SISTEM ANALISIS KONTEN WEBSITE MENGGUNAKAN
DATA CLICKSTREAM DAN ALGORITME APRIORI PADA
REKAMAN SESI LOG
(STUDI KASUS PADA KEMENTERIAN PERTANIAN INDONESIA)SUPRIYADI
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGORBOGOR 2013
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa tesis berjudul Sistem Analisis Konten
Website Menggunakan Data Clickstream pada Rekaman Sesi Log adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apapun kepada perguruan tinggi manapun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam daftar pustaka di bagian akhir tesis ini. Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor. Bogor, November 2013 Supriyadi NRP G651110581 * Pelimpahan hak cipta atas karya tulis dari penelitian kerja sama dengan pihak luar IPB harus didasarkan pada perjanjian kerjasama yang terkait
RINGKASAN
SUPRIYADI. Sistem Analisis Konten Website Menggunakan Data Clickstream pada Rekaman Sesi Log. Dibimbing oleh YANI NURHADRYANI dan ARIF IMAM SUROSO
Situs Web (Website) merupakan satu set halaman web yang saling berhubungan, biasanya meliputi sebuah homepage, umumnya terletak pada server yang sama, disiapkan dan dipelihara sebagai kumpulan informasi oleh perorangan, kelompok atau organisasi. Penggalian data (data mining) pada sebuah server
website mengenai data clickstream biasanya dilakukan oleh pengembang dan
pemilik web tersebut. Secara umum ada tiga tahap penting dalam penggalian data
website yang perlu dilakukan, langkah pertama yaitu untuk membersihkan data
sebagai iterasi awal dan mempersiapkan untuk mengambil data pola penggunaan oleh pengguna situs Web. Langkah ke dua adalah mengekstrak pola penggunaan dari data yang sudah diperoleh, dan langkah ke tiga adalah untuk membangun sebuah model prediktif didasarkan pada data yang sudah diekstrak sebelumnya.
Penelitian dilakukan dengan mengambil data sekunder Website Kementrian Pertanian Republik Indonesia atau Departemen Pertanian Republik Indonesia (Deptan) dengan menggunakan interval waktu log server selama dua bulan yaitu bulan November 2012 s.d. Desember 2012. Pemilihan data tersebut hanya sebagai sampel untuk dianalisis guna pengembangan perangkat lunak yang bisa mengolah data access log untuk periode kapan pun.
Pengolahan data dan proses preprocessing data log menggunakan perangkat lunak yang dikembangkan berbasis web dan disimpan dalam DBMS mysql. Pengembangan perangkat lunak komputer tersebut menggunakan analisis database dengan mengacu pada analisis keranjang belanja dengan minimum
support dan confidence yang ditentukan sebesar 1% dan 0.2%. Dari hasil analisis
diperoleh halaman yang memiliki akses tertinggi adalah halaman index1.php. Walaupun /index1.php merupakan halaman yang memiliki akses tertinggi hal tersebut tidak menunjukan halaman tersebut paling menarik kontennya karena /index1.php adalah defaultnya halaman utama website Deptan. Halaman yang memiliki hits tertinggi selain halaman utama (/index1.php) adalah halaman /event.php. /respon.php, /pengumuman/cover_es.htm, /wap/index.php, /tampil.php, /diralamatskpd/tampil.php dan /news/detail.php. Pada proses scan ke2 diperoleh tujuh kaidah assosiasi yang memenuhi. Untuk pengembangan konten yang berkaitan dengan link maka bisa ditempatkan sugesti link dari halamanhalaman yang memenuhi kaidah ke halaman yang memiliki hits yang rendah. Website Deptan memiliki ratarata kunjungan halaman web (hits) yang relatif merata untuk setiap halamnnya, hal tersebut dilihat dari rata-rata nilai
support dan confidence yang kecil, dan yang tertinggi nilai support-nya adalah
sekitar 8%.
SUMMARY
SUPRIYADI. Sistem Analisis Konten Website Menggunakan Data Clickstream pada Rekaman Sesi Log. Supervised by YANI NURHADRYANI and ARIF IMAM SUROSO Website is a set of interconnected web pages, usually includes a homepage, generally located on the same server, prepared and maintained as a collection of information by an individual, group or organization . Data mining of clickstream data on a website server is usually done by the developer and owner of the web . In general there are three important stages in the data mining website that needs to be done, the first step is to clean up the data as the initial iteration and prepare to take the data usage patterns by users of our site. Step two is to extract usage patterns from the data obtained, and the third step is to build a predictive model based on the data that has been extracted earlier.
The study was conducted by taking secondary data Website of Kementrian Pertanian Republik Indonesia atau Departemen Pertanian Republik Indonesia (Deptan) with the interval of time using server log for two months ie November 2012 sd December 2012. The selection of the data is only as a sample to be analyzed in order to develop software that can process data access logs for the period at any time.
Data processing and process log data preprocessing software developed using webbased and stored in a MySQL DBMS. The computer software development using database analysis with reference to the market basket analysis with minimum support and confidence were set at 1 % and 0.2 %. From the results obtained by analysis of the page that has the highest access is index1.php page. Although /index1.php a page that has the highest access pages it does not reveal the most attractive because of its content / index1.php is the default main page of the Deptan Website. Page that has the highest hits in addition to the main page (/index1.php) is a page /event.php, /respon.php, /announcements /cover_es.htm, /wap/index.php, /tampil.php, /diralamatskpd/tampil.php and /news/detail.php . On the 2nd scan obtained seven rules of association that meets . For the development of content related to the link could be placed suggestion links from pages that meet the rule to a page that has a low hits. Deptan website has an average web page visits (hits) are relatively evenly distributed to each halamnnya, it is seen from the average value of support and confidence are small , and the highest value of his support is around 8 %. Keywords : Clickstream data, Market basket analysis, Database analysis.
@ Hak Cipta Milik IPB, Tahun 2013
Hak Cipta Dilindungi Undangundang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik atau tinjauan suatu masalah ; dan pengutipan tidak merugikan kepentingan IPB Dilarang mengumumkan dan memperbanyak sebagian atau seluruh karya tulis ini dalam bentuk apapun tanpa izin IPBSISTEM ANALISIS KONTEN WEBSITE MENGGUNAKAN
DATA CLICKSTREAM DAN ALGORITME APRIORI PADA
REKAMAN SESI LOG
(STUDI KASUS PADA KEMENTRIAN PERTANIAN INDONESIA)SUPRIYADI
TesisSebagai Salah Satu Syarat untuk Memperoleh Gelar Magister Komputer
pada
Program Studi Ilmu Komputer
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
Judul Penelitian : Sistem Analisis Konten Website Menggunakan Data Clickstream dan Algoritme Apriori Pada Rekaman Sesi Log. Nama : Supriyadi NIM : G651110581 Disetujui oleh Komisi Pembimbing Dr Yani Nurhadryani, SSi, MT Dr Arif Imam Suroso, MSc Ketua Anggota Diketahui oleh, Ketua Program Studi Dekan Sekolah Pascasarjana Ilmu Komputer Dr Yani Nurhadryani, SSi, MT Dr Ir Dahrul Syah, MScAgr Tanggal Ujian : 26 September 2013 Tanggal Lulus:
Puji syukur penulis panjatkan kehadirat Allah SWT atas segala karunia-Nya sehingga tesis ini berhasil diselesaikan. Tema yang diambil dalam penelitian ini adalah rekaman data sesi log web server, dengan judul Sistem Analisis Konten
Website Menggunakan Data Clickstream dan Algoritme Apriori Pada Rekaman
Sesi Log. Tesis ini disusun sebagai salah satu syarat untuk memperoleh gelar Magister Komputer pada Program Ilmu Komputer Sekolah Pascasarjana Institut Pertanian Bogor.
Pada kesempatan ini penulis menyampaikan penghargaan dan ucapan terima kasih kepada :
1. Ibu Dr Yani Nurhadryani, SSi, MT dan Bapak Dr Arif Imam Suroso, MSc selaku komisi pembimbing yang telah meluangkan waktu, tenaga dan pikiran sehingga tesis ini dapat diselesaikan.
2. Bapak Dr Irman Hermadi, MS selaku dosen penguji yang telah memberikan arahan dan masukan untuk perbaikan tesis ini.
3. Kedua orangtuaku Bapak (alm) dan Ibu tercinta, yang selalu tak kenal lelah mendukung dan mendoakan siang dan malam.
4. Keluargaku tercinta yang selalu membantu dan berdoa siang dan malam untuk kelancaran penyusunan laporan tesis ini.
5. Staff Pengajar Program Studi Ilmu Komputer
6. Staff Administrasi Departemen Ilmu Komputer atas kerja samanya membantu kelancaran proses administrasi hingga akhir studi.
7. Pimpinan dan staff Pusdatin Kementerian Pertanian Indonesia yang telah membantu dalam memberikan arahan di tempat penelitian dan menyediakan data utama dalam penelitian ini.
8. Rekan-rekan di STMIK Kharisma Karawang
9. Rekan-rekan MKOM13 yang setia berdiskusi dan membantu dengan ikhlas.
Penulis menyadari bahwa masih banyak kekurangan dalam penulisan tesis ini, namun demikian penulis berharap tesis ini dapat bermanfaat untuk bidang ilmu komputer, bidang pendidikan dan bidang umum lainnya.
