dan Ayah yang selalu memberikan dorongan semangat, dukungan, perhatian kepada penulis. Mas Agung semoga lancar hidup dirantau dan adikku Rahayu semoga lancar sekolahya. Nenek, atas segala perhatian dan do’anya.
• Nur Malahayati, terima kasih atas kehadiranmu yang selalu mencerahkan hari-hariku. • Arief my roommate, Yudi, Rio, Ipunk, Edo my nakama, Daus, Anggoro i won’t forget
both of you, Wahyu, Dani A, Dani S, Deni, Rosit, W’ndo thanks for the joy. Rina, Esi, Lintang, Arta, Mey And All of my friends in 40’s thanks for all the moments in the past four years. Gommenasai untuk semua kesalahan yang tak disengaja.
• Seluruh anggota keluarga besar Statistika IPB atas semua kebersamaan yang diberikan semasa kuliah. I’m glad to be a part of the great family of statistics at IPB.
• Bu Dedeh, Bu Mar, Bu Sulis, Mang Soed, Bu Aat, Mang Dur, Mang Herman, Pak Heri, dan Pak Yan yang telah memberikan banyak sekali bantuan selama masa perkuliahan. • Semua pihak yang telah memberikan dukungan kepada penulis yang tidak dapat disebut
satu persatu sehingga karya ilmiah ini dapat diselesaikan.
Penulis menyadari bahwa penulisan karya ilmiah ini masih jauh dari sempurna. Oleh karena itu kritik dan saran yang membangun sangat penulis harapkan sebagai pemicu untuk dapat berkarya lebih baik lagi. Semoga karya ilmiah ini bermanfaat bagi pihak yang membutuhkan.
Bogor, Januari 2008
RIWAYAT HIDUP
Penulis dilahirkan di Jakarta pada tanggal 26 Juli 1985 dari pasangan Kurmanto dan Sudarti sebagai anak ketiga dari 4 bersaudara. Penulis menempuh pendidikan dasar di SD Negeri Baru 01 Pagi Jakarta hingga tahun 1997. Kemudian melanjutkan pendidikan menengah pertama di SLTP Negeri 103 Jakarta hingga tahun 2000. Pada tahun 2003 penulis menyelesaikan pendidikan menengah atas di SMU Negeri 39 Jakarta dan pada tahun yang sama diterima di Departemen Statistika Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor melalui jalur Undangan Seleksi Masuk IPB (USMI).
DAFTAR ISI
Halaman
DAFTAR ISI... iv
DAFTAR TABEL ... v
DAFTAR LAMPIRAN ... v
PENDAHULUAN Latar Belakang ... 1
Tujuan ... 1
TINJAUAN PUSTAKA Credit Scoring Model... 2
Diskretisasi (Binning) ... 2
Supervised Methods versus Unsupervised Methods... 2
Metode Diskretisasi Entropi ... 2
Metode Diskretisasi Khi Kuadrat ... 3
Weight of Evidence (WoE) ... 3
Information Value (InV) ... 4
Indeks Asosiasi Symmetric Uncertainty Coefficient... 4
BAHAN DAN METODE Bahan ... 4
Metode ... 5
HASIL DAN PEMBAHASAN Deskripsi WoE Peubah Numerik ... 5
Deskripsi WoE Peubah Kategorik ... 6
Indeks Asosiasi dan Information value ... 7
SIMPULAN DAN SARAN Simpulan ... 8
Saran ... 8
DAFTAR PUSTAKA ... 8
DAFTAR TABEL
Halaman
1. Diskretisasi entropi peubah rasio antara cicilan dan pendapatan ... 5
2. Diskretisasi khi kuadrat peubah rasio antara cicilan dan pendapatan... 5
3. Diskretisasi entropi peubah pendapatan per tahun ... 5
4. Diskretisasi khi kuadrat peubah pendapatan per tahun ... 5
5. Diskretisasi entropi peubah banyaknya tanggungan ... 6
6. Diskretisasi khi kuadrat peubah banyaknya tanggungan... 6
7. Diskretisasi entropi peubah status kepemilikan rumah ... 6
8. Diskretisasi khi kuadrat peubah status kepemilikan rumah ... 6
9. Diskretisasi entropi peubah kode pekerjaan... 7
10. Diskretisasi khi kuadrat peubah kode pekerjaan ... 7
11. Urutan peubah terpilih beserta metode diskretisasinya berdasarkan nilai InV... 7
12. Urutan peubah terpilih beserta metode diskretisasinya berdasarkan nilai UC... 7
DAFTAR LAMPIRAN
1. Perhitungan WoE tiap kategori pada masing-masing peubah kategorik sebelum diskretisasi atau kategorisasi ulang ... 9
PENDAHULUAN
Latar Belakang
Credit scoring model telah banyak digunakan oleh berbagai organisasi keuangan seperti bank dan penyedia jasa kredit sebagai alat yang efisien dan menguntungkan.
Credit scoring model adalah suatu metode untuk mengevaluasi kelayakan kredit seseorang berdasarkan rumus tertentu atau suatu aturan tertentu. Hasil dari credit scoring model
berupa model matematik yang mampu mengklasifikasi atau menduga kualitas kredit seseorang ke dalam suatu gugus keputusan. Model ini dibangun berdasarkan informasi data historis berupa karakteristik-karakteristik kreditur yang dimiliki oleh organisasi keuangan (debitur) yang memberikan kreditnya. Data yang dibutuhkan untuk membangun model umumnya harus cukup besar. Dengan semakin besarnya data yang ditelaah maka data tersebut akan semakin rentan terhadap munculnya data hilang, pencilan, dan ketidakkonsistenan (Kantardzic 2003). Oleh karena itu perlu dilakukan suatu proses awalan terhadap data (data preprocessing) untuk mempersiapkan data sebelum dilakukan analisis lebih lanjut.
Salah satu cara dalam data preprocessing
adalah melakukan diskretisasi data atau biasa disebut binning. Diskretisasi data juga memegang peranan penting dalam membangun
credit scoring model. Metode diskretisasi mampu memilah-milah suatu selang data kontinu atau numerik ke dalam sub-sub selang berdasarkan algoritma tertentu. Metode ini juga bermanfaat untuk mengkategori ulang kategori-kategori pada peubah diskret atau kategorik. Metode ini sangat bermanfaat karena beberapa algoritma klasifikasi yang biasa digunakan dalam membangun credit scoring model hanya menerima data berskala diskret.
Penelitian ini bertujuan membandingkan metode diskretisasi entropi (entropy based discretization) dengan diskretisasi khi kuadrat (chi squared discretization) dari berbagai metode diskretisasi yang sudah ada. Kedua metode ini diterapkan pada data kredit konsumtif sebuah bank.
Tujuan
Tujuan yang ingin dicapai dalam penelitian ini antara lain :
1. Membandingkan hasil kategori yang didapatkan dari metode diskretisasi entropi (entropy based discretization) dengan
diskretisasi khi kuadrat (chi squared discretization).
2. Melihat keeratan hubungan antara peubah yang telah didiskretkan dengan peubah target.
TINJAUAN PUSTAKA
Pada umumnya sistem penilaian kredit menggunakan kartu skor (scorecard) sebagai model atau aturan pengklasifikasi kreditur atau penduga bagi kualitas kreditnya. Kartu skor bisa dituliskan sebagai model matematik sebagai berikut :
∑
∑
= = = = q i i i p j jj C H S X c
H skor 1 (.) 1 ) ( ) (
C
j = Karakteristik (peubah X ke-j)kartu skor.
X
i(c)
= Kategori ke-i dari peubah X.S
i = Skor atau nilai pembobot kategorike-i.
Nilai skor ditentukan oleh kumulatif dari setiap peubah atau karekteristik kreditur. Kreditur yang terpetakan ke dalam kategori dari peubah ke-j mendapat nilai pembobot yang sesuai dengan kategori yang ia dapatkan. Artinya kreditur hanya mendapat satu nilai pembobot kategori untuk setiap peubahnya. Berdasarkan hal tersebut, metode diskretisasi memegang peranan penting dalam membangun sebuah credit scoring model karena peubah atau karakteristik yang diamati bisa berupa peubah numerik. Diskretisasi entropi dan khi kuadrat dipilih karena metode tersebut menggunakan proporsi kejadian sukses dan gagal untuk kejadian biner. Kedua metode tersebut cocok digunakan karena pada umumnya masalah credit scoring model adalah bagaimana mendeteksi perbedaan dari dua distribusi dari dua kejadian kualitas kredit (good dan bad atau terima dan tolak kredit sebagai peubah target atau respon dari model) sehingga debitur bisa mendapatkan gambaran yang jelas mengenai karakteristik krediturnya.
