PERBANDINGAN METODE PEMULUSAN
(SMOOTHING)
EKSPONENSIAL DAN ARIMA (BOX-JENKINS)
SEBAGAI METODE PERAMALAN INDEKS
HARGA SAHAM GABUNGAN (IHSG)
SKRIPSI
WARSINI
070803042
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
PERBANDINGAN METODE PEMULUSAN
(SMOOTHING)
EKSPONENSIAL DAN ARIMA (BOX-JENKINS)
SEBAGAI METODE PERAMALAN INDEKS
HARGA SAHAM GABUNGAN (IHSG)
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Sains
WARSINI
070803042
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : PERBANDINGAN METODE PEMULUSAN
(SMOOTHING) EKSPONENSIAL DAN ARIMA
(BOX-JENKINS) SEBAGAI METODE PERAMALAN INDEKS HARGA SAHAM GABUNGAN (IHSG)
Kategori : SKRIPSI
Nama : WARSINI
Nomor Induk Mahasiswa : 070803042
Program Studi : SARJANA (SI) MATEMATIKA Departemen : MATEMATIKA
Fakultas : MATEMATIKA DAN ILMU PENGETAHUAN ALAM (FMIPA) UNIVERSITAS SUMATERA UTARA
Diluluskan di Medan, Juli 2011
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Drs. Gim Tarigan, M.Si Drs. Rachmad Sitepu, M.Si NIP. 19550202 198601 1 001 NIP. 19530418 198703 1 001
Diketahui/Disetujui oleh
Departemen Matematika FMIPA USU Ketua,
Prof. Dr. Tulus, M.Si
PERNYATAAN
PERBANDINGAN METODE PEMULUSAN (SMOOTHING) EKSPONENSIAL DAN BOX-JENKINS (ARIMA) SEBAGAI METODE PERAMALAN
INDEKS HARGA SAHAM GABUNGAN (IHSG)
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Juli 2011
PENGHARGAAN
Bismillahirrahmanirrahim
Puji dan syukur penulis sampaikan kepada Allah SWT Yang Maha Esa dan Kuasa atas limpahan rahmat dan karunia-Nya sehingga skripsi ini dapat diselesaikan.
Skripsi ini merupakan salah satu syarat yang harus dipenuhi dan diselesaikan oleh seluruh mahasiswa Fakultas FMIPA Departemen Matematika. Pada skripsi ini penulis mengambil judul skripsi tentang “Perbandingan Metode Pemulusan
(Smoothing) Eksponensial dan ARIMA (Box-Jenkins) sebagai Metode Peramalan
Indeks Harga Saham Gabungan (IHSG).”
Dalam penyusunan skripsi ini banyak pihak yang membantu, oleh karena itu dalam kesempatan ini penulis mengucapkan banyak terimakasih terutama kepada Ayahanda Muhdori dan Ibunda Dartem yang penulis sayangi yang telah memberi motivasi, kasih sayang, nasehat dalam penyusunan skripsi ini. Buat kakak-kakakku tersayang Muriyati, Pariyati yang telah banyak memberi bantuan materi dan perhatian. Tak lupa keponakanku yang manis Bunga yang selalu menjadi pelepas suntuk saat mengerjakan skripsi ini, terimakasih juga penulis sampaikan kepada:
1. Drs. Rachmad Sitepu, M.Si. selaku dosen dan pembimbing I yang berkenan dan rela mengorbankan waktu, tenaga dan pikiran guna memberikan petunjuk dan bimbingannya dalam penulisan skripsi ini.
2. Drs. Gim Tarigan, M.Si. selaku dosen dan pembimbing II yang juga berkenan dan rela mengorbankan waktu, tenaga dan pikiran guna memberikan petunjuk dan bimbingannya dalam penulisan skripsi ini.
3. Bapak Drs. Suwarno Ariswoyo, M.Si dan Drs. Henry Rani, M.Si selaku komisi penguji atas masukan dan saran yang telah diberikan demi perbaikan skripsi ini. 4. Bapak Dr. Sutarman, M.Sc. selaku Dekan FMIPA USU.
5. Bapak Prof. Dr. Tulus, M.Si dan Ibu Dra. Mardiningsih, M.Si selaku ketua dan sekretaris Departemen Matematika FMIPA USU.
6. Sahabatku Lia, Novi, Zulham, Erna, Mizwar, Dian, Siska, Kessy, Rizky, Memel, Nely, Lulu dan masih banyak lagi yang tak tersebutkan namanya yang telah banyak membantu penulis dengan memberikan semangat dan doa dalam menyelesaikan tulisan ini.
7. Buat orang yang spesial terimakasih atas motivasi dan dukungan selama kuliah sampai penyelesaian penulisan skripsi ini.
Penulis juga menyadari masih banyak kekurangan dalam skripsi ini, baik dalam teori maupun penulisannya. Oleh karena itu, penulis mengharapkan saran dari pembaca demi perbaikan bagi penulis, semoga segala kebaikan dalam bentuk bantuan yang telah diberikan mendapat balasan dari Allah SWT.
Akhirnya penulis berharap agar kiranya tulisan ini bermanfaat bagi para pembaca.
Medan, Juli 2011 Penulis
ABSTRAK
Metode pemulusan (smoothing) eksponensial dan metode ARIMA (Box-Jenkins) merupakan metode peramalan deret berkala yang digunakan untuk meramalkan pola data mendatang yang diharapkan dapat mendekati data aktual. Dalam penelitian ini kedua metode tersebut digunakan untuk meramalkan nilai Indeks Harga Saham Gabungan (IHSG) untuk periode berikutnya. Untuk membandingkan kedua metode tersebut, digunakan Mean Absolute Percentage Error (MAPE) yang diperoleh dari masing-masing persamaan estimasi kedua metode tersebut. Persamaan estimasi dengan menggunakan metode pemulusan eksponensial adalah: Ft+ 1 = 0,9 Xt + 0,1 Ft. Persamaan estimasi dengan menggunakan rumus ARIMA (2,1,2) adalah : Xt = 1,5584
COMPARISON OF METHODS SMOOTHING EXPONENTIAL AND BOX-JENKINS (ARIMA) AS A METHOD OF FORECASTING
JOINT STOCK PRICE INDEX (CSPI)
ABSTRACT
Method of smoothing exponential and methods ARIMA (Box-Jenkins) time series forecasting methods are used to predict future patterns of data that is expected to approach the actual data. In this study both methods were used to predict the value of Composite Stock Price Index (JCI) for the next period. To compare the two methods, used Mean Absolute Percentage Error (MAPE) obtained from each equation of the second estimation method. Estimation equation using exponential smoothing methods are: Ft+ 1 = 0,9 Xt + 0,1 Ft. Equation estimated by using the formula ARIMA (2,1,2) is:
DAFTAR ISI
1.3.3 Metode Pemulusan yang Digunakan ... 6
1.4 Tujuan Penelitian ... 7
1.5 Kontribusi Penelitian... 7
Bab 3 Pembahasan ... 29
3.1 Contoh Data Deret Berkala yang Digunakan ... 29
3.2 Pengujian Data ... 30
3.3 Analisa Data Deret Berkala ... 31
3.4 Metode Pemulusan (Smoothing) ... 34
3.4.1 Identifikasi Model Peramalan Menggunakan Metode Pemulusan 34 3.4.2 Estimasi Model Sementara ... 34
3.4.3 Menentukan Bentuk Persamaan Metode Pemulusan ... 39
3.5 Metode Arima (Box-Jenkins)... 40
3.5.1 Indentifikasi Model ARIMA ... 40
3.5.2 Tahap Estimasi dan Diagnostik ... 41
3.6 Perbandingan Metode Pemulusan (Smoothing) dengan Metode ARIMA (Box-Jenkins) dalam Peramalan ... 46
Bab 4 Kesimpulan dan Saran 4.1 Kesimpulan ... 48
4.2 Saran ... 49
Daftar Pustaka ... 50
DAFTAR TABEL
DAFTAR GAMBAR
Halaman Gambar 2.1 Flowchart tahapan dalam Model ARIMA………23
DAFTAR LAMPIRAN
Halaman
Lampiran A : Uji Kecukupan Data………51 Lampiran B : Perhitungan Tingkat Keakuratan Antara Data Aktual dan Ramalan
dengan Metode ARIMA (Bx-Jenkins)………52 Lampiran C : Perhitungan Tingkat Keakuratan Antara Data Aktual dan Ramalan
ABSTRAK
Metode pemulusan (smoothing) eksponensial dan metode ARIMA (Box-Jenkins) merupakan metode peramalan deret berkala yang digunakan untuk meramalkan pola data mendatang yang diharapkan dapat mendekati data aktual. Dalam penelitian ini kedua metode tersebut digunakan untuk meramalkan nilai Indeks Harga Saham Gabungan (IHSG) untuk periode berikutnya. Untuk membandingkan kedua metode tersebut, digunakan Mean Absolute Percentage Error (MAPE) yang diperoleh dari masing-masing persamaan estimasi kedua metode tersebut. Persamaan estimasi dengan menggunakan metode pemulusan eksponensial adalah: Ft+ 1 = 0,9 Xt + 0,1 Ft. Persamaan estimasi dengan menggunakan rumus ARIMA (2,1,2) adalah : Xt = 1,5584
COMPARISON OF METHODS SMOOTHING EXPONENTIAL AND BOX-JENKINS (ARIMA) AS A METHOD OF FORECASTING
JOINT STOCK PRICE INDEX (CSPI)
ABSTRACT
Method of smoothing exponential and methods ARIMA (Box-Jenkins) time series forecasting methods are used to predict future patterns of data that is expected to approach the actual data. In this study both methods were used to predict the value of Composite Stock Price Index (JCI) for the next period. To compare the two methods, used Mean Absolute Percentage Error (MAPE) obtained from each equation of the second estimation method. Estimation equation using exponential smoothing methods are: Ft+ 1 = 0,9 Xt + 0,1 Ft. Equation estimated by using the formula ARIMA (2,1,2) is:
BAB 1
PENDAHULUAN
1.1Latar Belakang
Peramalan merupakan studi terhadap data historis untuk menemukan hubungan,
kecenderungan dan pola data yang sistematis (Makridakis, 1999). Peramalan
menggunakan pendekatan statistik maupun non statistik keduanya bertujuan untuk
meramalkan pola data mendatang yang diharapkan mendekati data aktual.