Bogor, November 2013
DAFTAR TABEL ix DAFTAR GAMBAR x DAFTAR LAMPIRAN xi 1 PENDAHULUAN 1 Latar Belakang 1 Perumusan Masalah 2 Tujuan Penelitian 2 Manfaat Penelitian 2 Ruang Lingkup 3 2 TINJAUAN PUSTAKA 5 Data Clickstream 5 Web Mining 5
Analisis Keranjang Belanja 7
SDLC Model 8
3 METODE PENELITIAN 9
Bahan Penelitian 9
Alur Penelitian 9
Memilih Data Log 10
Pra Proses 11
Transformasi Data 18
Penemuan dan Analisis Pola 24
4 HASIL DAN PEMBAHASAN 31
Pemecahan data Log dan Konversi ke file .csv 31
Membersihkan Data dan Pemilihan String 31
Struktur Data Pohon dan Membentuk Node 32
Analisis Database 34
Analisis Asosiasi 34
Pengembangan Sistem Komputer untuk Pengolahan Data 37
5 SIMPULAN DAN SARAN 46
Simpulan 46
Saran 46
DAFTAR PUSTAKA 47
Halaman 1 Spesifikasi berkas bahan penelitian 9 2 Penjelasan format string log Web Server Apache 11 3 Pengelompokan data log dan penggunaannya 13 4 Jenisjenis status HTP 15 5 Contoh format data log yang akan diteliti 17 6 Penguraian String Request 19 7 Contoh kumpulan file yang diakses oleh pegguna (host) 20 8 Pengkodean struktur direktori file dalam halaman web sebagai node 22 9 Rangkaian (sequential) akses halaman Web 22 10 Sebaran frekuensi akses halaman web 23 11 Pemisahan string dengan spasi kosong 24 12 Pemisahan string useragent dengan spasi kosong 25 13 Daftar subdomain situs web Deptan 25 14 Keterangan penulisan url 26 15 Contoh transaksi akses node 28 16 Data hasil pemecahan file access_log 31 17 Tahapan pembersihan data transaksi web Deptan 31 18 Daftar node 33 19 Hasil scan/prunning pertama kandidat 1itemset 35 20 Hasil scan/prunning kedua kandidat 2itemset 36 21 Hasil perhitungan support dan confidence kaidah asosiasi 2itemset 37 22 Definisi Use Case 38 23 Uraian Skenario Impor Data Log 39 24 Uraian Skenario Bersihkan Data Log 40 25 Uraian Skenario Membuat Node 40 26 Uraian Skenario Membuat Node 41 27 Uraian Skenario Membuat 1Itemset Node 42 28 Uraian Skenario Membuat 2Itemset Node 42
Halaman 1 Tahapan utama proses penelitan 9 2 Tahapan rinci proses penelitan 10 3 Ilustrasi Proses Pemecahan data log 11 4 Ilustrasi Proses konversi ke file csv 12 5 Contoh representasi struktur pohon Web Deptan 24 6 Struktur data Pohon 30 7 Skema pembentukan tabel log 37 8 Use Case Diagram 43 9 Class Diagram 44
DAFTAR LAMPIRAN
Halaman 1 Sequence Diagram 50 2 Tampilan antarmuka aplikasi 53 3 Struktur data tabel 56 4 Panduan menjalankan Aplikasi 581 PENDAHULUAN
Latar Belakang
Situs Web (Website) merupakan satu set halaman web yang saling berhubungan, biasanya meliputi sebuah homepage, umumnya terletak pada server yang sama, disiapkan dan dipelihara sebagai kumpulan informasi oleh perorangan, kelompok atau organisasi. Semakin hari semakin banyak pengguna yang mengakses Website, hal tersebut mengakibatkan terjadinya globalisasi informasi. Pengguna bisa dengan bebas mengunggah dan mengunduh data dalam berbagai bentuk berkas digital melalui jaringan internet sesuai dengan kemampuan dan kebutuhan informasi yang dicari.
Hal utama yang melatarbelakangi penelitian ini adalah perilaku pengunjung sangat bervariasi tapi keseluruan aktifitasnya terekam semua oleh Web Server dan disimpan dalam bentuk file offline. File tersebut dikenal dengan dama file
access.log atau session.log yang isinya terdiri dari data aktifitas log suatu server
web. Data tersebut merupakan rekaman setiap kali pengguna melakukan perubahan proses klik (clickstream) terhadap link yang ada dalam halaman web, dapat dianalisis, digali (mining) menjadi suatu informasi bagi pengembang web dalam mengembangkan webnya.
Penggalian data (data mining) pada sebuah server website mengenai kontennya biasanya dilakukan oleh pengembang dan pemilik web tersebut. Secara umum ada tiga tahap penting dalam penggalian data website yang perlu dilakukan (Srivastava et al. 2000), langkah pertama yaitu untuk membersihkan data sebagai iterasi awal dan mempersiapkan untuk mengambil data pola penggunaan oleh pengguna situs Web. Langkah ke dua adalah mengekstrak pola penggunaan dari data yang sudah diperoleh, dan langkah ke tiga adalah untuk membangun sebuah model prediktif didasarkan pada data yang sudah diekstrak sebelumnya. Seperti yang dilakukan oleh Montgomery et al. (1999) yang dalam penelitiannya lebih menekankan pada rute (path) klik yang dilakukan oleh pengguna Website dengan melakukan penambangan data (mining) secara real time. Kemudian Sule Gunduz dan Tamer Ozsu (2003) juga melakukan analisis Clickstream untuk mengembangkan model prediksi dengan merepresentasikan prilaku pengguna situs Web dalam bentuk pohon prilaku (tree). Penelitian tersebut lebih menekankan pada penelahan data yang berkaitan dengan prilaku pengguna situs
web, sehingga data rekaman prilaku pengguna situs Web tersebut dapat digunakan
pihak pengembang web.
Dengan memadukan analisis empiris, Tingliang Huang (2012) memanfaatkan analisis Clickstream untuk melakukan penelitian pada bidang
Management Inventory dengan fokus bahasan pada manfaat penelaahan pengguna
Web untuk mengelola data persediaan barang dengan menggunakan analisis empiris.
bagian dari teknik dalam Web Usage Mining (WUM), yang bisa dikembangkan sebagai Business Intelligence (BI) dengan melakukan klasifikasi pengguna (Abdurrahman et al. 2009). Sehingga mendorong para peneliti untuk ikut berpartisipasi dalam mengembangakan perangkat lunak untuk menganalisis data
clickstream. Ada yang menggunakan Pemrograman Java (Dinucă 2012) dan
algoritme apriori untuk mengembangkan aplikasi komputer yang bisa menggali informasi dari data clickstream. Karena besarnya data teks yang diolah dibutuhkan banyak teknik untuk mereduksi waktu pengolahan data access log, seperti menggunakan teknik komputasi paralel (Wang Tong et al. 2005).
Perumusan Masalah
Proses pembentukan data clickstream terjadi secara kontinyu tanpa henti selama web server dinyalakan, dan semua aktifitas log direkam semua walaupun sebenarnya bisa diatur sesuai kebutuhan, sehingga data yang akan dijadikan bahan kajian akan bercampur dengan data lainnya. Dengan melihat data clickstream tersebut dapat diperoleh rumusan masalah seperti berikut:
1. Proses perekaman data clickstream dilakukan tanpa henti dalam kurun waktu pengujian tertentu, sehingga file teks yang terbentuk sangat banyak.
2. Bagaimana mengelompokan dan membersihkan data clickstream sesuai dengan kebutuhan?
3. Bagaimana memetakan file dan folder yang ada dalam website ke dalam bentuk struktur data pohon (tree)?
Tujuan Penelitian
Penelitian ini merupakan salah satu penelitian pada bidang Web Usage
Mining, yang bertujuan untuk :
1. Menghasilkan data yang akurat sebagai acuan untuk mengembangkan konten Website agar pada pengembangan berikutnya bisa menjadi lebih efisien sesuai dengan kebutuhan user.. 2. Mengembangkan perangkat lunak yang dapat membantu mengelola data Clickstream menjadi data statistik yang mudah dimengerti dan bermanfaat untuk melihat tingkat frekuensi akses terhadap halaman Web. Manfaat Penelitian Hasil akhir penelitian ini diharapkan dapat bermanfaat bagi beberapa pihak terkait yaitu: 1. Pengembang Website
Dalam mengelola dan mengembangkan isi dari halaman web nya agar memudahkan user dalam melakukan navigasi.
2. Pihak manajemen atau pengelola suatu instansi
Data statistik mengenai konten web yang dihasilkan bisa dijadikan acuan dalam mengambil kebijakan untuk pengembangan konten website institusinya. 3. Peneliti bidang Web Mining
Bisa dijadikan bahan informasi tambahan bagi para peneliti tentang implementasi Algoritme Apriori dalam menganalisis keterhubungan antar halaman Website.
Ruang Lingkup Penelitian dan Bahan Penelitian
Berkaitan dengan rentang waktu pelaksanaan penelitian ini, maka perlu dibatasi ruang lingkup penelitiannya supaya lebih terarah, yaitu sebagai berikut:
1. Penelitian difokuskan pada satu area Web Mining yaitu Web Usage Mining
(WUM).
2. Aplikasi yang dikembangkan hanya untuk melakukan proses preprocessing dan pemodelan data untuk WUM menggunakan algoritme Apriori.