Nilai pembobot kategori tiap peubah biasanya memiliki pola yang mirip dengan
digunakan untuk mengevaluasi tingkat prediksi dan asosiasi antara peubah hasil metode diskretisasi entropi dan khi kuadrat dengan peubah target.
Credit Scoring Model
Credit scoring model adalah suatu metode untuk mengevaluasi kelayakan kredit seseorang berdasarkan rumus tertentu atau suatu aturan tertentu (Hollowel 2004). Model ini dibangun berdasarkan informasi data historis di masa lalu. Informasi mengenai data diri, pengalaman kredit seperti riwayat pembayaran tagihan seseorang, telat membayar, cicilan-cicilan, dan umur rekening (account), dikumpulkan dari aplikasi kredit dan laporan kredit.
Diskretisasi (Binning)
Proses diskretisasi merupakan proses transformasi data kuantitatif ke dalam data kualitatif. Teknik ini digunakan untuk mereduksi jumlah nilai suatu peubah yang berskala numerik atau kontinu dengan cara memilah-milah selang nilai data peubah ke dalam sub-sub selang nilai.
Secara umum, proses diskretisasi terdiri dari 4 tahapan, yaitu:
1. Mengurutkan nilai kontinu yang akan didiskretisasi.
2. Mengevaluasi titik potong sebagai pemisah selang atau penggabung selang yang berdekatan.
3. Berdasarkan kriteria tertentu, dilakukan pemisahan atau penyatuan selang nilai.
4. Menghentikan proses pada titik tertentu.
Binning memetakan nilai-nilai sebuah peubah ke dalam satu gugus bin. Sebuah bin
bisa terdiri dari satu nilai saja, suatu gugus nilai yang terbatas, selang kontinu, data hilang, atau bahkan nilai yang tidak ada sebelumnya (Hollowel 2004). Label selang nantinya digunakan untuk menggantikan nilai data aktual.
Supervised Methods versus Unsupervised Methods
Metode diskretisasi dikelompokkan ke dalam dua grup yaitu metode diskretisasi tersupervisi (supervised discretization methods) dan tidak tersupervisi (unsupervised discretization methods). Metode diskretisasi tersupervisi adalah metode diskretisasi yang membagi selang nilai ke dalam sub-sub selang berdasarkan kriteria tertentu berupa suatu
gugus kelas atau peubah kategorik yang berpadanan dengan peubah yang akan didiskretisasi. Algoritma dari metode ini hanya bisa dijalankan jika terdapat sebuah peubah kategorik sebagai peubah target yang berisikan pengkelasan dari objek atau pengamatan (Jiawei dan Micheline 2001). Metode ini menggunakan informasi kelas tersebut ketika memilih titik-titik potong sebagai alat pemisah antar bin. Contoh metode diskretisasi tersupervisi antara lain : 1RD, ChiMerge, entropy based discretization, Zeta, ID3.
Metode diskretisasi tidak tersupervisi atau
unsupervised methods tidak menggunakan informasi kelas. Metode ini tidak membutuhkan sebuah peubah kategorik sebagai peubah target yang dijadikan sebagai dasar diskretisasinya. Metode ini membagi selang nilai kontinu ke dalam beberapa sub selang berdasarkan pertimbangan pengguna. Pertimbangan yang diambil bersifat subyektif dimana pengguna menentukan mekanisme diskretisasinya. Contoh metode tidak tersupervisi antara lain : equal width interval
dan equal freq interval. Keduametode tersebut bersifat subyektif karena jumlah kategori atau
bin yang diinginkan ditentukan oleh pengguna dengan pertimbangan-pertimbangan tertentu. Metode ini mungkin memberikan hasil yang kurang baik pada kasus dimana distribusi nilai kontinu tidak seragam karena metode diskretisasi tidak tersupervisi sangat rentan terhadap data pencilan (Liu et.al 1990).
Metode Diskretisasi Entropi
Metode diskretisasi entropi(Entropy based discretization) merupakan salah satu metode diskretisasi tersupervisi. Metode ini menggunakan entropi sebagai bagian dari proses pemisahan selang data kontinu. Entropi merupakan ukuran keseragaman bagi selang data tertentu yang dibagi. Entropi mengukur variasi selang data awal yang berpadanan dengan peubah kategorik target dengan cara menghitung besaran proporsi munculnya suatu kelas dari peubah target. Besaran nilai entropi berkisar antara 0 sampai 1. Nilai entropi nol mengindikasikan bahwa selang data tersebut memiliki kelas yang sama untuk setiap pengamatannya. Semakin tinggi nilai entropi (mendekati 1) maka selang data tersebut cenderung memiliki proporsi kelas yang semakin seimbang atau sama banyak.
pemilahan selang oleh sebuah nilai T dilakukan secara rekursif terhadap sub selang yang baru hingga kondisi tertentu terpenuhi (Jiawei dan Micheline 2001).
Algoritma metode diskretisasi entropi adalah sebagai berikut :
1. Setiap nilai tengah antara dua nilai data dalam atribut dipertimbangkan sebagai batas selang potensial atau T. Yang nantinya nilai T akan membagi selang S menjadi dua yaitu S1 dan S2.
2. Nilai batas selang (T) dipilih yang memiliki nilai informasi kelas entropi saat T memotong S minimum berdasarkan rumus :
),
(
|
|
|
|
)
(
|
|
|
|
)
,
(
2 2 1 1S
Ent
S
S
S
Ent
S
S
T
S
E
=
+
|S1| = banyaknya observasi dalam S1
|S2| = banyaknya observasi dalam S2
|S| = banyaknya observasi sebelum dipisah.
Semua nilai T yang mungkin dievaluasi hingga didapatkan satu nilai T yang meminimumkan rumus di atas.
Entropi Si didefinisikan sebagai berikut :
∑
=−
=
m i ij iji
p
p
S
Ent
1
2
(
),
log
)
(
ij
p
= peluang suatu individu masuk ke dalam kelas ke-j pada selang Si. Nilai batas T juga bisa dipilih berdasarkan nilai perolehan informasi pemisah (information gain of the split) maksimum atau yang terbesar dengan rumus sebagai berikut:)
,
(
)
(
)
,
(
S
T
Ent
S
E
S
T
Gain
=
−
3. Proses penentuan nilai batas selang dilakukan secara rekursif terhadap sub selang yang baru hingga kondisi tertentu terpenuhi.
Metode Diskretisasi Khi Kuadrat
Khi kuadrat (chi squared) merupakan salah satu algoritma diskretisasi yang menganalisa kualitas beberapa selang berdasarkan nilai statistik χ2. Uji khi kuadrat atau tabel kontingensi biasa digunakan untuk menguji kebebasan antara dua selang atau kategori. Dari karakteristik tersebut, statistik uji ini digunakan dalam metode diskretisasi untuk memilah selang nilai numerik sehingga untuk mendapatkan hasil diskret dari metode ini, selang data S dipilah oleh satu titik potong T terlebih dahulu menjadi dua sub selang
sebelum dievaluasi dengan statistik uji khi kuadrat. Jika selang yang terbentuk dinyatakan saling bebas berdasarkan uji khi kuadrat, maka nilai T tidak dijadikan titik potong sehingga S1
dan S2 sehingga tetap dijadikan satu selang.
Proses evaluasi selang dilakukan secara rekursif ke setiap sub selang yang baru terbentuk (Kantardzic 2003).
Proses pemilihan nilai T dari sekian banyak kandidat T dalam S, yang akan memilah selang S didasarkan statistik uji khi kuadrat yang memiliki nilai χ2 terbesar atau nilai uji paling nyata dari semua selang yang dievaluasi. Rumus χ2 dihitung berdasarkan rumus berikut :
∑∑
= =−
=
2 1 1 22
(
)
i k j ij ij ij
E
E
A
χ
k = Jumlah kelas
Aij = Jumlah data aktual selang ke-i, kelas ke-j
Eij = Frekuensi harapan Aij = (Ri.Cj)/N
Ri = Jumlah data aktual selang ke-i Cj = Jumlah data aktual kelas ke-j N = Total data aktual
Weight of Evidence (WoE)
Weight of Evidence (WoE) merupakan perbandingan proporsi kategori tertentu suatu peubah untuk kelompok status kolektibilitas. Status kolektibilitas adalah sebuah atribut atau peubah yang menunjukkan status kelas kredit seseorang atau nasabah. Peubah status kolektibilitas merupakan peubah target dalam membangun credit scoring model. Data status tersebut biasanya berbentuk biner yaitu good
dan bad atau respon dan no respon. Status
good bisa didefinisikan sebagai nasabah yang tidak pernah lalai membayar sedangkan bad
bisa didefinisikan sebagai nasabah yang lalai atau pailit (Hollowel 2004).