Analisa deret waktu merupakan analisa yang berhubungan erat dengan
peramalan. Kondisi data yang ada sesuai dengan urutan waktu atau memiliki periode
tertentu. Secara umum, semua aktifitas yang dilakukan manusia sering mengalami
ketidakpastian dalam hal pengambilan keputusan sehingga diperlukan suatu
peramalan untuk memprediksi kejadian di masa yang akan datang.
Selama ini banyak peramalan dilakukan dengan menggunakan metode-metode
statistika seperti metode smoothing, Box-Jenkins, ekonometri, regresi, fungsi transfer
dan sebagainya. Metode-metode tersebut diharapkan dapat mengidentifikasi model
yang digunakan untuk meramalkan kondisi pada waktu yang akan datang sehingga
Penggunaan teknik peramalan diawali dengan pola data pada waktu terdahulu.
Untuk mengembangkan model yang sesuai dengan menggunakan asumsi bahwa pola
data pada waktu yang lalu akan berulang lagi pada waktu yang akan datang.
Selanjutnya model digunakan untuk meramalkan kondisi pada waktu yang akan
datang.
Dalam pemulusan (smoothing) eksponensial terdapat satu atau lebih parameter
pemulusan yang ditentukan secara eksplisit dan hasil pilihan menentukan bobot yang
dikenakan pada nilai observasi (Makridakis, 1999). Dengan menggunakan nilai
observasi yang telah diketahui, dapat dihitung nilai kesalahan pencocokan suatu
ukuran dari model. Jika nilai observasi baru tersedia, maka dapat dihitung nilai
kesalahan peramalan (forecasting error).
Model Autoregressive Integrated Moving Average (ARIMA) merupakan
metode yang secara intensif dikembangkan oleh George Box dan Gwilym Jenkins.
ARIMA adalah teknik untuk mencari pola yang paling cocok dari sekelompok data.
Metode ini merupakan gabungan dari metode pemulusan, regresi, dan metode
dekomposisi. Metode ARIMA memanfaatkan sepenuhnya data masa lalu dan data
sekarang untuk menghasilkan peramalan yang akurat. Metode ARIMA akan bekerja
dengan baik apabila data pada deret waktu yang digunakan bersifat dependen atau
berhubungan satu sama lain secara statistik (Makridakis, 1999).
Indeks Harga Saham Gabungan atau yang lebih dikenal dengan IHSG tentu
menjadi sebuah istilah yang akrab di telinga sebagian masyarakat, terlebih bagi para
investor pasar saham. IHSG sering dijadikan acuan guna melihat representasi
pergerakan pasar saham secara keseluruhan. Kenaikan atau penurunan tajam harga
satu saham memang berpengaruh terhadap pergerakan IHSG. Namun seberapa besar
Pada penelitian ini penulis mencoba menganalisa perbandingan nilai
peramalan Indeks Harga Saham Gabungan (IHSG) menggunakan metode ARIMA dan
metode pemulusan (smoothing) eksponensial dengan mengidentifikasi model yang
digunakan untuk meramalkan nilai pada waktu yang akan datang sehingga error-nya
menjadi seminimal mungkin.
Kedua model di atas memiliki persamaan dan perbedaan diantara keduanya.
Berdasarkan uraian di atas, maka penulis memilih judul “Perbandingan Metode
Pemulusan (Smoothing) Eksponensial dan ARIMA (Box-Jenkins) Sebagai
Metode Peramalan Indeks Harga Saham Gabungan (IHSG).”
1.2Perumusan Masalah
Masalah yang akan dibahas dalam penelitian ini adalah menentukan metode apakah
yang terbaik dalam meramalkan Indeks Harga Saham Gabungan (IHSG) secara tepat.
1.3 Tinjauan Pustaka
Adapun teori yang digunakan dalam penelitian ini adalah sebagai berikut:
1.3.1 Metode Box-Jenkins
Metode ARIMA Box-Jenkins pada intinya sama seperti metode pemulusan yang
didasarkan pada analisis data deret berkala. Pendekatan ARIMA secara teoritis dan
menetapkan pola deret berkala dan metodologi yang digunakan untuk
mengekstrapolasi pola-pola tersebut untuk masa yang akan datang lebih didasarkan
pada teori statistik yang telah berkembang dengan baik.
Dalam metode Box-Jenkins tidak dibutuhkan adanya asumsi tentang adanya
suatu pola yang tetap. Pendekatan Box-Jenkins dimulai dengan mengadakan asumsi
adanya pola percobaan yang disesuaikan dengan data historis, sehingga kesalahan
dapat diminimalkan. Selanjutnya pendekatan Box-Jenkins akan memberikan informasi
secara tepat untuk keadaan atau situasi yang akan datang.
Makridakis (1999) menyebutkan dasar-dasar dalam analisis Metode
Box-Jenkins yaitu:
1. Plot Data
Langkah awal dalam mengidentifikasi model ARIMA adalah memplot data deret
berkala secara grafis. Dari plot data tersebut dapat diketahui pola data dan dari
pola data tersebut cukup dapat diketahui kestasioneran atau ketidakstasioneran
dari data yang akan diramalkan.
2. Koefisien Autokorelasi ( rk )
Koefisien autokorelasi mirip dengan koefisien korelasi, hanya saja koefisien
autokorelasi berfungsi untuk menunjukkan keeratan hubungan antara nilai
variabel yang sama tetapi pada waktu yang berbeda.
Autokorelasi memberikan informasi yang penting tentang susunan atau struktur
data dan pola data. Dari suatu kumpulan data acak atau random yang lengkap,
autokorelasi diantara nilai-nilai data dari ciri yang musiman atau siklis akan
mempunyai autokorelasi yang kuat. Dengan mengetahui nilai koefisien autokorelasi,
dapat diketahui ciri, pola dan jenis data, sehingga dapat memenuhi maksud untuk
Menurut Hendranata (2003), Model Box-Jenkins (ARIMA) dibagi kedalam 3
kelompok, yaitu model autoregressive (AR), moving average (MA), dan model
campuran ARIMA (autoregressive moving average) yang mempunyai karakteristik
dari dua model pertama.
1. Autoregressive Model (AR)
Bentuk umum model autoregressive dengan ordo p (AR(p)) atau model ARIMA
(p,0,0) dinyatakan sebagai berikut:
dengan, μ' = suatu konstanta
= parameter autoregresif ke-p
et = nilai kesalahan pada saat t
2. Moving Average Model (MA)
Bentuk umum model moving average ordo q (MA(q)) atau ARIMA (0,0,q)
dinyatakan sebagai berikut:
dengan, μ' = suatu konstanta
θ1sampai θq adalah parameter-parameter moving average
et-k= nilai kesalahan pada saat t – k
3. Model campuran
a. Proses ARMA
ARIMA (1,0,1) dinyatakan sebagai berikut:
atau
AR(1) MA(1)
b. Proses ARIMA
Apabila nonstasioneritas ditambahkan pada campuran proses ARMA, maka
model umum ARIMA (p,d,q) terpenuhi. Persamaan untuk kasus sederhana
ARIMA (1,1,1) adalah sebagai berikut:
pembedaan AR (1) MA (1) pertama
1.3.2 Metode Pemulusan (Smoothing)
Nilai rata-rata merupakan penaksir atau estimator yang meminimumkan nilai tengah
kesalahan kuadrat (MSE) (Assauri,1984). Jika nilai tengah tersebut dipakai sebagai
peramal maka metode peramalan memerlukan pengetahuan tentang kondisi yang
menentukan kecocokannya. Untuk nilai rata-rata, maka kondisinya harus stasioner
Jika deret waktu mengandung trend (kecenderungan) keatas atau kebawah,
atau pengaruh musiman atau keduanya sekaligus maka rata-rata sederhana tidak dapat
menggambarkan pola data tersebut.
Secara umum metode smoothing diklasifikasikan menjadi dua bagian (Assauri,
1984), yaitu:
1. Metode Rata-rata
Tujuan dari metode rata-rata adalah untuk memanfaatkan data masa lalu dalam
mengembangkan suatu sistem peramalan pada periode mendatang.
Metode rata-rata terdiri dari :
a. Nilai tengah kesalahan
b. Rata-rata bergerak tunggal (Single Moving Average)
c. Rata-rata bergerak ganda (Double Moving Average)
d. Kombinasi rata-rata bergerak lainnya
2. Metode Pemulusan (Smoothing) Eksponensial
Dalam pemulusan eksponensial terdapat satu atau lebih parameter pemulusan yang
ditentukan secara eksplisit, dan hasil pemilihan ini menetukan bobot yang
dikenakan pada nilai observasi.
Metode pemulusan eksponensial terdiri dari :
a. Smoothing Eksponensial Tunggal
b. Smoothing Eksponensial Ganda
1. Metode Linier satu parameter dari Brown
2. Metode dua parameter dari Holt
1.3.3 Metode Pemulusan yang digunakan
Untuk mendapatkan suatu hasil yang baik harus diketahui cara peramalan yang tepat.
Data deret berkala yang digunakan setelah diplot dalam grafis tidak menunjukkan pola
data trend linier dan dapat juga dilihat dari plot autokorelasi dan nilai-nilai
korelasinya. Maka metode peramalan analisa time series yang digunakan untuk
meramalkan data deret berkala yang digunakan adalah Metode Smoothing
Eksponensial Tunggal Satu Parameter.