3. Bahan data yang akan diolah hanya untuk data clickstream dari Apache Web
Server.
4. Hasil akhirnya berupa data statistik yang bisa dijadikan acuan dalam pengembangan isi dari Website
5. Menganalisis data offline yakni bukan menganalisis data realtime secara langsung. Data berasal dari file yang diambil dari file akses log (access.log) yang diambil dari Web Server Departemen Pertanian Indonesia (Deptan). 6. Dalam pelaksanaannya penelitian ini akan menggunakan bahan dan alat
sebagai berikut:
a. Data dasar adalah file access.log
b. Perangkat pengolah data menggunakan satu set sistem komputer dengan menggunakan Processor Intel Atom N450(1.66Ghz)
c. Web Server yang digunakan adalah yang berbasis Open Source yaitu Apache Web Server
d. Editor teks menggunakan Open Office, Blue Fish dan Geany
e. Bahasa Pemrograman bebasis Web (HTML, XML, JavaScript, AJAX, PHP dan CSS)
2 TINJAUAN PUSTAKA
Data ClickstreamClickstream yaitu proses pencatatan atau perekaman data klik pada layar
komputer yang dilakukan oleh pengguna pada saat browsing web atau menggunakan aplikasi perangkat lunak dengan lokasi analisis pada area halaman
web atau aplikasi, login pada klien atau di dalam web server, router, atau server proxy (Moe WW et al. 2004), atau Clickstream adalah serangkaian link yang
sudah diklik oleh pengguna ketika mengakses halaman web (freedictionary 2013). Data clickstream ini biasanya disimpan dalam sebuah file access.log yang berada di web server. Setiap pengguna melakukan proses klik terhadap menu yang ada di monitor dalam hal ini halaman web, maka Web server akan merekamnya dan disimpan dalam file access.log. Sehingga akan banyak informasi dan data yang tersiimpan di dalamnya dan bisa dianalisis menggunakan metode yang ada dalam
data mining. Proses menganalisis data clickstream merupakan bagian dari Web Usage Mining (WUM) yang melakukan discovery data dengan menggunakan data sekunder yang ada pada web server, yaitu meliputi data access log, browser log, user profiles, registration data, user session, cookies, user queries dan juga data mouse click (Abdurrahman et al. 2006). Web Mining Dengan adanya Website kita bisa menyampaikan informasi kepada khalayak ramai dengan mudah dan cepat tanpa batas wilayah, sehingga siapapun bisa mengasksesnya dengan bebas pula, kecuali yang menyertakan beberapa syarat akses. Sedangkan cara atau teknik data mining untuk mengekstrak data dari data
Web dikenal dengan istilah Web Mining (Srivastava 2005).
Ada tiga kelompok yang termasuk ke dalam Web Mining, yaitu :
1. Web Content Mining (WCM)
Merupakan kelompok Web Mining dengan melakukan proses ekstraksi menggunakan data yang berasal dari isi suatu dokumen Website (J. Srivastava 2005). isi suatu dokumen web tersebut bisa berupa teks, gambar, audio, video dan data record dalam bentuk list dan tabel. Hasil dari penelitian bidang WCM biasanya berupa klasifikasi Website dan implementasi pada mesin pencarian seperti Google.
2. Web Structure Mining (WSM)
Merupakan teknik dalam Web Mining dengan mengambil atau melakukan ekstraksi data yang berasal dari struktur halaman atau struktur dokumen sebuah Website (Srivastava, 2005). Halaman dianggap sebagai node dan
G={V,E}, dengan G adalah graph, V adalah verteks dan E adalah edge. Penelitian bidang WSM sangat bermanfaat untuk mengetahui pola prilaku pengguna atau pengunjung suatu Website.
3. Web Usage Mining (WUM)
Merupakan teknik analisis dan pencarian pola dalam clickstream dan keterhubungan data yang terkumpul atau terbentuk pada saat terjadi interaksi pengguna dengan sumber daya Website (Mobaser 2007). Secara umum ada tiga tahapan proses yang dilakukan dalam WUM, yaitu:
a. Pengumpulan data dan pra proses (data collection and preprocessing) Pada tahap ini data Clickstream dibersihkan dan dipecah ke dalam beberapa kumpulan data transaksi pengguna yang menggambarkan aktifitas pengguna ketika mengakses Website. Pada tahapan ini yang diperhatikan adalah sumber dan tipe data (penggunaan data, isi data, struktur data dan pengguna data), tahapan pra proses (pembersihan data, identifikasi pageview, identifikasi pengguna, sessionization, pelengkapan jalur atau path dan integrasi data) b. Pemodelan data untuk WUM Untuk memudahkan dalam menentukan dan menganalisis pola maka perlu dilakukan proses pemodelan data yang sudah dibersihkan ke dalam bentuk yang lebih mudah dikerjakan dengan menggunakan teknik data mining, biasanya dimodelkan dalam bentuk matriks, yaitu matriks transaksi dan matriks pageview. c. Penemuan Pola (pattern discovery) dan Analisis Pola (pattern analysis) Pada tahap ini dilakukan pencarian dan analisis pola biasanya menggunakan perumusan analisis yang ada dalam ilmu statistik yang meliputi analisis session, analisis klaster, analisis assosiasi dan korelasi menggunakan algoritme Apriori.
Adapun fungsi dari WUM dapat dijelaskan sebagai berikut (Pramudiono 2004): 1. Personalisasi
Melakukan personalisasi website sesuai dengan kebutuhan dan keinginan pengguna
2. Meningkatkan performa website
WUM menyediakan fasilitas untuk mendeteksi kepuasan pengguna, analisis trafik data, transmisi jaringan serta distribusi data, sehingga apabila dianalisis dengan baik akan dihasilkan bahan rujukan untuk meningkatkan performa website menjadi lebih baik.
3. Modifikasi dan pengembangan situs
Untuk mengembangkan website dibutuhkan data yang akurat mengenai kekurangan dan kelebihan suatu website, timbal balik informasi (feed back) yang diberikan oleh pengguna website sangat berguna dalam mengambil keputusan rancang ulang website.
4. Karakteristik penggunaan
Analisis Keranjang Belanja (Market Basket Analysis)
Fungsi association rules seringkali disebut dengan analisis keranjang belanja (Market Basket Analysis) yang digunakan untuk menemukan relasi atau korelasi diantara himpunan itemitem. Analisis keranjang belanja adalah analisis dari kebiasaan membeli customer dengan mencari asosiasi dan korelasi antara itemitem berbeda yang diletakan customer dalam keranjang belanjanya. Analisis keranjang belanja dapat digunakan secara efektif pada bidang Web Mining terutama untuk mengilustrasikan aturan assosiasi yang terdapat pada data log, misalnya terdapat aturan sebagai berikut:
Halaman X and Halaman Y implies Halaman Z (X and Y => Z), memiliki nilai
confidence 90%, hal ini berarti jika seirang pengguna atau pengunjung
mengunjungi halaman A dan B maka terdapat kemungkinan 90% pengguna tersebut akan mengunjungi halaman Z, sehinnga perlu disediakan link langsung dari halaman A taau B ke C. Salahsatu algoritme yang umum digunakan dalam analisis keranjang belanja adalah Algoritme Apriori, yaitu algoritme analisis keranjang pasar yang digunakan untuk menghasilkan aturan asosiasi (Goswami et al. 2010) dengan tujuan utama adalah untuk mencari maksimal frequent itemset (didapatkan juga frequent itemset yang tidak maksimal). Istilah penting dalam Algoritme Apriori : a. Itemset adalah himpunan dari itemitem (dalam hal ini adalah halaman web) yang terekam pada data log.
Itemset I = {I1, I2, I3,... In}
b. Transaksi atau Kejadian N merupakan sekumpulan n transaksi
N = {T1, T2, T3,... Tn}; T N, T I. ∈ ⊆
c. Kaidah asosiasi adalah peluang bahwa itemitem tertentu hadir bersama sama.
X > Y dimana X dan Y adalah itemset
d. Support, supp(X) dari suatu itemset X adalah rasio dari jumlah transaksi
dimana suatu itemset muncul dengan total jumlah transaksi.
Supp(X) = TNTX ; TX adalah Transaksi atau kemunculan X, X I;⊆ TN adalah jumlah total transaksi.
e. Setiap itemset X diasosiasikan dengan himpunan transaksi TX ={T N | T ∈ ⊇ X} yang merupakan himpunan transaksi yang memuat itemset X.
f. Confidence (keyakinan) adalah nilai probabilitas adanya itemset X pada
suatu transaksi, maka juga ada itemset Y pada transaksi tersebut.
Conf(X → Y) = Supp X ∪Y Supp X ;
System Development Life Cycle (SDLC ) Model
Bahan dan data yang akan diolah dalam penelitian ini merupakan data teks yang berukuran besar dan ada kemungkinan banyak variasi untuk beberapa Web
Server yang berbeda. Agar hasil penelitian ini bisa berkelanjutan maka perlu
dikembangkan sebuah sistem yang terkomputerisasi untuk menggantikan pengolahan data manual ke dalam bentuk terkomputerisasi, sehingga sistem yang dikembangkan bisa berlaku untuk data yang berasal dari berbagai Web Server Apache yakni bukan hanya yang berasal dari Web Server Departemen Pertanian. Akan tetapi dalam pengembangannya Sistem ini menggunakan data sampel yang berasal dari data akses log Web Server departemen Pertanian Indonesia.