WoE merupakan selisih atau besarnya perbedaan antara log odds tiap bin (kategori) dengan log odds total. Dalam proses membangun credit scoring model, WoE
berfungsi menunjukkan tingkat resiko seseorang.
WoE tiap bin didefinisikan sebagai berikut:
dimana
( )
100
⎟⎟
.
⎠
⎞
⎜⎜
⎝
⎛
=
G Gi Gn
n
i
f
=( )
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
=
B Bi Bn
n
i
f
100
=Information Value (InV)
Information value menghitung jarak antara dua distribusi, yang dalam hal ini distribusi antara good dan bad dalam satu peubah (Hollowel 2004). Dengan kata lain suatu besaran yang menyatakan seberapa jauh kolektibilitas good dengan bad dalam satu peubah.
InV juga sering digunakan dalam proses membangun credit scoring model sebagai indikator yang menunjukkan tingkat prediksi peubah input terhadap peubah target berupa status kolektibilitas kreditur. Tingkat prediksi
InV dibagi ke dalam beberapa kategori yaitu kurang dari 0.02 peubah dikatakan tidak prediktif, 0.02 hingga 0.1 tingkat prediksinya lemah, 0.1 hingga 0.3 memiliki tingkat prediksi pertengahan (medium), dan lebih dari 0.3 memiliki tingkat prediksi yang kuat (Hababou
et.al 2006). InV biasa digunakan untuk memilih peubah dari suatu gugus peubah yang berpotensi untuk dimasukkan ke dalam model, dimana peubah dengan InV yangg besar berpeluang tinggi untuk masuk ke dalam credit scoring model.
InV dari peubah kategorik dipengaruhi oleh WoE tiap kategori dalam peubah. InV
didefinisikan sebagai berikut :
∑
= ⎥⎦ ⎤ ⎢ ⎣ ⎡ − = q i B G B G i f i f i f i f InV1 ()
) ( log 100 ) ( ) ( , atau
∑
= − = q i B G i WoE i f i f InV 1 ) ( 100 ) ( ) ()
(
i
WoE
= WoE tiap bin ke-i dari peubah inputIndeks Asosiasi Symmetric Uncertainty Coefficient
Indeks asosiasi merupakan indeks yang mengukur keeratan hubungan antara dua buah peubah kategorik. Indeks asosiasi symmetric uncertainty coefficient merupakan salah satu dari sekian banyak metode pengukuran asosiasi. Indeks uncertainty coefficient
mengukur asosiasi antara dua buah peubah
dengan skala pengukuran nominal sehingga sesuai untuk mengukur tingkat asosiasi antara peubah hasil diskretisasi dengan peubah target kolektibilitas. Indeks ini dihitung hanya berdasarkan banyaknya nilai pasangan yang konkordan dan diskordan dari pengamatan. Nilai uncertainty coefficient berkisar antara 0 sampai 1. Jika dua peubah saling bebas, maka nilai uncertainty coefficient (UC) akan mendekati nilai nol. Nilai indeks uncertainty coefficient (UC) dihitung berdasarkan rumus berikut :
P e r s e n t a s e i n d i v i d u
good dalam bin ke-i
Persentase individu bad
dalam bin ke-i
)
(
)
(
)]
(
)
(
)
(
[
2
Y
H
X
H
XY
H
Y
H
X
H
UC
+
−
+
=
X = Peubah baris Y = Peubah kolom N = Jumlah pengamatan
H(X) =
∑
⎟
⎠
⎞
⎜
⎝
⎛
⎟
⎠
⎞
⎜
⎝
⎛
−
i i in
n
n
n
. .ln
H(Y) =
∑
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
−
j j jn
n
n
n
. .ln
H(XY)=
∑∑
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
−
i j ij ijn
n
n
n
ln
. in
= Total baris ke-ij
n
. = Total kolom ke-jij
n
= Pengamatan pada baris ke-i dan kolom ke-j.(SAS Institute Inc. 2003).
BAHAN DAN METODE
Bahan
Bahan penelitian yang digunakan merupakan data sekunder sebuah bank terdiri atas 1000 observasi.
Peubah input yang digunakan yaitu : 1. DSR (Debt Salary Ratio atau rasio antara
cicilan dan pendapatan)
2. Gross annual income (pendapatan per tahun dalam rupiah)
3. Number of dependants (banyaknya tanggungan)
4. Residence status (status kepemilikan rumah)
5. Job code (kode pekerjaan)
Sedangkan peubah targetnya adalah status kolektibilitas nasabah berupa status good dan
Metode
Langkah–langkah metode penelitian : a.Diskretisasi data numerik
1.Melakukan transformasi atau binning
dengan kriteria penghentian algoritma yang digunakan adalah minimum observasi dalam bin sebanyak 25.
2.Dari hasil transformasi tadi dilakukan perhitungan WoE dan InV.
b.Diskretisasi data kategorik 1.Menghitung WoE data diskret.
2.Mentransformasi data dengan nilai WoE. 3.Menghitung kembali nilai WoE dan InV.
c.Membandingkan hasil binning atau diskretisasi berdasarkan indeks asosiasi dan
InV.
Nilai α yang digunakan pada metode khi kuadrat adalah 0.2. Data penelitian ini diolah menggunakan software Microsoft Excel, SAS Enterprise Miner 3.4, dan Minitab 14.
HASIL DAN PEMBAHASAN
Deskripsi WoE Peubah Numerik
Data numerik didiskretisasi menggunakan metode entropi dan khi kuadrat. Proses diskretisasi menggunakan kedua metode tersebut menghasilkan struktur yang membagi selang nilai data numerik ke dalam sub-sub selang berdasarkan algoritmanya masing-masing. Dengan menggunakan kriteria penghentian algoritma diskretisasi berupa minimum observasi dalam bin sebanyak 25 didapatkan bentuk optimal untuk kedua peubah numerik.
Berdasarkan hasil diskretisasi, peubah rasio antara cicilan dan pendapatan hasil metode entropi menghasilkan 7 titik potong sehingga peubah rasio antara cicilan dan pendapatan terbagi ke dalam 8 bin. Sedangkan hasil metode khi kuadrat untuk peubah yang sama, dihasilkan 6 titik potong atau didapatkan 7 bin. Diskretisasi metode entropi pada peubah pendapatan per tahun didapatkan 6 titik potong atau 7 bin sedangkan hasil dari metode khi kuadrat untuk peubah ini didapatkan 5 titik potong atau 6 bin.
Hasil diskretisasi dan nilai WoE peubah rasio antara cicilan dan pendapatan dan pendapatan per tahun yang didapatkan dari metode entropidan khi kuadrat disajikan pada Tabel 1 sampai 4.
Tabel 1 Diskretisasi entropi peubah rasio antara cicilan dan pendapatan.
Bin WoE
(inf, 16.269) -0.174 [16.269, 17.003) 0.894 [17.003, 17.997) -1.040 [17.997, 19.697) -0.050 [19.697, 20.41) 1.924 [20.41, 38.006) 0.320 [38.006, 38.911) -0.864
[38.911, inf) -0.036
Tabel 2 Diskretisasi khi kuadrat peubah rasio antara cicilan dan pendapatan.
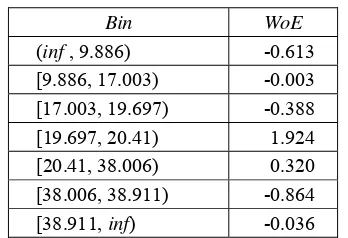
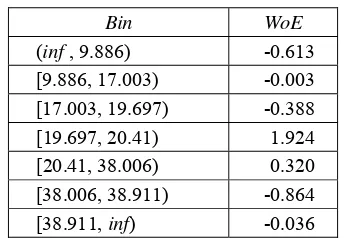
Bin WoE
(inf , 9.886) -0.613 [9.886, 17.003) -0.003 [17.003, 19.697) -0.388 [19.697, 20.41) 1.924 [20.41, 38.006) 0.320 [38.006, 38.911) -0.864
[38.911, inf) -0.036
Tabel 3 Diskretisasi entropi peubah pendapatan per tahun.
Bin WoE
(inf , 53.4 juta) -0.068 [53.4 juta , 57.6 juta) -1.101 [57.6 juta , 63.0 juta) 1.043 [63.0 juta , 72.4 juta) -0.150 [72.4 juta , 99.0 juta) 2.032 [99.0 juta , 139.7 juta) 0.027
[139.7 juta , inf) 6.440
Tabel 4 Diskretisasi khi kuadrat peubah pendapatan per tahun.
Bin WoE
(inf, 37.3 juta) -0.141 [37.3 juta, 51.0 juta) 0.380 [51.0 juta, 60.0 juta) -0.676 [60.0 juta , 99.0 juta) 0.921 [99.0 juta , 139.7 juta) 0.027
[139.7 juta , inf) 6.440
positif menunjukkan resiko yang rendah atau cenderung menjadi good pada kategori yang dimaksud.