Bentuk umum dari Metode Smoothing Eksponensial Tunggal Satu Parameter adalah:
Keterangan:
Ft+1 = ramalan satu periode kedepan
Yt = data aktual pada periode t
Ft = ramalan pada periode t
α = parameter pemulusan ( 0 < α < 1 )
1.4 Tujuan Penelitian
Tujuan dari penelitian ini adalah:
1. Membandingkan metode smoothing eksponensial dan ARIMA untuk
2. Mendapatkan persamaan estimasi peramalan menggunakan metode
smoothing eksponensial dan ARIMA.
3. Mendapatkan nilai ketepatan ramalan dari metode smoothing
eksponensial dan ARIMA.
1.5 Kontribusi Penelitian
Dengan adanya penelitian ini diharapkan dapat menambah ilmu pengetahuan
khususnya model pemulusan (smoothing) eksponensial dan ARIMA bagi penulis dan
pembaca di bidang peramalan, sehingga dapat digunakan untuk memprediksi atau
meramalkan nilai periode yang akan datang.
1.6 Metodologi Penelitian
Untuk mencapai tujuan penelitian, adapun langkah-langkah yang dilakukan adalah:
1. Memilih dan mengumpulkan data yang stasioner
2. Mengidentifikasi model sementara
3. Melakukan estimasi parameter dari model sementara
4. Melakukan diagnostik untuk menentukan apakah model memadai
BAB 2
LANDASAN TEORI
Pada bab ini akan dijelaskan teori-teori yang menjadi dasar dan landasan dalam penelitian sehingga membantu mempermudah pembahasan selanjutnya. Teori tersebut meliputi arti dan peranan metode peramalan, metode deret berkala, tahapan metode yang dipakai, uji statistik yang digunakan serta ketepatan ramalan yang digunakan.
2.1 Arti dan Peranan Metode Peramalan
Metode peramalan merupakan cara untuk memperkirakan secara kuantitatif apa yang akan terjadi pada masa yang akan datang dengan dasar data yang relevan pada masa lalu. Dengan kata lain metode peramalan ini digunakan dalam peramalan yang bersifat objektif.
Keberhasilan dari suatu peramalan sangat ditentukan oleh:
1. Pengetahuan dan teknik tentang informasi yang lalu yang dibutuhkan
2. Teknik dan metode peramalannya
Oleh karena keberhasilan tersebut, dapat dikatakan baik tidaknya suatu ramalan yang disusun ditentukan oleh metode yang digunakan juga baik tidaknya informasi kuantitatif yang digunakan. Selama informasi yang digunakan tidak dapat meyakinkan, maka hasil peramalan yang disusun akan sulit dipercaya ketepatan ramalannya.
Metode peramalan merupakan cara memperkirakan apa yang akan terjadi pada masa yang akan datang secara sistematis, sehingga metode peramalan sangat berguna untuk dapat memperkirakan secara sistematis atas dasar data yang relevan pada masa yang lalu, dengan demikian metode peramalan diharapkan dapat memberikan objektivitas yang lebih besar.
2.2 Jenis-Jenis Metode Peramalan
Berdasarkan sifatnya, peramalan dibedakan atas dua macam, yaitu:
Peramalan kualitatif adalah peramalan yang didasarkan atas data kualitatif pada masa lalu. Hasil peramalan yang dibuat sangat bergantung pada orang yang menyusunnya. Hal ini penting karena hasil peramalan tersebut ditentukan berdasarkan pemikiran yang bersifat intuisi, pendapat dan pengetahuan serta pengalaman dari orang yang menyusunnya.
2. Peramalan Kuantitatif
Peramalan kuantitatif adalah peramalan yang didasarkan atas data kuantitatif pada masa lalu. Hasil peramalan yang dibuat sangat bergantung pada metode yang dipergunakan dalam peramalan tersebut. Dengan metode yang berbeda akan diperoleh hasil peramalan yang berbeda. Baik tidaknya metode yang dipergunakan ditentukan oleh perbedaan atau penyimpangan antara hasil ramalan dengan kenyataan yang terjadi. Semakin kecil penyimpangan antara hasil ramalan dengan kenyataan yang terjadi berarti metode yang dipergunakan semakin baik.
Peramalan kuantitatif hanya dapat digunakan apabila terdapat tiga kondisi sebagai berikut (Assauri, Sofyan,1984) :
1. Adanya informasi tentang keadaan masa lalu
2. Informasi tersebut dapat dihitung dalam bentuk data
3. Dapat diasumsikan bahwa pola yang lalu akan berkelanjutan pada masa yang
akan datang.
Adapun jenis metode peramalan kuantitatif adalah sebagai berikut:
1. Metode peramalan yang didasarkan dari penggunaan analisa metode pola
antara variabel yang akan diperkirakan dengan variabel waktu, yang
merupakan deret waktu (time series)
2. Metode peramalan yang didasarkan dari penggunaan analisa pola hubungan
antara variabel yang akan diperkirakan dengan variabel lain yang
mempengaruhi yang disebut dengan metode korelasi atau sebab akibat (causal
methods).(Assauri,Sofyan,1991)
2.3 Metode Deret Berkala
Menurut Santoso (2009:13-14) dalam bukunya memberikan defenisi dari data deret berkala (time series) adalah data yang ditampilkan berdasarkan waktu, seperti data bulanan, data harian, data mingguan atau jenis waktu yang lain. Ciri data deret berkala adalah adanya rentang waktu tertentu, bukannya data pada satu waktu tertentu.
Tujuan dari metode deret berkala adalah untuk menggolongkan data, memahami sistem serta melakukan peramalan berdasarkan sifatnya untuk masa depan. Persamaan dan kondisi awal dalam peramalan runtun waktu mungkin diketahui kedua-duanya atau mungkin saja hanya salah satunya. Sehingga dibutuhkan suatu aturan yang digunakan untuk menentukan perkembangan dan keakuratan sistem.
Untuk memilih suatu metode yang tepat yang digunakan dalam mengolah data deret berkala adalah dengan mempertimbangkan jenis pola data, sehingga metode yang paling tepat dengan pola tersebut dapat diuji.
Pola data deret berkala dapat dibagi menjadi empat bagian yaitu sebagai berikut (Assauri, Sofyan,1991):
1. Pola Data Horizontal
Pola data ini terjadi bila fluktuasi disekitar nilai rata-rata yang konstan 2. Pola Data Musiman
Pola yang menunjukkan perubahan yang berulang-ulang secara periodik dalam deret waktu. Pola ini terjadi bila suatu deret dipengaruhi oleh faktor musiman, misalnya kuartal tahun tertentu, bulanan atau hari-hari pada minggu tertentu. 3. Pola Data Siklis
Pola data yang menunjukkan gerakan naik turun dalam jangka panjang dari suatu kurva trend. Terjadi bila datanya dipengaruhi oleh fluktuasi ekonomi jangka panjang seperti yang berhubungan dengan siklus bisnis.
4. Pola Data Trend
Pola yang menunjukkan kenaikan atau penurunan jangka panjang dalam data.
2.4 Analisa Deret Berkala
Makridakis (1999) menyatakan bahwa untuk menganalisa data deret berkala digunakan langkah-langkah sebagai berikut:
1. Plot Data
Memplot data secara grafis adalah hal yang paling baik untuk menganalisis data deret berkala. Hal ini dilakukan untuk melihat apakah ada gejala trend (penyimpangan nilai tengah) atau pengaruh musiman pada suatu data.
2. Koefisien Autokorelasi
Koefisien autokorelasi adalah korelasi antara deret berkala dengan deret berkala itu sendiri dengan selisih waktu (lag) 0, 1, 2 periode atau lebih. Misalnya diketahui persamaan (2.1) adalah model AR atau ARIMA (2,0,0) yang menggambarkan Yt sebagai suatu kombinasi linier dengan dua nilai sebelumnya.
Koefisien korelasi sederhana antara Yt dengan Yt-1 dapat dicari dengan menggunakan persamaan sebagai berikut:
Karena rumus tersebut secara statistik akan menyulitkan, maka dibuat asumsi untuk menyederhanakannya. Data Yt diasumsikan stasioner (baik nilai tengah maupun variansinya) sehingga kedua nilai Ytdan Yt-1dapat diasumsikan bernilai sama (dan kita dapat membuat subskrip dengan menggunakan ) dan dua deviasi standar
dapat diukur satu kali saja yaitu dengan menggunakan seluruh data Yt yang diketahui. Dengan menggunakan asumsi-asumsi penyederhanaan ini, maka persamaan (2.2) menjadi sebagai berikut:
stasioneritas. Autokorelasi untuk time-lag 1, 2, 3,..., k dapat dicari dan dinotasikan rk sebagai berikut:
Untuk menentukan apakah secara statistik suatu koefisien autokorelasi nilainya berbeda secara signifikan dari nol atau tidak, maka perlu dihitung galat standar dari rk dengan rumus sebagai berikut:
Koefisien autokorelasi dari data random mempunyai distribusi sampling yang
mendekati kurva normal dengan nilai tengah nol dan kesalahan standar . Dari nilai
kesalahan standar dan sebuah nilai interval kepercayaan dapat diperoleh sebuah
rentang nilai. Suatu koefisien autokorelasi disimpulkan tidak berbeda secara signifikan apabila nilainya berada pada rentang nilai tersebut dan sebaliknya.
3. Koefisien Autokorelasi Parsial
Dalam analisis regresi, jika variabel tidak bebas Y diregresikan kepada variabel-variabel bebas X1dan X2 maka akan muncul pertanyaan bahwa sejauh mana variabel X mampu menerangkan keadaan Y apabila mula-mula X2 dipisahkan. Ini berarti meregresikan Y kepada X2 dan menghitung galat sisa (residual error) kemudian meregresikan lagi nilai sisa tersebut kepada Xt. Di dalam analisis deret berkala juga berlaku konsep yang sama. Autokorelasi parsial digunakan untuk mengukur tingkat keeratan (association) antara Xt dan Xt-k apabila pengaruh dari time-lag 1,2,3,...,k-1 dianggap terpisah. Koefisien autokorelasi parsial berorde m didefenisikan sebagai koefisien autoregresif terakhir dari model AR(m).