Pengembangan sistem dilakukan dengan mengimplementasikan tahapan pengembangan perangkat lunak yaitu SDLC Model (System Development Life
Cycle). Adapun tahapannya terdapat 5 fase (Satzinger et al 2007) yaitu: 1. Tahap Perencanan (Project Plannnng Phase) 2. Tahap Analisis (Analysis Phase) 3. Tahap Desain (Design Phase) 4. Tahap Implementasi (Implementation Phase) 5. Tahap Dukungan/Perawatan (Support Phase) Gambar 2.2 Tahapan pengembangan sistem
3 METODE PENELITIAN
Bahan PenelitianPenelitian dilakukan dengan mengambil data sekunder Website Kementerian Pertanian Republik Indonesia atau Departemen Pertanian Republik Indonesia (Deptan) dengan menggunakan interval waktu log server selama dua bulan yaitu bulan November 2012 s.d. Desember 2012. Pemilihan data tersebut hanya sebagai sampel untuk dianalisis guna pengembangan perangkat lunak yang bisa mengolah data access log untuk periode kapan pun.
Data clickstream disimpan oleh web server dalam berkas access.log dengan spesifikasi data seperti berikut: Tabel 1. Spesifikasi berkas bahan penelitian Identitas Keterangan Nama berkas access_log Jenis berkas Teks Sifat berkas Offline Jenis Web server Apache 2 Lokasi penyimpanan /log/apache2/access_log Ukuran berkas 632,15 MB Alamat url http://www.deptan.go.id Alur penelitian Secara umum penelitian ini dilakukan dengan mengikuti tiga tahapan utama seperti yang tertera pada gambar 3.1 berikut (Mobasher 2007): Gambar 1. Tahapan utama proses penelitan Gambar 3.1 hanya mememuat tahapan umum dalam metodologi penelitian ini, tahapan yang lebih khusus akan dijelaskan secara lebih rinci pada bagianbagian selanjutnya dengan mengikuti tahapan rinci seperti tertera pada gambar 3.2 berikut ini yang merupakan penjabaran dari tahapan umum penelitian di atas: Pengumpulan data dan pra proses (Data collection and preprocessing) Pemodelan data untuk WUM (Data Modeling for Web Usage Mining) Penemuan dan Analisis Pola (Pattern discovery and analysis)
66.249.73.7 - - [04/Nov/2012:04:08:33 +0700] GET /bpsdm/spp-kupang/index.php HTTP/1.1 200 37803 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; )"
66.249.73.7 - - [04/Nov/2012:04:08:35 +0700]
"GET /pengumuman/LombaHPS30_bkp/PANDUAN_LOMBA_POSTER.pdf HTTP/1.1" 200 97568 "-" "DoCoMo/2.0 N905i(c100;TB;W24H16) )"
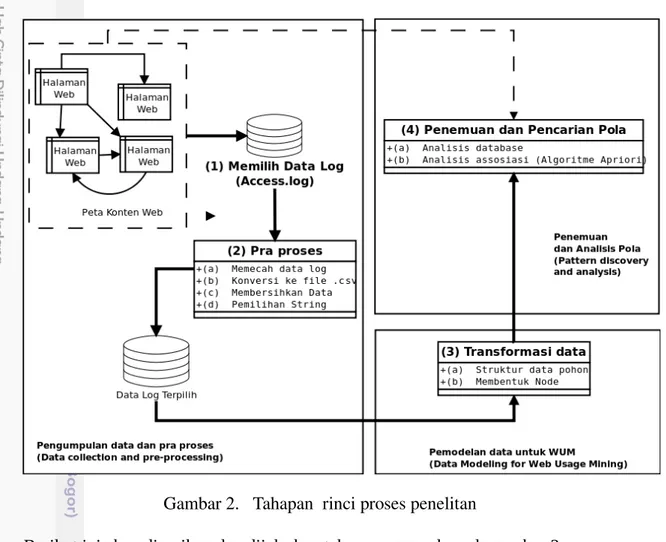
Gambar 2. Tahapan rinci proses penelitan
Berikut ini akan diuraikan dan dijelaskan tahapan yang ada pada gambar 2.
1. Memilih data Log
Server yang dianalsis adalah menggunakan Opensource Web Server yaitu
Apache. Web Server Apache menyimpan semua data log dalam file access.log seperti contoh berikut:
String log di atas mengikuti format log pada web server Apache (http://httpd.apache.org) dengan penjelasan sebagai berikut :
Log sederhana : LogFormat "%h %l %u %t \"%r\" %>s %b"
Kombinasi Log : LogFormat "%h %l %u %t \"%r\" %>s %b \"% {Referer}i\" \"%{User-agent}i\""
Tabel 2. Penjelasan format string log Web Server Apache
No String Penjelasan Keterangan
1 %h IP Address client atau remote host yang meminta layanan ke server host
2 %l Merupakan proses identifikasi log user atau client log identification
3 %u Merupakan userid dari seseorang yang meminta
dokumen berdasarkan otentikasi HTTP userid 4 %t Waktu ketika permintaan diterima oleh server time
5 \"%r\" Berisi sebaris permintaan yang ditulis oleh client, diapit
dalam tanda petik dua request line 6 %>s Kode status yang diberikan oleh server kepada client status
7 %b Ukuran data atau dokumen yang diberikan kepada client byte
8 \%"{Referer}i"%\ Rujukan HTTP request header yang telah dirujuk atau
diikutsertakan oleh client referer identification 9 \"%{User-agent}i\" Identifikasi browser yang digunakan oleh client user agent
identification
2. Pra Proses a. Memecah data log
Data access log merupakan file teks yang berukuran sangat besar, apalagi jika
Website yang dianalisis jumlah transaksinya cukup tinggi. Besarnya data teks
tersebut menyebabkan waktu untuk membuka data sangat lama, bahkan ada beberapa teks editor yang tidak bisa membuka file access.log tersebut karena terlalu banyaknya baris yang akan dibaca. Sebagai bahan pembanding jumlah maksimum baris data yang bisa ditampung oleh openoffice spreadsheet dan Microsoft Excel adalah 1024x1024 = 10242 = 220 = 1048576 baris, sedangkan data log jumlah barisnya bisa melebihi 2 jutaan baris. Teknik pemecahan data ini tidak seperti memotong file terkompresi rar atau teknik spliter (seperti HJSplit) yang tidak melihat isi file tersebut yang penting file dipotong-potong dengan ukuran tertentu dan untuk membukanya harus disatukan terlebih dahulu. Teknik yang dilakukan disini adalah dengan cara membuka terlebih dahulu keseluruhan file teks dengan editor khusus, kemudian untuk beberapa baris tertentu dipotong (cut) dan dipindahkan ke file yang baru untuk disimpan, berikut ini gambaran prosesnya: Gambar 3. Ilustrasi Proses Pemecahan data log Baris 1 Baris 2 Baris 3 Baris 4 Baris 5 Baris 6 Baris 1 Baris 2 Baris 5 Baris 6 Baris 3 Baris 4 access.log access.log_1 access.log_2 access.log_3
b. Konversi ke file .csv (Comma Separated Value)
Agar data bisa diolah lebih fleksibel, maka diubah terlebih dahulu ke dalam bentuk .csv, karena dari format csv bisa dikonversi kebentuk lain, seperti format
sql atau spreadsheet.
Gambar 4. Ilustrasi Proses konversi ke file csv
c. Membersihkan data
Pada tahapan ini dilakukan proses pembuangan string atau variabel yang tidak dibutuhkan dalam penelitian, hal ini sangat diperlukan karena data yang dianalisis merupakan data string yang cukup besar, sehingga apabila variabel yang tidak dibutuhkan dibuang maka waktu untuk pemrosesan data bisa lebih efisien. Data yang akan dibersihkan merupakan data log yang sudah dipecah dan sudah dalam bentuk csv. Karkteristik dari file csv adalah hanya memiliki satu string pemisah (sparator) dan satu string penutup tiap fields.
Contoh baris data yang belum bersih :
$string= 66.249.73.7 04/Nov/2012:04:11:40] GET /wap/index.php? option="component" HTTP/1.1
Seanjutnya apabila dengan kode PHP kita akan memisahkan string diatas berdasarkan sparator spasi kosong maka kodenya seperti berikut :
$data = str_getcsv($string ,' ');
Artinya data $string akan dipisahkan dengan spasi kosong menjadi array $data berikut ini:
0 1 2 3 4
66.249.73.