Pada Tabel 1, kategori peubah rasio antara cicilan dan pendapatan yang memiliki resiko paling tinggi didapatkan oleh bin ketiga. Artinya pengamatan atau kreditur yang rasio antara cicilan dan pendapatannya antar [17.003, 17.997) memiliki peluang paling tinggi untuk mendapatkan status bad dibandingkan kategori lainnya. Hasil diskretisasi yang didapatkan oleh kedua metode, entropi dan khi kuadrat, bisa berbeda hasilnya baik dari titik potong yang didapat maupun jumlah kategori yang terbentuk. Hal ini mengakibatkan nilai WoE
yang didapatkan pada tiap peubah bisa berbeda beda.
Secara intuitif pada peubah rasio antara cicilan dan pendapatan, semakin tinggi rasio cicilan dengan pendapatan, maka diharapkan semakin tinggi peluang pengamatan yang masuk dalam kategori itu untuk mendapat predikat bad. Namun hasil yang ditunjukkan oleh kedua metode diskretisasi terhadap peubah rasio antara cicilan dan pendapatan memperlihatkan bahwa semakin tinggi rasio cicilan dan pendapatan, maka semakin rendah resikonya hingga pada titik tertentu, resikonya akan kembali naik.
Dari Tabel 3, yang merupakan hasil diskretisasi entropi peubah pendapatan per tahun, bin 2 atau selang [53.4 juta, 57.6 juta) memiliki resiko yang tinggi dibandingkan bin
yang lain. Namun dapat dikatakan bahwa pendapatan yang rendah memiliki resiko tinggi untuk menjadi bad dibandingkan pendapatan yang tinggi karena bin pertama hasil diskretisasi entropi juga menunjukkan kecenderungan untuk menjadi bad. Hasil diskretisasi entropi dan khi kuadrat peubah pendapatan per tahunmemiliki pola yang mirip dimana semakin tinggi selang pendapatan maka cenderung akan beresiko kecil atau cenderung untuk menjadi good.
Deskripsi WoE Peubah Kategorik
Proses diskretisasi atau kategorisasi data peubah kategorik (banyaknya tanggungan, status kepemilikan rumah, dan kode pekerjaan) dilakukan setelah data digantikan dengan nilai
WoE untuk tiap kategorinya. Hasil dari tahap ini mengubah skala peubah tersebut dari nominal menjadi o r d i n a l s e h i n g g a me mu n g k i n k a n diterapkannya metode diskretisasi pada peubah tersebut. Nilai WoE
yang didapatkan tiap kategori peubah sebelum dilakukan diskretisasi terdapat pada Lampiran 1.
Hasil kategorisasi dan nilai WoE peubah banyaknya tanggungan, status kepemilikan rumah, dan kode pekerjaan yang didapatkan, disajikan pada Tabel 5 sampai 10 di bawah ini beserta pembahasannya.
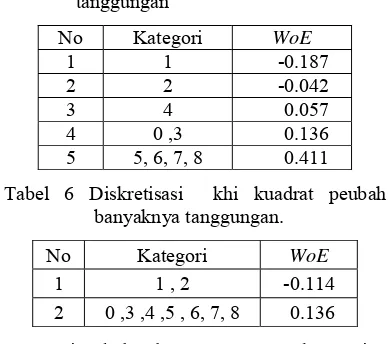
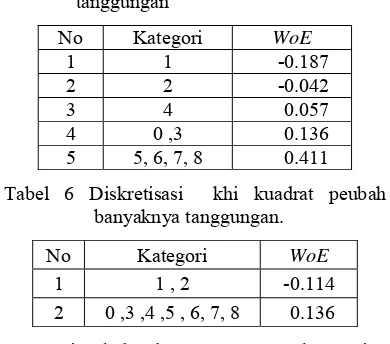
Tabel 5 Diskretisasi entropi peubah banyaknya tanggungan
No Kategori WoE
1 1 -0.187 2 2 -0.042
3 4 0.057
4 0 ,3 0.136
5 5, 6, 7, 8 0.411
Tabel 6 Diskretisasi khi kuadrat peubah banyaknya tanggungan.
No Kategori WoE
1 1 , 2 -0.114
2 0 ,3 ,4 ,5 , 6, 7, 8 0.136
Dari Tabel 5 dan 6, proses pengkategorian kedua metode diskretisasi di atas memperlihatkan hasil dari metode entropi dan khi kuadrat memiliki pola yang sama meski jumlah kategori yang didapatkan berbeda, dimana tanggungan sebanyak 1 dan 2 memiliki resiko lebih tinggi dibandingkan kategori yang lain. Dan tanggungan sebanyak lebih dari 2 atau tidak punya tanggungan sama sekali, memiliki resiko rendah untuk menjadi bad. Atau dengan kata lain, semakin banyak jumlah tanggungan atau tidak punya sama sekali maka resiko seseorang cenderung semakin kecil.
Tabel 7 Diskretisasi entropi peubah status kepemilikan rumah.
No Kategori WoE
1 Rented -0.358
2 Parents -0.138
3 Own 0.145
4 Others 0.266
5 Institution 0.448
6 Credit 0.509
Tabel 8 Diskretisasi khi kuadrat peubah status kepemilikan rumah.
No Kategori WoE
1 Rented, Parents -0.153
2 Own, Others,
Institution, Credit. 0.172
dari sebelum diterapkannya metode entropi. Tidak ada proses penggabungan ulang antar kategori untuk peubah tersebut. Sedangkan metode khi kuadrat menghasilkan dua kategori. Hasil dari proses kategorisasi oleh kedua metode cenderung sama. Perbedaannya hanya jumlah kategori yang terbentuk. Hasil keduanya menunjukkan bahwa kreditur yang memiliki rumah dengan status kepemilikan pribadi, memiliki resiko yang kecil untuk menjadi bad dibandingkan jika rumah tersebut bukan miliknya.
Tabel 9 Diskretisasi entropi peubah kode pekerjaan.
No Kategori WoE
1 Notaris, Peg. Yayasan -1.339 2 Pegawai Swasta -0.114
3 Guru/ Dosen, Peg. BUMN/
Peg. BUMD 0.460
4 Pegawai Negeri Sipil (PNS) 0.938
5
Akuntan, Paramedis, Dokter, Profesional, Employee, Pejabat Negara, Wiraswasta
2.097
Tabel 10 Diskretisasi khi kuadrat peubah kode pekerjaan.
No Kategori WoE
1 Notaris, Peg. Yayasan -1.339
2 Pegawai Swasta -0.114
3 Guru/ Dosen, Peg. BUMN/
Peg. BUMD, PNS 0.526
4
Akuntan, Paramedis, Dokter, Profesional, Employee, Pejabat Negara, Wiraswasta
2.097
Dari Tabel 9 dan 10, peubah kode pekerjaan setelah dikategorisasi dengan menggunakan metode entropi dan khi kuadrat menghasilkan jumlah kategori yang tidak jauh berbeda. Dengan menggunakan metode entropi, didapatkan 5 kategori sedangkan metode khi kuadrat menghasilkan 4 kategori.
Perbedaan hasil kategorisasi kedua metode tersebut ialah berdasarkan metode entropi, kategori Guru/ Dosen, pegawai BUMN/ pegawai BUMD dan PNS dipisahkan. Guru/ dosen dan pegawai BUMN/ pegawai BUMD digabung menjadi satu kategori sedangkan PNS terpisah menjadi kategori tersendiri. Sedangkan metode khi kuadrat menggabungan kategori guru/ dosen, pegawai BUMN/ pegawai BUMD dan PNS dijadikan satu kategori.
Selain perbedaan yang disebutkan tadi, hasil yang ditunjukkan oleh kedua metode tersebut terhadap peubah kode pekerjaan tidak
jauh berbeda. Kategori pekerjaan notaris dan pegawai yayasan serta pegawai swasta memiliki resiko yang relatif tinggi. Sedangkan untuk kategori pekerjaan yang lain resikonya relatif rendah.
Indeks Asosiasi dan Information Value
Nilai indeks asosiasi uncertainty coefficient (UC) dan information value (InV) digunakan untuk membandingkan hasil diskretisasi menggunakan metode entropi dengan metode khi kuadrat pada setiap peubah. semakin tinggi nilai InV yang didapatkan, maka semakin erat hubungannya dengan peubah target. Tingkat prediksi InV dibagi ke dalam beberapa kategori yaitu kurang dari 0.02 peubah dikatakan tidak prediktif, 0.02 hingga 0.1 tingkat prediksinya lemah, 0.1 hingga 0.3 memiliki tingkat prediksi pertengahan (medium), dan lebih dari 0.3 memiliki tingkat prediksi yang kuat. Sedangkan indeks asosiasi
UC memiliki selang nilai antara 0 hingga 1. Semakin besar nilai UC, maka tingkat asosiasi peubah prediktor terhadap target semakin tinggi. InV dan UC masing-masing peubah ada pada Lampiran 2 .