Berikut ini persamaan-persamaan yang masing-masing digunakan untuk menetapkan AR(1), AR(2),..., AR(m-1) dan proses AR(m).
(2.6)
(2.7)
(2.8)
Dari persamaan-persamaan diatas dapat dicari nilai-nilai taksiran . Perhitungan yang diperlukan akan memakan banyak waktu.
Oleh karena itu, lebih memuaskan untuk memperoleh taksiran berdasarkan pada koefisien autokorelasi. Penaksiran ini dapat
dilakukan dengan mengalikan ruas kiri dan kanan persamaan (2.6) dengan Xt-1 menjadi sebagai berikut:
(2.10)
2.5 Pengujian Data
Sebelum melakukan analisa terhadap data, langkah awal yang harus dilakukan adalah pengujian terhadap anggota sampel. Pengujian ini dimaksudkan untuk mengetahui apakah data yang diperoleh dapat diterima sebagai sampel. Rumus yang digunakan untuk menentukan jumlah anggota sampel adalah:
(2.11)
Keterangan:
N’ = Ukuran sampel yang dibutuhkan
N = Ukuran sampel percobaan
Yt = Data yang akan diamati
Apabila N’< N, maka sampel percobaan dapat diterima sebagai sampel.
2.6 Metode Pemulusan (smoothing)
Metode pemulusan (Pangestu, S.1996) merupakan metode peramalan dengan mengadakan penghalusan terhadap masa lalu, yaitu dengan pengambilan rata-rata dari nilai beberapa tahun kedepan.
2.6.1 Klasifikasi dalam Metode Pemulusan
Secara umum metode smoothing diklasifikasikan menjadi dua bagian, yaitu:
1. Metode rata-rata
e. Nilai tengah kesalahan
f. Rata-rata bergerak tunggal (Single Moving Average)
g. Rata-rata bergerak ganda (Double Moving Average)
h. Kombinasi rata-rata bergerak lainnya
Tujuan dari metode rata-rata adalah untuk memanfaatkan data masa lalu dalam mengembangkan suatu sistem peramalan pada periode mendatang.
2. Metode Pemulusan (Smoothing) Eksponensial
Metode pemulusan eksponensial merupakan pengembangan dari metode average, yaitu peramalan dilakukan dengan mengulangi perhitungan secara terus menerus dengan menggunakan data yang baru. Sekelompok metode yang menunjukkan pembobotan menurun secara eksponensial terhadap nilai observasi yang lebih tua atau dengan kata lain nilai observasi yang baru diberikan bobot yang relatif besar dibandingkan dengan nilai observasi yang lebih tua.
Metode Smoothing Eksponensial terdiri atas:
a. Smoothing Eksponensial Tunggal
b. Smoothing Eksponensial Ganda
1. Metode Linier satu parameter dari Brown
2. Metode dua parameter dari Holt
c. Smoothing Eksponensial Triple
2.6.2 Tahapan Metode Pemulusan
Berikut langkah-langkah yang perlu dilakukan dalam peramalan dengan menggunakan metode pemulusan (Makridakis, 1999):
1. Memilih suatu kelompok data untuk dianalisa
2. Memilih suatu metode pemulusan, dalam hal ini dipilih metode pemulusan
eksponensial
3. Gunakan metode pemulusan untuk meramalkan data yang akan dianalisa
5. Keputusan penilaian ramalan
2.6.3 Metode Pemulusan yang Digunakan
Untuk mendapatkan suatu hasil yang baik harus diketahui cara peramalan yang tepat. Data deret berkala yang digunakan setelah diplot dalam grafis tidak menunjukkan pola data trend linier dan dapat juga dilihat dari plot autokorelasi dan nilai-nilai korelasinya. Maka metode peramalan analisa time series yang digunakan untuk meramalkan data deret berkala yang digunakan adalah Metode Smoothing
Eksponensial Tunggal Satu Parameter.
Bentuk umum dari Metode Smoothing Eksponensial Tunggal Satu Parameter adalah:
(2.12)
Keterangan:
Ft+ 1 = ramalan satu periode kedepan
Yt = data aktual pada periode t Ft = ramalan pada periode t
α = parameter pemulusan ( 0 < α < 1 )
2.6.4 Ketepatan Ramalan
Ketepatan ramalan adalah suatu hal yang mendasar dalam peramalan, yaitu bagaimana mengukur kesesuaian suatu metode peramalan tertentu untuk suatu kumpulan data yang diberikan. Dalam pemodelan deret berkala (time series) dari data masa lalu yang diramalkan situasi yang akan terjadi di masa yang akan datang. Untuk menguji kebenaran ramalan ini digunakan ketepatan ramalan.
Beberapa kriteria yang digunakan untuk menguji ketepatan ramalan antara lain :
a. ME (Mean Error) / Nilai Tengah Kesalahan
c. MSE (Mean Square Error) / Nilai Tengah Kesalahan Kuadrat
d. MPE (Mean Percentage Error) / Nilai Tengah Kesalahan Persentase
e. MAPE (Mean Absolute Percentage Error) / Nilai Tengah Kesalahan
Persentase Error:
Keterangan :
= Xt– Ft
Xt = data aktual periode t
= (100) ; kesalahan persentase periode t
Ft = nilai ramalan periode t
N = banyaknya periode
Metode peramalan yang dipilih adalah metode peramalan yang memberikan
Mean Square Error (MSE) yang terkecil.
2.7 Metode ARIMA (Box-Jenkins)
Metode ARIMA (Box-Jenkins) adalah metode peramalan yang tidak menggunakan teori atau pengaruh antar variabel seperti pada model regresi. Sehingga metode ini tidak memerlukan penjelasan mengenai mana variabel bebas atau terikat. Metode ini juga tidak perlu melihat pola data seperti pada time series decomposition, artinya data yang akan diprediksi tidak perlu dibagi menjadi komponen trend, musiman, siklis atau irregular (acak). Metode ini secara murni melakukan prediksi hanya berdasarkan data-data historis yang ada (Santoso, 2009:152).
ARIMA merupakan suatu metode yang menghasilkan ramalan berdasarkan sintesis dari pola data secara historis (Arsyad,1995). Variabel yang digunakan adalah nilai-nilai terdahulu bersama nilai kesalahannya.
series stasioner tidak punya unsur trend, maka yang ingin dijelaskan dengan metode ini adalah unsur sisanya, yaitu error. Kelompok model time series linier yang termasuk dalam metode ini antara lain: autoregressive, moving average, autoregressive-moving average, dan autoregressive integrated moving average.
Makridakis (1999) menjelaskan bahwa model Autoregressive Integrated
Moving Average (ARIMA) merupakan metode yang telah dikembangkan oleh George
dan Gwilym Jenkins yang diterapkan untuk analisis deret berkala, peramalan dan pengendalian. Metode ini paling berbeda dari metode peramalan lain karena tidak mensyaratkan suatu pola data tertentu supaya model dapat bekerja dengan baik. Apabila metode ini digunakan untuk data deret berkala yang bersifat dependen (terikat) atau berhubungan satu sama lain secara statistik maka metode ini akan bekerja dengan baik.
Metode ARIMA dinotasikan sebagai ARIMA (p,d,q)
dengan,
p = orde atau derajat autoregressive (AR)
d = orde atau derajat differencing (pembedaan) dan
q = orde atau derajat moving average (MA)
dan untuk model ARIMA musiman dinotasikan sebagai berikut: ARIMA (p, d, q) (P, D, Q)s
dengan,
(P, D, Q) merupakan bagian yang musiman dari model
P = orde atau derajat autoregressive (AR)
D = orde atau derajat differencing (pembedaan) dan
Q = orde atau derajat moving average (MA)
2.7.1 Klasifikasi Model dalam Metode ARIMA (Box-Jenkins)
Model Box-Jenkins (ARIMA) dibagi kedalam 3 kelompok, yaitu model
autoregressive (AR), moving average (MA), dan model campuran ARIMA
(autoregressive moving average) yang mempunyai karakteristik dari dua model pertama (Hendranata 2003).
1. Autoregressive Model (AR)
Bentuk umum model autoregressive ordo p (AR(p)) atau model ARIMA (p,0,0) dinyatakan sebagai berikut:
(2.13)
= suatu konstanta
= parameter autoregressive ke-p
= nilai kesalahan pada saat t
2. Moving Average Model (MA)
Bentuk umum model moving average ordo q (MA(q)) atau ARIMA (0,0,q) dinyatakan sebagai berikut:
(2.14)
Keterangan:
= suatu konstanta
sampai adalah parameter-parameter moving average
= nilai kesalahan pada saat t-k
3. Model Campuran
a. Proses ARMA
Model umum untuk campuran proses AR(1) murni dan MA(1) murni, misal ARIMA (1,0,1) dinyatakan sebagai berikut:
(2.15)
atau
(2.16)
AR(1) MA(1)
b. Proses ARIMA
Apabila nonstasioneritas ditambahkan pada campuran proses ARMA, maka model umum ARIMA (p,d,q) terpenuhi. Persamaan untuk kasus sederhana ARIMA (1,1,1) adalah sebagai berikut:
(2.17)
pembedaan AR(1) MA(1) pertama
c. Model ARIMA dan Faktor Musiman
Musiman didefinisikan sebagai suatu pola yang berulang-ulang dalam selang waktu yang tetap. Untuk data yang stasioner, faktor musiman dapat ditentukan dengan mengidentifikasi koefisien autokorelasi pada dua atau tiga time-lag
nol menyatakan adanya suatu pola dalam data. Untuk mengenali adanya faktor musiman, seseorang harus melihat pada autokorelasi yang tinggi. Secara aljabar adalah sederhana tetapi dapat berkepanjangan. Oleh sebab itu, untuk tujuan ilustrasi diambil model umum ARIMA (1,1,1)(1,1,1)4 sebagai berikut.