7 04/Nov/2012:04:11:40] GET /wap/index.php?option="component"
HTTP/1.1 Akan tetapi yang akan jadi masalah adalah pada indek yang ke3 yaitu $data[3] = /wap/index.php?option="component", yaitu adanya tanda petik ganda dan hal ini akan menyebabkan intruksi str_ getcsv menolaknya karena tanda petik ganda (") dan tanda petik(') adalah default penutup (enclosed) fields dari file csv. Oleh karena itu maka perlu dilakukan pembersihan tanda petik ganda dan tanda petik sebelum dimuat ke dalam database. access.log access.log_1 access.log_2 access.log_3 access.log_1.csv access.log_2.csv access.log_3.csv
Selain berdasarkan tanda petik di atas, data log juga dibersihkan berdasarkan kelompok atau tipe dari berkas (file) sebagai berikut:
Tabel 3. Pengelompokan data log dan penggunaannya
No Jenis berkas Keterangan Penggunaan
1 .css (teks) Cascading Style Sheet, merupakan kelompok file untuk
mempercantik tampilan halaman web.
diabaikan 2 .js (teks) Javascript, merupakan client side script yang
berfungsi untuk membuat halaman web lebih interaktif, contohnya untuk membuat fungsi zoom gambar atau
mesagebox ketika mau menghapus email.
diabaikan
3 .xml (teks) eXtensible Markup Language, merupakan berkas atau
bahasa untuk mengatur struktur data web dalam susunan tag yang independen.
diabaikan
4 .bmp (gambar)
Bitmap, merupakan file gambar yang sering disertakan
dalam halaman web
diabaikan 5 .gif (gambar) Graphics Interchange Format, merupakan file gambar
yang sering disertakan dalam halaman web
diabaikan 6 .jpg (gambar) Join Photographis, merupakan file gambar yang sering
disertakan dalam halaman web
diabaikan 7 .png
(gambar)
Portable Network Graphics, merupakan file gambar
yang sering disertakan dalam halaman web
diabaikan 8 .odt/.doc
(teks)
Open Document Text/ Document, merupakan file
dokumen teks (words).
digunakan
9 .ods/.xls (teks)
Open Document Sheet / Excels, merupakan file sheet (Spread sheet).
digunakan
10 .pdf (teks) Portable Data Format, merupakan file teks portable
yang biasanya readonly.
digunakan
11 .mp3 (audio) Media Player 3, file audio untuk melengkapi halaman web
diabaikan 12 .mp4/.mpeg
(.video)
Media Player 4/ Media Player Expert Graphics, file
video untuk melengkapi halaman web
diabaikan 13 .swf
(multimedia)
Flash file, merupakan berkas audio video biasanya
dalam bentuk animasi
diabaikan 14 .jsp (teks) Java Server Page, merupakan Server Side Script untuk
mengembangkan Website.
digunakan
15 .asp (teks) Active Server Page, merupakan Server Side Script
untuk mengembangkan Website.
digunakan
16 .html (teks) Hypertext Markup Language, merupakan Client Side Script untuk mengembangkan Website.
digunakan
17 .php (teks) PHP Hypertext Preprocessor, merupakan Server Side
Script untuk mengembangkan Website.
No Jenis berkas Keterangan Penggunaan
18 .sql (teks) Structured Query Language, file backup database
dalam bentuk teks
diabaikan 19 .ico (gambar) Icon, merupakan file gambar untuk dijadikan logo
ikon setiap halaman web
diabaikan
Keterangan: digunakan = digunakan sebagai data atau bahan penelitian diabaikan = tidak digunakan sebagai data atau bahan penelitian
d. Pemilihan String
Pada penelitian ini berfokus pada proses penelusuran frekuensi kunjungan terhadap setiap halaman Web yang ada pada halaman web http://www.deptan.go.id, sehingga dari data log yang ada hanya akan diambil beberapa data yang dibutuhkan. Seperti sudah dijelaskan sebelumnya bahawa dalam rangkaian format string log sederhana terdapat susunan seperti berikut :
LogFormat "%h %l %u %t \"%r\" %>s %b \ %"{Referer}i"%\
\"%{User-agent}i\""
Dari format string log di atas tidak semua blok string diambil, hanya beberapa saja yang digunakan sesuai dengan kebutuhan penelitian ini maka yang digunakan sebagai bahan adalah:
LogFormat "%h %t \"%r\" %>s
Pengambilan empat kelompok string di atas berdasarkan keperluan data yang akan diolah, yaitu:
a) %h merupakan kelompok string yang menggambarkan host yang mengakses
web server, adapun identitas yang dicatat adalah berupa alamat host atau IP Address. data ini sangat bermanfaat untuk mengetahui siapa yang mengakses
halaman web.
b) %t merupakan runtunan waktu (time series) yang dilakukan oleh tiap host dalam satu sesi log, data ini sangat bermanfaat untuk membentuk satu rangkaian graph per sekali log untuk tiap host.
c) %r adalah sekumpulan string yang berisi metode transfer data (POST/GET) dan permintaan (request) halaman web oleh pengguna, data ini akan dijadikan sebagai bahan dasar untuk dijadikan node dalam rangkaian graph. d) %s adalah status yang dihasilkan oleh protokol HTTP (Hyper Text Transfer
Protocol) mengenai berhasil tidaknya proses komunikasi antara peminta
layanan (client) dan pemberi layanan web (web server). Secara garis besar terdapat lima kelompok kode status HTTP, yaitu:
1) Kelompok 1xx (Provisional response)
merupakan keolmpok kode status yang menyatakan status sementara ketika sedang terjadi proses permintaan
2) Kelompok 2xx (successful)
3) Kelompok 3xx (Redirected)
Menyatakan bahwa permintaan tidak error atau secara umum bisa diterima, akan tetapi lokasi yang dituju tidak ada atau sedang dialihkan. 4) Kelompok 4xx (Request Error)
Permintaan yang diberikan tidak bisa diproses. 5) Kelompok 5xx (Server Error)
Permintaan tidak bisa diproses karena server yang dituju sedang error. Berikut ini adalah daftar kode status HTTP secara detil yang diambil dari sumber http://support.google.com/webmasters dan http://hc.apache.org :
Tabel 4. Jenis-Jenis status HTTP
No Kode Deskripsi
1 100 (Continue) Mengindikasikan bagian permintaan pertama sudah diterima, dan menunggu untuk istirahat, dan client harus melanjutkan permintaannya. 2 101 (Switching protocols) client meminta untuk bertukar protolol dan server mengetahunya untuk merealisasikan. 3 200 (Successful) Server berhasil memroses permintaan dari client.
4 201 (Created) Server berhasil memroses permintaan dari client kemudian server membuat resource baru 5 202 (Accepted) Permintaan diterima oleh server tapi tidak dapat diproses.
6 203 (Non-authoritative information) Server berhasil diproses, akan tetapi iformasi yang diberikan berasal dari sumber atau server lain. 7 204 (No content) Permintaan berhasil diproses, akan tetapi server tidak memberikan hasil apa-apa. 8 205 (Reset content) Permintaan berhasil diproses, akan tetapi server tidak memberikan hasil apa-apa, perbedaan dengan 204, status 205 membutuhkan reset page
oleh client, contoh membersihkan form input.
9 206 (Partial content) Server berhasil memroses sebagaian dari GET request. 10 300 (Multiple choices)
Server memiliki beberapa cara untuk menyelelesaikan permintaan,
Server bisa meilih sendiri atau memeberikan pilihan kepada client dalam meyelesaikan proses permintaannya.
11 301 (Moved permanently) Permintaan dari client dialihkan secara permanen ke sumber lain. 12 302 (Moved temporarily)
Server merespon permintaan dengan mengalihkan ke sumber lain, akan tetapi untuk selanjutnya client harus melakukan permintaan ke lokasi aslinya.
13 303 (See other location) Memberikan respon bahwa seharusnya client melakukan GET request tersendiri ke lokasi lain untuk memperoleh informasi.
14 304 (Not modified)
Halaman yang diminta belum dimodifikasi sejak permintaan terakhir, pada saat terjadi seperti ini server tidak memberikan hasil apa-apa, sangat berguna untuk mennghemat bandwith.
No Kode Deskripsi
diminta. 16 307 (Temporary redirect)
Server merespon permintaan dengan mengalihkan ke sumber lain, akan tetapi untuk selanjutnya client harus melakukan permintaan ke lokasi aslinya tapi untuk permintaan GET dan HEAD request akan otomatis dialhkan ke lokasi lain.
17 400 (Bad request) Server tidak memahapi perintah atau permintaan dari client.
18 401 (Not authorized) Permintaan yang diberikan membutuhkan otorisasi.
19 403 (Forbidden) Permintaan terkena blok (refusing), biasanya berkaitan dengan hak akses folder web 20 404 (Not found) Server tidak menemukan halaman yang diminta.
21 405 (Method not allowed) The method specified in the request is not allowed.
22 406 (Not acceptable) The requested page can't respond with the content characteristics requested. 23 407 (Proxy authentication required) Mirip dengan 401, akan tetapi otentikasinya menggunakan proxy. 24 408 (Request timeout) Server kehabisan waktu tunggu untuk satu permintaan.
25 409 (Conflict) Server memiliki konflik ketika menyelesikan permintaan.
26 410 (Gone)
Terjadi apabila resource yang diminta sudah dibuang secara permanen sama dengan 404 tapi terkadang 404 tidak akurat dalam melakukannya dan harus dipadukan dengan 301 untuk mengetahui lokasi barunya. 27 411 (Length required) Server tidak bisa menerima permintaan tanpa menyertakan panjang isi header fields. 28 412 (Precondition failed) Server tidak menemukan prakondisi yang disertakan pada saat melakukan permintaan. 29 413 (Request entity too large) Server tidak bisa memroses permintaan karena terlalu besar untuk diproses. 30 414 (Requested URI is too long) Pa jang url yang diminta terlalu panjang.