Tabel 11 dan 12 di bawah ini merupakan peubah input yang terurut dari yang paling besar hingga paling kecil berdasarkan nilai indeks asosiasi InV dan UC.
Tabel 11 Urutan peubah terpilih beserta metode diskretisasinya berdasarkan nilai InV.
Peubah Metode InV
Pendapatan per tahun Entropi 0.4028 Rasio antara cicilan
dan pendapatan Entropi 0.2359 Kode pekerjaan Entropi 0.1368 Status kepemilikan
rumah Entropi 0.0314
Banyaknya
tanggungan Entropi 0.0193
Tabel 12 Urutan peubah terpilih beserta metode diskretisasinya berdasarkan nilai UC.
Peubah Metode UC
Pendapatan per tahun Entropi 0.2390 Kode pekerjaan Khi kuadrat 0.0184 rasio antara cicilan
dan pendapatan Entropi 0.0142 Status kepemilikan
rumah Khi kuadrat 0.0031 Banyaknya
Berdasarkan Tabel 11, peubah terpilih berdasarkan information value (InV), peubah pendapatan per tahun, rasio antara cicilan dan pendapatan, serta kode pekerjaan digambarkan sebagai peubah yang sangat erat hubungannya dan cukup tinggi tingkat prediksinya terhadap peubah target atau peubah status kolektibilitas
good dan bad. Peubah pendapatan per tahun mendapatkan InV lebih besar dari 0.3 sehingga dikatakan tingkat prediksi peubah pendapatan per tahun tinggi. InV peubah rasio antara cicilan dan pendapatan dan kode pekerjaan berkisar antara 0.1 dan 0.3 sehingga termasuk dalam tingkat prediksi pertengahan. Sedangkan peubah status kepemilikan rumah dan banyaknya tanggungan mendapat peringkat lebih rendah dibandingkan tiga peubah yang disebutkan di awal karena nilai InV kedua peubah tersebut kurang dari 0.1 dan mempunyai tingkat prediksi yang lemah terhadap peubah target.
Hasil yang tidak jauh berbeda juga ditunjukkan oleh Tabel 12. Nilai indeks asosiasi uncertainty coefficient (UC) memilih peubah pendapatan per tahun, rasio antara cicilan dan pendapatan, serta kode pekerjaan sebagai peubah dengan tingkat asosiasi yang tinggi dibandingkan peubah status kepemilikan rumah dan banyaknya tanggungan.
Perbedaan dari kedua Tabel 11 dan 12, ialah metode diskretisasi yang terbaik yang terpilih pada masing-masing peubah. Berdasarkan InV, metode entropi paling baik digunakan pada semua peubah prediktor. Berdasarkan UC, metode entropi hanya sesuai digunakan oleh peubah numerik sedangkan metode khi kuadrat lebih sesuai digunakan pada peubah kategorik. Secara umum, metode entropi bekerja lebih baik dalam mendiskretisasi peubah numerik dibandingkan khi kuadrat. Hal ini dilihat dari peubah numerik pendapatan per tahun dan rasio antara cicilan dan pendapatan hasil diskretisasi metode entropi yang terpilih dan mendapat peringkat yang tinggi berdasarkan kedua kriteria UC dan InV di atas.
SIMPULAN DAN SARAN
Simpulan
Hasil diskretisasi peubah prediktor menggunakan entropi dan khi kuadrat bisa sangat berbeda. Secara umum, untuk data kredit konsumtif yang digunakan pada penelitian ini, jumlah kategori yang didapatkan dari metode entropi, lebih banyak daripada
metode khi kuadrat. Selain itu juga metode entropi mampu mendiskretisasi peubah numerik lebih baik pada data yang diterapkan dibandingkan metode khi kuadrat berdasarkan kriteria UC dan InV. Tetapi masih belum cukup bukti untuk mengambil kesimpulan yang serupa untuk diskretisasi atau pengkategorian peubah kategorik menggunakan metode entropi dan khi kuadrat
Berdasarkan nilai indeks asosiasi UC dan
InV peubah pendapatan per tahun,rasio antara cicilan dan pendapatan serta kode pekerjaan digambarkan sebagai peubah yang sangat erat hubungannya dan tinggi tingkat prediksinya dengan target, disusul peubah status kepemilikan rumah dan banyaknya tanggungan.
Saran
Hasil diskretisasi yang didapatkan sangat bergantung terhadap koleksi data yang ada dan diperlukan data yang cukup besar. Semakin banyak data yang digunakan maka hasil diskretisasi yang didapatkan akan mendekati keadaan yang sesungguhnya. Karena selang nilai peubah atau atribut yang terbentuk berdasarkan proporsi status good dan bad
mungkin tidak terjadi secara kebetulan saja. Isu yang muncul dari proses diskretisasi ialah ukuran selang atau selang hasil diskretisasi. Jika selang terlalu kecil, mungkin hasil yang didapatkan tidak mendukung kejadian yang sesungguhnya. Sedangkan jika terlalu lebar, mungkin akan mengurangi tingkat kepercayaan. Sehingga diperlukan pemahaman terhadap data yang dihadapi sehingga didapatkan metode diskretiasi yang sesuai.
DAFTAR PUSTAKA
Han, Jiawei dan Kember, Micheline. 2001.
Data Mining : Concepts And Techniques.
Academic Press. San Diego
Kantardzic, Mehmed. 2003. Data Mining : Concepts, Models, Methods, And Algorithms. IEEE and Wiley Inter-Science. New York.
Hollowel. 2004. A fair Isaac white paper : Technology Guide To The Scorecard Module. (http://www.fairisaac.com/). [22 Juni 2007]
technique. DMKD 6:393-423. (http://dl.comp.nus.edu.sg/dspace/bitstrea
m/1900.100/1386/1/report.pdf). [22 Juni 2007]
SAS Institute Inc. 2003. Enterprise miner version 4.3 SAS User’s guide. Cary. NC : SAS Institute Inc.
Hababou, Moez, Cheng A.Y., dan Falk R. 2006. Variable Selection In Credit Card Industry. Royal Bank of Scotland. Bridgeport.
(http://www.nesug.org/proceedings/ nesug06/an/da23.pdf).
Lampiran 1. Perhitungan WoE tiap kategori pada masing-masing peubah kategorik sebelum diskretisasi atau kategorisasi ulang.
Peubah job code Group WoE
Notaris -1.6270 Pegawai Yayasan -1.2215
Pegawai swasta -0.1136 Guru /Dosen 0.3189 Pegawai BUMN/BUMD 0.4690 Pegawai Negri Sipil 0.9380
Akuntan 1.3687 Paramedis 1.3687 Profesional 1.3687
Employee 1.7742
Dokter 2.4673 Pejabat Negara 2.6215
Wiraswasta 2.6215
Peubah residence status Group WoE Rented -0.3583 Parents -0.1374 Own 0.1445 Others 0.2658 Institution 0.4482 Credit 0.5088 Peubah number of dependants
Group WoE
0 0.1398 1 -0.1874 2 -0.0420 3 0.1246 4 0.0570 5 0.1623 7 0.6731 8 0.6731 6 1.3663
Lampiran 2. Indeks asosiasi UC dan InV peubah input.
Peubah Metode InV UC
Entropi 0.23585 0.0142 Rasio antara cicilan dan pendapatan
Khi kuadrat 0.19223 0.0117 Entropi 0.40279 0.2390 Pendapatan per tahun
Khi kuadrat 0.22769 0.1690 Entropi 0.01925 0.0017 Banyaknya tanggungan
Khi kuadrat 0.01543 0.0019 Entropi 0.03139 0.0028 Status kepemilikan rumah
Khi kuadrat 0.02624 0.0031 Entropi 0.13683 0.0176 Kode pekerjaan
DISKRETISASI PEUBAH
CREDIT SCORING MODEL
MENGGUNAKAN
METODE ENTROPI DAN KHI KUADRAT
BAYU ALFIANSYAH
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PENDAHULUAN
Latar Belakang
Credit scoring model telah banyak digunakan oleh berbagai organisasi keuangan seperti bank dan penyedia jasa kredit sebagai alat yang efisien dan menguntungkan.