(2.18)
2.7.2 Tahapan Metode ARIMA
Metode ARIMA diharapkan dapat menyelesaikan suatu data time series apakah dengan proses AR murni/ ARIMA (p,0,0) atau MA murni/ ARIMA (0,0,q) atau proses ARMA/ ARIMA (p,0,q) atau proses ARIMA (p,d,q).
Langkah-langkah penerapan metode ARIMA secara berturut-turut adalah :
1. Identifikasi model
2. Penaksiran parameter
3. Pemeriksaan diagnostic
4. Peramalan
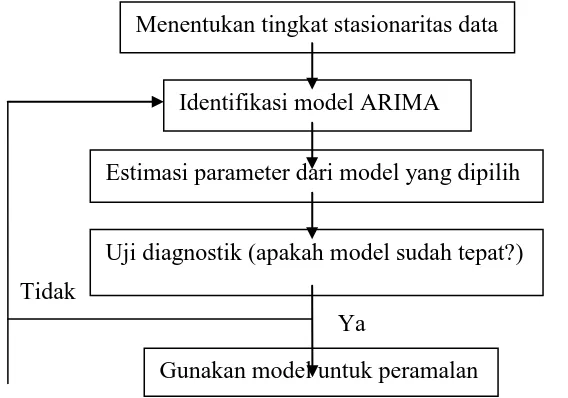
Berikut flowchart tahapan metode ARIMA (Box-Jenkins):
Tidak
Ya
Gambar 2.1 Flowchart tahapan dalam model ARIMA (Box-Jenkins)
2.7.3 Model Umum dan Uji Stasioner
Identifikasi model ARIMA
Estimasi parameter dari model yang dipilih
Uji diagnostik (apakah model sudah tepat?) Menentukan tingkat stasionaritas data
Suatu data runtun waktu dikatakan stasioner jika nilai rata-ratanya tidak berubah. Langkah pertama yang dilakukan dengan menghitung nilai-nilai autokorelasi dari deret data asli. Apabila nilai tersebut turun dengan cepat ke atau mendekati nol sesudah nilai kedua atau ketiga menandakan bahwa data stasioner di dalam bentuk aslinya. Sebaliknya, apabila nilai autokorelasinya tidak turun ke nol dan tetap positif menandakan data tidak stasioner.
Apabila data yang menggunakan model ARIMA tidak stasioner, perlu dilakukan modifikasi untuk menghasilkan data yang stasioner. Salah satu cara yang umum dipakai adalah metode pembedaan (differencing), yaitu mengurang nilai data pada suatu periode dengan nilai data periode sebelumnya. Metode Box-Jenkins hanya dapat diterapkan, menjelaskan, atau mewakili data yang stasioner atau telah dijadikan stasioner melalui proses differencing. Karena data stasioner tidak mempunyai unsur trend, maka yang ingin dijelaskan dengan metode ini adalah unsur sisanya, yaitu error. Apabila tetap tidak stasioner dilakukan pembedaan pertama lagi. Untuk kebanyakan tujuan praktis, suatu maksimum dari dua pembedaan akan mengubah data menjadi deret stasioner.
2.7.4 Identifikasi Model
Langkah selanjutnya setelah data deret waktu stasioner adalah menetapkan model ARIMA (p,d,q) yang cocok (tentatif), yaitu menetapkan berapa p, d, dan q. Jika pada pengujian stasioneritas dilakukan tanpa proses pembedaan (differencing) d maka diberi nilai 0, dan jika melalui pembedaan pertama maka bernilai 1 dan seterusnya.
Pada identifikasi model data times series yang stationer digunakan:
1. ACF atau Autocorrelation Function yaitu fungsi yang menunjukkan besarnya
korelasi antara pengamatan pada waktu ke t dengan pengamatan pada
waktu-waktu sebelumnya.
2. PACF atau Partial Autocorrelation Function yaitu fungsi yang
menunjukkan besarnya korelasi parsial antara pengamatan pada waktu ke t dengan
pengamatan-pengamatan pada waktu-waktu sebelumnya.
Dalam memilih berapa p dan q dapat dibantu dengan mengamati pola fungsi
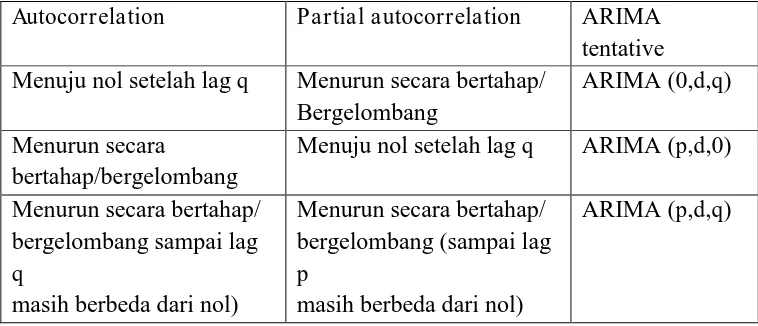
Tabel 2.1 Pola Autokolerasi dan Autokorelasi Parsial
Autocorrelation Partial autocorrelation ARIMA
tentative Menuju nol setelah lag q Menurun secara bertahap/
Bergelombang
masih berbeda dari nol)
Menurun secara bertahap/ bergelombang (sampai lag
p
masih berbeda dari nol)
ARIMA (p,d,q)
Pada umumnya, peneliti harus mengindentifikasi autokorelasi yang secara eksponensial menjadi nol. Jika autokorelasi secara eksponensial melemah menjadi nol berarti terjadi proses AR. Jika autokorelasi parsial melemah secara eksponensial berarti terjadi proses MA. Jika keduanya melemah berarti terjadi proses ARIMA (Arsyad, 1995).
2.7.5 Penaksiran Parameter Model
Setelah berhasil menetapkan identifikasi model sementara, selanjutnya parameter-parameter AR dan MA, musiman dan tidak musiman harus ditetapkan dengan cara yang terbaik. Terdapat dua cara yang mendasar untuk mendapatkan parameter-parameter terbaik dalam mencocokkan deret berkala yang sedang dimodelkan (Makridakis,1999) yaitu sebagai berikut :
1. Dengan cara mencoba-coba menguji beberapa nilai yang berbeda dan memilih
satu nilai tersebut (sekumpulan nilai, apabila terdapat lebih dari satu parameter
yang akan ditaksir) yang meminimumkan jumlah kuadrat nilai sisa (sum of
squared residuals).
2. Perbaikan secara iteratif memilih taksiran awal dan kemudian membiarkan
program komputer memperhalus penaksiran tersebut secara iteratif.
Sebagai contoh untuk keperluan estimasi maka model ARIMA (2,1,0) diubah menjadi:
Nilai estimasi parameter , diperoleh dengan
menyelesaikan perhitungan berikut:
(2,20)
2.7.6 Uji Diagnostik
Uji diagnostik yaitu memeriksa atau menguji apakah model telah dispesifikasi secara benar atau apakah telah dipilih p, d, dan q yang benar.
Berikut beberapa cara yang digunakan untuk memeriksa model:
1. Jika model dispesifikasi dengan benar, maka kesalahannya harus random atau
merupakan suatu proses antar error tidak berhubungan, sehingga fungsi
autokolerasi dari kesalahan tidak berbeda dengan nol secara statistik. Jika tidak
demikian, spesifikasi model yang lain perlu diduga dan diperiksa. Jika
pemeriksaan ini menyimpulkan bahwa kesalahannya random, spesifikasi model
yang lain bisa juga diduga dan diperiksa untuk dibandingkan dengan spesifikasi
benar yang pertama.
2. Dengan menggunakan modified Box-Pierce (Ljung-Box) Q statistic untuk menguji
apakah fungsi autokorelasi kesalahan semuanya tidak berbeda dari nol. Rumusan
statistik itu adalah:
(2.21)
dengan,
Q = hasil perhitungan statistik Box-Pierce
n = banyaknya data asli
rk = nilai koefisien autokorelasi time lag k
m = jumlah maksimum time lag yang diinginkan
Jika model cukup tepat, maka statistik Q akan berdistribusi χ2. Jika nilai Q
lebih besar dari nilai tabel Chi-Square dengan derajat kebebasan m-p-q dimana p
belum dianggap memadai. Apabila hasil pengujian menunjukkan model belum memadai, analisis harus diulangi dengan mengikuti langkah-langkah yang ada selanjutnya dengan model yang baru.
3. Dengan menggunakan t statistik untuk menguji apakah koefisien model secara
individu berbeda dari nol. Seperti halnya dalam regresi, ciri model yang baik
adalah jika semua koefisien modelnya secara statistik berbeda dari nol. Jika tidak
demikian, variabel yang ada pada koefisien tersebut seharusnya dilepas dan
spesifikasi dengan model yang lain diduga dan diuji. Jika terdapat banyak
spesifikasi model yang lolos dalam uji diagnostik, yang terbaik dari model itu
adalah model dengan koefisien lebih sedikit (prinsip parsimony).
4. Mempelajari nilai sisa (residual) untuk melihat apakah masih terdapat beberapa
pola yang belum diperhitungkan. Nilai sisa (galat) yang tertinggal sesudah
dilakukan pencocokan model ARIMA diharapkan hanya merupakan gangguan
acak. Oleh karena itu, apabila autokorelasi dan parsial dari nilai sisa diperoleh,
diharapkan akan ditemukan model yang tidak ada autokorelasi yang nyata dan
model yang tidak ada parsial yang nyata.
2.7.7 Peramalan dengan Model ARIMA
BAB 3
PEMBAHASAN
Pada bab ini akan dijelaskan perolehan data kemudian penganalisaan data dengan
metode pemulusan (smoothing) eksponensial dan metode ARIMA (Box-jenkins)
khususnya dalam bidang peramalan. Setelah dianalisa kemudian dibandingkan nilai
MAPE dari hasil peramalan dengan menggunakan kedua metode tersebut sehingga
dapat diketahui metode mana yang paling baik digunakan dalam peramalan.