31 415 (Unsupported media type) Format permintaan tidak didukung oleh halaman yang diminta. 32 416 (Requested range not satisfiable) Rentang permintaan tidak tersedia di server.
33 417 (Expectation failed) Server tidak dapat menyetujui persyaratan Expect request-header. 34 500 (Internal server error) Server error dan tidak dapat melayani permintaan client.
35 501 (Not implemented) Server tidak memiliki fungsionalitas untuk menyelesaikan permintaan.
36 502 (Bad gateway) The server was acting as a gateway or proxy and received an invalid response from the upstream server. 37 503 (Service unavailable) Server tidak tersedia bisa dikarenakan overloaded atau down untuk perawatan. 38 504 (Gateway timeout) Server bertindak sebagai gateway atau proxy dan tidak menerima
No Kode Deskripsi
permintaan tepat waktu dari server upstream.
39 505 (HTTP version not supported) Server tidak mendukung versi dari HTTP protocol yang digunakan oleh client.
Adanya pembuangan sebagian string log dikarenakan adanya beberapa pertimbangan yaitu :
1. %l (log identification)
Merupakan identitas log pengguna, apabila host yang tidak punya id maka statusnya akan berisi string "" atau kosong, sehingga apabila string ini dimasukan dalam penelitian, akan banyak host yang tidak terekam pada saat pembersihan data log.
2. %b (byte),
Pada penelitian ini tidak memperhatikan ukuran data yang terjadi selama proses kunjungan web atau transaksi, semua dianggap sebagai satu proses. 3. %"{Referer}i"% Adalah identifikasi referensi url sebelumnya atau rujukan HTTP request header yang telah dirujuk atau diikutsertakan oleh client dalam penelitian ini tidak diperlukan karena tidak akan meneliti mengenai rute dari path. 4. "%{User-agent}i Identifikasi browser yang digunakan oleh pengguna, dalam penelitian ini yang akan diteliti adalah frekuensi akses terhadap halaman web tanpa memandang alat yang digunakan untuk mengakses website.
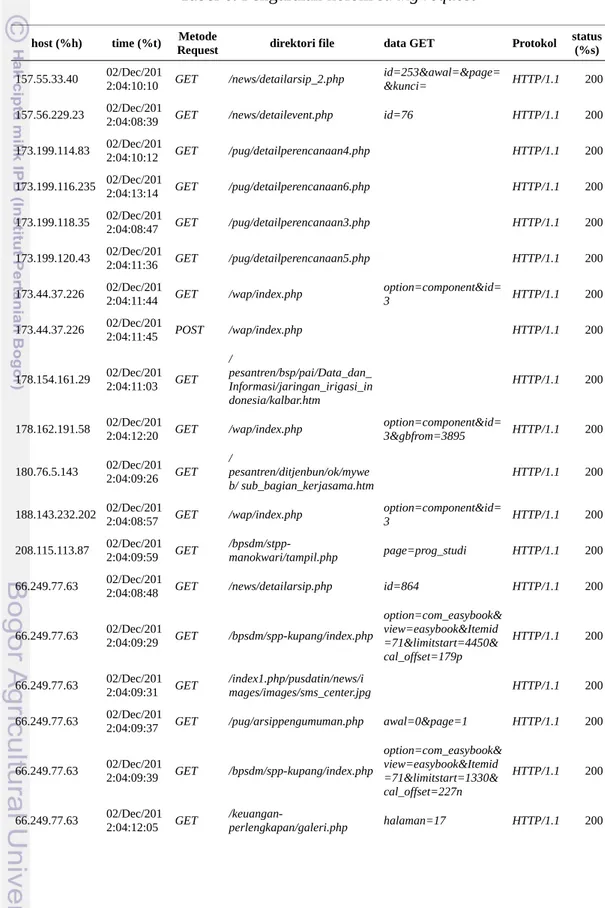
Berikut ini contoh data log dengan format "%h %t \"%r\" %>s yang diambil untuk beberapa host yang mengakses web server pada tanggal 02 Desember 2012:
Tabel 5. Contoh format data log yang akan diteliti
host (%h) time (%t) string request (%r) status
(%s)
157.55.33.40 02/Dec/2012:04:10:10 GET /news/detailarsip_2.php?
id=253&awal=&page=&kunci= HTTP/1.1
200 157.56.229.23 02/Dec/2012:04:08:39 GET /news/detailevent.php?id=76 HTTP/1.1 200 173.199.114.83 02/Dec/2012:04:10:12 GET /pug/detailperencanaan4.php HTTP/1.1 200 173.199.116.235 02/Dec/2012:04:13:14 GET /pug/detailperencanaan6.php HTTP/1.1 200 173.199.118.35 02/Dec/2012:04:08:47 GET /pug/detailperencanaan3.php HTTP/1.1 200 173.199.120.43 02/Dec/2012:04:11:36 GET /pug/detailperencanaan5.php HTTP/1.1 200 173.44.37.226 02/Dec/2012:04:11:44 GET /wap/index.php?option=component&id=3
HTTP/1.1 200
host (%h) time (%t) string request (%r) status (%s) 178.154.161.29 02/Dec/2012:04:11:03 GET /pesantren/bsp/pai/Data_dan_Informasi/jaringa n_irigasi_indonesia/kalbar.htm HTTP/1.1 200
178.162.191.58 02/Dec/2012:04:12:20 GET /wap/index.php?
option=component&id=3&gbfrom=3895 HTTP/1.1 200 180.76.5.143 02/Dec/2012:04:09:26 GET /pesantren/ditjenbun/ok/myweb/sub_bagian_ke rjasama.htm HTTP/1.1 200
188.143.232.202 02/Dec/2012:04:08:57 GET /wap/index.php?option=component&id=3
HTTP/1.1 200
188.143.232.202 02/Dec/2012:04:08:58 POST /wap/index.php HTTP/1.1 200 208.115.113.87 02/Dec/2012:04:09:59 GET /bpsdm/stpp-manokwari/tampil.php?
page=prog_studi HTTP/1.1 200 66.249.77.63 02/Dec/2012:04:08:48 GET /news/detailarsip.php?id=864 HTTP/1.1 200 66.249.77.63 02/Dec/2012:04:09:29 GET /bpsdm/spp-kupang/index.php?
option=com_easybook&view=easybook&Itemi d=71&limitstart=4450&cal_offset=179p HTTP/1.1 200 66.249.77.63 02/Dec/2012:04:09:31 GET /index1.php/pusdatin/news/images/images/sms _center.jpg HTTP/1.1 200 e. Integrasi database
Setelah semua data disiapkan dalam format csv, maka perlu ada sinkronisasi dengan database yang akan dirancang agar data log tersebut bisa dintegrasikan atau diimpor ke dalam database. Secara umum isi tabel dalam database meliputi tiga kelompok yaitu: 1. Kelompok tabel untuk menampung data mentah atau data awal 2. Kelompok tabel untuk menampung data yang sudah dibersihkan 3. Kelompok tabel untuk menampung data hasil pengolahan dengan teknik data mining (Algoritme Apriori) 3. Transformasi Data a. Struktur Data Pohon
Kolom data sebagai bahan awal pembentukan node adalah kolom request line. Dari data request tersebut bisa diambil beberapa informasi yang selanjutnya bisa dijadikan sebagai node dalam struktur data pohon. Adapun alasan kolom request yang diambil untuk pembentukan node adalah:
a. Pada kolom tersebut berisi metode request (POST/GET), file dan halaman web yang diakses.