Credit scoring model adalah suatu metode untuk mengevaluasi kelayakan kredit seseorang berdasarkan rumus tertentu atau suatu aturan tertentu. Hasil dari credit scoring model
berupa model matematik yang mampu mengklasifikasi atau menduga kualitas kredit seseorang ke dalam suatu gugus keputusan. Model ini dibangun berdasarkan informasi data historis berupa karakteristik-karakteristik kreditur yang dimiliki oleh organisasi keuangan (debitur) yang memberikan kreditnya. Data yang dibutuhkan untuk membangun model umumnya harus cukup besar. Dengan semakin besarnya data yang ditelaah maka data tersebut akan semakin rentan terhadap munculnya data hilang, pencilan, dan ketidakkonsistenan (Kantardzic 2003). Oleh karena itu perlu dilakukan suatu proses awalan terhadap data (data preprocessing) untuk mempersiapkan data sebelum dilakukan analisis lebih lanjut.
Salah satu cara dalam data preprocessing
adalah melakukan diskretisasi data atau biasa disebut binning. Diskretisasi data juga memegang peranan penting dalam membangun
credit scoring model. Metode diskretisasi mampu memilah-milah suatu selang data kontinu atau numerik ke dalam sub-sub selang berdasarkan algoritma tertentu. Metode ini juga bermanfaat untuk mengkategori ulang kategori-kategori pada peubah diskret atau kategorik. Metode ini sangat bermanfaat karena beberapa algoritma klasifikasi yang biasa digunakan dalam membangun credit scoring model hanya menerima data berskala diskret.
Penelitian ini bertujuan membandingkan metode diskretisasi entropi (entropy based discretization) dengan diskretisasi khi kuadrat (chi squared discretization) dari berbagai metode diskretisasi yang sudah ada. Kedua metode ini diterapkan pada data kredit konsumtif sebuah bank.
Tujuan
Tujuan yang ingin dicapai dalam penelitian ini antara lain :
1. Membandingkan hasil kategori yang didapatkan dari metode diskretisasi entropi (entropy based discretization) dengan
diskretisasi khi kuadrat (chi squared discretization).
2. Melihat keeratan hubungan antara peubah yang telah didiskretkan dengan peubah target.
TINJAUAN PUSTAKA
Pada umumnya sistem penilaian kredit menggunakan kartu skor (scorecard) sebagai model atau aturan pengklasifikasi kreditur atau penduga bagi kualitas kreditnya. Kartu skor bisa dituliskan sebagai model matematik sebagai berikut :
∑
∑
= = = = q i i i p j jj C H S X c
H skor 1 (.) 1 ) ( ) (
C
j = Karakteristik (peubah X ke-j)kartu skor.
X
i(c)
= Kategori ke-i dari peubah X.S
i = Skor atau nilai pembobot kategorike-i.
Nilai skor ditentukan oleh kumulatif dari setiap peubah atau karekteristik kreditur. Kreditur yang terpetakan ke dalam kategori dari peubah ke-j mendapat nilai pembobot yang sesuai dengan kategori yang ia dapatkan. Artinya kreditur hanya mendapat satu nilai pembobot kategori untuk setiap peubahnya. Berdasarkan hal tersebut, metode diskretisasi memegang peranan penting dalam membangun sebuah credit scoring model karena peubah atau karakteristik yang diamati bisa berupa peubah numerik. Diskretisasi entropi dan khi kuadrat dipilih karena metode tersebut menggunakan proporsi kejadian sukses dan gagal untuk kejadian biner. Kedua metode tersebut cocok digunakan karena pada umumnya masalah credit scoring model adalah bagaimana mendeteksi perbedaan dari dua distribusi dari dua kejadian kualitas kredit (good dan bad atau terima dan tolak kredit sebagai peubah target atau respon dari model) sehingga debitur bisa mendapatkan gambaran yang jelas mengenai karakteristik krediturnya.
Nilai pembobot kategori tiap peubah biasanya memiliki pola yang mirip dengan
PENDAHULUAN
Latar Belakang
Credit scoring model telah banyak digunakan oleh berbagai organisasi keuangan seperti bank dan penyedia jasa kredit sebagai alat yang efisien dan menguntungkan.
Credit scoring model adalah suatu metode untuk mengevaluasi kelayakan kredit seseorang berdasarkan rumus tertentu atau suatu aturan tertentu. Hasil dari credit scoring model
berupa model matematik yang mampu mengklasifikasi atau menduga kualitas kredit seseorang ke dalam suatu gugus keputusan. Model ini dibangun berdasarkan informasi data historis berupa karakteristik-karakteristik kreditur yang dimiliki oleh organisasi keuangan (debitur) yang memberikan kreditnya. Data yang dibutuhkan untuk membangun model umumnya harus cukup besar. Dengan semakin besarnya data yang ditelaah maka data tersebut akan semakin rentan terhadap munculnya data hilang, pencilan, dan ketidakkonsistenan (Kantardzic 2003). Oleh karena itu perlu dilakukan suatu proses awalan terhadap data (data preprocessing) untuk mempersiapkan data sebelum dilakukan analisis lebih lanjut.
Salah satu cara dalam data preprocessing
adalah melakukan diskretisasi data atau biasa disebut binning. Diskretisasi data juga memegang peranan penting dalam membangun
credit scoring model. Metode diskretisasi mampu memilah-milah suatu selang data kontinu atau numerik ke dalam sub-sub selang berdasarkan algoritma tertentu. Metode ini juga bermanfaat untuk mengkategori ulang kategori-kategori pada peubah diskret atau kategorik. Metode ini sangat bermanfaat karena beberapa algoritma klasifikasi yang biasa digunakan dalam membangun credit scoring model hanya menerima data berskala diskret.
Penelitian ini bertujuan membandingkan metode diskretisasi entropi (entropy based discretization) dengan diskretisasi khi kuadrat (chi squared discretization) dari berbagai metode diskretisasi yang sudah ada. Kedua metode ini diterapkan pada data kredit konsumtif sebuah bank.
Tujuan
Tujuan yang ingin dicapai dalam penelitian ini antara lain :
1. Membandingkan hasil kategori yang didapatkan dari metode diskretisasi entropi (entropy based discretization) dengan
diskretisasi khi kuadrat (chi squared discretization).
2. Melihat keeratan hubungan antara peubah yang telah didiskretkan dengan peubah target.
TINJAUAN PUSTAKA
Pada umumnya sistem penilaian kredit menggunakan kartu skor (scorecard) sebagai model atau aturan pengklasifikasi kreditur atau penduga bagi kualitas kreditnya. Kartu skor bisa dituliskan sebagai model matematik sebagai berikut :
∑
∑
= = = = q i i i p j jj C H S X c
H skor 1 (.) 1 ) ( ) (
C
j = Karakteristik (peubah X ke-j)kartu skor.
X
i(c)
= Kategori ke-i dari peubah X.S
i = Skor atau nilai pembobot kategorike-i.
Nilai skor ditentukan oleh kumulatif dari setiap peubah atau karekteristik kreditur. Kreditur yang terpetakan ke dalam kategori dari peubah ke-j mendapat nilai pembobot yang sesuai dengan kategori yang ia dapatkan. Artinya kreditur hanya mendapat satu nilai pembobot kategori untuk setiap peubahnya. Berdasarkan hal tersebut, metode diskretisasi memegang peranan penting dalam membangun sebuah credit scoring model karena peubah atau karakteristik yang diamati bisa berupa peubah numerik. Diskretisasi entropi dan khi kuadrat dipilih karena metode tersebut menggunakan proporsi kejadian sukses dan gagal untuk kejadian biner. Kedua metode tersebut cocok digunakan karena pada umumnya masalah credit scoring model adalah bagaimana mendeteksi perbedaan dari dua distribusi dari dua kejadian kualitas kredit (good dan bad atau terima dan tolak kredit sebagai peubah target atau respon dari model) sehingga debitur bisa mendapatkan gambaran yang jelas mengenai karakteristik krediturnya.
Nilai pembobot kategori tiap peubah biasanya memiliki pola yang mirip dengan
digunakan untuk mengevaluasi tingkat prediksi dan asosiasi antara peubah hasil metode diskretisasi entropi dan khi kuadrat dengan peubah target.
Credit Scoring Model
Credit scoring model adalah suatu metode untuk mengevaluasi kelayakan kredit seseorang berdasarkan rumus tertentu atau suatu aturan tertentu (Hollowel 2004). Model ini dibangun berdasarkan informasi data historis di masa lalu. Informasi mengenai data diri, pengalaman kredit seperti riwayat pembayaran tagihan seseorang, telat membayar, cicilan-cicilan, dan umur rekening (account), dikumpulkan dari aplikasi kredit dan laporan kredit.
Diskretisasi (Binning)
Proses diskretisasi merupakan proses transformasi data kuantitatif ke dalam data kualitatif. Teknik ini digunakan untuk mereduksi jumlah nilai suatu peubah yang berskala numerik atau kontinu dengan cara memilah-milah selang nilai data peubah ke dalam sub-sub selang nilai.