3.1 Contoh Data Deret Berkala yang Digunakan
Dalam penentuan hasil ramalan dengan metode pemulusan eksponensial dan ARIMA
digunakan contoh data Indeks Harga Saham Gabungan (IHSG) selama 52 hari pada
PT. Telekomunikasi Indonesia Tbk. Sumber data yang dipergunakan diambil dari text
book (literatur). Data yang akan digunakan untuk perbandingan metode pemulusan
Tabel 3.1 Data IHSG Selama 52 Hari
Xt Xt Xt Xt
1 223,34 14 223,56 27 241,14 40 251,80
2 222,24 15 223,07 28 241,48 41 251,07
3 221,17 16 225,36 29 246,74 42 248,05
4 218,88 17 227,60 30 248,73 43 249,76
5 220,05 18 226,82 31 248,83 44 251,66
6 219,61 19 229,69 32 248,78 45 253,41
7 216,40 20 229,30 33 249,61 46 252,04
8 217,33 21 228,96 34 249,90 47 248,78
9 219,69 22 229,99 35 246,45 48 247,76
10 219,32 23 233,05 36 247,57 49 249,27
11 218,25 24 235,00 37 247,76 50 247,95
12 220,30 25 236,17 38 247,81 51 251,41
13 222,54 26 238,31 39 250,68 52 254,67
Sumber data IHSG selama 52 hari pada PT. Telekomunikasi Indonesia Tbk
3.2 Pengujian Data
Sebelum melakukan penganalisaan data terlebih dahulu dilakukan uji pengambilan
sampel. Hal ini diperlukan untuk menentukan apakah banyak sampel data dapat
diterima atau tidak.
Dari data diperoleh:
N = 52
Karena N’ < N, maka sampel percobaan dapat diterima sebagai sampel.
3.3 Analisa Data Deret Berkala
Analisa data dapat diartikan sebagai penjabaran atas pengukuran data kuantitatif
menjadi suatu penyajian yang lebih mudah dimengerti dan menguraikan masalah
secara parsial atau keseluruhan. Analisa data ini dilakukan agar diperoleh hasil
peramalan yang lebih akurat untuk periode yang akan datang.
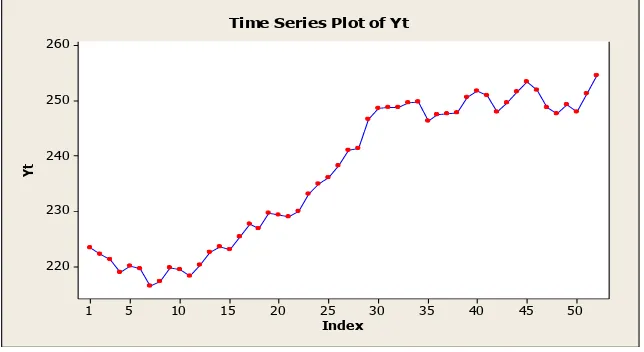
Dengan menggunakan alat bantu software komputer minitab, diperoleh plot
data yang dapat dilihat pada gambar sebagai berikut:
Index
Time Series Plot of Yt
Gambar 3.1 Plot Data
Grafik pada gambar 3.1 memperlihatkan bahwa data IHSG naik yang
menunjukkan adanya trend dalam data tersebut, karena adanya trend jelas menjadi
penyebab data tidak stasioner. Untuk menguji kestasioneran data diperlukan koefisien
dengan menggunakan persamaan (2.4) yang telah tertera pada landasan teori
sebelumnya. Persamaannya adalah sebagai berikut:
dengan adalah rata-rata dari data yang dibutuhkan.
Untuk k=1, maka diperoleh:
Nilai 0,9599 menunjukkan bahwa nilai berturut-turut Yt dengan lag 1
berkorelasi dengan yang lainnya. Adapun kesalahan standar error adalah .
Dengan tingkat kepercayaan 95%, maka 95% dari seluruh koefisien-koefisien
autokorelasi yang didasarkan pada sampel harus terletak didalam batas interval -1,96
sampai dengan 1,96. Nilai 1,96 diperoleh menggunakan tabel distribusi Z dari kurva normal dengan α=0,5 sehingga dapat dituliskan dengan:
Dengan menggunakan tingkat kepercayaan 95%, maka nilai koefisien
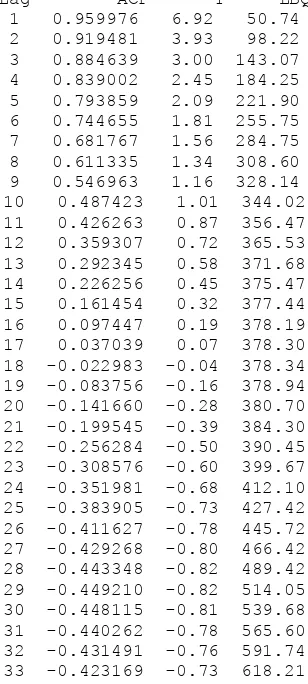
autokorelasi dalam batas interval diatas sudah stasioner. Dengan software yang sama,
Lag
(with 5% significance limits for the autocorrelations)
Gambar 3.2 Plot Autokorelasi Data
Berikut adalah tabel yang berisi nilai-nilai autokorelasi:
Tabel 3.2 Nilai-nilai autokorelasi
34 -0.414246 -0.71 644.98 35 -0.403997 -0.69 671.94 36 -0.395865 -0.67 699.44 37 -0.383445 -0.64 726.96 38 -0.365112 -0.61 753.70 39 -0.343341 -0.57 779.16 40 -0.319562 -0.52 803.06 41 -0.294233 -0.48 825.16 42 -0.268132 -0.43 845.35 43 -0.241174 -0.39 863.49 44 -0.214341 -0.35 879.62 45 -0.180177 -0.29 892.64 46 -0.144840 -0.23 902.46 47 -0.121678 -0.20 910.77 48 -0.100496 -0.16 917.86 49 -0.073479 -0.12 922.92 50 -0.052332 -0.08 926.76 51 -0.027579 -0.04 928.90
3.4. Metode Pemulusan (smoothing)
3.4.1 Identifikasi Model Peramalan Dengan Metode Pemulusan Eksponensial
Berdasarkan analisa data deret berkala dengan memplot data, autokorelasi, serta
nilai-nilai autokorelasi terhadap data dapat dilihat pola data bersifat acak. Pola data yang
bersifat acak dapat digunakan pada peramalan smoothing eksponensial tunggal dengan
Metode Smoothing Tunggal Satu Parameter. Pada dasarnya bukan model terlebih
dahulu yang ditetapkan, tetapi smoothing eksponensial sebagai suatu model yang
direncanakan. Proses perencanaan ini akhirnya terpakai setelah terlebih dahulu
dilakukan pemeriksaan yaitu sesuai dengan ketentuan literatur bahwa apabila error
dari pada data membentuk kurva pada eksponensial, maka data dapat dimodelkan
kepada smoothing eksponensial hal ini dapat kita lihat pada lampiran C.
3.4.2 Estimasi Model Peramalan Sementara
Estimasi ini berguna untuk membandingkan ukuran-ukuran ketepatan model
1. ME (Nilai tengah kesalahan)
2. MSE (Nilai tengah kesalahan kuadrat)
3. MAE (Nilai tengah kesalahan absolute)
4. MAPE (Nilai tengah kesalahan persentase absolute)
Penentuan nilai parameter (α) pemulusan yang besarnya 0 < α < 1 dengan cara trial dan error. Adapun nilai parameter pemulusan pada smoothing eksponensial yang
dipilih penulis adalah sebagai berikut:
α = 0,115 α = 0,3
α = 0,118 α = 0,5
α = 0,7
α = 0,125 α = 0,9
Pemakaian nilai-nilai parameter diatas dengan alasan nilai pemulusan tersebut
merupakan nilai-nilai parameter yang menghasilkan nilai MSE terkecil.