b. Seluruh tipe data yang diakses atau diunduh akan dicatat tanpa terkecuali. Berikut ini contoh proses transformasi data log menjadi struktur data pohon dengan diawali dari data tabel 3.4:
Tabel 6. Penguraian kolom string request
host (%h) time (%t) RequestMetode direktori file data GET Protokol status (%s)
157.55.33.40 02/Dec/2012:04:10:10 GET /news/detailarsip_2.php id=253&awal=&page=&kunci= HTTP/1.1 200 157.56.229.23 02/Dec/2012:04:08:39 GET /news/detailevent.php id=76 HTTP/1.1 200 173.199.114.83 02/Dec/2012:04:10:12 GET /pug/detailperencanaan4.php HTTP/1.1 200 173.199.116.235 02/Dec/2012:04:13:14 GET /pug/detailperencanaan6.php HTTP/1.1 200 173.199.118.35 02/Dec/2012:04:08:47 GET /pug/detailperencanaan3.php HTTP/1.1 200 173.199.120.43 02/Dec/2012:04:11:36 GET /pug/detailperencanaan5.php HTTP/1.1 200 173.44.37.226 02/Dec/2012:04:11:44 GET /wap/index.php option=component&id=3 HTTP/1.1 200 173.44.37.226 02/Dec/2012:04:11:45 POST /wap/index.php HTTP/1.1 200
178.154.161.29 02/Dec/2012:04:11:03 GET / pesantren/bsp/pai/Data_dan_ Informasi/jaringan_irigasi_in donesia/kalbar.htm HTTP/1.1 200
178.162.191.58 02/Dec/2012:04:12:20 GET /wap/index.php option=component&id=3&gbfrom=3895 HTTP/1.1 200
180.76.5.143 02/Dec/2012:04:09:26 GET /
pesantren/ditjenbun/ok/mywe
b/ sub_bagian_kerjasama.htm HTTP/1.1 200
188.143.232.202 02/Dec/2012:04:08:57 GET /wap/index.php option=component&id=3 HTTP/1.1 200 208.115.113.87 02/Dec/2012:04:09:59 GET /bpsdm/stpp-manokwari/tampil.php page=prog_studi HTTP/1.1 200 66.249.77.63 02/Dec/2012:04:08:48 GET /news/detailarsip.php id=864 HTTP/1.1 200
66.249.77.63 02/Dec/2012:04:09:29 GET /bpsdm/spp-kupang/index.php
option=com_easybook& view=easybook&Itemid =71&limitstart=4450& cal_offset=179p
HTTP/1.1 200
66.249.77.63 02/Dec/2012:04:09:31 GET /index1.php/pusdatin/news/i mages/images/sms_center.jpg HTTP/1.1 200 66.249.77.63 02/Dec/2012:04:09:37 GET /pug/arsippengumuman.php awal=0&page=1 HTTP/1.1 200
66.249.77.63 02/Dec/2012:04:09:39 GET /bpsdm/spp-kupang/index.php
option=com_easybook& view=easybook&Itemid =71&limitstart=1330& cal_offset=227n
HTTP/1.1 200
host (%h) time (%t) RequestMetode direktori file data GET Protokol status (%s)
66.249.77.63 02/Dec/2012:04:12:54 GET /
pusdatin/statistik/metodologi/
tar.pdf HTTP/1.1 404
Untuk pembentukan struktur data pohon perlu dibatasi data yang akan diolah agar tidak semua data masuk yaitu sebagai berikut:
1. Batasan runtunan waktu dalam hal ini dibatasi dengan rentang per satu hari, dengan asumsi apabila berganti hari maka rangkaian rute akan dibarukan lagi, hal ini akan menimbulkan permasalahan ketika ada pengguna yang mengakses web dimulai beberapa saat sebelum pergantian hari dan belum mengakhiri proses akses ketika berganti hari misalnya dari pukul 23:00 sampai dengan pukul 02:00 dini, akan tetapi berdasarkan data yang ada kemungkinan tersebut sangat kecil.
2. Data request yang digunakan adalah yang berhasil diproses oleh web server yaitu dengan kode status 200.
3. Data yang dikirim oleh metode GET tidak diikutsertakan karena dalam penelitian ini tidak membahas sampai ke elemen permintaan (query) tapi hanya pada level akses halaman, sehingga metode GET dan POST dianggap sama.
Berdasarkan kebutuhan dan batasan data di atas maka tabel 3.4 dengan menggunakan runtunan waktu per tanggal 02 Desember 2012 dengan status 200 dapat disederhanakan sebagai berikut:
Tabel 7. Contoh Kumpulan file yang diakses oleh pengguna (host) host (%h) direktori file
157.55.33.40 /news/detailarsip_2.php 157.56.229.23 /news/detailevent.php 173.199.114.83 /pug/detailperencanaan4.php 173.199.116.235 /pug/detailperencanaan6.php 173.199.118.35 /pug/detailperencanaan3.php 173.199.120.43 /pug/detailperencanaan5.php 173.44.37.226 /wap/index.php 173.44.37.226 /wap/index.php 178.154.161.29 /pesantren/bsp/pai/Data_dan_Informasi/jaringan_irigasi_indonesia/k albar.htm 178.162.191.58 /wap/index.php 180.76.5.143 /pesantren/ditjenbun/ok/myweb/ sub_bagian_kerjasama.htm 188.143.232.202 /wap/index.php 208.115.113.87 /bpsdm/stpp-manokwari/tampil.php 66.249.77.63 /news/detailarsip.php
host (%h) direktori file 66.249.77.63 /bpsdm/spp-kupang/index.php 66.249.77.63 /pug/arsippengumuman.php 66.249.77.63 /bpsdm/spp-kupang/index.php 66.249.77.63 /pesantren/berita/berita/alsin/ tabel_ujialsin.htm 66.249.77.63 /feati/diskusi/index.php 66.249.77.63 /keuangan-perlengkapan/galeri.php 66.249.77.63 /pusdatin/statistik/metodologi/ tar.pdf
Apabila digambarkan dalam bentuk struktur data pohon, maka isi tabel 3.5 akan menjadi struktur pohon berikut:
Gambar 5. Contoh representasi struktur pohon Web Deptan h tt p :/ /w w w .d ep ta n .g o. id bpsdm index.php index.php Spp-kupang stpp-manokwari
feati Spp-kupang index.php keuangan-perlengkapan galeri.php
news
detail-arsip-2.php
detail-event.php detail-arsip.php
pesantren berita berita alsin tabel_ujialsin.htm
pug arsippengumuman.php detailperencanaan4.php detailperencanaan3.php detailperencanaan5.php detailperencanaan6.php
pusdatin statistik metodologi tar.pdf wap index.php
b. Membentuk Node
Agar memudahkan dalam pengolahan data, maka perlu membuat indeks yang unix untuk setiap string rangkaiaian direktori file yang selanjutnya disebut node.
Tabel 8. Pengkodean struktur direktori file dan halaman Web sebagai Node
Pengkodean Direktori file
A /bpsdm/spp-kupang/index.php B /bpsdm/stpp-manokwari/tampil.php C /feati/diskusi/index.php D /keuangan-perlengkapan/galeri.php E /news/detailarsip_2.php F /news/detailarsip.php G /news/detailevent.php H /pesantren/berita/berita/alsin/ tabel_ujialsin.htm I /pesantren/bsp/pai/Data_dan_Informasi/jaringan_irigasi_indonesia/kalbar.htm J /pesantren/ditjenbun/ok/myweb/ sub_bagian_kerjasama.htm K /pug/arsippengumuman.php L /pug/detailperencanaan3.php M /pug/detailperencanaan4.php N /pug/detailperencanaan5.php O /pug/detailperencanaan6.php P /pusdatin/statistik/metodologi/ tar.pdf Q /wap/index.php
Berdasarkan pengodean pada tabel 3.6 dan halaman utama web Deptan (http://www.deptan.go.id) sebagai titik awal peneusuran maka rangkaian
(sekuential) kunjungan halaman web dan file yang diakses untuk masing-masing
host adalah sebagai berikut:
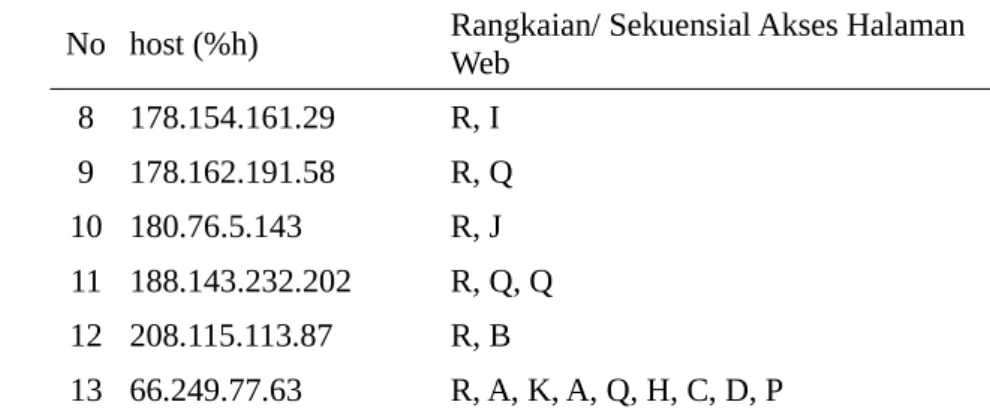
Tabel 9. Rangkaian (sequential) akses halaman web
No host (%h) Rangkaian/ Sekuensial Akses Halaman Web
1 157.55.33.40 R, E 2 157.56.229.23 R, G 3 173.199.114.83 R, M 4 173.199.116.235 R, O 5 173.199.118.35 R, L 6 173.199.120.43 R, N 7 173.44.37.226 R, Q, Q
No host (%h) Rangkaian/ Sekuensial Akses Halaman Web 8 178.154.161.29 R, I 9 178.162.191.58 R, Q 10 180.76.5.143 R, J 11 188.143.232.202 R, Q, Q 12 208.115.113.87 R, B 13 66.249.77.63 R, A, K, A, Q, H, C, D, P
Host yang memiliki rangkaian akses (tabel 3.8) halaman web terpanjang adalah
host dengan IP Address 66.249.77.63 yaitu R, A, K, A, Q, H, C, D, P. Untuk host yang lainnya hanya membentuk 3 dan 2 node rangkaian. Dari data tersebut bisa dikatakan bahwa host tersebut memiliki waktu paling lama akses pada web deptan dan cukup tertarik terhadap isinya. Sedangkan halaman yang paling banyak diakses adalah halaman Q sebanyak 6 kali, halaman A 2 kali sisanya masing-masing hanya 1 kali dan samasekali tidak ada yang akses yaitu halaman F, untuk lebih rincinya data disajikan sebagai berikut:
Tabel 10. Sebaran frekuensi akses halaman web
No host (%h) Node A B C D E F G H I J K L M N O P Q 1 157.55.33.40 R, E 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 2 157.56.229.23 R, G 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 3 173.199.114.83 R, M 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 4 173.199.116.235 R, O 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 5 173.199.118.35 R, L 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 6 173.199.120.43 R, N 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 7 173.44.37.226 R, Q, Q 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 8 178.154.161.29 R, I 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 9 178.162.191.58 R, Q 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 10 180.76.5.143 R, J 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 11 188.143.232.202 R, Q, Q 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 12 208.115.113.87 R, B 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 13 66.249.77.63 R, A, K, A, Q, H, C, D, P 2 0 1 1 0 0 0 1 0 0 1 0 0 0 0 1 1 Total 2 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 6
4. Penemuan dan Analsisis Pola a. Analisis Database
Untuk mengelola data log diperlukan sebuah tempat penampungan data atau basisdata (database). Data log pada dasarnya adalah data teks yang auto
generate mengikuti pola standar dari Web server, akan tetapi panjang atribut untuk
tiap kelompok string kadang tidak sama. seperti contoh berikut dengan terlebih dahulu tanda petiknya sudah dibuang:
1. 66.249.73.7 - - [04/Nov/2012:04:09:51 +0700] GET /wap/index.php
HTTP/1.1 200 4132 - SAMSUNG-SGH-E250/1.0 Profile/MIDP-2.0
Configuration/CLDC-1.1 UP.Browser/6.2.3.3.c.1.101 (GUI) MMP/2.0 (compatible; Googlebot-Mobile/2.1; +http:www.google.com/bot.html) 2. 180.76.5.136 - - [04/Nov/2012:04:09:59 +0700] GET
/daerah_new/sulsel/disbun1/Organisasi/index.php HTTP/1.1 200 1818 - Mozilla/5.0 (compatible; Baiduspider/2.0;
+http:www.baidu.com/search/spider.html)
Pada data 1 dan 2 di atas apabila dikonversi dalam bentuk csv dan dilakukan pemisahan dengan pemisah (sparator) spasi kosong maka akan terlihat seperti pada tabel 3.10.