Secara umum, proses diskretisasi terdiri dari 4 tahapan, yaitu:
1. Mengurutkan nilai kontinu yang akan didiskretisasi.
2. Mengevaluasi titik potong sebagai pemisah selang atau penggabung selang yang berdekatan.
3. Berdasarkan kriteria tertentu, dilakukan pemisahan atau penyatuan selang nilai.
4. Menghentikan proses pada titik tertentu.
Binning memetakan nilai-nilai sebuah peubah ke dalam satu gugus bin. Sebuah bin
bisa terdiri dari satu nilai saja, suatu gugus nilai yang terbatas, selang kontinu, data hilang, atau bahkan nilai yang tidak ada sebelumnya (Hollowel 2004). Label selang nantinya digunakan untuk menggantikan nilai data aktual.
Supervised Methods versus Unsupervised Methods
Metode diskretisasi dikelompokkan ke dalam dua grup yaitu metode diskretisasi tersupervisi (supervised discretization methods) dan tidak tersupervisi (unsupervised discretization methods). Metode diskretisasi tersupervisi adalah metode diskretisasi yang membagi selang nilai ke dalam sub-sub selang berdasarkan kriteria tertentu berupa suatu
gugus kelas atau peubah kategorik yang berpadanan dengan peubah yang akan didiskretisasi. Algoritma dari metode ini hanya bisa dijalankan jika terdapat sebuah peubah kategorik sebagai peubah target yang berisikan pengkelasan dari objek atau pengamatan (Jiawei dan Micheline 2001). Metode ini menggunakan informasi kelas tersebut ketika memilih titik-titik potong sebagai alat pemisah antar bin. Contoh metode diskretisasi tersupervisi antara lain : 1RD, ChiMerge, entropy based discretization, Zeta, ID3.
Metode diskretisasi tidak tersupervisi atau
unsupervised methods tidak menggunakan informasi kelas. Metode ini tidak membutuhkan sebuah peubah kategorik sebagai peubah target yang dijadikan sebagai dasar diskretisasinya. Metode ini membagi selang nilai kontinu ke dalam beberapa sub selang berdasarkan pertimbangan pengguna. Pertimbangan yang diambil bersifat subyektif dimana pengguna menentukan mekanisme diskretisasinya. Contoh metode tidak tersupervisi antara lain : equal width interval
dan equal freq interval. Keduametode tersebut bersifat subyektif karena jumlah kategori atau
bin yang diinginkan ditentukan oleh pengguna dengan pertimbangan-pertimbangan tertentu. Metode ini mungkin memberikan hasil yang kurang baik pada kasus dimana distribusi nilai kontinu tidak seragam karena metode diskretisasi tidak tersupervisi sangat rentan terhadap data pencilan (Liu et.al 1990).
Metode Diskretisasi Entropi
Metode diskretisasi entropi(Entropy based discretization) merupakan salah satu metode diskretisasi tersupervisi. Metode ini menggunakan entropi sebagai bagian dari proses pemisahan selang data kontinu. Entropi merupakan ukuran keseragaman bagi selang data tertentu yang dibagi. Entropi mengukur variasi selang data awal yang berpadanan dengan peubah kategorik target dengan cara menghitung besaran proporsi munculnya suatu kelas dari peubah target. Besaran nilai entropi berkisar antara 0 sampai 1. Nilai entropi nol mengindikasikan bahwa selang data tersebut memiliki kelas yang sama untuk setiap pengamatannya. Semakin tinggi nilai entropi (mendekati 1) maka selang data tersebut cenderung memiliki proporsi kelas yang semakin seimbang atau sama banyak.
pemilahan selang oleh sebuah nilai T dilakukan secara rekursif terhadap sub selang yang baru hingga kondisi tertentu terpenuhi (Jiawei dan Micheline 2001).
Algoritma metode diskretisasi entropi adalah sebagai berikut :
1. Setiap nilai tengah antara dua nilai data dalam atribut dipertimbangkan sebagai batas selang potensial atau T. Yang nantinya nilai T akan membagi selang S menjadi dua yaitu S1 dan S2.
2. Nilai batas selang (T) dipilih yang memiliki nilai informasi kelas entropi saat T memotong S minimum berdasarkan rumus :
),
(
|
|
|
|
)
(
|
|
|
|
)
,
(
2 2 1 1S
Ent
S
S
S
Ent
S
S
T
S
E
=
+
|S1| = banyaknya observasi dalam S1
|S2| = banyaknya observasi dalam S2
|S| = banyaknya observasi sebelum dipisah.
Semua nilai T yang mungkin dievaluasi hingga didapatkan satu nilai T yang meminimumkan rumus di atas.
Entropi Si didefinisikan sebagai berikut :
∑
=−
=
m i ij iji
p
p
S
Ent
1
2
(
),
log
)
(
ij
p
= peluang suatu individu masuk ke dalam kelas ke-j pada selang Si. Nilai batas T juga bisa dipilih berdasarkan nilai perolehan informasi pemisah (information gain of the split) maksimum atau yang terbesar dengan rumus sebagai berikut:)
,
(
)
(
)
,
(
S
T
Ent
S
E
S
T
Gain
=
−
3. Proses penentuan nilai batas selang dilakukan secara rekursif terhadap sub selang yang baru hingga kondisi tertentu terpenuhi.
Metode Diskretisasi Khi Kuadrat
Khi kuadrat (chi squared) merupakan salah satu algoritma diskretisasi yang menganalisa kualitas beberapa selang berdasarkan nilai statistik χ2. Uji khi kuadrat atau tabel kontingensi biasa digunakan untuk menguji kebebasan antara dua selang atau kategori. Dari karakteristik tersebut, statistik uji ini digunakan dalam metode diskretisasi untuk memilah selang nilai numerik sehingga untuk mendapatkan hasil diskret dari metode ini, selang data S dipilah oleh satu titik potong T terlebih dahulu menjadi dua sub selang
sebelum dievaluasi dengan statistik uji khi kuadrat. Jika selang yang terbentuk dinyatakan saling bebas berdasarkan uji khi kuadrat, maka nilai T tidak dijadikan titik potong sehingga S1
dan S2 sehingga tetap dijadikan satu selang.
Proses evaluasi selang dilakukan secara rekursif ke setiap sub selang yang baru terbentuk (Kantardzic 2003).
Proses pemilihan nilai T dari sekian banyak kandidat T dalam S, yang akan memilah selang S didasarkan statistik uji khi kuadrat yang memiliki nilai χ2 terbesar atau nilai uji paling nyata dari semua selang yang dievaluasi. Rumus χ2 dihitung berdasarkan rumus berikut :
∑∑
= =−
=
2 1 1 22
(
)
i k j ij ij ij
E
E
A
χ
k = Jumlah kelas
Aij = Jumlah data aktual selang ke-i, kelas ke-j
Eij = Frekuensi harapan Aij = (Ri.Cj)/N
Ri = Jumlah data aktual selang ke-i Cj = Jumlah data aktual kelas ke-j N = Total data aktual
Weight of Evidence (WoE)
Weight of Evidence (WoE) merupakan perbandingan proporsi kategori tertentu suatu peubah untuk kelompok status kolektibilitas. Status kolektibilitas adalah sebuah atribut atau peubah yang menunjukkan status kelas kredit seseorang atau nasabah. Peubah status kolektibilitas merupakan peubah target dalam membangun credit scoring model. Data status tersebut biasanya berbentuk biner yaitu good
dan bad atau respon dan no respon. Status
good bisa didefinisikan sebagai nasabah yang tidak pernah lalai membayar sedangkan bad
bisa didefinisikan sebagai nasabah yang lalai atau pailit (Hollowel 2004).
WoE merupakan selisih atau besarnya perbedaan antara log odds tiap bin (kategori) dengan log odds total. Dalam proses membangun credit scoring model, WoE
berfungsi menunjukkan tingkat resiko seseorang.
WoE tiap bin didefinisikan sebagai berikut:
dimana
( )
100
⎟⎟
.
⎠
⎞
⎜⎜
⎝
⎛
=
G Gi Gn
n
i
f
=( )
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
=
B Bi Bn
n
i
f
100
=Information Value (InV)
Information value menghitung jarak antara dua distribusi, yang dalam hal ini distribusi antara good dan bad dalam satu peubah (Hollowel 2004). Dengan kata lain suatu besaran yang menyatakan seberapa jauh kolektibilitas good dengan bad dalam satu peubah.