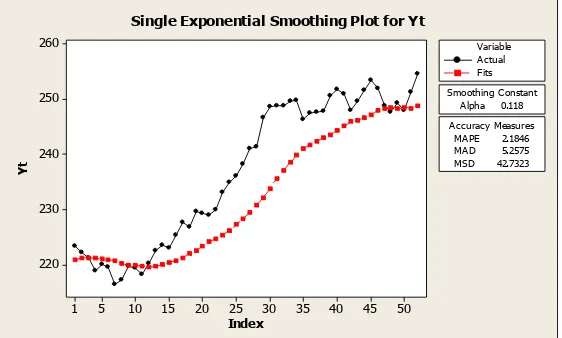
Dengan nilai parameter pemulusan α = 0,118 diperoleh:
1. Plot pemulusan peramalan, dapt dilihat pada gambar 3.3 sebagai berikut:
Index Single Exponential Smoothing Plot for Yt
Gambar 3.3 Plot Pemulusan dengan α = 0,118
2. Ukuran ketepatan peramalan, yaitu:
MAE = 5,2575
MAPE = 2,1846
Dengan nilai parameter α = 0,115 diperoleh:
1. Plot pemulusan peramalan, dapat dilihat pada gambar 3.4 sebagai berikut:
Index
Single Exponential Smoothing Plot for Yt
Gambar 3.4 Plot Pemulusan dengan α = 0,115
2. Ukuran ketepatan ramalan, yaitu:
MAE = 5,3554
MSE = 44,2597
MAPE = 2,224
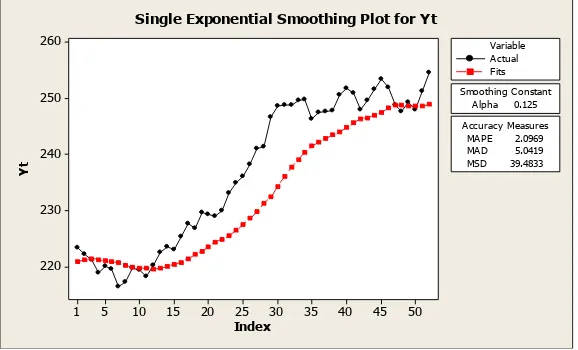
Dengan nilai parameter α = 0,125 diperoleh:
1. Plot pemulusan peramalan, dapat dilihat pada gambar 3.5 sebagai berikut:
Index Single Exponential Smoothing Plot for Yt
Gambar 3.5 Plot Pemulusan dengan α = 0,125
2. Ukuran ketepatan ramalan, yaitu:
MAE = 5,0419
MAPE = 2,0960
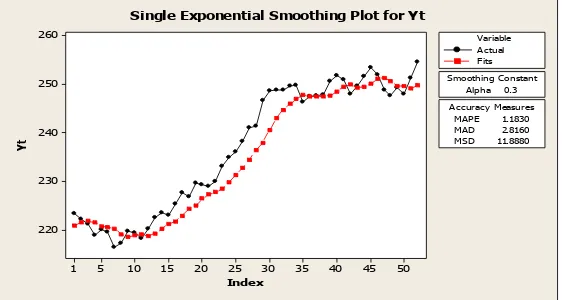
Dengan nilai parameter α = 0,3 diperoleh:
1. Plot pemulusan peramalan, dapat dilihat pada gambar 3.6 sebagai berikut:
Index
Single Exponential Smoothing Plot for Yt
Gambar 3.6 Plot Pemulusan dengan α = 0,3
2. Ukuran ketepatan ramalan, yaitu:
MAE = 2,8160
MSE = 11,8880
MAPE = 1,1830
Dengan nilai parameter α = 0,5 diperoleh:
1. Plot pemulusan peramalan, dapat dilihat pada gambar 3.7 sebagai berikut:
Index
Single Exponential Smoothing Plot for Yt
Gambar 3.7 Plot Pemulusan dengan α = 0,5
2. Ukuran ketepatan ramalan, yaitu:
MAE = 2,08581
MSE = 6,6158
Dengan nilai parameter α = 0,7 diperoleh:
1. Plot pemulusan peramalan, dapat dilihat pada gambar 3.8 sebagai berikut:
Index
Single Exponential Smoothing Plot for Yt
Gambar 3.8 Plot Pemulusan dengan α = 0,7
2. Ukuran ketepatan ramalan, yaitu:
MAE = 1,76814
MSE = 4,91671
MAPE = 0,74332
Dengan nilai parameter α = 0,9 diperoleh:
1. Plot pemulusan peramalan, dapat dilihat pada gambar 3.9 sebagai berikut:
Index Single Exponential Smoothing Plot for Yt
Gambar 3.9 Plot Pemulusan dengan α = 0,9
2. Ukuran ketepatan ramalan, yaitu:
MSE = 1,66668
MAPE = 0,70214
Dari plot pemulusan gambar diatas dapat dilihat bahwa yang menghasilkan nilai MSE terkecil yaitu pada nilai parameter pemulusan α = 0,9 dengan nilai MSE = 1,66668.
3.4.3 Menentukan Bentuk Persamaan Peramalan Metode Pemulusan
Eksponensial
Adapun langkah-langkah yang dilakukan untuk menentukan bentuk persamaan
peramalan dengan menggunakan Metode Smoothing Eksponensial Tunggal Satu
Parameter adalah sebagai berikut:
1. Menentukan nilai parameter pemulusan yang besarnya 0 < α < 1 dengan cara
trial dan error.
2. Masukkan kedalam rumus pemulusan eksponensial tunggal yaitu:
Maka persamaan peramalan yang digunakan dengan α = 0,9 adalah sebagai berikut:
Hasil perhitungan peramalan 52 nilai dapat dilihat pada tabel 3.4 sebagai
berikut:
Tabel 3.3
Perhitungan Peramalan Smoothing Eksponensial Tunggal Satu Parameter
No Xt Ft et No Xt Ft et
3.5 Metode ARIMA (Box-Jenkins)
Pengolahan data IHSG selama 52 hari dengan menggunakan metode ARIMA
(Box-Jenkins) ini akan diolah dengan menggunakan software Minitab 14. Pengolahan data
menggunakan minitab 14 ini karena selain software ini memiliki semua unsur-unsur
pengolahan data dengan ARIMA yang lengkap serta penggunaannya juga sangat
3.5.1 Identifikasi Model
Pada analisa data sebelumnya, telah dihasilkan koefisien autokorelasi beserta plot
datanya yang ditunjukkan pada gambar (3.1) dan gambar (3.2). Dari plot data dapat
dilihat data deret berkala tidak stasioner.
Untuk itu, sebelum diproses lebih jauh dengan ARIMA, maka perlu dilakukan
proses pembedaan (differencing). Langkah awal yang harus dilakukan adalah dengan
menentukan nilai d (differencing) atau pembeda mulai dari angka terkecil, yakni 1.
Hal ini sesuai dengan prinsip parsimoni yang selalu berusaha untuk memilih model
yang sederhana. Dengan demikian angka d pada model ARIMA (p,d,q) menjadi 1,
sehingga dapat diidentifikasikan bahwa pada data dapat digunakan model ARIMA
(p,1,q). tahap ini akan dilakukan pada saat proses estimasi dan diagnostik.
3.5.2 Tahap estimasi (penaksiran) parameter dan diagnostik
Proses estimasi dan diagnostik dalam minitab dapat dilakukan secara bersamaan
(sekaligus). Secara teoritis, proses estimasi dilakukan dengan memasukkan berbagai
model, namun mengacu pada prinsip parsimoni yakni menggunakan model yang
paling sederhana. Misalnya mulai dari ARIMA (1,1,0), ARIMA (0,1,1) dan
seterusnya.
Proses estimasi dan diagnostik untuk ARIMA (1,1,1) :
1. Tetap pada file Yt, klik menu STAT TIME SERIES ARIMA
Sehingga muncul kotak dialog yang harus diisi beberapa hal.
2. Pengisian :
a. Masukan variabel Yt pada kotak SERIES.
b. Abaikan kotak FIT SEASONAL MODEL, karena data tidak
c. Pada kolom NONSEASONAL, isi : AUTOREGRESIVE = 1,
DIFFERENCE = 1 dan MOVING AVERAGE = 1
d. Biarkan kotak INCLUDE CONSTANT TERM IN MODEL tetap
aktif, karena output nanti akan menampilkan konstanta untuk
persamaan ARIMA.
3. Buka kotak FORECASTS dan kemudian isi kotak LEAD dengan angka 20
(karena data yang akan diramalkan selama 20 periode), selanjutnya tekan
OK untuk kembali ke kotak dialog utama.
4. Buka kotak GRAPHS, pada bagian RESIDUAL PLOTS, aktifkan pilihan
ACF OF RESIDUALS dan PACF OF RESIDUALS. Kemudian tekan OK
untuk kembali ke kotak dialog dan tekan OK dari kotak dialog utama untuk
proses data.
ACF of Residuals for Yt
(with 5% significance limits for the autocorrelations)
Lag
PACF of Residuals for Yt
(with 5% significance limits for the partial autocorrelations)
Gambar 3.11 Output PACF model ARIMA (1,1,1)
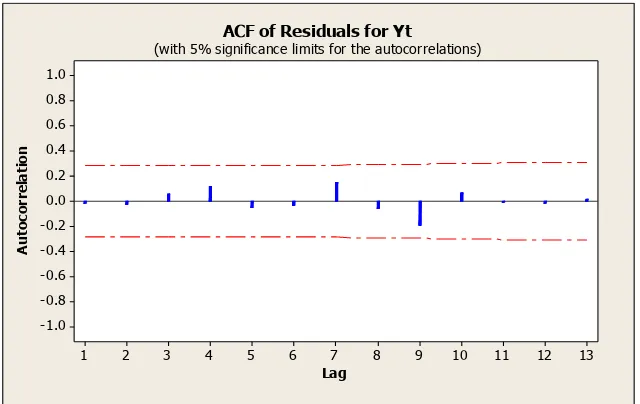
Kedua grafik pada Gambar 3.10 dan Gambar 3.11 menunjukkan data sudah
stasioner karena grafiknya tidak turun lambat dan linier. Hal ini menunjukkan bahwa
dengan melakukan pembedaan dengan lag 1, terbukti sudah tidak ada autokorelasi
lagi. Dengan demikian model ARIMA (1,1,1) sudah dapat digunakan untuk prediksi,
namun tetap perlu dibandingkan dengan model lain yang kemungkinan juga layak
untuk digunakan
Output nilai estimasi model ARIMA (1,1,1) :
Estimates at each iteration
Iteration SSE Parameters Unable to reduce sum of squares any further Final Estimates of Parameters
Number of observations: Original series 52, after differencing 51 Residuals: SS = 170.279 (backforecasts excluded)
MS = 3.547 DF = 48
Modified Box-Pierce (Ljung-Box) Chi-Square statistic Lag 12 24 36 48
Chi-Square 5.5 19.0 24.5 38.6 DF 9 21 33 45 P-Value 0.787 0.587 0.857 0.737
Nilai MS pada residual model ARIMA (1,1,1) adalah 3,547. Nilai ini nantinya
akan dibandingkan dengan nilai MS pada model-model ARIMA yang lain.
Perbandingan angka MS ini adalah bagian dari kegiatan diagnostik, khususnya untuk
mencari model dengan MS terkecil namun lolos uji grafik ACF dan PACF. Jika model
ARIMA (1,1,1) ini nantinya dipakai untuk peramalan, maka persamaan estimasinya
dengan menggunakan rumus AR yang terdiferensiasi adalah sebagai berikut :
Yt = µ + 1 (Yt-1 )+ 1 (Yt-1) + et
Dengan demikian, prediksi data ke 53 sampai 72 (20 periode ke depan)
menjadi : Yt = 0,8865- 0,4595 (Yt-1 ) - 0,6778 ( Yt-1) + et
Hasil peramalan dengan model ARIMA (1,1,1) sebagai berikut :
Forecasts from period 52
Selanjutnya akan dilakukan proses estimasi dan diagnostik untuk model
ARIMA (0,1,1), ARIMA (1,1,0), ARIMA (2,1,0), ARIMA (0,1,2), ARIMA (1,1,2),
Dari delapan model yang telah ditentukan, maka akan diambil satu model
terbaik yang nantinya akan digunakan peramalan. Pemilihan model terbaik ini
ditentukan oleh beberapa hal, yakni :
1. Model yang terpilih harus memiliki nilai probabilitas (p) pada persamaan
estimasinya dibawah 0,05.