Tabel 11. Pemisahan string dengan spasi kosong
1 2 3 4 5 6 7 8 9 10 1 1 66.249.73.7 - - [04/Nov/2012:04:09:5 1 +0700 ] GE T /wap/index.php HTTP/1.1 200 4132 -180.76.5.136 - - [04/Nov/2012:04:09:5 9 +0700 ] GE T /daerah_new/sulsel/disbun1/ Organisasi/index.php HTTP/1.1 200 1818
-Terlihat tepat satu kelompok string ditampung dalam satu kolom, kecuali kelompok string %t dan \"%r\" ditampung lebih dari 1 kolom, hal ini akan berpengaruh terhadap perancangan fields yang akan dibuat dalam tabel log.
%h %l %u %t \"%r\" %>s %b \%"{Referer}i"%\
1 2 3 4 5 6 7 8 9 10 11
Begitupun dengan kelompok string \"%{User-agent}i%\" harus ditampung oleh lebih dari satu kolom, apalagi jumlah variabel stringnya tidak sama, hal ini berbeda dengan kelompok %t yang pasti akan ditampung oleh 2 kolom dan %r akan cukup ditampung oleh 3 kolom. seperti terlihat pada tabel 3.11 data user agent untuk data 1 harus ditampung dalam 9 kolom, sedangkan data 2 cukup dengan 4 kolom. Untuk bererapa data ada yang mencapai 15 kolom, sehingga dalam perancangan tabel untuk menampung data useragent disediakan 20 kolom:
Tabel 12. Pemisahan string useragent dengan spasi kosong 1 2 3 4 5 6 7 8 9 SAMSUNG- SGH-E250/1.0 Profile/ MIDP-2.0 Configurati on/CLDC-1.1 UP.Browser/6.2.3.3.c .1.101 (GUI ) M MP /2.0 (com patib le; Googlebo t-Mobile/2. 1; +http:www.google.com/b ot.html) Mozilla/5.0 (compat ible; Baiduspider /2.0; +http:www.baidu.co m/search/spider.html) Data log mentah disimpan dalam tabel yang belum menganut aturan database seperti primary key ataupun index, hal ini dilakukan agar semua data terkam dulu dalam bentuk tabel untuk memudahkan dalam melakukan query. b. Analisis Assosiasi
Analisis asosiasi merupakan analisis mengenai keterhubungan antara halaman web yang dikunjungi oleh pengguna. Teknik yang diigunakan adalah menggunakan teknik dalam data mining yaitu analisis keranjang belanja (market
basket analysis) dengan menggunakan salahsatu algoritme yang sudah umum
dikenal yaitu algoritme apriori.
Adapun objek yang dijadikan itemset adalah direktori yang ada dalam website atau selanjutnya dikenal dengan node.
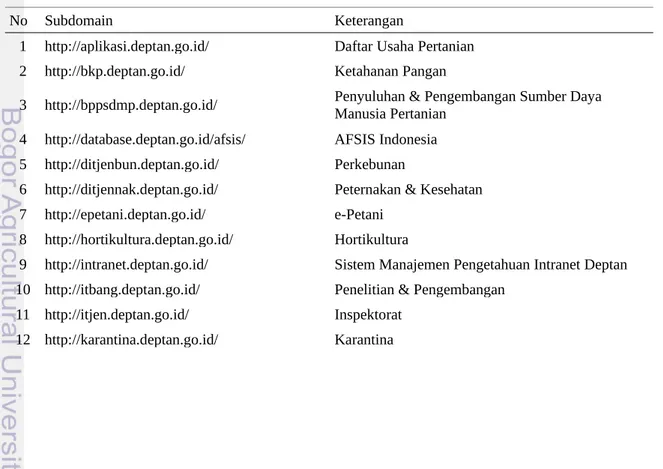
Website Deptan memiliki alamat url http://www.deptan.go.id, yang terdiri dari beberapa subdomain dan folder di dalamnya. Adapun subdomain yang ada pada Situs web Deptan adalah sebagai berikut (berdasarkan data acces_log dan penelusuran online):
Tabel 13. Daftar Subdomian Situs Web Deptan
No Subdomain Keterangan
1 http://aplikasi.deptan.go.id/ Daftar Usaha Pertanian 2 http://bkp.deptan.go.id/ Ketahanan Pangan
3 http://bppsdmp.deptan.go.id/ Penyuluhan & Pengembangan Sumber Daya Manusia Pertanian 4 http://database.deptan.go.id/afsis/ AFSIS Indonesia
5 http://ditjenbun.deptan.go.id/ Perkebunan
6 http://ditjennak.deptan.go.id/ Peternakan & Kesehatan 7 http://epetani.deptan.go.id/ e-Petani
8 http://hortikultura.deptan.go.id/ Hortikultura
9 http://intranet.deptan.go.id/ Sistem Manajemen Pengetahuan Intranet Deptan 10 http://itbang.deptan.go.id/ Penelitian & Pengembangan
11 http://itjen.deptan.go.id/ Inspektorat 12 http://karantina.deptan.go.id/ Karantina
No Subdomain Keterangan
13 http://litbang.deptan.go.id/berita/one/852/ Kulit Buah Manggis Instan BB-Pascapanen Curi Perhatian Pengunjung PF2N Batam
14 http://lpse.deptan.go.id Layanan Pengadaan Secara Elektronik 15 http://mail.deptan.go.id Web Mail Kementan
16 http://multimedia.deptan.go.id Portal Multimedia Pertanian 17 http://perundangan.deptan.go.id Basisdata Undang-Undang 18 http://pphp.deptan.go.id/ Pengolahan & Pemasaran Hasil 19 http://ppvt.setjen.deptan.go.id/ PVT Perizinan
20 http://psp.deptan.go.id/ Prasarana & Sarana
21 http://puap.deptan.go.id/ Pengembangan Usaha Agribisnis Perdesaan (PUAP) 22 http://pusdatin.deptan.go.id/ Data Teknologi Informasi
23 http://pustaka-deptan.go.id/agritek.php Koleksi teknologi pertanian tepat guna (agriTEK) 24 http://pustaka.litbang.deptan.go.id/ Pustaka Publikasi
25 http://setjen.deptan.go.id/ Sekretariat 26 http://tanamanpangan.deptan.go.id/ Tanaman Pangan
Dari ke 26 Subdomain tersebut masingmasing memiliki file index dan folder yang independen yang bertujuan agar pemeliharaan bisa dibagibagi dan menjadi tanggung jawab masingmasing direktorat. Antara Subdomain dan folder keduanya memiliki fungsi yang sama yaitu untuk mengelompokan fungsi dan data. Tetapi ada perbedaaan penulisan alamat url ketika user melakukan browsing
internet antara alamat url dalam subdomain dan alamat url dalam folder situs
utama web Deptan, contoh sebagai berikut:
Tabel 14. Keterangan penulisan url
Penulisan url Keteragan
http://www.deptan.go.id/tanamanpangan tanamanpangan pada url ini berlaku sebagai folder
yang ada dalam url http://www.deptan.go.id http://tanamanpangan.deptan.go.id/ atau
http://www.tanamanpangan.deptan.go.id/
tanamanpangan pada url ini berlaku sebagai
subdomain url http://www.deptan.go.id
Semua alamat url baik sebagai folder ataupun sebagai Subdomain akan ditulis di dalam satu data log yang tersimpan di server web Deptan dengan alamat utamanya adalah http://www.deptan.go.id dengan. Walaupun ada perbedaan penulisan url pada web browser, tapi format penulisan data lognya disamakan, sehingga pada penelitian ini antara subdomain dan folder dianggap sebagai alamat yang sama.