InV juga sering digunakan dalam proses membangun credit scoring model sebagai indikator yang menunjukkan tingkat prediksi peubah input terhadap peubah target berupa status kolektibilitas kreditur. Tingkat prediksi
InV dibagi ke dalam beberapa kategori yaitu kurang dari 0.02 peubah dikatakan tidak prediktif, 0.02 hingga 0.1 tingkat prediksinya lemah, 0.1 hingga 0.3 memiliki tingkat prediksi pertengahan (medium), dan lebih dari 0.3 memiliki tingkat prediksi yang kuat (Hababou
et.al 2006). InV biasa digunakan untuk memilih peubah dari suatu gugus peubah yang berpotensi untuk dimasukkan ke dalam model, dimana peubah dengan InV yangg besar berpeluang tinggi untuk masuk ke dalam credit scoring model.
InV dari peubah kategorik dipengaruhi oleh WoE tiap kategori dalam peubah. InV
didefinisikan sebagai berikut :
∑
= ⎥⎦ ⎤ ⎢ ⎣ ⎡ − = q i B G B G i f i f i f i f InV1 ()
) ( log 100 ) ( ) ( , atau
∑
= − = q i B G i WoE i f i f InV 1 ) ( 100 ) ( ) ()
(
i
WoE
= WoE tiap bin ke-i dari peubah inputIndeks Asosiasi Symmetric Uncertainty Coefficient
Indeks asosiasi merupakan indeks yang mengukur keeratan hubungan antara dua buah peubah kategorik. Indeks asosiasi symmetric uncertainty coefficient merupakan salah satu dari sekian banyak metode pengukuran asosiasi. Indeks uncertainty coefficient
mengukur asosiasi antara dua buah peubah
dengan skala pengukuran nominal sehingga sesuai untuk mengukur tingkat asosiasi antara peubah hasil diskretisasi dengan peubah target kolektibilitas. Indeks ini dihitung hanya berdasarkan banyaknya nilai pasangan yang konkordan dan diskordan dari pengamatan. Nilai uncertainty coefficient berkisar antara 0 sampai 1. Jika dua peubah saling bebas, maka nilai uncertainty coefficient (UC) akan mendekati nilai nol. Nilai indeks uncertainty coefficient (UC) dihitung berdasarkan rumus berikut :
P e r s e n t a s e i n d i v i d u
good dalam bin ke-i
Persentase individu bad
dalam bin ke-i
)
(
)
(
)]
(
)
(
)
(
[
2
Y
H
X
H
XY
H
Y
H
X
H
UC
+
−
+
=
X = Peubah baris Y = Peubah kolom N = Jumlah pengamatan
H(X) =
∑
⎟
⎠
⎞
⎜
⎝
⎛
⎟
⎠
⎞
⎜
⎝
⎛
−
i i in
n
n
n
. .ln
H(Y) =
∑
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
−
j j jn
n
n
n
. .ln
H(XY)=
∑∑
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
−
i j ij ijn
n
n
n
ln
. in
= Total baris ke-ij
n
. = Total kolom ke-jij
n
= Pengamatan pada baris ke-i dan kolom ke-j.(SAS Institute Inc. 2003).
BAHAN DAN METODE
Bahan
Bahan penelitian yang digunakan merupakan data sekunder sebuah bank terdiri atas 1000 observasi.
Peubah input yang digunakan yaitu : 1. DSR (Debt Salary Ratio atau rasio antara
cicilan dan pendapatan)
2. Gross annual income (pendapatan per tahun dalam rupiah)
3. Number of dependants (banyaknya tanggungan)
4. Residence status (status kepemilikan rumah)
5. Job code (kode pekerjaan)
Sedangkan peubah targetnya adalah status kolektibilitas nasabah berupa status good dan
dimana
( )
100
⎟⎟
.
⎠
⎞
⎜⎜
⎝
⎛
=
G Gi Gn
n
i
f
=( )
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
=
B Bi Bn
n
i
f
100
=Information Value (InV)
Information value menghitung jarak antara dua distribusi, yang dalam hal ini distribusi antara good dan bad dalam satu peubah (Hollowel 2004). Dengan kata lain suatu besaran yang menyatakan seberapa jauh kolektibilitas good dengan bad dalam satu peubah.
InV juga sering digunakan dalam proses membangun credit scoring model sebagai indikator yang menunjukkan tingkat prediksi peubah input terhadap peubah target berupa status kolektibilitas kreditur. Tingkat prediksi
InV dibagi ke dalam beberapa kategori yaitu kurang dari 0.02 peubah dikatakan tidak prediktif, 0.02 hingga 0.1 tingkat prediksinya lemah, 0.1 hingga 0.3 memiliki tingkat prediksi pertengahan (medium), dan lebih dari 0.3 memiliki tingkat prediksi yang kuat (Hababou
et.al 2006). InV biasa digunakan untuk memilih peubah dari suatu gugus peubah yang berpotensi untuk dimasukkan ke dalam model, dimana peubah dengan InV yangg besar berpeluang tinggi untuk masuk ke dalam credit scoring model.
InV dari peubah kategorik dipengaruhi oleh WoE tiap kategori dalam peubah. InV
didefinisikan sebagai berikut :
∑
= ⎥⎦ ⎤ ⎢ ⎣ ⎡ − = q i B G B G i f i f i f i f InV1 ()
) ( log 100 ) ( ) ( , atau
∑
= − = q i B G i WoE i f i f InV 1 ) ( 100 ) ( ) ()
(
i
WoE
= WoE tiap bin ke-i dari peubah inputIndeks Asosiasi Symmetric Uncertainty Coefficient
Indeks asosiasi merupakan indeks yang mengukur keeratan hubungan antara dua buah peubah kategorik. Indeks asosiasi symmetric uncertainty coefficient merupakan salah satu dari sekian banyak metode pengukuran asosiasi. Indeks uncertainty coefficient
mengukur asosiasi antara dua buah peubah
dengan skala pengukuran nominal sehingga sesuai untuk mengukur tingkat asosiasi antara peubah hasil diskretisasi dengan peubah target kolektibilitas. Indeks ini dihitung hanya berdasarkan banyaknya nilai pasangan yang konkordan dan diskordan dari pengamatan. Nilai uncertainty coefficient berkisar antara 0 sampai 1. Jika dua peubah saling bebas, maka nilai uncertainty coefficient (UC) akan mendekati nilai nol. Nilai indeks uncertainty coefficient (UC) dihitung berdasarkan rumus berikut :
P e r s e n t a s e i n d i v i d u
good dalam bin ke-i
Persentase individu bad
dalam bin ke-i
)
(
)
(
)]
(
)
(
)
(
[
2
Y
H
X
H
XY
H
Y
H
X
H
UC
+
−
+
=
X = Peubah baris Y = Peubah kolom N = Jumlah pengamatan
H(X) =
∑
⎟
⎠
⎞
⎜
⎝
⎛
⎟
⎠
⎞
⎜
⎝
⎛
−
i i in
n
n
n
. .ln
H(Y) =
∑
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
−
j j jn
n
n
n
. .ln
H(XY)=
∑∑
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
−
i j ij ijn
n
n
n
ln
. in
= Total baris ke-ij
n
. = Total kolom ke-jij
n
= Pengamatan pada baris ke-i dan kolom ke-j.(SAS Institute Inc. 2003).
BAHAN DAN METODE
Bahan
Bahan penelitian yang digunakan merupakan data sekunder sebuah bank terdiri atas 1000 observasi.
Peubah input yang digunakan yaitu : 1. DSR (Debt Salary Ratio atau rasio antara
cicilan dan pendapatan)
2. Gross annual income (pendapatan per tahun dalam rupiah)
3. Number of dependants (banyaknya tanggungan)
4. Residence status (status kepemilikan rumah)
5. Job code (kode pekerjaan)
Sedangkan peubah targetnya adalah status kolektibilitas nasabah berupa status good dan
Metode
Langkah–langkah metode penelitian : a.Diskretisasi data numerik
1.Melakukan transformasi atau binning
dengan kriteria penghentian algoritma yang digunakan adalah minimum observasi dalam bin sebanyak 25.
2.Dari hasil transformasi tadi dilakukan perhitungan WoE dan InV.
b.Diskretisasi data kategorik 1.Menghitung WoE data diskret.
2.Mentransformasi data dengan nilai WoE. 3.Menghitung kembali nilai WoE dan InV.
c.Membandingkan hasil binning atau diskretisasi berdasarkan indeks asosiasi dan
InV.
Nilai α yang digunakan pada metode khi kuadrat adalah 0.2. Data penelitian ini diolah menggunakan software Microsoft Excel, SAS Enterprise Miner 3.4, dan Minitab 14.
HASIL DAN PEMBAHASAN
Deskripsi WoE Peubah Numerik
Data numerik didiskretisasi menggunakan metode entropi dan khi kuadrat. Proses diskretisasi menggunakan kedua metode tersebut menghasilkan struktur yang membagi selang nilai data numerik ke dalam sub-sub selang berdasarkan algoritmanya