2. Model yang terpilih harus memiliki nilai MS (mean of square ) yang
terkecil.
3. Model terpilih harus lulus uji grafik ACF dan PACF.
Dengan mempertimbangkan 3 hal diatas maka hanya model ARIMA (2,1,2)
yang memiliki nilai probabilitas (p) < 0,05. Model ARIMA (2,1,2) memiliki nilai p
pada AR(2) = 0,000 dan MA(2) = 0,000. Sehingga model ini sudah dipilih sebagai
model yang terbaik. Selanjutnya model ARIMA (2,1,1) akan diuji apakah terdapat
autokorelasi atau tidak dengan uji garfik ACF dan PACF. Berikut adalah gambar ACF
dan PACF dari model ARIMA (2, 1, 2):
ACF of Residuals for Yt
(with 5% significance limits for the autocorrelations)
Lag
PACF of Residuals for Yt
(with 5% significance limits for the partial autocorrelations)
Gambar 3.11 Grafik PACF model ARIMA (2,1,2)
Dari Gambar 3.10 dan Gambar 3.11 dapat diketahui bahwa kedua garfik
tersebut tidak turun lambat dan linier. Sehingga tidak menunjukkan adanya
autokorelasi. Sehingga model ARIMA (2,1,2) sudah layak digunakan untuk peramalan
data IHSG untuk periode berikutnya. Persamaan estimasi dengan menggunakan rumus
ARIMA (2,1,2) adalah :
Xt = (1+1 )Xt-1 - 2 Xt-2 + µ - 2 et-1 - 2 et-2 + et
Xt = (1-0,6668) Xt-1 - (-0,8582)Xt-2 + 1,5584+ (0,9233) et-1+ (0,9149 et-2+ et
Xt = 0,3332 Xt-1 + 0,8582Xt-2 + 1,5584 + 0,9233 et-1+ 0,9149 et-2+ et
Xt = 1,5584 + 0,3332 Xt-1 + 0,8582 Xt-2 + 0,9233 et-1+ 0,9149 et-2+ et
Final Estimates of Parameters
Type Coef SE Coef T P Differencing: 1 regular difference
Number of observations: Original series 52, after differencing 51 Residuals: SS = 156.534 (backforecasts excluded)
MS = 3.403 DF = 46
Modified Box-Pierce (Ljung-Box) Chi-Square statistic Lag 12 24 36 48
Chi-Square 4.1 18.3 23.1 37.6 DF 7 19 31 43 P-Value 0.767 0.501 0.844 0.704
3.6 Perbandingan Metode Pemulusan (Smoothing) dengan Metode ARIMA
(Box-Jenkins) dalam Peramalan
Kriteria keakuratan ramalan meggunakan kedua metode tersebut ditentukan dengan
menghitung nilai Mean Absolute Percentage Error (MAPE) didapat dari persamaan
di bawah ini :
PE =
x 100%dengan,
= nilai aktual pada waktu t.
= nilai ramalan pada waktu t.
MAPE =
dengan,
n = banyak data
|PE| = nilai absolute PE
Berdasarkan Lampiran B dan Lampiran C yang merupakan data hasil
pengukuran tingkat keakuratan peramalan data IHSG dengan metode pemulusan
(smoothing) eksponensial dan metode ARIMA (Box-Jenkins) diperoleh nilai MAPE
masing-masing, yaitu 0,0070 dan 0,0063. Nilai MAPE hasil peramalan dengan metode
ARIMA (Box-Jenkins) lebih kecil dibandingkan nilai MAPE dengan metode
pemulusan (smoothing). Sehingga peramalan dengan menggunakan metode ARIMA
BAB 4
KESIMPULAN DAN SARAN
4.1 KESIMPULAN
Dari hasil penelitian, pembahasan dan pengolahan data dengan software Minitab 14,
maka penulis dapat memberikan kesimpulan sebagai berikut :
1. Hasil peramalan dengan menggunakan metode ARIMA (Box-Jenkins) lebih
baik dibandingkan metode pemulusan (smoothing) karena nilai MAPE hasil
peramalannya lebih kecil.
2. Nilai MAPE hasil peramalan data Indeks Harga Saham Gabungan (IHSG)
dengan menggunakan metode Pemulusan (smoothing) dan metode ARIMA
(Box-Jenkins) masing-masing adalah 0,0070 dan 0,0063.
3. Dalam Metode Pemulusan, jika pola data yang digunakan mengandung unsur trend semakin tinggi nilai α yang digunakan, maka MSE semakin kecil. Persamaan estimasi dengan menggunakan metode pemulusan adalah:
Ft+ 1 = 0,9 Yt + 0,1 Ft
4. Model ARIMA yang terbaik adalah model ARIMA (2,1,2) karena satu-satunya
model yang memiliki nilai probabilitas (p) pada AR(2) = 0,000 dan MA(2) =
0,000. Persamaan estimasi dengan menggunakan rumus ARIMA (2,1,2) adalah
4.2 SARAN
Berdasarkan hasil penelitian, maka saran yang dapat disampaikan adalah sebagai
berikut :
1. Dalam menentukan metode peramalan yang akan di gunakan, sebaiknya
memperhatikan pola data yang akan diamati.
2. Model ARIMA yang lain perlu diteliti untuk mendapatkan hasil nilai error
DAFTAR PUSTAKA
Abraham, Bovas. 1942. Statistical Methods for Forecasting. The United States of America
Arsyad, Lincolin. 1995. Peramalan Bisnis. Jakarta: Gralia Indonesia.
Assauri, Sofyan. 1984. Metode Peramalan. Jakarta: Gramedia.
Djalal, Nachrowi dan Hardius. 2004. Teknik Pengambilan Keputusan. Jakarta: PT.Gramedia India Sarana Indonesia
Ginting, Rosnani. 2007. Sistem Produksi. Yogyakarta: Graha Ilmu.
Isyuanita, Astin. 1999. PERAMALAN PENJUALAN PRODUKSI MINUMAN
DENGAN METODE ARIMA (BOX-JENKINS). Skripsi : Universitas Sumatera
Utara.
Makridakis, Spyros. , Steven C. Wheelwright, dan Victor E. McGee. 1999. Metode dan Aplikasi Peramalan. Jakarta: Erlangga.
Marlina. 1999. PERAMALAN PENJUALAN PRODUKSI LATEKS PADA PT.SRI
RAHAYU AGUNG KEBUN KOTARI KABUPATEN SERDANG BEDAGAI.
Skripsi : Universitas Sumatera Utara
Muis, Saludin. 2008. Meramal Pergerakan Harga Saham. Yogyakarta : Graha Ilmu.
Sarwoko. 2007. Statistik Inferensi. Yogyakarta: Penerbit Andi.
Santoso, Singgih. 2009. Business Forecasting. Jakarta: Elex Media Komputindo.
Hendranata, Anton. ARIMA (Autoregressive Moving Average), Manajemen
KeuanganSektor Publik FEUI, 2003.
http://daps.bps.go.id/file_artikel/77/arima.pdf. Diakses tanggal 28 April 2011.
http://www.scribd.com/doc/51766119/ARIMA-sekilas. Diakses tanggal 28 April 2011.
LAMPIRAN A : UJI KECUKUPAN DATA
Periode Yt Yt2 Periodee Yt Yt2
1 223,34 49.880,76 27 241,14 58.148,50
2 222,24 49.390,62 28 241,48 58.312,59
3 221,17 48.916,17 29 246,74 60.880,63
4 218,88 47.908,45 30 248,73 61.866,61
5 220,05 48.422,00 31 248,83 61.916,37
6 219,61 48.228,55 32 248,78 61.891,49
7 216,40 46.828,96 33 249,61 62.305,15
8 217,33 47.232,33 34 249,90 62.450,01
9 219,69 48.263,70 35 246,45 60.737,60
10 219,32 48.101,26 36 247,57 61.290,90
11 218,25 47.633,06 27 247,76 61.385,02
12 220,30 48.532,09 38 247,81 61.409,80
13 222,54 49.524,05 39 250,68 62.840,46
14 223,56 49.979,07 40 251,80 63.403,24
15 223,07 49.760,22 41 251,07 63.036,14
16 225,36 50.787,13 42 248,05 61.528,80
17 227,60 51.801,76 43 249,76 62.380,06
18 226,82 51.447,31 44 251,66 63.332,76
19 229,69 52.757,50 45 253,41 64.216,63
20 229,30 52.578,49 46 252,04 63.524,16
21 228,96 52.422,68 47 248,78 61.891,49
23 233,05 54.312,30 49 249,27 62.135,53
24 235,00 55.225,00 50 247,95 61.479,20
25 236,17 55.776,27 51 251,41 63.206,99
26 238,31 56.791,66 52 254,67 64.856,81
LAMPIRAN B: PERHITUNGAN TINGKAT KEAKURATAN ANTARA DATA AKTUAL DAN RAMALAN DENGAN METODE ARIMA
(BOX-JENKINS)
Periode Data Aktual
( )
Ramalan
(
Error PE = x
100%
|PE|
1 223.34
-
-
-
-
2 222.24 223.34 -1.1 -0.00495 0.00495
3 221.17 223.736 -2.56603 -0.0116 0.0116
4 218.88 221.299 -2.41901 -0.01105 0.01105
5 220.05 220.1905 -0.14052 -0.00064 0.00064
6 219.61 220.4757 -0.86574 -0.00394 0.00394
7 216.4 220.7539 -4.35394 -0.02012 0.02012